1. Introduction
Multi-modal generative modeling is a crucial area of research in machine learning that aims to develop models capable of generating data according to multiple modalities, such as images, text, audio, and more. This is important because real-world observations are often captured in various forms; thus, combining multiple modalities describing the same information can be an invaluable asset. For instance, images and text can provide complementary information in describing an object, while audio and video can capture different aspects of a scene. Multimodal generative models can help in tasks such as data augmentation [
1,
2,
3], missing modality imputation [
4,
5,
6,
7], and conditional generation [
8,
9].
Multimodal models have flourished over the past years and seen tremendous interest from academia and industry, especially in the content creation sector. Whereas most recent approaches focus on specialization, by considering text as a primary input to be associated mainly with images [
10,
11,
12,
13,
14,
15,
16] and videos [
17,
18,
19], in this work we target an established literature with more general scope and in which all modalities are considered equally important.
Multi modal generative models aim at
high-quality data generation, as well as at generative
coherence across all modalities. These objectives apply to both joint generation of new data and to conditional generation of missing modalities given a disjoint set of available modalities. The predominant literature in this field is based on extensions of the Variational Autoencoder (VAE) [
20] to the multimodal domain; initially interested in learning joint latent representation of multimodal data, such works have mostly focused on generative modeling.
In short, multimodal VAEs relies on combinations of unimodal VAEs, and the design space mainly consists of the way in which the unimodal latent variables are combined to construct the joint posterior distribution. Early works such as [
21] adopted a product-of-experts approach, whereas others [
22] considered a mixture-of-experts approach. While product-based models achieve high generative quality, they suffer in terms of both joint and conditional coherence. This has been found to be due to mis-calibration issues on the part of the experts [
22,
23]. On the other hand, mixture-based models produce coherent but qualitatively poor samples. A first attempt to address the so-called
coherence–quality tradeoff [
24] was represented by the mixture of products of experts approach [
23]. However, recent comparative studies [
24] have shown that none of the existing approaches fulfill the criteria of both generative quality and coherence. A variety of techniques are aimed at finding a better operating point, such as contrastive learning techniques [
25], hierarchical schemes [
26], total correlation-based calibration of single-modality encoders [
27], and different training objectives [
28]. More recently, in [
29], explicitly separated shared and private latent spaces were considered as a way to overcome the aforementioned limitations.
In
Section 2, we investigate the limitations of multimodal VAEs and prepared the ground to substantiate a new approach which overcomes the shortcomings in the state of the art. We further investigate the tradeoff [
24] between generative coherence and quality, and argue that it is intrinsic to all variants of multimodal VAEs. We indicate two root causes of the problem: latent variable collapse [
30,
31] and information loss due to mixture subsampling. To tackle these issues, in
Section 3 of this work we propose a new approach that uses a set of independent and unimodal
deterministic autoencoders with the latent variables simply concatenated in a joint latent variable. Joint and conditional generative capabilities are provided by an additional model that learns a probability density associated with the joint latent variable. We propose an extension of score-based diffusion models [
32] to operate on the multimodal latent space. Thus, we derive both forward and backward dynamics that are compatible with the multimodal nature of the latent data. In
Section 4, we propose a novel multi-time diffusion process that can both be used for joint and conditional generation. We label our approach Multi-modal Latent Diffusion (MLD).
Our experimental evaluation of MLD in
Section 5 provides compelling evidence of the superiority of our approach for multimodal generative modeling. We compare MLD to a large variety of VAE-based alternatives on several real-life multimodal datasets in terms of generative quality and both joint and conditional coherence. Our model outperforms alternatives in all possible scenarios, even those that are notoriously difficult because the modalities might be only loosely correlated. We note that recent works have explored the joint generation of multiple modalities [
33,
34]; however, such approaches are application-specific, e.g., text-to-image, and essentially only target two modalities. When relevant, we compare our method to additional recent alternatives to multimodal diffusion [
35,
36] and show the superior performance of MLD.
2. Limitations of Multimodal VAEs
In this work, we consider multimodal VAEs [
21,
22,
23,
29] as the standard modeling approach to tackle both joint and conditional generation of multiple modalities. Our goal here is the need to go beyond such a standard approach in order to overcome limitations that affect multimodal VAEs, which result in a tradeoff between generation quality and generative coherence [
24,
29].
Consider the random variable , consisting of the set M of modalities sampled from the (unknown) multimodal data distribution . We indicate the marginal distribution of a single modality by and the collection of a generic subset of modalities by , with , where is a set of indexes; for example, given , we would have .
We begin by considering unimodal VAEs as particular instances of the Markov chain , where Z is a latent variable and is the generated variable. Models are specified by the two conditional distributions, called the encoder and decoder . For a given prior distribution , the objective is to define a generative model with samples that are distributed as similarly as possible to the original data.
In the case of multimodal VAEs, we consider the general family of Mixture of Product of Experts (MOPOE) [
23], which includes as particular cases many existing variants such as Product of Experts (MVAE) [
21] and Mixture of Expert (MMVAE) [
22]. Formally, a collection of
K arbitrary subsets of modalities
along with weighting coefficients
define the posterior
, with
. To lighten the notation, we use
in place of
, noting that the various
can have both different parameters
and functional forms. For example, in the MOPOE [
23] parametrization, we have
. Our exposition is more general, and is not limited to this assumption. The selection of the posterior can be understood as the result induced by the two step procedure where (i) each subset of modalities
is encoded into specific latent variables
and (ii) the latent variable
Z is obtained as
with probability
. Optimization is performed with respect to the following evidence lower bound (ELBO) [
23,
24]:
A well known limitation called the latent collapse problem [
30,
31] affects the quality of the latent variables
Z. Consider the hypothetical case of arbitrary flexible encoders and decoders. Posteriors with zero mutual information with respect to model inputs are valid maximizers of Equation (
1). To prove this, it is sufficient to substitute the posteriors
and
into Equation (
1) to observe that the optimal value of
is achieved [
30,
31]. The problem of information loss is exacerbated in the case of multimodal VAEs [
24]. Intuitively, even if the encoders
carry relevant information about their inputs
, step (ii) of the multimodal encoding procedure described above induces a further information bottleneck. Some fraction
of the time, the latent variable
Z will be a copy of
, which only provides information about the subset
. No matter how good the encoding step is, the information about
that is not contained in
cannot be retrieved.
The variable collapse problem can be analyzed through the lenses of self-reconstruction, whereby a multimodal VAE is evaluated by simply reconstructing the same modality it receives as input. We have observed that these models tend to encode input samples into a latent space with possible information loss, leading to inconsistent reconstruction. This is particularly shown by the quantitative results in
Table A7, with notable difficulty in reconstructing the SVHN modality.
Furthermore, if the latent variable carries zero mutual information with respect to the multimodal input, a coherent
conditional generation of a set of modalities given others is impossible, as
for any generic sets
. While the factorization
,
(we use
here instead of
to unclutter the notation) could enforce preservation of information and guarantee better quality of the
jointly generated data, in practice the latent collapse phenomenon induces multimodal VAEs to converge towards suboptimal a operating regime. When the posterior
collapses onto the uninformative prior
, the ELBO in Equation (
1) reduces to the sum of modality-independent reconstruction terms:
where, paradoxically, the quality of the approximation of the various marginal distributions is extremely high, while there is a complete lack of joint coherence.
General principles to avoid latent collapse involve explicitly forcing the learning of informative encoders
via
annealing of the Kullback-Leibler (KL) term in the ELBO and the reduction of the representational power of encoders and decoders. While
annealing [
37] has been explored in the multimodal VAEs literature, [
21] with limited improvements reported, reducing the flexibility of the encoders/decoders clearly impacts the generation quality. Hence, the presence of the tradeoff; in order to improve coherence, the flexibility of encoders/decoders should be constrained, which in turn impacts generative quality. This tradeoff has recently been addressed in the literature on multimodal VAEs [
24,
29]; however, our experimental results in
Section 5 indicate that there is ample room for improvement and that a new approach is truly needed.
3. Our Approach: Multimodal Latent Diffusion
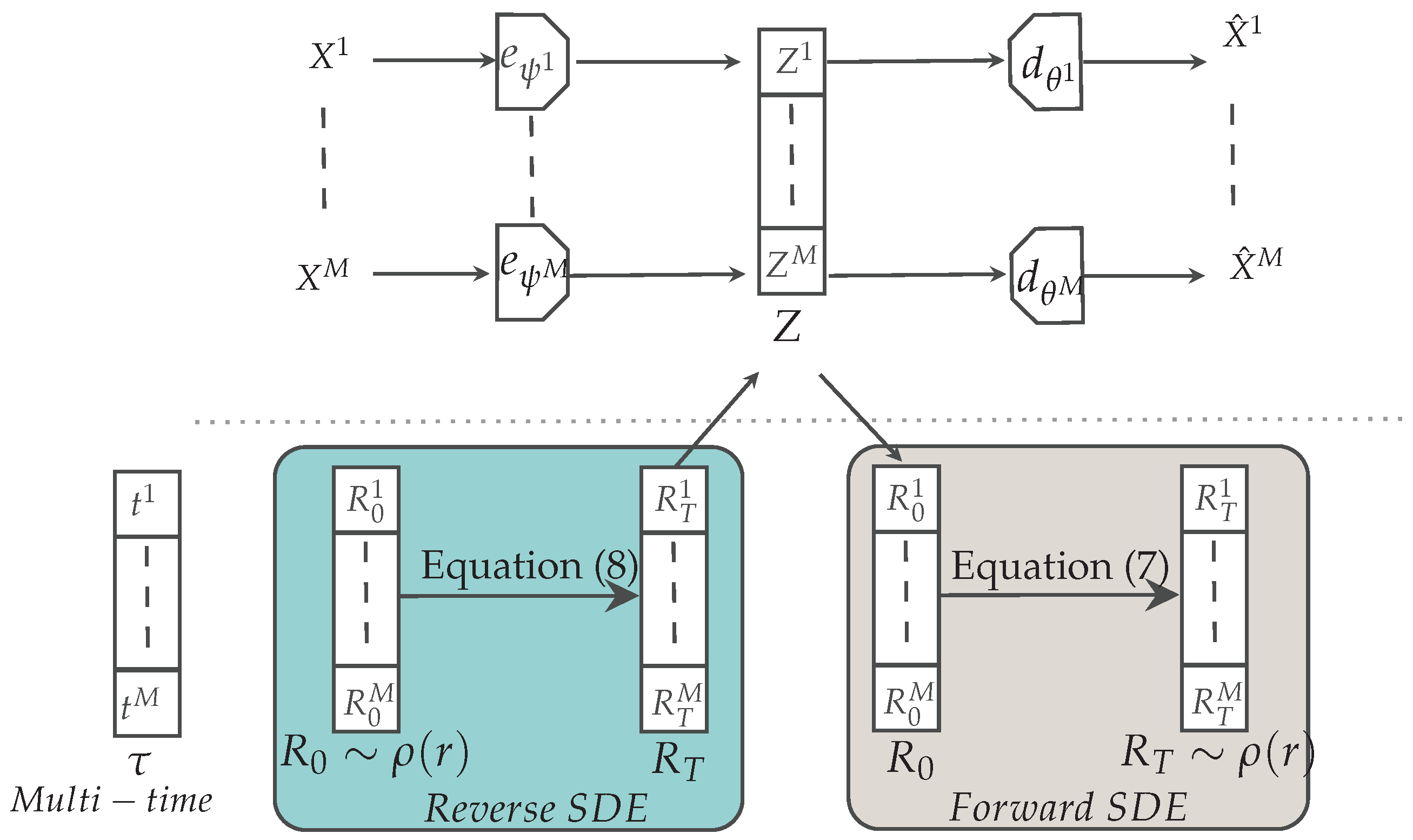
We propose a new method for multimodal generative modeling that by design does not suffer from the limitations discussed in
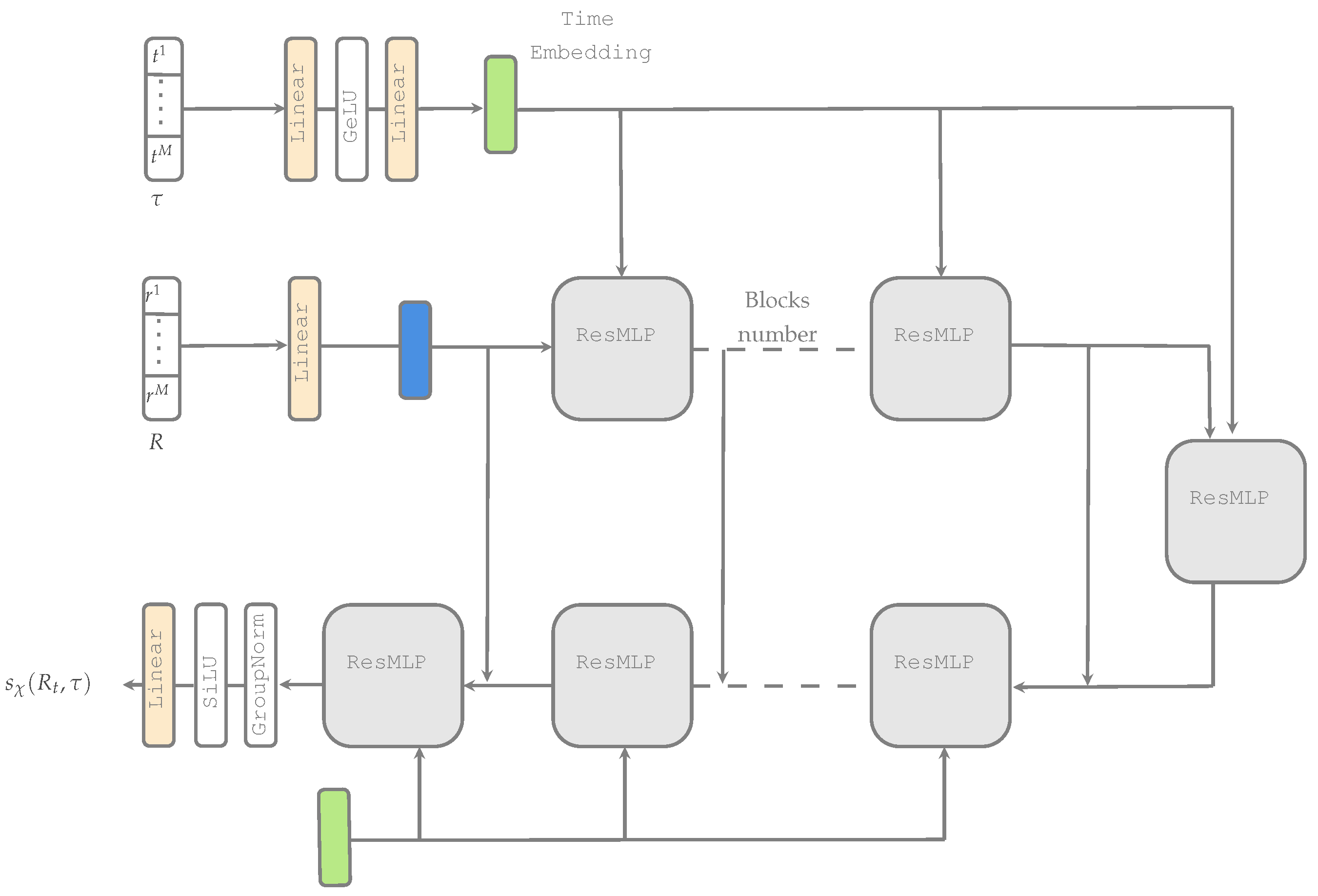
Section 2. Our objective is to enable both high quality and coherent joint/conditional data generation using a simple design (see
Figure 1 for a schematic representation). As an overview, we use deterministic unimodal autoencoders whereby each modality
is encoded through its encoder
(which is a short form for
) into the modality-specific latent variable
and decoded into the corresponding
. Our approach can be interpreted as a latent variable model in which the different latent variables
are concatenated as
. This corresponds to the parameterization of the two conditional distributions as
and
, respectively. Then, in place of an ELBO, we optimize the parameters of our autoencoders by minimizing the following sum of modality-specific losses:
where
can be any valid distance function, e.g, the square norm ‖·‖
2. The parameters
are modality-specific; thus, minimization of Equation (
3) corresponds to individual training of the different autoencoders. Because the mapping from input to latent is deterministic, there is no loss of information between
X and
Z (note that as the measures are not absolutely continuous with respect to the Lebesgue measure, the mutual information is
). Moreover, this choice avoids any form of interference in the backpropagated gradients corresponding to the unimodal reconstruction losses. Consequently, gradient conflict issues [
38], in which stronger modalities pollute weaker ones, are avoided.
To enable such a simple design to become a generative model, it is sufficient to generate samples from the induced latent distribution and decode them as .
To obtain such samples, we follow the two-stage procedure described in [
39,
40,
41], where samples from the lower-dimensional
are obtained through a score-based generative model. These models have shown tremendous performance in fitting complex distributions [
10,
42], an ability which aligns with our objective of learning the distribution within a multimodal latent space. Furthermore, the conditioning mechanism inherent in score-based models facilitates highly coherent generation. MLD is further enhanced by a multi-time diffusion process, a novel mechanism that allows for the generation of any subset of modalities, and which we explain in
Section 4.
It may be helpful at this point to clarify that the two-stage training of MLD is carried out separately. Unimodal deterministic autoencoders are pretrained first, followed by the training of the score-based diffusion model, which is explained in more detail later.
To conclude this overview of our method, for joint data generation it is possible to sample from noise, perform backward diffusion, and then decode the generated multimodal latent variable to obtain the corresponding data samples. For conditional data generation, given one modality, the reverse diffusion is guided by this modality, while the other modalities are generated by sampling from noise. The generated latent variable is then decoded to obtain data samples of the missing modality.
Joint and Conditional Multimodal Latent Diffusion Processes
In the first stage of our method, the deterministic encoders project the input modalities into the corresponding latent spaces . This transformation induces a distribution for the latent variable , resulting from the concatenation of unimodal latent variables.
Joint generation: To generate a new sample for all modalities, we use a simple score-based diffusion model in latent space [
32,
39,
40,
42,
43]. This requires reversing a stochastic noising process, starting from a simple Gaussian distribution. Formally, the noising process is defined by a Stochastic Differential Equation (SDE) of the form
where
and
are the drift and diffusion terms, respectively, and
is a Wiener process. The time-varying probability density
of the stochastic process at time
, where
T is finite, satisfies the Fokker–Planck equation [
44] with initial conditions
. We assume the uniqueness and existence of a stationary distribution
for the process in Equation (
4), though this is not necessary for the validity of the method [
45]. The forward diffusion dynamics depend on the initial conditions
. We consider
to be the initial condition for the diffusion process, which is equivalent to
. Under loose conditions [
46], a time-reversed stochastic process exists, with a new SDE of the form
indicating that, in principle, simulation of Equation (
5) allows samples to be generated from the desired distribution
. In practice, we use a
parametric score network to approximate the true score function, and we approximate
with the stationary distribution
. Indeed, the generated data distribution
is close (in the KL sense) to the true density as described by [
45,
47]:
where the first term on the right-hand side is referred to as the score-matching objective, and is the loss over which the score network is optimized, while the second is a vanishing term for
.
To conclude, joint generation of all modalities is achieved through simulation of the reverse-time SDE in Equation (
5), followed by a simple decoding procedure. Indeed, optimally trained decoders (achieving zero in Equation (
3)) can be used to transform
into samples from
.
Conditional generation. Given a generic partition of all modalities into non-overlapping sets , where , conditional generation requires samples from the conditional distribution , which are based on masked forward and backward diffusion processes.
Given conditioning latent modalities , we consider a modified forward diffusion process with initial conditions and with . The composition operation concatenates generated () and conditioning latents (). As an illustration, consider such that and such that ; then, .
More formally, we define the following masked forward-diffusion SDE:
The mask contains M vectors , one per modality, with the corresponding cardinality. If modality , then ; otherwise, . Then, the effect of masking is to “freeze” the part of the random variable corresponding to the conditioning latent modalities throughout the diffusion process. We naturally associate the conditional time-varying density with this modified forward process.
To sample from
, we derive the reverse-time dynamics of Equation (
7) as follows:
with initial conditions
and
. Then, we approximate
by its corresponding steady-state distribution
and the true (conditional) score function
by a conditional score network
.
4. Multi-Time Diffusion to Learn the Conditional Score Network
A correctly optimized score network
allows samples from the joint distribution
to be obtained through simulation of Equation (
5). Similarly, through the simulation of Equation (
8), a
conditional score network
allows for sampling from
. In
Section 4.1, we extend the guidance mechanisms used in classical diffusion models to allow multimodal conditional generation. A naïve alternative is to rely on the unconditional score network
for the conditional generation task by casting it as an
in-painting objective. Intuitively, any missing modality could be recovered in the same way that a unimodal diffusion model can recover masked information. In
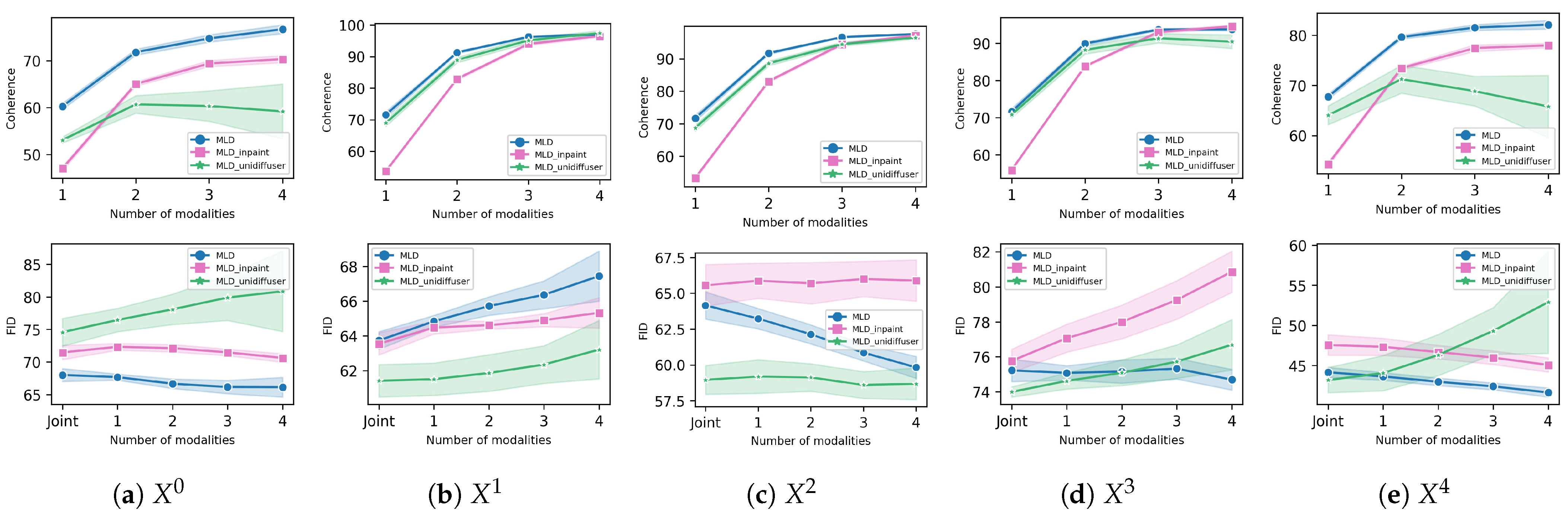
Section 4.3, we discuss the implicit assumptions underlying in-painting from an information-theoretic perspective and argue that such assumptions are difficult to satisfy in the context of multimodal data. This intuition is corroborated by ample empirical evidence, where our method consistently outperforms alternatives.
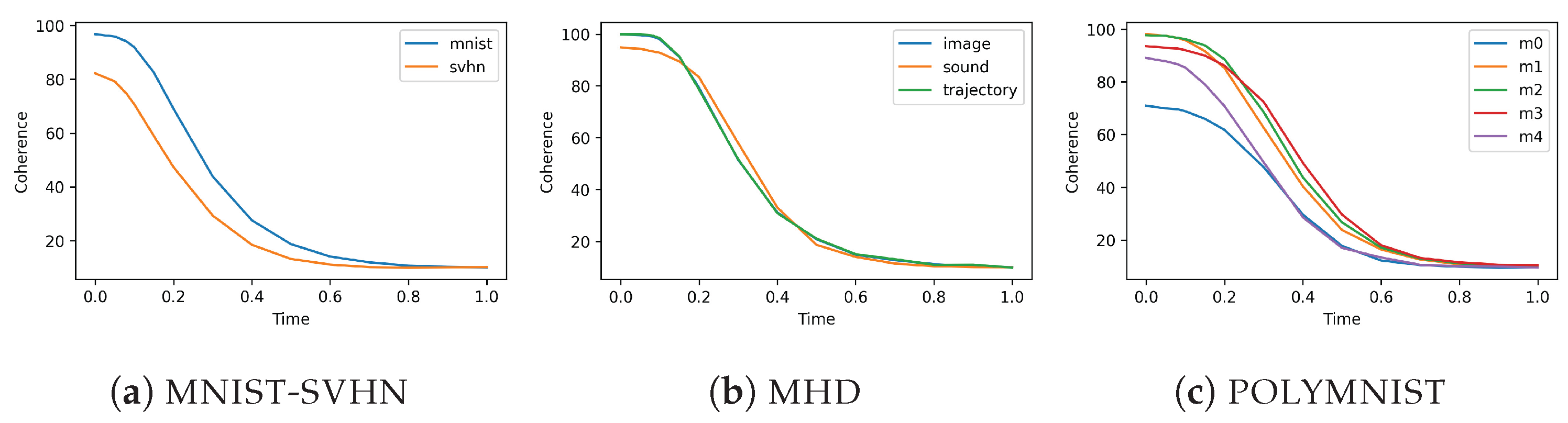
4.1. Multi-Time Diffusion
We propose a modification to the classifier-free guidance technique [
48] to learn a score network that can generate conditional and unconditional samples from any subset of modalities. Instead of training a separate score network for each possible combination of conditional modalities, which is computationally infeasible, we use a single architecture that accepts all modalities as inputs and a
multi-time vector . The multi-time vector serves two purposes: it is both a conditioning signal and the time at which we observe the diffusion process.
Training: Learning the conditional score network relies on randomization. As discussed in
Section 3, we consider an arbitrary partitioning of all modalities in two disjoint sets,
and
; set
contains randomly selected conditioning modalities, while the remaining modalities belong to set
. During training, the parametric score network estimates
, whereby set
is randomly chosen at every step. This is achieved by the
masked diffusion process from Equation (
7), which only diffuses modalities in
. More formally, the score network input is
, along with a multi-time vector
. As a follow-up of the example in
Section 3, given
such that
and
such that
, we have
.
More precisely, the algorithm for multi-time diffusion training (see
Appendix A for the pseudo-code) proceeds as follows. At each step, a set of conditioning modalities
is sampled from a predefined distribution
, where
and
with
, where
is the powerset of all modalities. The corresponding set
and mask
are constructed, and a sample
X is drawn from the training dataset. The corresponding latent variables
and
are computed using the pretrained encoders and a diffusion process starting from
is simulated for a randomly chosen diffusion time
t using the conditional forward SDE with the mask
. The score network is then fed the current state
and multi-time vector
and the difference between the score network’s prediction and the true score is computed while applying mask
. The score network parameters are updated using stochastic gradient descent, and this process is repeated for a total of
L training steps. Clearly, when
, training proceeds the same as for an unmasked diffusion process, as mask
allows all of the latent variables to be diffused.
Conditional generation: Any valid numerical integration scheme for Equation (
8) can be used for conditional sampling (see
Appendix A for an implementation using the Euler–Maruyama integrator). First, conditioning modalities in set
are encoded into the corresponding latent variables
. Then, numerical integration is performed with a step size of
, starting from initial conditions
with
. At each integration step, the score network
is fed the current state of the process and the multi-time vector
. Before updating the state, the masking is applied. Finally, the generated modalities are obtained thanks to the decoders as
. Inference time conditional generation is not randomized; the conditioning modalities are the ones that are available, whereas those remaining are the ones we wish to generate.
Any-to-any multimodality has been recently studied through the composition of modality-specific diffusion models [
49] by designing cross-attention and training procedures that allow for arbitrary conditional generation. This work by Tang et al. [
49] relies on latent interpolation of input modalities, which is akin to mixture models, and uses it as conditioning signal for individual diffusion models. This is substantially different from the joint nature of the multimodal latent diffusion we present in our work; instead of forcing entanglement through cross-attention between score networks, our model relies on a joint diffusion process whereby modalities naturally co-evolve according. Another recent work [
50], targeted multimodal conversational agents, wherein the strong underlying assumption is to consider one modality, i.e., text, as a guide for the alignment and generation of other modalities. Even if conversational objectives are orthogonal to our work, techniques akin to instruction-following for cross-generation are an interesting illustration of the powerful capabilities of in-context learning on the part of LLMs [
51,
52].
4.2. Multimodal Interaction
MLD treats the latent spaces of each modality as variables that evolve differently through the diffusion process according to a multi-time vector. The masked multi-time training enables the model to learn the score of all the combinations of conditionally diffused modalities, using the frozen modalities as the conditioning signal through a randomized scheme. By learning the score function of the diffused modalities at different time steps, the score model captures the correlation between the modalities.
At test time, the diffusion time of each modality is chosen so as to modulate its influence on the generation. For joint generation, the model uses the unconditional score, which corresponds to using the same diffusion time for all modalities. Thus, all the modalities influence each other equally. This ensures that the modality interaction information is faithful to the information characterizing the observed data distribution. The model can also generate modalities conditionally using the conditional score by freezing the conditioning modalities during the reverse process. The frozen state is similar to the final state of the revere process, where information is not perturbed; thus, the influence of the conditioning modalities is maximal. Subsequently, the generated modalities reflect the necessary information from the conditioning modalities and achieve the desired correlation.
4.3. In-Painting and Its Implicit Assumptions
Under certain assumptions, given an unconditional score network
that approximates the true score
, it is possible to obtain a conditional score network
to approximate
. We start by observing the equality
where, with a slight abuse of notation, we indicate with
the density associated with the event; the portion corresponding to
of the latent variable
Z is equal to
, given that the whole diffused latent
at time
t is equal to
. In the literature, the quantity
is typically approximated by dropping its dependency on
. This approximation can be used to manipulate Equation (
9) as
. Further, Monte Carlo approximations [
32,
53] of the integral allows for implementation of a practical scheme in which an approximate conditional score network is used to generate conditional samples. This approach, known in the literature as
in-painting, provides high quality results in several
unimodal application domains [
32,
53].
By fixing
, the KL divergence between
and
quantifies the discrepancy between the true and approximated conditional probabilities. Similarly, the expected KL divergence
provides information about the average discrepancy. Simple manipulations allow this to be recast as a discrepancy in terms of the mutual information
. Information about
is contained in
, as the latter is the result of a diffusion with the former as initial conditions, corresponding to the Markov chain
, and in
through the Markov chain
. The positive quantity
is close to zero whenever the rate of loss of information with respect to the initial conditions is similar for the two subsets
and
. In other terms,
whenever the portion
of the whole
is a sufficient statistic for
.
The assumptions underlying the approximation are in general not valid in the case of multimodal learning, where the robustness to stochastic perturbations of latent variables corresponding to the various modalities can vary greatly. In
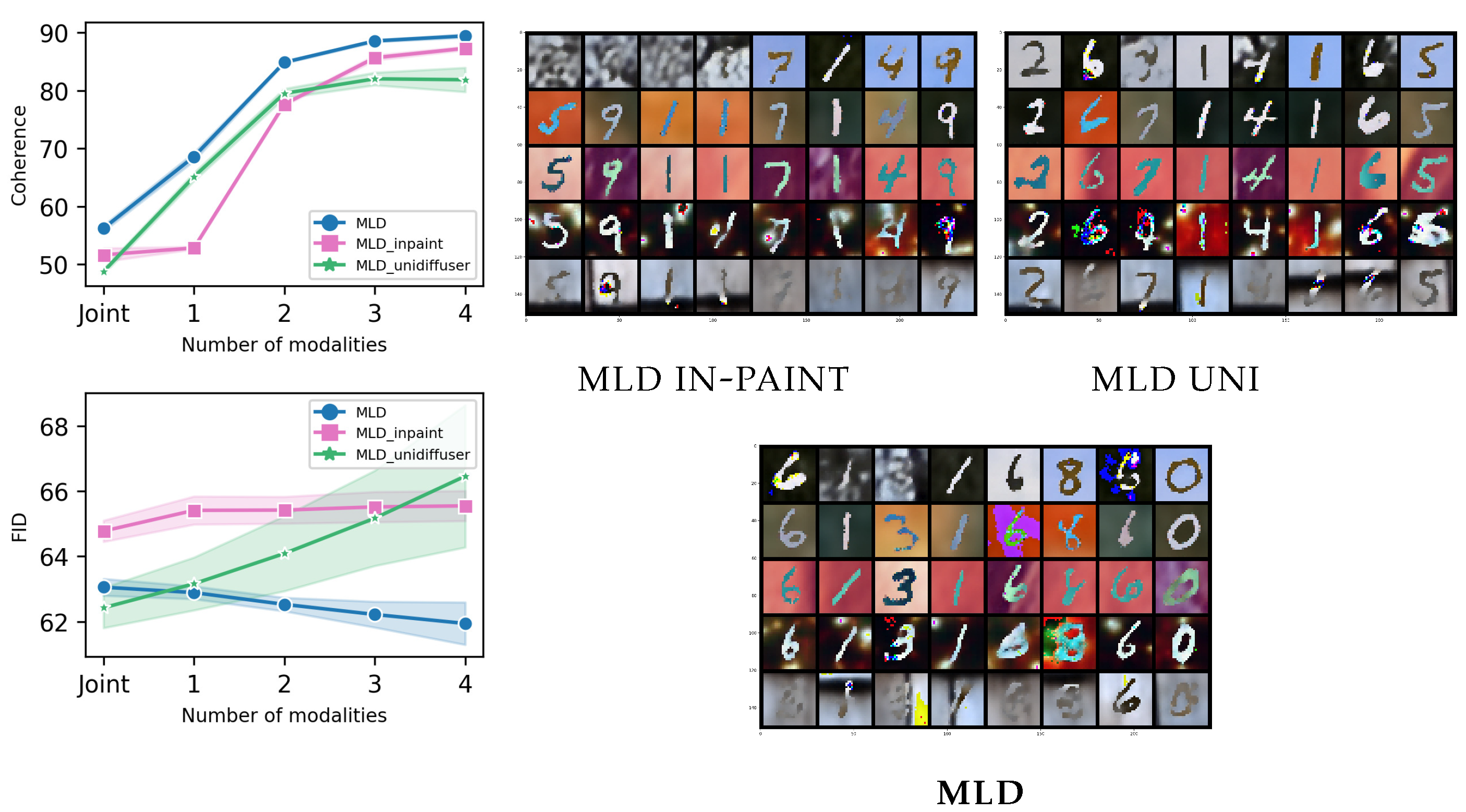
Appendix B, our claims are empirically supported by ample analysis performed on real data showing that our multi-time diffusion approach consistently outperforms in-painting.
5. Experiments
We compared our MLD method to MVAE [
21], MMVAE [
22], MOPOE [
23], Hierarchical Genertive Model (NEXUS) [
26], Multi-view Total Correlation Autoencoder (MVTCAE) [
27], and MMVAE+ [
29], re-implementing all competitors in the same code base as our method and selecting their best hyperparameters as indicated by the authors (see
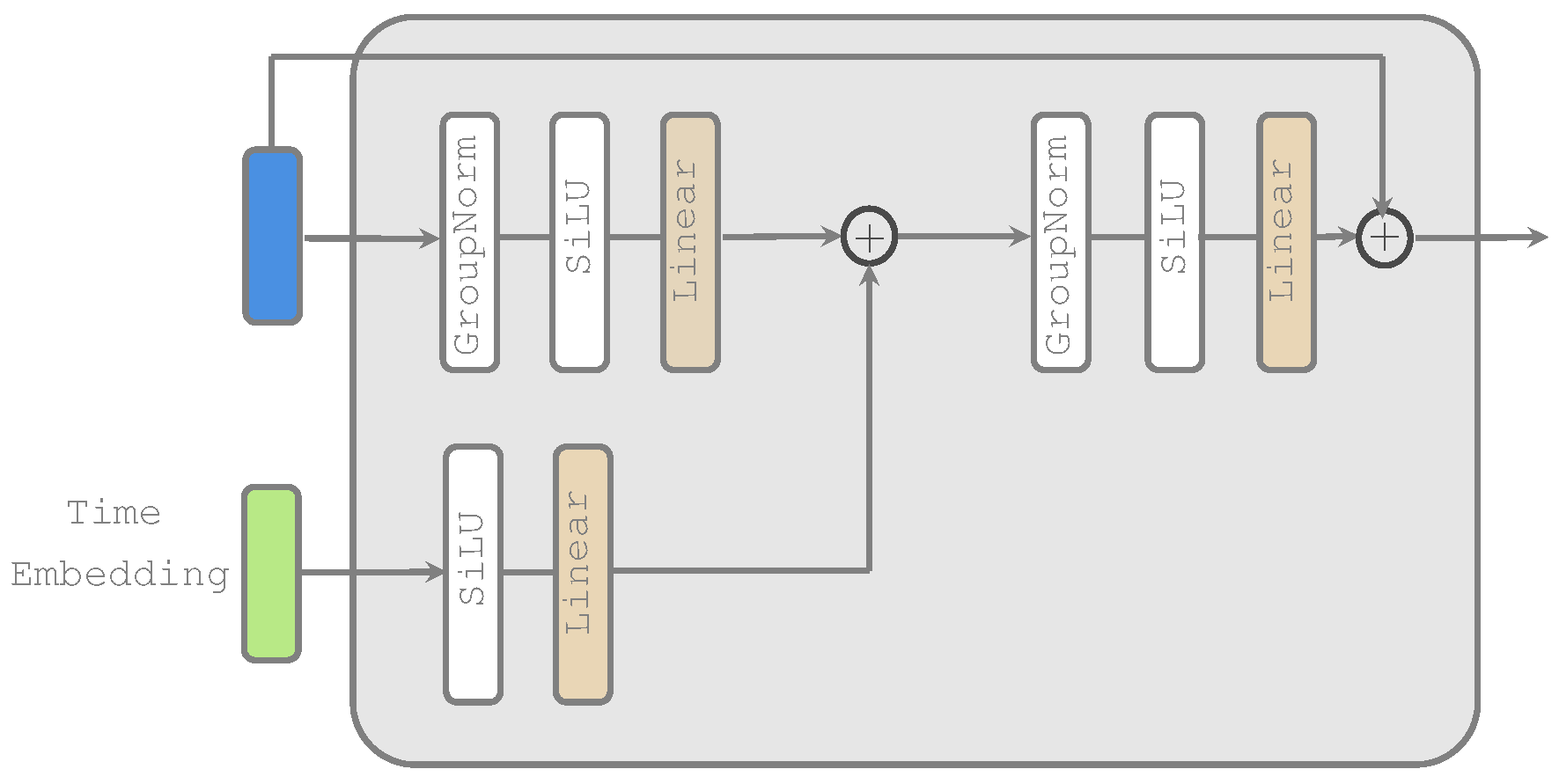
Appendix D for more details). For a fair comparison, we used the same encoder/decoder architecture for all models. For MLD, the score network was implemented using a simple stacked multilayer perceptron (MLP) with skip connections (see
Appendix A for more details). MLD was also contrasted with multimodal diffusion-based approaches: [
35] in
Appendix B and [
36] in
Section 5.5.
Evaluation metrics: Coherence was measured as in [
22,
23,
29], using pretrained classifiers on the generated data and checking the consistency of their outputs.
Generative quality was computed using the Fréchet Inception Distance (FID) [
54] and Fréchet Audio Distance (FAD) [
55] scores for images and audio, respectively. Full details on the metrics are included in
Appendix C. All results were averaged over five seeds. We report the standard deviations in
Appendix E.
Results: Overall, MLD largely outperformed the alternatives from the literature in terms of both coherence and generative quality. The VAE-based models suffered from the coherence–quality tradeoff as well as from modality collapse for highly heterogeneous datasets. We proceed to show this on several standard benchmarks from the multimodal VAE-based literature; see
Appendix C for details on the datasets.
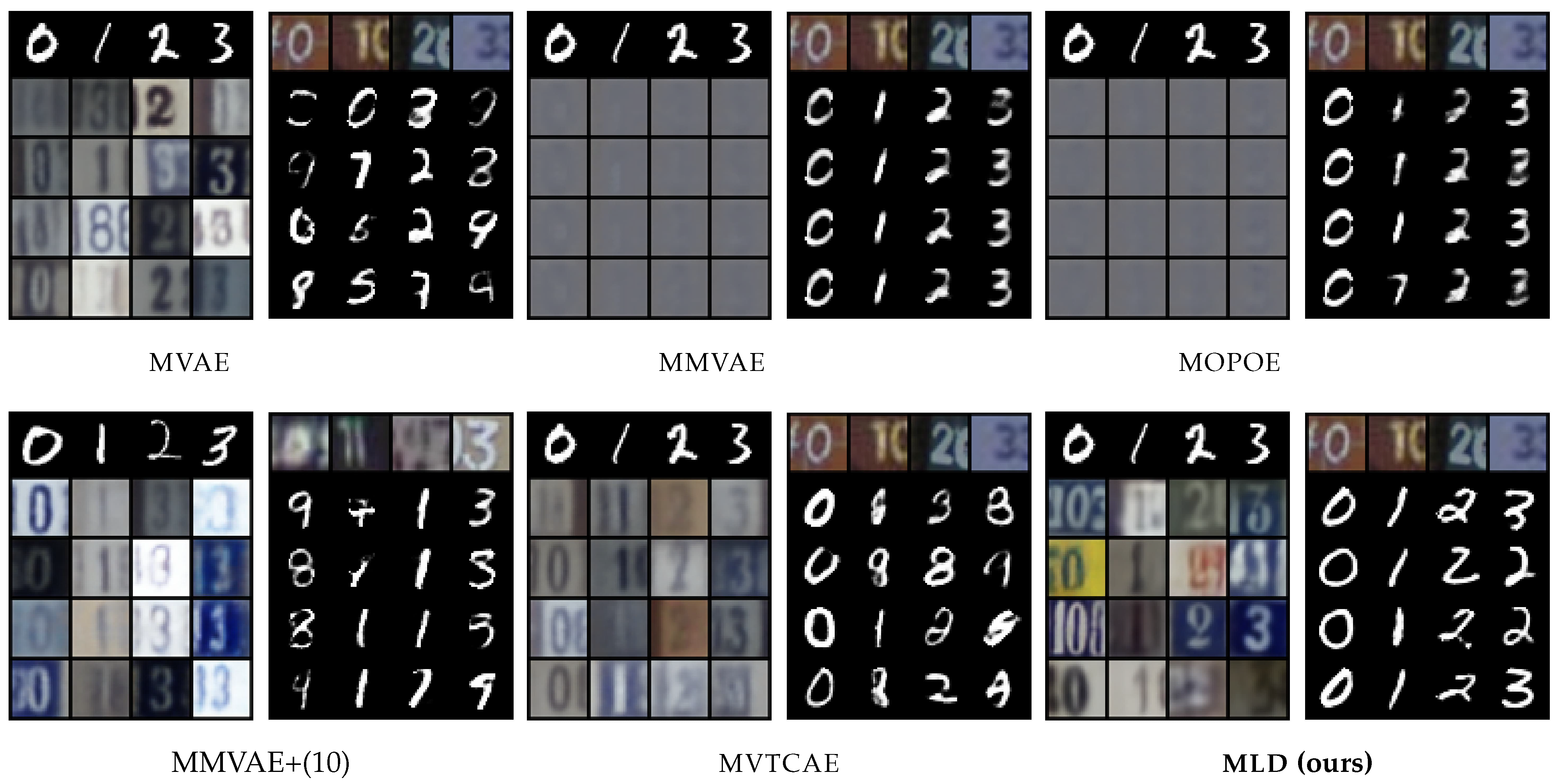
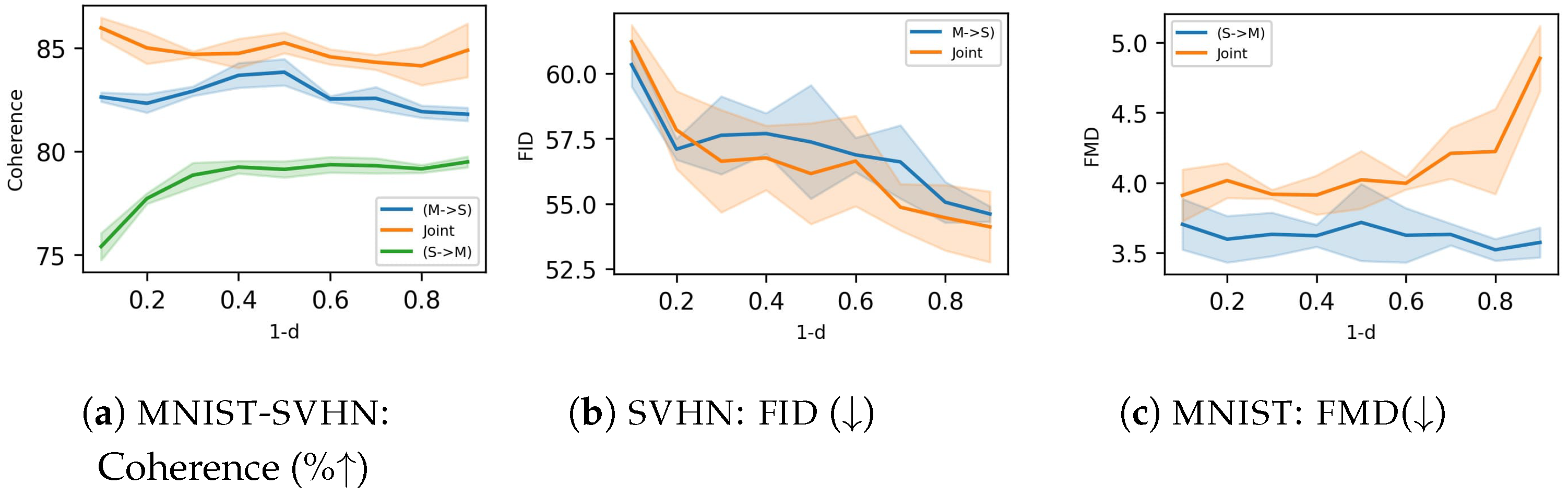
5.1. MNIST-SVHN
The first dataset we consider is
MNIST-SVHN [
22], where the two modalities differ in complexity. High variability, noise, and ambiguity make attaining good coherence for the SVHN modality a challenging task. Overall, MLD outperforms all VAE-based alternatives in terms of coherency, especially in terms of joint generation and conditional generation of MNIST given SVHN (see
Table 1). The mixture models, MMVAE and MOPOE, suffer from modality collapse (poor SVHN generation), whereas the product-of-experts models MVAE and MVTCAE generate better-quality samples at the expense of SVHN to MNIST conditional coherence. Joint generation is poor for all VAE models. Interestingly, these models also fail at SVHN self-reconstruction, which we discuss in
Appendix E. MLD also achieves the best performance in terms of generation quality, as confirmed by qualitative results (
Figure 2) showing, for example, how MLD conditionally generates multiple SVHN digits within one sample given the input MNIST image, whereas the other methods fail to do so.
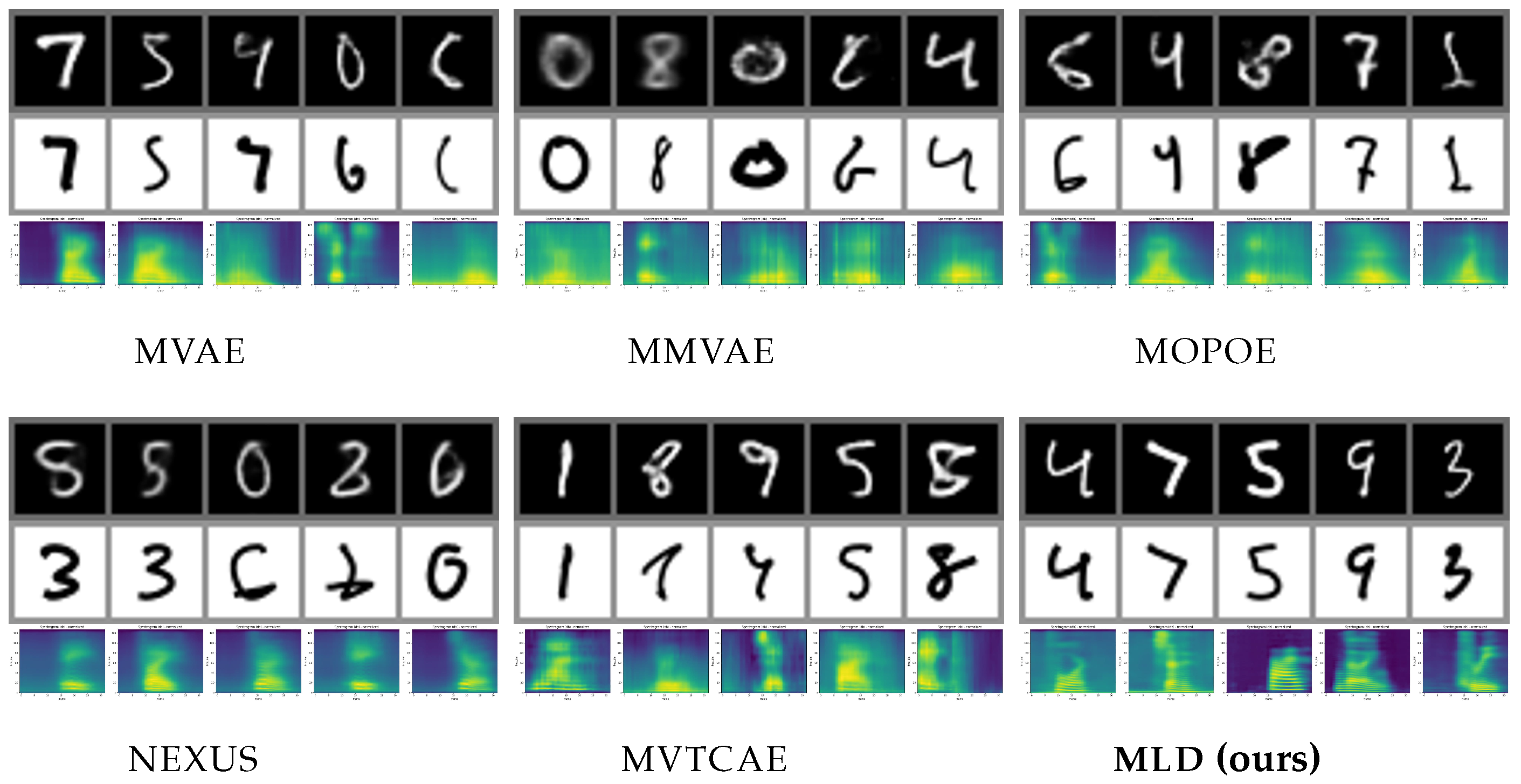
5.2. MHD
The Multimodal Handwritten Digits dataset (
MHD) [
26] contains gray-scale images of digits, the motion trajectory of the handwriting, and the sounds of the spoken digits. In our experiments, we did not use the label as a fourth modality. While the images and trajectories share a good amount of information, the sound modality contains a great deal more modality-specific variation. Consequently, both conditional generation involving the sound modality and joint generation represent challenging tasks. Coherency-wise, (
Table 2) MLD outperforms all the competitors, with the biggest difference seen in joint generation and generation from sound to other modalities. On the latter task, MVTCAE performs better than other competitors, but is still worse than MLD. MLD dominates the alternatives in terms of generation quality (
Table 3). This is true both for image and sound modalities, for which some VAE-based models struggle to produce high-quality results, demonstrating the limitation of these methods in handling highly heterogeneous modalities. MLD, on the other hand, achieves high generation quality for all modalities, possibly due to the independent training of the autoencoders avoiding interference.
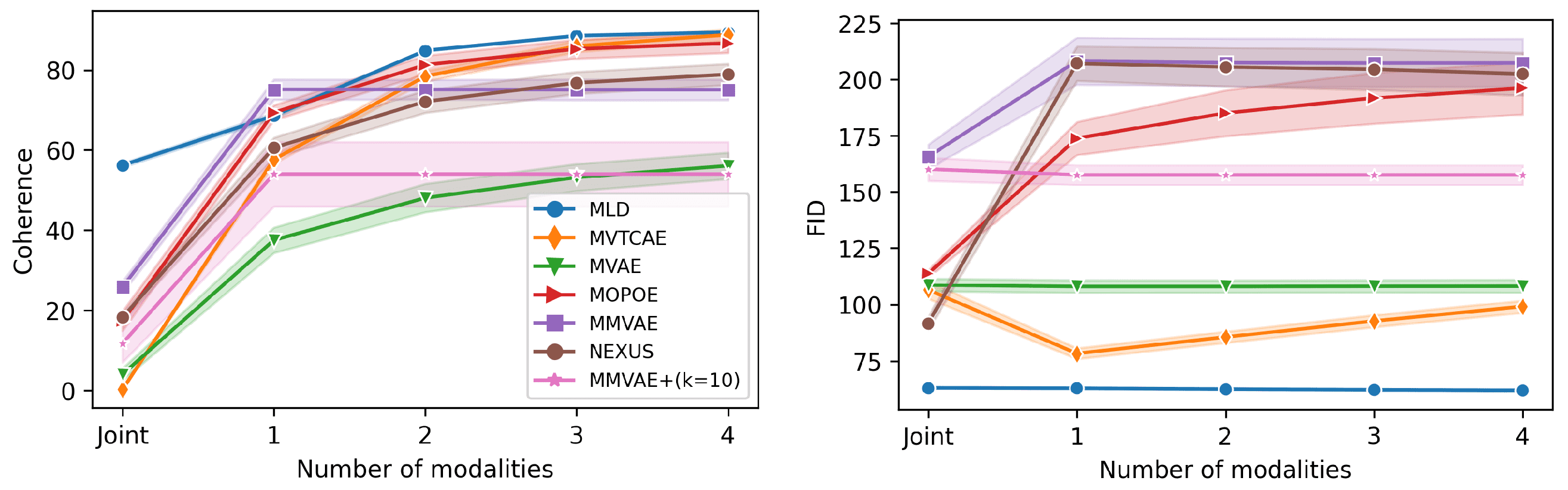
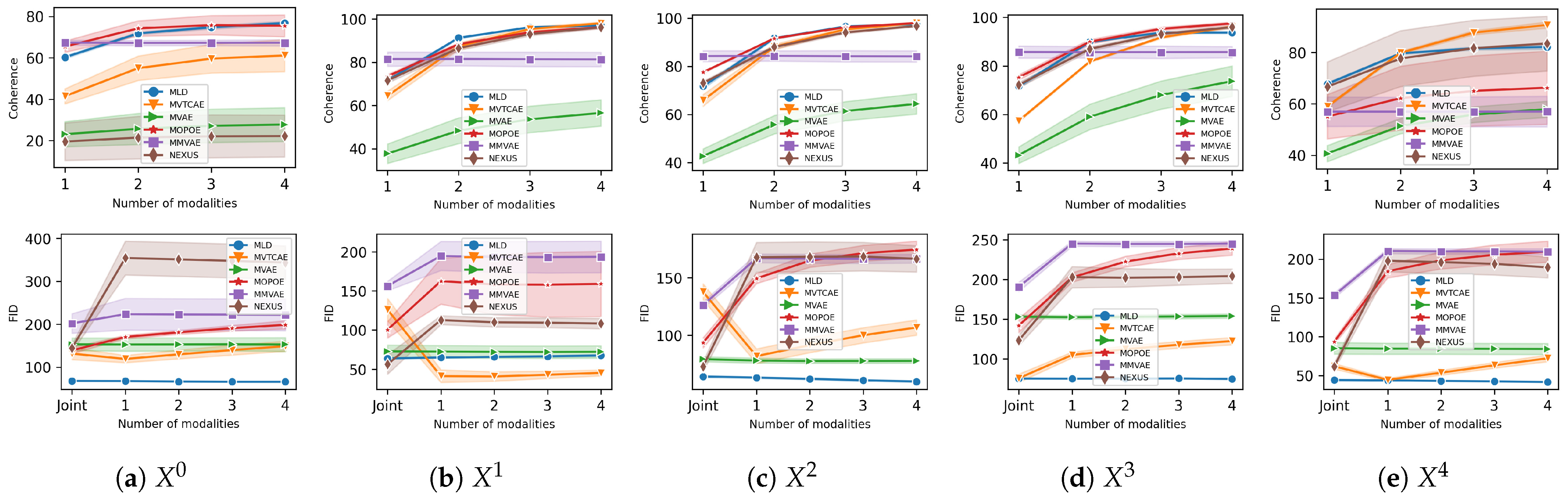
5.3. POLYMNIST
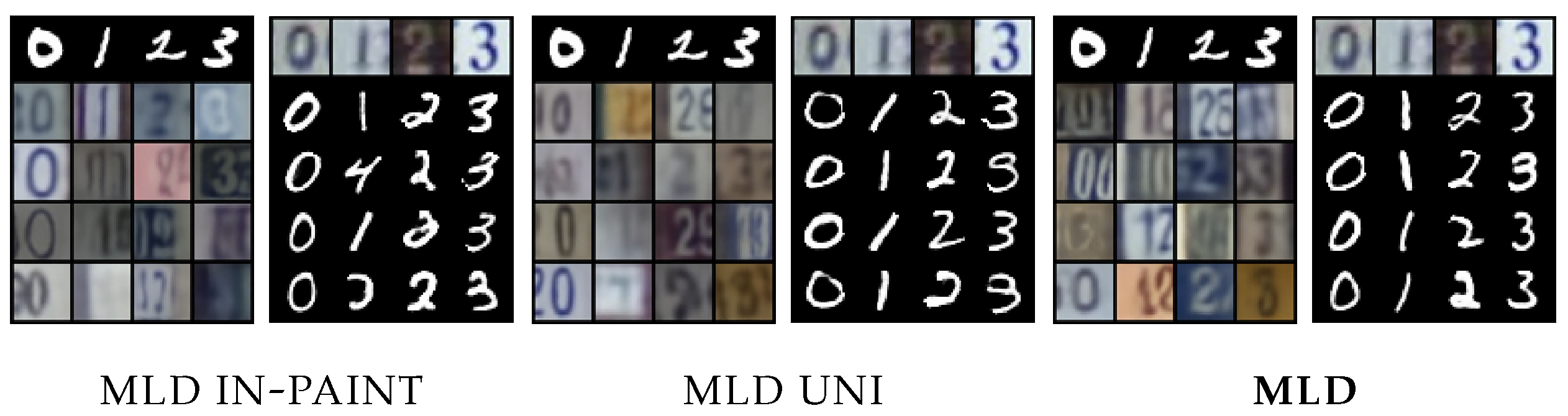
The
POLYMNIST dataset [
23] consists of five modalities synthetically generated using MNIST digits and varying the background images. The homogeneous nature of the modalities is expected to mitigate gradient conflict issues in VAE-based models and consequently reduce modality collapse. However, MLD still outperforms all alternatives, as shown in
Figure 3 and
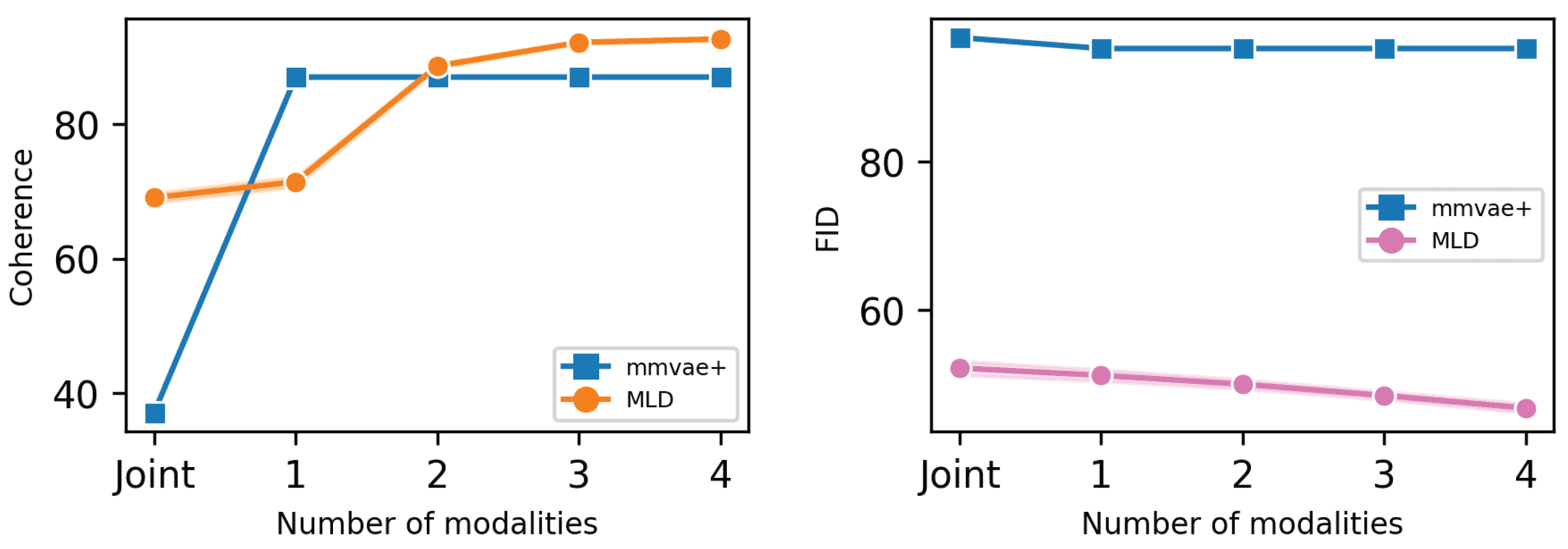
Figure 4. Concerning generation coherence, MLD achieves the best performance in all cases, with the one exception of a single observed modality. On the qualitative performance side, not only is MLD superior to all alternatives, its results are stable when more modalities are considered, a capability that not all competitors share.
5.4. CUB
Next, we explored the Caltech Birds
CUB [
22] dataset, following the experimental protocol in [
24] using real bird images instead of ResNet-features as in [
22].
Figure 5 presents qualitative results for caption-to-image conditional generation. MLD is the only model capable of generating bird images with convincing coherence. Clearly, none of the VAE-based methods is able to achieve sufficient caption-to-image conditional generation quality using the same simple autoencoder architecture. Note that an image autoencoder with larger capacity considerably improves the generative performance of MLD, suggesting that careful engineering applied to modality-specific autoencoders is a promising avenue for future work. We report quantitative results in
Appendix E, where we show the generation quality FID metric. Due to the unavailability of the labels in this dataset, the coherence evaluation performed with the previous datasets was not possible. Thus, we resorted to CLIP-Score (CLIP-S) [
56], an image-captioning metric. Despite its limitations for the considered dataset [
57], CLIP-S shows that MLD outperforms all competitors.
5.5. CelebAMask-HQ
Finally, we considered the CelebAMask-HQ dataset [
58], which consists of three modalities: face images, each having a segmentation mask and text attributes. We followed the same experimental protocol as in [
36], including the autoencoder base architecture. The image generation quality was evaluated in terms of FID score. The attributes and the mask, both having binary values, were evaluated against the ground truth in terms of the
score. The competitors’ performance results are reported from [
36]. The quantitative results in
Table 4 show that MLD outperforms the competitors in terms of generation quality. Our method achieves the best
score in generation of the attribute modalities given the image and mask modalities. In mask generation, MOPOE and MVTCAE achieve the best performance, with MLD achieving the second-best performance in mask generation conditioning on both the image and attribute modalities. Overall, MLD stands out with the best image quality generation, while being on par with the competition in terms of mask and attribute generation coherence.
Figure 6 shows the qualitative results for MLD on the joint generation task. It can be observed that our method succeeds at generating all three modalities with high coherence and quality. The same observation is valid for the conditional generation tasks (see
Figure 7,
Figure 8 and
Figure 9).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



























