


Bayesian Non-Parametric Inference for Multivariate Peaks-over-Threshold Models


Abstract
:1. Introduction
2. A Multivariate PoT Model
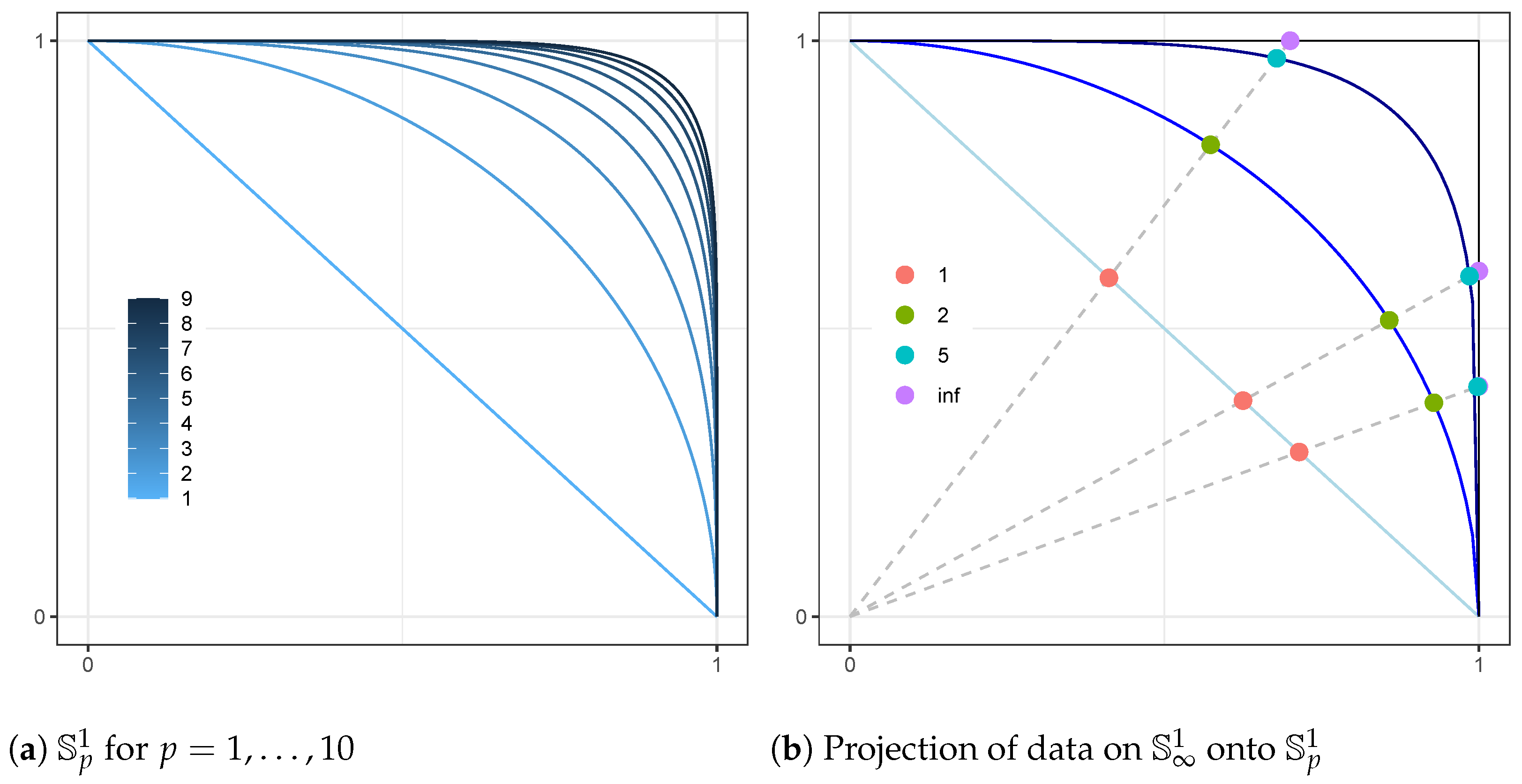
3. Estimation of the Angular Measure
3.1. Projected Gamma Family
3.2. Tail Probabilities for the PoT Model
Inference for the Projected Gamma Mixture Model
4. Scoring Criteria for Distributions on the Infinity-Norm Sphere
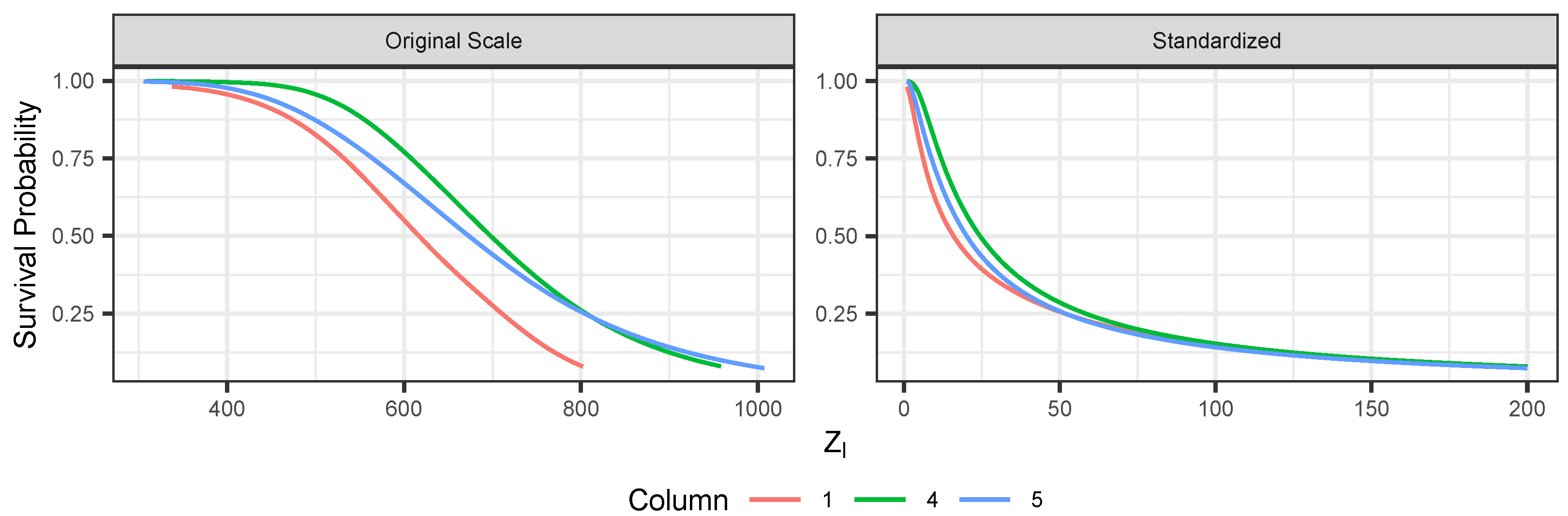
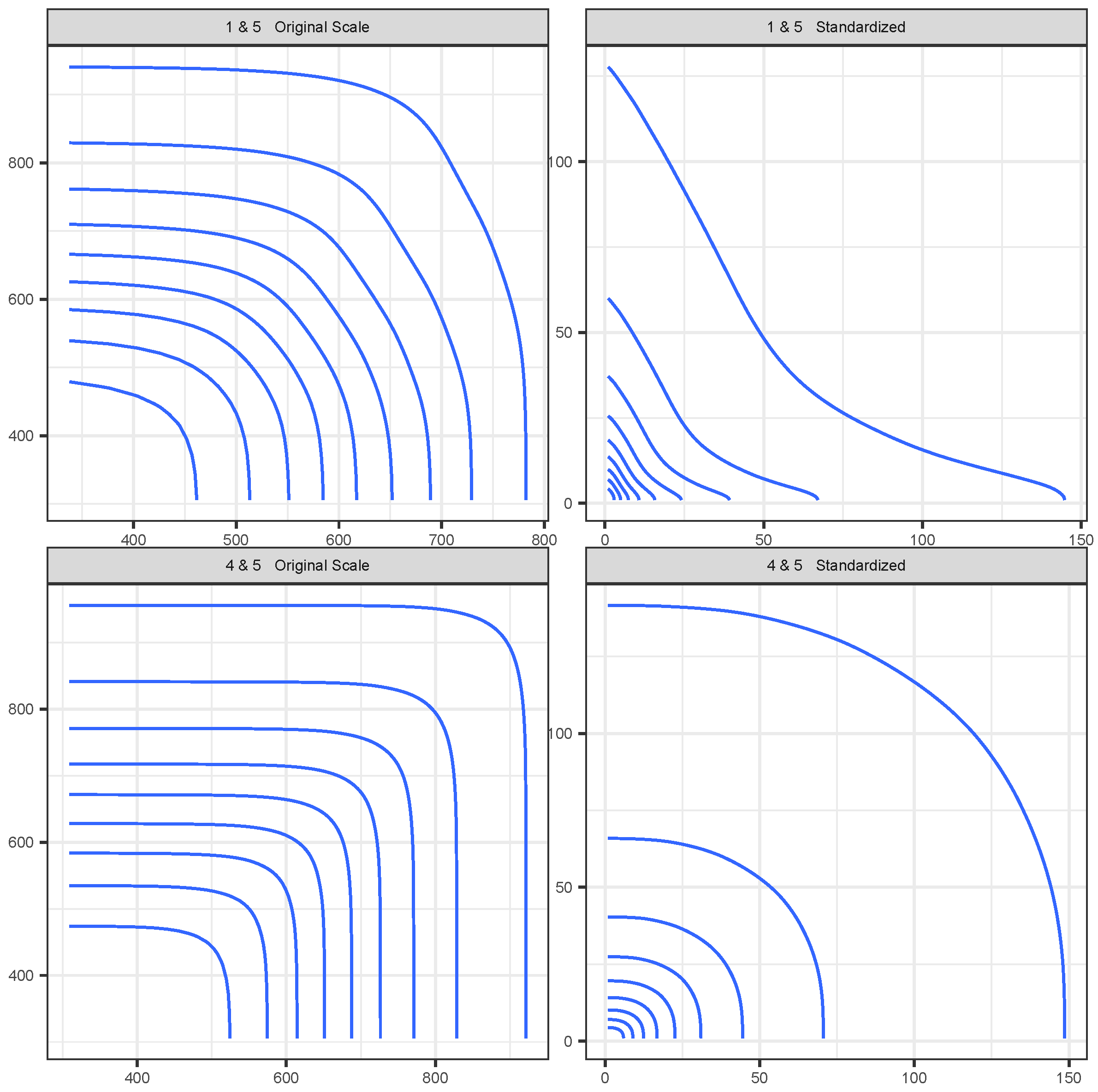
5. Data Illustrations
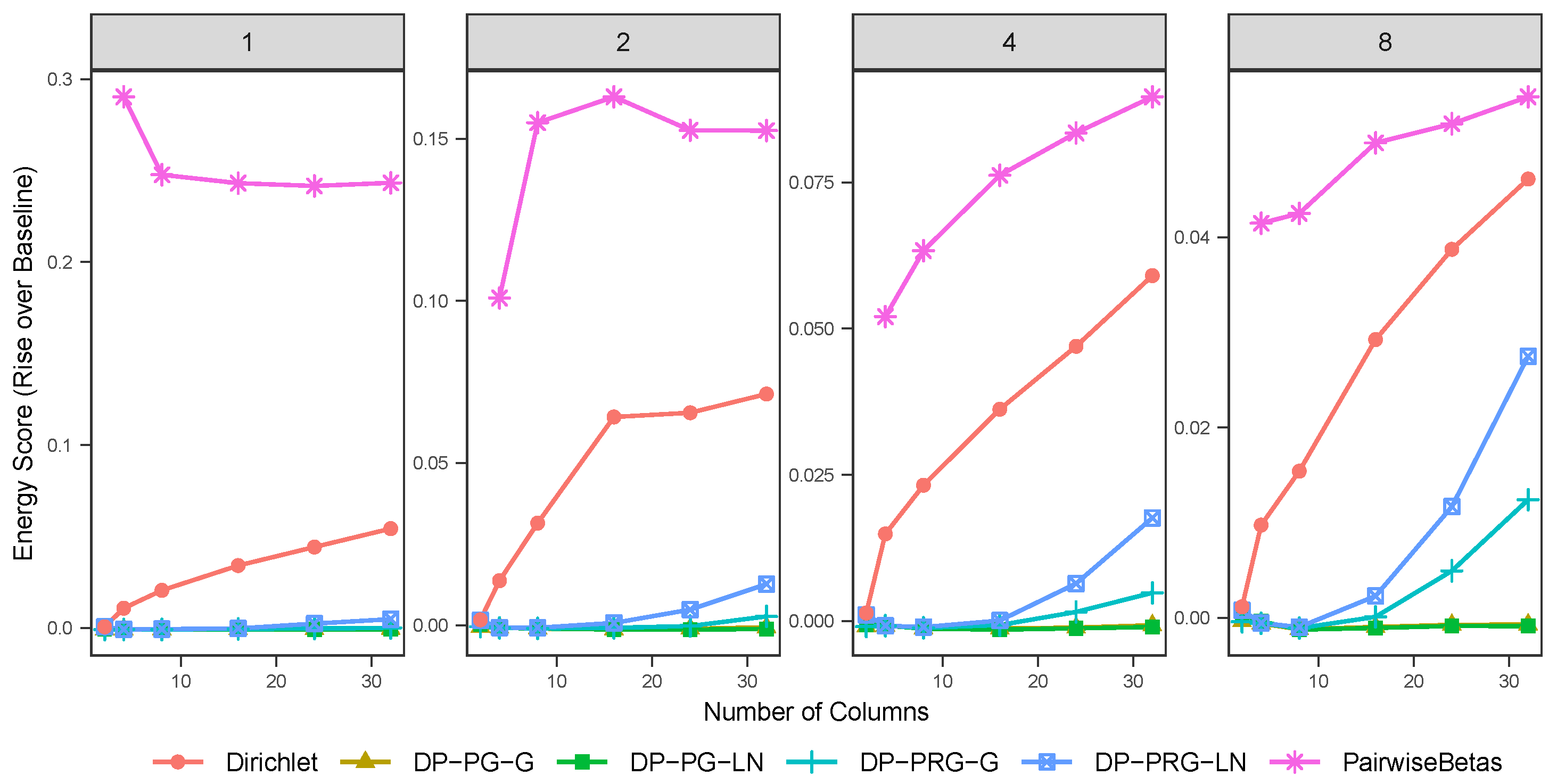
5.1. Simulation Study
| Algorithm 1 Simulated Angular Dataset Generation Routine. , are the parameters of the mixture component distribution; is the probability vector assigning weight mixture components; is the mixture component identifier for each simulated observation. |
|
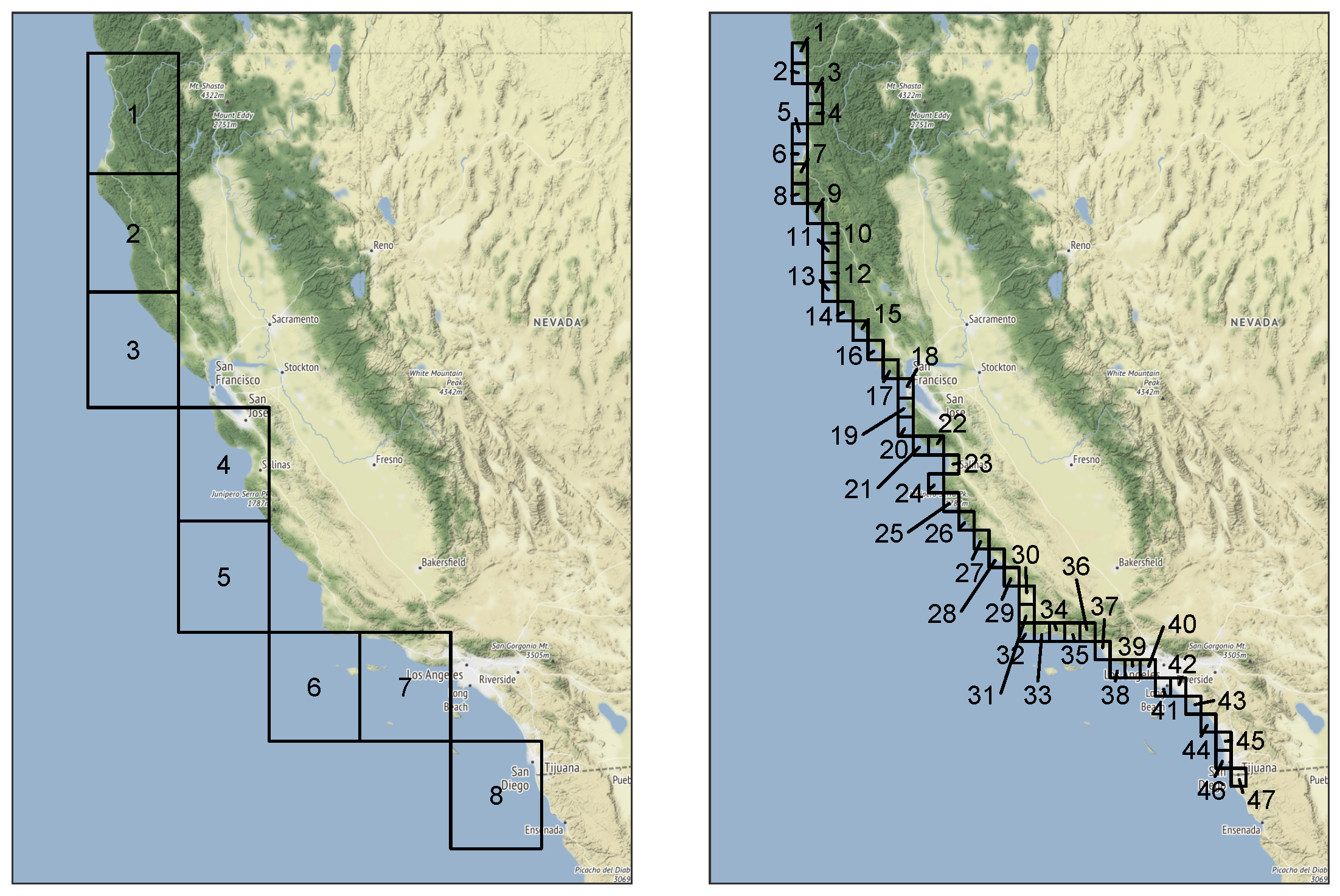
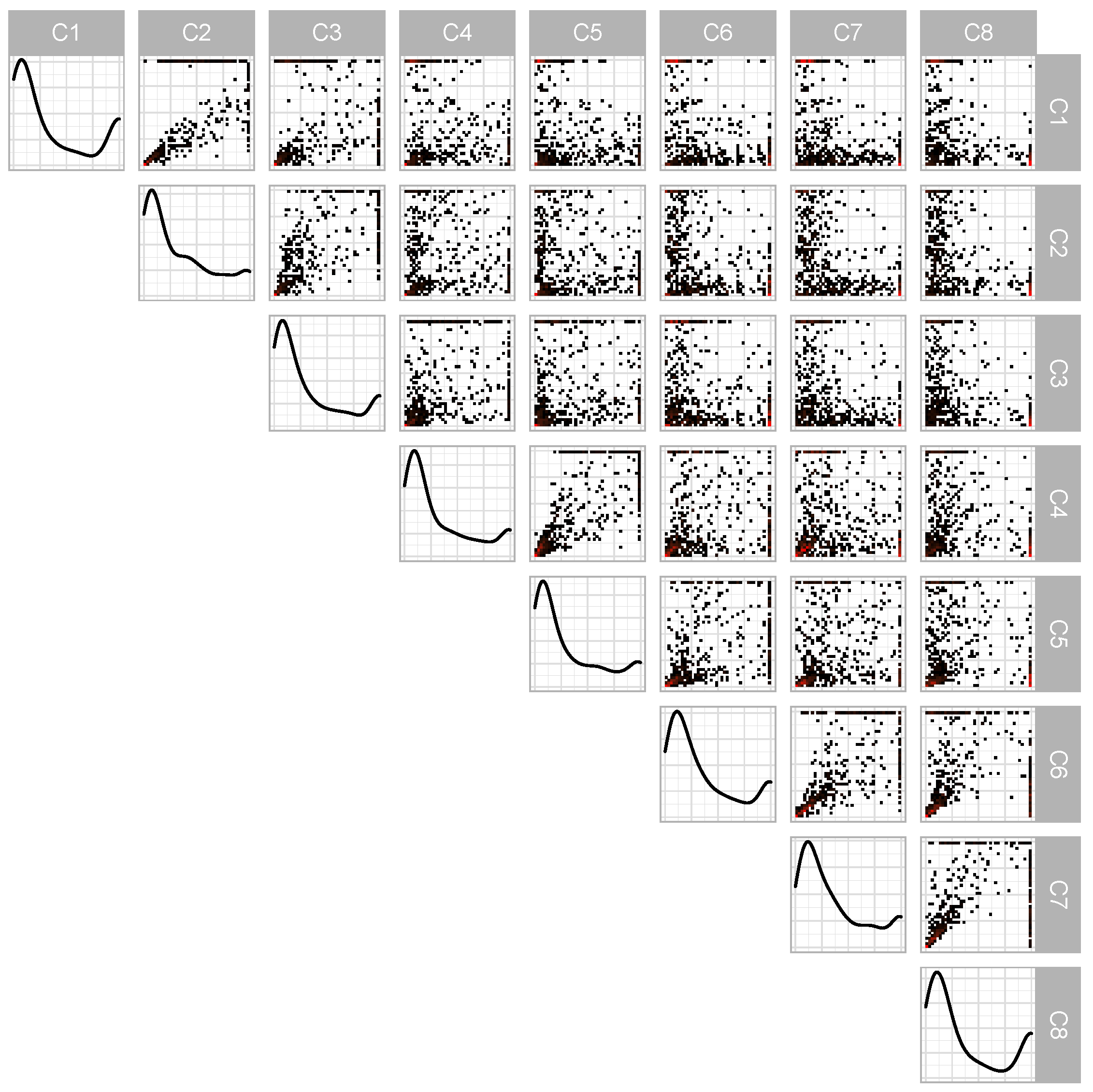
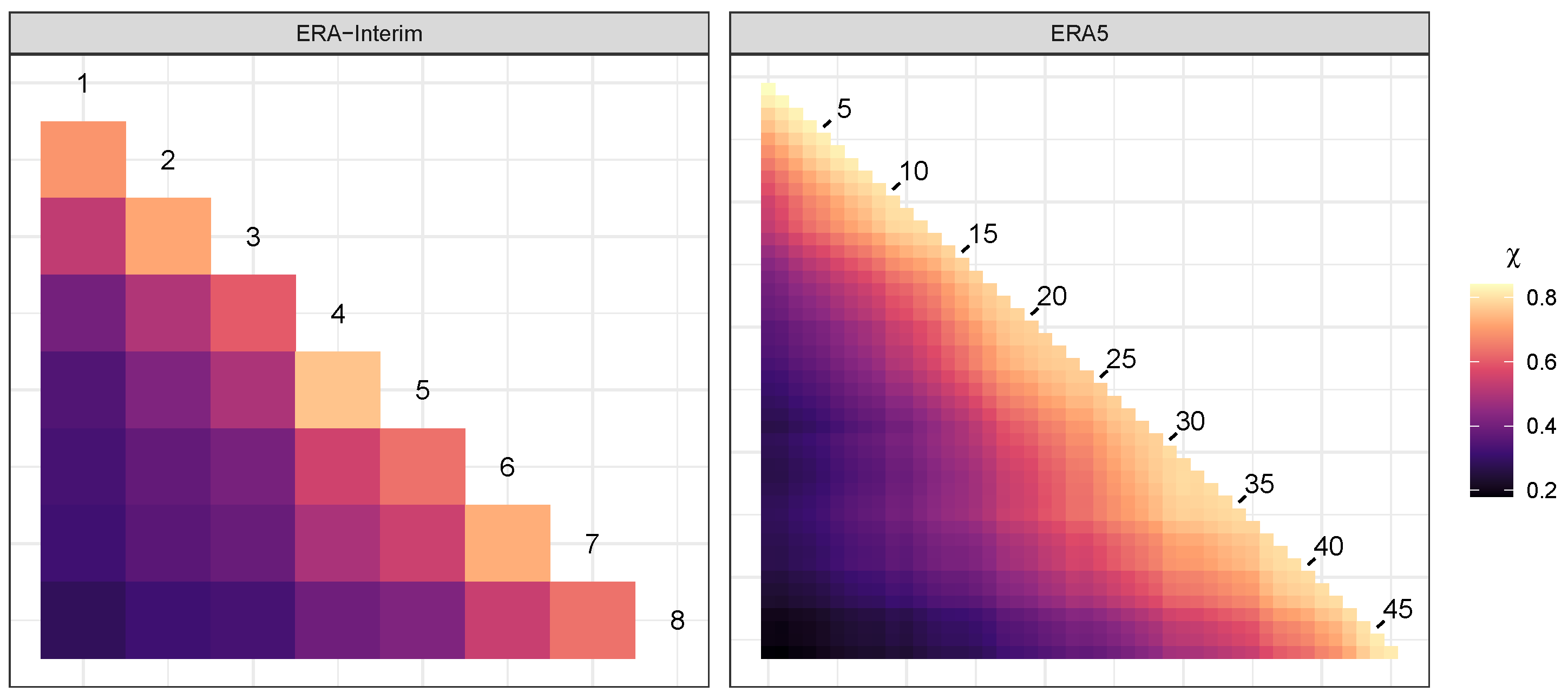
5.2. Integrated Vapor Transport
| Algorithm 2 Data preprocessing to isolate and transform data exhibiting extreme behavior. represents the radial component, and the angular component. The declustering portion is relevant for data correlated in time. |
|
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Coles, S.G. An Introduction to Statistical Modelling of Extreme Values; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar] [CrossRef]
- De Haan, L.; Ferreira, A. Extreme Value Theory: An Introduction; Springer: Berlin/Heidelberg, Germany, 2006; Volume 21. [Google Scholar] [CrossRef]
- Rootzén, H.; Tajvidi, N. Multivariate generalized Pareto distributions. Bernoulli 2006, 12, 917–930. [Google Scholar] [CrossRef]
- Falk, M.; Guillou, A. Peaks-over-Threshold stability of multivariate generalized Pareto distributions. J. Multivar. Anal. 2008, 99, 715–734. [Google Scholar] [CrossRef]
- Michel, R. Some notes on multivariate generalized Pareto distributions. J. Multivar. Anal. 2008, 99, 1288–1301. [Google Scholar] [CrossRef]
- Rootzén, H.; Segers, J.; Wadsworth, J.L. Multivariate peaks over thresholds models. Extremes 2018, 21, 115–145. [Google Scholar] [CrossRef]
- Rootzén, H.; Segers, J.; Wadsworth, J.L. Multivariate generalized Pareto distributions: Parametrizations, representations, and properties. J. Multivar. Anal. 2018, 165, 117–131. [Google Scholar] [CrossRef]
- Kiriliouk, A.; Rootzén, H.; Segers, J.; Wadsworth, J.L. Peaks Over Thresholds Modeling With Multivariate Generalized Pareto Distributions. Technometrics 2019, 61, 123–135. [Google Scholar] [CrossRef]
- Renard, B.; Lang, M. Use of a Gaussian copula for multivariate extreme value analysis: Some case studies in hydrology. Adv. Water Resour. 2007, 30, 897–912. [Google Scholar] [CrossRef]
- Falk, M.; Padoan, S.A.; Wisheckel, F. Generalized Pareto copulas: A key to multivariate extremes. J. Multivar. Anal. 2019, 174, 104538. [Google Scholar] [CrossRef]
- Ferreira, A.; de Haan, L. The generalized Pareto process; with a view towards application and simulation. Bernoulli 2014, 20, 1717–1737. [Google Scholar] [CrossRef]
- Boldi, M.O.; Davison, A.C. A mixture model for multivariate extremes. J. R. Stat. Soc. Ser. Stat. Methodol. 2007, 69, 217–229. [Google Scholar] [CrossRef]
- Sabourin, A.; Naveau, P. Bayesian Drichlet mixture model for multivariate extremes: A re-parametrization. Comput. Stat. Data Anal. 2014, 71, 542–567. [Google Scholar] [CrossRef]
- Hanson, T.E.; de Carvalho, M.; Chen, Y. Bernstein polynomial angular densities of multivariate extreme value distributions. Stat. Probab. Lett. 2017, 128, 60–66. [Google Scholar] [CrossRef]
- Guillotte, S.; Perron, F.; Segers, J. Non-parametric Bayesian inference on bivariate extremes. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2011, 73, 377–406. [Google Scholar] [CrossRef]
- Jentsch, A.; Kreyling, J.; Beierkuhnlein, C. A new generation of climate-change experiments: Events, not trends. Front. Ecol. Environ. 2007, 5, 365–374. [Google Scholar] [CrossRef]
- Vousdoukas, M.I.; Mentaschi, L.; Voukouvalas, E.; Verlaan, M.; Jevrejeva, S.; Jackson, L.P.; Feyen, L. Global probabilistic projections of extreme sea levels show intensification of coastal flood hazard. Nat. Commun. 2018, 9, 2360. [Google Scholar] [CrossRef]
- Li, C.; Zwiers, F.; Zhang, X.; Chen, G.; Lu, J.; Li, G.; Norris, J.; Tan, Y.; Sun, Y.; Liu, M. Larger increases in more extreme local precipitation events as climate warms. Geophys. Res. Lett. 2019, 46, 6885–6891. [Google Scholar] [CrossRef]
- Resnick, S. Extreme Values, Regular Variation, and Point Processes; Applied Probability; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Núñez-Antonio, G.; Geneyro, E. A multivariate projected Gamma model for directional data. Commun. Stat.-Simul. Comput. 2021, 50, 2721–2742. [Google Scholar] [CrossRef]
- Ferguson, T.S. Prior Distributions on Spaces of Probability Measures. Ann. Stat. 1974, 2, 615–629. [Google Scholar] [CrossRef]
- Antoniak, C.E. Mixtures of Dirichlet Processes with Applications to Bayesian Nonparametric Problems. Ann. Stat. 1974, 2, 1152–1174. [Google Scholar] [CrossRef]
- Müller, P.; Quintana, F.A.; Jara, A.; Hanson, T. Bayesian Nonparametric Data Analysis; Springer: Berlin/Heidelberg, Germany, 2015; Volume 1. [Google Scholar]
- Ascolani, F.; Lijoi, A.; Rebaudo, G.; Zanella, G. Clustering consistency with Dirichlet process mixtures. Biometrika 2022, 110, 551–558. [Google Scholar] [CrossRef]
- Neal, R.M. Markov Chain Sampling Methods for Dirichlet Process Mixture Models. J. Comput. Graph. Stat. 2000, 9, 249–265. [Google Scholar] [CrossRef]
- Escobar, M.D.; West, M. Bayesian density estimation and inference using mixtures. J. Am. Stat. Assoc. 1995, 90, 577–588. [Google Scholar] [CrossRef]
- Earl, D.J.; Deem, M.W. Parallel tempering: Theory, applications, and new perspectives. Phys. Chem. Chem. Phys. 2005, 7, 3910–3916. [Google Scholar] [CrossRef]
- Gneiting, T.; Raftery, A.E. Strictly Proper Scoring Rules, Prediction, and Estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Berg, C.; Christensen, J.P.R.; Ressel, P. Harmonic Analysis on Semigroups: Theory of Positive Definite and Related Functions; Springer: Berlin/Heidelberg, Germany, 1984; Volume 100. [Google Scholar]
- Pappas, T. The Joy of Mathematics: Discovering Mathematics All Around You; Wide World Pub Tetra: Frederick, MD, USA, 1989. [Google Scholar]
- Cooley, D.; Davis, R.A.; Naveau, P. The pairwise beta distribution: A flexible parametric multivariate model for extremes. J. Multivar. Anal. 2010, 101, 2103–2117. [Google Scholar] [CrossRef]
- Sabourin, A. BMAmevt: Multivariate Extremes: Bayesian Estimation of the Spectral Measure, R Package Version 1.0.5; 2023. Available online: https://CRAN.R-project.org/package=BMAmevt (accessed on 10 April 2024).
- Ralph, F.M.; Iacobellis, S.; Neiman, P.; Cordeira, J.; Spackman, J.; Waliser, D.; Wick, G.; White, A.; Fairall, C. Dropsonde observations of total integrated water vapor transport within North Pacific atmospheric rivers. J. Hydrometeorol. 2017, 18, 2577–2596. [Google Scholar] [CrossRef]
- Neiman, P.J.; White, A.B.; Ralph, F.M.; Gottas, D.J.; Gutman, S.I. A water vapour flux tool for precipitation forecasting. In Proceedings of the Institution of Civil Engineers-Water Management; Thomas Telford Ltd.: London, UK, 2009; Volume 162, pp. 83–94. [Google Scholar] [CrossRef]
- Berrisford, P.; Kållberg, P.; Kobayashi, S.; Dee, D.; Uppala, S.; Simmons, A.; Poli, P.; Sato, H. Atmospheric conservation properties in ERA-Interim. Q. J. R. Meteorol. Soc. 2011, 137, 1381–1399. [Google Scholar] [CrossRef]
- Dee, D.P.; Uppala, S.; Simmons, A.; Berrisford, P.; Poli, P.; Kobayashi, S.; Andrae, U.; Balmaseda, M.; Balsamo, G.; Bauer, P.; et al. The ERA-Interim reanalysis: Configuration and performance of the data assimilation system. Q. J. R. Meteorol. Soc. 2011, 137, 553–597. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- de Carvalho, M.; Kumukova, A.; Dos Reis, G. Regression-type analysis for multivariate extreme values. Extremes 2022, 25, 595–622. [Google Scholar] [CrossRef]
- Mhalla, L.; de Carvalho, M.; Chavez-Demoulin, V. Regression-type models for extremal dependence. Scand. J. Stat. 2019, 46, 1141–1167. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) | |||||
|---|---|---|---|---|---|
| Source | Pairwise Betas | PG-G | PG-LN | PRG-G | PRG-LN |
| ERA-Interim | 0.7966 | ||||
| ERA5 | 1.4349 | ||||
| (b) | |||||
| Source | Pairwise Betas | PG-G | PG-LN | PRG-G | PRG-LN |
| ERA-Interim | |||||
| ERA5 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trubey, P.; Sansó, B. Bayesian Non-Parametric Inference for Multivariate Peaks-over-Threshold Models. Entropy 2024, 26, 335. https://doi.org/10.3390/e26040335
Trubey P, Sansó B. Bayesian Non-Parametric Inference for Multivariate Peaks-over-Threshold Models. Entropy. 2024; 26(4):335. https://doi.org/10.3390/e26040335
Chicago/Turabian StyleTrubey, Peter, and Bruno Sansó. 2024. "Bayesian Non-Parametric Inference for Multivariate Peaks-over-Threshold Models" Entropy 26, no. 4: 335. https://doi.org/10.3390/e26040335
APA StyleTrubey, P., & Sansó, B. (2024). Bayesian Non-Parametric Inference for Multivariate Peaks-over-Threshold Models. Entropy, 26(4), 335. https://doi.org/10.3390/e26040335