
Hill Climbing-Based Efficient Model for Link Prediction in Undirected Graphs

 ,
,  and
and 
Abstract
:1. Introduction
- We introduce a different approach to link prediction based on hill climbing criteria with quasi and local complex network features.The proposed method computes the cost function value, and the lower cost function provides a higher accuracy result.
- We conduct studies on many complex networks of various sizes and structures, assessing the different link prediction approaches.
Motivation
- The proposed work simultaneously makes use of many topological properties.
- In order to overcome the shortcomings of other algorithms, the revised hill climbing base solution is offered. In each state, it selects the lowest-cost topological feature for link prediction.
- Compared to other prediction indexes, it improved link prediction accuracy.
- The proposed approach has only been evaluated on undirected networks, ignoring directed and weighted networks.
- The proposed work also requires longer execution times for large networks, similar to other algorithms.
2. Preliminary
2.1. Similarity-Based Methods
2.2. Embedding-Based Methods
2.3. Probabilistic-Based Method
3. Materials and Methods
3.1. Evaluation Metric
3.2. Datasets

{kind=link}
{kind=link}
{kind=link}
| Datasets | N | E | MaxD | Avg D | |
|---|---|---|---|---|---|
| Elegans [58] | 279 | 2287 | 268 | 16.394 | 0.059 |
| US Air [59] | 500 | 2980 | 139 | 11.92 | 0.024 |
| Routers [61] | 3722 | 6258 | 103 | 2.493 | 0.00091 |
| US Power Grid [60] | 4939 | 6594 | 19 | 2.67 | 0.00054 |
| Yeast [62] | 1458 | 1948 | 56 | 2.7 | 0.0.0018 |
| Karate [63] | 33 | 78 | 17 | 4.5882 | 0.1477 |
| Dolphin [60] | 62 | 159 | 12 | 5.1290 | 0.0841 |
| Hamsters [64] | 2426 | 16631 | 273 | 13.710 | 0.0057 |
| RouteViews [65] | 6474 | 13,895 | 1459 | 4.293 | 0.00067 |
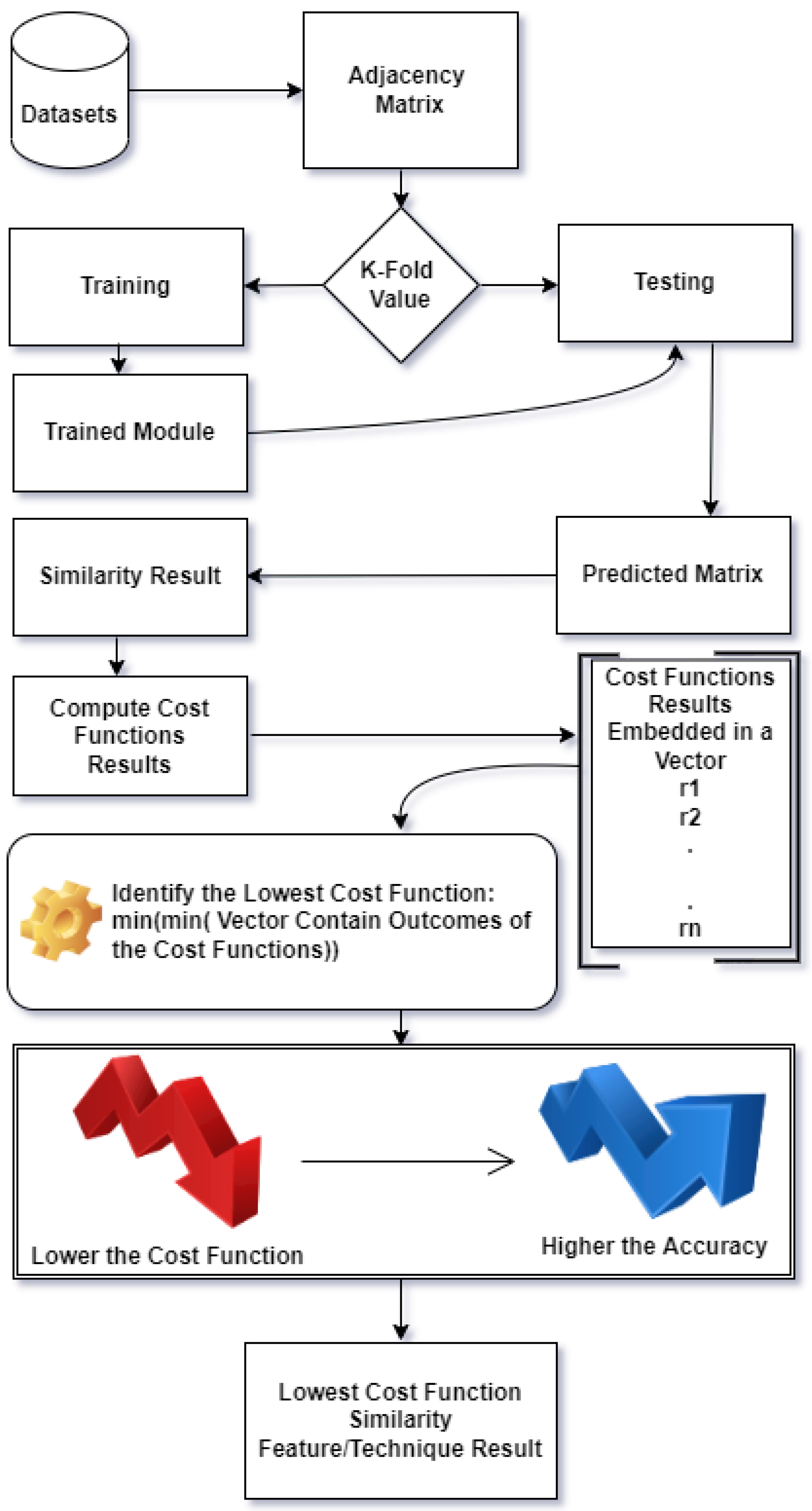
3.3. Methodology
- Selection of Source Node: The source node x has been selected following the dataset sequence.
- Backtrack-less: At this stage, various quasi and local feature algorithms are applied to identify the targeted node y for source node x. Usually, each algorithm works based on one or two complex network features. These features or techniques are used to find similarity, and then the cost function is used to compute the cost value for each feature. All the cost function results are then embedded in a vector and compared with each other. Finally, identified the lowest cost and highest similarity feature. As a result of a higher similarity (between pairs of nodes x and y) and a low-cost feature/technique, the targeted node has been identified (link predicted). This phenomenon is called “backtrack-less walk”. Because it does not move toward the last node to compare it to the present node, which is the pure workflow of hill climbing, this is the major difference between hill climbing and our proposed work, presented in this paper for link prediction.
- Incremental: Once the targeted node y has been discovered using the lowest cost feature(s) algorithm, we move to the next node. Each node is expressed with a numerical value in the datasets, such as . The next node is thus chosen randomly. This approach has been followed to predict links across the whole network.
| Algorithm 1 Hill-Climbing-Based Link Prediction |
|
3.4. Comparative Analysis
4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Urena, R.; Kou, G.; Dong, Y.; Chiclana, F.; Herrera-Viedma, E. A review on trust propagation and opinion dynamics in social networks and group decision making frameworks. Inf. Sci. 2019, 478, 461–475. [Google Scholar] [CrossRef]
- Coquidé, C.; Georgeot, B.; Giraud, O. Distinguishing humans from computers in the game of go: A complex network approach. EPL (Europhys. Lett.) 2017, 119, 48001. [Google Scholar] [CrossRef] [Green Version]
- Wu, M.; Ye, Z.; Wen, X.; Jiang, X. Air traffic complexity recognition method based on complex networks. J. Beijing Univ. Aeronaut. Astronaut. 2020, 46, 839–850. [Google Scholar]
- Bodaghi, A.; Goliaei, S.; Salehi, M. The number of followings as an influential factor in rumor spreading. Appl. Math. Comput. 2019, 357, 167–184. [Google Scholar] [CrossRef]
- Zengping, Z.; Yu, H.; Kuanyun, G.; Bo, L.; Yinghao, Z. Scale-free Characteristics and Link Prediction in Complex Railway Network. J. Phys. Conf. Ser. 2021, 1955, 012099. [Google Scholar] [CrossRef]
- Sahhaf, S.; Tavernier, W.; Papadimitriou, D.; Careglio, D.; Kumar, A.; Glacet, C.; Coudert, D.; Nisse, N.; Fàbrega, L.; Vilà, P.; et al. Routing at large scale: Advances and challenges for complex networks. IEEE Netw. 2017, 31, 108–118. [Google Scholar] [CrossRef] [Green Version]
- Liben-Nowell, D.; Kleinberg, J. The link-prediction problem for social networks. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1019–1031. [Google Scholar] [CrossRef] [Green Version]
- Gallagher, B.; Tong, H.; Eliassi-Rad, T.; Faloutsos, C. Using ghost edges for classification in sparsely labeled networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 256–264. [Google Scholar]
- Huang, Z.; Zeng, D.D. A link prediction approach to anomalous email detection. In Proceedings of the 2006 IEEE International Conference on Systems, Man and Cybernetics, Taipei, Taiwan, 8–11 October 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2, pp. 1131–1136. [Google Scholar]
- Kaya, B. A hotel recommendation system based on customer location: A link prediction approach. Multimed. Tools Appl. 2020, 79, 1745–1758. [Google Scholar] [CrossRef]
- Dhannuri, S.P.; Sonbhadra, S.K.; Agarwal, S.; Nagabhushan, P.; Syafrullah, M.; Adivarta, K. Privacy control in social networks by trust aware link prediction. In Proceedings of the 2019 6th International Conference on Electrical Engineering, Computer Science and Informatics (EECSI), Bandung, Indonesia, 18–20 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 410–415. [Google Scholar]
- Folino, F.; Pizzuti, C. Link prediction approaches for disease networks. In Proceedings of the International Conference on Information Technology in Bio-and Medical Informatics, Vienna, Austria, 4–5 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 99–108. [Google Scholar]
- Gul, H.; Al-Obeidat, F.; Moreira, F.; Tahir, M.; Amin, A. Real-World Protein Particle Network Reconstruction Based on Advanced Hybrid Features. In Proceedings of the International Conference on Information Technology and Applications, Dubai, United Arab Emirates, 13–14 November 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 15–22. [Google Scholar]
- Lü, L.; Zhou, T. Linkprediction in complex networks: A survey. Phys. A Stat. Mech. Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef] [Green Version]
- Pavlov, M.; Ichise, R. Finding experts by link prediction in co-authorship networks. FEWS 2007, 290, 42–55. [Google Scholar]
- Zhang, Q.M.; Shang, M.S.; Lü, L. Similarity-based classification in partially labeled networks. Int. J. Mod. Phys. C 2010, 21, 813–824. [Google Scholar] [CrossRef] [Green Version]
- Lei, C.; Ruan, J. A novel link prediction algorithm for reconstructing protein–protein interaction networks by topological similarity. Bioinformatics 2013, 29, 355–364. [Google Scholar] [CrossRef] [PubMed]
- Pinto, M.; Rodrigues, A.; Varajão, J.; Gonçalves, R. Model of funcionalities for the development of B2B E-Commerce solutions. In Innovations in SMEs and Conducting E-Business: Technologies, Trends and Solutions; IGI Global: Hershey, PA, USA, 2011; pp. 35–60. [Google Scholar]
- Martínez, V.; Berzal, F.; Cubero, J.C. A survey of link prediction in complex networks. ACM Comput. Surv. (CSUR) 2016, 49, 1–33. [Google Scholar] [CrossRef]
- Aghabozorgi, F.; Khayyambashi, M.R. A new similarity measure for link prediction based on local structures in social networks. Phys. A Stat. Mech. Appl. 2018, 501, 12–23. [Google Scholar] [CrossRef]
- Pecli, A.; Cavalcanti, M.C.; Goldschmidt, R. Automatic feature selection for supervised learning in link prediction applications: A comparative study. Knowl. Inf. Syst. 2018, 56, 85–121. [Google Scholar] [CrossRef]
- Li, S.; Liu, M.; Li, H.; Hui, Y.; Chen, Z. Effects of structural damping on wind-induced responses of a 243-meter-high solar tower based on a novel elastic test model. J. Wind Eng. Ind. Aerodyn. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Wasim, M. Link Prediction Using Double Degree Equation with Mutual and Popular Nodes. In Trends and Applications in Information Systems and Technologies: Volume 4; Springer: Berlin/Heidelberg, Germany, 2021; p. 328. [Google Scholar]
- Gao, H.; Huang, J.; Cheng, Q.; Sun, H.; Wang, B.; Li, H. Link prediction based on linear dynamical response. Phys. A Stat. Mech. Appl. 2019, 527, 121397. [Google Scholar] [CrossRef]
- Clauset, A.; Moore, C.; Newman, M.E. Hierarchical structure and the prediction of missing links in networks. Nature 2008, 453, 98. [Google Scholar] [CrossRef] [Green Version]
- Zhu, B.; Xia, Y. An information-theoretic model for link prediction in complex networks. Sci. Rep. 2015, 5, 13707. [Google Scholar] [CrossRef] [Green Version]
- Pech, R.; Hao, D.; Pan, L.; Cheng, H.; Zhou, T. Link prediction via matrix completion. EPL (Europhys. Lett.) 2017, 117, 38002. [Google Scholar] [CrossRef] [Green Version]
- Prajapati, K.; Shah, H.; Mehta, R. A Survey of Link Prediction in Social Network Using Deep Learning Approach. 2020. Available online: http://ir.paruluniversity.ac.in/xmlui/handle/123456789/7878 (accessed on 28 June 2022).
- Xu, J.; Liu, A.; Xiong, N.; Wang, T.; Zuo, Z. Integrated collaborative filtering recommendation in social cyber-physical systems. Int. J. Distrib. Sens. Netw. 2017, 13, 1550147717749745. [Google Scholar] [CrossRef] [Green Version]
- Esslimani, I.; Brun, A.; Boyer, A. Densifying a behavioral recommender system by social networks link prediction methods. Soc. Netw. Anal. Min. 2011, 1, 159–172. [Google Scholar] [CrossRef]
- Perez-Cervantes, E.; Mena-Chalco, J.P.; De Oliveira, M.C.F.; Cesar, R.M. Using link prediction to estimate the collaborative influence of researchers. In Proceedings of the 2013 IEEE 9th International Conference on e-Science, Beijing, China, 22–25 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 293–300. [Google Scholar]
- Huang, S.; Ma, L. Social Network Link Prediction Algorithm Based on Node Similarity. In Proceedings of the 2022 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1357–1360. [Google Scholar]
- Lü, L.; Jin, C.H.; Zhou, T. Similarity index based on local paths for link prediction of complex networks. Phys. Rev. E 2009, 80, 046122. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Y.; Liu, S.; Yu, F.; Yang, X. Link prediction algorithm based on the initial information contribution of nodes. Inf. Sci. 2022, 608, 1591–1616. [Google Scholar] [CrossRef]
- Kerrache, S.; Alharbi, R.; Benhidour, H. A scalable similarity-popularity link prediction method. Sci. Rep. 2020, 10, 6394. [Google Scholar] [CrossRef] [Green Version]
- Bai, M.; Hu, K.; Tang, Y. Link prediction based on a semi-local similarity index. Chin. Phys. B 2011, 20, 128902. [Google Scholar] [CrossRef]
- Liu, W.; Lü, L. Link prediction based on local random walk. EPL (Europhys. Lett.) 2010, 89, 58007. [Google Scholar] [CrossRef] [Green Version]
- Divakaran, A.; Mohan, A. Temporal link prediction: A survey. New Gener. Comput. 2020, 38, 213–258. [Google Scholar] [CrossRef]
- Wang, H.; Le, Z. Seven-layer model in complex networks link prediction: A survey. Sensors 2020, 20, 6560. [Google Scholar] [CrossRef]
- Wang, P.; Xu, B.; Wu, Y.; Zhou, X. Link prediction in social networks: The state-of-the-art. Sci. China Inf. Sci. 2015, 58, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et des Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar]
- Adamic, L.A.; Adar, E. Friends and neighbors on the web. Soc. Netw. 2003, 25, 211–230. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Lü, L.; Zhang, Y.C. Predicting missing links via local information. Eur. Phys. J. B 2009, 71, 623–630. [Google Scholar] [CrossRef]
- Feng, X.; Zhao, J.; Xu, K. Link prediction in complex networks: A clustering perspective. Eur. Phys. J. B 2012, 85, 3. [Google Scholar] [CrossRef] [Green Version]
- Barabâsi, A.L.; Jeong, H.; Néda, Z.; Ravasz, E.; Schubert, A.; Vicsek, T. Evolution of the social network of scientific collaborations. Phys. A Stat. Mech. Appl. 2002, 311, 590–614. [Google Scholar] [CrossRef] [Green Version]
- Ravasz, E.; Somera, A.L.; Mongru, D.A.; Oltvai, Z.N.; Barabási, A.L. Hierarchical organization of modularity in metabolic networks. Science 2002, 297, 1551–1555. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leicht, E.A.; Holme, P.; Newman, M.E. Vertex similarity in networks. Phys. Rev. E 2006, 73, 026120. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.X.; Lü, L.; Zhang, Q.M.; Zhou, T. Uncovering missing links with cold ends. Phys. A Stat. Mech. Appl. 2012, 391, 5769–5778. [Google Scholar] [CrossRef] [Green Version]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Airoldi, E.M.; Blei, D.; Fienberg, S.; Xing, E. Mixed membership stochastic blockmodels. Adv. Neural Inf. Process. Syst. 2008, 21. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Qiu, J.; Dong, Y.; Ma, H.; Li, J.; Wang, K.; Tang, J. Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 5–9 February 2018; pp. 459–467. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational graph auto-encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Lichtenwalter, R.N.; Lussier, J.T.; Chawla, N.V. New perspectives and methods in link prediction. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–28 July 2010; pp. 243–252. [Google Scholar]
- Fındık, O.; Özkaynak, E. Link prediction based on node weighting in complex networks. Soft Comput. 2021, 25, 2467–2482. [Google Scholar] [CrossRef]
- Jinseop, K.; Marcus, K. From Caenorhabditis elegans to the human connectome: A specific modular organization increases metabolic, functional and developmental efficiency. Philos. Trans. R. Soc. B 2014, 369, 20130529. [Google Scholar]
- Colizza, V.; Pastor-Satorras, R.; Vespignani, A. Reaction-diffusion processes and metapopulation models in heterogeneous networks. Nat. Phys. 2007, 3, 027104. [Google Scholar] [CrossRef] [Green Version]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the AAAI, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Spring, N.; Mahajan, R.; Wetherall, D. Measuring ISP topologies with Rocketfuel. In Proceedings of the SIGCOMM, Pittsburgh, PA, USA, 19–23 August 2002; Volume 32, pp. 133–145. [Google Scholar]
- Von Mering, C.; Krause, R.; Snel, B.; Cornell, M.; Oliver, S.G.; Fields, S.; Bork, P. Comparative assessment of large-scale data sets of protein–protein interactions. Nature 2002, 417, 399–403. [Google Scholar] [CrossRef]
- Zachary, W.W. An Information Flow Model for Conflict and Fission in Small Groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 2-es. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Keikha, M.M.; Rahgozar, M.; Asadpour, M. Community aware random walk for network embedding. Knowl.-Based Syst. 2018, 148, 47–54. [Google Scholar] [CrossRef] [Green Version]
- Pech, R.; Hao, D.; Lee, Y.L.; Yuan, Y.; Zhou, T. Link prediction via linear optimization. Phys. A Stat. Mech. Appl. 2019, 528, 121319. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Zhang, X.D. Predicting missing links in complex networks based on common neighbors and distance. Sci. Rep. 2016, 6, 38208. [Google Scholar] [CrossRef] [PubMed]



| Previous Work | Elegans | Routers | US Power | Yeast | Karate | Dolphin |
|---|---|---|---|---|---|---|
| Double-Degree [52] | X | 65.07% | 85.97% | 83.99% | X | X |
| Node2Vec [66] | X | 58.98% | 85.98% | 78.95% | X | X |
| LINE [53] | X | 67.03% | 82.09% | 85.97% | X | X |
| SDNE [67] | X | 65.52% | 84.03% | 84.05% | X | X |
| CARE [66] | X | 65.28% | 89.65% | 88.59% | X | X |
| CELP [66] | X | 68.88% | 91.08% | 90.68% | X | X |
| CALP [66] | X | 70.99% | 92.27% | 91.77% | X | X |
| LO [68] | 67.51% | X | X | 80.16% | 63.82% | 73.04% |
| CND [69] | 85.79% | X | X | 80.16% | 63.82% | 73.04% |
| Proposed | 88.24% | 82.03% | 93.02% | 94.97% | 78.01% | 82.65% |
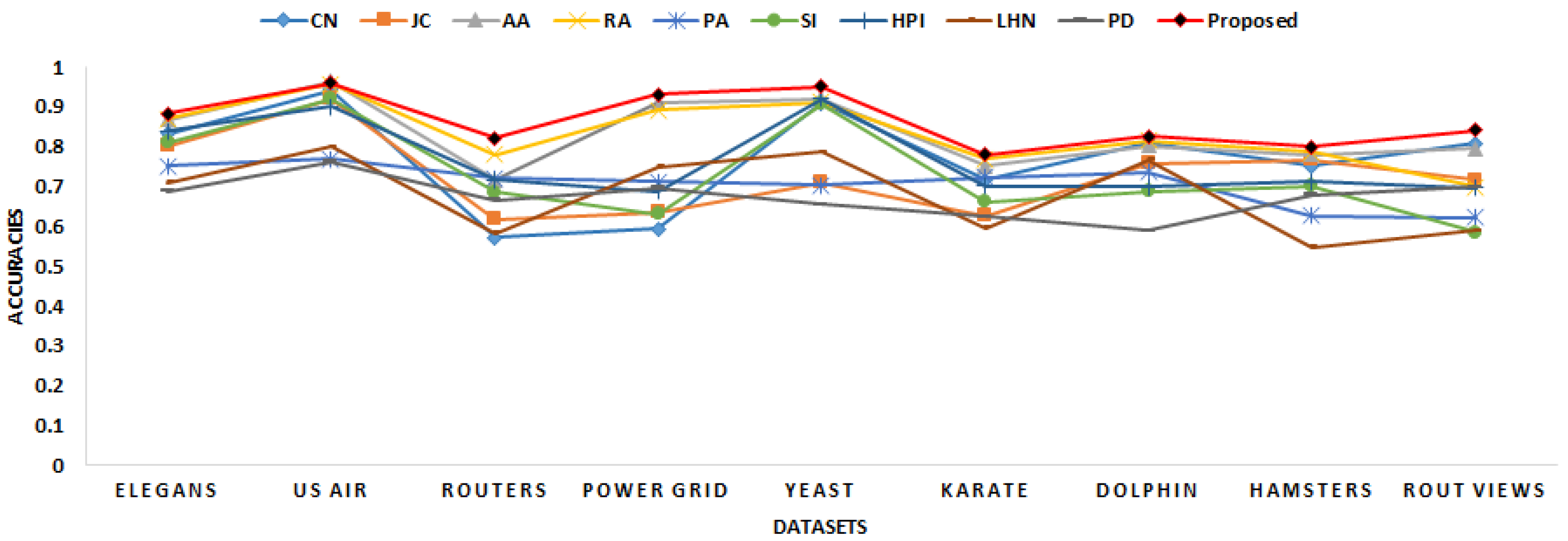
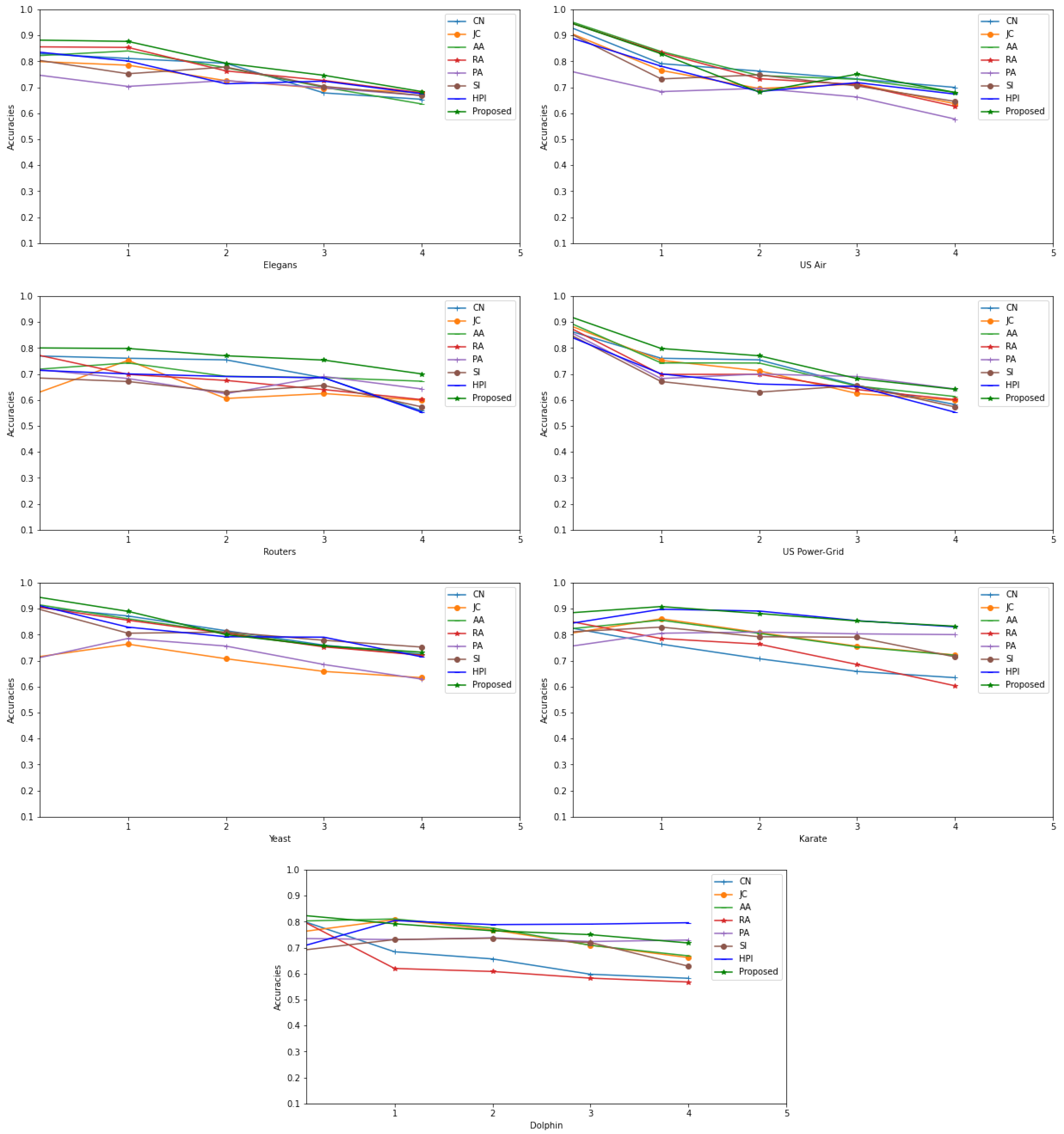
| Datasets | CN | JC | AA | RA | PA | SI | HPI | LHN | PD | Proposed |
|---|---|---|---|---|---|---|---|---|---|---|
| Elegans | 0.8312 | 0.8007 | 0.8671 | 0.8701 | 0.7512 | 0.8093 | 0.8389 | 0.7101 | 0.6883 | 0.8824 |
| US Air | 0.9423 | 0.9202 | 0.9631 | 0.9572 | 0.7682 | 0.9201 | 0.8998 | 0.8002 | 0.7624 | 0.9581 |
| Routers | 0.5708 | 0.6169 | 0.7161 | 0.7795 | 0.7204 | 0.6859 | 0.7154 | 0.5832 | 0.6656 | 0.8203 |
| US Power Grid | 0.5927 | 0.6354 | 0.9083 | 0.8913 | 0.7108 | 0.6308 | 0.6885 | 0.7491 | 0.6955 | 0.9302 |
| Yeast | 0.9086 | 0.7105 | 0.9206 | 0.9108 | 0.7035 | 0.9076 | 0.9207 | 0.7864 | 0.6553 | 0.9497 |
| Karate | 0.7167 | 0.6253 | 0.7502 | 0.7691 | 0.7233 | 0.6624 | 0.7005 | 0.5965 | 0.6237 | 0.7801 |
| Dolphin | 0.8103 | 0.7587 | 0.8021 | 0.0.8145 | 0.7355 | 0.6878 | 0.6991 | 0.7658 | 0.5896 | 0.8265 |
| Hamsters | 0.7502 | 0.7658 | 0.7789 | 0.7854 | 0.6254 | 0.6999 | 0.7125 | 0.5471 | 0.6785 | 0.8001 |
| Route Views | 0.8088 | 0.7165 | 0.7953 | 0.0.6987 | 0.6214 | 0.5844 | 0.6963 | 0.5896 | 0.6987 | 0.8399 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gul, H.; Al-Obeidat, F.; Amin, A.; Moreira, F.; Huang, K. Hill Climbing-Based Efficient Model for Link Prediction in Undirected Graphs. Mathematics 2022, 10, 4265. https://doi.org/10.3390/math10224265
Gul H, Al-Obeidat F, Amin A, Moreira F, Huang K. Hill Climbing-Based Efficient Model for Link Prediction in Undirected Graphs. Mathematics. 2022; 10(22):4265. https://doi.org/10.3390/math10224265
Chicago/Turabian StyleGul, Haji, Feras Al-Obeidat, Adnan Amin, Fernando Moreira, and Kaizhu Huang. 2022. "Hill Climbing-Based Efficient Model for Link Prediction in Undirected Graphs" Mathematics 10, no. 22: 4265. https://doi.org/10.3390/math10224265