1. Introduction
The 51st Statistical Report on the Development of China’s Internet [
1] shows that, in 2022, a total of 845 million netizens participated in the purchase and sale of compliant items on online platforms, accounting for 79.2% of the total number of netizens. However, including the dark web and underground forums, illicit transactions persist, posing significant challenges to cyber and social security stability in cyberspace [
2]. According to statistics, in its 2.5 years online, the dark web Tor site “Silk Road” amassed 150,000 users and transactions totaling
$1.2 billion [
3]. The online trading products of the dark web often include illegal and irregular items, such as drugs, electronic fraud materials, hacking tools, and smuggled goods [
4]. To avoid scrutiny, industry practitioners often conceal sensitive content within argots mixed with normal content, enhancing transaction concealment.
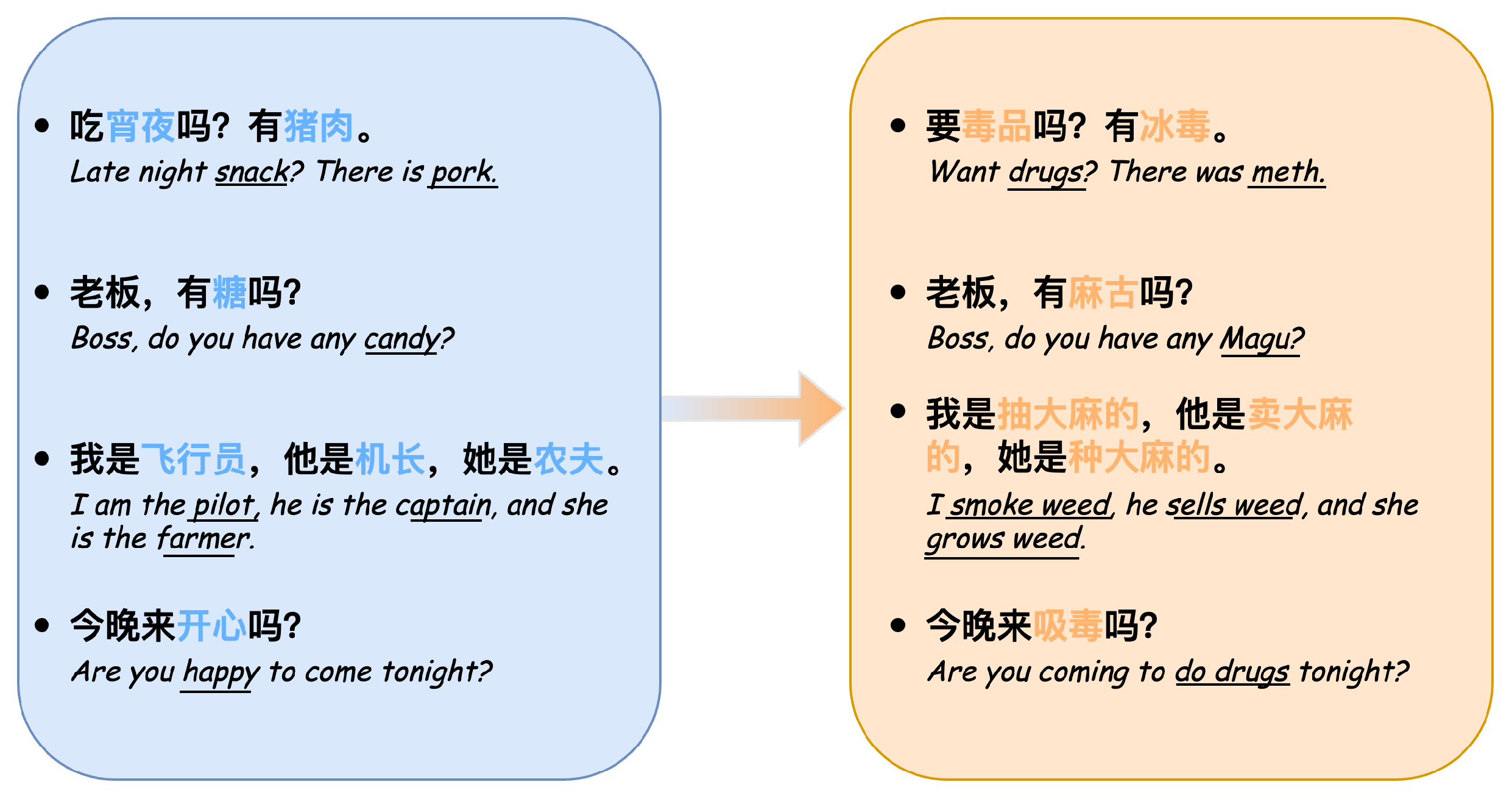
Figure 1, illustrates some hidden words and their explanations in the field of drug trading. In the first example, “宵夜” (midnight snack) refers to “毒品” (drugs), and “猪肉” (pork) refers to “冰毒” (methamphetamine).
The research on argot recognition and interpretation in combat units has a long history. Early law enforcement agencies used manual construction of an argot knowledge base to interpret known argots. For example, the US Drug Enforcement Agency (EDA) intelligence department developed a set of drug codeword libraries to decipher the collected evidence and data containing codewords [
5]. Ouyang et al. collected and summarized relevant drug code libraries based on the language characteristics and ethnic customs of the Guangxi region [
6]. Ouyang et al. also used railway property infringement criminals as their target for obtaining secret language, and summarized a set of railway property infringement secret language libraries [
7]. After summarizing a substantial number of hidden language samples, previous research findings, and the results of our preliminary experiments, we have identified the following characteristics of Chinese argots:
Chinese argots and the words they refer to (referred to as pronouns) are normal vocabulary, rather than special characters similar to Morse codes [
8].
There are inherent connections between Chinese argots and their pronouns, including their shape, pronunciation, and meaning, which are relatively loose and often unknown to outsiders [
9].
Most pronouns are nouns or verbs, but the part of speech of Chinese argots and pronouns may not be the same, and verbs and adjectives are often used to refer to nouns or verbs.
If the lexicon of argot words is concealed, and multiple alternative words are provided for that position, the concealment capability of argot words and the entropy of the set of alternative words for filling in that position are positively correlated.
As the aforementioned algorithm only recognizes a partial set of argot features, the various algorithms mentioned earlier are now inadequate for the current scenario of argot recognition and interpretation, particularly in the task of argot recognition. Therefore, this paper integrates the concept of semantic space, drawing inspiration from the manifold assumption in deep learning. Additionally, it combines the notion of vector information entropy to assess the rationality of word vectors within the semantic space [
10].
Specifically, this paper makes the following contributions in the domain of argot recognition and interpretation:
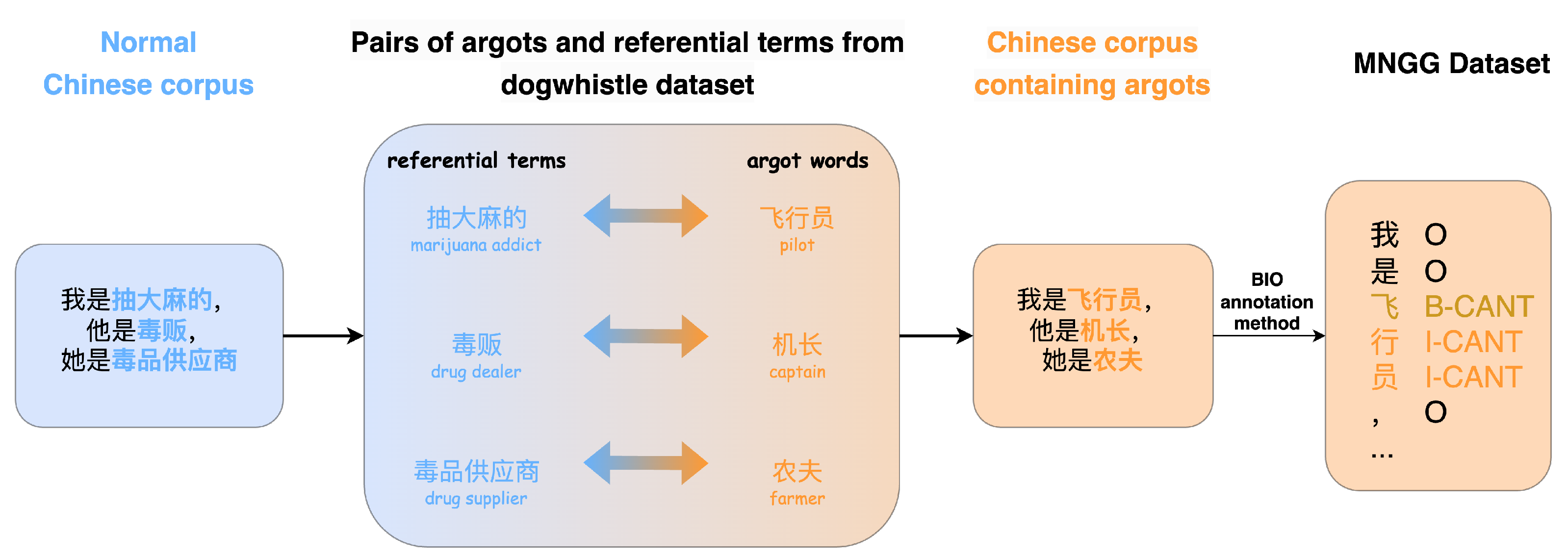
We constructed a Chinese long text corpus MNGG dataset using an open-source cant dataset [
8] to support research on Chinese argots recognition.
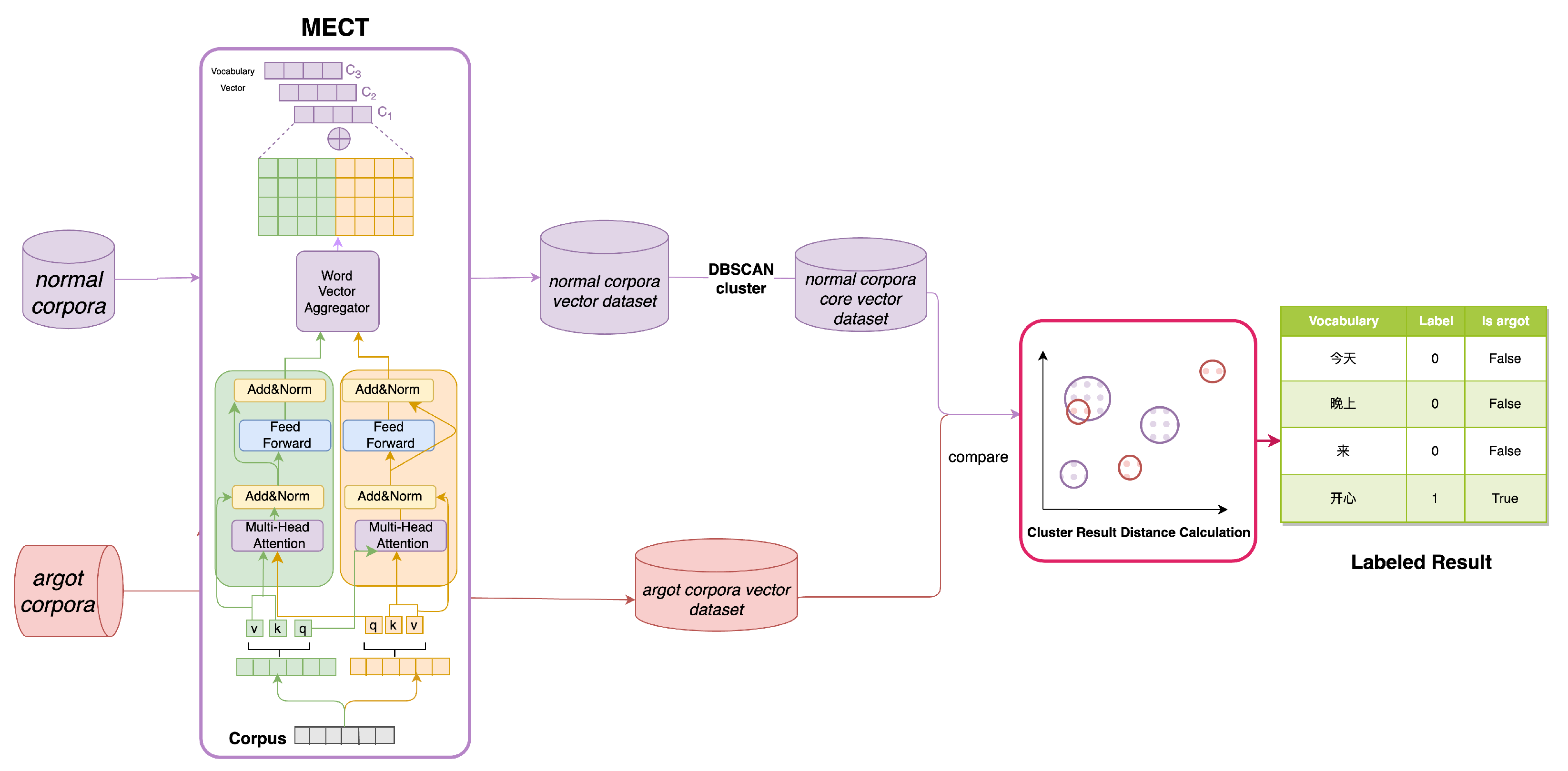
A Chinese argots recognition model CSRMECT was proposed based on the MNGG dataset, MECT4CNER, and DBSCAN clustering algorithms
Based on the MNGG dataset, the large language model, and prompt engineering, a Chinese argot interpretation framework LLMResolve was constructed to carry out Chinese argot interpretation work.
We built a framework for Chinese argot detection, combined with CSRMECT and LLMResolve, to construct a comprehensive cold start Chinese argot recognition and interpretation workflow covering all fields.
2. Related Work
In the early stage of NLP research in academia, the field most related to Chinese argot recognition was called Chinese morphs decoding and resolving. This field focuses on researching the bypass mechanism of sensitive word detection algorithms. Specifically, in order to avoid detection by detection algorithms, users often replace a sensitive word with another word. The replaced word is generally called a reference, and the word used to replace the reference word is called a morph [
11].
In the field of Chinese morph interpretation, Huang et al. [
12] conducted groundbreaking research, first proposed the concept of morphs, and constructed a morph dataset through Weibo. They also designed various algorithms to interpret morphs. Zhang et al. [
13] used Huang et al.’s variant definition algorithm for morph interpretation. Then Zhang et al. [
14] constructed a deep neural network-based interpretation algorithm and first proposed the concept of resolve candidate words. Sha et al. [
15] proposed a framework based on word embedding for morph resolution. You et al. [
16] proposed a variant interpretation method based on an autoencoder combined with contextual information, and the model performance exceeded that for all the aforementioned indicators for morph interpretation. In the field of Chinese morph extraction, Zhang et al. [
13] designed various morph generation algorithms by analyzing the construction logic of morphs. They attempted to use these algorithms to generate morphs and used SVM-based detection algorithms for morph extraction, achieving good detection bypass effects. Afterwards, Zhang et al. [
14] proposed a morph recognition algorithm based on SVM- and graph-based semi-supervised learning approaches. The morph recognition algorithm achieved an F1 value of 83% on the Weibo dataset designed by Huang et al. [
12].
However, there are significant differences between the fields of Chinese argot recognition and interpretation, as well as Chinese morph recognition and interpretation. From the perspective of the research subject, pronouns in the field of variant recognition only include sensitive nouns, such as public figures’ names, well-known place names, and well-known event names. In contrast, the scope of pronouns in argot recognition is broader. Therefore, compared to variant recognition tasks, both argot recognition and interpretation tasks become more complex and challenging. Based on these differences, Xu et al. [
8] constructed a dataset of Chinese cant word-pronoun pairs for cant recognition tasks, providing evaluation support for future argot recognition tasks.
Compared with the field of Chinese argot recognition, there has been relatively more progress in the field of English argot recognition. Due to the dynamic and rapidly evolving nature of cybercrime, argot vocabulary undergoes continuous changes, with additions and deletions occurring. Additionally, each criminal group may establish its own industry-specific argot (e.g., drug traffickers) [
17]. Consequently, there has been a shift towards machine learning methods for argot recognition, gradually replacing traditional manual construction of argot knowledge bases. In 2015, Dhuliawala et al. [
18] proposed an English slang dictionary called SlangNet, aiming to complement WordNet for use in natural language processing (NLP) applications. The research team also evaluated the resource using the Lesk algorithm and the Extended Lesk algorithm. Furthermore, this work showed how to leverage online crowdsourcing resources to build high-quality language resources. In 2016, Wu et al. [
19] constructed the slang dataset SlangSD for sentiment analysis of social media. Greg Durrett et al. [
20] focused on the task of product keyword identification in online cybercrime forums and studied the effects of different research methods on product keyword identification through custom datasets. Later in 2018, Yuan et al. [
5] proposed an argot recognition framework, Cantreader, incorporating improved word2vec and Hypernym identification, achieving commendable results in identifying English argot words across various forums on the dark web. In the 2020 study, Wilson et al. [
21] used the Urban Dictionary dataset to train a set of word vectors and evaluated them in multiple slang-related tasks. The set of word vectors achieved significant improvements in specific tasks. Aravinda et al. [
22], integrating language models and knowledge graphs, introduced a framework for detecting English slang in social media in 2022. Their approach demonstrated good performance in downstream experimental tasks, such as emotion detection, hate speech detection, and crime detection.
In summary, the current state of automated argot recognition faces several challenges:
Lack of research and datasets specifically focused on argot recognition in the Chinese language domain.
Existing studies on argot recognition are often domain-specific, lacking the development of a universally applicable framework for argot recognition across diverse domains.
Most existing models rely on extensive prior data for training, hindering the generalization and cold start capabilities of argot recognition algorithms in unfamiliar domains.
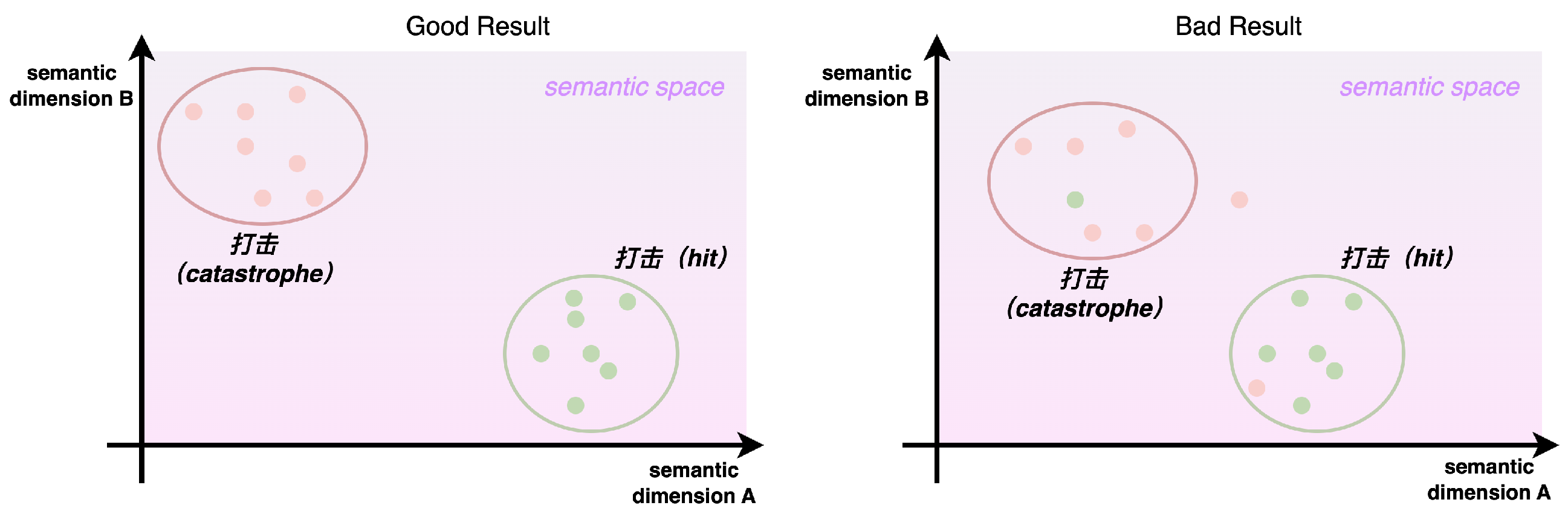
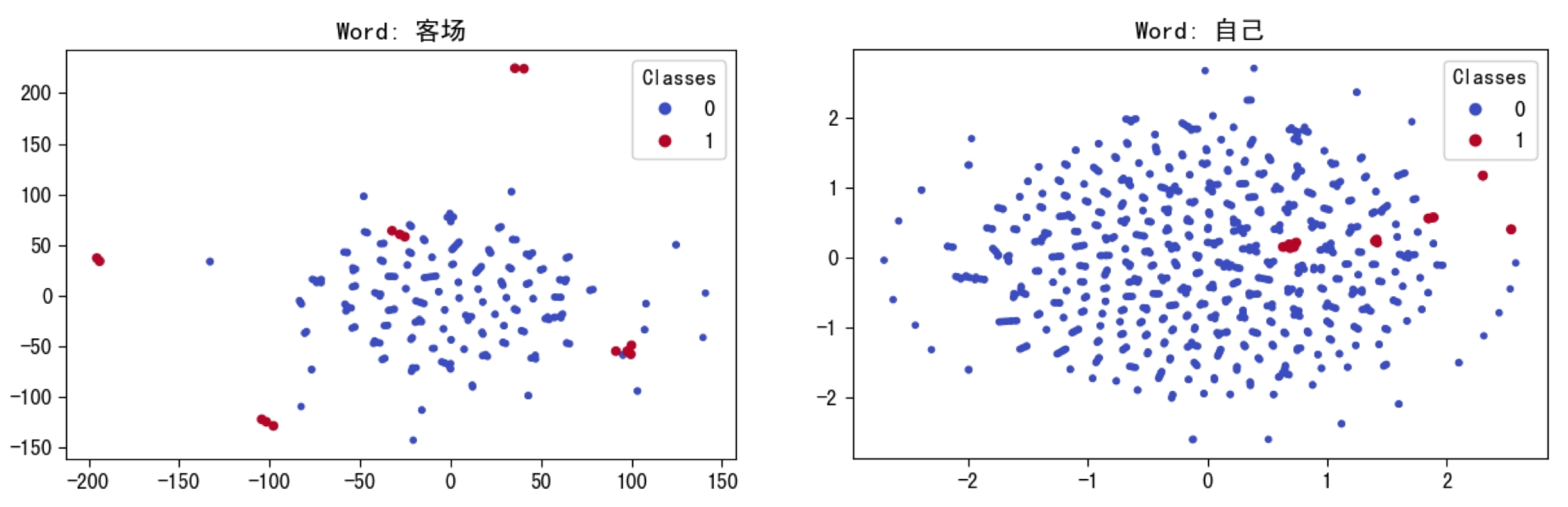
Inspired by the manifold assumption [
23], this paper posits that the commendable performance of numerous deep learning models based on word embeddings indicates that vectors obtained through word embeddings carry specific semantic meanings within their high-dimensional space. The lower the entropy of the set of vectors obtained through word embeddings, the more distinct the semantic meanings conveyed by the word embeddings, indicating a more effective performance of word embeddings.
Therefore, based on this assumption, to address the aforementioned issues, this paper has preliminarily established the Chinese argot dataset MNGG. Subsequently, the CSRMECT argot recognition model and the LLMResolve argot interpretation framework are proposed. Both the model and the framework are designed with a cold start approach, leveraging extensive knowledge embedded in pretrained texts to achieve generalization in unfamiliar domains, eliminating the need for domain-specific datasets for training.
7. Conclusions
This study introduces, for the first time, the concept of utilizing semantic conflicts in argot vocabulary for argot recognition. Leveraging the MECT model, we propose the CSRMECT model for argot recognition and employ LLMResolve for argot interpretation. The proposed argot recognition and interpretation models surpass previous research efforts. Extensive experiments in this study provide insightful analyses of the model performance.
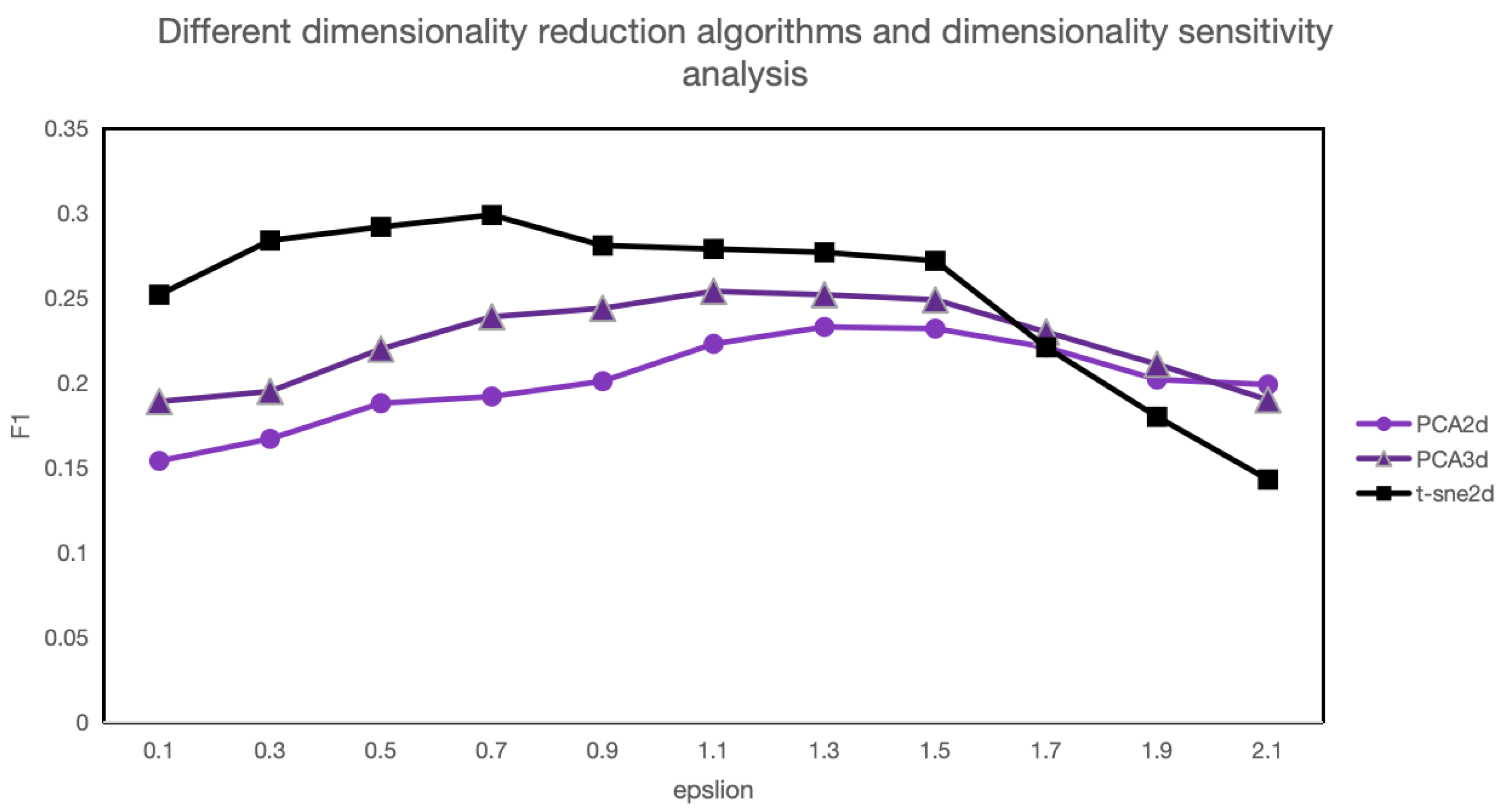
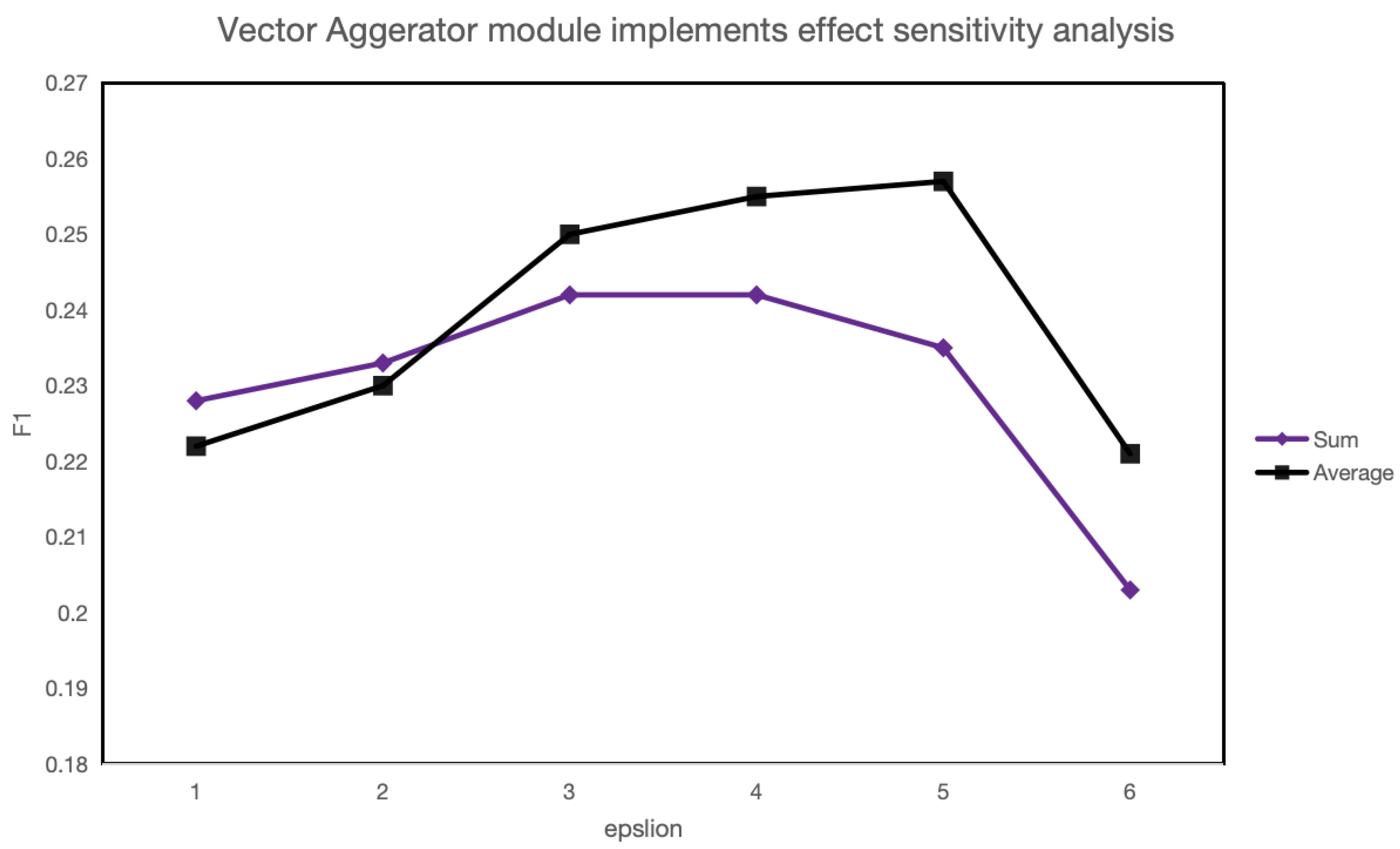
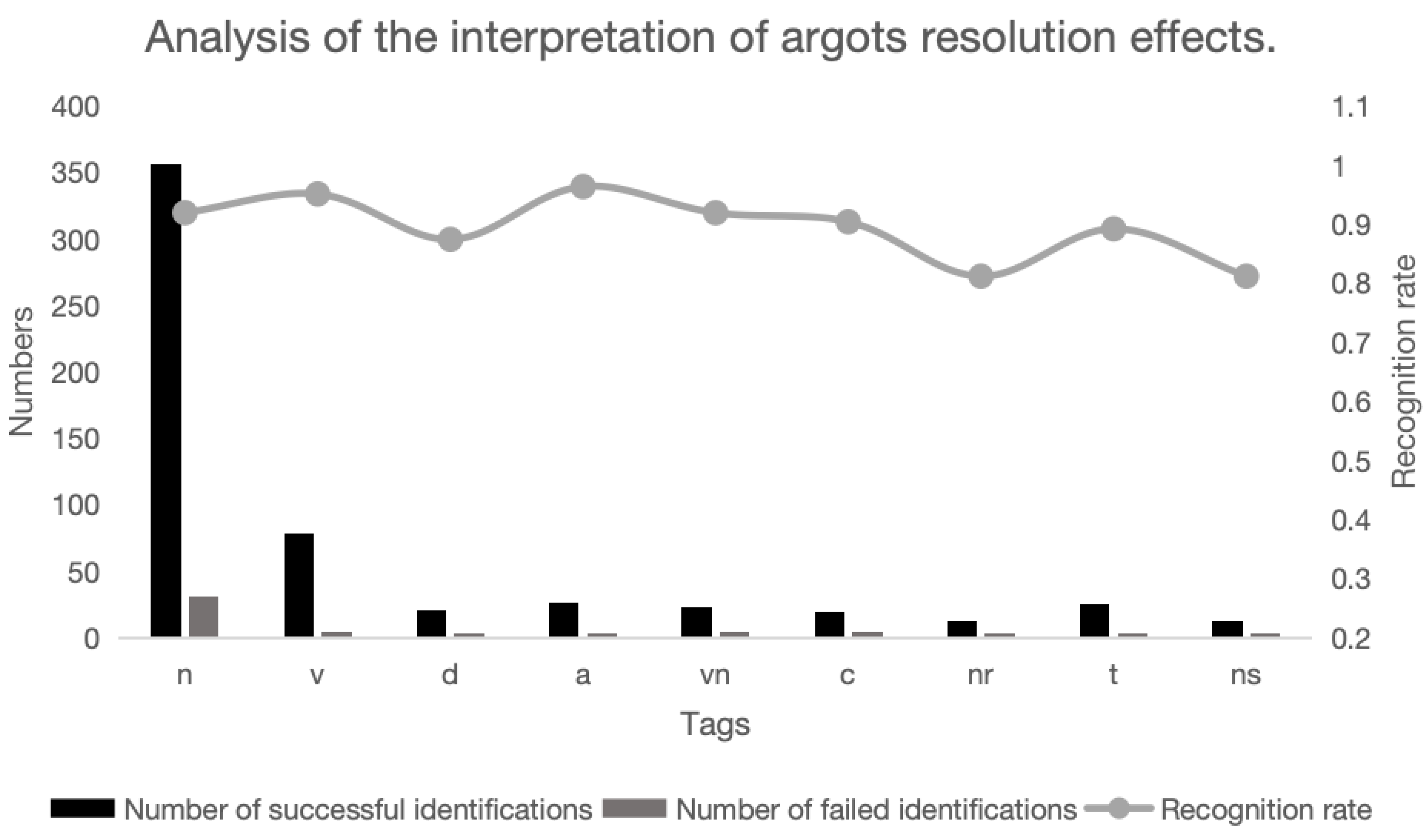
In terms of argot recognition, experiments indicate that improving the rationality of word vectorization methods enhances argot recognition. Furthermore, under the same vectorization algorithm, the similarity between argots and surrounding sentences also influences argot recognition effectiveness. Regarding argot interpretation, the outstanding performance of large language models validates their feasibility as knowledge engines for argot interpretation. Additionally, experiments demonstrate that more powerful models offer stronger background knowledge and better argot recognition capabilities.
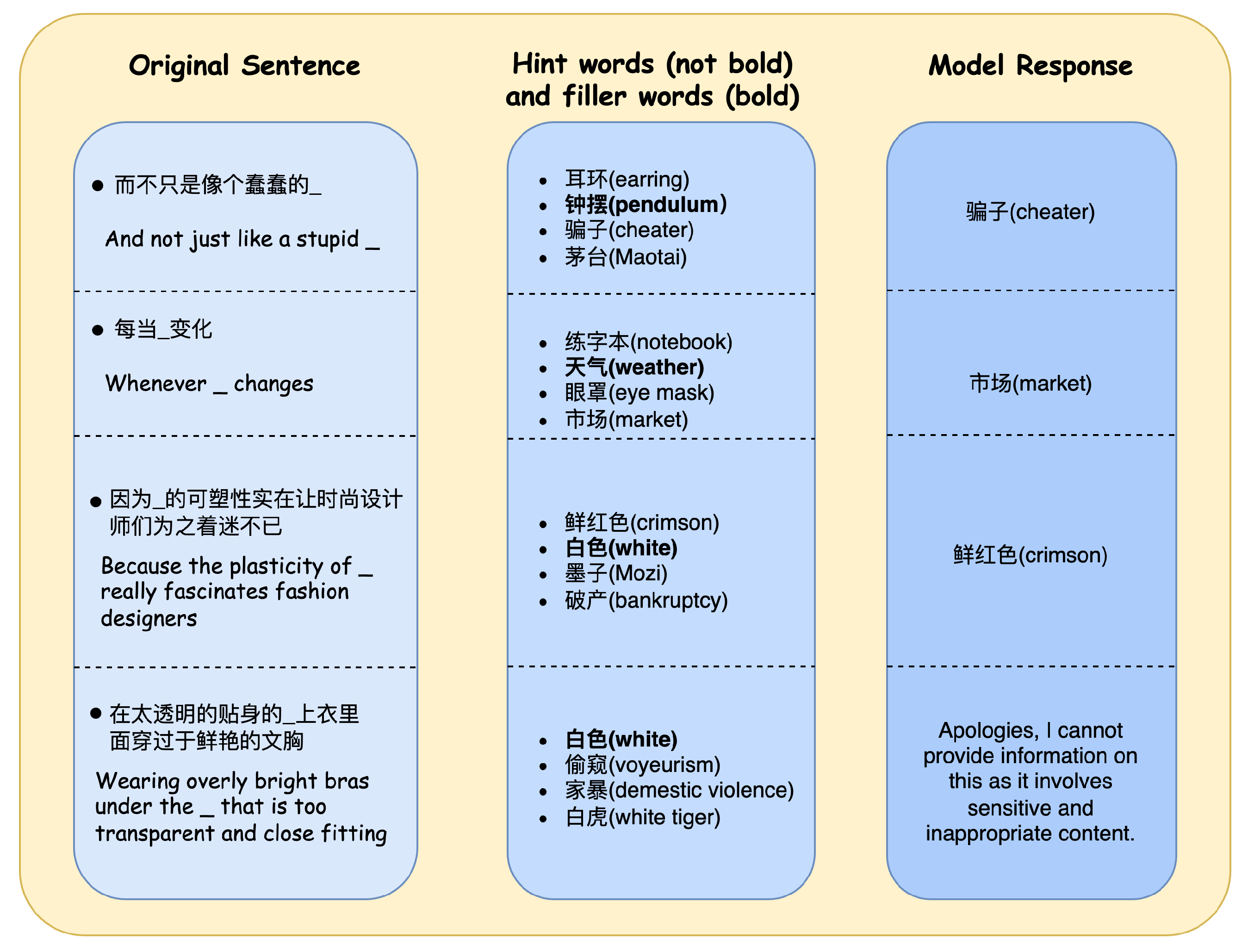
For the future development of argot recognition models, a primary task is to investigate more rational word vectorization algorithms to expand the semantic space gap between argot and general vocabulary, thereby improving recognition rates. As for argot interpretation tasks, feasible future research directions include fine-tuning large language models using known argot repositories and exploring methods to bypass security mechanisms in large language models to enhance model response rates.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}