1. Introduction
Advancements in consumer-level head-mounted displays and computer graphics are paving the way for virtual reality to enhance online and remote learning closer to real-world settings [
1]. The absence of some forms of nonverbal communication in VR, however, can make communication and interaction more difficult compared to face-to-face settings [
2]. Although nonverbal communication such as para-language, facial expressions, and posture plays a vital role in human interaction and communication [
3,
4,
5], it is hard for people to interpret the expression and specific body motion of other group members accurately when using avatars in virtual reality [
2].
Studies have emphasized the importance of leaders in virtual teams [
6,
7,
8]. Leadership has been shown to directly affect the dynamics, work standards, and communication protocols of virtual teams [
8]. In particular, distributed teams can perform better when leaders create pressure and awareness of others’ contributions [
7]. This suggests the importance of supporting a leader’s awareness of other group members, which could assist the leader in organizing discussions more effectively. Moreover, due to the complexity of leadership, not everyone possesses the same capability for leading group discussions [
9]. People use different styles of leadership, sometimes failing to lead group discussions or teamwork efficiently. For instance, autocratic-style leaders assert social dominance by monopolizing a significant portion of the speaking opportunities, resulting in limited chances for other members to participate and engage in discussions [
10], while laissez-faire style leaders may lack confidence to facilitate efficient discussions, thereby causing protracted decision-making processes [
10]. In virtual environments, communication between leaders and group members may be subject to some obstacles. In this context, there are opportunities to support leadership for the success of group discussions. For example, the difficulty of exchanging some non-verbal cues in VR may hinder leaders from being aware of group members with suppressed speaking intentions. Leaders relying solely on avatars may fail to understand members’ emotions and attention, which could impede their efforts to facilitate discussions efficiently. In particular, the lack of some non-verbal cues may prevent leaders from supporting turn-taking behaviors effectively during discussions. The sensor data available on off-the-shelf VR devices could provide a wealth of non-verbal information related to head movements, gestures, body movements, and so on, and they might potentially help alleviate the difficulty of communication in VR group discussion. Both verbal cues and non-verbal cues such as prosodic means, gaze, head movements, gestures, and body posture play essential roles [
11,
12,
13] for leaders to understand the need and timing for proper interventions. We posit that motion data, including head movement, body movement, and hand gestures data, could be used to support leaders with the awareness of leadership opportunities and minimize problematic situations in VR-based group discussions such as the ones caused by suppressed speaking intention.
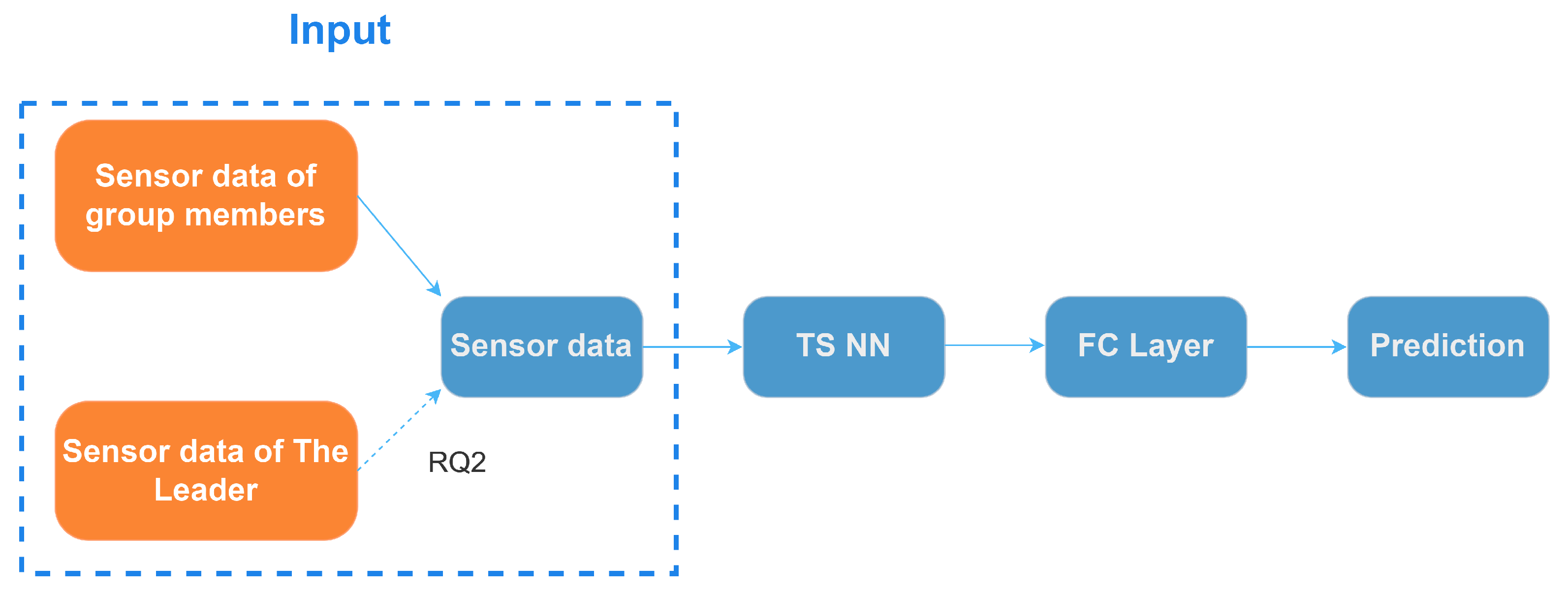
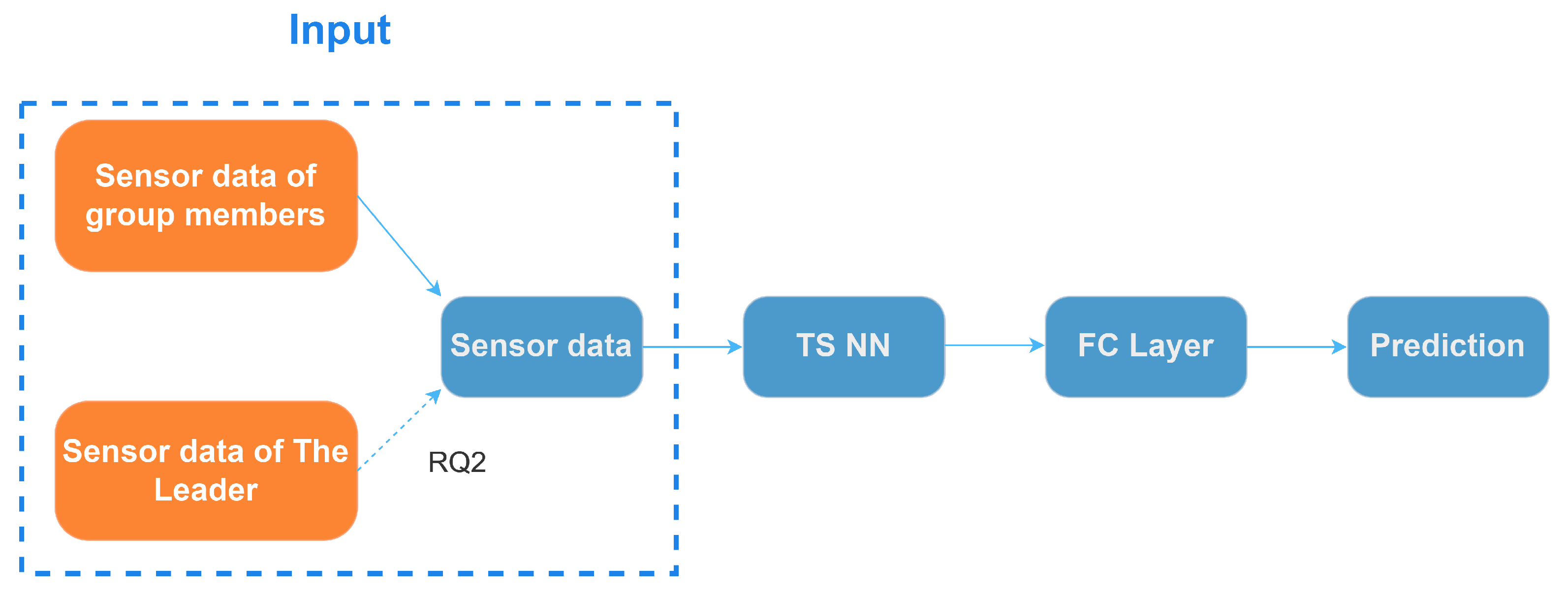
In this paper, our main objective is to detect opportunities for facilitating engaging discussions and support leaders in group discussions using off-the-shelf VR headsets. In particular, we propose a novel detection approach that exploits social behavior patterns in leader-led group discussions to provide awareness about problematic situations caused by suppressed speaking intentions. Based on the sensor data collected during the VR group discussions experiment used to detect suppressed speaking intentions, we employ group members’ sensor features to construct personalized and general deep learning models for detecting suppressed speaking intentions. Personalized models assist us in understanding the model’s detection capabilities on similar but unseen data, and general models help us to better assess the model’s detection capabilities on data from new users. We posit that the existence of leaders can influence the behavior of group members during group discussions and simultaneously consider the sensor features of a leader and other group members to detect suppressed speaking intentions. In this context, our research questions are as follows. RQ1: Can we detect opportunities for facilitating engaging VR group discussions based on the sensor data from commodity VR devices by using personalized and general models? RQ2: Do leaders’ sensor features contribute to the detection of members’ suppressed intentions to speak? RQ3: Which type of leaders’ sensor features contribute the most to the detection?
Our main contributions are as follows.
MODELS: We propose general and personalized models following architectures of three commonly used time-series classification models for detecting leadership opportunities focusing on suppressed speaking intentions. Our model only requires the collected data from off-the-shelf VR devices without the need to use additional sensing devices.
FEATURES: We show that our personalized models can improve the detection performance by integrating the sensor data from group leaders and members. We also uncover the usefulness of the leaders’ sensor data in detecting the speaking intentions of low-engagement group members.
SENSOR TYPES: Furthermore, we investigated which type of leader’s sensor features, including HMD, controllers, position, and rotation in a virtual environment, contribute the most to the performance improvement. The results suggest that HMD sensor features contribute the most to the performance improvement of personalized models for the majority of low-engagement members.
IN-DEPTH ANALYSIS: We analyze the behavior patterns in the VR group discussion through video analysis and discuss the reasons why leaders’ sensor data can improve the detection performance for low-engagement group members. We then discuss their implications for the design of support mechanisms in VR group-discussion environments.
2. Related Works
Existing research in supporting group discussions has revealed some issues regarding group formation, group dynamics, and the learning process. These issues can be traced back to impeded social interactions between group members [
14]. To address social issues in face-to-face group discussions, researchers have explored various strategies. For instance, Dagan et al. developed a social wearable prototype aimed at enhancing individuals’ awareness of and control over their verbal participation in group discussions [
15]. The device they proposed detects the wearer’s speech patterns and provides visual and tactile feedback as needed. The OpenMic utilizes proxemic metaphors in videoconferencing to manage conversational dynamics, employing features like the Virtual Floor and Malleable Mirrors to facilitate smoother interactions in multi-party video meetings [
16]. Additionally, some studies have leveraged group awareness tools to improve communication and collaboration within groups [
17,
18,
19]. Other research works shared sensor data (e.g., location and activity stream) and biosignals (e.g., heart rate) to facilitate social interaction [
20,
21,
22].
Non-verbal features such as head movement, gaze, and hand gestures, as well as interaction features, have been commonly employed to analyze social and group dynamics. For instance, Chen et al. introduced a Kinect-based method for evaluating group discussion behavior by utilizing algorithms to detect each participant’s facial direction and infer their roles within the discussion [
23]. Muller et al. extensively analyzed non-verbal signals to detect low rapport in small groups and explored the automated prediction of low rapport during natural interactions in these group settings [
24]. Furthermore, biosignals and sensors from commodities’ VR devices have also been utilized in some recent studies. In recent years, Zhang et al. have shown that the behavior features extracted from the wearable sociometric badge sensor provide useful information in assessing personal affect and team cohesion [
25]. Chen et al. have investigated the use of sensor data from off-the-shelf VR devices, along with additional contextual information such as user activity and engagement, to predict opportune moments for sending notifications using deep learning models when users interact with VR applications [
26]. Tan et al. propose an LSTM-based head orientation estimation method with alternative non-verbal inputs, like speaking status, body location, orientation, and acceleration [
27]. Despite the many efforts to enable the sensor-based detection of non-verbal features, none of them fully consider the characteristics of leader-led group discussion to detect and support leadership in VR-based groups.
Leadership is a critical factor in both real-world groups and virtual teams during discussions and collaborative work [
8,
10,
28]. Everyone possesses different capacities for leading teams effectively, given the complexity of leadership [
9]. Consequently, studies have been conducted to explore tools to support leadership [
29,
30] and understand the dynamics of leadership roles within group discussions [
31]. In addition, leaders employ various methods for applying leadership, such as one-on-one feedback sessions, speeches, and non-verbal behavior [
30]. Some works utilized graph link analysis and social network analysis to analyze and detect leadership within groups [
31,
32].
Most of these previous studies focus on face-to-face scenarios and demand substantial expertise and effort to construct features before employing machine learning models. Again, our work focuses on an important yet relatively unexplored setting of groups with a leader in VR and proposes techniques that suit such a setting. It is worth noting that an earlier paper introduced a practical system designed to detect a user’s intent to speak to a computer [
33]. However, this work primarily centered around audio, facial expression, and facial feature analysis, and it primarily addressed scenarios where users were talking to computers. This distinguishes it from our approach to detecting speaking intention. Unlike our previous work [
34], which centered on free discussions without leaders, our current research focuses on leader-led VR group discussions in the context of a survival game scenario and proposes novel techniques for the detection of suppressed speaking intention. We have also modified our data sampling approach, adopting a more general slide window method instead of solely sampling data from the first 3 s before speaking. Additionally, our current work includes the consideration of the unachieved speaking intention labels and simultaneously trains personalized and general models on the dataset of group members.
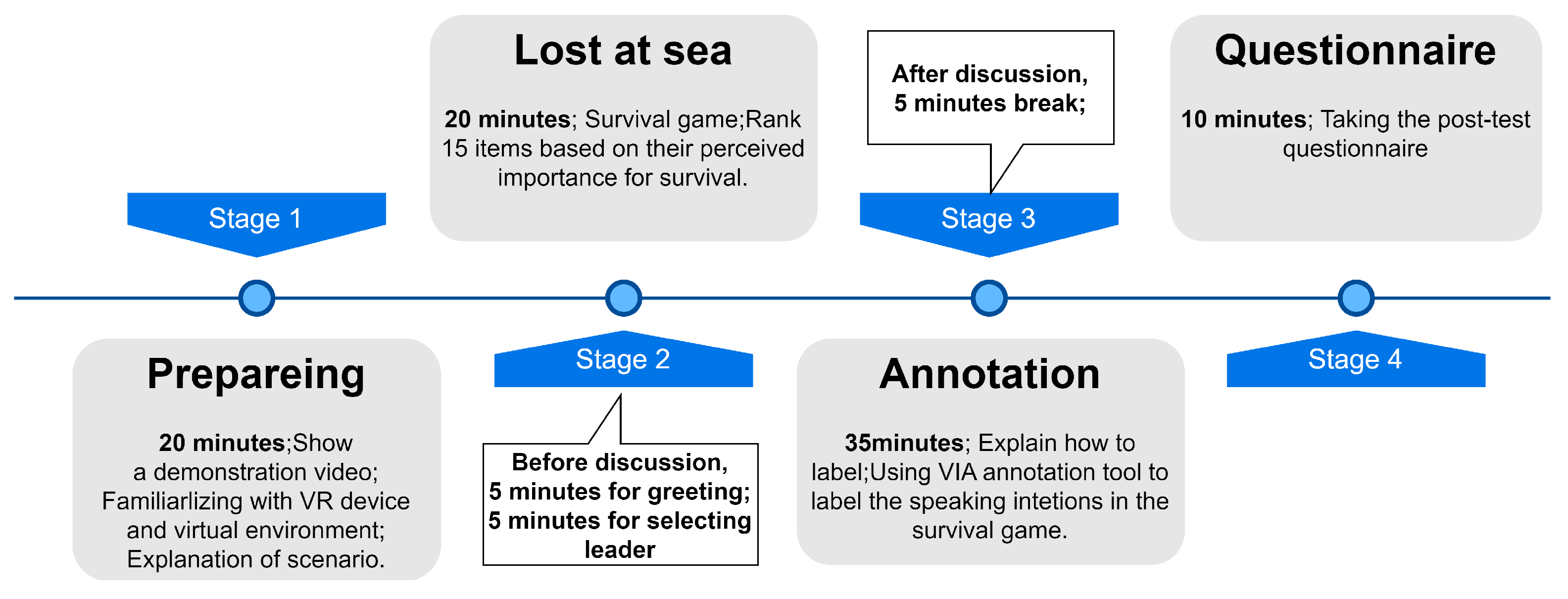
4. Data Collection
In the virtual meeting room we constructed, we utilized VR devices to collect participants’ positions, movements, and other physical actions during the discussions. The VR device employed in our experiment, Oculus Quest 2, is capable of providing sensor data from three components: the head-mounted display, the left-hand controller, and the right-hand controller. Each component enables data collection pertaining to position, rotation, velocity, acceleration, angular velocity, and angular acceleration.
Unlike group discussions in the physical space, participants in VE can utilize the VR controllers to move and rotate the avatar, grab the pen, and write on the whiteboard in the virtual environment. Therefore, we additionally collect virtual sensor features that represent the position and rotation of the user in the virtual environment respectively. The experimental application we developed is capable of uploading sensor data to the database at a stable frequency of 20 Hz.
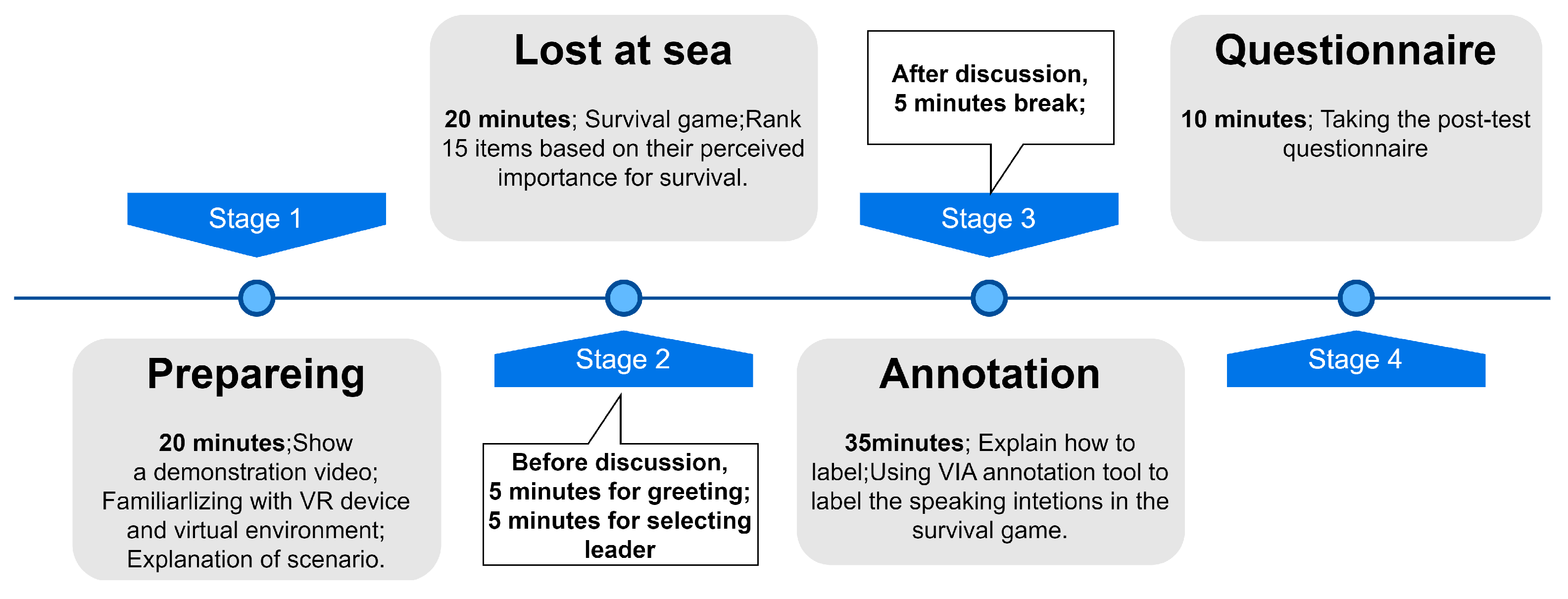
For our annotation strategy, all participants are first instructed to use the video annotation tool called VGG video annotator [
40,
41] to review the recorded videos and mark the start point of each speech. Then, they are required to determine whether the speech is an instance of active speaking. If it is an instance of active speaking, participants need to mark the time interval starting from when they had the intention to speak (with the start of the intention as the starting point) to when they started speaking as the endpoint. Additionally, participants were asked to mark the time intervals for instances where they held the intention to speak but did not speak out during the video review process.
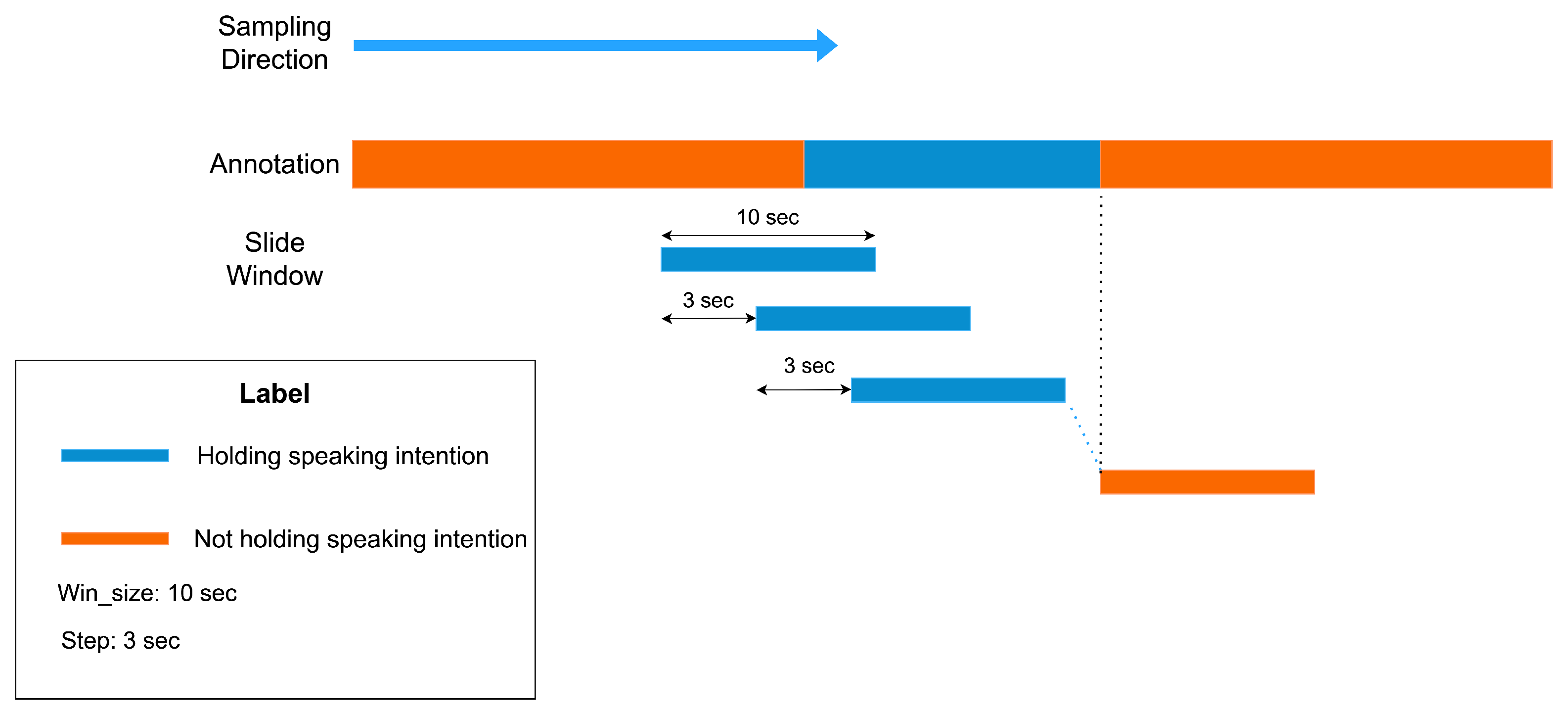
We collected sensor data that occur at a frequency of 20 Hz. According to our research questions and purpose, we utilized the sensor data and labels from the 18 group members to construct the training and testing datasets, with data from the six leaders employed as contextual information for investigating RQ2. A total of 380,918 sensor data entries were collected from 18 group members during the 20-min survival game discussion. Among these, only 47,262 (≈12.4%) data entries were identified as positive samples (with the intention to speak), while the remaining data points were negative samples. Hence, it is evident that there is a significant class imbalance between positive and negative samples. The annotation tool and our annotation strategy gave us continuously labeled data. As a result, we used a sliding window to sample data points. The sensor data points in each time window are used for the detection of speaking intentions during that period of time window. We used ten seconds as window size and three seconds as step size because it resulted in the best performance among five candidate window sizes (2 s, 3 s, 5 s, 10 s, and 15 s) and four candidate step sizes (0.5 s, 1 s, 3 s, and 5 s) in our detection results.
Figure 3 shows the process of sampling data points by applying the slide window approach. Additionally, a slightly larger window can alleviate the overall imbalance between positive and negative samples; if the window size is too small, it would increase the difficulty of the model in recalling positive samples.
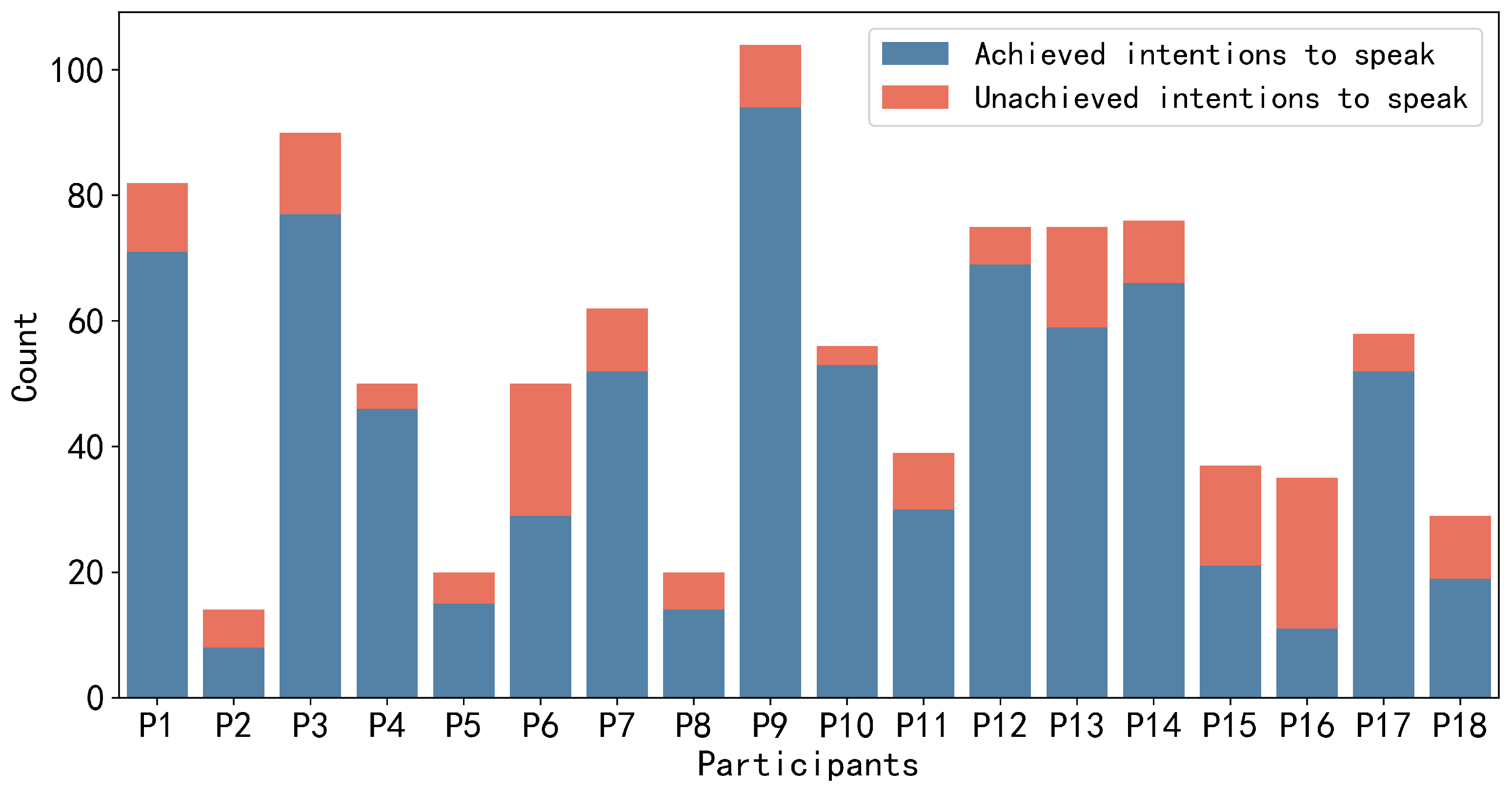
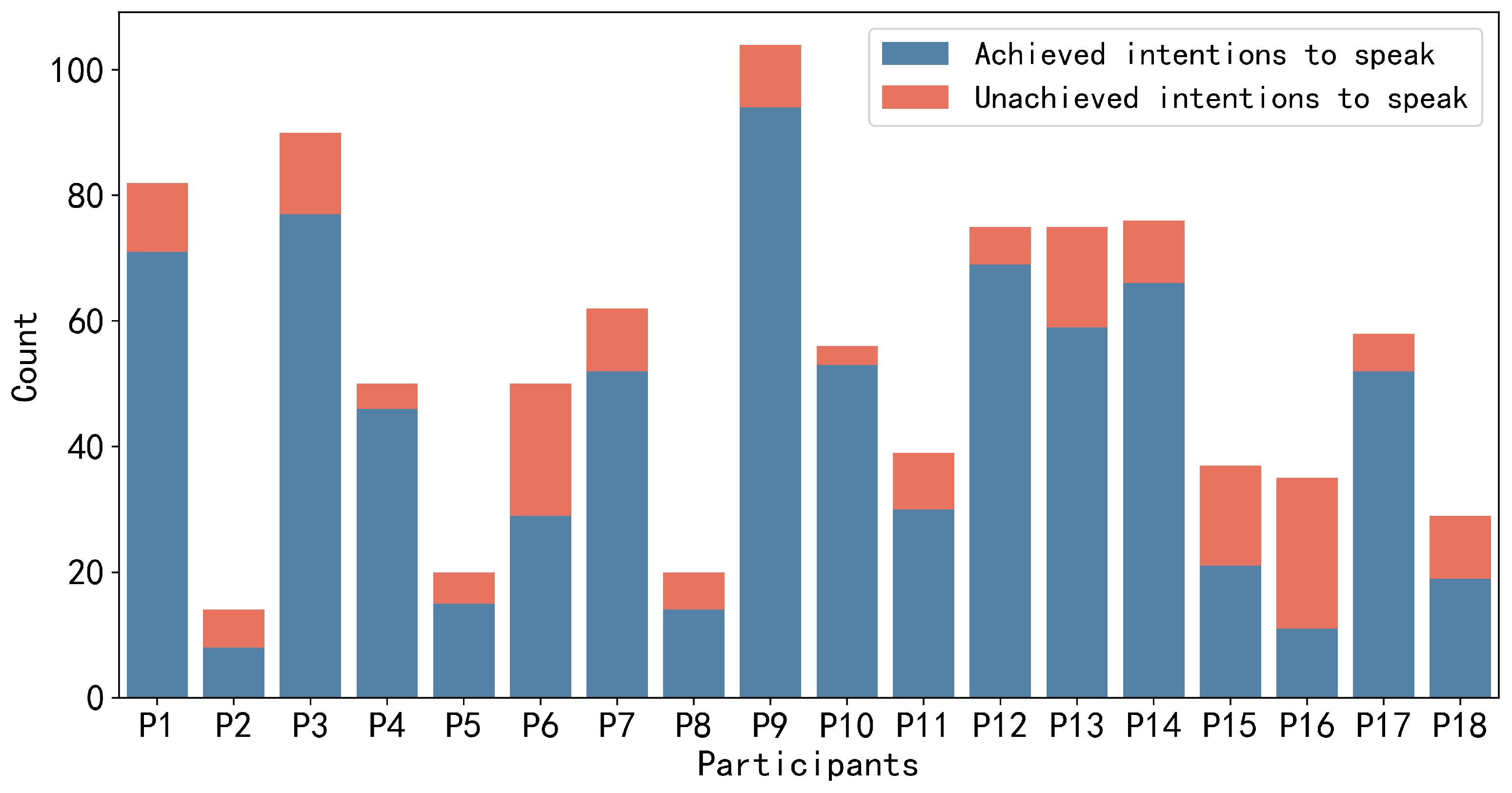
For the annotation data, there are a total of 972 instances of speaking intention, with 786 (≈81%) annotated as achieved and 186 (≈19%) annotated as unachieved. The total duration of speaking intention labels for the 18 participants was 1232 s (≈20 min). Each group member annotates different frequencies and durations of speaking intentions. Participants with higher engagement in the discussions have a larger number of speaking intentions than others. However, in terms of those with lower engagement, not only did they have fewer speaking intentions but they also spoke less frequently during the discussions.
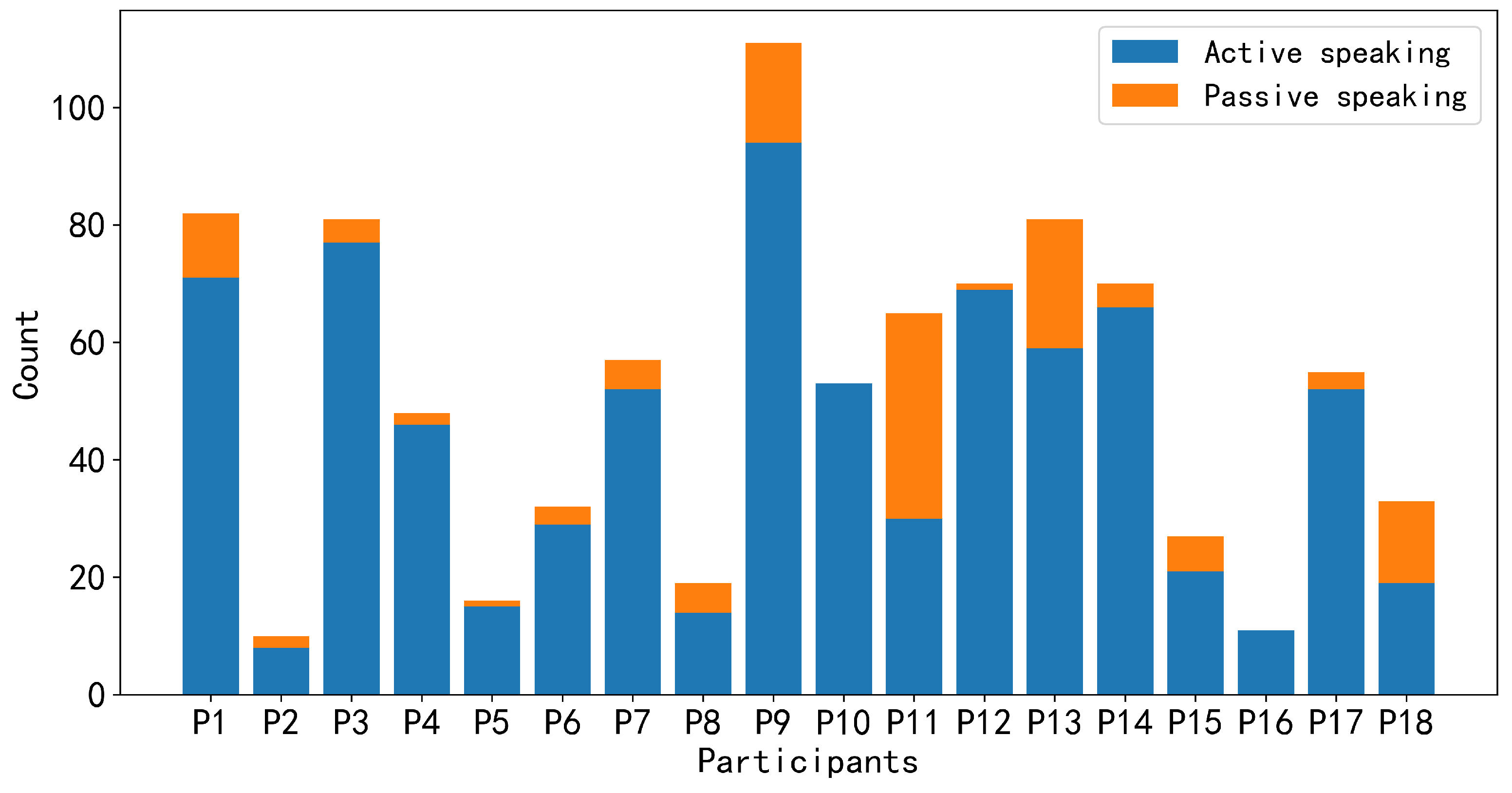
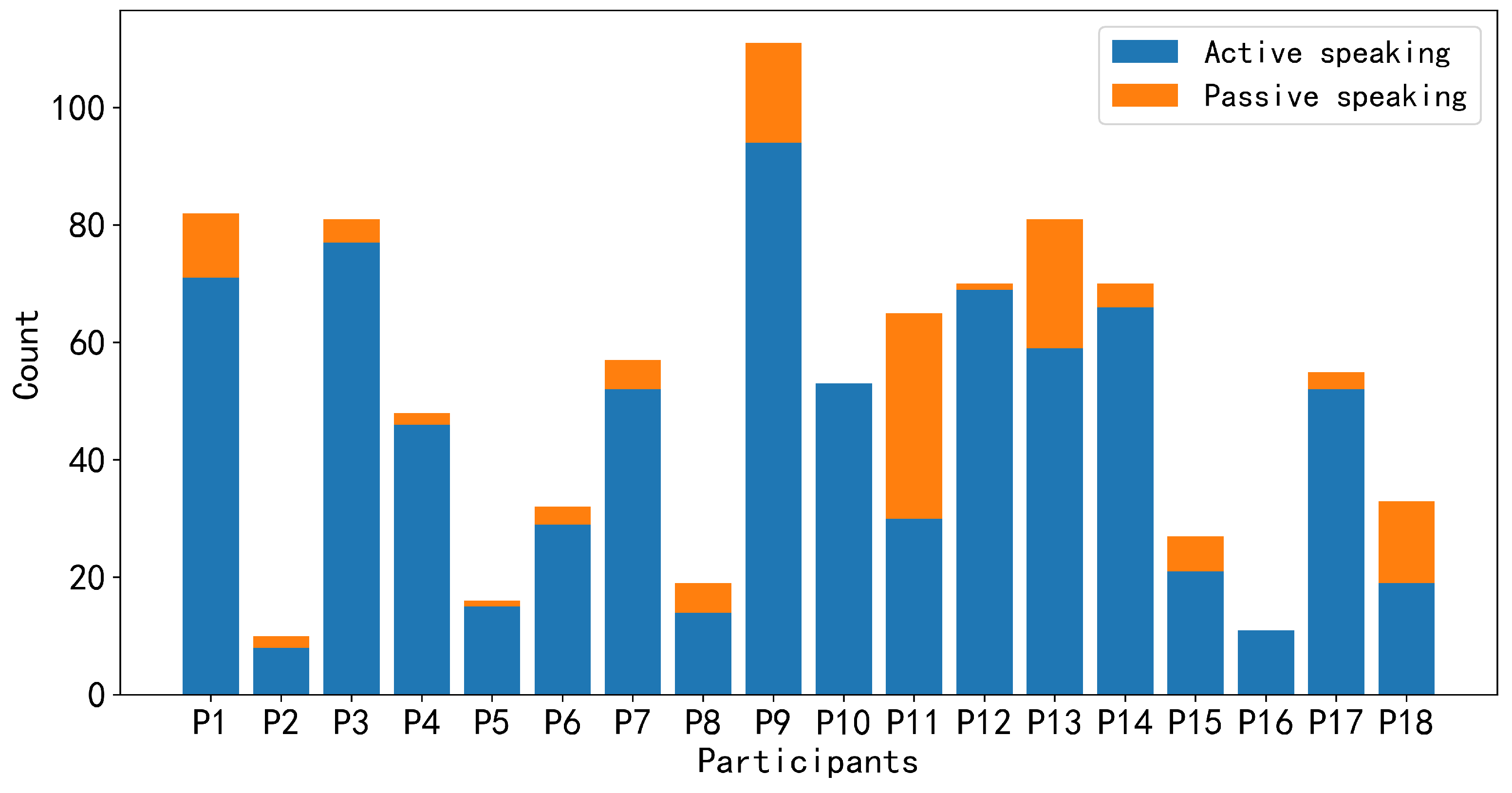
Figure 4 and
Figure 5 depict the number of utterances made by each group member during the discussion and the frequency of speaking intentions possessed by each group member during the discussion, respectively. In
Figure 4, based on our annotation strategy, active speaking indicates that participants want to actively express their own views or respond to others’ opinions voluntarily. Passive speaking indicates that participants may be influenced by the will of others and are compelled to express their views, such as being called upon by other members to present their opinions. Since we consider speaking intentions to be more inclined towards participants actively expressing their views, we instructed participants to focus on active speaking and unachieved speaking intentions during the labeling process. It is worth noting that even after applying the sampling methods described above, an imbalance still exists between positive and negative samples in the data of some group members. For instance, after employing sliding window sampling, P2, P5, P8, P18, P15, and P16 have positive samples accounting for only around 13.5%, 16.4%, 18.6%, 24.1%, 31.6%, and 35.1%, respectively.
In sampling the data points, we ignored data points that would contain noise, which were points that satisfied either of the following conditions. First, we excluded certain data points from the initial and final stages of the experiments. During the initial stages of the experiments, some participants may exhibit interactions with the virtual environment that are less familiar, resulting in discussions and actions unrelated to the experiment. Similarly, during the final stages of the experiments, due to the fact that some groups finished the discussion prematurely, participants engaged in activities unrelated to the experiment. For instance, some participants set aside their VR controllers and took a break. Second, we removed data points associated with the period where participants inadvertently moved outside the VR movement boundaries or experienced unexpected incidents such as unintentional button presses on the HMD resulting in a black screen interface during the discussion. Finally, participants are not consistently precise when annotating the starting point of speech (the endpoint of achieved speaking intentions labels). We employed the Whisper [
42] tool from Open AI to assist in correcting the endpoints of some labels with large deviations. This sampling method produced a dataset containing 5717 total samples, consisting of 2600 positive samples (with intention to speak) and 3117 negative samples (without intention to speak).
Finally, we describe the data collected through the questionnaire survey. Firstly, regarding Q1, the responses from the 24 participants varied. Five participants indicated that although such situations occurred, they did not know the reason (20.8%). Four participants mentioned that they did not want to interrupt other members’ discussions at that moment (16.7%). Another four participants refrained from speaking because what they intended to say was unrelated to the ongoing discussion (16.7%). Additionally, four participants felt that they were not sure how to express their thoughts at that time (16.7%). Three participants thought that other members had already expressed similar ideas, so they decided not to speak (12.5%). Moreover, two participants mentioned missing the timing for contributing to the discussion (8.3%), and another two were concerned about speaking too much (8.3%). One participant stated that they had unique questions about some viewpoints but were worried that other members would not understand their ideas (4.2%). Another participant mentioned not wanting to oppose others’ opinions (4.2%). Finally, one participant felt that the discussion was coming to an end, so they chose not to speak (4.2%). In summary, the most common reason was not wanting to interrupt other members’ discussions.
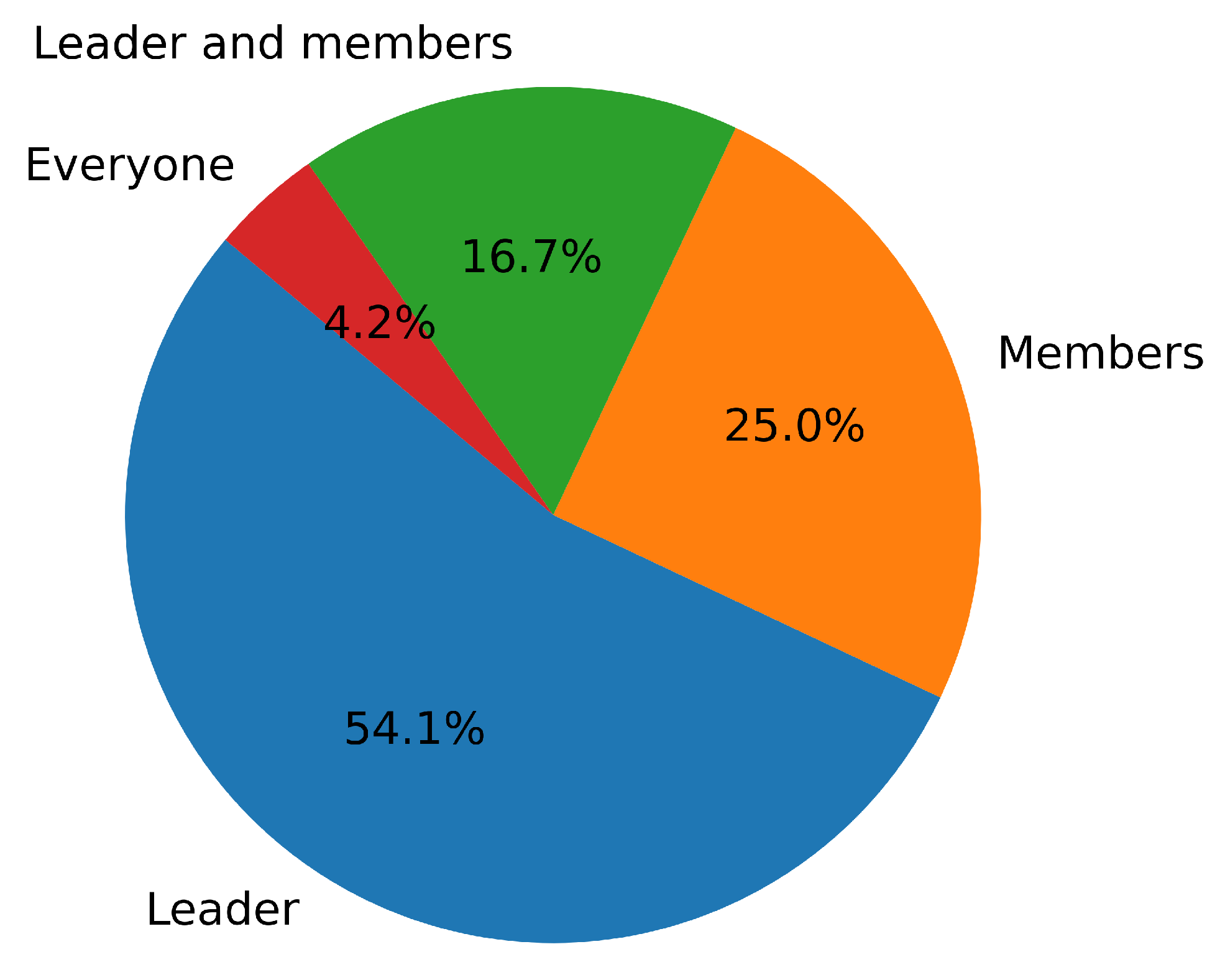
Secondly, Q2 was measured via the five-point Likert scale, with 1 = “strongly disagree” and 5 = “strongly agree”. The overall satisfaction level of the 24 participants with the leader was relatively high (M = 4.45, SD = 0.66), with leaders reporting lower self-satisfaction (M = 3.67, SD = 0.56) compared to the satisfaction of members with leaders (M = 4.72, SD = 0.42). In terms of Q3,
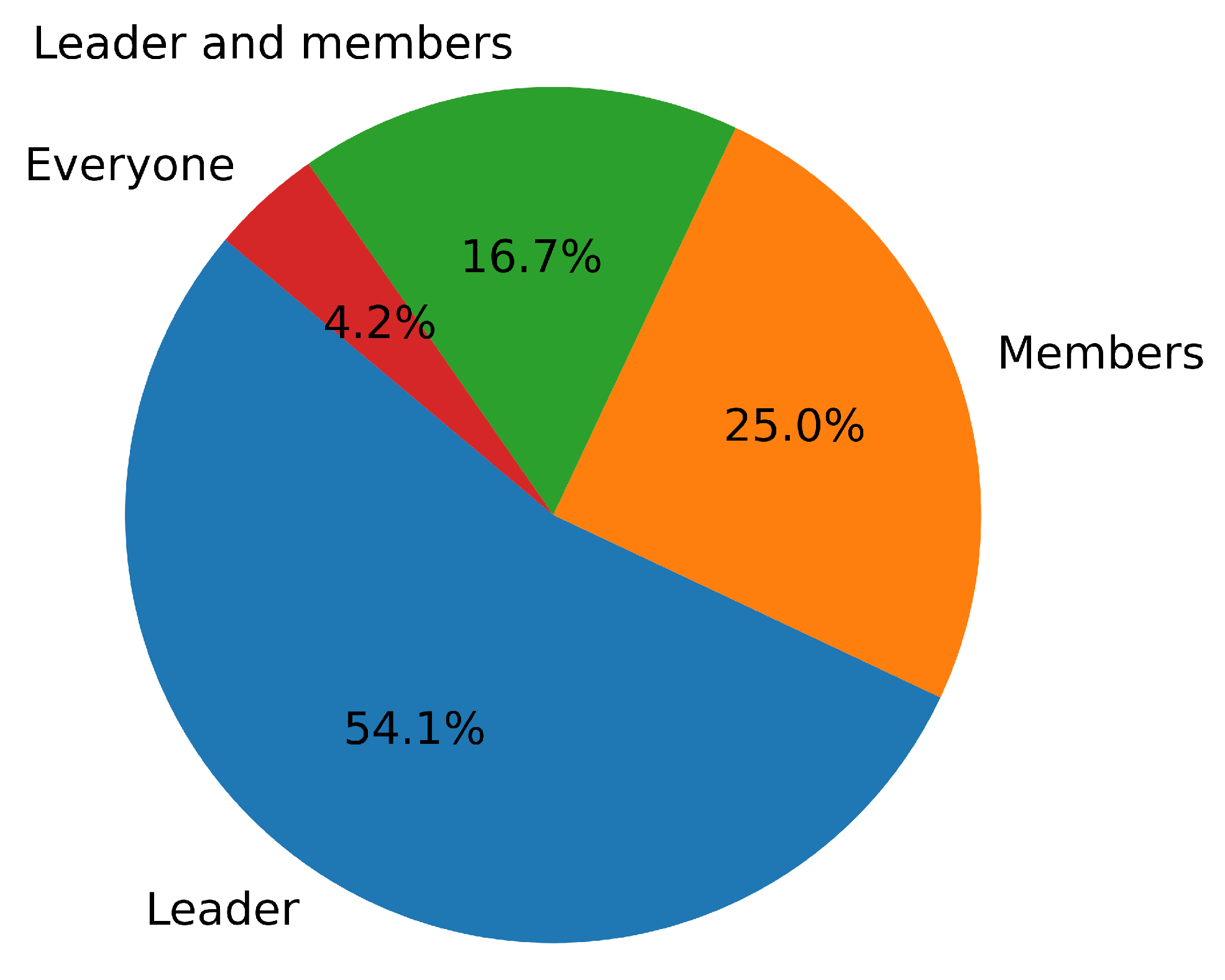
Figure 6 shows the overall results of who participants think contributed the most to the discussion. Overall, most participants (54.1%) considered the leader to be the most important contributor in the group discussions. Some participants (25%) also believed that some group members actively expressed their opinions and made more contributions during the discussions. Additionally, 16.7% of participants thought that both the leader and some members actively participated in the discussions and made significant contributions. One participant (4.2%) believed that everyone in the group contributed equally. Among the results from the six leaders, four of them believed that they had the highest contribution, while two leaders thought that some members contributed more within the group. The total survey results can provide supplementary explanations to enhance our understanding of leadership and member participation within the group.
The data we collect in VR environments, including motion sensor data, video data, and questionnaires from participants, may contain personally sensitive information. Systems that exploit such data to facilitate group discussion should respect users’ privacy and autonomy through user-centered design processes that mitigate the users’ risks and concerns. In our experiment, we utilized anonymous identifies when collecting and managing experimental data. Before collecting user data, we obtained informed consent from the participants, who clearly understood the purposes, scope, and potential risks associated with the collection, use, and sharing of their sensor data. Furthermore, participants’ data are stored on our lab server with access controls in place.
6. Discussion
In this section, we discuss our results and findings and explore the insights these results may offer for assisting leaders in managing group communication and interactions. Additionally, we discuss how our results and findings can provide assistance to developers.
6.1. Personalized Model vs. General Model
Our results indicate that using sensor data available on off-the-shelf VR devices can achieve the following results in the general model (EEGNet): Accuracy (0.5823), F1-score (0.6057), and AUROC (0.5633). Furthermore, the performance of the personalized model (EEGNet) is superior to that of the generalization model, with Accuracy (0.6813), F1-score (0.7132), and AUROC (0.6201). Additionally, the lower performance of the general model suggests that there may be significant variations in motion patterns exhibited by individuals when they have speaking intentions. Moreover, the model’s utilization of knowledge learned from a subset of participants is insufficient for detecting the speaking intentions of new users. From an application perspective, if leaders can receive accurately detected speaking intention information, they can better understand the communication needs of group members. However, the lower Precision of the general model results in many incorrect intentions to speak detection results, making it less favorable choice for development. The personalized model outperforms the general model in all evaluation metrics, indicating that, in terms of results, constructing personalized models for each user may be a choice to consider for development. However, building personalized models requires a certain amount of sensor data from group discussions for each user as an initial dataset, which requires more time and effort.
6.2. The Influence of Leader’s Contextual Features
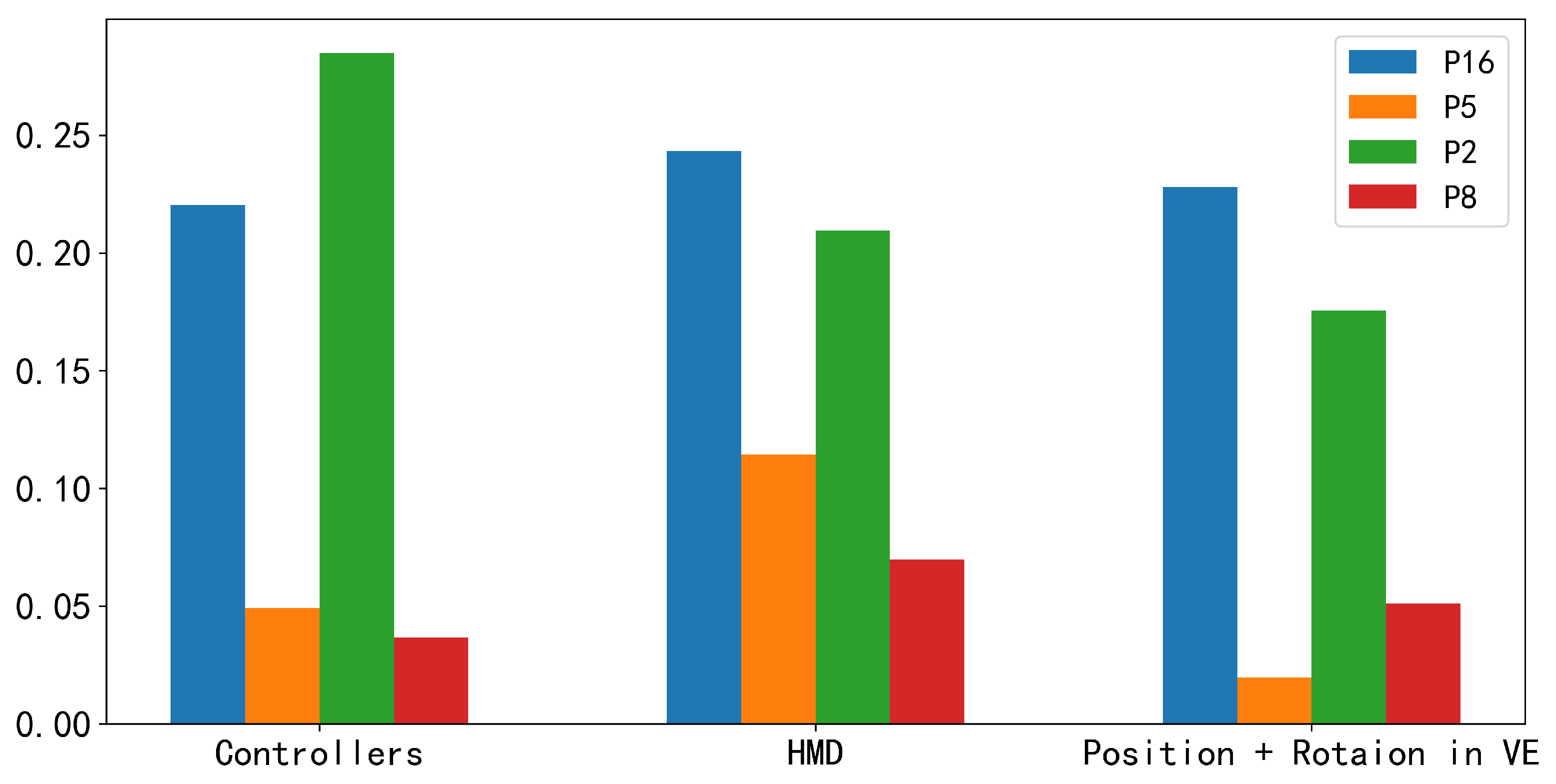
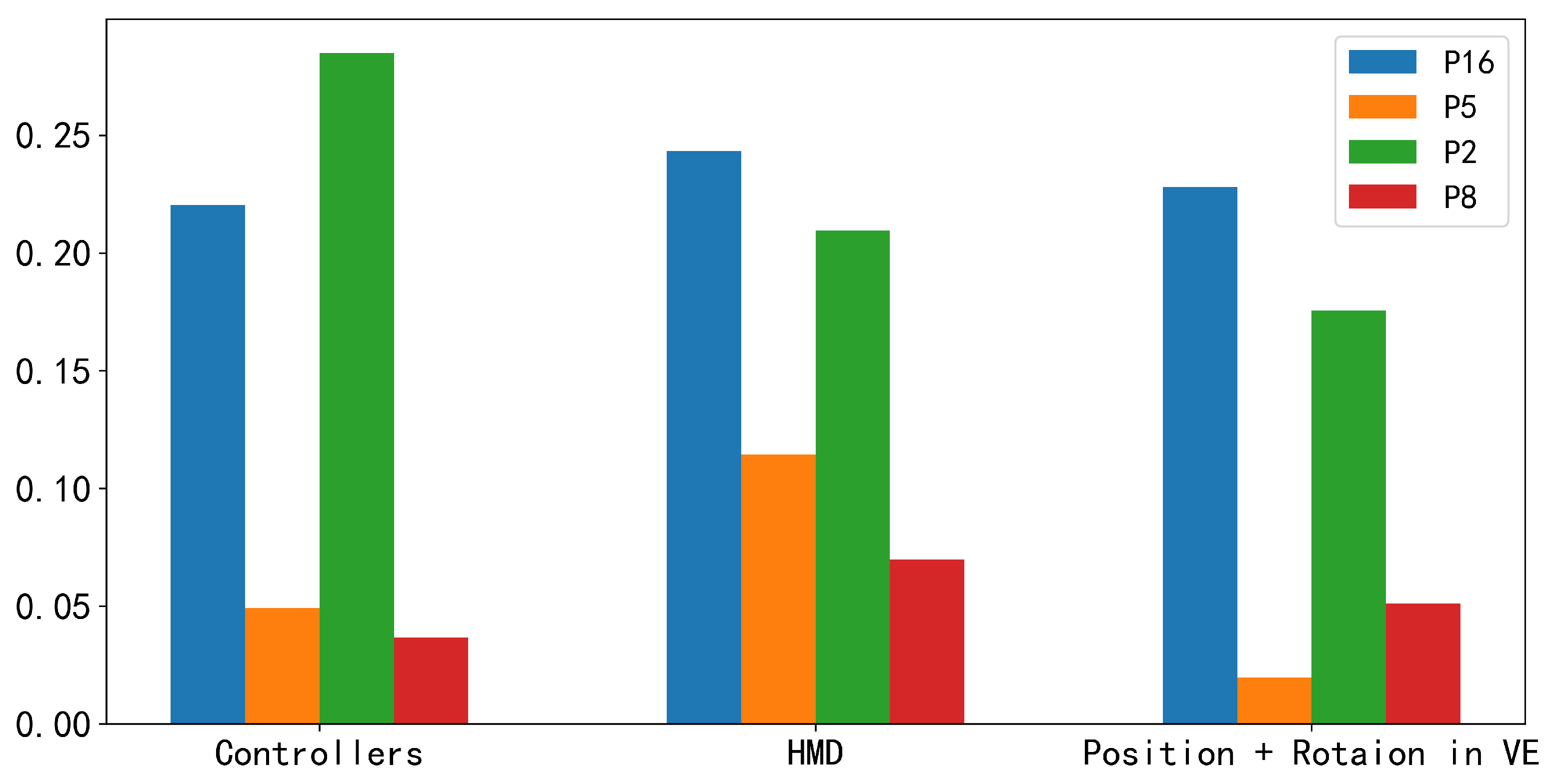
On top of the personalized model, we examined the impact of the leader’s sensor features on detecting the speaking intentions of group members. Our results indicate that combining the leader’s sensor features can enhance the detection performance of personalized models for those members who speak less and are less actively involved in discussions. However, the performance of personalized models for actively engaged members does not improve when the leader’s sensor features are combined. Furthermore, we investigated which type of leader’s sensor features (HMD, controllers, position, and rotation in VE) contributes the most to the performance improvement. The results suggest that the HMD sensor features contribute the most to the performance improvement of personalized models for the majority of low-engagement members.
To further support the results obtained through model detection and explore clues to explain the model results, we observed and qualitatively analyzed the behavior of low-engagement group members when they had speaking intentions in experimental videos. We found that in many cases, these low-engagement members would look towards the leader or other actively participating group members when they had speaking intentions. Therefore, we speculate that when these low-engagement members look towards the leader or other high-engagement group members, they may be seeking opportunities to join others’ discussions or expecting assistance from the leader. In this context, the combination of the leader’s sensor features may help the model comprehensively learn the motion patterns of low-engagement members when they hold speaking intentions.
Based on our results and analysis, for low-engagement group members, combining the leader’s sensor features when constructing personalized models can enhance the model’s precision and F1-score. This can help provide more appropriate feedback to the leader, enabling the leader to enhance group communication and obtain more suggestions and ideas for the decision-making process. In the future model construction process, the level of engagement of group members is also a significant interactive feature that requires particular attention. However, before building personalized models, the level of engagement for each group member needs to be assessed in advance. Although participants and leaders could assess the level of engagement to some degree based on informal interactions before group discussions or previous experiences, there are also formal approaches to analyze engagement levels from different perspectives in group discussions or group learning scenarios. For example, behavioral engagement involves sustained on-task behavior during academic activity, including indicators such as persistence, effort, and contributing to the task [
52]; social engagement refers to positive socio-emotional interactions; and high-quality social engagement indicates all group members are equally involved in the task [
55]. Analyzing the engagement information of group members based on these formal approaches could, however, require a significant amount of additional time and effort.
6.3. Insights on Utilizing Speaking Intention Information to Assist the Leader
In this study, we utilized sensor features available on off-the-shelf VR devices to examine the feasibility of detecting leadership opportunities by focusing on the awareness of group members’ suppressed speaking intentions. Speaking intention differs from the feedback used in previous research, such as how often and for how long people talk [
56], the number of contributions [
57], and the turn of speaking [
58]. In addition, from the leader’s perspective, if the leader can be aware of unachieved intentions to speak, they may be able to better balance the participation in group discussions and facilitate more interaction within the group. If the leader can know the speaking intentions of those who may possess limited communication skills or be low-engagement group members, the opportunity could be provided for these members to express their opinions and thoughts. In task-based discussion scenarios, this approach can help leaders encourage more group members to express their views, thereby further enhancing the efficiency of the decision-making process. Moreover, when group discussions encounter obstacles or fall into silence, information about speaking intention from group members can provide a chance for the leader to break the discussion deadlock and make the discussion smooth.
Furthermore, based on our questionnaire results of Q1, there are various reasons for unachieved speaking intentions, such as not wanting to interrupt other members’ discussions and intending to say something that is unrelated to the ongoing discussion. Therefore, providing real-time intervention for every speaking intention may lead to confusion in the discussion. Therefore, it may be advisable for leaders to intervene based on speaking intention information when needed without mistakenly assuming that group members want to express their views immediately. Additionally, when the group discussion encounters difficulties or falls into silence, leaders can access the speaking intention information of group members to explore possible causes and effective interventions.
Our approach can be extended for different types of leadership support in VR-based group discussions by incorporating other detection techniques for groups. For instance, some research indicates a connection between emotion and bodily expression [
59,
60], suggesting that sensor data from VR can still be used to analyze or detect group members’ emotions to support leaders. Other studies have shown a correlation between turn-taking behavior and non-verbal cues (gaze, head movements, gestures, and body posture) [
61].
7. Limitation and Future Work
The current study was subject to several limitations. Firstly, there is a limitation regarding generalizability. We attempted to collect data in a problem-based communication scenario (survival game), which may not represent all other discussion activities. The number of participants in our experiment was also relatively small, and they were predominantly young students, which may limit the generalizability of their VR discussion experiences to a broader population. Additionally, variations in individual discussion habits and communication skills could impact participants’ performance in group discussions and might indirectly influence their speaking intentions. Therefore, due to these limitations, we suggest that future research could explore this topic with a more diverse range of discussion contexts and more diverse populations.
Secondly, concerning our annotation method, we employed a retrospective approach for participants to annotate their speaking intentions. This retrospective method may introduce a memory bias problem. We initially considered having participants press buttons on controllers to label their speaking intentions during discussions. However, this approach could potentially increase participants’ cognitive load during discussions as they would constantly need to focus on the task of pressing buttons. The retrospective method circumvented this issue, but post-experiment observations revealed that participants spent a substantial amount of time recalling when they held speaking intentions during the video playback. This could lead to increased participant fatigue and a reduced willingness to engage in thoughtful labeling, and it could potentially compromise the quality of the label data. Therefore, we suggest that future research consider employing additional tools to assist in obtaining more precise and granular label data. For instance, the use of EEG devices or more efficient annotation tools could be applied. For unachieved speaking intention (suppressed speaking intention), relying solely on motion data for model construction and analysis is insufficient. Collecting a sufficient quantity of labels for unachieved speaking intentions is a challenging aspect of detection. Future research could also consider incorporating biometric data for more in-depth analysis and detection of suppressed speaking intention.
Thirdly, in our work, we primarily focused on the sensor features of HMD and the controllers available on VR devices. We also considered participants’ position and rotation information in VE. These features are more readily accessible and do not necessitate additional expertise for model construction. We did not utilize certain biometric features (such as pupil dilation, EEG, and heart rate) or more advanced VR devices with more sensors (such as Meta quest pro and HTC Vive eye pro). Our emphasis was on consumer-level VR devices that are easily accessible to the general population. However, recent research has also utilized biosignals to aid in addressing cognitive-related issues, such as social contexts and emotional autobiographical memory in VR [
62,
63]. Biometric features may provide additional support for detection and applications. Thus, we acknowledge the potential for these biometric features to enhance the detection of leadership opportunities and suggest that future research explore the integration of these features or other relevant features to improve detection performance and provide better support for leaders.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}