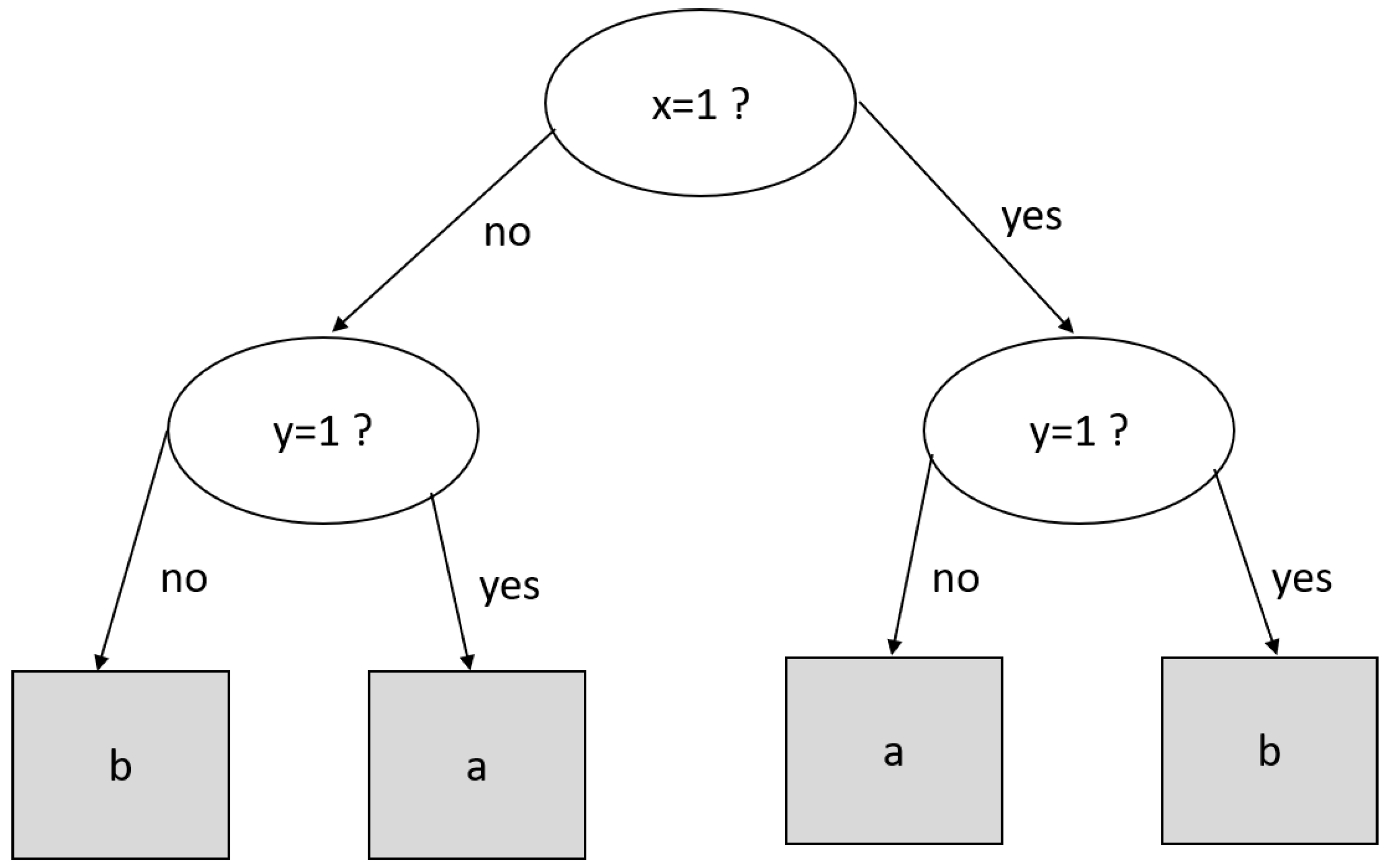
A decision tree is a supervised data mining technique that creates a tree-like structure, where the non-leaf node tests a given attribute [
45]. The outcome gives us the path to reach a leaf node, where the classification label is found. For example, let (
x = 3,
y = 1) be a tuple to be classified by the decision tree of
Figure 1. If we test
, we must follow the left path to reach
and finally arrive at the leaf node with the classification label “
a”.
In general, the cornerstone of the construction process of decision trees is the evaluation of all attributes to find the best node and the best split condition on this node to classify the tuple with the lower error rate. This evaluation is carried out by information gain on each attribute
a [
45]:
where
is the entropy of the database after being partitioned by the condition
c of a given attribute
a and
is the entropy induced by
c. The tree’s construction needs to evaluate several partition conditions
c on all attributes of the database, then chooses the pair of attribute–condition with the highest value. Once a pair is chosen, the process evaluates the partitioned database recursively using a different attribute–condition. The reader is referred to [
45] for details on decision tree construction and computation of (
14).
3.2. Two-Parameter Fractional Tsallis Decision Tree
Following a similar fashion, a two-parameter fractional decision tree can be induced by the information gain obtained by rewritten (
14) using (
13):
An alternative informativeness measure for constructing decision trees is the Gini index, or Gini coefficient, which is calculated by
The Gini index can be deduced from Tsallis entropy (
4) using
[
14]. On the other hand, the two-parameter fractional Tsallis entropy with
,
,
reduces to the Gini index. Hence, Gini decision trees are a particular case of both Tsallis and two-parameter fractional Tsallis trees.
The main issue with Renyi and Tsallis decision trees is the estimation of
-value to obtain a better classification than the one produced by the classical decision trees. Trial and error is the accepted approach for this purpose. It consists of testing several values in a given interval, usually
, and comparing the classification rates. This approach becomes unfeasible in two-parameter fractional Tsallis decision trees as it is needed to tune
q,
, and
. A representation of a database as a complex network is introduced to face this issue. This representation lets us compute
and
following the approach in [
22], which is the basis for determining the fractional decision tree parameters.
3.3. Network’s Construction
A network is a powerful tool to model the relationships among entities or parts of a system. When those relationships are complex, i.e., properties that cannot be found by examining single components, something emerges that is called a complex network. Thus, networks as a skeleton of complex systems [
46] have attracted considerable attention in different areas of science [
47,
48,
49,
50,
51]. Following this approach, a representation of the relationships among attributes (system entities) of a database (system) as a network is obtained.
The attribute’s name will be concatenated before the value of a given row to distinguish the same value that might appear on different attributes. Consider the first record of the database shown on the top of
Figure 2. The first node will be
, the second node will be
, and the third node will be
. These nodes belong to the same record, so they must be connected; see dotted lines of the network in the middle of
Figure 2. We next consider the second record; the nodes
and
will be added to the network. Note that the node
was added in the previous step. We may now add the links between these three nodes. This procedure is repeated for each record in the database.
The outcome is a complex network that exhibits non-simple topological features [
52], which cannot be predicted by analyzing single nodes as occurs in random graphs or lattices [
53].
3.4. Computation of Two-Parameter Fractional Tsallis Decision Tree Parameters
By the technique introduced in [
22], the parameters
and
—on the network representation of the database—of the two-parameter fractional Tsallis decision tree are defined to be
where
is the number of nodes in the box
obtained by the box-covering algorithm [
54],
n is the number of nodes of the network, and
is the average degree of the nodes of the
box. Similarly, two values of
are computed as follows [
22]:
where
is the diameter of the box
,
is the diameter of the network, and
is the number of links among the boxes
. The computation of
and
will be explained later.
Inspired by the right-hand term of (
19) and (
20) (named
) with the fact that
is a normalized measure of the number of boxes to cover the network [
20], an approximation of the
-value for the two-parameter fractional decision tree is introduced:
Similarly, from the right hand of (
21) and (
22) (named
), a second approximation of the
-value is given by
where
is the minimum number of boxes of diameter
l to cover the network,
n,
,
,
.
The process to compute the minimum number of boxes
of diameter
l to cover the network
G is shown in
Figure 3. A dual network (
) is created only with the nodes of the original network,
Figure 3b. Then, the links in
are added following the rule: two nodes
i,
j, in the dual network, are connected if the distance between
is greater than or equal to
l. In our example,
, and node one is selected to start. Node one will be connected in
with nodes five and six since their distance is four and three. The procedure is repeated with the remaining nodes to obtain the dual network shown in
Figure 3b. Next, the nodes will be colored as follows: two directly connected nodes in
must not have the same color. Finally, the nodes colored in
are mapped to
G; see
Figure 3c. The minimum number of boxes to cover the network given
l equals the number of colors in
G. In addition, the nodes in the same color belong to the same box. In practice,
; thus,
of the example are shown in
Table 1. For details of the box-covering algorithm, the reader is referred to [
54].
Now, we are ready to compute
. Two boxes were found following the previous example for for
; see
Figure 4a. The
is the average link per node between the nodes of this box; for this reason, the link between nodes four and six is omitted in this computation. Similarly,
. The
is the degree of each node of the renormalized network; see the network of
Figure 4b.
In our example,
. The renormalization converts each box into a super node, preserving the connections between boxes. On the other hand, it is known that
and
; in the first case, each box contains a node, and in the second one, there is one box to cover the network that contains all nodes. For this reason, the
and
are not defined for
and
, respectively. This force to
as was stated in (
19)–(
24). Additionally, note that the right hand of (
19) and (
20) (
), (
21) and (
22) (
) are “pseudo matrices”, where each row has
values; see
Table 1. Consequently,
and
are also “pseudo matrices”.
The network represents the relationships between attribute-value (nodes) of each record and the relationships between different database records. For example, the dotted lines in
Figure 2 show the relationships between the first record’s attribute value. Links of the node ZIP.08510 are the relationships between the three records, and the links of PHONE.54-76-90 are the relationships between the first and third one. The box-covering algorithm groups these relationships into boxes (network records). The network in the middle of
Figure 2 shows that the three boxes (in orange, green, and blue) coincide with the number of records in the database. However, the attribute value of each box does not coincide entirely with records in the database since box-covering finds the minimum number of boxes with the maximum number of attributes where the boxes are mutually exclusive.
The nodes in each box (network record) are enough to differentiate the records in the database. For example, the first network record consists of name, phone, and zip values (nodes in orange). The second record in the database can be differentiated from the first by its name and phone (values of those attributes are the second network record in green). The third one can be distinguished from the two others by its name (the third network record in blue). The cost of differentiating the first network record (measured by ) is the highest; meanwhile, the lowest is for the third. Thus, measures the local differentiation cost for the network records.
On the other hand,
measures the global differentiation cost (by
). For example, the global cost for the first network record is two, and one for the second and third; see the renormalized network (at the bottom of
Figure 2). It means that the first network record needs to be differentiated from two network records, and the second and third only need to be distinguished from the first. Note that
,
for a given
l relies on the topology network that captures the relationships of the records and their values. Finally,
is the ratio between network records (normalized number of boxes
) and the local differentiation cost; meanwhile,
is the ratio between network records and the global differentiation cost.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}