

State Space Modeling of Event Count Time Series



Abstract
:1. Introduction
2. Materials and Methods
2.1. Independent Components Linear State Space (IC-LSS) Models
2.2. Nonlinear State Space (NLSS) Models
2.3. Iterated Extended Kalman Filter (IEKF)
2.4. Singular Value Decomposition Iterated Extended Kalman Filter (SVD-IEKF)
2.5. Non-Dynamic Regression Model: Gaussian Case
2.6. Non-Dynamic Regression Model: Poisson Case
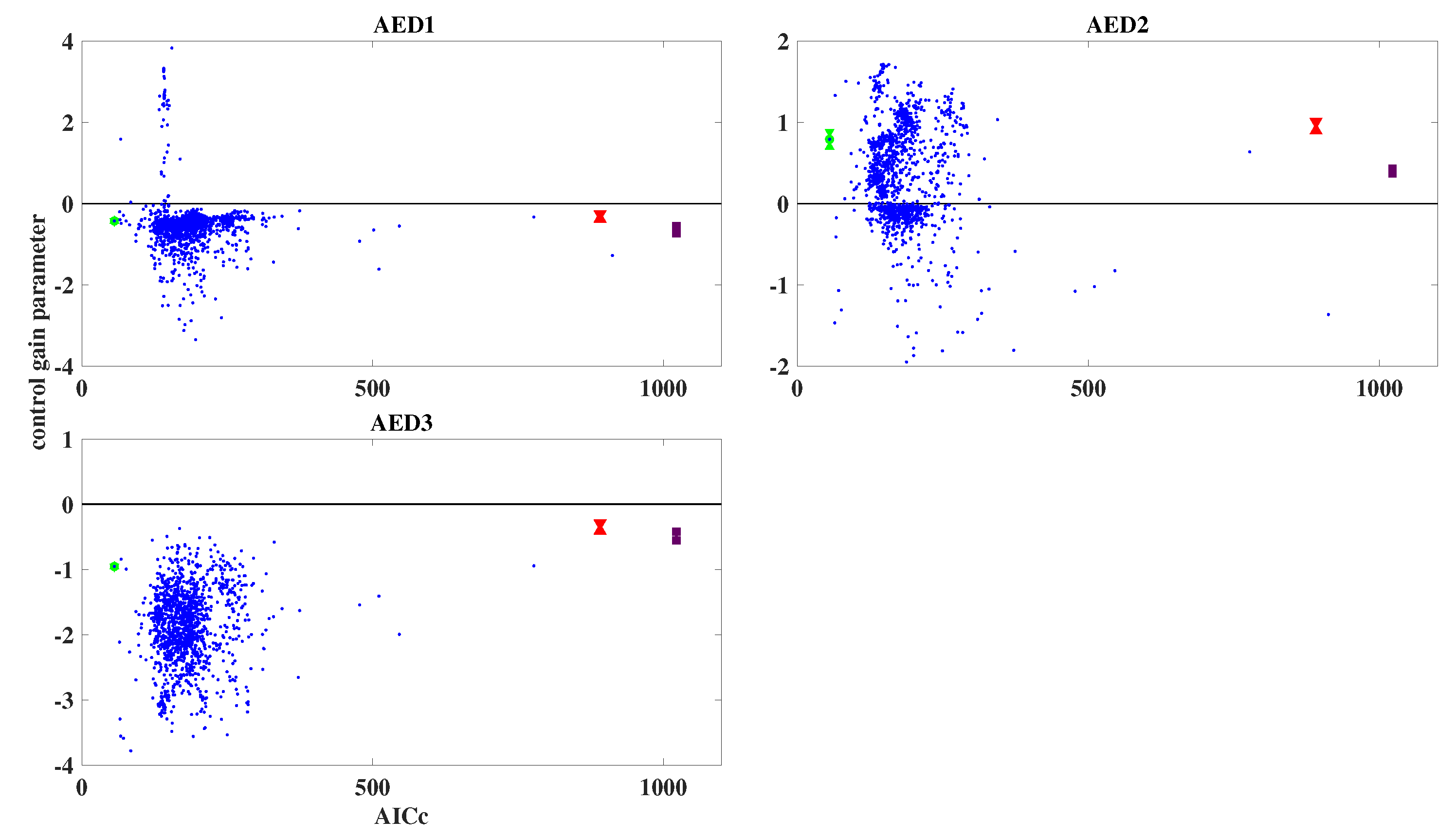
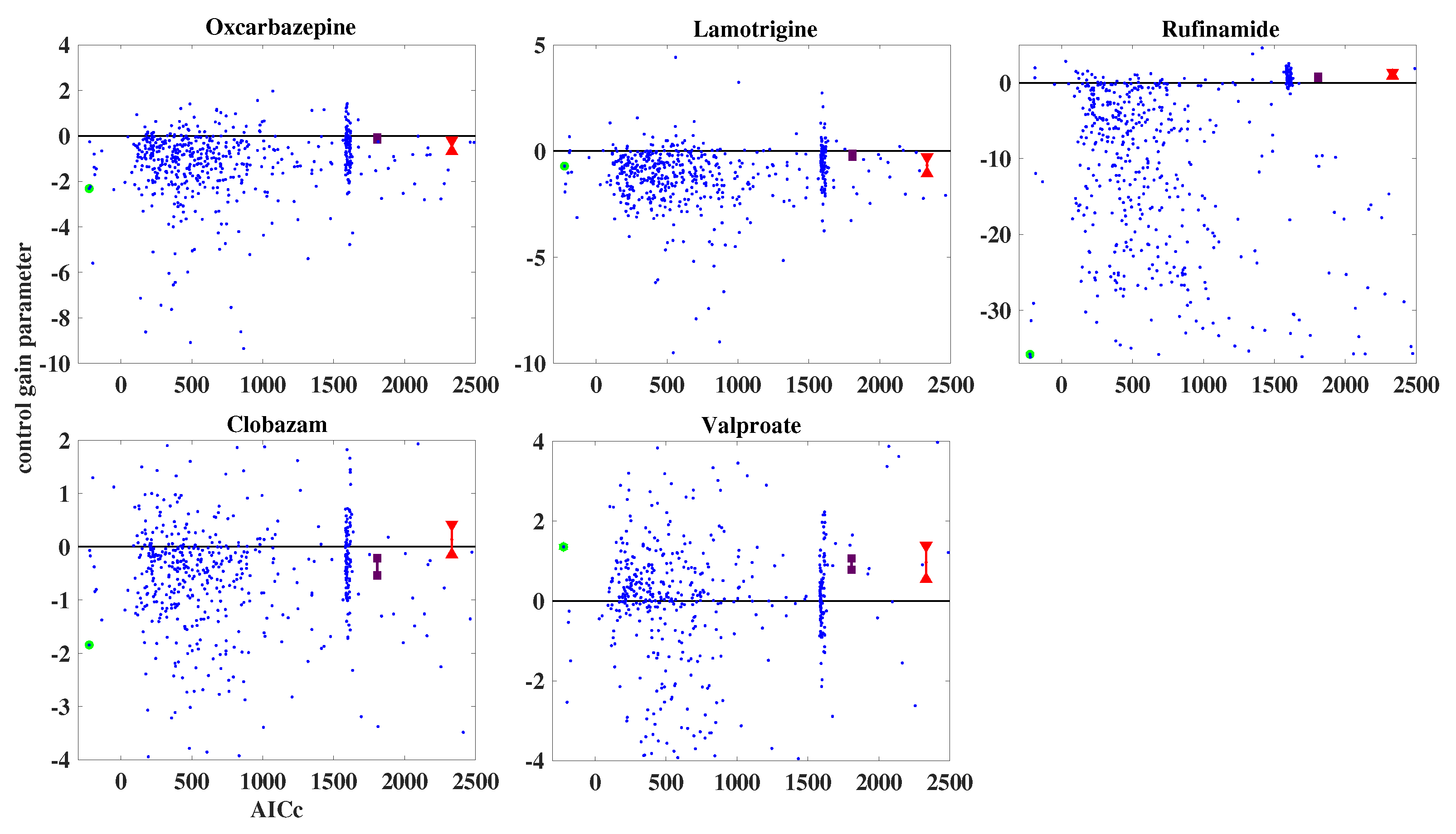
2.7. Parameter Estimation and Ensembles of Models
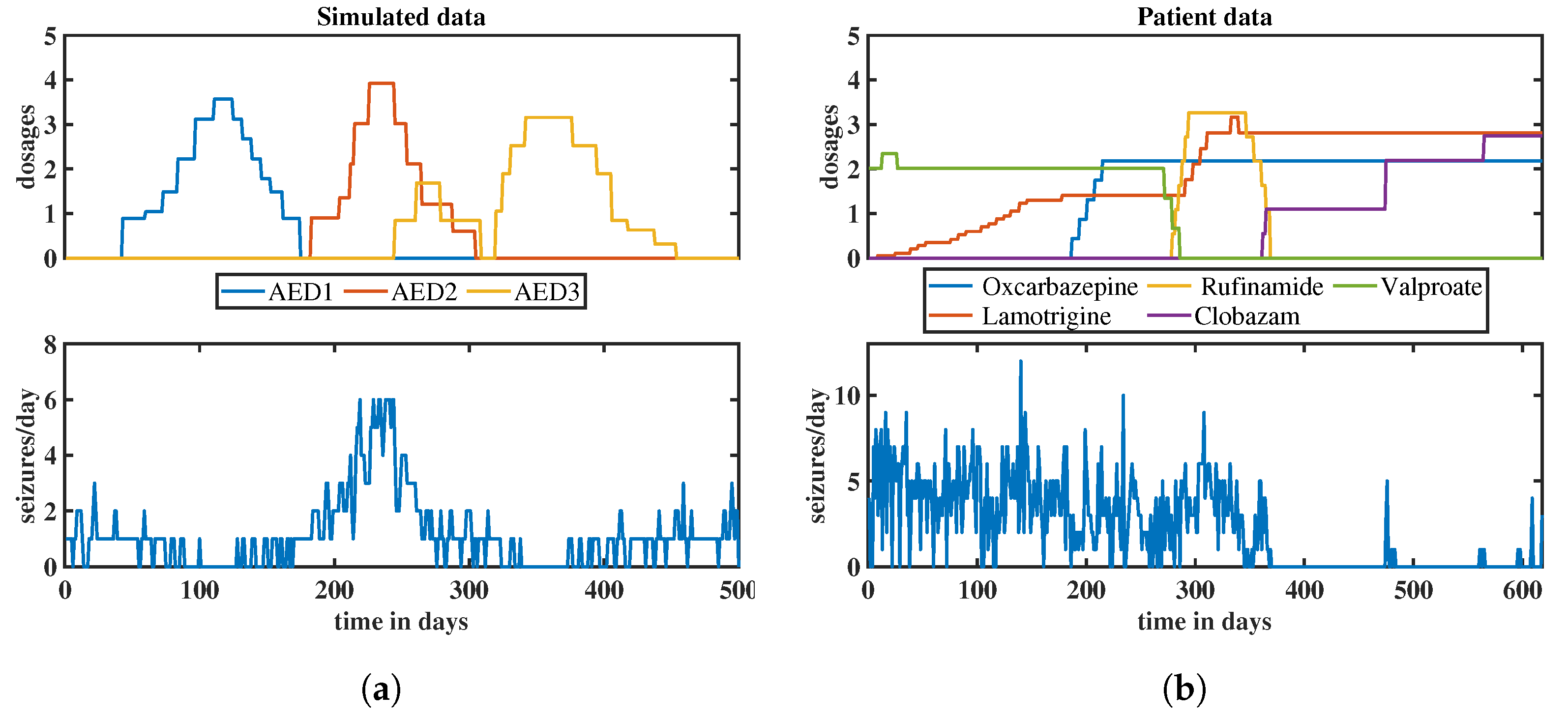
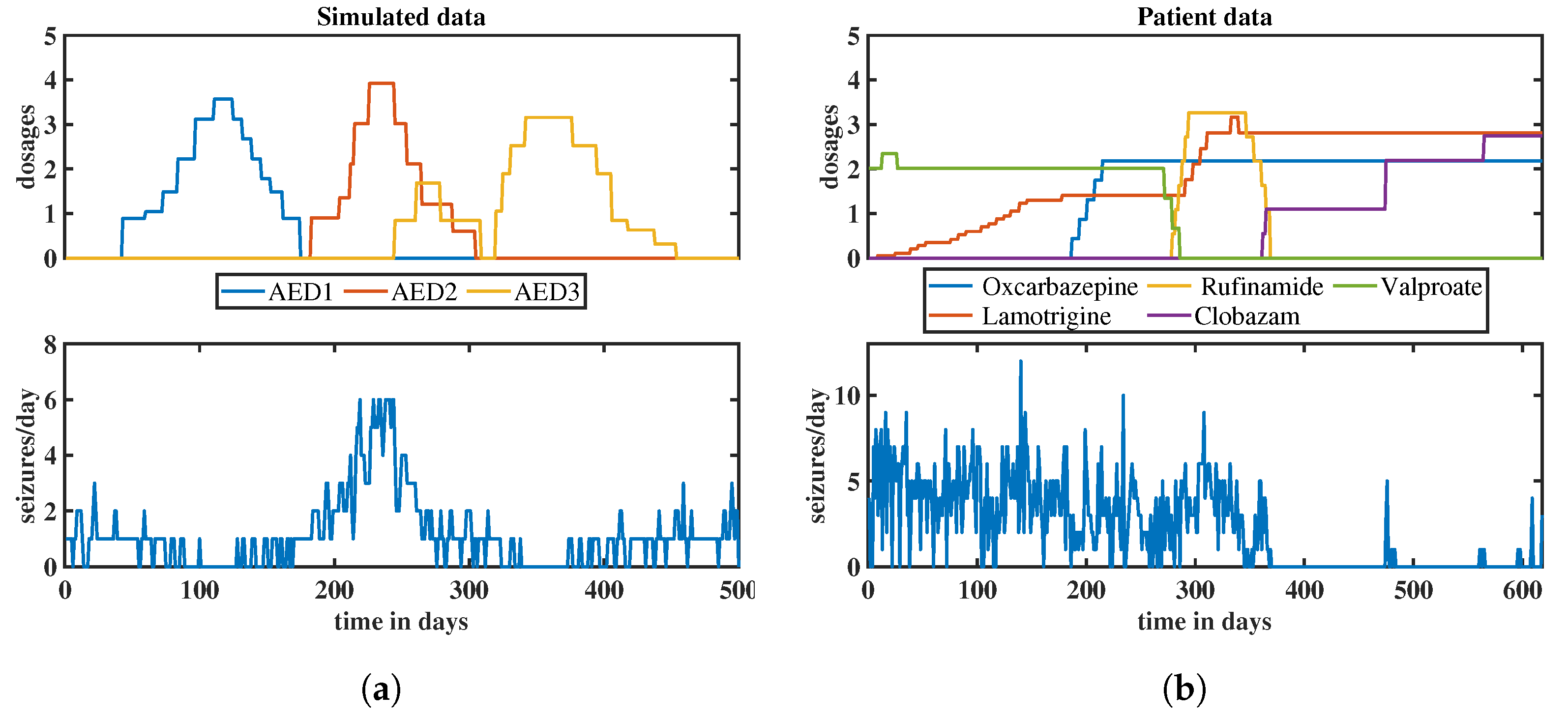
2.8. Simulated Data
2.9. Patient Data
3. Results
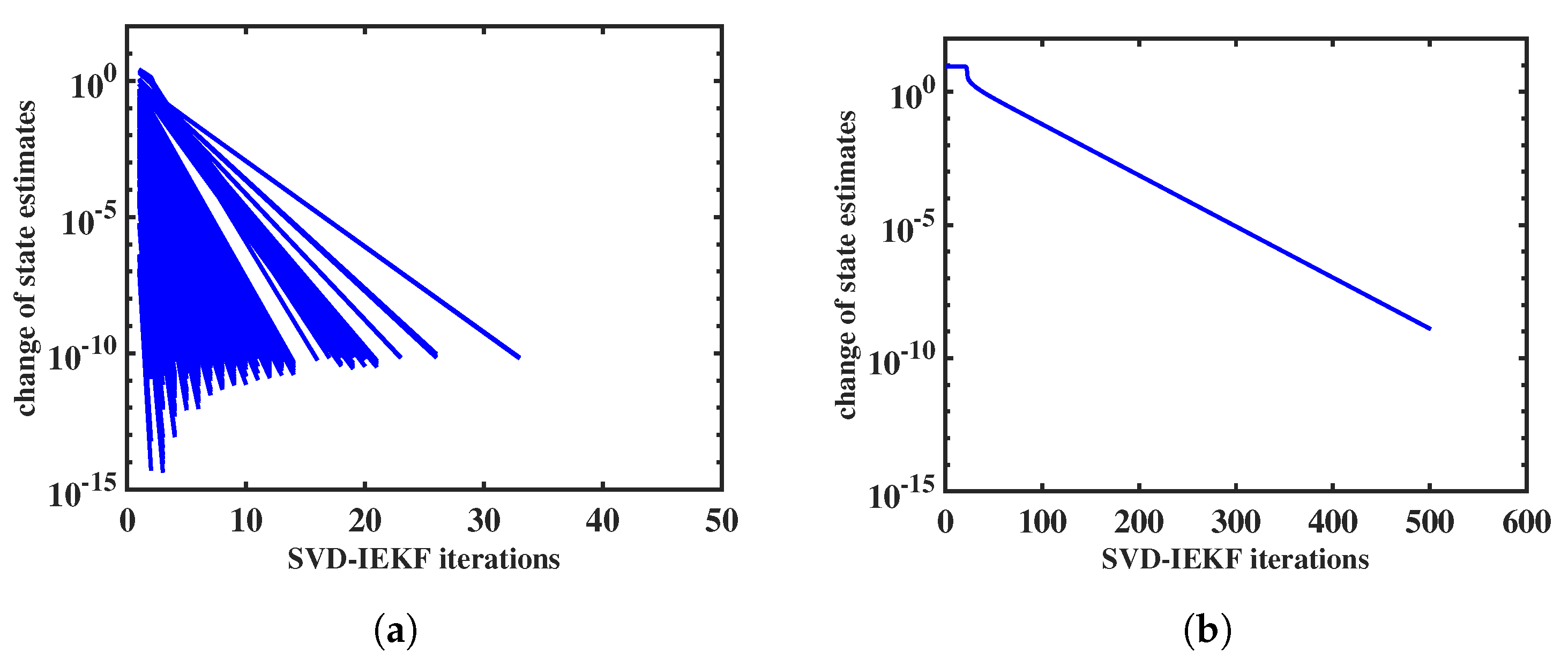
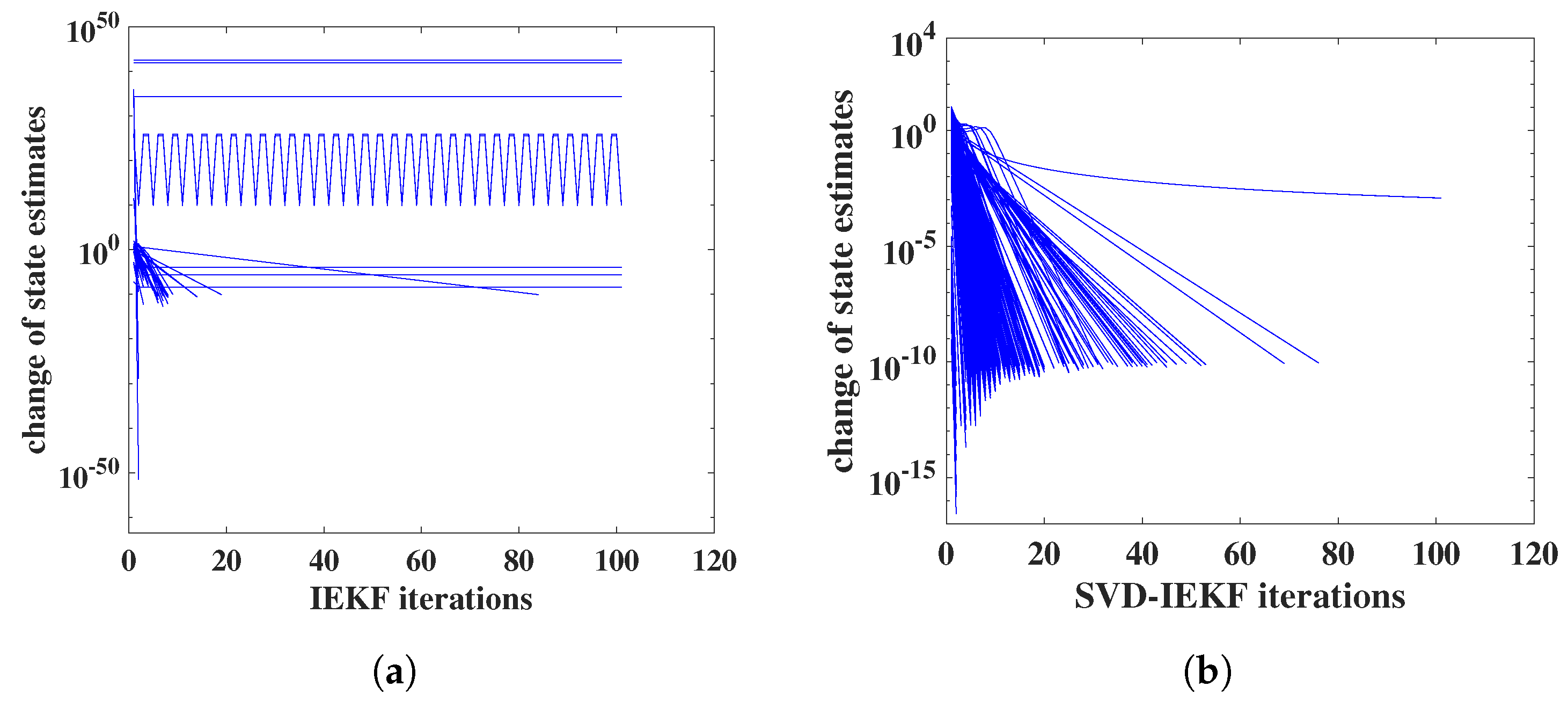
3.1. Convergence Behavior of Iteration
3.2. Results of Ensemble Approach: Simulated Data
3.3. Result of Ensemble Approach: Patient Data
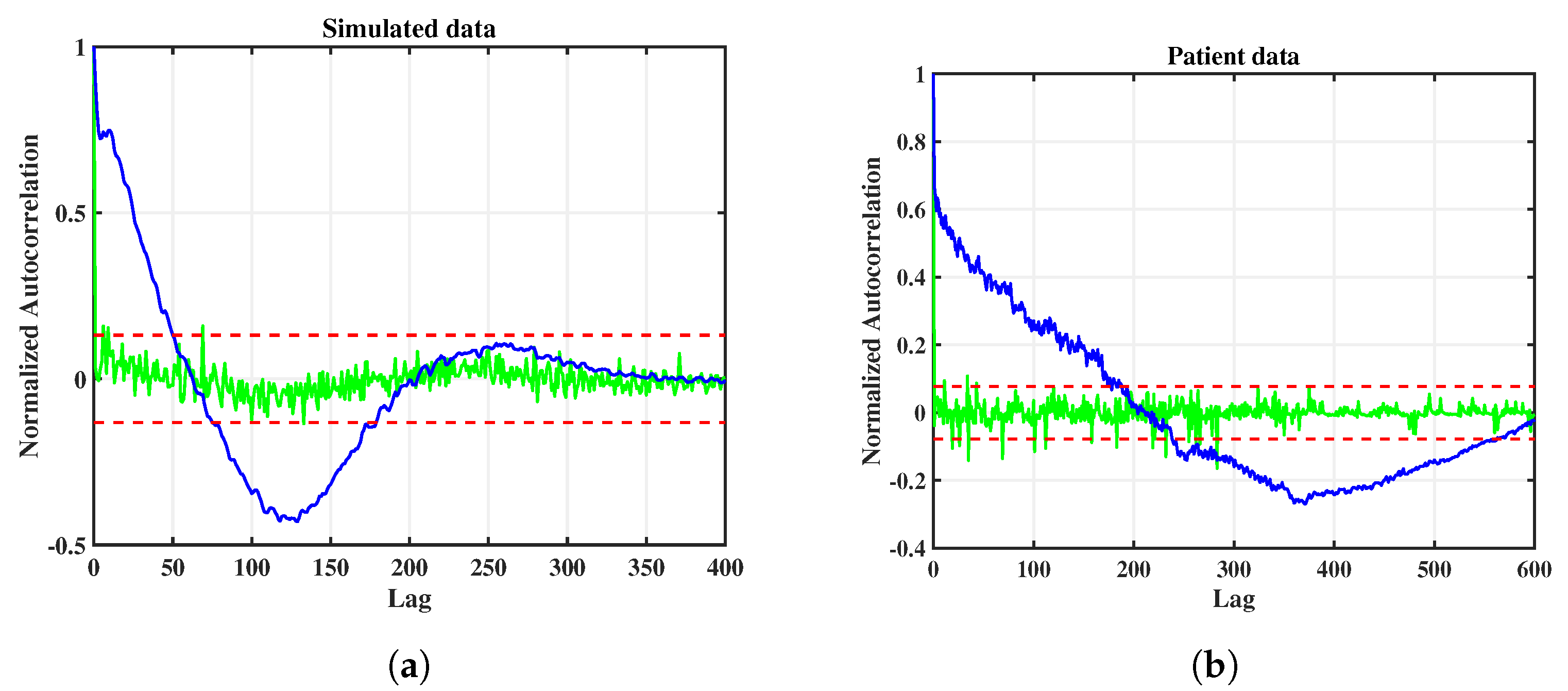
3.4. Innovation Whiteness Test
4. Discussion
- In an initial study, we had proposed to analyze event count time series by purely linear Gaussian state space modeling, using the standard linear Kalman filter [24].
- Then, as a generalization, we employed nonlinear state space modeling, such that a linear dynamical equation was combined with a nonlinear observation function; the exponential function was chosen. State space modeling was performed by the iterated extended Kalman filter (IEKF) [25].
- As a further step of improvement, the standard IEKF was replaced by the numerically superior singular value decomposition variant of the IEKF [26].
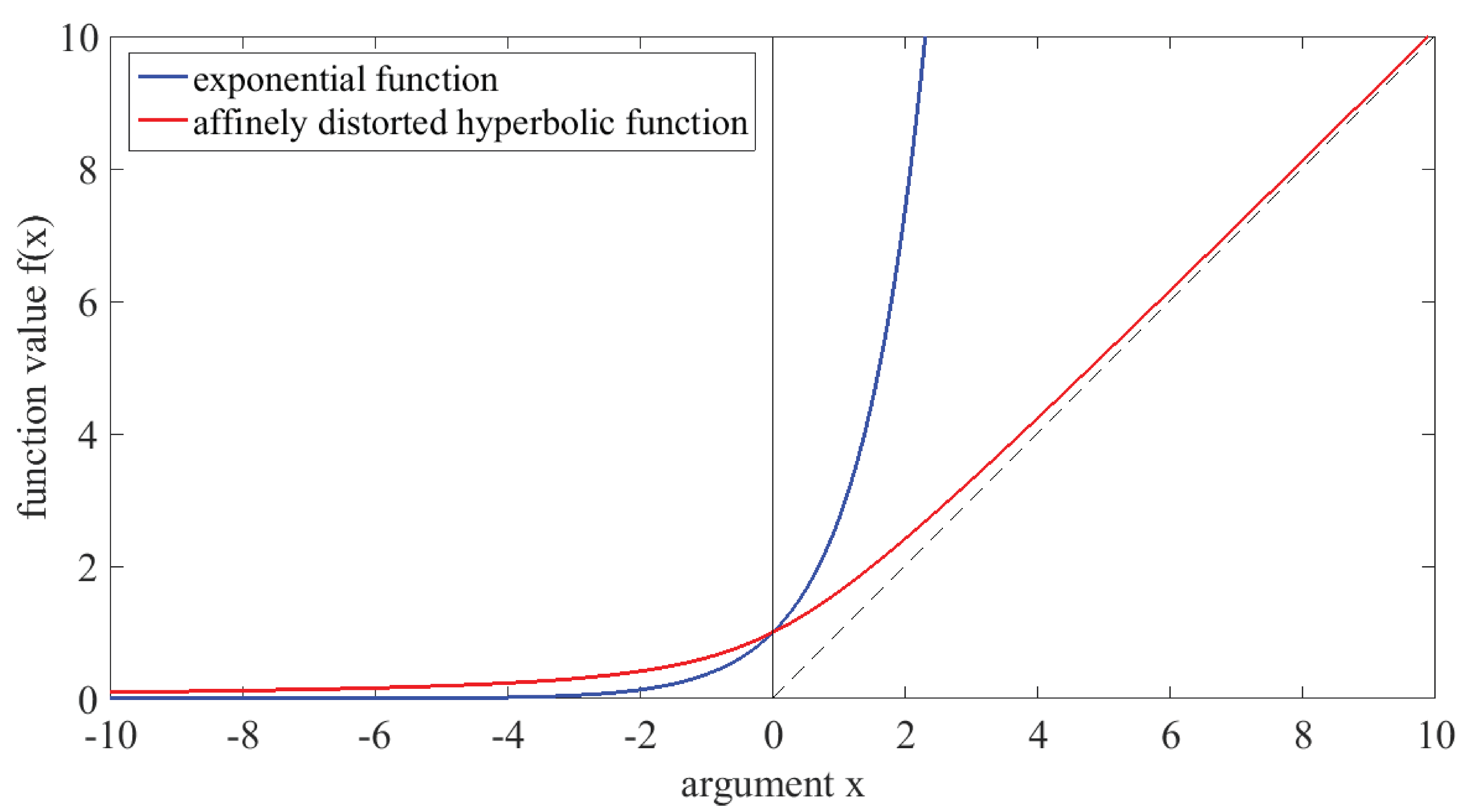
- In the present paper, we replaced the exponential function with the “affinely distorted hyperbolic” function; alternatively, the “softplus function” of Weiß and coworkers could also have been employed. We have not yet systematically compared both functions, but expect that they would display similar performance.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AED | Anti-epileptic drug |
| IC-LSS | Independent components linear state space |
| NLSS | Nonlinear state space |
| AR | Autoregressive |
| ARMA | Autoregressive moving average |
| IEKF | Iterated extended Kalman filter |
| SVD | Singular value decomposition |
| CD | Cholesky decomposition |
| BFGS | Broyden–Fletcher–Goldfarb–Shanno |
| AICc | corrected Akaike information criterion |
Appendix A. Block Diagonal Structure of A and Q
Appendix B. Iterated Extended Kalman Filter (IEKF) Algorithms
| Algorithm A1 Iterated Extended Kalman Filter (IEKF) |
| Require: Initial state estimate: Require: Initial covariance matrix:
|
| Algorithm A2 Singular Value Decomposition Iterated Extended Kalman Filter (SVD-IEKF) |
| Require: Initial state estimate: Require: Initial covariance matrix: Require: Factorized dynamic noise covariance matrix: Require: Factorized observation noise covariance matrix:
|
Appendix C. Matlab Code for Generating Simulated Data
| Listing A1. MATLAB code for generating simulated data |
 |
References
- Nelder, J.; Wedderburn, R. Generalized linear models. J. R. Stat. Soc. Ser. A 1972, 135, 370–384. [Google Scholar] [CrossRef]
- West, M.; Harrison, P.J.; Migon, H.S. Dynamic generalized linear models and Bayesian forecasting. J. Am. Stat. Assoc. 1985, 80, 73–83. [Google Scholar] [CrossRef]
- Fahrmeir, L.; Tutz, G.; Hennevogl, W.; Salem, E. Multivariate Statistical Modelling Based on Generalized Linear Models, 2nd ed.; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2001; Volume 425. [Google Scholar]
- McKenzie, E. Some simple models for discrete variate time series. J. Am. Water Resour. Assoc. 1985, 21, 645–650. [Google Scholar] [CrossRef]
- Rydberg, T.H.; Shephard, N. BIN Models for Trade-by-Trade Data. Modelling the Number of Trades in a Fixed Interval of Time; Technical Report; Nuffield College: Oxford, UK, 1999. [Google Scholar]
- Weiß, C.H. An Introduction to Discrete-Valued Time Series; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Liu, M.; Zhu, F.; Li, J.; Sun, C. A Systematic Review of INGARCH Models for Integer-Valued Time Series. Entropy 2023, 25, 922. [Google Scholar] [CrossRef] [PubMed]
- Kailath, T.; Sayed, A.; Hassibi, B. Linear Estimation; Prentice Hall: Hoboken, NY, USA, 2000. [Google Scholar]
- Galka, A.; Ozaki, T.; Muhle, H.; Stephani, U.; Siniatchkin, M. A data-driven model of the generation of human EEG based on a spatially distributed stochastic wave equation. Cogn. Neurodyn. 2008, 2, 101–113. [Google Scholar] [CrossRef]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: Princeton, NY, USA, 1994. [Google Scholar]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice with MATLAB, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Skoglund, M.; Hendeby, G.; Axehill, D. Extended Kalman filter modifications based on an optimization view point. In Proceedings of the 18th International Conference on Information Fusion, Washington, DC, USA, 6–9 July 2015; pp. 1856–1861. [Google Scholar]
- Wang, L.; Libert, G.; Manneback, P. Kalman filter algorithm based on singular value decomposition. In Proceedings of the 31st IEEE Conference on Decision and Control, Tucson, AZ, USA, 16–18 December 1992; pp. 1224–1229. [Google Scholar]
- Zeger, S.L.; Irizarry, R.; Peng, R.D. On time series analysis of public health and biomedical data. Annu. Rev. Public Health 2006, 27, 57–79. [Google Scholar] [CrossRef]
- Zeger, S.L. A regression model for time series of counts. Biometrika 1988, 75, 621–629. [Google Scholar] [CrossRef]
- Allard, R. Use of time-series analysis in infectious disease surveillance. Bull. World Health Organ. 1998, 76, 327. [Google Scholar]
- Albert, P.S. A two-state Markov mixture model for a time series of epileptic seizure counts. Biometrics 1991, 47, 1371–1381. [Google Scholar] [CrossRef]
- Balish, M.; Albert, P.S.; Theodore, W.H. Seizure frequency in intractable partial epilepsy: A statistical analysis. Epilepsia 1991, 32, 642–649. [Google Scholar] [CrossRef]
- Krauss, G.L.; Sperling, M.R. Treating patients with medically resistant epilepsy. Neurol. Clin. Pract. 2011, 1, 14–23. [Google Scholar] [CrossRef] [PubMed]
- Kanner, A.M.; Ashman, E.; Gloss, D.; Harden, C.; Bourgeois, B.; Bautista, J.F.; Abou-Khalil, B.; Burakgazi-Dalkilic, E.; Park, E.L.; Stern, J.; et al. Practice guideline update summary: Efficacy and tolerability of the new antiepileptic drugs I: Treatment of new-onset epilepsy: Report of the Guideline Development, Dissemination, and Implementation Subcommittee of the American Academy of Neurology and the American Epilepsy Society. Neurology 2018, 91, 74–81. [Google Scholar] [PubMed]
- Tharayil, J.J.; Chiang, S.; Moss, R.; Stern, J.M.; Theodore, W.H.; Goldenholz, D.M. A big data approach to the development of mixed-effects models for seizure count data. Epilepsia 2017, 58, 835–844. [Google Scholar] [CrossRef] [PubMed]
- Chiang, S.; Vannucci, M.; Goldenholz, D.M.; Moss, R.; Stern, J.M. Epilepsy as a dynamic disease: A Bayesian model for differentiating seizure risk from natural variability. Epilepsia Open 2018, 3, 236–246. [Google Scholar] [CrossRef]
- Wang, E.; Chiang, S.; Cleboski, S.; Rao, V.; Vannucci, M.; Haneef, Z. Seizure count forecasting to aid diagnostic testing in epilepsy. Epilepsia 2022, 63, 3156–3167. [Google Scholar] [CrossRef]
- Galka, A.; Boor, R.; Doege, C.; von Spiczak, S.; Stephani, U.; Siniatchkin, M. Analysis of epileptic seizure count time series by ensemble state space modelling. In Proceedings of the 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 5601–5605. [Google Scholar]
- Moontaha, S.; Galka, A.; Meurer, T.; Siniatchkin, M. Analysis of the effects of medication for the treatment of epilepsy by ensemble Iterative Extended Kalman filtering. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 187–190. [Google Scholar]
- Moontaha, S.; Galka, A.; Siniatchkin, M.; Scharlach, S.; von Spiczak, S.; Stephani, U.; May, T.; Meurer, T. SVD Square-root Iterated Extended Kalman Filter for Modeling of Epileptic Seizure Count Time Series with External Inputs. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; pp. 616–619. [Google Scholar]
- Galka, A.; Wong, K.F.K.; Ozaki, T.; Muhle, H.; Stephani, U.; Siniatchkin, M. Decomposition of neurological multivariate time series by state space modelling. Bull. Math. Biol. 2011, 73, 285–324. [Google Scholar] [CrossRef]
- Weiß, C.H.; Zhu, F.; Hoshiyar, A. Softplus INGARCH models. Stat. Sin. 2022, 32, 1099–1120. [Google Scholar] [CrossRef]
- Kalman, R.E.; Bucy, R.S. New results in linear filtering and prediction theory. J. Basic Eng. 1961, 83, 95–108. [Google Scholar] [CrossRef]
- Jazwinski, A. Stochastic Processes and Filtering Theory; Academic Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Björck, Å. Numerical Methods in Matrix Computations; Texts in Applied Mathematics; Springer: Berlin/Heidelberg, Germany, 2015; Volume 59. [Google Scholar]
- Kulikova, M.V.; Tsyganova, J.V. Improved discrete-time Kalman filtering within singular value decomposition. IET Control Theory Appl. 2017, 11, 2412–2418. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Kulikova, M.V.; Kulikov, G.Y. SVD-based factored-form Cubature Kalman Filtering for continuous-time stochastic systems with discrete measurements. Automatica 2020, 120, 109110. [Google Scholar] [CrossRef]
- Godolphin, E.; Triantafyllopoulos, K. Decomposition of time series models in state-space form. Comput. Stat. Data Anal. 2006, 50, 2232–2246. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Meaning and/or Name | Dimension |
|---|---|---|
| data vector | n | |
| observation noise vector | n | |
| state vector | m | |
| dynamical noise vector | m | |
| external control vector | u | |
| observation matrix | ||
| state transition matrix | ||
| observation noise covariance matrix | ||
| dynamical noise covariance matrix | ||
| control gain matrix |
| Anti-Epileptic Drug | AED1 | AED2 | AED3 |
|---|---|---|---|
| correct values | |||
| estimated values (best model) | |||
| estimated errors (best model) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moontaha, S.; Arnrich, B.; Galka, A. State Space Modeling of Event Count Time Series. Entropy 2023, 25, 1372. https://doi.org/10.3390/e25101372
Moontaha S, Arnrich B, Galka A. State Space Modeling of Event Count Time Series. Entropy. 2023; 25(10):1372. https://doi.org/10.3390/e25101372
Chicago/Turabian StyleMoontaha, Sidratul, Bert Arnrich, and Andreas Galka. 2023. "State Space Modeling of Event Count Time Series" Entropy 25, no. 10: 1372. https://doi.org/10.3390/e25101372
APA StyleMoontaha, S., Arnrich, B., & Galka, A. (2023). State Space Modeling of Event Count Time Series. Entropy, 25(10), 1372. https://doi.org/10.3390/e25101372