Seasonal Drought Forecasting for Latin America Using the ECMWF S4 Forecast System



Abstract
:1. Introduction
2. Study Area, Datasets and Methods
2.1. Forecasts: The ECMWF Seasonal Forecast System (S4)
2.2. Observations: The GPCC Full Data Reanalysis Version 6.0
2.3. Drought Indicator: The Standardized Precipitation Index (SPI)
2.4. Drought Detection and Verification Methods
3. Results and Discussion
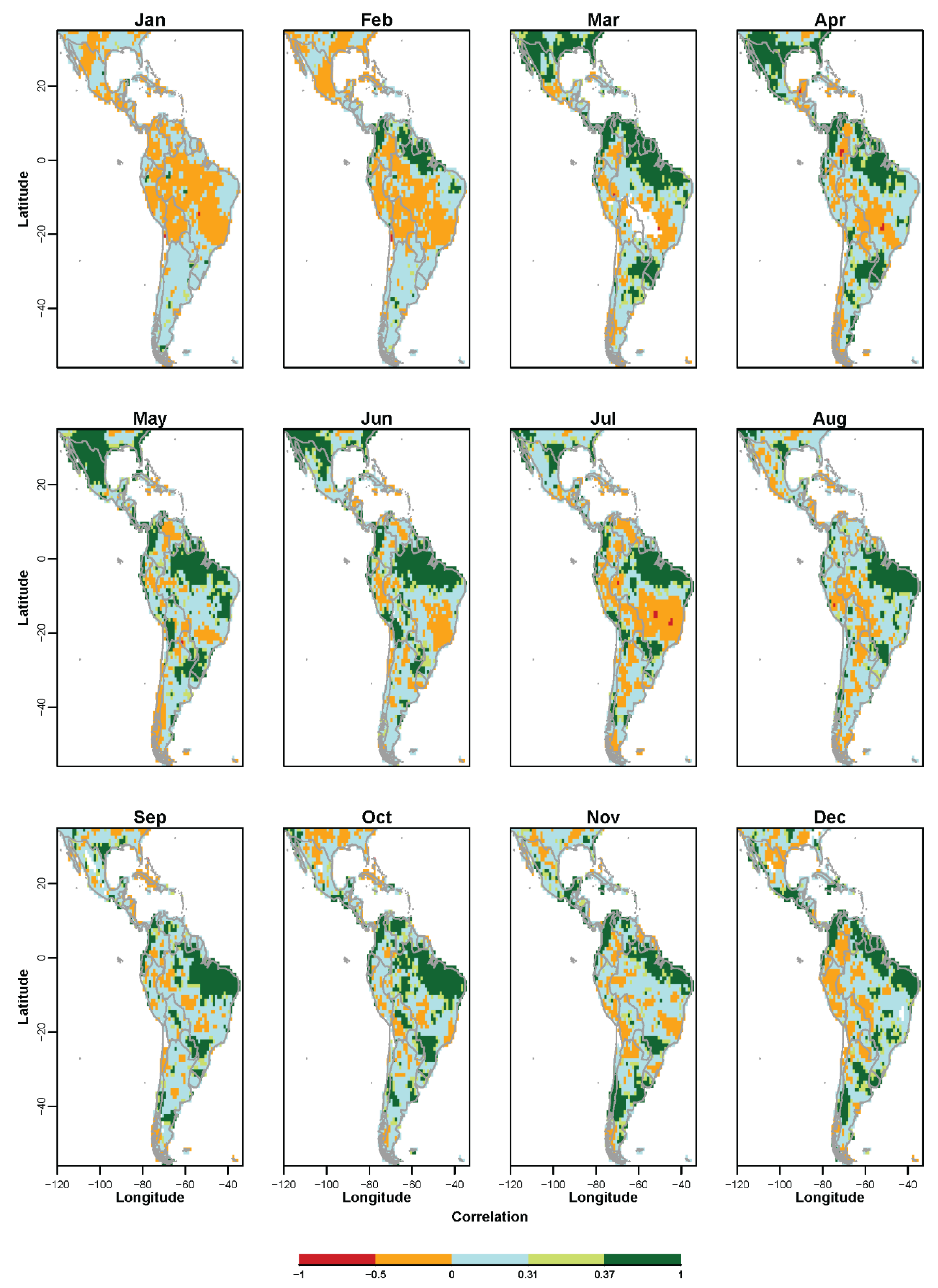
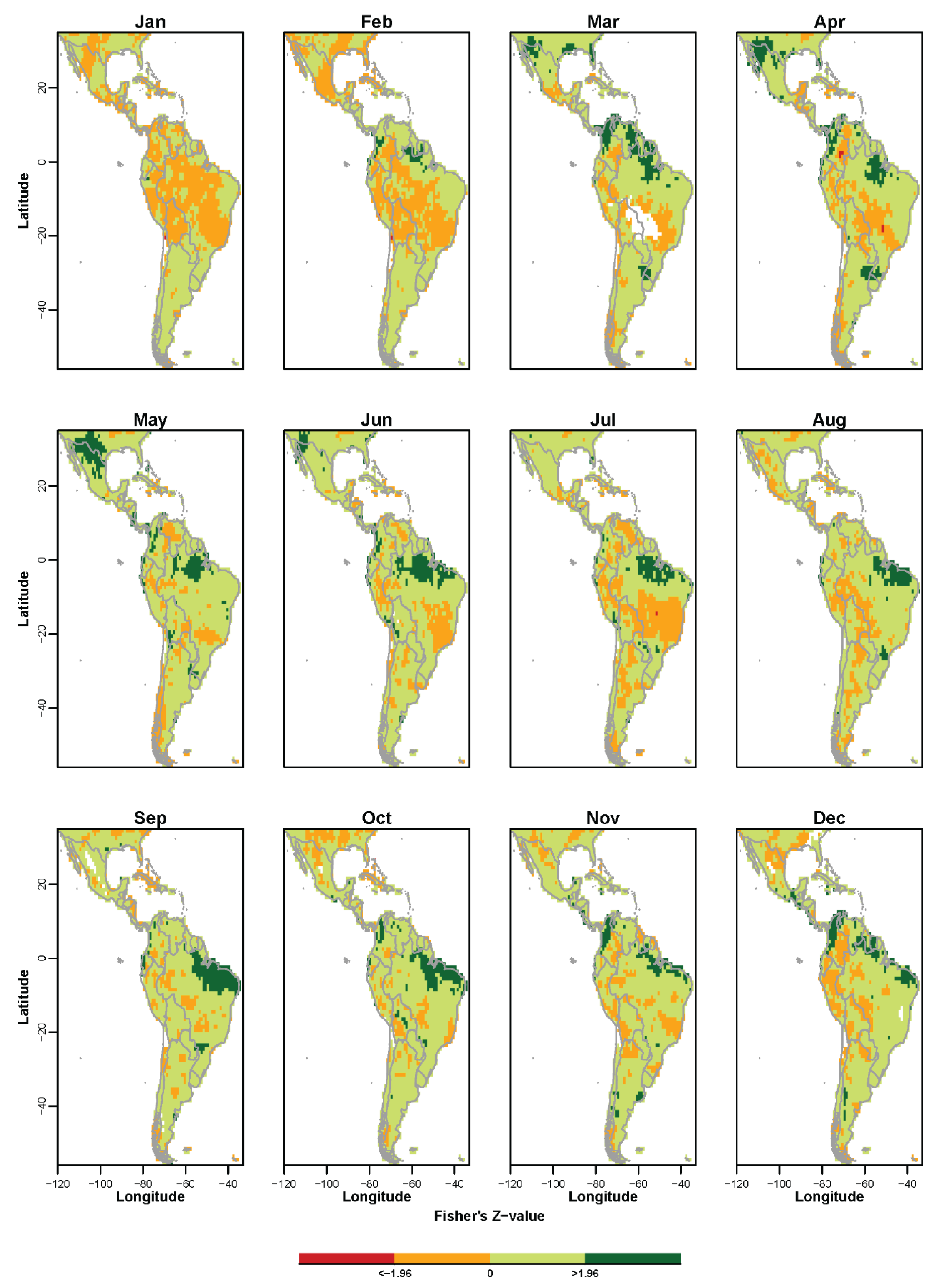
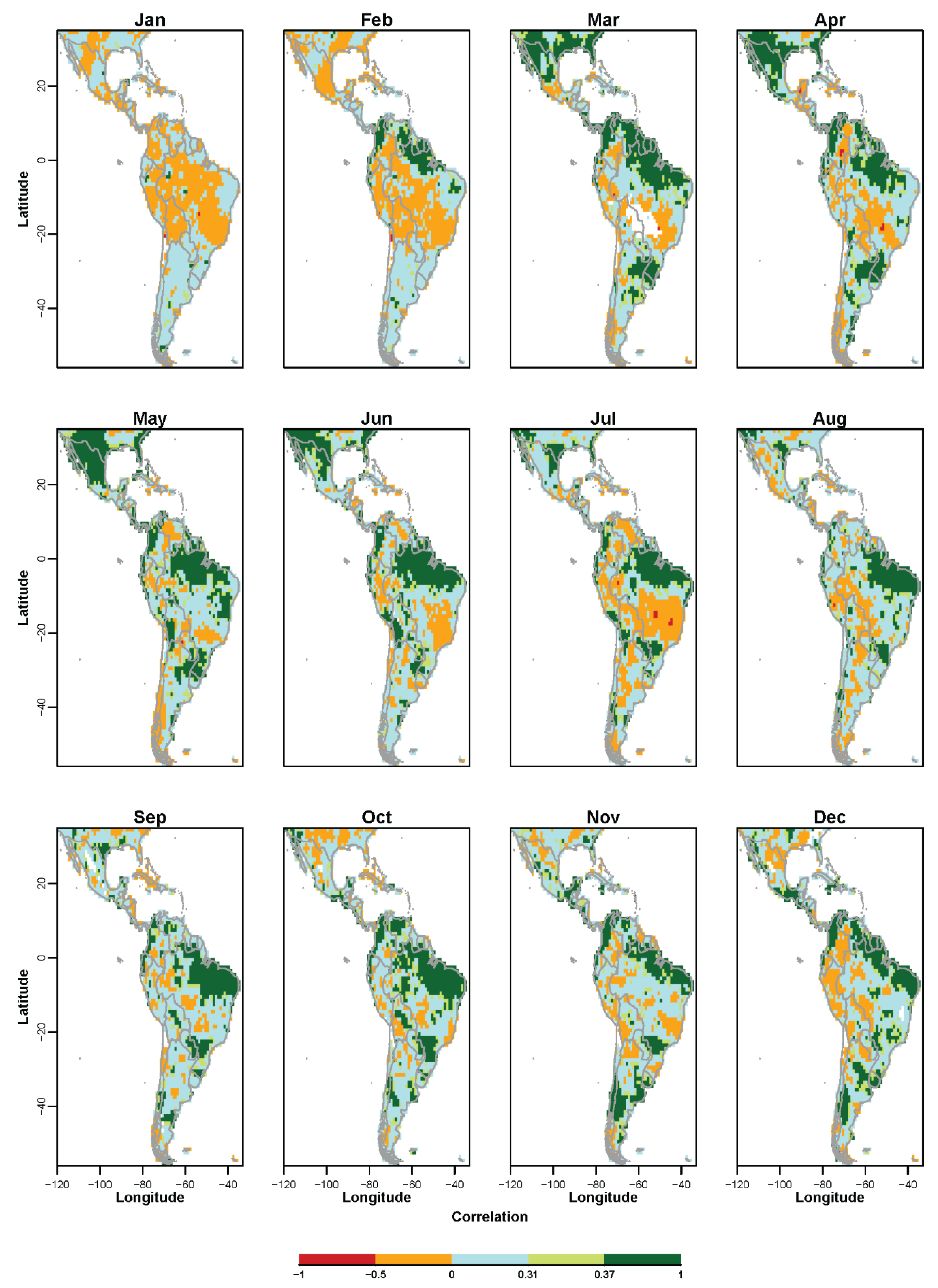
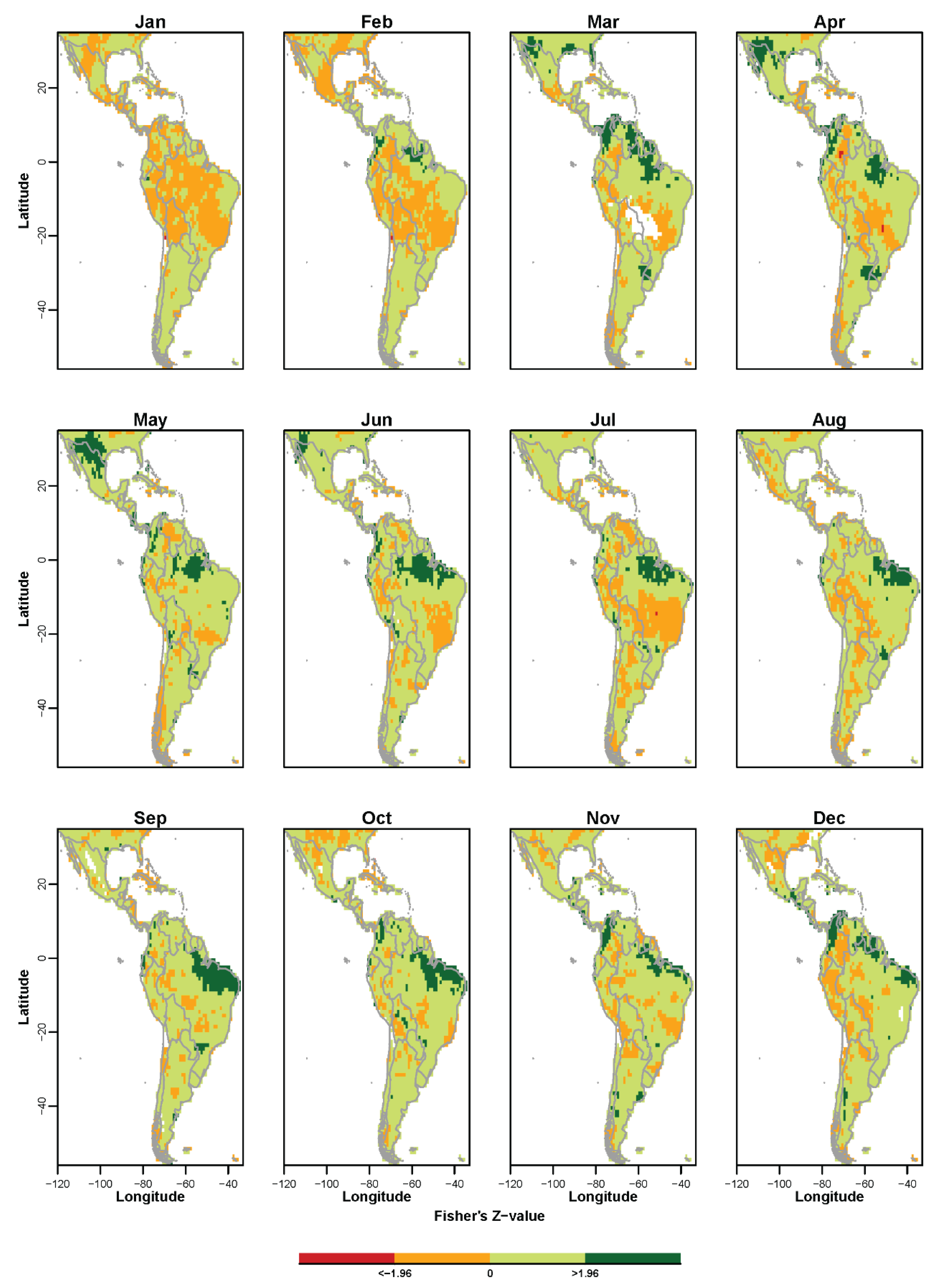
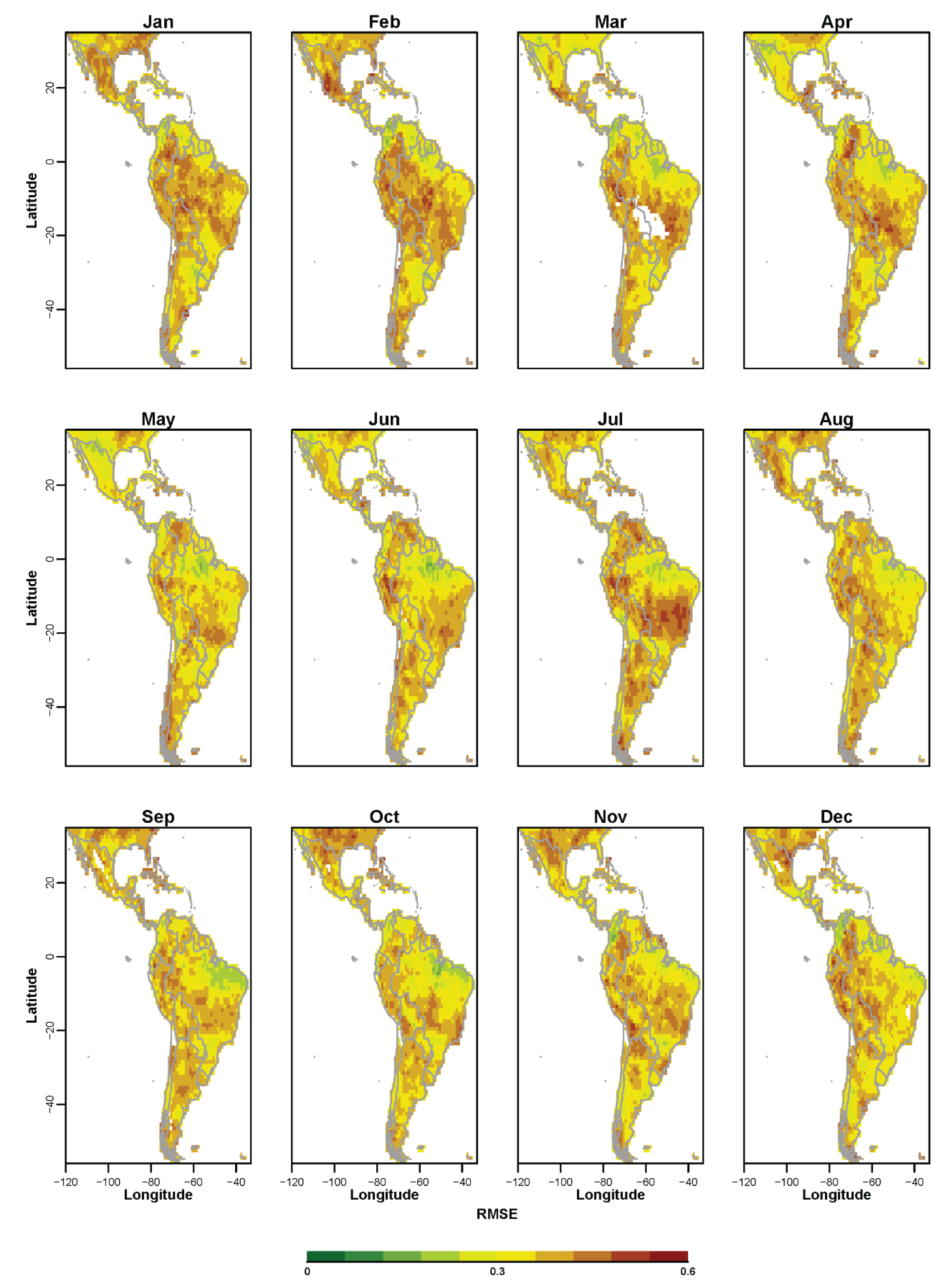
3.1. Non-Probabilistic Forecasts of Continuous SPI Values
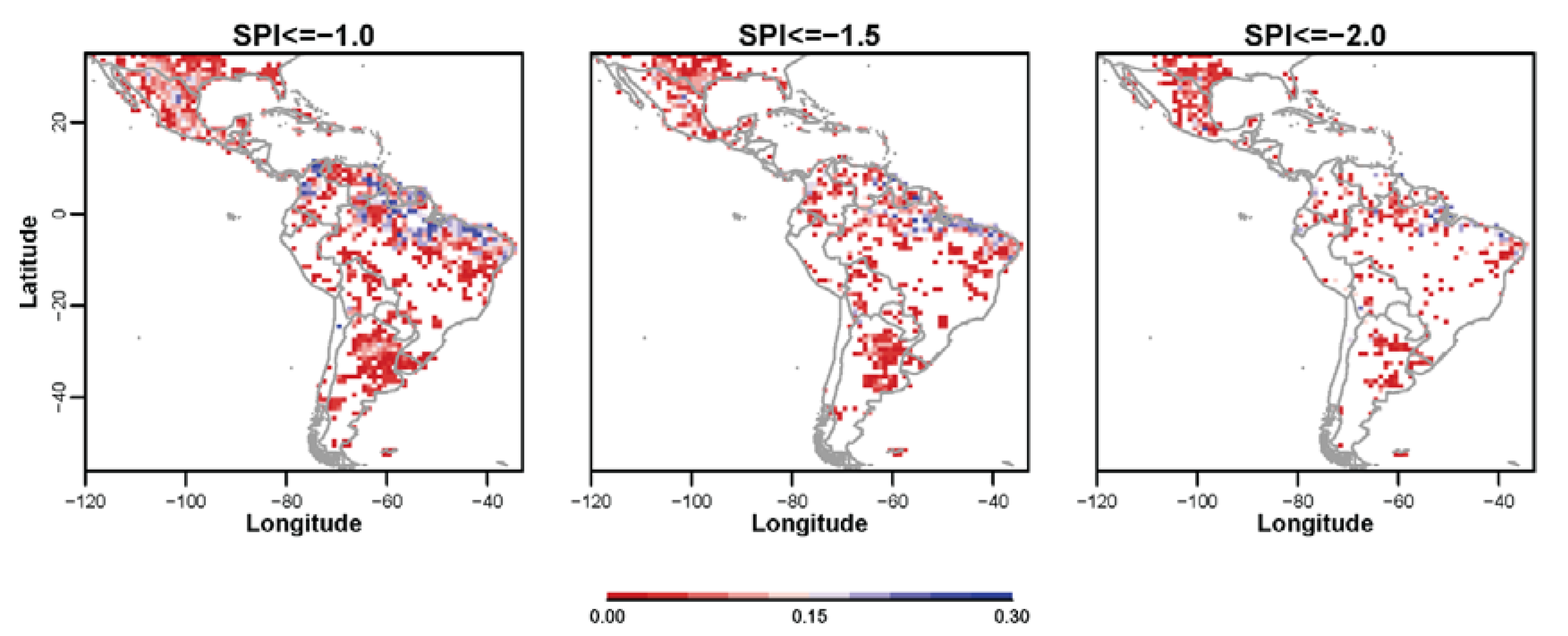
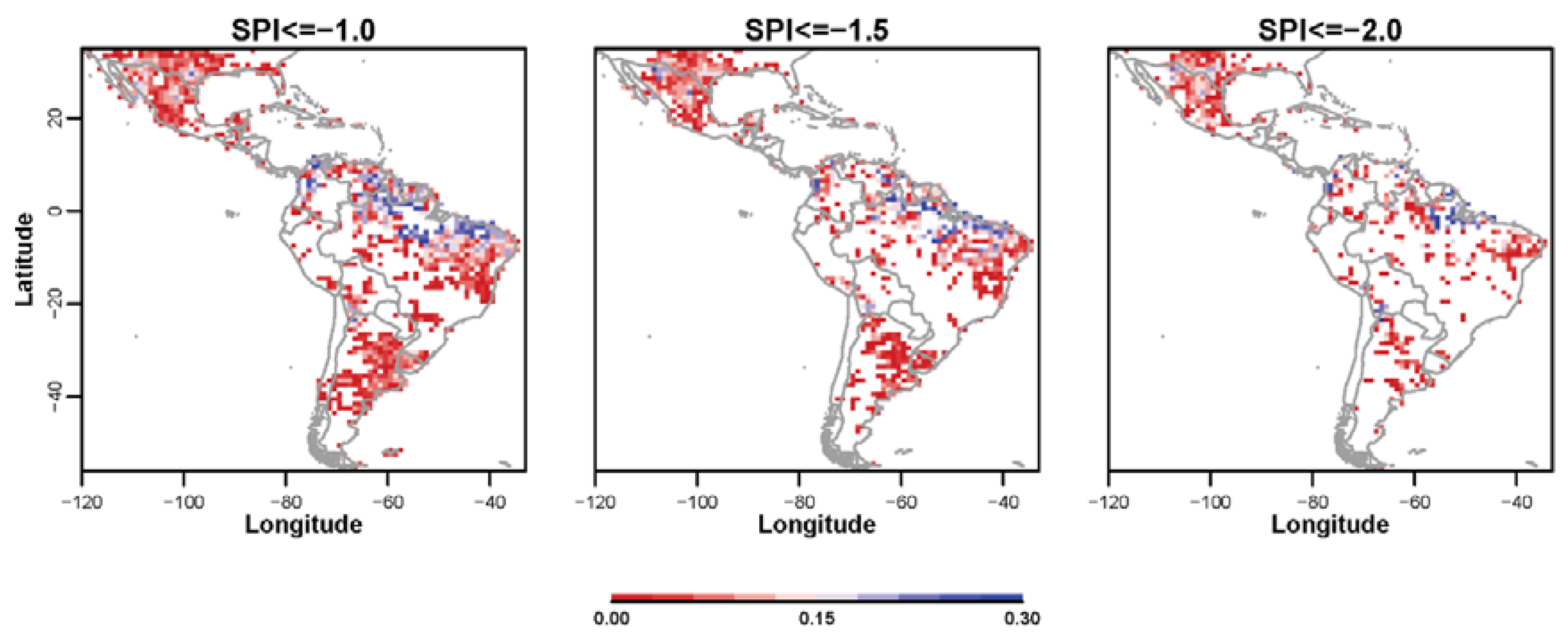
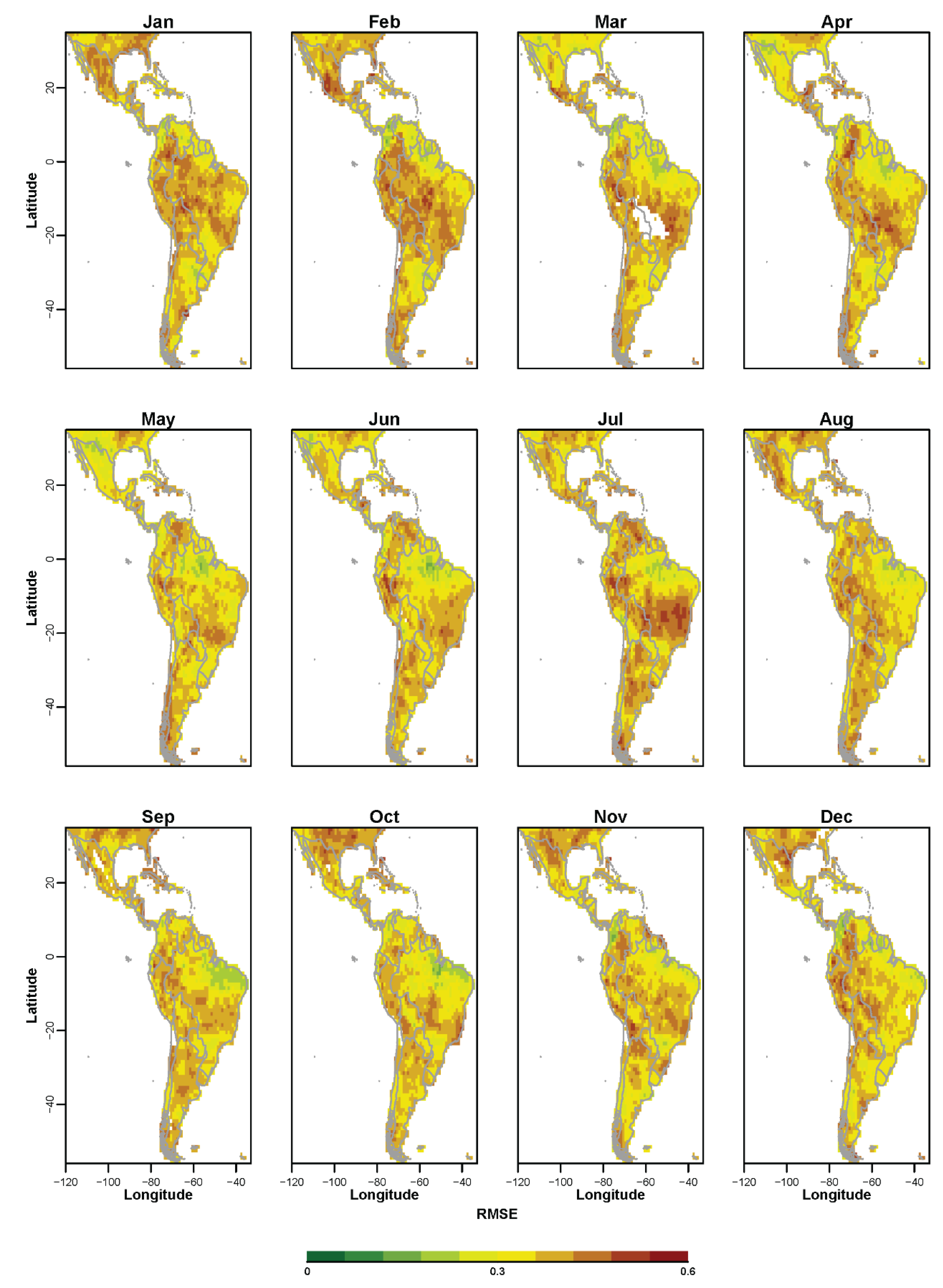
3.2. Non-Probabilistic Forecasts of Categorical SPI Values
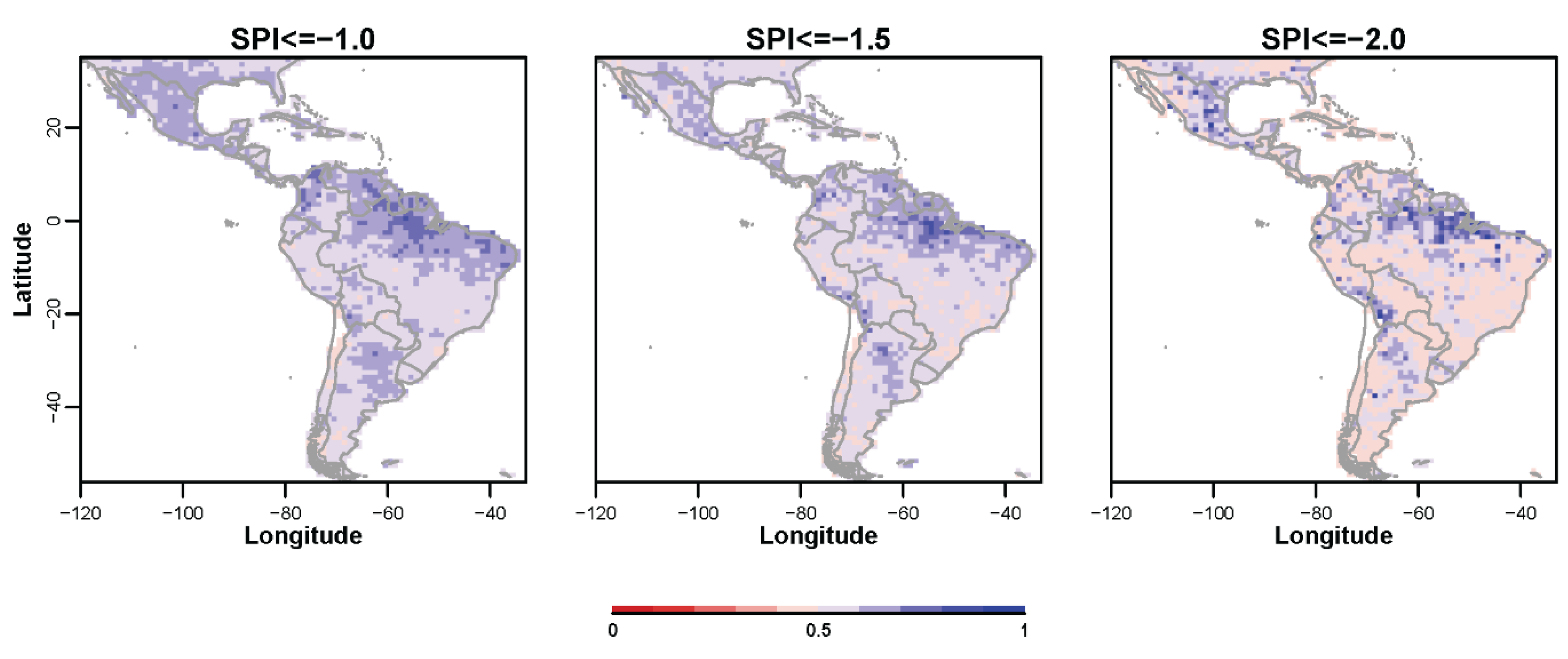
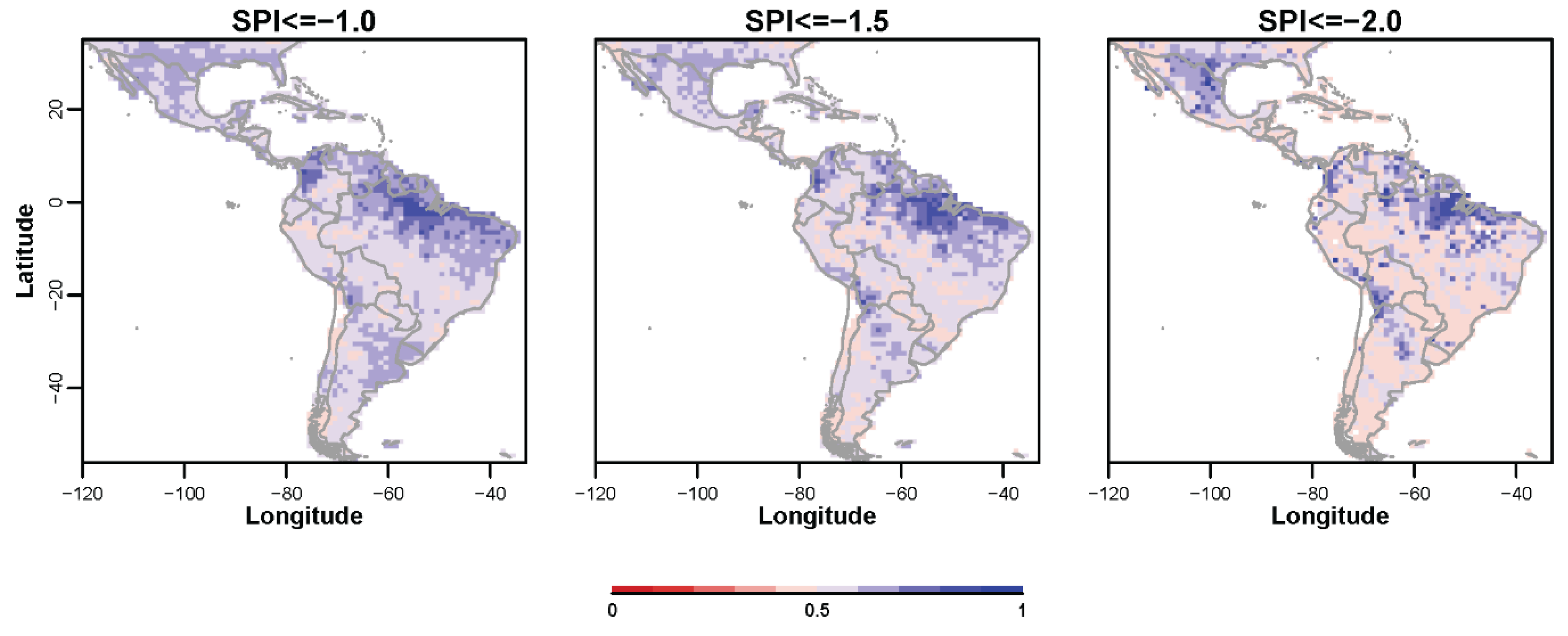
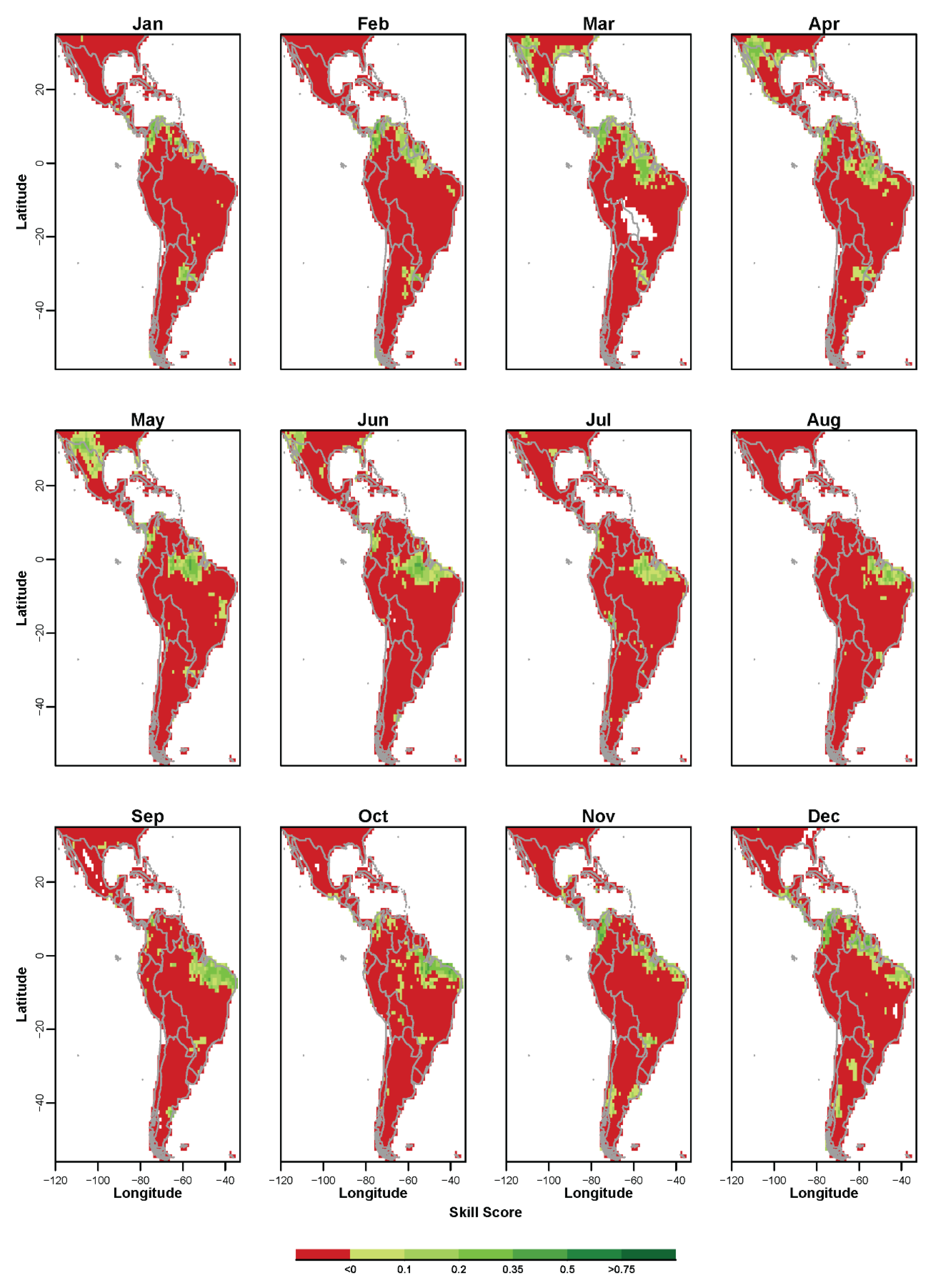
3.3. Probabilistic Forecasts of Categorical SPI Values
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Description of the Validation Metrics
Appendix A.1. Nonprobabilistic Forecasts of Continuous SPI Values
Appendix A.2. Nonprobabilistic Forecasts of Categorical SPI Values

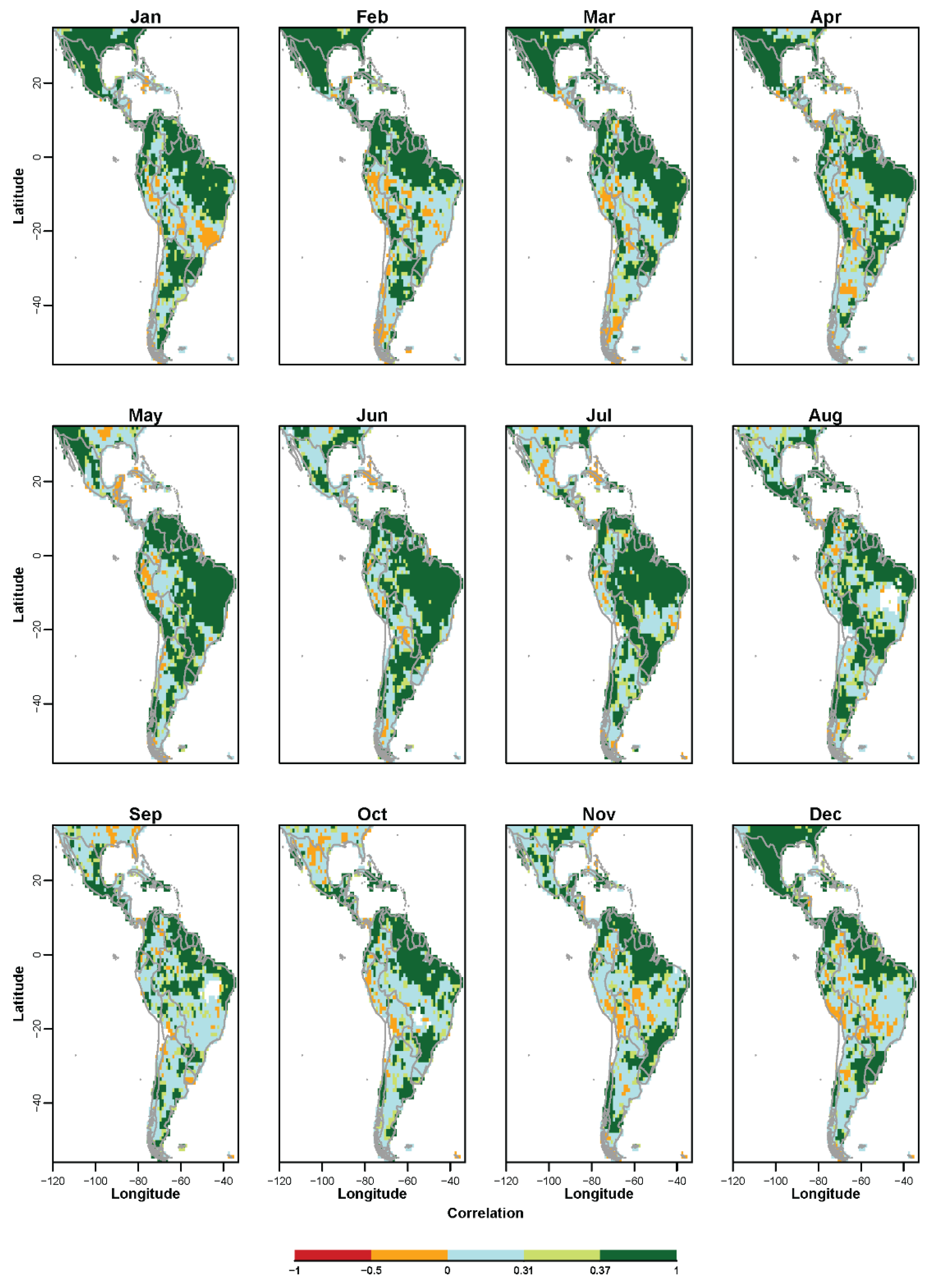{kind=link}
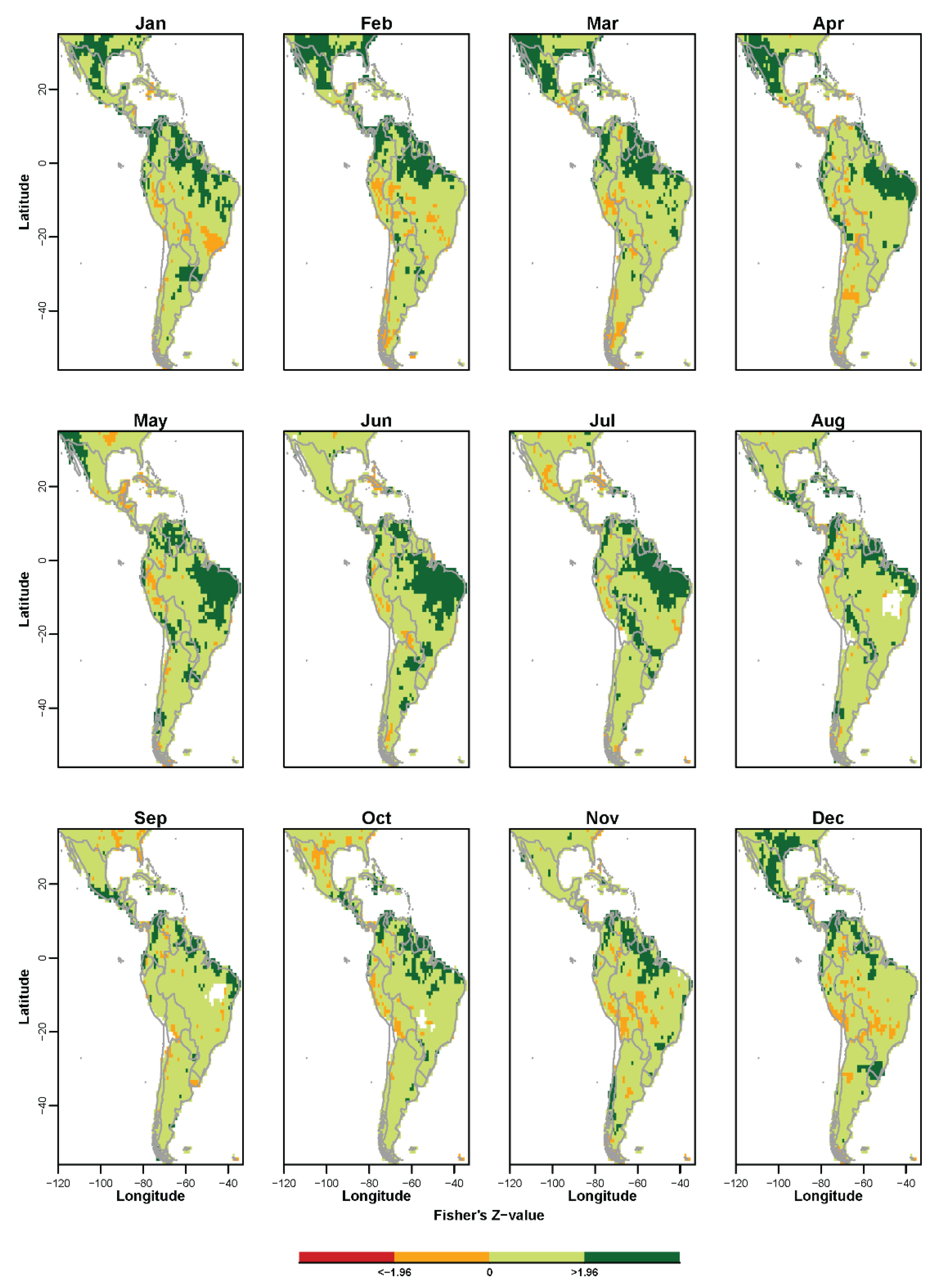{kind=link}
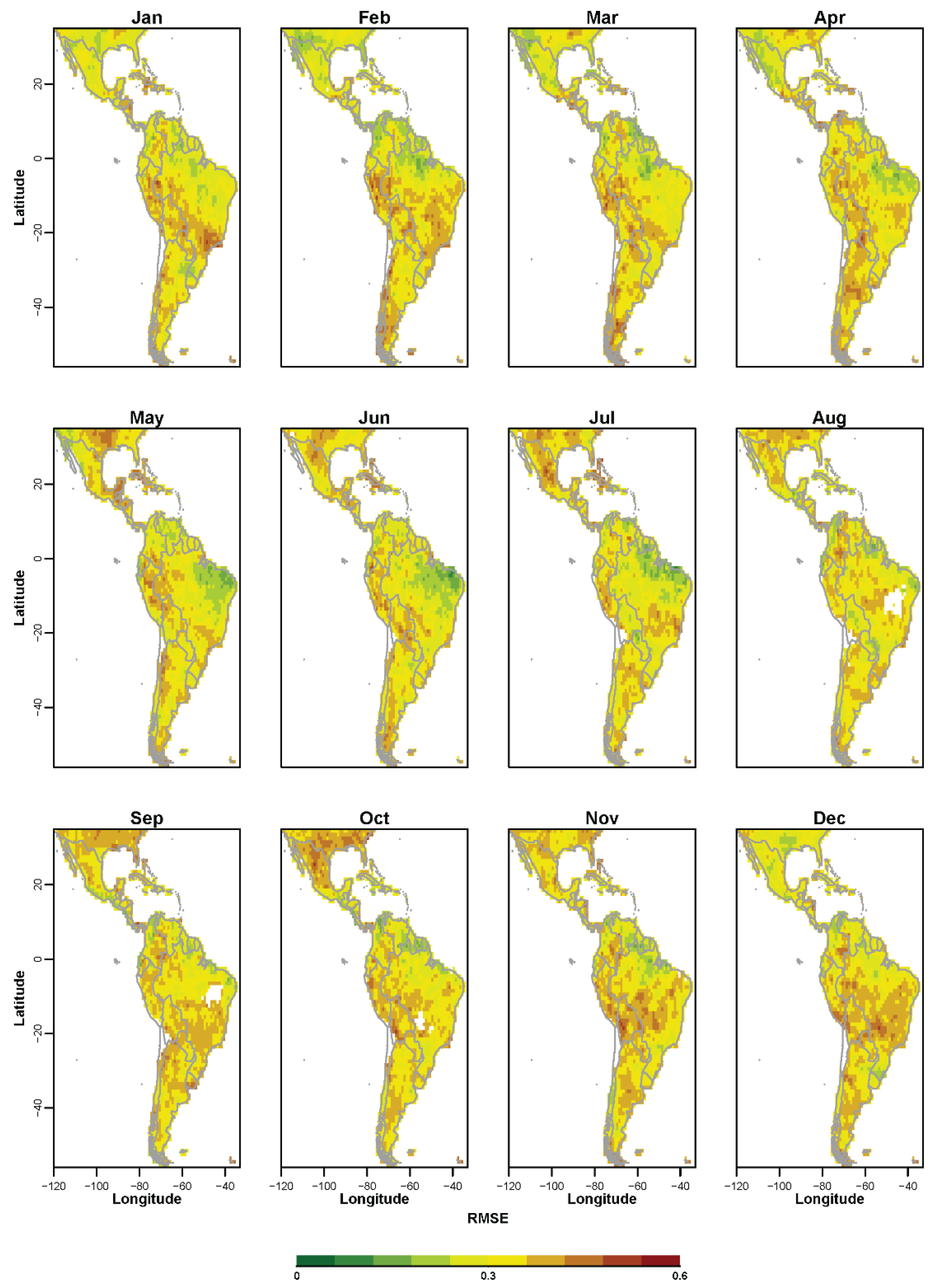{kind=link}
{kind=link}
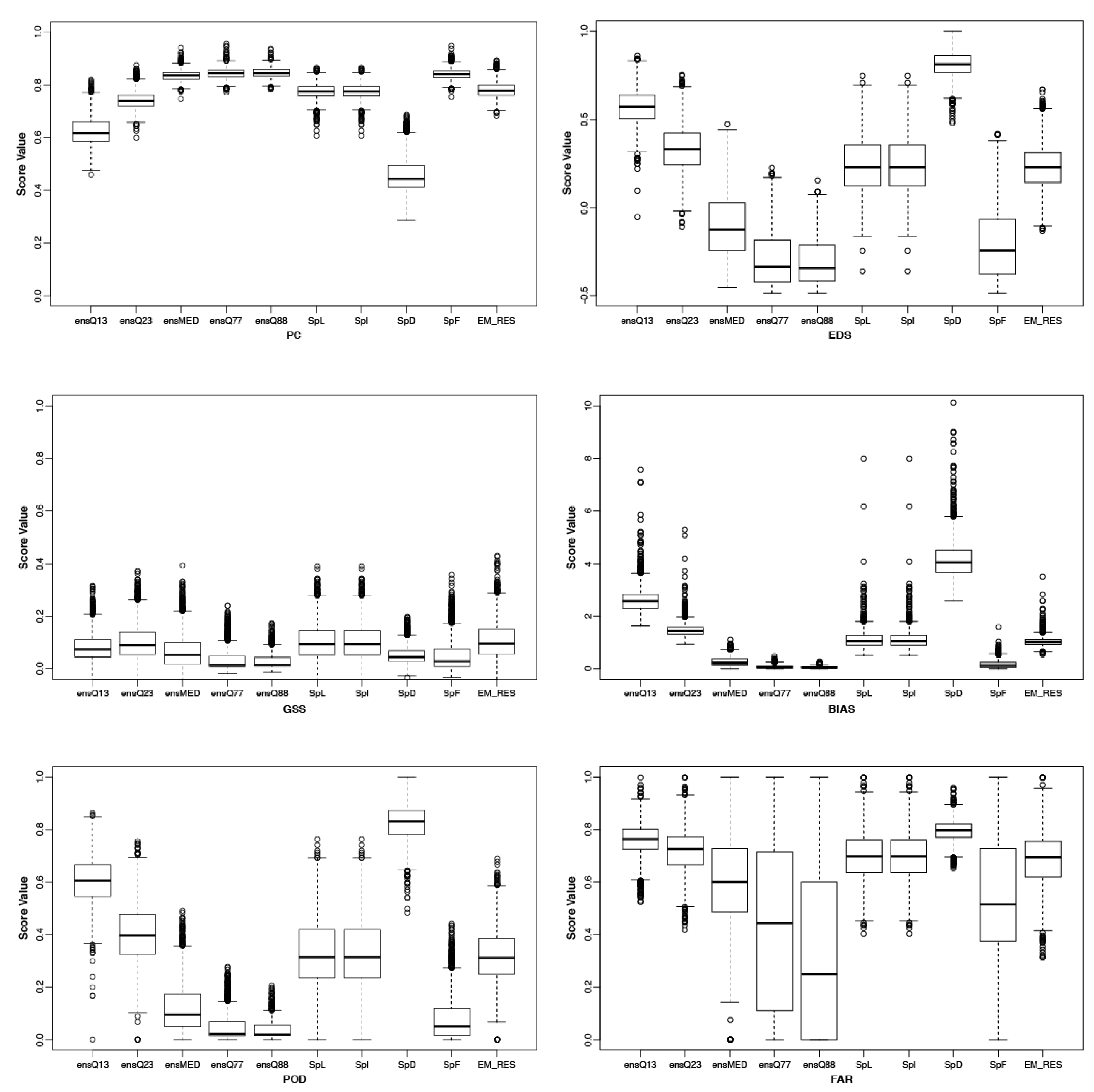{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SPI Value | Class | Cumulative Probability | Probability of Event [%] |
|---|---|---|---|
| SPI > 2.00 | Extreme wet | 0.977–1.000 | 2.3% |
| 1.50 < SPI < 2.00 | Severe wet | 0.933–0.977 | 4.4% |
| 1.00 < SPI < 1.50 | Moderate wet | 0.841–0.933 | 9.2% |
| −1.00 < SPI < 1.00 | Near normal | 0.159–0.841 | 68.2% |
| −1.50 < SPI < −1.00 | Moderate dry | 0.067–0.159 | 9.2% |
| −2.00 < SPI < −1.50 | Severe dry | 0.023–0.067 | 4.4% |
| SPI < −2.00 | Extreme dry | 0.000–0.023 | 2.3% |
| Name | Definition | Type |
|---|---|---|
| 13th percentile (Q13) | Member located at the 13% of the CDF | Individual |
| 23th percentile (Q23) | Member located at the 23% of the CDF | Individual |
| Median (MED) | Member located at the 50% of the CDF | Individual |
| 77th percentile (Q77) | Member located at the 77% of the CDF | Individual |
| 88th percentile (Q88) | Member located at the 88% of the CDF | Individual |
| Large spread (SpL) | Sum of the extreme members (Q13 + Q88) | Partially integrative |
| Low spread (Spl) | Sum of the members (Q23 + Q78) | Partially integrative |
| Dry spread (SpD) | Sum of the dry members (Q13 + Q23) | Partially integrative |
| Flood spread (SpF) | Sum of the wet members (Q77 + Q88) | Partially integrative |
| Mean (EM_RES) | Ensemble mean | Integrative |
Appendix A.3. Probabilistic Forecast of Categorical SPI Values


References
- Carrão, H.; Singleton, A.; Naumann, G.; Barbosa, P.; Vogt, J. An optimized system for the classification of meteorological drought intensity with applications in frequency analysis. J. Appl. Meteorol. Climatol. 2014, 53, 1943–1960. [Google Scholar] [CrossRef]
- Goddard, S.; Harms, S.K.; Reichenbach, S.E.; Tadesse, T.; Waltman, W.J. Geospatial decision support for drought risk management. Commun. ACM 2003, 46, 35–37. [Google Scholar] [CrossRef]
- Dai, A. Drought under global Warming: A review. Wiley Interdiscip. Rev. Clim. Chang. 2011, 2, 45–65. [Google Scholar] [CrossRef]
- Lloyd-Hughes, B. The impracticality of a universal drought definition. Theor. Appl. Climatol. 2014, 117, 607–611. [Google Scholar] [CrossRef]
- Steinemann, A.C.; Cavalcanti, L.F. Developing multiple indicators and triggers for drought plans. J. Water Res. Plan. Manag. 2006, 132, 164–174. [Google Scholar] [CrossRef]
- Heim, R.R. A review of twentieth-century drought indices used in the United States. Bull. Am. Meteorol. Soc. 2002, 83, 1149–1165. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguerıa, S.; Lopez-Moreno, J.I. A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef]
- McKee, T.B.; Doeskin, N.J.; Kleist, J. The relationship of drought frequency and duration to time scales. In Proceedings of the 8th Conference on Applied Climatology, American Meteorological Society, Anaheim, CA, USA, 17–22 January 1993; pp. 179–184. [Google Scholar]
- Svoboda, M.; Hayes, M.; Wood, D. Standardized Precipitation Index User Guide; WMO-No. 1090; World Meteorological Organization (WMO): Geneva, Switzerland, 2012. [Google Scholar]
- Mishra, A.K.; Singh, V.P. A review of drought concepts. J. Hydrol. 2010, 391, 202–216. [Google Scholar] [CrossRef]
- Kim, T.-W.; Valds, J.B. Nonlinear model for drought forecasting based on a conjunction of wavelet transforms and neural networks. J. Hydrol. Eng. 2003, 8, 319–328. [Google Scholar] [CrossRef]
- Mishra, A.K.; Desai, V.R.; Singh, V.P. Drought forecasting using a hybrid stochastic and neural network model. J. Hydrol. Eng. 2007, 12, 626–638. [Google Scholar] [CrossRef]
- Mishra, A.K.; Desai, V.R. Drought forecasting using stochastic models. Stoch. Environ. Res. Risk Assess. 2005, 19, 326–339. [Google Scholar] [CrossRef]
- Vitart, F.; Buizza, R.; Alonso Balmaseda, M.; Balsamo, G.; Bidlot, J.-R.; Bonet, A.; Fuentes, M.; Hofstadler, A.; Molteni, F.; Palmer, T.N. The new VAREPS-monthly forecasting system: A first step towards seamless prediction. Q. J. R. Meteorol. Soc. 2008, 134, 1789–1799. [Google Scholar] [CrossRef]
- Nijssen, B.; Shukla, S.; Lin, C.; Gao, H.; Zhou, T.; Ishottama; Sheffield, J.; Wood, E.F.; Lettenmaier, D.P. A prototype global drought information system based on multiple land surface models. J. Hydrometeorol. 2014, 15, 1661–1676. [Google Scholar] [CrossRef]
- Yuan, X.; Wood, E.F. Multimodel seasonal forecasting of global drought onset. Geophys. Res. Lett. 2013, 40, 4900–4905. [Google Scholar] [CrossRef] [Green Version]
- Hao, Z.; AghaKouchak, A.; Nakhjiri, N.; Farahmand, A. Global integrated drought monitoring and prediction system. Sci. Data 2014, 1, 140001. [Google Scholar] [CrossRef] [PubMed]
- Dutra, E.; Wetterhall, F.; Di Giuseppe, F.; Naumann, G.; Barbosa, P.; Vogt, J.; Pozzi, W.; Pappenberger, F. Global meteorological drought Part 1: Probabilistic monitoring. Hydrol. Earth Syst. Sci. 2014, 18, 2657–2667. [Google Scholar] [CrossRef]
- Dutra, E.; Pozzi, W.; Wetterhall, F.; Di Giuseppe, F.; Magnusson, L.; Naumann, G.; Barbosa, P.; Vogt, J.; Pappenberger, F. Global meteorological drought Part 2: Seasonal forecasts. Hydrol. Earth Syst. Sci. 2014, 18, 2669–2678. [Google Scholar] [CrossRef] [Green Version]
- Spennemann, P.C.; Rivera, J.A.; Osman, M.; Saulo, A.C.; Penalba, O.C. Assessment of seasonal soil moisture forecasts over Southern South America with emphasis on dry and wet events. J. Hydrometeorol. 2017, 18, 2297–2311. [Google Scholar] [CrossRef]
- Sheffield, J.; Andreadis, K.M.; Wood, E.F.; Lettenmaier, D.P. Global and continental drought in the second half of the twentieth century: Severity–area–duration analysis and temporal variability of large-scale events. J. Clim. 2009, 22, 1962–1981. [Google Scholar] [CrossRef]
- Zhao, M.; Running, S.W. Drought-induced reduction in global terrestrial net primary production from 2000 through 2009. Science 2010, 329, 940–943. [Google Scholar] [CrossRef] [PubMed]
- Vargas, W.M.; Naumann, G.; Minetti, J.L. Dry spells in the river Plata Basin: An approximation of the diagnosis of droughts using daily data. Theor. Appl. Climatol. 2011, 104, 159–173. [Google Scholar] [CrossRef]
- Field, C.B.; Barros, V.; Stocker, T.F.; Qin, D.; Dokken, D.J.; Ebi, K.L.; Mastrandrea, M.D.; Mach, K.J.; Plattner, G.-K.; Allen, S.K.; et al. (Eds.) Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation; Cambridge University Press: New York, NY, USA, 2012; pp. 1–19. [Google Scholar]
- Penalba, O.C.; Rivera, J.A. Future changes in drought characteristics over Southern South America projected by a CMIP5 multi-model ensemble. Am. J. Clim. Chang. 2013, 2, 173–182. [Google Scholar] [CrossRef]
- Trenberth, K.E.; Stepaniak, D. Indices of El Niño evolution. J. Clim. 2011, 14, 1697–1701. [Google Scholar] [CrossRef]
- FAO. Aquastat Database. Food and Agriculture Organization of the United Nations (FAO). 2017. Available online: http://www.fao.org/nr/water/aquastat/main/index.stm (accessed on 15 October 2017).
- Magrin, G.; Garcia, C.G.; Choque, D.C.; Gimenez, J.C.; Moreno, A.R.; Nagy, G.J.; Nobre, C.; Villamizar, A. Climate change, Impacts, adaptation and vulnerability. In Contribution of Working Group II to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change; Parry, M.L., Canziani, O.F., Palutikof, J.P., van der Linden, P., Hanson, C.E., Eds.; Cambridge University Press: Cambridge, UK, 2007; pp. 581–615. [Google Scholar]
- Llano, M.P.; Vargas, W.; Naumann, G. Climate variability in areas of the world with high production of soya beans and Corn: Its relationship to crop yields. Meteorol. Appl. 2012, 19, 385–396. [Google Scholar] [CrossRef]
- Molteni, F.; Stockdale, T.; Balmaseda, M.; Balsamo, G.; Buizza, R.; Ferranti, L.; Magnunson, L.; Mogensen, K.; Palmer, T.; Vitart, F. The new ECMWF seasonal forecast system (System 4). In Technical Memorandum No. 656; European Centre for Medium Range Weather Forecasts: Berkshire, UK, 2011. [Google Scholar]
- Rudolf, B.; Becker, A.; Schneider, U.; Meyer-Christoffer, A.; Ziese, M. New full data reanalysis version 5 provides high-quality gridded monthly precipitation data. GEWEX News 2011, 21, 4–5. [Google Scholar]
- Naumann, G.; Barbosa, P.; Carrão, H.; Singleton, A.; Vogt, J. Monitoring drought conditions and their uncertainties in Africa using TRMM data. J. Appl. Meteorol. Climatol. 2012, 51, 1867–1874. [Google Scholar] [CrossRef]
- Svoboda, M.; LeComte, D.; Hayes, M.; Heim, R.; Gleason, K.; Angel, J.; Rippey, B.; Tinker, R.; Palecki, M.; Stooksbury, D.; et al. The drought monitor. Bull. Am. Meteorol. Soc. 2002, 83, 1181–1190. [Google Scholar] [CrossRef]
- Steinemann, A. Drought indicators and Triggers: A stochastic approach to evaluation. JAWRA 2003, 39, 1217–1233. [Google Scholar] [CrossRef]
- Hayes, M.J.; Svoboda, M.D.; Wilhite, D.A.; Vanyarkho, O.V. Monitoring the 1996 drought using the standardized precipitation index. Bull. Am. Meteorol. Soc. 1999, 80, 429–438. [Google Scholar] [CrossRef]
- Wu, H.; Hayes, M.J.; Wilhite, D.A.; Svoboda, M.D. The effect of the length of record on the standardized precipitation index calculation. Int. J. Climatol. 2005, 25, 505–520. [Google Scholar] [CrossRef] [Green Version]
- Sepulcre-Canto, G.; Horion, S.; Singleton, A.; Carrão, H.; Vogt, J. Development of a combined drought indicator to detect agricultural drought in Europe. Earth Syst. Sci. 2012, 12, 3519–3531. [Google Scholar] [CrossRef]
- Ntale, H.K.; Gan, T.Y. Drought indices and their application to east Africa. Int. J. Climatol. 2003, 23, 1335–1357. [Google Scholar] [CrossRef]
- Hofer, B.; Carrao, H.; Mcinerney, D. Multi-disciplinary forest fire danger assessment in Europe: The potential to integrate long-term drought information. IJSDIR 2012, 7, 300–322. [Google Scholar]
- Lavaysse, C.; Vogt, J.; Pappenberger, F. Early warning of drought in Europe using the monthly ensemble system from ECMWF. Hydrol. Earth Syst. Sci. 2015, 19, 3273–3286. [Google Scholar] [CrossRef] [Green Version]
- Mo, K.C.; Lyon, B. Global meteorological drought prediction using the North American multi-model ensemble. J. Hydrometeorol. 2015, 16, 1409–1424. [Google Scholar] [CrossRef]
- Vera, C.S.; Alvarez, M.S.; Gonzalez, P.L.; Liebmann, B.; Kiladis, G.N. Seasonal cycle of precipitation variability in South America on intraseasonal timescales. Clim. Dyn. 2017, 1–11. [Google Scholar] [CrossRef]
- González, P.L.; Vera, C.S. Summer precipitation variability over South America on long and short intraseasonal timescales. Clim. Dyn. 2014, 43, 1993–2007. [Google Scholar] [CrossRef]
- González, P.L.; Vera, C.S.; Liebmann, B.; Kiladis, G. Intraseasonal variability in subtropical South America as depicted by precipitation data. Clim. Dyn. 2008, 30, 727–744. [Google Scholar] [CrossRef]
- Ghelli, A.; Primo, C. On the use of the extreme dependency score to investigate the performance of an NWP model for rare events. Meteorol. Appl. 2009, 16, 537–544. [Google Scholar] [CrossRef] [Green Version]
- Ruscica, R.C.; Sörensson, A.A.; Menéndez, C.G. Pathways between soil moisture and precipitation in southeastern South America. Atmos. Sci. Lett. 2015, 16, 267–272. [Google Scholar] [CrossRef] [Green Version]
- Spennemann, P.C.; Saulo, A.C. An estimation of the land–atmosphere coupling strength in South America using the Global Land Data Assimilation System. Int. J. Climatol. 2015, 35, 4151–4166. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences, 2nd ed.; Academic Press: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Quan, X.W.; Hoerling, M.P.; Lyon, B.; Kumar, A.; Bell, M.A.; Tippett, M.K.; Wang, H. Prospects for dynamical prediction of meteorological drought. J. Appl. Meteorol. Climatol. 2012, 51, 1238–1252. [Google Scholar] [CrossRef]
- Lavaysse, C.; Carrera, M.; Blair, S.; Gagnon, N.; Frenette, R.; Charron, M.; Yau, M.K. Impact of surface parameter uncertainties within the Canadian regional ensemble prediction system. Mon. Weather Rev. 2013, 141, 1506–1526. [Google Scholar] [CrossRef]
- Stephenson, D.B.; Casati, B.; Ferro, C.A.T.; Wilson, C.A. The extreme dependency Score: A non-vanishing measure for forecasts of rare events. Meteorol. Appl. 2008, 15, 41–50. [Google Scholar] [CrossRef]









© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carrão, H.; Naumann, G.; Dutra, E.; Lavaysse, C.; Barbosa, P. Seasonal Drought Forecasting for Latin America Using the ECMWF S4 Forecast System. Climate 2018, 6, 48. https://doi.org/10.3390/cli6020048
Carrão H, Naumann G, Dutra E, Lavaysse C, Barbosa P. Seasonal Drought Forecasting for Latin America Using the ECMWF S4 Forecast System. Climate. 2018; 6(2):48. https://doi.org/10.3390/cli6020048
Chicago/Turabian StyleCarrão, Hugo, Gustavo Naumann, Emanuel Dutra, Christophe Lavaysse, and Paulo Barbosa. 2018. "Seasonal Drought Forecasting for Latin America Using the ECMWF S4 Forecast System" Climate 6, no. 2: 48. https://doi.org/10.3390/cli6020048
APA StyleCarrão, H., Naumann, G., Dutra, E., Lavaysse, C., & Barbosa, P. (2018). Seasonal Drought Forecasting for Latin America Using the ECMWF S4 Forecast System. Climate, 6(2), 48. https://doi.org/10.3390/cli6020048