
Deterring Deepfake Attacks with an Electrical Network Frequency Fingerprints Approach





Abstract
:1. Introduction
- Designing of an effective spectral estimation technique using both parametric and non-parametric methods for IF detection.
- Utilizing a Robust Filtering Algorithm (RFA) over a weighted SNR to identify the harmonic ENF embedded in media recordings to enhance the ENF signal estimation in the identified ENF.
- Implementing an effective detection technique against deepfake attacks and an integrated Singular Spectrum Analysis (SSA) based on the correlation coefficient values to reduce the number of false positives in a real-time video broadcasting scenario.
- Demonstrating experimental analysis on the video and audio deepfake attacks’ detection using the RFA technique and comparing its effectiveness against traditional spectral estimation techniques.
2. Background and Related Work
2.1. Deepfake Detection Using Traditional and Trained Models
2.2. ENF Applications in Digital Multimedia
2.3. ENF-Based Digital Media Authentication
3. Robust ENF Estimation Techniques
3.1. Non-Parametric Spectral Estimation Techniques
3.2. Parametric Spectral Estimation Techniques
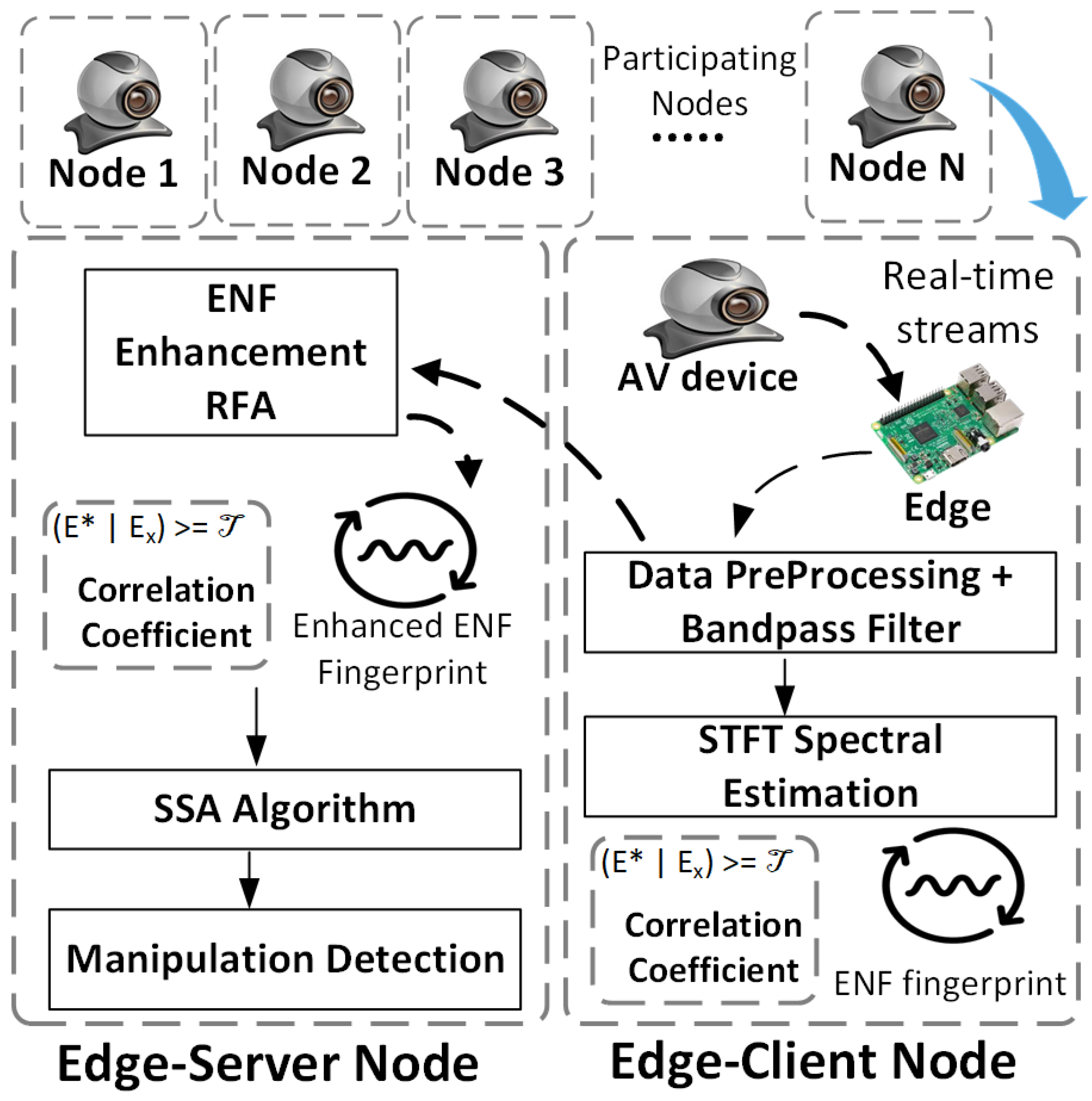
3.3. Robust ENF Enhancement Techniques
3.3.1. Weighted Harmonics Combination
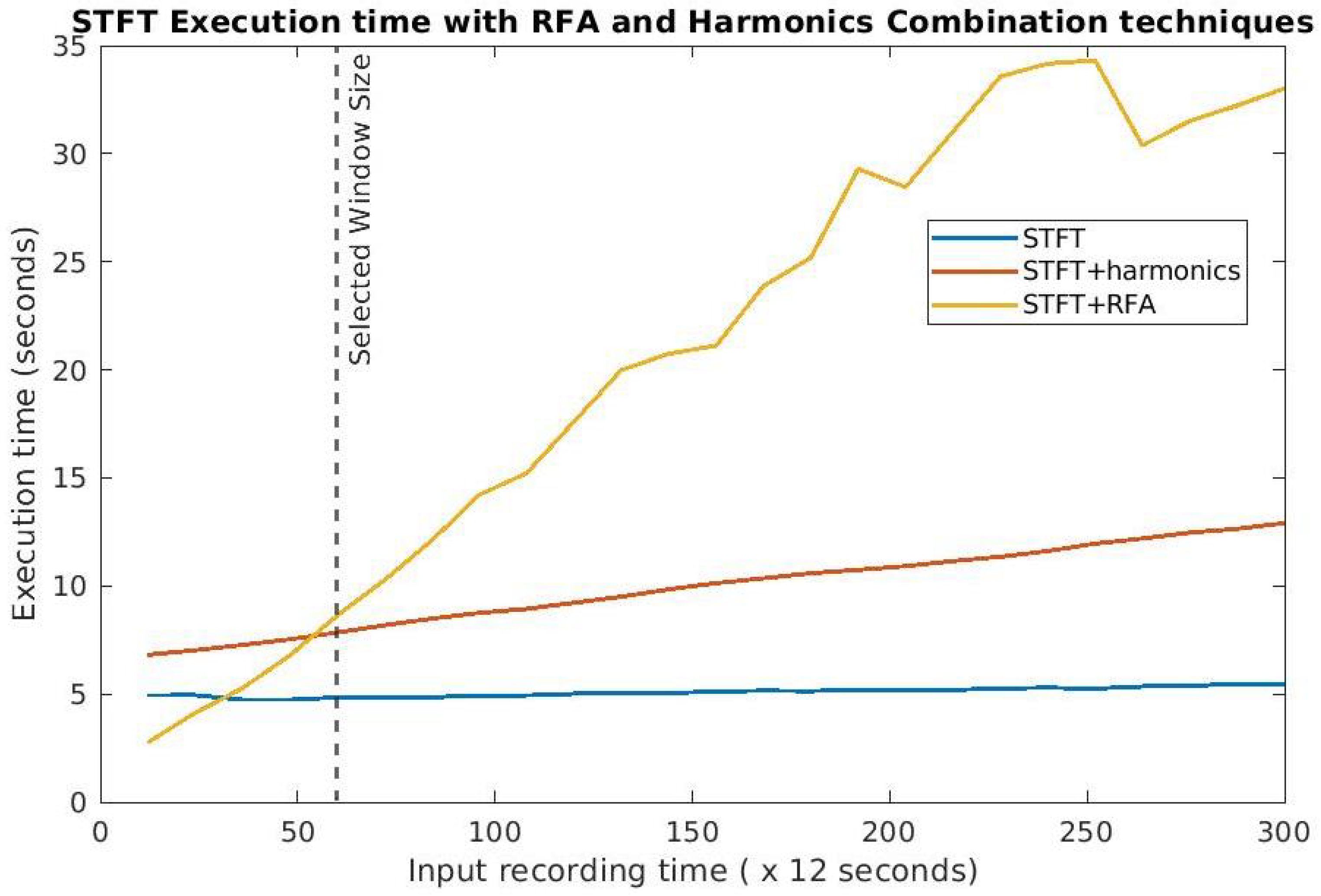
3.3.2. Robust Filtering Algorithm
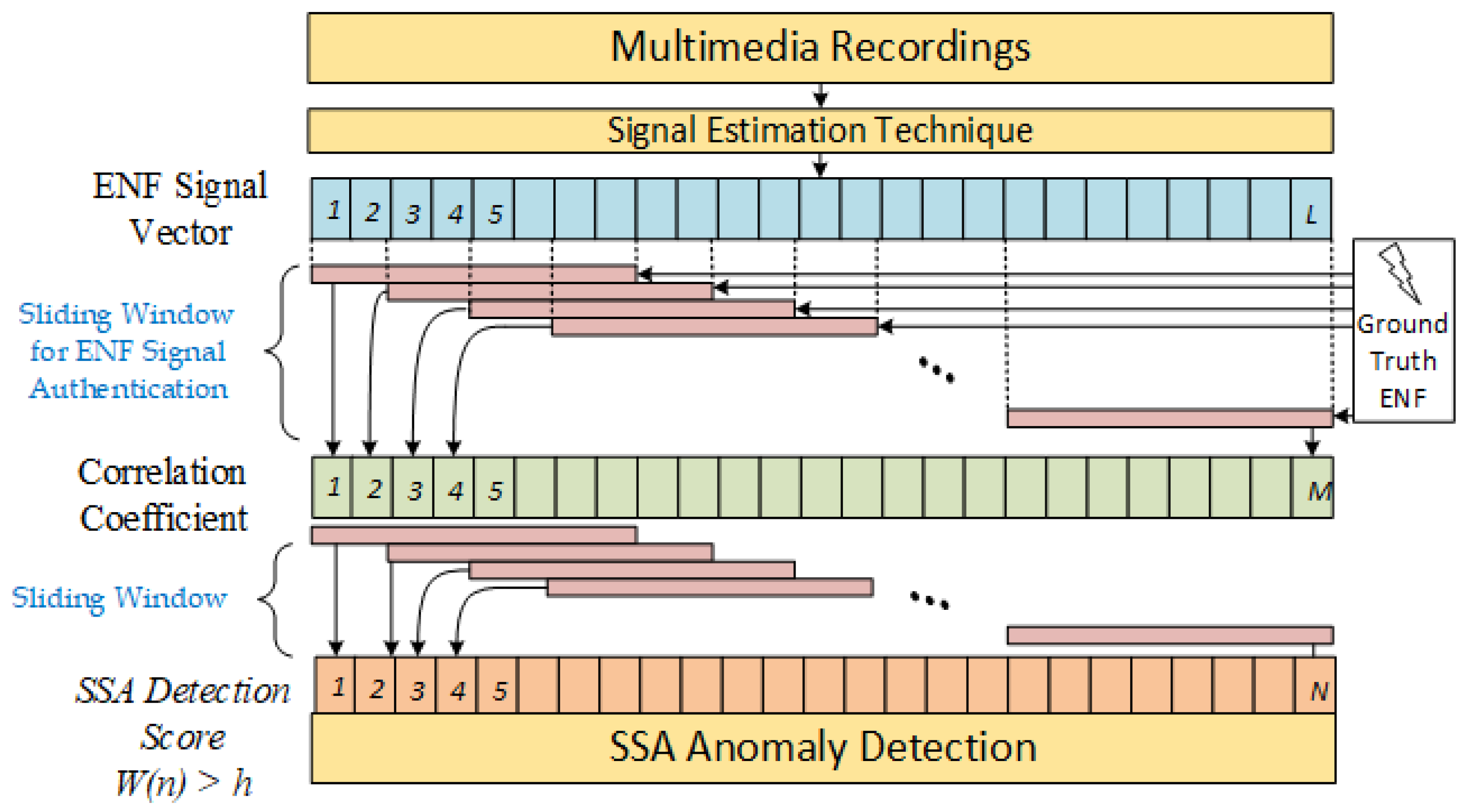
3.4. ENF Similarity Verification Using the Correlation Coefficient
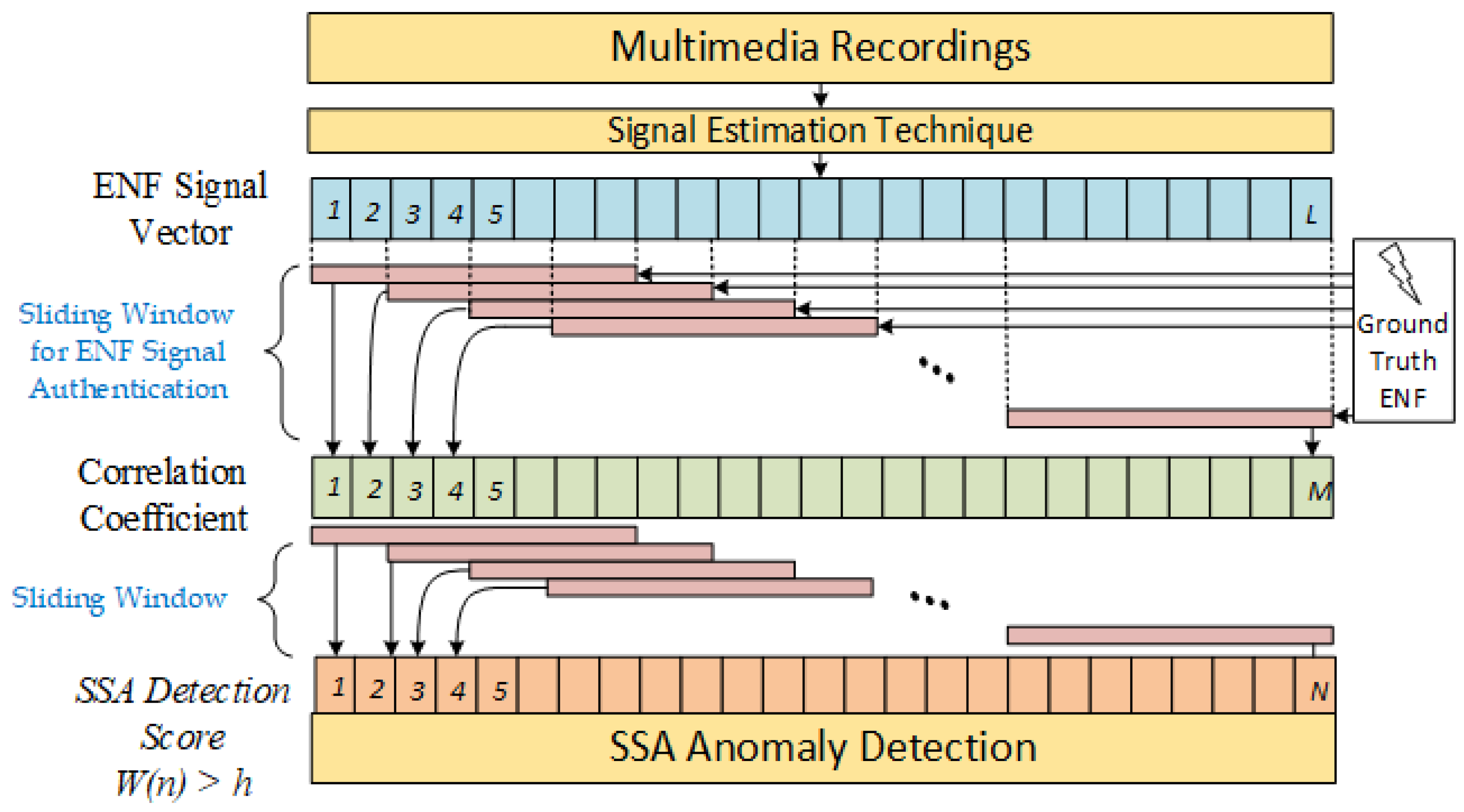
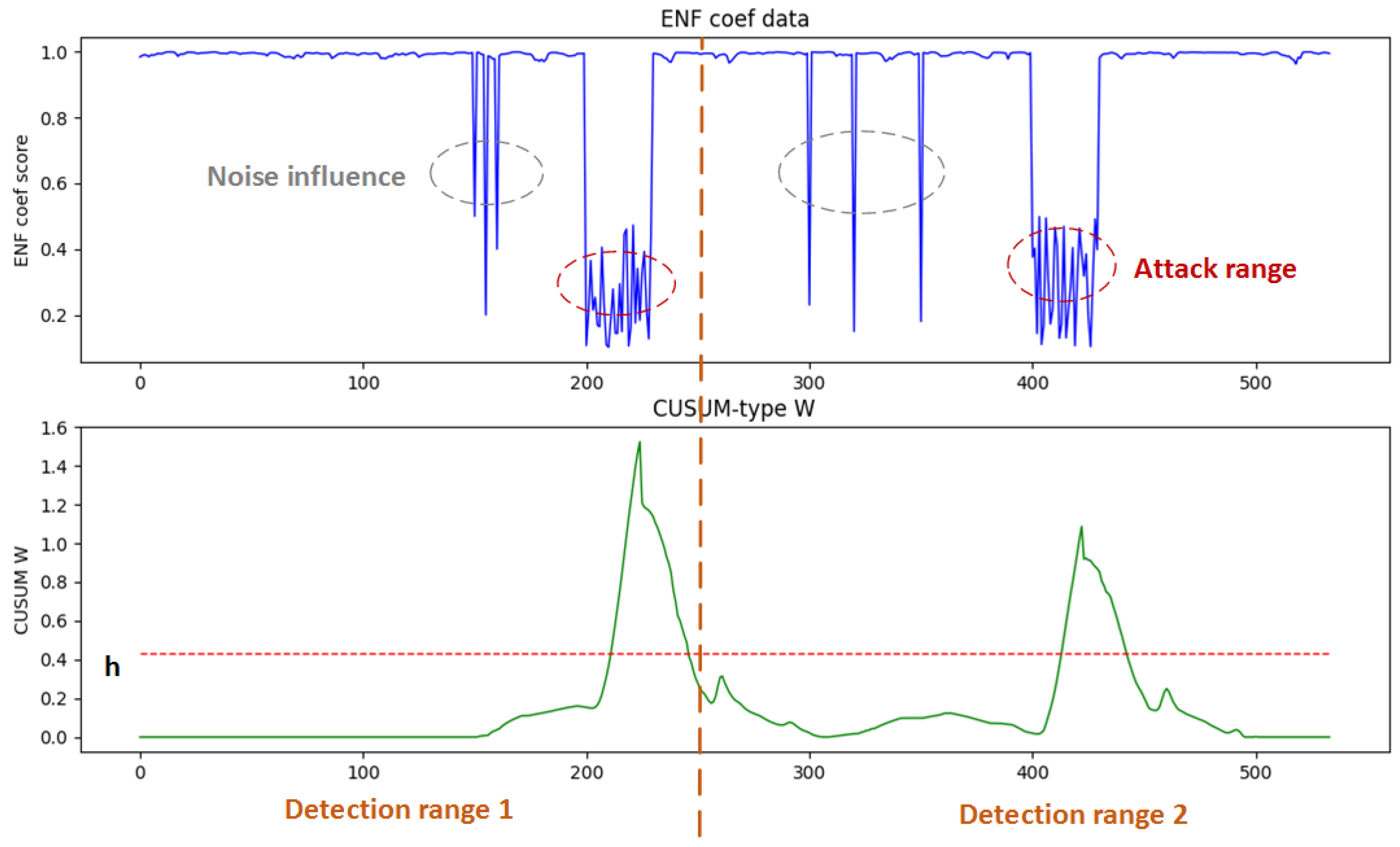
4. ENF-Based Anomaly Detection Using Singular Spectrum Analysis
4.1. SSA for Anomaly Detection
4.2. SSA Algorithm
- Creating the base matrix of size () using the initial correlation coefficient values and ,
- Using the base matrix, also known as the Hankel matrix, we compute , and the Singular-Value Decomposition (SVD) of the matrix R results in M eigen vectors and eigen values. Among the M eigen vectors, eigen vectors are selected to create a group I. The group I consists of l-dimensional vectors in subspace of M-dimensional space . The eigen values computed from the matrix R are arranged in descending order, and the top l values are selected for the matrix I, respectively, such that the subspace consists of the features of .
- With the base matrix established, next, a test matrix is constructed of size () with a lag p from the base matrix and . The resulting matrix is
- With the test matrix and the l-dimensional subspace , the detection statistics of abnormal fluctuations in the input values can be calculated with the sum of the squared Euclidean distance between the column vectors of and subspace . The column vectors of are represented as , , …, . The detection statistics for n iterating over is given as,
- With the iterating values, the detection scores are normalized and represented as
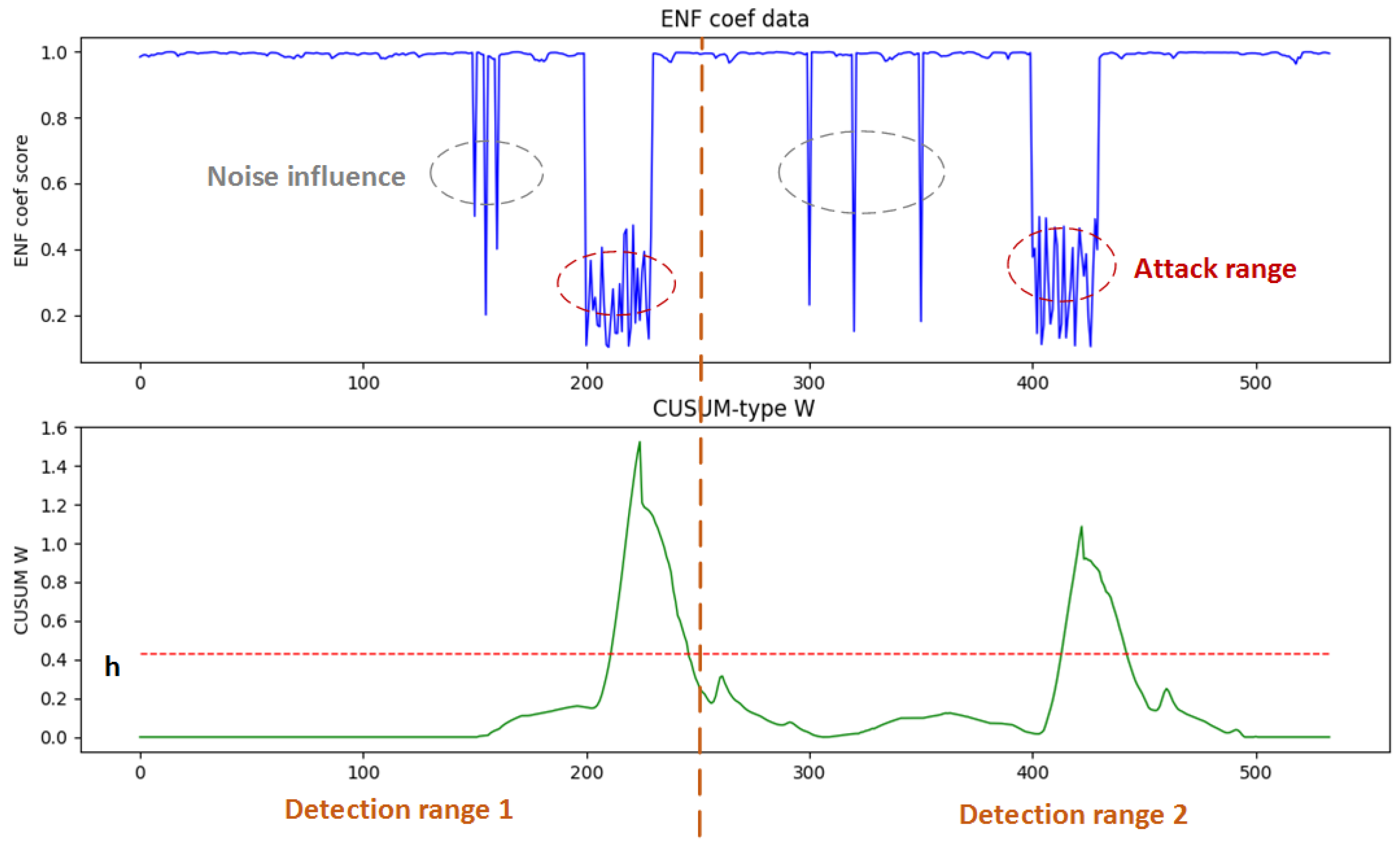
- The Cumulative Sum of deviations (CUSUM) in the detection statistics are then calculated to eliminate false positives and seek major changes in the input values. A threshold h is used to detect the fluctuations in the correlation coefficient of the ENF values. The detection score iswhere represents .
5. Experimental Study and Performance Analysis
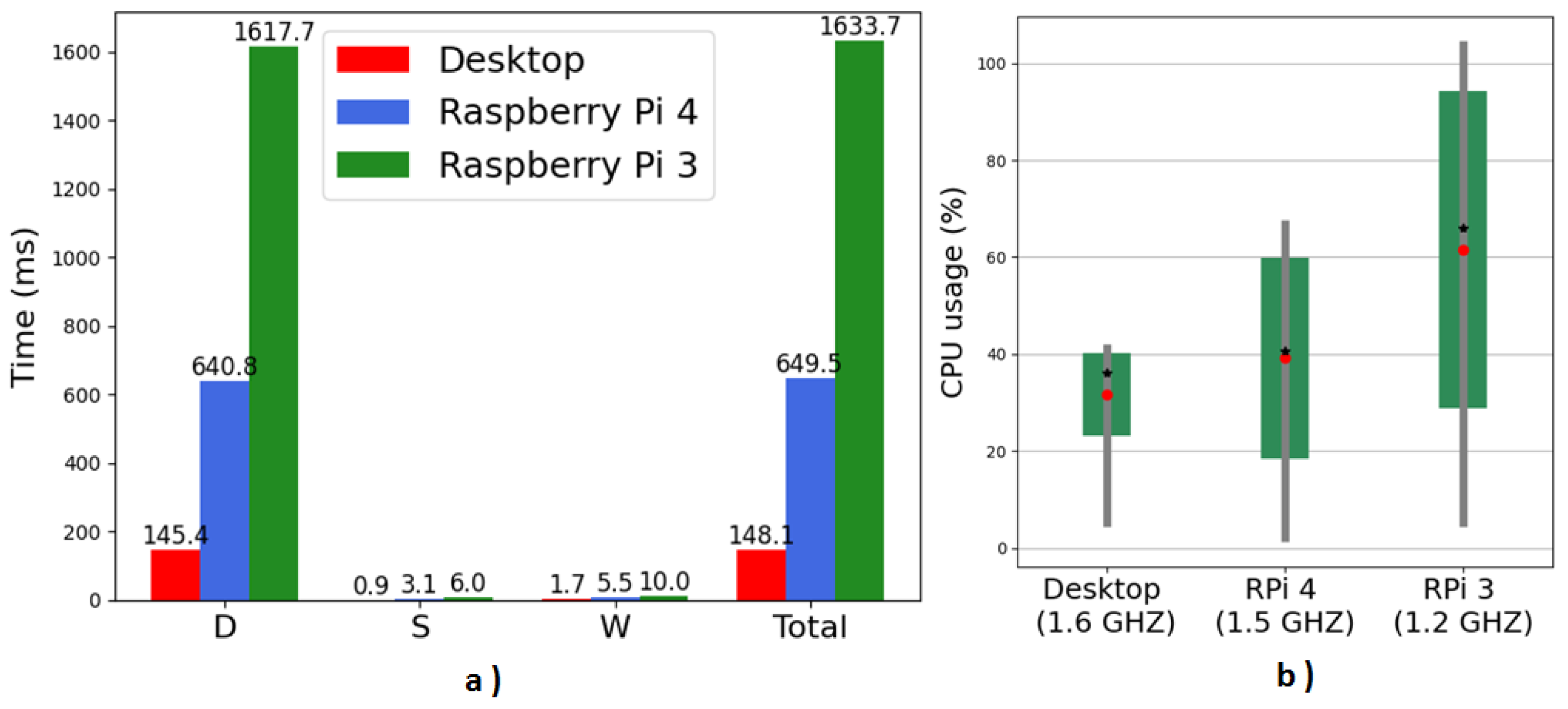
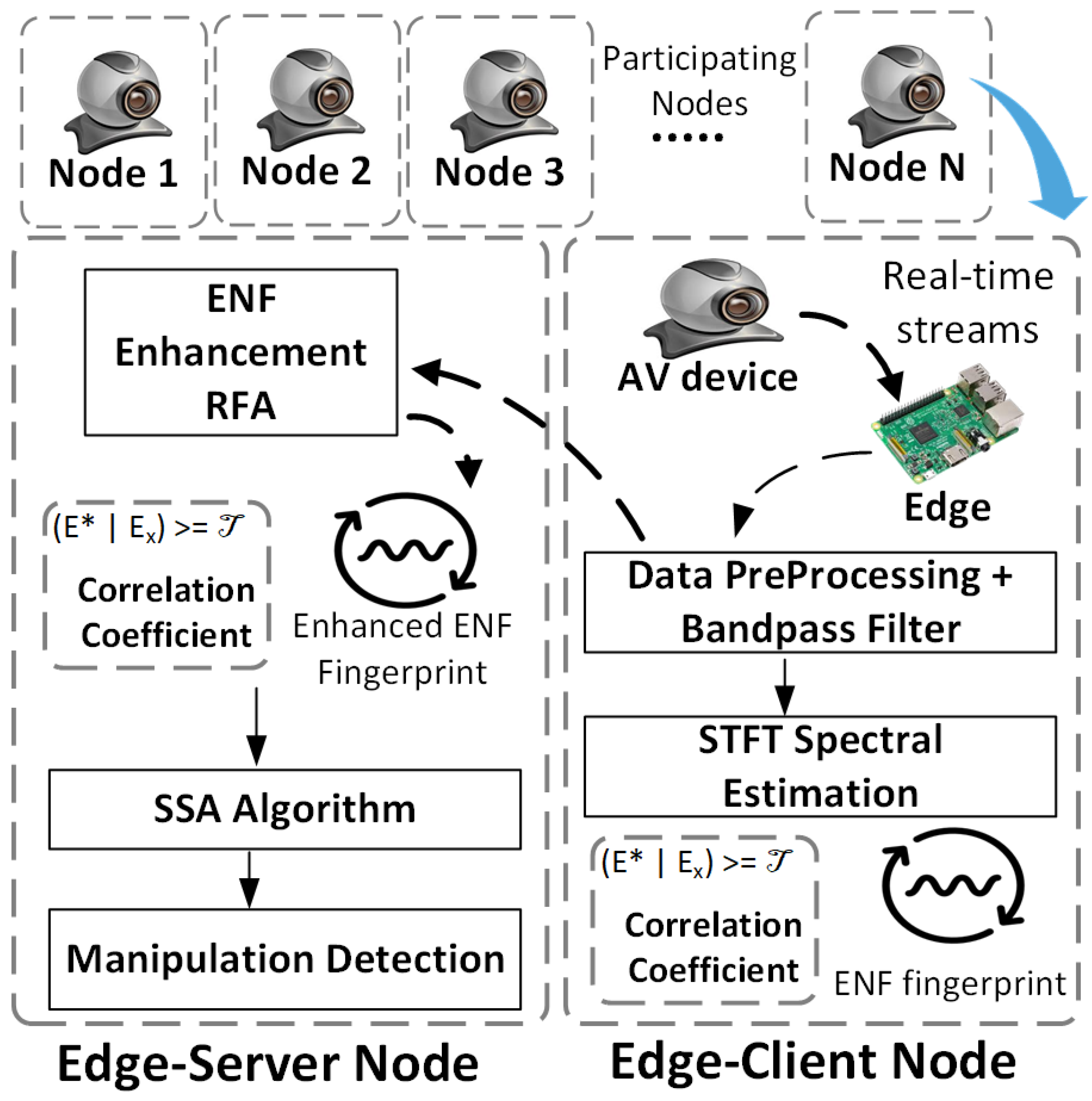
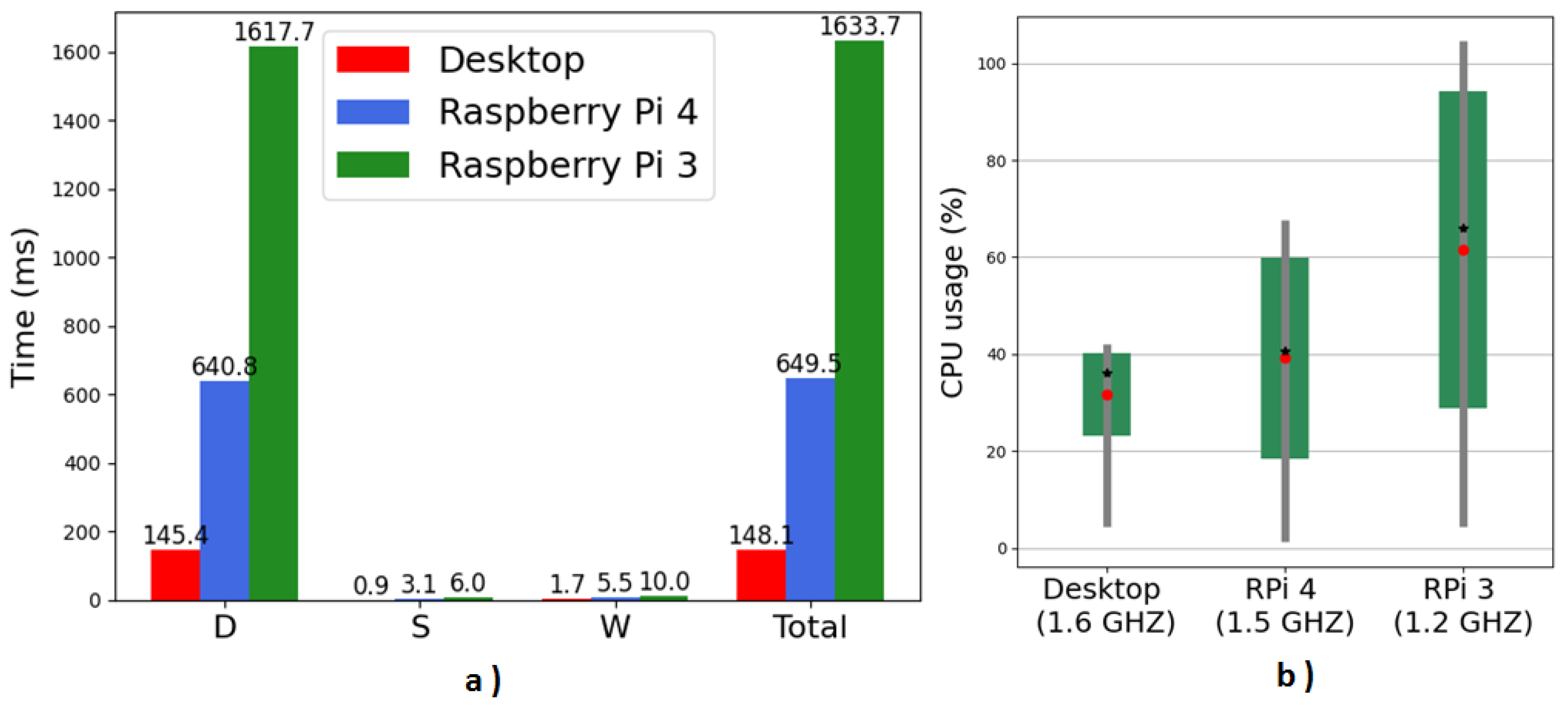
5.1. Prototype Implementation
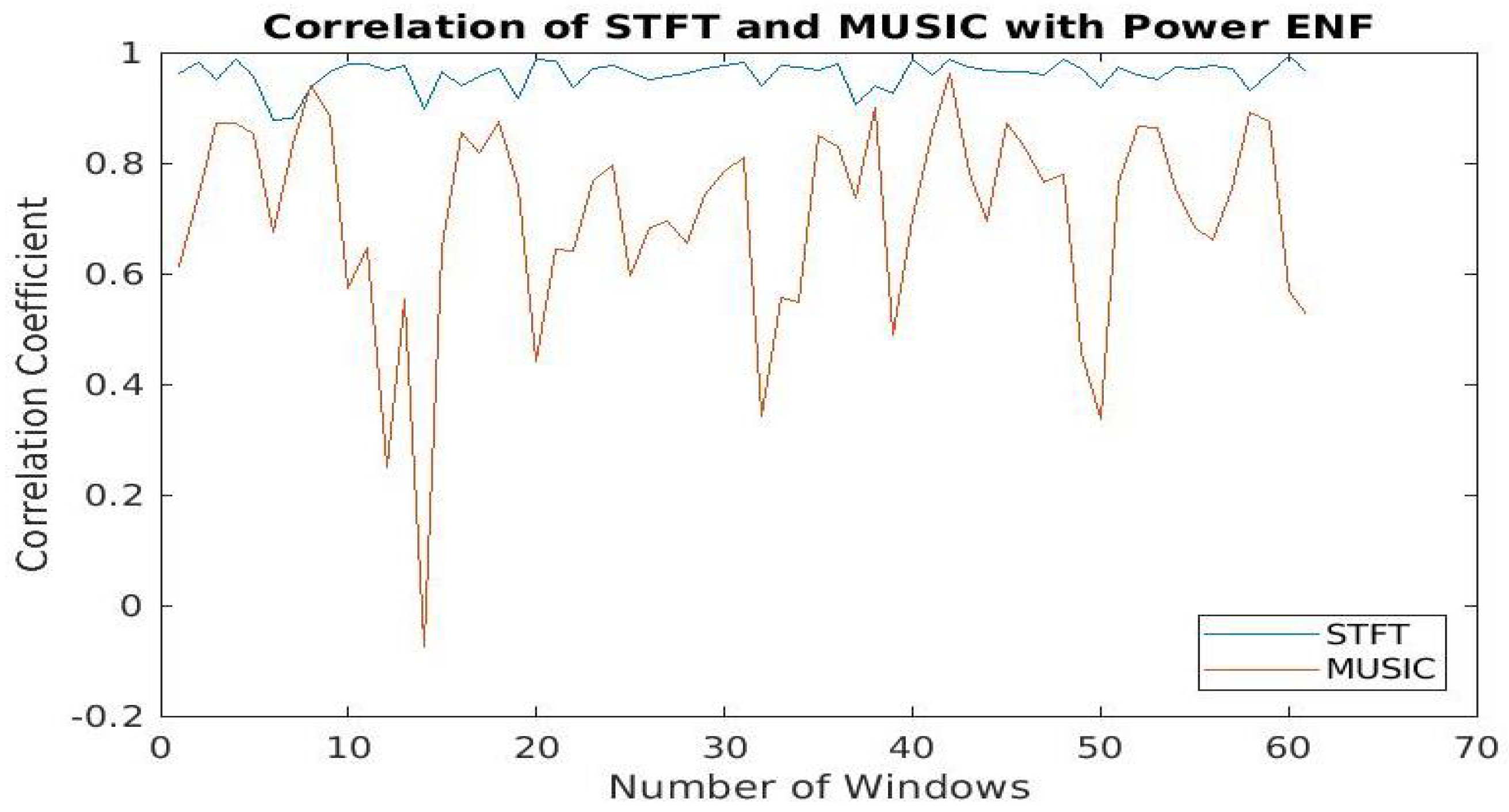
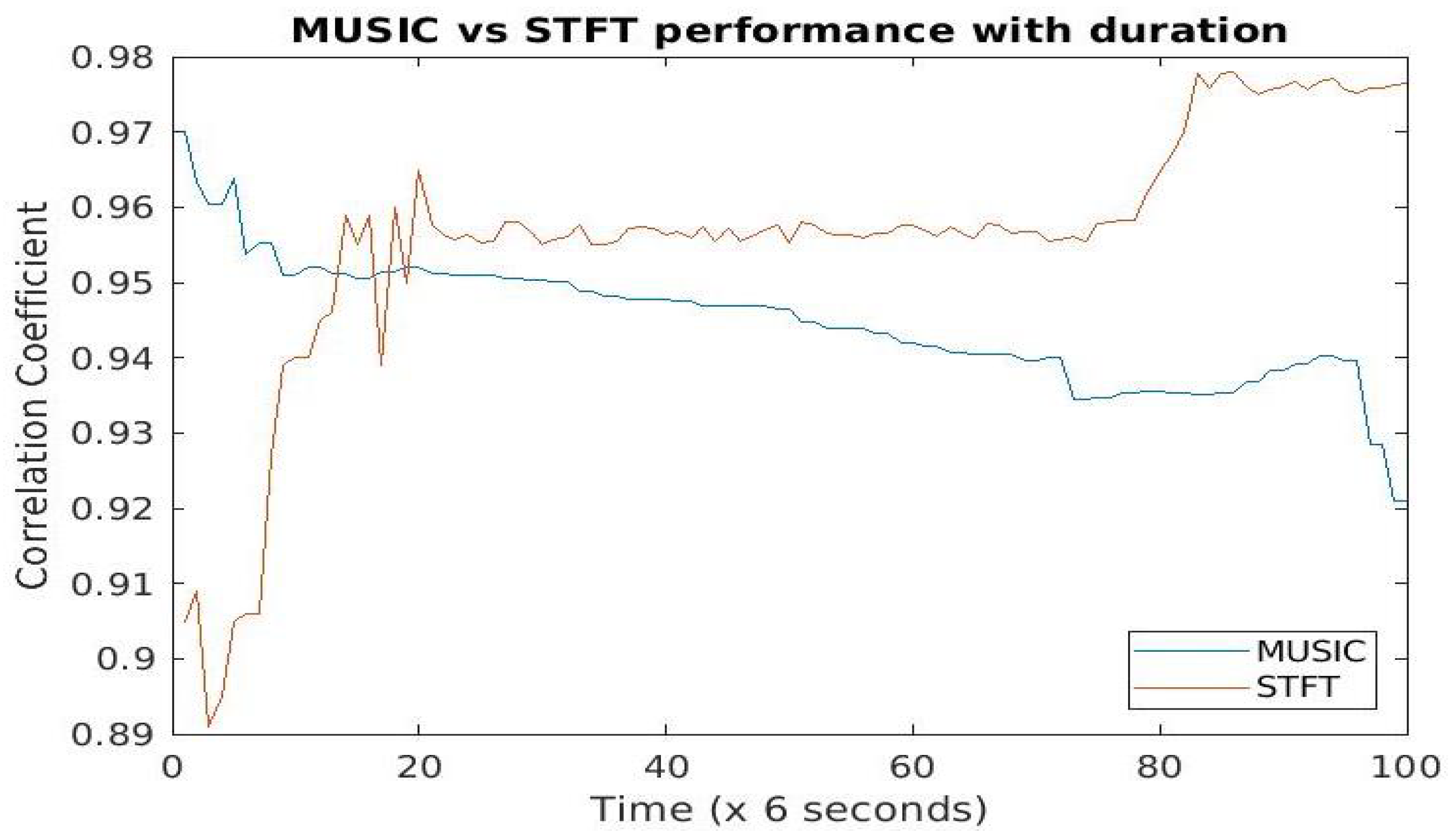
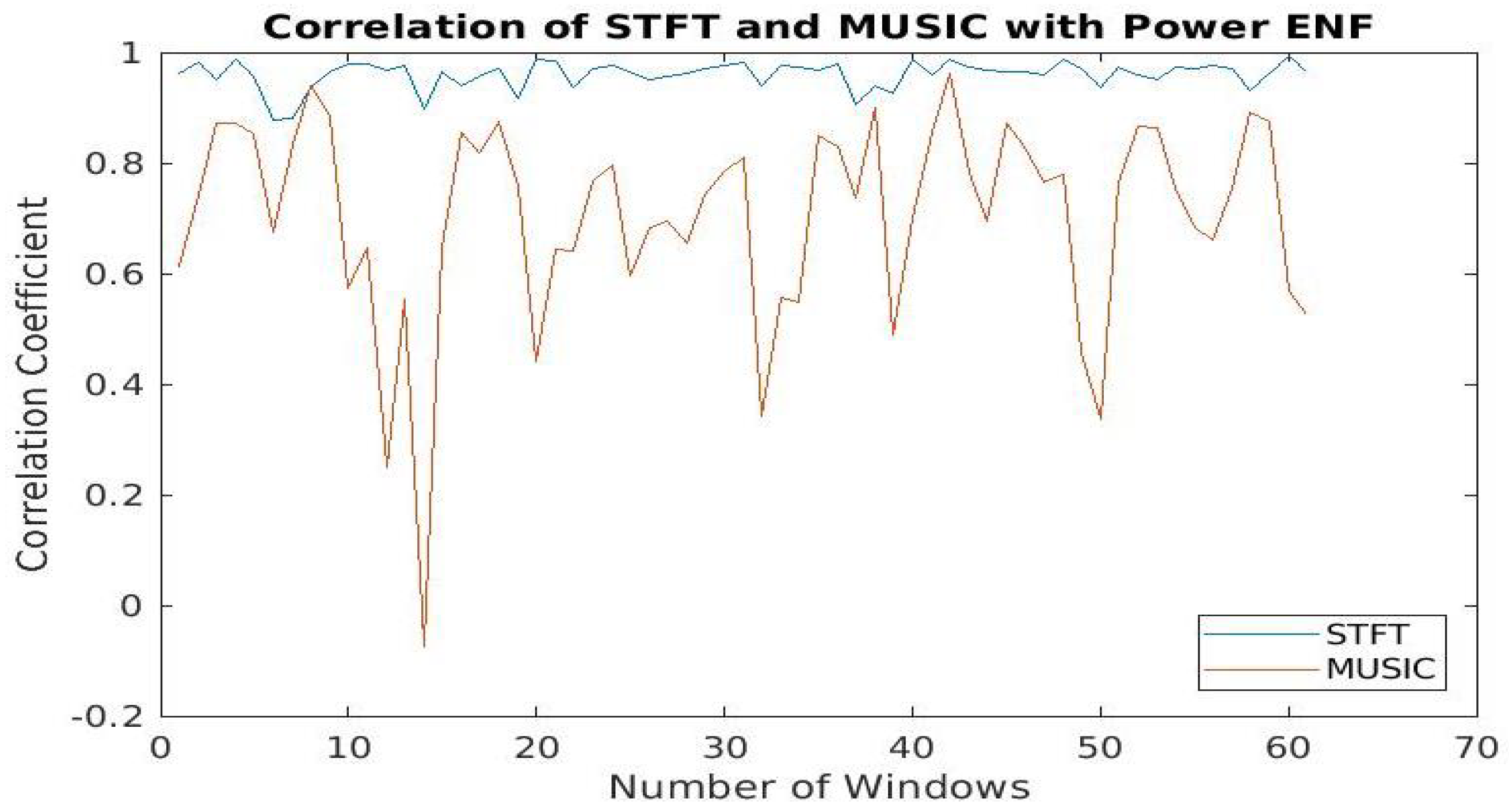
5.2. Effects of Spectral Estimation Techniques against Deepfakes
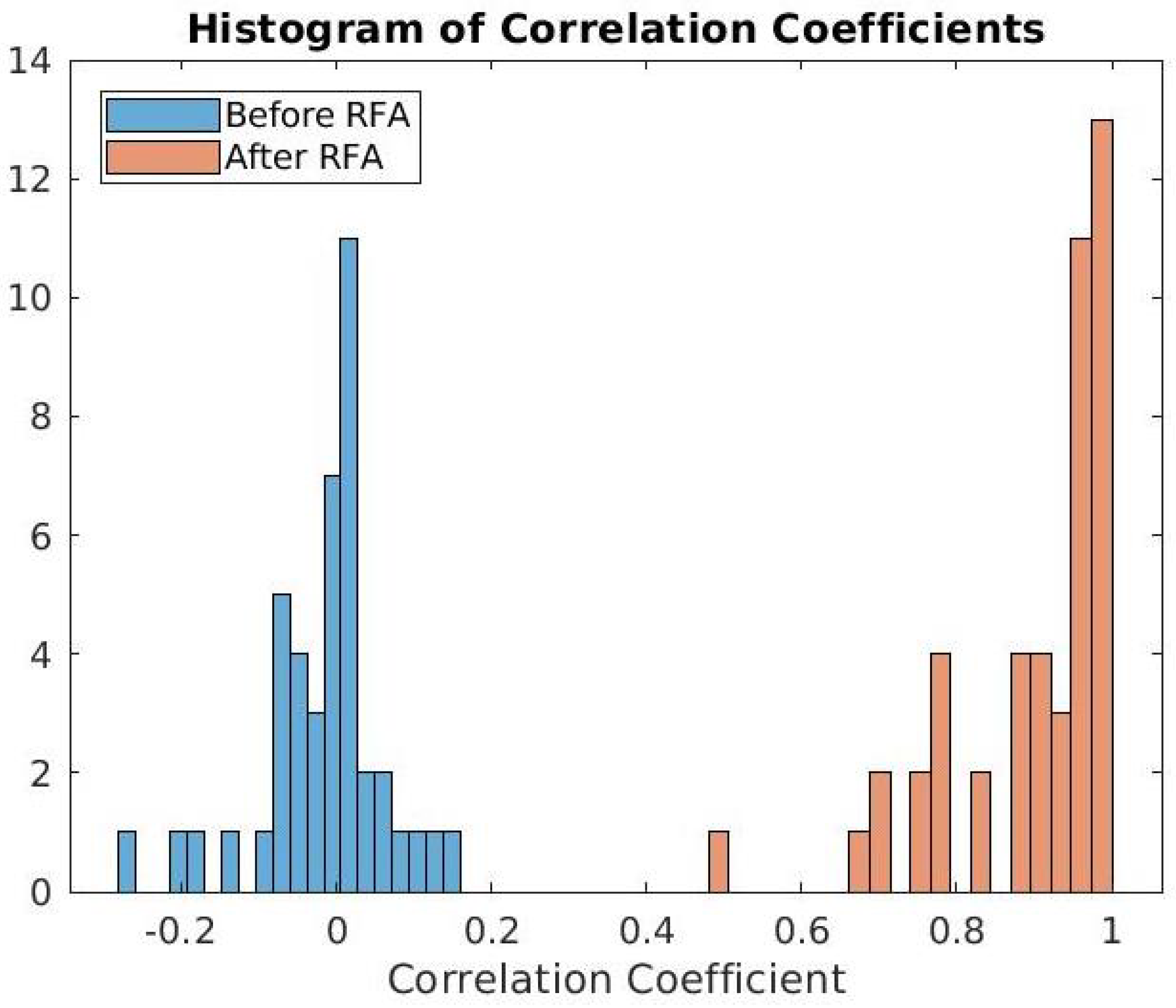
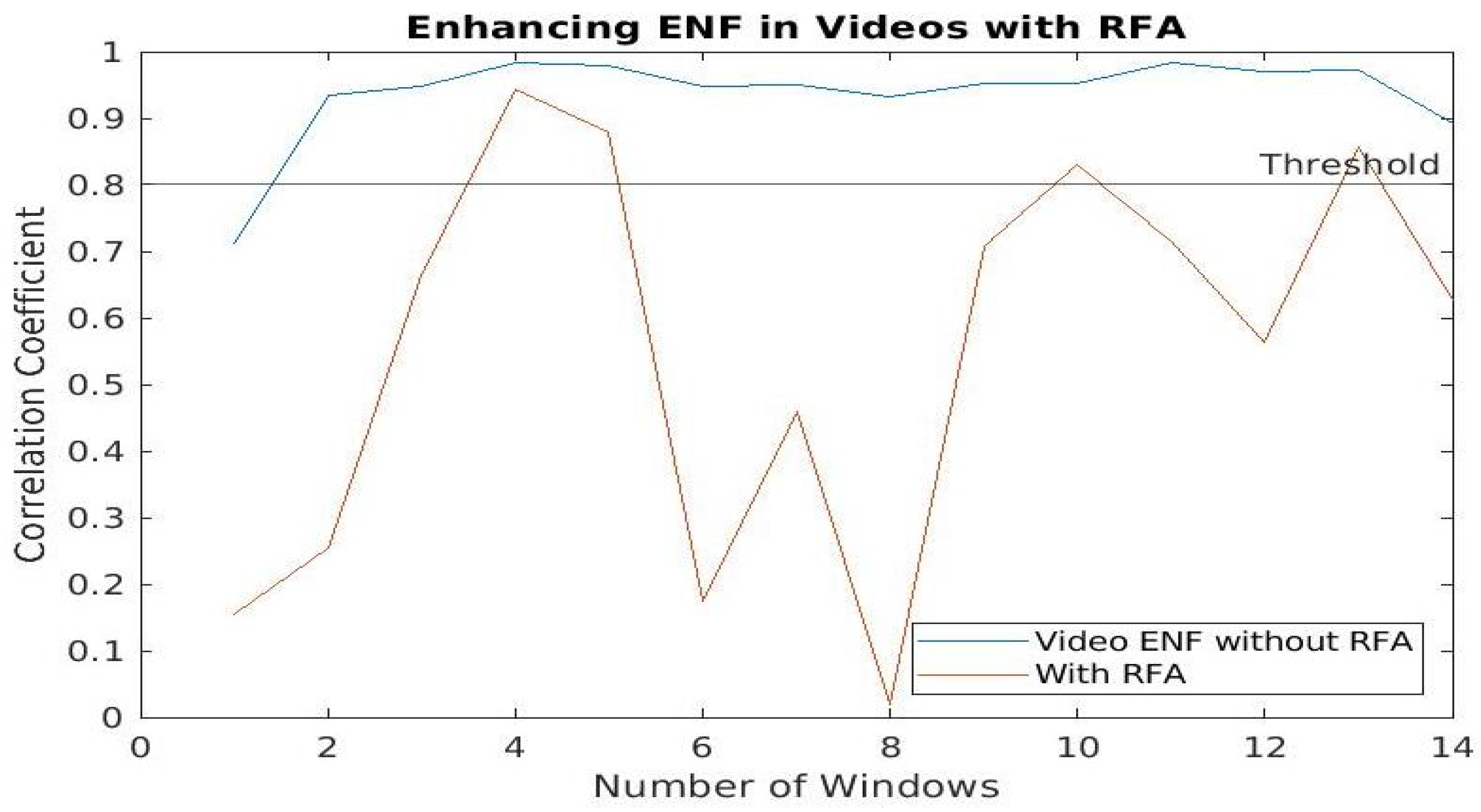
5.3. ENF Enhancement Using the RFA
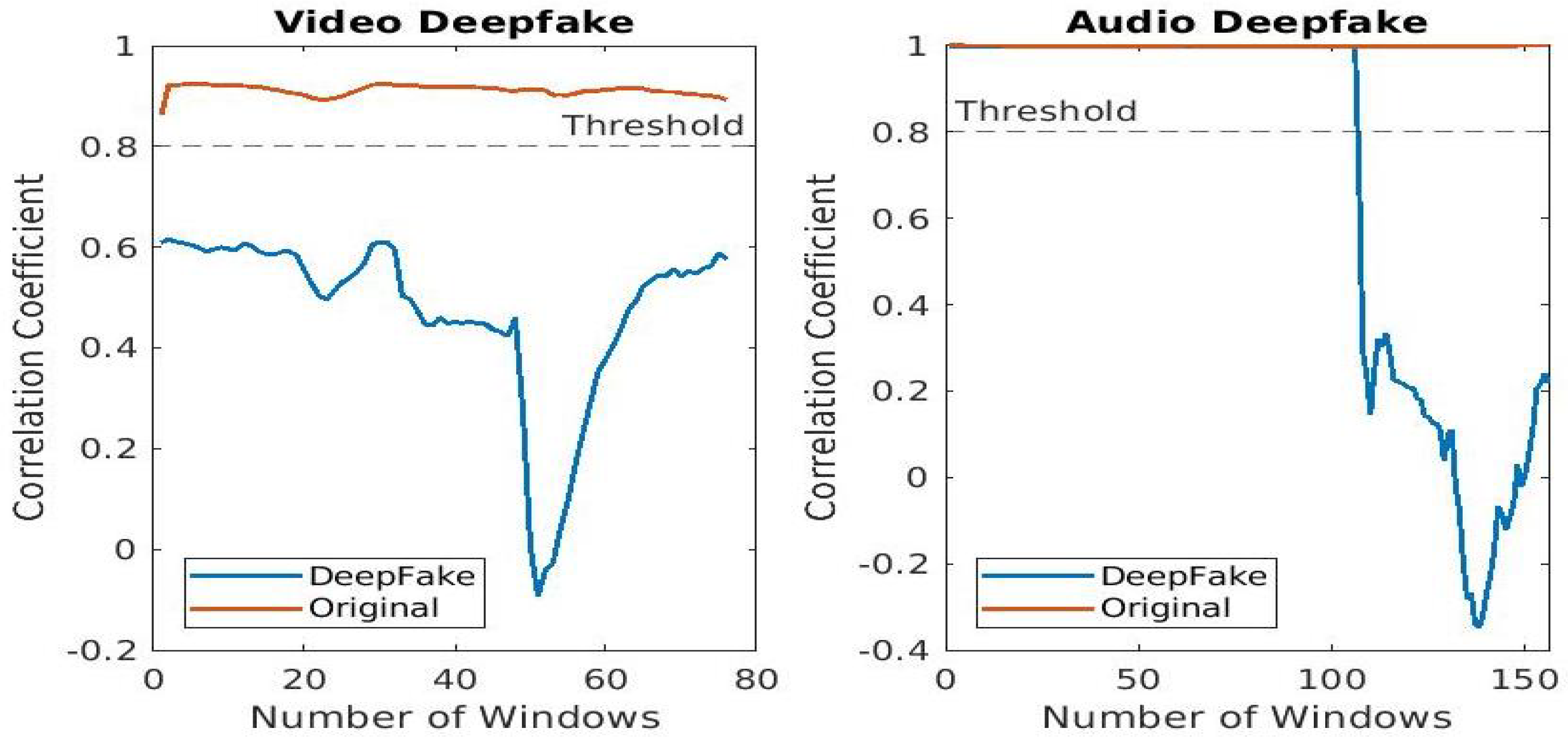
5.4. SSA Performance Analysis
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AVS | Audio and/or Video Stream |
| CMOS | Complementary Metal–Oxide Semiconductor |
| CCD | Charge-Coupled Device |
| CUSUM | Cumulative Sum of deviations |
| DL | Deep Learning |
| ENF | Electrical Network Frequency |
| FFT | Fast Fourier Transform |
| FPS | Frames Per Second |
| GAN | General Adversarial Network |
| IF | Instantaneous Frequency |
| IoVT | Internet of Video Things |
| LAN | Local Area Network |
| MUSIC | Multiple Signal Classification |
| ML | Machine learning |
| PRNU | Photo-Response Non-Uniformity |
| PSD | Power Spectral Density |
| RFA | Robust Filtering Algorithm |
| SFM | Sinusoid Frequency Modulate |
| SNR | Signal-to-Noise Ratio |
| SSA | Singular Spectrum Analysis |
| STFD | Sinusoidal Time-Frequency Distribution |
| STFT | Short-Time Fourier Transform |
| SVD | Singular-Value Decomposition |
References
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Chan, C.; Ginosar, S.; Zhou, T.; Efros, A.A. Everybody dance now. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 5933–5942. [Google Scholar]
- Crystal, D.T.; Cuccolo, N.G.; Ibrahim, A.; Furnas, H.; Lin, S.J. Photographic and video deepfakes have arrived: How machine learning may influence plastic surgery. Plast. Reconstr. Surg. 2020, 145, 1079–1086. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pandey, C.K.; Mishra, V.K.; Tiwari, N.K. Deepfakes: When to Use It. In Proceedings of the 2021 10th International Conference on System Modeling & Advancement in Research Trends (SMART), Virtual, 10–11 December 2021; pp. 80–84. [Google Scholar]
- Rothkopf, J. Deepfake Technology Enters the Documentary World. The New York Times, 1 July 2020. [Google Scholar]
- Palmer, A. Experts Warn Digitally-Altered’Deepfakes’ Videos of Donald Trump, Vladimir Putin, and Other World Leaders Could Be Used to Manipulate Global Politics by 2020. Daily Mail, 12 March 2018. [Google Scholar]
- Villasenor, J. Artificial Intelligence, Deepfakes, and the Uncertain Future of Truth. Available online: https://www.brookings.edu/blog/techtank/2019/02/14/artificial-intelligence-deepfakes-and-the-uncertain-future-of-truth/ (accessed on 2 April 2019).
- Cole, S. This Open-Source Program Deepfakes You during Zoom Meetings, in Real Time. 2020. Available online: https://www.vice.com/enus/article/g5xagy/this-open-source-program-deepfakes-you-during-zoom-meetings-in-real-time (accessed on 18 April 2022).
- TelanganaToday. Now You Can ‘Deepfake’ Elon Musk in Zoom. 2020. Available online: https://telanganatoday.com/now-you-can-deepfake-elon-musk-in-zoom (accessed on 18 April 2022).
- Thalen, M. Show up as a Celebrity to Your Next Zoom Meeting with This Deepfake Tool. 2020. Available online: https://www.dailydot.com/debug/live-deepfake-zoom-skype/ (accessed on 18 April 2022).
- Poulsen, K. We Found the Guy Behind the Viral ‘Drunk Pelosi’ Video. 2019. Available online: https://www.thedailybeast.com/we-found-shawn-brooks-the-guy-behind-the-viral-drunk-pelosi-video (accessed on 18 April 2022).
- Warner, B. Deepfake Video of Mark Zuckerberg Goes Viral on Eve of House A.I. Hearing. 2019. Available online: http://fortune.com/2019/06/12/deepfake-mark-zuckerberg/ (accessed on 18 April 2022).
- Verdoliva, L. Media forensics and deepfakes: An overview. IEEE J. Sel. Top. Signal Process. 2020, 14, 910–932. [Google Scholar] [CrossRef]
- Hall, H.K. Deepfake Videos: When Seeing Isn’t Believing. Cathol. Univ. J. Law Technol. 2018, 27, 51–76. [Google Scholar]
- Manheim, K.M.; Kaplan, L. Artificial Intelligence: Risks to Privacy and Democracy. Forthcom. Yale J. Law Technol. 2019, 21, 106. [Google Scholar]
- Miller, M.J. How Cyberattacks and Disinformation Threaten Democracy. 2018. Available online: https://www.pcmag.com/article/361663/how-cyberattacks-and-disinformation-threaten-democracy (accessed on 18 April 2022).
- Parkin, S. The Rise of the Deepfake and the Threat to Democracy. 2019. Available online: https://www.theguardian.com/technology/ng-interactive/2019/jun/22/the-rise-of-the-deepfake-and-the-threat-to-democracy (accessed on 18 April 2022).
- Holroyd, M.; Olorunselu, F. Deepfake Zelenskyy Surrender Video Is the ‘First Intentionally Used’ in Ukraine War. 2022. Available online: https://www.euronews.com/my-europe/2022/03/16/deepfake-zelenskyy-surrender-video-is-the-first-intentionally-used-in-ukraine-war (accessed on 18 April 2022).
- Wakefield, J. Deepfake Presidents Used in Russia-Ukraine War. 2022. Available online: https://www.bbc.com/news/technology-60780142 (accessed on 18 April 2022).
- Johnson, T. DARPA Is Racing to Develop Tech that Can Identify Hoax Videos. 2018. Available online: https://taskandpurpose.com/deepfakes-hoax-videos-darpa/ (accessed on 18 April 2022).
- Knight, W. The US Military Is Funding an Effort to Catch Deepfakes and Other AI Trickery. 2018. Available online: https://www.technologyreview.com/s/611146/the-us-military-is-funding-an-effort-to-catch-deepfakes-and-other-ai-trickery/ (accessed on 18 April 2022).
- Korshunov, P.; Marcel, S. Deepfakes: A new threat to face recognition? Assessment and detection. arXiv 2018, arXiv:1812.08685. [Google Scholar]
- Foster, B. Deepfakes and AI: Fighting Cybersecurity Fire with Fire. 2020. Available online: https://threatpost.com/deepfakes-ai-fighting-cybersecurity-fire/154978/ (accessed on 18 April 2022).
- Gandhi, A.; Jain, S. Adversarial perturbations fool deepfake detectors. arXiv 2020, arXiv:2003.10596. [Google Scholar]
- Neekhara, P.; Hussain, S.; Jere, M.; Koushanfar, F.; McAuley, J. Adversarial Deepfakes: Evaluating Vulnerability of Deepfake Detectors to Adversarial Examples. arXiv 2020, arXiv:2002.12749. [Google Scholar]
- Grigoras, C. Applications of ENF analysis in forensic authentication of digital audio and video recordings. J. Audio Eng. Soc. 2009, 57, 643–661. [Google Scholar]
- Cooper, A.J. The electric network frequency (ENF) as an aid to authenticating forensic digital audio recordings—An automated approach. In Proceedings of the Audio Engineering Society Conference: 33rd International Conference: Audio Forensics-Theory and Practice, Denver, CO, USA, 5–7 June 2008. [Google Scholar]
- Bollen, M.H.; Gu, I.Y. Signal Processing of Power Quality Disturbances; John Wiley & Sons: Hoboken, NJ, USA, 2006; Volume 30. [Google Scholar]
- Liu, Y.; You, S.; Yao, W.; Cui, Y.; Wu, L.; Zhou, D.; Zhao, J.; Liu, H.; Liu, Y. A distribution level wide area monitoring system for the electric power grid–FNET/GridEye. IEEE Access 2017, 5, 2329–2338. [Google Scholar] [CrossRef]
- Chai, J.; Liu, F.; Yuan, Z.; Conners, R.W.; Liu, Y. Source of ENF in battery-powered digital recordings. In Audio Engineering Society Convention 135; Audio Engineering Society: New York, NY, USA, 2013. [Google Scholar]
- Fechner, N.; Kirchner, M. The humming hum: Background noise as a carrier of ENF artifacts in mobile device audio recordings. In Proceedings of the 2014 Eighth International Conference on IT Security Incident Management & IT Forensics, Münster, Germany, 12–14 May 2014; pp. 3–13. [Google Scholar]
- Garg, R.; Varna, A.L.; Hajj-Ahmad, A.; Wu, M. “Seeing” ENF: Power-signature-based timestamp for digital multimedia via optical sensing and signal processing. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1417–1432. [Google Scholar] [CrossRef]
- Su, H.; Hajj-Ahmad, A.; Garg, R.; Wu, M. Exploiting rolling shutter for ENF signal extraction from video. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5367–5371. [Google Scholar]
- Nagothu, D.; Chen, Y.; Aved, A.; Blasch, E. Authenticating video feeds using electric network frequency estimation at the edge. EAI Endorsed Trans. Secur. Saf. 2021, 7, e4. [Google Scholar] [CrossRef]
- Nagothu, D.; Chen, Y.; Blasch, E.; Aved, A.; Zhu, S. Detecting malicious false frame injection attacks on surveillance systems at the edge using electrical network frequency signals. Sensors 2019, 19, 2424. [Google Scholar] [CrossRef] [Green Version]
- Nagothu, D.; Schwell, J.; Chen, Y.; Blasch, E.; Zhu, S. A study on smart online frame forging attacks against video surveillance system. In Proceedings of the Sensors and Systems for Space Applications XII, Baltimore, MD, USA, 15–16 April 2019; Volume 11017, p. 110170L. [Google Scholar]
- Vatansever, S.; Dirik, A.E.; Memon, N. Factors affecting enf based time-of-recording estimation for video. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2497–2501. [Google Scholar]
- Su, H.; Hajj-Ahmad, A.; Wu, M.; Oard, D.W. Exploring the use of ENF for multimedia synchronization. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 4613–4617. [Google Scholar]
- Hajj-Ahmad, A.; Garg, R.; Wu, M. ENF-based region-of-recording identification for media signals. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1125–1136. [Google Scholar] [CrossRef]
- Jung, T.; Kim, S.; Kim, K. Deepvision: Deepfakes detection using human eye blinking pattern. IEEE Access 2020, 8, 83144–83154. [Google Scholar] [CrossRef]
- Li, Y.; Lyu, S. Exposing deepfake videos by detecting face warping artifacts. arXiv 2018, arXiv:1811.00656. [Google Scholar]
- Matern, F.; Riess, C.; Stamminger, M. Exploiting visual artifacts to expose deepfakes and face manipulations. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 83–92. [Google Scholar]
- Marra, F.; Gragnaniello, D.; Verdoliva, L.; Poggi, G. Do gans leave artificial fingerprints? In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 506–511. [Google Scholar]
- Ciftci, U.A.; Demir, I.; Yin, L. How do the hearts of deep fakes beat? deep fake source detection via interpreting residuals with biological signals. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; pp. 1–10. [Google Scholar]
- Jeong, Y.; Kim, D.; Min, S.; Joe, S.; Gwon, Y.; Choi, J. BiHPF: Bilateral High-Pass Filters for Robust Deepfake Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 48–57. [Google Scholar]
- Durall, R.; Keuper, M.; Keuper, J. Watch your up-convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 7890–7899. [Google Scholar]
- Frank, J.; Eisenhofer, T.; Schönherr, L.; Fischer, A.; Kolossa, D.; Holz, T. Leveraging frequency analysis for deep fake image recognition. In Proceedings of the International Conference on Machine Learning PMLR, Virtual, 13–18 July 2020; pp. 3247–3258. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. IEEE Trans. Inf. Forensics Secur. 2019, 15, 144–159. [Google Scholar] [CrossRef] [Green Version]
- Lukas, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Li, W.; Yuan, Y.; Yu, N. Passive detection of doctored JPEG image via block artifact grid extraction. Signal Process. 2009, 89, 1821–1829. [Google Scholar] [CrossRef]
- Cozzolino, D.; Thies, J.; Rossler, A.; Nießner, M.; Verdoliva, L. SpoC: Spoofing camera fingerprints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 990–1000. [Google Scholar]
- Garg, R.; Hajj-Ahmad, A.; Wu, M. Feasibility Study on Intra-Grid Location Estimation Using Power ENF Signals. arXiv 2021, arXiv:2105.00668. [Google Scholar]
- Hajj-Ahmad, A.; Garg, R.; Wu, M. Spectrum combining for ENF signal estimation. IEEE Signal Process. Lett. 2013, 20, 885–888. [Google Scholar] [CrossRef]
- Chuang, W.H.; Garg, R.; Wu, M. How secure are power network signature based time stamps? In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; pp. 428–438. [Google Scholar]
- Nagothu, D.; Xu, R.; Chen, Y.; Blasch, E.; Aved, A. Detecting Compromised Edge Smart Cameras using Lightweight Environmental Fingerprint Consensus. In Proceedings of the 19th ACM Conference on Embedded Networked Sensor Systems, Coimbra, Portugal, 15–17 November 2021; pp. 505–510. [Google Scholar]
- Hajj-Ahmad, A.; Garg, R.; Wu, M. Instantaneous frequency estimation and localization for ENF signals. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Hollywood, CA, USA, 3–6 December 2012; pp. 1–10. [Google Scholar]
- Hua, G.; Zhang, H. ENF signal enhancement in audio recordings. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1868–1878. [Google Scholar] [CrossRef]
- Moskvina, V.; Zhigljavsky, A. An algorithm based on singular spectrum analysis for change-point detection. Commun. Stat.-Simul. Comput. 2003, 32, 319–352. [Google Scholar] [CrossRef]
- Hassani, H. Singular spectrum analysis: Methodology and comparison. J. Data Sci. 2007, 5, 239–257. [Google Scholar] [CrossRef]
- Perov, I.; Gao, D.; Chervoniy, N.; Liu, K.; Marangonda, S.; Umé, C.; Dpfks, M.; Facenheim, C.S.; Rp, L.; Jiang, J.; et al. Deepfacelab: A simple, flexible and extensible face swapping framework. arXiv 2020, arXiv:2005.05535. [Google Scholar]
- Descript|Create Podcasts, Videos, and Transcripts. Available online: https://www.descript.com/ (accessed on 18 April 2022).
- Nagothu, D.; Xu, R.; Chen, Y.; Blasch, E.; Aved, A. DeFake: Decentralized ENF-Consensus Based DeepFake Detection in Video Conferencing. In Proceedings of the 2021 IEEE 23rd International Workshop on Multimedia Signal Processing (MMSP), Tampere, Finland, 6–8 October 2021; pp. 1–6. [Google Scholar]
- Xu, R.; Nagothu, D.; Chen, Y. Econledger: A proof-of-enf consensus based lightweight distributed ledger for iovt networks. Future Internet 2021, 13, 248. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Media | 60 Hz | 120 Hz | 180 Hz | 240 Hz | 300 Hz | 360 Hz |
|---|---|---|---|---|---|---|
| Power | 39.88 | 2.456 | 38.647 | 0 | 14.48 | 4.534 |
| Audio | 9.761 | 0.888 | 27.94 | 7.106 | 43.717 | 10.585 |
| Video | 0 | 8.396 | 0 | 90.163 | 0 | 1.439 |
| Device | Redbarn HPC | Raspberry Pi 3 (B) | Raspberry Pi 4 (B) |
|---|---|---|---|
| CPU | 3.4 GHz, Core (TM) i7-2600K (8 cores) | 1.2 GHz, Quad core Cortex-A72 (ARM v8) | 1.5 GHz, Quad core Cortex-A72 (ARM v8) |
| Memory | 8 GB DDR3 | 1 GB SDRAM | 4 GB SDRAM |
| Storage | 350 G HDD | 64 GB (microSD) | 64 GB (microSD) |
| OS | Ubuntu 18.04 | Raspbian (Jessie) | Raspbian (Jessie) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nagothu, D.; Xu, R.; Chen, Y.; Blasch, E.; Aved, A. Deterring Deepfake Attacks with an Electrical Network Frequency Fingerprints Approach. Future Internet 2022, 14, 125. https://doi.org/10.3390/fi14050125
Nagothu D, Xu R, Chen Y, Blasch E, Aved A. Deterring Deepfake Attacks with an Electrical Network Frequency Fingerprints Approach. Future Internet. 2022; 14(5):125. https://doi.org/10.3390/fi14050125
Chicago/Turabian StyleNagothu, Deeraj, Ronghua Xu, Yu Chen, Erik Blasch, and Alexander Aved. 2022. "Deterring Deepfake Attacks with an Electrical Network Frequency Fingerprints Approach" Future Internet 14, no. 5: 125. https://doi.org/10.3390/fi14050125
APA StyleNagothu, D., Xu, R., Chen, Y., Blasch, E., & Aved, A. (2022). Deterring Deepfake Attacks with an Electrical Network Frequency Fingerprints Approach. Future Internet, 14(5), 125. https://doi.org/10.3390/fi14050125