1. Introduction
A variety of problems in, e.g., management science, mathematics, computer science, chemistry, biology, sociology, epidemiology etc. deal with quantifying centrality in complex networks. Thus, numerous measures have been proposed including Freeman’s degree centrality [
1], Katz’s centrality [
2], Hubbell’s centrality [
3], Bonacich’s eigenvector centrality designed for systematic networks [
4], Bonacich and Lloyd’s alpha centrality conceptualized for asymmetric networks [
5], Stephenson and Zelen’s information centrality [
6], etc. Generally, methods mentioned above exclusively characterize limited parts of what it implies for an actor to be “vital” to the network. As was noted by Borgatti [
7], centrality measures, or these measures’ probably well-known understandings, make certain presumptions about the way in which traffic flows through a network. For instance, Freeman’s closeness [
1] counts exclusively geodesic routes, evidently accepting that nodes communicate with other nodes via the shortest routes. Other approaches such as flow betweenness [
8] do not assume shortest paths but do assume proper paths in which no node is visited more than once (for more details, see [
7]). Google’s PageRank algorithm [
9] is constructed on the assumption that the probability of individuals surfing heterogeneous websites is equal, which does not correspond to reality. Thus, it is obvious to draw the following conclusions that centrality’s measures are then coordinated to the sorts of moves that they are suitable which implies a specific centrality is ideal for one application, yet is regularly imperfect for an alternate application. Despite that, methods mentioned above also has its’ own limitations and shortcomings. For instance, Freeman’s degree [
1] focuses on a node’s local activity while the global activity is ignored and fails to describe the propagation of influence. Supposing that plenty of nodes are not included in other node pairs’ shortest path, consequently, the value of betweenness centrality will be zero. Since Katz centrality [
2] takes all the paths between the nodes pairs in the process of calculating influence, its high computational complexity makes it hard to be applied in large-scale networks. Eigenvector centrality [
4] owns slow convergence rate and may produce an endless loop. In addition, what is not often recognized by the neighborhood-based and path-based centrality measures mentioned above is that structural complexity and uncertainty plays a significant role in the analysis of network centrality. The graph entropy—the concept of which was first presented by Rashevsky [
10] and Trucco [
11]—has been applied extensively to evaluate networks’ structural complexity and uncertainty and describe social influence. Rashevsky treated the entropy of a graph
as its topological information content [
10]. The value of graph entropy can be obtained by using various graph invariants such as the number of vertices [
12], the vertex degree sequence [
13] and extended degree sequences (i.e., second neighbor, third neighbor etc.) [
14]. Bonchev [
15] suggested that the structure of a given network can be treated as a consequence of an arbitrary function. Inspired by this novel insight, for a given network, Shannon’s information entropy is applied to compute its structural information content and measure its uncertainty. Since then, graph entropy based on Shannon’s theory plays an essential role in social networks analysis. However relatively little work [
16,
17,
18] has been done to prove the efficiency of the application of Shannon’s theory to calculate network centrality.
Motivated by the above discussion, this paper is aimed to introduce a novel entropy centrality model based on decompositions of a graph into subgraphs and calculation on the entropy of neighbor nodes. By using entropy theory, the proposed method can be well qualified to depict the uncertain of social influence, consequently can be useful for detecting vital nodes. By quantifying the local influence of a node on its neighbors and the indirect influence on its two-hop neighbors (the definition of two-hop neighbor can be seen in
Section 3), the proposed methods characterizes associations among node pairs and captures the process of influence propagation. We also provide the performance evaluation for our proposed model by using four real-world datasets and three artificial networks built by using Barabasi-Albert, Erdos-Renyi and Watts-Stroggatz. Other five methods including degree centrality, betweenness centrality, closeness centrality, eigenvector centrality and PageRank are also applied to the same selected networks for comparison. The extensive analytical results prove the effectiveness of the proposed model.
In the next section, we start our survey on centrality methods. In
Section 3, we give a brief introduction of the definitions of graph. In
Section 4 we provide an overview of Shannon’s entropy. In
Section 5, we use entropy centrality to design an algorithm to quantify the influence of nodes in networks. In
Section 6, we conduct experiments based on four real-world datasets with varied sizes and densities to validate the efficiency of the model presented by various models such as Barabasi-Albert, Erdos-Renyi and Watts-Stroggatz. Conclusion and future work of this paper can be seen in
Section 7.
2. Literature Review
In this section, we investigated some of the most well-known methods that had been presented to identify the vital nodes in different network topologies such as the classical centrality measures and many other approaches. Diverse measures of centrality catch distinctive parts of what it implies for an actor to be “powerful” to the given networks. Thus, the definition of centrality varies from person to person. Freeman [
1] argued that the centrality of a node could be determined by reference to any of three different structural attributes of that node: its degree, its betweenness, or its closeness. While degree centrality, the number of adjacencies for a node, is a straightforward index of the node’s activity; betweenness centrality, based upon the number of the shortest paths between pairs of other nodes that pass through the node is useful as an index of the potential of a node for network control; and closeness centrality, computed as the sum of shortest paths between the node and all other nodes, indicates its effectiveness or correspondence autonomy.
Katz [
2] introduced a measure of centrality known as Katz centrality which computed influence by taking into consideration the number of walks between a pair of nodes. As noted by Katz, the attenuation factor
can be interpreted as the chance that an edge is effectively traversed. Also, the parameter
shows the relative significance of endogenous versus exogenous factors in the determination of centrality. Eigenvector centrality first suggested by Bonacich [
4] has turned out to be one of symmetric network centrality’s standard measures and can identify the centrality power of a node in the light of the idea that associations with high-scoring nodes contribute more to the node’s score being referred to than rise to associations with low-scoring nodes. To deal with the condition of asymmetric network, Bonacich and Lloyd [
5] supposed that the eigenvectors of asymmetric matrices were not orthogonal, so the equations were a bit different and conceptualized alpha centrality approach. Google’s PageRank [
9], among others, is a case of alpha centrality. Stephenson and Zelen [
6] defined the information centrality using the “information” contained in all possible paths between pairs of points. Estrada and Rodríguez-Velázquez [
19] introduced the subgraph centrality which was obtainable mathematically from the spectra of the network’s adjacency matrix characterized the involvement of each actor in all subgraphs in the given network. A novel approach of centrality measuring based on game theoretical concepts could be found in Gómez et al. [
20]. Gómez et al. [
21] illustrated how to extend the classical betweenness centrality measure at the point when the issue is demonstrated as a bi-criteria network flow optimization issue. Newman [
22] extended the conventional conception of betweenness which implicitly assumed that information spread only along those shortest paths and proposed a betweenness measure that relaxed this assumption, including contributions from essentially all paths between nodes, not just the shortest.
Recently, Du et al. [
23] firstly introduced TOPIS as a mew measure of centrality. Gao et al. [
24] improved the original evidential centrality by taking node degree distributions and global structure information into consideration. A novel measure of node influence based on comprehensive use of the degree method, H-index and coreness metrics was suggested by Lü et al. [
25]. Considering the limitations of degree centrality and restriction of closeness centrality and betweenness centrality in large-scale networks, Chen et al. [
26] proposed a semi-local centrality method. Also, Chen et al. [
27] introduced a so-called ClusterRank method, which takes the influence of neighbor nodes and clustering coefficient into consideration. Zeng and Zhang [
28] improved the established k-shell method by rethinking the significant connections between nodes and removed nodes and proposed a mixed degree decomposition method. Pei et al. [
29] confirmed that the most influential actors are situated in the k-core across disparate social platforms. Martin et al. [
30] made the point that the eigenvector centrality has lost the capacity to distinguish among the remaining nodes and introduced an alternative centrality definition called nonbacktracking centrality. The LeaderRank algorithm was modified by introducing a variant based on allocating degree-dependent weights onto associations constructed by ground nodes [
31]. Zhao et al. [
32] identified the most effective spreaders by using community-based theory. Consequently, the network is divided into serval independent sets with different colors. Min et al. [
33] studied the human behavior and concluded that individuals who play a significant role in connecting various communities is expected to be an effective spreader of influence. Gleich [
34] provided a comprehensive summary of the areas in which PageRank can be applied. Lü et al. [
35] conducted a perturbative analysis in the adjacency matrix and explained centrality from the perspective of link predictability. Morone and Makse [
36] recommended that the problem of finding the minimal set of influential spreaders can be cleverly mapped onto optimal percolation in networks.
Motivated by the original work owing to Shannon [
37], Rashevsky [
10] first studied the relations between the topological properties of graphs and their information content and introduced the concept of graph entropy. Mowshowitz [
38] defined a measure of the structural information content of a graph and explored its mathematical properties. Since then, entropy measures are utilized to investigate networks’ structural complexity and play an essential part in varieties of application fields, including biology, chemistry and sociology. Everett [
39] presented a new concept of role similarity generated from structural equivalence and introduced a new measure of structural complexity based on the entropy measure developed by Mowshowitz [
38]. With the purpose of acquiring a continuous quantitative measure of robot team diversity, Balch [
40] developed the concept of hierarchic social entropy—an application of Shannon’s information entropy metric to robotic groups. Tutzauer [
41] offered an entropy-based measure of centrality that is suitable for traffic propagating by flows along paths and proved its extensive applicability. Emmert-Streib and Dehmer [
42] elaborated the idea of calculating hierarchical structures’ topological entropy by assigning two probability distributions—for nodes and for edges—and proved that these entropic measures could be computed efficiently. Inspired by small scale-free networks’ discussion, the off-diagonal complexity (OdC) was proposed by Claussen [
43] as a novel approach to quantify the complexity of undirected networks. For deriving graph entropy measures, Dehmer [
44] outlined a different approach which took use of means of certain information functions to allocate a probability value to each node in a given graph. Kim and Wilhelm [
45] presented various measures that could compute this complexity, such as the relative number of non-isomorphic one-edge-deleted subgraphs, denoted as
. Anand and Bianconi [
46] illustrated how to characterize a network ensemble’s Shannon entropy and how it was connected with the Gibbs and von Neumann entropies of network ensembles. Dehmer and Mowshowitz [
14] provided a more extensive overview on methods for measuring the entropy of graphs and demonstrated the wide applicability of entropy measures.
In a more recent contribution, Cao and Dehmer [
16] showed a new graph entropy measure which depends on the number of vertex by introducing arbitrary information functional and investigated its’ mathematical properties. Furthermore, Cao and Dehmer [
47] proved further extremal properties of the re-defined graph entropies. Chen and Dehmer [
17] proved bounds for entropies based on the study of Cao and Dehmer [
16] and came up with interrelations between different measures. Nikolaev et al. [
18] presented a measure of centrality as flow destination’s entropy in a random walk flow with Markovian property. Nie et al. [
48] investigated strategies for network attack and established a new design known as mapping entropy (ME) to recognize the significance of a node in the complex network based on the knowledge of the neighbors of a node. Fei and Deng [
49] addressed the problem of how to identify influential nodes in complex networks by using relative entropy and the TOPSIS method, which combines the advantages of existing centrality measures and demonstrated the effectiveness of the proposed method based on experimental results. Peng et al. [
50] characterized the features of mobile social networks and presented an evaluation model to quantify influence by analyzing and calculating the friend entropy and communication frequency entropy between users to depict the uncertainty and complexity of social influence.
3. Preliminaries
Given an undirected, unweighted graph
, where
represents finite, nonempty set of nodes (vertices) and
are the set of edges. It is known that if
, which means node
is adjacent to node
. Furthermore, node
is known as the neighbor of node
. The neighborhood of
is the set of the neighbors of
. Also, we can use the incidence matrix to characterize the incident relationship between nodes. The elements of incidence matrix
has two values which is 1 and 0, described as follows.
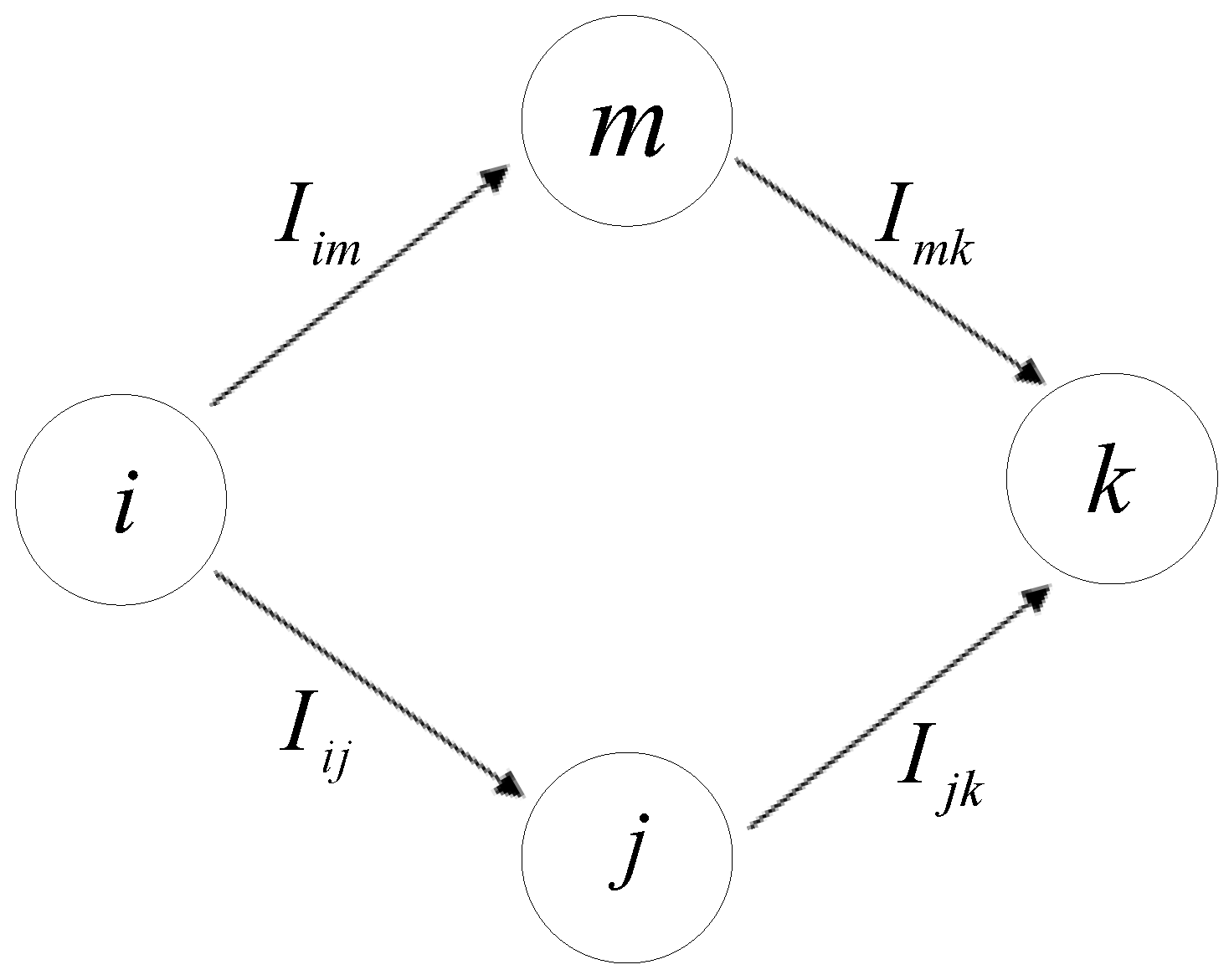
Now we introduce the definition of one-hop neighbors and two-hop neighbors. Given a directed or undirected graph with nodes and edges, if node and node are directly connected with edge , namely, , we call node and node are one-hop neighbors. That means node only need to perform a simple one-hop jump in order to reach node . The idea is inspired by wireless multi-hop network. In wireless multi-hop networks, node communicates neighbor nodes within its communication range. Consistent with wireless multi-hop networks, in social network, because of limited social power, individuals construct connections only with other individuals located in the neighborhood area or in so called local-world. Motivated by the above discussions, we now suppose that if node and are directly linked in the network, possesses the effective power to influence . Then the local influence of node on its adjacent nodes can be defined as . Analogously consider a connected network represented by graph with nodes and edges, if node and node are not directly connected, namely, , while node and have common neighbor node , which means there is a path from node to , that is, has one two-hop neighbor node , or has one two-hop neighbor node . Communication or information transmission is achieved by two hops between node and . Similarly, individual has the capability to affect the way that thinks or behaves through influencing their common neighbor node and vice versa. According to the above analysis, thus the indirect impact of node having on its two-hop neighbors can be defined as . So, a network represented by a responding graph can be decomposed into sub-network, which is constructed by nodes and its’ neighbors. Based on these mathematical preliminaries, we present the following model to assess the power of each node via degree-based entropies.
6. Performance Evaluation
To verify the efficiency of the proposed model, in this paper, we conduct several experiments on real social network data and compare with other centrality models to examine the relative drawbacks and disadvantages. The experiment is conducted using four datasets with varying sizes and densities including: (i) Zachary’s karate club (for more details, see [
60]): in Zachary’s study [
60], 34 members of a university-based karate club were observed for a period of three years, from 1970 to 1972. Also, the network was built on the basis of friendships between members; (ii) USAir97 (The data can be downloaded from
http://mrvar.fdv.uni-lj.si/pajek/): the undirected network, which is constructed by 332 nodes and 2126 edges, depicts the direct air line between American airports. Each node indicates an airport and an edge represents a direct route between the two airports; (iii) Co-authorships in network science [
61]: the undirected network compiled by M. Newman reflects collaboration of scientists engaged in research of network theory; (iv) E-mail network URV: the social network describes email exchanges among users in University at Rovira i Virgili [
62].
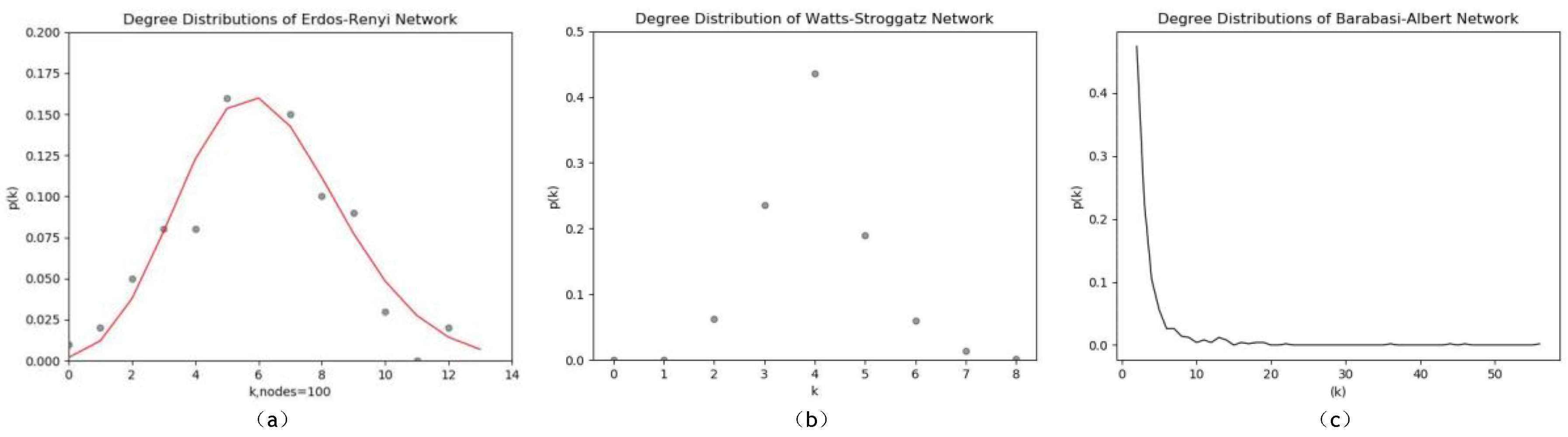
We also analyze how the proposed method works for artificial networks modeled by the following three models including: Erdos-Renyi, Watts-Stroggatz and Barabasi-Albert. The description of the three artificial networks are stated as follows: (i) Erdos-Renyi graph in
. The network consists of 100 nodes and 308 edges; (ii) A small world network constructed by using Watts-Stroggatz model. The network has 500 nodes and 1000 edges. Each node in this network owns 5 neighbors and the random reconnection probability is 0.3; (iii) We generate a Barabasi-Albert scale-free network with 500 nodes, 996 edges. Degree distributions of the three artificial networks are illustrated in
Figure 5.
In order to evaluate the efficiency of the proposed model, other five classical centrality measures which comprise Degree Centrality (DC), Betweenness Centrality (BC), Closeness Centrality (CC), Eigenvector Centrality (EC) and PageRank (PR) are also applied to the same networks for comparison. First, we employ the proposed model and the other measures mentioned above to identify the ten most vital nodes of the karate club network. The results are shown in
Table 4. Similarly, the results of the remaining networks are shown in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 respectively.
According to the results shown in
Table 4, in karate club network there are eight and nine same nodes between the proposed method and BC and CC in the top-10 list. Furthermore, the proposed method shares the same nine nodes with EC. Note that the top 10 nodes are the same using the proposed methods, DC approach and PR measure. It can be concluded that the top-10 ranked nodes categorized by our proposed model are more vital than other nodes in the karate club network. Based on the result shown in
Table 5, in UsAir97 network, the number of the same nodes in the top-10 list between the proposed model and other five centrality measures is nine, five, seven and seven, respectively in DC, BC, CC and PR. It is worth noting the top 10 nodes are the same using the proposed methods and EC measure. In collaboration network, the seven same nodes are identified by the proposed model and PR. What’s more, the proposed model and EC has detected the same top 4 nodes. In addition, the fact that the 10 most vital nodes are the same based on the DC and proposed methods is really noteworthy. In E-mail network URV, five same nodes in the top-10 list are identified by the proposed model, EC, DC as well as PR. Furthermore, the most influential node is the same by using the proposed model, EC, DC and PR.
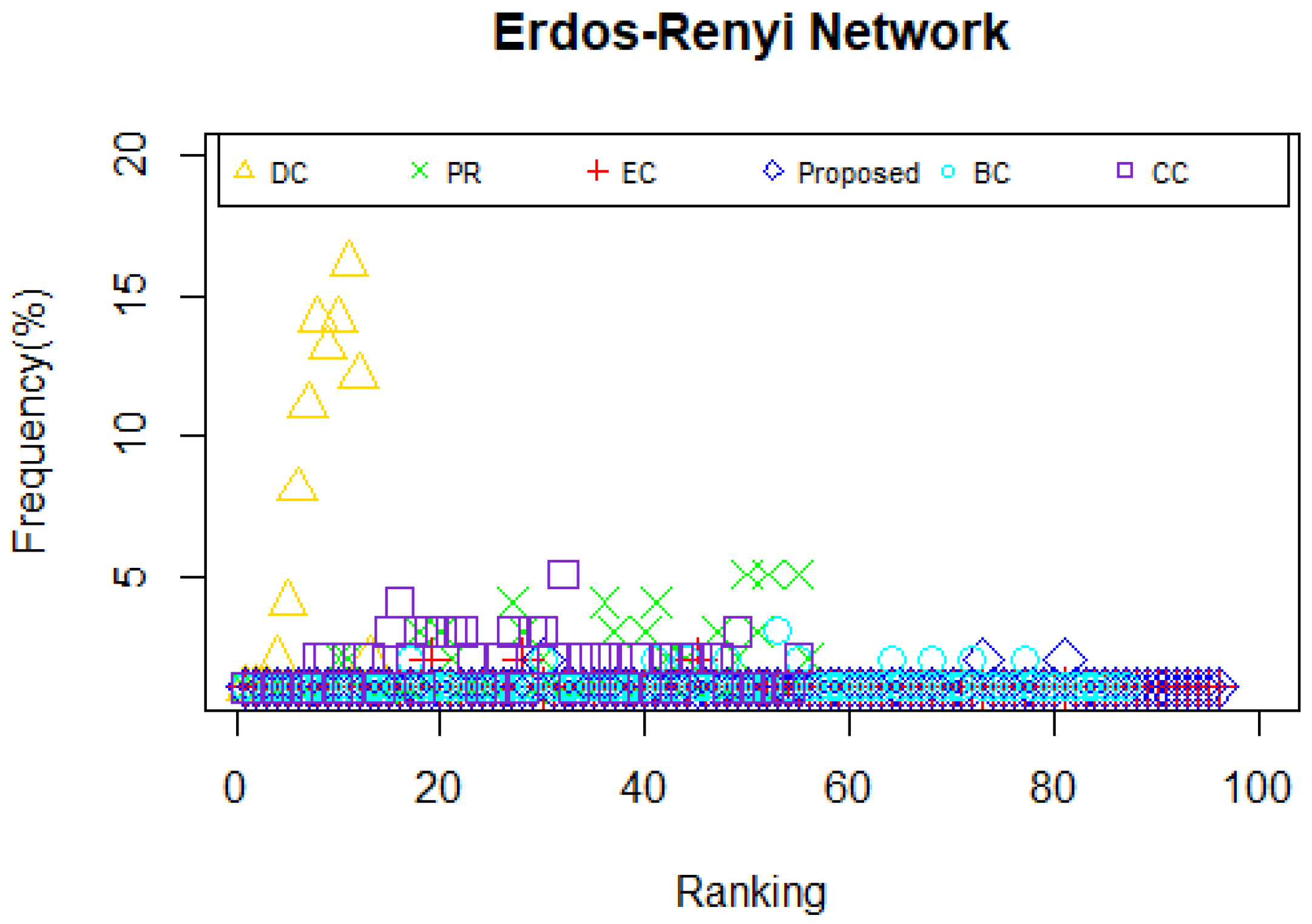
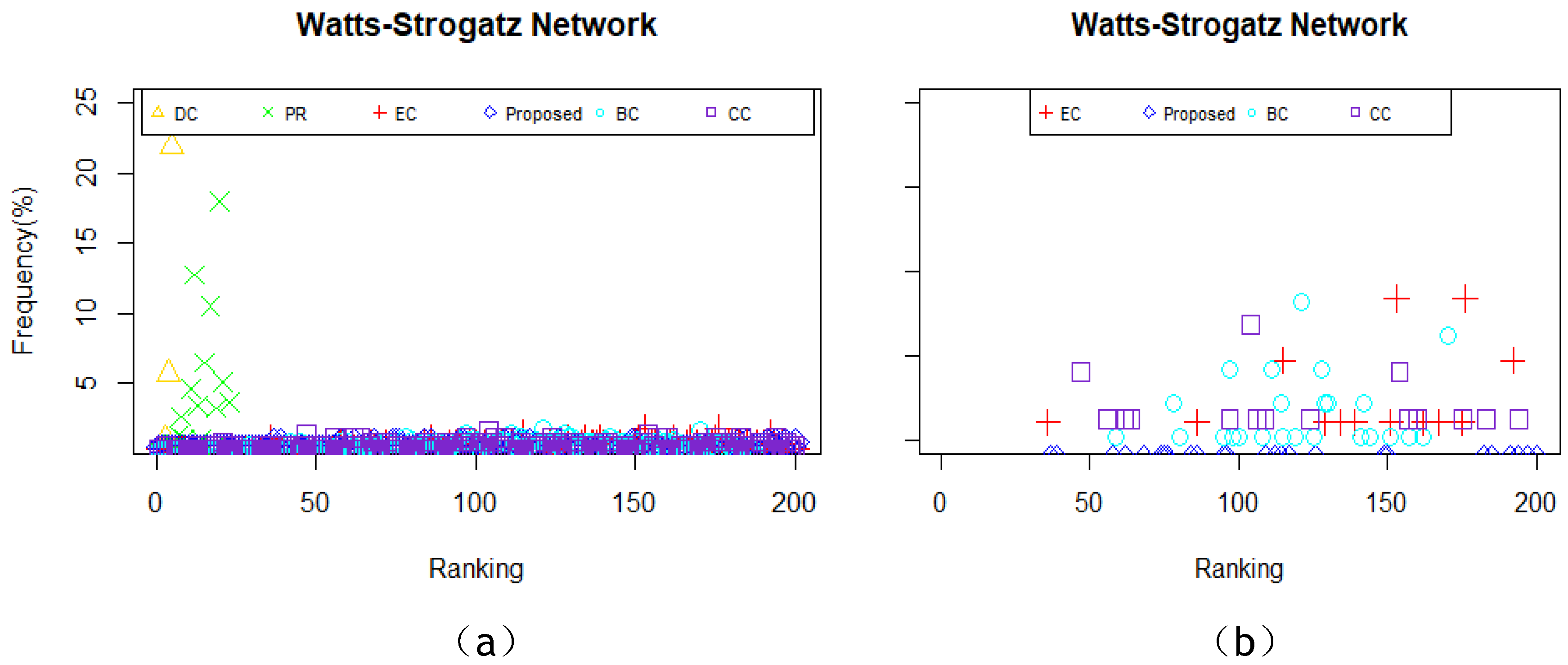
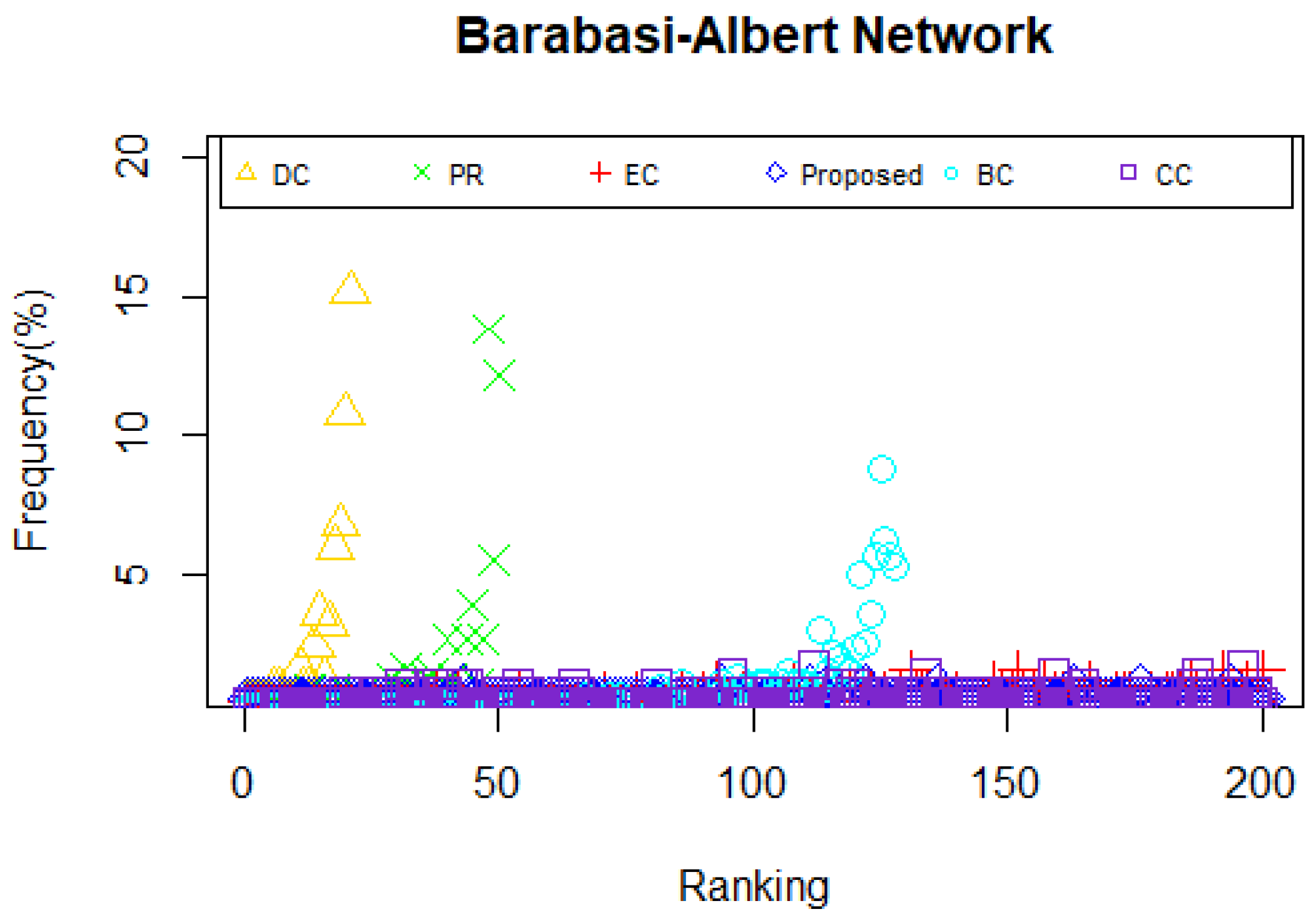
As is shown in
Table 8, in Erdos-Renyi network, in comparison with the proposed model and DC, CC or BC, there are seven same actors in the top-10 list. Moreover, there are eight same nodes in the top-10 list between the proposed model and BC. The top-3 lists applying DC, BC, CC, PR and the proposed model are the same. In Watts-Stroggatz network, in comparison with the proposed model and DC, PR or EC, there are five same actors in the top-10 list. Also, the most vital nodes are the same by using DC, EC, PR and the proposed model. In Barabasi-Albert network, the fact the 10 most influential nodes identified by PR, BC, DC and the proposed model are the same is notable. Also, the number of the same actors in the top-10 list between the proposed model and the other two measures are eight and nine, respectively in EC and CC. As deliberated above, it can be concluded that the proposed method is proved to be effective on identifying the ten most influential nodes in the selected networks.
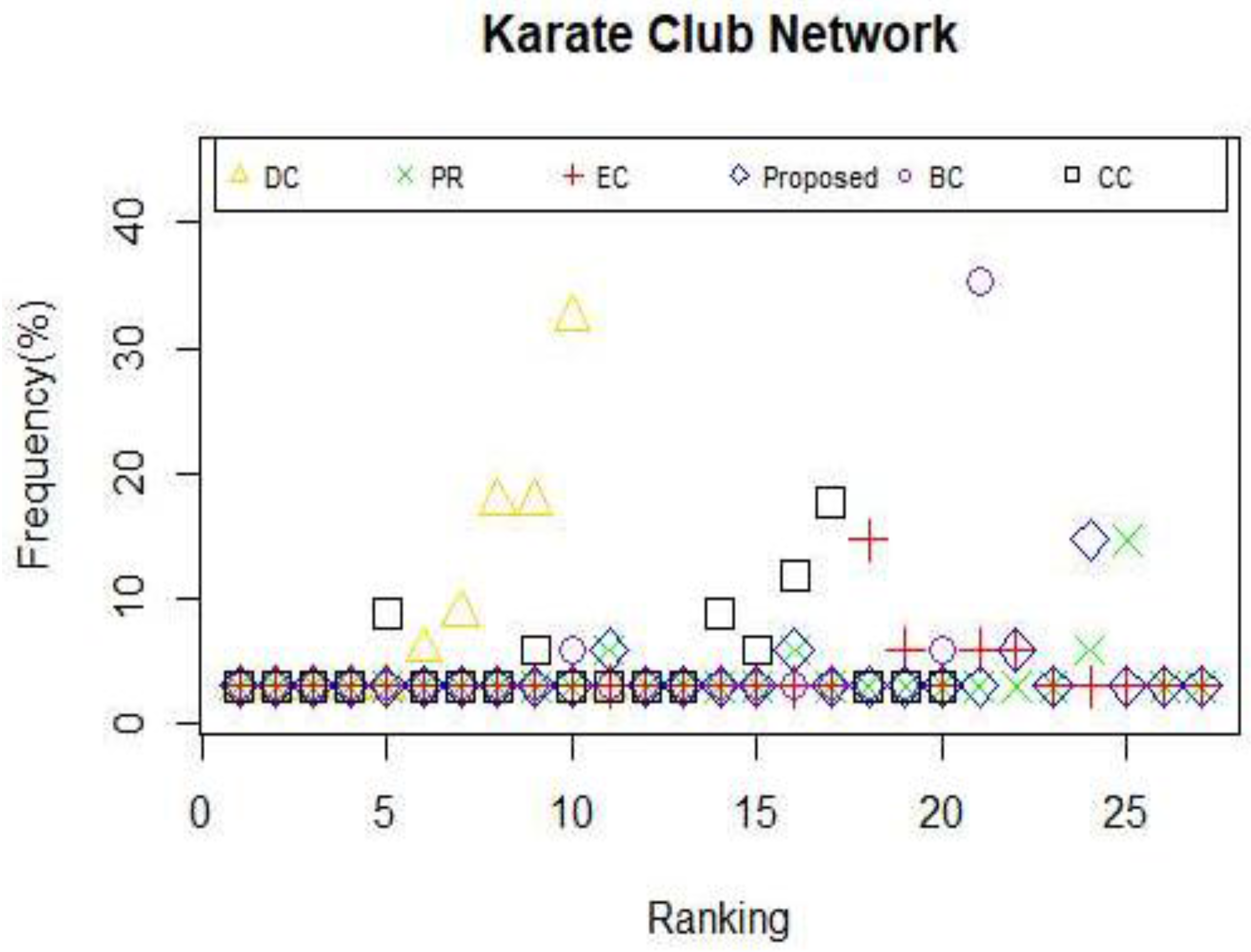
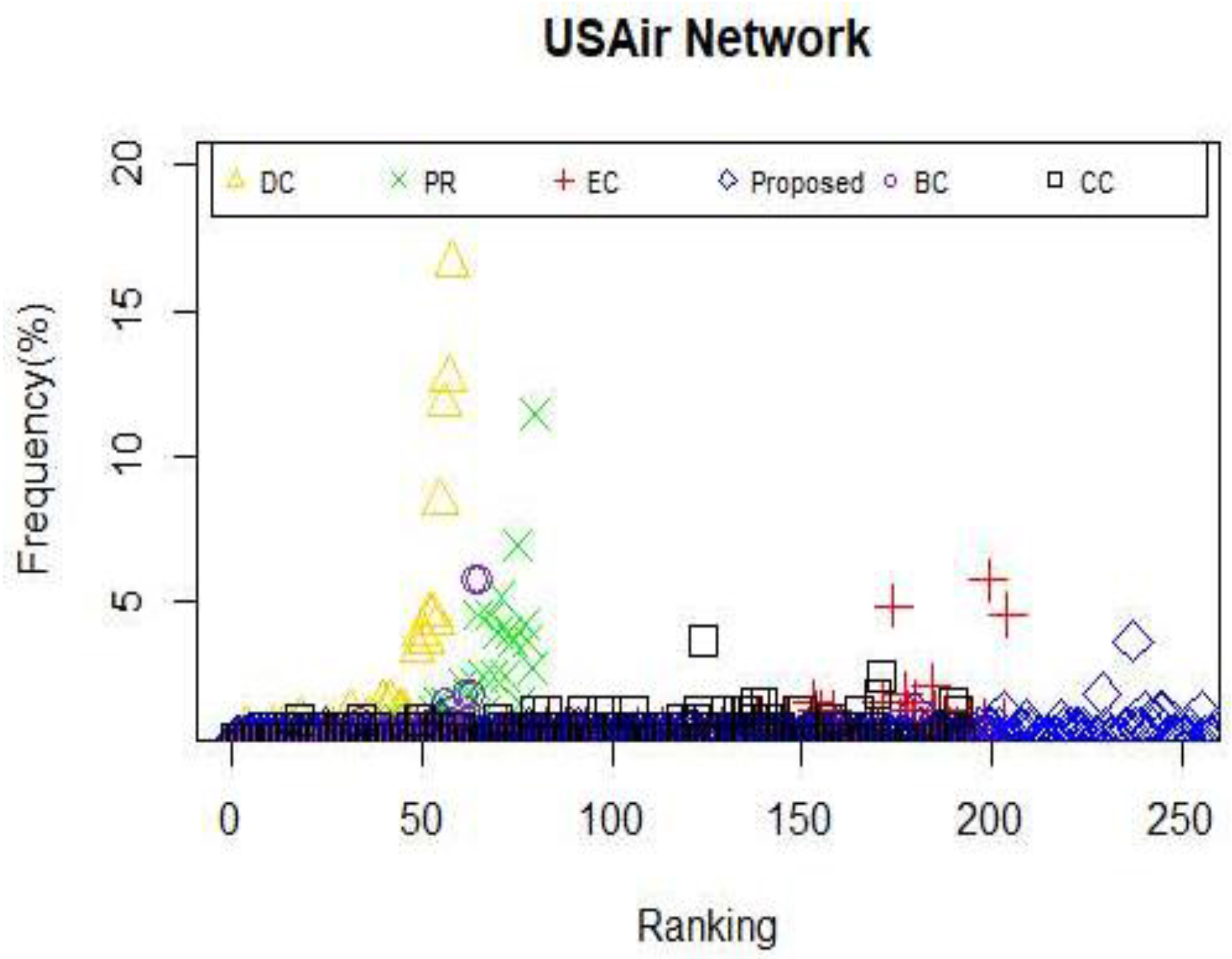
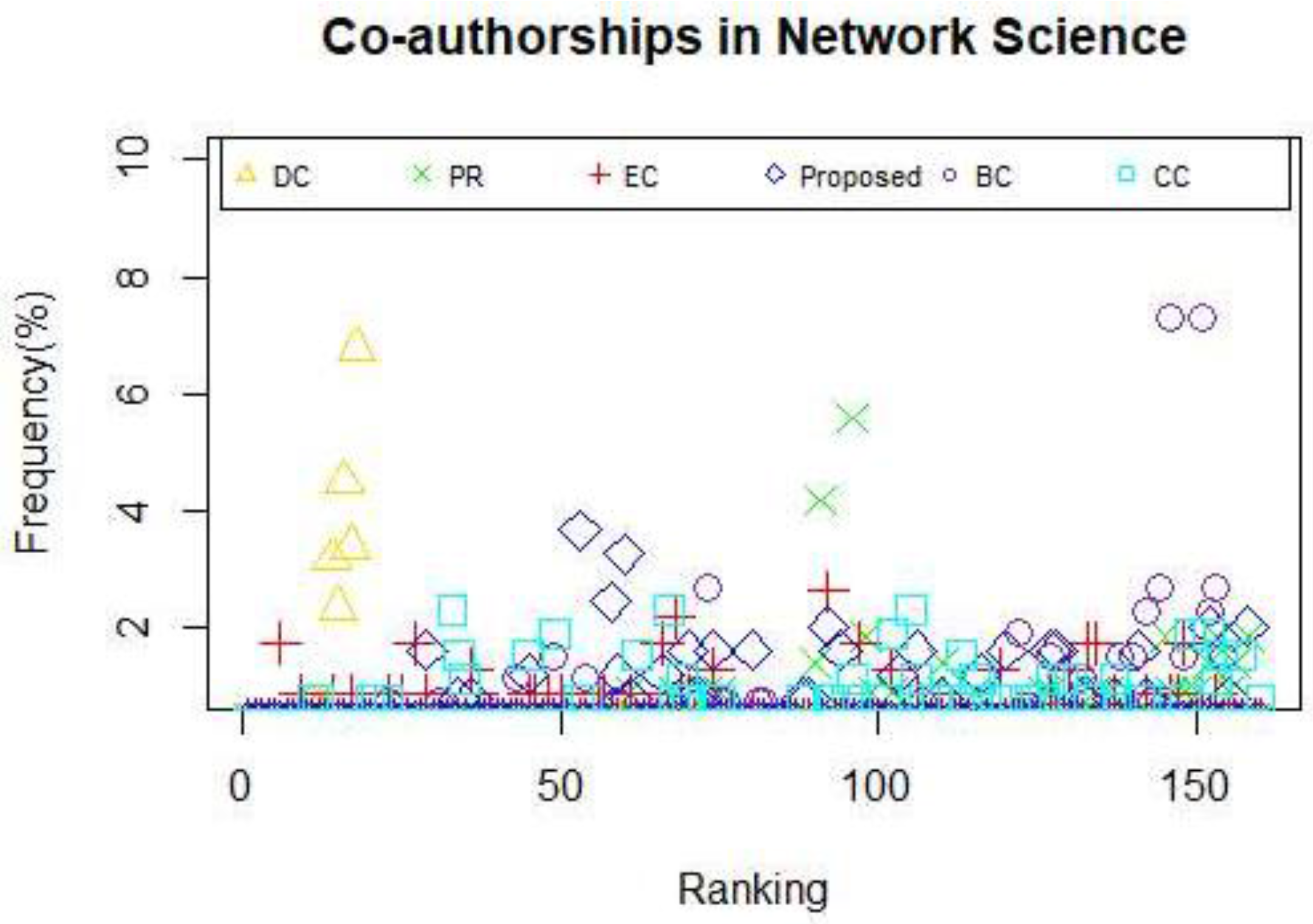
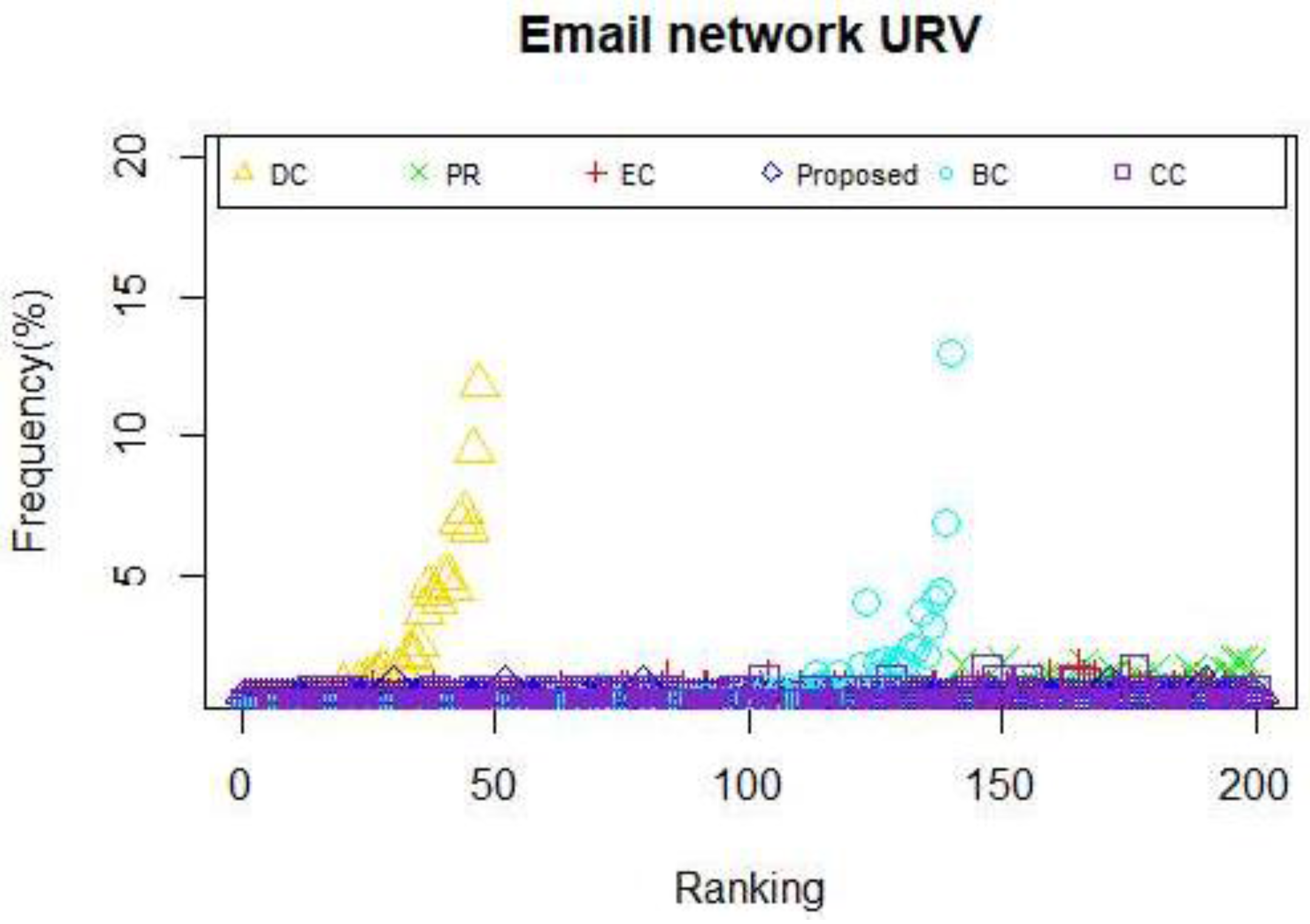
When applying the centrality method such as DC and CC, the situation that multiple nodes possess the same centrality value appear. Moreover, if a node does not belong to the shortest path of other node pairs, consequently, the value of BC of that node will be zero, which is exactly the dilemma we face when betweenness centrality is utilized to identify the powerful nodes in Zachary’s karate club network and USAir network. What occurs when we use a measure that leads to multiple nodes with the same centrality value? One of two things must happen: either the capability to explain the given measure is completely lost or we can only obtain poor answers. Consistent with what we have discussed above, we can draw the conclusion that an effective or a distinguished approach grant the overwhelming majority of nodes different weight during the calculation so that nodes in a given network can be categorized. Therefore, the frequency of nodes with the same centrality value is considered as a key indicator to assess the efficiency of a certain model. Clearly, the relationship between the efficiency and the frequency is negative. Motivated by this idea, we explore other properties of the proposed model and other centrality methods mentioned above by computing the frequency of nodes with the same centrality value in the selected networks. The results are shown in
Figure 6,
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11 and
Figure 12.
From the results illustrated in
Figure 6 and
Figure 7, it can be reckoned that the proposed model owns the least nodes with the same centrality value. So do PR and EC. In contrast, other measures have too many nodes with the same centrality value to identify the influential nodes. As for the collaboration network, the proposed model has a better performance compared with DC, PR and CC, which can be seen in
Figure 8. As is illustrated in
Figure 9, the proposed model is more suitable for detecting vital nodes than other methods.
As is showed in
Figure 10, the proposed model and EC owns the least number of nodes with same centrality value. As is illustrated in
Figure 11a, DC and PR is no longer fit to identify vital nodes, thus, we remove these two methods and draw a new image of the frequency of nodes with the same centrality value. The results can be seen in
Figure 11b. It is clear that the proposed model beats all the other four from this perspective. Moreover, the conclusion that the proposed model and EC outperforms the remaining measures can be drawn based on the results in
Figure 12.
Consistent with these results, a conclusion can be drawn that the proposed model is more valid than others to identify vital nodes from this perspective.
Note that even though the top 10 nodes of the karate club network are the same using the proposed methods and PR measure, the sequences are still different. Then the question arises. How can we prove that the proposed model is more effective compared with the wildly used PR method? In this research, we intend to introduce the susceptible-infectious (SI) model which describes the transmission of infectious diseases between susceptible and infective individuals and also can be used to characterize social influence’s propagation dynamics process. In the process of epidemic spreading, each node can be in two discrete states, either susceptible or infected. SI model supposes that nodes in susceptible can be infected by the infected nodes with the probability, denoted as
, which indicates the power of the infected nodes. Fei and Deng [
49] point out, in the unweighted network, the value of
can be obtain by using the equation stated as follows.
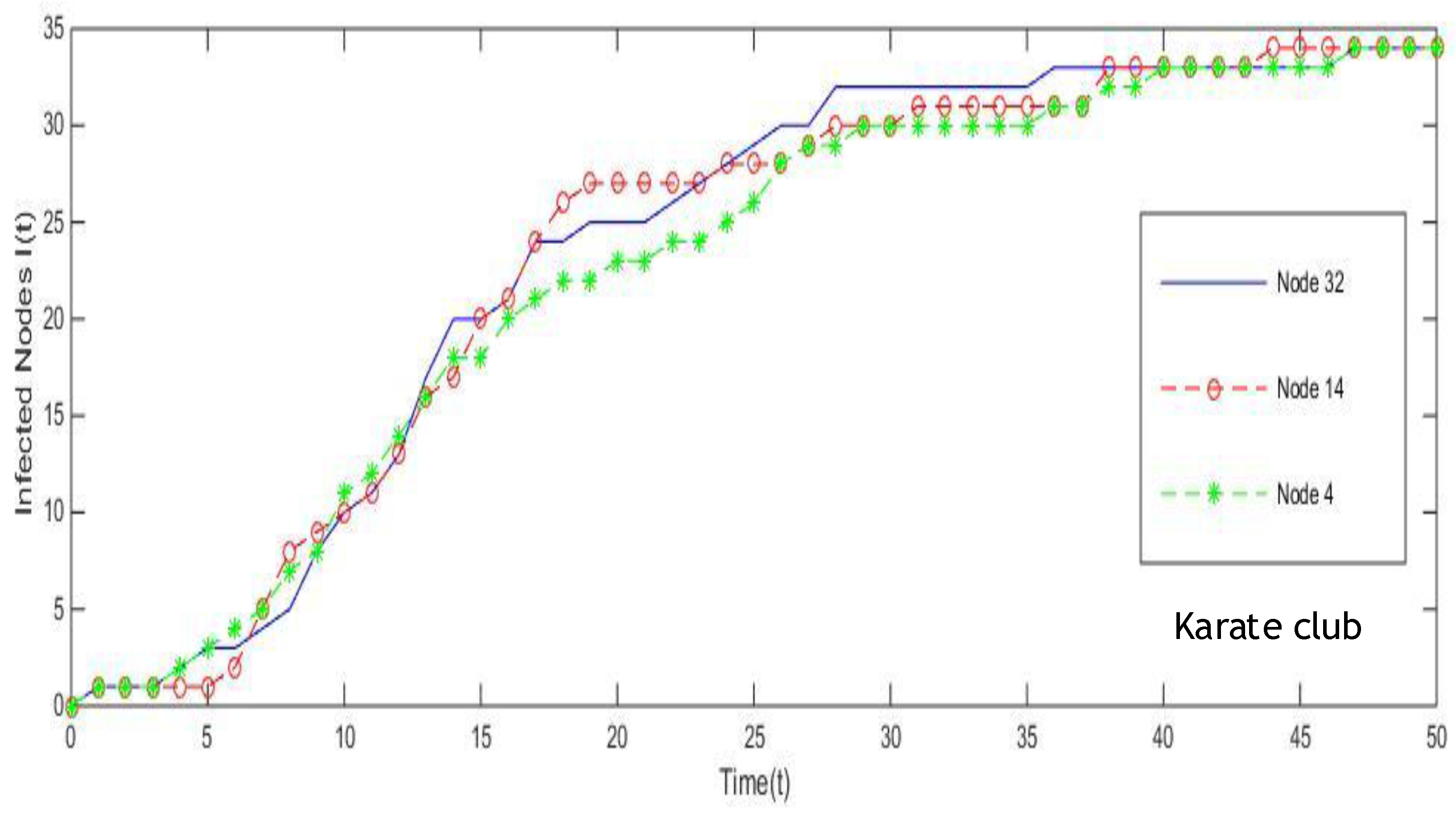
Now let us recall the Zackary’s karate club case, note that node 14, node 32 and node 4 all rank 7th in the top 10 list when EC, PR and the proposed model are respectively adopted to measure centrality. The results can also be seen in
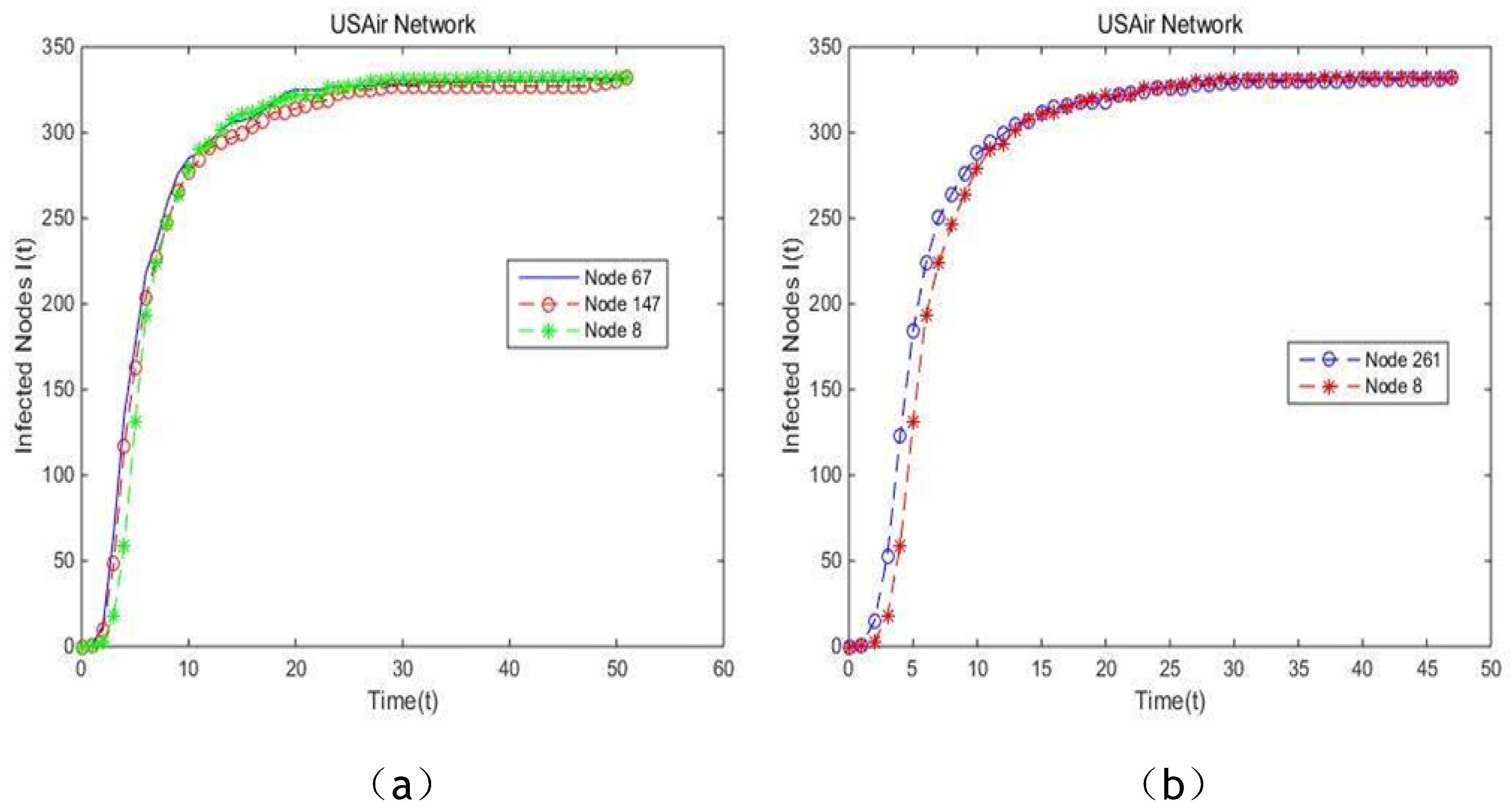
Table 4. In addition, the same situation in which node 147, node 8 and node 67 all rank 8th in the top 10 list when EC, PR and the proposed model are respectively adopted to measure centrality in USAir97 network appears. Also, node 261 and node 8 rank 2nd on the condition that BC and the proposed model are respectively applied in USAir97 network. The same situation also appears in Collaboration network and Email network. Inspired by SI model, we treat node 14, node 32 and node 4 as infectious source which spread
times in karate club network, then the number of infected nodes
will be counted when the end of the dissemination. That is the spreading ability of single node is considered as an index to evaluate the effectiveness of the proposed model and the existing centrality measures. By introducing SI model, the results of experiments on four real networks are shown in
Figure 13,
Figure 14,
Figure 15 and
Figure 16, respectively.
Figure 17,
Figure 18 and
Figure 19 illustrates the results of the other three artificial networks, respectively.
In general, the number of infected nodes increases as propagation time and finally reaches a stable value. From
Figure 13, in karate club network, PR shows similar efficiency with the proposed method for their curves are almost overlapping. While the proposed model outperforms PR and EC for the spreading rate, which means node 32 is more influential compared with node 14 and node 4. Also, this comparison is in line with our approach. In UsAir97 network, the curve generated from the proposed method is smoother and steeper in comparison with the curve of BC, which can be seen in
Figure 14b. Indicated by
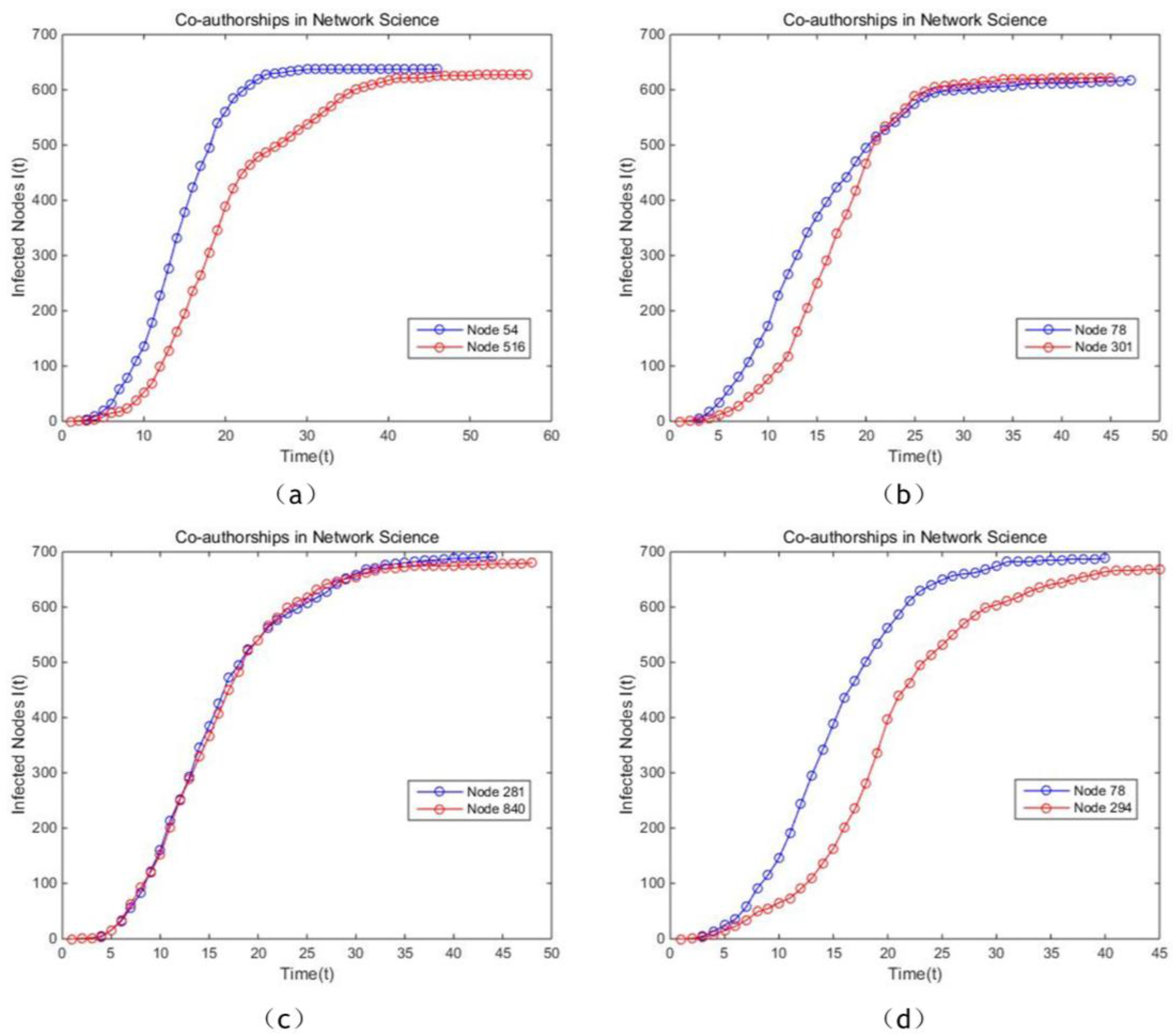
Figure 14a, the same conclusion that the proposed model outperforms slightly PR and EC and has higher stability. In Collaboration network, time step of this simulation is set for 10,000, in order to reduce calculation time. It is apparent that the proposed model is more effective for identifying the vital node compared with BC, CC and PR, since the curve of the proposed model is smoother, which is supported by
Figure 15a,b,d. Also, nodes sorted by our method show higher spread speed and finally infect more nodes in comparison with the nodes ranked by BC, EC and PR. Moreover, the proposed model indicates comparable effectiveness with EC, which can be concluded from
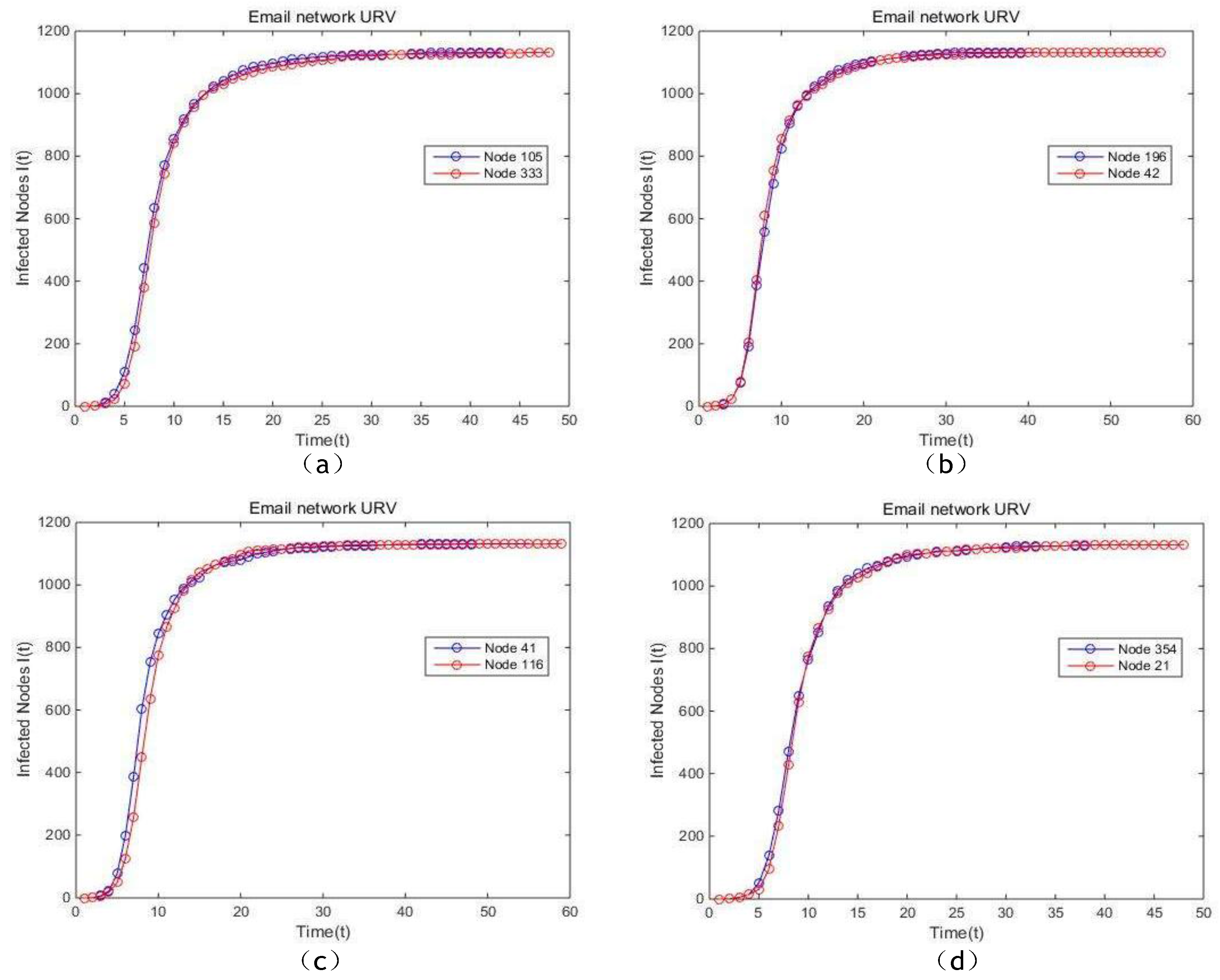
Figure 15c. In the Email network, the curves of the proposed model, BC, CC and PR almost completely coincide, which means theses four methods show similar effectiveness. From the results shown in
Figure 16c, the slope of the curve of the proposed model is slightly higher compared with the curves of EC, which indicates that the spread rate of nodes ranked by us is higher. In addition, the total infectious time of the nodes sorted by the proposed model is significantly shorter.
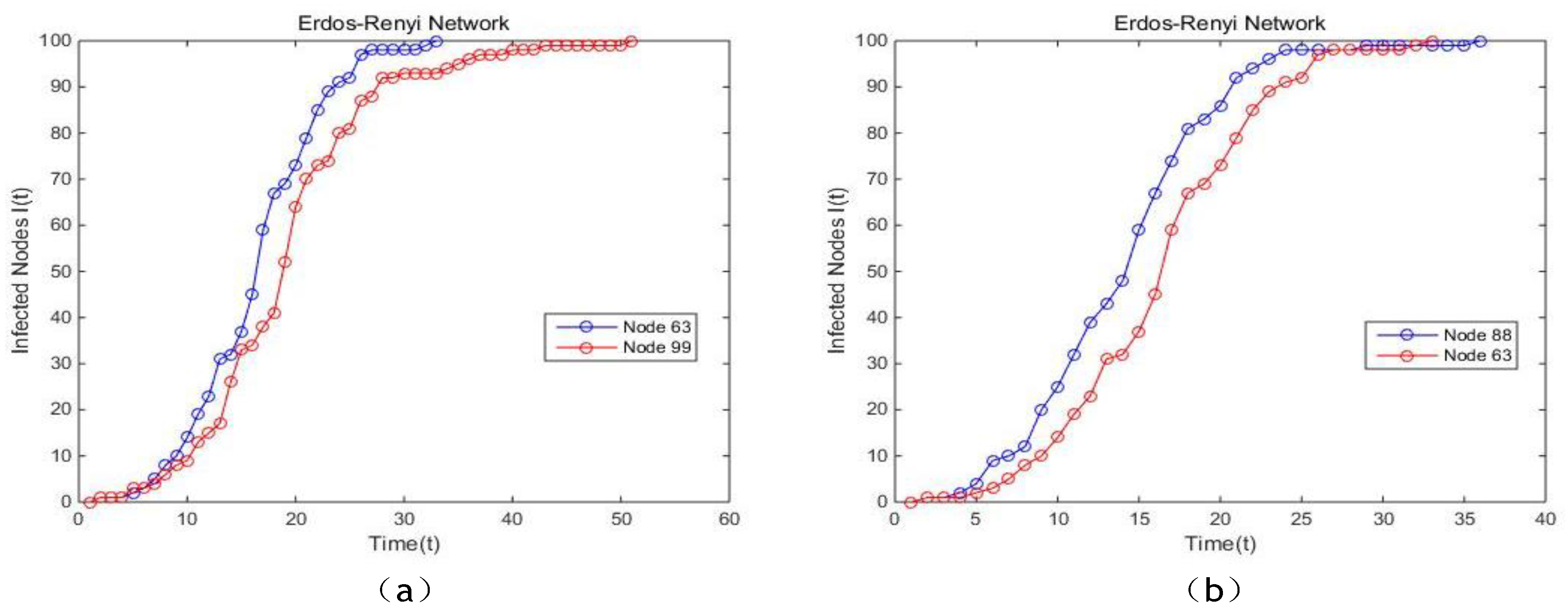
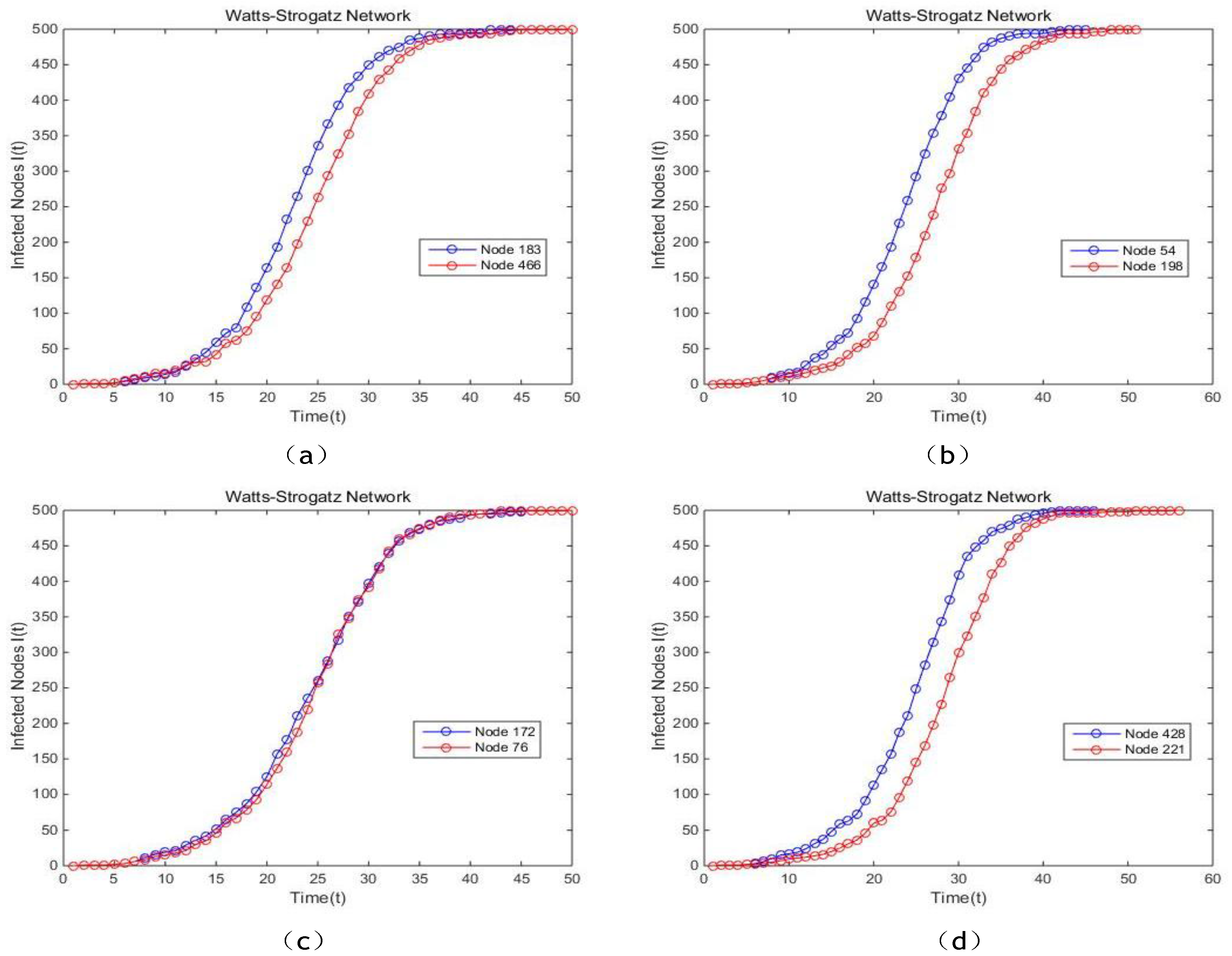
In the artificial network modeled by Erdos-Renyi, it is apparent that the proposed model is more suitable for identifying the vital node compared with BC, CC and PR, because the curves generated by our method is steeper and smoother, which indicates that the spreading speed of nodes ranked by our method is higher, as well as proves that single node selected by the proposed model is more influential. In Watts-Stroggatz network, based on the results illustrated in
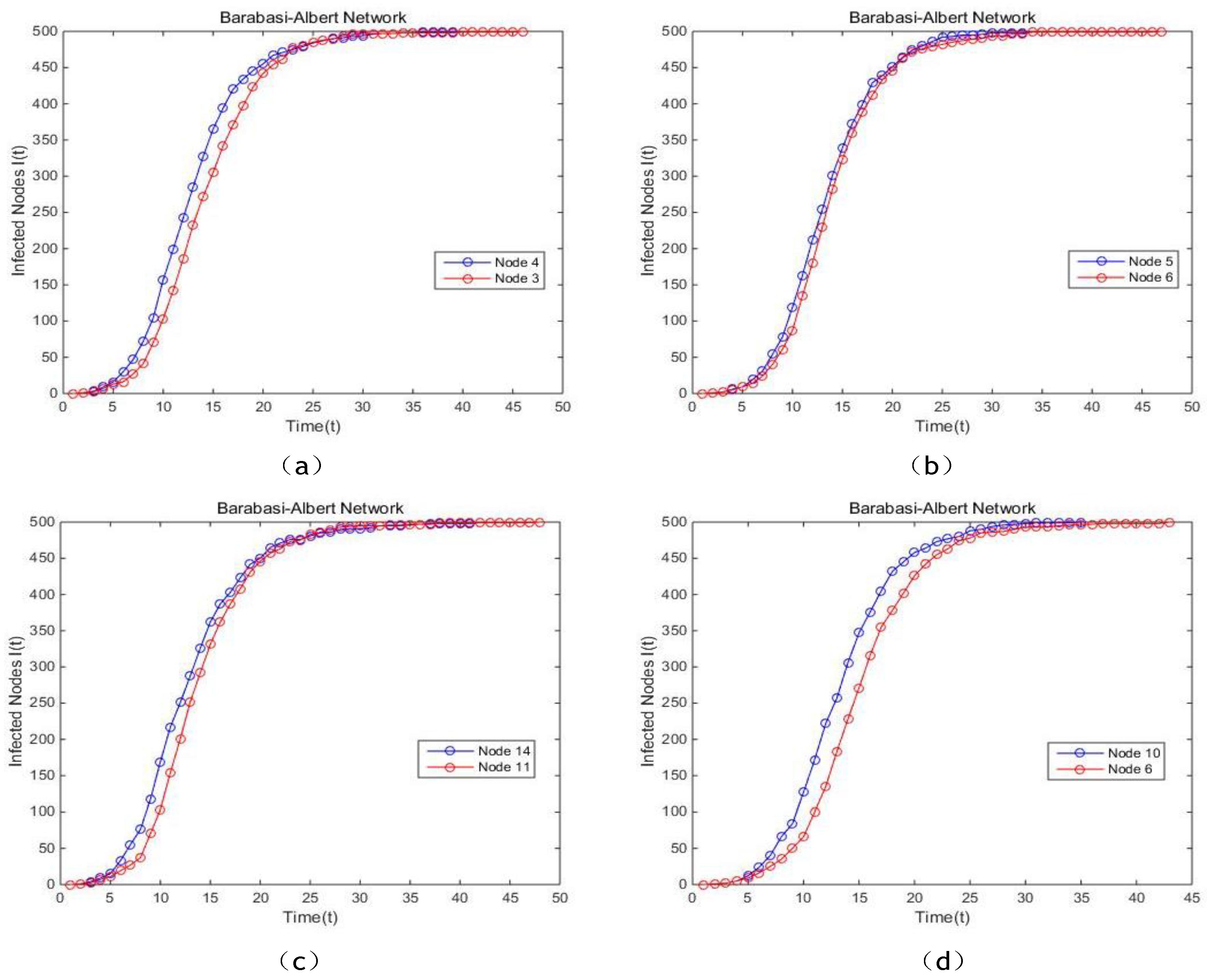
Figure 18a,b,d, it can be concluded that the single node sorted by our method possess significantly higher spreading rate, consequently infects all the other nodes in a shorter time. The curves of the proposed model and EC are almost overlapping, which means they present a similar performance. In Barabasi-Albert network, it is not difficult to come to the conclusion that the proposed model has a better performance compared with BC, EC and PR because of the faster speed of the dissemination. Also, the curves generated by the proposed model are more stable and smoother. In conclusion, the proposed method is validated to be preferable to other centrality methods referred above.
7. Conclusions and Discussion
In this paper, on the purpose of quantifying influence in networks, we introduce a novel type of centrality measure based on decompositions of a graph into subgraphs and calculation on the entropy of neighbor nodes. The efficiency of the proposed model is analyzed on the foundation of real-world data sets and three artificial networks which consists of Barabasi-Albert network, Erdos-Renyi network and Watts-Stroggatz network. The four datasets are Zackary’s karate club, USAir97, Collaboration network and Email network URV respectively. The extensive analytical results show that the proposed model outperforms the well-known measures including degree centrality, betweenness centrality, closeness centrality, eigenvector centrality and PageRank.
In our work, we define a new centrality metric and prove its effectiveness by using various real-world networks with different sizes and densities. It is obvious that perfect mechanisms, free of any presumptions or limitations, do not exist. The method proposed by us also has its own limitations and relies on specific assumptions. We try to summarize the presumptions and biases that present in our method. First, Equation (11) used to characterize how influence propagates through the network is subject to certain assumption that paths between nodes and their two-hop neighbors are endowed with the equal weight. Second, in this paper we assume that we may not hold steady connections to friends, neighbors or partners at three degrees of separation, which indicates that we could not affect nor be affected by people at three degrees and beyond. Furthermore, it is clear that the computational complexity can be significantly reduced by accepting this assumption. Now, we would like to identity and explore all the potential limitations in our proposed model. The real-world networks based on which we test the effectiveness of the proposed model are undirected, unweighted and static. Even though these networks vary from diverse sizes and densities. With respect to weighted networks, appropriate modifications must be made to Equation (5). Another noteworthy limitation of the work is an exclusive focus on undirected graphs. The concept that a directed graph can be changed into another undirected graph may be a reasonable explanation. However, the proposed method loses the capacity to capture the dynamic process, which is described by scientists such as Grindrod and Higham [
63,
64], Barrat et al. [
65], Lentz et al. [
66], Gómez et al. [
67], Lambiotte et al. [
68] and Liu et al. [
69]. Albeit with the limitations and constraints, we invite other researchers to innovate and suggest alternatives. We hope our work will play a role in stimulating interest in this area. Also, we are fond of applying new and better models regarding how to measure influence in complex networks.
As for the future work, more graphs with different structures will be used to validate our proposed method. It is also possible that the proposed model which relies on local network structure characterized by its edges can be functional for social network community detection and visualization. Besides, we will investigate the potential properties of the proposed model and extend its application areas.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}