
Mutual Information Neural-Estimation-Driven Constellation Shaping Design and Performance Analysis




Abstract
1. Introduction
- We propose novel MINE-driven high-order constellation shaping schemes, where a DNN-based MINE module is explicitly introduced to address the exact MI calculation problem. In MINE optimization, the MI is estimated by backpropagation from abundant samples without explicit knowledge of the channel information, which traditional methods struggle with.C Additionally, a DNN-based encoder and probability generator are employed to adaptively optimize the point locations and probability distributions with respect to the varying signal-to-noise ratio (SNR). Unlike the E2E system, our MINE-driven system does not involve the decoder, thus avoiding the training loss and computational complexity attributed to decoding.
- Our DNN-based deign is a lightweight model, due to the simple network structure involved on the transmitter side. Our MINE-driven schemes have less time and computational complexity than the E2E and other recent DL-based schemes. Note that our MINE-PCS has the least number of floating point operations (FLOPs) and parameters, while our MINE-GCS has the lowest training time per SNR.
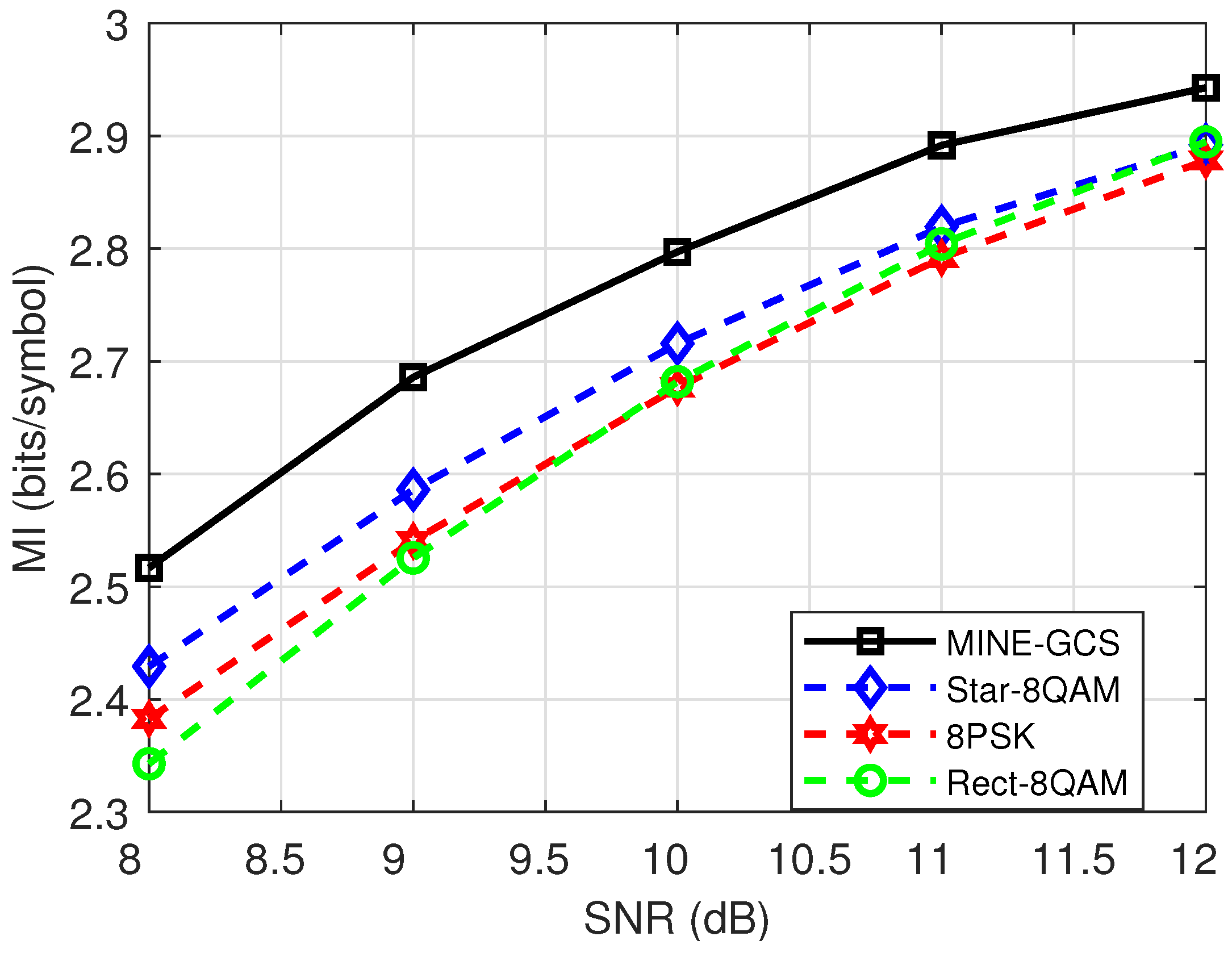
- As expected, our MINE-driven schemes performed much better with AWGN over the studied parameter ranges of SNR of practical interest compared to the unshaped QAM and other DL-based schemes. For example, with a higher-order design, 64-ary MINE-GCS could achieve an MI gain of about 0.1 bits/symbol.
2. System Model
2.1. Signal Model
2.2. MI Metric
2.3. The MINE Principle
3. Constellation Shaping Design
3.1. The MINE-Based MI Estimation
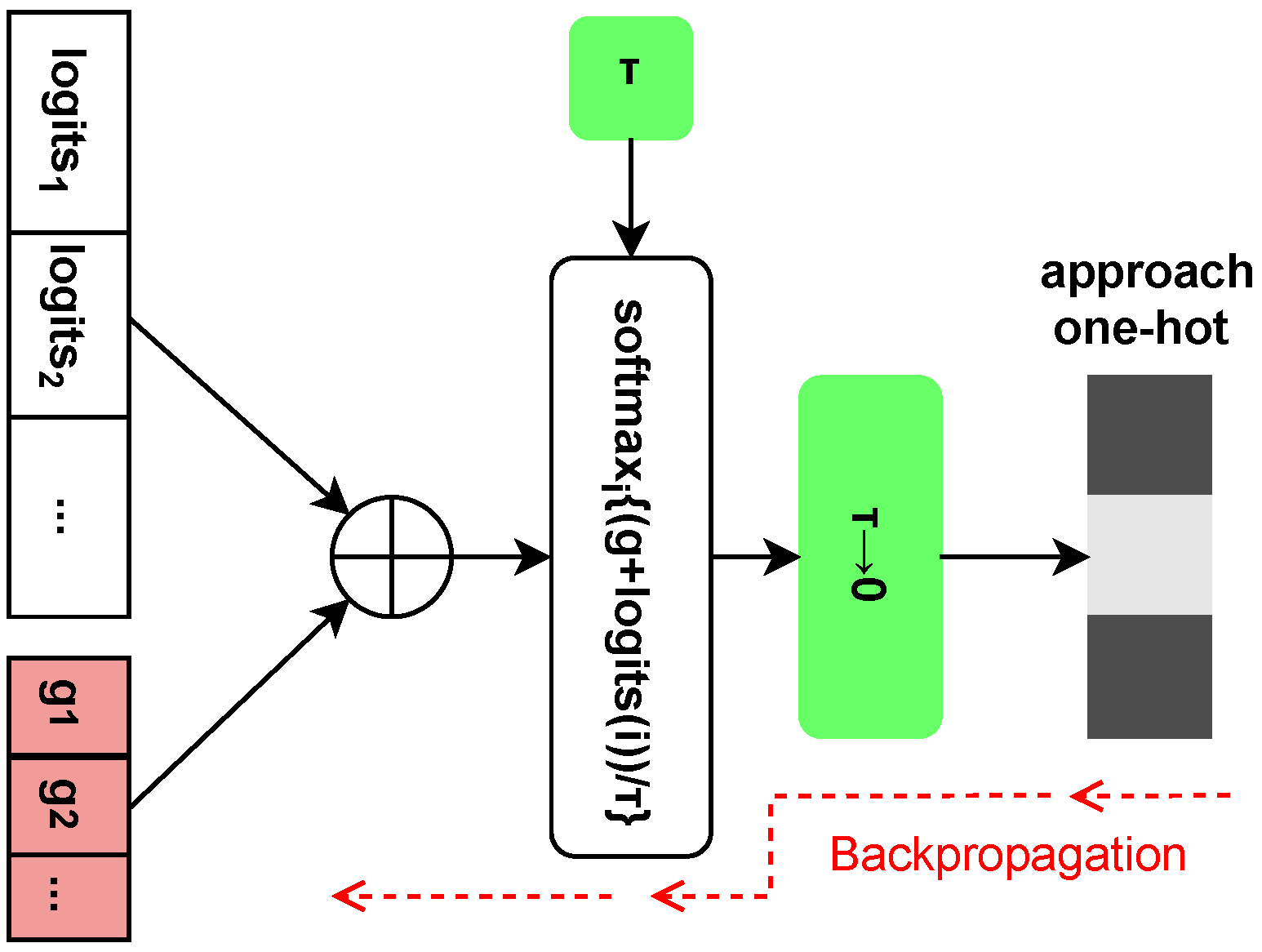
3.2. MINE-GCS Design Architecture
3.3. MINE-PCS Design Architecture
3.4. MINE-JCS Design Architecture
4. Numerical Results
4.1. Experimental Settings
4.1.1. DNN Architecture and Hyper-Parameters
4.1.2. Comparative Methods
- E2E-GCS: We first considered a comparative E2E-GCS structure, which included the modulation and demodulation modules to be trained. The modulation module was consistent with the modulation module in Figure 1a. For the demodulation module, the decoder DNN had an input layer with 2 neurons, an output layer with M units, and 3 hidden layers, each containing 128 units. Moreover, the Leaky ReLU activation function and Adam optimizer were used in the training. The specific settings of the E2E-GCS demodulation module and decoder network are shown in Figure 4. The symbol-metric demapper was implemented as a DNN-based categorical classifier with trainable parameter . Categorical cross-entropy (CE) was used as the loss function to update the model parameters, which is given by ([20] Equation (3)).where represents the input vector of the encoder, represents the softmax function, and is the score generated by the decoder.
- 2019Stark-PCS and 2019Stark-JCS: Recently, ref. [13] also proposed a trainable E2E communication system for a AWGN channel, which corresponds to the comparative E2E-based 2019Stark-PCS and 2019Stark-JCS schemes we employ here. In order to train the modulator and demodulator together, the complex categorical CE loss function was set to be equivalent to maximizing the MI of the channel inputs X and outputs Y, while minimizing the KL divergence between the true posterior distribution and the distribution learned by the receiver. Note that the autoencoder in [13] was mainly leveraged to perform probabilistic shaping, and the influence of source entropy was removed in the PCS training to avoid the unwanted effect of source entropy reduction caused by minimizing the categorical CE.
4.1.3. Complexity Analysis
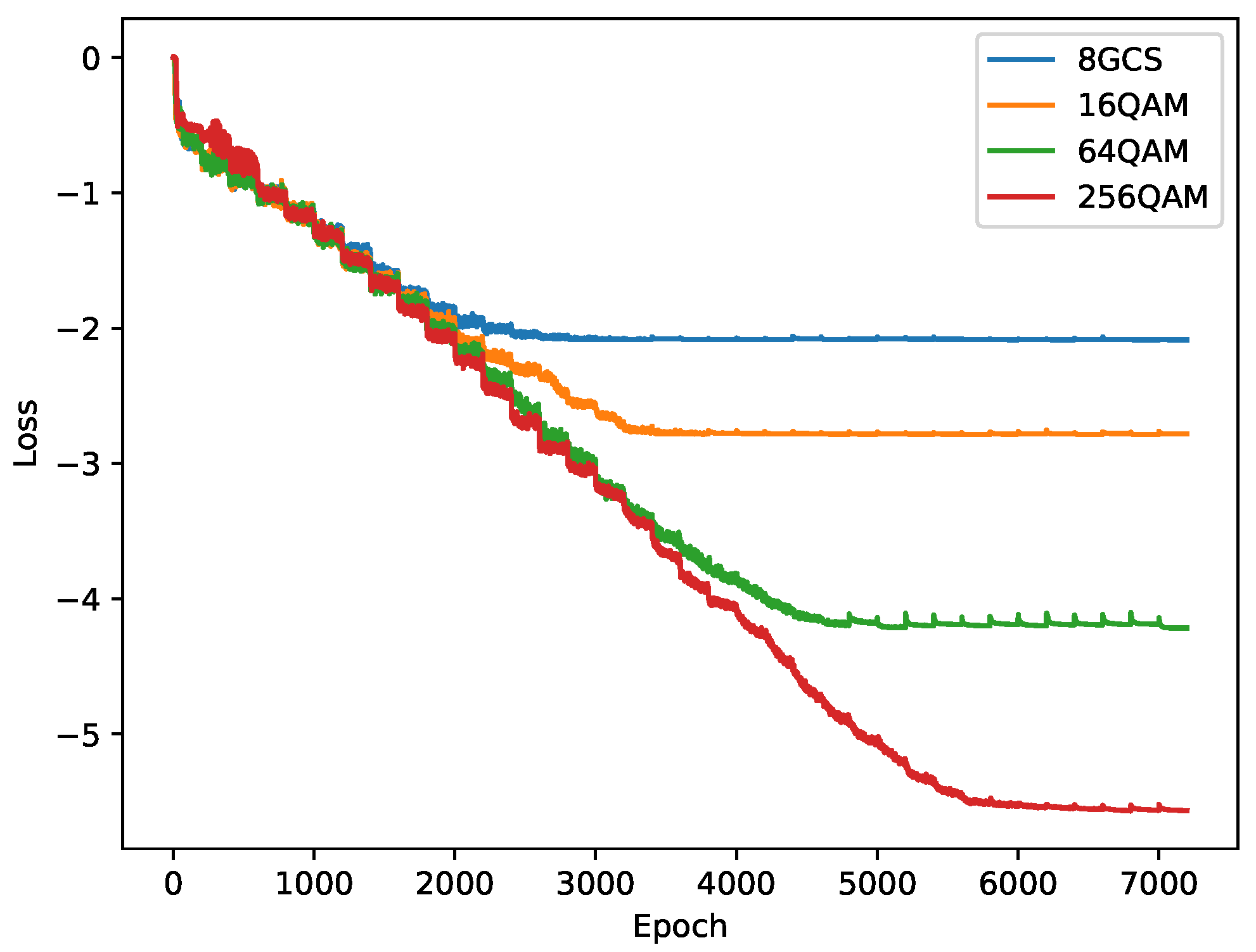
4.2. MINE-Driven Optimized Constellations
4.3. MI Performance Analysis for AWGN Test Channel
4.4. MI Performance Analysis in Test Channel
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pisek, E.; Rajan, D.; Abu-Surra, S.; Cleveland, J.R. Capacity-approaching TQC-LDPC convolutional codes enabling power-efficient decoders. IEEE Trans. Commun. 2017, 65, 1–13. [Google Scholar] [CrossRef]
- Pisek, E.; Rajan, D.; Cleveland, J.R. Trellis-based QC-LDPC convolutional codes enabling low power decoders. IEEE Trans. Commun. 2015, 63, 1939–1951. [Google Scholar] [CrossRef]
- Mazur, M.; Lorences-Riesgo, A.; Schröder, J.; Andrekson, P.A.; Karlsson, M. High spectral efficiency PM-128QAM comb-based superchannel transmission enabled by a single shared optical pilot tone. J. Lightw. Technol. 2018, 36, 1318–1325. [Google Scholar] [CrossRef]
- Wang, Q.; Quan, Z.; Song, T.; Wu, M.-W.; Li, Y.; Kam, P.-Y. M-APSK constellation optimization in the presence of phase reference error. IEEE Wirel. Commun. Lett. 2020, 9, 2154–2158. [Google Scholar] [CrossRef]
- Boch, E. High-capacity ethernet backhaul radio systems for advanced mobile data networks. IEEE Microw. Mag. 2009, 10, 108–114. [Google Scholar] [CrossRef]
- Singya, P.K.; Shaik, P.; Kumar, N.; Bhatia, V.; Alouini, M.-S. A survey on higher-order QAM constellations: Technical challenges, recent advances, and future trends. IEEE Open J. Commun. Soc. 2021, 2, 617–655. [Google Scholar] [CrossRef]
- Sun, Z.; Tang, D.; Zuo, W.; Cui, H.; Wu, Z.; Qiao, Y. Triple-convex probabilistic constellation shaping PAM8 in IM/DD system. IEEE Photon. Technol. Lett. 2023, 35, 846–849. [Google Scholar] [CrossRef]
- Modonesi, R.; Dalai, M.; Migliorati, P.; Leonardi, R. A note on probabilistic and geometric shaping for the AWGN channel. IEEE Commun. Lett. 2020, 24, 2119–2122. [Google Scholar] [CrossRef]
- Yankov, M.P.; Zibar, D.; Larsen, K.J.; Christensen, L.P.B.; Forchhammer, S. Constellation shaping for fiber-optic channels with QAM and high spectral efficiency. IEEE Photon. Technol. Lett. 2014, 26, 2407–2410. [Google Scholar] [CrossRef]
- Pilori, D.; Bertignono, L.; Nespola, A.; Forghieri, F.; Bosco, G. Comparison of probabilistically shaped 64QAM with lower cardinality uniform constellations in long-haul optical systems. J. Lightw. Technol. 2018, 36, 501–509. [Google Scholar] [CrossRef]
- Wu, K.; He, J.; Zhou, Z.; He, J.; Shi, J. Probabilistic amplitude shaping for a 64-QAM OFDM W-Band RoF system. IEEE Photon. Technol. Lett. 2019, 31, 1076–1079. [Google Scholar] [CrossRef]
- Ding, J.; Sang, B.; Wang, Y.; Kong, M.; Wang, F.; Zhu, B.; Zhao, L.; Zhou, W.; Yu, J. High spectral efficiency WDM transmission based on hybrid probabilistically and geometrically shaped 256QAM. J. Lightw. Technol. 2021, 39, 5494–5501. [Google Scholar] [CrossRef]
- Stark, M.; Aoudia, F.A.; Hoydis, J. Joint learning of geometric and probabilistic constellation shaping. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An introduction to deep learning for the physical layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Hjelm, R.D.; Fedorov; Lavoie-Marchildon, A.; Grewal, S.; Bachman, K.; Trischler, P.A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2019, arXiv:1808.06670. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeshwar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, D. Mutual information neural estimation. Proc. Int. Conf. Mach. Learn. 2018, 80, 530–539. [Google Scholar]
- Omidi, A.; Zeng, M.; Lin, J.; Rusch, L.A. Geometric constellation shaping using initialized autoencoders. In Proceedings of the 2021 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Bucharest, Romania, 24–28 May 2021; pp. 1–5. [Google Scholar]
- Jovanovic, O.; Yankov, M.P.; Ros, F.D.; Zibar, D. End-to-end learning of a constellation shape robust to channel condition uncertainties. J. Lightw. Technol. 2022, 40, 3316–3324. [Google Scholar] [CrossRef]
- Aref, V.; Chagnon, M. End-to-end learning of joint geometric and probabilistic constellation shaping. In Proceedings of the Optical Fiber Communication Conference 2022, San Diego, CA, USA, 6–10 March 2022; pp. 1–3. [Google Scholar]
- Dzieciol, H.; Liga, G.; Sillekens, E.; Bayvel, P.; Lavery, D. Geometric shaping of 2-D constellations in the presence of laser phase noise. J. Lightw. Technol. 2021, 39, 481–490. [Google Scholar] [CrossRef]
- Ash, R.B. Basic Probability Theory; Courier Corporation: Chelmsford, MA, USA, 2008. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Courier Corporation: Chelmsford, MA, USA, 1997. [Google Scholar]
- Donsker, M.D.; Varadhan, S.S. Asymptotic evaluation of certain markov process expectations for large time. IV. Commun. Pure Appl. Math. 1983, 36, 183–212. [Google Scholar] [CrossRef]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-GAN: Training generative neural samplers using variational divergence minimization. Proc. Neural Int. Process. Syst. 2016, 29, 271–279. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with Gumbel-Softmax. arXiv 2017, arXiv:1611.01144. [Google Scholar]
- Paszke, A. PyTorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Wang, Q.; Ji, X.; Qian, L.P.; Liu, Z.; Du, X.; Kam, P.-Y. MINE-based geometric constellation shaping in AWGN channel. In Proceedings of the 2023 IEEE/CIC International Conference on Communications in China (ICCC Workshops), Dalian, China, 10–12 August 2023; pp. 1–5. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Values |
|---|---|
| Number of hidden layers | Encoder (3), MINE (2) |
| Number of hidden neurons | Encoder (256), MINE (40) |
| Loss function | Equation (9) |
| Learning rate | 0.01 |
| Batch size | 800 |
| Epoch | 200 |
| Optimizer | Adam [29] |
| Training cycle | Encoder (every 10 epoch), |
| MINE (every 1 epoch) |
| Hyperparameters | Values |
|---|---|
| Number of hidden layers | Probability generator (1), |
| MINE (2) | |
| Number of hidden neurons | Probability generator (128), |
| MINE (40) | |
| Loss function | Equation (9) |
| Learning rate | 0.01 |
| Batch size | 5000 |
| Epoch | 2000 |
| Optimizer | Adam |
| Training cycle | Probability generator (every 1 |
| epoch), MINE (every 1 epoch) |
| FLOPs | Params | Training Time for per SNR | |
|---|---|---|---|
| MINE-GCS | 0.1391 M | 0.14 M | 0.8380 s |
| E2E-GCS | 0.1708 M | 0.172 M | 70.6799 s |
| MINE-PCS | 5576 | 5881 | 1.4815 s |
| 2019Stark-PCS | 0.0177 M | 0.0181 M | 6.1650 s |
| FLOPs | Params | |
|---|---|---|
| MINE | 3400 | 3561 |
| Probability Generator | 2176 | 2320 |
| Encoder (MINE- and E2E-GCS) | 0.1357 M | 0.1365 M |
| Decoder (E2E-GCS) | 0.0171 M | 0.0172 M |
| Encoder (2019Stark-PCS) | 640 | 772 |
| Decoder (2019Stark-PCS) | 0.017 M | 0.0173 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, X.; Wang, Q.; Qian, L.; Kam, P.-Y. Mutual Information Neural-Estimation-Driven Constellation Shaping Design and Performance Analysis. Entropy 2025, 27, 451. https://doi.org/10.3390/e27040451
Ji X, Wang Q, Qian L, Kam P-Y. Mutual Information Neural-Estimation-Driven Constellation Shaping Design and Performance Analysis. Entropy. 2025; 27(4):451. https://doi.org/10.3390/e27040451
Chicago/Turabian StyleJi, Xiuli, Qian Wang, Liping Qian, and Pooi-Yuen Kam. 2025. "Mutual Information Neural-Estimation-Driven Constellation Shaping Design and Performance Analysis" Entropy 27, no. 4: 451. https://doi.org/10.3390/e27040451
APA StyleJi, X., Wang, Q., Qian, L., & Kam, P.-Y. (2025). Mutual Information Neural-Estimation-Driven Constellation Shaping Design and Performance Analysis. Entropy, 27(4), 451. https://doi.org/10.3390/e27040451