

A Multi-Scale Deep Learning Algorithm for Enhanced Forest Fire Danger Prediction Using Remote Sensing Images


Abstract
1. Introduction
- Spatial and temporal limitations: Most existing models rely on localized data or data from specific time periods, limiting their applicability across different geographic regions and climatic conditions. Given the complexity of forest fires and the diversity of their driving factors, models need broader spatial coverage and longer temporal scales to improve prediction accuracy and generalizability.
- Inconsistency of fire danger characteristics across regions: Factors such as vegetation type, topography, climate conditions, and human activities can vary greatly from one region to another, leading to models that perform well in one area but poorly in another. To enhance prediction performance across diverse environmental conditions, models must be adaptable to this heterogeneity.
- Inability to extract fire danger-related information from remote sensing images: Current models struggle to accurately extract and interpret spatial information from remote sensing images, such as vegetation cover, vegetation types, ground object information, spatial information, and topography, which are crucial for assessing fire danger levels. This limitation prevents models from fully utilizing remote sensing data to detect subtle variations in the landscape, leading to less precise and reliable fire danger assessment.
- “Forest fire danger prediction network SESMTML”: A novel method for predicting forest fire danger using computer vision, which leverages the strengths of convolutional neural networks (CNNs) and Transformer [63,64] to extract both local and global features, as well as contextual information from remote sensing images. This approach allows for comprehensive mining and aggregation of multi-level visual features related to fire danger, enhancing prediction accuracy and reliability. Extensive experiments on the FireRisk [65] dataset demonstrate that SESMTML achieves superior performance in forest fire danger prediction.
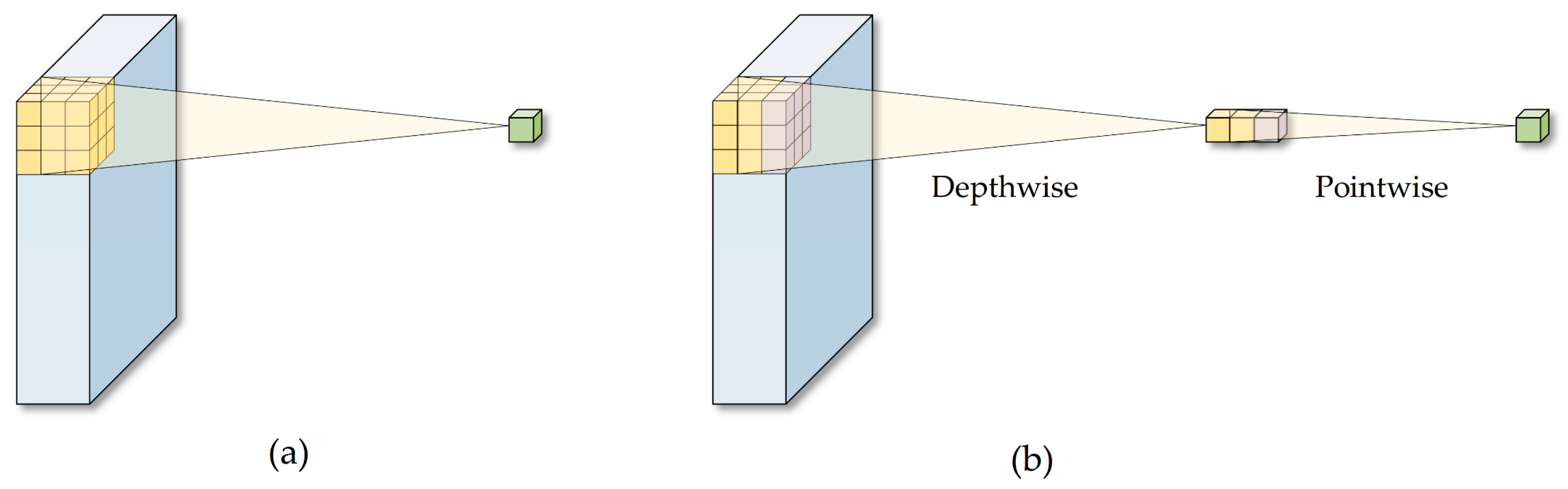
- “Multi-scale depth feature extraction module”: To improve computational efficiency and adaptability for high-resolution remote sensing image processing, we introduce depth separable convolution [66,67] in place of the standard convolution within the residual blocks of the ResNet34 [68] backbone network, forming the DSConvBlock component. This modification allows for more focused and efficient spatial feature extraction and channel feature fusion, leading to enhanced feature extraction capabilities and improved performance in predicting forest fire danger.
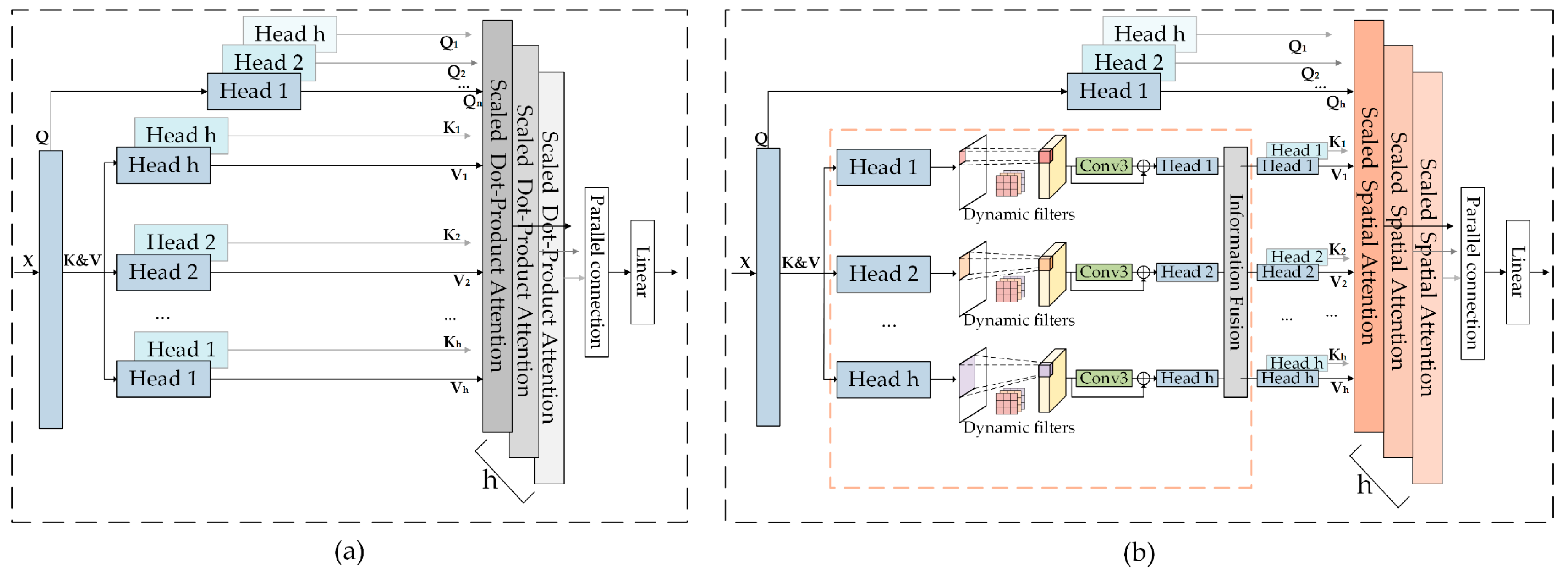
- “Multi-scale fire danger perception module”: The multi-scale fire danger perception module utilizes the multi-scale multi-headed self-attention (SMMSA) mechanism to capture complex patterns and background information at various scales, which are crucial for identifying fire hazards in remotely sensed imagery. Additionally, incorporating the spatial attention mechanism (SAM) [69] further improves the model’s ability to focus on critical areas in the input features, enhancing sensitivity and accuracy in spatial information processing. The squeeze-excite multi-layer perceptron (SE-MLP) module, combining SENet [70] with MLP, enables dynamic feature reweighting by modeling dependencies between convolutional feature channels, thereby improving the model’s representation efficiency and robustness.
2. Materials and Methods
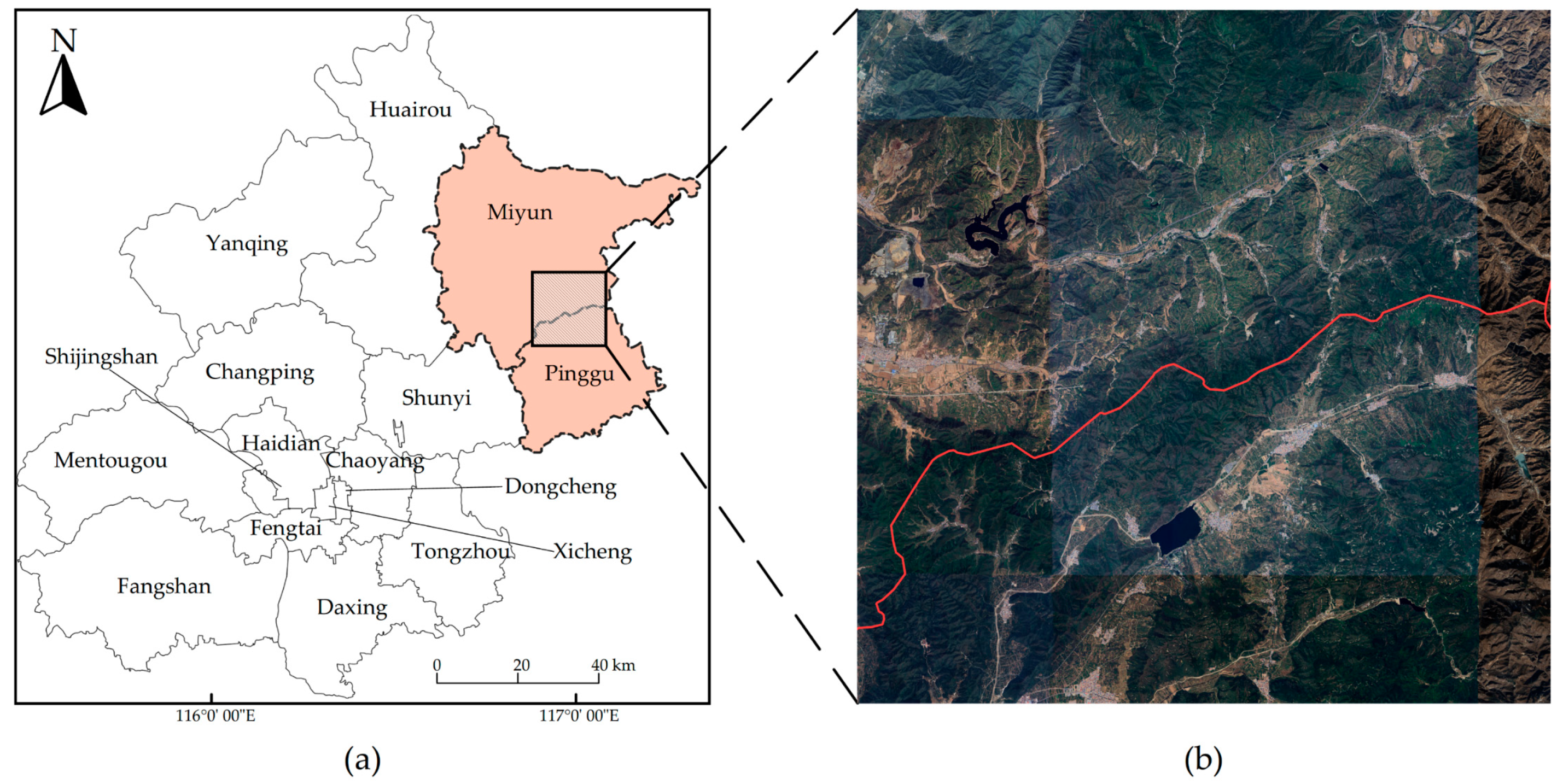
2.1. Study Area
2.2. Feature Extraction Strategy for Fire Danger in SESMTML
2.3. SESMTML Overall Architecture
2.3.1. Multi-Scale Depth Feature Extraction Module
2.3.2. Multi-Scale Fire Danger Perception Module
2.3.3. Multi-Scale Information Aggregation Module
2.3.4. Fire Danger Level Fusion Module
2.4. Datasets and Preprocessing
2.5. Evaluation of Indicators
3. Results
3.1. Training and Experimental Comparison Platform
3.2. Comprehensive Study of SESMTML
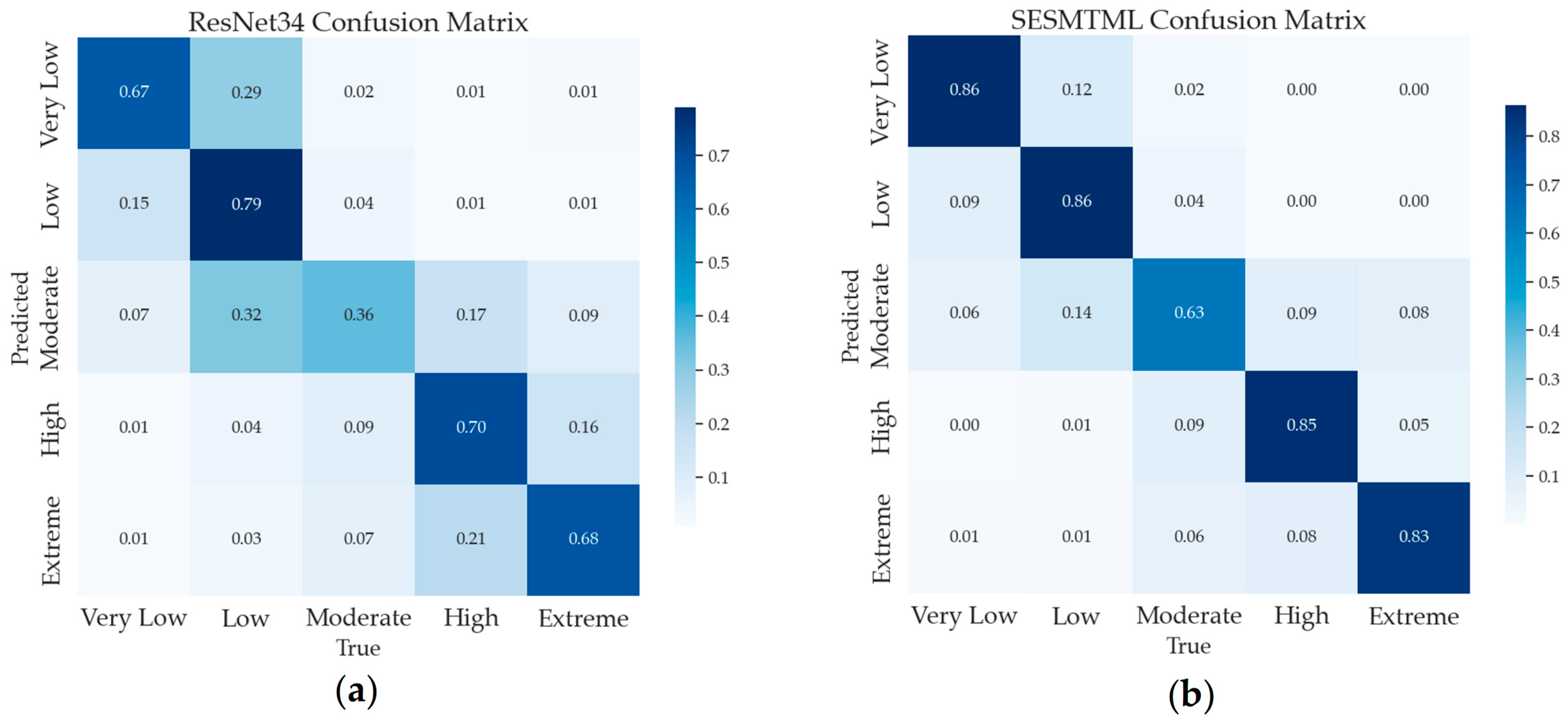
3.3. Comparisons of Other Model
3.4. Ablation Study
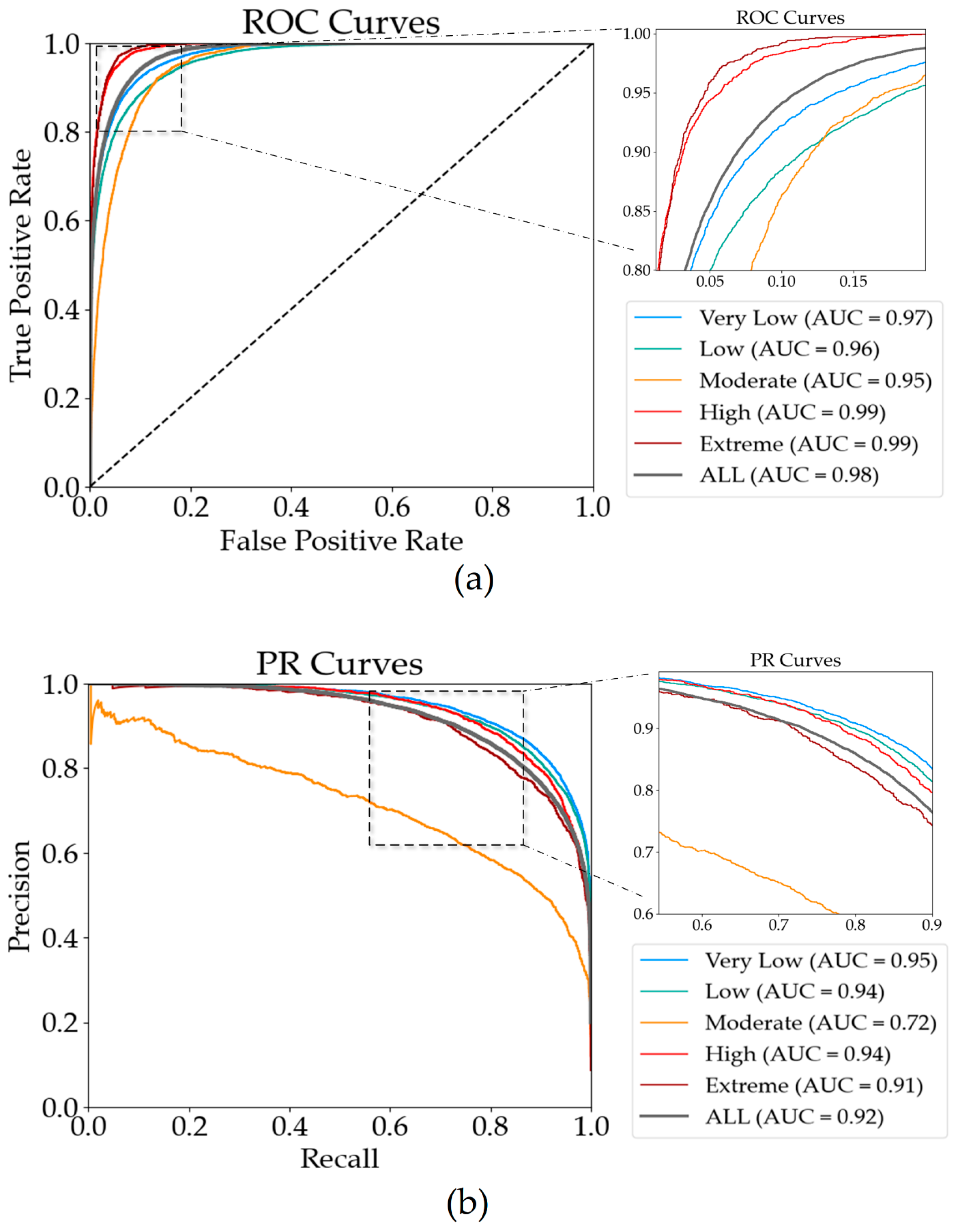
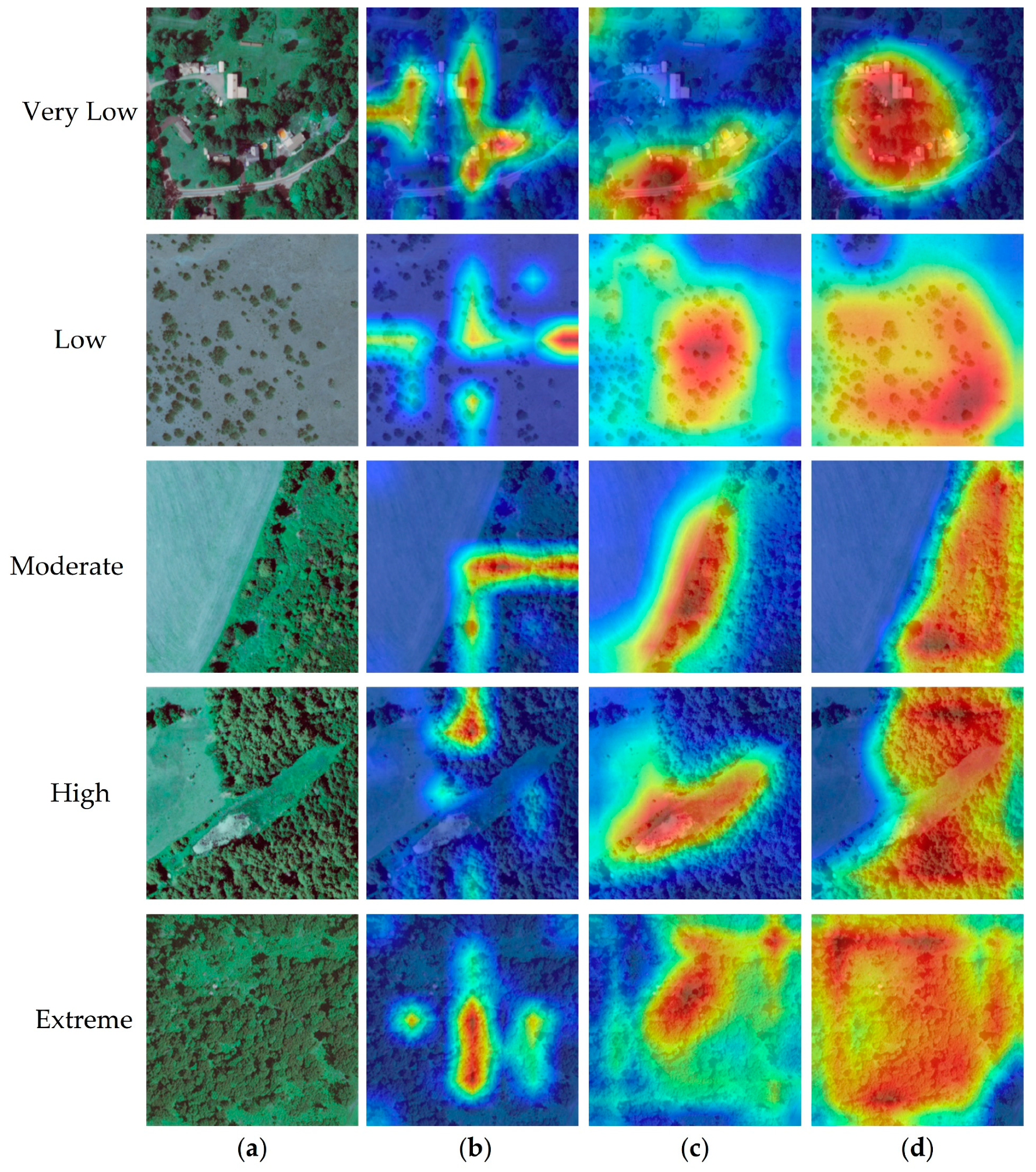
3.5. Visual Analysis
3.6. Fire Danger Zoning Map of Study Area
4. Discussion
4.1. Comparison of Key Findings with Previous Studies
4.2. Limitations and Future Perspectivess
- Performance on moderate-danger categories: A key limitation of SESMTML is its relatively lower predictive accuracy for the moderate fire danger category. This could be attributed to data imbalance, where the smaller sample size for moderate-danger images may have restricted the model’s learning capacity. Additionally, the overlap in feature characteristics between different fire danger categories might have contributed to misclassification. Future work could focus on addressing these issues through advanced data augmentation techniques or by integrating cost-sensitive learning approaches to enhance the model’s predictive consistency across all danger categories.
- Generalizability across regions: SESMTML’s generalizability across diverse geographic regions and environmental conditions remains to be rigorously validated. Although promising results were achieved in the selected study areas, the model’s applicability to other regions characterized by varying climatic conditions, vegetation types, or topographic features has yet to be comprehensively assessed. Future studies should aim to extend the model’s testing and refinement across different environments to establish its universal applicability.
- Computational complexity: Despite the integration of multiple deep learning modules, SESMTML’s computational complexity could pose challenges for real-time deployment, particularly in resource-constrained settings. Future work could investigate the development of more lightweight model variants or the application of model compression techniques to reduce computational overhead while preserving high predictive performance.
- Model interpretability: Similar to many deep learning models, SESMTML tends to be less interpretable than traditional statistical methods, making it difficult to understand the underlying reasons for its predictions. This lack of transparency can impede trust and limit its practical application in decision-making processes. Future research could focus on enhancing model interpretability by incorporating explainable AI techniques. These techniques could provide clearer insights into the factors driving the model’s predictions, thereby facilitating more informed decision-making in forest fire management.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carta, F.; Zidda, C.; Putzu, M.; Loru, D.; Anedda, M.; Giusto, D. Advancements in forest fire prevention: A comprehensive survey. Sensors 2023, 23, 6635. [Google Scholar] [CrossRef] [PubMed]
- Saleh, A.; Zulkifley, M.A.; Harun, H.H.; Gaudreault, F.; Davison, I.; Spraggon, M. Forest fire surveillance systems: A review of deep learning methods. Heliyon 2024, 10, 23127. [Google Scholar] [CrossRef] [PubMed]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A review on early forest fire detection systems using optical remote sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, G.; Yang, S.; Tan, Y.; Yang, Z.; Pang, Z. Machine learning for predicting forest fire occurrence in Changsha: An innovative investigation into the introduction of a forest fuel factor. Remote Sens. 2023, 15, 4208. [Google Scholar] [CrossRef]
- Meng, Q.; Huai, Y.; You, J.; Nie, X. Visualization of 3D forest fire spread based on the coupling of multiple weather factors. Comput. Graph. 2023, 110, 58–68. [Google Scholar] [CrossRef]
- Sevinç, V. Mapping the forest fire risk zones using artificial intelligence with risk factors data. Environ. Sci. Pollut. Res. 2023, 30, 4721–4732. [Google Scholar] [CrossRef]
- Das, J.; Mahato, S.; Joshi, P.K.; Liou, Y.A. Forest fire susceptibility zonation in Eastern India using statistical and weighted modelling approaches. Remote Sens. 2023, 15, 1340. [Google Scholar] [CrossRef]
- Stocks, B.J.; Lynham, T.J.; Lawson, B.D.; Alexander, M.E.; Wagner, C.V.; McAlpine, R.S.; Dube, D.E. Canadian forest fire danger rating system: An overview. For. Chron. 1989, 65, 258–265. [Google Scholar] [CrossRef]
- Mölders, N. Comparison of Canadian forest fire danger rating system and national fire danger rating system fire indices derived from Weather Research and Forecasting (WRF) model data for the June 2005 Interior Alaska wildfires. Atmos. Res. 2010, 95, 290–306. [Google Scholar] [CrossRef]
- Hanes, C.C.; Wotton, M.; Bourgeau-Chavez, L.; Woolford, D.G.; Bélair, S.; Martell, D.; Flannigan, M.D. Evaluation of new methods for drought estimation in the Canadian Forest Fire Danger Rating System. Int. J. Wildland Fire 2023, 32, 836–853. [Google Scholar] [CrossRef]
- Deeming, J.E.; Burgan, R.E.; Cohen, J.D. The National Fire-Danger Rating System, 1978; US Department of Agriculture, Forest Service, Intermountain Forest and Range Experiment Station: Ogden, UT, USA, 1977; Volume 39, pp. 1–16. [Google Scholar]
- Andrews, P.L.; Bradshaw, L.S. FIRES: Fire Information Retrieval and Evaluation System: A Program for Fire Danger Rating Analysis; U.S. Department of Agriculture, Forest Service, Intermountain Research Station: Missoula, MT, USA, 1997; Volume 367, pp. 1–10. [Google Scholar]
- San-Miguel-Ayanz, J.; Barbosa, P.M.; Schmuck, G.; Libertà, G.; Meyer-Roux, J. The European forest fire information system (EFFIS). In Proceedings of the Joint Workshop of Earsel SIG and GOFC/GOLD: Innovative Concepts and Methods in Fire Danger Estimation, Ghent, Belgium, 5–7 June 2003; pp. 183–187. [Google Scholar]
- San-Miguel-Ayanz, J.; Barbosa, P.; Liberta, G.; Schmuck, G.; Schulte, E.; Bucella, P. The European forest fire information system: A European strategy towards forest fire management. In Proceedings of the 3rd International Wildland Fire Conference, Sydney, Australia, 3–6 October 2003; pp. 1–12. [Google Scholar]
- Loupian, E.A.; Bartalev, S.A.; Ershov, D.V.; Kotel’nikov, R.V.; Balashov, I.V.; Bourtsev, M.A.; Egorov, V.A.; Efremov, V.Y.; Zharko, V.O.; Kovganko, K.A.; et al. Satellite data processing management in Forest Fires Remote Monitoring Information System (ISDM-Rosleskhoz) of the Federal Agency for Forestry. Sovr. Probl. Distantsionnogo Zondirovaniya Zemli Iz Kosmosa 2015, 12, 222–250. [Google Scholar]
- Kotel’Nikov, R.V.; Lupyan, E.A.; Bartalev, S.A.; Ershov, D.V. Space monitoring of forest fires: History of the creation and development of ISDM-Rosleskhoz. Contemp. Probl. Ecol. 2020, 13, 795–802. [Google Scholar] [CrossRef]
- Baranovskiy, N.V.; Vyatkina, V.A.; Chernyshov, A.M. Deterministic–Probabilistic Prediction of Forest Fires from Lightning Activity Taking into Account Aerosol Emissions. Atmosphere 2022, 14, 29. [Google Scholar] [CrossRef]
- Baranovskiy, N.V. (Ed.) Forest Fire Danger Prediction Using Deterministic-Probabilistic Approach; IGI Global: Hershey, PA, USA, 2021; Volume 4, pp. 54–60. [Google Scholar]
- Baranovskiy, N.V. Predicting Forest Fire Numbers Using Deterministic-Probabilistic Approach. In Predicting, Monitoring, and Assessing Forest Fire Dangers and Risks; IGI Global: Hershey, PA, USA, 2020; pp. 89–100. [Google Scholar]
- Baranovskiy, N. Deterministic-Probabilistic Approach to Predict Lightning-Caused Forest Fires in Mounting Areas. Forecasting 2021, 3, 695–715. [Google Scholar] [CrossRef]
- Eden, J.M.; Krikken, F.; Drobyshev, I. An Empirical Prediction Approach for Seasonal Fire Risk in the Boreal Forests. Int. J. Climatol. 2020, 40, 2732–2744. [Google Scholar] [CrossRef]
- O’Connor, C.D.; Calkin, D.E.; Thompson, M.P. An Empirical Machine Learning Method for Predicting Potential Fire Control Locations for Pre-Fire Planning and Operational Fire Management. Int. J. Wildland Fire 2017, 26, 587–597. [Google Scholar] [CrossRef]
- Anderson, W.R.; Cruz, M.G.; Fernandes, P.M.; McCaw, L.; Vega, J.A.; Bradstock, R.A.; Fogarty, L.; Gould, J.; McCarthy, G.; Marsden-Smedley, J.B.; et al. A generic, empirical-based model for predicting rate of fire spread in shrublands. Int. J. Wildland Fire 2015, 24, 443–460. [Google Scholar] [CrossRef]
- Cruz, M.G.; Gould, J.S.; Alexander, M.E.; Sullivan, A.L.; McCaw, W.L.; Matthews, S. Empirical-based models for predicting head-fire rate of spread in Australian fuel types. Aust. For. 2015, 78, 118–158. [Google Scholar] [CrossRef]
- Koo, E.; Pagni, P.; Woycheese, J.; Stephens, S.; Weise, D.; Huff, J. A simple physical model for forest fire spread rate. Fire Saf. Sci. 2005, 8, 851–862. [Google Scholar] [CrossRef]
- Bodrožić, L.; Marasović, J.; Stipaničev, D. Fire Modeling in Forest Fire Management. In Proceedings of the CEEPUS Spring School, Kielce, Poland, 29 August–11 September 2005; pp. 1–6. [Google Scholar]
- Taylor, S.W.; Woolford, D.G.; Dean, C.B.; Martell, D.L. Wildfire Prediction to Inform Fire Management: Statistical Science Challenges. Stat. Sci. 2013, 28, 586–615. [Google Scholar] [CrossRef]
- Bianchini, G.; Caymes-Scutari, P.; Méndez-Garabetti, M. Evolutionary-Statistical System: A parallel method for improving forest fire spread prediction. J. Comput. Sci. 2015, 6, 58–66. [Google Scholar] [CrossRef]
- Han, J.G.; Ryu, K.H.; Chi, K.H.; Yeon, Y.K. Statistics based predictive geo-spatial data mining: Forest fire hazardous area mapping application. In Proceedings of the Web Technologies and Applications: 5th Asia-Pacific Web Conference, APWeb 2003, Xian, China, 23–25 April 2003; pp. 370–381. [Google Scholar]
- Bianchini, G. Wildland Fire Prediction Based on Statistical Analysis of Multiple Solutions; Universitat Autònoma de Barcelona: Barcelona, Spain, 2006. [Google Scholar]
- de Santana, R.O.; Delgado, R.C.; Schiavetti, A. Modeling susceptibility to forest fires in the Central Corridor of the Atlantic Forest using the frequency ratio method. J. Environ. Manag. 2021, 296, 113343. [Google Scholar] [CrossRef] [PubMed]
- Hong, H.; Jaafari, A.; Zenner, E.K. Predicting spatial patterns of wildfire susceptibility in the Huichang County, China: An integrated model to analysis of landscape indicators. Ecol. Indic. 2019, 101, 878–891. [Google Scholar] [CrossRef]
- Sivrikaya, F.; Küçük, Ö. Modeling forest fire risk based on GIS-based analytical hierarchy process and statistical analysis in Mediterranean region. Ecol. Inform. 2022, 68, 101537. [Google Scholar] [CrossRef]
- Parajuli, A.; Manzoor, S.A.; Lukac, M. Areas of the Terai Arc landscape in Nepal at risk of forest fire identified by fuzzy analytic hierarchy process. Environ. Dev. 2023, 45, 100810. [Google Scholar] [CrossRef]
- Si, L.; Shu, L.; Wang, M.; Zhao, F.; Chen, F.; Li, W.; Li, W. Study on forest fire danger prediction in plateau mountainous forest area. Nat. Hazards Res. 2022, 2, 25–32. [Google Scholar] [CrossRef]
- Hong, H.; Naghibi, S.A.; Moradi Dashtpagerdi, M.; Pourghasemi, H.R.; Chen, W. A comparative assessment between linear and quadratic discriminant analyses (LDA-QDA) with frequency ratio and weights-of-evidence models for forest fire susceptibility mapping in China. Arab. J. Geosci. 2017, 10, 167. [Google Scholar] [CrossRef]
- Arif, M.; Alghamdi, K.K.; Sahel, S.A.; Alosaimi, S.O.; Alsahaft, M.E.; Alharthi, M.A.; Arif, M. Role of machine learning algorithms in forest fire management: A literature review. J. Robot. Autom. 2021, 5, 212–226. [Google Scholar]
- Yang, S.; Lupascu, M.; Meel, K.S. Predicting forest fire using remote sensing data and machine learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Menlo Park, CA, USA, 2–9 February 2021. [Google Scholar]
- Soualah, L.; Bouzekri, A.; Chenchouni, H. Hoping the best, expecting the worst: Forecasting forest fire risk in Algeria using fuzzy logic and GIS. Trees For. People 2024, 17, 100614. [Google Scholar] [CrossRef]
- Gao, C.; Lin, H.; Hu, H. Forest-fire-risk prediction based on random forest and backpropagation neural network of Heihe area in Heilongjiang province, China. Forests 2023, 14, 170. [Google Scholar] [CrossRef]
- Tan, C.; Feng, Z. Mapping forest fire risk zones using machine learning algorithms in Hunan province, China. Sustainability 2023, 15, 6292. [Google Scholar] [CrossRef]
- Shao, Y.; Feng, Z.; Sun, L.; Yang, X.; Li, Y.; Xu, B.; Chen, Y. Mapping China’s forest fire risks with machine learning. Forests 2022, 13, 856. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Gayen, A.; Lasaponara, R.; Tiefenbacher, J.P. Application of learning vector quantization and different machine learning techniques to assessing forest fire influence factors and spatial modelling. Environ. Res. 2020, 184, 109321. [Google Scholar] [CrossRef]
- Shmuel, A.; Heifetz, E. Global wildfire susceptibility mapping based on machine learning models. Forests 2022, 13, 1050. [Google Scholar] [CrossRef]
- Singh, S.S.; Jeganathan, C. Using ensemble machine learning algorithm to predict forest fire occurrence probability in Madhya Pradesh and Chhattisgarh, India. Adv. Space Res. 2024, 73, 2969–2987. [Google Scholar] [CrossRef]
- Ge, X.; Yang, Y.; Peng, L.; Chen, L.; Li, W.; Zhang, W.; Chen, J. Spatio-temporal knowledge graph based forest fire prediction with multi source heterogeneous data. Remote Sens. 2022, 14, 3496. [Google Scholar] [CrossRef]
- Khennou, F.; Ghaoui, J.; Akhloufi, M.A. Forest fire spread prediction using deep learning. In Proceedings of the Geospatial Informatics XI, Online, FL, USA, 12–17 April 2021. [Google Scholar]
- Yandouzi, M.; Grari, M.; Idrissi, I.; Moussaoui, O.; Azizi, M.; Ghoumid, K.; Elmiad, A.K. Review on forest fires detection and prediction using deep learning and drones. J. Theor. Appl. Inf. Technol. 2022, 100, 4565–4576. [Google Scholar]
- Omar, N.; Al-Zebari, A.; Sengur, A. Deep learning approach to predict forest fires using meteorological measurements. In Proceedings of the 2021 2nd International Informatics and Software Engineering Conference (IISEC), Ankara, Turkey, 16–17 December 2021. [Google Scholar]
- Shao, Y.; Wang, Z.; Feng, Z.; Sun, L.; Yang, X.; Zheng, J.; Ma, T. Assessment of China’s forest fire occurrence with deep learning, geographic information and multisource data. J. For. Res. 2023, 34, 963–976. [Google Scholar] [CrossRef]
- Zheng, S.; Gao, P.; Wang, W.; Zou, X. A highly accurate forest fire prediction model based on an improved dynamic convolutional neural network. Appl. Sci. 2022, 12, 6721. [Google Scholar] [CrossRef]
- Miao, X.; Li, J.; Mu, Y.; He, C.; Ma, Y.; Chen, J.; Wei, W.; Gao, D. Time Series Forest Fire Prediction Based on Improved Transformer. Forests 2023, 14, 1596. [Google Scholar] [CrossRef]
- Hodges, J.L.; Lattimer, B.Y. Wildland fire spread modeling using convolutional neural networks. Fire Technol. 2019, 55, 2115–2142. [Google Scholar] [CrossRef]
- Lin, X.; Li, Z.; Chen, W.; Sun, X.; Gao, D. Forest fire prediction based on long-and short-term time-series network. Forests 2023, 14, 778. [Google Scholar] [CrossRef]
- Lai, C.; Zeng, S.; Guo, W.; Liu, X.; Li, Y.; Liao, B. Forest fire prediction with imbalanced data using a deep neural network method. Forests 2022, 13, 1129. [Google Scholar] [CrossRef]
- Ananthi, J.; Sengottaiyan, N.; Anbukaruppusamy, S.; Upreti, K.; Dubey, A.K. Forest fire prediction using IoT and deep learning. Int. J. Adv. Technol. Eng. Explor. 2022, 9, 246–256. [Google Scholar]
- McCarthy, N.F.; Tohidi, A.; Aziz, Y.; Dennie, M.; Valero, M.M.; Hu, N. A deep learning approach to downscale geostationary satellite images for decision support in high impact wildfires. Forests 2021, 12, 294. [Google Scholar] [CrossRef]
- Xu, C.; Zhu, G.; Shu, J. A combination of lie group machine learning and deep learning for remote sensing scene classification using multi-layer heterogeneous feature extraction and fusion. Remote Sens. 2022, 14, 1445. [Google Scholar] [CrossRef]
- Cheng, W.; Feng, Y.; Song, L.; Wang, X. DMF2Net: Dynamic multi-level feature fusion network for heterogeneous remote sensing image change detection. Knowl. Based Syst. 2024, 300, 112159. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, C.; Han, M. MLFC-net: A multi-level feature combination attention model for remote sensing scene classification. Comput. Geosci. 2022, 160, 105042. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; White, J.C.; Wulder, M.A.; Næsset, E. Remote sensing in forestry: Current challenges, considerations and directions. For. Int. J. For. Res. 2024, 97, 11–37. [Google Scholar] [CrossRef]
- Tavakol Sadrabadi, M.; Innocente, M.S. Vegetation cover type classification using cartographic data for prediction of wildfire behaviour. Fire 2023, 6, 76. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–6 December 2017. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Shen, S.; Seneviratne, S.; Wanyan, X.; Kirley, M. Firerisk: A remote sensing dataset for fire risk assessment with benchmarks using supervised and self-supervised learning. In Proceedings of the 2023 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 29 November–1 December 2023. [Google Scholar]
- Guo, Y.; Li, Y.; Wang, L.; Rosing, T. Depthwise convolution is all you need for learning multiple visual domains. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, J.; Sun, G.; Li, W.; Yu, X.; Zhang, C.; Gong, Y.; Tu, L. Impacts of land use change and climate variations on annual inflow into the Miyun Reservoir, Beijing, China. Hydrol. Earth Syst. Sci. 2016, 20, 1561–1572. [Google Scholar] [CrossRef]
- Fu, L.; Zhao, D.; Wu, B.; Xu, Z.; Zeng, Y. Variations in forest aboveground biomass in Miyun Reservoir of Beijing over the past two decades. J. Soils Sediments 2017, 17, 2080–2090. [Google Scholar] [CrossRef]
- Wang, X.; Gong, W.; Huang, X.; Liu, T.; Zhou, Y.; Li, H. Assessment of eco-environmental quality on land use and land cover changes using remote sensing and GIS: A case study of Miyun county. Nat. Environ. Pollut. Technol. 2018, 17, 739–746. [Google Scholar]
- Xie, S.; Liu, L.; Zhang, X.; Yang, L. Mapping the annual dynamics of land cover in Beijing from 2001 to 2020 using Landsat dense time series stack. ISPRS J. Photogramm. Remote Sens. 2022, 185, 201–218. [Google Scholar] [CrossRef]
- Sun, T.; Wu, J.; Xiao, C.; Teng, W. Effect of different types of vegetations on soil and water conservation in the Miyun Reservoir buffer zone. J. Nat. Resour. 2009, 24, 1146–1154. [Google Scholar]
- Cheng, L.; Zhang, Y.; Sun, H. Vegetation cover change and relative contributions of associated driving factors in the ecological conservation and development zone of Beijing, China. Pol. J. Environ. Stud. 2020, 29, 53–65. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Jia, B.; Zhang, W.; Ma, J.; Liu, X. Woody plant diversity spatial patterns and the effects of urbanization in Beijing, China. Urban For. Urban Green. 2020, 56, 126873. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11027–11036. [Google Scholar]
- Maxwell, A.E.; Warner, T.A.; Vanderbilt, B.C.; Ramezan, C.A. Land cover classification and feature extraction from national agriculture images program (NAIP) orthoimages: A review. Photogramm. Eng. Remote Sens. 2017, 83, 737–747. [Google Scholar] [CrossRef]
- Dillon, G.K.; Menakis, J.; Fay, F. Wildland fire potential: A tool for assessing wildfire risk and fuels management needs. In Proceedings of the Large Wildland Fires Conference, Missoula, MT, USA, 19–23 May 2014; pp. 60–76. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 20–21 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Google Earth. Miyun and Pinggu Districts, Beijing, 40°16′24.4″ N 116°59′21.6″ W, Elevation 75m. Available online: https://earth.google.com/web/ (accessed on 1 July 2024).
- Esri. “Esri Land Use Land Cover LULC” [Web Map]. Land Cover 2050-Country. 2024. Available online: https://www.arcgis.com/apps/mapviewer/index.html?layers=cfcb7609de5f478eb7666240902d4d3d (accessed on 25 August 2024).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types | Number | Very-Low | Low | Moderate | High | Extreme |
|---|---|---|---|---|---|---|
| Training | 49,221 | 15,412 | 17,645 | 5967 | 6007 | 4190 |
| Testing | 21,093 | 6604 | 7562 | 2557 | 2533 | 1837 |
| Total | 70,314 | 22,016 | 25,207 | 8524 | 8540 | 6027 |
| System Components | Configuration |
|---|---|
| Operating system | Ubuntu 22.04 |
| Programming language | Python 3.10.1 |
| Framework | PyTorch 2.1.0 |
| CPU | Intel(R) Xeon(R) Gold 6430 |
| GPU | GeForce RTX 4090(24 GB) |
| CUDA | CUDA 12.1 |
| CuDNN | 10.2 |
| RAM | 120 GB |
| Training Hyperparameters | Value |
|---|---|
| Batch size | 128 |
| Epochs | 50 |
| Image size | 320 |
| Optimizer | Adamw [83] |
| Optimizer epsilon | 1 × 10−8 |
| Learning rate scheduler | cosine |
| Initial learning rate | 1 × 10−5 |
| Warmup epochs | 5 |
| Warmup learning rate | 1 × 10−6 |
| Learning rate decay rate | 0.1 |
| Class | Instances | OA (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|---|
| All | 21,093 | 83.18 | 83.05 | 83.18 | 83.10 |
| Very Low | 6604 | 86.31 | 86.76 | 86.31 | 86.53 |
| Low | 7562 | 86.39 | 84.95 | 86.39 | 85.67 |
| Moderate | 2557 | 63.43 | 68.29 | 63.43 | 65.77 |
| High | 2533 | 85.27 | 84.24 | 85.27 | 84.76 |
| Extreme | 1837 | 83.28 | 80.78 | 83.29 | 82.02 |
| Method | OA (%) | Precision (%) | Recall (%) | F1 Score (%) | Params (M) |
|---|---|---|---|---|---|
| ResNet34 | 67.86 | 64.70 | 63.88 | 63.72 | 21.80 |
| VGG16 | 73.57 | 71.49 | 70.20 | 70.73 | 138.36 |
| DenseNet-121 | 72.09 | 69.98 | 69.30 | 69.57 | 7.98 |
| ConvNext | 67.96 | 64.71 | 63.71 | 64.09 | 88.60 |
| MobileNetV2 | 75.19 | 73.41 | 72.65 | 72.99 | 3.50 |
| EfficientNetV2 | 66.73 | 63.81 | 62.58 | 63.09 | 21.45 |
| Swin-Transformer | 68.53 | 66.06 | 64.62 | 65.21 | 87.77 |
| SESMTML (Ours) | 83.18 | 83.05 | 83.18 | 83.10 | 30.08 |
| Model | MDFEM | MFDPM | MIAM | FDLFM | OA (%) | Precision (%) | Recall (%) | F1 Score (%) |
|---|---|---|---|---|---|---|---|---|
| 1. base | – | – | – | – | 67.86 | 64.70 | 63.88 | 63.72 |
| 2 | √ | – | – | – | 71.58 | 72.24 | 71.58 | 71.60 |
| 3 | √ | – | – | √ | 73.67 | 73.44 | 73.67 | 73.30 |
| 4 | √ | √ | – | √ | 79.44 | 79.39 | 79.44 | 79.36 |
| 5 | √ | – | √ | √ | 76.66 | 76.61 | 76.66 | 76.59 |
| 6. ours | √ | √ | √ | √ | 83.18 | 83.05 | 83.18 | 83.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Jiang, H.; Wang, S.; Ma, X. A Multi-Scale Deep Learning Algorithm for Enhanced Forest Fire Danger Prediction Using Remote Sensing Images. Forests 2024, 15, 1581. https://doi.org/10.3390/f15091581
Yang J, Jiang H, Wang S, Ma X. A Multi-Scale Deep Learning Algorithm for Enhanced Forest Fire Danger Prediction Using Remote Sensing Images. Forests. 2024; 15(9):1581. https://doi.org/10.3390/f15091581
Chicago/Turabian StyleYang, Jixiang, Huiping Jiang, Sen Wang, and Xuan Ma. 2024. "A Multi-Scale Deep Learning Algorithm for Enhanced Forest Fire Danger Prediction Using Remote Sensing Images" Forests 15, no. 9: 1581. https://doi.org/10.3390/f15091581
APA StyleYang, J., Jiang, H., Wang, S., & Ma, X. (2024). A Multi-Scale Deep Learning Algorithm for Enhanced Forest Fire Danger Prediction Using Remote Sensing Images. Forests, 15(9), 1581. https://doi.org/10.3390/f15091581