
Detecting Leadership Opportunities in Group Discussions Using Off-the-Shelf VR Headsets

 , ,
, ,
Abstract
1. Introduction
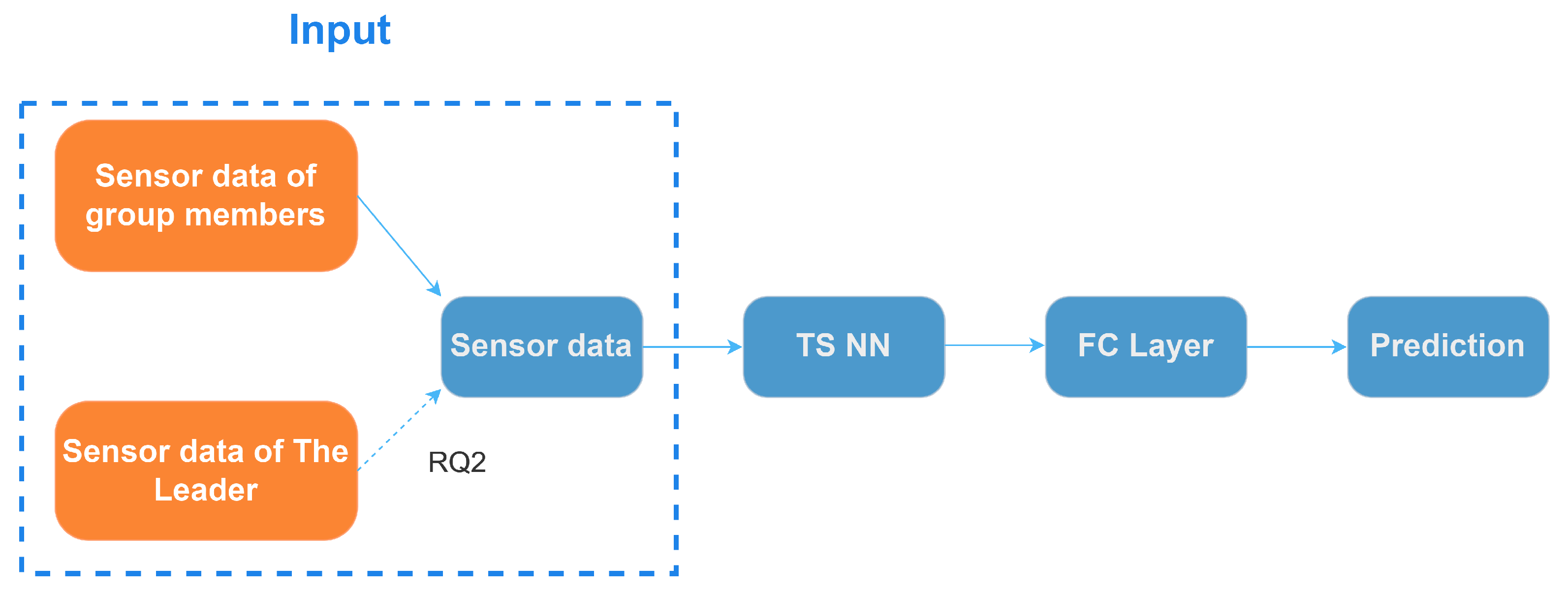
- MODELS: We propose general and personalized models following architectures of three commonly used time-series classification models for detecting leadership opportunities focusing on suppressed speaking intentions. Our model only requires the collected data from off-the-shelf VR devices without the need to use additional sensing devices.
- FEATURES: We show that our personalized models can improve the detection performance by integrating the sensor data from group leaders and members. We also uncover the usefulness of the leaders’ sensor data in detecting the speaking intentions of low-engagement group members.
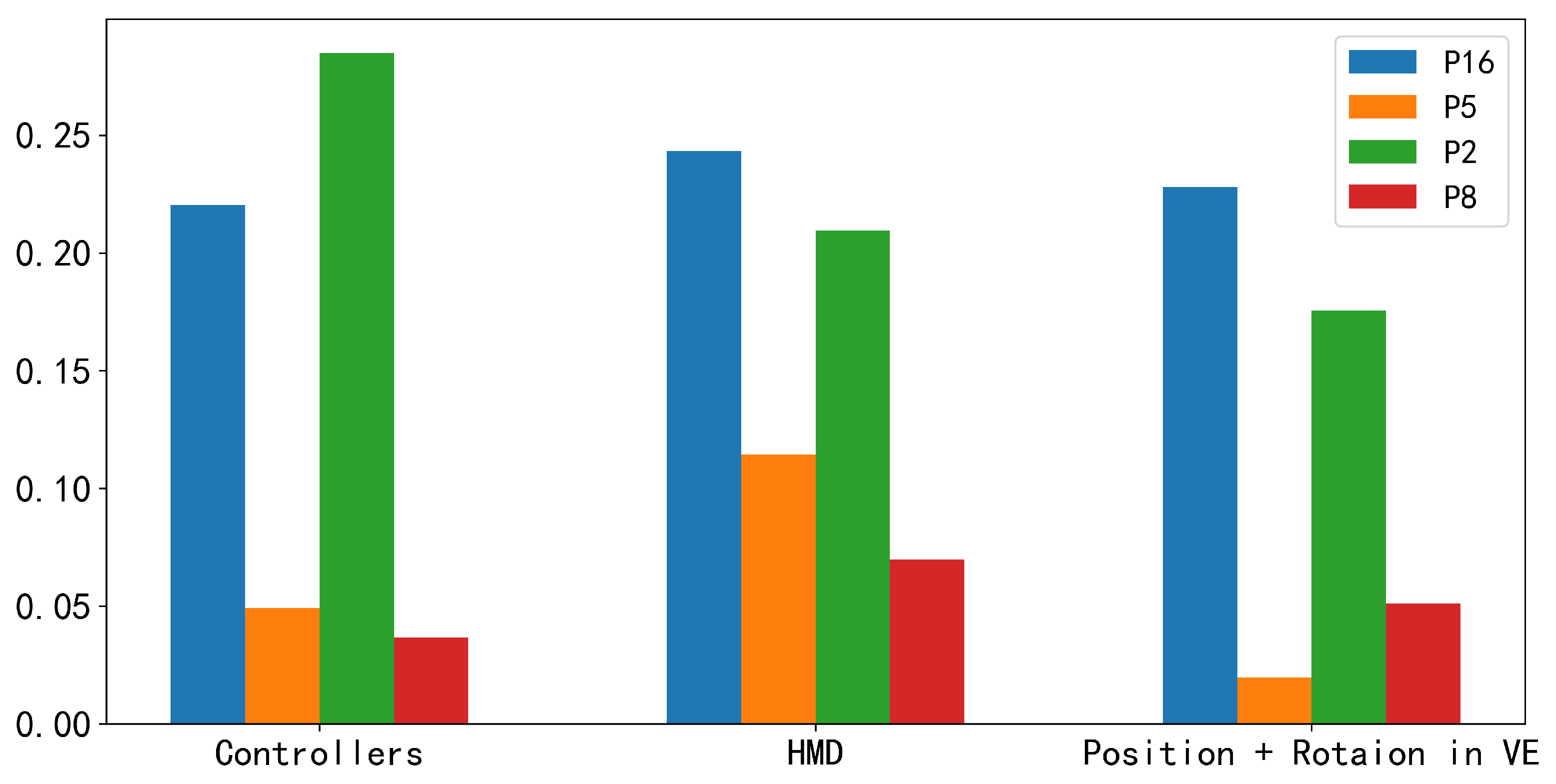
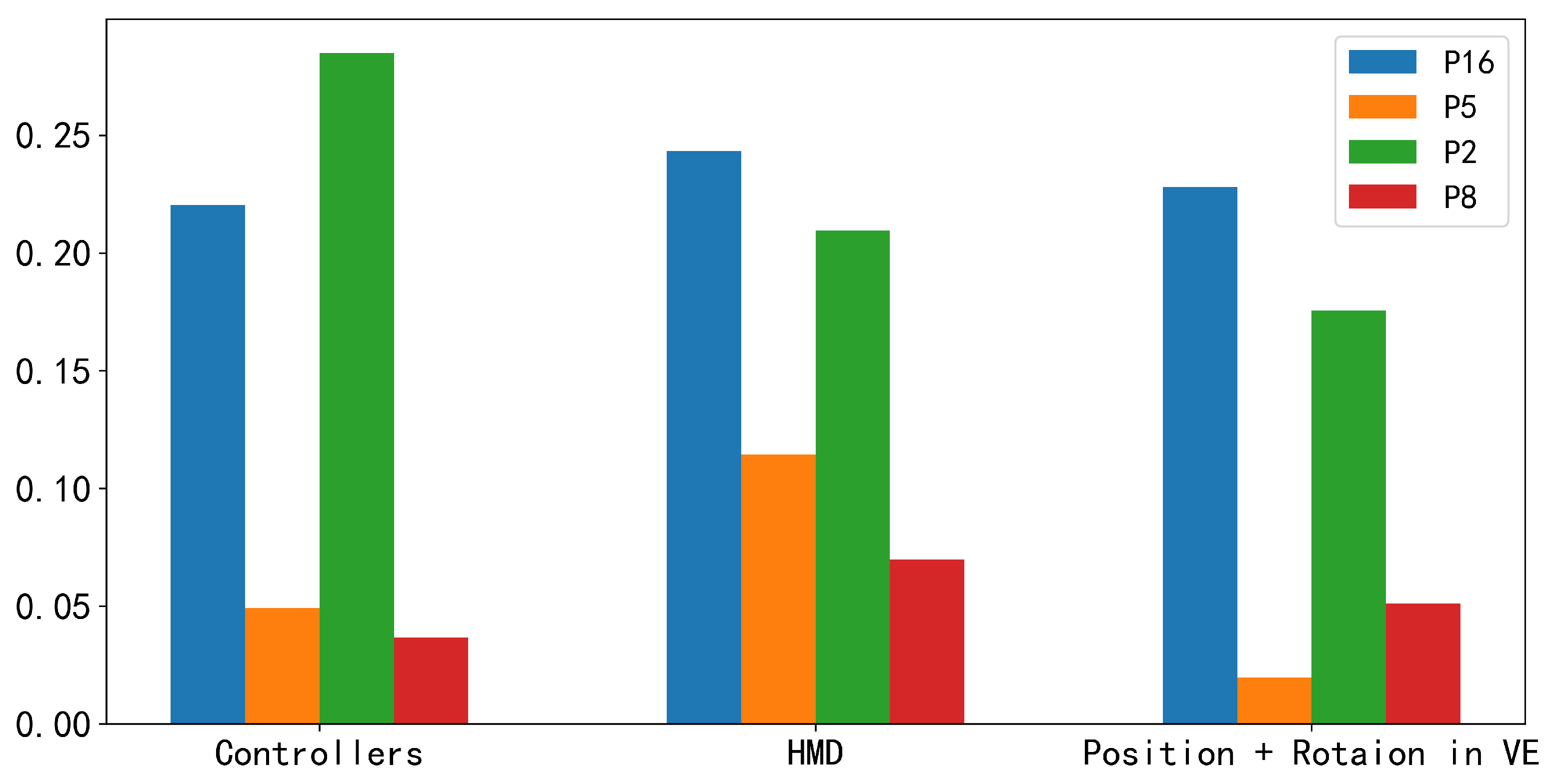
- SENSOR TYPES: Furthermore, we investigated which type of leader’s sensor features, including HMD, controllers, position, and rotation in a virtual environment, contribute the most to the performance improvement. The results suggest that HMD sensor features contribute the most to the performance improvement of personalized models for the majority of low-engagement members.
- IN-DEPTH ANALYSIS: We analyze the behavior patterns in the VR group discussion through video analysis and discuss the reasons why leaders’ sensor data can improve the detection performance for low-engagement group members. We then discuss their implications for the design of support mechanisms in VR group-discussion environments.
2. Related Works
3. Experiment Design
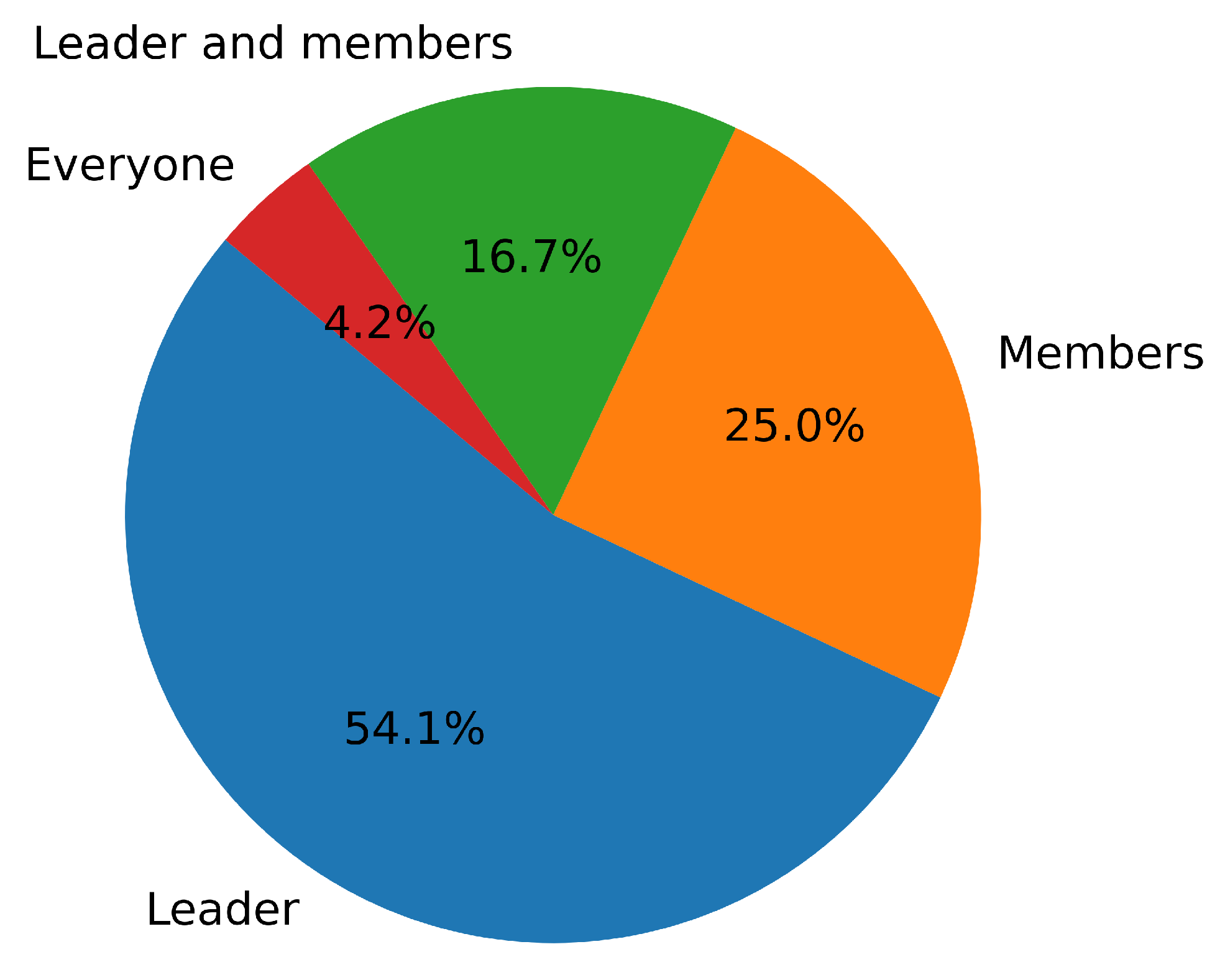
3.1. Participants
3.2. Experimental Setup
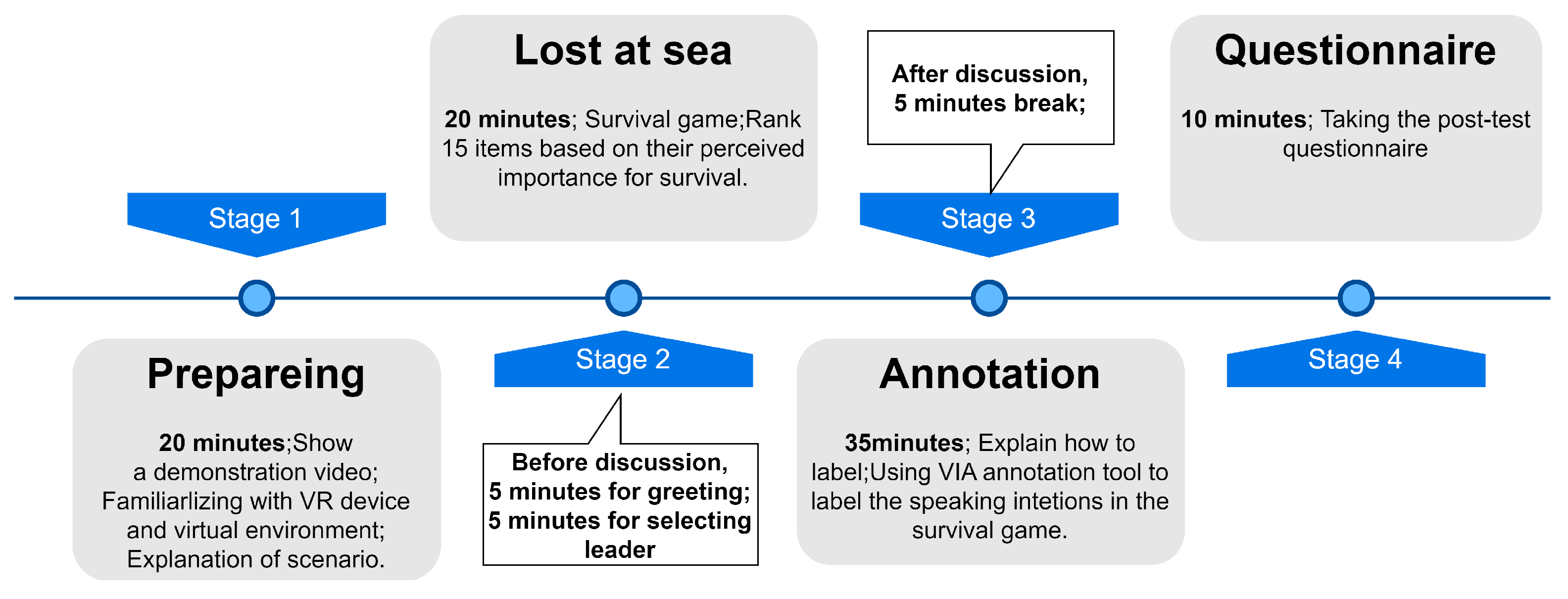
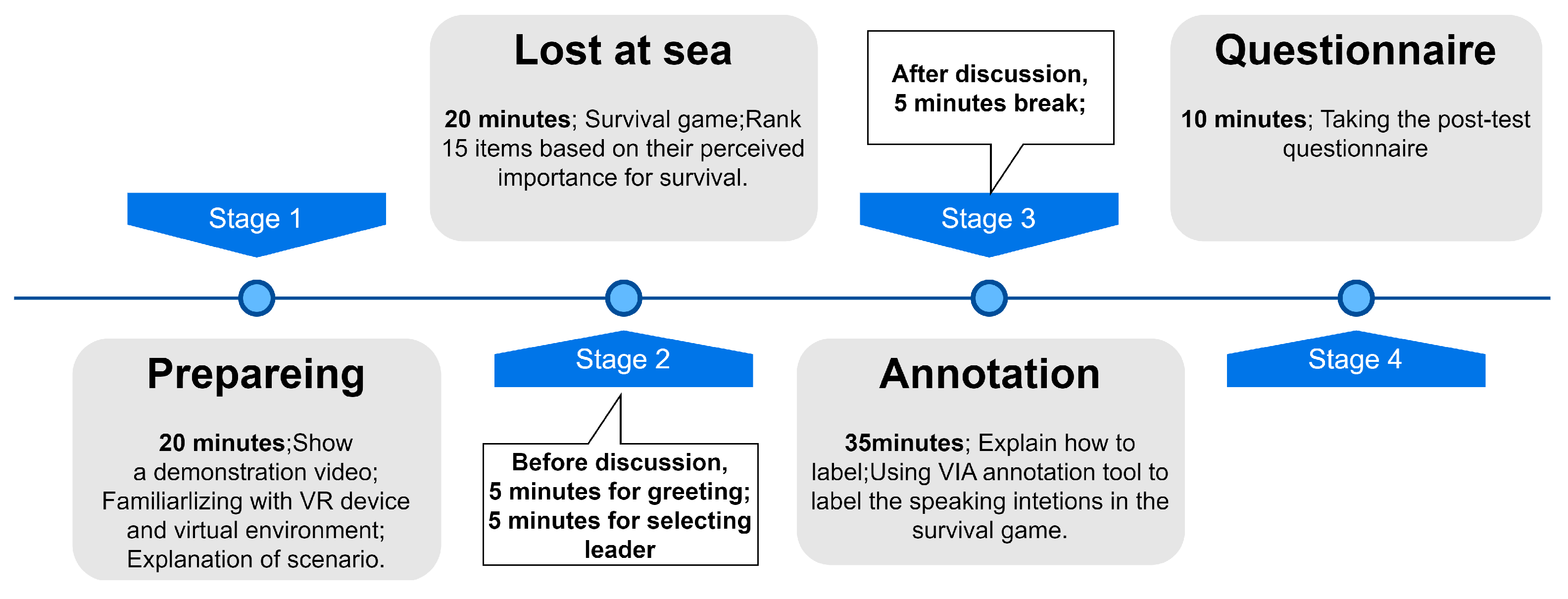
3.3. Procedure
- When there is no ongoing conversation and you intend to initiate a discussion on a new topic.
- When you intend to participate in a discussion among other individuals on a topic.
- When you intend to express your own thoughts or provide a response in a discussion on a topic.
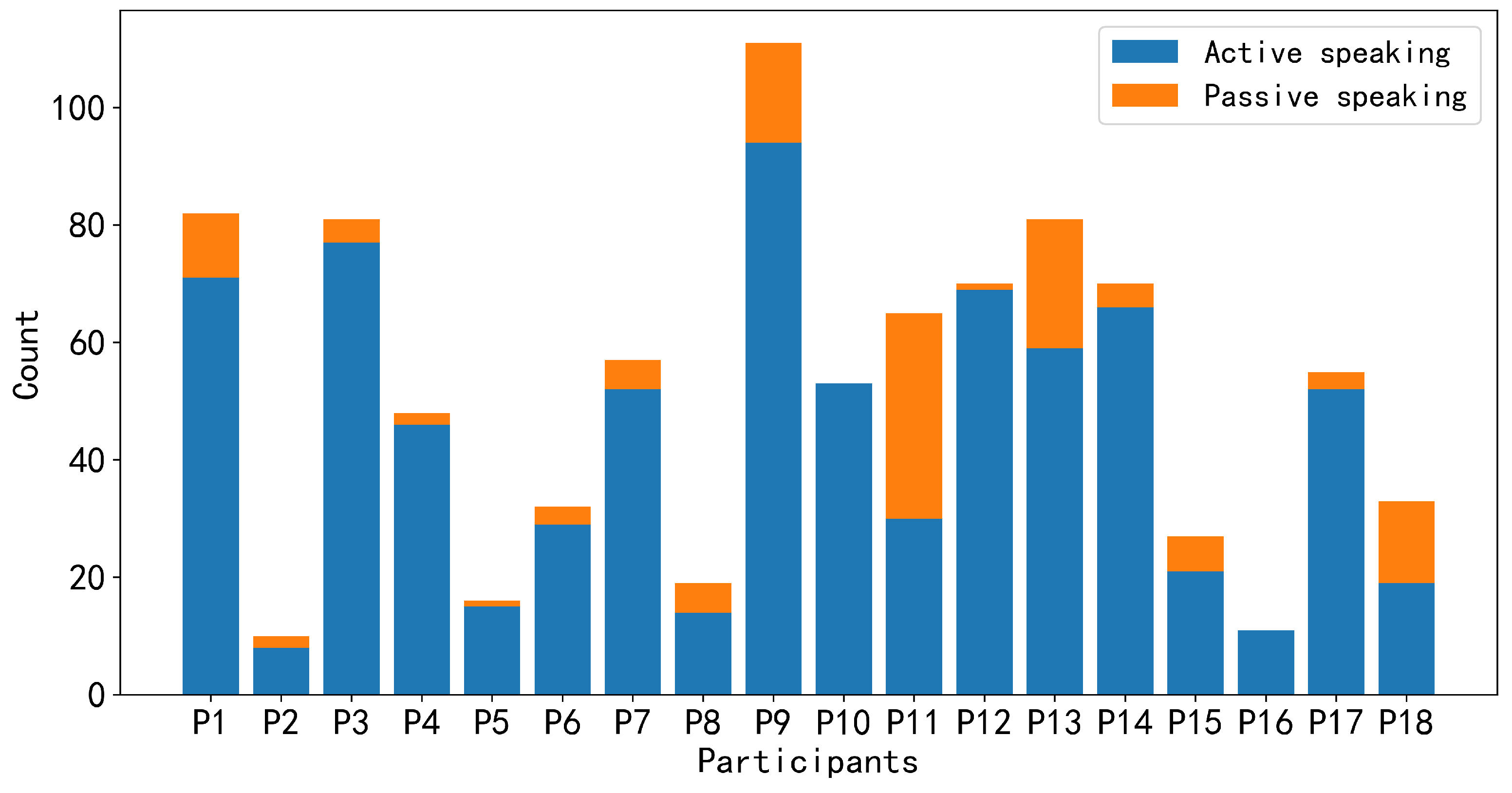
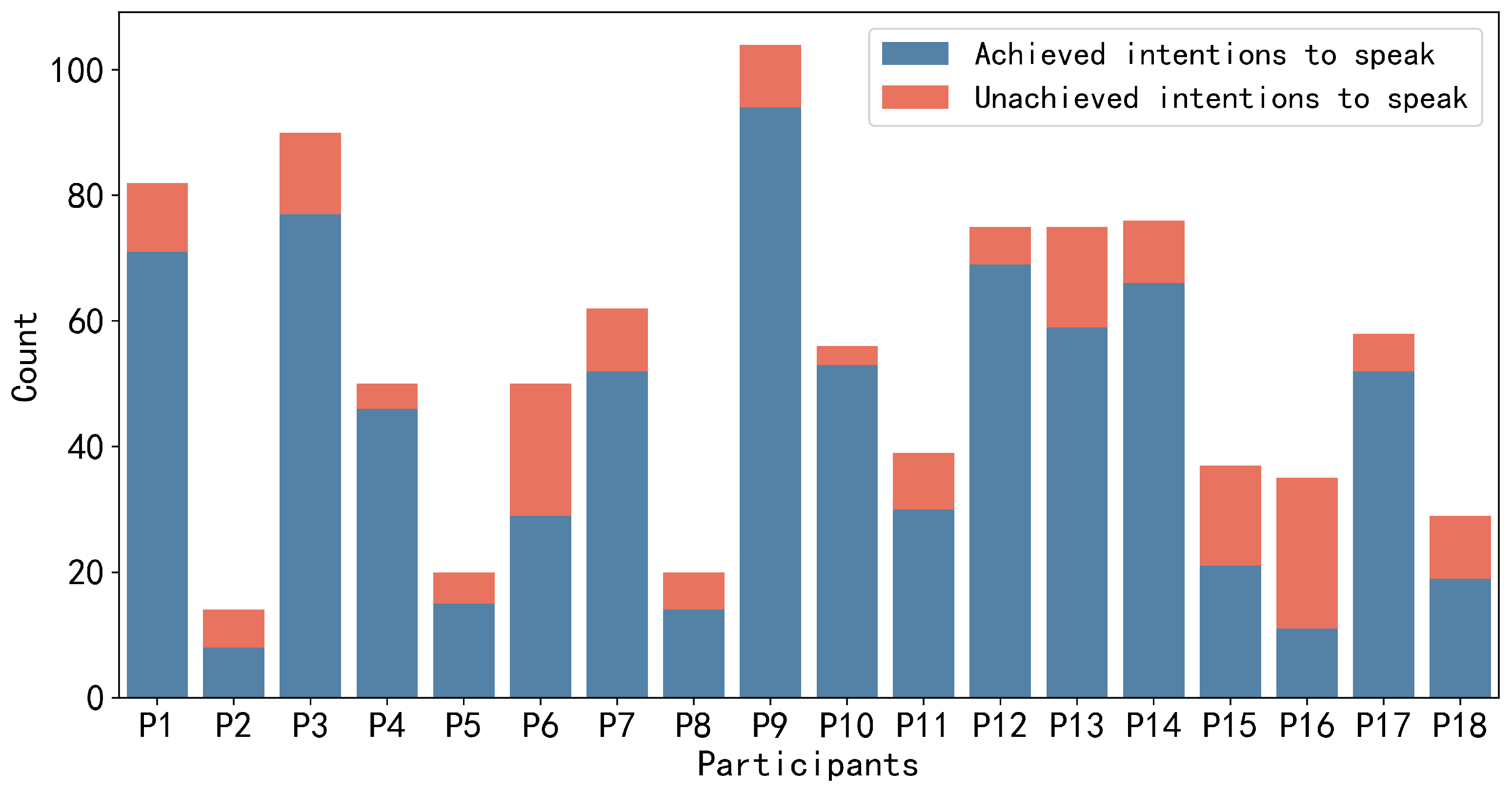
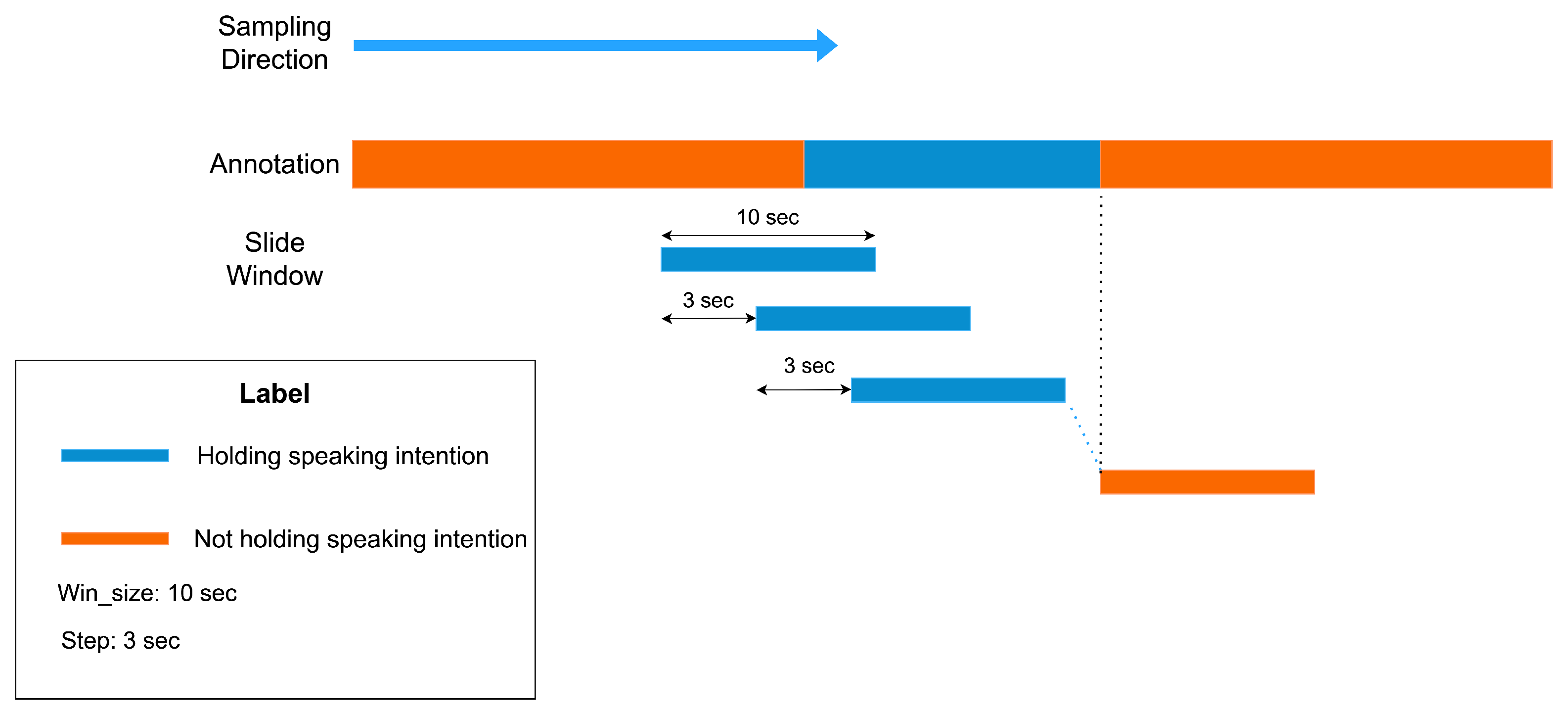
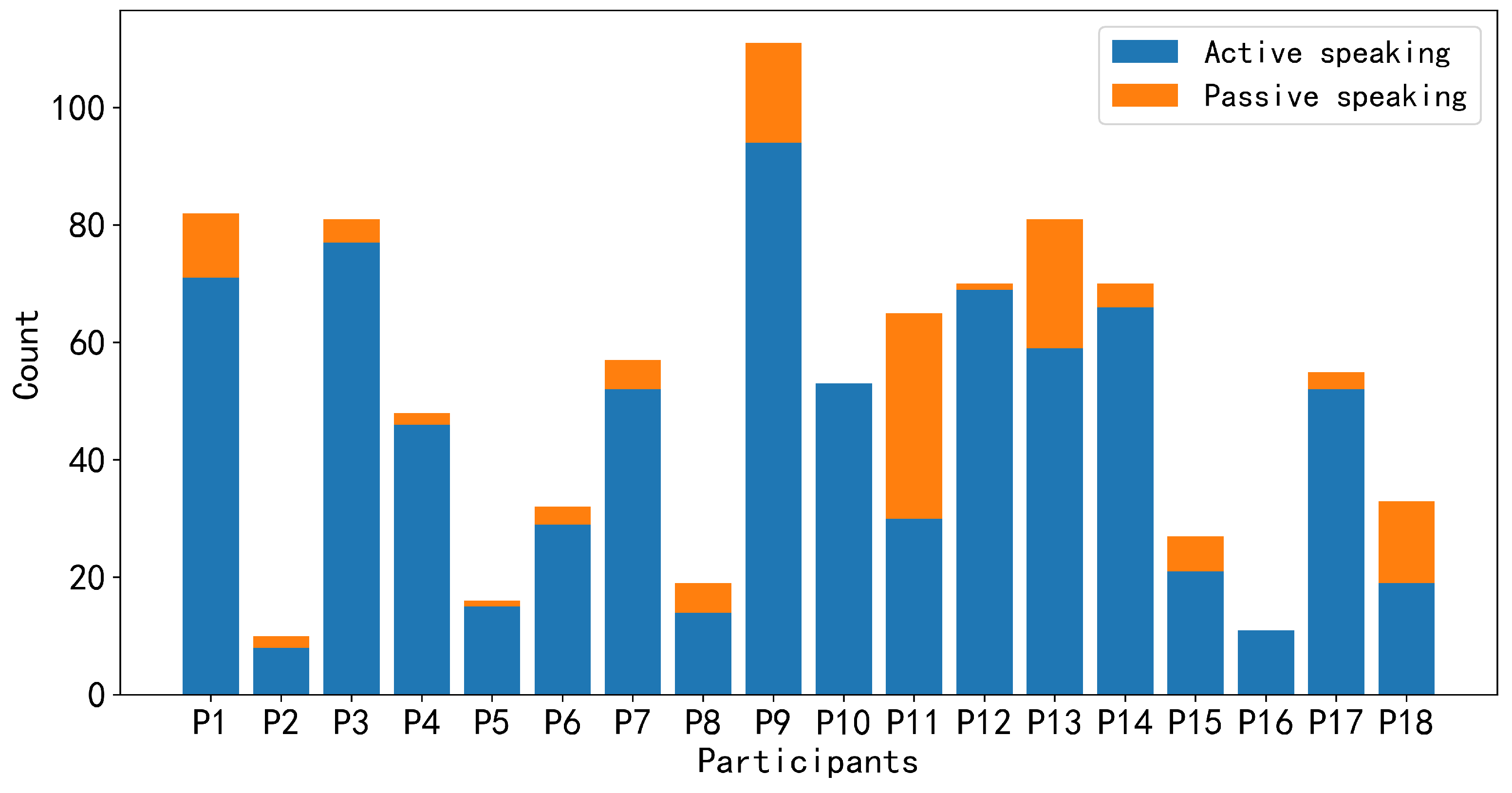
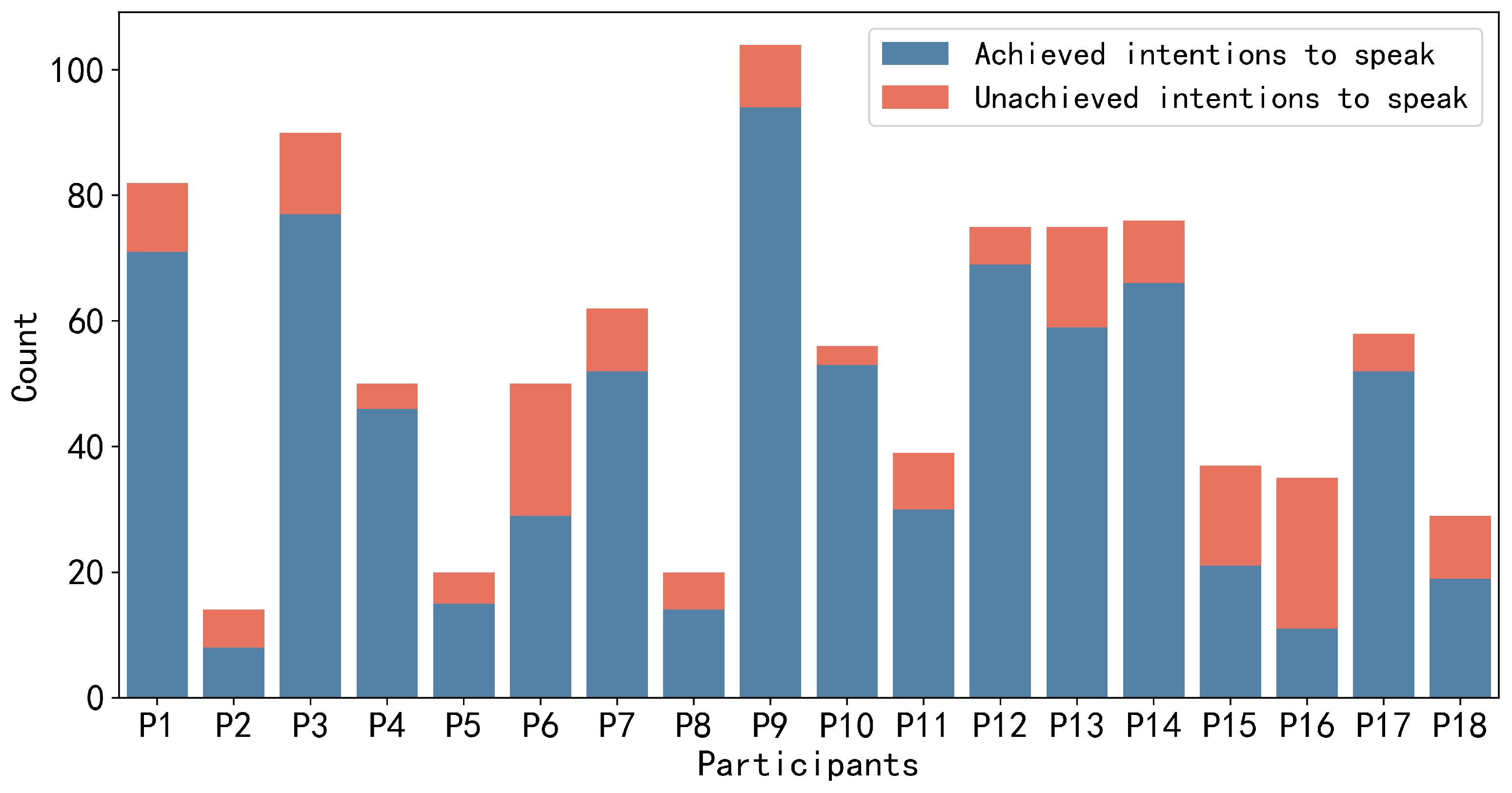
4. Data Collection
5. Analysis and Result
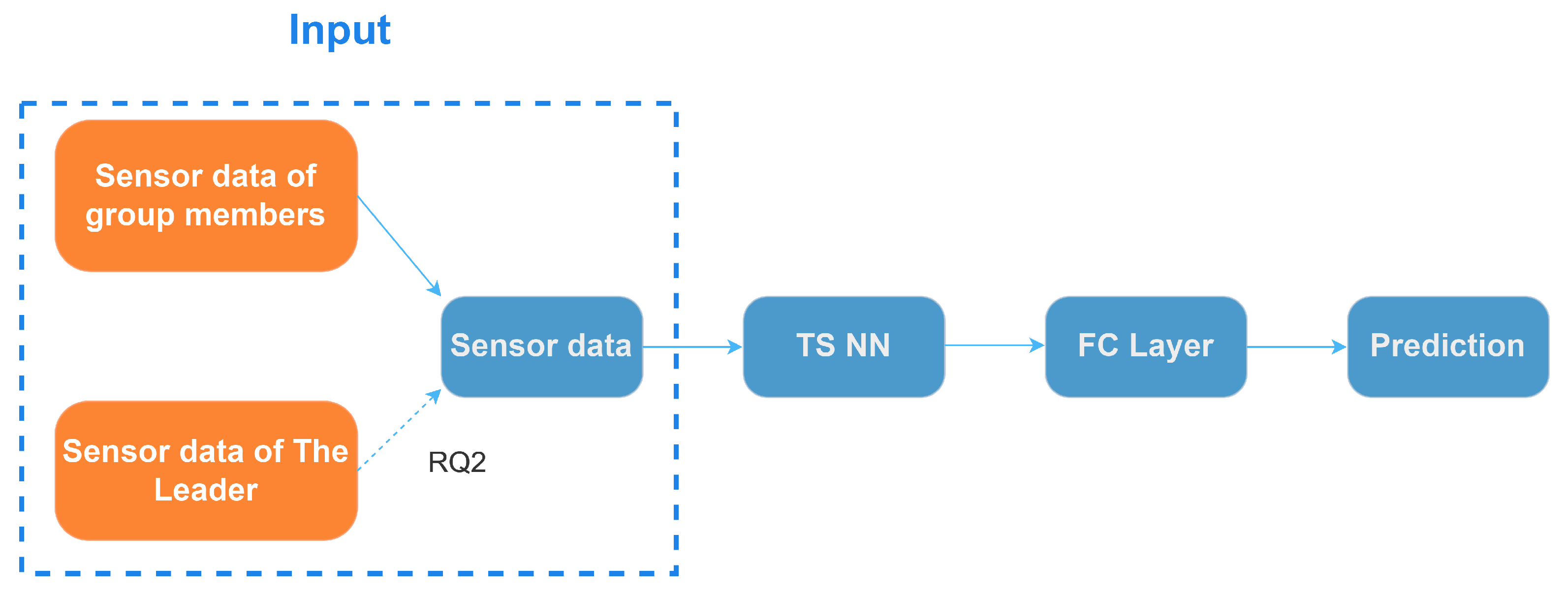
5.1. Deep Learning Model
5.2. Validation Method
5.3. Analysis of Model Performance
5.3.1. Performance of Personalized and General Models
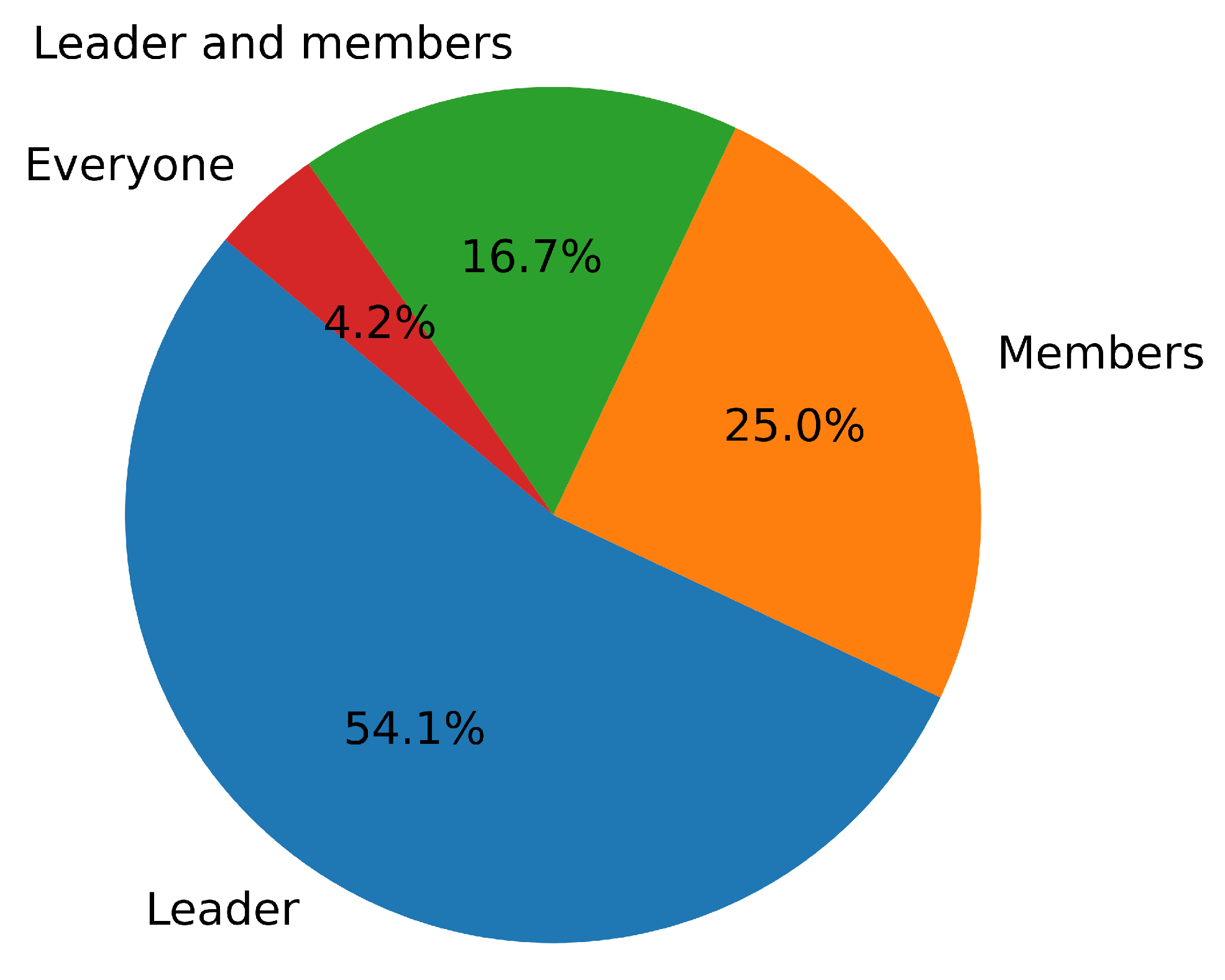
5.3.2. The Leader’s Contextual Influence on Members’ Speaking Intention Prediction
5.3.3. The Qualitative Findings of Members’ Behavior When Holding Intentions to Speak
5.3.4. Suppressed Speaking Intention
6. Discussion
6.1. Personalized Model vs. General Model
6.2. The Influence of Leader’s Contextual Features
6.3. Insights on Utilizing Speaking Intention Information to Assist the Leader
7. Limitation and Future Work
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gao, H.; Bozkir, E.; Hasenbein, L.; Hahn, J.U.; Göllner, R.; Kasneci, E. Digital transformations of classrooms in virtual reality. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; pp. 1–10. [Google Scholar]
- Moustafa, F.; Steed, A. A longitudinal study of small group interaction in social virtual reality. In Proceedings of the 24th ACM Symposium on Virtual Reality Software and Technology, Tokyo, Japan, 28 November–1 December 2018; pp. 1–10. [Google Scholar]
- Burgoon, J.K.; Walther, J.B. Nonverbal expectancies and the evaluative consequences of violations. Hum. Commun. Res. 1990, 17, 232–265. [Google Scholar] [CrossRef]
- Duck, S. Human Relationships; Sage: Newcastle, UK, 1998. [Google Scholar]
- Guerrero, L.K.; Floyd, K. Nonverbal Communication in Close Relationships; Routledge: London, UK, 2006. [Google Scholar]
- Bell, B.S.; Kozlowski, S.W. A typology of virtual teams: Implications for effective leadership. Group Organ. Manag. 2002, 27, 14–49. [Google Scholar] [CrossRef]
- Weisband, S. Maintaining awareness in distributed team collaboration: Implications for leadership and performance. In Distributed Work; MIT Press: Cambridge, MA, USA, 2002; pp. 311–333. [Google Scholar]
- Lewis, S.; Ellis, J.B.; Kellogg, W.A. Using virtual interactions to explore leadership and collaboration in globally distributed teams. In Proceedings of the 3rd International Conference on Intercultural Collaboration, Copenhagen, Denmark, 19–20 August 2010; pp. 9–18. [Google Scholar]
- Hoch, J.E.; Kozlowski, S.W. Leading virtual teams: Hierarchical leadership, structural supports, and shared team leadership. J. Appl. Psychol. 2014, 99, 390–403. [Google Scholar] [CrossRef]
- Forsyth, D.R.; Burnette, J. Advanced Social Psychology: The State of the Science; Baumeister, R.F., Finkel, E.J., Eds.; Oxford University Press: Oxford, UK, 2010; pp. 495–534. [Google Scholar]
- Duncan, S. Some signals and rules for taking speaking turns in conversations. J. Personal. Soc. Psychol. 1972, 23, 283–292. [Google Scholar] [CrossRef]
- Goffman, E. Forms of Talk; University of Pennsylvania Press: Philadelphia, PA, USA, 1981. [Google Scholar]
- Studdert-Kennedy, M. Hand and Mind: What Gestures Reveal about Thought. Lang. Speech 1994, 37, 203–209. [Google Scholar] [CrossRef]
- Bodemer, D.; Dehler, J. Group awareness in CSCL environments. Comput. Hum. Behav. 2011, 27, 1043–1045. [Google Scholar] [CrossRef]
- Dagan, E.; Márquez Segura, E.; Flores, M.; Isbister, K. ‘Not Too Much, Not Too Little’Wearables For Group Discussions. In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, ON, Canada, 21–26 April 2018; pp. 1–6. [Google Scholar]
- Hu, E.; Grønbæk, J.E.S.; Houck, A.; Heo, S. OpenMic: Utilizing Proxemic Metaphors for Conversational Floor Transitions in Multiparty Video Meetings. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, Hamburg, Germany, 23–29 April 2023; pp. 1–17. [Google Scholar]
- Phielix, C.; Prins, F.J.; Kirschner, P.A.; Erkens, G.; Jaspers, J. Group awareness of social and cognitive performance in a CSCL environment: Effects of a peer feedback and reflection tool. Comput. Hum. Behav. 2011, 27, 1087–1102. [Google Scholar] [CrossRef]
- Wang, A.; Yu, S.; Wang, M.; Chen, L. Effects of a visualization-based group awareness tool on in-service teachers’ interaction behaviors and performance in a lesson study. Interact. Learn. Environ. 2019, 27, 670–684. [Google Scholar] [CrossRef]
- Liu, M.; Liu, L.; Liu, L. Group awareness increases student engagement in online collaborative writing. Internet High. Educ. 2018, 38, 1–8. [Google Scholar] [CrossRef]
- Massa, P.; Leonardi, C.; Lepri, B.; Pianesi, F.; Zancanaro, M. If you are happy and you know it, say “I’m here”: Investigating parents’ location-sharing preferences. In Proceedings of the Human-Computer Interaction—INTERACT 2015: 15th IFIP TC 13 International Conference, Bamberg, Germany, 14–18 September 2015; pp. 315–332. [Google Scholar]
- Rooksby, J.; Rost, M.; Morrison, A.; Chalmers, M. Personal Tracking as Lived Informatics. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 18–23 April 2014; pp. 1163–1172. [Google Scholar] [CrossRef]
- Liu, F.; Dabbish, L.; Kaufman, G. Supporting Social Interactions with an Expressive Heart Rate Sharing Application. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 77. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, W.; Li, W.; Xu, J.; Cheng, W. Kinect-based Behavior Measurement in Group Discussion. In Proceedings of the 2019 The World Symposium on Software Engineering, Wuhan, China, 20–23 September 2019; pp. 125–129. [Google Scholar]
- Müller, P.; Huang, M.X.; Bulling, A. Detecting low rapport during natural interactions in small groups from non-verbal behaviour. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 153–164. [Google Scholar]
- Zhang, Y.; Olenick, J.; Chang, C.H.; Kozlowski, S.W.J.; Hung, H. TeamSense: Assessing Personal Affect and Group Cohesion in Small Teams through Dyadic Interaction and Behavior Analysis with Wearable Sensors. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 150. [Google Scholar] [CrossRef]
- Chen, K.W.; Chang, Y.J.; Chan, L. Predicting opportune moments to deliver notifications in virtual reality. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, New Orleans, LA, USA, 30 April–5 May 2022; pp. 1–18. [Google Scholar]
- Tan, S.; Tax, D.M.J.; Hung, H. Multimodal Joint Head Orientation Estimation in Interacting Groups via Proxemics and Interaction Dynamics. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2021, 5, 35. [Google Scholar] [CrossRef]
- Chen, G.; Kanfer, R. Toward a systems theory of motivated behavior in work teams. Res. Organ. Behav. 2006, 27, 223–267. [Google Scholar] [CrossRef]
- Luther, K.; Fiesler, C.; Bruckman, A. Redistributing leadership in online creative collaboration. In Proceedings of the 2013 Conference on Computer Supported Cooperative Work, San Antonio, TX, USA, 23–27 February 2013; pp. 1007–1022. [Google Scholar]
- Benke, I.; Vetter, S.; Maedche, A. LeadBoSki: A Smart Personal Assistant for Leadership Support in Video-Meetings. In Proceedings of the Companion Publication of the 2021 Conference on Computer Supported Cooperative Work and Social Computing, Virtual, 23–27 October 2021; pp. 19–22. [Google Scholar]
- Wang, W.; Li, J.; Zhang, X. Role Analysis of CSCL Online Synchronous Dialogue from the Perspective of Social Network Analysis: Researching Collaborative Learning Based on Tencent Online Documents as An Example. In Proceedings of the 13th International Conference on Education Technology and Computers, Wuhan, China, 22–25 October 2021; pp. 202–208. [Google Scholar]
- Kjærgaard, M.B.; Blunck, H.; Wüstenberg, M.; Grønbask, K.; Wirz, M.; Roggen, D.; Tröster, G. Time-lag method for detecting following and leadership behavior of pedestrians from mobile sensing data. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications (PerCom), San Diego, CA, USA, 18–22 March 2013; pp. 56–64. [Google Scholar]
- De Cuetos, P.; Neti, C.; Senior, A.W. Audio-visual intent-to-speak detection for human-computer interaction. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, Proceedings (Cat. No. 00CH37100), Istanbul, Turkey, 5–9 June 2000; Volume 4, pp. 2373–2376. [Google Scholar]
- Chen, J.; Gu, C.; Zhang, J.; Liu, Z.; Konomi, S. Sensing the Intentions to Speak in VR Group Discussions. Sensors 2024, 24, 362. [Google Scholar] [CrossRef]
- Lost at Sea. 2023. Available online: https://insight.typepad.co.uk/lost_at_sea.pdf (accessed on 9 June 2023).
- Gibson, D.R. Participation shifts: Order and differentiation in group conversation. Soc. Forces 2003, 81, 1335–1380. [Google Scholar] [CrossRef]
- Gibson, D.R. Taking turns and talking ties: Networks and conversational interaction. Am. J. Sociol. 2005, 110, 1561–1597. [Google Scholar] [CrossRef]
- Foster, D.E. A method of comparing follower satisfaction with the authoritarian, democratic, and laissez-faire styles of leadership. Commun. Teach. 2002, 16, 4–6. [Google Scholar]
- Bass, B.M.; Bass, R. The Bass Handbook of Leadership: Theory, Research, and Managerial Applications; Simon and Schuster: New York, NY, USA, 2009. [Google Scholar]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). Version: X.Y.Z. 2016. Available online: http://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 15 June 2023).
- Dutta, A.; Zisserman, A. The VIA Annotation Software for Images, Audio and Video. In Proceedings of the 27th ACM International Conference on Multimedia, New York, NY, USA, 15–16 October 2019. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Hüsken, M.; Stagge, P. Recurrent neural networks for time series classification. Neurocomputing 2003, 50, 223–235. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Ismail Fawaz, H.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.A.; Petitjean, F. Inceptiontime: Finding alexnet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Harford, S. Multivariate LSTM-FCNs for time series classification. Neural Netw. 2019, 116, 237–245. [Google Scholar] [CrossRef]
- Keras. 2015. Available online: https://keras.io (accessed on 8 July 2023).
- Züger, M.; Müller, S.C.; Meyer, A.N.; Fritz, T. Sensing interruptibility in the office: A field study on the use of biometric and computer interaction sensors. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–14. [Google Scholar]
- Fredricks, J.A.; Blumenfeld, P.C.; Paris, A.H. School engagement: Potential of the concept, state of the evidence. Rev. Educ. Res. 2004, 74, 59–109. [Google Scholar] [CrossRef]
- Sinha, S.; Rogat, T.K.; Adams-Wiggins, K.R.; Hmelo-Silver, C.E. Collaborative group engagement in a computer-supported inquiry learning environment. Int. J. Comput. Support. Collab. Learn. 2015, 10, 273–307. [Google Scholar] [CrossRef]
- Smith, H.J.; Neff, M. Communication behavior in embodied virtual reality. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; pp. 1–12. [Google Scholar]
- Rogat, T.K.; Adams-Wiggins, K.R. Other-regulation in collaborative groups: Implications for regulation quality. Instr. Sci. 2014, 42, 879–904. [Google Scholar] [CrossRef]
- Li, J.V.; Kreminski, M.; Fernandes, S.M.; Osborne, A.; McVeigh-Schultz, J.; Isbister, K. Conversation Balance: A Shared VR Visualization to Support Turn-taking in Meetings. In Proceedings of the CHI Conference on Human Factors in Computing Systems Extended Abstracts, New Orleans, LA, USA, 30 April–5 May 2022; pp. 1–4. [Google Scholar]
- Janssen, J.; Erkens, G.; Kirschner, P.A. Group awareness tools: It’s what you do with it that matters. Comput. Hum. Behav. 2011, 27, 1046–1058. [Google Scholar] [CrossRef]
- Bergstrom, T.; Karahalios, K. Conversation Clock: Visualizing audio patterns in co-located groups. In Proceedings of the 2007 40th Annual Hawaii International Conference on System Sciences (HICSS’07), Big Island, HI, USA, 3–6 January 2007; p. 78. [Google Scholar]
- Kleinsmith, A.; Bianchi-Berthouze, N. Affective body expression perception and recognition: A survey. IEEE Trans. Affect. Comput. 2012, 4, 15–33. [Google Scholar] [CrossRef]
- Ly, S.T.; Lee, G.S.; Kim, S.H.; Yang, H.J. Emotion recognition via body gesture: Deep learning model coupled with keyframe selection. In Proceedings of the 2018 International Conference on Machine Learning and Machine Intelligence, Hanoi, Vietnam, 28–30 September 2018; pp. 27–31. [Google Scholar]
- Sacks, H.; Schegloff, E.A.; Jefferson, G. A simplest systematics for the organization of turn taking for conversation. In Studies in the Organization of Conversational Interaction; Elsevier: Amsterdam, The Netherlands, 1978; pp. 7–55. [Google Scholar]
- Wang, Z.; Larrazabal, M.A.; Rucker, M.; Toner, E.R.; Daniel, K.E.; Kumar, S.; Boukhechba, M.; Teachman, B.A.; Barnes, L.E. Detecting Social Contexts from Mobile Sensing Indicators in Virtual Interactions with Socially Anxious Individuals. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2023, 7, 134. [Google Scholar] [CrossRef]
- Gupta, K.; Chan, S.W.T.; Pai, Y.S.; Strachan, N.; Su, J.; Sumich, A.; Nanayakkara, S.; Billinghurst, M. Total VREcall: Using Biosignals to Recognize Emotional Autobiographical Memory in Virtual Reality. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 55. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Question Content | Question Type |
|---|---|---|
| Q1 | Have you ever held the intention to speak during the discussion but did not speak out? If yes, please write down the reason. | Open-ended question |
| Q2 | In the group discussion, you were satisfied with the leader’s performance. | 5-point Likert scale |
| Q3 | Who do you think contributed the most to the discussion and why? | Open-ended question |
| EEG Net Layer | Input Shape | |
|---|---|---|
| Conv2D | ||
| BN | ||
| DepConv | ||
| BN+ELU | ||
| AvgPooling | ||
| Dropout | ||
| SepConv | ||
| BN+ELU | ||
| AvgPooling | ||
| Dropout | ||
| Flatten | ||
| Dense | 180 |
| Personalized Model | General Model | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Models | Acc | F1. | Prec. | Recall | AUC | Acc | F1. | Prec. | Recall | AUC |
| Baseline | 0.5098 | 0.4889 | 0.4729 | 0.5060 | 0.5071 | 0.5002 | 0.4702 | 0.4522 | 0.4897 | 0.4950 |
| EEGNet | 0.6813 | 0.7132 | 0.6201 | 0.8393 | 0.6058 | 0.5823 | 0.6057 | 0.5041 | 0.7585 | 0.5633 |
| InceptionTime | 0.6785 | 0.7069 | 0.5908 | 0.8798 | 0.6053 | 0.5338 | 0.6293 | 0.4803 | 0.9122 | 0.5312 |
| MLSTM-FCN | 0.6789 | 0.6968 | 0.6084 | 0.8153 | 0.5925 | 0.5383 | 0.5590 | 0.4840 | 0.6616 | 0.5390 |
| Personalized Model without Context | Personalized Model with Context | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Group Members | Acc | F1. | Prec. | Recall | AUC | Acc | F1. | Prec. | Recall | AUC |
| P16 | 0.5172 | 0.5327 | 0.3883 | 0.8481 | 0.5444 | 0.8437 | ||||
| P5 | 0.7374 | 0.6082 | 0.5184 | 0.7357 | 0.6369 | 0.6955 | ||||
| P2 | 0.4656 | 0.4928 | 0.3419 | 0.8821 | 0.5190 | 0.7501 | ||||
| P8 | 0.7256 | 0.6295 | 0.4960 | 0.8614 | 0.7463 | 0.6185 | 0.8506 | 0.5751 | ||
| Personalized Model without Context | Personalized Model with Context | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Group Members | Acc | F1. | Prec. | Recall | AUC | Acc | F1. | Prec. | Recall | AUC |
| P16 | 0.6112 | 0.4561 | 0.3766 | 0.5780 | 0.6016 | |||||
| P5 | 0.7882 | 0.6570 | 0.6192 | 0.6998 | 0.7298 | 0.6728 | 0.6047 | 0.6373 | ||
| P2 | 0.4467 | 0.2751 | 0.1725 | 0.6786 | 0.5073 | |||||
| P8 | 0.7344 | 0.4155 | 0.4197 | 0.4114 | 0.6959 | 0.6288 | 0.5515 | |||
| Low-Engagement Members | Head Orientation | Count |
|---|---|---|
| P2 | look around two whiteboards | 4 |
| look at whiteboard and leader | 3 | |
| look at the leader and other members | 3 | |
| look at whiteboard | 2 | |
| look at survival item panel and other members | 2 | |
| P5 | look at survival item panel | 12 |
| look at whiteboard and leader | 10 | |
| P8 | look at whiteboard and survival item panel | 7 |
| look at survival item panel | 6 | |
| look at leader and whiteboard | 4 | |
| look at whiteboard | 2 | |
| look at the leader and other members | 1 | |
| P16 | look at survival item panel and whiteboard | 10 |
| look at leader | 7 | |
| look at the leader and other members | 6 | |
| look at leader and whiteboard | 4 | |
| look at survival item panel | 3 | |
| look around two whiteboards | 3 | |
| look at whiteboard | 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, C.; Chen, J.; Zhang, J.; Yang, T.; Liu, Z.; Konomi, S. Detecting Leadership Opportunities in Group Discussions Using Off-the-Shelf VR Headsets. Sensors 2024, 24, 2534. https://doi.org/10.3390/s24082534
Gu C, Chen J, Zhang J, Yang T, Liu Z, Konomi S. Detecting Leadership Opportunities in Group Discussions Using Off-the-Shelf VR Headsets. Sensors. 2024; 24(8):2534. https://doi.org/10.3390/s24082534
Chicago/Turabian StyleGu, Chenghao, Jiadong Chen, Jiayi Zhang, Tianyuan Yang, Zhankun Liu, and Shin’ichi Konomi. 2024. "Detecting Leadership Opportunities in Group Discussions Using Off-the-Shelf VR Headsets" Sensors 24, no. 8: 2534. https://doi.org/10.3390/s24082534
APA StyleGu, C., Chen, J., Zhang, J., Yang, T., Liu, Z., & Konomi, S. (2024). Detecting Leadership Opportunities in Group Discussions Using Off-the-Shelf VR Headsets. Sensors, 24(8), 2534. https://doi.org/10.3390/s24082534