
Technical Language Processing of Nuclear Power Plants Equipment Reliability Data

Abstract
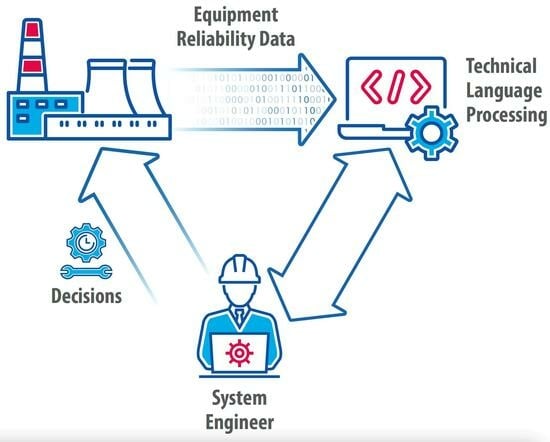
1. Introduction
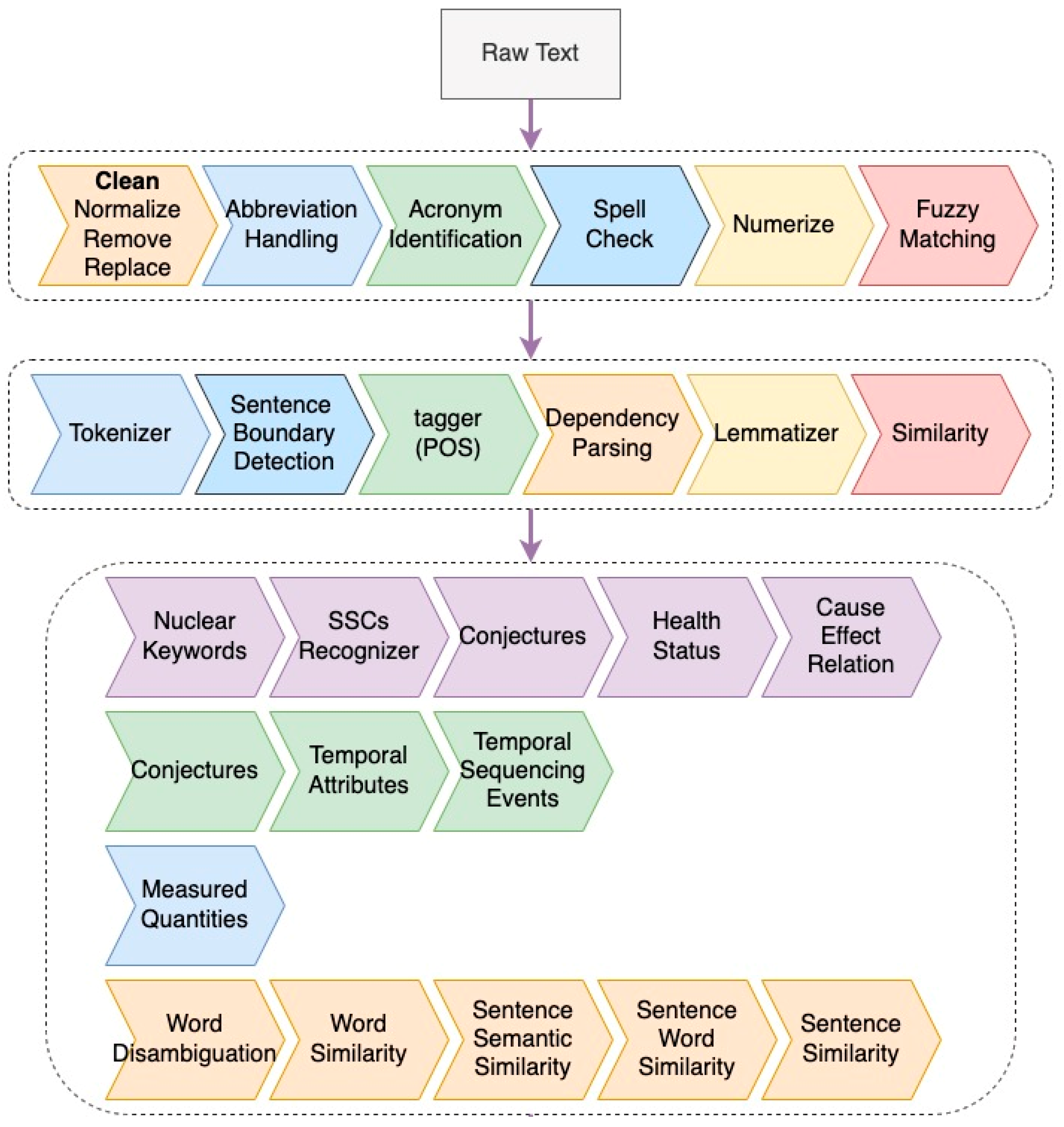
2. Knowledge Extraction Methods
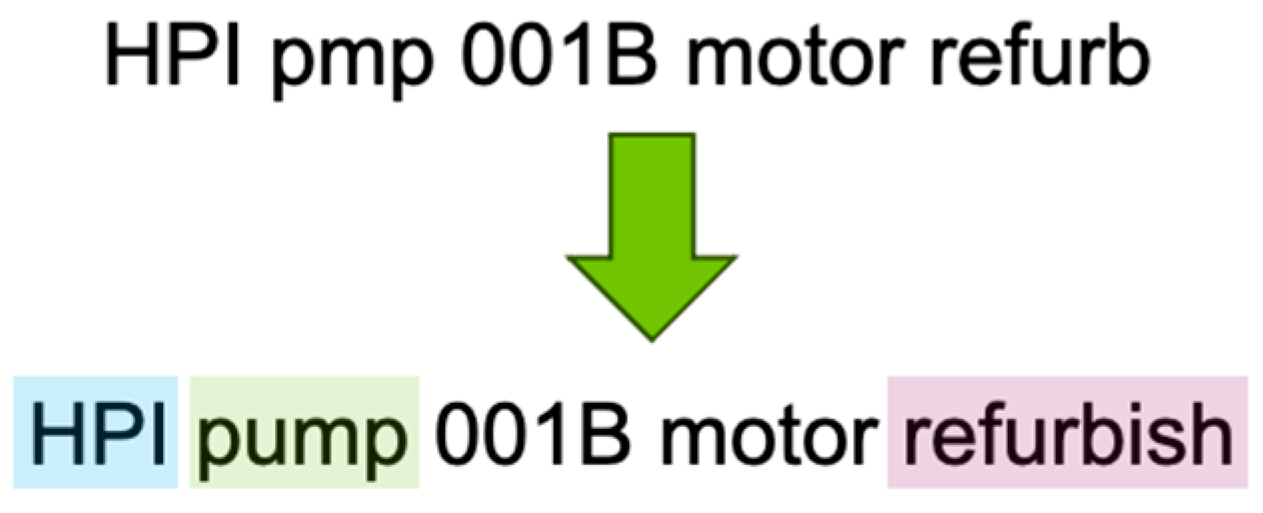
- Text preprocessing: The provided raw text is cleaned and processed in order to identify specific nuclear entities and acronyms (e.g., HPI in reference to a high-pressure injection system), and to identify and correct typos (i.e., through a spell check method) and abbreviations (e.g., “pmp” meaning “pump”).
- Syntactic analysis: The goal of this analysis is to identify the relationship between words contained within a sentence, the focus being on understanding the logical meaning of sentences or parts of sentences (e.g., subjects, predicates, and complements).
- Semantic analysis: We rely on the results of this analysis to identify the nature of the event(s) described in the text, along with their possible relationships (temporal or causal).
2.1. Spellcheck, Acronym, and Abbreviation Handling

2.2. Sentence Segmentation
2.3. Tokenization
- (1)
- Does the substring match a tokenizer exception rule? For example, “don’t” does not contain whitespace but should be split into two tokens, “do” and “n’t”.
- (2)
- Can a prefix, suffix, or infix be split off (e.g., punctuation such as commas, periods, hyphens, or quotation marks)?
2.4. Part of Speech
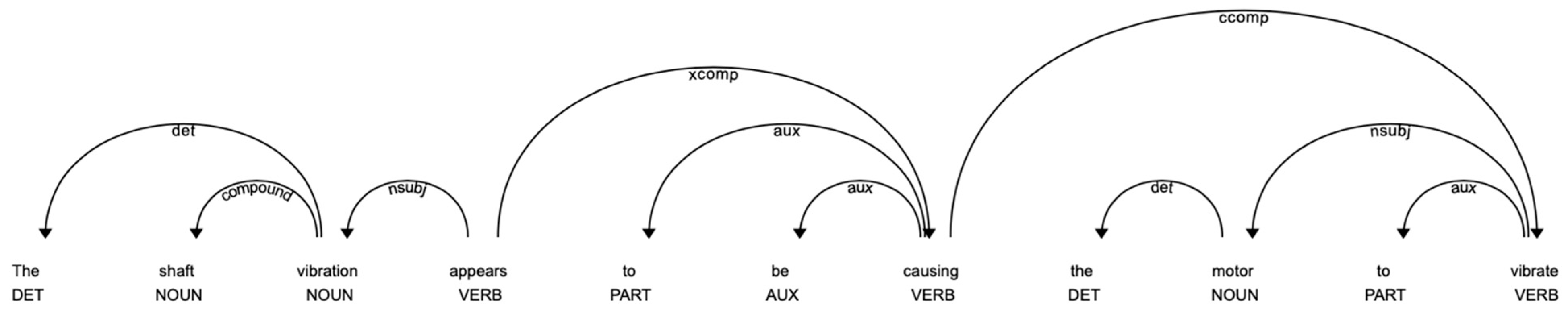
2.5. Dependency Parsing
2.6. Lemmatization
2.7. Coreference Resolution
2.8. Identification of Temporal Quantities
2.9. Identification of Temporal Sequencing of Events
- Order: sequential occurrence of events
- Concurrency: (nearly) simultaneous occurrence of events from beginning to end
- Coincidence: temporal intersection of events.
2.10. Identification of Measured Quantities
2.11. Identification of Location Attributes
2.12. Identification of Nuclear Entities
2.13. Identification of Conjectures
2.14. Identification of Health Status
2.15. Identification of Cause–Effect Relations
- Relations between subjects and verbs contained in a sentence that are designed to reconstruct the causal relations (see Table 20). The list of these relations was developed by applying the methods described in Section 2.4 and Section 2.5 to a portion of the CausalBank [54] dataset, which contains about 314 million pairs of cause–effect statements.
- NLP relations composed of multiple words that indicate a casual transition between clauses contained in a sentence or between sentences (see Table 21).
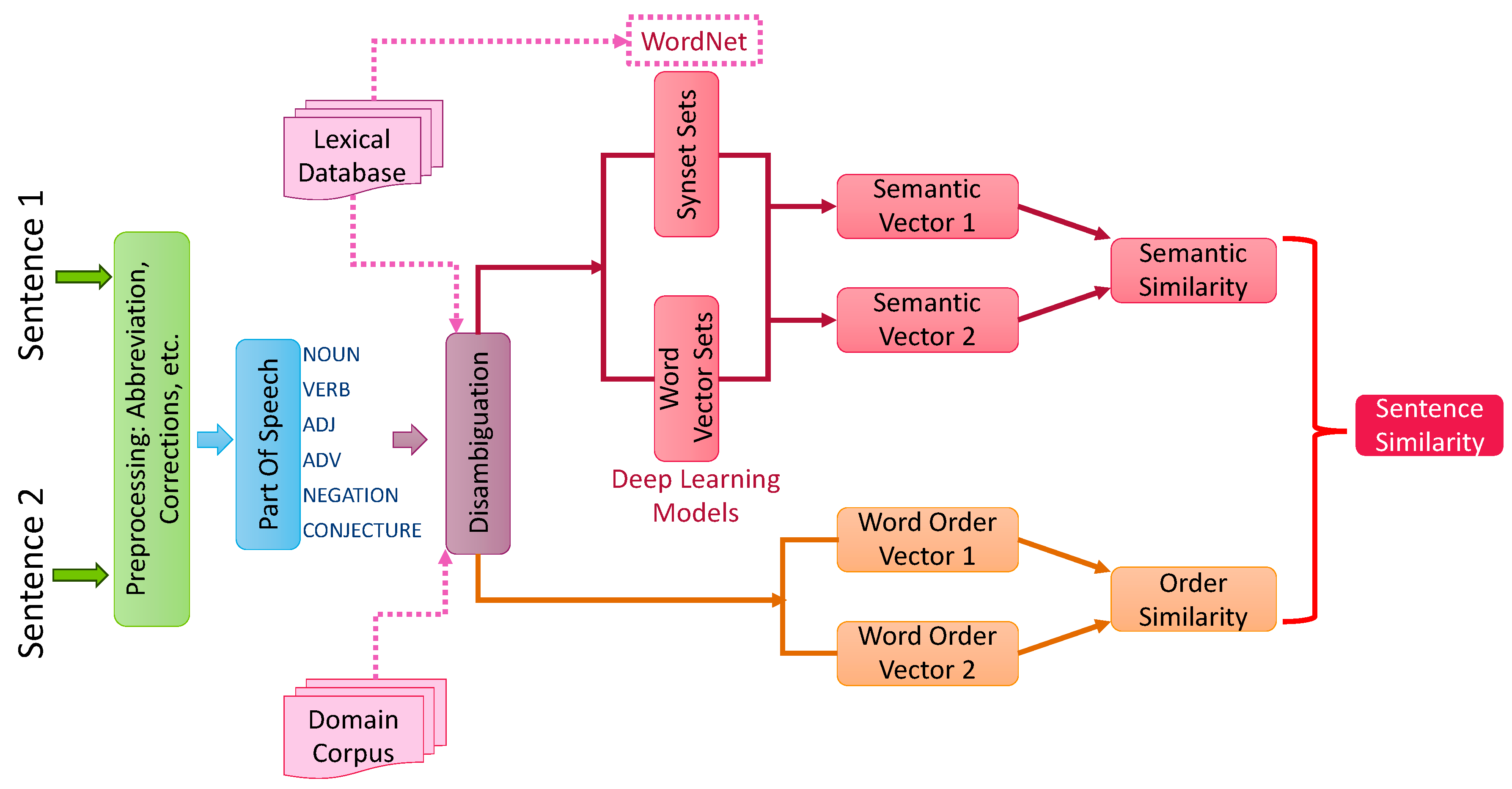
2.16. Identification of Text Similarity
- indicates the path length between and .
- indicates the path depth between and .
- and are functions which decompose the contribution to respectively for path length and depth between and .
- α ∈ [0, 1], β ∈ (0, 1] are scaling parameters for the contribution of the path length and depth, respectively.
3. Applications of NLP Knowledge Extraction Methods
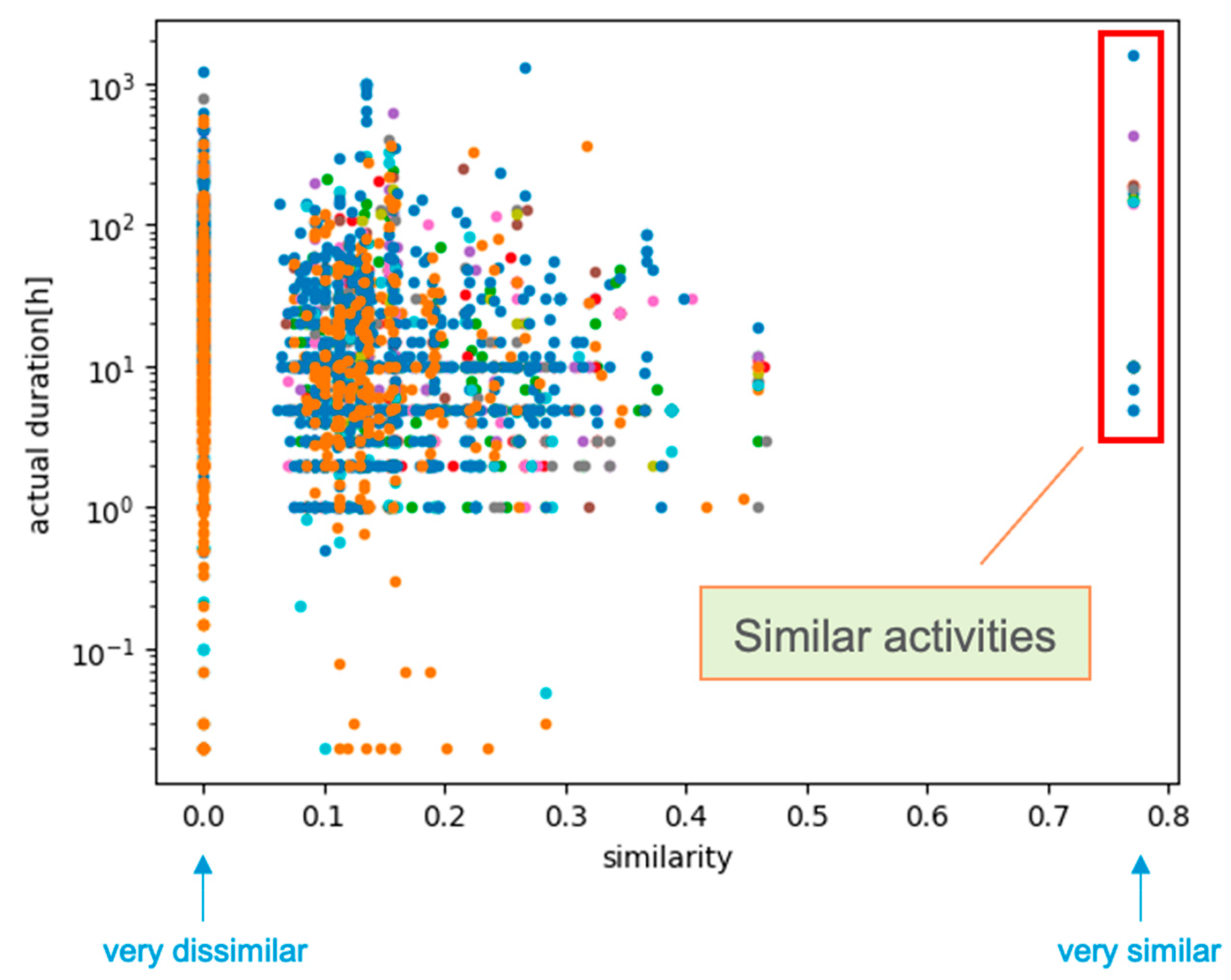
3.1. Analysis of NPP ER Data
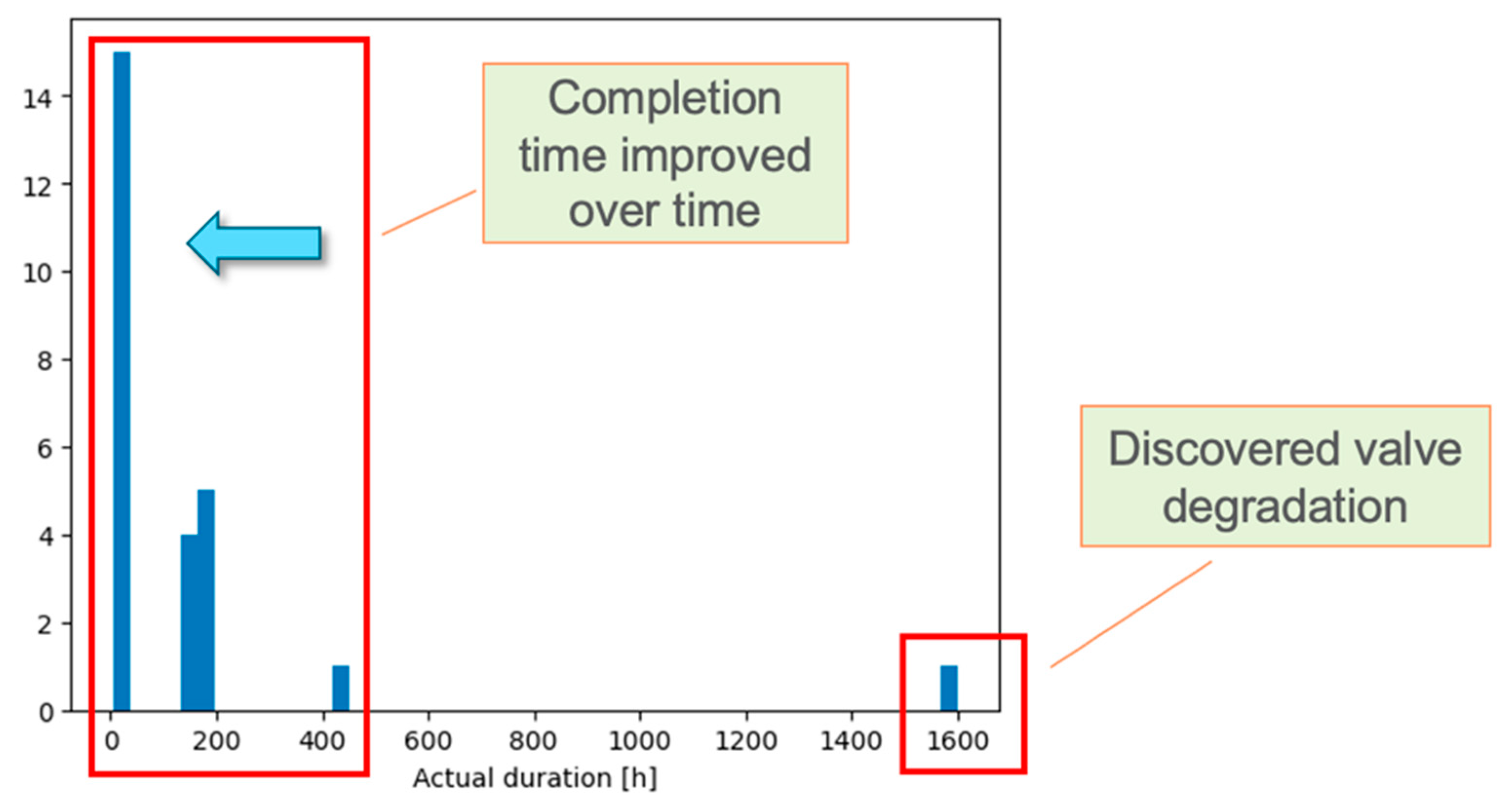
3.2. Analysis of Plant Outage Data
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Banks, J.; Merenich, J. Cost Benefit Analysis for Asset Health Management Technology. In Proceedings of the Proceedings Annual Reliability and Maintainability Symposium, Orlando, FL, USA, 22–25 January 2007; pp. 95–100. [Google Scholar]
- Zio, E.; Compare, M. Evaluating maintenance policies by quantitative modeling and analysis. Reliab. Eng. Syst. Saf. 2013, 109, 53–65. [Google Scholar] [CrossRef]
- Compare, M.; Baraldi, P.; Zio, E. Challenges to IoT-Enabled Predictive Maintenance for Industry 4.0. IEEE Internet Things J. 2020, 7, 4585–4597. [Google Scholar] [CrossRef]
- Pipe, K. Practical prognostics for Condition Based Maintenance. In Proceedings of the 2008 International Conference on Prognostics and Health Management (PHM), Denver, CO, USA, 6–9 October 2008; pp. 1–10. [Google Scholar]
- Vichare, N.; Pecht, M. Prognostics and health management of electronics. In Encyclopedia of Structural Health Monitoring; Wiley: Hoboken, NJ, USA, 2009. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-Driven Methods for Predictive Maintenance of Industrial Equipment: A Survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Zio, E. Data-driven prognostics and health management (PHM) for predictive maintenance of industrial components and systems. Risk-Inf. Methods Appl. Nucl. Energy Eng. 2024, 2024, 113–137. [Google Scholar]
- Coble, J.; Ramuhalli, P.; Bond, L.; Hines, J.W.; Upadhyaya, B. A review of prognostics and health management applications in nuclear power plants. Int. J. Progn. Heal. Manag. 2015, 6, 2271. [Google Scholar] [CrossRef]
- Zhao, X.; Kim, J.; Warns, K.; Wang, X.; Ramuhalli, P.; Cetiner, S.; Kang, H.G.; Golay, M. Prognostics and Health Management in Nuclear Power Plants: An Updated Method-Centric Review With Special Focus on Data-Driven Methods. Front. Energy Res. 2021, 9, 696785. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Park, J.; Kim, Y.; Jung, W. Use of a Big Data Mining Technique to Extract Relative Importance of Performance Shaping Factors from Event Investigation Reports. In International Conference on Applied Human Factors and Ergonomics; Springer: Cham, Switzerland, 2017; pp. 230–238. [Google Scholar]
- Zhao, Y.; Diao, X.; Huang, J.; Smidts, C. Automated identification of causal relationships in nuclear power plant event reports. Nucl. Technol. 2019, 205, 1021–1034. [Google Scholar] [CrossRef]
- Al Rashdan, A.; Germain, S.S. Methods of data collection in nuclear power plants. Nucl. Technol. 2019, 205, 1062–1074. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B.; Brachman, R.; Dietterich, T. Introduction to Semi-Supervised Learning; Morgan and Claypool Publishers: San Rafael, CA, USA, 2009. [Google Scholar]
- Chapelle, O.; Schlkopf, B.; Zien, A. Semi-Supervised Learning, 1st ed.; The MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Jurafsky, D.; Martin, J. Speech and Language Processing; Pearson International Edition: London, UK, 2008. [Google Scholar]
- Indurkhya, N.; Damerau, F.J. Handbook of Natural Language Processing, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Clark, A.; Fox, C.; Lappin, S. The Handbook of Computational Linguistics and Natural Language Processing, 1st ed.; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Khurana, D.; Koli, A.; Khatter, K.; Singh, S. Natural language processing: State of the art, current trends and challenges. Multimedia Tools Appl. 2023, 82, 3713–3744. [Google Scholar] [CrossRef]
- Baud, R.H.; Rassinoux, A.-M.; Scherrer, J.-R. Natural Language Processing and Semantical Representation of Medical Texts. Methods Inf. Med. 1992, 31, 117–125. [Google Scholar] [CrossRef] [PubMed]
- Mooney, R.J.; Bunescu, R. Mining knowledge from text using information extraction. ACM SIGKDD Explor. Newsl. 2005, 7, 3–10. [Google Scholar] [CrossRef]
- Sbattella, L.; Tedesco, R. Knowledge Extraction from Natural Language. In Methodologies and Technologies for Networked Enterprises; Lecture Notes in Computer Science; Anastasi, G., Bellini, E., Di Nitto, E., Ghezzi, C., Tanca, L., Zimeo, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7200. [Google Scholar] [CrossRef]
- Krallinger, M.; Rabal, O.; Lourenco, A.; Oyarzabal, J.; Valencia, A. Information retrieval and text mining technologies for chemistry. Chem. Rev. 2017, 117, 7673–7761. [Google Scholar] [CrossRef]
- Yan, R.; Jiang, X.; Wang, W.; Dang, D.; Su, Y. Materials information extraction via automatically generated corpus. Sci. Data 2022, 9, 401. [Google Scholar] [CrossRef] [PubMed]
- Chasseray, Y.; Barthe-Delanoë, A.-M.; Négny, S.; Le Lann, J.-M. Knowledge extraction from textual data and performance evaluation in an unsupervised context. Inf. Sci. 2023, 629, 324–343. [Google Scholar] [CrossRef]
- Björne, J.; Salakoski, T. Biomedical Event Extraction Using Convolutional Neural Networks and Dependency Parsing. In Proceedings of the BioNLP 2018 Workshop, Melbourne, Australia, July 2018; pp. 98–108. Available online: https://aclanthology.org/W18-2311/ (accessed on 1 February 2024).
- VanGessel, F.G.; Perry, E.; Mohan, S.; Barham, O.M.; Cavolowsky, M. Natural language processing for knowledge discovery and information extraction from energetics corpora. Propellants Explos. Pyrotech. 2023, 48, 109. [Google Scholar] [CrossRef]
- Shetty, P.; Ramprasad, R. Machine-Guided Polymer Knowledge Extraction Using Natural Language Processing: The Example of Named Entity Normalization. J. Chem. Inf. Model. 2021, 61, 5377–5385. [Google Scholar] [CrossRef]
- Yang, X.; Zhuo, Y.; Zuo, J.; Zhang, X.; Wilson, S.; Petzold, L. PcMSP: A dataset for scientific action graphs extraction from polycrystalline materials synthesis procedure text. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6033–6046. [Google Scholar]
- Bravo, Á.; Piñero, J.; Queralt-Rosinach, N.; Rautschka, M.; Furlong, L.I. Extraction of relations between genes and diseases from text and large-scale data analysis: Implications for translational research. BMC Bioinform. 2015, 16, 55. [Google Scholar] [CrossRef]
- Giorgi, J.; Bader, G.; Wang, B. A sequence-to-sequence approach for document-level relation extraction. In Proceedings of the 21st Workshop on Biomedical Language Processing, Dublin, Ireland, 26 May 2022; pp. 10–25. [Google Scholar]
- Weston, L.; Tshitoyan, V.; Dagdelen, J.; Kononova, O.; Trewartha, A.; Persson, K.A.; Ceder, G.; Jain, A. Named entity recognition and normalization applied to large-scale information extraction from the materials science literature. J. Chem. Inf. Model. 2019, 59, 3692–3702. [Google Scholar] [CrossRef]
- Alani, H.; Kim, S.; Millard, D.E.; Hall, M.J.; Weal, W.W.; Hall, M.J.; Lewis, W.; Shadbolt, N.R.; Paul, H. Automatic ontology-based knowledge extraction and tailored biography generation from the web. IEEE Intell. Syst. 2002, 18, 14–21. [Google Scholar] [CrossRef]
- Souili, A.; Cavallucci, D.; Rousselot, F. Natural Language Processing (NLP)—A Solution for Knowledge Extraction from Patent Unstructured Data. Procedia Eng. 2015, 131, 635–643. [Google Scholar] [CrossRef][Green Version]
- Dagdelen, J.; Dunn, A.; Lee, S.; Walker, N.; Rosen, A.S.; Ceder, G.; Persson, K.A.; Jain, A. Structured information extraction from scientific text with large language models. Nat. Commun. 2024, 15, 1418. [Google Scholar] [CrossRef] [PubMed]
- Brundage, M.P.; Sexton, T.; Hodkiewicz, M.; Dima, A.; Lukens, S. Technical language processing: Unlocking maintenance knowledge. Manuf. Lett. 2021, 27, 42–46. [Google Scholar] [CrossRef]
- Dima, A.; Lukens, S.; Hodkiewicz, M.; Sexton, T.; Brundage, M.P. Adapting natural language processing for technical text. Appl. AI Lett. 2021, 2, 33. [Google Scholar] [CrossRef] [PubMed]
- Woods, C.; Selway, M.; Bikauna, T.; Stumptnerb, M.; Hodkiewiczc, M. An Ontology for Maintenance Activities and Its Application to Data Quality. Semant. Web. 2023, 2023, 3067–4281. [Google Scholar] [CrossRef]
- Han, X.; Gao, T.; Lin, Y.; Peng, H.; Yang, Y.; Xiao, C.; Liu, Z.; Li, P.; Zhou, J.; Sun, M. More data, more relations, more context and more openness: A review and outlook for relation extraction. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Suzhou, China, 4–7 December 2020; pp. 745–758. Available online: https://aclanthology.org/2020.aacl-main.75 (accessed on 1 February 2024).
- Zhuang, W. Architecture of Knowledge Extraction System based on NLP. In Proceedings of the ICASIT 2021: 2021 International Conference on Aviation Safety and Information Technology, Changsha, China, 18–20 December 2021; pp. 294–297. [Google Scholar]
- Shimorina, A.; Heinecke, J.; Herledan, F. Knowledge Extraction From Texts Based on Wikidata. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Track, Seattle, WA, USA, 10–15 July 2022; pp. 297–304. [Google Scholar]
- Honnibal, M.; Montani, I. SpaCy 2: Natural language understanding with Bloom embeddings. Convolutional Neural Netw. Increm. Parsing 2017, 7, 411–420. [Google Scholar]
- Sadvilkar, N.; Neumann, M. PySBD: Pragmatic Sentence Boundary Disambiguation. In Proceedings of Second Workshop for NLP Open Source Software (NLP-OSS), Association for Computational Linguistics, Online, November 2020; pp. 110–114. Available online: https://aclanthology.org/2020.nlposs-1.15/ (accessed on 15 January 2024).
- Bird, S.; Loper, E.; Klein, E. Natural Language Processing with Python; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Sanampudi, S.K.; Kumari, G. Temporal Reasoning in Natural Language Processing: A Survey. Int. J. Comput. Appl. 2010, 1, 68–72. [Google Scholar] [CrossRef]
- Pustejovsky, J.; Verhagen, M.; Sauri, R.; Littman, J.; Gaizauskas, R.; Katz, G.; Mani, I.; Knippen, R.; Setzer, A. TimeBank 1.2 LDC2006T08. Web Download; Linguistic Data Consortium: Philadelphia, PA, USA, 2006. [Google Scholar]
- Moerchen, F. Temporal pattern mining in symbolic time point and time interval data. In Proceedings of the KDD’10: The 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Nashville, TN, USA, 30 March–2 April 2010; pp. 1–2. [Google Scholar]
- Gopfert, J.; Kuckertz, P.; Weinand, J.M.; Kotzur, L.; Stolten, D. Measurement Extraction with Natural Language Processing: A Review. Find. Assoc. Comput. Linguist. EMNLP 2022, 2022, 2191–2215. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 11, 39–41. [Google Scholar] [CrossRef]
- Altinok, D. Mastering spaCy: An End-to-End Practical Guide to Implementing NLP Applications Using the Python Ecosystem; Packt Publishing: Birmingham, UK, 2021. [Google Scholar]
- Fang, X.; Zhan, J. Sentiment analysis using product review data. J. Big Data 2015, 2, 5. [Google Scholar] [CrossRef]
- Mohri, M.; Rostamizadeh, A.; Talwalkar, A. Foundations of Machine Learning; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Doan, S.; Yang, E.W.; Tilak, S.S.; Li, P.W.; Zisook, D.S.; Torii, M. Extracting health-related causality from twitter messages using natural language processing. BMC Med. Inform. Decis. Mak. 2019, 19, 71–77. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Ding, X.; Liu, T.; Hu, J.E.; Van Durme, B. Guided Generation of Cause and Effect. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence IJCAI-20, Yokohama, Japan, 7–15 January 2020. [Google Scholar]
- Hendrickx, I.; Kim, S.; Kozareva, Z.; Nakov, P.; Séaghdha, D.Ó.; Padó, S.; Pennacchiotti, M.; Romano, L.; Szpakowicz, S. SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations between Pairs of Nominals. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 33–38. [Google Scholar]
- Wang, J.; Dong, Y. Measurement of Text Similarity: A Survey. Information 2020, 11, 421. [Google Scholar] [CrossRef]
- Gomaa, W.H.; Fahmy, A. A survey of text similarity approaches. Int. J. Comput. Appl. 2013, 68, 13–18. [Google Scholar]
- Navigli, R.; Martelli, F. An Overview of Word and Sense Similarity. Nat. Lang. Eng. 2019, 25, 693–714. [Google Scholar] [CrossRef]
- Li, Y.; McLean, D.; Bandar, Z.; O’Shea, J.; Crockett, K. Sentence similarity based on semantic nets and corpus statistics. IEEE Trans. Knowl. Data Eng. 2006, 18, 1138–1150. [Google Scholar] [CrossRef]
- Li, Y.; Bandar, Z.; McLean, D. An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 2003, 15, 871–882. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Time | Duration | Frequency |
|---|---|---|---|
| 11/3/2005 3 November 2005 Yesterday Tomorrow Thursday Last Week | Friday morning 12:30 a.m. 3 p.m. 12:30 12:00 a.m. 20 min ago | 10 h last 5 months 2 days 2 days couple of days 1988–1992 | every Friday every 4 h every month twice a year thrice a day |
| Approximation | |
|---|---|
| About | Around |
| Almost | Closely |
| Nearly | Circa |
| Roughly | Close |
| Approximately | More or less |
| Nearly | Roughly |
| Relations |
|---|
| [verb] + [at, on] + “time instance” |
| [verb] + [at, on] + [approximation] + “time instance” |
| [verb] + for + “time duration” |
| [verb] + for + [approximation] + “time duration” |
| [noun] + [verb] + “time duration” |
| [noun] + [verb] + [approximation] “time duration” |
| Keywords | Structures | ||
|---|---|---|---|
| Verbs | Adjectives | Adverbs | |
| Antedate Follow Postdate Precede Predate Succeed | After Before Consecutive Earlier Following Former Later Next Past Precedent Previous | Afterward Consecutively Consequently Directly Hereafter Later Next Previously Subsequently Successively Then | Soon after After that After a while |
| Keywords | Structures | ||
|---|---|---|---|
| Verbs | Adjectives | Adverbs | |
| Accompany Conform Correspond Harmonize Parallel | Accompanying Attending Coexistent Concomitant Concurrent Imminent Simultaneous Synchronic | When Thereupon While During | At that point At that moment At that time At that instant In the end On that occasion |
| Relations |
|---|
| Event_1 + [order verb] + Event_2 |
| Event_1 + [verb] + [adverb] + Event_2 |
| Event_1 + [verb] + [adjective] + Event_2 |
| Relations |
|---|
| Event_1 + [verb] + [adverb] + Event_2 |
| Event_1 + [verb] + [adjective] + Event_2 |
| one half three halves 0.1 10% 3 cm multiplied by 2 75–80% | 4:1 ratio 5th percentile within 5th and 95th percentile the 3rd quartile scored 6 on a 7 point scale between three and four |
| Relation | |
|---|---|
| [neutral verb] + “quantity value” | “quantity value” + [negative noun] |
| [neutral verb] + “quantity delta value” | “quantity delta value” + [negative noun] |
| “quantity value” + [neutral noun] | [positive verb] + “quantity value” |
| “quantity delta value” + [neutral noun] | [positive verb] + “quantity delta value” |
| [negative verb] + “quantity value” | “quantity value” + [positive noun] |
| [negative verb] + “quantity delta value” | “quantity delta value” + [positive noun] |
| Proximity | Located Above | Located Below |
|---|---|---|
| Across from Adjacent Alongside Approaching Beside Close Close by Contiguous Distant from In proximity Near Nearby Next to | Above Anterior Atop Beyond High On top of Over Overhead Upward | Below Beneath Bottom Deep Down Down from Downward Low Posterior Under Underneath |
| Relations |
|---|
| [verb] + “location keyword” + noun |
| Subj + “location keyword” + obj |
| Class | Group | Examples |
|---|---|---|
| Mechanical components | Fasteners | Anchor bolt, cap screw, latch, pin |
| Rotary elements | Cam, shaft, gear, pulley | |
| Structural | Beam, column, sleeve, socket | |
| Purpose-specific | Filter, manifold, blade | |
| Non-mechanical components | Electrical/electronic | Amplifier, relay, buzzer, capacitor |
| Hydraulic/Pneumatic | Coupler, filter, pipe | |
| Assets | Mechanical | Engine, vessel |
| Electrical | AC bus, alternator, generator, transformer | |
| Hydraulic/Pneumatic | Pump, valve, condenser, fan | |
| Electronic | Computer, tablet, controller | |
| I&C | Digital meter, FPGA, transmitter, sensor | |
| Nuclear fuel | Fuel rod, control blade | |
| NPP elements | Systems | Feedwater, switchyard, feedwater |
| Architectural | Containment, control room, pump house | |
| Tools and treatments | Tools | Jigsaw, solder gun, tape, crane |
| Treatments | Bolting, riveting, grinding, infrared testing | |
| Operands | Electrical | AC current, electromagnetic |
| Hydraulic/Pneumatic | Compressed air, steam, gasoline, water | |
| Compounds | Materials | Plastic, plywood, concrete, polyethylene |
| Reactions | Chemical reaction | Combustion, oxidation, evaporation |
| Degradation mechanism | Corrosion, dissolution, fatigue | |
| Failure type | Leak, rupture, brittle fracture |
| Keyword | ||
|---|---|---|
| Expected | Hypothetical(ly) | Anticipated |
| Possible | Likely | Foreseen |
| Probable | Unlikely | Impending |
| Feasible | Potential | Upcoming |
| Plausible | Uncertain | Brewing |
| Presumed | Forthcoming | Looming |
| Relation | Example |
|---|---|
| Subj + “future verb” | The pump will fail |
| Subj + “conjecture keyword” + “verb” | The pump is likely to fail |
| Conditional + subj + “verb” + “conjecture keyword” + “verb” | If the pump overheats, it is expected to fail |
| Subj + “past verb” + hypothesis | The pump failed because it overheated |
| Relation | Example |
|---|---|
| Subj + “status verb” | Pump was not functioning |
| Subj + “status verb” + “status adjective” | Pump performance was acceptable |
| Subj + “status verb” + “status adverb” + obj | Pump was partially working |
| “status adjective” + subj + “status verb” | Unresponsive pump was observed |
| “status noun” + “prep” + “status verb” | Deterioration of pump impeller was observed |
| Nouns | Verbs | Adjectives | Adverbs |
|---|---|---|---|
| Breakdown | Disabled | Unacceptable | Inaccurately |
| Collapse | Reject | Improper | Erroneously |
| Decline | Stop | Inadmissible | Wrongly |
| Deficiency | Block | Undesirable | Inadequately |
| Deterioration | Halt | Unsatisfactory | Incompletely |
| Failing | Oppose | Unacceptable | Partially |
| Decay | Inhibit | Unsuitable | Imperfectly |
| Nouns | Verbs | Adjectives | Adverbs |
|---|---|---|---|
| Accomplishment Achievement Enhancement Progression Solution | Enable Empower Facilitate Permit Set up Endow Let Make | Ready Fit Capable Apt Available Adequate Competent Proficient | Accurately Nicely Perfectly Precisely Properly Rightly Accurately Appropriately |
| Nouns | Verbs | Adjectives |
|---|---|---|
| Analysis Assessment Diagnosis Evaluation Exploration Investigation Probe | Inspect Monitor Measure Witness Examine Note Recognize View Watch | Acceptable Usable Attainable Consistent Constant Stable Unaffected Uninterrupted Untouched |
| Nouns | Verbs | Adverbs |
|---|---|---|
| Augment Backfire Begin Bring about Build-up Cause Change Combat Compensate Counter Create Deactivate Decelerate Decrease | Augment Backfire Begin Bring about Build-up Cause Change Combat Compensate Counter Create Deactivate Decelerate Decrease | Afterwards Consequently Eventually Finally Hence So Subsequently Then Therefore Thus Ultimately |
| Relations | DAG |
|---|---|
| Event_A + “causal verb” (active) + Event_B | A → B |
| Event_A + “causal verb” (passive) + Event_B | B → A |
| Event_A + [to be] a “causal noun” + Event_B | A → B |
| Event_A + [to be] a “effect noun” + Event_B | B → A |
| The “causal noun” of + Event_A + [to be] + Event_B | B → A |
| The “effect noun” of + Event_A + [to be] + Event_B | A → B |
| Clause_A; + “cause/effect structure” + Clause_B | A → B or B → A |
| “Cause/effect structure” + Clause_A; + Clause_B | A → B or B → A |
| Clause_A. “Cause/effect structure” + Clause_B | A → B or B → A |
| Event_A + (verb, “causal adverb”) + Event_B | A → B |
| Structures |
|---|
| In response to |
| Attributed to |
| As a result of |
| For this reason |
| In consequence |
| In this way |
| In such a way |
| A leak was noticed from the RCP pump 1A. RCP pump 1A pressure gauge was found not operating. RCP pump 1A pressure gauge was found inoperative. RCP pump 1A had signs of past leakage. The Pump is not experiencing enough flow during test. Slight Vibrations is noticed—likely from pump shaft deflection. Pump flow meter was not responding. Rupture of pump bearings caused pump shaft degradation. Rupture of pump bearings caused pump shaft degradation and consequent flow reduction. Power supply has been found burnout. Pump test failed due to power supply failure. Pump inspection revealed excessive impeller degradation. Pump inspection revealed excessive impeller degradation likely due to cavitation. Oil puddle was found in proximity of RCP pump 1A. Anomalous vibrations were observed for RCP pump 1A. Several cracks on pump shaft were observed; they could have caused pump failure within few days. RCP pump 1A was cavitating and vibrating to some degree during test. This is most likely due to low flow conditions rather than mechanical issues. Cavitation was noticed but did not seem severe. The pump shaft vibration appears to be causing the motor to vibrate as well. Pump had noise of cavitation which became faint after OPS bled off the air. Low flow conditions most likely causing cavitation. The pump shaft deflection is causing the safety cage to rattle. The Pump is not experiencing enough flow for the pumps to keep the check valves open during test. Pump shaft made noise. Vibration seems like it is coming from the pump shaft. Visible pump shaft deflection. Pump bearings appear in acceptable condition. Pump made noises—not enough to affect performance. Pump shaft has a slight deflection. |
| SSC Entities | Status/Health Status | SSC Entities | Status/Health Status |
|---|---|---|---|
| Pump | A leak from rcp | Impeller | Excessive degradation |
| Pump | Not gauge operating | Pump | Found in proximity of rcp (Oil puddle) |
| Pump | Gauge inoperative | Pump | Anomalous vibrations for 1a |
| Pump | 1a signs of past leakage | Pump shaft | Several cracks |
| Pump | Not enough flow during test | Pump | Failure |
| Pump shaft | Deflection | Pump | cavitating |
| Pump | Not meter responding | Pump shaft | Vibration |
| Pump bearings | Rupture | Motor | Vibrate |
| Pump shaft | Degradation | Pump | Noise of cavitation … |
| Pump bearings | Rupture | Pump shaft | Deflection |
| Pump shaft | Degradation | Pump | Not enough flow for the pumps |
| Power supply | Burnout | Pump shaft | Noise |
| Pump | Test | Pump shaft | Vibration |
| Pump supply | Failure | Pump shaft | Deflection |
| Pump | Inspection | Pump bearings | Acceptable condition |
| Impeller | Excessive degradation | Pump | Noises |
| Pump | Inspection | Pump shaft | A slight deflection |
| Text after Rule-Based NER | Identified Cause–Effect Relations |
|---|---|
| Rupture of pump bearings caused pump shaft degradation. | (pump bearings: Rupture) “caused” (pump shaft: degradation) |
| Rupture of pump bearings caused pump shaft degradation and consequent flow reduction. | (pump bearings: Rupture) “caused” (pump shaft: degradation) |
| Pump test failed due to power supply failure. | (Pump: test failed) “due to” (power supply: failure) |
| Pump inspection revealed excessive impeller degradation. | (Pump: inspection) “revealed” (impeller: degradation) |
| Pump inspection revealed excessive impeller degradation likely due to cavitation. | (Pump: inspection) “revealed” (impeller: degradation) |
| Several cracks on pump shaft were observed; they could have caused pump failure within few days. | (pump shaft: Several cracks) “caused” (pump: failure) |
| The pump shaft deflection is causing the safety cage to rattle. | None |
| Coreference Examples | Identified Coreference |
|---|---|
| Several cracks on pump shaft were observed; they could have caused pump failure within few days. | (Several cracks, they) |
| Vibration seems like it is coming from the pump shaft. | (Vibration, it) |
| Pump Inspection Revealed Excessive Impeller Degradation Likely Due to Cavitation. |
| Several cracks on pump shaft were observed; they could have caused pump failure within few days. |
| Vibration seems like it is coming from the pump shaft. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Mandelli, D.; Cogliati, J. Technical Language Processing of Nuclear Power Plants Equipment Reliability Data. Energies 2024, 17, 1785. https://doi.org/10.3390/en17071785
Wang C, Mandelli D, Cogliati J. Technical Language Processing of Nuclear Power Plants Equipment Reliability Data. Energies. 2024; 17(7):1785. https://doi.org/10.3390/en17071785
Chicago/Turabian StyleWang, Congjian, Diego Mandelli, and Joshua Cogliati. 2024. "Technical Language Processing of Nuclear Power Plants Equipment Reliability Data" Energies 17, no. 7: 1785. https://doi.org/10.3390/en17071785
APA StyleWang, C., Mandelli, D., & Cogliati, J. (2024). Technical Language Processing of Nuclear Power Plants Equipment Reliability Data. Energies, 17(7), 1785. https://doi.org/10.3390/en17071785