
Analysis of the Financial Information Contained in the Texts of Current Reports: A Deep Learning Approach


Abstract
:1. Introduction
1.1. Sentiment Analysis of Financial Texts—Current Approach and Methods
- —sentiment indicator;
- —number of positive words in the text;
- —number of negative words in the text;
- —sum of the number of positive and negative words (Henry and Leone 2009).
- Selecting the type of financial texts to be studied;
- Acquisition and preparation of text dataset;
- Dictionary selection;
- Design of the sentiment indicator;
- Determining the sentiment based on the value of the indicator.
- Selecting the type of financial texts to be studied;
- Preparation of training and test data—obtaining a large amount of text data of a given type and labeling them, i.e., manually assigning the sentiment value;
- Selection and preparation of the ML model;
- Training the model, i.e., calculating its parameters;
- Testing the model on a predefined dataset;
- Determining sentiment using a trained model.
1.1.1. Main Drawbacks of Dictionary-Based and ML Methods
1.2. New Approach to Analyse Sentiment from Financial Text Data Based on Deep Learning (DL)
- Elimination of the manual task of developing dictionaries and labeling data;
- Independence from the subjective assessment of the researcher;
- Takes into account the broad context of words and their meaning in financial texts.
2. Materials and Methods
2.1. Data Sources and Transformation of Data into a Form Suitable for the ML Model
- t—event window width of 9 days (period starting 4 days before the publication of the report and ending 4 days after that date);
- —stock i’ cumulative abnormal return at period t;
- —stock i’ return at period t;
- —S&P 500 index return at period t.
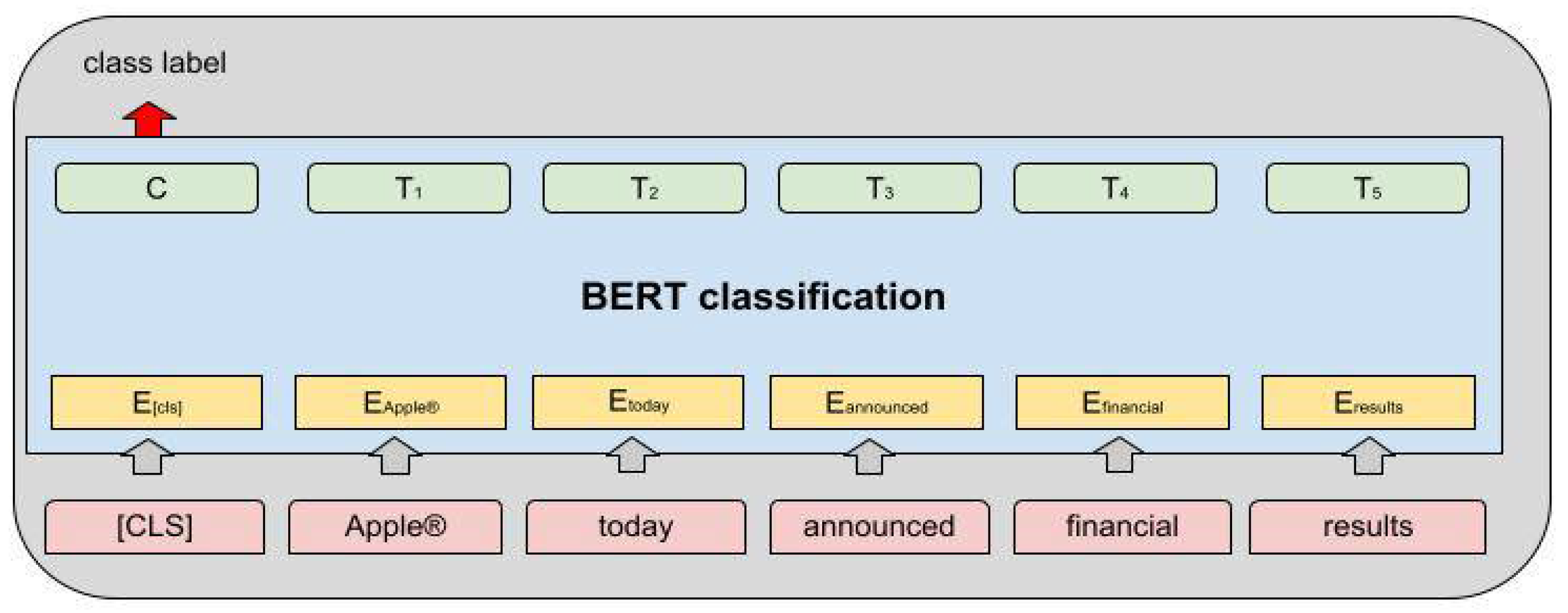
2.2. Basic Features of the BERT Model Used for Sentiment Analysis
- Q—query matrix;
- K—key matrix;
- V—value matrix;
- —queries and keys of dimension.
- It is currently one of the best performing models in natural language processing.
- Through the attention mechanism, it takes into account the broader context of words in the text.
- It takes into account the order of words in the text.
- It can be easily adapted to different categories of NLP tasks.
- Is less computationally demanding than other state-of-the-art models.
2.3. Baseline Model for Performance Comparison
3. Results
- P—precision;
- TP—the number of true positives;
- FP—the number of false positives.
- A—accuracy;
- TP—the number of true positives;
- TN—the number of true negatives;
- Total—the total number of samples.
“apple reports fourth quarter results services revenue reaches all-time high of $12.5 billion eps sets new fourth quarter record of $3.03 cupertino, California—30 October 2019—apple® today announced financial results for its fiscal 2019 fourth quarter ended 28 September 2019. the company posted quarterly revenue of $64 billion, an increase of 2 percent from the year-ago quarter, and quarterly earnings per diluted share of $3.03, up 4 percent. international sales accounted for 60 percent of the quarter’s revenue. “we concluded a groundbreaking fiscal 2019 with our highest q4 revenue ever, fueled by accelerating growth from services, wearables and ipad,” said tim cook, apple’s ceo. “ with customers and reviewers raving about the new generation of iphones, today’s debut of new, noise-cancelling airpods pro, the hotly anticipated arrival of apple tv+ just two days away ….”
“(nasdaq: aal) today reported its first-quarter 2019 results, including these highlights: “we want to thank our 130,000 team members for the outstanding job they did to take care of our customers, despite the challenges with our fleet during the quarter. their hard work led american to record revenue performance under difficult operating conditions,” said chairman and ceo doug parker. “as we progress toward the busy summer travel period, demand for our product remains strong. however, our near-term earnings forecast has been affected by the grounding of our boeing 737 max fleet, which we have removed from scheduled flying through aug. 19. we presently estimate the grounding of the 737 max will impact our 2019 pre-tax earnings by approximately $350 million. with the recent run-up in oil prices, fuel expenses for the year are also expected to be approximately $650 million higher than we forecast just three months ago ….”
Discussion
4. Conclusions
- Event Study;
- Market efficiency research;
- Investment strategies;
- Support for investment analysts using fundamental analysis.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Type of Text Data | Research Literature | ||
|---|---|---|---|
| Primary sources | Annual reports (K-10) | (Li 2006) (Loughran and McDonald 2011) (Jegadeesh and Wu 2013) | |
| Management Discussion and Analysis—MD&A included in annual and quarterly reports (10-Q and 10-K) | (Feldman et al. 2008) (Davis and Tama-Sweet 2012) | ||
| Information about initial public offerings (S-1) | (Loughran and McDonald 2013) | ||
| IPO prospectuses | (Jegadeesh and Wu 2013) (Ferris et al. 2013) | ||
| Earnings press releases | (Henry 2006a, 2006b) (Henry and Leone 2009) (Doran et al. 2012) (Davis and Tama-Sweet 2012) (Demers and Vega 2011) | ||
| Earnings conference calls | (Davis and Tama-Sweet 2012) (Larcker and Zakolyukina 2012) (Price et al. 2012) (Borochin et al. 2017) (Davis et al. 2015) | ||
| Restatements of financial reports | (Durnev and Mangen 2011) | ||
| Analyst reports | (Huang et al. 2014) | ||
| Others based on variety of primary sources | (Rogers et al. 2011) | ||
| Information on changes in the balance of ownership (13D) | (Aydogdu et al. 2019) | ||
| Information on changes in auditors of companies | (Holowczak et al. 2019) | ||
| Secondary sources | Media | Press and news services, such as Wall Street Journal, Dow Jones News Service, The New York Times, The Financial Times, The Times, The Guardian, Mirror, Thomson Reuters | (Cowles 1933) (Tetlock 2007) (Tetlock et al. 2008) (Engelberg 2008) (Sinha 2016) (García 2013) (Carretta et al. 2013) (Engelberg et al. 2012) (Ferguson et al. 2015) (Buehlmaier 2015) (Liu and McConnell 2013) |
| Stock message boards | (Antweiler and Frank 2004) (Das and Chen 2007) | ||
| Internet and social media | (Bollen et al. 2011) (Bartov et al. 2018) (Sun et al. 2016) | ||
References
- Antweiler, Werner, and Murray Z. Frank. 2004. Is All That Talk Just Noise? The Information Content of Internet Stock Message Boards. The Journal of Finance 59: 1259–94. [Google Scholar] [CrossRef]
- Aydogdu, Murat, Hakan Saraoglu, and David Louton. 2019. Using long short-term memory neural networks to analyze SEC 13D filings: A recipe for human and machine interaction. Intelligent Systems in Accounting, Finance and Management 26: 153–63. [Google Scholar] [CrossRef]
- Bartov, Eli, Lucile Faurel, and Partha S. Mohanram. 2018. Can Twitter Help Predict Firm-Level Earnings and Stock Returns? The Accounting Review 93: 25–57. [Google Scholar] [CrossRef] [Green Version]
- Bollen, Johan, Huina Mao, and Xiaojun Zeng. 2011. Twitter mood predicts the stock market. Journal of Computational Science 2: 1–8. [Google Scholar] [CrossRef] [Green Version]
- Borochin, Paul, Jim Cicon, Jared DeLisle, and S. McKay Price. 2017. The Effects of Conference Call Tones on Market Perceptions of Value Uncertainty. Available online: https://doi.org/10.2139/ssrn.2579907 (accessed on 18 December 2017).
- Buehlmaier, Matthias M. M. 2015. The Role of Media in Takeovers: Theory and Evidence. Available online: https://ssrn.com/abstract=167316 (accessed on 26 February 2015).
- Carretta, Alessandro, Vincenzo Farina, Elvira Anna Graziano, and Marco Reale. 2013. Does Investor Attention Influence Stock Market Activity? The Case of Spin-Off Deals. In Asset Pricing, Real Estate and Public Finance over the Crisis. Edited by Alessandro Carretta and Gianluca Mattarocci. London: Palgrave Macmillan, pp. 7–24. [Google Scholar] [CrossRef] [Green Version]
- Cowles, Alfred, 3rd. 1933. Can Stock Market Forecasters Forecast? Journal of the Econometric Society 1: 309–24. [Google Scholar] [CrossRef] [Green Version]
- Das, Sanjiv R., and Mike Y. Chen. 2007. Yahoo! for Amazon: Sentiment Extraction from Small Talk on the Web. Management Science 53: 1375–88. [Google Scholar] [CrossRef] [Green Version]
- Davis, Angela K., and Isho Tama-Sweet. 2012. Managers’ Use of Language Across Alternative Disclosure Outlets: Earnings Press Releases versus MD&A*: Language in Earnings Press Releases vs. MD&A. Contemporary Accounting Research 29: 804–37. [Google Scholar] [CrossRef]
- Davis, Angela K., Jeremy M. Piger, and Lisa M. Sedor. 2011. Beyond the Numbers: Measuring the Information Content of Earnings Press Release Language. AAA 2008 Financial Accounting and Reporting Section (FARS) Paper. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1911-3846.2011.01130.x (accessed on 1 October 2021).
- Davis, Angela K., Weili Ge, Dawn Matsumoto, and Jenny Li Zhang. 2015. The effect of manager-specific optimism on the tone of earnings conference calls. Review of Accounting Studies 20: 639–73. [Google Scholar] [CrossRef]
- Demers, Elizabeth, and Clara Vega. 2011. Linguistic Tone in Earnings Announcements: News or Noise? FRB International Finance Discussion Paper. Available online: https://www.researchgate.net/publication/228258461_Linguistic_Tone_in_Earnings_Announcements_News_or_Noise (accessed on 1 October 2021).
- Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv arXiv:1810.04805. [Google Scholar]
- Doran, James S., David R. Peterson, and S. McKay Price. 2012. Earnings Conference Call Content and Stock Price: The Case of REITs. The Journal of Real Estate Finance and Economics 45: 402–34. [Google Scholar] [CrossRef]
- Durnev, Art, and Claudine Mangen. 2011. The Real Effects of Disclosure Tone: Evidence from Restatements. Available online: https://dx.doi.org/10.2139/ssrn.1650003 (accessed on 12 September 2011).
- El-Haj, Mahmoud, Paul Edward Rayson, Steven Eric Young, Martin Walker, Andrew Moore, Vasiliki Athanasakou, and Thomas Schleicher. 2016. Learning Tone and Attribution for Financial Text Mining. Paper presented at Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, May 23–28; pp. 1820–25. [Google Scholar]
- Engelberg, Joseph. 2008. Costly Information Processing: Evidence from Earnings Announcements. AFA 2009 San Francisco Meetings Paper. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1107998 (accessed on 1 October 2021).
- Engelberg, Joseph E., Adam V. Reed, and Matthew C. Ringgenberg. 2012. How are shorts informed? Journal of Financial Economics 105: 260–78. [Google Scholar] [CrossRef]
- Feldman, Ronen, Suresh Govindaraj, Joshua Livnat, and Benjamin Segal. 2008. The Incremental Information Content of Tone Change in Management Discussion and Analysis. NYU Working Paper No. 2451/27580. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1280743 (accessed on 1 October 2021).
- Ferguson, Nicky J., Dennis Philip, Herbert Y. T. Lam, and Jie Michael Guo. 2015. Media Content and Stock Returns: The Predictive Power of Press. Multinational Finance Journal 19: 1–31. [Google Scholar] [CrossRef] [Green Version]
- Ferris, Stephen P., Qing Hao, and Min-Yu Liao. 2013. The Effect of Issuer Conservatism on IPO Pricing and Performance. Review of Finance 17: 993–1027. [Google Scholar] [CrossRef]
- García, Diego. 2013. Sentiment during Recessions: Sentiment during Recessions. The Journal of Finance 68: 1267–300. [Google Scholar] [CrossRef]
- Healy, Paul M., and Krishna G. Palepu. 2013. Business Analysis & Valuation: Using Financial Statements, 5th ed. Mason: South-Western, Cencage Learning, pp. 12–14. [Google Scholar]
- Henry, Elaine. 2006a. Are Investors Influenced by How Earnings Press Releases Are Written? Available online: https://journals.sagepub.com/doi/abs/10.1177/0021943608319388 (accessed on 1 October 2021).
- Henry, Elaine. 2006b. Market Reaction to Verbal Components of Earnings Press Releases: Event Study Using a Predictive Algorithm. Journal of Emerging Technologies in Accounting 3: 1–19. [Google Scholar] [CrossRef]
- Henry, Elaine, and Andrew J. Leone. 2009. Measuring Qualitative Information in Capital Markets Research. Available online: https://dx.doi.org/10.2139/ssrn.1470807 (accessed on 9 September 2009).
- Holowczak, Richard, David Louton, and Hakan Saraoglu. 2019. Testing market response to auditor change filings: A comparison of machine learning classifiers. The Journal of Finance and Data Science 5: 48–59. [Google Scholar] [CrossRef]
- Huang, Allen H., Amy Y. Zang, and Rong Zheng. 2014. Evidence on the Information Content of Text in Analyst Reports. The Accounting Review 89: 2151–80. [Google Scholar] [CrossRef] [Green Version]
- Jegadeesh, Narasimhan, and Di Wu. 2013. Word power: A new approach for content analysis. Journal of Financial Economics 110: 712–29. [Google Scholar] [CrossRef] [Green Version]
- Kearney, Colm, and Sha Liu. 2014. Textual sentiment in finance: A survey of methods and models. International Review of Financial Analysis 33: 171–85. [Google Scholar] [CrossRef] [Green Version]
- Kliger, Doron, and Gregory Gurevich. 2014. Event Studies for Financial Research: A Comprehensive Guide. Basingstoke: Palgrave Macmillan. [Google Scholar]
- Larcker, David F., and Anastasia A. Zakolyukina. 2012. Detecting Deceptive Discussions in Conference Calls: Detecting deceptive discussions in conference calls. Journal of Accounting Research 50: 495–540. [Google Scholar] [CrossRef]
- Li, Feng. 2006. Do Stock Market Investors Understand the Risk Sentiment of Corporate Annual Reports? Available online: https://dx.doi.org/10.2139/ssrn.898181 (accessed on 21 April 2006).
- Li, Feng. 2010. The Information Content of Forward-Looking Statements in Corporate Filings-A Naïve Bayesian Machine Learning Approach: The information content of corporate filings. Journal of Accounting Research 48: 1049–102. [Google Scholar] [CrossRef]
- Liu, Baixiao, and John J. McConnell. 2013. The role of the media in corporate governance: Do the media influence managers’ capital allocation decisions? Journal of Financial Economics 110: 1–17. [Google Scholar] [CrossRef]
- Loughran, Tim, and Bill McDonald. 2011. When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. The Journal of Finance 66: 35–65. [Google Scholar] [CrossRef]
- Loughran, Tim, and Bill McDonald. 2013. IPO first-day returns, offer price revisions, volatility, and form S-1 language. Journal of Financial Economics 109: 307–26. [Google Scholar] [CrossRef]
- MacKinlay, A. Craig. 1997. Event Studies in Economics and Finance. Journal of Economic Literature 35: 13–39. [Google Scholar]
- Price, S. McKay, James S. Doran, David R. Peterson, and Barbara A. Bliss. 2012. Earnings conference calls and stock returns: The incremental informativeness of textual tone. Journal of Banking & Finance 36: 992–1011. [Google Scholar] [CrossRef]
- Rogers, Jonathan L., Andrew Van Buskirk, and Sarah L. C. Zechman. 2011. Disclosure Tone and Shareholder Litigation. The Accounting Review 86: 2155–83. [Google Scholar] [CrossRef]
- Sinha, Nitish Ranjan. 2016. Underreaction to News in the US Stock Market. Quarterly Journal of Finance 6: 1650005. [Google Scholar] [CrossRef]
- Sun, Andrew, Michael Lachanski, and Frank J. Fabozzi. 2016. Trade the tweet: Social media text mining and sparse matrix factorization for stock market prediction. International Review of Financial Analysis 48: 272–81. [Google Scholar] [CrossRef]
- Tetlock, Paul C. 2007. Giving Content to Investor Sentiment: The Role of Media in the Stock Market. The Journal of Finance 62: 1139–68. [Google Scholar] [CrossRef]
- Tetlock, Paul C., Maytal Saar-Tsechansky, and Sofus Macskassy. 2008. More Than Words: Quantifying Language to Measure Firms’ Fundamentals. The Journal of Finance 63: 1437–67. [Google Scholar] [CrossRef]




| Scientific Publication | Study Period | Source of Text Data | Content Analysis Methods | Models | Event Window Width | Market Response |
|---|---|---|---|---|---|---|
| (Henry 2006b) | 1998–2002 | Earnings press releases | Dictionary based (Diction 5.0) | Linear regression, event study | 3 days | The tone of press releases influences the market response as measured by the CAR |
| (Henry and Leone 2009) | 2004–2006 | Earnings press releases | Dictionary based (Henry DICTION, GI/Harvard) | Linear regression, event study | 3 days | The tone of press releases influences the market response as measured by the CAR, with stronger negative tone influence. |
| (Doran et al. 2012) | 2004–2007 | Earnings conference calls | Dictionary based (Henry DICTION, GI, Henry) | Linear regression, event study | 2 days, 9 days, 21 days | The tone of conference calls has an impact on the market response measured by the CAR—significant in the 2-day range |
| (Davis et al. 2011) | 1998–2003 | Earnings press releases | Dictionary based (DICTION) | Linear regression, event study | 3 days | The language of press releases influences the market response as measured by the CAR |
| (Demers and Vega 2011) | 1998–2006 | Earnings press releases | Dictionary based (DICTION, GI/Harvard, LM) | Linear regression, event study | 3 days | The optimism expressed by management in the press releases has an informative content that is valued by the market CAR |
| (Price et al. 2012) | 2004–2007 | Earnings conference calls | Dictionary based (GI/Harvard Henry) | Linear regression, event study | 3 days, 59 days | The language of conference calls influences the market response as measured by the CAR |
| Categories of Events | Scope of Information |
|---|---|
| Registrant’s business and operations | Entry and termination of material definitive agreement, bankruptcy or receivership, reporting of shutdowns and patterns of violations in mines. |
| Financial Information | Acquisition or disposition of assets, results of operations and financial condition, creation and change of a balance sheet or off-balance sheet liability, costs associated with exit or disposal activities, material impairments. |
| Securities and trading markets | Issues concerning delisting for any class of the registrant’s common equity, unregistered sales of equity securities, modification to rights of security holders. |
| Matters related to accountants and financial statements | Changes in company’s certifying accountant, non-reliance on previously issued financial statements or a related audit report or completed interim review. |
| Corporate governance and management | Changes in control of registrant, changes in management stuff, amendments to articles of incorporation or bylaws, change in fiscal year, temporary suspension of trading under registrant’s employee benefit plans, amendments to the registrant’s code of ethics, change in shell company status, submission of matters to a vote of security holders, shareholder director nominations. |
| Asset-backed securities | Informational and computational material, change of servicer or trustee, change in credit or other external support, failure in securities distribution. |
| Fair disclosure regulation | Disclosure of any information that has been shared with other certain individuals or entities. |
| Other Events | Any events, with respect to which information is not otherwise called for by the 8-K form, that the registrant deems of importance to security holders. |
| Financial statements and exhibits | Pro forma financial information and exhibits, financial statements of businesses or funds acquired, pro forma financial information, shell company transactions, other exhibits. |
| Text | Class Label |
|---|---|
| “(nasdaq: akam), the world’s largest and most trusted cloud delivery platform, today reported financial results for the fourth quarter and full-year ended 31 December 2018. “we were very pleased with our strong finish to the year. both revenue and earnings exceeded our expectations due to the very rapid growth of our cloud security business, robust seasonal traffic and our continued focus on operational excellence,” said dr. tom leighton, ceo of akamai. “as a result, we achieved our fifth consecutive quarter of non-gaap operating margin improvement, and we are well on our way to achieving our 30% margin goal in 2020 …” | POSITIVE (1) |
| “(nasdaq: chrw) today reported financial results for the quarter ended 30 September 2019. “the third quarter provided challenges in both our north american surface transportation and global forwarding segments. our net revenues, operating income, and eps results finished below our long-term expectations. we anticipated an aggressive industry pricing environment coming into the second half of this year driven by excess capacity and softening demand and knew we faced difficult comparisons versus our strong double-digit net revenue growth in the second half of last year. our results were negatively impacted by truckload margin compression in north america,” said bob biesterfeld, chief executive officer …” | NEGATIVE (0) |
| Model | Validation Accuracy | Precision POSITIVE | Precision NEGATIVE |
|---|---|---|---|
| BERT | 52.68% | 62.38% | 55.00% |
| Baseline | 44.97% | 59.00% | 48.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wujec, M. Analysis of the Financial Information Contained in the Texts of Current Reports: A Deep Learning Approach. J. Risk Financial Manag. 2021, 14, 582. https://doi.org/10.3390/jrfm14120582
Wujec M. Analysis of the Financial Information Contained in the Texts of Current Reports: A Deep Learning Approach. Journal of Risk and Financial Management. 2021; 14(12):582. https://doi.org/10.3390/jrfm14120582
Chicago/Turabian StyleWujec, Maciej. 2021. "Analysis of the Financial Information Contained in the Texts of Current Reports: A Deep Learning Approach" Journal of Risk and Financial Management 14, no. 12: 582. https://doi.org/10.3390/jrfm14120582