Spatial and Temporal Entropies in the Spanish Football League: A Network Science Perspective

 , and
, and
Abstract
:1. Introduction
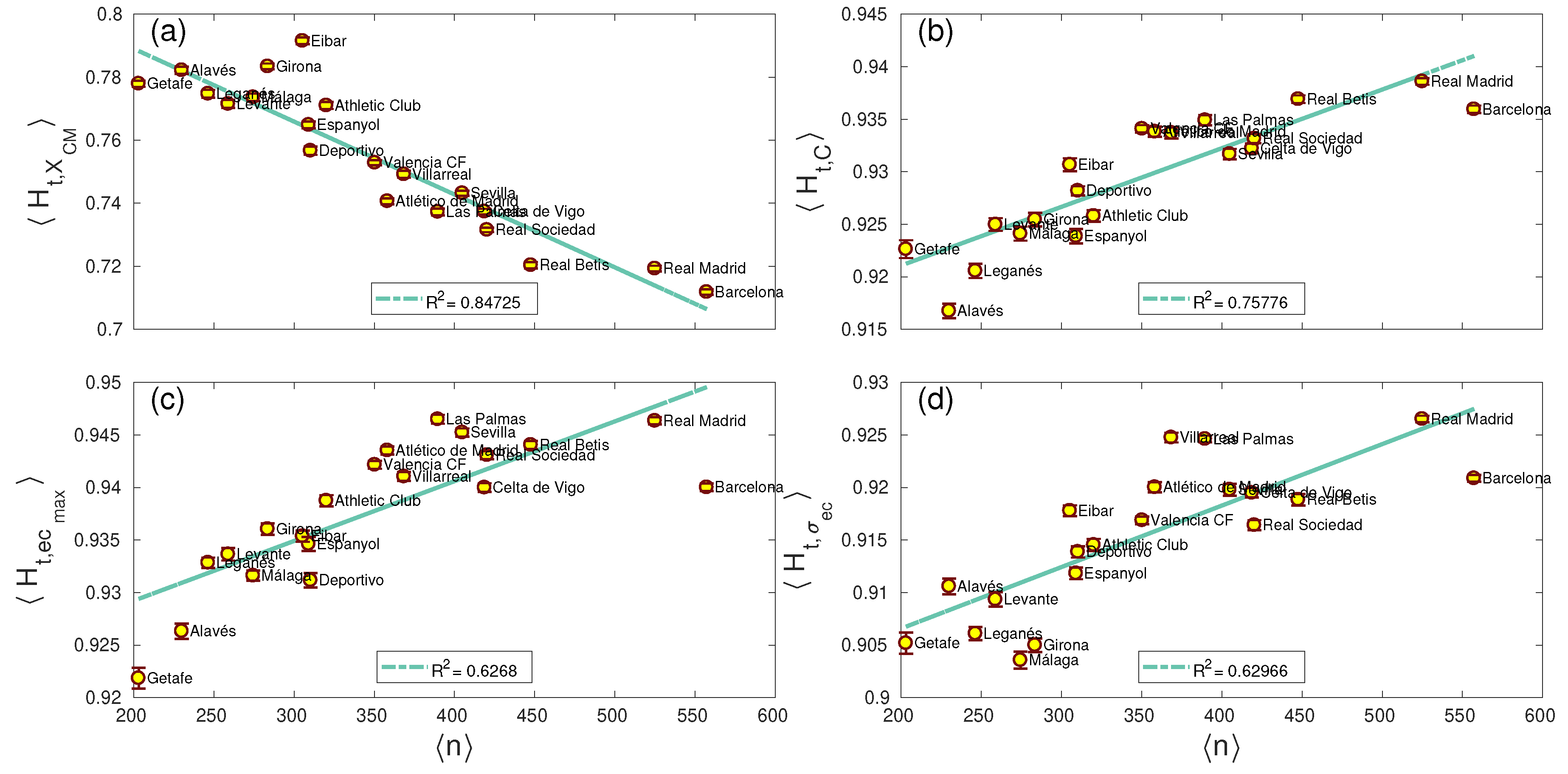
2. Results
2.1. Datasets
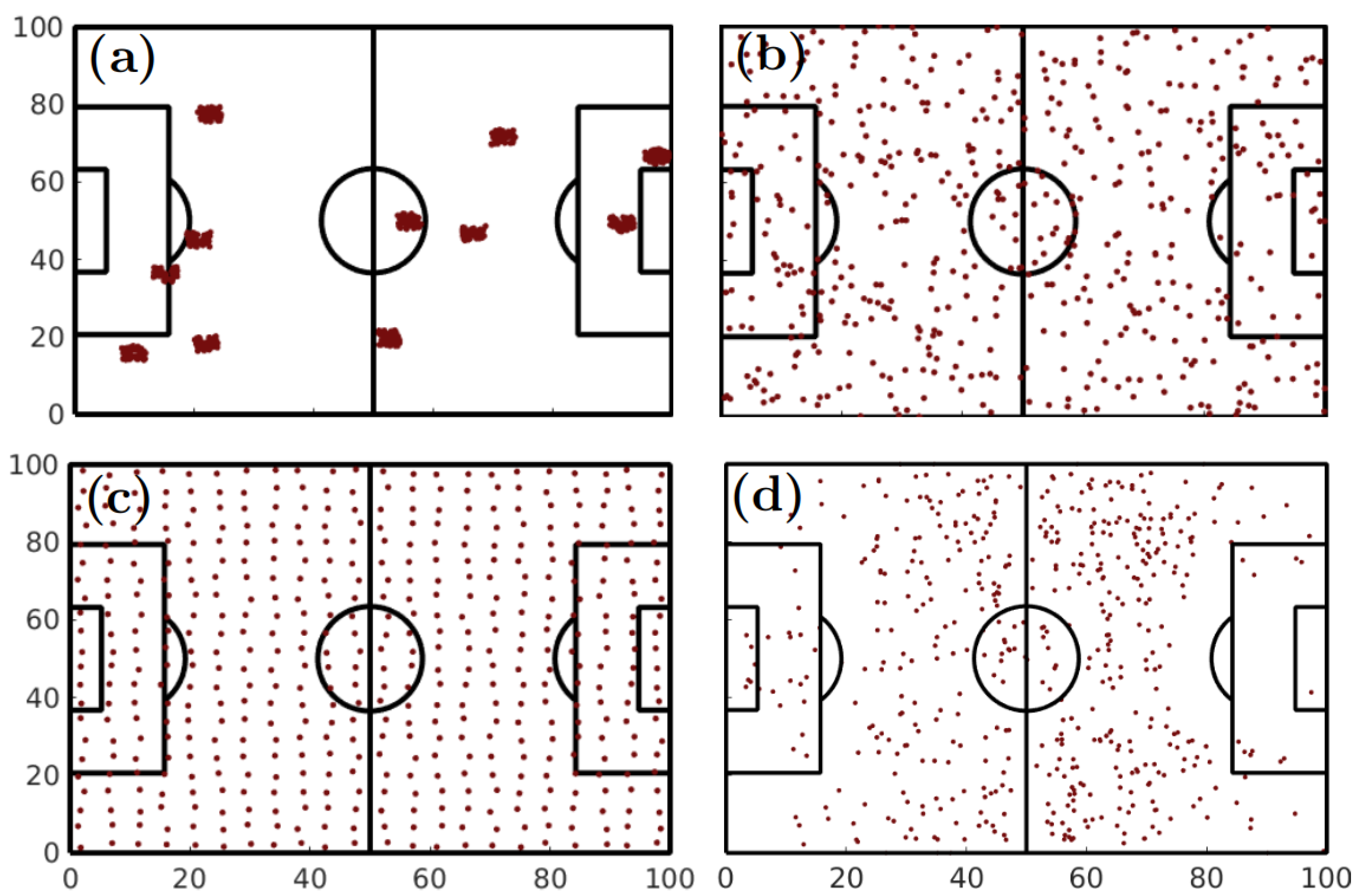
2.2. Spatial Analysis: Quantifying Spatial Entropy
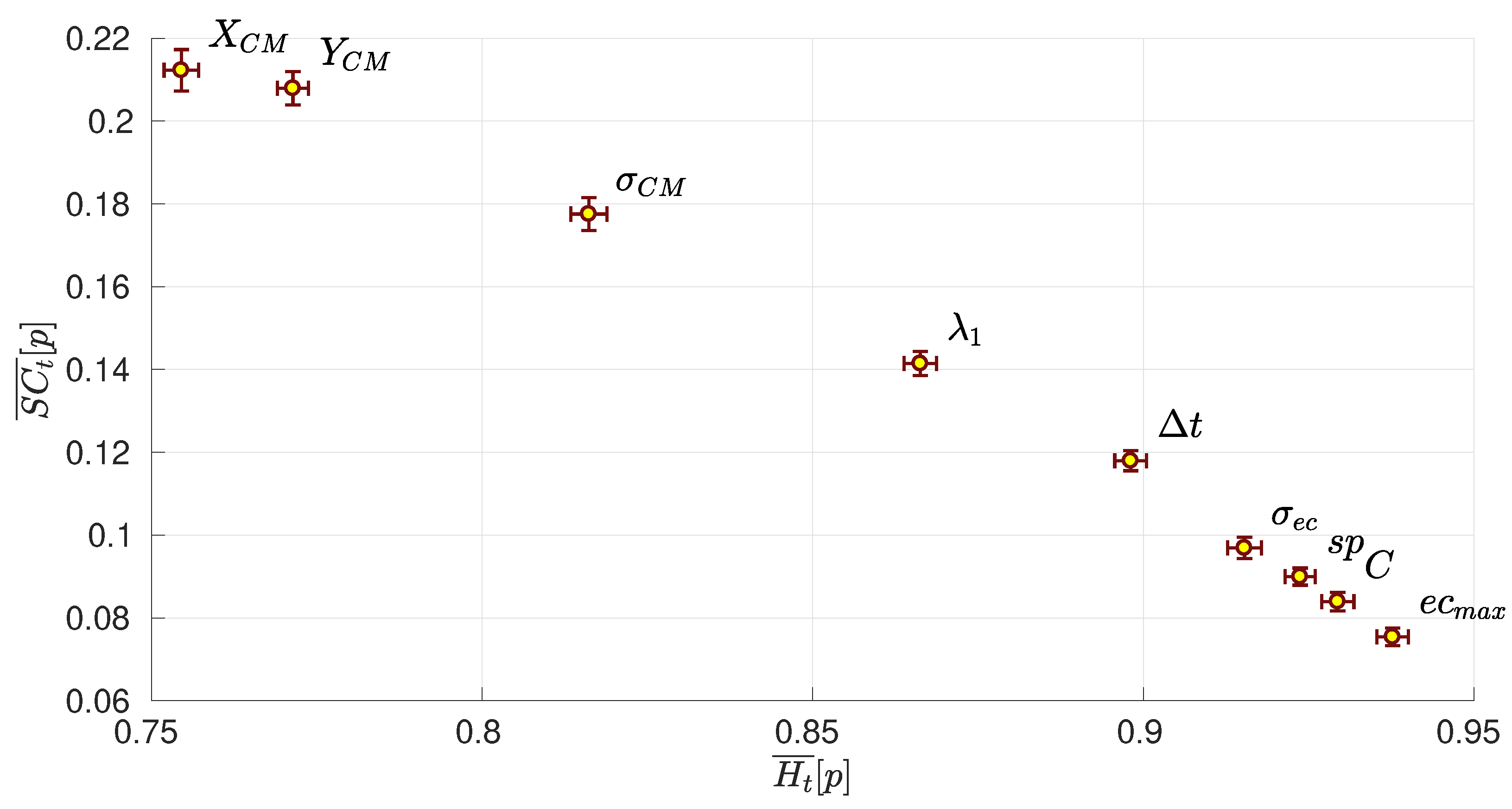
2.3. Temporal Entropy and Complexity of Football Passing Networks
3. Discussion
4. Methods
4.1. Definition of Network Metrics
4.1.1. Centroid Coordinates and Dispersion
4.1.2. Clustering Coefficient
4.1.3. Shortest Path Length
4.1.4. Largest Eigenvalue of the Adjacency Matrix
4.1.5. Eigenvector Centrality: Maximum Value and Dispersion
4.1.6. 50-Pass Network Time
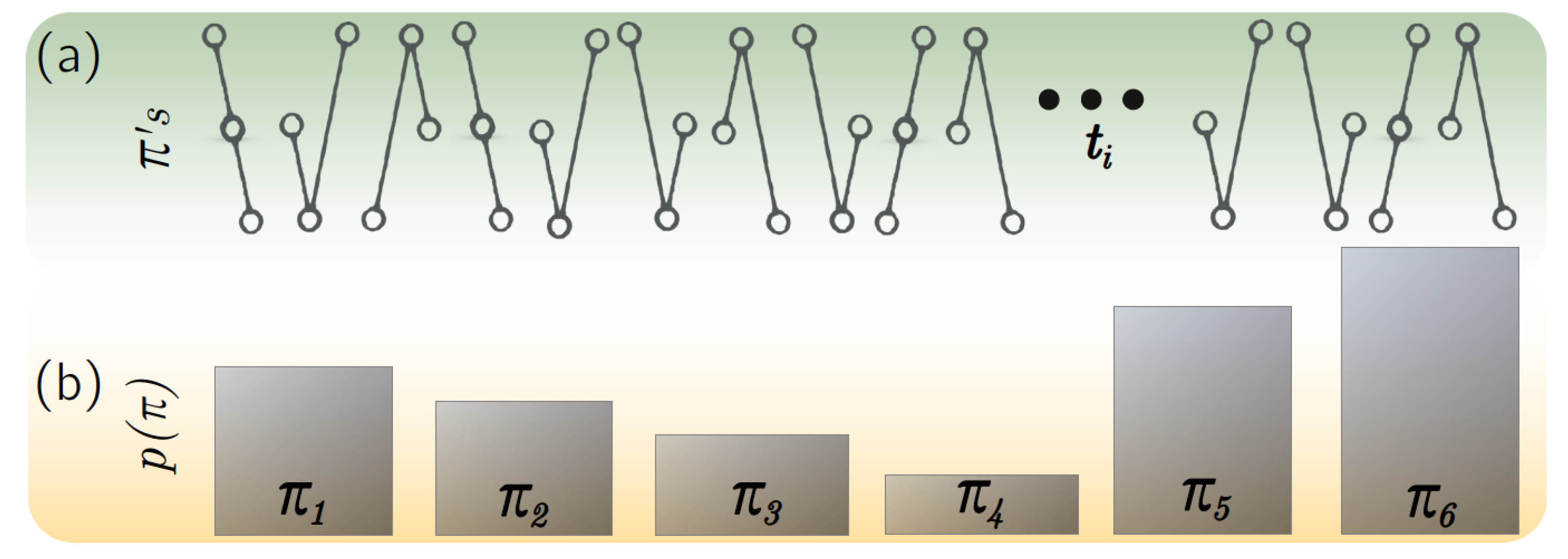
4.2. Temporal Entropy and Complexity
Author Contributions
Funding
Conflicts of Interest
Appendix A

References
- Duch, J.; Waitzman, J.S.; Amaral, L.A.N. Quantifying the Performance of Individual Players in a Team Activity. PLoS ONE 2010, 5, e10937. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cintia, P.; Rinzivillo, S.; Pappalardo, L. A network-based approach to evaluate the performance of football teams. In Proceedings of the Machine Learning and Data Mining for Sports Analytics Workshop, Porto, Portugal, 9 Novermber 2015. [Google Scholar]
- Pina, T.J.; Paulo, A.; Araújo, D. Network Characteristics of Successful Performance in Association Football. A Study on the UEFA Champions League. Front. Psychol. 2017, 8, 1173. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, J.; Silva, P.; Duarte, R.; Davids, K.; Garganta, J. Team sports performance analysed through the lens of social network theory: Implications for research and practice. Sports Med. 2017, 47, 1689–1696. [Google Scholar] [CrossRef] [PubMed]
- Buldú, J.M.; Busquets, J.; Martínez, J.H.; Herrera-Diestra, J.L.; Echegoyen, I.; Galeano, J.; Luque, J. Using network science to analyse football passing networks: Dynamics, space, time, and the multilayer nature of the game. Front. Psychol. 2018, 9, 1900. [Google Scholar] [CrossRef] [Green Version]
- Gudmundsson, J.; Horton, M. Spatio-temporal analysis of team sports. ACM Comput. Surv. 2017, 50, 22. [Google Scholar] [CrossRef] [Green Version]
- Felipe, J.L.; Garcia-Unanue, J.; Viejo-Romero, D.; Navandar, A.; Sánchez-Sánchez, J. Validation of a Video-Based Performance Analysis System (Mediacoach) to Analyze the Physical Demands during Matches in LaLiga. Sensors 2019, 19, 4113. [Google Scholar] [CrossRef] [Green Version]
- Couceiro, M.; Clemente, F.; Martins, F.; Machado, J. Dynamical stability and predictability of football players: The study of one match. Entropy 2014, 16, 645–674. [Google Scholar] [CrossRef] [Green Version]
- Rossi, A.; Pappalardo, L.; Cintia, P.; Iaia, F.M.; Fernández, J.; Medina, D. Effective injury forecasting in soccer with GPS training data and machine learning. PLoS ONE 2018, 13, e0201264. [Google Scholar] [CrossRef] [Green Version]
- Sampaio, J.; Maçãs, V. Measuring tactical behaviour in football. Int. J. Sports Med. 2012, 33, 395–401. [Google Scholar] [CrossRef]
- Ric, A.; Hristovski, R.; Gonçalves, B.; Torres, L.; Sampaio, J.; Torrents, C. Timescales for exploratory tactical behaviour in football small-sided games. J. Sports Sci. 2016, 34, 1723–1730. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E.J. Networks: An Introduction, 1st ed.; Oxford University Press: New York, NY, USA, 2010. [Google Scholar]
- Buldú, J.M.; Busquets, J.; Echegoyen, I.; Seirul.lo, F. Defining a historic football team: Using Network Science to analyze Guardiola’s FC Barcelona. Sci. Rep. 2019, 9, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cotta, C.; Mora, A.M.; Merelo, J.J.; Merelo-Molina, C. A network analysis of the 2010 FIFA world cup champion team play. J. Syst. Sci. Complex. 2013, 26, 21–42. [Google Scholar] [CrossRef]
- Narizuka, T.; Yamamoto, K.; Yamazaki, Y. Statistical properties of position-dependent ball-passing networks in football games. Physica A 2014, 412, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Gyarmati, L.; Kwak, H.; Rodríguez, P. Searching for a Unique Style in Soccer. In Proceedings of the ACM International Conference on Knowledge Discovery and Data Mining (KDD) Workshop on Large-Scale Sports Analytics, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Clemente, F.M.; Santos Couceiro, M.; Lourenço Martins, F.M.; Sousa Mendes, R. Using Network Metrics in Soccer: A Macro-Analysis. J. Hum. Kinet. 2015, 45, 123–134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- López Peña, J.; Sánchez Navarro, R. Who can replace Xavi? A passing motif analysis of football players. arXiv 2015, arXiv:1506.07768. [Google Scholar]
- Gonçalves, B.; Coutinho, D.; Santos, S.; Lago-Penas, C.; Jiménez, S.; Sampaio, J. Exploring team passing networks and player movement dynamics in youth association football. PLoS ONE 2017, 12, e0171156. [Google Scholar] [CrossRef]
- Shorrocks, A.F. Inequality decomposition by factor components. Econometrica 1982, 50, 193–211. [Google Scholar] [CrossRef] [Green Version]
- Borooah, V.K.; Mangan, J. Measuring competitive balance in sports using generalized entropy with an application to English premier league football. Appl. Econ. 2012, 44, 1093–1102. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef] [Green Version]
- Duarte, R.; Araújo, D.; Folgado, H.; Esteves, P.; Marques, P.; Davids, K. Capturing complex, non-linear team behaviours during competitive football performance. J. Syst. Sci. Complex. 2013, 26, 62–72. [Google Scholar] [CrossRef]
- Ochs, W. Basic properties of the generalized Boltzmann-Gibbs-Shannon entropy. Rep. Math. Phys. 1976, 9, 135–155. [Google Scholar] [CrossRef]
- Silva, P.; Duarte, R.; Esteves, P.; Travassos, B.; Vilar, L. Application of entropy measures to analysis of performance in team sports. Int. J. Perform. Anal. Sport 2016, 16, 753–768. [Google Scholar] [CrossRef]
- Zanin, M.; Zunino, L.; Rosso, O.A.; Papo, D. Permutation entropy and its main biomedical and econophysics applications: A review. Entropy 2012, 14, 1553–1577. [Google Scholar] [CrossRef]
- Football. Available online: https://www.optasports.com/sports/football (accessed on 1 February 2020).
- Clark, P.J.; Evans, F.C. Distance to nearest neighbor as a measure of spatial relationships in populations. Ecology 1954, 35, 445–453. [Google Scholar] [CrossRef]
- Aguirre, J.; Papo, D.; Buldú, J.M. Successful strategies for competing networks. Nat. Phys. 2013, 9, 230–234. [Google Scholar] [CrossRef] [Green Version]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef]
- Martín, M.T.; Plastino, A.; Rosso, O.A. Generalized statistical complexity measures: Geometrical and analytical properties. Physica A 2006, 369, 439. [Google Scholar] [CrossRef]
- Rosso, O.A.; De Micco, L.; Larrondo, H.A.; Martín, T.M.; Plastino, A. Generalized statistical complexity measure. Int. J. Bifurc Chaos 2010, 20, 775–785. [Google Scholar] [CrossRef]
- Rosso, O.A.; Larrondo, H.A.; Martín, M.T.; Plastino, A.; Fuentes, M.A. Distinguish noise from chaos. Phys. Rev. Lett. 2007, 99, 154102. [Google Scholar] [CrossRef] [Green Version]
- Cazelles, B. Symbolic dynamics for identifying similarity between rhythms of ecological time series. Ecol. Lett. 2004, 7, 755–763. [Google Scholar] [CrossRef]
- Tiana-Alsina, J.; Torrent, M.C.; Rosso, O.A.; Masoller, C.; Garcia-Ojalvo, J. Quantifying the statistical complexity of low-frequency fluctuations in semiconductor lasers with optical feedback. Phys. Rev. A 2010, 82, 013819. [Google Scholar] [CrossRef]
- Lange, H.; Rosso, O.A.; Hauhs, M. Ordinal pattern and statistical complexity analysis of daily stream flow time series. Eur. Phys. J. 2013, 222, 535–552. [Google Scholar]
- Martínez, J.H.; Herrera-Diestra, J.L.; Chavez, M. Detection of time reversibility in time series by ordinal patterns analysis. Chaos 2018, 28, 123111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boccaletti, S.; Bianconi, G.; Criado, R.; Del Genio, C.I.; Gómez-Gardenes, J.; Romance, M.; Sendina-Nadal, I.; Wang, Z.; Zanin, M. The structure and dynamics of multilayer networks. Phys. Rep. 2014, 544, 1–122. [Google Scholar] [CrossRef] [Green Version]
- Kivelä, M.; Arenas, A.; Barthelemy, M.; Gleeson, J.P.; Moreno, Y.; Porter, M.A. Multilayer networks. J. Complex Netw. 2014, 2, 203–271. [Google Scholar] [CrossRef] [Green Version]
- Ahnert, S.E.; Garlaschelli, D.; Fink, T.M.A.; Caldarelli, G. Ensemble approach to the analysis of weighted networks. Phys. Rev. E 2007, 76, 016101. [Google Scholar] [CrossRef] [Green Version]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of small-world networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connection with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Van Mieghem, P. Graph Spectra for Complex Networks, 1st ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time (Seconds) | Team | Player 1 | Player 2 | ||||
|---|---|---|---|---|---|---|---|
| … | … | … | … | … | … | … | … |
| 128 | Real Madrid | Ramos | 33.47 | 58.35 | Modrić | 42.30 | 58.75 |
| 130 | Real Madrid | Modrić | 59.36 | 70.00 | Benzema | 60.10 | 74.90 |
| 136 | Real Madrid | Benzema | 60.15 | 80.15 | Vinícius | 65.40 | 86.50 |
| … | … | … | … | … | … | … | … |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez, J.H.; Garrido, D.; Herrera-Diestra, J.L.; Busquets, J.; Sevilla-Escoboza, R.; Buldú, J.M. Spatial and Temporal Entropies in the Spanish Football League: A Network Science Perspective. Entropy 2020, 22, 172. https://doi.org/10.3390/e22020172
Martínez JH, Garrido D, Herrera-Diestra JL, Busquets J, Sevilla-Escoboza R, Buldú JM. Spatial and Temporal Entropies in the Spanish Football League: A Network Science Perspective. Entropy. 2020; 22(2):172. https://doi.org/10.3390/e22020172
Chicago/Turabian StyleMartínez, Johann H., David Garrido, José L Herrera-Diestra, Javier Busquets, Ricardo Sevilla-Escoboza, and Javier M. Buldú. 2020. "Spatial and Temporal Entropies in the Spanish Football League: A Network Science Perspective" Entropy 22, no. 2: 172. https://doi.org/10.3390/e22020172
APA StyleMartínez, J. H., Garrido, D., Herrera-Diestra, J. L., Busquets, J., Sevilla-Escoboza, R., & Buldú, J. M. (2020). Spatial and Temporal Entropies in the Spanish Football League: A Network Science Perspective. Entropy, 22(2), 172. https://doi.org/10.3390/e22020172