
Tracking of Ubiquitin Signaling through 3.5 Billion Years of Combinatorial Conjugation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Fifty Shades of Ubiquitin
2.1. Ubiquitin and Ubls of Multicellular Eukaryotes
2.2. Yeast Ubls
2.3. Ubiquitin and Ubls in Protozoa
2.4. Archean and Bacterial Ubls
2.5. Ubiquitin and Ubiquitin-like Proteins: Different but Similar
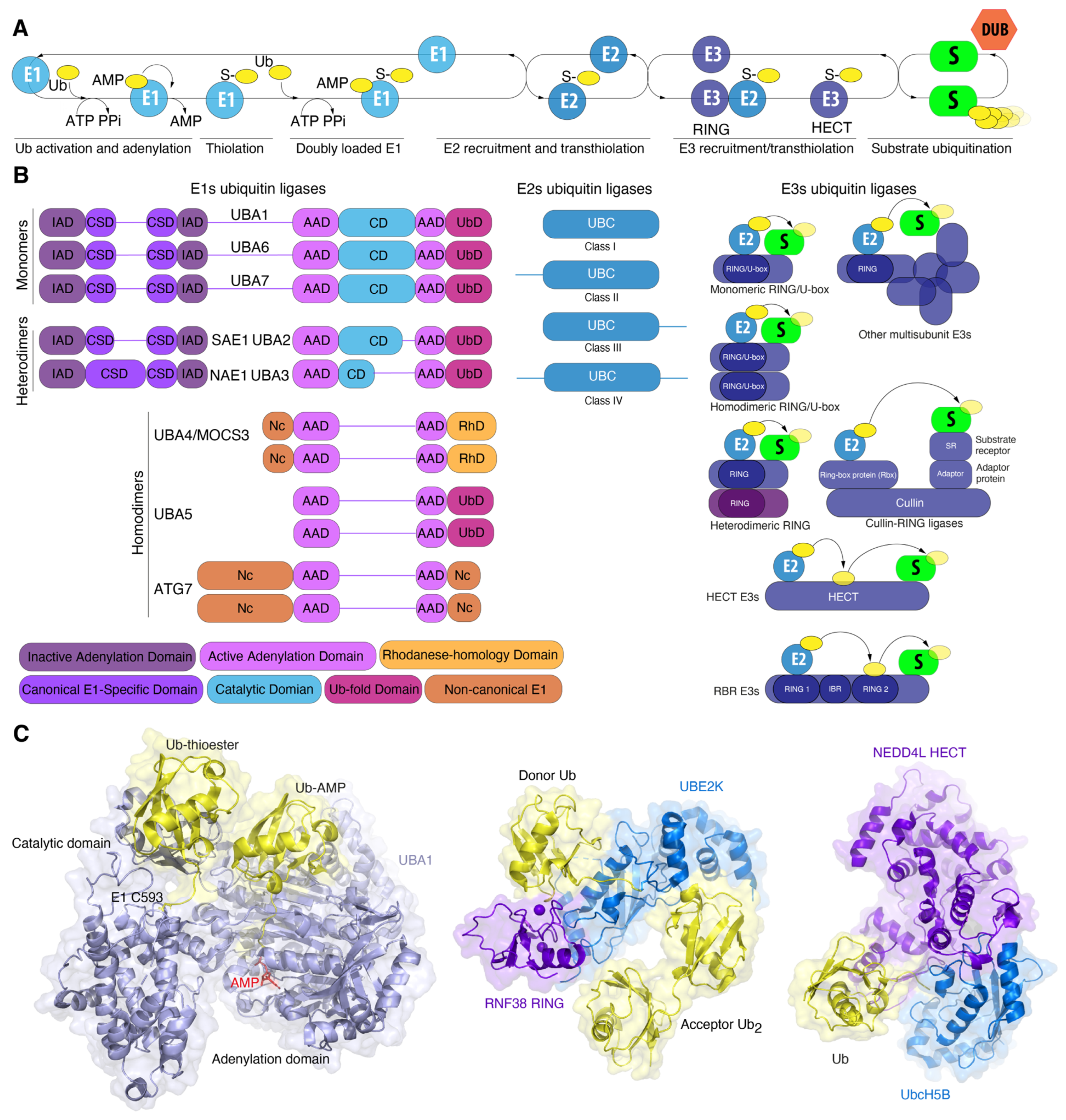
3. Ubiquitin Conjugation Machinery: Billions of Years of Improvement
3.1. E1 Activating Enzyme: Snow White and the Seven Dwarfs
3.2. Eukaryotic E1
3.3. Prokaryotic E1 Analogues
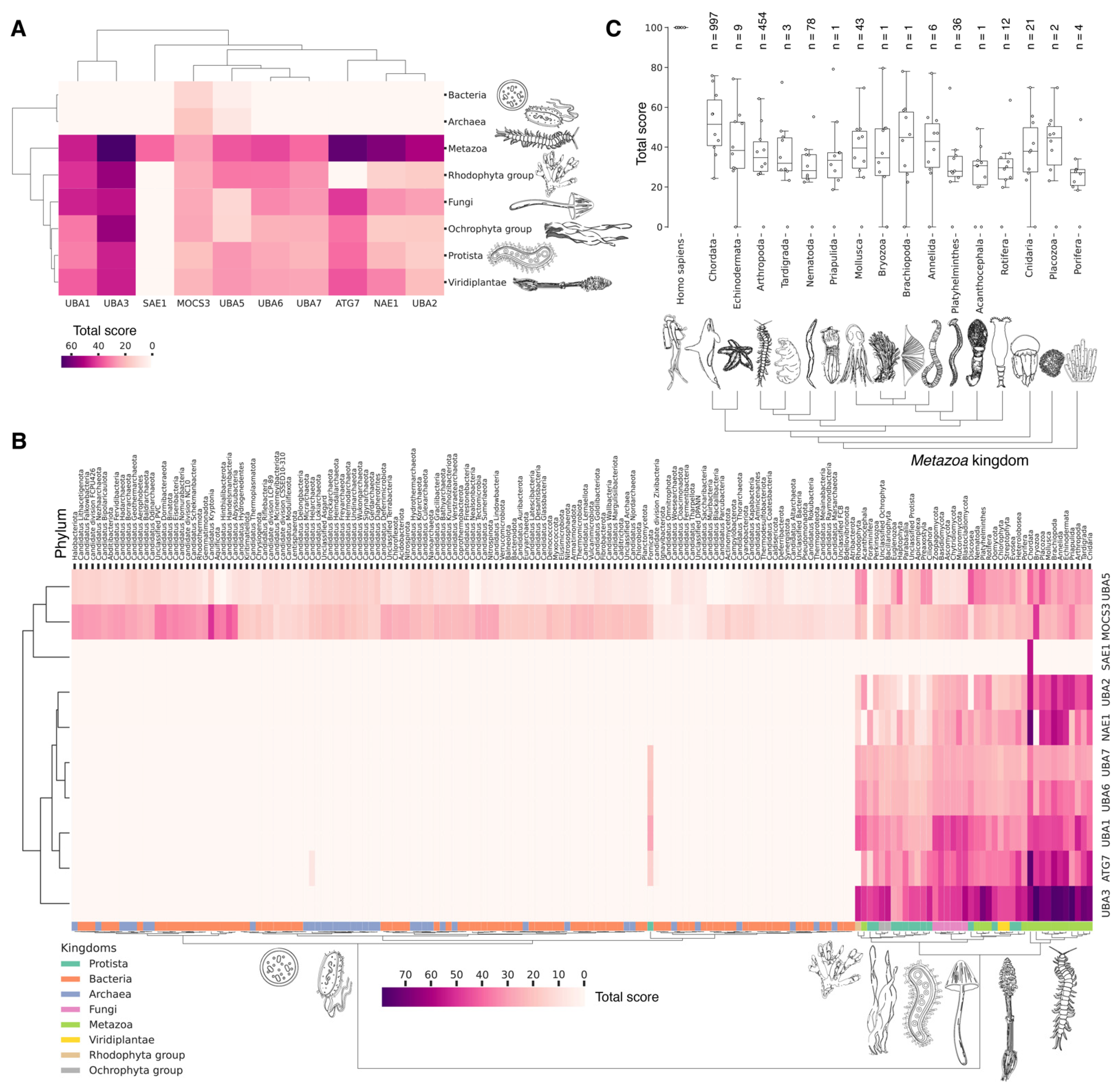
3.4. Evolutional Profiling of E1 Activating Enzyme
3.5. Who Is Next? The E2 Conjugating Enzyme Superfamily
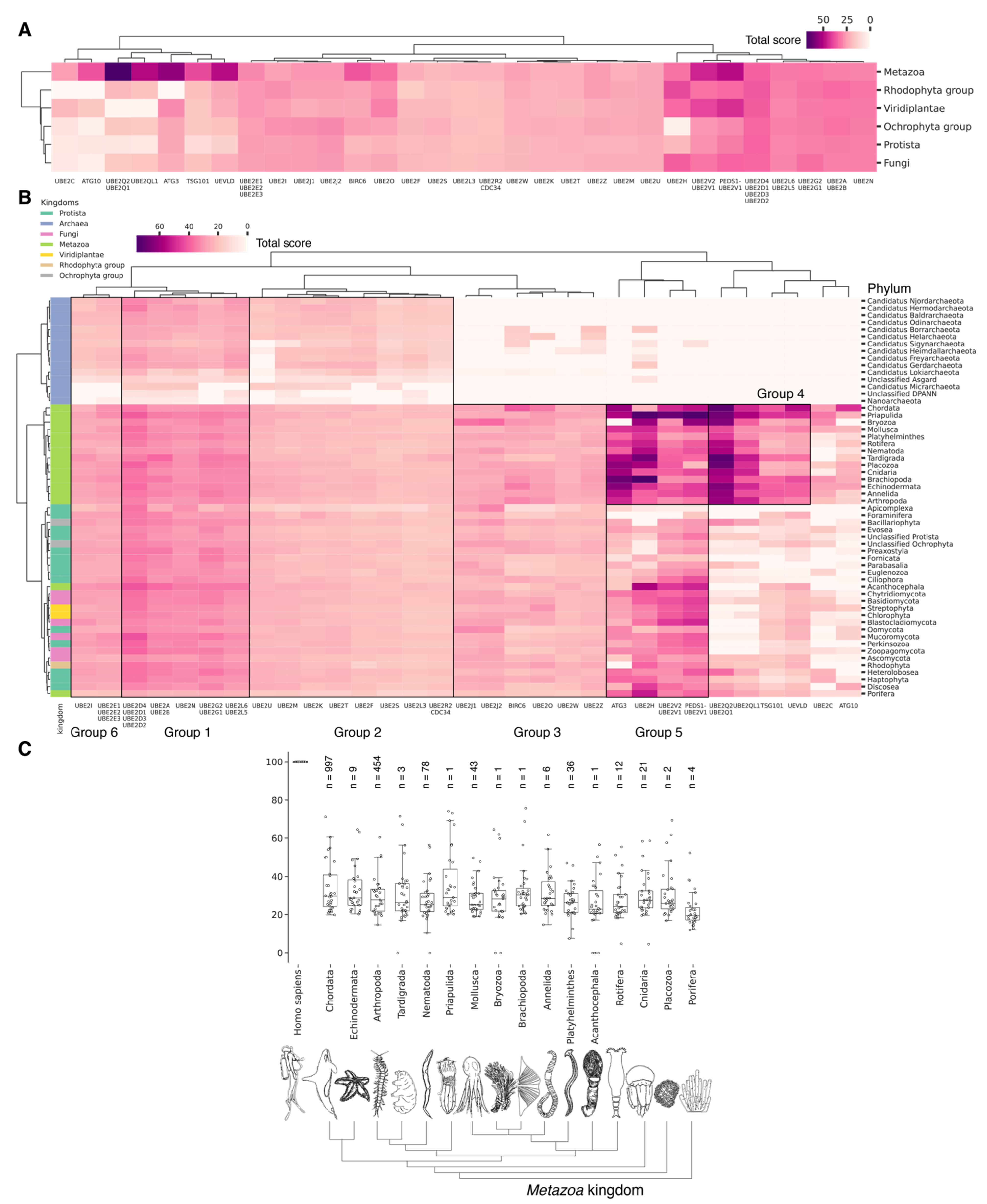
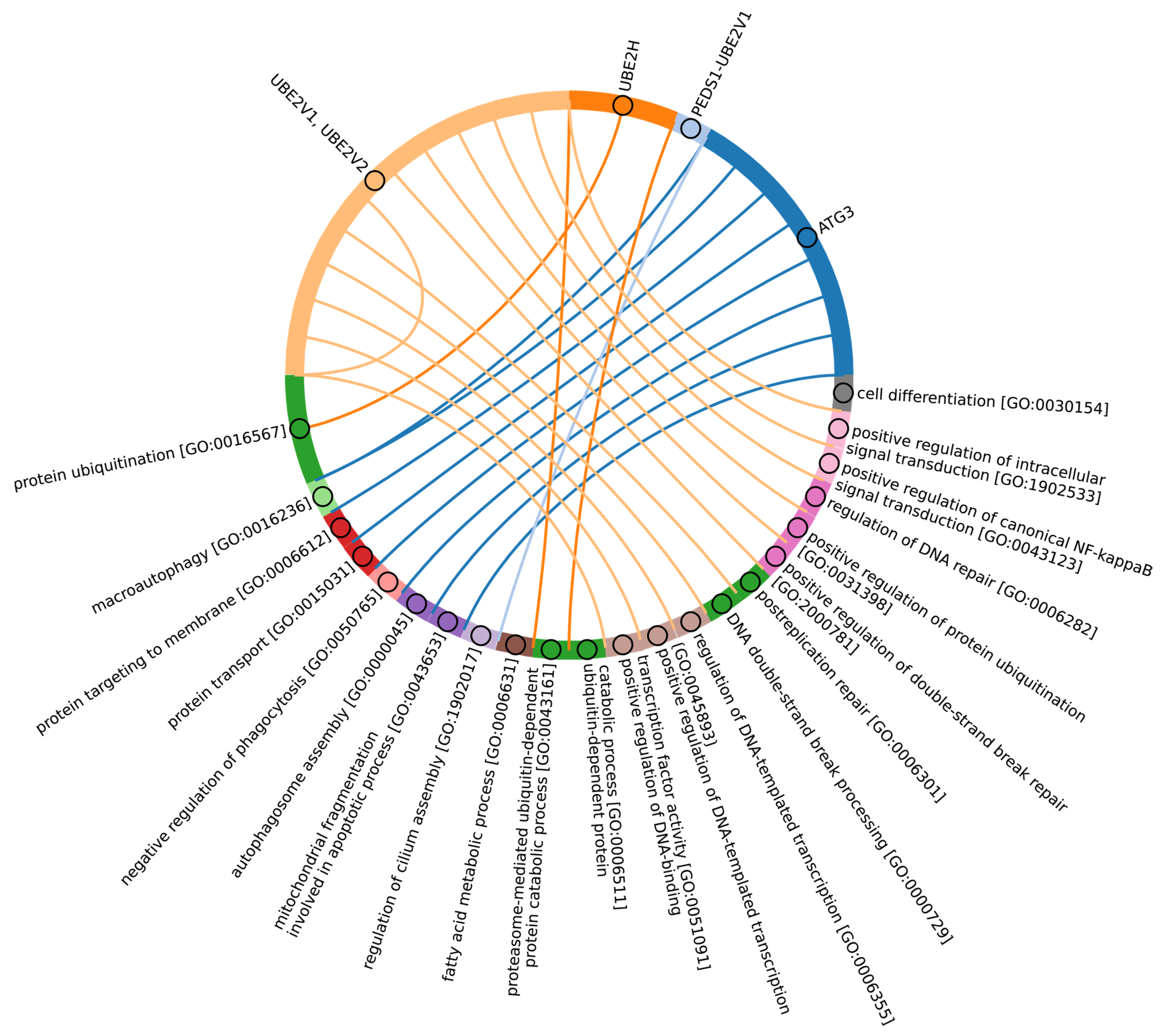
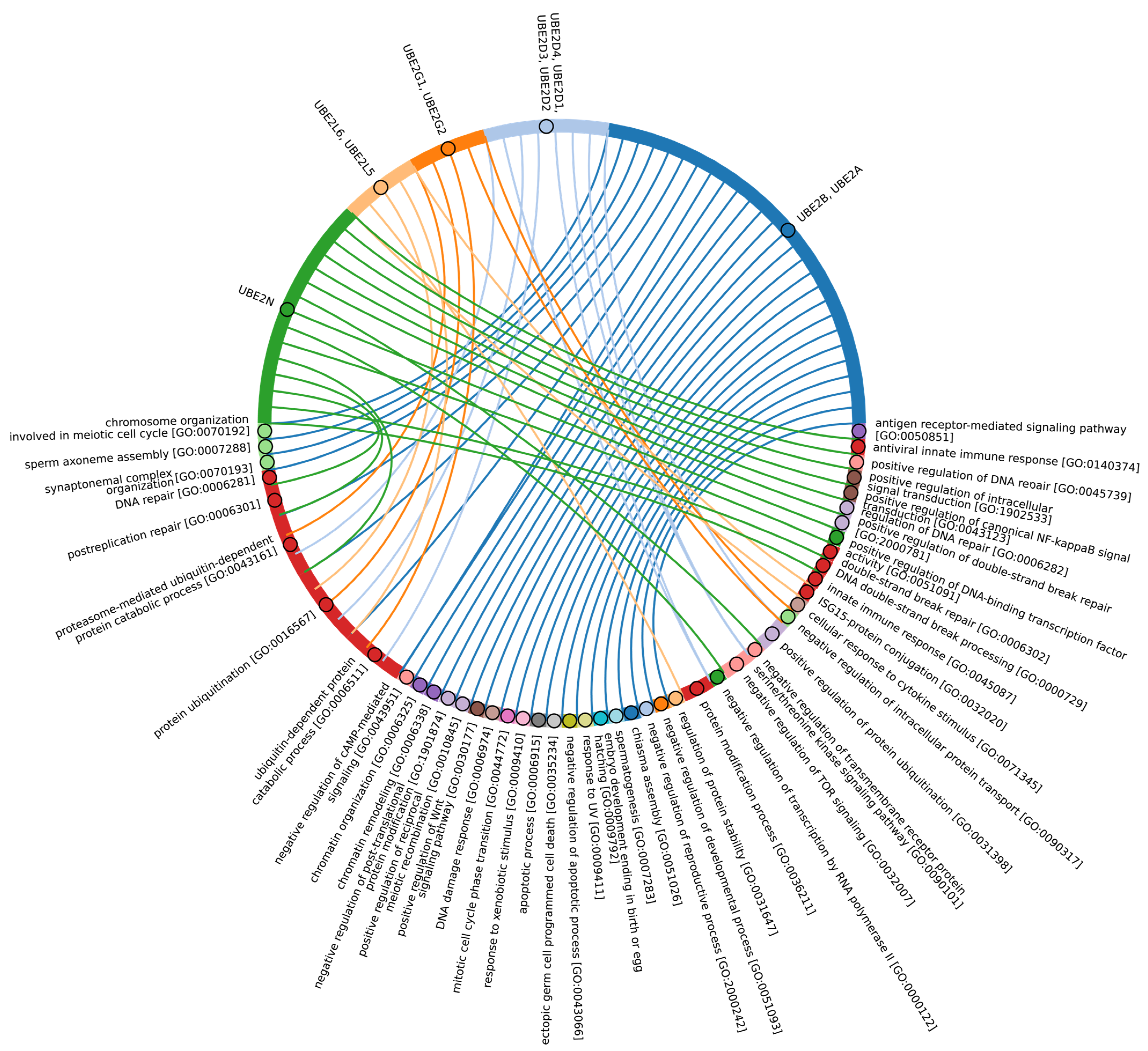
3.6. Evolutional Profiling of E2 Conjugating Enzymes
3.7. The Army of Conjugators: E3 Ligases
3.8. Prokaryotic E3 Analogues
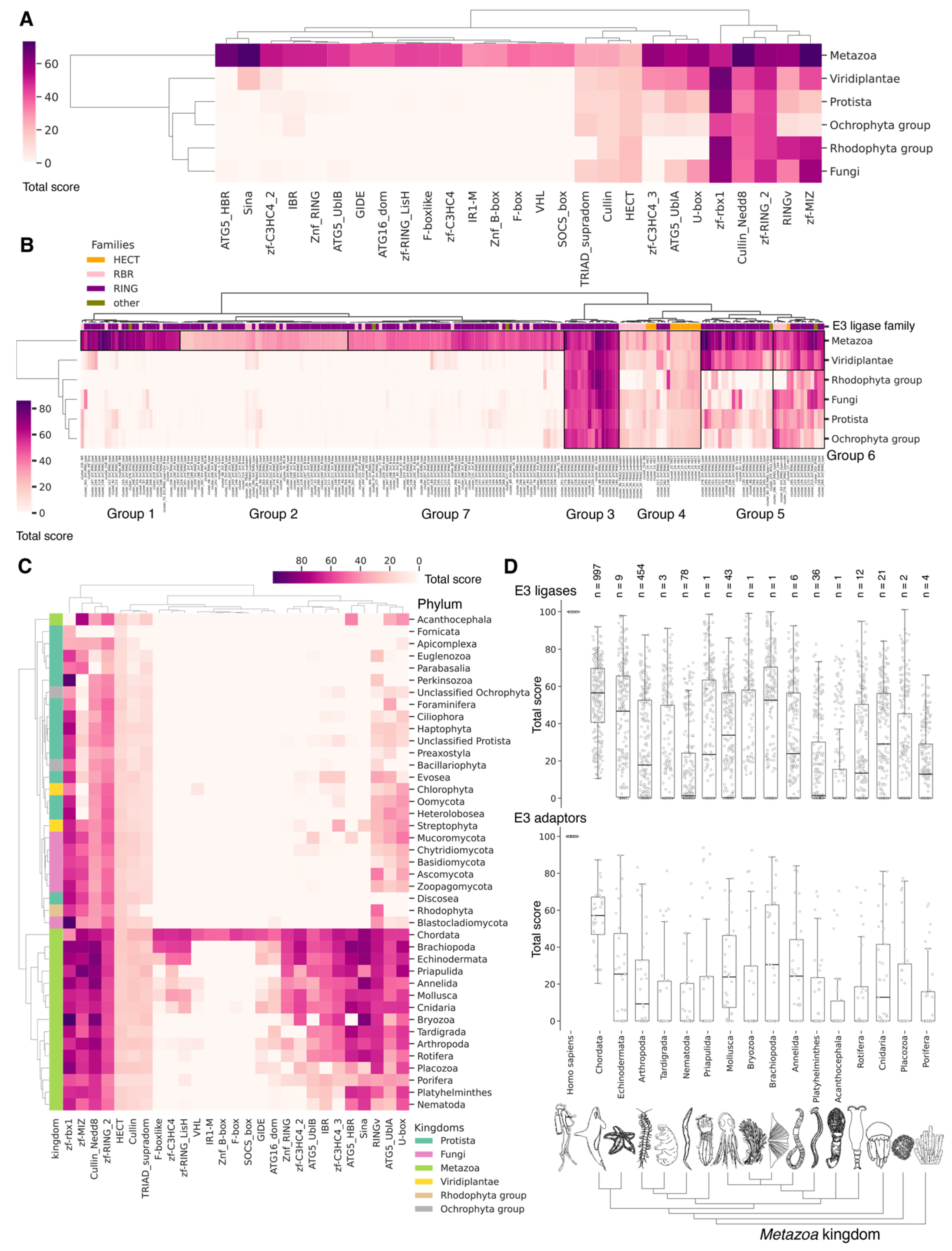
3.9. Evolutional Profiling of E3 Ligases
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Ciechanover, A.; Heller, H.; Katz-Etzion, R.; Hershko, A. Activation of the Heat-Stable Polypeptide of the ATP-Dependent Proteolytic System. Proc. Natl. Acad. Sci. USA 1981, 78, 761–765. [Google Scholar] [CrossRef] [PubMed]
- Wilkinson, K.D.; Urban, M.K.; Haas, A.L. Ubiquitin Is the ATP-Dependent Proteolysis Factor I of Rabbit Reticulocytes. J. Biol. Chem. 1980, 255, 7529–7532. [Google Scholar] [CrossRef] [PubMed]
- Hershko, A.; Ciechanover, A.; Heller, H.; Haas, A.L.; Rose, I.A. Proposed Role of ATP in Protein Breakdown: Conjugation of Protein with Multiple Chains of the Polypeptide of ATP-Dependent Proteolysis. Proc. Natl. Acad. Sci. USA 1980, 77, 1783–1786. [Google Scholar] [CrossRef] [PubMed]
- Ciechanover, A.; Heller, H.; Elias, S.; Haas, A.L.; Hershko, A. ATP-Dependent Conjugation of Reticulocyte Proteins with the Polypeptide Required for Protein Degradation. Proc. Natl. Acad. Sci. USA 1980, 77, 1365–1368. [Google Scholar] [CrossRef] [PubMed]
- Dikic, I.; Schulman, B.A. An expanded lexicon for the ubiquitin code. Nat. Rev. Mol. Cell Biol. 2022, 24, 273–287. [Google Scholar] [CrossRef]
- Burroughs, A.M.; Iyer, L.M.; Aravind, L. Functional Diversification of the RING Finger and Other Binuclear Treble Clef Domains in Prokaryotes and the Early Evolution of the Ubiquitin System. Mol. BioSystems 2011, 7, 2261–2277. [Google Scholar] [CrossRef]
- Cappadocia, L.; Lima, C.D. Ubiquitin-like Protein Conjugation: Structures, Chemistry, and Mechanism. Chem. Rev. 2018, 118, 889–918. [Google Scholar] [CrossRef] [PubMed]
- French, M.E.; Koehler, C.F.; Hunter, T. Emerging Functions of Branched Ubiquitin Chains. Cell Discov. 2021, 7, 6. [Google Scholar] [CrossRef]
- Berrocal, D.A.P.; Witting, K.F.; Ovaa, H.; Mulder, M.P.C. Hybrid Chains: A Collaboration of Ubiquitin and Ubiquitin-Like Modifiers Introducing Cross-Functionality to the Ubiquitin Code. Front. Chem. 2020, 7, 931. [Google Scholar] [CrossRef]
- Yang, C.S.; Jividen, K.; Spencer, A.; Dworak, N.; Ni, L.; Oostdyk, L.T.; Chatterjee, M.; Kuśmider, B.; Reon, B.; Parlak, M.; et al. Ubiquitin Modification by the E3 Ligase/ADP-Ribosyltransferase Dtx3L/Parp9. Mol. Cell 2017, 66, 503–516. [Google Scholar] [CrossRef]
- Jentsch, S.; Pyrowolakis, G. Ubiquitin and Its Kin: How Close Are the Family Ties? Trends Cell Biol. 2000, 10, 335–342. [Google Scholar] [CrossRef] [PubMed]
- Grabbe, C.; Dikic, I. Functional Roles of Ubiquitin-like Domain (ULD) and Ubiquitin-Binding Domain (UBD) Containing Proteins. Chem. Rev. 2009, 109, 1481–1494. [Google Scholar] [CrossRef] [PubMed]
- Wolf, Y.I.; Aravind, L.; Grishin, N.V.; Koonin, E.V. Evolution of Aminoacyl-tRNA Synthetases-Analysis of Unique Domain Architectures and Phylogenetic Trees Reveals a Complex History of Horizontal Gene Transfer Events. Genome Res. 1999, 9, 689–710. [Google Scholar] [CrossRef] [PubMed]
- Sankaranarayanan, R.; Dock-Bregeon, A.C.; Romby, P.; Caillet, J.; Springer, M.; Rees, B.; Ehresmann, C.; Ehresmann, B.; Moras, D. The Structure of Threonyl-tRNA Synthetase-tRNAThr Complex Enlightens Its Repressor Activity and Reveals an Essential Zinc Ion in the Active Site. Cell 1999, 97, 371–381. [Google Scholar] [CrossRef]
- Vertegaal, A.C.O. Signalling Mechanisms and Cellular Functions of SUMO. Nat. Rev. Mol. Cell Biol. 2022, 23, 715–731. [Google Scholar] [CrossRef] [PubMed]
- Koegl, M.; Hoppe, T.; Schlenker, S.; Ulrich, H.D.; Mayer, T.U.; Jentsch, S. A Novel Ubiquitination Factor, E4, Is Involved in Multiubiquitin Chain Assembly. Cell 1999, 96, 635–644. [Google Scholar] [CrossRef] [PubMed]
- Soucy, T.A.; Dick, L.R.; Smith, P.G.; Milhollen, M.A.; Brownell, J.E. The NEDD8 Conjugation Pathway and Its Relevance in Cancer Biology and Therapy. Genes Cancer 2010, 1, 708–716. [Google Scholar] [CrossRef]
- Masucci, M.G. Viral Ubiquitin and Ubiquitin-like Deconjugases—Swiss Army Knives for Infection. Biomolecules 2020, 10, 1137. [Google Scholar] [CrossRef]
- Kolathur, K.K.; Sharma, P.; Kadam, N.Y.; Shahi, N.; Nishitha, A.; Babu, K.; Mishra, S.K. The Ubiquitin-like Protein Hub1/UBL-5 Functions in Pre-mRNA Splicing in Caenorhabditis Elegans. FEBS Lett. 2023, 597, 448–457. [Google Scholar] [CrossRef]
- Walczak, C.P.; Leto, D.E.; Zhang, L.; Riepe, C.; Muller, R.Y.; DaRosa, P.A.; Ingolia, N.T.; Elias, J.E.; Kopito, R.R. Ribosomal Protein RPL26 Is the Principal Target of UFMylation. Proc. Natl. Acad. Sci. USA 2019, 116, 1299–1308. [Google Scholar] [CrossRef]
- Scavone, F.; Gumbin, S.C.; Rosa, P.A.D.; Kopito, R.R. RPL26/uL24 UFMylation Is Essential for Ribosome-Associated Quality Control at the Endoplasmic Reticulum. Proc. Natl. Acad. Sci. USA 2023, 120, e2220340120. [Google Scholar] [CrossRef] [PubMed]
- Van den Heuvel, J.; Ashiono, C.; Gillet, L.; Dörner, K.; Wyler, E.; Zemp, I.; Kutay, U. Processing of the Ribosomal Ubiquitin-like Fusion Protein FUBI-eS30/FAU Is Required for 40S Maturation and Depends on USP36. eLife 2021, 10, e70560. [Google Scholar] [CrossRef] [PubMed]
- Aleshin, V.V.; Konstantinova, A.V.; Mikhailov, K.V.; Nikitin, M.A.; Petrov, N.B. Do We Need Many Genes for Phylogenetic Inference? Biochemistry 2007, 72, 1313–1323. [Google Scholar] [CrossRef] [PubMed]
- Martín-Villanueva, S.; Gutiérrez, G.; Kressler, D.; de la Cruz, J. Ubiquitin and Ubiquitin-Like Proteins and Domains in Ribosome Production and Function: Chance or Necessity? Int. J. Mol. Sci. 2021, 22, 4359. [Google Scholar] [CrossRef] [PubMed]
- Martín-Villanueva, S.; Fernández-Pevida, A.; Kressler, D.; de la Cruz, J. The Ubiquitin Moiety of Ubi1 Is Required for Productive Expression of Ribosomal Protein El40 in Saccharomyces cerevisiae. Cells 2019, 8, 850. [Google Scholar] [CrossRef]
- Ryu, K.Y.; Maehr, R.; Gilchrist, C.A.; Long, M.A.; Bouley, D.M.; Mueller, B.; Ploegh, H.L.; Kopito, R.R. The Mouse Polyubiquitin Gene UbC Is Essential for Fetal Liver Development, Cell-Cycle Progression and Stress Tolerance. EMBO J. 2007, 26, 2693–2706. [Google Scholar] [CrossRef] [PubMed]
- Mirzalieva, O.; Juncker, M.; Schwartzenburg, J.; Desai, S. ISG15 and ISGylation in Human Diseases. Cells 2022, 11, 538. [Google Scholar] [CrossRef]
- Magor, K.E.; Navarro, D.M.; Barber, M.R.W.; Petkau, K.; Fleming-Canepa, X.; Blyth, G.A.D.; Blaine, A.H. Defense Genes Missing from the Flight Division. Dev. Comp. Immunol. 2013, 41, 377–388. [Google Scholar] [CrossRef]
- Shepard, J.D.; Freitas, B.T.; Rodriguez, S.E.; Scholte, F.E.M.; Baker, K.; Hutchison, M.R.; Longo, J.E.; Miller, H.C.; O’Boyle, B.M.; Tandon, A.; et al. The Structure and Immune Regulatory Implications of the Ubiquitin-Like Tandem Domain within an Avian 2′–5′ Oligoadenylate Synthetase-Like Protein. Front. Immunol. 2022, 12, 794664. [Google Scholar] [CrossRef]
- Finley, D.; Özkaynak, E.; Varshavsky, A. The Yeast Polyubiquitin Gene Is Essential for Resistance to High Temperatures, Starvation, and Other Stresses. Cell 1987, 48, 1035–1046. [Google Scholar] [CrossRef] [PubMed]
- Finley, D.; Bartel, B.; Varshavsky, A. The Tails of Ubiquitin Precursors Are Ribosomal Proteins Whose Fusion to Ubiquitin Facilitates Ribosome Biogenesis. Nature 1989, 338, 394–401. [Google Scholar] [CrossRef] [PubMed]
- Finley, D.; Ulrich, H.D.; Sommer, T.; Kaiser, P. The Ubiquitin-Proteasome System of Saccharomyces Cerevisiae. Genetics 2012, 192, 319–360. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, M.J.; Lee, M.; Le Roch, K.G. The Ubiquitin System: An Essential Component to Unlocking the Secrets of Malaria Parasite Biology. Mol. BioSystems 2014, 10, 715–723. [Google Scholar] [CrossRef] [PubMed]
- Osaka, F.; Saeki, M.; Katayama, S.; Aida, N.; Toh-E, A.; Kominami, K.; Toda, T.; Suzuki, T.; Chiba, T.; Tanaka, K.; et al. Covalent modifier NEDD8 is essential for SCF ubiquitin-ligase in fission yeast. EMBO J. 2000, 19, 3475–3484. [Google Scholar] [CrossRef]
- Hochstrasser, M. Evolution and Function of Ubiquitin-like Protein-Conjugation Systems. Nat. Cell Biol. 2000, 2, E153–E157. [Google Scholar] [CrossRef]
- Yin, Z.; Popelka, H.; Lei, Y.; Yang, Y.; Klionsky, D.J. The Roles of Ubiquitin in Mediating Autophagy. Cells 2020, 9, 6. [Google Scholar] [CrossRef]
- Komatsu, M.; Chiba, T.; Tatsumi, K.; Lemura, S.I.; Tanida, I.; Okazaki, N.; Ueno, T.; Konminani, E.; Natsume, T.; Tanaka, K. A Novel Protein-Conjugating System for Ufm1, a Ubiquitin-Fold Modifier. EMBO J. 2004, 23, 1977–1986. [Google Scholar] [CrossRef] [PubMed]
- Pergolizzi, B.; Bozzaro, S.; Bracco, E. Dictyostelium as Model for Studying Ubiquitination and Deubiquitination. Int. J. Dev. Biol. 2019, 63, 529–539. [Google Scholar] [CrossRef]
- Swindle, J.; Ajioka, J.; Eisen, H.; Sanwal, B.; Jacquemot, C.; Browder, Z.; Buck, G. The Genomic Organization and Transcription of the Ubiquitin Genes of Trypanosoma Cruzi. EMBO J. 1988, 7, 1121–1127. [Google Scholar] [CrossRef]
- Kirchhoff, L.V.; Kim, K.S.; Engman, D.M.; Donelson, J.E. Ubiquitin Genes in Trypanosomatidae. J. Biol. Chem. 1988, 263, 12698–12704. [Google Scholar] [CrossRef]
- Catic, A.; Sun, Z.Y.J.; Ratner, D.M.; Misaghi, S.; Spooner, E.; Samuelson, J.; Wagner, G.; Ploegh, H.L. Sequence and Structure Evolved Separately in a Ribosomal Ubiquitin Variant. EMBO J. 2007, 26, 3474–3483. [Google Scholar] [CrossRef] [PubMed]
- Archibald, J.M.; Teh, E.M.; Keeling, P.J. Novel Ubiquitin Fusion Proteins: Ribosomal Protein P1 and Actin. J. Mol. Biol. 2003, 328, 771–778. [Google Scholar] [CrossRef] [PubMed]
- Sibbald, S.J.; Hopkins, J.F.; Filloramo, G.V.; Archibald, J.M. Ubiquitin Fusion Proteins in Algae: Implications for Cell Biology and the Spread of Photosynthesis. BMC Genom. 2019, 20, 38. [Google Scholar] [CrossRef] [PubMed]
- Stoltzfus, A. On the Possibility of Constructive Neutral Evolution. J. Mol. Evol. 1999, 49, 169–181. [Google Scholar] [CrossRef]
- Karpiyevich, M.; Artavanis-Tsakonas, K. Ubiquitin-like Modifiers: Emerging Regulators of Protozoan Parasites. Biomolecules 2020, 10, 1403. [Google Scholar] [CrossRef]
- Fuchs, A.C.D.; Maldoner, L.; Wojtynek, M.; Hartmann, M.D.; Martin, J. Rpn11-Mediated Ubiquitin Processing in an Ancestral Archaeal Ubiquitination System. Nat. Commun. 2018, 9, 2696. [Google Scholar] [CrossRef] [PubMed]
- Hennell James, R.; Caceres, E.F.; Escasinas, A.; Alhasan, H.; Howard, J.A.; Deery, M.J.; Ettema, T.J.G.; Robinson, N.P. Functional Reconstruction of a Eukaryotic-like E1/E2/(RING) E3 Ubiquitylation Cascade from an Uncultured Archaeon. Nat. Commun. 2017, 8, 1120. [Google Scholar] [CrossRef] [PubMed]
- Humbard, M.A.; Miranda, H.V.; Lim, J.M.; Krause, D.J.; Pritz, J.R.; Zhou, G.; Chen, S.; Wells, L.; Maupin-Furlow, J.A. Ubiquitin-like Small Archaeal Modifier Proteins (SAMPs) in Haloferax Volcanii. Nature 2010, 463, 54–60. [Google Scholar] [CrossRef] [PubMed]
- Veen, A.G.V.D.; Schorpp, K.; Schlieker, C.; Buti, L.; Damon, J.R.; Spooner, E.; Ploegh, H.L.; Jentsch, S. Role of the Ubiquitin-like Protein Urm1 as a Noncanonical Lysine-Directed Protein Modifier. Proc. Natl. Acad. Sci. USA 2011, 108, 1763–1770. [Google Scholar] [CrossRef]
- Wang, F.; Liu, M.; Qiu, R.; Ji, C. The Dual Role of Ubiquitin-like Protein Urm1 as a Protein Modifier and Sulfur Carrier. Protein Cell 2011, 2, 612–619. [Google Scholar] [CrossRef]
- Makarova, K.S.; Koonin, E.V. Archaeal Ubiquitin-like Proteins: Functional Versatility and Putative Ancestral Involvement in tRNA Modification Revealed by Comparative Genomic Analysis. Archaea 2010, 2010, 710303. [Google Scholar] [CrossRef] [PubMed]
- Iyer, L.M.; Burroughs, A.M.; Aravind, L. The Prokaryotic Antecedents of the Ubiquitin-Signaling System and the Early Evolution of Ubiquitin-like β-Grasp Domains. Genome Biol. 2006, 7, R60. [Google Scholar] [CrossRef] [PubMed]
- Millman, A.; Melamed, S.; Leavitt, A.; Doron, S.; Bernheim, A.; Hör, J.; Garb, J.; Bechon, N.; Brandis, A.; Lopatina, A.; et al. An Expanded Arsenal of Immune Systems That Protect Bacteria from Phages. Cell Host Microbe 2022, 30, 1556–1569. [Google Scholar] [CrossRef] [PubMed]
- Chambers, L.R.; Ye, Q.; Cai, J.; Gong, M.; Ledvina, H.E.; Zhou, H.; Whiteley, A.T.; Suhandynata, R.T.; Corbett, K.D. Bacterial Antiviral Defense Pathways Encode Eukaryotic-like Ubiquitination Systems. bioRxiv 2023. [Google Scholar] [CrossRef]
- Maupin-Furlow, J.A. Prokaryotic Ubiquitin-like Protein Modification. Annu. Rev. Microbiol. 2014, 68, 155–175. [Google Scholar] [CrossRef]
- Lake, M.W.; Wuebbens, M.M.; Rajagopalan, K.V.; Schindelin, H. Mechanism of Ubiquitin Activation Revealed by the Structure of a Bacterial MoeB-MoaD Complex. Nature 2001, 414, 325–329. [Google Scholar] [CrossRef] [PubMed]
- Taylor, S.V.; Kelleher, N.L.; Kinsland, C.; Chiu, H.J.; Costello, C.A.; Backstrom, A.D.; McLafferty, F.W.; Begley, T.P. Thiamin Biosynthesis in Escherichia coli. Identification of This Thiocarboxylate as the Immediate Sulfur Donor in the Thiazole Formation. J. Biol. Chem. 1998, 273, 16555–16560. [Google Scholar] [CrossRef] [PubMed]
- Leimkühler, S.; Wuebbens, M.M.; Rajagopalan, K.V. Characterization of Escherichia coli MoeB and Its Involvement in the Activation of Molybdopterin Synthase for the Biosynthesis of the Molybdenum Cofactor. J. Biol. Chem. 2001, 276, 34695–34701. [Google Scholar] [CrossRef]
- Grau-Bové, X.; Sebé-Pedrós, A.; Ruiz-Trillo, I. The Eukaryotic Ancestor Had a Complex Ubiquitin Signaling System of Archaeal Origin. Mol. Biol. Evol. 2015, 32, 726–739. [Google Scholar] [CrossRef]
- Burroughs, A.M.; Iyer, L.M.; Aravind, L. Natural History of the E1-like Superfamily: Implication for Adenylation, Sulfur Transfer, and Ubiquitin Conjugation. Proteins Struct. Funct. Bioinform. 2009, 75, 895–910. [Google Scholar] [CrossRef]
- Walden, H.; Podgorski, M.S.; Huang, D.T.; Miller, D.W.; Howard, R.J.; Minor, D.L.; Holton, J.M.; Schulman, B.A. The Structure of the APPBP1-UBA3-NEDD8-ATP Complex Reveals the Basis for Selective Ubiquitin-like Protein Activation by an E1. Mol. Cell 2003, 12, 1427–1437. [Google Scholar] [CrossRef] [PubMed]
- Lois, L.M.; Lima, C.D. Structures of the SUMO E1 Provide Mechanistic Insights into SUMO Activation and E2 Recruitment to E1. EMBO J. 2005, 24, 439–451. [Google Scholar] [CrossRef] [PubMed]
- Olsen, S.K.; Capili, A.D.; Lu, X.; Tan, D.S.; Lima, C.D. Active Site Remodelling Accompanies Thioester Bond Formation in the SUMO E1. Nature 2010, 463, 906–912. [Google Scholar] [CrossRef]
- Olsen, S.K.; Lima, C.D. Structure of a Ubiquitin E1-E2 Complex: Insights to E1-E2 Thioester Transfer. Mol. Cell 2013, 49, 884–896. [Google Scholar] [CrossRef] [PubMed]
- Hann, Z.S.; Ji, C.; Olsen, S.K.; Lu, X.; Lux, M.C.; Tan, D.S.; Lima, C.D. Structural Basis for Adenylation and Thioester Bond Formation in the Ubiquitin E1. Proc. Natl. Acad. Sci. USA 2019, 116, 15475–15484. [Google Scholar] [CrossRef] [PubMed]
- Noda, N.N. Structural Biology of the Atg8 and Atg12 Conjugation Systems. Autophagy Rep. 2023, 2, 16555–16560. [Google Scholar] [CrossRef]
- Schlieker, C.D.; Veen, A.G.V.D.; Damon, J.R.; Spooner, E.; Ploegh, H.L. A Functional Proteomics Approach Links the Ubiquitin-Related Modifier Urm1 to a tRNA Modification Pathway. Proc. Natl. Acad. Sci. USA 2008, 105, 18255–18260. [Google Scholar] [CrossRef] [PubMed]
- Leidel, S.; Pedrioli, P.G.A.; Bucher, T.; Brost, R.; Costanzo, M.; Schmidt, A.; Aebersold, R.; Boone, C.; Hofmann, K.; Peter, M. Ubiquitin-Related Modifier Urm1 Acts as a Sulphur Carrier in Thiolation of Eukaryotic Transfer RNA. Nature 2009, 458, 228–232. [Google Scholar] [CrossRef]
- Ravichandran, K.E.; Kaduhr, L.; Skupien-Rabian, B.; Shvetsova, E.; Sokołowski, M.; Krutyhołowa, R.; Kwasna, D.; Brachmann, C.; Lin, S.; Guzman Perez, S.; et al. E2/E3-independent Ubiquitin-like Protein Conjugation by Urm1 Is Directly Coupled to Cysteine Persulfidation. EMBO J. 2022, 41, e111318. [Google Scholar] [CrossRef]
- Schulman, B.A.; Wade Harper, J. Ubiquitin-like Protein Activation by E1 Enzymes: The Apex for Downstream Signalling Pathways. Nat. Rev. Mol. Cell Biol. 2009, 10, 319–331. [Google Scholar] [CrossRef] [PubMed]
- Aichem, A.; Pelzer, C.; Lukasiak, S.; Kalveram, B.; Sheppard, P.W.; Rani, N.; Schmidtke, G.; Groettrup, M. USE1 Is a Bispecific Conjugating Enzyme for Ubiquitin and FAT10, Which FAT10ylates Itself in Cis. Nat. Commun. 2010, 1, 13. [Google Scholar] [CrossRef] [PubMed]
- Termathe, M.; Leidel, S.A. Urm1: A Non-Canonical Ubl. Biomolecules 2021, 11, 139. [Google Scholar] [CrossRef] [PubMed]
- Dohmen, E.; Klasberg, S.; Bornberg-Bauer, E.; Perrey, S.; Kemena, C. The Modular Nature of Protein Evolution: Domain Rearrangement Rates across Eukaryotic Life. BMC Evol. Biol. 2020, 20, 30. [Google Scholar] [CrossRef] [PubMed]
- Mahmoud, S.A.; Chien, P. Regulated Proteolysis in Bacteria. Annu. Rev. Biochem. 2018, 87, 677–696. [Google Scholar] [CrossRef]
- Maupin-Furlow, J.A. Proteolytic Systems of Archaea: Slicing, Dicing, and Mincing in the Extreme. Emerg. Top. Life Sci. 2018, 2, 561–580. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Yazaki, E.; Sakamoto, H.; Yamamoto, H.; Mizushima, N. Evolutionary Diversification of the Autophagy-Related Ubiquitin-like Conjugation Systems. Autophagy 2022, 18, 2969–2984. [Google Scholar] [CrossRef] [PubMed]
- Shemi, A.; Ben-Dor, S.; Vardi, A. Elucidating the Composition and Conservation of the Autophagy Pathway in Photosynthetic Eukaryotes. Autophagy 2015, 11, 701–715. [Google Scholar] [CrossRef] [PubMed]
- Lee, P.C.W.; Dodart, J.C.; Aron, L.; Finley, L.W.; Bronson, R.T.; Haigis, M.C.; Yankner, B.A.; Harper, J.W. Altered Social Behavior and Neuronal Development in Mice Lacking the Uba6-Use1 Ubiquitin Transfer System. Mol. Cell 2013, 50, 172–184. [Google Scholar] [CrossRef]
- Wenzel, D.M.; Stoll, K.E.; Klevit, R.E. E2s: Structurally Economical and Functionally Replete. Biochem. J. 2011, 433, 31–42. [Google Scholar] [CrossRef]
- Wu, P.Y.; Hanlon, M.; Eddins, M.; Tsui, C.; Rogers, R.S.; Jensen, J.P.; Matunis, M.J.; Weissman, A.M.; Wolberger, C.P.; Pickart, C.M. A Conserved Catalytic Residue in the Ubiquitin-Conjugating Enzyme Family. EMBO J. 2003, 22, 5241–5250. [Google Scholar] [CrossRef]
- Yunus, A.A.; Lima, C.D. Lysine Activation and Functional Analysis of E2-Mediated Conjugation in the SUMO Pathway. Nat. Struct. Mol. Biol. 2006, 13, 491–499. [Google Scholar] [CrossRef] [PubMed]
- Cook, B.W.; Shaw, G.S. Architecture of the Catalytic HPN Motif Is Conserved in All E2 Conjugating Enzymes. Biochem. J. 2012, 445, 167–174. [Google Scholar] [CrossRef] [PubMed]
- Stewart, M.D.; Ritterhoff, T.; Klevit, R.E.; Brzovic, P.S. E2 Enzymes: More than Just Middle Men. Cell Res. 2016, 26, 423–440. [Google Scholar] [CrossRef] [PubMed]
- Schelpe, J.; Monté, D.; Dewitte, F.; Sixma, T.K.; Rucktooa, P. Structure of UBE2Z Enzyme Provides Functional Insight into Specificity in the FAT10 Protein Conjugation Machinery. J. Biol. Chem. 2016, 291, 630–639. [Google Scholar] [CrossRef]
- Hormaechea-Agulla, D.; Kim, Y.; Song, M.S.; Song, S.J. New Insights into the Role of E2s in the Pathogenesis of Diseases: Lessons Learned from UBE2O. Mol. Cells 2018, 41, 168–178. [Google Scholar] [CrossRef] [PubMed]
- Wijk, S.J.L.; Timmers, H.T.M. The Family of Ubiquitin-conjugating Enzymes (E2s): Deciding between Life and Death of Proteins. FASEB J. 2010, 24, 981–993. [Google Scholar] [CrossRef] [PubMed]
- Ponts, N.; Yang, J.; Chung, D.W.D.; Prudhomme, J.; Girke, T.; Horrocks, P.; Le Roch, K.G. Deciphering the Ubiquitin-Mediated Pathway in Apicomplexan Parasites: A Potential Strategy to Interfere with Parasite Virulence. PLoS ONE 2008, 3, e2386. [Google Scholar] [CrossRef] [PubMed]
- Burroughs, A.M.; Jaffee, M.; Iyer, L.M.; Aravind, L. Anatomy of the E2 ligase fold: Implications for enzymology and evolution of ubiquitin/Ub-like protein conjugation. J. Struct. Biol. 2008, 162, 205–218. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- Rehman, S.A.A.; Cazzaniga, C.; Di Nisio, E.; Antico, O.; Knebel, A.; Johnson, C.; Şahin, A.T.; Ibrahim, P.E.G.F.; Lamoliatte, F.; Negri, R.; et al. Discovery and characterization of noncanonical E2-conjugating enzymes. Sci. Adv. 2024, 10, eadh0123. [Google Scholar] [CrossRef]
- Grzmil, P.; Altmann, M.E.; Adham, I.M.; Engel, U.; Jarry, H.; Schweyer, S.; Wolf, S.; Mänz, J.; Engel, W. Embryo Implantation Failure and Other Reproductive Defects in Ube2q1-Deficient Female Mice. Reproduction 2013, 145, 45–56. [Google Scholar] [CrossRef] [PubMed]
- Bouron, A.; Fauvarque, M.O. Genome-Wide Analysis of Genes Encoding Core Components of the Ubiquitin System during Cerebral Cortex Development. Mol. Brain 2022, 15, 72. [Google Scholar] [CrossRef]
- Toma-Fukai, S.; Hibi, R.; Naganuma, T.; Sakai, M.; Saijo, S.; Shimizu, N.; Matsumoto, M.; Shimizu, T. Crystal Structure of GCN5 PCAF N-Terminal Domain Reveals Atypical Ubiquitin Ligase Structure. J. Biol. Chem. 2020, 295, 14630–14639. [Google Scholar] [CrossRef] [PubMed]
- Deshaies, R.J.; Joazeiro, C.A.P. RING Domain E3 Ubiquitin Ligases. Annu. Rev. Biochem. 2009, 78, 399–434. [Google Scholar] [CrossRef] [PubMed]
- Petroski, M.D.; Deshaies, R.J. Function and Regulation of Cullin-RING Ubiquitin Ligases. Nat. Rev. Mol. Cell Biol. 2005, 6, 9–20. [Google Scholar] [CrossRef] [PubMed]
- Schrock, M.S.; Stromberg, B.R.; Scarberry, L.; Summers, M.K. APC/C Ubiquitin Ligase: Functions and Mechanisms in Tumorigenesis. Semin. Cancer Biol. 2020, 67, 80–91. [Google Scholar] [CrossRef] [PubMed]
- Huang, L.; Kinnucan, E.; Wang, G.; Beaudenon, S.; Howley, P.M.; Huibregtse, J.M.; Pavletich, N.P. Structure of an E6AP-UbcH7 Complex: Insights into Ubiquitination by the E2-E3 Enzyme Cascade. Science 1999, 286, 1321–1326. [Google Scholar] [CrossRef]
- Verdecia, M.A.; Joazeiro, C.A.P.; Wells, N.J.; Ferrer, J.L.; Bowman, M.E.; Hunter, T.; Noel, J.P. Conformational Flexibility Underlies Ubiquitin Ligation Mediated by the WWP1 HECT Domain E3 Ligase. Mol. Cell 2003, 11, 249–259. [Google Scholar] [CrossRef]
- Kamadurai, H.B.; Souphron, J.; Scott, D.C.; Duda, D.M.; Miller, D.J.; Stringer, D.; Piper, R.C.; Schulman, B.A. Insights into Ubiquitin Transfer Cascades from a Structure of a UbcH5B∼Ubiquitin-HECTNEDD4L Complex. Mol. Cell 2009, 36, 1095–1102. [Google Scholar] [CrossRef]
- Kamadurai, H.B.; Qiu, Y.; Deng, A.; Harrison, J.S.; Macdonald, C.; Actis, M.; Rodrigues, P.; Miller, D.J.; Souphron, J.; Lewis, S.M. Mechanism of Ubiquitin Ligation and Lysine Prioritization by a HECT E3. eLife 2013, 2, e00828. [Google Scholar] [CrossRef] [PubMed]
- Sluimer, J.; Distel, B. Regulating the Human HECT E3 Ligases. Cell. Mol. Life Sci. 2018, 75, 3121–3141. [Google Scholar] [CrossRef]
- Dove, K.K.; Stieglitz, B.; Duncan, E.D.; Rittinger, K.; Klevit, R.E. Molecular Insights into RBR E3 Ligase Ubiquitin Transfer Mechanisms. EMBO Rep. 2016, 17, 1221–1235. [Google Scholar] [CrossRef] [PubMed]
- Toma-Fukai, S.; Shimizu, T. Structural Diversity of Ubiquitin E3 Ligase. Molecules 2021, 26, 6682. [Google Scholar] [CrossRef] [PubMed]
- Cotton, T.R.; Lechtenberg, B.C. Chain Reactions: Molecular Mechanisms of RBR Ubiquitin Ligases. Biochem. Soc. Trans. 2020, 48, 1737–1750. [Google Scholar] [CrossRef] [PubMed]
- Jain, J.; Jain, S.K.; Walker, L.A.; Tekwani, B.L. Inhibitors of Ubiquitin E3 Ligase as Potential New Antimalarial Drug Leads. BMC Pharmacol. Toxicol. 2017, 18, 40. [Google Scholar] [CrossRef] [PubMed]
- Pisano, A.; Albano, F.; Vecchio, E.; Renna, M.; Scala, G.; Quinto, I.; Fiume, G. Revisiting Bacterial Ubiquitin Ligase Effectors: Weapons for Host Exploitation. Int. J. Mol. Sci. 2018, 19, 3576. [Google Scholar] [CrossRef]
- Piscatelli, H.; Kotkar, S.A.; McBee, M.E.; Muthupalani, S.; Schauer, D.B.; Mandrell, R.E.; Leong, J.M.; Zhou, D. The Ehec Type Iii Effector Nlel Is an E3 Ubiquitin Ligase That Modulates Pedestal Formation. PLoS ONE 2011, 6, e19331. [Google Scholar] [CrossRef]
- Diao, J.; Zhang, Y.; Huibregtse, J.M.; Zhou, D.; Chen, J. Crystal Structure of SopA, a Salmonella Effector Protein Mimicking a Eukaryotic Ubiquitin Ligase. Nat. Struct. Mol. Biol. 2008, 15, 65–70. [Google Scholar] [CrossRef]
- Lin, D.Y.W.; Diao, J.; Chen, J. Crystal Structures of Two Bacterial HECT-like E3 Ligases in Complex with a Human E2 Reveal Atomic Details of Pathogen-Host Interactions. Proc. Natl. Acad. Sci. USA 2012, 109, 1925–1930. [Google Scholar] [CrossRef]
- Bullones-Bolaños, A.; Bernal-Bayard, J.; Ramos-Morales, F. The NEL Family of Bacterial E3 Ubiquitin Ligases. Int. J. Mol. Sci. 2022, 23, 7725. [Google Scholar] [CrossRef]
- Imachi, H.; Nobu, M.K.; Nakahara, N.; Morono, Y.; Ogawara, M.; Takaki, Y.; Takano, Y.; Uematsu, K.; Ikuta, T.; Ito, M.; et al. Isolation of an Archaeon at the Prokaryote–Eukaryote Interface. Nature 2020, 577, 519–525. [Google Scholar] [CrossRef] [PubMed]
- Enchev, R.I.; Schulman, B.A.; Peter, M. Protein Neddylation: Beyond Cullin-RING Ligases. Nat. Rev. Mol. Cell Biol. 2015, 16, 30–44. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Park, S.H.; Choi, W.H.; Lee, M.J. Evaluation of Immunoproteasome-Specific Proteolytic Activity Using Fluorogenic Peptide Substrates. Immune Netw. 2022, 22, e28. [Google Scholar] [CrossRef]
- Wimuttisuk, W.; Singer, J.D. The Cullin3 Ubiquitin Ligase Functions as a Nedd8-Bound Heterodimer. Mol. Biol. Cell 2007, 18, 899–909. [Google Scholar] [CrossRef] [PubMed]
- Calabrese, M.F.; Scott, D.C.; Duda, D.M.; Grace, C.R.R.; Kurinov, I.; Kriwacki, R.W.; Schulman, B.A. A RING E3-Substrate Complex Poised for Ubiquitin-like Protein Transfer: Structural Insights into Cullin-RING Ligases. Nat. Struct. Mol. Biol. 2011, 18, 947–949. [Google Scholar] [CrossRef] [PubMed]
- Baek, K.; Krist, D.T.; Prabu, J.R.; Hill, S.; Klügel, M.; Neumaier, L.M.; von Gronau, S.; Kleiger, G.; Schulman, B.A. NEDD8 Nucleates a Multivalent Cullin–RING–UBE2D Ubiquitin Ligation Assembly. Nature 2020, 578, 461–466. [Google Scholar] [CrossRef] [PubMed]
- Kim, W.D.; Mathavarajah, S.; Huber, R.J. The Cellular and Developmental Roles of Cullins, Neddylation, and the COP9 Signalosome in Dictyostelium Discoideum. Front. Physiol. 2022, 13, 827435. [Google Scholar] [CrossRef] [PubMed]
- Roach, J.C.; Glusman, G.; Smit, A.F.A.; Huff, C.D.; Hubley, R.; Shannon, P.T.; Rowen, L.; Pant, K.P.; Goodman, N.; Bamshad, M.; et al. Analysis of Genetic Inheritance in a Family Quartet by Whole-Genome Sequencing. Science 2010, 328, 636–639. [Google Scholar] [CrossRef]
- Domingo, E.; García-Crespo, C.; Lobo-Vega, R.; Perales, C. Mutation Rates, Mutation Frequencies, and Proofreading-Repair Activities in Rna Virus Genetics. Viruses 2021, 13, 1882. [Google Scholar] [CrossRef]
- Drake, J.W.; Charlesworth, B.; Charlesworth, D.; Crow, J.F. Rates of Spontaneous Mutation. Genetics 1998, 148, 1667–1686. [Google Scholar] [CrossRef]
- Irwin, N.A.T.; Pittis, A.A.; Richards, T.A.; Keeling, P.J. Systematic Evaluation of Horizontal Gene Transfer between Eukaryotes and Viruses. Nat. Microbiol. 2022, 7, 327–336. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kaminskaya, A.N.; Evpak, A.S.; Belogurov, A.A., Jr.; Kudriaeva, A.A. Tracking of Ubiquitin Signaling through 3.5 Billion Years of Combinatorial Conjugation. Int. J. Mol. Sci. 2024, 25, 8671. https://doi.org/10.3390/ijms25168671
Kaminskaya AN, Evpak AS, Belogurov AA Jr., Kudriaeva AA. Tracking of Ubiquitin Signaling through 3.5 Billion Years of Combinatorial Conjugation. International Journal of Molecular Sciences. 2024; 25(16):8671. https://doi.org/10.3390/ijms25168671
Chicago/Turabian StyleKaminskaya, Alena N., Alena S. Evpak, Alexey A. Belogurov, Jr., and Anna A. Kudriaeva. 2024. "Tracking of Ubiquitin Signaling through 3.5 Billion Years of Combinatorial Conjugation" International Journal of Molecular Sciences 25, no. 16: 8671. https://doi.org/10.3390/ijms25168671
APA StyleKaminskaya, A. N., Evpak, A. S., Belogurov, A. A., Jr., & Kudriaeva, A. A. (2024). Tracking of Ubiquitin Signaling through 3.5 Billion Years of Combinatorial Conjugation. International Journal of Molecular Sciences, 25(16), 8671. https://doi.org/10.3390/ijms25168671