Estimation of the Gender Ratio of Chickens Based on Computer Vision: Dataset and Exploration


Abstract
:1. Introduction
- Labor intensive—It is time consuming and mentally boring for workers to conduct such operations.
- Poor performance—It is difficult to count the chickens in motion, and thus can cause repeats or miscalculations.
2. Related Work
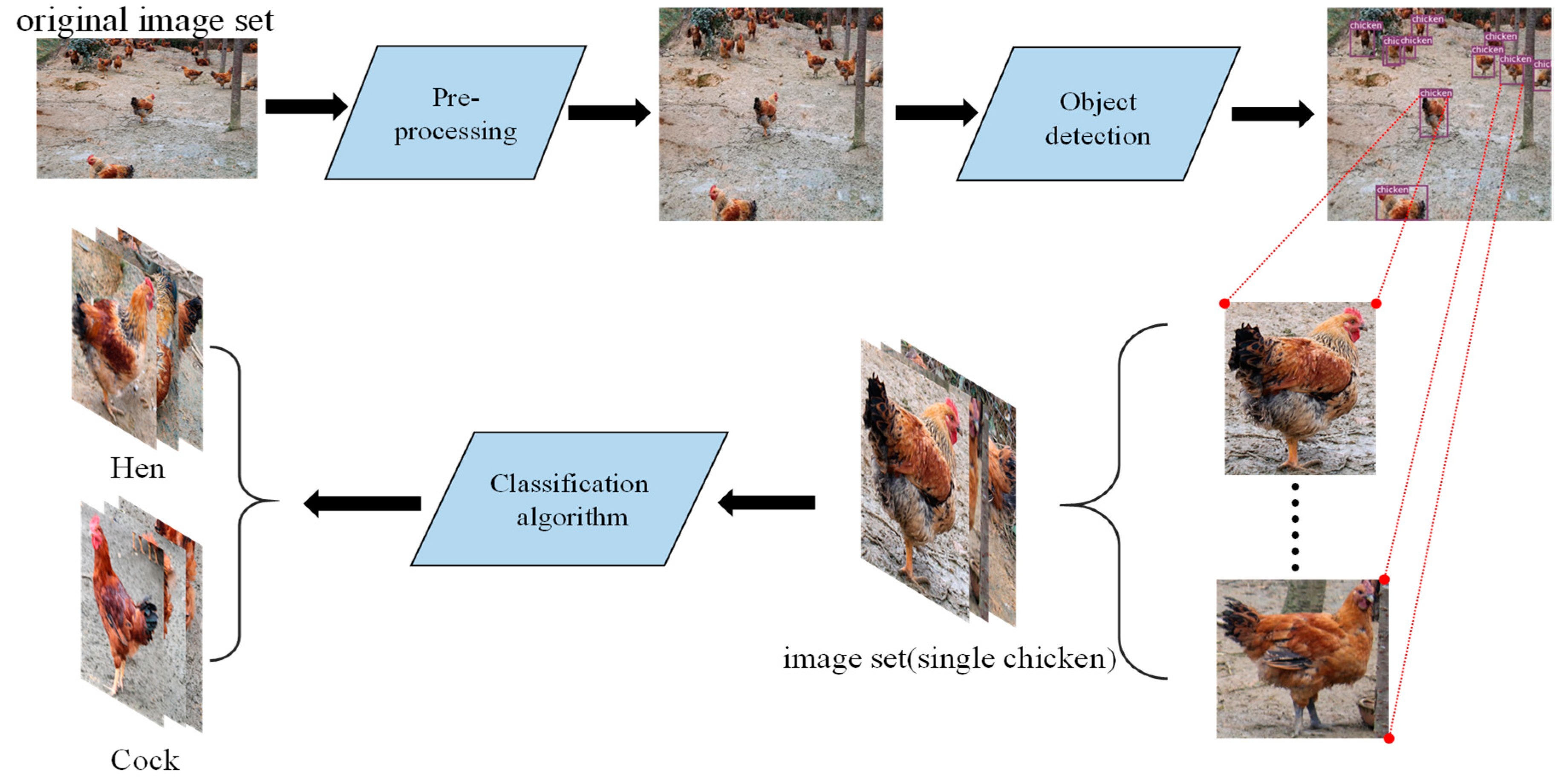
2.1. YOLOv3-Based Detection Network for Single Chicken
2.2. Proposed Classifier For Chicken Gender Classification
2.2.1. AlexNet
2.2.2. VGGNet
2.2.3. ResNet
2.2.4. Densenet
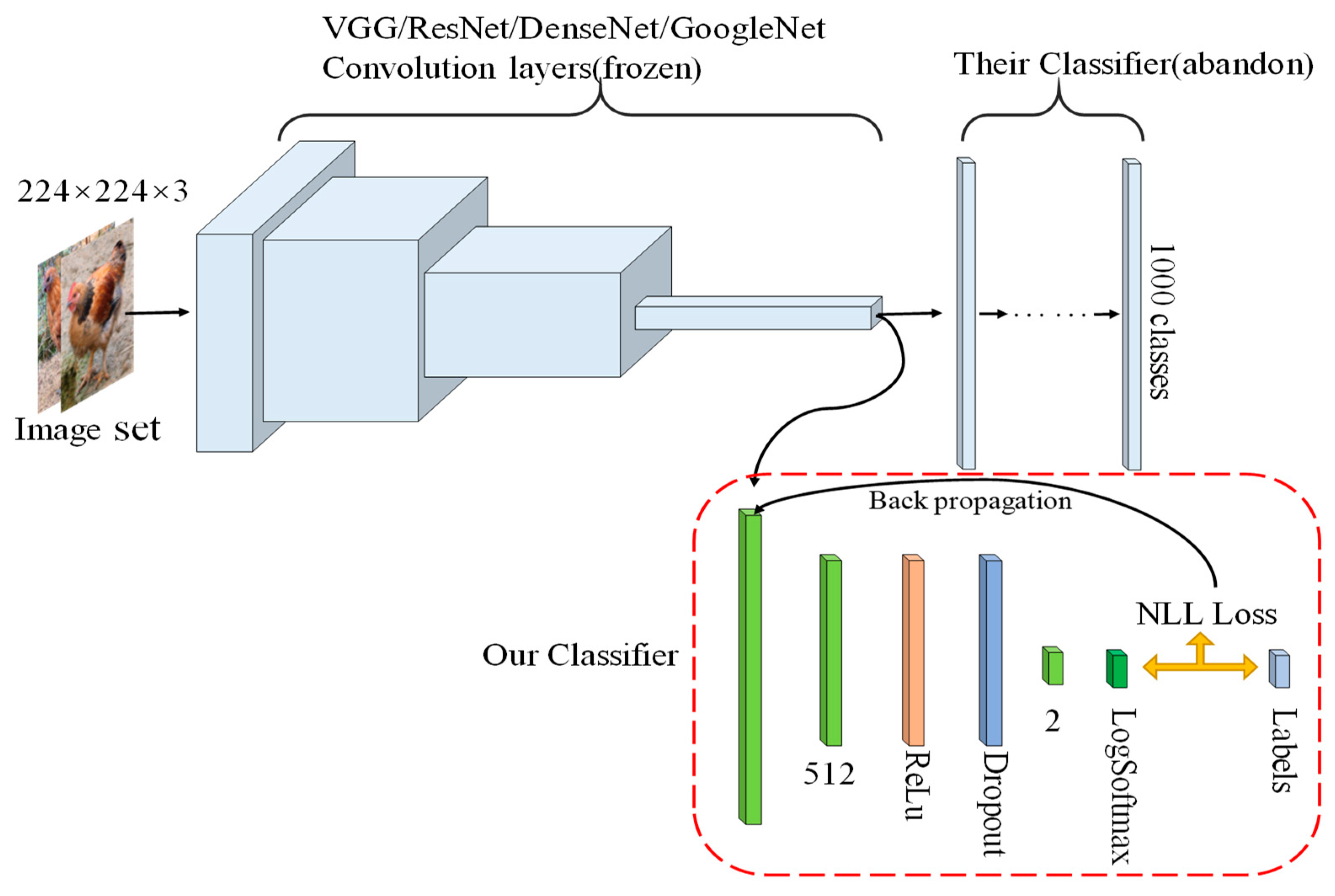
2.2.5. Our classifier
3. Materials and Methods
3.1. Acquisition of Materials
3.2. Data Preprocessing
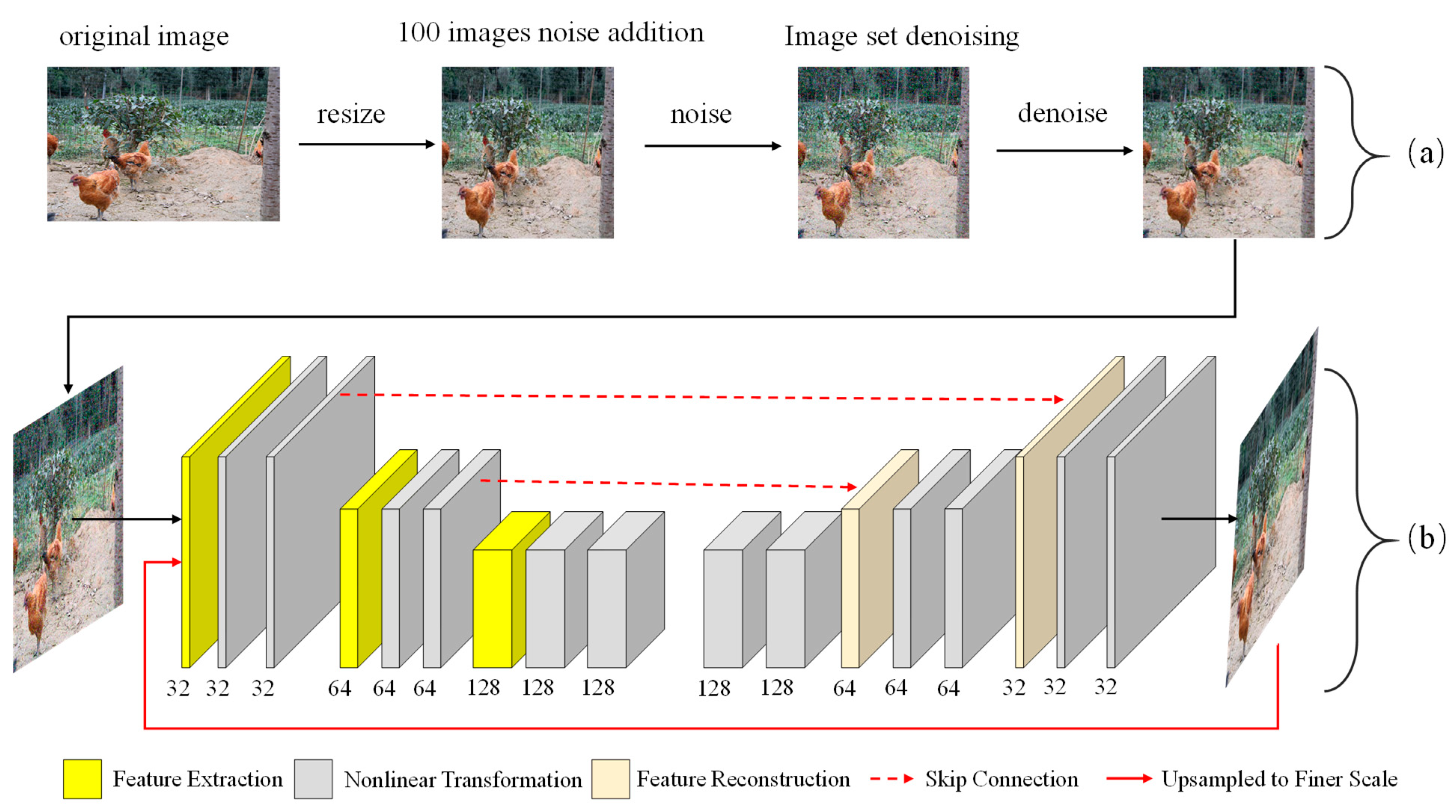
3.2.1. Image Resize and Denoise
3.2.2. Image Deblurring
3.3. Detection and Evaluation Methods
3.4. Experimental Environment
4. Results and Discussion
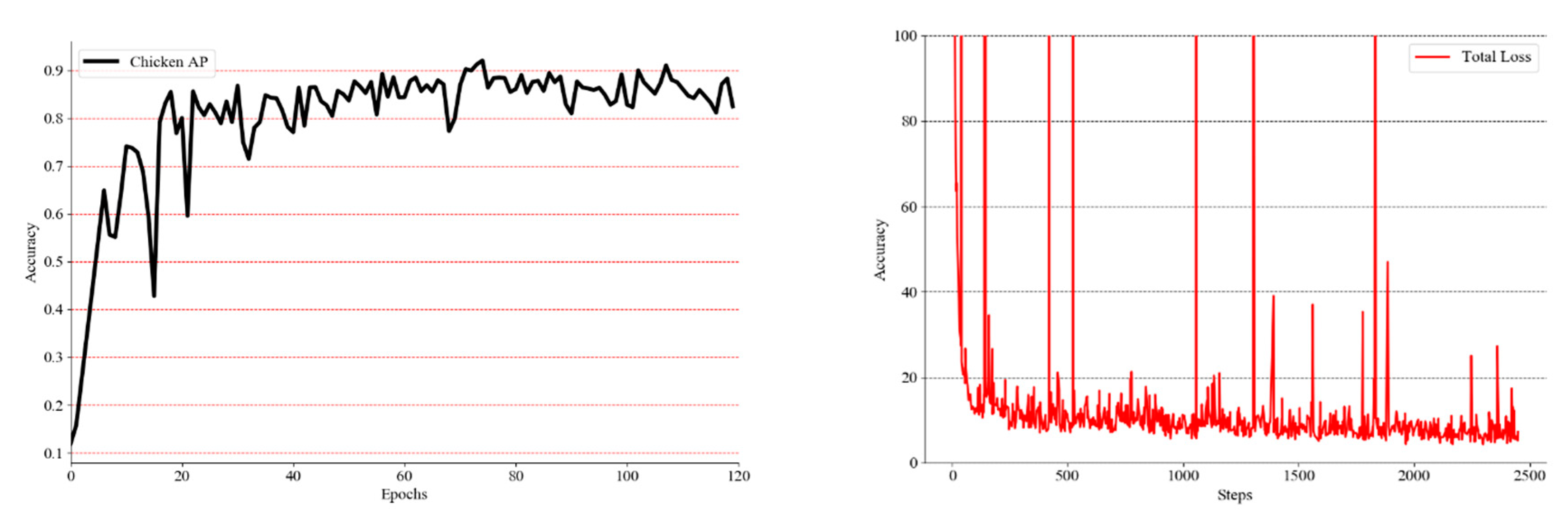
4.1. Experimental Results
- (1)
- Experiments on the application of YOLOv3 detection algorithm in a dataset that contains 800 chicken flocks.
- (2)
- Based on the test results, 1000 single chicken pictures with obvious features were selected to form a classification dataset.
- (3)
- A lightweight classifier, suitable for small dataset, was designed. Traditional classification networks perform well for a large dataset ImageNet, but it is difficult to handle the classification of small datasets.
- (4)
- The original classifiers of VGG-16, VGG-19, ResNet-18, ResNet-34, DenseNet-121 and AlexNet were discarded, and the feature map after convolution was inputted into the designed classifier for classification experiments.
- (5)
- The above network convolution layers were frozen, and only the classifier was optimized and compared with the optimization of the overall network
- (6)
- It was observed whether BN (Batch Normalization) improves network generalization and accuracy for this dataset after adding BN to VGG-16 and VGG-19 in the experiment.
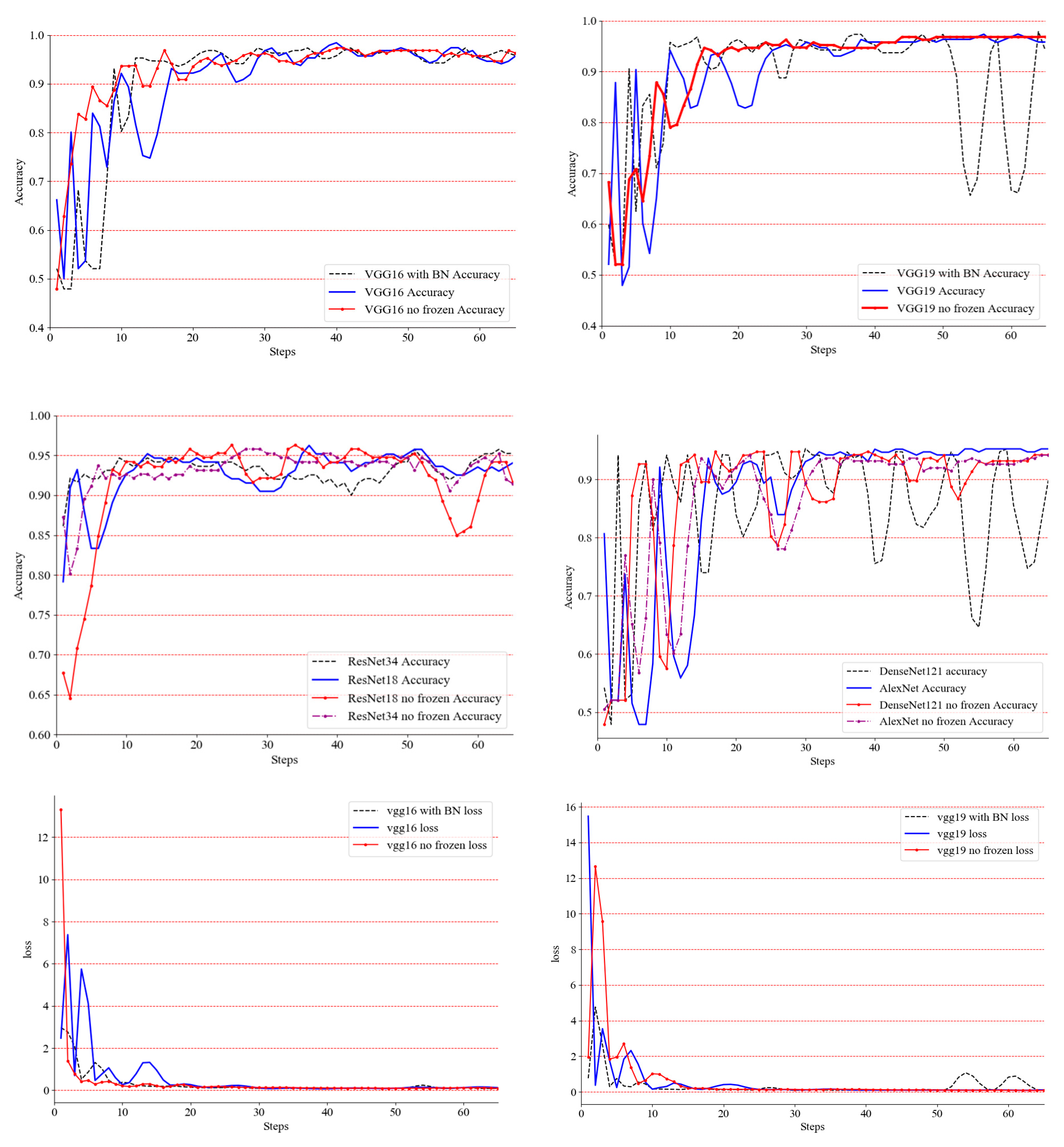
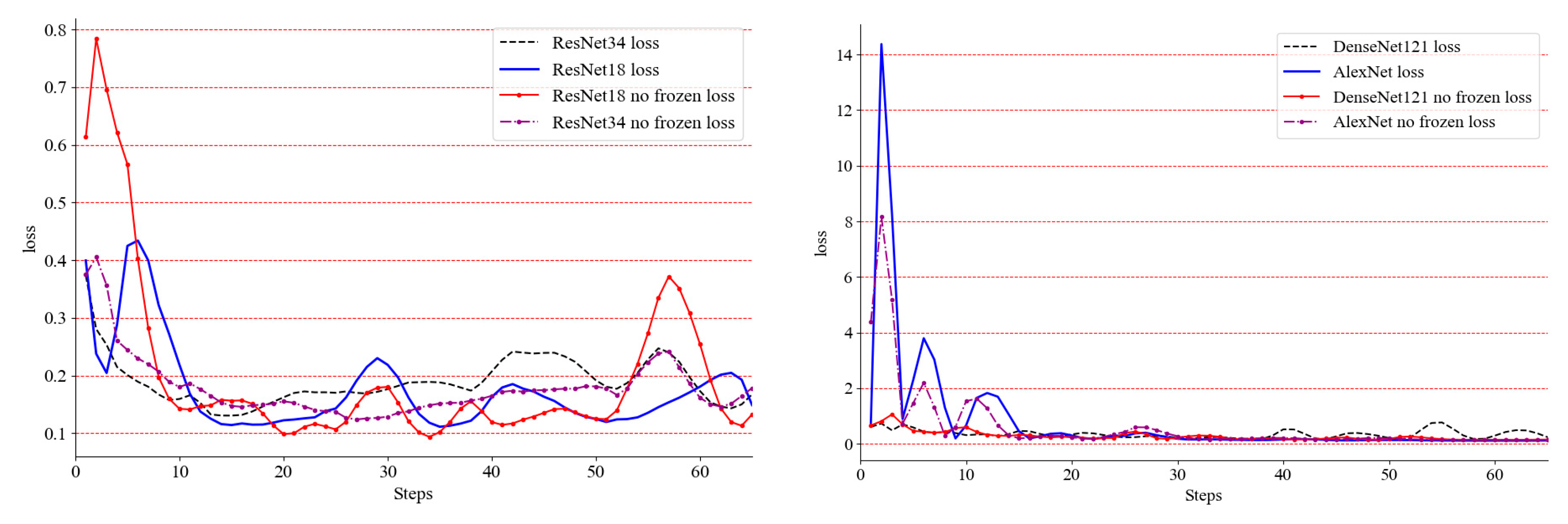
- After the above experiments, for classification networks, such as VGG-16, VGG-19, ResNet-18, ResNet-34, DenseNet-121 and AlexNet, the accuracy and loss of the early training process are severely oscillated, but the late convergence effect is better.
- VGG-16, with or without BN, under the optimized classifier only or global training, gave better results and will converge to a higher classification accuracy. Its structure is suitable for the designed classifier and dataset.
- DenseNet-121 did not perform well in global optimization and it still fluctuated severely in experiments only under the optimized classifier in the later period. After preliminary analysis, its deep network framework is not suitable for such small datasets. The AlextNet network converges well eventually, and its performance in the classifier is also ideal.
- VGG-19 is not suitable for adding BN on this dataset. After adding BN, it oscillates severely. Experiments under global optimization and experiments that were only under the optimized classifier performed well in accuracy and convergence. It proves that VGG-19’s global optimization is the best classification network, whose accuracy converges to 96.85%.
- ResNet-18 and ResNet-34 have higher precision in the later stage, but the final convergence effect is not ideal, and oscillation still exists.
- (1)
- The density of free-range chickens is low, so there is no chicken overlap problem.
- (2)
- In broiler farms, there are generally only two chicken species involved, namely Sanhuang chicken and Taoyuan chicken. This dataset is taken from these two species. Most breeds of chickens only change color according to breed differences, but gender differences still exist and are the same. Therefore, the problem that the classifier is not universal, due to the large in-class distance, is not involved.
4.2. Discussion and Outlook
- (1)
- In terms of processing accuracy, the source of object detection is the image collected by a single camera on the breeding environment. Due to the fixed position of the camera and the single collection angle, the information of the overall breeding environment cannot be obtained by a single camera, so the information acquired is single and limited. The movement of chickens may also lead to a huge error between the information obtained by a single camera and the actual situation. Therefore, farms should consider deploying multiple cameras in the breeding environment to conduct all-round and multi-angle information collection in the breeding environment, and to calculate the overall situation of the chicken farm by integrating the information taken by multiple cameras. Considering that the image information collected by the camera may be overlapped by a large number of chicken individuals, although it may interfere with the object detection (which does not mean that the accuracy will decrease directly), the purpose of our study was to make a judgment on the gender ratio in the chicken population, rather than by simply counting. In general, although there may be some individuals missing from the target test, the small number of these individuals and their gender ratio- are approximately the same, as the population as a whole will not have a significant impact on the gender ratio of the overall flock.
- (2)
- In terms of processing speed, in order to meet a farmer’s need to know at any time, real-time processing of the images collected by the camera is required. This is also the reason why we initially considered using an object detection model instead of instance segmentation or semantic segmentation and other models (the latter two are relatively slow in processing speed). Among the many object detection models, we considered using YOLOv3 model for processing, which is also an advanced model in the one-stage methods in object detection fields. Compared with the two-stage method, the former has a higher processing speed under the same hardware conditions. Compared with other one-stage methods (such as YOLOv2), the related reasons have been described in Section 2.1, which will not be repeated here.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Statistical Communiqué, Statistical Communiqué of the People's Republic of China on the 2018 National Economic and Social Development. 2018. Available online: http://www.stats.gov.cn/english/PressRelease/201902/t20190228_1651335.html (accessed on 20 December 2019).
- Henchion, M.; McCarthy, M.; Resconi, V.C.; Troy, D. Meat consumption: Trends and quality matters. Meat Sci. 2014, 98, 561–568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, G.; Pan, D. Study on the determinants of cost and benefit of layer industry in China. China Poult. 2011. [Google Scholar] [CrossRef]
- Chotesangasa, R. Effects of mating ratio, cock number in the flock and breeder age on fertility in Thai Native chicken flock. Kasetsart J. 2001, 35, 122–131. [Google Scholar]
- Li, Y.; Zhan, K.; Zhu, L.; Li, J.; Liu, W.; Ma, R.; Cui, H.; Zhang, X.; Liu, Z. Effects of male/female ratio on production performance, blood biochemical indicators, feather condition and antibody level of layer breeders in mating cages. China Poult. 2018, 40. [Google Scholar] [CrossRef]
- Hu, C.; Yang, C.; Yang, L.; Xia, B.; Yu, C.; Xiong, X.; Song, X.; Qiu, M.; Zhang, Z.; Peng, H.; et al. Study on the ratio of male to female of natural mating in caged chicken with high quality meat. China Poult. 2016, 38. [Google Scholar]
- Yang, C.-C.; Chao, K.; Chen, Y.-R.; Early, H.L. Systemically diseased chicken identification using multispectral images and region of interest analysis. Optics East 2004, 5587, 121–132. [Google Scholar]
- Dawkins, M.S.; Lee, H.-J.; Waitt, C.D.; Roberts, S.J. Optical flow patterns in broiler chicken flocks as automated measures of behaviour and gait. Appl. Anim. Behav. Sci. 2009, 119, 203–209. [Google Scholar] [CrossRef]
- Dawkins, M.S.; Cain, R.; Roberts, S.J. Optical flow, flock behaviour and chicken welfare. Anim. Behav. 2012, 84, 219–223. [Google Scholar] [CrossRef]
- Banerjee, D.; Biswas, S.; Daigle, C.; Siegford, J. Remote activity classification of hens using wireless body mounted sensors. In Proceedings of the 2012 Ninth International Conference on Wearable and Implantable Body Sensor Networks, London, UK, 10–12 May 2012; pp. 107–112. [Google Scholar]
- Wang, L.; Wang, C.; Zhang, K. Design and implementation of network video surveillance system for laying hens farm based on ARM. Trans. Chin. Soc. Agric. Mach. 2012. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Vukotić, V.; Chappelier, V.; Furon, T. Are classification deep neural networks good for blind image watermarking? Entropy 2020, 22, 198. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Jing, W.; Zhou, M.; Li, Y. Multi-scale feature fusion for coal-rock recognition based on completed local binary pattern and convolution neural network. Entropy 2019, 21, 622. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Chen, Y.; Cai, N.; Cheng, W.; Wang, H. Utilizing amari-alpha divergence to stabilize the training of generative adversarial networks. Entropy 2020, 22, 410. [Google Scholar] [CrossRef] [Green Version]
- Tian, M.; Guo, H.; Chen, H.; Wang, Q.; Long, C.; Ma, Y. Automated pig counting using deep learning. Comput. Electron. Agric. 2019, 163, 104840. [Google Scholar] [CrossRef]
- Abu Jwade, S.; Guzzomi, A.; Mian, A. On farm automatic sheep breed classification using deep learning. Comput. Electron. Agric. 2019, 167, 105055. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, Q.; Yin, X.; Wu, D.; Song, H.; He, D. FLYOLOv3 deep learning for key parts of dairy cow body detection. Comput. Electron. Agric. 2019, 166, 104982. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. Proceedings of CVPR 2018: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–22 June 2018. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of CVPR 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. Proceedings of ICCV 2015: IEEE International Conference on Computer Vision, Santiago, Chile, 11–16 December2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. Proceedings of CVPR 2016: IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. Proceedings of ECCV 2016: European Conference on Computer Vision, Amsterdam, The Netherlands, 7–12 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. Proceedings of CVPR 2017: IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Proceedings of ICML 2015: International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proceedings of CVPR 2019: IEEE Conference on Computer Vision and Pattern Recognition, Los Angle, CA, USA, 15–21 June 2019. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Proceedings of NIPS 2012: The Conference and Workshop on Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–8 December 2012. [Google Scholar]
- Alom, Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sagan, V.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.S.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. Proceedings of CVPR 2016: IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. Proceedings of CVPR 2017: IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. Proceedings of CVPR 2015: IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- CVPR. CVPR 2017 Best Paper Award. 2017. Available online: http://cvpr2017.thecvf.com/program/main_conference (accessed on 20 December 2019).
- Yao, H.; Zhu, D.-L.; Jiang, B.; Yu, P. Negative log likelihood ratio loss for deep neural network classification. Adv. Intell. Syst. Comput. 2019, 1069, 276–282. [Google Scholar]
- Boyat, A.K.; Joshi, B.K. A review paper: Noise models in digital image processing. signal image Process. Int. J. 2015, 6, 63–75. [Google Scholar] [CrossRef]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better. Proceedings of ICCV 2019: IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. Proceedings of CVPR 2018: IEEE Conference on Computer Vision and Pattern Recognition, 8–14 September 2018. [Google Scholar]
- CVPR. CVPR Home Page. 2019. Available online: http://cvpr2019.thecvf.com (accessed on 20 December 2019).
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. Proceedings of CVPR 2019: IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 3848–3856. [Google Scholar]
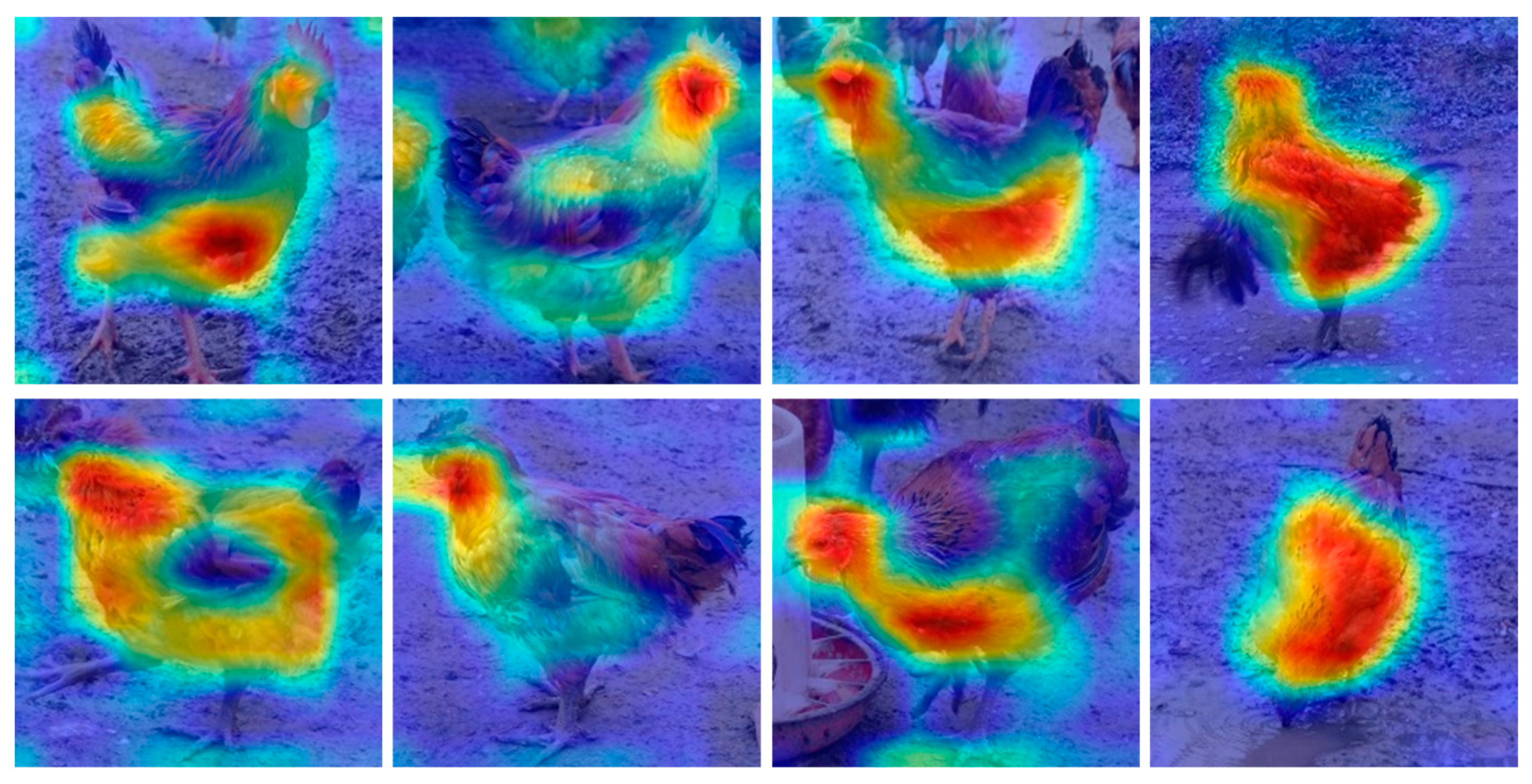
- Ramprasaath, R.; Selvaraju, A.D.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-Cam: Why did you say that? Visual explanations from deep networks via gradient-based localization. Proceedings of ICCV 2017: IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AlexNet | VGG | ResNet | DenseNet | |||
|---|---|---|---|---|---|---|
| 8-layer | 16-layer | 19-layer | 18-layer | 34-layer | 121-layer | |
| Conv1_x | 11×11,96 | 3×3,64 3×3,64 | 3×3,64 3×3,64 | 7×7,64 stride 2 | 7×7,64 stride 2 | |
| 3×3 overlapping pool,stride 2 | 3×3 max pool, stride 2 | 3×3 max pool,stride 2 | ||||
| Conv2_x | 5×5,256 | 3×3,128 3×3,128 | 3×3,128 3×3,128 | 1×1,32 | ||
| 3×3 max pool,stride 2 | 3×3 max pool, stride 2 | 2×2 average pool,stride 2 | ||||
| Conv3_x | 3×3,384 | 3×3,256 3×3,256 3×3,256 | 3×3,256 3×3,256 3×3,256 3×3,256 | 1×1,32 | ||
| 3×3 max pool, stride 2 | 2×2 average pool,stride 2 | |||||
| Conv4_x | 3×3,384 | 3×3,512 3×3,512 3×3,512 | 3×3,512 3×3,512 3×3,512 3×3,512 | 1×1,32 | ||
| 3×3 max pool, stride 2 | 2×2 average pool,stride 2 | |||||
| Conv5_x | 3×3,256 | 3×3,512 3×3,512 3×3,512 | 3×3,512 3×3,512 3×3,512 3×3,512 | |||
| 3×3 max pool,stride 2 | 3×3 max pool, stride 2 | average pool | 7×7 global average pool, stride 2 | |||
| Classification layer | fc 4906 | fc 4906 | fc 1000 | fc 1000 | ||
| fc 4906 | fc 4906 | |||||
| fc 1000 | fc 1000 | |||||
| softmax | softmax | softmax | softmax | |||
| Learning Rate | Batch Size | Maximum Number of Epochs | Iterations Per epoch | Momentum | Decay | |
|---|---|---|---|---|---|---|
| YOLOv3 | 0.01 | 4 | 120 | 160 | 0.9 | 0.0005 |
| Classifier | 0.01 | 64 | 5 | 13 | - | - |
| Process Mode | Epoch1 (%) | Epoch2 (%) | Epoch3 (%) | Epoch4 (%) | Epoch5 (%) | |
|---|---|---|---|---|---|---|
| AlexNet | frozen | 55.88 | 89.33 | 94.17 | 94.71 | 95.24 |
| not frozen | 63.41 | 86.67 | 93.70 | 91.98 | 92.61 | |
| VGG-16 | frozen | 81.68 | 96.23 | 95.31 | 96.82 | 95.16 |
| with BN | 95.29 | 96.28 | 97.34 | 96.82 | 95.16 | |
| not frozen | 93.75 | 93.75 | 95.76 | 96.82 | 95.73 | |
| VGG-19 | frozen | 88.54 | 92.53 | 93.60 | 96.33 | 96.85 |
| with BN | 95.26 | 95.78 | 96.80 | 95.71 | 85.43 | |
| not frozen | 83.34 | 95.73 | 94.66 | 96.25 | 96.80 | |
| ResNet-18 | frozen | 94.17 | 92.61 | 96.25 | 95.16 | 93.55 |
| not frozen | 93.62 | 95.29 | 95.21 | 94.77 | 89.33 | |
| ResNet-34 | frozen | 94.12 | 94.17 | 92.55 | 93.67 | 94.64 |
| not frozen | 92.68 | 94.19 | 94.19 | 93.67 | 94.25 | |
| DenseNet-121 | frozen | 81.60 | 94.12 | 94.71 | 83.89 | 85.53 |
| not frozen | 92.55 | 94.74 | 93.70 | 93.70 | 93.18 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Y.; Yu, H.; Mu, J.; Li, J.; Pu, H. Estimation of the Gender Ratio of Chickens Based on Computer Vision: Dataset and Exploration. Entropy 2020, 22, 719. https://doi.org/10.3390/e22070719
Yao Y, Yu H, Mu J, Li J, Pu H. Estimation of the Gender Ratio of Chickens Based on Computer Vision: Dataset and Exploration. Entropy. 2020; 22(7):719. https://doi.org/10.3390/e22070719
Chicago/Turabian StyleYao, Yuanzhou, Haoyang Yu, Jiong Mu, Jun Li, and Haibo Pu. 2020. "Estimation of the Gender Ratio of Chickens Based on Computer Vision: Dataset and Exploration" Entropy 22, no. 7: 719. https://doi.org/10.3390/e22070719
APA StyleYao, Y., Yu, H., Mu, J., Li, J., & Pu, H. (2020). Estimation of the Gender Ratio of Chickens Based on Computer Vision: Dataset and Exploration. Entropy, 22(7), 719. https://doi.org/10.3390/e22070719