1. Introduction
The behavior of the group of autonomous agents includes a variety of physical and cognitive actions, like collective motion and cooperative decision-making. Each of these actions depends on the individual abilities of the agents, on the division of the agents among the teams, and on the division of labor between the agents and the teams.
To simplify control of the teams’ and the group’s activities, some of the agents are often determined as leaders, whose task is to influence the other agents and promote them to fulfill the mission. Such procedures are widely known as elections in distributed systems, which are considered both in social and political processes and in different contexts of computer science and robots’ control [
1,
2,
3].
Given a group of communicating agents, elections are conducted as follows: The agents consider the candidate agents, and after deliberations, they identify and label a certain agent as the leader. Then, the elected leader influences the other agents and coordinates their activities [
1]. Certainly, each team in the group can elect its leader, and then these leaders elect the leader of the group, which results in hierarchical control in the system.
The process that is close to the election of the leader is the selection of the leader [
4,
5,
6,
7]. In this process, the leader is selected according to the known characteristics of the agents and their correspondence with the characteristics required for fulfilling the mission of the group. Usually, after the section of the leader, the other agents are considered followers. Note that, in contrast to the election of the leader, the leader selection is not necessarily conducted by the agents but can be processed by the central coordinator or controller of the group.
Now, assume that the group leader or the team leader already exists. Then rises an inverse problem—to distinguish the leaders in the distributed system. Namely, given a group of communicating agents, it is required to identify the leaders, which are the agents who mostly influence the other agents in the group.
In the paper, the problem of distinguishing the leading agents is considered in the context of the classification problem [
8,
9]. In such a classification, it is assumed that the agents have different levels of expertise, and the cooperative classification is obtained by a certain version of plurality voting.
The most popular method of avoiding the influence of non-competent agents uses the weighted opinions of the agents. This method was implemented in the well-known Dawid–Skene algorithm [
10,
11], which iterates the expectation of the correct choice with respect to the agents’ expertise and maximizes the likelihood of the agents’ expertise with respect to the expected correct choice.
Another approach to selecting the competent agents was implemented in the algorithms [
12,
13], which are based on the similarities of the agents’ classifications, and in the algorithm [
14], where the competent agents are selected using the expectation bias [
15].
After selecting the subgroup of competent agents, the resulting classification is obtained using the opinions of these agents and ignoring the opinions of non-competent agents.
However, studies in social psychology [
16], which can be traced back to the well-known experiments by Asch [
17,
18], demonstrate that the opinion of the group member is highly influenced by the opinions of the other members of the group. Consequently, competent agents are not necessarily the most influential or leading agents. Together with that, it is reasonable to assume that the leader must be competent in certain fields and be elected on the basis of this competence (see the 11th rule by Peterson [
19]).
In the paper, we suggest a method of distinguishing the leaders in the group. The method considers the connectivity between the agents and creates the subgroups by maximizing the distances between the partitions formed by these subgroups.
Note that the elections in the group are internal processes in which the leaders are identified following certain criteria known to the agents, while distinguishing the leaders is an external operation in which the agents are characterized by their relations with the other agents. Thus, the distinguished leaders can differ from the elected leaders: elections specify who will govern, and distinguishing specifies who must govern.
The rest of the paper is organized as follows:
Section 2 includes a formulation of the problem, and
Section 3 considers an example that clarifies the problems of classification, distinguishing the competent agents, and distinguishing the leading agents.
Section 4 presents a suggested solution based on the connectivity between the agents and the Rokhlin distance between the agents’ subgroups.
Section 5 presents the methods of distinguishing the experts, and
Section 6 considers two examples that illustrate the relationship between the group of experts and the group of leaders.
Section 7 concludes the discourse.
2. Problem Formulation
The main problem considered in the paper is the problem of distinguishing the leaders in the group of agents. As indicated above, this problem differs from the problem of electing the leader and requires consideration of communication between the agents.
We consider the problem in the context of the classification of given items by a group of agents, where some of the agents are experts in the field of classification and others are deletants.
Consideration of these two problems gives rise to the third problem, which is the problem of relations between the group of leaders and the group of experts.
2.1. Distinguishing the Leaders
Let be a group of communicating agents conducting a certain common mission. Communication between the agents is defined by the directed graph in which the vertices are associated with the agents and the edges are defined by the adjacency matrix such that if agent communicates with agent and otherwise.
The problem of distinguishing the leaders in group is formulated as follows: Given the adjacency matrix it is required to recognize a subgroup of the agents such that the agents have maximal influence in the group .
Consideration of the agent’s influence in the group is based on the following intuition inspired by the flows on graphs (see, e.g., [
20]). Assume that each vertex
in the graph
is a source of unique colored flow and that the color of the vertex is a mix of its own color and the colors of the incoming flows. Then, the influence of the agent is associated with the impact of its vertex on the colors of the other vertices in the graph
.
The vertices
associated with the leading agents
are called the leading vertices. The leading agent such that its vertex in the graph
has no predecessors is called a dictator, and the leading agent whose vertex is a separating vertex (see, e.g., [
21]) is called a monarch.
2.2. Distinguishing the Experts
Let be a set of items, which represent certain objects, concepts, or symbols. Classification problem requires to label the items , , by labels, , such that each item is labeled by a single label.
Formally, the problem is to distribute the items , , over sets , , called classes, such that each item is included only in one class and that there is no item which is not included in some classes. Then, the resulting classification is the partition of the set , where , , for , and .
If classification is conducted by a single agent, then the resulting classification depends on the competence of this agent. The quality of classification is defined by the difference between the classification and the correct classification . Certainly, the correct classification is not available to the agent and is used for testing the classification methods.
Now assume that the classification is conducted by the indicated above group
of agents where each agent
,
, provides classification represented by the partition
. By the general assumption of “the wisdom of the crowd” techniques [
8,
9], some combination of the agents’ classification will provide classification
, which is as close as possible to the correct classification
.
Then, the problem is to aggregate the agents’ partitions into a single partition such that it, as best as possible, represents the correct partition .
The simplest method of creating the partition is plurality voting. By this method, the item is included in the class which was chosen by most agents (the ties are broken randomly). Despite its popularity, this method strongly depends on the competence of the agents, such that non-competent agents can influence the resulting classification.
To avoid such influence, in more sophisticated methods [
10,
11,
12,
13,
14], the problem is divided into two stages. First, using the agents’ classifications
,
, the agents competent in certain classes are distinguished, and second, the resulting classification
is obtained by aggregation of the classes provided by the competent agents.
2.3. Relationship between the Leaders and the Experts
Finally, assume that the group of communicating agents classifies the set of items to classes , .
In addition, assume that the group of the agents includes a non-empty subgroup of leaders and non-empty subgroup of experts.
Then, the problem is to check whether there exists a relationship between the set of leaders and the set of experts, and if it exists, what this relationship is.
We assume that in real-world situations, such a relationship is possible, and the leaders are assumed to be experts in at least one class. The problem is to confirm or withdraw this hypothesis.
3. Illustrative Example
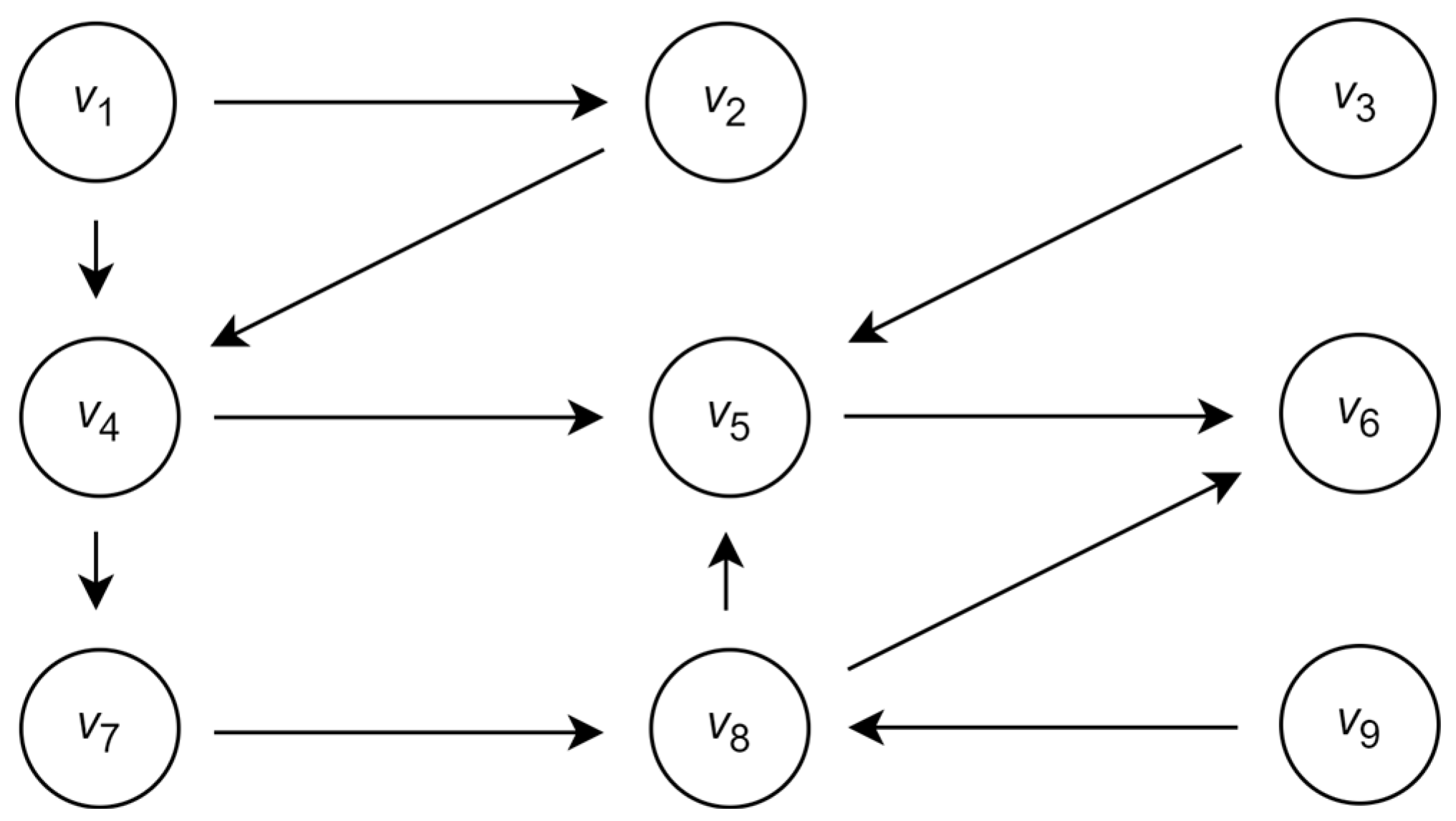
Assume that the group
includes
communicating agents and that communication between the agents is defined by the directed graph
, where the vertices
are associated with the agents and the edges
specify the communication between the corresponding agents. The graph
is shown in
Figure 1.
The sets of input and output vertices in this graph are presented in
Table 1.
As indicated above, in consideration of the agents’ impacts, each vertex of the graph is considered a source of the unique colored flow. The color absorbed by the vertex is a mix of its own color and the colors of the incoming flows. The impact of the agent is considered to be the impact of its vertex on the color of the other vertices. Then, intuitively, the vertex with a maximal number of predecessors and successors is associated with the agents with maximal influence.
Following the cardinality of the sets of input and output vertices, it can be supposed that the set of vertices associated with the candidates to the leading agents is such that is a dictator and is a monarch. In addition, because of the maximal number of predecessors, intuitively, vertex can also be considered a candidate for the leading vertex.
Assume that the agents
from the group
distribute
items
from the set
over
classes
. The results of the classification are shown in
Table 2.
In the table, the first agent
included the item
into the class
, the item
into the class
, the item
into the class
and so on, such that the partition
created by the first agent is
The second agent
included the item
into the class
, the item
into the class
, the item
into the class
and so on, such that the second agent is
and so on. Correct classification is represented by the following partition:
and the partition obtained by the plurality voting is
It is seen that the classifications provided by the agents , , are rather far from the correct classification as well as the aggregated classification obtained by plurality voting.
However, some agents created certain classes that are equivalent to the classes in the correct classification, namely,
agent —class ,
agent —class ,
agent —classes and ,
agent —class ,
agent —class ,
agent —classes and .
The other agents , and provided completely erroneous classifications, where despite the correct classification of some items, all obtained classes differ from the classes appearing in the correct classification. Then, aggregating the appropriate classes from the classifications created by the agents and avoiding classifications created by the agents , provides correct classification .
In the considered case of random classifications and relations between the agents, a possible set of leaders is and possible set of experts is , which means that there is no clear relationship between these sets. However, since in real-world situations, the leader must be competent in at least one field of knowledge, the absence of such a relationship is not obvious, and its consideration is reasonable.
4. Distinguishing the Group of Leaders Using the Entropy-Based Metric
Let be a group of agents and be the directed graph representing communication between the agents such that the vertices are associated with the agents and the edges define communication between the agents , .
Denote by a predecessor of the vertex such that the shortest path from to in the graph is of the length , and by a successor of the vertex such that the shortest path from to in the graph is of the length . In particular, is a direct predecessor of and is a direct successor of . For completeness, we also say that .
It is clear that each and all its predecessors are the predecessors of each successor of , and each and all its successors are the successors of each predecessor of .
For a vertex , denote by , the set of its predecessors and by the set of all its successors . The set of direct predecessors is denoted by and the set of direct successors is denoted by .
Given a graph , let be the set of direct predecessors of the vertex , be the sets of direct predecessors of the vertices , be the sets of direct predecessors of the vertices and so on, up to, but not including, the set that already appears among the sets of direct predecessors obtained at the previous steps.
Similarly, let be the set of direct successors of the vertex , be the sets of direct successors of the vertices , be the sets of direct successors of the vertices and so on, up to, but not including, the set that already appears among the sets of direct successors obtained at the previous steps.
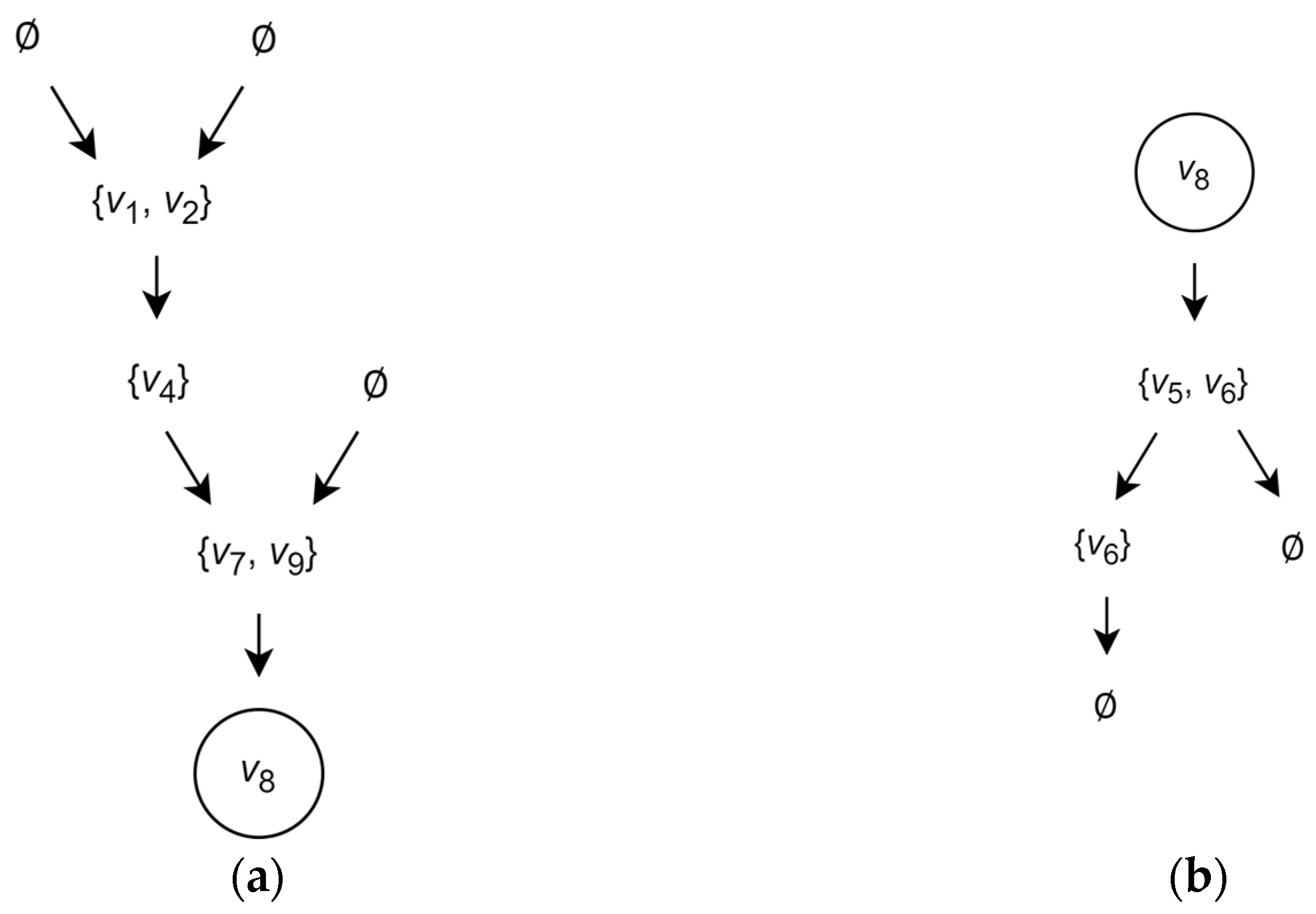
Finally, for the vertex let us form the predecessors’ tree and the successors’ tree . In the tree , the root is associated with the set and the leaves at their levels are associated with the sets , and so on, respectively. Similarly, in the , the root is associated with the set and the leaves at their levels are associated with the sets , and so on.
For illustration, the predecessors’ tree
and the successors’ tree
of the vertex
in the graph
are shown in
Figure 2.
The sets associated with the leaves of the trees and form, respectively, the predecessor cover and the successor cover of certain subsets of the set of vertices.
For example, the predecessor and successor covers of the vertex are and .
The predecessor cover
of the subset
of vertices is a set
of the predecessor covers
of the vertices
, and the successor cover
of the subset
of vertices is a set
of the successor covers
of the vertices
.
For example, for the indicated above set of vertices, the predecessor and successor covers are and .
Then, we say that the subset is a set of leading vertices if the distance between its predecessor cover and successor cover is maximal over all possible subsets of the set .
The agents associated with the leading vertices are called the leaders and the group of leading agents is called the leading group.
Distance
between the covers
and
can be calculated using different methods. Here, we suggest the distance measure, which is based on the Rokhlin metric [
22]. Since in the considered task, the main stress is on the communication between the agents and on the classification of the data items, the use of such an entropy-based metric is reasonable. Together with that, since the suggested method deals with formal sets of vertices in the graph, the other measures, e.g., the Ornstein distance [
23,
24], can be applied. For a comparison between the Rokhlin distance and the Ornstein distance, see [
25]. Note that both Rokhlin and Ornstein metrics require the defined probability measure on the sets; if such a probability does not exist, then the normalized Hamming distance [
12] can be used.
The Rokhlin metric is defined as follows. Let
be a probability space with a probability measure
on
, and let
,
,
,
, be a partition of
. The entropy of the partition
is the value
where
is base
and it is assumed that
. In addition, let
,
,
,
, be another partition of
. Then the conditional entropy of partition
given partition
is the value
where
and
.
The Rokhlin metric [
22], which defines the distance between partitions
and
is a sum
For basic properties of this metric and its role in dynamical systems theory, see [
26,
27]; for additional properties and comparison with the Ornstein metric, see [
25].
To apply this metric for measuring the distance between the covers and , note again that each of these sets does not necessarily cover the set of vertices , but the subsets and of this set. Then, let us add to each of these sets the set which completes it to the cover of .
Namely, the set
is completed with the set
and the set
is completed with the set
. As a result, the sets
cover the set
of vertices.
Then, it is required to define the probability measure
on the set of vertices. Since there is no additional information about the agents, we assume that
for each vertex
, and
for each subset
of vertices.
For the conditional entropy, we have
In this formula, the first term is equivalent to the conditional entropy of the sets
and
, the second term represents the influence of the sets
and
to the elements of the sets
and
, and the last term defines the conditional entropy of
with respect to
.
This definition is a direct extension of the definition of conditional entropy of the partitions. In fact, if the sets
and
are covers of
, then
and
. Then,
and if
and
are partitions of
, then it is equivalent to the definition of the conditional entropy.
Note that since and are covers of the set , the conditional entropy does not necessarily meet all the properties of the conditional entropy defined for the partitions. However, here, we will not consider specific properties of the conditional entropy of the covers but will use it directly to define the distance between the predecessor cover and the successor cover .
The distance
between the predecessor cover
and the successor cover
is defined by the Rokhlin distance between the covers
and
of the set
of vertices as
For example, the distance between the predecessor cover and the successor cover is calculated as follows:
The completed sets for the covers
and
are
and
. Then, the completed covers of the set
of vertices are
and
The probability of each vertex
is
. Then, conditional entropies
and
are (the zero terms are omitted).
The distance between the predecessor and successor covers of the set
of vertices is
For comparison, the distance between the indicated above predecessor cover
and the successor cover
of the vertex
is
Then, the group of the agents associated with the vertices of the group is preferable as a group of leaders than a group , which includes only one agent associated with the vertex .
Hereby, we defined the group of leading agents and suggested the criterion for its recognition among the other agents in the group . The same procedure can be continued over the group and then recurrently over the obtained groups up to distinguishing a unique leading agent.
The algorithmic solution to the problem of distinguishing the leading agents is a complex task which requires an exhaustive search among all possible subsets of the agents from the group or, that is, the same, among all possible subsets of vertices from the set . Together with that, certain heuristics omitting the vertices with a relatively small number of predecessors and successors can strongly decrease the number of candidate solutions.
5. Distinguishing the Group of Experts
Assume that the group of agents considers the set of items and each agent , , provides partition of the set to classes. The resulting classification is an aggregated partition created from the agents’ partitions , , and to obtain the correct partition it is required to recognize partitions provided by the competent agents and avoid partitions provided by non-competent agents.
Distinguishing the experts is based on the assumption that the agents with the same competence in the same fields provide similar classifications of the items related to their field of expertise and can provide different classifications of the items that are outside of the scope of their competence [
12]. In other words, we follow the well-known phrase by Father Dominique Bouhours ([
28] (p. 125), punctuation and grammar preserved):
“Great Minds often think alike on the same Occasions, and we are not always to suppose, that such Thoughts are borrow’d from one another when exprest by Persons of the same heroick Sentiments.”
Following this assumption, agent is considered a weak expert in a certain class if the agent’s partition includes and there exist the other agents , such that their partitions , ,… include . If the partition class is at the same position as in the partitions , ,…, then the agent is called strong expert or expert, for briefness.
The number of agents with equivalent classes required for specifying the agent as an expert varies and depends on the number of agents in the group. Following general statistical assumptions, we say that the number of such agents is at least of and, for small groups, is not less than .
As indicated above, there exist several algorithms of classification that implement the difference between the opinions of competent and non-competent agents [
10,
11,
12,
13]. In particular, the Distance-Based Collaborative Classification (DBCC) algorithm [
12] directly considers the normalized Hamming distance
between the partitions
and
with respect to each class
where
is a symmetric difference between the classes
and
.
If on the set
of items, a probability measure
is defined, then using this measure, the distance between the partitions
and
of
with respect to the class
can be defined as
or in the form of the Rokhlin metric as
Below, we assume that the experts are already distinguished by these or other methods and consider the relationship between the group of leaders and the group of experts.
6. Relationship between the Group of Leaders and the Group of Experts
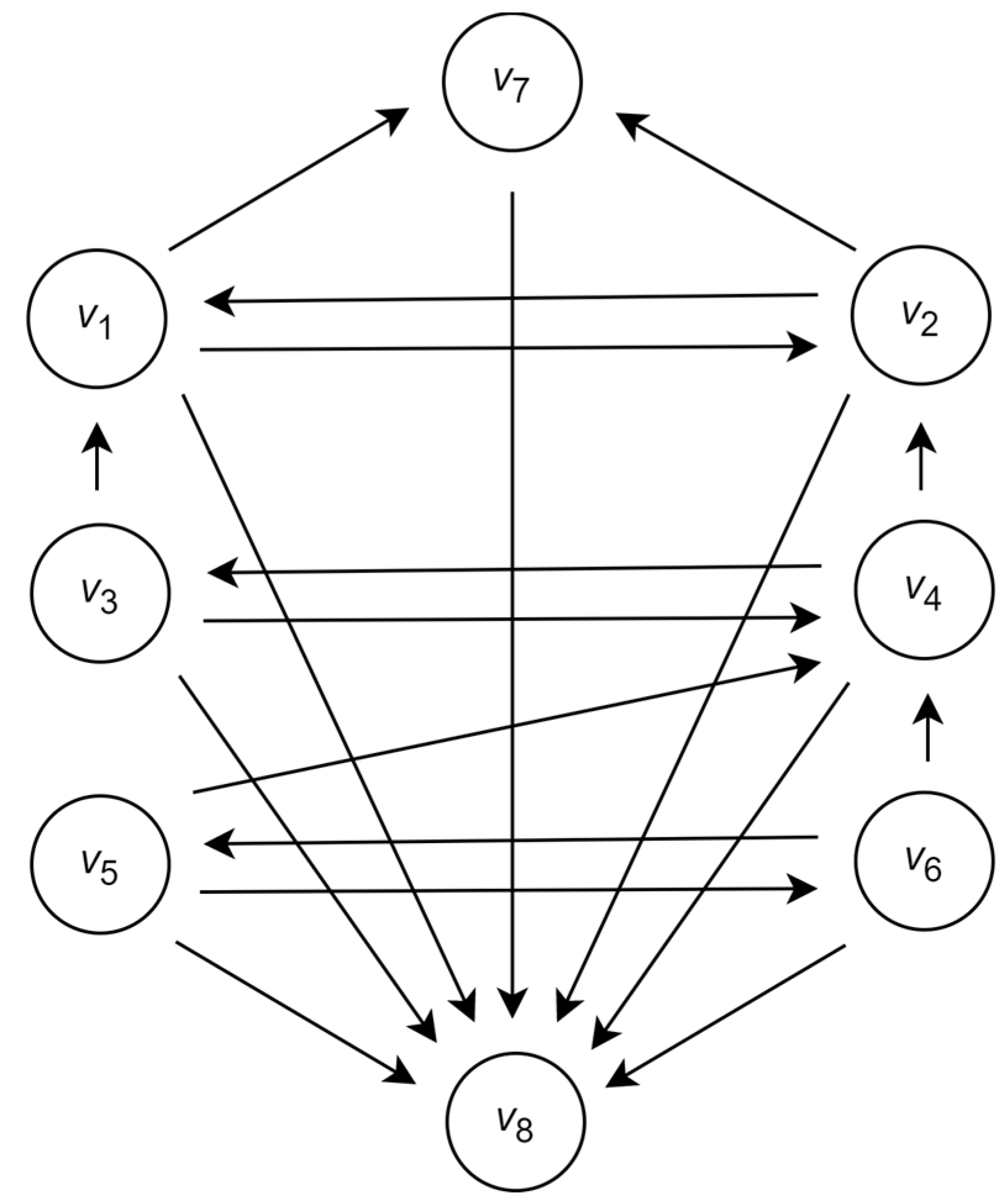
Let us return to the above example and assume that the distinguished group of experts is . Our aim is to check whether this group of experts is also a group of leaders.
Denote by
, the set of vertices in the graph
associated with the agents from the group
of experts. Then, following the presented above procedure of distinguishing the group of leading agents, the distance between the predecessor partition
and the successor partition
is
It is seen that the predecessor partition and successor partition of the set are closer than the predecessor partition and successor partition of the previously distinguished set of vertices associated with the agents from the set of candidate leaders (distance ). Moreover, partitions and are closer than the partitions and of the vertex (distance ).
Now, let us consider the classifications provided by the candidate group
of leaders. We have
Despite the competence of agent
in class
of agent
in class
and of agent
in class
, the resulting plurality voting partition is (item
is labeled randomly)
which is far from the correct partition
.
Thus, in the considered example with random relations between the agents and and randomly chosen classifications , , the group of experts strongly differs from the group of leading agents.
However, as indicated above, it is reasonable to assume that the agent elected to be a leader or a member of the group of leaders is competent in certain fields [
19].
Following this assumption, let us consider the other example and form a group of leaders starting with the agents’ expertise [
13]. Assume that the group
of
agents classifies
items
from the set
over
classes
. The agents’ classifications are shown in
Table 3.
By the Wisdom in the Crowd (WICRO) algorithm [
13], the agents are divided into clusters based on the number of agreements about the classes for each item
. The clusters obtained by the agents are summarized in
Table 4.
Following the table, and are the agents that agree that the item should be in the class and the item should be in the class ; , , and are the agents that agree that the item should be in the class and so on.
In addition, it is seen that the agents and appear both in the cluster and in the cluster together with the agent . Thus, we assume that the agents and are predecessors and successors of each other and both are predecessors of the agent . The same holds for the agents and and the agent .
Also, the agents and appear in two clusters and , while each of the agents and appear in only one of these two clusters. So, we assume that the agents and are predecessors and successors of each other and both are predecessors of the agents and .
Finally, the agent does not appear in any cluster, so we assume that this agent is a successor of all other agents.
Associating the agents with the vertices and the relations between the agents with the edges, one obtains the directed graph
shown in
Figure 3.
Similarly to
Table 1, the sets of input and output vertices in this graph are presented in
Table 5.
Following this graph, the clear leader is the agent associated with the vertex and additional leaders are the agents and associated with the vertices and . Together with that, according to the structure of the graph, none of the agents is a dictator or monarch.
The further application of the majority voting in the group of leading agents results in the classification that is correct for items , , and , is incorrect for items , and , and with probability can be correct for each of the items and .
7. Conclusions
The paper considered the problem of distinguishing the leaders in the group of autonomous agents.
In the paper, we suggested a definition of the leading agents, which are the agents that maximally divide the group. For calculating the distances between the subgroups of the agents, we use the entropy-based Rokhlin metric, which was extended for measuring the distances between the covers of the sets.
In the framework of classification problems, the paper considers the relationship between the competent agents and the leading agents and presents an example of distinguishing the leaders based on their expertise in certain fields of knowledge.
The suggested method can be used in programming the division of labor in the swarm activity dynamics and in the analysis of the data fusion in the records obtained by the wisdom of the crowd techniques.
Further research will include verification of the method on a wider range of data and consideration of the relations between the properties of the graphs, the groups of the distinguished leading agents, and the levels of their expertise.








{kind=link}
{kind=link}
{kind=link}