
Multi-Agent Deep Reinforcement Learning-Based Fine-Grained Traffic Scheduling in Data Center Networks


Abstract
:1. Introduction
2. Related Works
3. System Scheme and Implementation
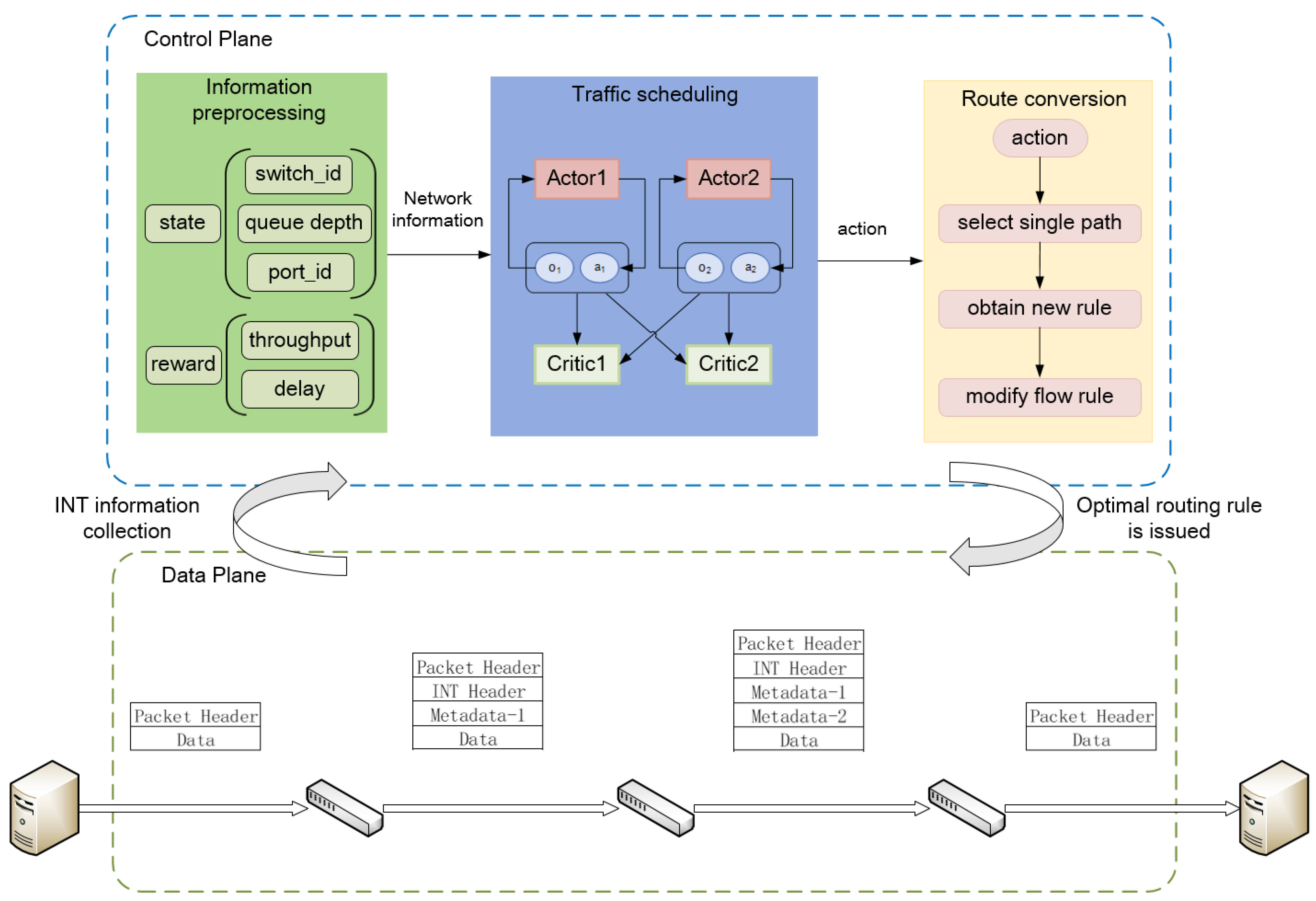
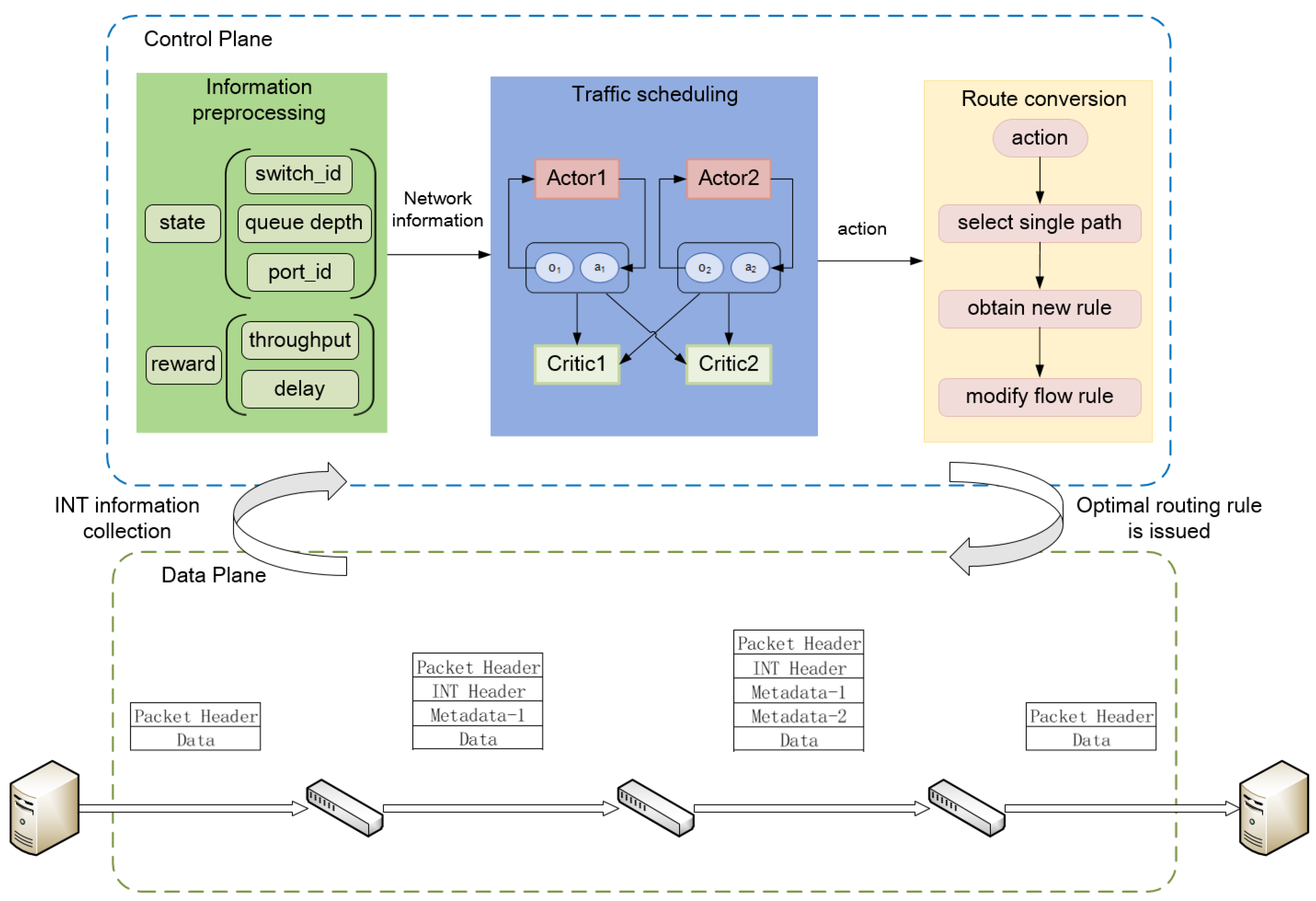
3.1. MAFS Traffic Scheduling System
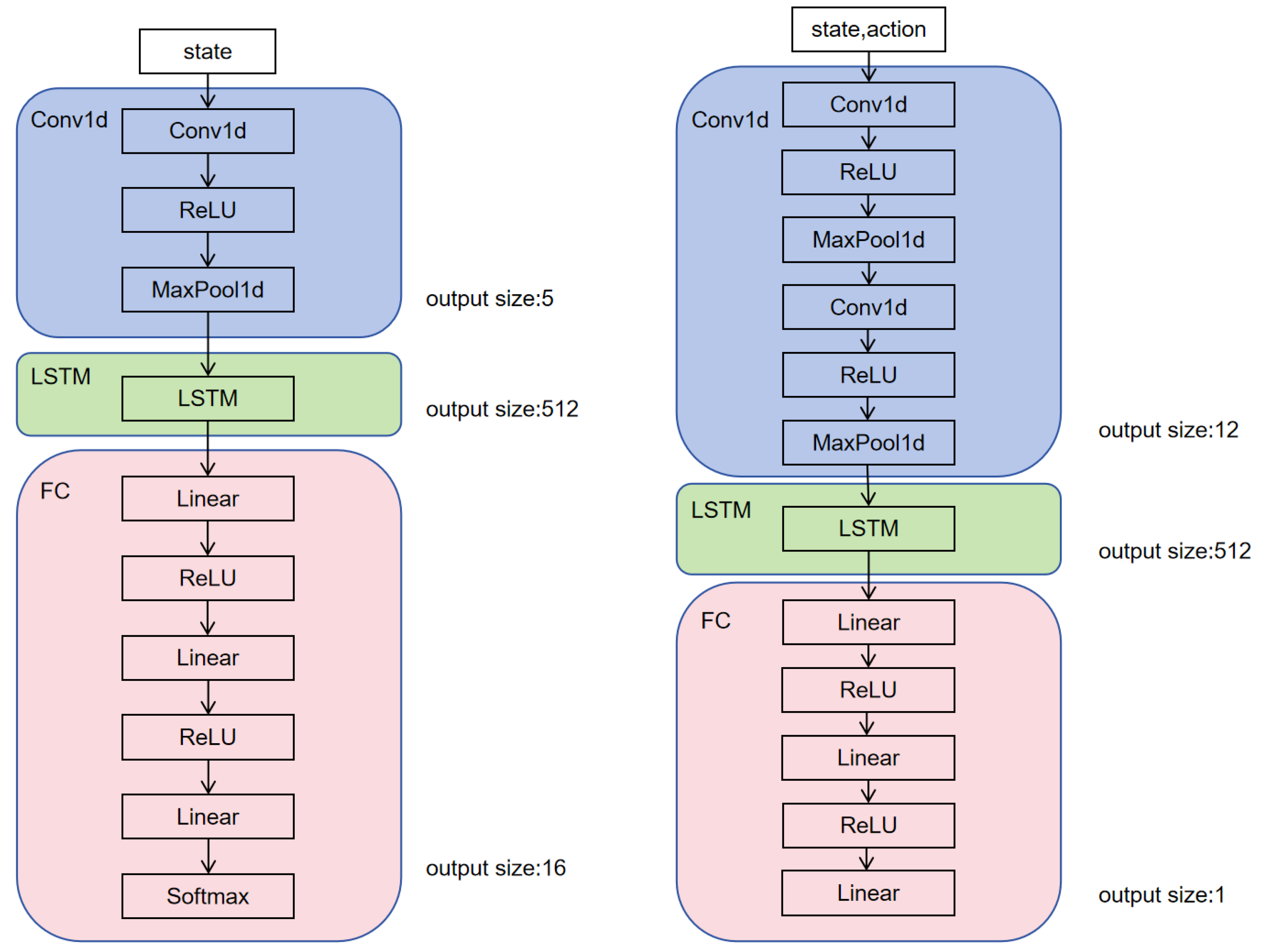
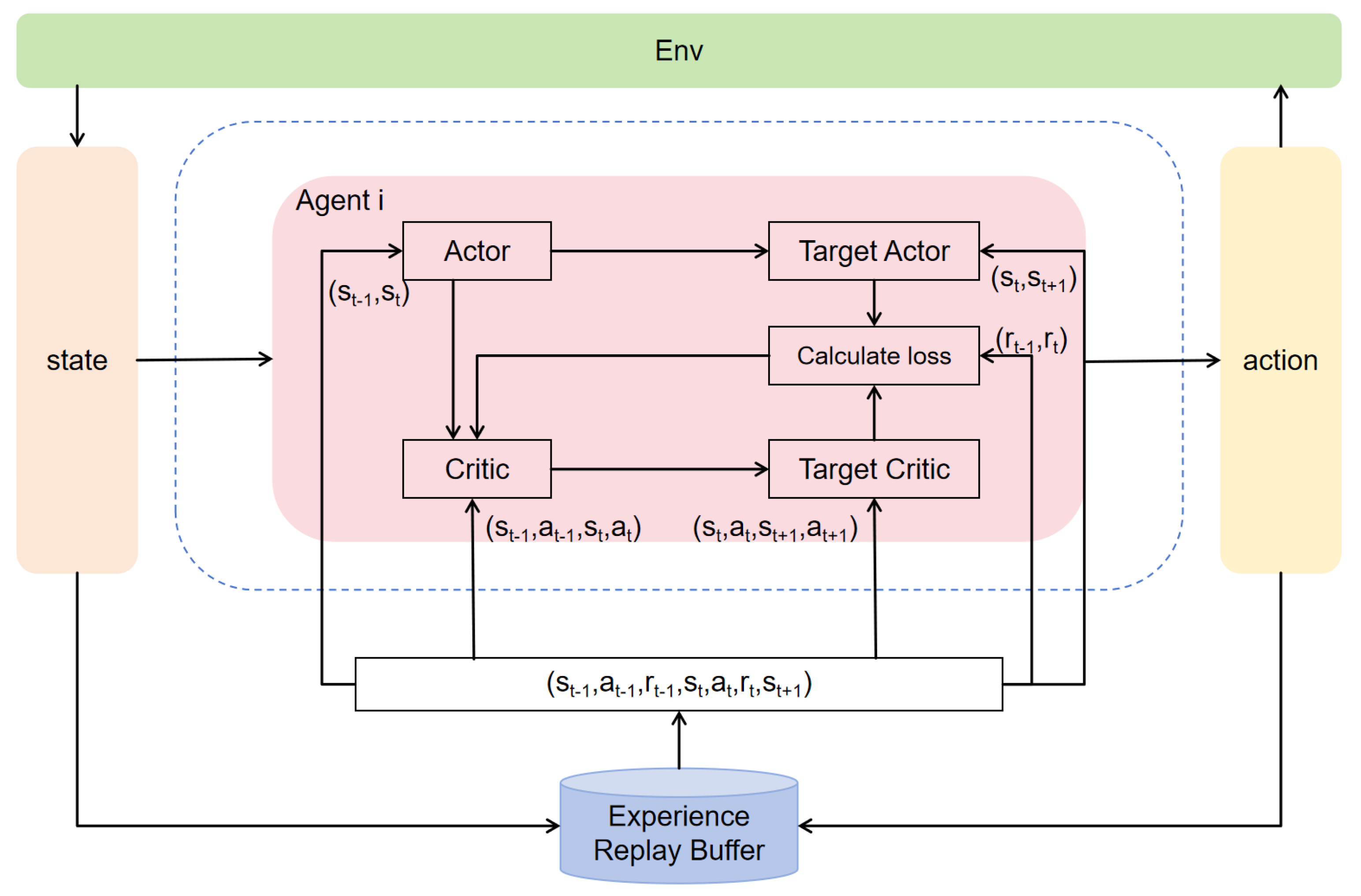
3.2. CTN-MADDPG Intelligent Network Model
3.3. Multi-Step Experience Replay Strategy
4. Implementation of MAFS Traffic Scheduling Algorithm
4.1. Key Parameter Setting
4.2. The Algorithm of MAFS
| Algorithm 1 MAFS Method |
| Require: Data plane information collected by INT; |
| Ensure: Optimal path; |
|
5. Experiment
5.1. Experimental Environment Setting
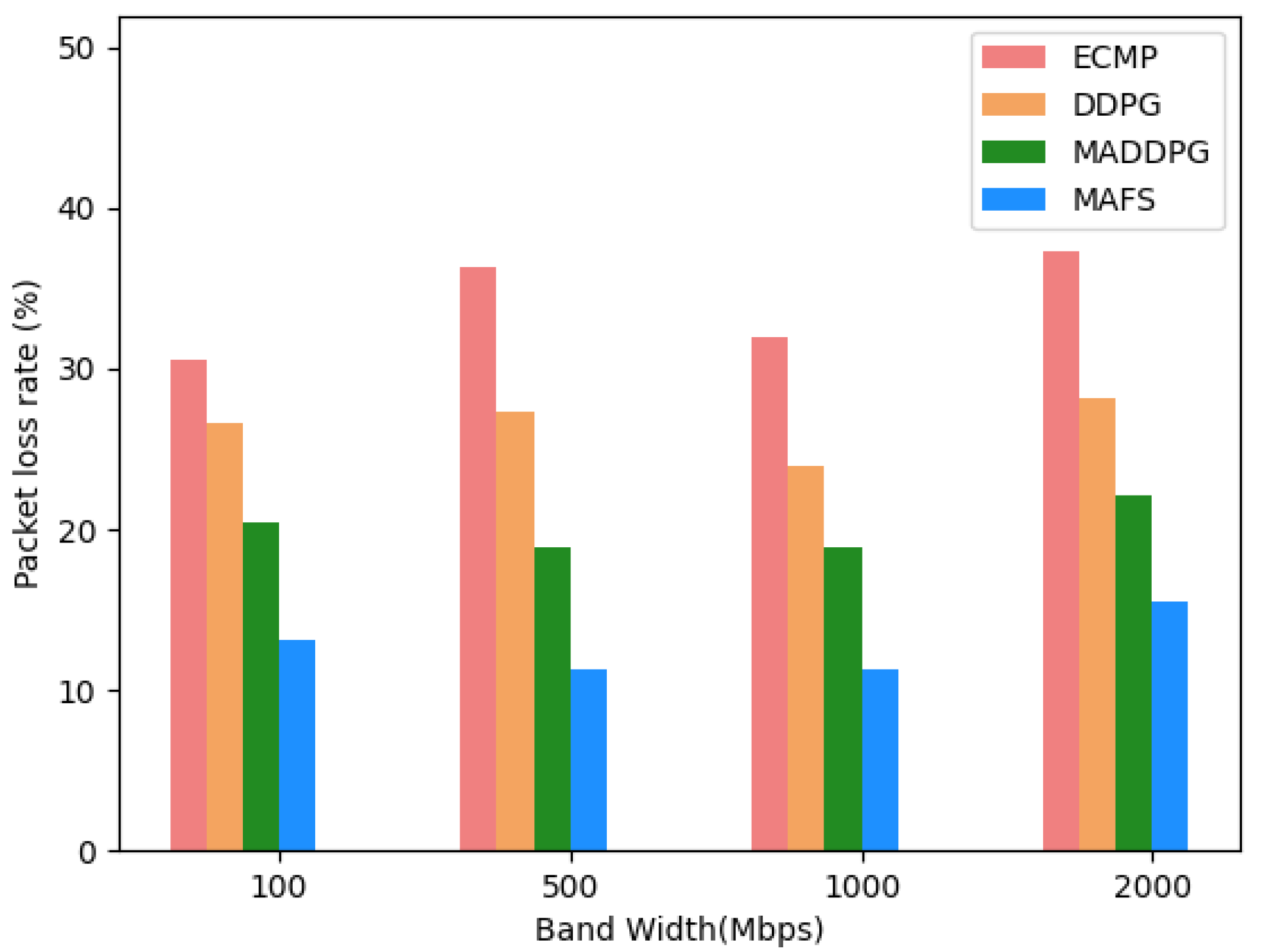
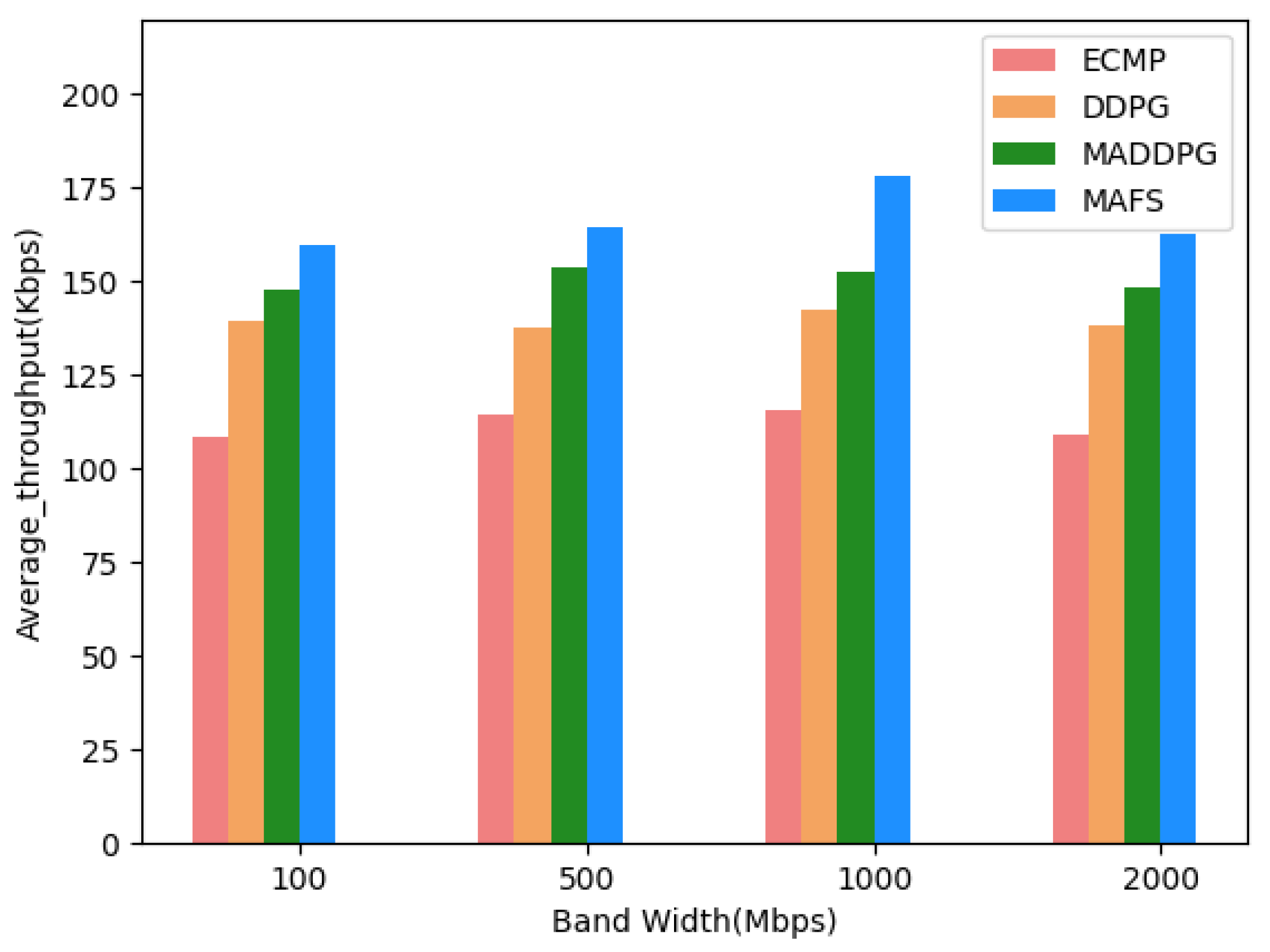
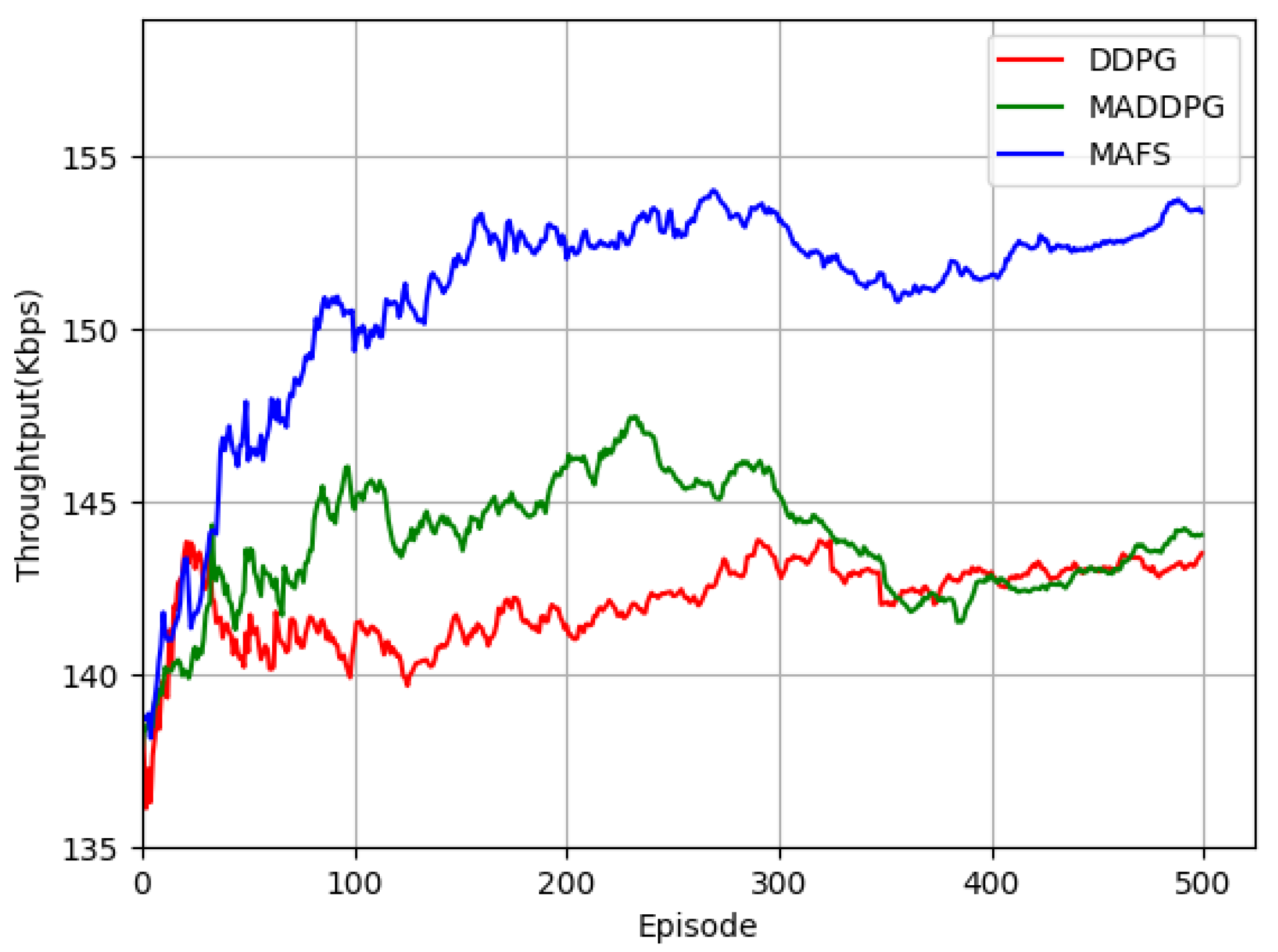
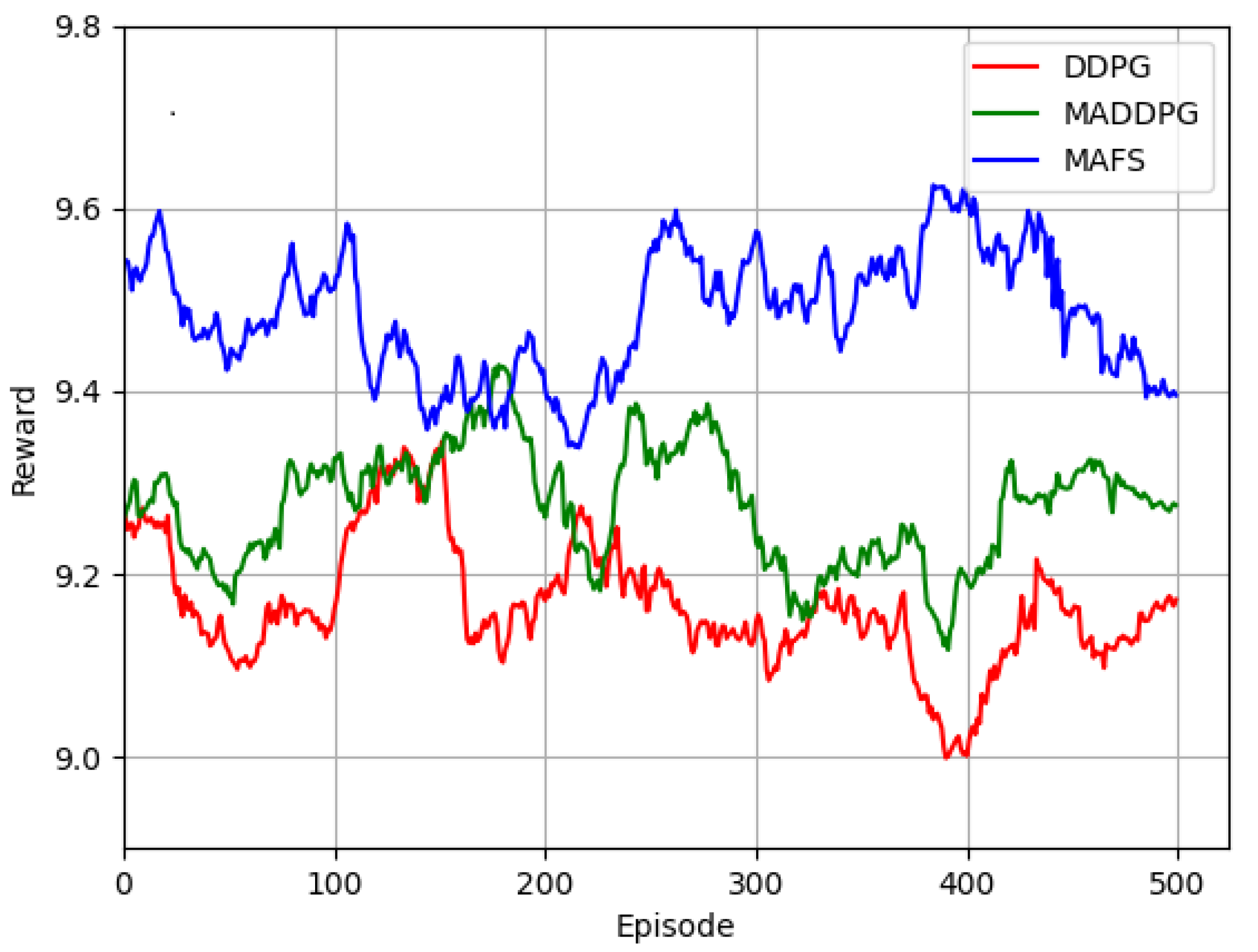
5.2. Experimental Results and Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Q.; Giambene, G.; Yang, L.; Fan, C.; Chen, X. Analysis of Inter-Satellite Link Paths for LEO Mega-Constellation Networks. IEEE Trans. Veh. Technol. 2021, 70, 2743–2755. [Google Scholar] [CrossRef]
- Bhardwaj, S.; Panda, S.N. Performance evaluation using RYU SDN controller in software-defined networking environment. Wirel. Pers. Commun. 2022, 122, 701–723. [Google Scholar] [CrossRef]
- PEI, P. Integrated Guidance and Control for Missile Using Deep Reinforcement Learning. J. Astronaut. 2021, 42, 1293. [Google Scholar]
- Sun, Y.; Cao, L.; Chen, X. Overview of multi-agent deep reinforcement learning. Comput. Eng. Appl. 2020, 56, 13–24. [Google Scholar]
- Kim, C.; Sivaraman, A.; Katta, N.; Bas, A.; Dixit, A.; Wobker, L.J. In-band network telemetry via programmable dataplanes. In Proceedings of the ACM SIGCOMM, London, UK, 17–21 August 2015; pp. 1–2. [Google Scholar]
- Mao, B.; Tang, F.; Fadlullah, Z.M.; Kato, N. An intelligent route computation approach based on real-time deep learning strategy for software defined communication systems. IEEE Trans. Emerg. Top. Comput. 2019, 9, 1554–1565. [Google Scholar] [CrossRef]
- Novaes, M.P.; Carvalho, L.F.; Lloret, J.; Proenca, M.L. Long short-term memory and fuzzy logic for anomaly detection and mitigation in software-defined network environment. IEEE Access 2020, 8, 83765–83781. [Google Scholar] [CrossRef]
- Ye, J.-L.; Chen, C.; Chu, Y.H. A weighted ECMP load balancing scheme for data centers using P4 switches. In Proceedings of the 2018 IEEE 7th International Conference on Cloud Networking (CloudNet), Tokyo, Japan, 22–24 October 2018; pp. 1–4. [Google Scholar]
- Wang, S.; Zhang, J.; Huang, T.; Pan, T.; Liu, J.; Liu, Y. Flow distribution-aware load balancing for the datacenter. Comput. Commun. 2017, 106, 136–146. [Google Scholar] [CrossRef]
- Zhang, H.; Tang, F.; Barolli, L. Efficient flow detection and scheduling for SDN-based big data centers. J. Ambient. Intell. Humaniz. Comput. 2019, 10, 1915–1926. [Google Scholar] [CrossRef]
- Al-Fares, M.; Radhakrishnan, S.; Raghavan, B.; Huang, N.; Vahdat, A. Hedera: Dynamic flow scheduling for data center networks. In Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation (NSDI), San Jose, CA, USA, 28–30 April 2010; pp. 89–92. [Google Scholar]
- Curtis, A.R.; Kim, W.; Yalagandula, P. Mahout: Low-overhead datacenter traffic management using end-host-based elephant detection. In Proceedings of the 2011 Proceedings IEEE INFOCOM, Shanghai, China, 10–15 April 2011; pp. 1629–1637. [Google Scholar]
- Zhang, Y.; Cui, L.; Zhang, Y. A stable matching based elephant flow scheduling algorithm in data center networks. Comput. Netw. 2017, 120, 186–197. [Google Scholar] [CrossRef]
- Li, C.; Jiang, K.; Luo, Y. Dynamic placement of multiple controllers based on SDN and allocation of computational resources based on heuristic ant colony algorithm. Knowl.-Based Syst. 2022, 241, 108330. [Google Scholar] [CrossRef]
- Park, J.; Hwang, J.; Yeom, K. Nsaf: An approach for ensuring application-aware routing based on network qos of applications in sdn. Mob. Inf. Syst. 2019, 2019, 3971598. [Google Scholar] [CrossRef]
- Mammeri, Z. Reinforcement learning based routing in networks: Review and classification of approaches. IEEE Access 2019, 7, 55916–55950. [Google Scholar] [CrossRef]
- Ying, L.I.; Fang, W.; Dong-Sheng, J.; Fei, Z. A Q-learning Based Routing Approach for Wireless Sensor Network. Comput. Technol. Autom. 2017. [Google Scholar] [CrossRef]
- Zhou, Y.; Cao, T.; Xiang, W. Anypath routing protocol design via Q-learning for underwater sensor networks. IEEE Internet Things J. 2020, 8, 8173–8190. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, Z.; Chen, L.; Wang, X. Reinforcement learning-based opportunistic routing protocol for underwater acoustic sensor networks. IEEE Trans. Veh. Technol. 2021, 70, 2756–2770. [Google Scholar] [CrossRef]
- Dhurandher, S.K.; Singh, J.; Obaidat, M.S.; Woungang, I.; Srivastava, S.; Rodrigues, J.J. Reinforcement learning-based routing protocol for opportunistic networks. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Yuan, Z.; Zhou, P.; Wang, S.; Zhang, X. Research on routing optimization of SDN network using reinforcement learning method. In Proceedings of the 2019 2nd International Conference on Safety Produce Informatization (IICSPI), Chongqing, China, 28–30 November 2019; pp. 442–445. [Google Scholar]
- Zuo, Y.; Wu, Y.; Min, G.; Cui, L. Learning-based network path planning for traffic engineering. Future Gener. Comput. Syst. 2019, 92, 59–67. [Google Scholar] [CrossRef]
- Pham, T.A.Q.; Hadjadj-Aoul, Y.; Outtagarts, A. Deep reinforcement learning based QoS-aware routing in knowledge-defined networking. In Proceedings of the Quality, Reliability, Security and Robustness in Heterogeneous Systems: 14th EAI International Conference, Qshine 2018, Ho Chi Minh City, Vietnam, 3–4 December 2018; Proceedings 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 14–26. [Google Scholar]
- Xu, Z.; Wu, K.; Zhang, W.; Tang, J.; Wang, Y.; Xue, G. PnP-DRL: A plug-and-play deep reinforcement learning approach for experience-driven networking. IEEE J. Sel. Areas Commun. 2021, 39, 2476–2486. [Google Scholar] [CrossRef]
- Fang, Q.; Xu, X.; Wang, X.; Zeng, Y. Target-driven visual navigation in indoor scenes using reinforcement learning and imitation learning. CAAI Trans. Intell. Technol. 2022, 7, 167–176. [Google Scholar] [CrossRef]
- Kim, D.; Moon, S.; Hostallero, D.; Kang, W.J.; Lee, T.; Son, K.; Yi, Y. Learning to schedule communication in multi-agent reinforcement learning. arXiv 2019, arXiv:1902.01554. [Google Scholar]
- Li, S.; Wu, Y.; Cui, X.; Dong, H.; Fang, F.; Russell, S. Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 4213–4220. [Google Scholar]
- He, B.; Wang, J.; Qi, Q.; Sun, H.; Liao, J. RTHop: Real-time hop-by-hop mobile network routing by decentralized learning with semantic attention. IEEE Trans. Mob. Comput. 2021, 22, 1731–1747. [Google Scholar] [CrossRef]
- Available online: https://github.com/philtabor/Multi-Agent-Deep-Deterministic-Policy-Gradients (accessed on 12 January 2024).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Tool | Description |
|---|---|
| Operating System | Ubuntu 18.04 64-bit |
| Network Simulation Platform | Mininet 2.2.2 |
| Virtual Switch | Bmv2 Software Switch |
| Programming Languages | Python, P4 |
| Traffic Generation Tool | iperf |
| Python Management Software | Anaconda |
| Parameter Name | Value | Description |
|---|---|---|
| BATCH _SIZE | 1024 | Size of mini-batch sampling |
| MEMORY _CAPACITY | 10,000 | Capacity of buffer pool |
| MAX _EPISODE | 500 | Maximum number of episodes |
| MAX _STEP | 25 | Maximum number of steps per episode |
| LR _A | 0.01 | Actor network learning rate |
| LR _C | 0.02 | Critic network learning rate |
| GAMMA | 0.99 | Discount factor |
| TAU | 0.01 | Target network hyperparameter |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Liu, Y.; Li, W.; Yang, Z. Multi-Agent Deep Reinforcement Learning-Based Fine-Grained Traffic Scheduling in Data Center Networks. Future Internet 2024, 16, 119. https://doi.org/10.3390/fi16040119
Wang H, Liu Y, Li W, Yang Z. Multi-Agent Deep Reinforcement Learning-Based Fine-Grained Traffic Scheduling in Data Center Networks. Future Internet. 2024; 16(4):119. https://doi.org/10.3390/fi16040119
Chicago/Turabian StyleWang, Huiting, Yazhi Liu, Wei Li, and Zhigang Yang. 2024. "Multi-Agent Deep Reinforcement Learning-Based Fine-Grained Traffic Scheduling in Data Center Networks" Future Internet 16, no. 4: 119. https://doi.org/10.3390/fi16040119