Abstract
Binomial autoregressive models are frequently used for modeling bounded time series counts. However, they are not well developed for more complex bounded time series counts of the occurrence of n exchangeable and dependent units, which are becoming increasingly common in practice. To fill this gap, this paper first constructs an exchangeable Conway–Maxwell–Poisson-binomial (CMPB) thinning operator and then establishes the Conway–Maxwell–Poisson-binomial AR (CMPBAR) model. We establish its stationarity and ergodicity, discuss the conditional maximum likelihood (CML) estimate of the model’s parameters, and establish the asymptotic normality of the CML estimator. In a simulation study, the boxplots illustrate that the CML estimator is consistent and the qqplots show the asymptotic normality of the CML estimator. In the real data example, our model takes a smaller AIC and BIC than its main competitors.
1. Introduction
Bounded time series of counts are commonly observed in real-world applications. Its (binomial) index of dispersion (as a function of n, and ) is defined by where n is the predetermined upper limit of the range, and . If its , then it is under-dispersed, if its , then it is equi-dispersed, while if its , then it is over-dispersed (or the extra-binomial variation).
A popular tool to establish a binomial autoregressive model (BAR) is the binomial thinning operator “∘” [1], which is introduced by
where X is a non-negative integer-valued random variable, is an i.i.d. Bernoulli random variable sequence with and independent of X. McKenzie [2] used the binomial thinning operator given in (1) to establish the binomial AR(1) model, which is a popular model for bounded time series and defined as follows
where is the predetermined upper limit of the range; follows the binomial distribution with ; and with and ; the counting series at time t are independent of the random variables ; and all the counting series in “” and “” are mutually independent sequences of independent Bernoulli random variables with parameters and , respectively. The binomial AR(1) process given in (2) is now well understood and it is an ergodic Markov chain with a stationary distribution with and . Hence, its , i.e., the BAR model given in (2), applies to equi-dispersed time series with finite range; see [3,4,5,6,7] for more discussion about the BAR(1) model.
Weiß and Pollett [8] extended the binomial AR(1) model as the density-dependent BAR(1) model (denoted as the DDBAR(1) model), whose thinning probabilities vary over time by assuming and . In particular, for given n, if and , the DDBAR(1) model allows to analyze bounded integer-valued time series with under-dispersion, equi-dispersion and over-dispersion, see Section 4 in [8] for more details. To model extra-binomial variation for time series counts, Weiß and Kim [9] proposed the beta-binomial AR (BBAR) model based on the beta-binomial thinning operator “”, which is introduced by
where X is a non-negative integer-valued random variable, is an i.i.d. Bernoulli random variable sequence with and , is independent of X.
As discussed in Weiß [10], the BAR(1) model, DDBAR(1) model, and BBAR(1) model can be interpreted as a system with n mutually independent units and each unit being either in state “1” or state “0”. Assume is the number of units being in state “1” at time t. Then ( or ) is the number of units still in state “1” at time t with survival probability (random survival probability or ), ( or ) is the number of units, which moved from state “0” to state “1” at time t with revival probability (random revival probability or ). It is worth mentioning that all of BAR(1), DDBAR(1), and BBAR(1) models are aimed at a system with n independent units, but not a system with n dependent units, i.e., the counting series in “∘” is independent and identically distributed, but not dependent. To solve this dilemma, Kang et al. [11] proposed a generalized binomial AR (GBAR) model based on the generalized binomial thinning operator “”, which is proposed by Ristić et al. [12] and given as follows
where , and are two independent random sequences of iid random variables with Bernoulli() and Bernoulli() distributions, Z is a Bernoulli() random variable and is responsible for the cross-dependence, , , and Z are mutually independent and each of them is independent of X.
Unfortunately, the GBAR model [11] can not use to analyze under-dispersed or equi-dispersed bounded data. To fill this gap, we are inspired by the Conway–Maxwell–Poisson-binomial (CMPB) distribution [13] and construct the Conway–Maxwell–Poisson-binomial thinning operator, whose counting series is exchangeablility. Furthermore, we propose a new Conway–Maxwell–Poisson-binomial autoregressive (CMPBAR) model, which not only allows us to analyze bounded data with over-dispersion but also allows us to model bounded data with equi-dispersion or under-dispersion. The second contribution of this paper is that we discuss the CML estimation of the parameters involved in the new model, and establish the asymptotic normality of the CML estimator. To illustrate that the new model is more flexible and superior, we apply the new model on the weekly rainy days at Hamburg–Neuwiedenthal in Germany.
The paper is organized as follows. Section 2 first gives a brief review of the Conway–Maxwell–Poisson-binomial distribution, then gives the definition of the exchangeable Conway–Maxwell–Poisson-binomial thinning operator and that of the Conway–Maxwell–Poisson-binomial AR model. The conditional maximum likelihood estimation and its asymptotic properties are established in Section 3. Section 4 gives a simulation study and Section 5 gives real data to show the better performance of the new model. Conclusions are made in Section 6.
2. Model Formulation and Stability Properties
2.1. Conway–Maxwell–Poisson-Binomial Distribution
For readability, we first give a brief review of the CMPB distribution introduced by Shmueli et al. [13].
A random variable X taking values in is said to follow the Conway–Maxwell–Poisson-binomial distribution with parameters , if the probability mass function (pmf) of X takes the form where , , and is the predetermined upper limit of the range.
For simplicity, we write . Denote , the pmf of X can be rewritten as
where , and is the predetermined upper limit of the range. Therefore, we obtain the moment-generating function of X as . Furthermore,
where and (see Shmueli et al. [13], Borges et al. [14], Daly and Gaunt [15], and Kadane [16] for more detailed discussion).
Unfortunately, the specific range of the BID for the CMPB distribution can not be obtained by (4). To solve this dilemma, we give an example in Figure 1 with , when and are varying from and , respectively.
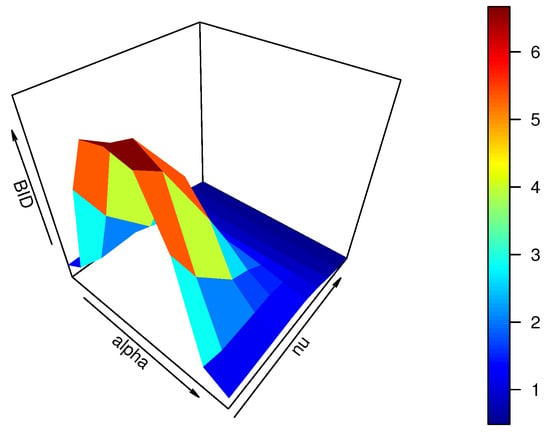
Figure 1.
Plot of the BID of the CMPB distribution for different choices of and .
From Figure 1, the BID of the CMPB distribution takes a value, which may be less than 1, equal to 1, or greater than 1 for different values and . Additionally, it implies that the CMPB distribution allows us to analyze bounded time series counts with under-dispersion, equi-dispersion, and over-dispersion.
To further explore the dynamic change of the BID with varying from for given and , 0, 0.5, 1, 1.5, or 2, we present the plots of the BID in Figure 2.
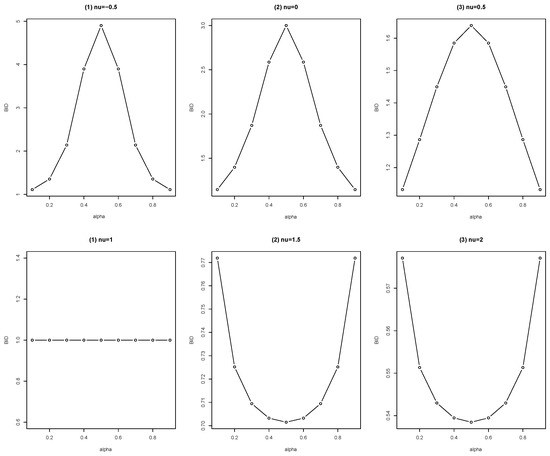
Figure 2.
Plots of the BID of the CMPB distribution for different choices of .
From Figure 2, we obtain the following observations. First, if , the BID is no less than 1. To be precise, its BID is increasing to maximum when is varying from 0 to 0.5, and then decreasing to 1 when is varying from 0.5 to 1. Second, if , its BID = 1, for all . Third, if , its BID is no more than 1. Precisely, its BID is decreasing to the minimum when is varying from 0 to 0.5, and then increasing to 1 when is varying from 0.5 to 1. To sum up, the Conway–Maxwell–Poisson-binomial distribution allows under-dispersion, equi-dispersion, and over-dispersion for bounded time series data.
Remark 1.
By (3), the pmf of the CMPB is expressed as that of the power series distribution and if , , if , the CMPB reduces to binomial distribution with parameter α.
2.2. Conway–Maxwell–Poisson-Binomial Thinning Operator
By Shmueli et al. [13], the CMPB distribution is a distribution on the sum of n dependent Bernoulli components without specifying anything else about the joint distribution of those components. Precisely, if , there exists a Bernoulli variable sequence such that , where
with and .
Definition 1.
Let . Then the exchangeable Conway–Maxwell–Poisson-binomial thinning operator is introduced by
where X is a non-negative random variable, is an exchangeable Bernoulli variable sequence with its pmf taking the form (5) and independent of X.
To generate the random number of “”, we first let , then . Therefore, and the conditional binomial index of dispersion (CBID) is where , , and .
Second, we let , then the pmf of takes the form (3). Third, we let , . By (3), the pmf of the can be rewritten as
Furthermore,
by which an algorithm is used to generate a random number of with can be expressed as follows.
Remark 2.
By Kadane [16], the counting series in Definition 1 is a dependent Bernoulli variable sequence with exchangeability of order 2. To account for the concept of exchangeability, we assume π is a permutation of . Then . By the definition of exchangeability in Section 6 in Kadane [16], is n-exchangeable. Kadane [16] stated that “de Finetti’s Theorem shows that sums of exchangeable random variables are mixtures of Binomial random variables. Because the marginal distribution of each component is Bernoulli, interest centers on the joint distribution of pairs of such variables”. By Theorem 4 in Kadane [16], n-exchangeability applies to every permutation of length n, it implies that is exchangeable for each . Hence, is exchangeable with order 2 because every pair has the same distribution as every other pair, i.e., every pair of has the same distribution as every other pair and for any pair , and , , , and ; see [16] for more discussion.
2.3. Binomial Autoregressive Model with the CMPB Operator
Now, we define the BAR(1) model with the CMPB operator by
where , , both and are the CMPB thinning operators given in Definition 1, their counting series and are the exchangeable Bernoulli variable sequence with their pmfs taking the form (5), is independent of , , , and all the thinnings at time t are independent of , , .
For simplicity, we denote the new model as the CMPBAR(1) model. By (8), is a Markov chain and its one-step transition probability takes the form
where and with and and .
Theorem 1.
If satisfies (8), then is ergodicity and strictly stationarity.
Proof.
Similar to that of Theorem 1 in Kang et al. [11], the state space of is . Because , so the state space of is an equivalence class. Furthermore, is an irreducible and aperiodic Markov chain; therefore, is ergodic with a unique stationary distribution by [17]. □
By Definition 1 and (8), for given , given in (8) consists of two independent parts and , where and . Denote and . Then
and the conditional binomial index of dispersion (CBID) is
where , , , , , .
Unfortunally, because of the complexity of and , we can not obtain the marginal distribution of and its the autocorrelation structure, including the , , and BID. To resolve this dilemma, for given , we create some plots of the BID (in Figure 3) by generating some samples from the CMPBAR(1) model with and sample size , when = (0.2, 0.2), (0.2, 0.5), (0.2, 0.6), (0.5, 0.6), i.e., = (0.25, 0.25), (0.25, 1), (0.25, 1.5), (1, 1.5).
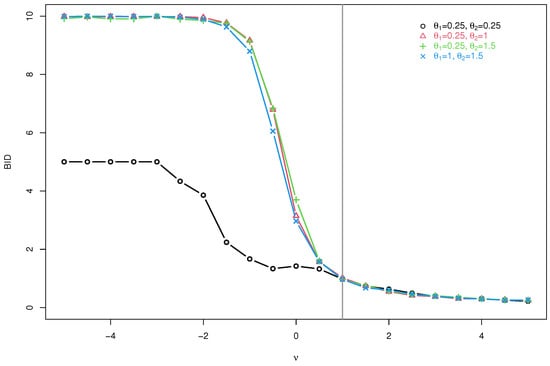
Figure 3.
Plots of BID of the CMPBAR model.
From Figure 3, we have the following observations. First, if , the BID of the CMPBAR(1) model is greater than 1, i.e., the CMPBAR(1) model allows us to analyze bounded integer-valued time series with overdispersion. Second, if , the BID of the CMPBAR(1) model is less than 1, i.e., the CMPBAR(1) model allows us to analyze bounded integer-valued time series with underdispersion. Third, if , the CMPBAR(1) model becomes to the BAR(1) given in (2) and its BID is equal to 1, i.e., equi-dispersed bounded integer-valued time series is allowed.
3. Parameter Estimation
In this section, we use the conditional maximum likelihood method to estimate the parameters (denoted as ) involving in the CMPBAR(1) model. Let be a realization of , and generate by the CMPBAR(1) process based on Algorithm 1, where represents the size of sample.
| Algorithm 1: Random number generation algorithm for the CMPB distribution |
By using (9), the conditional log-likelihood function can be written as:
where and with m = , , , and . Then the CML estimate is obtained by minimizing (10).
Assumption 1.
If there exists a , such that , a.s., then , where is the probability measure under the true parameter with .
Theorem 2.
Let be generalized by the CMPBAR(1) model. If Assumption 1 holds, there exists an estimator such that
where and .
Proof.
To prove the consistence of , we denote . Hence, . Similar to the first item of Theorem 4 in Chen et al. [18], we can verify that the assumptions of Theorem 4.1.2 in Amemiya [19] hold under Assumption 1, i.e., attains a strict local maximum at ; therefore, there exists an estimator such that .
In the following, we prove the asymptotic normality of . It is easy to see , , and exist and are three times continuous differentiable in . Thus, there exist a such that attains the maximum value at Therefore,
Similar to the second item of Theorem 4 in [18], we can prove that
by Theorem 4.1.3 in Amemiya [19]. Furthermore,
by using ergodic theorem. Using the Martingale central limit theorem and the Cramér device, it is direct to show that
Then the asymptotic normal distribution of is obtained based on the Taylor series expansion of around . □
4. Simulation
In this section, we conduct a simulation study to illustrate the large sample property of the CMPBAR(1) model.
In the simulation, we fix , let sample size , and use the function in R to optimize in (10). To check the finite sample performance, we use the following parameter combinations of as
where and 1.5 to reflect overdispersion, equidispersion, and underdispersion, respectively.
For the simulated sample, performances of mean and standard deviation (sd) are given. For a scale parameter , , where is the estimator of in the ith replication and . Summaries of the simulation results are given in Table 1, Table 2 and Table 3.

Table 1.
Mean and sd in parentheses of estimates for (A1)–(A4).
Table 2.
Mean and sd in parentheses of estimates for (B1)–(B4).
Table 3.
Mean and sd in parentheses of estimates for (C1)–(C4).
To illustrate the consistency and the asymptotic normality of the CML estimators, we present the boxplots of the CML estimates for (A1), (B1), and (C1) in Figure 4, Figure 5, and Figure 6, and their qqplots with in Figure 7, Figure 8, and Figure 9, respectively. Others are similar and we omit them.
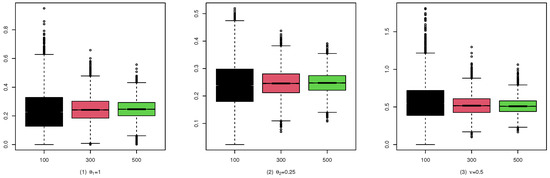
Figure 4.
Boxplots of the CML estimates for (A1).
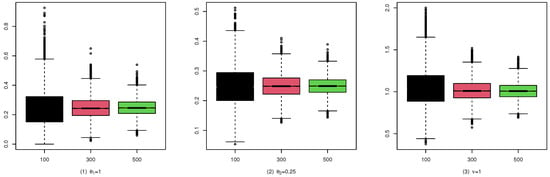
Figure 5.
Boxplots of the CML estimates for (B1).
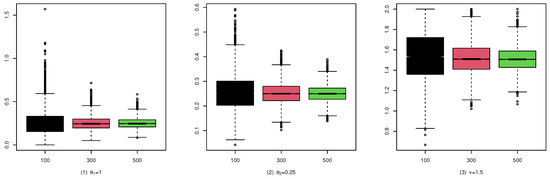
Figure 6.
Boxplots of the CML estimates for (C1).
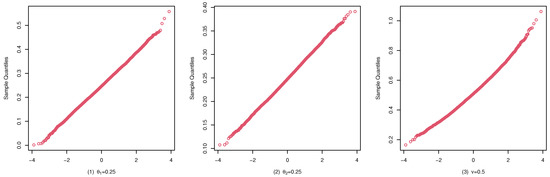
Figure 7.
qqplots of the CML estimates for (A1) with .
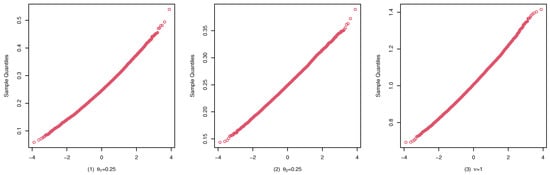
Figure 8.
qqplots of the CML estimates for (B1) with .
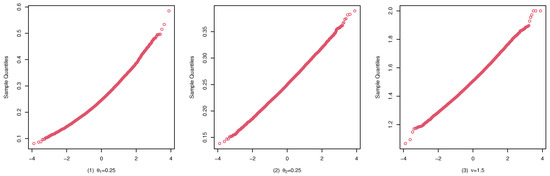
Figure 9.
qqplots of the CML estimates for (C1) with .
These studies indicate that the CML method seems to perform reasonably well. First, Table 1, Table 2 and Table 3 show that the standard deviation of the CML estimator is decreasing with the sample size increase and the mean of the CML estimator is closer to the true parameter value in general cases. Second, Figure 4, Figure 5 and Figure 6 account for the location and dispersion of the estimates, all of which indicate the consistency of the estimators. Third, Figure 7, Figure 8 and Figure 9 indicate the asymptotic normality of the CML estimator.
5. Real Data Example
In this section, we consider the number of weekly rainy days for the period from 1 January 2005 to 31 December 2010 at Hamburg–Neuwiedenthal in Germany, where a week is defined as being from Saturday to Friday and The data were collected from the German Weather Service (http://www.dwd.de/, accessed on 12 December 2018). The sample path and the ACF and PACF plots of the observations are given in Figure 10 and Figure 11, respectively.
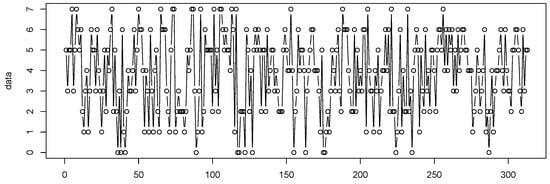
Figure 10.
Path of the weekly rainy days.
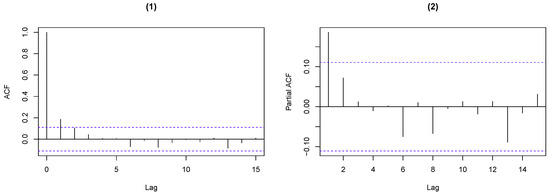
Figure 11.
ACF and PACF plots of the weekly rainy days. (1) shows that the ACF exhibits significant value for lag 1, and (2) presents that the PACF indicates an AR(1)-like autocorrelation structure.
By computation, the sample mean and variance are 3.8371 and 3.6753, and the BID of the data is 1.2371, which implies the data exhibits extra-binomial variation. Hence, we use the CMPBAR(1) model, BAR(1) model [2], BBAR(1) model [9], and GBAR(1) model [11] to fit data by the CML method. We compare the estimated standard error (SE), −log-likelihood (−log-lik), Akaike’s information criterion (AIC) and Bayesian information criterion (BIC), which are summarized in Table 4, including the fitted results of the CML estimate.
Table 4.
Estimates for the weekly rainy days and SE are shown in parentheses.
From Table 4, the CMPBAR(1) model takes the smallest values of the −log-lik, AIC, and BIC. Hence, the CMPBAR(1) model might be more appropriate for the weekly rainy days.
To illustrate the adequacy of the CMPBAR(1) model, we consider the fitted Pearson residual analysis of the CMPBAR(1) model. By computation, the mean and variance of the fitted Pearson residual are and , respectively. The residual analysis in Figure 12 shows that this model performs rather well.
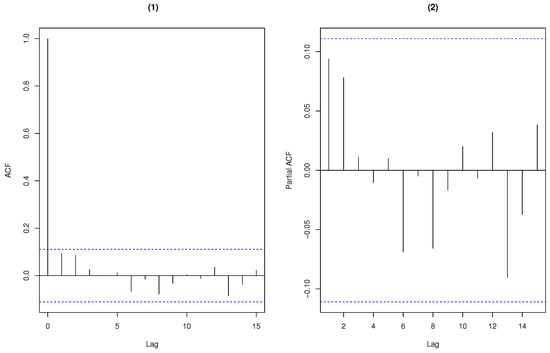
Figure 12.
Pearson residual analysis of the weekly rainy days. (1) ACF (2) PACF.
In addition, to further check the adequacy of the CMPBAR(1) model, we present the probability integral transform (PIT) (if the fitted model is adequate, its PIT histogram looks like that of a uniform distribution, see [10] for more discussion) in Figure 13 based on the fitted CMPBAR(1) model.
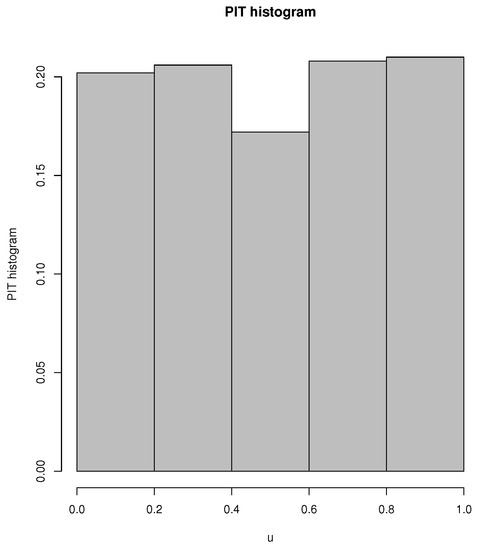
Figure 13.
PIT histogram based on the fitted CMPBAR(1) model.
As can be seen in Figure 13, the PIT histogram of the CMPBAR(1) model is close to uniformity, i.e., the PIT histogram confirms that the fitted CMPBAR(1) model works reasonably well for the weekly rainy days.
6. Concluding Remarks
This paper considers a new CMPB thinning operator and proposes a new CMPBAR(1) model, which provides an available method to model bounded data with under-dispersion, equi-dispersion, and over-dispersion. We discuss some properties of the new model, the estimate of the parameters, and its large-sample properties. Simulations are conducted to examine the finite sample performance of estimators. A real data example is provided to illustrate the applicability of the CMPBAR(1) model.
There are several directions in which we plan to take this work forward. First, the random coefficient CMPBAR(1) model can be introduced by
where and , “” is the CMPB thinning operator and the counting series in “”, and that in “” is independent and all of the counting series at time t is independent of ; see Weiß and Pollett [8] for the random coefficient BAR(1) model. Second, a correlated sign-thinning operator can be established by
where sign(x) = 1 if and sign(x)= if , is an exchangeable Bernoulli variable sequence with its pmf taking the form (5). Based on the correlated sign thinning operator, one can construct a -valued autoregressive model to analyze data with a range and under-dispersed, equi-dispersed, and over-dispersed. Third, a class of Conway–Maxwell–Poisson-binomial generalized autoregressive conditional heteroskedasticity models can be considered by
where is the parameter vector involving in the model (see Ristić et al. [20] and Chen et al. [18] for ARCH-type models, Lee and Lee [21] and Chen et al. [22] for GARCH-type models for bounded data). In addition, a semi-parameter version can be considered by
where is the parameter vector involved in the model, is the covariate process imposed in the observe process , and is the parameter vector involving in .
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/e25010126/s1.
Author Contributions
Conceptualization, H.C.; methodology, H.C. and J.Z.; software, H.C. and J.Z.; validation, H.C., J.Z. and X.L.; formal analysis, H.C.; investigation, H.C.; resources, H.C.; data curation, H.C. and J.Z.; writing—original draft preparation, H.C.; writing—review and editing, H.C.; visualization, H.C., J.Z. and X.L.; supervision, H.C., J.Z. and X.L. All authors have read and agreed to the published version of the manuscript.
Funding
Chen’s work is supported by the Natural Science Foundation of Henan Province No. 222300420127 and Postdoctoral research in Henan Province No. 202103051. Liu’s work is supported by the Basic Research Programs of Shanxi Province No. 202103021223084.
Data Availability Statement
The weekly rainy days for the period from 1st January 2005 to 31st December 2010 at Hamburg–Neuwiedenthal in Germany is collected from the German Weather Service (http://www.dwd.de/ accessed on 12 December 2018), where a week is defined as being from Saturday to Friday and and the data can be found in supplementary materials.
Acknowledgments
The authors thank the Editor-in-Chief and the anonymous referees for the valuable comments and suggestions that result in a substantial improvement of this paper.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Steutel, F.W.; van Harn, K. Discrete analogues of self-decomposability and stability. Ann. Probab. 1979, 7, 893–899. [Google Scholar] [CrossRef]
- McKenzie, E. Some simple models for discrete variate time series. Water Resour Bull. 1985, 21, 645–650. [Google Scholar] [CrossRef]
- Weiß, C.H. Monitoring correlated processes with binomial marginals. J. Appl. Stat. 2009, 36, 399–414. [Google Scholar] [CrossRef]
- Weiß, C.H. Jumps in binomial AR(1) processes. Stat. Probab. Lett. 2009, 79, 2012–2019. [Google Scholar] [CrossRef]
- Weiß, C.H. A new class of autoregressive models for time series of binomial counts. Commun. Stat.-Theory Methods 2009, 38, 447–460. [Google Scholar] [CrossRef]
- Weiß, C.H.; Kim, H.Y. Binomial AR(1) processes: Moments, cumulants, and estimation. Statistics 2013, 47, 494–510. [Google Scholar] [CrossRef]
- Weiß, C.H.; Kim, H.Y. Parameter estimation for binomial AR(1) models with applications in finance and industry. Stat. Pap. 2013, 54, 563–590. [Google Scholar] [CrossRef]
- Weiß, C.H.; Pollett, P.K. Binomial autoregressive processes with density dependent thinning. J. Time Ser. Anal. 2014, 35, 115–132. [Google Scholar] [CrossRef]
- Weiß, C.H.; Kim, H.Y. Diagnosing and modeling extra-binomial variation for time-dependent counts. Appl. Stoch. Model. Bus. Ind. 2014, 30, 588–608. [Google Scholar] [CrossRef]
- Weiß, C.H. An Introduction to Discrete-Valued Time Series; John Wiley & Sons: Chichester, UK, 2018. [Google Scholar]
- Kang, Y.; Wang, D.H.; Yang, K. Extended binomial AR(1) processes with generalized binomial thinning operator. Commun. Stat.-Theory Methods 2020, 49, 3498–3520. [Google Scholar] [CrossRef]
- Ristić, M.M.; Nastić, A.S.; Ilić, A.V.M. A geometric time series model with dependent Bernoulli counting series. J. Time Ser. Anal. 2013, 34, 466–476. [Google Scholar] [CrossRef]
- Shmueli, G.; Minka, T.P.; Kadane, J.B.; Borle, S.; Boatwright, P. A useful distribution for fitting discrete data: Revival of the Conway-Maxwell-Poisson distribution. Appl. Stat. 2005, 54, 127–142. [Google Scholar] [CrossRef]
- Borges, P.; Rodrigues, J.; Balakrishnan, N.; Bazn, J. A COM-Poisson type generalization of the binomial distribution and its properties and applications. Stat. Probab. Lett. 2014, 87, 158–166. [Google Scholar] [CrossRef]
- Daly, F.; Gaunt, R.E. The Conway-Maxwell-Poisson distribution: Distributional theory and approximation. ALEA Lat. Am. J. Probabability Math. Stat. 2016, 13, 635–658. [Google Scholar] [CrossRef]
- Kadane, J.B. Sums of possibly associated bernoulli variables: The Conway-Maxwell-Binomial distribution. Bayesian Anal. 2016, 11, 363–374. [Google Scholar] [CrossRef]
- Seneta, E. Non-Negative Matrices and Markov Chains, 2nd ed.; Springer: New York, NY, USA, 1983. [Google Scholar]
- Chen, H.; Li, Q.; Zhu, F. Two classes of dynamic binomial integer-valued ARCH models. Braz. J. Probab. Stat. 2020, 34, 685–711. [Google Scholar] [CrossRef]
- Amemiya, T. Advanced Econometrics; Harvard University Press: Cambridge, UK, 1985; pp. 110–112. [Google Scholar]
- Ristić, M.M.; Weiß, C.H.; Janjić, A.D. A binomial integer-valued ARCH model. Int. J. Biostat. 2016, 12, 20150051. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Lee, S. CUSUM test for general nonlinear integer–valued GARCH models: Comparison study. Ann. Inst. Stat. Math. 2019, 71, 1033–1057. [Google Scholar] [CrossRef]
- Chen, H.; Li, Q.; Zhu, F. A new class of integer-valued GARCH models for time series of bounded counts with extra-binomial variation. AStA Adv. Stat. Anal. Vol. 2022, 106, 243–270. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).