
Data Structure and Management Protocol to Enhance Name Resolving in Named Data Networking


Abstract
:1. Introduction
2. Related Work
3. Proposed Solution
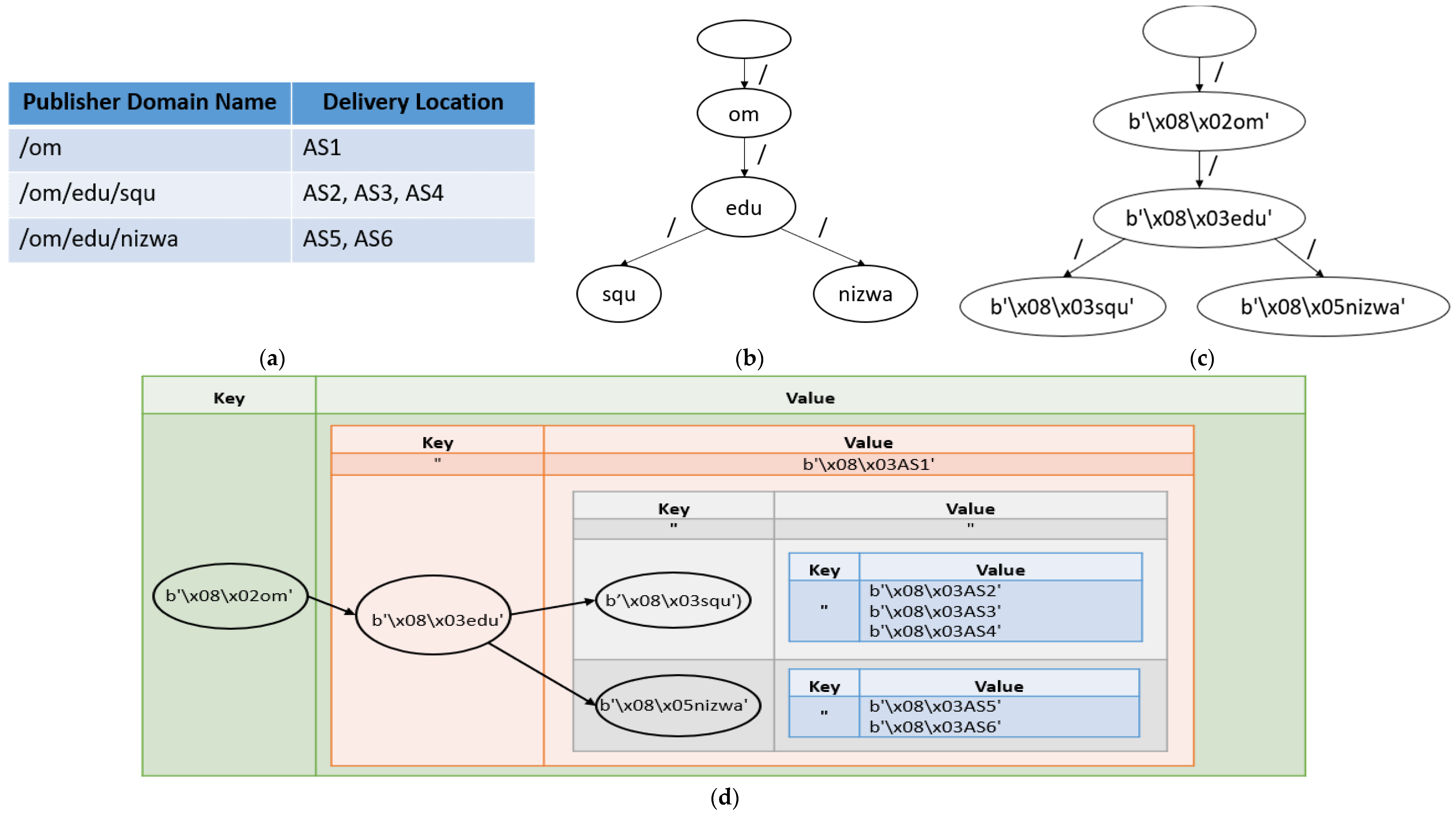
3.1. Proposed Encoded Component Hash Trie (ECHT) Data Structure
3.1.1. ECHT Design Overview
3.1.2. ECHT Operations
- ECHT Insertion and Deletion Operations
- ECHT Lookup Operation
3.2. Proposed PNP Protocol (PNPP)
- ADD: A two-component message that contains the producer’s domain name and its corresponding delivery locations. Their data types are of NDN name and a list of NDN names, respectively. This message is encapsulated in an ApplicationParameters element of an NDN Interest packet. The Name element of this Interest is set to the NDN name of the PNPS. Upon receiving this message, the PNPS triggers the ECHT insert operation, which will decide if a new node will be added or an entry_value will be modified.
- REMOVE: On the structure level, REMOVE is similar to ADD, with one difference being the second component is an optional one. If the delivery location component is present, PNPS will modify the associated ECHT entry_value, and when it is absent, the whole node along with its entry_value will be removed from the ECHT.
- GET: A one-component message that contains the producer’s domain name in NDN name format. This message is encapsulated in an ApplicationParameters element of an NDN Interest packet. The Name element of this Interest is set to the NDN name of the PNPS. Upon receiving this message, the PNPS triggers the ECHT exact matching lookup operation.
- GETBCM: This is the same as GET, but it triggers a BCM lookup operation instead, and therefore, it receives a two-component reply instead of one from ECHT. A sample of a GET message is shown in Figure 4.
4. Experimental Setup and Results
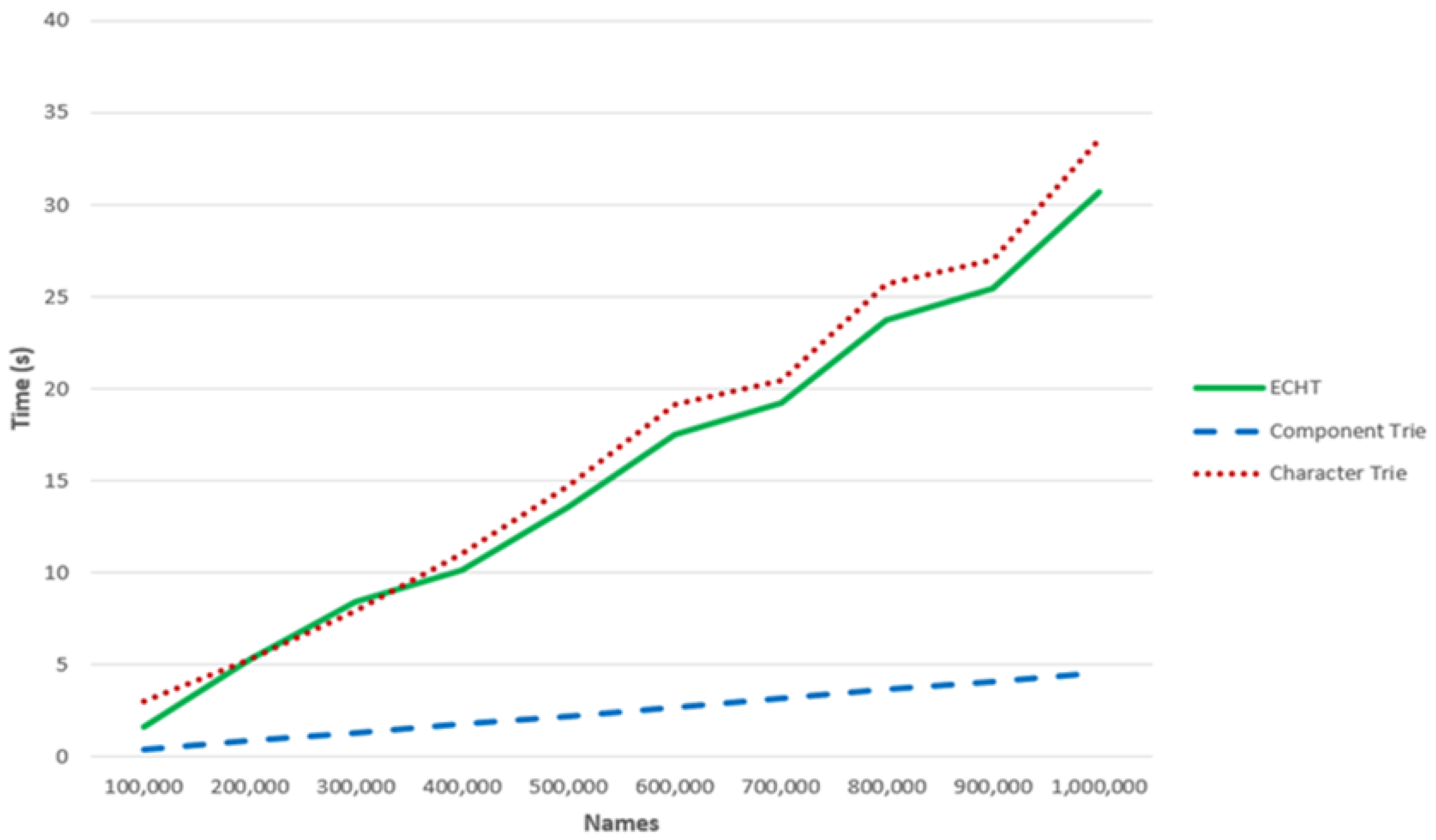
4.1. Time Performance
- GET Positive: This experiment focused on testing the exact matching mechanism using a preset of 100,000 different names that were randomly selected from the one million dataset. The preset has one column, and each row is in TLV encoded format, i.e., a list of byte arrays.
- GET Negative: This experiment focused on testing the exact matching mechanism using the previous preset, but where each row was manipulated as follows, For the sake of simplicity, we will use human-readable strings for names instead of the actual list of byte-arrays:
- ○
- Insert 1-byte-char “x” as a prefix for each name component, i.e., the name “/om/edu/squ” becomes “/xom/edu/squ”, “/om/xedu/squ”, and “/om/edu/xsqu”. This technique ensures that competing algorithms are tested for fast query exits at various depths.
- ○
- Insert 1-byte-char “x” as a suffix for each name component, i.e., the name “/om/edu/squ” becomes “/omx/edu/squ”, “/om/edux/squ”, and “/om/edu/squx”. This technique ensures that competing algorithms are tested for delayed query exits at various depths.
- ○
- Insert 1-byte-char “x” as a suffix component for each name, i.e., the name “/om/edu/squ” becomes “/om/edu/squ/x”. This technique ensures that competing algorithms are tested for maximum depth at each query.
- BCM Positive: This experiment focused on testing the best component matching mechanism using the GET Positive preset.
- BCM Negative: This experiment focused on testing the best component matching mechanism using the GET Negative preset. This preset size was multiple times bigger than the original 100,000 preset. In the interest of clarity, we normalized the result to 100,000.
4.2. Throughput Performance
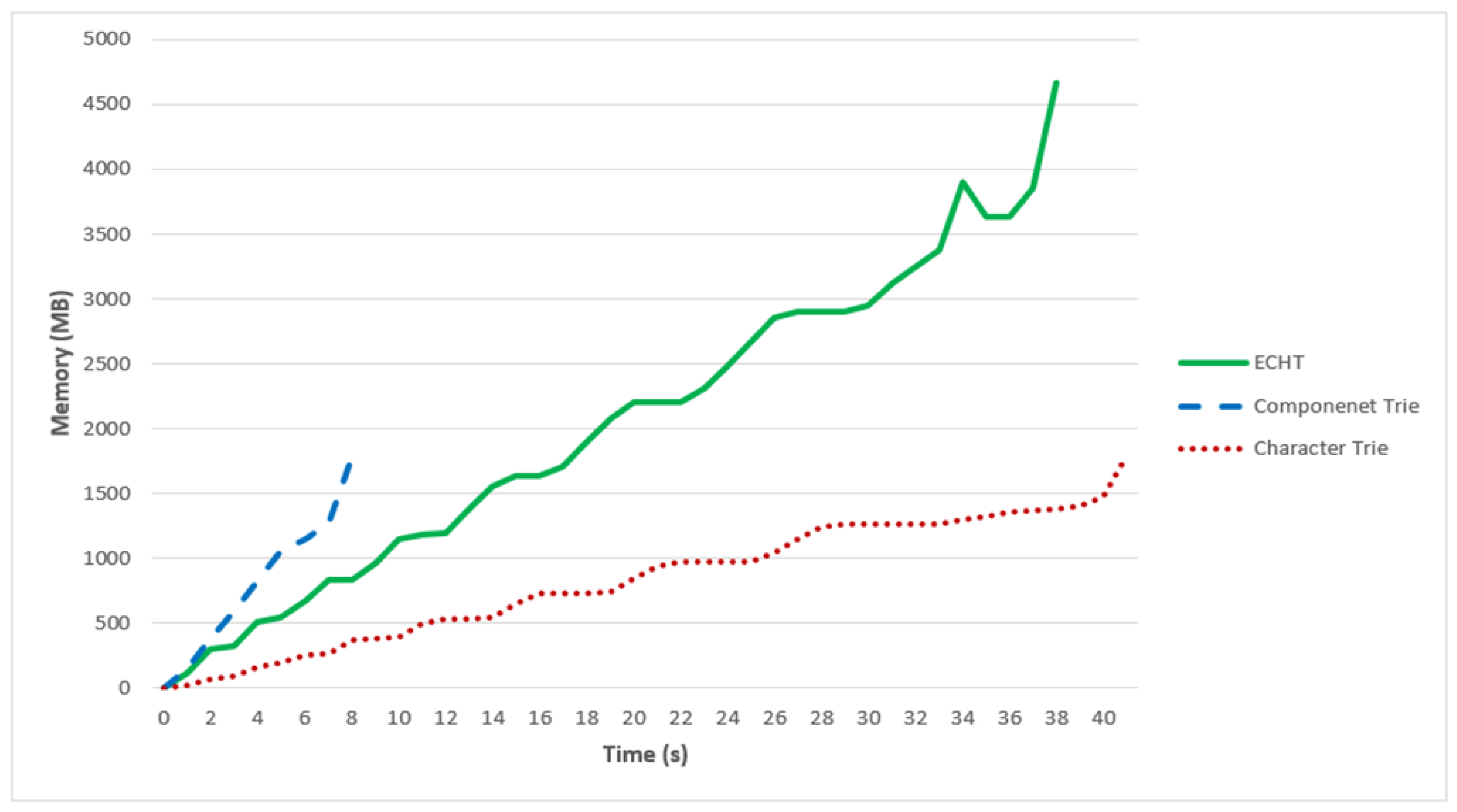
4.3. Memory Consumption
4.4. Use Case Scenario
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aldaoud, M.; Al-Abri, D.; Awadalla, M.; Kausar, F. Leveraging ICN and SDN for Future Internet Architecture: A Survey. Electronics 2023, 12, 1723. [Google Scholar] [CrossRef]
- Aldaoud, M.; Al-Abri, D.; Awadalla, M.; Kausar, F. N-BGP: An efficient BGP routing protocol adaptation for named data networking. Int. J. Commun. Syst. 2022, 35, e5266. [Google Scholar] [CrossRef]
- Aldaoud, M.; Al-Abri, D.; Awadalla, M.; Kausar, F. Towards a Scalable Named Data Border Gateway Protocol. In Proceedings of the 2022 International Conference on Electrical, Computer, Communications and Mechatronics Engineering (ICECCME), Male, Maldives, 16–18 November 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Anjum, A.; Agbaje, P.; Mitra, A.; Oseghale, E.; Nwafor, E.; Olufowobi, H. Towards named data networking technology: Emerging applications, use cases, and challenges for secure data communication. Future Gener. Comput. Syst. 2024, 151, 12–31. [Google Scholar] [CrossRef]
- Majed, A.; Wang, X.; Yi, B. Name Lookup in Named Data Networking: A Review. Information 2019, 10, 85. [Google Scholar] [CrossRef]
- Wang, Y.; Dai, H.; Jiang, J.; He, K.; Meng, W.; Liu, B. Parallel Name Lookup for Named Data Networking. In Proceedings of the 2011 IEEE Global Telecommunications Conference—GLOBECOM 2011, Houston, TX, USA, 5–9 December 2011; pp. 1–5. [Google Scholar] [CrossRef]
- Seo, J.; Lim, H. Bitmap-based priority-NPT for packet forwarding at named data network. Comput. Commun. 2018, 130, 101–112. [Google Scholar] [CrossRef]
- Lee, J.; Lim, H. A new name prefix trie with path compression. In Proceedings of the 2016 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 26–28 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, Y.; He, K.; Dai, H.; Meng, W.; Jiang, J.; Liu, B.; Chen, Y. Scalable Name Lookup in NDN Using Effective Name Component Encoding. In Proceedings of the 2012 IEEE 32nd International Conference on Distributed Computing Systems, Macau, China, 18–21 June 2012; pp. 688–697. [Google Scholar] [CrossRef]
- Feng, S.; Zhang, M.; Zheng, R.; Wu, Q. A Fast Name Lookup Method in NDN Based on Hash Coding. In Proceedings of the 3rd International Conference on Mechatronics and Industrial Informatics (ICMII 2015), Zhuhai, China, 30–31 October 2015. [Google Scholar] [CrossRef]
- Saxena, D.; Raychoudhury, V.; Becker, C.; Suri, N. Reliable Memory Efficient Name Forwarding in Named Data Networking. In Proceedings of the 2016 IEEE Intl Conference on Computational Science and Engineering (CSE) and IEEE Intl Conference on Embedded and Ubiquitous Computing (EUC) and 15th Intl Symposium on Distributed Computing and Applications for Business Engineering (DCABES), Paris, France, 24–26 August 2016; pp. 48–55. [Google Scholar] [CrossRef]
- Afanasyev, A.; Jiang, X.; Yu, Y.; Tan, J.; Xia, Y.; Mankin, A.; Zhang, L. NDNS: A DNS-Like Name Service for NDN. In Proceedings of the 2017 26th International Conference on Computer Communication and Networks (ICCCN), Vancouver, BC, Canada, 31 July–3 August 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Type-Length-Value (TLV) Encoding. Available online: https://docs.named-data.net/NDN-packet-spec/current/tlv.html.accessed (accessed on 6 September 2023).
- Aumasson, J.-P.; Bernstein, D.J. SipHash: A Fast Short-Input PRF. In Progress in Cryptology—INDOCRYPT 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 489–508. [Google Scholar]
- NDN-Team. NDN Technical Memo: Naming Conventions. (NDN, Technical Report NDN-0022). 2022. Available online: https://named-data.net/techreports.html (accessed on 27 February 2024).
- NDN-Team. TLV Type Registry: Assigned Numbers. Available online: https://docs.named-data.net/NDN-packet-spec/current/types.html#types (accessed on 12 October 2023).
- Li, Z.; Xu, Y.; Zhang, B.; Yan, L.; Liu, K. Packet Forwarding in Named Data Networking Requirements and Survey of Solutions. IEEE Commun. Surv. Tutor. 2019, 21, 1950–1987. [Google Scholar] [CrossRef]
- Yusuf, A.D.; Abdullahi, S.; Boukar, M.M.; Yusuf, S.I. Collision Resolution Techniques in Hash Table: A Review. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 757–762. [Google Scholar] [CrossRef]
- GeeksforGeeks. Open Addressing Collision Handling Technique in Hashing. Available online: https://www.geeksforgeeks.org/open-addressing-collision-handling-technique-in-hashing/?ref=lbp (accessed on 4 September 2023).
- Pygtrie. Available online: https://pygtrie.readthedocs.io/en/latest/ (accessed on 12 October 2023).
- Hevey, D. Network analysis: A brief overview and tutorial. Health Psychol. Behav. Med. 2018, 6, 301–328. [Google Scholar] [CrossRef] [PubMed]
- The Majestic Million. Available online: https://majestic.com/reports/majestic-million (accessed on 9 October 2023).
- NDN-Team. NDN Packet Format Specification 0.3 Documentation. Available online: https://named-data.net/doc/NDN-packet-spec/current/intro.html (accessed on 6 September 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Separate Chaining | Open Addressing (Linear Probing) | |
|---|---|---|
| Implementation | Simple | More computation |
| Cache performance | Worse since keys are stored using a linked list | Better, since keys are stored in the same table |
| Space utilization | 1. Waste spaces 2. Extra space for links | 1. No waste spaces 2. No need for extra spaces |
| Clustering | No clustering | Suffers from clustering |
| Mapping time complexity (worst case) | ||
| Operations time complexity (worst case) | [19], where | [19], where |
| Entry | Producer Name | Delivery Location |
|---|---|---|
| 1 | /com/google | /AS1, /AS3, /AS5, /AS6 |
| 2 | /com/googletagmanager | /AS2, /AS4, /AS5, /AS6 |
| 3 | /org/Wikipedia/en | /AS1, /AS7, /AS8, /AS9 |
| . . | . . | . . |
| 1,000,000 | /ru/audimanual | /AS2, /AS5, /AS7, /AS9 |
| Parameter | Specification |
|---|---|
| Names dataset | Majestic Million |
| Number of delivery locations | 10 |
| Each delivery location length | 4 bytes |
| Trie used | component, character, ECHT |
| Number of components per name | 2 to 5 |
| Initial dataset | 1,000,000 names |
| Lookup names | 100,000 names |
| Added names | 100,000 names |
| ECHT | Component Trie | Character Trie | |
|---|---|---|---|
| Name/ms | 335.964 | 9.196 | 8.576 |
| Abbreviation | Description |
|---|---|
| BMC | Best Component Match |
| DNS | Domain Name System |
| ECHT | Encoded Component Hash Trie |
| FIB | Forwarding Information Base |
| IDR | Inter-Domain Routing |
| LPM | Longest Prefix Match |
| N-BGP | Named Data Border Gateway Protocol |
| NDN | Named Data Networking |
| PNP | Peer Name Provider |
| PNPC | Peer Name Provider Client |
| PNPP | Peer Name Provider Protocol |
| PNPS | Peer Name Provider Server |
| TLV | Type-Length-Value |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldaoud, M.; Al-Abri, D.; Awadalla, M.; Kausar, F. Data Structure and Management Protocol to Enhance Name Resolving in Named Data Networking. Future Internet 2024, 16, 118. https://doi.org/10.3390/fi16040118
Aldaoud M, Al-Abri D, Awadalla M, Kausar F. Data Structure and Management Protocol to Enhance Name Resolving in Named Data Networking. Future Internet. 2024; 16(4):118. https://doi.org/10.3390/fi16040118
Chicago/Turabian StyleAldaoud, Manar, Dawood Al-Abri, Medhat Awadalla, and Firdous Kausar. 2024. "Data Structure and Management Protocol to Enhance Name Resolving in Named Data Networking" Future Internet 16, no. 4: 118. https://doi.org/10.3390/fi16040118
APA StyleAldaoud, M., Al-Abri, D., Awadalla, M., & Kausar, F. (2024). Data Structure and Management Protocol to Enhance Name Resolving in Named Data Networking. Future Internet, 16(4), 118. https://doi.org/10.3390/fi16040118