1. Introduction
Michael Conrad, who explored biocomputing based on a protein chip, described how molecular interactions can implement computation by regarding the conformation changes in molecules as the state changes in the computation [
1,
2]. If any two molecules with different conformations colliding with each other rapidly lead to one specific conformation, then the computational efficiency is very high, although the computational universality is very low. In contrast, if two molecules colliding entail one molecule whose conformation can be constantly modified, it implies that the various states of computation can be accessed by these molecules and that the computational universality is very high. Since some conformations arrive after the long wandering of conformation changes, the time to access these conformations is so long that the computational efficiency is very low. This thinking results in the trade-off principle between the computational universality and efficiency in bioinspired or natural computing [
1]. After Conrad, although various biomaterial computing techniques have been developed while referring to that trade-off, the relation between natural computing and the trade-off is still unclear since computing is usually based on the Turing machine [
3,
4,
5,
6,
7,
8].
The trade-off principle is ubiquitously found in biological systems as the dilemma between generalists and specialists [
9,
10,
11,
12,
13]. If the environment in which a species lives is constantly changing, and if the species has not adapted to any specific environment too much, then the species can live in the various environments to some extent. This species is called a generalist. In contrast, if a species is adapted only to a specific environment, the species is called a specialist [
10,
11]. The contrast between a specialist and generalist is also found in machine learning. An excessive generalist is compared to undercomputing in learning, while an excessive specialist is compared to overfitting in machine learning [
14].
While the trade-off and/or the dilemma suggests that the computational universality (generalist) and efficiency (specialist) can be quantified and compared with each other, they are neither systematically argued nor quantified in a certain space of the computation. Instead, the contrast between the universality and efficiency might be compared to the phase transition between chaos and order [
15,
16,
17,
18,
19]. The chaotic dynamics implementing state wandering can be compared to a universal and low efficiency computation, and the oscillating dynamics can be compared to non-universal and high efficiency computation. The specific dynamics implementing state wandering among multiple attractors can be compared to the critical state or balance of the universal and highly efficient computation and is sometimes called the edge of chaos or self-organized criticality [
20,
21,
22]. In the phase transition, the chaos and order can be quantified with respect to the order parameter corresponding to the temperature. The phase transition is found not only in the continuous dynamics but also in cellular automata (CA) [
15,
23,
24] by using the chaos and order in their behaviors [
25,
26,
27].
Although the edge of chaos in CA suggests balancing the universal and highly efficient computation, there is little research to bridge the phase transition with the trade-off between the universality and efficiency. On the one hand, the computational universality has been strictly investigated in terms of the Turing machine [
28,
29,
30] and/or logical gates [
31,
32]. For instance, it has been argued as to how to implement a universal Turing machine as simply as possible in CA [
27,
29]. In this framework, the machine either has universality or not, and there is no notion such as the degree of computational universality. On the other hand, there is no strict research on the relation between the edge of chaos and the balance of the universality and efficiency. Although the computation at the edge of chaos might contribute to balancing the universality and efficiency, it has not been determined how the critical computations are close to the optimal solution and/or balancing. Thus, self-organized criticality is used not as the search for optimal solutions but as metaheuristics [
33,
34]. Because there is no quantification to bridge the universality and efficiency, no detailed research proceeds on this issue. Therefore, it is a novel idea to quantify the degree of universality and bridge the computational universality and computational efficiency.
It is remarkable whether the perspective of the phase transition between chaos and order is founded under the framework of synchronous updating. Rather, there is no synchronous clock in natural biological systems or biocomputing, and they work by asynchronous updating. This behavior implies that asynchronous CA can emulate natural computing in the sense of Conrad’s research. If the transition rule is asynchronously updated to cells, then behaviors such as the critical state are ubiquitously found in the rule space of CA and are referred to as the universal criticality [
35,
36]. Recently, asynchronous updating in CA has been shown to lead to the phase transition coupled with the critical state expressed by the power law [
37,
38,
39,
40]. While knowledge regarding the large difference between synchronous and asynchronous updating has accumulated [
41,
42,
43,
44,
45,
46], there has been little research on how asynchronous updating in CA can influence the trade-off between the universality and efficiency and/or the phase transition of chaos and order.
With this background, first, we define the computational universality and efficiency in the behaviors of elementary cellular automata (ECA) and quantify the degree of the universality and efficiency. We show that there is a trade-off between the computational universality and efficiency in synchronous ECA. This is the first attempt to elucidate the trade-off between the universality and efficiency in the research field of CA. Second, we show that the asynchronous updating in ECA can break the trade-off principle and analyze what contributes to the break of the trade-off. This work provides a novel perspective on how asynchronous updating can play a role in balancing universal and efficient computing.
2. The Trade-Off Principle in Synchronous ECA
Since ECA was proposed by Wolfram, some rules have been studied by information processing and by constructing logical gates [
25,
26,
27]. Most of them are studied in the form of synchronous updating. ECAs are defined by a set of the binary sequences of cells,
Bn with
B = {0, 1} and a transition rule
fr:
B3 →
B, where
fr is synchronously updated to all cells and
r represents the rule number mentioned below. The transition rule with synchronous updating is expressed as
If a transition rule
fr is adapted to all cells in
Bn (i.e., global adaption), then we assign the global use by
G(
fr):
Bn+2 →
Bn such that
The transition rule is coded by the rule number,
r, such that for
x, y, z ∈
B,
The rule number, r = 18, is represented as R18, where d1 = d4 = 1 and ds = 0 with s ≠ 1, 4. There are 256 rules in ECA since there are 2 possible outputs for 8 inputs of a triplet.
How can one define the computational universality and efficiency? Given an initial state of
Bn with random boundary conditions, reachable states are determined by a transition rule. For the case of R0, only one state consists of all 0 for any initial states; this implies that (0, 0, …, 0) =
G(
f0)(
a0,
a1, …,
an+1) for any (
a0,
a1, …,
an+1) ∈
Bn+2. By contrast, R204, of which
d2 =
d3 =
d6 =
d7 = 1 and
d0 =
d1 =
d4 =
d5 = 0, can show that (
a1,
a2, …,
an) =
G(
f204)(
a0,
a1, …,
an+1) for any (
a0,
a1, …,
an+1) ∈
Bn+2 and that all possible states can be reached if an adequate initial condition is prepared. It is easy to see that R204 shows a locally frozen pattern (class 2). For R90 or R150, all possible states can be reached, although the generated patterns are chaotic (class 3). Thus, the ratio of reachable states for all possible initial conditions can reveal the computational universality. Given 2
n all possible initial states with random boundary conditions, the computational universality of rule
r,
U(
r), is defined by
where for a set
S, #
S represents the cardinality of a set
S,
R(
B2) represents one element set randomly determined from
B2, and superscript
T represents
T numbers iteration of
fr. If
n = 2, then
U(0) = #{(0, 0)} = 1, and
U(204) = #{(0, 0), (0, 1), (1, 0), (1, 1)} = 4
UN(
r) represents the normalized computational universality. Here, we call elements of a set,
SR(
r), reachable states.
Next, we define the computational efficiency of a transition rule
r. To separate from the computational universality, the computational efficiency is expressed by the average time to reach the reachable states. For each reachable state
X ∈
SR(
r), the average time to reach
X represented by τ
r(
X) is expressed as
where
B* =
Bn ×
R(
B2),
T(
G(
fTr)(
Y) =
X) implies time
T such that
G(
fTr)(
Y) =
X. Since the time
T is computed for any
Y ∈
B*, it can lead to
G(
fTr)(
Y) ≠
X. At that case, if
G(
fTr)(
Y) =
X is not obtained within 2
n time steps, then
T(
G(
fTr)(
Y) =
X) is a constant value,
Tθ. For the case of R204 in which any initial condition is not changed by the transition,
G(
fr)(
Y) =
Y with
T = 1 and then for any
X ∈
SR(
r), τ
r(
X) = (1 +
Tθ(#
B* − 1)). The computational efficiency is defined by
Since E(r) is the average time to reach the reachable state, the smaller E(r) is, the more efficient ECA r is.
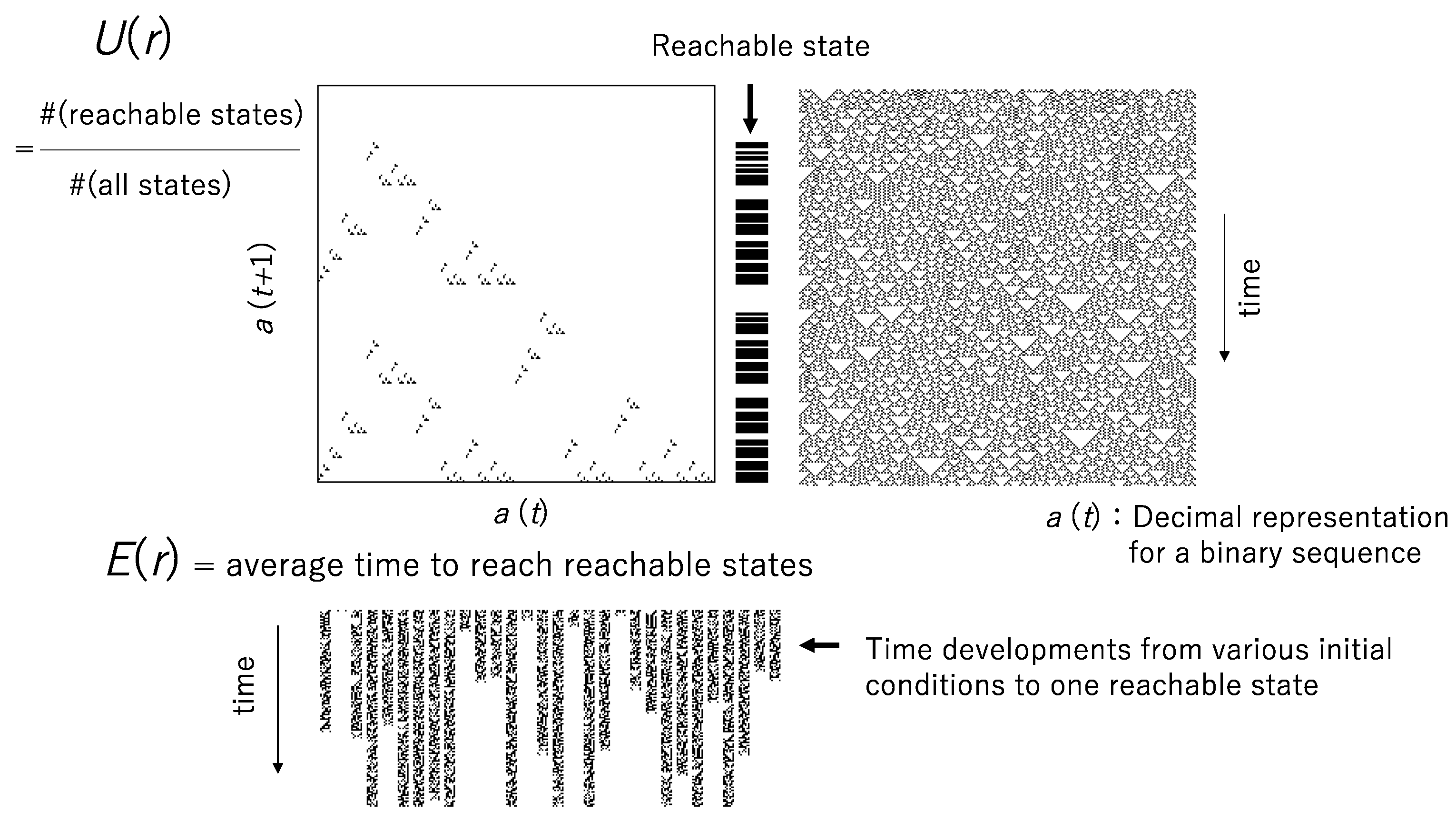
Figure 1 shows a graphical explanation for the computational universality
U(
r) and the computational efficiency
E(
r). The pattern generated by R18 is shown in
Figure 1 right above, and the return map
a(
t + 1) plotted against
a(
t) is shown in
Figure 1 left above, where
a(
t) is the decimal expression for a binary sequence. Since
a(
t + 1) is calculated for any
a(
t) in [0.0, 1.0], a set of
a(
t + 1) represents the computational universality. The computational efficiency is obtained from the average time to the reachable states, where the time to a reachable state is obtained from the average of time from all possible initial states to the reachable state, as shown in
Figure 1 below.
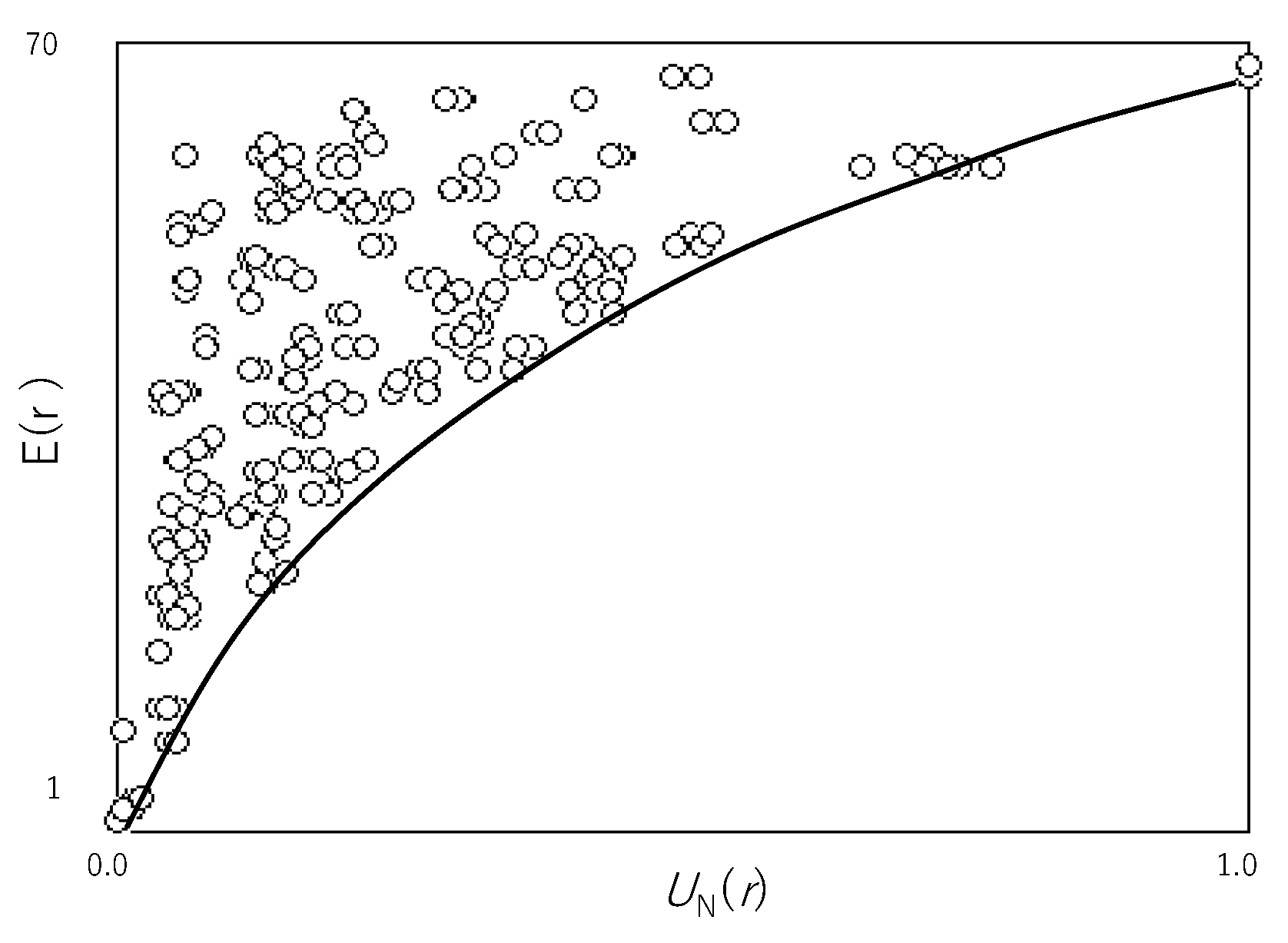
Figure 2 shows
E(
r) plotted against
UN(
r) for all rules in ECA. Since
E(
r) reveals the average time to reachable states, the smaller
E(
r) is, the more efficient
E(
r) is. Thus, the minimal point of
E(
r) for each computational universality reveals the maximal efficiency for each computational universality. This maximal efficiency is why the solid line representing the lower margin of a cloud of (
UN(
r),
E(
r)) shows the relationship between the computational universality and efficiency. The greater the universality is, the less the efficiency is. It is clear that the solid line shows the trade-off between the computational universality and efficiency.
As mentioned before, the trade-off shown in
Figure 2 is obtained by ECA implemented by synchronous updating. If the transition is updated in asynchronous fashion, then what happens with respect to the trade-off between the computational universality and efficiency is discussed below.
3. The Trade-Off Breaking by Asynchronous Updating
Asynchronous updating in CA can be implemented using various approaches. One approach is to define the order of updating as defined in the form of bijection from a set of cell sites to the order of updating [
35,
36,
42]. Here, we implement asynchronous updating by introducing the probability variable
p ∈ [0.0, 1.0] [
37,
38,
39,
40]. The transition rule is adapted to each cell with the probability, such that
Figure 3 shows the time development of the ECA with the probability, where the transition rule is R22. Since the probability
p implies the probability of which the transition rule is not applied to a cell, the time development with a small
p mimics the time development of synchronous ECA.
We estimate
E(
r) and
UN(
r) for asynchronous ECA with the probability, compared to the trade-off between
E(
r) and
UN(
r) in synchronous ECA. For the sake of comparison, the lower margin of the distribution of (
UN(
r),
E(
r)) obtained for synchronous ECA is expressed as a monotonous increasing step function. The interval [0.0, 1.0] is divided into
m subintervals. The
kth subinterval, Int
k, is [(
k − 1)∗1.0/
m,
k∗1.0/
m]. In each subinterval,
and the monotonous increasing step function,
EMIN(
k) is defined by
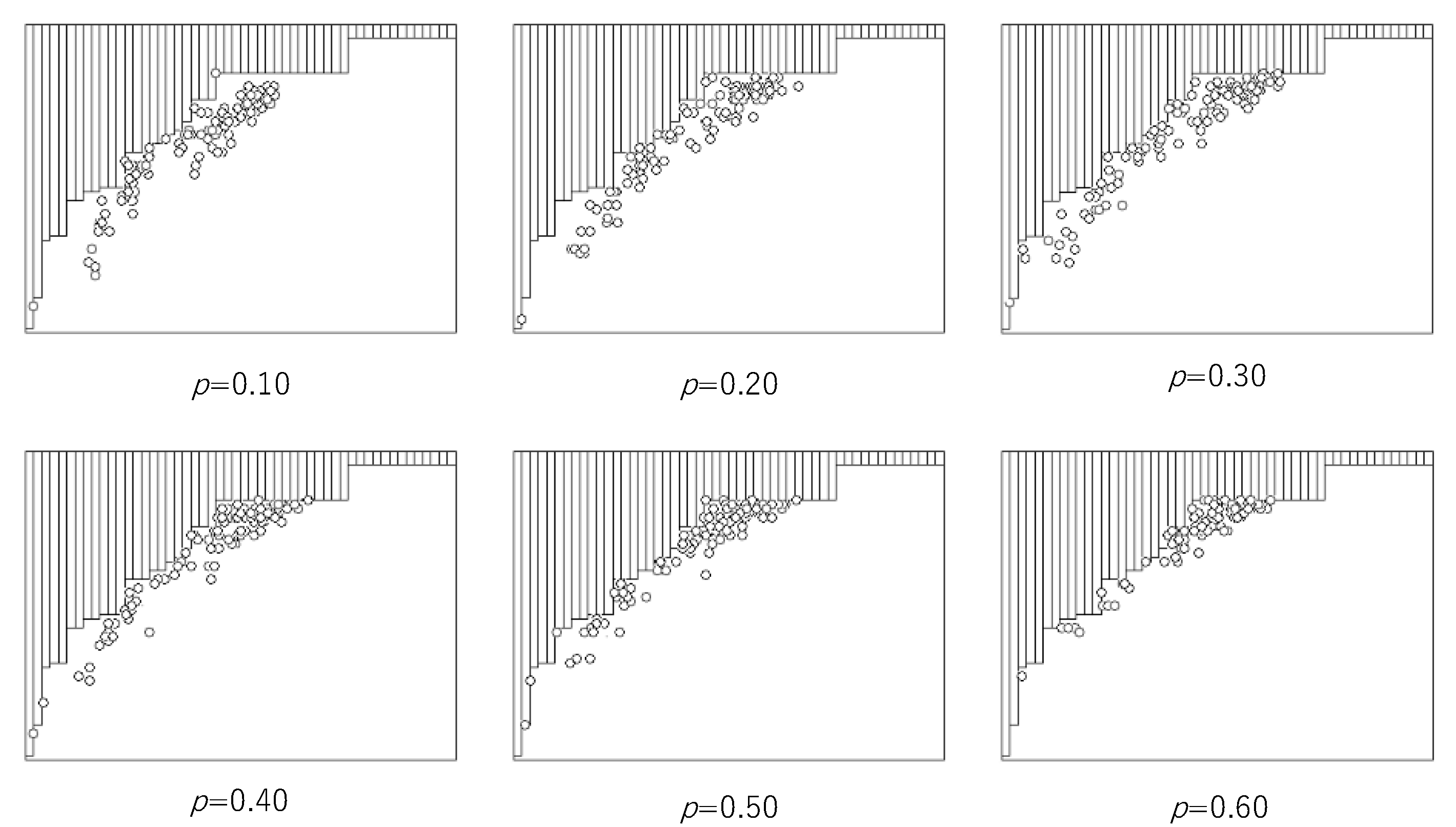
Figure 4 shows the breaking trade-off between the computational universality and efficiency by asynchronous ECA with the probability
p, where the lower margin of the distribution of (
UN(
r),
E(
r)) is expressed as Equation (13), and
m = 52. In each graph, the horizontal and vertical lines are the same as those in
Figure 2. In
Figure 4, all pairs of (
UN(
r),
E(
r)) obtained by synchronous updating are hidden by bars above the increasing step function. The pairs of (
UAN(
r),
EA(
r)) obtained by asynchronous updating with the probability
p are represented by circles below the increasing step function. It is easy to see that asynchronous updating with a wide region of
p entails breaking the trade-off.
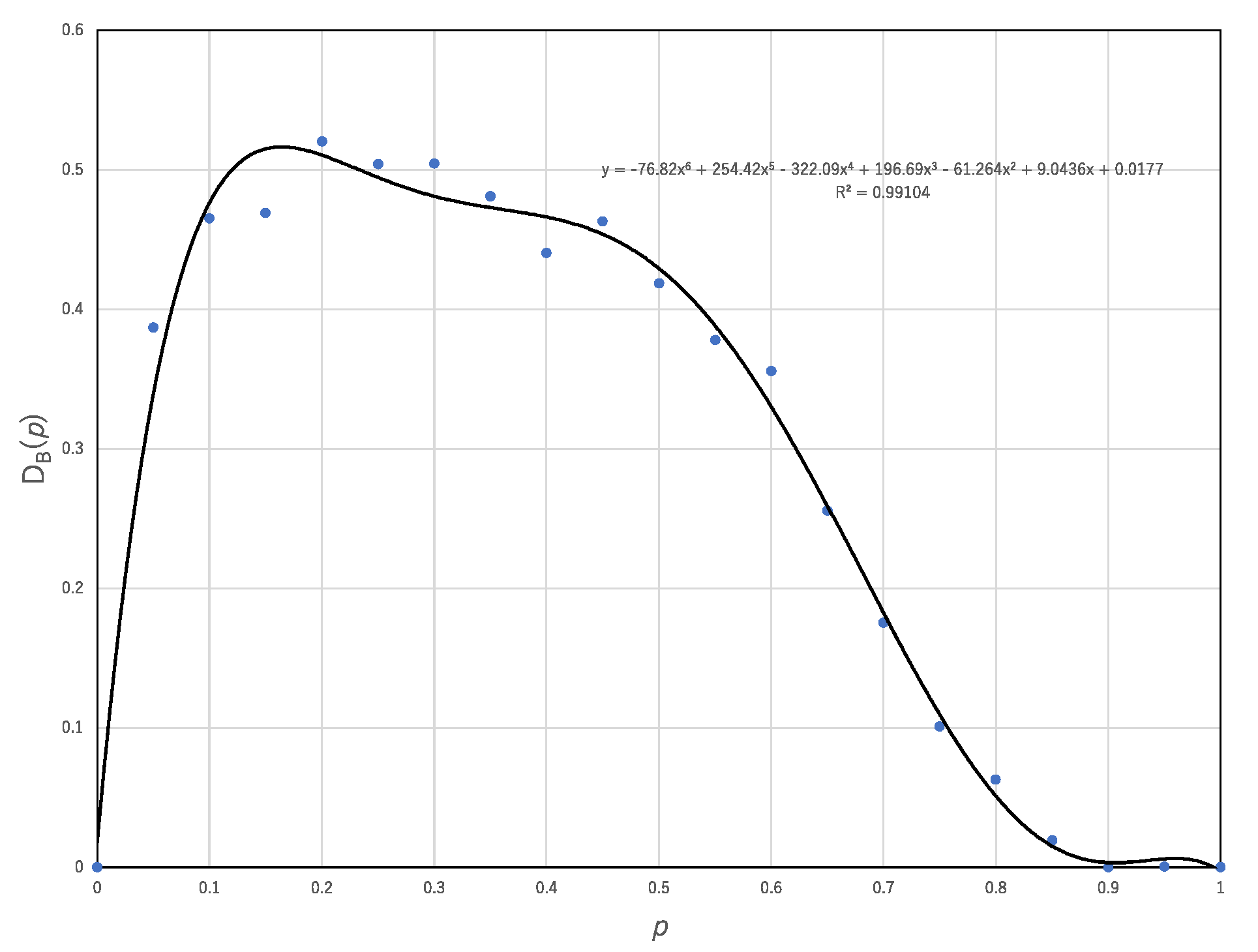
Figure 5 shows the breaking degree of the trade-off plotted against the probability,
p. As shown in
Figure 4, one can count the number of (
UAN(
r),
EA(
r)) breaking the trade-off obtained by synchronous ECA, which is represented by circles below the lower margin of the distribution of (
UN(
r),
E(
r)) with synchronous updating. The breaking degree,
DB(
p) for ECA asynchronously updated with the probability,
p, is defined by
where the number 256 represents the number of all ECAs.
Figure 5 shows that approximately 50% of transition rules break the trade-off. This result implies that asynchronous updating can reach the reachable states more quickly than synchronous updating so far as the computational universality of asynchronous updating is the same as that of synchronous updating.
The next question arises regarding how asynchronous updating can break the trade-off between the computational universality and efficiency. It is strongly relevant for the universal criticality resulting from asynchronous updating. As mentioned before, the perspective of the phase transition and/or the edge of chaos is obtained in the framework of synchronous updating. We previously proposed the asynchronously updated automata implemented by a bijective map from the address of the cell to the order of updating (order-oriented asynchronous updating) [
35,
36]. Even if a transition rule shows either order (class 1, 2) or chaos (class 3) in synchronous updating, the same transition rule operated by the order-oriented asynchronous updating shows cluster-like patterns that mix the order with chaos (class 4). Since the cluster-like patterns are characterized by the power law in time development, it can be considered that asynchronous updating entails universality that is independent of the structure of a transition rule.
Asynchronous updating can mix with various transition rules. Even if a transition (0, 0, 1) → 1 is defined, if the transition rule is not applied to a cell, then the state of a middle cell in a triplet is not changed, which implies (0, 0, 1) → 0. This results in an apparent change in the transition rule from R18 to R16 since
d1 = 1 is replaced by
d1 = 0. Here, the transition rule approximated for a pair of binary sequences, (
a1t,
a2t, …,
ant) and (
a1t+1,
a2t+1, …,
ant+1) is called an apparent rule. For R18, one can see various apparent changes in the transition rule, as shown in
Table 1. If
p = 0.0, then the apparent rule is the same as the transition rule, R18. The larger
p is, the more apparent the change in
ds is. The lowest row shows the case of
p = 1.0, which leads to the apparent rule being R204. In 0 <
p < 1, time development can be interpreted to be generated by various apparent rules showing classes 1, 2 and 3 in time and space. That is why a cluster-like pattern is generated by mixing with up class 1, 2 and 3 transitions.
Mixing with classes 1, 2 and 3 results from asynchronous updating; thus, it can ubiquitously generate cluster-like patterns and/or critical behavior. Since such behaviors correspond to the edge of chaos or the critical state in the phase transition, they can reveal the balance of the computational universality and efficiency. Additionally, these behaviors can entail breaking the trade-off between the universality and efficiency.
To manifest how asynchronous updating breaks the trade-off between the computational universality and efficiency, we approximate the transition of configurations by the asynchronous updating of a single rule by the synchronous updating of multiple rules. Then, we estimate how the number of multiple rules and segmentations can contribute to breaking the trade-off.
Given a binary sequence, the asynchronous updating of a single transition rule defined by
d*s with
s = 0, 1 …, 7, is adapted to the binary sequence. It results in a pair of binary sequence such as
For this pair, a binary sequence (
a1t,
a2t, …,
ant) is divided into multiple segments,
where in a segment {(
u,
aut), (
u+1,
au+1t), …, (
w,
awt)}, for any
s ∈ {0, …, 7}, if there exists (
ak−1t,
akt,
ak+1t) ∈
B3 such that
s = 4
ak−1t + 2
akt +
ak+1t,
k ∈ {
u,
u + 1, …,
w},
and otherwise,
This implies that for each segment, one can uniquely determine the corresponding rule defined by ds with s = 0, 1 …, 7 and that a sequence, (aut, au+1t, …, awt); (aut+1, au+1t+1, …, awt+1) can be interpreted as a transition generated by the synchronous updating of a single transition rule. Thus, segmentation (10) implies the approximation of which each segment can be generated by a single transition rule and a whole sequence can be synchronously generated by multiple transition rules.
Figure 6 shows an example of the approximation by the synchronous updating of multiple rules. The top pair of binary sequences with “Syn” is a transition generated by the synchronous updating of the rule, R18. The top second pair with “Asyn” is a transition generated by asynchronous updating with a certain probability. Please note that due to the probability, there are some cells where
akt+1 =
akt. In
Figure 6, a transition generated by asynchronous updating is divided into three segments. Algorithmically, the segmentation is implemented from left to right. From the first cell, one can determine
d1 =
a1t+1 = 1, and then
d2 =
a2t+1 = 0,
d4 =
a3t+1 = 1. At the fourth cell at
t+1, one obtains
d1 =
a4t+1 = 0 and that conflicts with
d1 = (
a1t+1) = 1. That is why the first segment is terminated by the third cell at
t+1, which is expressed as {(0,
a0t), (1,
a1t), (2,
a2t), (3,
a3t)}. For a transition rule, only
d1,
d2 and
d4 are determined, and
d0,
d3,
d5,
d6 and
d7 are not determined in that segment, {(0,
a0t), (1,
a1t), (2,
a2t), (3,
a3t)}. The undetermined value
ds for a transition rule is represented by the blue cell in
Figure 6. By definition (18), the undetermined
ds is substituted by
d*s, which is defined by R18 in
Figure 6. Thus, for the first segment in
Figure 6, one can obtain R18. Similarly, it results in three segments, and the second and third segments are approximated by R16 and R6, respectively.
Figure 7 shows some examples of a pair of time developments by the asynchronous updating of a single rule and the corresponding time development emulated by the synchronous updating of multiple rules. In a pair of time developments, left above, the left diagram represents the time development of the asynchronous updating of R18 with a probability of 0.2. For this asynchronous CA, given 10
4 cells whose values are randomly set, the segmentation procedure is run. This process results in
N1 segments and
N2 transition rules. By using
N1 segments and
N2 transition rules, the approximated time development is emulated. First, at each cell, it is probably determined whether the segment is cut or not, with the probability of
N1/10
4 (segmentation process). Second, a transition rule randomly chosen from
N2 transition rules is applied to each segment, and the state of cells is updated (update process). Both segmentation and update processes are performed for each time step, which leads to time development, as shown in the right diagram of each pair. Clearly, the synchronous updating of multiple rules can emulate the time development of asynchronous updating of a single rule. In other words, the behavior of asynchronous CA can be estimated by synchronous CA with multiple rules.
Given
p, a transition rule, and 10
4 cells whose states are randomly determined, the asynchronous updating of the transition rule with probability
p is applied to 10
4 cells. For a pair of binary sequences of the initial configuration and results of application of the transition rule, the segmentation process is applied. This process results in a pair of the number of rules and the number of segments.
Figure 8 shows the normalized number of segments (
N1/10
4) against
p for some of the asynchronous updating of the transition rules, R110, R50, R90 and R18. The data for each transition rule are approximated by a polynomial function: for R110,
y = 0.1081
x4 − 0.1643
x3 − 0.5596
x2 + 0.6087
x + 0.0048, R
2 = 0.99594; for R50,
y = −2.7514
x4 + 5.9832
x3 − 4.492
x2 + 1.2555
x + 0.0143, R
2 = 0.98422; for R90,
y = −1.1571
x4 + 2.6079
x3 − 2.2464
x2 + 0.7964
x + 0.0051, R
2 = 0.99293; and for R18,
y = −2.0516
x4 + 4.4103
x3 − 3.3139
x2 + 0.9666
x + 0.0016, R
2 = 0.98778.
For the same approximation,
Figure 9 shows the normalized number of rules (
N2/256) against
p for each transition rule. The data for each transition rule are approximated by a polynomial function: for R110,
y = −0.3159
x4 + 0.706
x3 − 0.5401
x2 + 0.1619; for R50,
y = −2.7529
x4 + 4.7656
x3 − 3.7832
x2 + 1.9264
x + 0.0054, R
2 = 0.98541; for R90,
y = −0.6852
x4 + 1.5296
x3 − 1.1948
x2 + 0.3817
x + 0.0208, R
2 = 0.90307; and for R18,
y = −2.0516
x4 + 4.4103
x3 − 3.3139
x2 + 0.9666
x + 0.0016, R
2 = 0.98778.
Both curves, the normalized number of segments and the normalized number of transition rules against
p show convex functions for each transition rule (
Figure 8 and
Figure 9).
Figure 10 shows the normalized number of segments against
p and normalized number of transition rules against
p averaged over all 256 transition rules. The former and latter graphs are approximated by
y = −0.9837
x4 + 1.9304
x3 − 1.4477
x2 + 0.5047
x + 0.0047, R
2 = 0.99594, and
y = −0.6488
x4 + 1.333
x3 − 1.0644
x2 + 0.4345
x + 0.0125, R
2 = 0.98811, respectively. The normalized number of rules and segments in the approximation might contribute to an increase in the computational efficiency since it can increase the diversity of the configurations. However, it is not necessary that the diversity of configurations is implemented by the diversity of rules. R90 and R150 can compute any configurations if the corresponding initial condition is prepared.
Therefore, if the asynchronous updating of R90 (R150) is applied to an initial configuration, then one can obtain not multiple rules but multiple segments in the approximation of synchronous updating. This procedure implies that all segments can be synchronously updated by a single rule, R90 (R150). It is the case that the diversity of configurations can be achieved by a single rule. There are some similar cases with R90 and R150. Those transition rules show chaotic and/or spatially propagating wave patterns referred to as class 3 or 4. These classes are shown by the high value of the number of segmentations divided by the number of rules (represented by #Segments/#Rules) in the approximation. In contrast, if the approximated rules cannot contribute to the diversity, then one obtains many various rules contributing to the diversity. These transition rules show locally stable behavior called class 1 or class 2. In this case, one can see a high value of #Rules/#Segments.
We estimate whether #Segments/#Rules or #Rules/#Segments can influence the break of the trade-off between the computational universality and computational efficiency.
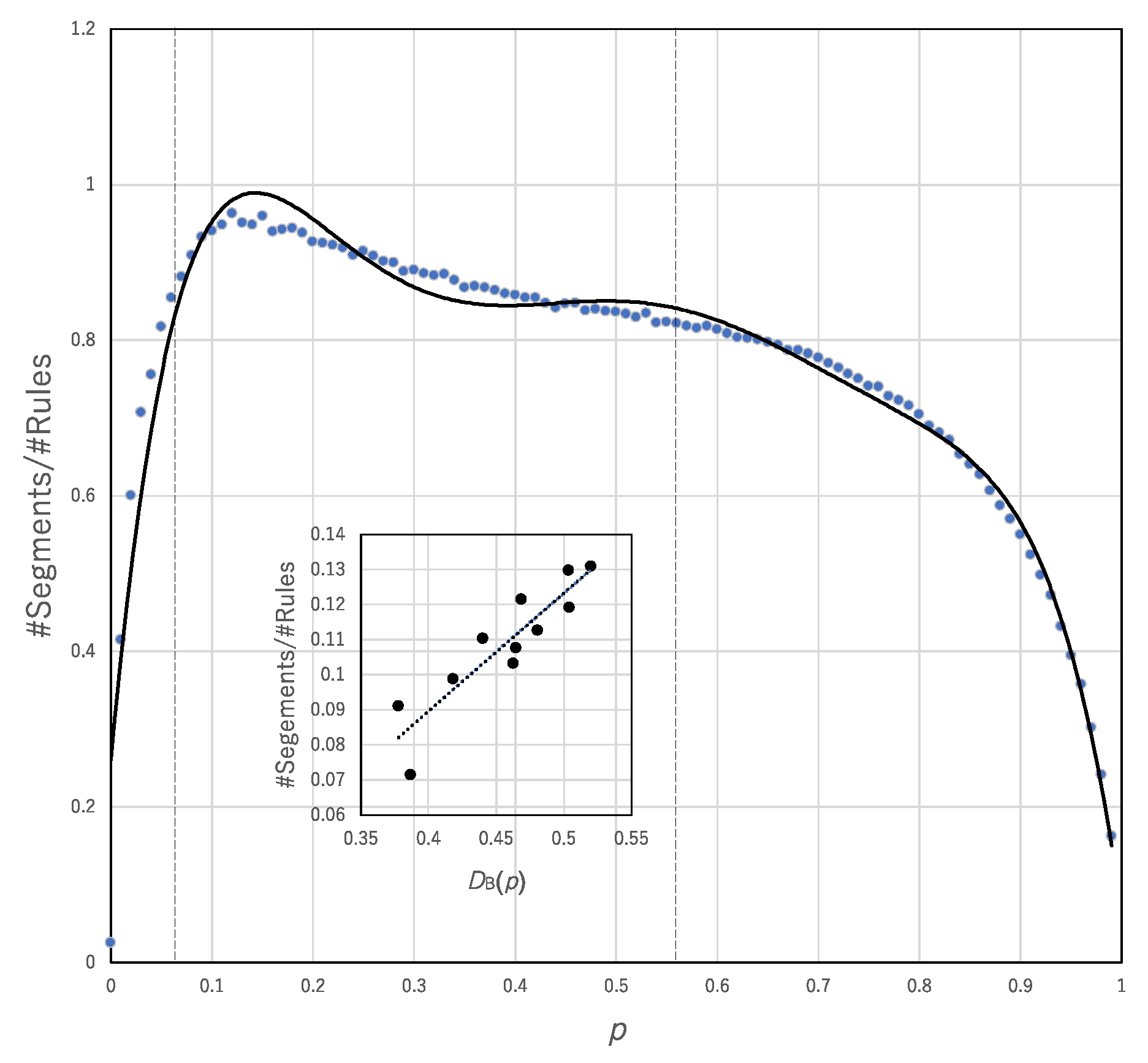
Figure 11 shows #Segments/#Rules plotted against
p. The range 0.5 <
p < 5.5 surrounded by broken lines represents the range in which the trade-off is broken. In that range, the coefficient of determination between #Segments/#Rules and the degree of break of the trade-off,
DB(
p), is very high (R
2 = 0.82076), whereas the correlation between #Rules/#Segments and
DB(
p) is very low (R
2 = 0.56706). This finding suggests that the diversity resulting from a smaller number of transition rules (i.e., class 3 or 4-like behavior) contributes to breaking the trade-off compared with the diversity resulting from a large number of transition rules (i.e., class 1 or 2-like behavior). In other words, although there are both effects of generalists with high #Segments/#Rules and specialists with high #Rules/#Segment in asynchronous updating, only effect from generalists can contribute to break of the trade-off.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}