Abstract
A clustered distributed storage system (DSS), also called a rack-aware storage system, is a distributed storage system in which the nodes are grouped into several clusters. The communication between two clusters may be restricted by their connectivity; that is to say, the communication cost between nodes differs depending on their location. As such, when repairing a failed node, downloading data from nodes that are in the same cluster is much cheaper and more efficient than downloading data from nodes in another cluster. In this article, we consider a scenario in which the failed nodes only download data from nodes in the same cluster, which is an extreme and important case that leverages the fact that the intra-cluster bandwidth is much cheaper than the cross-cluster repair bandwidth. Also, we study the problem of repairing multiple failures in this article, which allows for collaboration within the same cluster, i.e., failed nodes in the same cluster can exchange data with each other. We derive the trade-off between the storage and repair bandwidth for the clustered DSSs and provide explicit code constructions achieving two extreme points in the trade-off, namely the minimum storage clustered collaborative repair (MSCCR) point and the minimum bandwidth clustered collaborative repair (MBCCR) point, respectively.
1. Introduction
Cloud distributed storage systems (DSSs), built on a huge number of storage nodes, have been applied widely (e.g., Google File System [1], Facebook [2], and Total Recall [3]). In a DSS, failures occur frequently, degrading the system’s reliability. To ensure the reliability of DSSs, erasure coding has been widely used to improve their tolerance of failures.
A class of erasure codes, namely regenerating codes, for cloud distributed storage systems was proposed by Dimakis et al. [4], aiming to reduce the repair bandwidth (or repair traffic) during node failures. More specifically, suppose that a data file is encoded and stored on n nodes, each of which stores symbols. A data collector can retrieve the data file by connecting to any k nodes, which is called the recovery property. When a node failure occurs, the system will trigger a repair process to recover the data on the failed node by downloading data from some other nodes. The total amount of data downloaded from these other nodes is called the repair bandwidth, which consists of symbols. The fundamental trade-off between the amount of data stored on each node and the repair bandwidth was studied in [4]. There are two extreme points on the trade-off curve, namely the minimum storage repair (MSR) point and the minimum bandwidth repair (MBR) point, which minimize the data stored on each node and the repair bandwidth, respectively.
The pioneering work [4] proposed studying a single failure in a cloud distributed storage system. Later, collaborative regenerating codes (CRCs) were proposed [5,6,7] for studying cases when multiple failures happen and are repaired simultaneously in a DSS, which has been shown to improve the repair bandwidth compared to repairing multiple failures sequentially.
The former studies considered the communication cost between the nodes to be homogeneous. However, in a realistic system, the storage nodes may be geographically separated in their locations, and hence the communication cost of downloading data from a geographically close helper node may be quite different from that of downloading from a helper node that is further away geographically. The model of a clustered (or rack-aware) distributed storage system assumes that the nodes are grouped into several clusters (racks) and assumes that the communication cost of downloading data from a node within the same cluster (rack) (which is also called the host cluster below) is much cheaper than downloading data from another cluster (rack). In fact, as shown in [8,9,10], the clustered structure incurs a substantial cross-cluster (cross-rack) bandwidth. The cross-cluster (cross-rack) capacity available per node in the worst case is only 1/5 to 1/20 of the intra-cluster (intra-rack) capacity, which indicates that the cross-cluster (cross-rack) bandwidth is more expensive than the intra-cluster (intra-rack) bandwidth.
Many attempts [11,12,13,14,15,16,17,18,19,20,21,22,23,24,25] have been made to reduce the cross-cluster bandwidth, in which repairing a single failure has been considered. Following these works, cases of clustered structures with multiple failures in each cluster were considered in [26,27,28,29,30,31,32], where the failed nodes downloaded data from other clusters so that the cross-cluster bandwidth applied.
As said, the cross-cluster (cross-rack) bandwidth is more expensive than the intra-cluster (intra-rack) bandwidth, so considering repairing multiple failures within the host cluster without cross-cluster traffic is an economical choice. In this article, we address the problem of repairing multiple failures in clustered storage systems, where multiple failures happen in each cluster. A data collector can retrieve the data file by connecting to any k nodes (from multiple clusters). We suppose the system has no cross-cluster bandwidth, and the target is to minimize the repair bandwidth within the host cluster. The main contributions of this article can be summarized as follows:
- (1)
- We first study the trade-off between the storage and repair bandwidth for clustered distributed storage systems for multiple failures with zero cross-cluster bandwidth using a conventional maximum-flow, min-cut analysis over an information flow graph;
- (2)
- We calculate the parameter values for two extreme points on the trade-off curve, namely the minimum storage clustered collaborative repair (MSCCR) point and the minimum bandwidth clustered collaborative repair (MBCCR) point;
- (3)
- We analyze the repair bandwidth performance using different system parameters at the MSCCR and MBCCR points;
- (4)
- We also provide explicit constructions to optimize the two extreme points on the trade-off curve, which implies that our constructions are optimal in terms of the repair bandwidth.
This article is organized as follows. Section 2 discusses related works. In Section 3, we briefly describe the clustered collaborative repair problem and introduce the standard notion of an information flow graph for the clustered collaborative repair problem. In Section 4, we give the min-cut bound (an upper bound on the file size) by inspecting the corresponding information flow graph. In Section 5, the two extreme points on the storage bandwidth trade-off curve, i.e., the MSCCR point and the MBCCR point, are identified. In Section 6, we analyze the normalized repair bandwidth at the MSCCR point and the MBCCR point and provide some results of simulations. In Section 7, we give the explicit code constructions for the MSCCR point and the MBCCR point, respectively. Finally, we conclude this article in Section 8 and point out further directions for future research.
2. Related Works
2.1. Collaborative Regenerating Codes
To reduce the repair bandwidth (repair traffic) when multiple failures happen in DSSs, collaborative regenerating codes (CRCs), or precisely fully collaborative regenerating codes, were proposed in [5,6,7]. Multiple failures were repaired simultaneously. The repair bandwidth of collaborative regenerating codes includes the amount of data exchanged between the failed nodes and the amount of data downloaded from the helper nodes. It has been shown [5,6,7] that collaborative repair improves the repair bandwidth compared to that when repairing multiple failures sequentially. Many attempts [33,34,35,36,37,38,39] have been made to construct collaborative regenerating codes at the minimum storage regenerating point and the minimum bandwidth regenerating point.
A related variant of fully collaborative regenerating codes is called partially collaborative regenerating codes [40], which can be viewed as a generalization of the collaborative repair mechanism and the sequential repair mechanism by allowing a subset of failed nodes to join the repair process collaboratively. A few constructions at the MSR point and the MBR point for partially collaborative regenerating codes were proposed in [41,42,43]. The problem of repairing multiple node failures has also been studied under the scenario of centralized repair [44,45], where a centralized node downloads data from some nodes that are still alive, computes the data, and then dispatches the data for all failed nodes.
2.2. Clustered Storage Codes
In a realistic system, the communication costs between storage nodes are heterogeneous when the nodes are geographically separated. The model of a clustered distributed storage system assumes that the nodes are grouped into several clusters. The model assumes that the communication cost of downloading data from a node within the same cluster is much cheaper than downloading data from another cluster.
A case with two clusters was studied in [11,12], and an upper bound on the file size that could be stored was derived. An explicit construction of maximum distance separable (MDS) array codes of rate 1/2 for a two-cluster case was proposed in [14]. A general case with more than two clusters was later studied in [13,14], where a single failed node was repaired by downloading data from the nodes in the host cluster and also from nodes in other clusters directly. An upper bound on the file size was proposed [13], and the existence of optimal repair codes was established via an information flow graph.
Recently, many attempts [15,16,17,18,19,20,21,22,23,24,25] have been made to reduce the cross-cluster bandwidth. In these works, a centralized node (also called a relay node/a compute unit) exists in each cluster, which collects data from the nodes within the cluster and then computes and dispatches data to repair the failed node. The failed node being repaired will download data from the centralized nodes in other clusters, indicating that the helpers are clusters rather than nodes. Hence, the model in these works can be seen as a centralized model, which is different from the model in [11,12,13,14] (which can be seen as a decentralized model), where the failed node being repaired directly downloads the data from nodes in other clusters without processing by the centralized node.
In [15], Hu et al. considered a clustered system with centralized nodes, and they derived an upper bound for the file size and showed the existence of minimum storage codes with optimal repair for the model. In [18], Hou et al. studied codes not only for the minimum storage but also for the minimum bandwidth. In [19], they derived the lower bound on the amount of information that needed to be accessed to repair a single failed node using an arbitrary number of helper racks. In [20], they proposed codes by product-matrix method for the minimum storage. Chen and Barg [21] further proposed a family of minimum storage rack-aware regenerating codes for all admissible parameters but with a high level of sub-packetization. Hou et al. [22] then proposed a family of minimum storage rack-aware regenerating codes that improved the sub-packetization level.
Clustered structures with multiple failures in each cluster were considered in [26,27,28,29,30,31,32]. In particular, Abdrashitov et al. [26] studied the problem of multiple node failures occurring in one cluster, and in their model, the data reconstruction was realized by connecting to any k clusters rather than any k nodes. Gupta and Lalitha [27,28,29] studied the case of multiple node failures occurring in more than one cluster, allowing for collaboration among clusters, where a centralized node existed for each cluster, the same setting as that seen in [15,16,17,18,19,21,22,23,24,25] as mentioned, and then the collaboration happened among the clusters instead of the nodes. Multiple node failures in a single cluster were considered in [30,31,32].
To conclude, we consider the problem of repairing multiple node failures in a clustered distributed storage system without a centralized node. The node repair happens within the host cluster (for the case of zero cross-cluster bandwidth), which is the most desirable setting, as mentioned, i.e., the intra-cluster bandwidth is much cheaper than the cross-cluster bandwidth. Within the cluster, the bandwidth will be further improved by utilizing the properties of collaborative regenerating codes.
3. The System Model
In this section, we will describe the clustered collaborative repair problem formally and the associated information flow graph that represents the problem.
A data object of size M is stored across n nodes, which is equally distributed across L clusters with l nodes each. Every node has a storage capacity of . In this clustered distributed storage system, any choice of k nodes allows for object retrieval, where (a case where will be equivalent to the case in [5,6]). The system triggers a repair process when t failures occur in one cluster, and the t failures are repaired collaboratively in each cluster. Each node being repaired will download a amount of data from the surviving nodes in its host cluster and exchange a amount of data with the other nodes being repaired. The repair bandwidth for each node is . For ease of reading, some of the frequently used notations are summarized in Table 1.

Table 1.
Summary of notations.
Following the information flow graph approach from the seminal work [4], we consider the corresponding information flow graph associated with this clustered collaborative repair problem, where the data flow from a source S to a data collector . Suppose that a data collector connects to a subset of k nodes that are involved in different clusters. Let denote the number of nodes connected by in cluster r, where (for any positive integer a, denote ). As such, we have . In each cluster r, the connected nodes are involved in different phases of repair (each repair phase is a repair process of t nodes), where each phase i involves a group of nodes such that . Let , where .
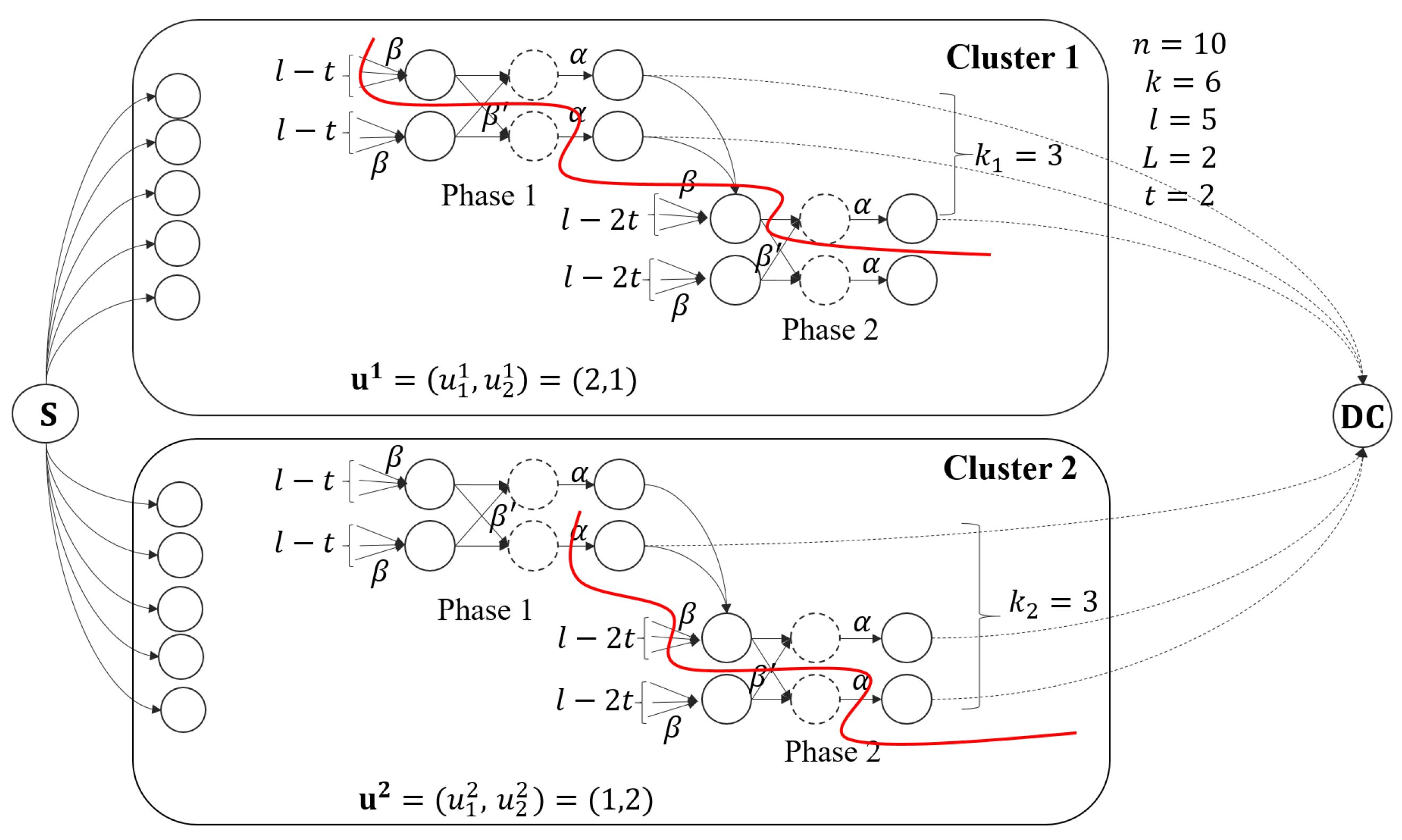
We give an example of the information flow graph for two clusters here. As shown in Figure 1, the file is stored in nodes, which are divided into clusters, and each cluster has nodes. In each cluster, nodes are being repaired simultaneously. The data collector can retrieve the file by connecting to nodes, where nodes from cluster 1 in two phases with , and nodes from cluster 2 in two phases with .
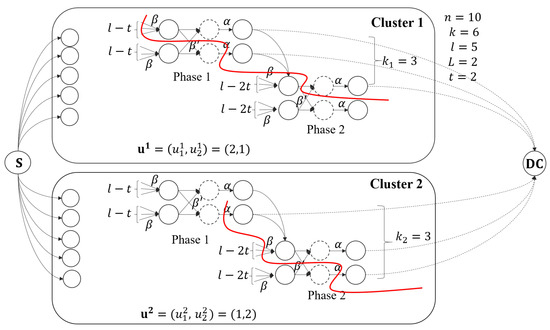
Figure 1.
The information flow graph for nodes and clusters with , , and . The red lines represent a possible cut on this flow graph.
4. Trade-Off Between the Storage Capacity and Repair Bandwidth
In this section, we derive a bound on the file size when the system parameters are fixed. The bound indicates the trade-off between the storage capacity and the repair bandwidth .
By inspecting the information flow graph, as described in Section 3, we can obtain the following min-cut bound.
Lemma 1.
The min-cut bound between the source S and the data collector is given by
where
The details of the examination for the cut in Lemma 1 are deferred to Appendix A. Here, we illustrate a possible cut in the information flow graph in Figure 1. The red lines in clusters 1 and 2 give a cut as an example. The contribution to the cut in cluster 1 is , and the contribution to the cut in cluster 2 is . So, this cut contains a amount of information.
According to the minimum cut–maximum flow theorem, we know that the file size M is bounded by the min-cut of the aforementioned information flow graph.
Theorem 1.
A file of size M stored in a clustered distributed storage system with multiple failures and zero cross-cluster bandwidth must satisfy
where is the parameter defined in Lemma 1.
An immediate corollary is as follows:
Corollary 1.
When , we have
which is the bound that can be derived from Theorem 1 in [13].
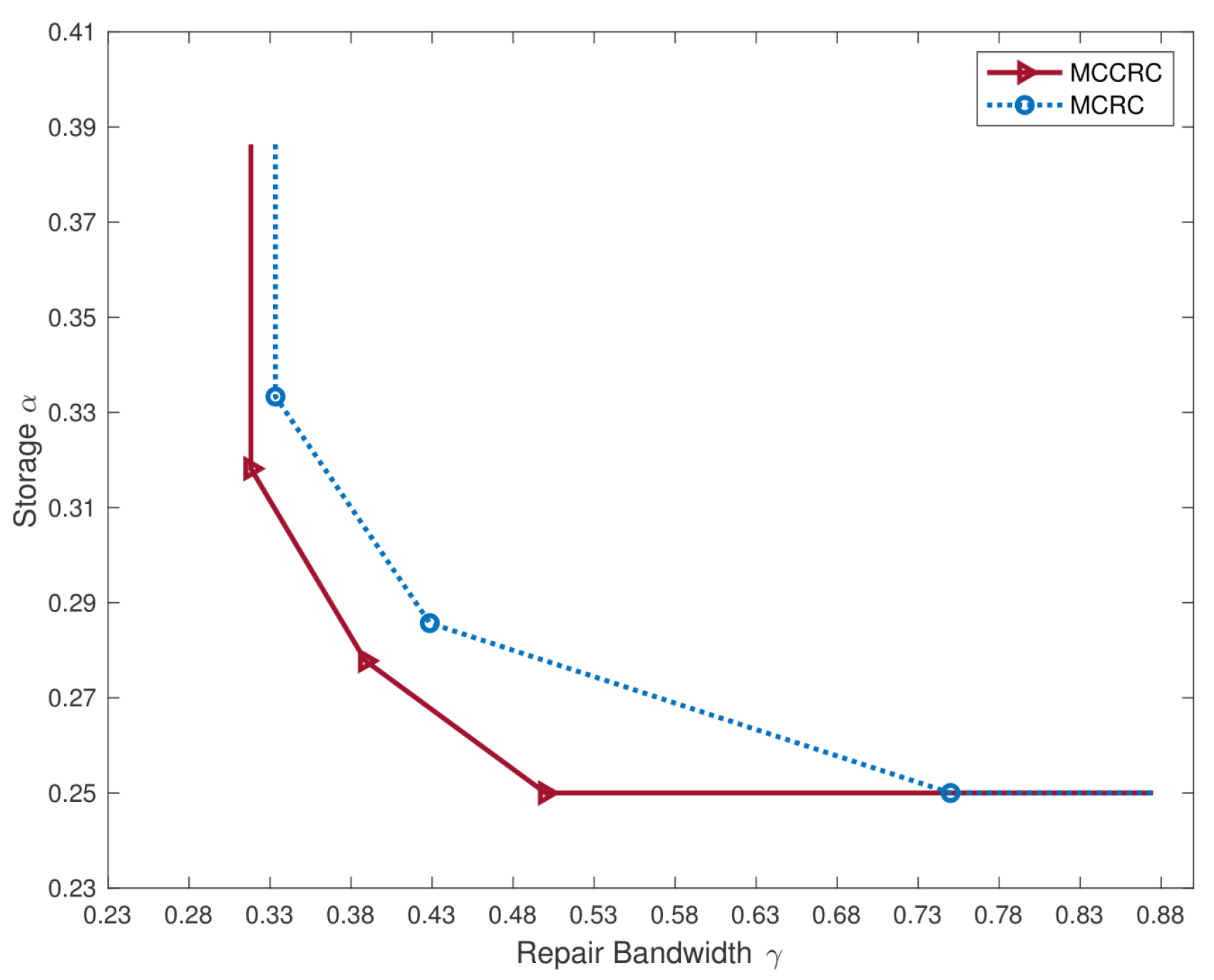
An example: The trade-off between the storage capacity and the repair bandwidth for clustered distributed storage systems equipped with the multi-clustered collaborative repair codes (MCCRCs) presented in this article is illustrated in Figure 2, compared with the trade-off for multi-clustered systems with a single failure to repair (i.e., systems equipped with multi-clustered repair codes (MCRCs)) [13]. The parameters in the example are specified as follows: the clustered system has nodes in clusters, each with a size of , and any nodes can retrieve the file. nodes need to be repaired in each cluster, where 2 nodes are repaired simultaneously for the MCCRC, while 2 nodes are repaired separately and sequentially for the MCRC. An immediate observation from Figure 2 is that the MCCRC employing collaboration further reduces the repair bandwidth compared to that with an MCRC when repairing multiple failures.
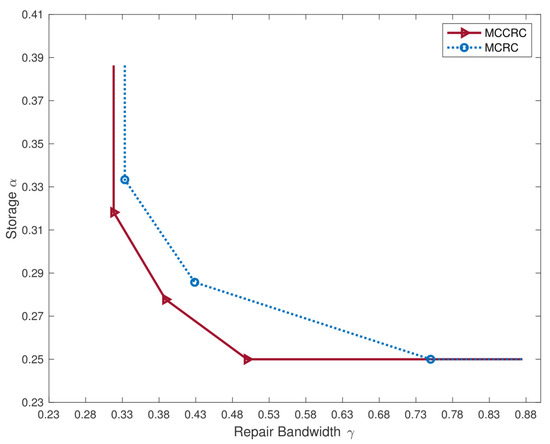
Figure 2.
The trade-off between the storage capacity and the repair bandwidth for an MCCRC and an MCRC [13].
5. Two Extreme Points
From Theorem 1, we can see that there are two special cases where the equality holds, namely the minimum storage clustered collaborative repair (MSCCR) point and the minimum bandwidth clustered collaborative repair (MBCCR) point. The values of the parameters in these two special cases are as follows.
The minimum storage clustered collaborative repair (MSCCR) point: Let , be the floor function; the parameters of the minimum storage clustered collaborative repair (MSCCR) point on the trade-off curve have the following values:
The minimum bandwidth clustered collaborative repair (MBCCR) point: Let , parameters of the minimum bandwidth clustered collaborative repair (MBCCR) point on the trade-off curve have the following values:
The details on identifying the parameters for the MSCCR point and the MBCCR point can be found in Appendix B.
6. Bandwidth Analysis
To understand the effect of the different values of the parameters on the repair bandwidth, we consider the normalized repair bandwidth . We will compute the value of the normalized repair bandwidth for different l values, the number of nodes in a cluster, at the minimum storage clustered collaborative repair (MSCCR) point and the minimum bandwidth clustered collaborative repair (MBCCR) point, respectively. It is shown that the normalized repair bandwidth is not monotonic with respect to l at the MSCCR point or the MBCCR point, respectively. Furthermore, we show that the performance of at the MSCCR and MBCCR points is different.
6.1. The MSCCR Point
The normalized repair bandwidth for the minimum storage is
where i is an integer, and .
It is shown that the normalized repair bandwidth at the MSCCR point is not monotonic with respect to the cluster size l. Specifically, on the interval , is increasing with respect to l. On the interval , is a decreasing function. The normalized repair bandwidth is a piecewise monotonic function with respect to l.
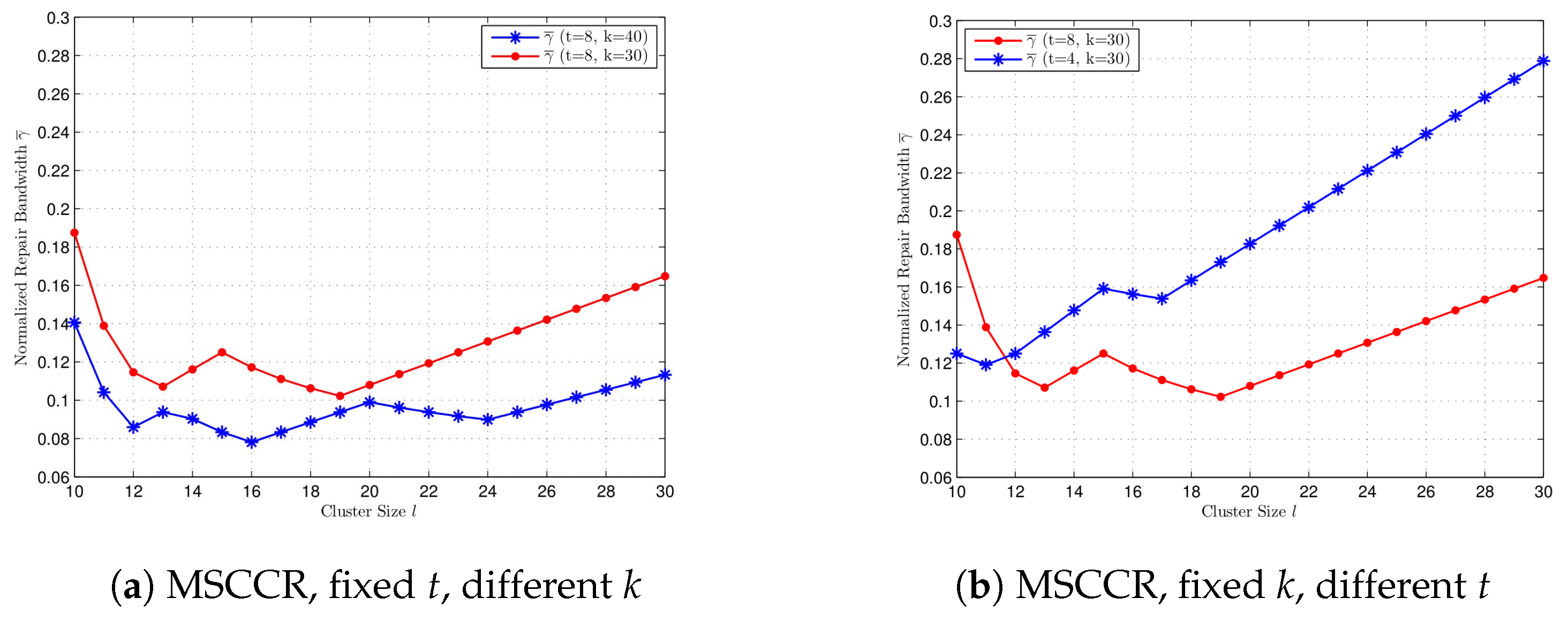
In Figure 3, we compare the normalized repair bandwidth at the MSCCR point with different k and t values, where . Since , we can select . In Figure 3a, we compare for and when . When t is fixed, a bigger value for k gives a smaller repair bandwidth at the MSCCR point for every . In Figure 3b, we compare for and when . When k is fixed, a bigger value for t not always gives a bigger but gives a smaller for the majority of l.
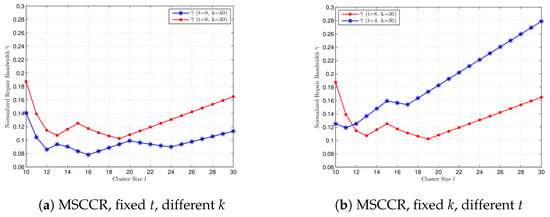
Figure 3.
Comparison of normalized repair bandwidth at MSCCR point for cluster size , with different k and t, respectively. (a) , , and . (b) , , and .
6.2. The MBCCR Point
The normalized repair bandwidth for the minimum storage is
where i is an integer, and .
We found that the normalized repair bandwidth at the MBCCR point was not monotonic with respect to the cluster size l. Specifically, on the interval , is a decreasing function. However, on the interval , is not a monotonic function with respect to l. Moreover, the normalized repair bandwidth at the MBCCR point is not a piecewise monotonic function with respect to l, which is different from the case at the MSCCR point.
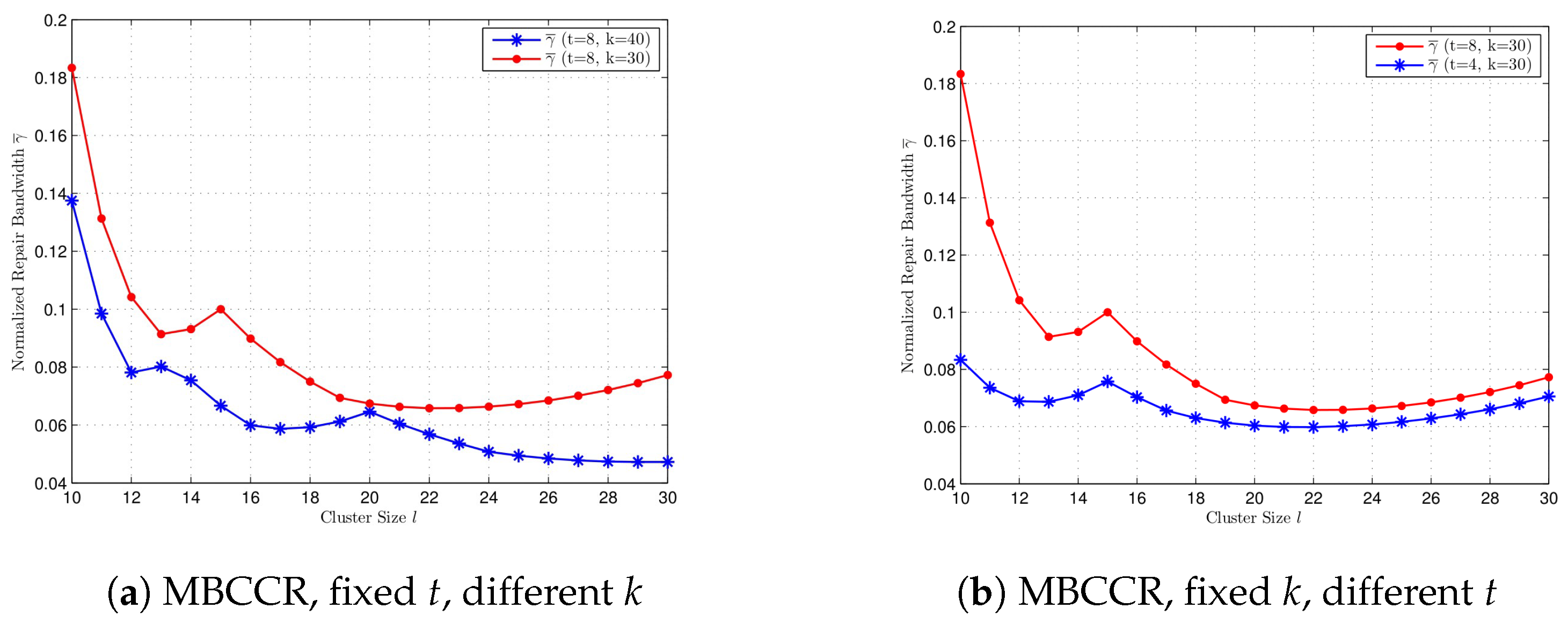
In Figure 4, we compare the normalized repair bandwidth at the MBCCR point with different values for k and t, where . We select . In Figure 4a, we compare for and when . When t is fixed, a bigger value for k gives a smaller repair bandwidth at the MBCCR point for every . In Figure 4b, we compare for and when . When k is fixed, a bigger value for t gives a bigger value for for every . It is shown that the performance of at the MBCCR point with different values of t is different from the case at the MSCCR point.
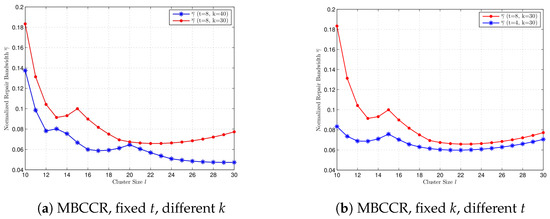
Figure 4.
Comparison of the normalized repair bandwidth at the MBCCR point for cluster size , with different k and t, respectively. (a) , , and . (b) , , and .
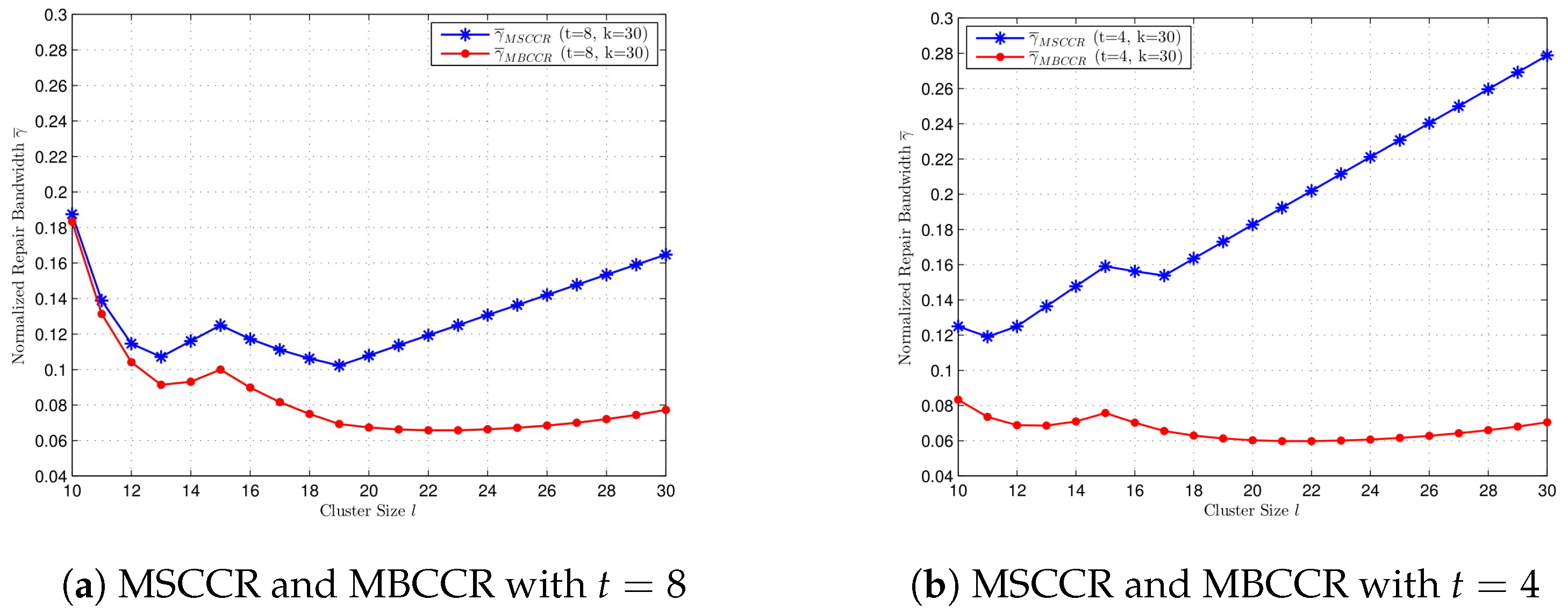
Moreover, we compare the normalized repair bandwidth at the MSCCR point and the MBCCR point. In Figure 5a, we compare at the MSCCR point and the MBCCR point with and . In Figure 5b, we compare at the MSCCR point and the MBCCR point with and . Obviously, with the same system parameters, at the MSCCR point is bigger than that at the MBCCR point. When the number of failures t changes, the lower t is, the greater the difference in between the MSCCR point and the MBCCR point. In other words, when k, l is fixed, fewer node failures occur, and the greater the benefit to the repair bandwidth of using MBCCR codes.
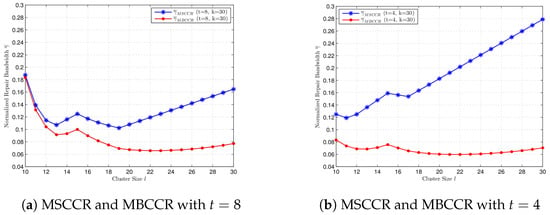
Figure 5.
Comparison of normalized repair bandwidth at MSCCR point and MBCCR point. (a) , . (b) , .
7. Code Constructions
In this section, we propose two constructions satisfying the conditions of the MBCCR point and the MSCCR point, respectively, with the parameters , . We use two layers of codes for encoding; the outer layer uses a maximum rank distance (MRD) code, for example, a Gabidulin code. We will introduce MRD codes and Gabidulin codes first.
Definition 1.
An rank metric code (where q is a prime) is a linear code over of the length N, the dimension K, and the maximum rank D [46,47]. A rank metric code that attains a Singleton-like bound on the rank metric is called a maximum rank distance (MRD) code.
Here, the rank distance between two vectors is defined as , where is the maximum number of linearly independent coordinates of over the base field , for a given basis of over . Codes utilizing this distance metric are referred to as rank metric codes.
Definition 2.
An rank metric code over the extension field achieving the maximum rank distance (for ) can be constructed using the following linearized polynomial:
This is referred to as a Gabidulin code. A codeword in a Gabidulin code is defined as
with the coefficients given by the information message, and are linearly independent over .
We remark that a linearized polynomial satisfies for any and . Given the evaluations of at any K linearly independent (over ) point in , one can recover and therefore reconstruct the message vector by performing polynomial interpolation (called the MDS property of Gabidulin code in the following content). These properties will be utilized in our code constructions.
7.1. Minimum Bandwidth Clustered Collaborative Repair (MBCCR) Codes
Consider a file of size (the file can be seen as a data object vector of the length M), where , with coefficients in the finite field and q being a prime. Encoding the object using an Gabidulin code, and . The codeword is first divided into L groups denoted by , , with each being in size.
Rewriting each , as the matrix form,
where is an matrix. For each , let be an matrix with the entries in satisfying the principles that any columns of are linearly independent, is an invertible matrix with the entries in , and any sub-matrix of is invertible. and can be constructed using a Vandermonde matrix.
Data placement in each cluster: In each cluster r, , node i, stores and . Since , node i stores symbols.
The repair of t failures in each cluster: In each cluster r, , without a loss of generality, suppose that the first t nodes fail. Each failed node i, downloads and from the nodes that are still alive j, . Since any columns of are linearly independent, the node i obtains ; furthermore, it can compute . The total number of symbols downloaded from the helper nodes to one new node in the download phase of the repair process is .
The missing can be obtained by contacting the other nodes being repaired. Node i contacts nodes and downloads from each, and then node i obtains . Since is invertible, node i can obtain . The total number of symbols downloaded during the collaboration process is , that is, ; thus, .
Data retrieval: When any k nodes are connected by a , at least linearly independent symbols over in can be obtained, where . Indeed, in each cluster r, although the storage capacity is , each cluster only contains linearly independent symbols since only linearly independent symbols in are coded. For the k nodes being contacted, the fewer clusters they are in, the fewer independent symbols can be obtained. When , at least clusters are being contacted, and we denote these clusters as cluster . We find that when all the nodes of (out of ) clusters are being contacted by the , the will obtain the fewest linearly independent symbols. Therefore, without a loss of generality, suppose that all of the nodes in clusters are being contacted; then, linearly independent symbols are obtained from cluster . In the cluster , only nodes are being contacted. Here, we notice that in each cluster, nodes are able to repair t failures; thus, at most symbols are linearly independent in each cluster. So, from nodes, only linear independent symbols are obtained since the construction has the property for in the same cluster r. Therefore, from any k nodes of the system, at least linearly independent symbols in are obtained, and they are all the codeword symbols of the outer Gabidulin code. Accordign to the MDS property of Gabidulin codes, any symbols are linearly independent and are able to retrieve the data object. Therefore, from any k nodes, the can obtain at least linearly independent symbols so that the file is retrieved.
The parameters of the construction are , , which satisfy the condition at the MBCCR point when .
In the MBCCR construction, we consider the information symbols over the finite field . There are two layers of codes in the constructions. The outer code is an Gabidulin code over , with and . The inner code is a product-matrix code over . The node size is mainly determined by the outer Gabidulin code. Each symbol in can be seen as the vector over the field of the length , without a loss of generality. Let ; so, the node size for the MBCCR code is . Furthermore, scales as , if we fix the number of clusters L to a relatively small number compared with the number of nodes n.
7.2. Minimum Storage Clustered Collaborative Repair (MSCCR) Codes
Consider a data object of size with coefficients in the finite field , where . Encoding the object of size M by an Gabidulin code, with . The codeword is first divided into L groups, denoted by , , with each being in size.
Rewriting each , as a matrix ,
where is a row vector of size . For each , let be a generator matrix of an MDS code over , where , for .
Data placement in each cluster: In each cluster r, , node i stores symbols , where
Repair of t failures in each cluster: In each cluster r, , when t nodes fail, without a loss of generality, we label t nodes from 1 to t. Then, these t nodes each contact the nodes that are still alive; say the i-th node among these t failed nodes connects to nodes and downloads from the alive nodes , . Using the MDS property of , node i can obtain and compute . The total number of symbols downloaded from the helper nodes to one node in the download phase of the repair process is .
The ith node contacts nodes , , and downloads to obtain the missing symbols. The total number of symbols downloaded during the collaboration process is , that is ; thus, .
Data retrieval: When any k nodes are connected by a , at least linearly independent symbols (over ) in are obtained, where . Indeed, in each cluster r, only linearly independent symbols in are coded and stored. For the k nodes being contacted, the fewer clusters they are in, the fewer linear independent symbols are obtained. When , at least clusters are contacted, and we denote these clusters as cluster . Without a loss of generality, suppose that all of the nodes in clusters are being contacted; then, linearly independent symbols are obtained. In the cluster , only nodes are being contacted, and then linear independent symbols are obtained. Therefore, from any k nodes, at least linearly independent symbols are obtained, and they are all of the codeword symbols of the outer Gabidulin code. According to the MDS property of Gabidulin codes, any symbols are linearly independent and are able to retrieve the object. Therefore, from any k nodes, the can obtain at least linearly independent symbols so that the file is retrieved.
The parameters of the construction are , , which satisfy the condition of the MSCCR point when .
In the MSCCR code construction, the outer code is a Gabidulin code over with , and the inner code is an -MDS code over . Similarly to the discussion for MBCCR codes, we know that the node size for MSCCR code is . Moreover, can be scaled as if L is a relatively small number compared with n.
We give a simple example of an MSCCR code below to illustrate the construction.
Example 1.
Consider a system with its parameters as shown in Figure 1. The parameters have the values , , .
We encode the object using an Gabidulin code. The obtained codeword is first divided into two groups denoted by , , with each being 6 in size.
Rewriting each (), as a matrix , that . For each , let be a generator matrix of an MDS code over , where , for . In each cluster , node i stores symbols and .
Repair: In each cluster , each failed node i, downloads from the nodes that are alive , . Using the MDS property of , the i-th failed node can obtain and compute . The total number of symbols downloaded from the helper nodes to one node in the download phase of the repair process is . Then, the ith node contacts nodes and downloads to obtain the missing 1 symbols. The total number of symbols downloaded during the collaboration process is 2, that is, ; thus, .
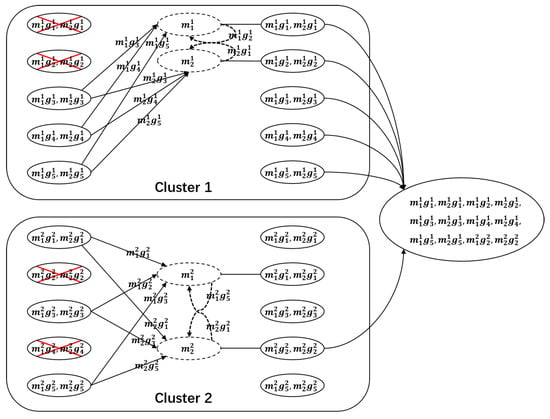
Data retrieval: When any six nodes are connected by a data collector, at least eight linearly independent symbols (over ) in are obtained. Indeed, in each cluster , only six symbols in are linearly independent. When six nodes are being contacted, with five from the first cluster and one from the second cluster, the will obtain the fewest linearly independent symbols. Specifically, six linearly independent symbols in are obtained from the first cluster, and from the second cluster, only two linear independent symbols are obtained, totalling eight linearly independent symbols over that are obtained, and they are all the codeword symbols of the outer Gabidulin code. According to the MDS property of Gabidulin codes, any eight linearly independent symbols over in are able to retrieve the object. Therefore, from any six nodes, the data collector can obtain at least eight linearly independent symbols, and then the file is retrieved.
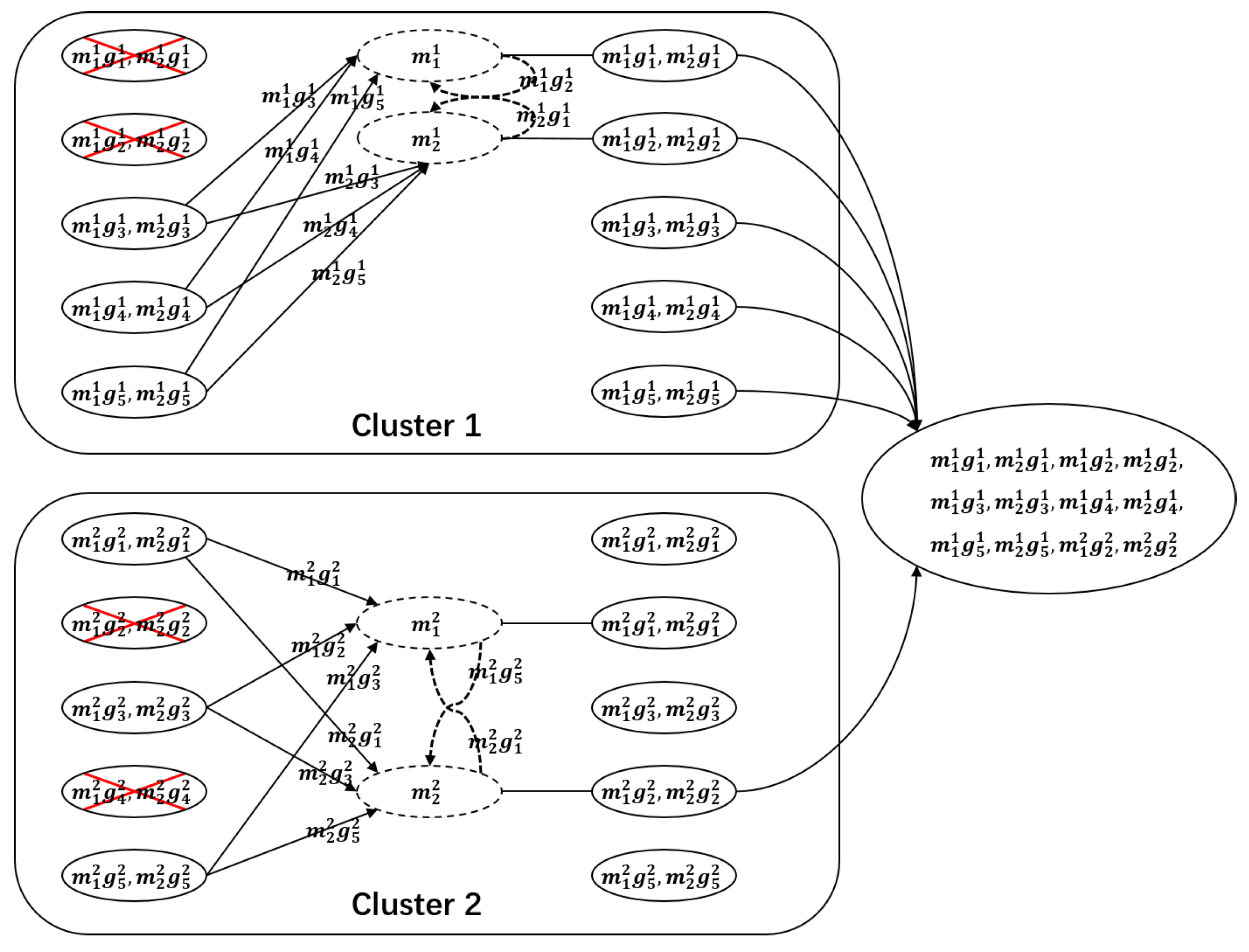
Figure 6 illustrates a possible scenario where in each cluster, nodes fail. In cluster , nodes 2 and 4 fail. The failed node 2 can be seen as the first failed node, and then it downloads from the nodes that are still alive . The failed node 4 can be seen as the second failed node and downloads from the alive nodes . When nodes are connected, 5 nodes from cluster 1 and 1 node from cluster 2, we obtain 12 symbols in . For example, in the second cluster, the fourth node is contacted, and then we obtain twelve symbols in , and eight of them are linearly independent over ; then, according t the MDS property of the outer Gabidulin code, the file can be retrieved.
Figure 6.
For a clustered distributed storage system with the parameters , , , , and . In each cluster , node i stores symbols . Each failed node downloads symbol from each of the alive nodes within the host cluster and exchanges symbol with another.
8. Conclusions
We have studied the repairing problem in a clustered distributed storage system, where each cluster is resilient to multiple failures within itself. A fundamental trade-off between the storage and repair bandwidth is derived by analyzing the associated information flow graph. Two extreme points on the trade-off curve, i.e., the MSCCR point and the MBCCR point, are studied. Their performance in terms of the repair bandwidth is studied as well. Furthermore, explicit and optimal code constructions for the two points are presented. We considered an ideal situation where the cross-cluster bandwidth is zero in this article. However, in a real clustered system, cross-cluster communication is possible, as stated in [8,9,10]. Therefore, a future direction for our study is to incorporate cross-cluster communication into the system. Moreover, since we proposed using Gabidulin codes as the outer codes for the optimal code constructions, which resulted in a larger node size, using other optimal or sub-optimal code constructions with a smaller node size would be another future direction.
Author Contributions
Conceptualization, methodology, formal analysis, investigation, S.L.; validation, S.L. and F.Y.; writing (original draft preparation), S.L., F.Y. and Q.W.; writing (review and editing), S.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the National Science Foundation of China under Grant No. 62401258 and in part by the Natural Science Foundation of Jiangsu Province under Grant No. BK20241380.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study.
Acknowledgments
The authors would like to thank the anonymous reviewers for their careful reading of the submitted manuscript and for their many valuable comments, which significantly improved the quality of this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Proof of Lemma 1.
We will adopt the following notations in the proof. In each cluster r, , the repair nodes during the ith phase of repair are denoted by , where j is the count of the nodes during the ith phase. Every node is seen as a logical triple , formed of an incoming node, a collaborating node, and an output node, used to model the storage capacity and the collaborative process.
Consider a data collector that connects to k output nodes corresponding to a set K of nodes from L clusters. For each cluster r, , say , where , , and . We show that any cut between S and in the graph has a capacity that satisfies (1). We can assume that all of the edges of the data collector have an infinite capacity, so we only need to consider the cut , with and . Since the repairs are only carried out in the host cluster, we obtain , and we can calculate the cut in each cluster separately. Let denote the edges in cluster r in the cut, with cut = . In each cluster r, we consider the following repair phases.
The first repair phase: In each cluster r, , let be the set of indices such that is the first group of output nodes in cluster r in corresponding to the first repair. The set contains nodes. Consider a subset of size m such that and . Then, m can take values between 0 and .
Consider first the m nodes . For each node , either (1) , and then edge , and the contribution to the cut is , or (2) , and then , and the contribution to the cut is at least .
Consider next the other nodes . For each node, the contribution comes from multiple sources. (1) The cut contains edges carrying coefficients: since are the first output nodes in , the edges come from the output nodes in U. (2) The cut contains at least edges carrying coefficients thanks to the coordination step: the node has incoming edges . However, , so the cut contains at least such edges carrying coefficients.
Therefore, the total contribution of these nodes in the cut is . Since the function is concave on the interval , Jensen’s inequality yields
The second repair phase: Let be the second group of output nodes in cluster r in corresponding to the second repair. We repeat the same reasoning. We first consider the m nodes , where the contribution of each node is .
Then, we consider the nodes . For each node, we have (1) the cut containing at least edges carrying : since these are the second group of output nodes in , and at most edges come from the output nodes in , at least edges come from the output nodes in U; (2) similarly to the first phase, the cut contains at least edges carrying .
Thus, the total contribution of these nodes is .
In general, for the ith repair phase,
Therefore, in each cluster r, the contribution to the cut is
where .
Notice that we have the restriction for because for , where , the cut contains , but are all from the former phases; hence, when , the contribution to the cut is 0. Therefore, we only need to count the contribution for i where .
Since cut = , summing the contributions in all of the clusters leads to bound (1). □
Appendix B. The Parameters for the MSCCR Point and the MBCCR Point
Appendix B.1. Parameters for the MSCCR Point
In each cluster, any nodes are able to repair t failures so that each cluster has at most linearly independent information symbols; hence, for any k out of n nodes, at least linearly independent information symbols can be obtained by the data collector, where . From the recovery property, we have . The MSCCR point provides the lowest possible storage while minimizing the repair bandwidth. Therefore, we minimize first. We denote for simplicity, and then , and each component of the sum in (2) is at least equal to ; then,
We consider two particular patterns of the repair phases to help determine the minimum storage clustered collaborative repair point: (i) , for any , and (ii) , for any .
For pattern (i), , , Equation (A4) corresponds to
and thus
Note that the right-hand side of Equation (A6) grows linearly with i; therefore,
For pattern (ii), , , Equation (A4) corresponds to
Here, we assume . For a case where , it can be reduced into the same condition with ; hence, we omit the analysis here. From Equation (A8), we obtain
which is equivalent to
The repair bandwidth is
where the inequality of (A11) comes from Equation (A7). Equation (A11) implies that grows linearly with ; therefore, we take the smallest value of , where . Hence,
Since (A12) holds for all , then we have the minimum values of , , , and as
Note that the parameters obtained indeed satisfy (2). Each term in the second sum of (2) is at most , the minimum of the second sum value is equal to , and the minimum over of the first sum is equal to M when all of the terms are . Thus, each element of the second sum must satisfy
Replacing with their values at the MSCCR point to obtain which is satisfied since . Therefore, the MSCCR point has the values of the parameters in (4).
Appendix B.2. Parameters for the MBCCR Point
The MBCCR point provides the lowest possible repair bandwidth while minimizing the storage . Therefore, to optimize , we let grow, and then each of the terms in (2), which contains and , is smaller than , and the minimum value of the storage capacity . Denote .
For pattern (ii), , . Here, we only consider due to limited space; for a case where , it can be reduced into the same result with . We denote for simplicity, and it is required that
Then, the equation is equivalent to
References
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google File System. ACM Sigops Oper. Syst. Rev. 2003, 37, 29–43. [Google Scholar] [CrossRef]
- Muralidhar, S.; Lloyd, W.; Roy, S.; Hill, C.; Lin, E.; Liu, W.; Pan, S.; Shankar, S.; Sivakumar, V.; Tang, L.; et al. f4: Facebook’s Warm BLOB Storage System. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 383–398. [Google Scholar]
- Bhagwan, R.; Tati, K.; Cheng, Y.C.; Savage, S.; Voelker, G.M. Total Recall: System Support for Automated Availability Management. In Proceedings of the First Symposium on Networked Systems Design and Implementation (NSDI 04), San Francisco, CA, USA, 29–31 March 2004. [Google Scholar]
- Dimakis, A.G.; Godfrey, P.B.; Wu, Y.; Wainwright, M.J.; Ramchandran, K. Network Coding for Distributed Storage Systems. IEEE Trans. Inf. Theory 2010, 56, 4539–4551. [Google Scholar] [CrossRef]
- Kermarrec, A.M.; Le Scouarnec, N.; Straub, G. Repairing Multiple Failures with Coordinated and Adaptive Regenerating Codes. In Proceedings of the 2011 International Symposium on Networking Coding, Beijing, China, 25–27 July 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Hu, Y.; Xu, Y.; Wang, X.; Zhan, C.; Li, P. Cooperative Recovery of Distributed Storage Systems from Multiple Losses with Network Coding. IEEE J. Sel. Areas Commun. 2010, 28, 268–276. [Google Scholar] [CrossRef]
- Shum, K.W.; Hu, Y. Cooperative Regenerating Codes. IEEE Trans. Inf. Theory 2013, 59, 7229–7258. [Google Scholar] [CrossRef]
- Ahmad, F.; Chakradhar, S.T.; Raghunathan, A.; Vijaykumar, T.N. ShuffleWatcher: Shuffle-aware Scheduling in Multi-tenant MapReduce Clusters. In Proceedings of the 2014 USENIX Annual Technical Conference (USENIX ATC 14), Philadelphia, PA, USA, 19–20 June 2014; pp. 1–13. [Google Scholar]
- Benson, T.; Akella, A.; Maltz, D.A. Network traffic characteristics of data centers in the wild. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, New York, NY, USA, 1–30 November 2010; pp. 267–280. [Google Scholar] [CrossRef]
- Vahdat, A.; Al-Fares, M.; Farrington, N.; Mysore, R.N.; Porter, G.; Radhakrishnan, S. Scale-Out Networking in the Data Center. IEEE Micro 2010, 30, 29–41. [Google Scholar] [CrossRef]
- Gastón, B.; Pujol, J.; Villanueva, M. A Realistic Distributed Storage System That Minimizes Data Storage and Repair Bandwidth. In Proceedings of the 2013 Data Compression Conference, Snowbird, UH, USA, 20–22 March 2013; p. 491. [Google Scholar] [CrossRef]
- Pernas, J.; Yuen, C.; Gastón, B.; Pujol, J. Non-homogeneous two-rack model for distributed storage systems. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 1237–1241. [Google Scholar] [CrossRef]
- Sohn, J.Y.; Choi, B.; Yoon, S.W.; Moon, J. Capacity of Clustered Distributed Storage. IEEE Trans. Inf. Theory 2019, 65, 81–107. [Google Scholar] [CrossRef]
- Sohn, J.; Choi, B.; Moon, J. A Class of MSR Codes for Clustered Distributed Storage. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2366–2370. [Google Scholar] [CrossRef]
- Hu, Y.; Lee, P.P.C.; Zhang, X. Double Regenerating Codes for hierarchical data centers. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 245–249. [Google Scholar] [CrossRef]
- Hu, Y.; Li, X.; Zhang, M.; Lee, P.P.C.; Zhang, X.; Zhou, P.; Feng, D. Optimal repair layering for erasure-coded data centers: From theory to practice. ACM Trans. Storage (TOS) 2020, 13, 1–24. [Google Scholar] [CrossRef]
- Tebbi, M.A.; Chan, T.H.; Sung, C.W. A code design framework for multi-rack distributed storage. In Proceedings of the 2014 IEEE Information Theory Workshop (ITW 2014), Hobart, Australia, 2–5 November 2014; pp. 55–59. [Google Scholar] [CrossRef]
- Hou, H.; Lee, P.P.C.; Shum, K.W.; Hu, Y. Rack-Aware Regenerating Codes for Data Centers. IEEE Trans. Inf. Theory 2019, 65, 4730–4745. [Google Scholar] [CrossRef]
- Hou, H.; Lee, P.P.C. Generalized Rack-aware Regenerating Codes for Jointly Optimal Node and Rack Repairs. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Victoria, Australia, 12–20 July 2021; pp. 2191–2196. [Google Scholar] [CrossRef]
- Yu, B.; Jiang, Z.; Huang, Z.; Song, L.; Hou, H. Product-Matrix Construction of Minimum Storage Rack-aware Regenerating Codes. In Proceedings of the 2023 International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 2–4 November 2023; pp. 287–292. [Google Scholar] [CrossRef]
- Chen, Z.; Barg, A. Explicit Constructions of MSR Codes for Clustered Distributed Storage: The Rack-Aware Storage Model. IEEE Trans. Inf. Theory 2020, 66, 886–899. [Google Scholar] [CrossRef]
- Hou, H.; Lee, P.P.C.; Han, Y.S. Minimum Storage Rack-Aware Regenerating Codes with Exact Repair and Small Sub-Packetization. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; pp. 554–559. [Google Scholar] [CrossRef]
- Jin, L.; Luo, G.; Xing, C. Optimal Repairing Schemes for Reed Solomon Codes with Alphabet Sizes Linear in Lengths under the Rack Aware Model. arXiv 2019, arXiv:1911.08016. [Google Scholar]
- Bao, H.; Wang, Y.; Xu, F. An Adaptive Erasure Code for JointCloud Storage of Internet of Things Big Data. IEEE Internet Things J. 2020, 7, 1613–1624. [Google Scholar] [CrossRef]
- Shen, Z.; Shu, J.; Lee, P.P.C. Reconsidering Single Failure Recovery in Clustered File Systems. In Proceedings of the 2016 46th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Toulouse, France, 28 June–1 July 2016; pp. 323–334. [Google Scholar] [CrossRef]
- Abdrashitov, V.; Prakash, N.; Médard, M. The storage vs repair bandwidth trade-off for multiple failures in clustered storage networks. In Proceedings of the 2017 IEEE Information Theory Workshop (ITW), Kaohsiung, Taiwan, 6–10 November 2017; pp. 46–50. [Google Scholar] [CrossRef]
- Gupta, S.; Lalitha, V. Rack-Aware Cooperative Regenerating Codes. In Proceedings of the 2020 International Symposium on Information Theory and Its Applications (ISITA), Virtual, 24–27 October 2020; pp. 264–268. [Google Scholar]
- Gupta, S.; Devi, B.R.; Lalitha, V. On Rack-Aware Cooperative Regenerating Codes and Epsilon-MSCR Codes. IEEE J. Sel. Areas Inf. Theory 2022, 3, 362–378. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, Z. Rack-Aware Regenerating Codes with Multiple Erasure Tolerance. IEEE Trans. Commun. 2022, 70, 4316–4326. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, D.; Li, S.; Tang, X. Rack-Aware MSR Codes with Error Correction Capability for Multiple Erasure Tolerance. IEEE Trans. Inf. Theory 2023, 69, 6428–6442. [Google Scholar] [CrossRef]
- Wang, J.; Guan, X. Rack-Aware Minimum-Storage Regenerating Codes with Optimal Access for Consecutive Node Failures. In Proceedings of the 2024 IEEE Information Theory Workshop (ITW), Shenzhen, China, 24–28 November 2024; pp. 259–264. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Z. Low-access repair of Reed-Solomon codes in rack-aware storage. In Proceedings of the 2023 IEEE International Symposium on Information Theory (ISIT), Taipei, Taiwan, 25–30 June 2023; pp. 1142–1147. [Google Scholar] [CrossRef]
- Le Scouarnec, N. Exact scalar minimum storage coordinated regenerating codes. In Proceedings of the 2012 IEEE International Symposium on Information Theory Proceedings, Cambridge, MA, USA, 1–6 July 2012; pp. 1197–1201. [Google Scholar] [CrossRef]
- Wang, A.; Zhang, Z. Exact cooperative regenerating codes with minimum-repair-bandwidth for distributed storage. In Proceedings of the 2013 Proceedings IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 400–404. [Google Scholar] [CrossRef]
- Jiekak, S.; Scouarnec, N.L. CROSS-MBCR: Exact minimum bandwidth coordinated regenerating codes. arXiv 2012, arXiv:1207.0854. [Google Scholar]
- Li, J.; Li, B. Cooperative repair with minimum-storage regenerating codes for distributed storage. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; pp. 316–324. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z. Scalar MSCR Codes via the Product Matrix Construction. IEEE Trans. Inf. Theory 2020, 66, 995–1006. [Google Scholar] [CrossRef]
- Ye, M.; Barg, A. Cooperative Repair: Constructions of Optimal MDS Codes for All Admissible Parameters. IEEE Trans. Inf. Theory 2019, 65, 1639–1656. [Google Scholar] [CrossRef]
- Ye, M. New Constructions of Cooperative MSR Codes: Reducing Node Size to exp(O(n)). IEEE Trans. Inf. Theory 2020, 66, 7457–7464. [Google Scholar] [CrossRef]
- Liu, S.; Oggier, F. On storage codes allowing partially collaborative repairs. In Proceedings of the 2014 IEEE International Symposium on Information Theory, Honolulu, HI, USA, 29 June–4 July 2014; pp. 2440–2444. [Google Scholar] [CrossRef]
- Liu, S.; Shum, K.W.; Li, C. Exact-Repair Codes with Partial Collaboration in Distributed Storage Systems. IEEE Trans. Commun. 2020, 68, 4012–4021. [Google Scholar] [CrossRef]
- Liu, S.; Oggier, F.E. On applications of orbit codes to storage. Adv. Math. Commun. 2016, 10, 113–130. [Google Scholar] [CrossRef]
- Liu, S.; Oggier, F. Two storage code constructions allowing partially collaborative repairs. In Proceedings of the 2014 International Symposium on Information Theory and its Applications, Melbourne, Australia, 26–29 October 2014; pp. 378–382. [Google Scholar]
- Zorgui, M.; Wang, Z. Centralized Multi-Node Repair Regenerating Codes. IEEE Trans. Inf. Theory 2019, 65, 4180–4206. [Google Scholar] [CrossRef]
- Rawat, A.S.; Koyluoglu, O.O.; Vishwanath, S. Centralized Repair of Multiple Node Failures with Applications to Communication Efficient Secret Sharing. IEEE Trans. Inf. Theory 2018, 64, 7529–7550. [Google Scholar] [CrossRef]
- Gabidulin, E.M. Theory of Codes with Maximum Rank Distance. Probl. Inform. Transm. 1985, 21, 1–12. [Google Scholar]
- Roth, R. Maximum-rank array codes and their application to crisscross error correction. IEEE Trans. Inf. Theory 1991, 37, 328–336. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).