1. Introduction
Although well-conducted randomized control trial experiments (RCTs) provide the most reliable evidence on the effectiveness of interventions, these are not always feasible for policy intervention analysis. RCTs involves randomly allocating participant units into two groups: the treament group which includes the participants who receive the intervention, and the control group. Selection bias and confounding variables are minimized due to randomization. Thus the differences between groups can be attributed to the intervention. However, when it comes to measuring the effect of policy interventions, there may be obstacled to the use of RCTS, such as economic obstacles (impact evaluation are costly) or political constraints (to give services to some groups and not to others can generate conflicts).
As alternative to RCTs, the interrupted time series analysis (ITSA) offers a quasi-experimental research design to measure the effect of an intervention when randomization is not possible [
1]. In an ITSA, the observations on the outcome before and after the intervention are used to test immediate and gradual effects of the intervention. ITSA has been used in various fields, such as financial economics [
2], health policies [
3] and regulatory actions [
4], to name but a few.
Segmented regression analysis is the recommended approach for analysing data from an ITSA [
5,
6]. It requires data which are are evenly spaced and have enought information before and after the intervention. Segmented regression analysis of interrupted times series data allows us to estimate immediate and gradual effects of the intervention on the outcome. Segmented regression analysis also allows us to assess whether factors other than the intervention could explain the change, controlling for factors such as seasonality or autocorrelation.
Segmented linear regression models have been the most widely used in practice. These models allow estimating the changes both in level and trend that follow an intervention. However, the assumption of linearity often may hold only over short intervals. Trends before and/or after the intervention may follow non-linear patterns, such as curvilinear trends. Some non-linear effects can be accommodated in linear models by using polynomial trends [
7] or transformations of the dependent variable such as the logarithmic transformation [
8]. Other non-linear trend structures may require other alternative models such as Box–Jenkins models [
9]. However, the greater complexity in the specification and interpretation of this type of model has led to their less use [
10].
Generalized Additive Models (GAMs) have been proposed as an alternative to characterize general non-linear regressions, without requiring the analyst to prespecify the form of the non-linear relationship [
11]. Recently, Sullivan et al. [
12] showed that GAMs can be useful for characterizing trends in longitudinal data collected in Single Subject (SS) designs. SS design is most often used in applied fields of psychology, education and human behaviour. SS design is a research design in which a single individual, or very small samples, is analyzed during a baseline period followed by an intervention that can change the outcome. This period can be followed by a return to baseline due to the removal of the intervention. This design can lead to a nonlinear relationship between time and outcomes that may not be easily detected using linear models.
In this paper, we assess whether the use of GAMs can be extended to estimate the impact of an intervention in any ITSA. Simulated data are used to evaluate the performance of the segmented linear regression models and GAMs in estimating the level change and the cumulative effect of an intervention. Data were simulated assuming linear and non-linear trends and the mean squared error (MSE) and the mean percentage error (MPE) are used to compare both methodologies. An illustrative example with real data is shown where the impact of the 2012 Spanish cost-sharing reform on pharmaceutical prescription on the volume of prescriptions dispensed from pharmacies is analyzed [
13].
The rest of the paper is organized as follows.
Section 2 describes the segmented linear regression models and GAMs applied to ITSA.
Section 3 describes the simulation exercise where the process followed to simulate the data and the comparison of the results for both models are shown.
Section 4 describes the application to real data. Finally,
Section 5 deals with the discussion and the conclusion of the paper.
3. Simulation Analysis
3.1. Data Generation Process
In this subsection we show how the simulated data were generated. For the sake of simplicity, we have assumed a fixed sample size of 100 for all time series, where the intervention affected the last 10 periods of the series. We have considered linear and non-linear trends before and after the intervention in the simulation process to study the performance of the segmented linear regression models and the GAMs in each of the cases. The number of simulations for each model was 500 and the possible autocorrelation in the series is considered assuming that the error term is distributed according to a first order autoregressive process AR(1) with parameter 0.3 and a standard deviation of the white noise process of 0.5.
The level change and the cumulative effect are analyzed and the performance of the models was evaluated through the comparison of estimated impacts of the intervention and the expected real impacts assumed in the simulation, using the mean squared error (MSE) and the mean percentage error (MPE).
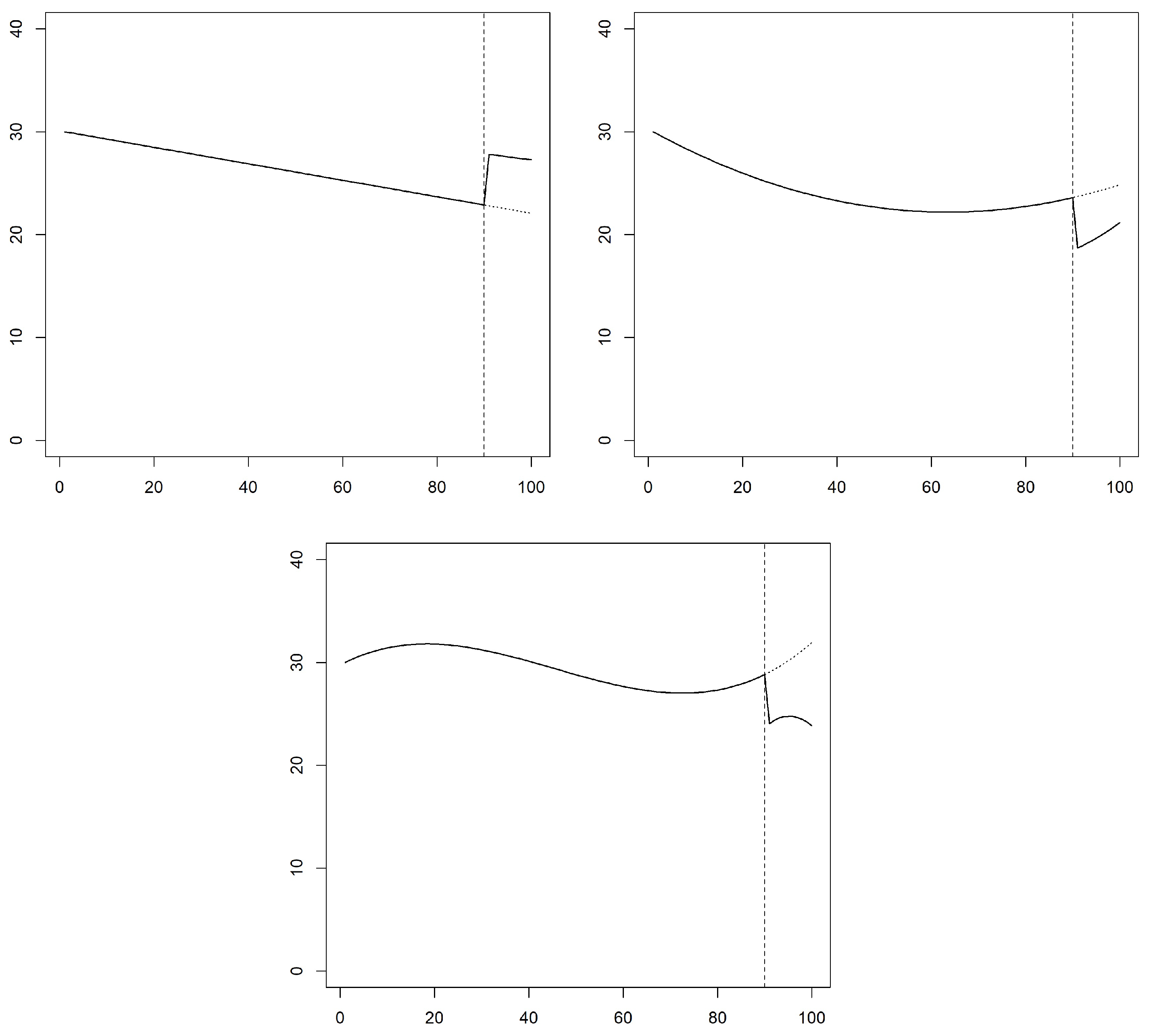
The first simulation model assumes a linear but different trend before and after the intervention. It also assumes a change in the level of 5 units.
Table 1 shows the parameters of this model.
Figure 1 shows the deterministic part of the time series, where it is easily observed the assumed impact of the intervention through the comparison of the series before and after the intervention. The expected level change is 5 and the expected cumulative effect which includes the change in trend is 50.9 (
).
The second simulation model assumes a quadratic trend.
Table 1 shows the parameters of this model and
Figure 1 shows the deterministic part of the simulated data. In this case we have assumed a negative level change of
and an expected cumulative effect of −44.075.
Finally, the third simulation model assumes a cubic function. With this example we try to show a nonlinear model with several trend changes during the pre-intervention period. A cubic function can accommodate this behaviour. In practice a great majority of time series can be adequately fitted with polynomials with a maximum degree of 3 [
21].
Table 1 and
Figure 1 show the behaviour of this model, where the expected level change is assumed to be
and the expected cumulative effect is
.
The models have been estimated using the R statistical software, version 4.0.4. The codes are provided in the
supplementary documents.
3.2. Results of the Simulation Analysis
Table 2 shows the results of the simulation analysis. Results include the mean and standard deviation of the level change estimated for the 500 simulations, along with the MSE and MPE obtained from the comparison with the expected level change for each simulation model. Similarly, the results for the cumulative effect are showed.
As expected, the segmented linear regression model obtains the best results for the linear simulation model. The mean level change is very close to the real expected level change (5.0218 and 5, respectively). The MSE is 0.1550 and the MPE is . The mean cumulative effect is 51.0629 versus the real expected cumulative effect of 50.9. The MPE for the cumulative effect is . Surprisingly, the GAM also obtains good results for the linear simulation model. The mean level change is 5.0246 although the dispersion is greater than that observed for the segmented linear regression model (0.4411 and 0.3935, respectively). The MPE for the level change is slightly higher, . The results are similar for the estimation of the cumulative effect, where the MPE is .
However, when the data are simulated from a non-linear model, the performance of the segmented linear regression model worsens. For the quadratic simulation model, the segmented linear regression model estimates a mean level change of when the real expected level change is . The MPE is . The MPE for the cumulative effect is even greater, . The flexibility of the GAM allows for a better fit for the non-linear simulation models. The mean estimated level change is , very close to the real level change of . The good results of the GAM are maintained when estimating the cumulative effect. The mean cumulative effect is and the real cumulative effect is . The MPE is .
For the more complex polynomial simulation model, the results of the GAM get worse, with an MPE of and for the estimation of the level change and the cumulative effect, respectively. However, these results are better than those obtained by the segmented linear regression model, where the MPEs are and , respectively.
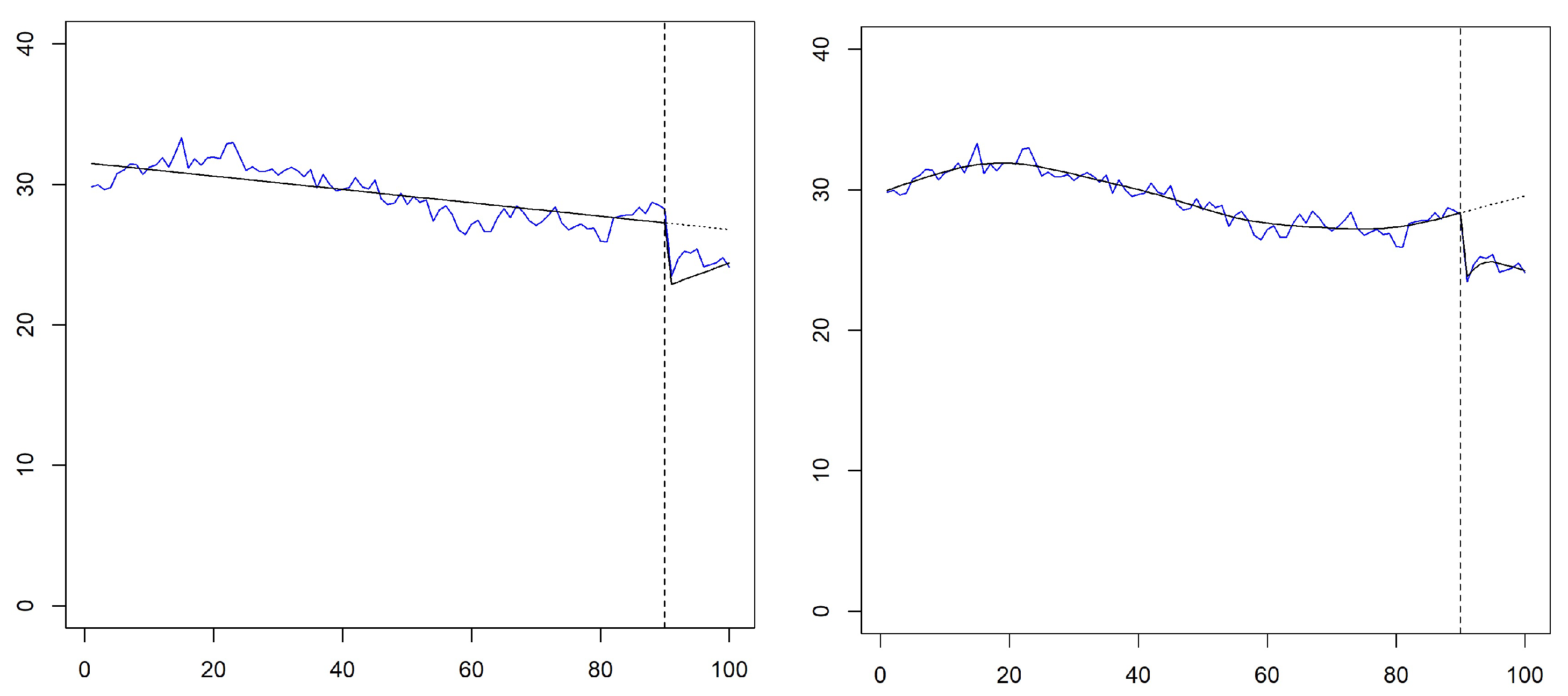
Figure 2 shows an illustrative example of how both models fit the same time series simulated from the polynomial model. The segmented linear regression model estimates a negative trend for the pre-intervention period. The level change is estimated at
, and the trend becomes a positive trend after the intervention, estimating a cumulative effect of
. The GAM fits a positive trend at the end of the pre-intervention period. The level change is now estimated at
. The estimated trend for the post-intervention period is lower than that observed before the intervention, and the cumulative effect is estimated at
.
4. Illustration with Real Data: Impact of the Cost-Sharing Reforms on Pharmaceutical Prescriptions Established in Spain
To illustrate the use of GAMs in a real-life application, we investigate the impact of the 2012 Spanish cost-sharing reforms on pharmaceutical prescription financed by the Spanish National Health Systems (SNHS) [
13]. In June 2012 Spain enacted a reform of the co-payment for outpatient prescription drugs scheme, implemented early July 2012. Cost-free arrangements for all pensioners’ drugs were replaced by a
co-payment subject to a monthly cap, depending on the income [
22].
We use data relating to dispensed prescriptions for Pharmacies and financed by the SNHS. Data were collected from reports published by the Spanish Ministry of Health. We use monthly data from January 2004 to December 2015. The per-capita total prescription dispensed was calculated by dividing by the resident population of Spain.
The segmented linear regression model and GAM are applied to this dataset. Besides the level and trend before and after the intervention we have included as explanatory variables the seasonality (using indicator variables for the segmented linear regression model and a smoothing function for the GAM) and an indicator variable for the month previous to the intervention which examines the “stockpiling” effect between the announcement and the implementation of the law [
23]. The codes are provided in the
supplementary documents.
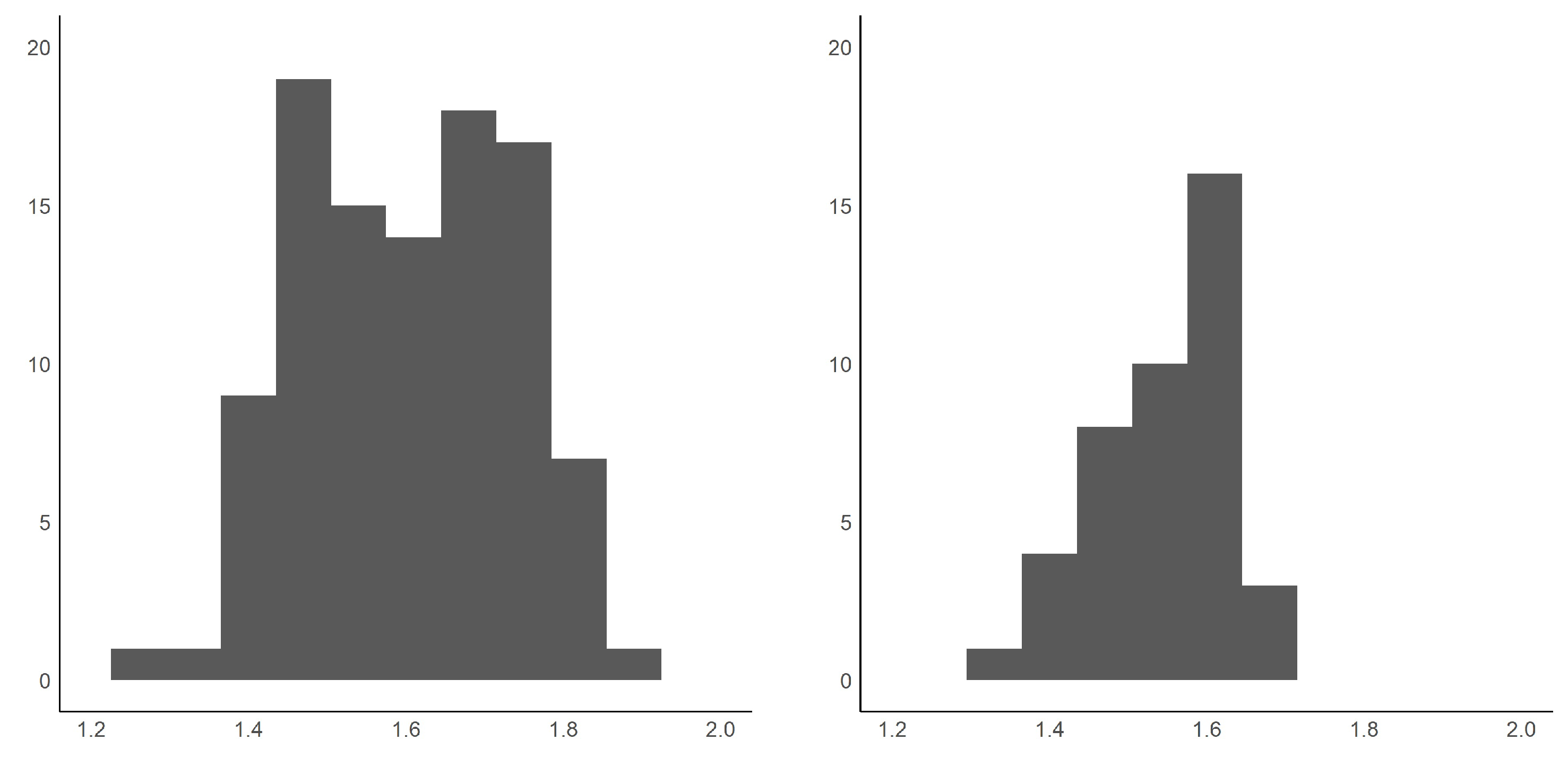
Table 3 shows the descriptive statistics for the dependent variable for the pre- and post- intervention periods. The mean number of prescriptions decreased after the reform. The histogram plots of the per-capita prescriptions are shown in
Figure 3. The Shapiro–Wilk normality tests confirm the normality hypothesis with
p-values of 0.0806 and 0.1066 for the pre- and post- intervention periods, respectively.
Table 4 shows the results of the segmented linear regression model. The level shift due to the new law is estimated at
, so the prescriptions per-capita decreased significantly as soon as the law was implemented. The upward trend of the series also decreases after the law in 0.0012 units. Combining both effects, the cumulative effect for the 42 months of law implementation is estimated in
:
. The rest of the coefficients shows a significant stockpiling effect, and a greater number of prescriptions during the month of January, compared to a lower number of prescriptions in the summer. The goodness of fit of the segmented linear regression model for these data is determined by an adjusted coefficient of determination of
. The coefficient of the autoregresive model for the error term is estimated in
and the residuals show a Durbin-Watson statistic of 2.007, showing that the Prais–Winsten estimation adequately controls for the autocorrelation.
Table 5 shows the results of the GAM. The model M1 includes three coefficients: the intercept, an indicator variable for the intervention (
) and the indicator variable for the month before the intervention which refers to the stockpiling effect. Besides, the model includes three terms to be smoothed, the secular trend
, the change in the trend after the intervention
and the seasonality
. For this last smooth term, the maximum possible dimensions of the basis used for the spline is set to 12 (
), the number of months, while
k is set by default as 9 for the rest of the smooth terms.
The level change is estimated in
:
, similar to that obtained by the segmented linear regression model,
. The stockpiling effect is statistically significant (
p-value: 0.0009). The results for the smooth terms are summarized by the effective degrees of freedom (EDF), which measure the complexity of a penalized smooth term. EDF can be interpreted as an estimate of how many parameters are needed to represent the smooth [
20]. If the EDF is equal to 1, a linear relationship cannot be rejected. In this analysis, the EDF is estimated at 4.167 for the secular trend showing its non-linearity. However, we cannot reject that the change in the trend after the intervention is linear. Seasonality is clearly non-linear. The cumulative effect is estimated at
:
, which is lower than that observed in the segmented linear regression model.
Due to the linearity of the
covariate, an alternative model M2, where
is included in the linear part of the model, is also shown in
Table 5. Estimates do not vary and the variable
is not statistically significant. The cumulative effect is also estimated in
:
. The normality and unbiased error distribution were verified through four residual plots (using the command
gam.check [
16]). We also checked that the default maximum possible dimensions of the basis used for the trend spline (
) was enough.
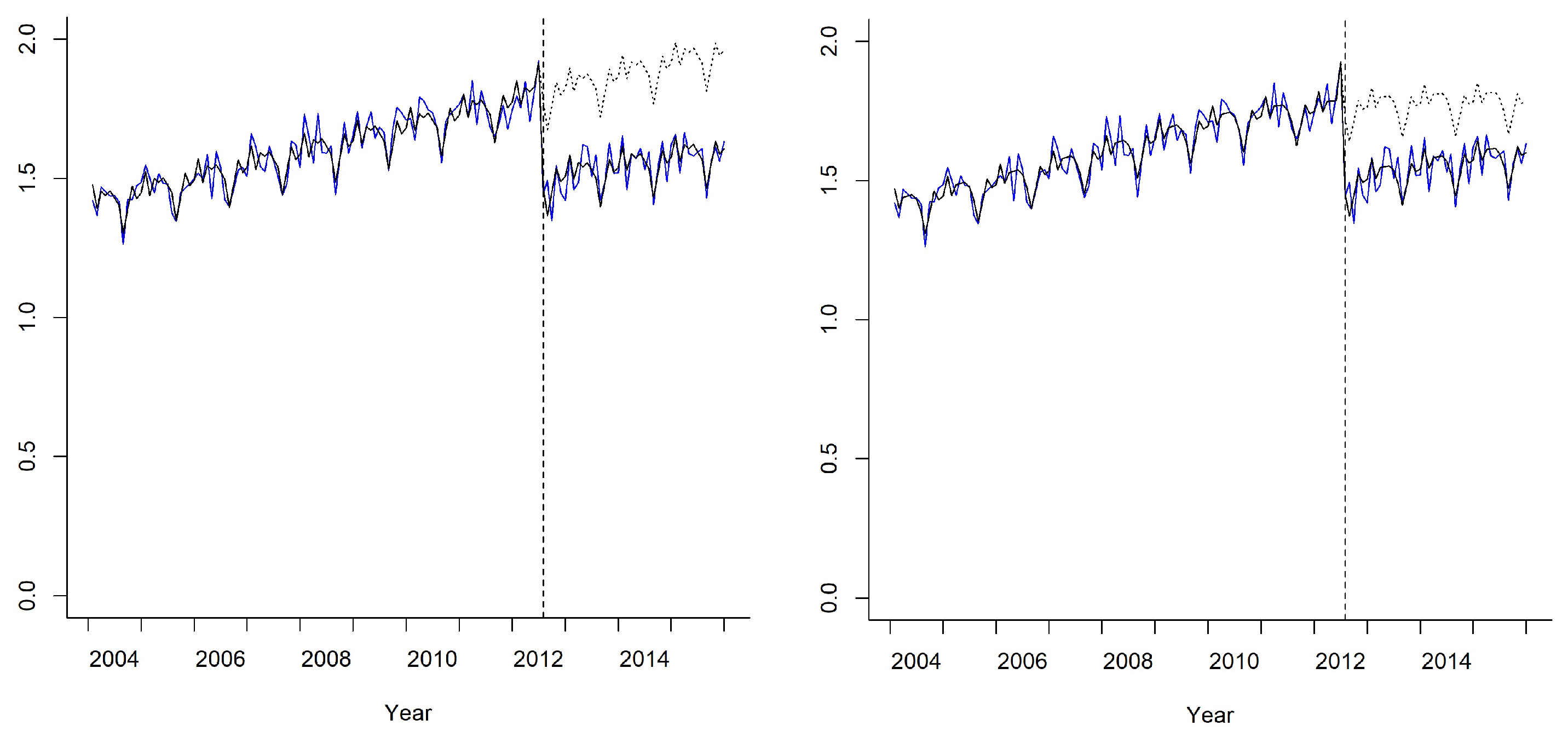
Figure 4 shows the fitted values for both models. The fits are similar, but the GAM predicts a lower trend for the post-intervention period if the intervention had not been performed, which leads to a smaller total impact. Even in this case where the linear model fits the data well, the difference in the total impact estimated by both models is statistically significant.
5. Conclusions
Interrupted time series analysis (ITSA) is a useful quasi-experimental design with which to evaluate the longitudinal effects of interventions. Its design is particularly useful for evaluating policy interventions. Segmented linear regression models have been the most used models to carry out this analysis. However, it may not be appropriate when trends are not linear and they cannot be transformed to be so.
In this paper, we show how generalized additive models (GAMs) [
24,
25,
26,
27] can be useful to accommodate nonlinear trends. GAM is a non-parametric regression-based method that can estimate non-linear trends in time series and can handle the irregular structure of some time series.
Our method generalizes the widely used regression methods applied to ITSA, which explicitly models the time series observed both before and after the intervention. The projection of the pre-intervention model for the post-intervention period can then be used as a counterfactual for the post-intervention period as if the intervention had not occurred.
The analysis with simulated data showed how GAMs improve on existing methods when the trend is non-linear, but they also show good performance when the trend is linear. The analysis with simulated data also showed how the segmented linear regression model fails as the trend model gets more complex. Other intervention effects, such as a pulse intervention, or other non-linear models for the trends, are also possible but we do not expect to observe different conclusions.
A real-life application where the impact of the 2012 Spanish cost-sharing reforms on pharmaceutical prescription is analyzed allows us to observe the differences that can be achieved when applying one or another methodology even in the case where the linear model fits the data well. GAMs also allow the inclusion of other explanatory (control) variables into the analysis assuming a linear or non-linear relationship with the outcome. In our example, the seasonality was included assuming a non-linear trend. The EDF has shown how the change in trend after the intervention () could be modeled linearly. In that case, we recommend its inclusion in the linear part of the model due to its simplicity of estimation and interpretation. The autocorrelation in the error term can also be considered with GAMs which makes this method flexible enough to be applied in most situations.
In addition to GAMs, there are other alternative statistical methods for dealing with non-linear trends. These methods can be divided into two categories: the first includes regression methods like GAM such as the autoregressive integrated moving average (ARIMA) [
10], and local regression (LOESS) [
28]. The second category includes computing methods such as recurrent neural networks (RNN) [
29], and other artificial intelligent systems. ARIMA models are usually considered robust for a long time-series only. These models have been used more in a predictive than an explanatory approach. To use ARIMA models we must to transform a time series into stationary one. ARIMA models are backward looking and not very flexible. Besides, ARIMA models are subjective and the reliability of the chosen model depends on the skill and experience of the researcher. Like GAMs, LOESS is a non-parametric regression method that fits a smooth line through data. But unlike LOESS, GAMs use flexible smoothing functions with automatic choice of smoothing parameteres. Finally, opacity is the most important disadvantage of RNN methods. Furthermore, training of RNN models can be difficult [
30].
GAMs allow for model shapes from linear to nonlinear trends, a balanced reducing of model uncertainty, and the identification of time–periods of significant events [
31]. However, the propensity to overfit is the main limitation of GAMs. Another limitation is that the model will lose predictability when the smoothed variables have values outside of the range of training dataset. GAMs are also restricted to be additive, thus important interactions can be missed. However, as with regular linear regression, we can manually add the interaction effects.









{kind=link}
{kind=link}
{kind=link}
{kind=link}