An Artificial Neural Network Based Solution Scheme for Periodic Computational Homogenization of Electrostatic Problems

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Homogenization Framework
2.1. Energy Formulation for Electrostatic Problems
2.2. Microscopic Boundary Value Problem
3. Artificial Neural Network Based Solution Scheme
3.1. Optimization Principle
3.2. Single Layer Perceptron (SLP)
3.3. Multilayer Perceptron (MLP)
4. Numerical Examples
4.1. One-Dimensional Example
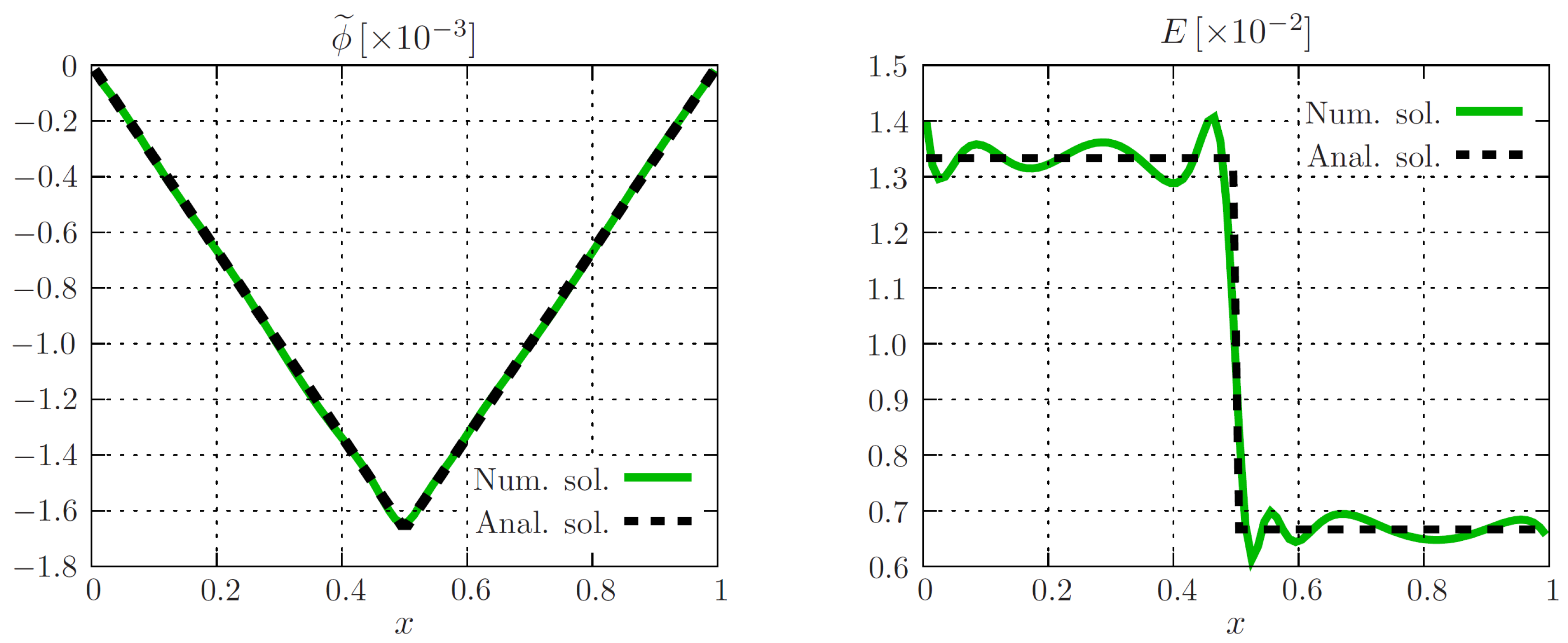
4.1.1. Global Neural Net Approach on Equidistant Grid
4.1.2. Piecewise-defined Neural Net Approach on Equidistant Grid
4.2. Two-Dimensional Example
4.2.1. Global Neural Net Approach on Equidistant Grid
4.2.2. Piecewise-Defined Neural Net Approach
4.3. Three-Dimensional Example
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. Matlab Script for Global One-Dimensional Example
1 % Evaluation point s in area 2 dx = 0.01; 3 x = dx/2:dx:1-dx/2; 4 5 % Applied macroscopic electricfield 6 E0 = 0.01; 7 8 % Electric permittivity in laminate 9 KK = zeros(size(x)); 10 KK(x > 1/2) = 2.0; 11 KK(x < 1/2) = 1.0; 12 13 % Number of hidden neurons 14 nn = 10; 15 16 % Initialize weights and biases 17 wb0 = rand(3*nn+1,1); 18 19 % Anonymous function handle 20 f = @(wb)neuralapprox(wb,KK,E0,x,dx,nn); 21 22 % Call unconstrained minimizer 23 opts = optimoptions(@fminunc,’Algorithm’,’quasi-newton’,... 24 ’StepTolerance’,1e-12,’OptimalityTolerance’,1e-12,... 25 ’MaxFunctionEvaluations’,10000,... 26 ’SpecifyObjectiveGradient’,true,’CheckGradients’,true,... 27 ’FiniteDifferenceType’,’central’,’MaxIterations’,10000); 28 [wb,f] = fminunc(f,wb0,opts) 29 30 function [f, g] = neuralapprox(wb,KK,E0,x,dx,nn) 31 32 % restore weights and biases for ANN 33 u = wb(1:nn); 34 w = wb(nn+1:2*nn); 35 b = wb(2*nn+1); 36 v = wb(2*nn+2:3*nn+1); 37 38 % Neural network response for feedforward net (FFN) (Eq. (13)) 39 z = w*x + u; 40 sigmoid = (1 + exp(-z)).^(-1); 41 ANN = sum(v.*sigmoid) + b; 42 43 % Spatial derivative response for feedforward net (Eq.(14)) 44 d_sigmoid = sigmoid.*(1 - sigmoid); 45 d_ANN = sum(v.*w.*d_sigmoid); 46 47 % Derivative of 1st FFN and dFFN/dx w.r.t. its weights (Eq.(15)) 48 d2_sigmoid = sigmoid.*(1 - sigmoid).^2 - sigmoid.^2.*(1 - sigmoid); 49 50 xmatr = x.*ones(size(z)); 51 ANN_du = v.*d_sigmoid; 52 ANN_dw = v.*d_sigmoid.*xmatr; 53 ANN_db = ones(size(x)); 54 ANN_dv = sigmoid; 55 56 d_ANN_du = v.*w.*d2_sigmoid; 57 d_ANN_dw = v.*d_sigmoid + v.*w.*d2_sigmoid.*xmatr; 58 d_ANN_db = zeros(size(x)); 59 d_ANN_dv = w.*d_sigmoid; 60 61 % Derivatives of the trial function phi = x*(1-x)*N (Eq.(24)&(15)) 62 d_phi_t = (1-2*x).*ANN + x.*(1-x).*d_ANN; 63 d_phi_t_du = (1-2*xmatr).*ANN_du + xmatr.*(1-xmatr).*d_ANN_du; 64 d_phi_t_dw = (1-2*xmatr).*ANN_dw + xmatr.*(1-xmatr).*d_ANN_dw; 65 d_phi_t_db = (1-2*x).*ANN_db + x.*(1-x).*d_ANN_db; 66 d_phi_t_dv = (1-2*xmatr).*ANN_dv + xmatr.*(1-xmatr).*d_ANN_dv; 67 68 % Cost function and its derivatives w.r.t. the weights (Eq.(26)) 69 JJ = 0.5*KK.*(E0 - d_phi_t).^2; 70 71 JJ_du = -KK.*(E0 - d_phi_t).*d_phi_t_du; 72 JJ_dw = -KK.*(E0 - d_phi_t).*d_phi_t_dw; 73 JJ_db = -KK.*(E0 - d_phi_t).*d_phi_t_db; 74 JJ_dv = -KK.*(E0 - d_phi_t).*d_phi_t_dv; 75 76 g1 = [JJ_du;JJ_dw;JJ_db;JJ_dv]; 77 78 f = dx*sum(JJ); 79 g = dx*sum(g1, 2); 80 81 end
Appendix B. Matlab Script for Piecewise-Defined One-Dimensional Example
1 % Evaluation points in area 2 dx = 0.01; 3 x = dx/2:dx:1-dx/2; 4 5 % Applied macroscopic load 6 E0 = 0.01; 7 8 % Electric permittivity in laminate 9 KK = zeros(size(x)); 10 KK(x > 1/2) = 2.0; 11 KK(x < 1/2) = 1.0; 12 13 % Number of hidden neurons 14 nn = 10; 15 16 % Initialize weights and biases 17 wb0 = rand(6*nn+2,1)*(E0/nn); 18 19 % Anonymous function handle 20 f = @(wb)neuralapprox(wb,KK,E0,x,dx,nn); 21 22 % Call unconstrained minimizer 23 opts = optimoptions(@fminunc,’Algorithm’,’quasi-newton’,... 24 ’SpecifyObjectiveGradient’,true,’CheckGradients’,true,... 25 ’FiniteDifferenceType’,’central’,’MaxIterations’,5000); 26 [wb,f] = fminunc(f,wb0,opts) 27 28 function [f, g] = neuralapprox(wb,KK,E0,xx,dx,nn) 29 %%% Cost function for interval [0,0.5] 30 31 % Restore weights and biases for first ANN 32 u = wb(1:nn); 33 w = wb(nn+1:2*nn); 34 b = wb(2*nn+1); 35 v = wb(2*nn+2:3*nn+1); 36 37 % Quadrature points for integration 38 x = xx(1:floor(size(xx,2)/2)); 39 K = KK(1:floor(size(KK,2)/2)); 40 41 % Neural network response for 1st feedforward net (FFN) (Eq.(13)) 42 z = w*x + u; 43 sigmoid = (1 + exp(-z)).^(-1); 44 ANN = sum(v.*sigmoid) + b; 45 46 % Spatial derivative response for 1st feedforward net (Eq.(14)) 47 d_sigmoid = sigmoid.*(1 - sigmoid); 48 d_ANN = sum(v.*w.*d_sigmoid); 49 50 % Derivative of 1st FFN and dFFN/dx w.r.t. its weights (Eq.(15)) 51 d2_sigmoid = sigmoid.*(1 - sigmoid).^2 - sigmoid.^2.*(1 - sigmoid); 52 53 xmatr = x.*ones(size(z)); 54 55 ANN_du = v.*d_sigmoid; 56 ANN_dw = v.*d_sigmoid.*xmatr; 57 ANN_db = ones(size(x)); 58 ANN_dv = sigmoid; 59 60 d_ANN_du = v.*w.*d2_sigmoid; 61 d_ANN_dw = v.*d_sigmoid + v.*w.*d2_sigmoid.*xmatr; 62 d_ANN_db = zeros(size(x)); 63 d_ANN_dv = w.*d_sigmoid; 64 65 % FFN and derivatives evaluated at the discontinuity (Eq.(28)&(15)) 66 z_disc = w*0.5 + u; 67 68 sigmoid_disc = (1 + exp(-z_disc)).^(-1); 69 d_sigmoid_disc = sigmoid_disc.*(1 - sigmoid_disc); 70 71 ANN_disc = sum(v.*sigmoid_disc) + b; 72 ANN_disc_du = v.*d_sigmoid_disc; 73 ANN_disc_dw = v.*d_sigmoid_disc*0.5; 74 ANN_disc_db = 1.0; 75 ANN_disc_dv = sigmoid_disc; 76 77 % Derivatives of the trial function phi = x*N_1 (Eq.(28)&(15)) 78 phi_t_disc = 0.5.*ANN_disc; 79 d_phi_t_disc_du = ANN_disc_du; 80 d_phi_t_disc_dw = ANN_disc_dw; 81 d_phi_t_disc_db = ANN_disc_db; 82 d_phi_t_disc_dv = ANN_disc_dv; 83 84 d_phi_t = ANN + x.*d_ANN; 85 86 d_phi_t_du = ANN_du + xmatr.*d_ANN_du; 87 d_phi_t_dw = ANN_dw + xmatr.*d_ANN_dw; 88 d_phi_t_db = ANN_db + x.*d_ANN_db; 89 d_phi_t_dv = ANN_dv + xmatr.*d_ANN_dv; 90 91 % Cost function and its derivatives w.r.t. the weights (Eq.(30)) 92 JJ = 0.5*K.*(E0 - d_phi_t).^2; 93 94 JJ_du = -K.*(E0 - d_phi_t).*d_phi_t_du; 95 JJ_dw = -K.*(E0 - d_phi_t).*d_phi_t_dw; 96 JJ_db = -K.*(E0 - d_phi_t).*d_phi_t_db; 97 JJ_dv = -K.*(E0 - d_phi_t).*d_phi_t_dv; 98 99 g1 = [JJ_du;JJ_dw;JJ_db;JJ_dv]; 100 101 f = dx*sum(JJ); 102 g = dx*sum(g1, 2); 103 104 %%% Cost function for interval [0.5,1.0] 105 106 % Restore weights and biases for second ANN 107 u = wb(3*nn+2:4*nn+1); 108 w = wb(4*nn+2:5*nn+1); 109 b = wb(5*nn+2); 110 v = wb(5*nn+3:6*nn+2); 111 112 % Quadrature points for integration 113 x = xx(floor(size(xx,2)/2)+1:end); 114 K = KK(floor(size(KK,2)/2)+1:end); 115 116 % Neural network response for 2nd feedforward net (FFN) (Eq.(13)) 117 z = w*x + u; 118 sigmoid = (1 + exp(-z)).^(-1); 119 ANN = sum(v.*sigmoid) + b; 120 121 % Spatial derivative response for 2nd feedforward net (Eq.(14)) 122 d_sigmoid = sigmoid.*(1 - sigmoid); 123 d_ANN = sum(v.*w.*d_sigmoid); 124 125 % Derivative of end FFN and dFFN/dx w.r.t. its weights (Eq.(28)&(15)) 126 d2_sigmoid = sigmoid.*(1 - sigmoid).^2 - sigmoid.^2.*(1 - sigmoid); 127 128 xmatr = x.*ones(size(z)); 129 130 ANN_du = v.*d_sigmoid; 131 ANN_dw = v.*d_sigmoid.*xmatr; 132 ANN_db = ones(size(x)); 133 ANN_dv = sigmoid; 134 135 d_ANN_du = v.*w.*d2_sigmoid; 136 d_ANN_dw = v.*d_sigmoid + v.*w.*d2_sigmoid.*xmatr; 137 d_ANN_db = zeros(size(x)); 138 d_ANN_dv = w.*d_sigmoid; 139 140 % Derivatives of the trial function 141 % phi = (0.5-x)*(1-x)*N_2 + 2*(1-x)*phi(0.5) (Eq.(28)&(15)) 142 d_phi_t = (2*x-1.5).*ANN + (0.5-x).*(1-x).*d_ANN - 2*phi_t_disc; 143 144 d_phi_t_du = (2*xmatr-1.5).*ANN_du + (0.5-xmatr).*(1-xmatr).*d_ANN_du; 145 d_phi_t_dw = (2*xmatr-1.5).*ANN_dw + (0.5-xmatr).*(1-xmatr).*d_ANN_dw; 146 d_phi_t_db = (2*x-1.5).*ANN_db + (0.5-x).*(1-x).*d_ANN_db; 147 d_phi_t_dv = (2*xmatr-1.5).*ANN_dv + (0.5-xmatr).*(1-xmatr).*d_ANN_dv; 148 149 % Cost function and its derivatives w.r.t. the weights (Eq.(30)) 150 JJ = 0.5*K.*(E0 - d_phi_t).^2; 151 152 JJ_du = -K.*(E0 - d_phi_t).*d_phi_t_du; 153 JJ_dw = -K.*(E0 - d_phi_t).*d_phi_t_dw; 154 JJ_db = -K.*(E0 - d_phi_t).*d_phi_t_db; 155 JJ_dv = -K.*(E0 - d_phi_t).*d_phi_t_dv; 156 157 JJ_disc_du = -K.*(E0 - d_phi_t).*d_phi_t_disc_du; 158 JJ_disc_dw = -K.*(E0 - d_phi_t).*d_phi_t_disc_dw; 159 JJ_disc_db = -K.*(E0 - d_phi_t).*d_phi_t_disc_db; 160 JJ_disc_dv = -K.*(E0 - d_phi_t).*d_phi_t_disc_dv; 161 162 g0 = [JJ_disc_du;JJ_disc_dw;JJ_disc_db;JJ_disc_dv]; 163 g1 = [JJ_du;JJ_dw;JJ_db;JJ_dv]; 164 165 f = f + dx*sum(JJ); 166 g = g - dx*sum(g0, 2); 167 g = [g;dx*sum(g1, 2)]; 168 end
Appendix C. Two-Dimensional Trial Function and Derivatives
Appendix D. Three-Dimensional Trial Function and Derivatives
References
- Hebb, D.O. The Organization of Behavior; John Wiley & Sons: New York, NY, USA, 1949. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Denning, D.E. An intrusion-detection model. IEEE Trans. Softw. Eng. 1987, 2, 222–232. [Google Scholar] [CrossRef]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Cham, Switzerland, 2008. [Google Scholar]
- Raissi, M.; Yazdani, A.; Karniadakis, G.E. Hidden fluid mechanics: A Navier–Stokes informed deep learning framework for assimilating flow visualization data. Available online: http://arxiv.org/abs/1808.04327 (accessed on 12 April 2019).
- Ghaboussi, J.; Garrett, J.H.; Wu, X. Knowledge-based modeling of material behavior with neural networks. J. Eng. Mech. 1991, 117, 132–153. [Google Scholar] [CrossRef]
- Huber, N.; Tsakmakis, C. A neural network tool for identifying the material parameters of a finite deformation viscoplasticity model with static recovery. Comput. Methods Appl. Mech. Eng. 2001, 191, 353–384. [Google Scholar] [CrossRef]
- Le, B.; Yvonnet, J.; He, Q.-C. Computational homogenization of nonlinear elastic materials using neural networks. Int. J. Numer. Methods Eng. 2015, 104, 1061–1084. [Google Scholar] [CrossRef]
- Bessa, M.; Bostanabad, R.; Liu, Z.; Hu, A.; Apley, D.W.; Brinson, C.; Chen, W.; Liu, W. A framework for data-driven analysis of materials under uncertainty: Countering the curse of dimensionality. Comput. Methods Appl. Mech. Eng. 2017, 320, 633–667. [Google Scholar] [CrossRef]
- Liu, Z.; Bessa, M.; Liu, W.K. Self-consistent clustering analysis: An efficient multi-scale scheme for inelastic heterogeneous materials. Comput. Methods Appl. Mech. Eng. 2016, 306, 319–341. [Google Scholar] [CrossRef]
- Voigt, W. Theoretische Studien über die Elastizitastsverhältnisse der Cristalle; Königliche Gesellschaft der Wissenschaften zu Göttingen: Göttingen, Germany, 1887. [Google Scholar]
- Reuss, A. Berechnung der fließgrenze von mischkristallen auf grund der plastizitätsbedingung für einkristalle. Zeitschrift für Angewandte Mathematik und Mechanik 1929, 9, 49–58. [Google Scholar] [CrossRef]
- Hill, R. The elastic behaviour of a crystalline aggregate. Proc. Phys. Soc. 1952, 65, 349. [Google Scholar] [CrossRef]
- Hashin, Z.; Shtrikman, S. A variational approach to the theory of the elastic behaviour of multiphase materials. J. Mech. Phys. Solids 1963, 11, 127–140. [Google Scholar] [CrossRef]
- Willis, J. Bounds and self-consistent estimates for the overall properties of anisotropic composites. J. Mech. Phys. Solids 1977, 25, 185–202. [Google Scholar] [CrossRef]
- Budiansky, B. On the elastic moduli of some heterogeneous materials. J. Mech. Phys. Solids 1965, 13, 223–227. [Google Scholar] [CrossRef]
- Hill, R. A self-consistent mechanics of composite materials. J. Mech. Phys. Solids 1965, 13, 213–222. [Google Scholar] [CrossRef]
- Mori, T.; Tanaka, K. Average stress in matrix and average elastic energy of materials with misfitting inclusions. Acta Mech. 1973, 21, 571–574. [Google Scholar] [CrossRef]
- Miehe, C.; Schröder, J.; Schotte, J. Computational homogenization analysis in finite plasticity. Simulation of texture development in polycrystalline materials. Comput. Methods Appl. Mech. Eng. 1999, 171, 387–418. [Google Scholar] [CrossRef]
- Schröder, J. A numerical two-scale homogenization scheme: The FE2–method. In Plasticity and Beyond; Schröder, J., Hackl, K., Eds.; Springer: Cham, Switzerland, 2014; pp. 1–64. [Google Scholar]
- Moulinec, H.; Suquet, P. A fast numerical method for computing the linear and nonlinear mechanical properties of composites. Académie des Sciences 1994, 2, 1417–1423. [Google Scholar]
- Zeman, J.; Vondřejc, J.; Novak, J.; Marek, I. Accelerating a fft-based solver for numerical homogenization of periodic media by conjugate gradients. J. Comput. Phys. 2010, 229, 8065–8071. [Google Scholar] [CrossRef]
- Fritzen, F.; Leuschner, M. Reduced basis hybrid computational homogenization based on a mixed incremental formulation. Comput. Methods Appl. Mech. Eng. 2013, 260, 143–154. [Google Scholar] [CrossRef]
- Ryckelynck, D. A priori hyperreduction method: An adaptive approach. J. Comput. Phys. 2005, 202, 346–366. [Google Scholar] [CrossRef]
- Lagaris, I.E.; Likas, A.; Fotiadis, D.I. Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans. Neural Netw. 1998, 9, 987–1000. [Google Scholar] [CrossRef] [PubMed]
- Hill, R. Elastic properties of reinforced solids: Some theoretical principles. J. Mech. Phys. Solids 1963, 11, 357–372. [Google Scholar] [CrossRef]
- Jackson, J.D. Classical Electrodynamics; Wiley: Hoboken, NJ, USA, 1999. [Google Scholar]
- Bensoussan, A.; Lions, J.-L.; Papanicolaou, G. Asymptotic Analysis for Periodic Structures; American Mathematical Society: Providence, RI, USA, 2011; Volume 374. [Google Scholar]
- Nemat-Nasser, S.; Lori, M.; Datta, S. Micromechanics: Overall properties of heterogeneous materials. J. Appl. Mech. 1996, 63, 561. [Google Scholar] [CrossRef]
- Terada, K.; Hori, M.; Kyoya, T.; Kikuchi, N. Simulation of the multi-scale convergence in computational homogenization approaches. Int. J. Solids Struct. 2000, 37, 2285–2311. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- MATLAB R2017b (Version 9.3.0). The MathWorks Inc.: Natick, MA, USA, 2017. Available online: https://www.mathworks.com/products/matlab.html (accessed on 12 April 2019).
- Rumelhart, D.E.; McClelland, J.L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A limited memory algorithm for bound constrained optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Zhu, C.; Byrd, R.H.; Lu, P.; Nocedal, J. Algorithm 778: L-bfgs-b: Fortran subroutines for large-scale bound-constrained optimization. ACM Trans. Math. Softw. 1997, 23, 550–560. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Gelebart, L.; Mondon-Cancel, R. Non-linear extension of fft-based methods accelerated by conjugate gradients to evaluate the mechanical behavior of composite materials. Comput. Mat. Sci. 2013, 77, 430–439. [Google Scholar] [CrossRef]
- Göküzüm, F.S.; Keip, M.-A. An algorithmically consistent macroscopic tangent operator for FFT-based computational homogenization. Int. J. Numer. Methods Eng. 2018, 113, 581–600. [Google Scholar] [CrossRef]
- Göküzüm, F.S.; Nguyen, L.T.K.; Keip, M.A. A multiscale fe-fft framework for electro-active materials at finite strains. Comput. Mech. 2019, 1–22. [Google Scholar] [CrossRef]
- Kabel, M.; Böhlke, T.; Schneider, M. Efficient fixed point and newton-krylov solvers for fft-based homogenization of elasticity at large deformations. Comput. Mech. 2014, 54, 1497–1514. [Google Scholar] [CrossRef]











© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Göküzüm, F.S.; Nguyen, L.T.K.; Keip, M.-A. An Artificial Neural Network Based Solution Scheme for Periodic Computational Homogenization of Electrostatic Problems. Math. Comput. Appl. 2019, 24, 40. https://doi.org/10.3390/mca24020040
Göküzüm FS, Nguyen LTK, Keip M-A. An Artificial Neural Network Based Solution Scheme for Periodic Computational Homogenization of Electrostatic Problems. Mathematical and Computational Applications. 2019; 24(2):40. https://doi.org/10.3390/mca24020040
Chicago/Turabian StyleGöküzüm, Felix Selim, Lu Trong Khiem Nguyen, and Marc-André Keip. 2019. "An Artificial Neural Network Based Solution Scheme for Periodic Computational Homogenization of Electrostatic Problems" Mathematical and Computational Applications 24, no. 2: 40. https://doi.org/10.3390/mca24020040