1. Introduction
Discretization of numerical attributes is an important technique used in data mining. Discretization is the process of converting numerical values of data records into discrete values associated with numerical intervals defined over the domains of the data records. As is well known, discretization based on entropy is very successive [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26]. Additionally, many new techniques have been proposed, e.g., discretization using statistical and logical analysis of data [
27], discretization using low-frequency values and attribute interdependency [
28], discretization based on rough-set theory [
29], a hybrid scheme of frequency and expected number of so-called segments of examples [
30], and an oversampling technique combined with randomized filters [
31]. Entropy-based discretization was also used for special purposes, e.g., for ranking [
32] and for stock-price forecasting [
33].
As follows from recent research [
13,
34,
35], one of the discretization methods, called multiple scanning and based on entropy, is especially successful. An important step of such discretization is merging intervals, conducted as the last step of discretization. As a result, some pairs of intervals are replaced by new, larger intervals. In this paper, we compare two methods of merging numerical intervals, based on the smallest and biggest entropy by skipping merging, i.e., no merging at all. Our results show that such interval merging is crucial for quality of discretization.
The multiple-scanning discretization method, as the name indicates, is based on scanning the entire set of attributes many times. During every scan, for every attribute, the best cutpoint is identified. The quality of a cutpoint is estimated by the conditional entropy of the decision given an attribute. The best cutpoint is associated with the smallest conditional entropy. For a specific scan, when all best cutpoints are selected, a set of subtables is created; each such subtable needs additional discretization. Every subtable is scanned again, and the best cutpoints are computed. There are two ways to end this process: either the stopping condition is satisfied, or the requested number of scans is achieved. If the stopping condition is not satisfied, discretization is completed by another discretization method called Dominant Attribute [
34,
35].
Dominant-attribute discretization uses a different strategy than multiple scanning, but it is also using many step approach to discretization. In every step, first the best attribute is selected by using the minimum of the conditional entropy of decision given attribute condition. Then, the best cutpoint is identified using the same principle. Discretization is complete when the stopping condition is satisfied.
The multiple-scanning methodology is better than two well-known discretization methods: Equal Interval Width and Equal Frequency per Interval enhanced to globalized methods [
34]. In Reference [
34], rule induction was used for data mining. Additionally, four other discretization methods, namely, the original C4.5 approach to discretization, and the same globalized versions of Equal Interval Width and Equal Frequency per Interval methods, and Multiple Scanning were compared in Reference [
35]; this time, data mining was based on the C4.5 generation of decision trees. Again, it was shown that the best discretization method is Multiple Scanning.
2. Discretization
Let
a be a numerical attribute,
be the smallest value of
a, and
be the largest value of
a. Discretization of
a is based on finding the numbers
,
, …,
, called cutpoints, where
,
,
<
for
l = 0, 1, …,
, and
k is a positive integer. Thus, domain
of
a is partitioned into
k intervals
In the remainder of this paper, such intervals are denoted as follows:
In practical applications, discretization is conducted on many numerical attributes.
Table 1 presents an example of a dataset with four numerical attributes: Length, Height, Width, and Weight, and eight cases. An additional symbolic variable, Quality, is the decision. Attributes are independent variables, while the decision is a dependent variable. The set of all cases is denoted by
U. In
Table 1,
U = {1, 2, 3, 4, 5, 6, 7, 8}.
Let
v be a variable and let
,
, …,
be values of
v, where
n is a positive integer. Let
S be a subset of
U. Let
be a probability of
in
S, where
i = 1, 2, …, n. An
entropy is defined as follows:
In this paper, we assume that all logarithms are binary.
Let
a be an attribute, let
,
, …,
be all values of
a restricted to
S, let
d be a decision and let
,
, …,
be all values of
d restricted to
S. Conditional entropy
of the decision
d given attribute
a is defined as follows:
where
is the conditional probability of the value
of the decision
d given
;
and
.
As is well known [
1,
4,
5,
7,
9,
10,
12,
13,
16,
21,
23,
24], discretization that uses conditional entropy of the decision-given attribute is believed to be one of the most successful discretization techniques.
Let
S be a subset of
U,
a be an attribute, and
q be a cutpoint splitting the set
S into two subsets,
and
. The corresponding conditional entropy, denoted by
is defined as follows:
where
denotes the cardinality of set
X. Usually, cutpoint
q for which
is the smallest is considered to be the best cutpoint.
We need a condition to stop discretization. Roughly speaking, the most obvious idea is to stop discretization when we may distinguish the same cases in the discretized dataset that were distinguishable in the original dataset with numerical attributes. The idea of distinguishability (indiscernibility) of cases is one of the basic ideas of rough-set theory [
36,
37]. Let
B be a subset of set
A of all attributes, and
. Indiscernibility relation
IND is defined as follows:
where
denotes the value of the attribute
for the case
. Obviously,
is an equivalence relation. For
, the equivalence class of
is denoted by
, and is called a B-elementary set.
A family of all sets
, where
, is a partition on
U, denoted by
. Additionally, for a decision
d, a
-elementary set is called a
concept. For
Table 1, and for
B = {
Length},
= {{1, 3}, {2, 4, 7, 8}, {5, 6}} and {
= {{1, 2, 3}, {4, 5}, {6}, {7, 8}}. None of the concepts {1, 2, 3}, {4, 5}, {6}, {7, 8} is
B-definable. It is a usual practice in rough-set theory to use for any
two sets, called lower and upper approximations of
X. The lower approximation of
X is defined as follows:
and is denoted by
. The upper approximation of
X is defined as follows:
and is denoted by
. For
Table 1,
{1, 2, 3} = {1, 3} and
{1, 2, 3} = {1, 2, 3, 4, 7, 8}.
Usually, discretization is stopped when so-called level of consistency [
4], defined as follows:
and denoted by
, is equal to 1. For
Table 1,
= {{1}, {2}, {3}, {4}, {5}, {6}, {7}, {8}}, so
=
X for any concept
X from
. On the other hand, for
B = {
Length},
2.1. Multiple Scanning
Special parameter t, selected by the user and called the total number of scans, is used in multiple-scanning discretization. During the first scan, for any attribute a from the set A, the best cutpoint is selected using the criterion of smallest entropy for all potential cutpoints splitting U, where d is the decision. Such cutpoints are created as the averages of two consecutive values of sorted attribute a. Once the best cutpoint is found, a new binary attribute is created, with two intervals as vales of , the first interval is defined as containing all original numerical values of a smaller than the selected cutpoint q, and the second interval contains the remaining original values of a. Partition is created, where is the set of all partially discretized attributes. For the next scans, starting from t = 2, set A is scanned again: for each block X of , for each attribute a, and for each remaining cutpoint of a, the best cutpoint is computed, and the best cutpoint among all blocks X of is selected as the next cutpoint of a. If parameter t is reached and , another discretization method, Dominant Attribute, is used. In the dominant-attribute strategy, the best attribute is first selected among partially discretized attributes, using the criterion of smallest conditional entropy , where is a partially discretized attribute. For the best attribute, best cutpoint q is selected, using the criterion of smallest entropy , where q splits S into and . For both and , we select the best attribute and then the best cutpoint, until , where is the set of discretized attributes.
We illustrate the multiple-scanning discretization method using the dataset from
Table 1. Since our dataset was small, we used just one scan. Initially, for any attribute
, all conditional entropies
should be computed for all possible cutpoints
q of
a. The set of all possible cutpoints for Length is {4.4, 4.6}. Similarly, the sets of all possible cutpoints for Height, Width, and Weight were {1.5, 1.7}, {1.75, 1.85} and {1.1, 1.5}, respectively. Furthermore,
The best cutpoint is 4.4. In a similar way, we selected the best cutpoints for the remaining attributes, Height, Width, and Weight. These cutpoints are 1.5, 1.75, and 1.1, respectively. Thus, the partially discretized dataset, after the first scan, is presented in
Table 2.
The dataset from
Table 2 needs an additional discretization since
= {{1, 4}, {2}, {3}, {5}, {6}, {7}, {8}},
= {{1, 2, 3}, {4, 5}, {6}, {7, 8}} and
As follows from
Table 2, Cases 1 and 4 need to be distinguished. A dataset from
Table 1, restricted to Cases 1 and 4, is presented in
Table 3.
Cases 1 and 4 from
Table 3 may be distinguished by any of the two following attributes: Length and Weight. Both attributes are of the same quality, as a result of a heuristic step we selected Length. A new cutpoint for Length was equal to 4.6. Thus, attribute Length has two cutpoints, 4.4 and 4.6.
Table 4 presents the next partially discretized dataset.
For the dataset from
Table 4,
and
= 1.
2.2. Interval Merging
In general, it is possible to simplify the result of discretization by interval merging. The idea is to replace two neighboring intervals, and , of the same attribute by one interval, . It can be conducted using two different techniques: safe merging and proper merging. In safe merging, for a given attribute, any two neighboring intervals and are replaced by interval , if for both intervals the decision value is the same.
In proper merging, two neighboring intervals and of the same attribute are replaced by interval , if the levels of consistency before merging and after merging are the same. A question is how to guide the search for such two neighboring intervals. In experiments described in this paper, two search criteria were implemented based on the smallest and the largest conditional entropy . Another possibility, also taken into account, is ignoring any merging at all.
It is clear that, for
Table 4, for the Length attribute, we may eliminate Cutpoint 4.4. As a result, a new data set, presented in
Table 5 is created. For the dataset from
Table 4,
and
= 1.
3. Experiments
Experiments described in this paper were conducted on 17 datasets with numerical attributes. These datasets presented in
Table 6 and are accessible in the Machine-Learning Repository, University of California, Irvine, except for bankruptcy. The bankruptcy dataset was given in Reference [
38].
For discretization, we applied the multiple-scanning method. The level of consistency was set to 1. We used three approaches to merging intervals in the last stage of discretization:
no merging at all,
proper merging based on the minimum of conditional entropy, and
proper merging based on the maximum of conditional entropy.
The discretized datasets were processed by the C4.5 decision-tree generating system [
39]. Note that the C4.5 system builds a decision tree using conditional entropy as well. The main mechanism of selecting the most important attribute
a in C4.5 is based on the maximum of mutual information, which in C4.5 is called an information gain. The mutual information is the difference between marginal entropy
and conditional entropy
, where
d is the decision. Since
is fixed, the maximum of mutual information is equivalent to the minimum of conditional entropy
. In our experiments, an error rate was computed using internal tenfold cross validation of C4.5.
Our methodology is illustrated by
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8, all restricted to the yeast dataset, one of 17 datasets used for experiments.
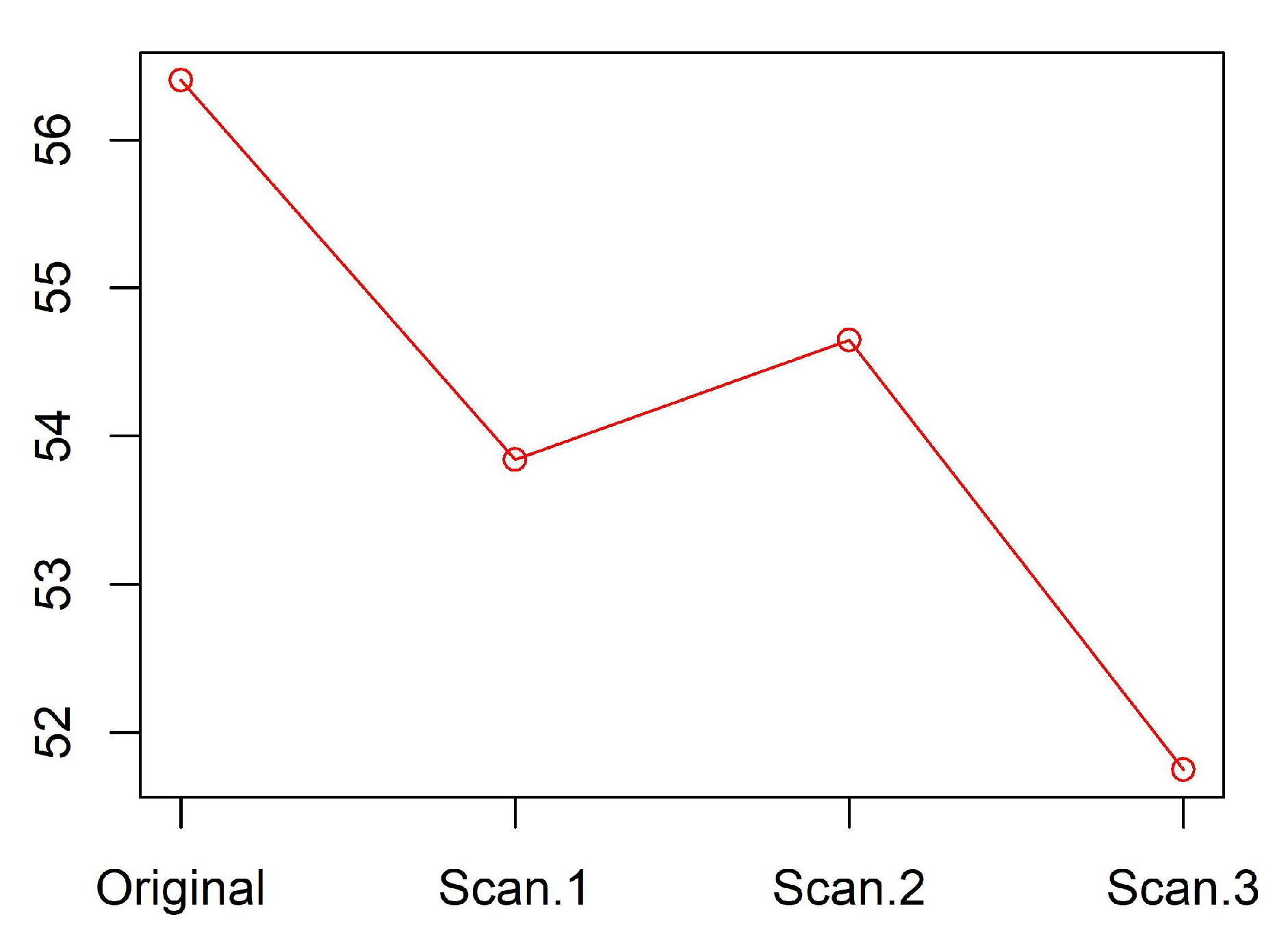
Figure 1 presents an error rate for three consecutive scans conducted on the yeast dataset.
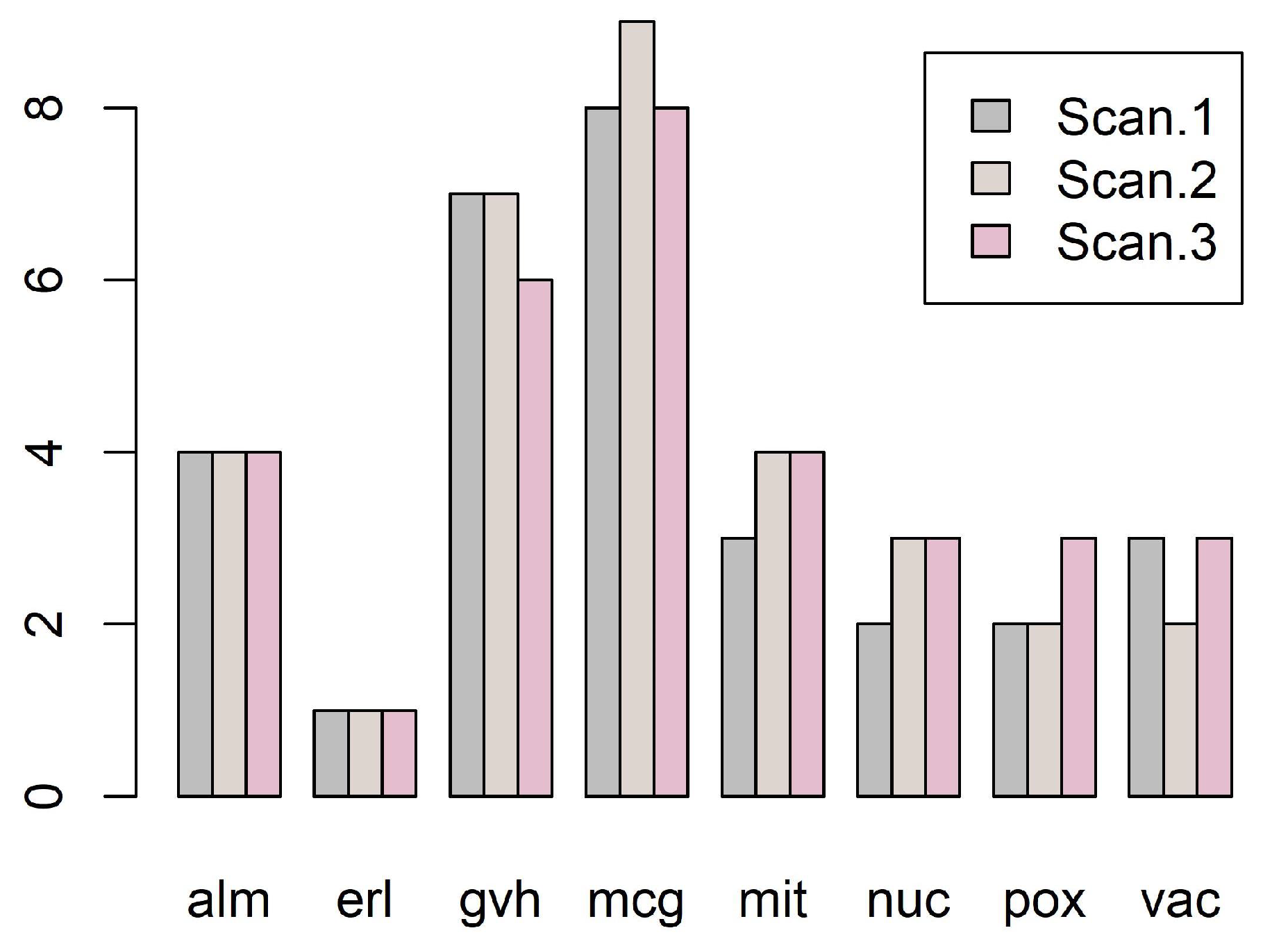
Figure 2 shows the number of discretization intervals for three scans on the same dataset.
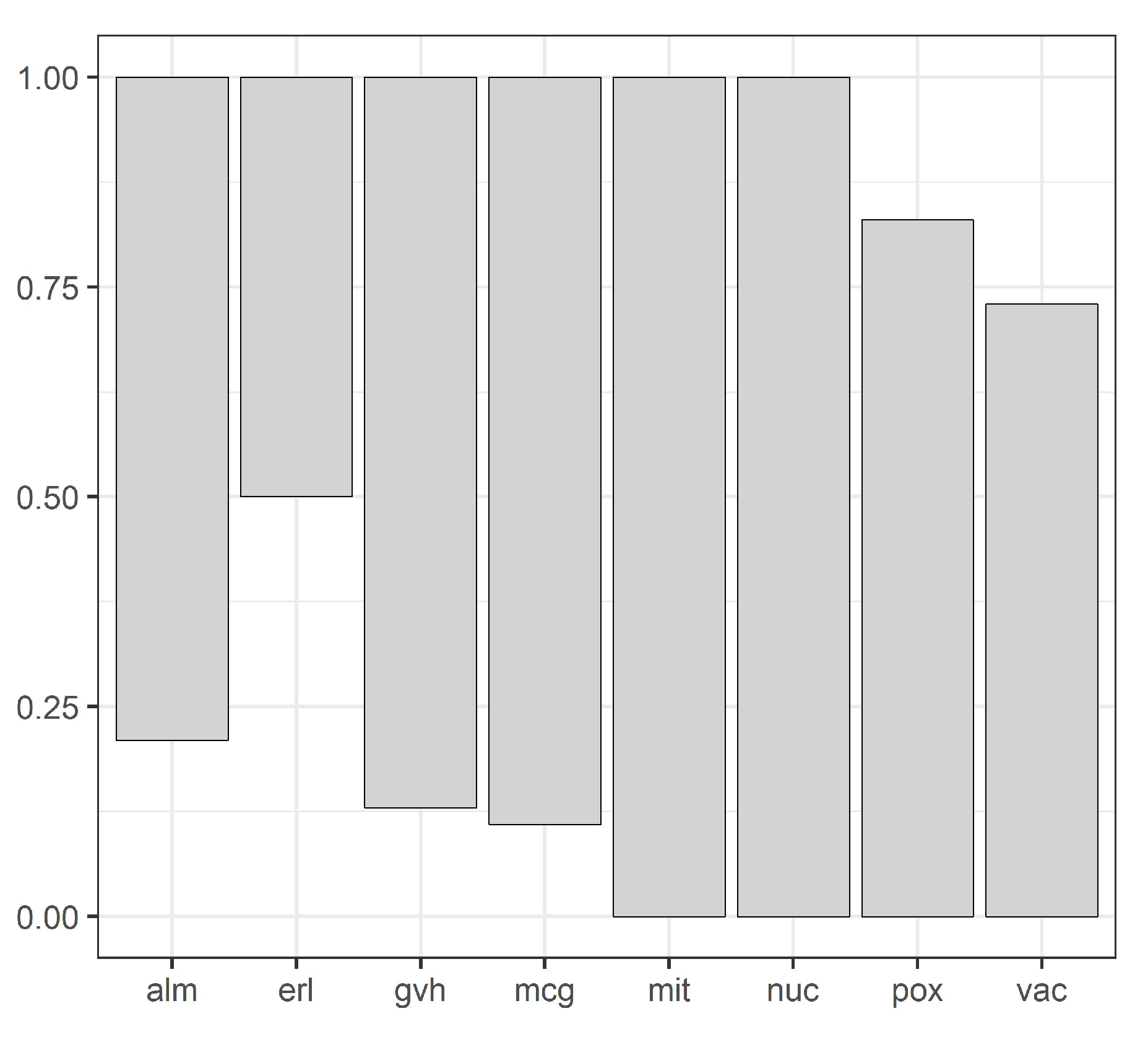
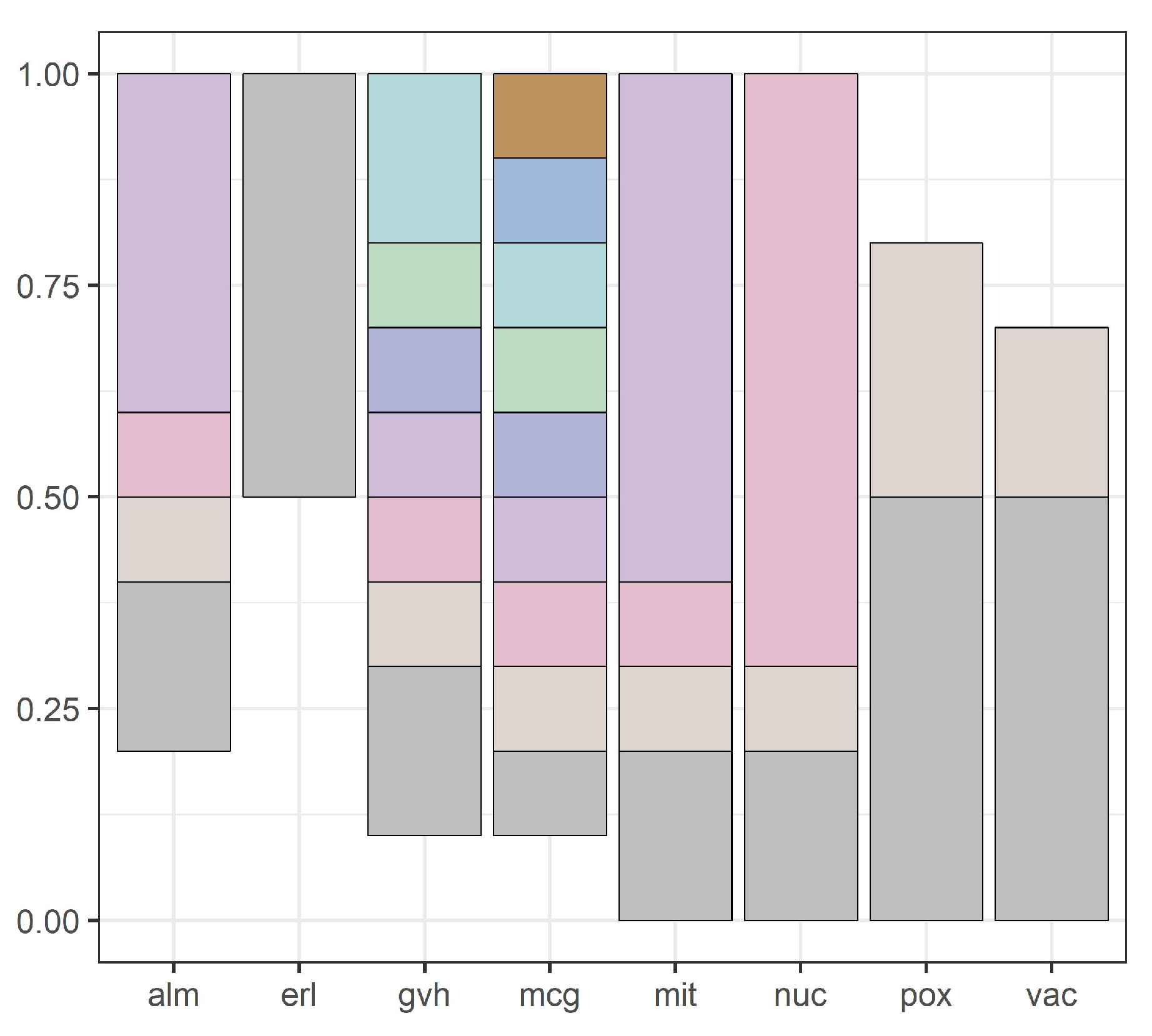
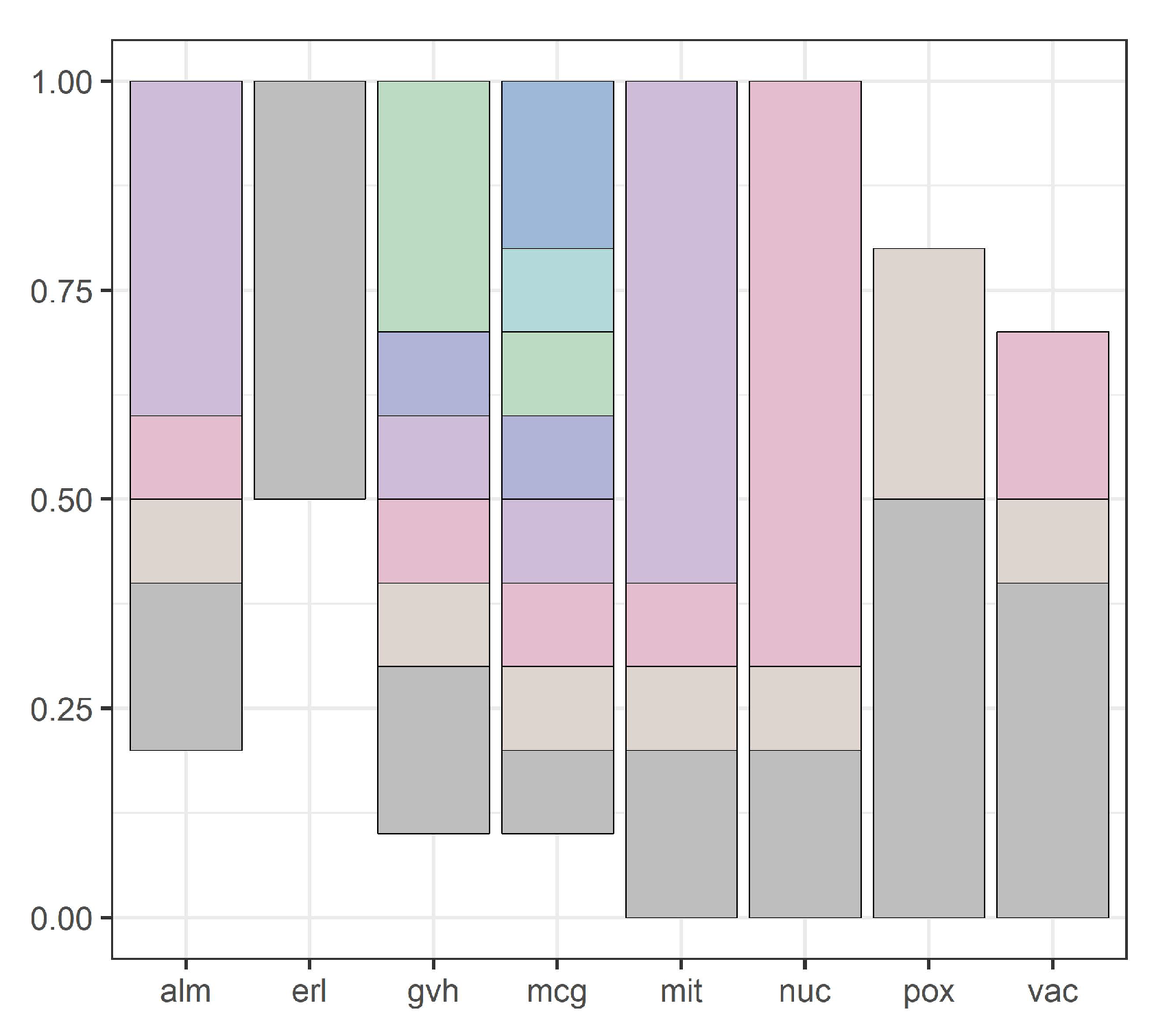
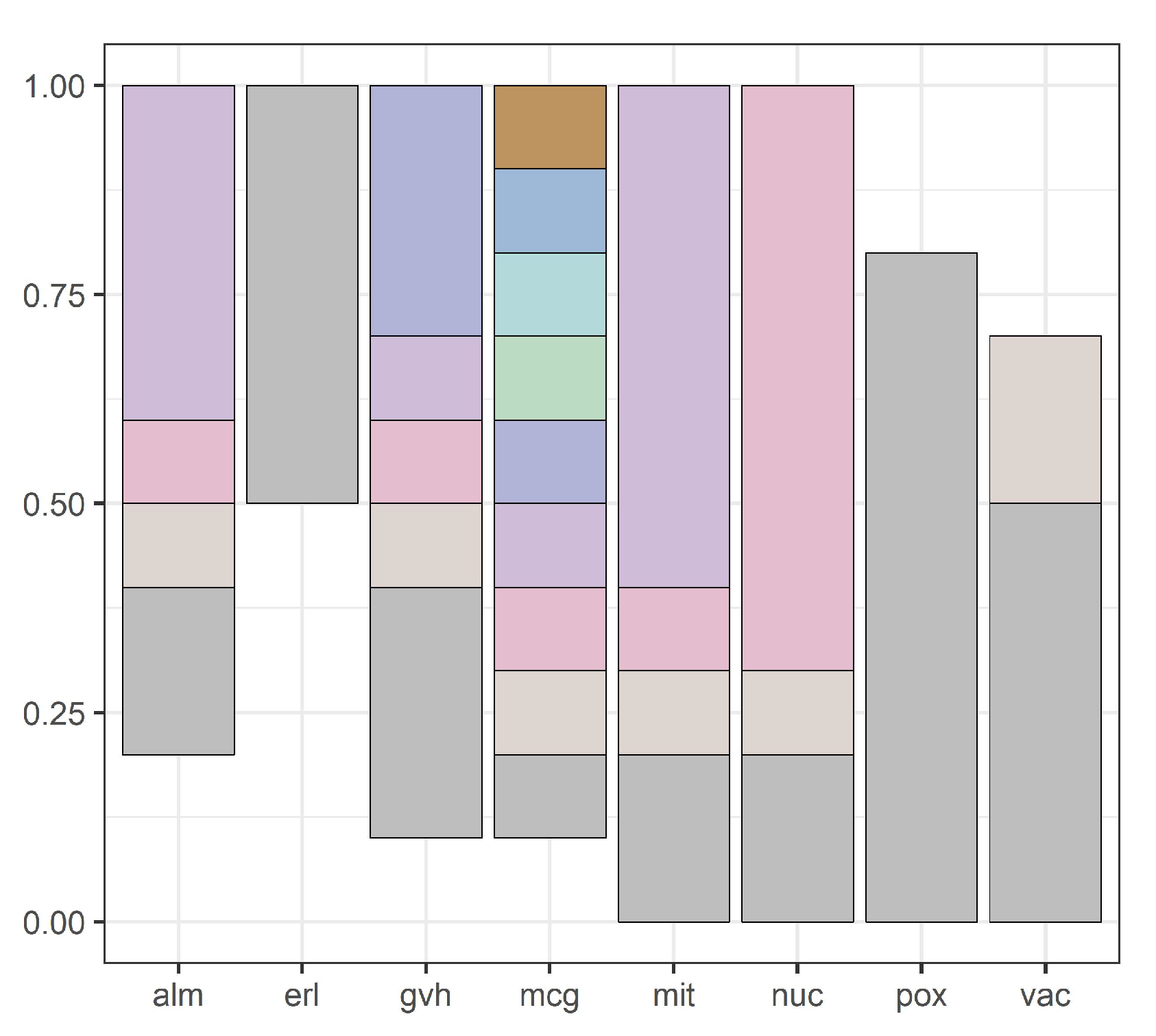
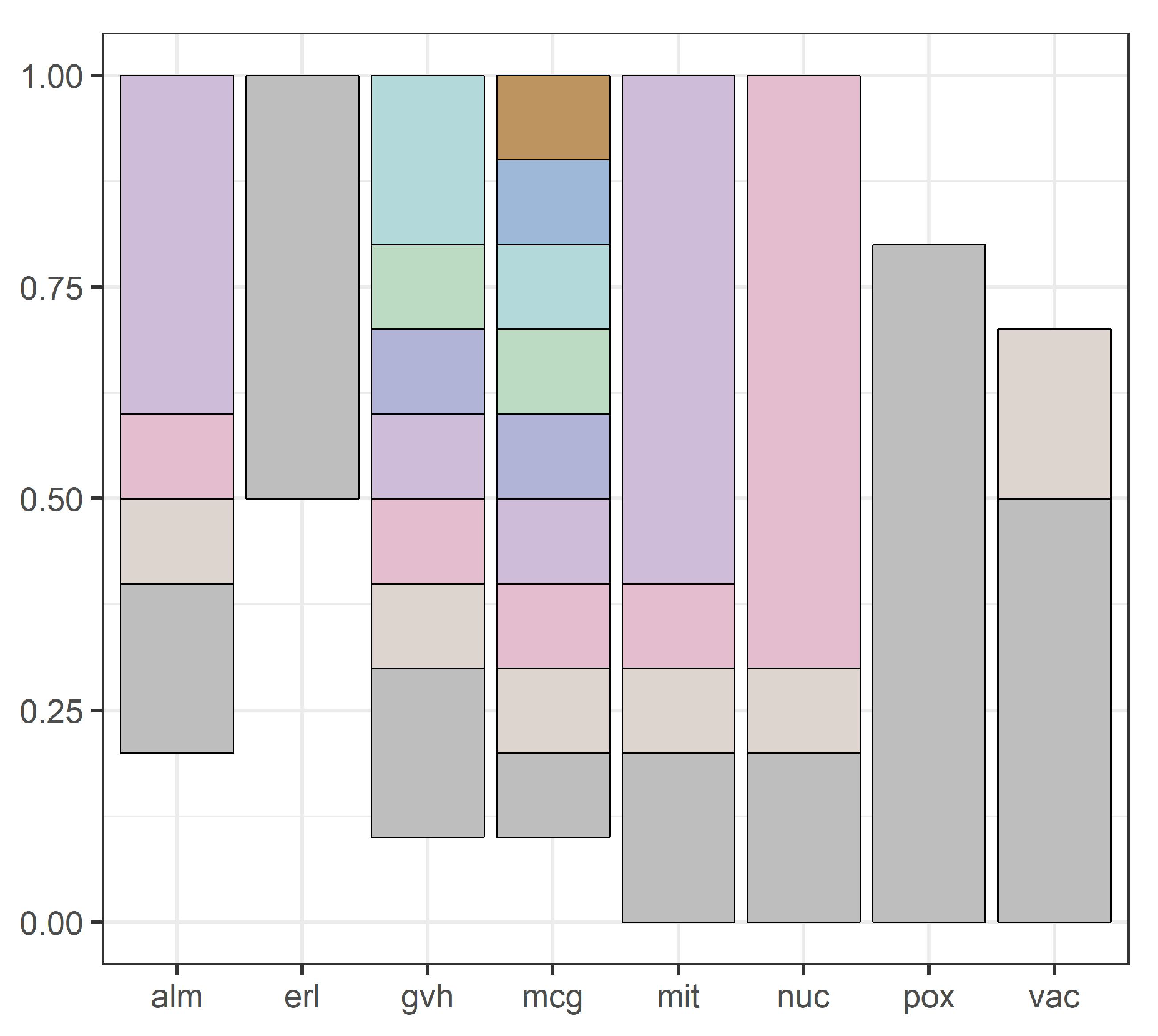
Figure 3 shows domains of all attributes for the yeast dataset, and
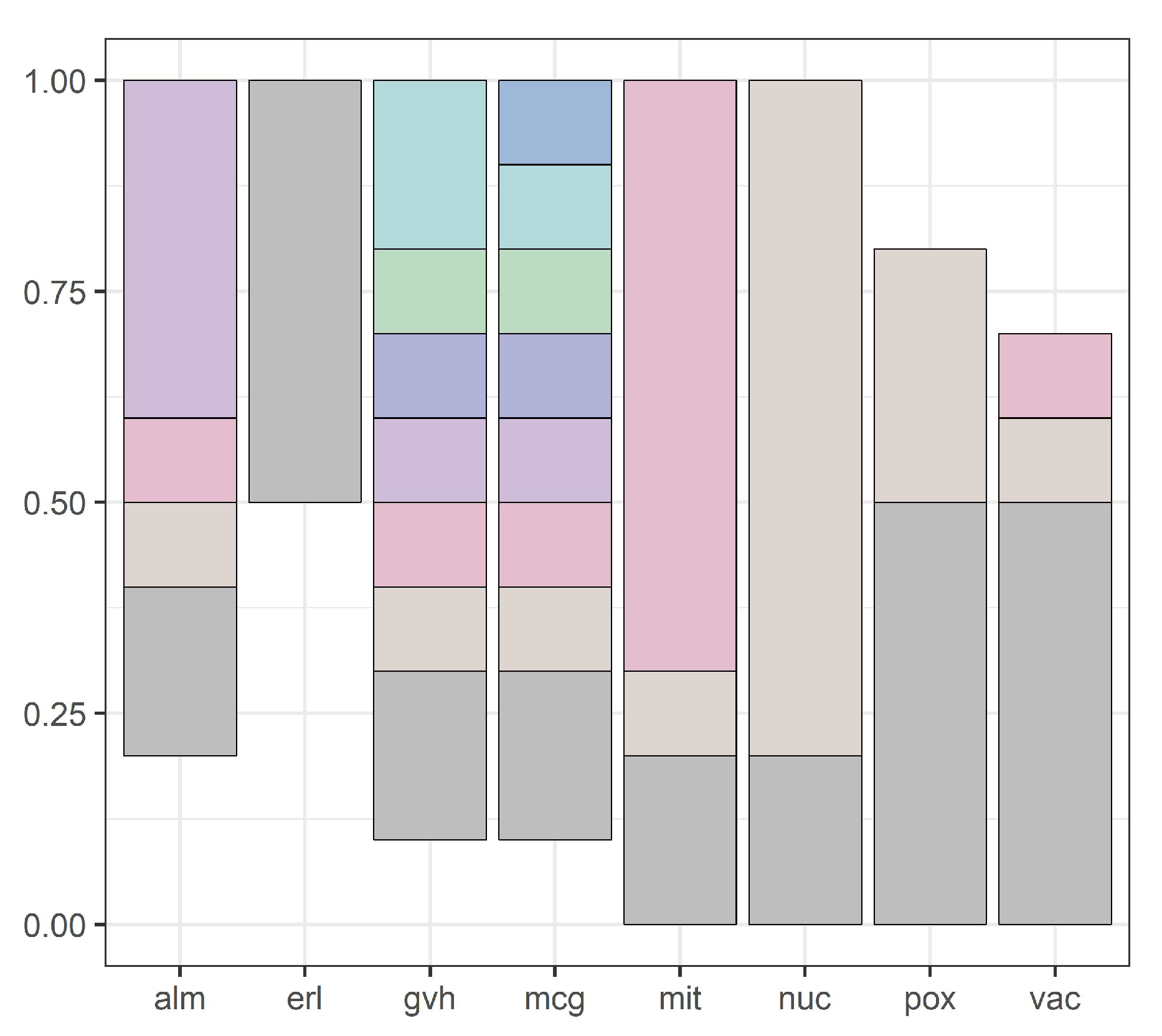
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show intervals of all attributes during interval scanning and merging.
Table 7 shows error rates for the three approaches to merging. Note that, for any dataset, we included only the smallest error rate with a corresponding scan number. The error rates were compared using the Friedman rank sum test combined with multiple comparison, with 5% level of significance. As follows from the Friedman test, the differences between all three approaches are statistically insignificant.
Thus, there is no universally best approach among no merging, merging based on minimum of conditional entropy, and merging based on maximum of conditional entropy.
Our next objective was to test the difference between all three approaches for a specific dataset. We conducted extensive experiments, with the repetition of 30 tenfold cross validations for every dataset and recorded averages and standard deviations in order to use the standard test for difference between averages. The corresponding
Z scores are presented in
Table 8. It is quite obvious that the choice of the correct approach to merging is highly significant in most cases, with the level of significance at 0.01, since the absolute value of the corresponding
Z-score is larger than 2.58. For example, for the ecoli dataset, merging of intervals based on minimum of conditional entropy is better than no merging, while for the leukemia dataset, it is the other way around. Similarly, for the ecoli dataset, no merging is better than merging based on the maximum of conditional entropy, while for the pima dataset it is the opposite.
Our future research plans include a comparison of our main methodology, multiple-scanning discretization, with discretization based on binning using histograms and chi-square analysis.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}