Abstract
Entropy measures the uncertainty associated with a random variable. It has important applications in cybernetics, probability theory, astrophysics, life sciences and other fields. Recently, many authors focused on the estimation of entropy with different life distributions. However, the estimation of entropy for the generalized Bilal (GB) distribution has not yet been involved. In this paper, we consider the estimation of the entropy and the parameters with GB distribution based on adaptive Type-II progressive hybrid censored data. Maximum likelihood estimation of the entropy and the parameters are obtained using the Newton–Raphson iteration method. Bayesian estimations under different loss functions are provided with the help of Lindley’s approximation. The approximate confidence interval and the Bayesian credible interval of the parameters and entropy are obtained by using the delta and Markov chain Monte Carlo (MCMC) methods, respectively. Monte Carlo simulation studies are carried out to observe the performances of the different point and interval estimations. Finally, a real data set has been analyzed for illustrative purposes.
1. Introduction
To analyze and evaluate the reliability of products, life tests are often carried out. For products with long lives and high reliability, a censoring scheme is often adopted during the test to save on time and costs. Two commonly used censoring schemes are Type-I and Type-II censoring, but these two censoring schemes do not have the flexibility of allowing the removal of units at points other than the terminal point of the experiment. To allow for more flexibility in removing surviving units from the test, more general censoring approaches are required. The progressive Type-II censoring scheme is appealing and has attracted much attention in the literature. This topic can be found in [1]. One may also refer to [2] for a comprehensive review on progressive censoring. One drawback of the Type-II progressive censoring scheme is that the length of the experiment may be quite long for long-life products. Therefore, Kundu and Joarder [3] proposed a Type-II progressive hybrid censoring scheme where the experiment terminates at a pre-specified time. However, for the Type-II progressive hybrid censoring scheme, the drawback is that the effective sample size is a random variable, which may be very small or even zero. To strike a balance between the total testing time and the efficiency in statistical inference, Ng et al. [4] introduced an adaptive Type-II progressive hybrid censoring scheme (ATII-PHCS). This censoring scheme is described as follows. Suppose that units are placed on test and denote the corresponding lifetimes from a distribution with the cumulative distribution function (CDF) and the probability density function (PDF) . The number of observed failures m and time T are specified in advance and . At the first failure time , units are randomly removed from the remaining units. Similarly, at the second failure time , units from the remaining units are randomly removed, and so on. If the mth failure occurs before time (i.e., ), the test terminates at time and all remaining units are removed, where and is specified in advance (). If the Jth failure occurs before time (i.e., where ), then we will not withdraw any units from the test by setting , and the test will continue until the failure unit number reaches the prefixed number m. At the time of the mth failure, all remaining units are removed and the test terminates, where .
The main advantage of ATII-PHCS is that it speeds up the test when the test duration exceeds the predetermined time and ensures we get the effective number of failures m. It also illustrates how an experimenter can control the experiment. If one is interested in getting observations early, one will remove fewer units (or even none). For convenience, we let . After the above test, we get one of the following observation data cases:
- Case I: if , where .
- Case II: if and , where .
The ATII-PHCS has been studied in recent years. Mazen et al. [5] discussed the statistical analysis of the Weibull distribution under an adaptive Type-II progressive hybrid censoring scheme. Zhang et al. [6] investigated the maximum likelihood estimations (MLEs) of the unknown parameters and acceleration factors in the step-stress accelerated life test, based on the tampered failure rate model with ATII-PHC samples. Cui et al. [7] studied the point and interval estimates of the parameters from the Weibull distribution, based on adaptive Type-II progressive hybrid censored data in a constant-stress accelerated life test. Ismail [8] proposed that the MLE of the Weibull distribution parameters and the acceleration factor were derived based on ATII-PHC schemes under a step-stress partially accelerated life test model. The statistical inference of the dependent competitive failure system under the constant-stress accelerated life test with ATII-PHC data was studied by Zhang et al. [9]. Under an adaptive Type-II progressive censoring scheme, Ye et al. [10] investigated the general statistical properties and then used the maximum likelihood technique to estimate the parameters of the extreme value distribution. Some other studies on the statistical inference of life models using ATII-PHCS were presented by Sobhi and Soliman [11] and Nassar et al. [12]. Xu and Gui [13] studied entropy estimation for the two-parameter inverse Weibull distribution under adaptive type-II progressive hybrid censoring schemes.
Entropy measures the uncertainty associated with a random variable. Let X be a random variable having a continuous CDF and PDF . Then, the Shannon entropy is defined as
In recent years, several scholars have studied the entropy estimation of different life distributions. Kang et al. [14] investigated the entropy estimators of a double exponential distribution based on multiply Type-II censored samples. Cho et al. [15] derived an estimation for the entropy function of a Rayleigh distribution based on doubly generalized Type-II hybrid censored samples. Baratpour et al. [16] developed the entropy of the upper record values and provided several upper and lower bounds for this entropy by using the hazard rate function. Cramer and Bagh [17] discussed the entropy of the Weibull distribution under progressive censoring. Cho et al. [18] obtained estimators for the entropy function of the Weibull distribution based on a generalized Type-II hybrid censored sample. Yu et al. [19] studied statistical inference in the Shannon entropy of the inverse Weibull distribution under progressive first-failure censoring.
In addition to the above-mentioned life distributions, the generalized Bilal (GB) distribution is also an important life distribution for analyzing lifetime data. The PDF and the CDF of the GB distribution, respectively, are given as
The Shannon entropy of the GB distribution is given by
where denotes the Euler–Mascheroni constant and .
The GB distribution was first introduced by Abd-Elrahman [20]. He investigated the properties of the probability density and failure rate function of this distribution. A comprehensive mathematical treatment of the GB distribution was provided, and the maximum likelihood estimations of unknown parameters were derived under the complete sample. Abd-Elrahman [21] provided the MLEs and Bayesian estimations of the unknown parameters and the reliability function based on a Type-II censored sample. Since the failure rate function of GB distribution has an upside-down bathtub shape, and it can also be monotonically decreasing or monotonically increasing at some selected values of the shape parameters , the GB model is very useful in survival analysis and reliability studies.
To the best of our knowledge, there has been no published work on the estimation of the entropy and parameters of GB distribution under an ATII-PHCS. As such, these issues are considered in this paper. The main objective of this paper is to provide the estimation of the entropy and unknown parameters of GB distribution under an ATII-PHCS by using the frequency and Bayesian methods.
The rest of this paper is organized as follows. In Section 2, the MLEs of the parameters and entropy of GB distribution are obtained, and approximate confidence intervals are constructed using the ATII-PHC data. In Section 3, the Bayesian estimation of the parameters and entropy under three different loss functions are provided using Lindley’s approximation method. In addition, the Bayesian credible intervals of the parameters and entropy are also obtained by using the Markov chain Monte Carlo (MCMC) method. In Section 4, Monte Carlo simulations are carried out to investigate the performance of different point estimates and interval estimates. In Section 5, a real data set is analyzed for illustrative purposes. Some conclusions are presented in Section 6.
2. Maximum Likelihood Estimation
In this section, the MLE and approximate confidence intervals of the parameters and entropy of GB distribution will be discussed under the ATII-PHCS. Based on the data in Case I and Case II, the likelihood functions can be respectively written as
where .
By combining , the likelihood functions can be written uniformly as
where and, for Case I, , and for Case II, .
The log-likelihood function is given by
By taking the first partial derivative of the log-likelihood function with regard to and and equating them to zero, the following results can be obtained:
where
The MLEs of and can be obtained by solving Equations (7) and (8), but the above two equations do not yield an analytical solution. Thus, we use the Newton–Raphson iteration method to obtain the MLEs of the parameters. For this purpose, we firstly calculate the second partial derivatives of the log-likelihood function with regard to and :
Let , where
On the basis of the above calculation results, we can implement the Newton–Raphson iteration method to obtain the MLEs of unknown parameters. The specific steps of this iteration method can be seen in Appendix B. After obtaining the MLE and of the parameters and , using the invariant property of MLEs, the MLE of the entropy for the generalized Bilal distribution is given by
Approximate Confidence Interval
In this subsection, the approximate confidence intervals of the parameters and the Shannon entropy are derived. Based on regularity conditions, the MLEs are an approximately bivariate normal distribution , where the covariance matrix is an estimation of and , and are given by Equations (10)–(13), respectively.
Thus, the approximate two-sided confidence intervals (CIs) for parameters are given by
where is the upper percentile of the standard normal distribution and , are the main diagonal elements of the matrix .
Next, we use the delta method to obtain the asymptotic confidence interval of the entropy . The delta method is a general approach to compute CIs for functions of MLEs. Under a progressive Type-II censored sample, the authors of [22] used the delta method to study the estimation of a new Weibull–Pareto distribution. The authors of [23] also used this method to investigate the estimation of the two-parameter bathtub lifetime model.
Let , where .
Then, the approximate estimates of is given by
where and are the MLEs of and , respectively, and denotes the inverse of the matrix . The elements of the matrix are given by Equations (10)–(13), respectively. Thus, is asymptotically distributed as . The asymptotic CI for the entropy is given by
where is the upper percentile of the standard normal distribution.
3. Bayesian Estimation
In this section, we discuss the Bayesian point estimation of the parameters and entropy for generalized Bilal distribution using Lindley’s approximation method under symmetric as well as asymmetric loss functions. Furthermore, the Bayesian CI of the parameters and entropy are also derived by using the Markov chain Monte Carlo method.
3.1. Loss Functions and Posterior Distribution
Choosing the loss function is an important part in the Bayesian inference. The commonly used symmetric loss function is the squared error loss (SEL) function, which is defined as
Two popular asymmetric loss functions are the Linex loss (LL) and general entropy loss (EL) functions, which are respectively given by
Here, is any function of and , and is an estimate of . The constant and represent the weight of errors on different decisions. Under the above loss functions, the Bayesian estimate of function can be calculated by
To derive the Bayesian estimates of the function , we consider prior distributions of the unknown parameters and as independent Gamma distributions and , respectively. Therefore, the joint prior distribution of and becomes
Based on the likelihood function and the joint prior distribution of and , the joint posterior density of parameters and can be written as
where
Therefore, the Bayesian estimate of under the SEL, LL and GEL functions are respectively given by
3.2. Lindley’s Approximation
From Equations (23)–(25), it is observed that all of these estimates of the are in the form of the ratio of two integrals which cannot be reduced to a closed form. Therefore, we use Lindley’s approximation method to obtain the Bayesian estimates. If we let , then the posterior expectation of a function can be approximated as in [18]:
where is the MLE of and
where denotes the log-likelihood function and denotes the th element of the matrix . All terms are estimated by MLEs of the parameters and .
Based on the above equations, we have
where are given by Equations (10)–(12), respectively.
Based on Lindley’s approximation, we can derive the Bayesian estimation of the two parameters, and , and the entropy under different loss functions.
3.2.1. Squared Error Loss Function
When or , the Bayesian estimations of the parameters and under the SEL function are given by, respectively,
where and are the MLEs of the parameters and , respectively.
Similarly, the Bayesian estimation of the entropy can be derived. We notice that
Thus, the Bayesian estimation of the entropy under the SEL function is given by
where represents the maximum likelihood estimate of .
3.2.2. Linex Loss Function
Based on Lindley’s approximation, the Bayesian estimations of two parameters, and , and the entropy under the LL function can, respectively, be given by
Here, and are the MLEs of the parameters and , and represents the MLE of . The detailed derivation of these Bayesian estimates is shown in Appendix C.
3.2.3. General Entropy Loss Function
Using Lindley’s approximation method, the Bayesian estimations of two parameters, and , and the entropy under the GEL function can, respectively, be given by
Here, and are the MLEs of the parameters and , and represents the MLE of . The detailed derivation of these Bayesian estimates is shown in Appendix D.
3.3. Bayesian Credible Interval
In the previous subsection, we used the Lindley’s approximation method to obtain the Bayesian point estimation of the parameters and entropy. However, this approximation method cannot determine the Bayesian CIs. Thus, the MCMC method is applied to obtain the Bayesian CI for the parameters and entropy. The MCMC method is a useful technique for estimating complex Bayesian models. The Gibbs sampling and Metropolis–Hastings algorithm are the two most frequently applied MCMC methods which are used in reliability analysis, statistical physics and machine learning, among other applications. Due to their practicality, they have gained some attention among researchers, and interesting results have been obtained. For example, Gilks and Wild [24] proposed adaptive rejection sampling to handle non-conjugacy in applications of Gibbs sampling. Koch [25] studied the Gibbs sampler by means of the sampling–importance resampling algorithm. Martino et al. [26] established a new approach, namely by recycling the Gibbs sampler to improve the efficiency without adding any extra computational cost. Panahi and Moradi [27] developed a hybrid strategy, combining the Metropolis–Hastings [28,29] algorithm with the Gibbs sampler to generate samples from the respective posterior, arising from the inverted, exponentiated Rayleigh distribution. In this paper, we adopt the method proposed in [27] to generate samples from the respective posterior arising from the GB distribution. From Equations (6) and (22), the joint posterior of the parameters can be written as
Here, Therefore, we have
where
It is observed that the posterior density of , given , is the PDF of the Gamma distribution . However, the posterior density of , given , cannot be reduced analytically to a known distribution. Therefore, we use the Metropolis–Hastings method with normal proposal distribution to generate random numbers from Equation (37). We use the next algorithm (Algorithm 1), proposed in [27], to generate random numbers from Equation (34) and construct the Bayesian credible interval of , and the entropy .
| Algorithm 1 The MCMC method |
| Step 1: Choose the initial value . |
| Step 2: At stage and for the given m, n and ATII-PH censored data, generate from the following: |
| Step 3: Generate from using the following steps. |
| Step 3-1: Generate from . |
| Step 3-2: Generate the from the uniform distribution U(0, 1). |
| Step 3-3: Set , where . |
| Step 4: Set . |
| Step 5: By repeating Steps 2–4 N times, we get . Furthermore, we compute , where and is the Shannon entropy of the GB distribution. |
Rearrange and into and , where and .
Then, the Bayesian credible interval of the two parameters and the entropy are given by , and .
4. Simulation Study
In this section, a Monte Carlo simulation study is carried out to observe the performance of different estimators of the entropy, in terms of the MSEs for different values of n, m, T and censoring schemes. In addition, the average 95% asymptotic confidence intervals (ACIs), Bayesian credible intervals (BCIs) of and the entropy, as well as the average interval length (IL), are computed, and the performances are also compared. We consider the following three different progressive censoring schemes (CSs):
- CS I:;
- CS II:;
- CS III: if is even or if is odd.
Based on the following algorithm proposed by Balakrishnan and Sandhu [30] (Algorithm 2), we can generate an adaptive Type-II progressive hybrid censored sample from the GB distribution.
| Algorithm 2. Generating a adaptive Type-II progressive hybrid censored sample from the GB distribution. |
| Step1: Generate independent observations , where follows the uniform distribution , . |
| Step 2: For the known censoring scheme , let . |
| Step 3: By setting , then is a Type-II progressive censored sample from the uniform distribution . |
| Step 4: Using the inverse transformation , , we obtain a Type-II progressive censored sample from the GB distribution; that is, , where denotes the GB distribution’s inverse cumulative functional expression with the parameter . The following theorem1 gives the uniqueness of the solution for the equation , . |
| Step 5: If there exists a real number satisfying , then we set index and record . |
| Step 6: Generate the first order statistics from the truncated distribution with a sample size . |
Theorem 1.
The equation has a unique solution, .
Proof.
See Appendix A. □
In the simulation study, we took the values of the parameters of the GB distribution as β = 1, λ = 2. In this case, H(f) = 0.2448. The hyperparameter values of the prior distribution were taken as . For the Linex loss function and general entropy loss function, we set and , respectively. In the Newton iterative algorithm and MCMC sampling algorithm, we chose the initial values of and as the value of was taken as . For different sample sizes n and different effective samples m and time T, we used 3000 simulated samples in each case. The average values and mean square errors (MSEs) of the MLEs and Bayesian estimations (BEs) for and the entropy were calculated. These results are reported in Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6.

Table 1.
The average maximum likelihood estimations (MLEs) and mean square errors (MSEs) of β, λ and the entropy (β = 1, λ = 2, H(f) = 0.2448).
Table 2.
The average Bayesian estimations and MSEs of β, λ and the entropy under the squared error loss functon (β = 1, λ = 2; β = 1, λ = 2, H(f) = 0.2448).
Table 3.
The average Bayesian estimations and MSEs of β, λ and the entropy under the Linex loss function (β = 1, λ = 2, T = 0.6, H(f) = 0.2448).
Table 4.
The average Bayesian estimations and MSEs of β, λ and the entropy under the Linex loss function (β = 1, λ = 2, T = 1.5, H(f) = 0.2448).
Table 5.
The average Bayesian estimations and MSEs of β, λ and the entropy under the general entropy loss function (β = 1, λ = 2, T = 0.6, H(f) = 0.2448).
Table 6.
The average Bayesian estimations and MSEs of β, λ and the entropy under the general entropy loss function (β = 1, λ = 2, T = 1.5, H(f) = 0.2448).
From Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6, the following observations can be made:
- For the fixed m and T values, the MSEs of the MLEs and Bayesian estimations of the two parameters and the entropy decreased when n increased. As such, we tended to get better estimation results with an increase in the test sample size;
- For the fixed n and m values, when T increased, the MSEs of the MLEs and Bayesian estimations of the two parameters and the entropy did not show any specific trend. This could be due to the fact that the number of observed failures was preplanned, and no additional failures were observed when T increased;
- In most cases, the MSEs of the Bayesian estimations under a squared error loss function were smaller than those of the MLEs. There was no significant difference in the MSEs between the Linex loss and general entropy loss functions;
- For fixed values of n, m and T, Scheme II was smaller than Scheme I and Scheme III in terms of the MSE.
To further demonstrate the conclusions, the MSEs are plotted when the sample size increases under different censoring schemes. The trends are shown in Figure 1 (values come from Table 1, Table 2, Table 3, Table 4, Table 5 and Table 6).
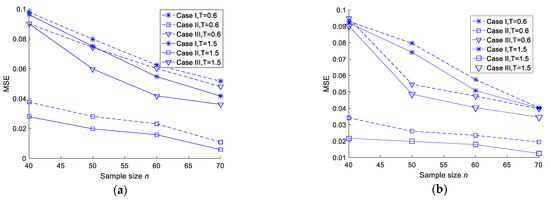
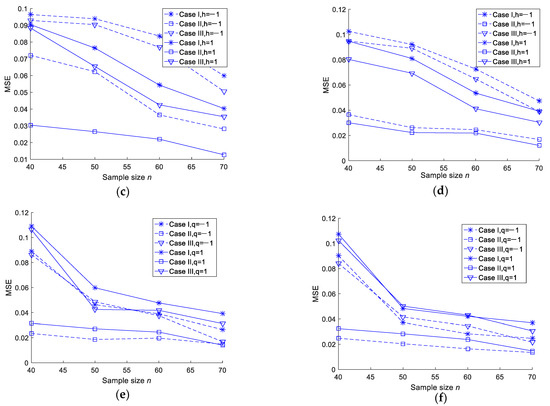
Figure 1.
MSEs of different entropy estimations. (a) MSEs of MLEs of entropy in the case of T = 0.6 and T = 1.5. (b) MSEs of Bayesian estimations of entropy under a squared error loss function in the case of T = 0.6 and T = 1.5. (c) MSEs of Bayesian estimations of entropy under a Linex loss function in the case of T = 0.6. (d) MSEs of Bayesian estimations of entropy under a Linex loss function in the case of T = 1.5. (e) MSEs of Bayesian estimations of entropy under a general entropy loss function in the case of T = 0.6. (f) MSEs of Bayesian estimations of entropy under a general entropy loss function in the case of T = 1.5.
Furthermore, the average 95% ACIs and BCIs of and the entropy, as well as the average lengths (ALs) and coverage probabilities of the confidence intervals, were computed. These results are displayed in Table A1, Table A2, Table A3 and Table A4 (See Appendix E).
- The coverage probability of the approximate confidence intervals and Bayes credible intervals became bigger when n increased while m and T remain fixed;
- For fixed values of n and m, when T increased, we did not observe any specific trend in the coverage probability of the approximate confidence intervals and Bayesian credible intervals;
- For fixed values of n and T, the average length of the approximate confidence intervals and Bayesian credible intervals were narrowed down when n increased;
- The average length of the Bayesian credible intervals was smaller than that of the asymptotic confidence intervals in most cases;
- For fixed values of n and m, when T increased, we did not observe any specific trend in the average length of the confidence intervals;
- For fixed values of n, m and T, Scheme II was smaller than Scheme I and Scheme III in terms of the average length of the credible interval;
- For fixed values of n, m and T, the coverage probability of the approximate confidence intervals and Bayesian credible intervals were bigger than Scheme I and Scheme III.
5. Real Data Analysis
In this subsection, a real data set is considered to illustrate the use of the inference procedures discussed in this paper. This data set consisted of 30 successive values of March precipitation in Minneapolis–Saint Paul, which were reported by Hinkley [31]. The data set points are expressed in inches as follows: 0.32, 0.47, 0.52, 0.59, 0.77, 0.81, 0.81, 0.9, 0.96, 1.18, 1.20, 1.20, 1.31, 1.35, 1.43, 1.51, 1.62, 1.74, 1.87, 1.89, 1.95, 2.05, 2.10, 2.20, 2.48, 2.81, 3.0, 3.09, 3.37 and 4.75 in.
This data was used by Barreto-Souza and Cribari-Neto [32] for fitting the generalized exponential-Poisson (GEP) distribution and by Abd-Elrahman [20] for fitting the Bilal and GB distributions. In the complete sample case, the MLEs of β and λ were 0.4168 and 1.2486, respectively. In this case, we calculated the maximum likelihood estimate of the entropy as H(f) = 1.2786. For the above data set, Abd-Elrahman [20] pointed out that the negative of the log likelihood, Kolmogorov–Smirnov (K–S) test statistics and its corresponding p value related to these MLEs were 38.1763, 0.0532 and 1.0, respectively. Based on the value of p, it is clear that the GB distribution was found to fit the data very well. Using the above data set, we generated an adaptive Type-II progressive hybrid censoring scheme with an effective failure number m (m = 20).
When we took T = 4.0 and the obtained data in Case I were as follows:
Case I: 0.32, 0.52, 0.77, 0.81, 0.96, 1.18, 1.20, 1.31, 1.35, 1.43, 1.51, 1.62, 1.74, 1.87, 1.89, 1.95, 2.10, 2.48, 2.81 and 3.37.
When we took T = 2.0, and , the obtained data in Case II were as follows:
Case II: 0.32, 0.47, 0.52, 0.59, 0.77, 0.81, 0.9, 0.96, 1.18, 1.20, 1.35, 1.43, 1.74, 1.87, 1.95, 2.10, 2.20, 2.48, 2.81 and 3.09.
Based on the above data, the maximum likelihood estimation and Bayesian estimation of the entropy and the two parameters could be calculated. For the Bayesian estimation, since we had no prior information about the unknown parameters, we considered the noninformative gamma priors of the unknown parameters as a = b = c = d = 0. For the Linex loss and general entropy functions, we set and , respectively. The MLEs and Bayesian estimations of the entropy and the two parameters were calculated by using the Newton–Raphson iteration and Lindley’s approximation method. These results are tabulated in Table 7 and Table 8. In addition, the 95% asymptotic confidence intervals (ACIs) and Bayesian credible intervals (BCs) of the two parameters and the entropy were calculated using the Newton–Raphson iteration, delta method and MCMC method. These results are displayed in Table 9.
Table 7.
MLEs and Bayesian estimations of the parameters and the entropy.
Table 8.
Bayesian estimations of the parameters and the entropy under two loss functions.
Table 9.
The 95% asymptotic confidence intervals (ACIs) and Bayesian credible intervals (BCIs) with the corresponding interval lengths (ILs) of the two parameters and the entropy.
From Table 7, Table 8 and Table 9, we can observe that the MLEs and Bayesian estimations of the parameters and the entropy were close to the estimations in the complete sample case. In most cases, the length of the Bayesian credible intervals was smaller than that of the asymptotic confidence intervals.
6. Conclusions
In this paper, we considered the estimation of parameters and entropy for generalized Bilal distribution using adaptive Type-II progressive hybrid censored data. Using an iterative procedure and asymptotic normality theory, we developed the MLEs and approximate confidence intervals of the unknown parameters and the entropy. The Bayesian estimates were derived by Lindley’s approximation under the square, Linex and general entropy loss functions. Since Lindley’s method failed to construct the intervals, we utilized Gibbs sampling together with the Metropolis–Hastings sampling procedure to construct the Bayesian credence intervals of the unknown parameters and the entropy. A Monte Carlo simulation was provided to show all the estimation results. The results illustrate that the proposed methods performed well. The applicability of the considered model in a real situation was illustrated, based on the data of March precipitation in Minneapolis–Saint Paul. It was observed that the considered model could be utilized to analyze this real data appropriately.
Author Contributions
Methodology and writing, X.S.; supervision, Y.S.; simulation study, K.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China (71571144, 71401134, 71171164, 11701406) and the Program of International Cooperation and Exchanges in Science and Technology funded by Shaanxi Province (2016KW-033).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not available.
Acknowledgments
The authors would like to thank the editors and the anonymous reviewers.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 1
We set then . The cumulative distribution function of GB distribution can be written as
By setting , then we get .
Set take the first derivative of with respect to y, and we have as .
Notice that is a monotonically increasing function when Thus, there is a unique solution to the equation when As such, we have proven that the equation has a unique solution ().
Appendix B. The Specific Steps of the Newton–Raphson Iteration Method
Step 1: Give the initial values of ; that is, .
Step 2: In the kth iteration, calculate and , where is the observed information matrix of the parameters and , and are given by Equations (10)–(13).
Step 3: Update with
Here, is the transpose of vector , and represents the inverse of the matrix .
Step 4: Setting , the MLEs of the parameters (denoted by and ) can be obtained by repeating Steps 2 and 3 until , where is a threshold value that is fixed in advance.
Appendix C. The Detailed Derivation of Bayesian Estimates of two Parameters () and the Entropy under the LL Function
In this case, we take , and then
Using Equation (26), the Bayesian estimation of parameter is given by
Similarly, the Bayesian estimation of parameter is obtained by
For the Bayesian estimation of the entropy, we have
The Bayesian estimation of the entropy under the LL function is given by
Appendix D. The Derivation of Bayesian Estimates of two Parameters and the Entropy under the GEL Function
In this case, we take and then and
Using Equation (26), the Bayesian estimation of parameter is given by
Similarly, the Bayesian estimation of parameter is obtained by
For the Bayesian estimation of the entropy under the general EL function, we take and then
Using Equation (26), the approximate Bayesian estimation of the entropy is given by
Appendix E
Table A1.
The average 95% approximate confidence intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2, H(f) = 0.2448, T = 0.6).
Table A1.
The average 95% approximate confidence intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2, H(f) = 0.2448, T = 0.6).
| (n, m) | SC | β AL | CP | λ AL | CP | H AL | CP |
|---|---|---|---|---|---|---|---|
| (40, 15) | I | (0.6598, 1.5736) 0.9138 | 0.9042 | (1.2220, 3.1773) 1.9573 | 0.9216 | (0.0293, 1.1866) 1.1573 | 0.9184 |
| II | (0.6711, 1.4742) 0.8031 | 0.9253 | (1.4238, 2.8658) 1.4420 | 0.9361 | (0.0393, 0.7733) 0.7340 | 0.929 | |
| III | (0.6343, 1.5347) 0.9004 | 0.9130 | (1.2645, 3.1064) 1.9319 | 0.9281 | (0.0254, 1.1244) 1.0990 | 0.9174 | |
| (50, 15) | I | (0.6421, 1.5458) 0.9037 | 0.9162 | (1.2837, 3.0913) 1.8076 | 0.9314 | (0.0203, 1.0469) 1.0266 | 0.9216 |
| II | (0.7102, 1.3884) 0.6782 | 0.9394 | (1.4416, 2.7246) 1.2830 | 0.9406 | (0.0438, 0.6924) 0.6486 | 0.9392 | |
| III | (0.6914, 1.5147) 0.8233 | 0.9253 | (1.3021, 2.9705) 1.6684 | 0.9370 | (0.0264, 1.0759) 1.0495 | 0.9261 | |
| (60, 30) | I | (0.6377, 1.5335) 0.8958 | 0.9374 | (1.3388, 3.0191) 1.6803 | 0.9487 | (0.0151, 0.9112) 0.8959 | 0.9393 |
| II | (0.7093, 1.3769) 0.6676 | 0.9516 | (1.4807, 2.6886) 1.2069 | 0.9542 | (0.0536, 0.6667) 0.6131 | 0.9461 | |
| III | (0.6934, 1.4786) 0.7852 | 0.9405 | (1.3955, 2.9630) 1.5675 | 0.9506 | (0.0325, 0.8630) 0.8305 | 0.9428 | |
| (70, 30) | I | (0.7329, 1.4293) 0.6964 | 0.9472 | (1.4068, 2.8432) 1.34364 | 0.9534 | (0.0298, 0.7943) 0.7645 | 0.9446 |
| II | (0.7247, 1.2859) 0.5602 | 0.9651 | (1.5369, 2.5891) 1.0522 | 0.9680 | (0.0614, 0.5498) 0.4884 | 0.9632 | |
| III | (0.7392, 1.3486) 0.6154 | 0.9514 | (1.4476, 2.7845) 1.3361 | 0.9573 | (0.0498, 0.7185) 0.6687 | 0.9521 |
Table A2.
The average 95% approximate confidence intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2, H(f) = 0.2448, T = 1.5).
Table A2.
The average 95% approximate confidence intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2, H(f) = 0.2448, T = 1.5).
| (n, m) | SC | β AL | CP | λ AL | CP | H AL | CP |
|---|---|---|---|---|---|---|---|
| (40, 15) | I | (0.5234, 1.8717) 1.3483 | 0.9231 | (1.2469, 3.2287) 1.9818 | 0.9274 | (0.0284, 1.1887) 1.1603 | 0.9267 |
| II | (0.6662, 1.4576) 0.7914 | 0.9372 | (1.4322, 2.8760) 1.4438 | 0.9405 | (0.0436, 0.7887) 0.7451 | 0.9393 | |
| III | (0.5619, 1.8110) 1.2491 | 0.9252 | (1.2679, 3.2045) 1.9364 | 0.9364 | (0.0212, 1.1173) 1.0961 | 0.9340 | |
| (50, 15) | I | (0.5601, 1.6810) 1.1209 | 0.9230 | (1.3076, 3.0214) 1.7136 | 0.9363 | (0.0245, 0.9304) 0.9059 | 0.9347 |
| II | (0.7124, 1.3705) 0.6581 | 0.9418 | (1.4548, 2.7213) 1.2665 | 0.9462 | (0.0458, 0.6740) 0.6282 | 0.9515 | |
| III | (0.6103, 1.5868) 0.9765 | 0.9336 | (1.3320, 2.9769) 1.6449 | 0.9372 | (0.0259, 0.8461) 0.8202 | 0.9347 | |
| (60, 30) | I | (0.6659, 1.5135) 0.8476 | 0.9418 | (1.3454, 3.0335) 1.6881 | 0.9521 | (0.0206, 1.0400) 1.0194 | 0.9464 |
| II | (0.7051, 1.3680) 0.6619 | 0.9592 | (1.4812, 2.6942) 1.2130 | 0.9574 | (0.0456, 0.6604) 0.6148 | 0.9531 | |
| III | (0.6913, 1.4513) 0.7600 | 0.9431 | (1.3775, 2.8768) 1.4983 | 0.9520 | (0.0237, 0.9934) 0.9697 | 0.9506 | |
| (70, 30) | I | (0.7381, 1.3951) 0.6570 | 0.9492 | (1.4501, 2.7820) 1.3319 | 0.9582 | (0.0321, 0.7553) 0.7232 | 0.9523 |
| II | (0.7573, 1.2850) 0.5277 | 0.9704 | (1.5514, 2.5845) 1.0331 | 0.9726 | (0.0647, 0.5680) 0.5033 | 0.9741 | |
| III | (0.7554, 1.3492) 0.5938 | 0.9546 | (1.4967, 2.7071) 1.2104 | 0.9615 | (0.0410, 0.7147) 0.6737 | 0.9591 |
Table A3.
The average 95% Bayesian credible intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2 H(f) = 0.2448, T = 0.6).
Table A3.
The average 95% Bayesian credible intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2 H(f) = 0.2448, T = 0.6).
| (n, m) | SC | β AL | CP | λ AL | CP | H AL | CP |
|---|---|---|---|---|---|---|---|
| (40, 15) | I | (0.5521, 1.2841) 0.7320 | 0.9194 | (1.0215, 2.4593) 1.4378 | 0.9241 | (0.0213, 1.1750) 1.1537 | 0.9263 |
| II | (0.6378, 1.3228) 0.6850 | 0.9433 | (1.2854, 2.5238) 1.2384 | 0.9472 | (0.0395, 0.7752) 0.7357 | 0.9380 | |
| III | (0.5670, 1.2953) 0.7283 | 0.9253 | (1.0579, 2.4762) 1.4183 | 0.9294 | (0.0224, 1.1192) 1.0968 | 0.9308 | |
| (50, 15) | I | (0.5924, 1.2871) 0.6947 | 0.9312 | (1.1731, 2.5054) 1.3323 | 0.9397 | (0.0298, 0.9231) 0.8933 | 0.9386 |
| II | (0.6897, 1.2921) 0.6024 | 0.9491 | (1.3580, 2.4935) 1.1355 | 0.9465 | (0.0548, 0.6751) 0.6203 | 0.9507 | |
| III | (0.6067, 1.2854) 0.6787 | 0.9342 | (1.2051, 2.4718) 1.2667 | 0.9354 | (0.0278, 0.8553) 0.8275 | 0.9326 | |
| (60, 30) | I | (0.6450, 1.2925) 0.6475 | 0.9481 | (1.1389, 2.4565) 1.3176 | 0.9536 | (0.0397, 1.0509) 1.0112 | 0.9394 |
| II | (0.6870, 1.2905) 0.6035 | 0.9614 | (1.3883, 2.4740) 1.0857 | 0.9656 | (0.0578, 0.6717) 0.6139 | 0.9562 | |
| III | (0.6565, 1.2812) 0.6247 | 0.9532 | (1.1919, 2.4423) 1.2504 | 0.9561 | (0.0319, 0.8408) 0.8029 | 0.9528 | |
| (70, 30) | I | (0.7062, 1.2494) 0.5432 | 0.9512 | (1.3068, 2.4374) 1.1306 | 0.9563 | (0.0324, 0.7516) 0.7192 | 0.9536 |
| II | (0.7451, 1.2449) 0.4998 | 0.9711 | (1.4821, 2.4494) 0.9673 | 0.9744 | (0.0701, 0.5672) 0.4971 | 0.9783 | |
| III | (0.7162, 1.2359) 0.5197 | 0.9583 | (1.3597, 2.4443) 1.0846 | 0.9604 | (0.0440, 0.7067) 0.6627 | 0.9578 |
Table A4.
The average 95% Bayesian credible intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2 H(f) = = 0.2448, T = 1.5).
Table A4.
The average 95% Bayesian credible intervals and average lengths and coverage probabilities of β, λ and the entropy (β = 1, λ = 2 H(f) = = 0.2448, T = 1.5).
| (n, m) | SC | β AL | CP | λ AL | CP | H AL | CP |
|---|---|---|---|---|---|---|---|
| (40, 15) | I | (0.5554, 1.2954) 0.7400 | 0.9218 | (1.0243, 2.4612) 1.4369 | 0.9354 | (0.0251, 1.1801) 1.1550 | 0.9258 |
| II | (0.6417, 1.3339) 0.6922 | 0.9439 | (1.2824, 2.5169) 1.2345 | 0.9485 | (0.0372, 0.7728) 0.7356 | 0.9394 | |
| III | (0.5696, 1.3033) 0.7337 | 0.9275 | (1.0556, 2.4672) 1.4116 | 0.9318 | (0.0241, 1.1200) 1.0959 | 0.9337 | |
| (50, 15) | I | (0.5954, 1.2947) 0.6993 | 0.9417 | (1.1722, 2.4804) 1.3002 | 0.9420 | (0.0224, 1.0231) 1.0007 | 0.9418 |
| II | (0.68902, 1.2954) 0.6062 | 0.9506 | (1.3599, 2.5034) 1.1435 | 0.9525 | (0.0479, 0.6710) 0.6239 | 0.9526 | |
| III | (0.6045, 1.2801) 0.6756 | 0.9359 | (1.2337, 2.5094) 1.2757 | 0.9364 | (0.0324, 1.0047) 0.9723 | 0.9371 | |
| (60, 30) | I | (0.6418, 1.2835) 0.6417 | 0.9494 | (1.1349, 2.4455) 1.3106 | 0.9548 | (0.0250, 0.9212) 0.8960 | 0.9417 |
| II | (0.6896, 1.2970) 0.6074 | 0.9628 | (1.3987, 2.4911) 1.0924 | 0.9662 | (0.0479, 0.6608) 0.6129 | 0.9573 | |
| III | (0.6600, 1.2856) 0.6256 | 0.9556 | (1.1549, 2.4283) 1.2734 | 0.9571 | (0.0217, 0.8359) 0.8142 | 0.9538 | |
| (70, 30) | I | (0.7061, 1.2472) 0.5411 | 0.9526 | (1.3179, 2.4521) 1.1342 | 0.9571 | (0.0363, 0.7509) 0.7146 | 0.9548 |
| II | (0.7451, 1.2413) 0.4962 | 0.9725 | (1.4663, 2.4268) 0.9605 | 0.9757 | (0.0778, 0.5701) 0.4923 | 0.9793 | |
| III | (0.7154, 1.2267) 0.5113 | 0.9594 | (1.3542, 2.4118) 1.0576 | 0.9624 | (0.0604, 0.7108) 0.6504 | 0.9585 |
References
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhauser: Boston, MA, USA, 2000. [Google Scholar]
- Balakrishnan, N. Progressive censoring methodology: An appraisal. Test 2007, 16, 211–259. [Google Scholar] [CrossRef]
- Kundu, D.; Joarder, A. Analysis of type-II progressively hybrid censored data. Comput. Stat. Data Anal. 2006, 50, 2509–2528. [Google Scholar] [CrossRef]
- Ng, H.K.T.; Kundu, D.; Chan, P.S. Statistical analysis of exponential lifetimes under an adaptive Type II progressive censoring scheme. Naval Res. Logist. 2010, 56, 687–698. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.; Zhang, C.; Dey, S. Analysis of weibull distribution under adaptive Type-II progressive hybrid censoring scheme. J. Indian Soc. Probab. Stat. 2018, 19, 25–65. [Google Scholar] [CrossRef]
- Zhang, C.; Shi, Y. Estimation of the extended Weibull parameters and acceleration factors in the step-stress accelerated life tests under an adaptive progressively hybrid censoring data. J. Stat Comput. Simulat. 2016, 86, 3303–3314. [Google Scholar] [CrossRef]
- Cui, W.; Yan, Z.; Peng, X. Statistical analysis for constant-stress accelerated life test with Weibull distribution under adaptive Type-II hybrid censored data. IEEE Access 2019. [Google Scholar] [CrossRef]
- Ismail, A.A. Inference for a step-stress partially accelerated life test model with an adaptive Type-II progressively hybrid censored data from Weibull distribution. J. Comput. Appl. Math. 2014, 260, 533–542. [Google Scholar] [CrossRef]
- Zhang, C.; Shi, Y. Inference for constant-stress accelerated life tests with dependent competing risks from bivariate Birnbaum-Saunders distribution based on adaptive progressively hybrid censoring. IEEE Trans. Reliab. 2017, 66, 111–122. [Google Scholar] [CrossRef]
- Ye, Z.S.; Chan, P.S.; Xie, M. Statistical inference for the extreme value distribution under adaptive Type-II progressive censoring schemes. J. Stat. Comput. Simulat. 2014, 84, 1099–1114. [Google Scholar] [CrossRef]
- Sobhi, M.M.; Soliman, A.A. Estimation for the exponentiated Weibull model with adaptive Type-II progressive censored schemes. Appl. Math. Model. 2016, 40, 1180–1192. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.E. Estimation of the inverse Weibull parameters under adaptive type-II progressive hybrid censoring scheme. J. Comput. Appl. Math. 2017, 315, 228–239. [Google Scholar] [CrossRef]
- Xu, R.; Gui, W.H. Entropy estimation of inverse Weibull Distribution under adaptive Type-II progressive hybrid censoring schemes. Symmetry 2019, 11, 1463. [Google Scholar] [CrossRef]
- Kang, S.B.; Cho, Y.S.; Han, J.T.; Kim, J. An estimation of the entropy for a double exponential distribution based on multiply Type-II censored samples. Entropy 2012, 14, 161–173. [Google Scholar] [CrossRef]
- Cho, Y.; Sun, H.; Lee, K. An estimation of the entropy for a Rayleigh distribution based on doubly-generalized Type-II hybrid censored samples. Entropy 2014, 16, 3655–3669. [Google Scholar] [CrossRef]
- Baratpour, S.; Ahmadi, J.; Arghami, N.R. Entropy properties of record statistics. Stat. Pap. 2017, 48, 197–213. [Google Scholar] [CrossRef]
- Cramer, E.; Bagh, C. Minimum and maximum information censoring plans in progressive censoring. Commun. Stat. Theory Methods 2011, 40, 2511–2527. [Google Scholar] [CrossRef]
- Cho, Y.; Sun, H.; Lee, K. Estimating the entropy of a weibull distribution under generalized progressive hybrid censoring. Entropy 2015, 17, 102–122. [Google Scholar] [CrossRef]
- Yu, J.; Gui, W.H.; Shan, Y.Q. Statistical inference on the Shannon entropy of inverse Weibull distribution under the progressive first-failure censoring. Entropy 2019, 21, 1209. [Google Scholar] [CrossRef]
- Abd-Elrahman, A.M. A new two-parameter lifetime distribution with decreasing, increasing or upside-down bathtub-shaped failure rate. Commun. Stat. Theory Methods 2017, 46, 8865–8880. [Google Scholar] [CrossRef]
- Abd-Elrahman, A.M. Reliability estimation under type-II censored data from the generalized Bilal distribution. J. Egypt. Math. Soc. 2019, 27, 1–15. [Google Scholar] [CrossRef]
- Mahmoud, M.; EL-Sagheer, R.M.; Abdallah, S. Inferences for new Weibull–Pareto distribution based on progressively Type-II censored data. J. Stat. Appl. Probab. 2016, 5, 501–514. [Google Scholar] [CrossRef]
- Ahmed, E.A. Bayesian estimation based on progressive Type-II censoring from two-parameter bathtub-shaped lifetime model: An Markov chain Monte Carlo approach. J. Appl. Stat. 2014, 41, 752–768. [Google Scholar] [CrossRef]
- Gilks, W.R.; Wild, P. Adaptive rejection sampling for Gibbs sampling. J. R. Stat. Soc. 1992, C41, 337–348. [Google Scholar] [CrossRef]
- Koch, K.R. Gibbs sampler by sampling-importance-resampling. J. Geod. 2007, 81, 581–591. [Google Scholar] [CrossRef]
- Martino, L.; Elvira, V.; Camps-Valls, G. The recycling gibbs sampler for efficient learning. Digit. Signal Process. 2018, 74, 1–13. [Google Scholar] [CrossRef]
- Panahi, H.; Moradi, N. Estimation of the inverted exponentiated Rayleigh distribution based on adaptive Type II progressive hybrid censored sample. J. Comput. Appl. Math. 2020, 364, 112345. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equations of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Sandhu, R.A. A simple simulational algorithm for generating progressive Type-II censored samples. Am. Stat. 1995, 49, 229–230. [Google Scholar]
- Hinkley, D. On quick choice of power transformations. Appl. Stat. 1977, 26, 67–96. [Google Scholar] [CrossRef]
- Barreto-Souza, W.; Cribari-Neto, F. A generalization of the exponential-Poisson distribution. Stat. Probab. Lett. 2009, 79, 2493–2500. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).