
Adaptive and Optimized RDF Query Interface for Distributed WFS Data



Abstract
:1. Introduction
- WFS is designed for querying data in a single WFS server. To query data distributed in multiple WFS servers, a data client needs to be implemented. In particular, the user query may require spatial joins of data from different servers. When this happens, the data client has to send out multiple WFS GetFeature requests derived from the user query and then integrate the multiple WFS responses to produce an answer to the original query. It is more convenient from users’ perspectives to consider the distributed data as centralized data so that a single user query can be used regardless of where the source data is located.In addition, user queries often involve the same intermediate results. Repeatedly requesting the same data adds unnecessary workload to the WFS servers, wastes network bandwidth, and increases the response time of the data client. This is especially critical under emergency situations when peak data requests might overwhelm data servers. Therefore, caching the results of the GetFeature requests is an important aspect for the implementation of the data client.For example, to display the flooded streets near high schools during a hurricane, where the school and street datasets are located in two WFS servers, it is necessary to first query each server with a WFS request and then integrate the extracted data from each server to get the answers. To handle these types of tasks, there are several possible design choices.The first choice is to provide a fixed set of user queries with predefined translation to WFS requests. However, users are limited to this set of queries and any new queries would require developers to revise the data client, which is not suitable for emergency situations.The second choice is to provide a separate query interface for each data source and allow users to overlay the query results on a base map to achieve the visual effect of spatial joins. However, if the different datasets have semantic heterogeneity problems, it is difficult to do this without human assistance or conversion. For example, a WFS may advertise as a “freeway”-feature data provider, whereas another WFS may advertise as a “highway”-feature data provider even though the “freeway” feature and the “highway” feature refer to the same concept. Users cannot automatically compose and synthesize the two feature datasets together without additional human interpretation or conversion.The third choice is to first integrate the distributed data into a flexible format such as Resource Description Framework (RDF) and then query the integrated data through an RDF query engine. However, this approach is not scalable to large datasets. In addition, for frequently updated geospatial data such as that for emergency management, it is infeasible to convert WFS features into RDF format each time there is a change.
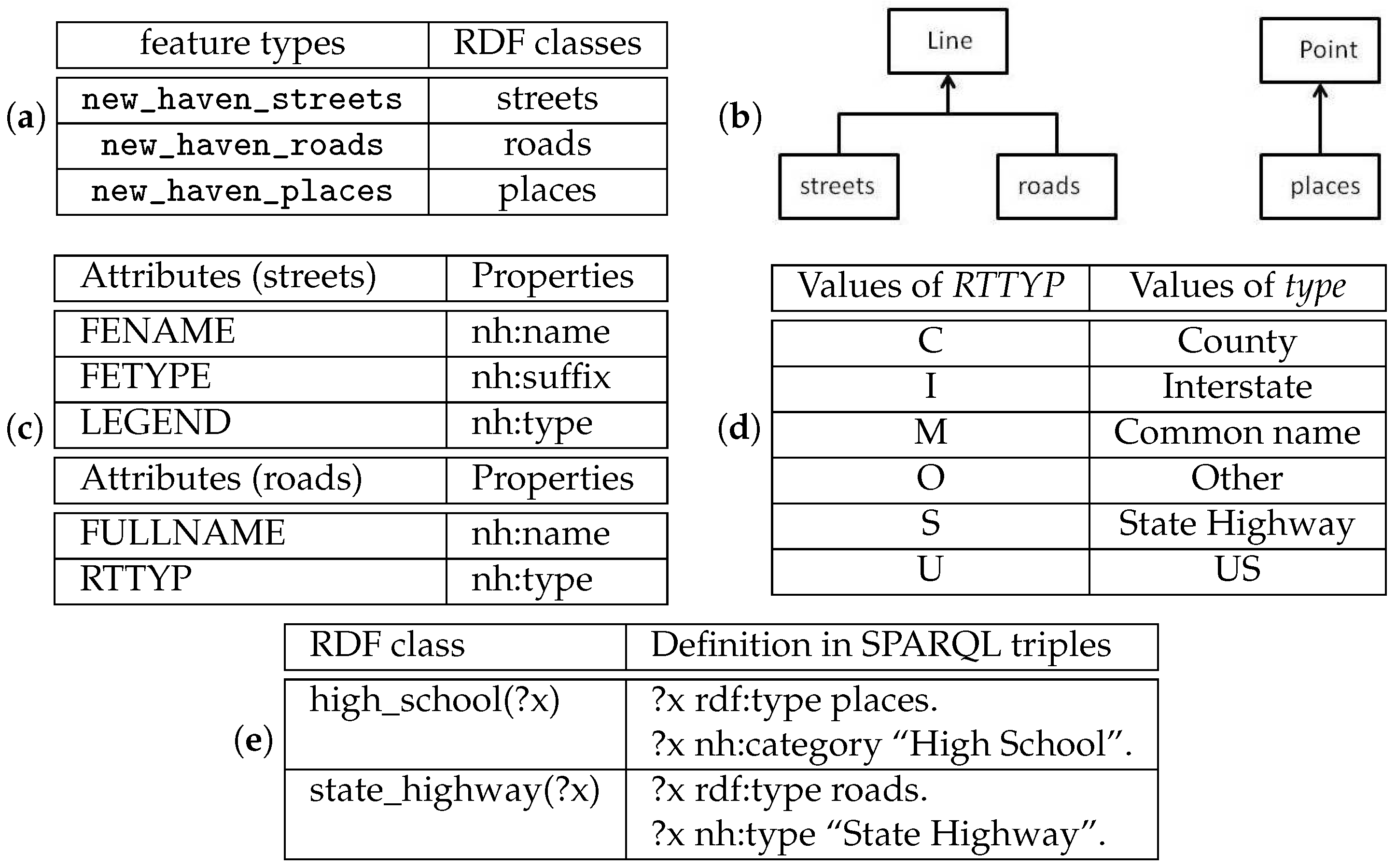
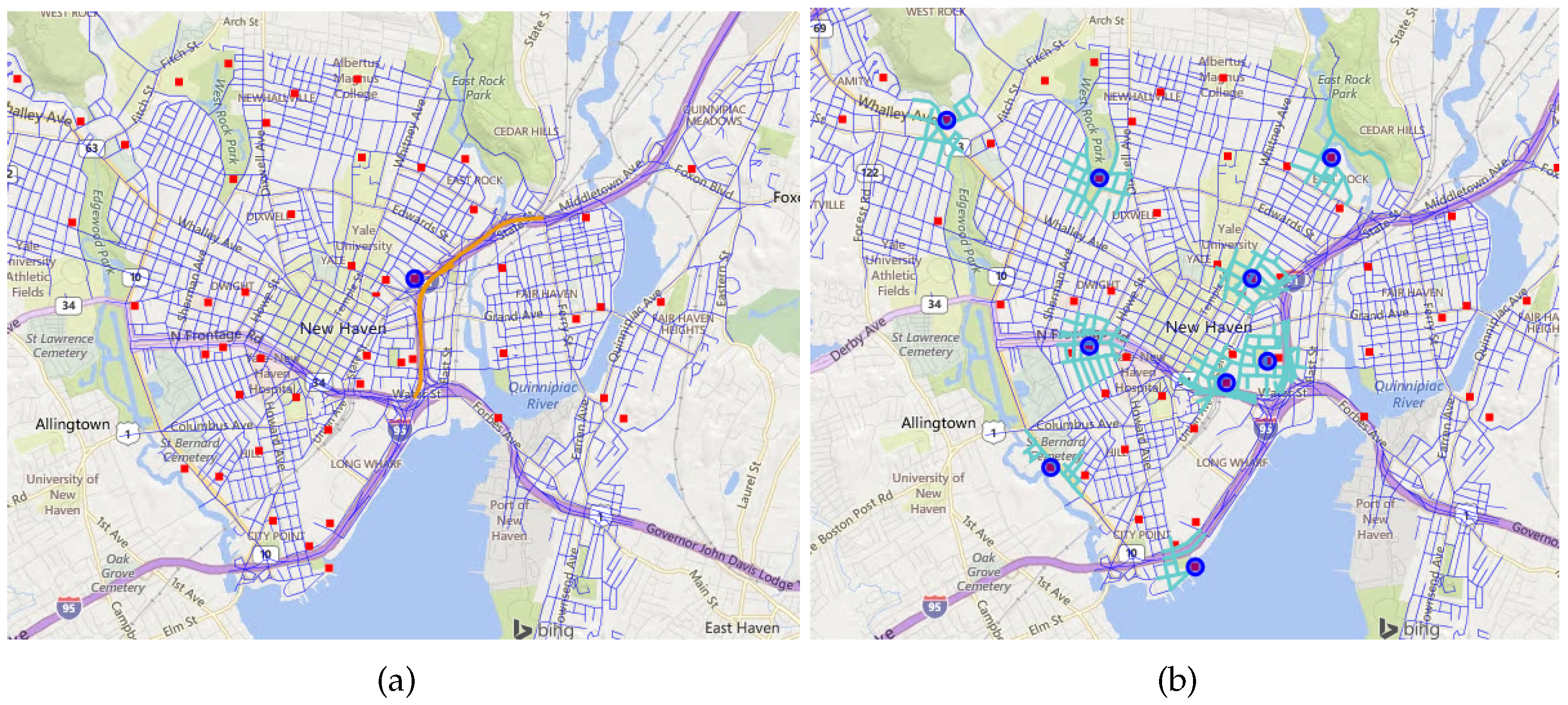
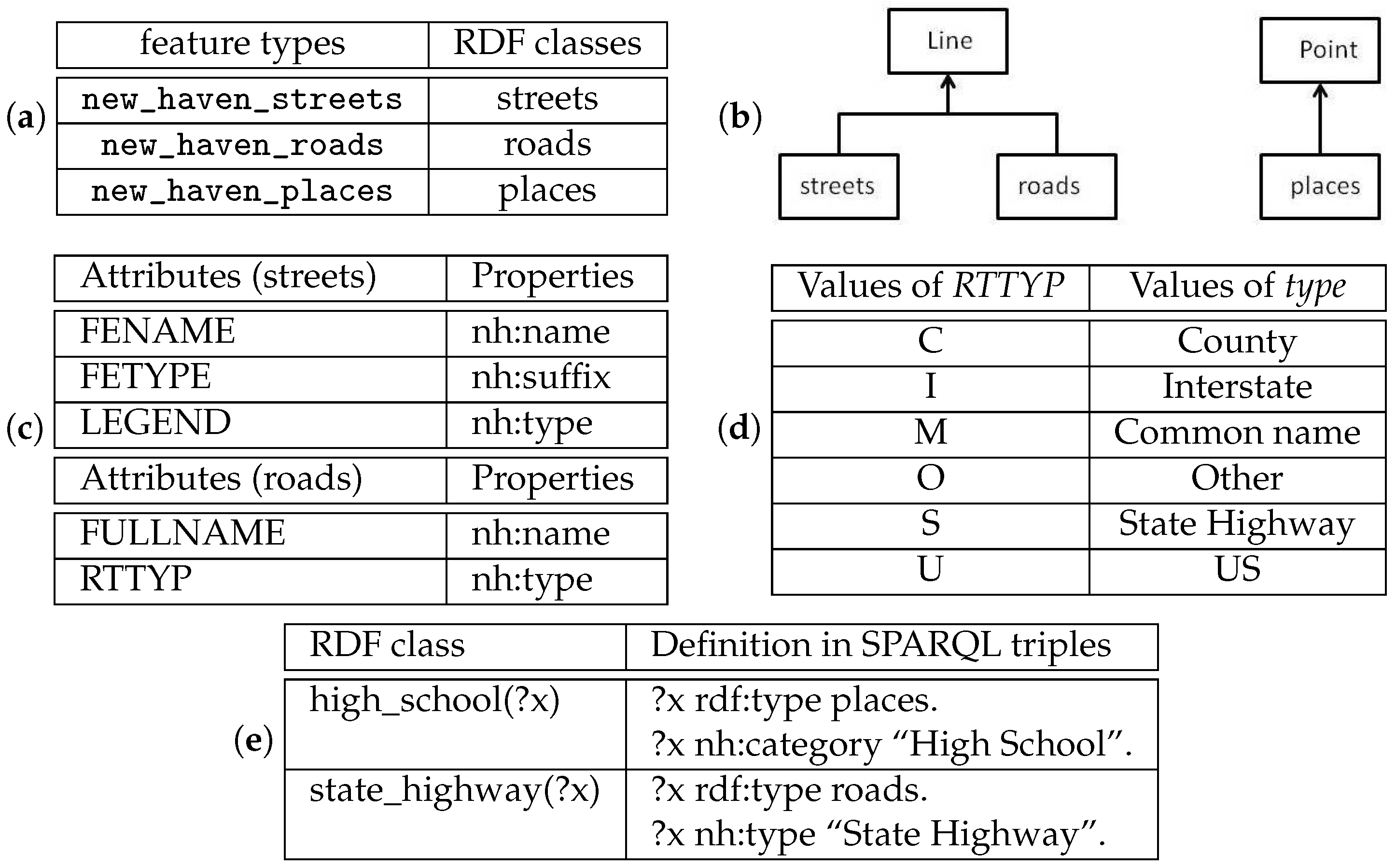
- The definitions of WFS features are often auto-generated from the underlying data sources, which may not correspond to the definitions of the same concepts in user applications.For example, to retrieve high schools near state highways and display the results on a map, a user has to find out the feature types, feature attributes, and values for encoding the suitable WFS requests. For example, the state highways and schools are contained in the feature type new_haven_road and new_haven_places, respectively, and the filters arewhere RTTYP is the attribute in new_haven_road to identify road type and S is the value for state highway while CATEGORY is the attribute in new_haven_places to identify the type of the place. Users have to guess the meaning of the feature types and attributes each time they want to encode a GetFeature request. Simple mistakes such as typographical errors can cause a GetFeature request to fail. Moreover, similar concepts at user level may be stored by different WFS features. For instance, to find the local roads, a user needs to query the feature type new_haven_street with the filter LEGEND PropertyIsEqualTo "Local Road".
2. Overview
2.1. RDF Query Interface
2.2. RDF Queries as WFS Requests
3. Related Work
4. RDF Mapping
5. Translate RDF Query to WFS Requests
5.1. Syntax
5.2. Translation Algorithm
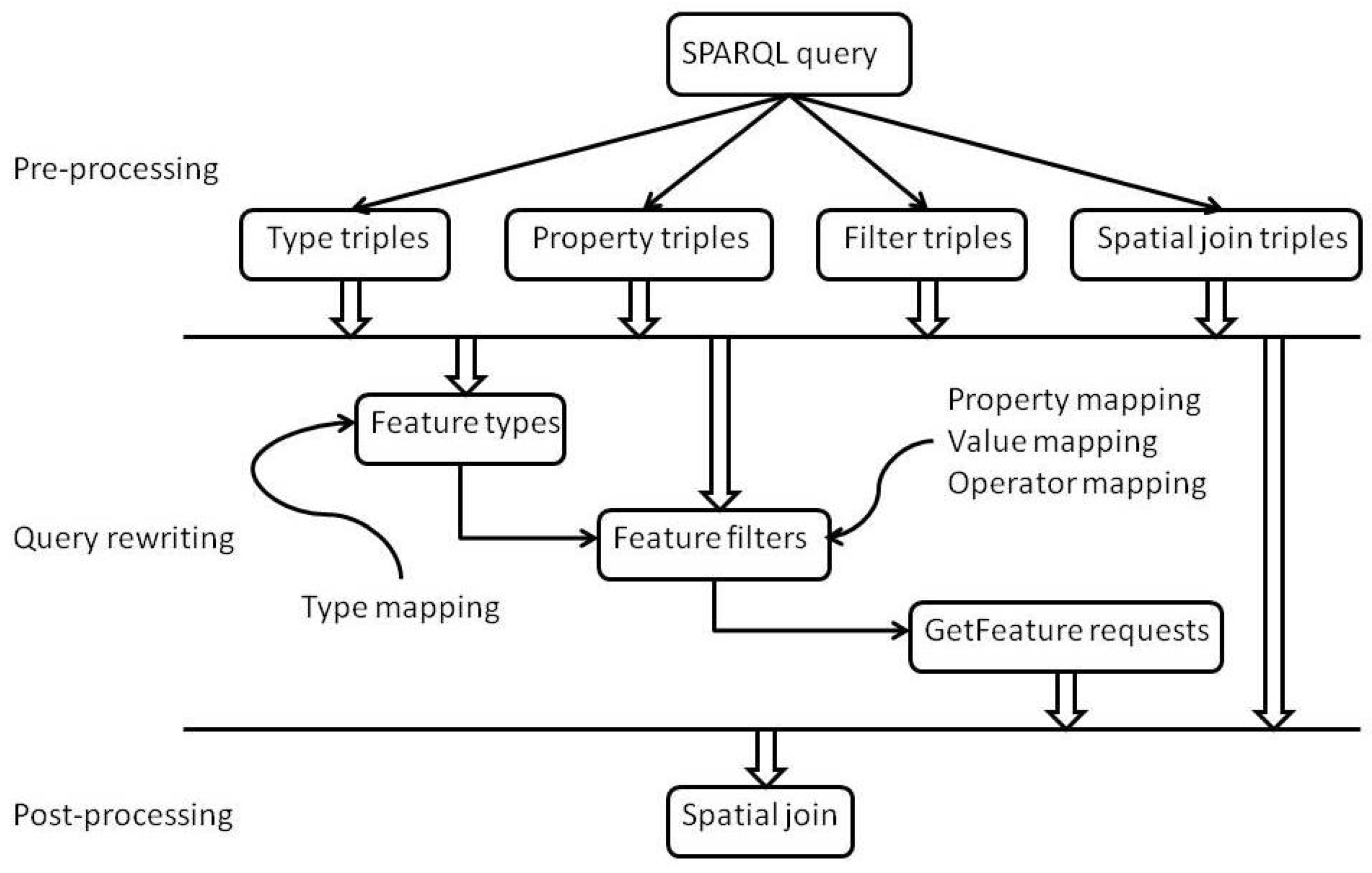
5.2.1. Pre-Processing
5.2.2. Query Rewriting
5.2.3. Post-Processing
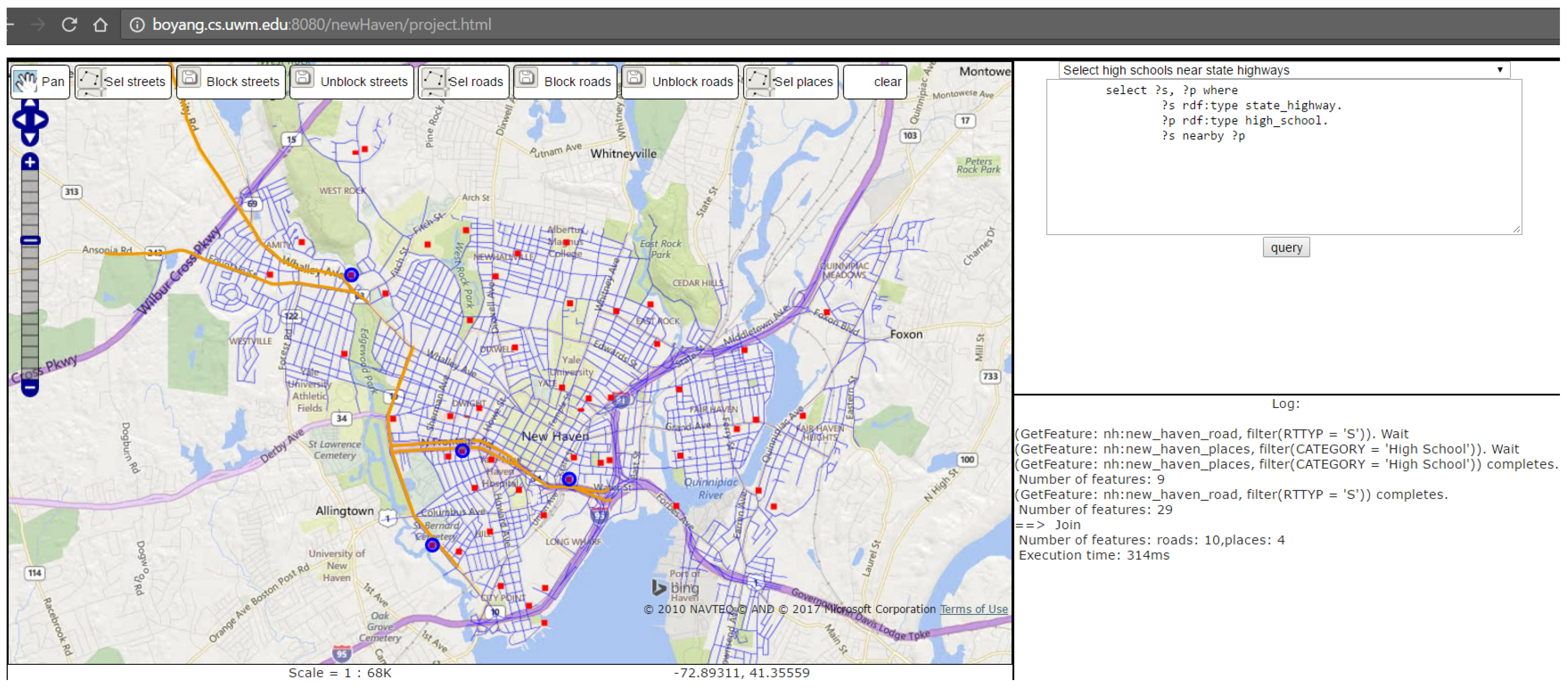
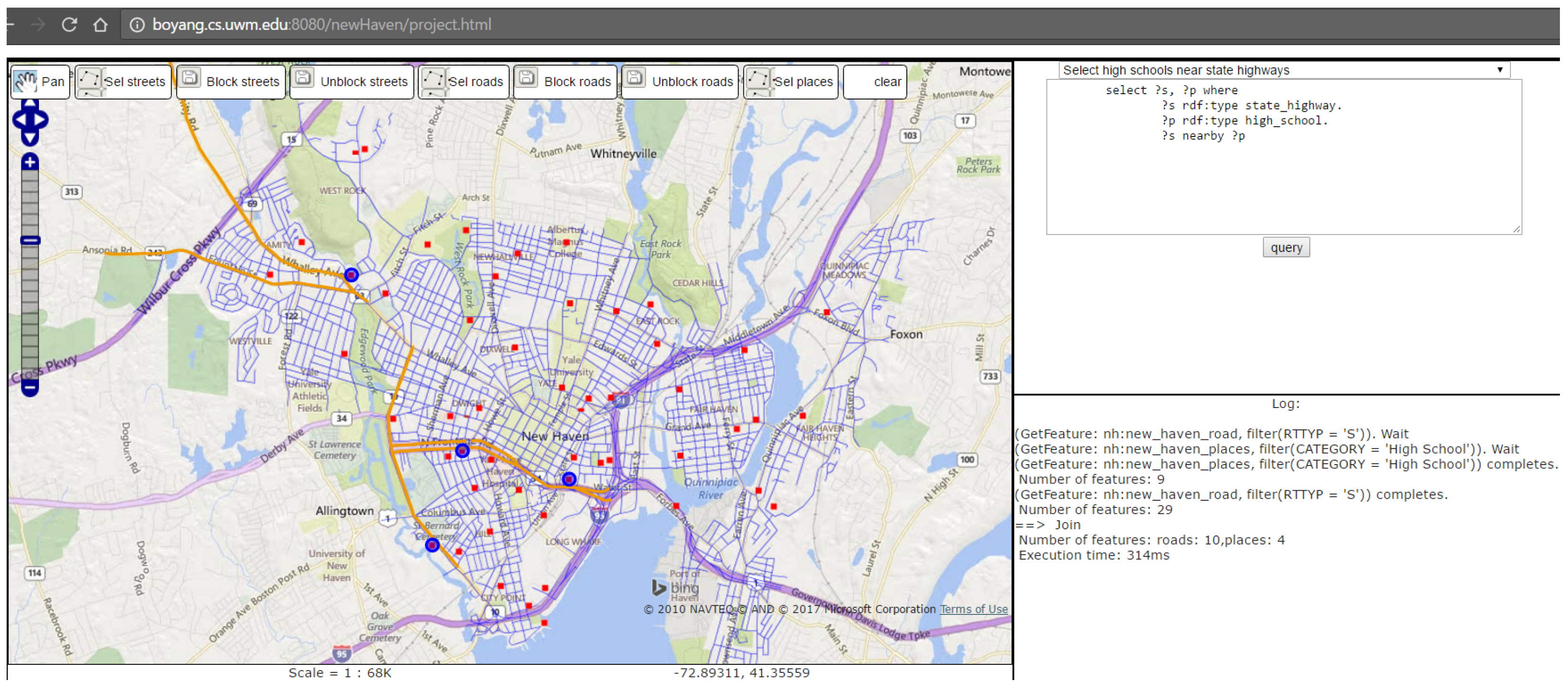
6. Implementation
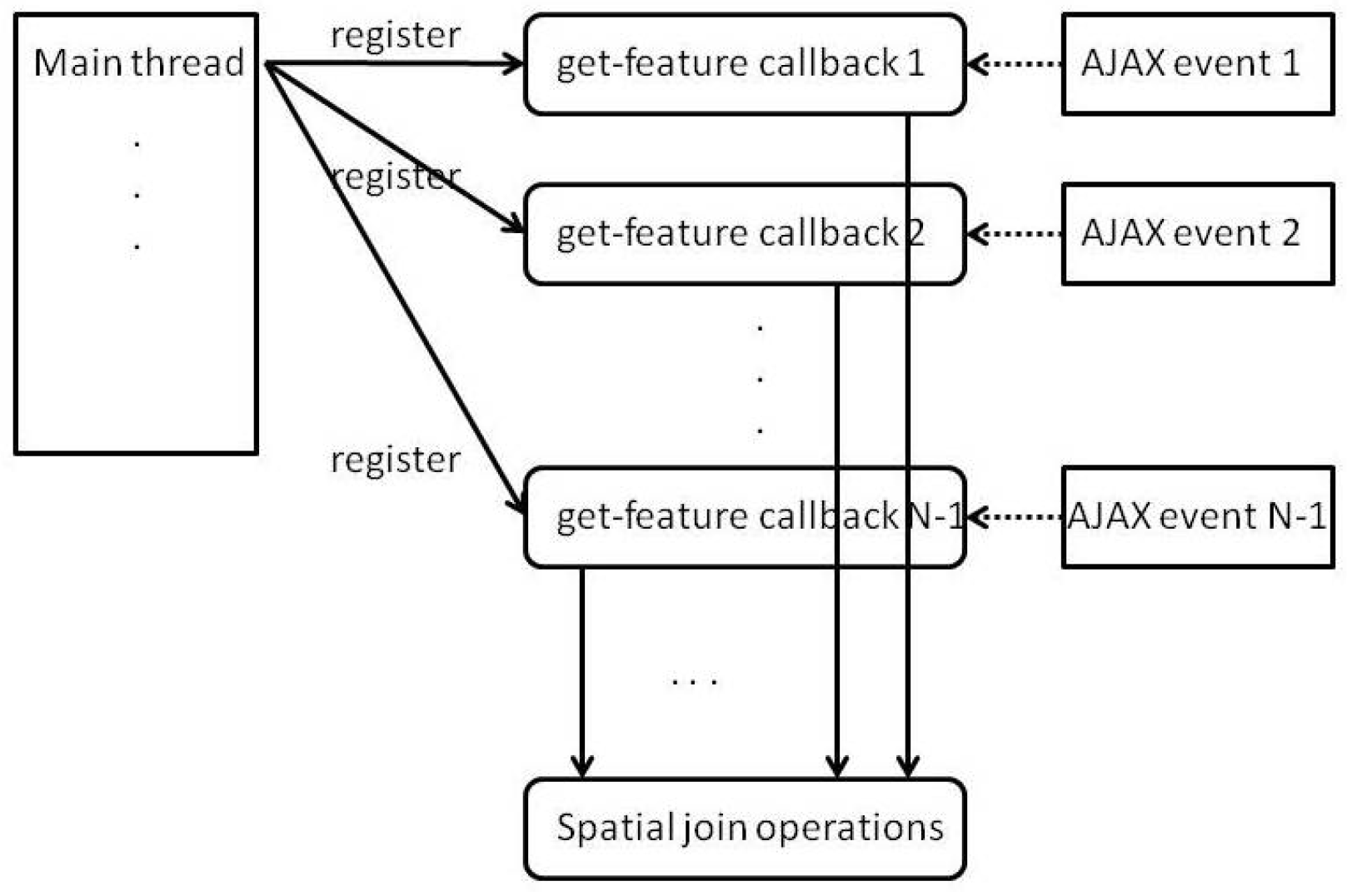
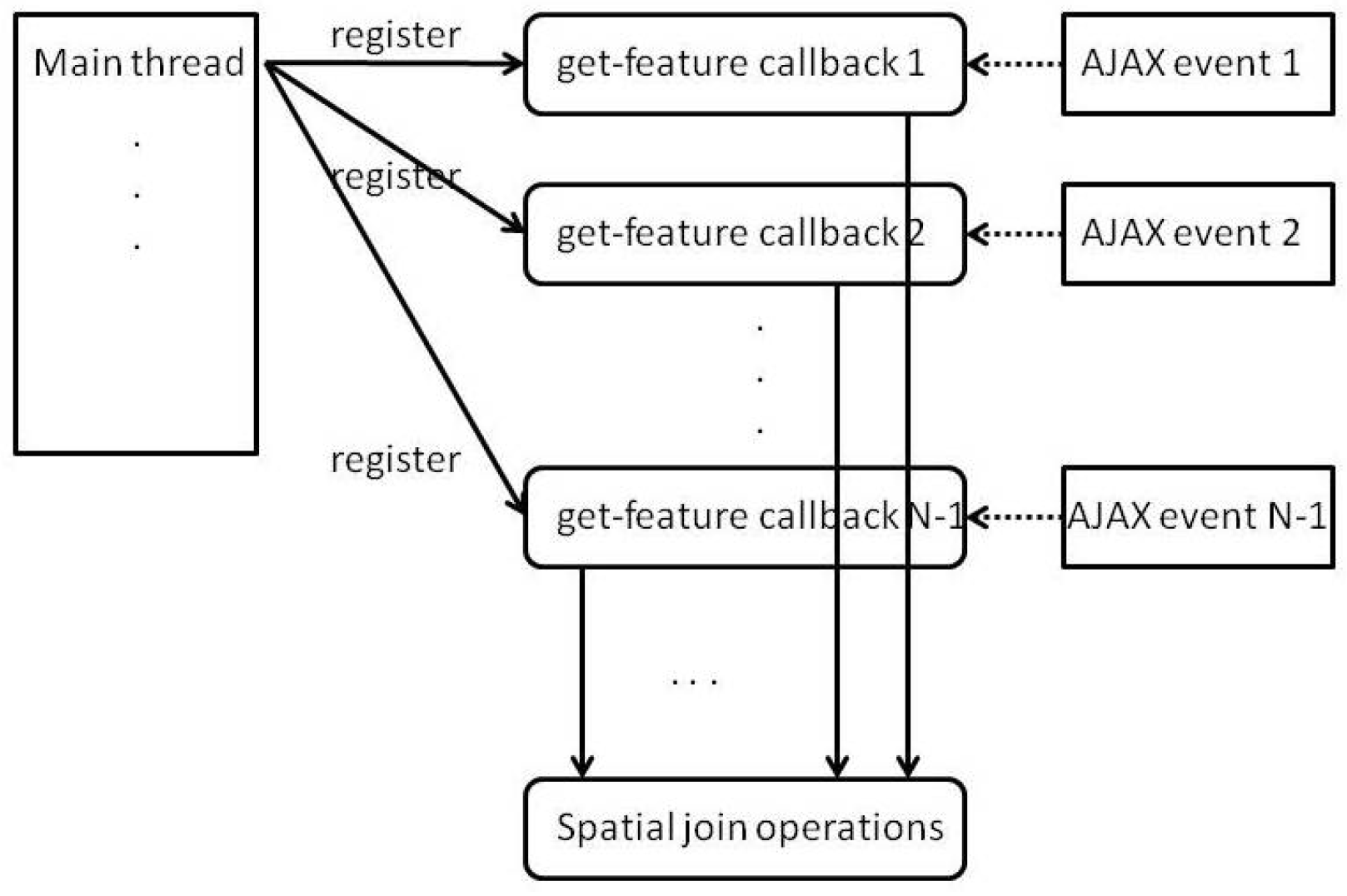
6.1. Feature Retrieval and Callbacks
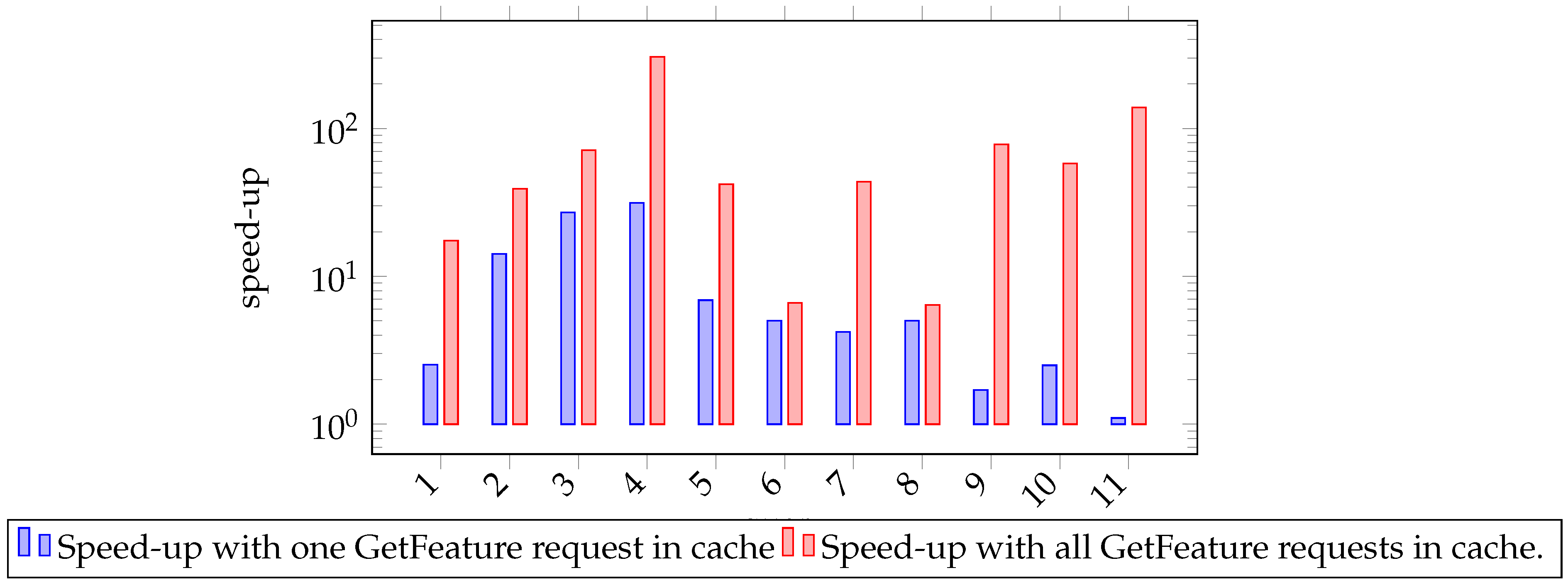
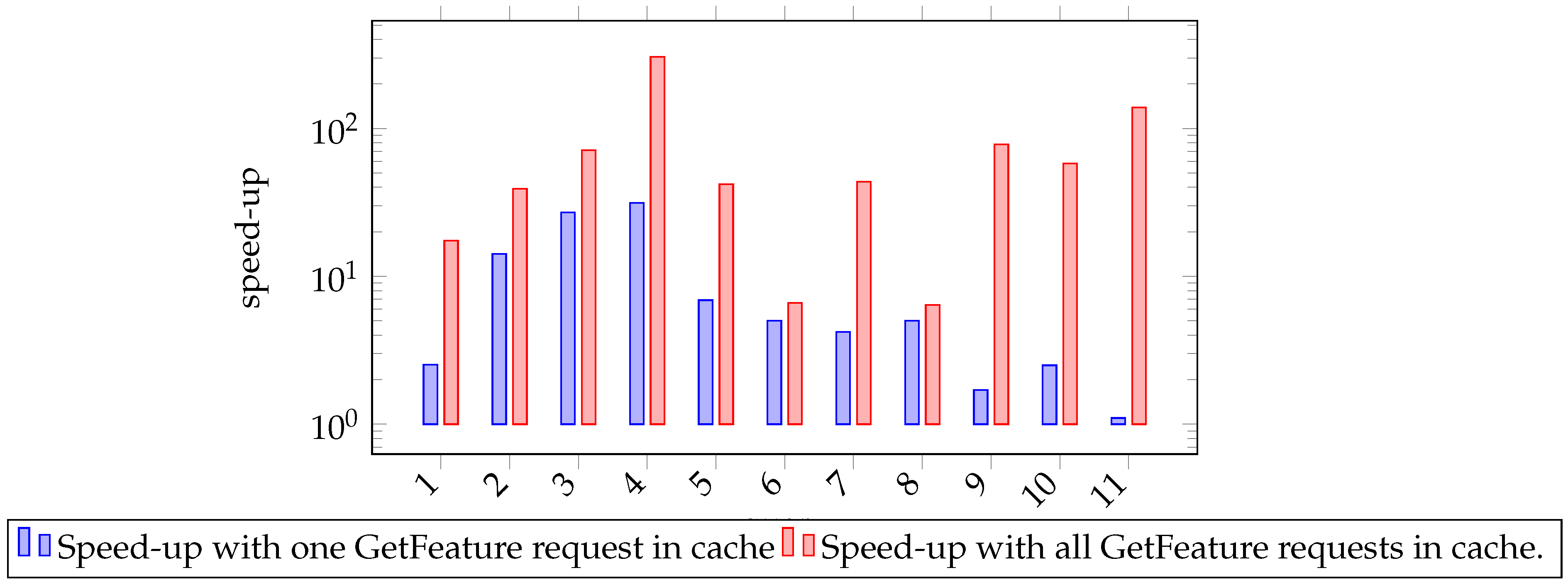
6.2. Caching
7. Evaluation
- Select high schools near state highways;
- Select roads near middle schools;
- Select streets near high schools;
- Select streets near “Fair Haven School” and less than 500 feet long;
- Select highways near high schools;
- Select the streets near the road “Connecticut Tpke”;
- Select the middle schools near interstates;
- Select the elementary schools and streets near the road “Connecticut Tpke”;
- Select streets and roads of the name “Lawrence”;
- Select features of the name “I-95”;
- Select features of the name “Q Bridge”.
8. Discussion
9. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Battle, R.; Kolas, D. Enabling the geospatial Semantic Web with Parliament and GeoSPARQL. Semantic Web 2012, 3, 355–370. [Google Scholar]
- Stadler, C.; Lehmann, J.; Hoffner, K.; Auer, S. LinkedGeoData: A core for a web of spatial open data. Semantic Web 2012, 3, 333–354. [Google Scholar]
- GeoServer—Open Source Server for Sharing Geospatial Data. Available online: http://geoserver.org (accessed on 3 April 2017).
- MapServer—Open Source Web Mapping. Available online: http://mapserver.org (accessed on 3 April 2017).
- OpenLayers—A High-Performance, Feature-Packed Library for All Your Mapping Needs. Available online: http://openlayers.org (accessed on 3 April 2017).
- SPARQL Query Language for RDF. Available online: https://www.w3.org/TR/rdf-sparql-query (accessed on 3 April 2017).
- GeoSPARQL-A Geographic Query Language for RDF Data. Available online: http://www.opengeospatial.org/standards/geosparql (accessed on 3 April 2017).
- Martin, D.; Paolucci, M.; Wagner, M. Toward semantic annotations of Web services: OWL-S from the SAWSDL Perspective. In Proceedings of the 6th International Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 340–352. [Google Scholar]
- Lausen, H.; Polleres, A.; Roman, D. Web Service Modeling Ontology (WSMO). Available online: http://www.w3.org/Submission/WSMO/ (accessed on 3 April 2017).
- Fensel, D.; Bussler, C.; Ding, Y.; Omelayenko, B. The Web Service Modeling Framework (WSMF). Electron. Commer. Res. Appl. 2002, 1, 113–137. [Google Scholar] [CrossRef]
- Akkiraju, R.; Farrell, J.; Miller, J.; Nagarajan, M.; Schmidt, T.; Sheth, A. Web Service Semantics - WSDL-S. Available online: https://www.w3.org/Submission/WSDL-S/ (accessed on 3 April 2017).
- Swift, T. An engine for computing well-founded models. Lect. Notes Comput. Sci. 2009, 5649, 514–518. [Google Scholar]
- Alves, M.; Damasio, C.; Correia, N. RDF query inference in Prolog. Commun. Comput. Inf. Sci. 2016, 649, 191–201. [Google Scholar]
- Papadimitriou, F. Artificial Intelligence in modelling the complexity of Mediterranean Ecosystems. Comput. Electron. Agric. 2012, 81, 87–96. [Google Scholar] [CrossRef]
- Shi, X.; Nellis, M.D. Semantic Web and service computation in GIScience applications: a perspective and prospective. Geocarto Int. 2014, 29, 400–417. [Google Scholar] [CrossRef]
- Yue, P. Semantic Web-Based Intelligent Geospatial Web Services; Springer Briefs in Computer Science; Springer: New York, NY, USA, 2013; p. 119. [Google Scholar]
- Janowicz, K.; Scheider, S.; Pehle, T.; Hart, G. Geospatial semantics and linked spatiotemporal data: Past, present, and future. Semantic Web 2012, 3, 321–332. [Google Scholar]
- Ashish, N.; Sheth, A. (Eds.) Semantic Web and Beyond: Geospatial Semantics and the Semantic Web: Foundations, Algorithms, and Applications; Springer: New York, NY, USA, 2011; p. 260. [Google Scholar]
- Zhao, P.; Di, L. (Eds.) Geospatial Web Services: Advances in Information Interoperability; IGI Global: Hershey, PA, USA, 2011; p. 552. [Google Scholar]
- Janowicz, K.; Raubal, M.; Levashkin, S. GeoSpatial Semantics. In Proceedings of the Third International Conference on GeoSpatial Semantics, GeoS 2009, Mexico City, Mexico, 3–4 December 2009. [Google Scholar]
- Di, L.; Zhao, P. Geospatial Semantic Web interoperability. In Encyclopedia of GIS; Springer: New York, NY, USA, 2008; pp. 70–77. [Google Scholar]
- Li, W.; Yang, C.; Raskin, R. A semantic enhanced model for searching in spatial web portals. In Proceedings of the AAAI Spring Symposium Semantic Scientific Knowledge Integration, Palo Alto, CA, USA, 26–28 March 2008; pp. 47–50. [Google Scholar]
- Lutz, M.; Klien, E. Ontology-based retrieval of geographic information. Int. J. Geogr. Inf. Sci. 2006, 20, 233–260. [Google Scholar] [CrossRef]
- Kuhn, W. Geospatial semantics: Why, of what, and how? J. Data Semant. 2005, 3, 1–24. [Google Scholar]
- Yue, P.; Di, L.; Yang, W.; Yu, G.; Zhao, P. Semantics-based automatic composition of geospatial web service chains. Comput. Geosci. 2007, 33, 649–665. [Google Scholar] [CrossRef]
- Wiegand, N.; Garcia, C. A task-based ontology approach to automated Geospatial Data Retrieval. Trans. GISA 2007, 11, 355–376. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, T.; Li, W.; Osleeb, J. Towards logic-based geospatial feature discovery and integration using web feature service and geospatial semantic web. Int. J. Geogr. Inf. Sci. 2010, 24, 903–923. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, T.; Li, W. A framework for geospatial semantic web based spatial decision support system. Int. J. Digit. Earth 2010, 3, 111–134. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, T.; Li, W. Automatic search of geospatial features for disaster and emergency management. Int. J. Appl. Earth Obs. Geoinf. 2010, 6, 409–418. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, T.; Li, W. Towards improving query performance of Web Feature Services (WFS) for disaster response. ISPRS Int. J. Geo-Inf. 2013, 2, 67–81. [Google Scholar] [CrossRef]
- Zhao, T.; Zhang, C.; Wei, M.; Peng, Z.R. Ontology-based geospatial data query and integration. In Geographic Information Science; Lecture Notes in Computer Science LNCS5266; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5266, pp. 370–392. [Google Scholar]
- Zhao, T.; Zhang, C.; Anselin, L.; Li, W.; Chen, K. A parallel approach for improving geo-SPARQL query performance. Int. J. Digit. Earth 2014, 8, 383–402. [Google Scholar] [CrossRef]
- Li, W.; Yang, C.; Nebert, D.; Raskinc, R.; Houser, P.; Wu, H.; Li, Z. A semantic-based web service discovery and chaining for building an Arctic spatial data infrastructure. Comput. Geosci. 2011, 37, 1752–1762. [Google Scholar] [CrossRef]
- Jones, J.; Kuhn, W.; Kebler, C.; Scheider, S. Making the web of data available via web feature services. In Proceedings of the 17th AGILE Conference on Geographic Information Science, Connecting a Digital Europe through Location and Place, Castellón, Spain, 3–6 June 2014. [Google Scholar]
- Spanos, D.E.; Stavrou, P.; Mitrou, N. Bringing relational databases into the semantic web: A survey. Semantic Web 2012, 3, 169–209. [Google Scholar]
- Tschirner, S.; Scherp, A.; Staab, S. Semantic access to INSPIRE how to publish and query advanced GML data. In Proceedings of the Workshop in Conjunction of 10th International Semantic Web Conference, Bonn, Germany, 23–27 October 2011. [Google Scholar]
- LOD4WFS-Linked Open Data for Web Feature Services Adapter. Available online: http://github.com/jimjonesbr/lod4wfs (accessed on 3 April 2017).
- Route Type Codes and Definitions. Available online: http://www.census.gov/geo/reference/rttyp.html (accessed on 3 April 2017).
- Flexible RDF Query Interface for Distributed WFS Data. Available online: http://boyang.cs.uwm.edu:8080/newHaven/project.html (accessed on 3 April 2017).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| type triple | ?r rdf:type roads. |
| ?p rdf:type places. | |
| property triple | ?p nh:type ?t. |
| ?p nh:category ?c. | |
| filter triple | ?t == "State Highway". |
| ?c == "High School". | |
| spatial join triple | ?r nearby ?p |
| Streets | Roads | Places | |
|---|---|---|---|
| # of instances | 3449 | 1537 | 54 |
| query time | 3910 ms | 1200 ms | 88 ms |
| total time | 6632 ms | 1832 ms | 131 ms |
| Query | Streets | Roads | Places | Features after Spatial Join |
|---|---|---|---|---|
| 1 | 29 | 9 | (road: 10, place: 4) | |
| 2 | 1537 | 4 | (road: 95, place: 4) | |
| 3 | 3449 | 9 | (street: 360, place: 9) | |
| 4 | 2481 | 1 | (street: 35, place: 1) | |
| 5 | 313 | 9 | (street: 46, place: 4) | |
| 6 | 3449 | 5 | (street: 349, road: 5) | |
| 7 | 9 | 4 | (road: 2, place: 1) | |
| 8 | 3449 | 5 | 32 | (street: 70, road: 5, place: 3) |
| 9 | 8 | 3 | (street: 8, road: 3) | |
| 10 | 42 | 2 | (street: 42, road: 2) | |
| 11 | 1 | (place: 1) |
| Query | Time (ms) | Time1 (ms) | Time2 (ms) | Data Size (kb) | Server/Network Time (ms) |
|---|---|---|---|---|---|
| 1 | 314 | 124 | 18 | 40.4/1.3 | 214/63 |
| 2 | 1953 | 138 | 50 | 465/1.0 | 1550/88 |
| 3 | 5780 | 214 | 81 | 394/1.3 | 3900/97 |
| 4 | 4266 | 136 | 14 | 279/0.84 | 3007/94 |
| 5 | 881 | 127 | 21 | 34.9/1.3/0.63 | 670/72/67 |
| 6 | 7116 | 1425 | 1085 | 394/19.5 | 4160/283 |
| 7 | 437 | 104 | 10 | 24.9/1.0 | 393/191 |
| 8 | 6718 | 1357 | 1056 | 394/19.5/2.3 | 3810/200/166 |
| 9 | 234 | 134 | 3 | 2.2/1.3 | 201/113 |
| 10 | 348 | 139 | 6 | 5.9/5.2/0.63 | 123/300/93 |
| 11 | 277 | 253 | 2 | 0.63/0.63/0.83 | 165/258/141 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, T.; Zhang, C.; Li, W. Adaptive and Optimized RDF Query Interface for Distributed WFS Data. ISPRS Int. J. Geo-Inf. 2017, 6, 108. https://doi.org/10.3390/ijgi6040108
Zhao T, Zhang C, Li W. Adaptive and Optimized RDF Query Interface for Distributed WFS Data. ISPRS International Journal of Geo-Information. 2017; 6(4):108. https://doi.org/10.3390/ijgi6040108
Chicago/Turabian StyleZhao, Tian, Chuanrong Zhang, and Weidong Li. 2017. "Adaptive and Optimized RDF Query Interface for Distributed WFS Data" ISPRS International Journal of Geo-Information 6, no. 4: 108. https://doi.org/10.3390/ijgi6040108
APA StyleZhao, T., Zhang, C., & Li, W. (2017). Adaptive and Optimized RDF Query Interface for Distributed WFS Data. ISPRS International Journal of Geo-Information, 6(4), 108. https://doi.org/10.3390/ijgi6040108