
Machine Learning Methods for Preterm Birth Prediction: A Review

 ,
,  ,
, 
Abstract
:1. Introduction
2. Preliminaries
2.1. Preterm Birth Prediction
2.2. Difficulties and Future Challenges
2.3. Data Imbalance
- undersampling:
- oversampling:
- information loss—due to the elimination of informative or useful samples, classification effectiveness deteriorates,
- data cleaning—because of eliminating irrelevant, redundant, or even noisy samples, classification effectiveness is falsely improved.
- SVM classifier—for a highly imbalanced classification, the majority class pushes the ideal decision boundary toward the minority class [21],
- random forest—classifier induces each constituent tree from a bootstrap sample of the training data [46]. In learning extremely imbalanced data, there is a significant probability that a bootstrap sample contains few or even none of the minority class, which results in a tree with poor performance for predicting the minority class [47].
3. Methods
3.1. Data Availability and Use
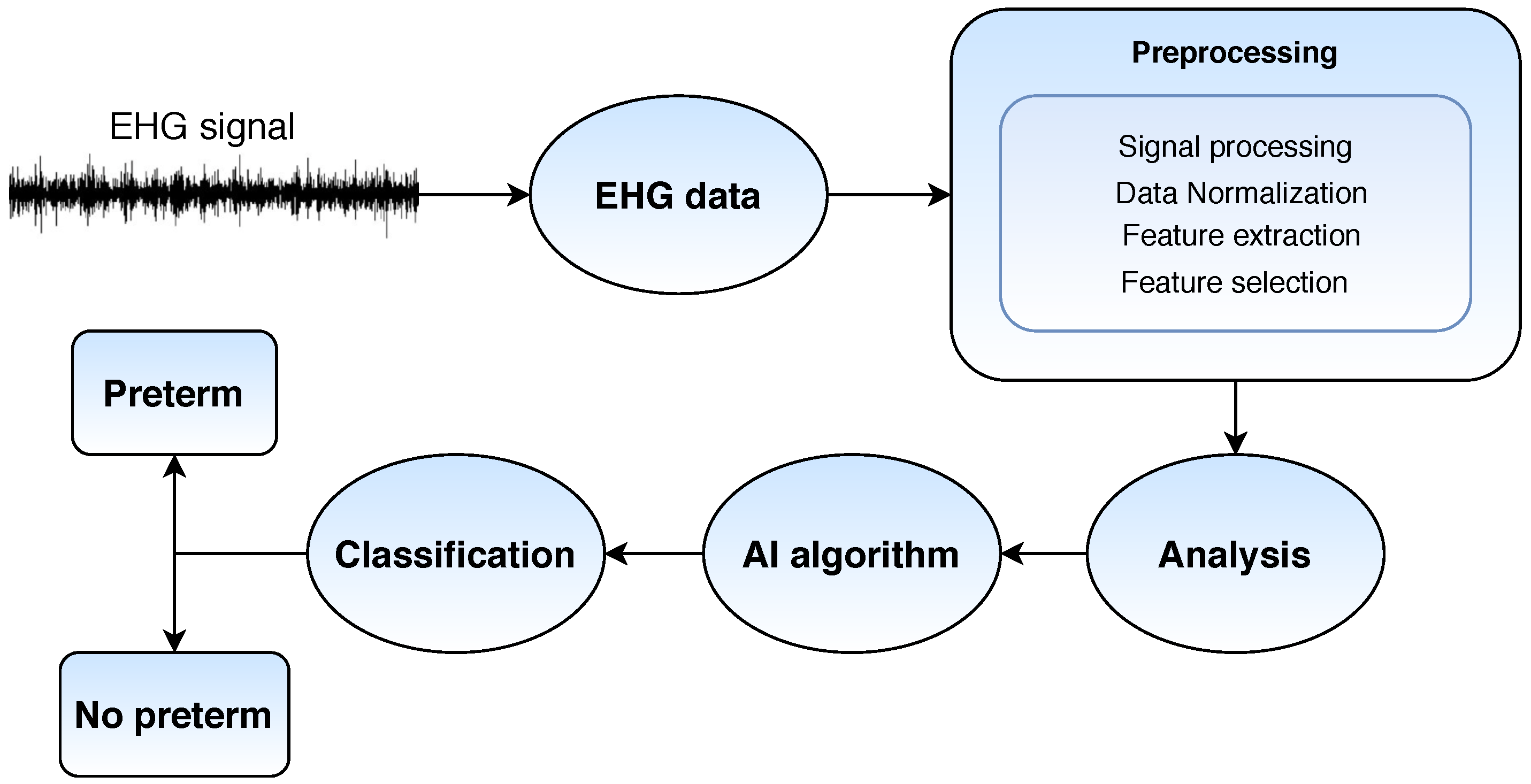
3.2. Electrohysterography
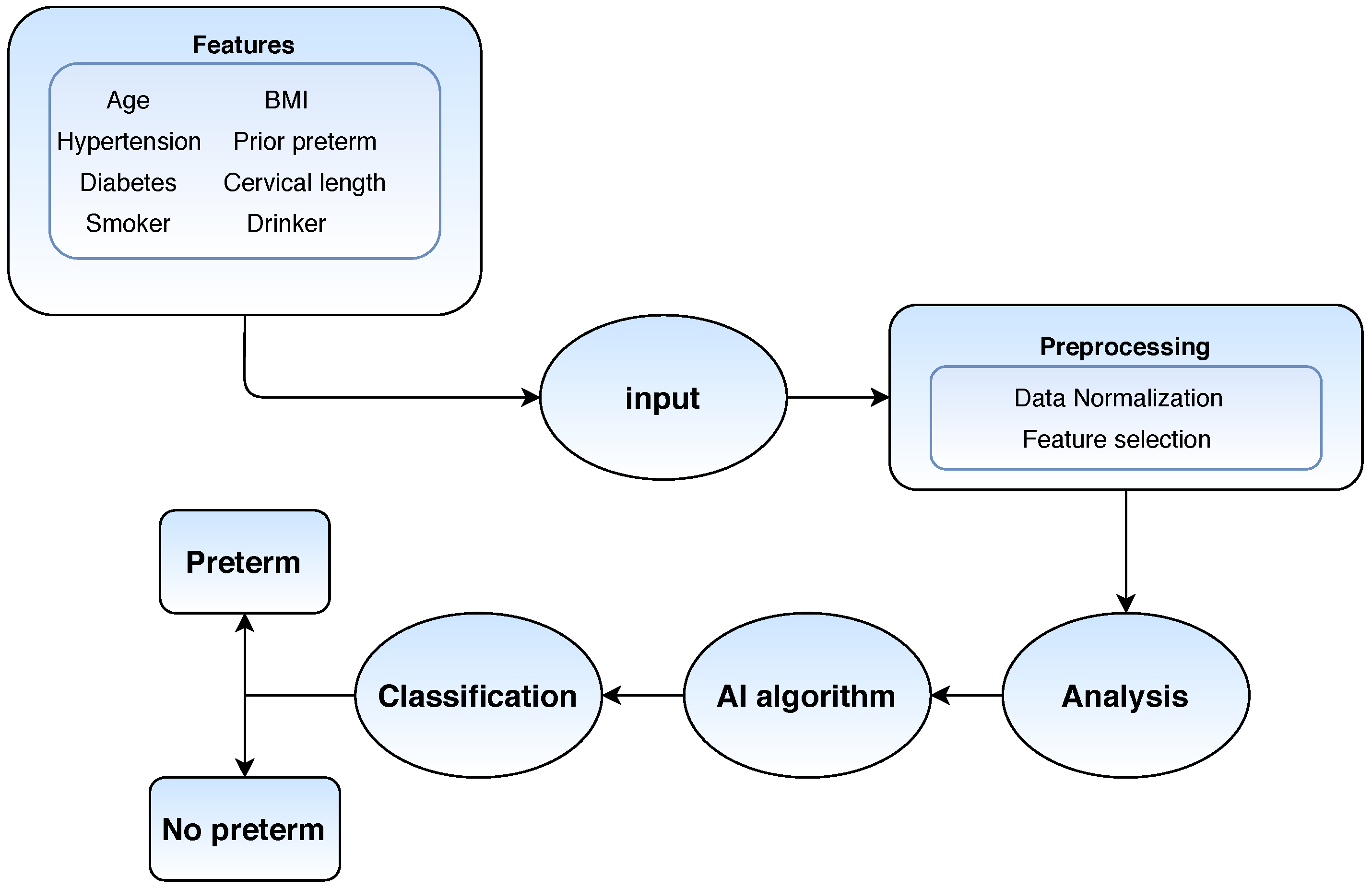
3.3. Electronic Health Records
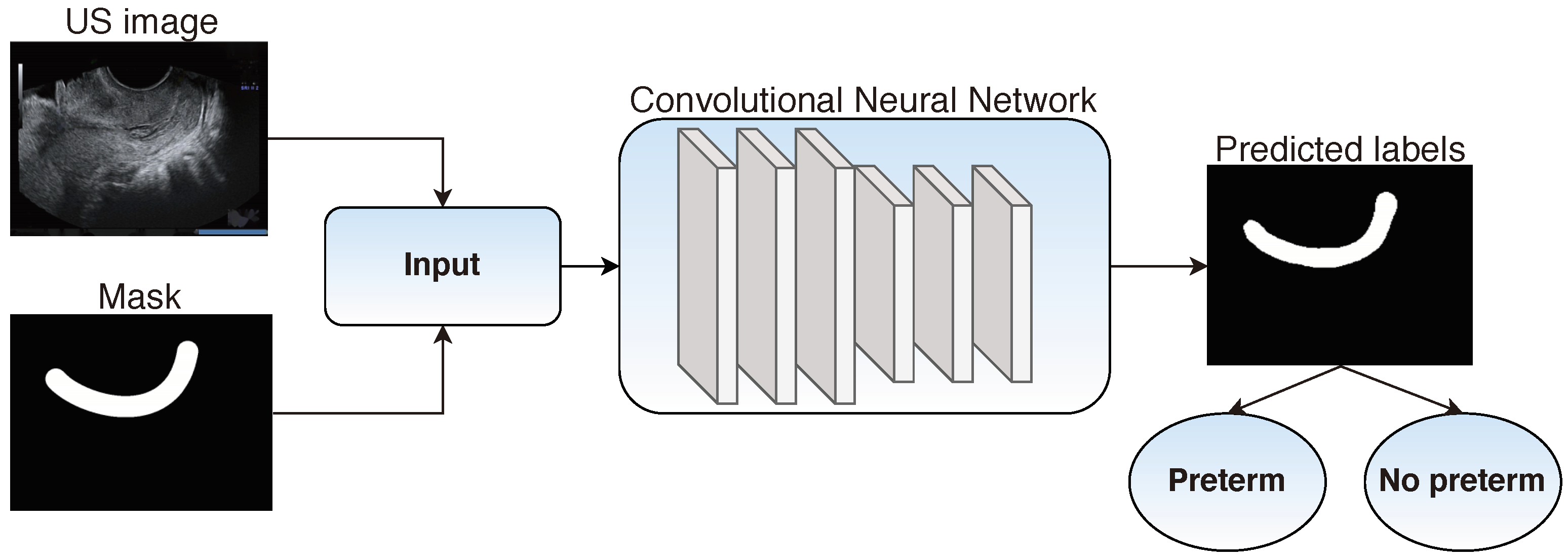
3.4. Transvaginal Ultrasound
3.5. Uterine Electromyography
4. Discussion
- National Institute of Child Health and Human Development (NICHD)—Maternal-Fetal Medicine Units Network (MFMU) (https://mfmunetwork.bsc.gwu.edu/PublicBSC/MFMU/MFMUPublic/datasets/ (accessed on 28 December 2020)),
- Better Outcomes Registry Network (BORN) Information System (https://www.bornontario.ca/en/data/data-dictionary-and-library.aspx (accessed on 28 December 2020)),
- Pregnancy Risk Monitoring Assessment (PRAMS) (https://www.cdc.gov/prams/state-success-stories/data-to-action-success.html (accessed on 28 December 2020)),
- Centers for Disease Control and Prevention (CDC)—National Center of Health Statistics (NCHS) (https://www.cdc.gov/nchs/data_access/ftp_data.htm (accessed on 28 December 2020)),
- Term-Preterm EHG Database (TPEHG) (https://physionet.org/content/tpehgdb/1.0.1/ (accessed on 28 December 2020)), and
- Term-Preterm EHG Dataset with Tocogram (TPEHGT) (https://physionet.org/content/tpehgt/1.0.0/ (accessed on 28 December 2020)) [94,100].
- EHG—Degbedzui et al. [89] who achieve accuracy of 0.997, recall 0.995, and specificity 1.0—using SVM classifier,
- EHR—Rawashdeh et al. [84] who achieve accuracy of 0.95, recall 1.0, and specificity 0.94—using random forest,
- TVS—Włodarczyk et al. [10] who achieve a recall of 0.68, and specificity 0.97—using convolutional neural networks, and
- EMG—Most et al. [91] who achieve a recall of 0.41 and specificity 0.92—using logistic regression.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Blencowe, H.; Cousens, S.; Oestergaard, M.Z.; Chou, D.; Moller, A.B.; Narwal, R.; Adler, A.; Garcia, C.V.; Rohde, S.; Say, L.; et al. National, regional, and worldwide estimates of preterm birth rates in the year 2010 with time trends since 1990 for selected countries: A systematic analysis and implications. Lancet 2012, 379, 2162–2172. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Johnson, H.L.; Cousens, S.; Perin, J.; Scott, S.; Lawn, J.E.; Rudan, I.; Campbell, H.; Cibulskis, R.; Li, M.; et al. Global, regional, and national causes of child mortality: An updated systematic analysis for 2010 with time trends since 2000. Lancet 2012, 379, 2151–2161. [Google Scholar] [CrossRef]
- Dbstet, A. WHO: Recommended definitions, terminology and format for statistical tables related to the perinatal period and use of a new certificate for cause of perinatal deaths. Acta Obstet Gynecol Scand 1977, 56, 247–253. [Google Scholar]
- Blencowe, H.; Cousens, S.; Chou, D. Born Too Soon: The global epidemiology of 15 million preterm births. Reprod. Health 10 2013, 10, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marlow, N. Full term; an artificial concept. Arch. Dis. Childhood Fetal Neonatal 2012, F158–F159. [Google Scholar] [CrossRef] [PubMed]
- Goldenberg, R.L.; Gravett, M.G.; Iams, J.; Papageorghiou, A.T.; Waller, S.A.; Kramer, M.; Culhane, J.; Barros, F.; Conde-Agudelo, A.; Bhutta, Z.A.; et al. The preterm birth syndrome: Issues to consider in creating a classification system. Am. J. Obstet. Gynecol. 2012, 206, 113–118. [Google Scholar] [CrossRef] [PubMed]
- Ward, R.M.; Beachy, J.C. Neonatal complications following preterm birth. BJOG Int. J. Obstet. Gynaecol. 2003, 110, 8–16. [Google Scholar] [CrossRef]
- Okitsu, O.; Mimura, T.; Nakayama, T.; Aono, T. Early prediction of preterm delivery by transvaginal ultrasonography. Ultrasound Obstet. Gynecol. 1992, 2, 402–409. [Google Scholar] [CrossRef] [PubMed]
- Włodarczyk, T.; Płotka, S.; Trzciński, T.; Rokita, P.; Sochacki-Wójcicka, N.; Lipa, M.; Wójcicki, J. Estimation of Preterm Birth Markers with U-Net Segmentation Network. In Smart Ultrasound Imaging and Perinatal, Preterm and Paediatric Image Analysis; Wang, Q., Gomez, A., Hutter, J., McLeod, K., Zimmer, V., Zettinig, O., Licandro, R., Robinson, E., Christiaens, D., Turk, E.A., et al., Eds.; Springer: Cham, Switzerland, 2019; pp. 95–103. [Google Scholar] [CrossRef] [Green Version]
- Włodarczyk, T.; Płotka, S.; Rokita, P.; Sochacki-Wójcicka, N.; Wójcicki, J.; Lipa, M.; Trzciński, T. Spontaneous Preterm Birth Prediction Using Convolutional Neural Networks. In Medical Ultrasound, and Preterm, Perinatal and Paediatric Image Analysis; Hu, Y., Licandro, R., Noble, J.A., Hutter, J., Aylward, S., Melbourne, A., Turk, E.A., Barrena, J.T., Eds.; Springer: Cham, Switzerland, 2020; pp. 274–283. [Google Scholar] [CrossRef]
- Tran, T.; Luo, W.; Phung, D.; Morris, J.; Rickard, K.; Venkatesh, S. Preterm birth prediction: Stable selection of interpretable rules from high dimensional data. In Proceedings of the 1st Machine Learning for Healthcare Conference, Los Angeles, CA, USA, 19–20 August 2016; pp. 164–177. [Google Scholar]
- Gao, C.; Osmundson, S.; Edwards, D.R.V.; Jackson, G.P.; Malin, B.A.; Chen, Y. Deep learning predicts extreme preterm birth from electronic health records. J. Biomed. Inf. 2019, 100, 103334. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the COLT ’92: Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar] [CrossRef]
- Bengio, Y. Learning Deep Architectures for AI; Now Publishers Inc.: Norwell, MA, USA, 2009; pp. 1–127. [Google Scholar] [CrossRef]
- Walani, S.R. Global burden of preterm birth. Int. J. Gynecol. Obstet. 2020, 150, 31–33. [Google Scholar] [CrossRef] [PubMed]
- Beck, S.; Wojdyla, D.; Say, L.; Bertran, A.P.; Meraldi, M.; Requejo, J.H.; Rubens, C.; Menon, R.; Look, P.V. The worldwide incidence of preterm birth: A systematic review of maternal mortality and morbidity. Bull. World Health Organ. 2010, 88, 31–38. [Google Scholar] [CrossRef]
- Institute of Medicine. Preterm Birth: Causes, Consequences, and Prevention; National Academies Press: Washington, DC, USA, 2007. [Google Scholar] [CrossRef]
- Vovsha, I.; Rajan, A.; Salleb-Aouissi, A.; Raja, A.; Radeva, A.; Diab, H.; Tomar, A.; Wapner, R. Predicting preterm birth is not elusive: Machine learning paves the way to individual wellness. In Proceedings of the 2014 AAAI Spring Symposium Series, Palo Alto, CA, USA, 24–26 March 2014; pp. 82–89. [Google Scholar]
- Fergus, P.; Cheung, P.; Hussain, A.; Al-Jumeily, D.; Dobbins, C.; Iram, S. Prediction of Preterm Deliveries from EHG Signals Using Machine Learning. PLoS ONE 2013, 8, e77154. [Google Scholar] [CrossRef]
- Glover, A.V.; Manuck, T.A. Screening for spontaneous preterm birth and resultant therapies to reduce neonatal morbidity and mortality: A review. Semin. Fetal Neonatal Med. 2018, 23, 126–132. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.; Krasser, S. SVMs Modeling for Highly Imbalanced Classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 39, 281–288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the class imbalance problem. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; pp. 192–201. [Google Scholar]
- Mac Namee, B.; Cunningham, P.; Byrne, S.; Corrigan, O.I. The problem of bias in training data in regression problems in medical decision support. Artif. Intell. Med. 2002, 24, 51–70. [Google Scholar] [CrossRef]
- Grzymala-Busse, J.W.; Goodwin, L.K.; Zhang, X. Increasing sensitivity of preterm birth by changing rule strengths. Pattern Recognit. Lett. 2003, 24, 903–910. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Wang, S.; Liu, W.; Wu, J.; Cao, L.; Meng, Q.; Kennedy, P.J. Training deep neural networks on imbalanced data sets. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 4368–4374. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Yao, X. Multiclass imbalance problems: Analysis and potential solutions. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 1119–1130. [Google Scholar] [CrossRef] [PubMed]
- Bi, J.; Zhang, C. An empirical comparison on state-of-the-art multi-class imbalance learning algorithms and a new diversified ensemble learning scheme. Knowl. Based Syst. 2018, 158, 81–93. [Google Scholar] [CrossRef]
- Japkowicz, N. Concept-learning in the presence of between-class and within-class imbalances. In Conference of the Canadian Society for Computational Studies of Intelligence; Stroulia, E., Matwin, S., Eds.; Springer: Berlin, Germany, 2001; pp. 67–77. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. In Proceedings of the Fourteenth International Conference on Machine Learning (ICML 1997), Nashville, TN, USA, 8–12 July 1997; pp. 179–186. [Google Scholar]
- Holte, R.C.; Acker, L.; Porter, B.W. Concept Learning and the Problem of Small Disjuncts. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI-89), Detroit, MI, USA, 20–25 August 1989; pp. 813–818. [Google Scholar]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory Undersampling for Class-Imbalance Learning. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 39, 539–550. [Google Scholar] [CrossRef]
- Van Hulse, J.; Khoshgoftaar, T.M.; Napolitano, A. Experimental perspectives on learning from imbalanced data. In Proceedings of the 24th international conference on Machine learning, Corvallis, OR, USA, 20–24 June 2007; pp. 935–942. [Google Scholar]
- Barandela, R.; Valdovinos, R.M.; Sánchez, J.S.; Ferri, F.J. The imbalanced training sample problem: Under or over sampling? In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Fred, A., Caelli, T.M., Duin, R.P.W., Campilho, A.C., de Ridder, D., Eds.; Springer: Berlin, Germany, 2004; pp. 806–814. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Chang, F.; Ma, L.; Qiao, Y. Target Tracking Under Occlusion by Combining Integral-Intensity-Matching with Multi-block-voting. In Lecture Notes in Computer Science; Huang, D.S., Zhang, X.P., Huang, G.B., Eds.; Springer: Berlin, Germany, 2005; pp. 77–86. [Google Scholar] [CrossRef]
- Bunkhumpornpat, C.; Sinapiromsaran, K.; Lursinsap, C. Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Theeramunkong, T., Kijsirikul, B., Cercone, N., Ho, T.B., Eds.; Springer: Berlin, Germany, 2009; pp. 475–482. [Google Scholar]
- Jo, T.; Japkowicz, N. Class imbalances versus small disjuncts. ACM SIGKDD Explor. Newsl. 2004, 6, 40–49. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning Deep Representation for Imbalanced Classification. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384.
- Drummond, C.; Holte, R.C. C4. 5, class imbalance, and cost sensitivity: Why under-sampling beats over-sampling. In Proceedings of the Workshop on Learning from Imbalanced Datasets II, ICML, Washington, DC, USA, 21 August 2003; pp. 1–8. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Liaw, A.; Breiman, L. Using Random Forest to Learn Imbalanced Data. Available online: https://statistics.berkeley.edu/sites/default/files/tech-reports/666.pdf (accessed on 28 December 2020).
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the Thirteenth International Conference (ICML ’96), Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Joshi, M.V.; Kumar, V.; Agarwal, R.C. Evaluating boosting algorithms to classify rare classes: Comparison and improvements. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001; pp. 257–264. [Google Scholar]
- Chawla, N.V.; Lazarevic, A.; Hall, L.O.; Bowyer, K.W. SMOTEBoost: Improving Prediction of the Minority Class in Boosting. In Knowledge Discovery in Databases: PKDD 2003; Lavrac, N., Gamberger, D., Todorovski, L., Blockeel, H., Eds.; Springer: Berlin, Germany, 2003; pp. 107–119. [Google Scholar] [CrossRef] [Green Version]
- Viola, P.; Jones, M. Fast and robust classification using asymmetric adaboost and a detector cascade. Adv. Neural Inf. Process. Syst. 2001, 14. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.332.9301&rep=rep1&type=pdf (accessed on 3 March 2021).
- Fan, W.; Stolfo, S.J.; Zhang, J.; Chan, P.K. AdaCost: Misclassification cost-sensitive boosting. In Proceedings of the Sixteenth International Conference on Machine Learning (ICML 1999), Bled, Slovenia, 27–30 June 1999; pp. 97–105. [Google Scholar]
- Domingos, P. Metacost: A general method for making classifiers cost-sensitive. In Proceedings of the fifth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 15–18 August 1999; pp. 155–164. [Google Scholar]
- Shen, L.; Lin, Z.; Huang, Q. Relay backpropagation for effective learning of deep convolutional neural networks. In European Conference on Computer Vision; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 467–482. [Google Scholar]
- Altman, N.S. An Introduction to Kernel and Nearest-Neighbor Nonparametric Regression. Am. Stat. 1992, 46, 175–185. [Google Scholar] [CrossRef] [Green Version]
- Rokach, L.; Maimon, O. Decision trees. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: Boston, MA, USA, 2005; pp. 165–192. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; pp. 278–282. [Google Scholar]
- Cramer, J.S. The origins of logistic regression. SSRN 2002. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Anthony, M.; Bartlett, P.L. Neural Network Learning: Theoretical Foundations; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Zeitlin, J.; Szamotulska, K.; Drewniak, N.; Mohangoo, A.; Chalmers, J.; Sakkeus, L.; Irgens, L.; Gatt, M.; Gissler, M.; Blondel, B.; et al. Preterm birth time trends in Europe: A study of 19 countries. BJOG Int. J. Obstet. Gynaecol. 2013, 120, 1356–1365. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hussain, A.; Fergus, P.; Al-Askar, H.; Al-Jumeily, D.; Jager, F. Dynamic neural network architecture inspired by the immune algorithm to predict preterm deliveries in pregnant women. Neurocomputing 2015, 151, 963–974. [Google Scholar] [CrossRef]
- Menard, M.; Newman, R.B.; Keenan, A.; Ebelingc, M. Prognostic significance of prior preterm twin delivery on subsequent singleton pregnancy. Am. J. Obstet. Gynecol. 1996, 174, 1429–1432. [Google Scholar] [CrossRef]
- Facco, F.L.; Nash, K.; Grobman, W.A. Are women who have had a preterm twin delivery at greater risk of preterm birth in a subsequent singleton pregnancy? Am. J. Obstet. Gynecol. 2007, 197, 253.e1–253.e3. [Google Scholar] [CrossRef] [PubMed]
- Heath, V.C.F.; Southall, T.R.; Souka, A.P.; Elisseou, A.; Nicolaides, K.H. Cervical length at 23 weeks of gestation: Prediction of spontaneous preterm delivery. Ultrasound Obstet. Gynecol. 1998, 12, 312–317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quinn, J.A.; Munoz, F.M.; Gonik, B.; Frau, L.; Cutland, C.; Mallett-Moore, T.; Kissou, A.; Wittke, F.; Das, M.; Nunes, T.; et al. Preterm birth: Case definition & guidelines for data collection, analysis, and presentation of immunisation safety data. Vaccine 2016, 34, 6047–6056. [Google Scholar] [CrossRef] [Green Version]
- Renzo, G.D.; O Herlihy, C.; van Geijn, H.; Copray, F. Organization of perinatal care within the European community. Eur. J. Obstet. Gynecol. Reprod. Biol. 1992, 45, 81–87. [Google Scholar] [CrossRef]
- Zeitlin, J.; Papiernik, E.; Bréart, G. Regionalization of perinatal care in Europe. Semin. Neonatol. 2004, 9, 99–110. [Google Scholar] [CrossRef]
- Iams, J.D.; Romero, R.; Culhane, J.F.; Goldenberg, R.L. Primary, secondary, and tertiary interventions to reduce the morbidity and mortality of preterm birth. Lancet 2008, 371, 164–175. [Google Scholar] [CrossRef]
- Skirton, H.; Goldsmith, L.; Jackson, L.; Lewis, C.; Chitty, L. Offering prenatal diagnostic tests: European guidelines for clinical practice. Eur. J. Hum. Genet. 2013, 22, 580–586. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fele-Žorž, G.; Kavšek, G.; Novak-Antolič, Ž.; Jager, F. A comparison of various linear and non-linear signal processing techniques to separate uterine EMG records of term and pre-term delivery groups. Med. Biol. Eng. Comput. 2008, 46, 911–922. [Google Scholar] [CrossRef]
- Bedathur, S.; Srivastava, D.; Valluri, S.R. (Eds.) Big Data Curation. In Proceedings of the 20th International Conference on Management of Data, Hyderabad, India, 17–19 December 2014. [Google Scholar]
- Grzymala-Busse, J.W.; Woolery, L.K. Improving prediction of preterm birth using a new classification scheme and rule induction. In Proceedings of the AMIA Annual Symposium on Computer Application in Medical Care, Washington, DC, USA, 5–9 November 1994; p. 730. [Google Scholar]
- Woolery, L.K.; Grzymala-Busse, J. Machine Learning for an Expert System to Predict Preterm Birth Risk. J. Am. Med. Inf. Assoc. 1994, 1, 439–446. [Google Scholar] [CrossRef] [Green Version]
- Mercer, B.; Goldenberg, R.; Das, A.; Moawad, A.; Iams, J.; Meis, P.; Copper, R.; Johnson, F.; Thom, E.; McNellis, D.; et al. The preterm prediction study: A clinical risk assessment system. Am. J. Obstet. Gynecol. 1996, 174, 1885–1895. [Google Scholar] [CrossRef]
- Goodwin, L.; Maher, S. Data mining for preterm birth prediction. In Proceedings of the 2000 ACM Symposium on Applied Computing—Volume 1, Como, Italy, 19–21 March 2000; pp. 46–51. [Google Scholar] [CrossRef]
- Frize, M.; Yu, N.; Weyand, S. Effectiveness of a hybrid pattern classifier for medical applications. Int. J. Hybrid Intell. Syst. 2011, 8, 71–79. [Google Scholar] [CrossRef]
- Weber, A.; Darmstadt, G.L.; Gruber, S.; Foeller, M.E.; Carmichael, S.L.; Stevenson, D.K.; Shaw, G.M. Application of machine-learning to predict early spontaneous preterm birth among nulliparous non-Hispanic black and white women. Ann. Epidemiol. 2018, 28, 783–789. [Google Scholar] [CrossRef]
- Esty, A.; Frize, M.; Gilchrist, J.; Bariciak, E. Applying Data Preprocessing Methods to Predict Premature Birth. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 6096–6099. [Google Scholar] [CrossRef]
- Prema, N.S.; Pushpalatha, M.P. Machine Learning Approach for Preterm Birth Prediction Based on Maternal Chronic Conditions. In Lecture Notes in Electrical Engineering; Sridhar, V., Padma, M., Rao, K., Eds.; Springer: Singapore, 2019; pp. 581–588. [Google Scholar] [CrossRef]
- Lee, K.S.; Ahn, K.H. Artificial Neural Network Analysis of Spontaneous Preterm Labor and Birth and Its Major Determinants. J. Korean Med. Sci. 2019, 34. [Google Scholar] [CrossRef]
- Rawashdeh, H.; Awawdeh, S.; Shannag, F.; Henawi, E.; Faris, H.; Obeid, N.; Hyett, J. Intelligent system based on data mining techniques for prediction of preterm birth for women with cervical cerclage. Comput. Biol. Chem. 2020, 85, 107233. [Google Scholar] [CrossRef]
- Koivu, A.; Sairanen, M. Predicting risk of stillbirth and preterm pregnancies with machine learning. Health Inf. Sci. Syst. 2020, 8. [Google Scholar] [CrossRef] [Green Version]
- Sadi-Ahmed, N.; Kacha, B.; Taleb, H.; Kedir-Talha, M. Relevant Features Selection for Automatic Prediction of Preterm Deliveries from Pregnancy ElectroHysterograhic (EHG) records. J. Med. Syst. 2017, 41. [Google Scholar] [CrossRef] [PubMed]
- Despotovic, D.; Zec, A.; Mladenovic, K.; Radin, N.; Turukalo, T.L. A Machine Learning Approach for an Early Prediction of Preterm Delivery. In Proceedings of the 2018 IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018; pp. 265–270. [Google Scholar] [CrossRef]
- Chen, L.; Xu, H. Deep neural network for semi-automatic classification of term and preterm uterine recordings. Artif. Intell. Med. 2020, 105, 101861. [Google Scholar] [CrossRef] [PubMed]
- Degbedzui, D.K.; Yüksel, M.E. Accurate diagnosis of term–preterm births by spectral analysis of electrohysterography signals. Comput. Biol. Med. 2020, 119, 103677. [Google Scholar] [CrossRef]
- Maner, W.L.; Garfield, R.E. Identification of Human Term and Preterm Labor using Artificial Neural Networks on Uterine Electromyography Data. Ann. Biomed. Eng. 2007, 35, 465–473. [Google Scholar] [CrossRef]
- Most, O.; Langer, O.; Kerner, R.; David, G.B.; Calderon, I. Can myometrial electrical activity identify patients in preterm labor? Am. J. Obstet. Gynecol. 2008, 199, 378.e1–378.e6. [Google Scholar] [CrossRef]
- Bode, O. Das elektrohysterogramm. Archiv Gynäkologie 1931, 146, 123–128. [Google Scholar] [CrossRef]
- Rabotti, C. Characterization of Uterine Activity by Electrohysterography; Eindhoven University of Technology: Eindhoven, The Netherlands, 2010. [Google Scholar] [CrossRef]
- Goldberger, A.L.; Amaral, L.A.N.; Glass, L.; Hausdorff, J.M.; Ivanov, P.C.; Mark, R.G.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101. [Google Scholar] [CrossRef] [Green Version]
- Sammut, C.; Webb, G.I. (Eds.) Encyclopedia of Machine Learning; Springer: Cham, Switzerland, 2010. [Google Scholar] [CrossRef]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Widyanto, M.R.; Nobuhara, H.; Kawamoto, K.; Hirota, K.; Kusumoputro, B. Improving recognition and generalization capability of back-propagation NN using a self-organized network inspired by immune algorithm (SONIA). Appl. Soft Comput. 2005, 6, 72–84. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. A. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Cawley, G.C.; Talbot, N.L. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Jager, F.; Libenšek, S.; Geršak, K. Characterization and automatic classification of preterm and term uterine records. PLoS ONE 2018, 13, e0202125. [Google Scholar] [CrossRef] [Green Version]
- Grzymala-Busse, J.W. LERS-A System for Learning from Examples Based on Rough Sets. In Intelligent Decision Support; Słowiński, R., Ed.; Springer: Dordrecht, The Netherlands, 1992; pp. 3–18. [Google Scholar] [CrossRef]
- Vega, F.; Matías, J.; Andrade, M.; Reigosa, M.; Covelo, E. Classification and regression trees (CARTs) for modelling the sorption and retention of heavy metals by soil. J. Hazard. Mater. 2009, 167, 615–624. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9. Available online: https://www.jmlr.org/papers/volume9/vandermaaten08a/vandermaaten08a.pdf?fbclid=IwAR0Bgg1eA5TFmqOZeCQXsIoL6PKrVXUFaskUKtg6yBhVXAFFvZA6yQiYx-M (accessed on 3 March 2021).
- Azur, M.J.; Stuart, E.A.; Frangakis, C.; Leaf, P.J. Multiple imputation by chained equations: What is it and how does it work? Int. J. Methods Psychiatr. Res. 2011, 20, 40–49. [Google Scholar] [CrossRef] [PubMed]
- Salzberg, S.L. C4.5: Programs for Machine Learning by J. Ross Quinlan. Morgan Kaufmann Publishers, Inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springe: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Sochacki-Wójcicka, N.; Wojcicki, J.; Bomba-Opon, D.; Wielgos, M. Anterior cervical angle as a new biophysical ultrasound marker for prediction of spontaneous preterm birth. Ultrasound Obstet. Gynecol. 2015, 46, 377–378. [Google Scholar] [CrossRef]
- Mehta, S.; Mercan, E.; Bartlett, J.; Weaver, D.; Elmore, J.G.; Shapiro, L. Y-Net: Joint segmentation and classification for diagnosis of breast biopsy images. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Frangi, A., Schnabel, J., Davatzikos, C., Alberola-López, C., Fichtinger, G., Eds.; Springer: Cham, Switzerland, 2018; pp. 893–901. [Google Scholar]
- Romero, R.; Dey, S.K.; Fisher, S.J. Preterm labor: One syndrome, many causes. Science 2014, 345, 760–765. [Google Scholar] [CrossRef] [Green Version]
- Ravi, M.; Beljorie, M.; Masry, K.E. Evaluation of the quantitative fetal fibronectin test and PAMG-1 test for the prediction of spontaneous preterm birth in patients with signs and symptoms suggestive of preterm labor. J. Matern. Fetal Neonatal Med. 2018, 32, 3909–3914. [Google Scholar] [CrossRef] [PubMed]
- Nikolova, T.; Uotila, J.; Nikolova, N.; Bolotskikh, V.M.; Borisova, V.Y.; Renzo, G.C.D. Prediction of spontaneous preterm delivery in women presenting with premature labor: A comparison of placenta alpha microglobulin-1, phosphorylated insulin-like growth factor binding protein-1, and cervical length. Am. J. Obstet. Gynecol. 2018, 219, 610.e1–610.e9. [Google Scholar] [CrossRef]
- Volpe, N.; Schera, G.B.L.; Dall Asta, A.; Pasquo, E.D.; Ghi, T.; Frusca, T. Cervical sliding sign: New sonographic marker to predict impending preterm delivery in women with uterine contractions. Ultrasound Obstet. Gynecol. 2019, 54, 557–558. [Google Scholar] [CrossRef]
- Baños, N.; Julià, C.; Lorente, N.; Ferrero, S.; Cobo, T.; Gratacos, E.; Palacio, M. Mid-Trimester Cervical Consistency Index and Cervical Length to Predict Spontaneous Preterm Birth in a High-Risk Population. Am. J. Perinatol. Rep. 2018, 08, e43–e50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baer, G.R.; Nelson, R.M. Preterm Birth: Causes, Consequences, and Prevention. C: A Review of Ethical Issues Involved in Premature Birth. Available online: https://www.ncbi.nlm.nih.gov/books/NBK11389/ (accessed on 28 December 2020).
- Phillips, M. International data-sharing norms: From the OECD to the General Data Protection Regulation (GDPR). Hum. Genet. 2018, 137, 575–582. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| Author | Data Type | Group Size | PTB % | Gestation Age (Week) | Data Source |
|---|---|---|---|---|---|
| Grzymała-Busse et al. [75] | EHR | 18,890 | - | - | St. Luke’s Regional Perinatal Center, Healthdyne Perinatal Services, Tokos Corporation |
| Woolery et al. [76] | EHR | 18,899 | - | - | St. Luke’s Regional Perinatal Center, Healthdyne Perinatal Services, Tokos Corporation |
| Mercer et al. [77] | EHR | 2929 | 10.55 | 23–24 | Maternal-Fetal Medicine Units Network |
| Goodwin et al. [78] | EHR | 63,167 | 22 | - | Duke University’s Medical Center |
| Frize et al. [79] | EHR | 113,000 | 17 | - | The Pregnancy Risk Assessment Monitoring System (PRAMS) database |
| Vovsha et al. [18] | EHR | 2929 | 10.55 | - | Maternal-Fetal Medicine Units Network |
| Tran et al. [11] | EHR | 18,836 | 6.81 | - | Royal North Shore (RNS) hospital |
| Weber et al. [80] | EHR | 336,214 | 1.02 | - | - |
| Esty et al. [81] | EHR | 782,000 | 7.09 | - | BORN (Better Outcomes Registry Network) Information System, PRAMS (Pregnancy Risk Monitoring Assessment) |
| Gao et al. [12] | EHR | 25,689 | 8.09 | - | Vanderbilt University Medical Center |
| Prema et al. [82] | EHR | 124 | 14.52 | - | Local hospitals of Mysuru, Karnataka state, India |
| Lee et al. [83] | EHR | 596 | 7.21 | 18–24 | Anam Hospital in Seoul, Korea |
| Rawashdeh et al. [84] | EHR | 274 | 9.49 | - | Fetal medicine unit in a tertiary hospital in NSW, Australia |
| Koivu et al. [85] | EHR | 15,883,784 | 9.65 | - | CDC - National Center of Health Statistics |
| Fergus et al. [19] | EHG | 300 | 12.67 | - | TPEHG |
| Hussain et al. [64] | EHG | 300 | 12.67 | - | TPEHG |
| Sadi-Ahmed et al. [86] | EHG | - | - | - | TPEHG |
| Despotovic et al. [87] | EHG | 160 | 11.73 | 22–25 | TPEHG |
| Chen et al. [88] | EHG | 31 | 41.94 | - | TPEHGT |
| Degbedzui et al. [89] | EHG | 300 | 12.67 | 22–32 | TPEHG |
| Włodarczyk et al. [9] | TVS | 354 | 10.97 | - | King’s College London, Medical University of Warsaw |
| Włodarczyk et al. [10] | TVS | 359 | 11.98 | - | King’s College London, Medical University of Warsaw |
| Maner et al. [90] | EMG | 185 | 27.57 | - | University of Texas Medical Branch |
| Most et al. [91] | EMG | 87 | 100 | - | - |
| Recording | Recording Week Median | Term Delivery | Preterm Delivery |
|---|---|---|---|
| Early Term | 23 | 143 | 19 |
| Late term | 30 | 119 | 19 |
| Author | Methods | Results | Data Type | Year |
|---|---|---|---|---|
| Woolery et al. [76] | LERS, ID3 Tree | Accuracy: 0.53–0.88 | EHR | 1994 |
| Grzymała-Busse et al. [75] | LERS, genetic algorithm | Accuracy: 0.68–0.90 | EHR | 1994 |
| Mercer et al. [77] | Univariate analysis and multivariate logistic regression | Recall: 0.18-0.24, Precision: 0.29–0.33 | EHR | 1996 |
| Goodwin et al. [78] | Neural networks, CART, logistic regression | AUC = 0.76 | EHR | 2000 |
| Maner et al. [90] | FFT, Kohonen Network | Accuracy = 0.82 | EHG | 2007 |
| Most et al. [91] | Bivariate analysis, CHI square logistic regression, Fisher’s test | Recall = 0.41, Specificity = 0.92 | EMG | 2008 |
| Frize et al. [79] | Neural network, decision tree | Recall: 0.65–0.66, Specificity: 0.71–0.84 | EHR | 2011 |
| Fergus et al. [19] | K-NN, decision trees, SVM | AUC = 0.95, Recall = 0.97, Specificity = 0.90 | EHG | 2013 |
| Vovsha et al. [18] | Logistic regression, SVM | Recall = 0.57, Specificity = 0.69 | EHR | 2014 |
| Hussain et al. [64] | DSIA (Dynamic Self-Organised Network), benchmark: SONIA, MLP, Fuzzy-SONIA, K-NN | AUC = 0.93, Recall = 0.89, Specificity = 0.91 | EHG | 2015 |
| Tran et al. [11] | Logistic regression, randomised gradient boosting, stochastic gradient boosting, random forest | AUC = 0.81 | EHR | 2016 |
| Sadi-Ahmed et al. [86] | Huang-Hilbert transform (HHT), IMF, SVM | AUC = 0.95, Recall = 0.99, Specificity = 0.98 | EHG | 2017 |
| Weber et al. [80] | Super learning (SL), K-NN, random forest, lasso regression, ridge regression, elastic net, Generalised Additive Models (GAM) | AUC = 0.67 | EHR | 2018 |
| Despotovic et al. [87] | Random forest, K-NN, SVM | Accuracy = 0.99, AUC = 0.99, Recall = 0.98 | EHG | 2018 |
| Esty et al. [81] | Decision trees, neural networks | AUC = 0.81, Recall = 0.91, Specificity = 0.72 | EHR | 2018 |
| Gao et al. [12] | BOW and word embedding (NLP), recurrent neural network (RNN), regularised logistic regression | AUC = 0.83, Recall = 0.966, Specificity = 0.70 | EHR | 2019 |
| Włodarczyk et al. [9] | Convolutional neural network (CNN), SVM, K-NN, Naive Bayes, Decision trees | Accuracy = 0.78, AUC = 0.78, Recall = 0.74, Precision = 0.85 | TVS | 2019 |
| Prema et al. [82] | SVM, logistic regression | Accuracy = 0.76, Recall = 0.84, Specificity = 0.73, Precision = 0.84 | EHR | 2019 |
| Lee et al. [83] | Naive Bayes, neural networks, SVM, logistic regression, decision trees, random forest | Accuracy = 0.92 | EHR | 2019 |
| Chen et al. [88] | Wavelet entropy, Stacked Sparse Autoencoder (SSAE) | Accuracy = 0.98, Recall = 0.98, Specificity = 0.98 | EHG | 2020 |
| Degbedzui et al. [89] | SVM | Accuracy = 0.997, Recall = 0.995, Specificity = 1.0 | EHG | 2020 |
| Rawashdeh et al. [84] | Naive Bayes, decision trees, K-NN, random forest, neural networks | Accuracy = 0.95, AUC = 0.98, Recall = 1.0, Specificity = 0.94 | EHR | 2020 |
| Włodarczyk et al. [10] | CNN - FCN, DeepLab, U-Net | Recall = 0.68, Specificity = 0.97 | TVS | 2020 |
| Koivu et al. [85] | Logistic regression, neural networks, gradient boosting | AUC = 0.64 | EHR | 2020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Włodarczyk, T.; Płotka, S.; Szczepański, T.; Rokita, P.; Sochacki-Wójcicka, N.; Wójcicki, J.; Lipa, M.; Trzciński, T. Machine Learning Methods for Preterm Birth Prediction: A Review. Electronics 2021, 10, 586. https://doi.org/10.3390/electronics10050586
Włodarczyk T, Płotka S, Szczepański T, Rokita P, Sochacki-Wójcicka N, Wójcicki J, Lipa M, Trzciński T. Machine Learning Methods for Preterm Birth Prediction: A Review. Electronics. 2021; 10(5):586. https://doi.org/10.3390/electronics10050586
Chicago/Turabian StyleWłodarczyk, Tomasz, Szymon Płotka, Tomasz Szczepański, Przemysław Rokita, Nicole Sochacki-Wójcicka, Jakub Wójcicki, Michał Lipa, and Tomasz Trzciński. 2021. "Machine Learning Methods for Preterm Birth Prediction: A Review" Electronics 10, no. 5: 586. https://doi.org/10.3390/electronics10050586