
A Compressed Sensing Measurement Matrix Construction Method Based on TDMA for Wireless Sensor Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Common Measurement Matrix and Performance Verification
2.1. CS Theory Overview
2.2. Common Measurement Matrices
2.2.1. Gaussian Random Measurement Matrix
2.2.2. Bernoulli Random Measurement Matrix
2.2.3. Sparse Random Measurement Matrix
2.2.4. Toeplitz and Circulant Measurement Matrix
2.3. Reconstructing Performance Validation
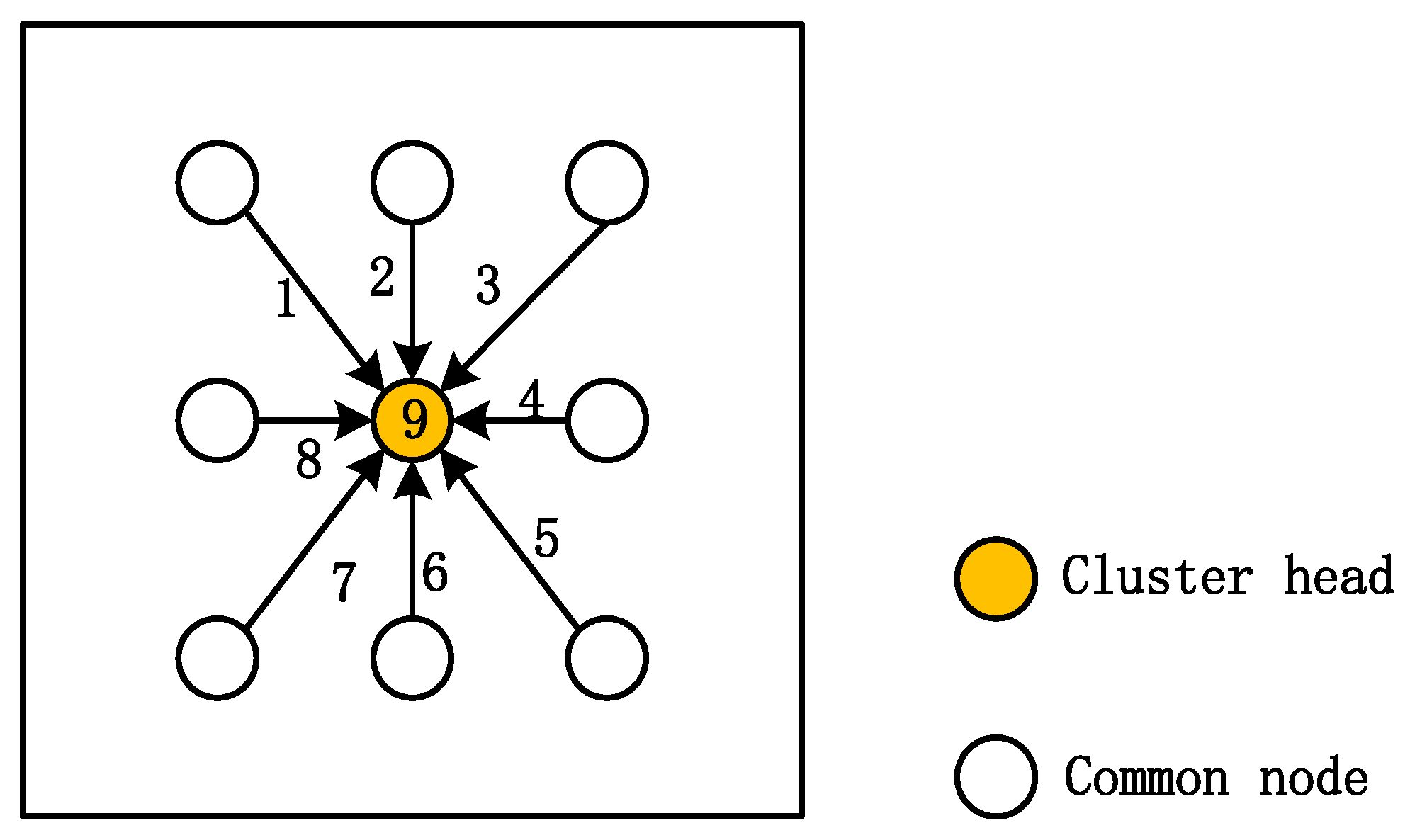
3. Measurement Matrix Construction Method based on TDMA
3.1. Random Measurement Matrix Construction Method Based on TDMA
- The node generates a list of d integers from with equal probability and no repetition to form the position list . These d integers represent the positions of the d non-zero values in the vector.
- A node randomly sorts a list based on the principle that the number of is and the number of is also to obtain a list of symbols .
- The element at this coded vector is , where , and the elements at the remaining positions are all 0.
3.2. Semi-Random Semi-Deterministic Measurement Matrix Construction Method Based on TDMA
- The number of non-zero elements in each column of the measurement matrix is d, which satisfies the requirement of the above theorem that the number of non-zero elements in each column of the matrix is equal. So is used as in Equation (21).
- An orthogonal matrix of size is used as to generate the nested matrices, because the orthogonal matrix has the smallest column coherence coefficient. Furthermore, to ensure that the nested matrix satisfies Equation (20), the values of the elements in the matrix are set to , which also satisfies the requirement of the above theorem that all elements of have the same absolute value.
- The final measurement matrix is constructed in the manner of Figure 6.
4. Simulation Experiments and Result Analysis
4.1. Comparative Analysis of Different d Values on the Reconstruction Performance
4.1.1. Simulation Results with the Length 100, Sparsity 10 and d 2, 4, 6, 8, 10
4.1.2. Simulation Results with the Length 200, Sparsity 5, 10, 15, 20 and d 2, 4, 6, 8, 10
4.1.3. Simulation Results with the Length 500, 1000, 1500, Sparsity 60 and d 2, 4, 6, 8, 10
4.2. Simulation Validation Based on Realistic Scenario
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Forster, A. Introduction to Wireless Sensor Networks; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Singh, P.K.; Paprzycki, M. Introduction on wireless sensor networks issues and challenges in current era. In Handbook of Wireless Sensor Networks: Issues and Challenges in Current Scenario’s; Springer: Cham, Switzerland, 2020; pp. 3–12. [Google Scholar]
- Roy, N.R.; Chandra, P. Analysis of data aggregation techniques in WSN. In Proceedings of the International Conference on Innovative Computing and Communications, Ostrava, Czech Republic, 21–22 March 2019; Springer: Singapore, 2020; pp. 571–581. [Google Scholar]
- Li, D.; Deng, Y.; Cheong, K.H. Multisource basic probability assignment fusion based on information quality. Int. J. Intell. Syst. 2021, 36, 1851–1875. [Google Scholar] [CrossRef]
- Deng, J.; Deng, Y.; Cheong, K.H. Combining conflicting evidence based on Pearson correlation coefficient and weighted graph. Int. J. Intell. Syst. 2021, 36, 7443–7460. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L.; Wu, X.; Skibniewski, M.J. Multi-classifier information fusion in risk analysis. Inf. Fusion 2020, 60, 121–136. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, L.; Li, Z.; Ding, L. Improved fuzzy Bayesian network-based risk analysis with interval-valued fuzzy sets and D–S evidence theory. IEEE Trans. Fuzzy Syst. 2019, 28, 2063–2077. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Kutyniok, G. (Eds.) Compressed Sensing: Theory and Applications; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Bajwa, W.U.; Haupt, J.D.; Sayeed, A.M.; Nowak, R.D. Joint Source-Channel Communication for Distributed Estimation in Sensor Networks. IEEE Trans. Inf. Theory 2007, 53, 3629–3653. [Google Scholar] [CrossRef]
- Tsaig, Y.; Donoho, D.L. Extensions of compressed sensing. Signal Process. 2006, 86, 549–571. [Google Scholar] [CrossRef]
- Mendelson, S.; Pajor, A.; Tomczak-Jaegermann, N. Uniform uncertainty principle for Bernoulli and subgaussian ensembles. Constr. Approx. 2008, 28, 277–289. [Google Scholar] [CrossRef]
- Bajwa, W.U.; Haupt, J.D.; Raz, G.M.; Wright, S.J.; Nowak, R.D. Toeplitz-structured compressed sensing matrices. In Proceedings of the IEEE/SP 14th Workshop on Statistical Signal Processing, Madison, WI, USA, 26–29 August 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 294–298. [Google Scholar]
- DeVore, R.A. Deterministic constructions of compressed sensing matrices. J. Complex. 2007, 23, 918–925. [Google Scholar] [CrossRef] [Green Version]
- Berinde, R.; Indyk, P. Sparse recovery using sparse random matrices. LATIN 2008. preprint. [Google Scholar]
- Yu, L.; Barbot, J.P.; Zheng, G.; Sun, H. Compressive sensing with chaotic sequence. IEEE Signal Process. Lett. 2010, 17, 731–734. [Google Scholar]
- Applebaum, L.; Howard, S.D.; Searle, S.; Calderbank, R. Chirp sensing codes: Deterministic compressed sensing measurements for fast recovery. Appl. Comput. Harmon. Anal. 2009, 26, 283–290. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Zhou, Q.; Tong, J. V-matrix-based scalable data aggregation scheme in WSN. IEEE Access 2019, 7, 56081–56094. [Google Scholar] [CrossRef]
- Zhang, D.G.; Zhang, T.; Zhang, J.; Dong, Y.; Zhang, X.D. A kind of effective data aggregating method based on compressive sensing for wireless sensor network. EURASIP J. Wirel. Commun. Netw. 2018, 2018, 159. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, O.; Yang, Y.; Liu, G.; Tong, X. Energy-efficient data gathering algorithm relying on compressive sensing in lossy WSNs. Measurement 2019, 147, 106875. [Google Scholar] [CrossRef]
- Qiao, J.; Zhang, X. The design of a dual-structured measurement matrix in compressed sensing. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 184–188. [Google Scholar]
- Ma, Z.; Zhang, D.; Liu, S.; Song, J.; Hou, Y. A novel compressive sensing method based on SVD sparse random measurement matrix in wireless sensor network. Eng. Comput. 2016, 33, 2448–2462. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.T.; Pan, T.; Zhu, G.M.; Pei, T.R. A Construction Algorithm of Measurement Matrix with Low Power Average Column Coherence. Acta Electron. Sin. 2014, 42, 1360–1364. [Google Scholar]
- Candes, E.J.; Eldar, Y.C.; Needell, D.; Randall, P. Compressed Sensing with Coherent and Redundant Dictionaries. Appl. Comput. Harmon. Anal. 2011, 31, 59–73. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Ye, H.; Wang, R. The construction of measurement matrices based on block weighing matrix in compressed sensing. Signal Process. 2016, 123, 64–74. [Google Scholar] [CrossRef]
- Hon, S. Circulant preconditioners for functions of Hermitian Toeplitz matrices. J. Comput. Appl. Math. 2019, 352, 328–340. [Google Scholar] [CrossRef] [Green Version]
- Malallah, F.L.; Shareef, B.T.; Saeed, M.G.; Yasen, K.N. Contactless Core-temperature Monitoring by Infrared Thermal Sensor using Mean Absolute Error Analysis. Recent Pat. Eng. 2021, 15, 100–111. [Google Scholar] [CrossRef]
- Ullah, K.; Garg, H.; Mahmood, T.; Jan, N.; Ali, Z. Correlation coefficients for T-spherical fuzzy sets and their applications in clustering and multi-attribute decision making. Soft Comput. 2020, 24, 1647–1659. [Google Scholar] [CrossRef]
- Ullah, K.; Mahmood, T.; Garg, H. Evaluation of the performance of search and rescue robots using T-spherical fuzzy hamacher aggregation operators. Int. J. Fuzzy Syst. 2020, 22, 570–582. [Google Scholar] [CrossRef]
- Xiao, F. CEQD: A complex mass function to predict interference effects. IEEE Trans. Cybern. 2021, 5, 72. [Google Scholar] [CrossRef]
- Xiao, F. CaFtR: A fuzzy complex event processing method. Int. J. Fuzzy Syst. 2021, 11, 1–14. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/garystafford/environmental-sensor-data-132k (accessed on 3 June 2021).










Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Y.; Liu, H.; Hou, J. A Compressed Sensing Measurement Matrix Construction Method Based on TDMA for Wireless Sensor Networks. Entropy 2022, 24, 493. https://doi.org/10.3390/e24040493
Yang Y, Liu H, Hou J. A Compressed Sensing Measurement Matrix Construction Method Based on TDMA for Wireless Sensor Networks. Entropy. 2022; 24(4):493. https://doi.org/10.3390/e24040493
Chicago/Turabian StyleYang, Yan, Haoqi Liu, and Jing Hou. 2022. "A Compressed Sensing Measurement Matrix Construction Method Based on TDMA for Wireless Sensor Networks" Entropy 24, no. 4: 493. https://doi.org/10.3390/e24040493
APA StyleYang, Y., Liu, H., & Hou, J. (2022). A Compressed Sensing Measurement Matrix Construction Method Based on TDMA for Wireless Sensor Networks. Entropy, 24(4), 493. https://doi.org/10.3390/e24040493