

Improved YOLOv5 Based on Multi-Strategy Integration for Multi-Category Wind Turbine Surface Defect Detection


Abstract
:1. Introduction
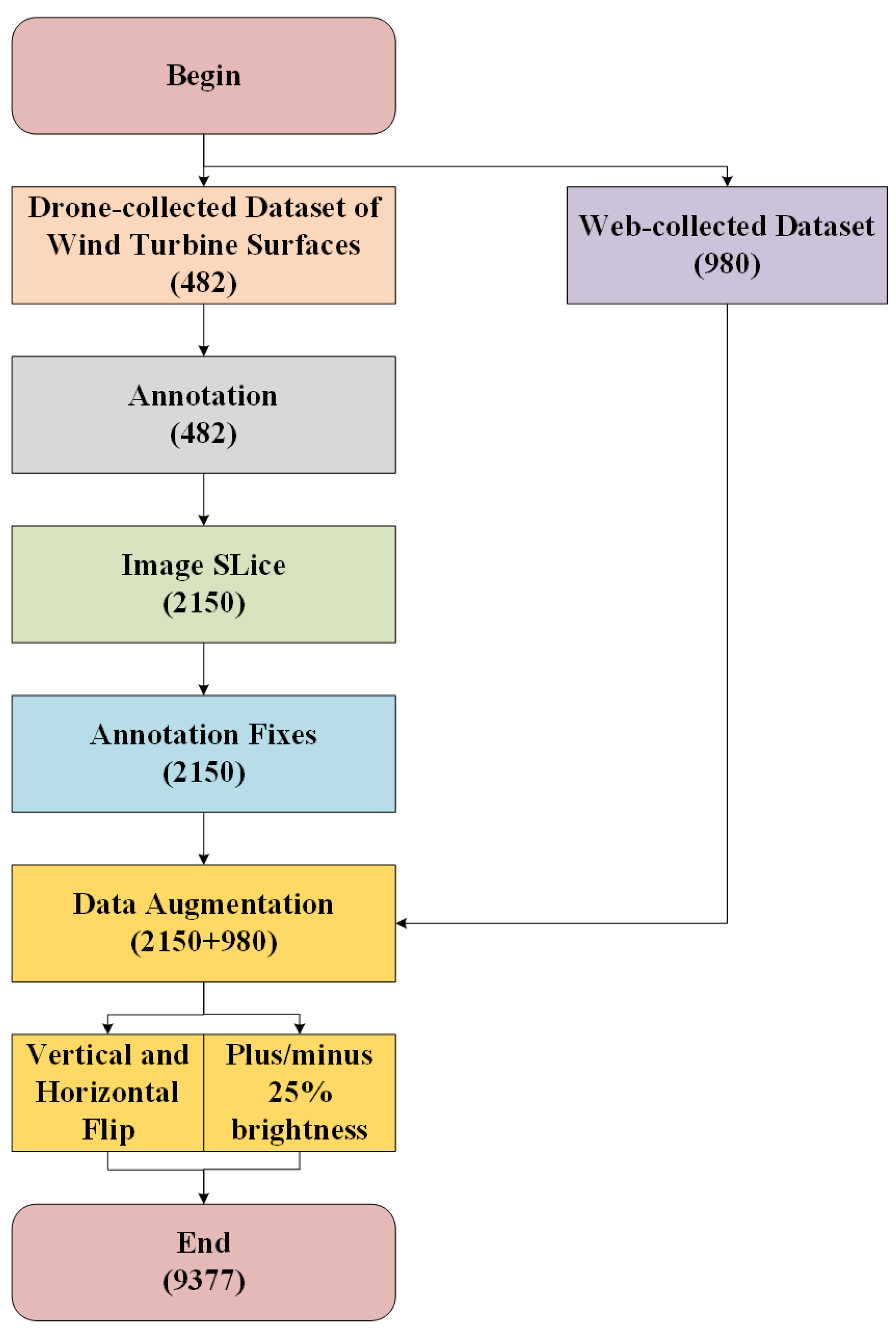
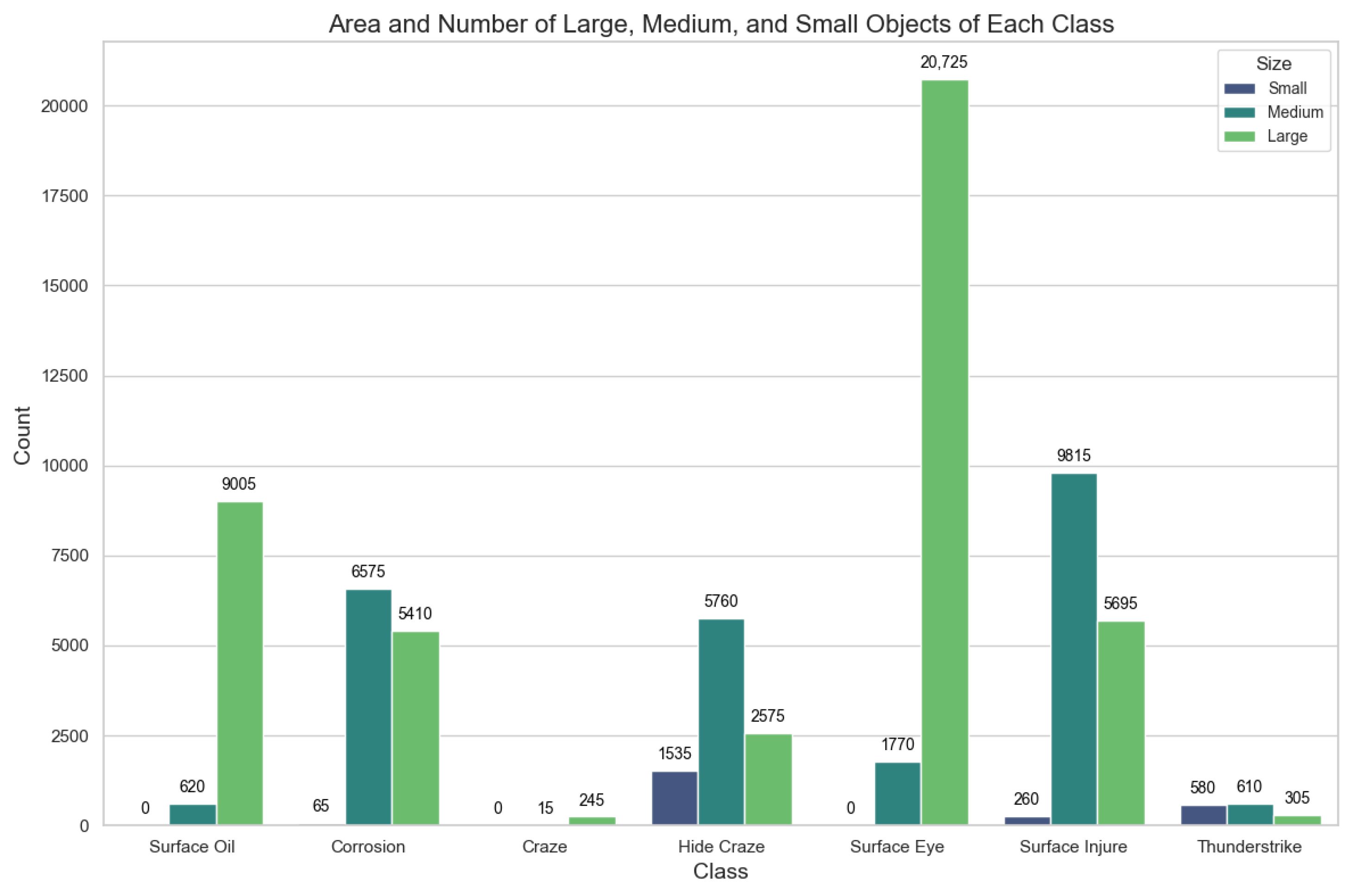
- In accordance with existing industry standards, we establish a benchmark dataset for wind turbine surface defects that comprises seven categories. This dataset is designed to cover all common surface defects, addressing the deficiency in categories within the field of wind turbine surface defect detection.
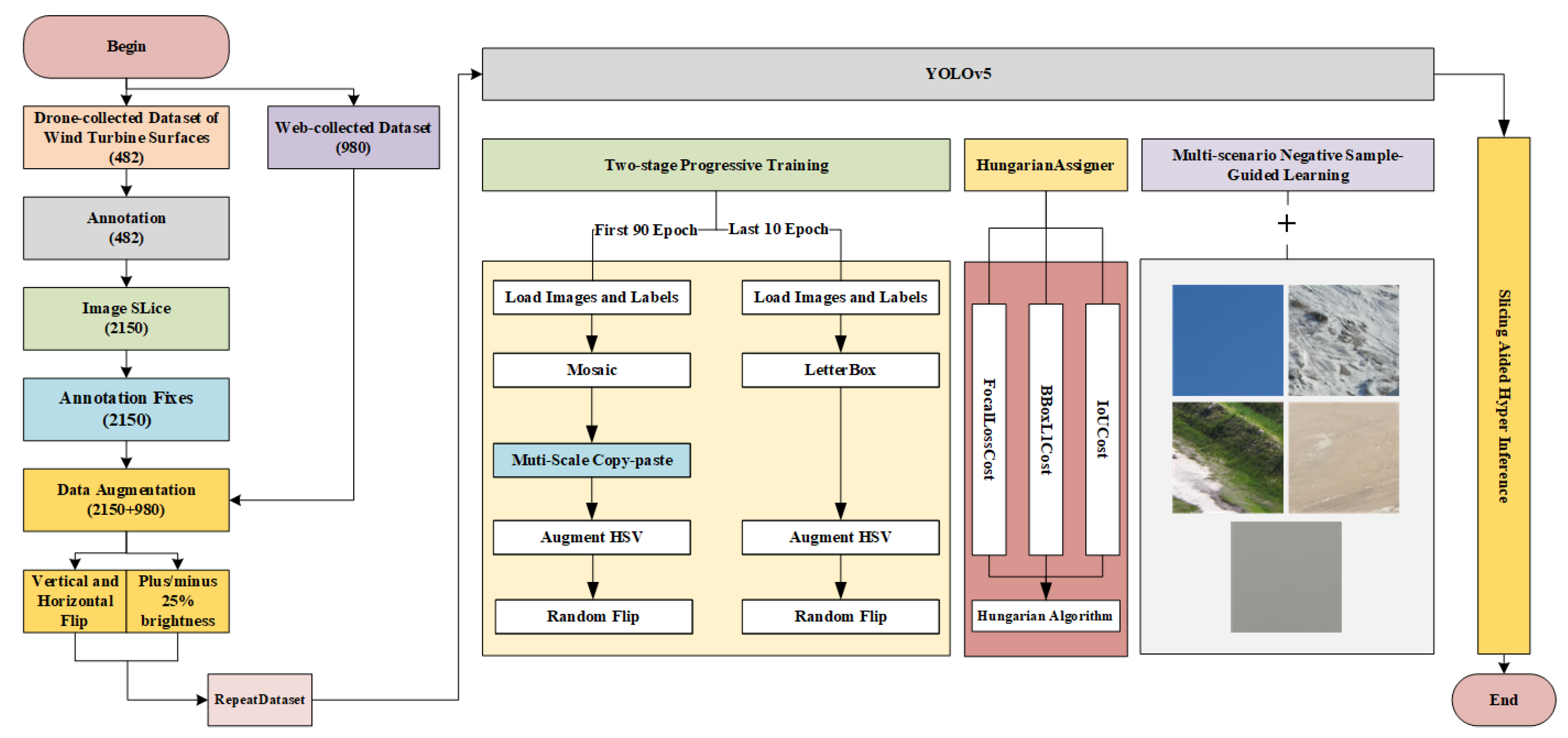
- To mitigate the issues of class imbalance among the samples and insufficient precision in detecting small-to-medium-sized targets, we devise a multi-scale copy-paste [29] data augmentation method. This approach increases the exposure of samples at different scales, significantly enhancing detection accuracy.
- We introduce a dynamic label assignment strategy based on the Hungarian algorithm [30] that involves weighing different losses, replacing the original static label assignment strategy, and enhancing the model’s ability to distinguish between positive and negative samples.
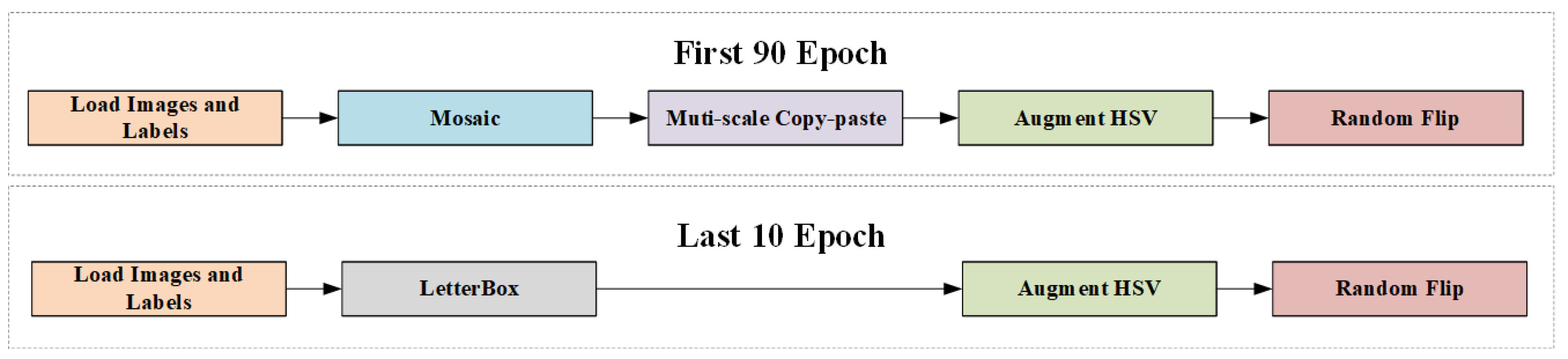
- To alleviate overfitting resulting from strong data augmentation, we propose a two-stage progressive training strategy. By designing two distinct training pipelines, the model naturally converges during the training process, thereby improving its generalization ability.
- We propose a multi-scenario negative sample-guided learning method to improve the model’s ability to learn the features under different background conditions by adding unlabeled background images covering the five scenarios of the wind turbine during the training process, contributing to increased generalization across various backgrounds and reducing misrecognition in backgrounds.
- We introduce slicing-aided hyper inference [31] to enable prediction inference in large images captured by actual unmanned aerial vehicles, facilitating wind turbine surface defect detection in real industrial scenarios.
2. Data Collection and Dataset Construction
- Surface oil: Dust, particulate matter, and oil from the environment adhere to the generator’s surface and may result from atmospheric particulate matter, oil vapors, etc. Accumulated dust and oil will reduce the surface finish, leading to increased friction on the generator’s surface and affecting the efficiency of turbine operation.
- Surface eye: Abrasion, wind-blown sand, and other natural factors result in the formation of uneven surface eyes. The irregular surface may cause abnormal airflow, increase aerodynamic resistance, and impact the aerodynamic performance of the wind turbine.
- Surface injury: Prolonged exposure to ultraviolet radiation, temperature fluctuations, and other factors result in aging and peeling of the coating, which may lead to corrosion, diminish protective capabilities, and reduce the overall weather resistance of the generator.
- Corrosion: Corrosion of the metal surface is induced by factors such as salt spray and chemical pollution in humid environments, and it can diminish the strength and rigidity of the leading edge of the blades, reducing the overall structural integrity of the blades and potentially leading to fatigue failure.
- Hide crack: This results from thermal and mechanical stress caused by external temperature and humidity variations. These cracks may gradually propagate internally, causing damage to the blade structure and consequently impacting the safe operation of the wind turbine.
- Lightning strike: When a wind turbine generator is struck by lightning, it generates high-temperature, high-energy arc discharges. Lightning strike marks may result in localized material damage and ablation, potentially affecting the strength and conductivity of the blades, particularly in severe cases.
- Crack: The high-speed rotation of blades subjects them to significant forces and torques during prolonged operation, potentially leading to open cracks at the blade tips and even outright breakage.
- Vertical and horizontal flipping: Flipping operations were employed to introduce mirror symmetry transformations, simulating different perspectives and angles that may occur during the actual operation of wind turbines. This aids the model in learning the shape features of defects in both the horizontal and vertical directions, enhancing its ability to recognize symmetric defects.
- Adding or reducing brightness by 25%: Brightness adjustments were applied, considering the significant impact of lighting conditions on wind turbine surfaces in real industrial scenarios. This expanded the dataset’s distribution in terms of illumination changes, facilitating the model’s adaptation to various lighting conditions in the images.
3. Improved Surface Defect Detection Algorithm for Wind Turbines Based on YOLOv5
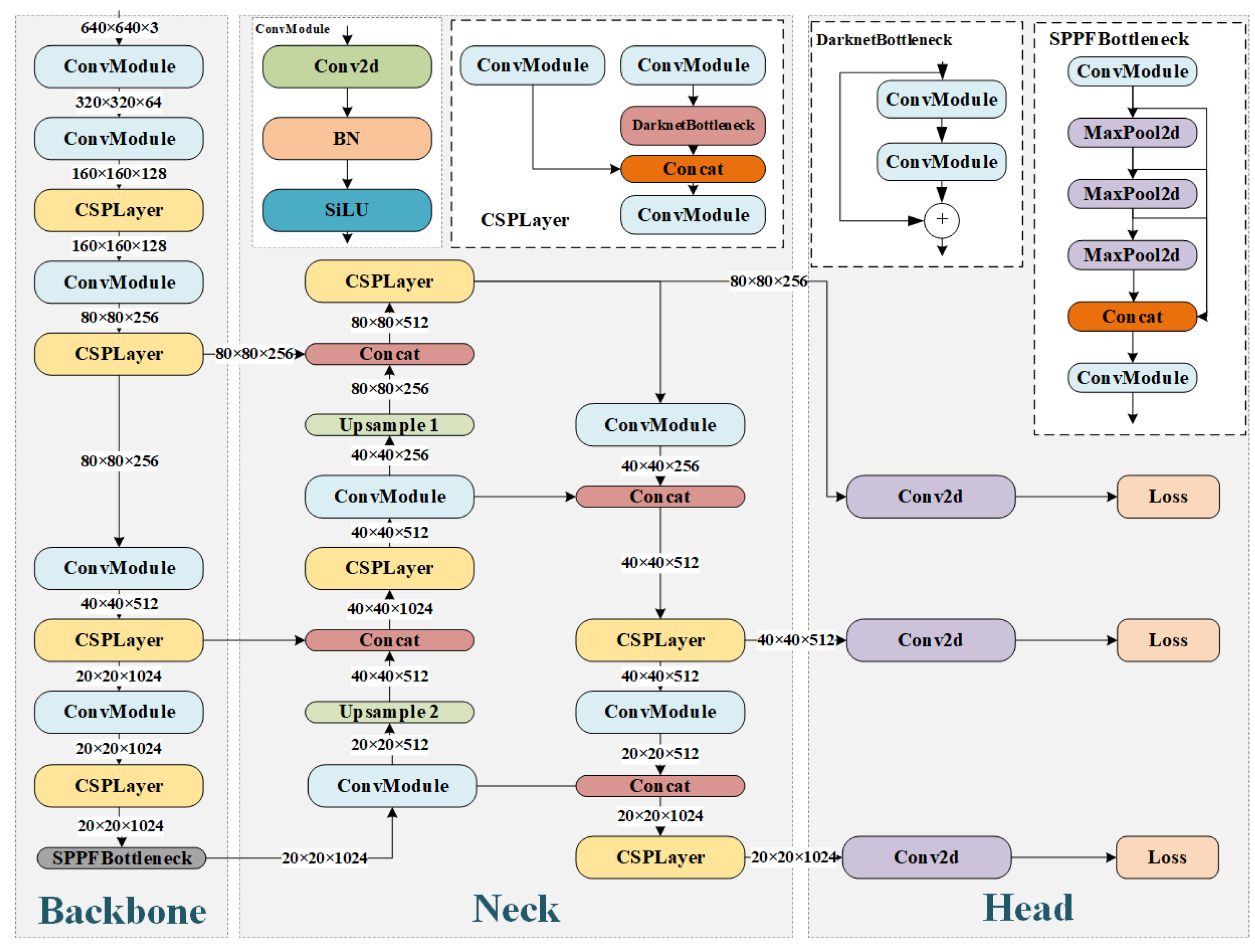
3.1. YOLOv5 Network Model
3.2. Improved Strategies of YOLOv5 for Surface Defect Detection
3.2.1. Multi-Scale Copy-Paste Algorithm
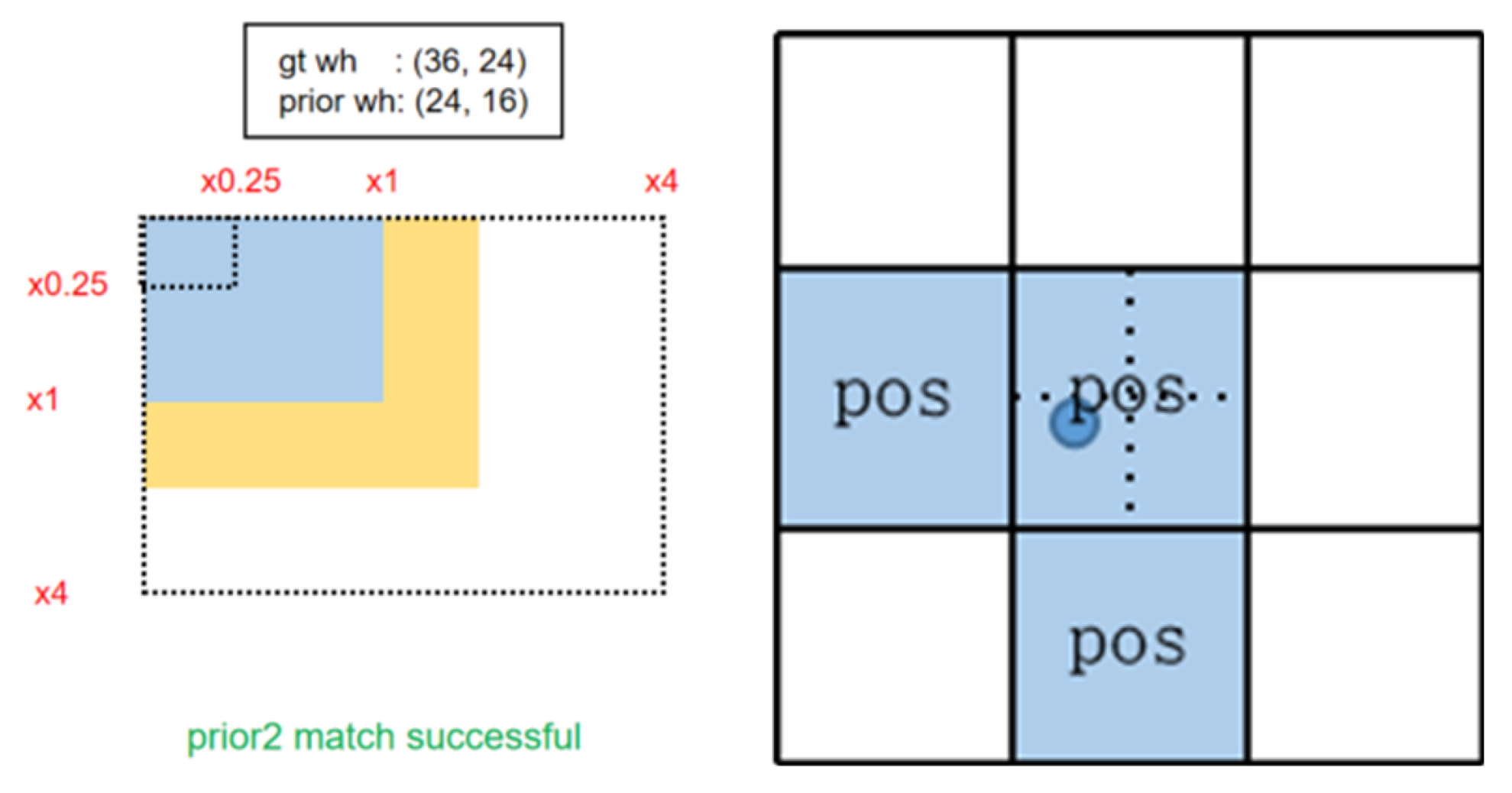
3.2.2. Dynamic Label Assignment Strategy Based on the Hungarian Algorithm
| Algorithm 1: Hungarian Dynamic Label Assignment Algorithm. |
Input:
|
3.2.3. Two-Stage Progressive Training
- Mosaic: This augmentation strategy involves randomly selecting four different images and merging them into a new image at a certain ratio, creating a mosaic effect for enhanced training.
- Letterbox: This technique fills the image edges with a gray background and scales the image to a specified size, preventing deformation caused by scaling.
- Augment HSV: This technique generates new training samples by adjusting the image’s hue, saturation, and value, enhancing the model’s robustness to changes in lighting and color.
- Random flip: This techniques randomly flips the image horizontally or vertically to increase data diversity.
3.2.4. Multi-Scenario Negative Sample-Guided Learning
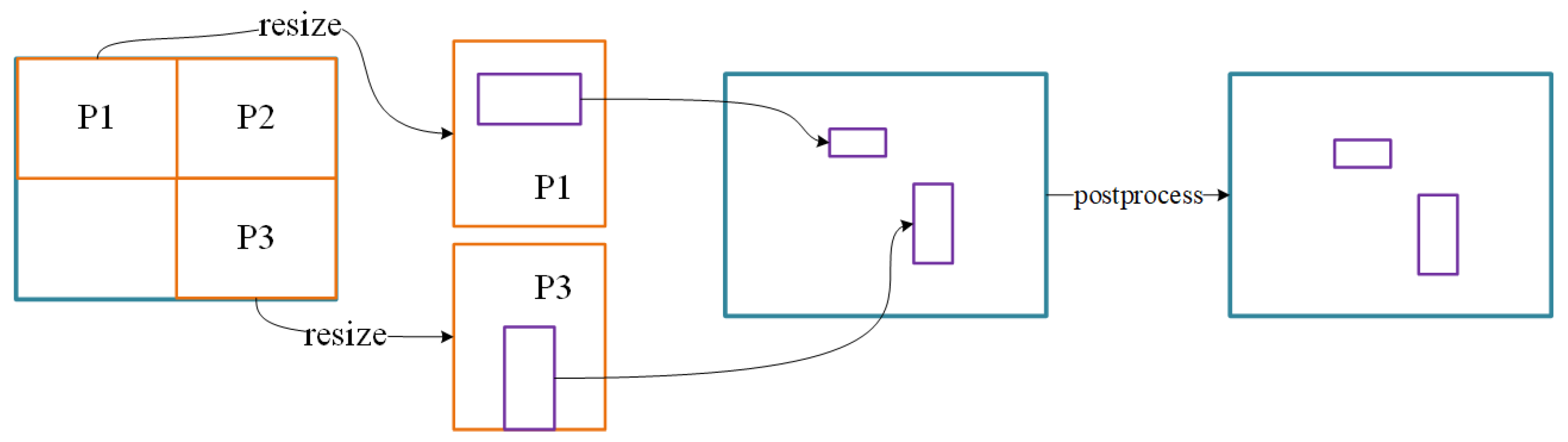
3.2.5. Slicing-Aided Hyper Inference
3.3. Experiments
3.3.1. Evaluation Metrics
3.3.2. Experimental Set-Ups
3.3.3. Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hwang, S.; An, Y.K.; Sohn, H. Continuous-wave line laser thermography for monitoring of rotating wind turbine blades. Struct. Health Monit. 2019, 18, 1010–1021. [Google Scholar] [CrossRef]
- Schubert, L.; Schulze, E.; Frankenstein, B.; Fischer, D.; Weihnacht, B.; Rieske, R. Monitoring system for windmill rotorblades based on optical connections. In Smart Sensor Phenomena, Technology, Networks, and Systems; SPIE: Bellingham, WA, USA, 2011; Volume 7982, pp. 310–317. [Google Scholar]
- Tarfaoui, M.; Khadimallah, H.; Shah, O.; Pradillon, J. Effect of spars cross-section design on dynamic behavior of composite wind turbine blade: Modal analysis. In Proceedings of the 4th International Conference on Power Engineering, Energy and Electrical Drives, Istanbul, Turkey, 13–17 May 2013; pp. 1006–1011. [Google Scholar]
- Abouhnik, A.; Albarbar, A. Wind turbine blades condition assessment based on vibration measurements and the level of an empirically decomposed feature. Energy Convers. Manag. 2012, 64, 606–613. [Google Scholar] [CrossRef]
- Bo, Z.; Yanan, Z.; Changzheng, C. Acoustic emission detection of fatigue cracks in wind turbine blades based on blind deconvolution separation. Fatigue Fract. Eng. Mater. Struct. 2017, 40, 959–970. [Google Scholar] [CrossRef]
- Junior, V.J.; Zhou, J.; Roshanmanesh, S.; Hayati, F.; Hajiabady, S.; Li, X.; Dong, H.; Papaelias, M. Evaluation of damage mechanics of industrial wind turbine gearboxes. Insight-Non-Destr. Test. Cond. Monit. 2017, 59, 410–414. [Google Scholar] [CrossRef]
- Tang, J.; Soua, S.; Mares, C.; Gan, T.H. An experimental study of acoustic emission methodology for in service condition monitoring of wind turbine blades. Renew. Energy 2016, 99, 170–179. [Google Scholar] [CrossRef]
- Choi, K.S.; Huh, Y.H.; Kwon, I.B.; Yoon, D.J. A tip deflection calculation method for a wind turbine blade using temperature compensated FBG sensors. Smart Mater. Struct. 2012, 21, 025008. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Phillips, J.J. ROI: The search for best practices. Train. Dev. 1996, 50, 42–48. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7036–7045. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9657–9666. [Google Scholar]
- Qiu, Z.; Wang, S.; Zeng, Z.; Yu, D. Automatic visual defects inspection of wind turbine blades via YOLO-based small object detection approach. J. Electron. Imaging 2019, 28, 043023. [Google Scholar] [CrossRef]
- Yao, Y.; Wang, G.; Fan, J. WT-YOLOX: An Efficient Detection Algorithm for Wind Turbine Blade Damage Based on YOLOX. Energies 2023, 16, 3776. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Zhang, R.; Wen, C. SOD-YOLO: A Small Target Defect Detection Algorithm for Wind Turbine Blades Based on Improved YOLOv5. Adv. Theory Simul. 2022, 5, 2100631. [Google Scholar] [CrossRef]
- Sanghyun, W.; Jongchan, P.; Joon-Young, L.; In, S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, L.; Zhang, Z. Automatic detection of wind turbine blade surface cracks based on UAV-taken images. IEEE Trans. Ind. Electron. 2017, 64, 7293–7303. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Luo, X. A two-stage data-driven approach for image-based wind turbine blade crack inspections. IEEE/ASME Trans. Mechatron. 2019, 24, 1271–1281. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, L.; Huang, C.; Luo, X. Wind Turbine Blade Damage Detection Based on the Improved YOLOv5 Algorithm. In Proceedings of the 2023 IEEE/IAS Industrial and Commercial Power System Asia (I & CPS Asia), Chongqing, China, 7–9 July 2023; pp. 1353–1357. [Google Scholar]
- Ye, X.; Wang, L.; Huang, C.; Luo, X. UAV-taken Wind Turbine Image Dehazing with a Double-patch Lightweight Neural Network. IEEE Internet Things J. 2023; early access. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing aided hyper inference and fine-tuning for small object detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 966–970. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Configuration |
|---|---|
| OS | Ubuntu 18.04.5 LTS |
| Python version | 3.9.16 |
| Pytorch version and CUDA version | 2.0.0+cu117 |
| GPU | Tesla V100S × 2 * |
| Video memory size | 32510MiB × 2 |
| Parameters | Configuration |
|---|---|
| Epoch | 100 |
| RepeatDataset | 5 |
| EMAHook | 0.0001 |
| Base_lr | 0.01 |
| Img_scale | 640 × 640 |
| Optimizer | SGD |
| Loss_obj | CrossEntropyLoss |
| IoULoss | CIoU |
| Method | mAP | mAP_50 | mAP_75 | mAP_s | mAP_m | mAP_l | Params (M) | FLOPs (G) | Time (s/img) * |
|---|---|---|---|---|---|---|---|---|---|
| Ours | 0.893 | 0.957 | 0.927 | 0.807 | 0.928 | 0.906 | 7.039 | 7.59 | 7.25 |
| yolov5-s | 0.862 | 0.94 | 0.884 | 0.621 | 0.764 | 0.838 | 7.039 | 7.59 | 6.75 |
| yolov6-s | 0.761 | 0.935 | 0.828 | 0.584 | 0.737 | 0.816 | 17.19 | 21.886 | 10.5 |
| yolov8-s | 0.623 | 0.85 | 0.676 | 0.437 | 0.552 | 0.699 | 11.138 | 14.278 | 7.5 |
| yolov7-e | 0.519 | 0.845 | 0.55 | 0.395 | 0.508 | 0.563 | 36.535 | 51.792 | 8 |
| yolox-s | 0.389 | 0.743 | 0.356 | 0.304 | 0.362 | 0.435 | 8.94 | 13.525 | 7.25 |
| MobileNetV2 | 0.865 | 0.933 | 0.891 | 0.743 | 0.896 | 0.872 | 6.796 | 6.637 | 6.5 |
| Mask R-CNN | 0.715 | 0.812 | 0.633 | 0.427 | 0.671 | 0.705 | 25.56 | 43.374 | 8.6 |
| Method | mAP | mAP_50 | mAP_75 | mAP_s | mAP_m | mAP_l | Time (s/img) * | |||
|---|---|---|---|---|---|---|---|---|---|---|
| Multi-Scale Copy-Paste | Hungarian Assigner | Negative Sample | Two-Stage Training | |||||||
| 0.783 | 0.952 | 0.876 | 0.621 | 0.764 | 0.838 | 6.75 | ||||
| √ | 0.866 | 0.936 | 0.885 | 0.709 | 0.868 | 0.904 | 7.25 | |||
| √ | 0.833 | 0.945 | 0.863 | 0.691 | 0.773 | 0.843 | 7 | |||
| √ | √ | 0.873 | 0.941 | 0.89 | 0.712 | 0.875 | 0.907 | 7 | ||
| √ | √ | √ | 0.854 | 0.947 | 0.899 | 0.722 | 0.899 | 0.877 | 7 | |
| √ | √ | √ | 0.875 | 0.942 | 0.891 | 0.7 | 0.864 | 0.908 | 7.25 | |
| √ | √ | √ | √ | 0.893 | 0.957 | 0.927 | 0.807 | 0.928 | 0.906 | 7.25 |
| Category | mAP | mAP_50 | mAP_75 | mAP_s | mAP_m | mAP_l |
|---|---|---|---|---|---|---|
| Corrosion | 0.793 | 0.955 | 0.91 | 0.876 | 0.767 | 0.845 |
| Crack | 0.876 | 1.0 | 1.0 | NAN | NAN | 0.88 |
| Hide Crack | 0.716 | 0.941 | 0.79 | 0.476 | 0.701 | 0.889 |
| Surface Eye | 0.765 | 0.936 | 0.839 | NAN | 0.748 | 0.767 |
| Surface Injury | 0.812 | 0.964 | 0.904 | 0.638 | 0.801 | 0.843 |
| Surface Oil | 0.838 | 0.953 | 0.91 | NAN | 0.723 | 0.85 |
| Lightning Strike | 0.681 | 0.918 | 0.776 | 0.492 | 0.741 | 0.793 |
| Category | mAP | mAP_50 | mAP_75 | mAP_s | mAP_m | mAP_l |
|---|---|---|---|---|---|---|
| Corrosion | 0.96 | 0.98 | 0.968 | 0.941 | 0.964 | 0.956 |
| Crack | 0.893 | 1.0 | 1.0 | NAN | NAN | 0.893 |
| Hide Crack | 0.885 | 0.979 | 0.918 | 0.732 | 0.879 | 0.979 |
| Surface Eye | 0.889 | 0.938 | 0.906 | NAN | 0.964 | 0.882 |
| Surface Injury | 0.938 | 0.965 | 0.944 | 0.938 | 0.951 | 0.923 |
| Surface Oil | 0.934 | 0.956 | 0.947 | NAN | 0.92 | 0.935 |
| Lightning Strike | 0.751 | 0.883 | 0.806 | 0.617 | 0.889 | 0.775 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, M.; Wang, X.; Wang, M.; Cheng, Y. Improved YOLOv5 Based on Multi-Strategy Integration for Multi-Category Wind Turbine Surface Defect Detection. Energies 2024, 17, 1796. https://doi.org/10.3390/en17081796
Lei M, Wang X, Wang M, Cheng Y. Improved YOLOv5 Based on Multi-Strategy Integration for Multi-Category Wind Turbine Surface Defect Detection. Energies. 2024; 17(8):1796. https://doi.org/10.3390/en17081796
Chicago/Turabian StyleLei, Mingwei, Xingfen Wang, Meihua Wang, and Yitao Cheng. 2024. "Improved YOLOv5 Based on Multi-Strategy Integration for Multi-Category Wind Turbine Surface Defect Detection" Energies 17, no. 8: 1796. https://doi.org/10.3390/en17081796
APA StyleLei, M., Wang, X., Wang, M., & Cheng, Y. (2024). Improved YOLOv5 Based on Multi-Strategy Integration for Multi-Category Wind Turbine Surface Defect Detection. Energies, 17(8), 1796. https://doi.org/10.3390/en17081796