
A Comparative Study of Traffic Signal Control Based on Reinforcement Learning Algorithms



Abstract
1. Introduction
- We present the traffic signal control problem as a Markov Decision Process (MDP) and employ the reinforcement learning algorithm (Q-learning and DQN) to acquire a dynamic and effective traffic signal control strategy. The evaluation of this paper covers vehicle traveling time, average speed, and lane occupancy rate to demonstrate the effectiveness of the proposed method.
- We propose a signal control framework based on Q-learning and Deep Q-Network (DQN) and define two different action spaces (Q-learning and DQN), which are different from other researchers’ approaches [20]. In Q-learning, the action space involves selecting the duration of each green light phase in the next loop. In DQN, the action space is related to the current phase versus the selected phase. If the phases coincide, the selected phase is executed, and if they do not, the system moves to the next phase, resulting in more efficient signal control.
2. Related Works
3. Method
3.1. Q-Learning
3.2. DQN
| Algorithm 1: DQN algorithm |
| Initialize replay memory D to capacity N Initialize observation steps S and total steps T: T = 0 Initialize action-value: For all episodes n = 1,2…N do of the traffic light |
| For t = 1 to K do |
| ) in D |
| Update T: T = T + 1 |
| If T > S do |
| ) from D |
End if Every C steps copy weights into target network |
| End for |
| End for |
3.3. TSC Setting
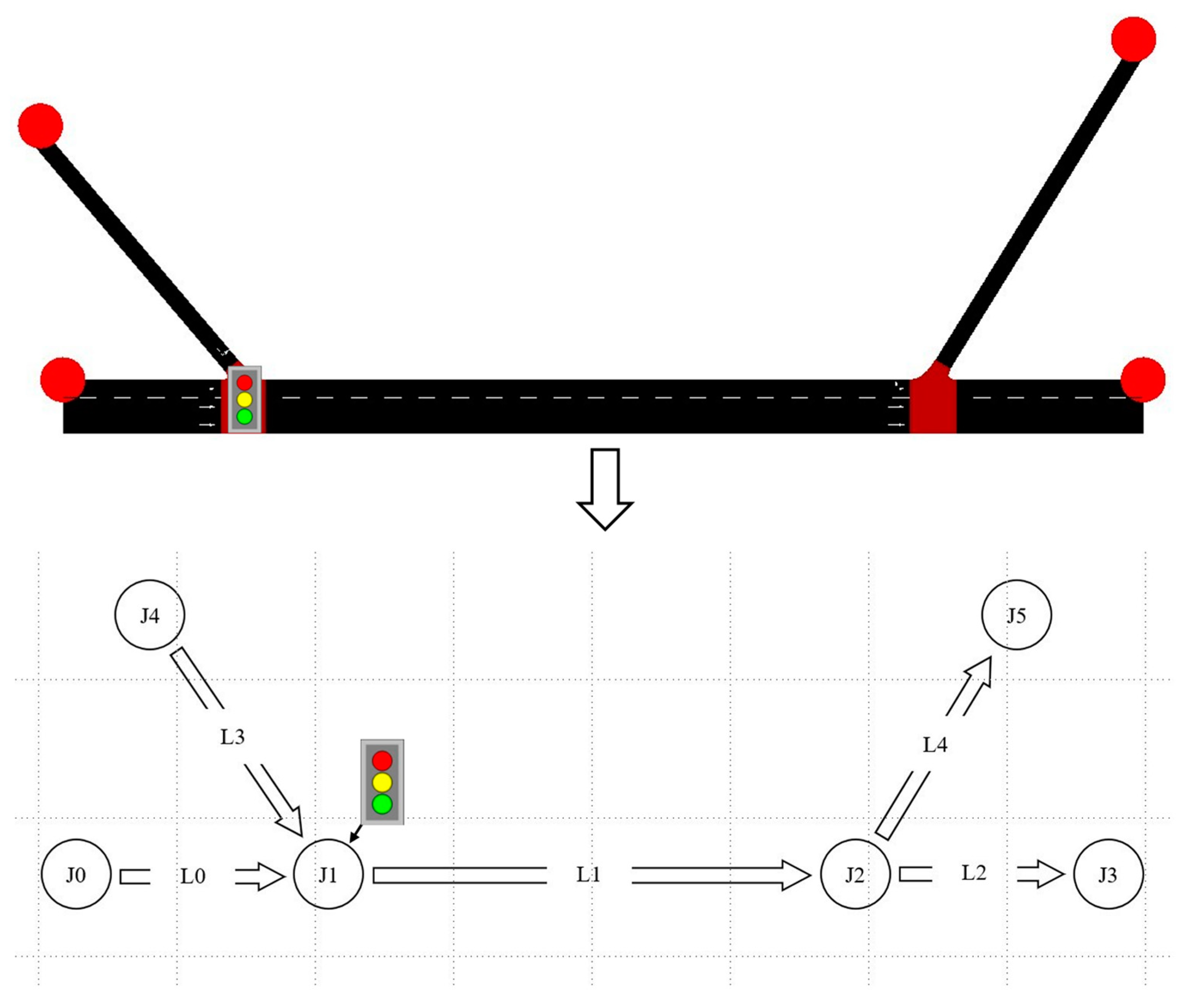
3.3.1. Road Model
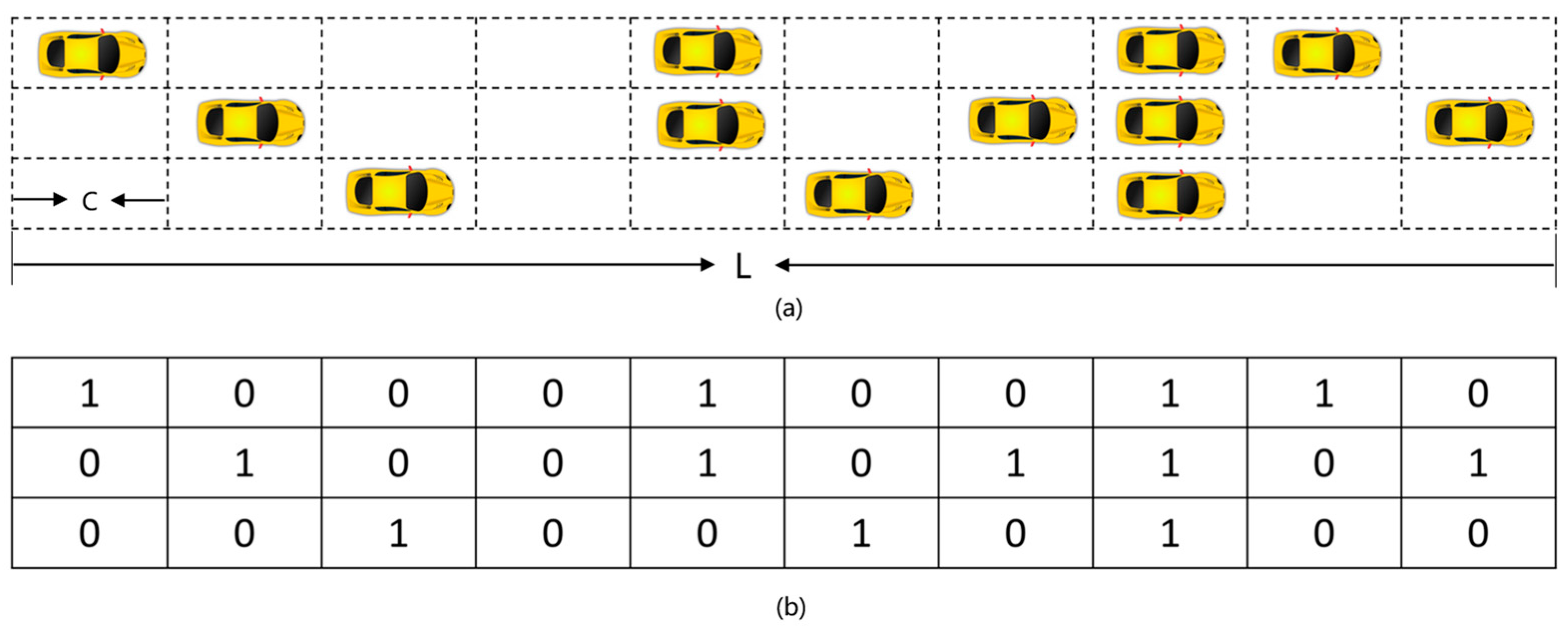
3.3.2. State Space
3.3.3. Action Space
3.3.4. Reward
4. Simulation
4.1. Simulation Platform
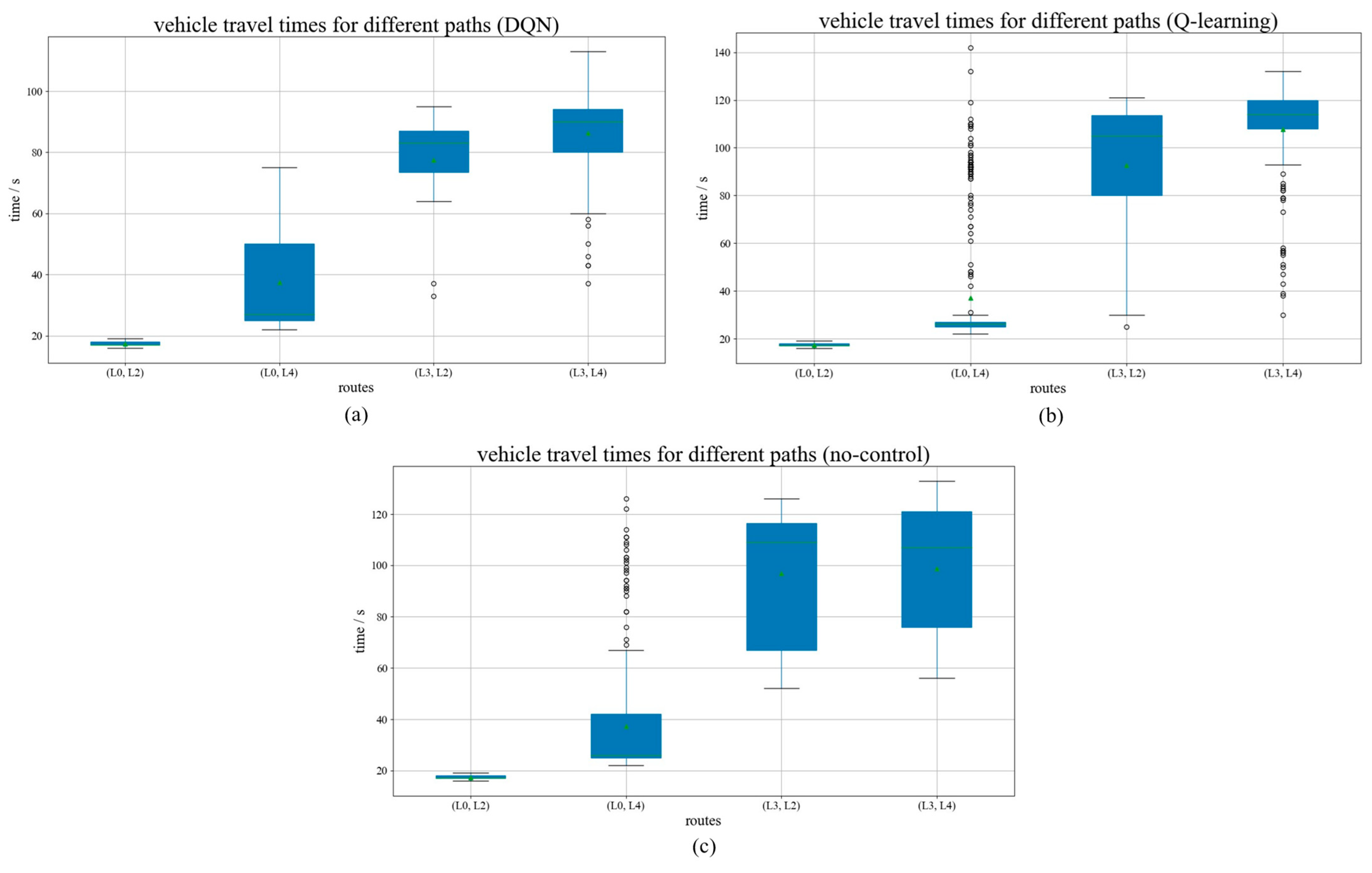
4.2. Experimental Results
5. Conclusions and Directions for Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pérez-Gil, Ó.; Barea, R.; López-Guillén, E.; Bergasa, L.M.; Gomez-Huelamo, C.; Gutiérrez, R.; Diaz-Diaz, A. Deep reinforcement learning based control for Autonomous Vehicles in CARLA. Multimed. Tools Appl. 2022, 81, 3553–3576. [Google Scholar] [CrossRef]
- Miao, W.; Li, L.; Wang, Z. A Survey on Deep Reinforcement Learning for Traffic Signal Control. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 1092–1097. [Google Scholar]
- Majstorovic, Ä.; Tisljaric, L.; Ivanjko, E.; Caric, T. Urban Traffic Signal Control under Mixed Traffic Flows: Literature Review. Appl. Sci. 2023, 13, 4484. [Google Scholar] [CrossRef]
- Zhu, T.M.; Boada, M.J.L.; Boada, B.L. Intelligent Signal Control Module Design for Intersection Traffic Optimization. In Proceedings of the IEEE 7th International Conference on Intelligent Transportation Engineering (ICITE), Beijing, China, 11–13 November 2022; pp. 522–527. [Google Scholar]
- Mu, Y.; Chen, S.F.; Ding, M.Y.; Chen, J.Y.; Chen, R.J.; Luo, P. CtrlFormer: Learning Transferable State Representation for Visual Control via Transformer. In Proceedings of the 39th International Conference on Machine Learning (ICML), Baltimore, MD, USA, 17–23 July 2022. [Google Scholar]
- You, C.X.; Lu, J.B.; Filev, D.; Tsiotras, P. Advanced planning for autonomous vehicles using reinforcement learning and deep inverse reinforcement learning. Robot. Auton. Syst. 2019, 114, 1–18. [Google Scholar] [CrossRef]
- Tan, J.R. A Method to Plan the Path of a Robot Utilizing Deep Reinforcement Learning and Multi-Sensory Information Fusion. Appl. Artif. Intell. 2023, 37, 2224996. [Google Scholar] [CrossRef]
- Lin, Y.; McPhee, J.; Azad, N.L. Longitudinal Dynamic versus Kinematic Models for Car-Following Control Using Deep Reinforcement Learning. In Proceedings of the IEEE Intelligent Transportation Systems Conference (IEEE-ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 1504–1510. [Google Scholar]
- Chen, J.; Zhou, Z.; Duan, Y.; Yu, B. Research on Reinforcement-Learning-Based Truck Platooning Control Strategies in Highway On-Ramp Regions. World Electr. Veh. J. 2023, 14, 273. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Xian, B.; Zhang, X.; Zhang, H.N.; Gu, X. Robust Adaptive Control for a Small Unmanned Helicopter Using Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 7589–7597. [Google Scholar] [CrossRef] [PubMed]
- Agostinelli, F.; Hocquet, G.; Singh, S.; Baldi, P. From Reinforcement Learning to Deep Reinforcement Learning: An Overview. In Braverman Readings in Machine Learning—Key Ideas from Inception to Current State; Rozonoer, L., Mirkin, B., Muchnik, I., Eds.; Part of the Lecture Notes in Computer Science Book Series; Springer: Cham, Switzerland, 2018; pp. 298–328. [Google Scholar] [CrossRef]
- Choi, S.; Le, T.P.; Nguyen, Q.D.; Abu Layek, M.; Lee, S.; Chung, T. Toward Self-Driving Bicycles Using State-of-the-Art Deep Reinforcement Learning Algorithms. Symmetry 2019, 11, 290. [Google Scholar] [CrossRef]
- Væhrens, L.; Alvarez, D.D.; Berger, U.; Bogh, S. Learning Task-independent Joint Control for Robotic Manipulators with Reinforcement Learning and Curriculum Learning. In Proceedings of the 21st IEEE International Conference on Machine Learning and Applications (IEEE ICMLA), Nassau, Bahamas, 12–14 December 2022; pp. 1250–1257. [Google Scholar]
- Levine, S.; Finn, C.; Darrell, T.; Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 2016, 17, 1334–1373. [Google Scholar]
- Schulman, J.; Moritz, P.; Levine, S.; Jordan, M.; Abbeel, P. High-dimensional continuous control using generalized advantage estimation. arXiv 2015, arXiv:1506.02438. [Google Scholar]
- Charpentier, A.; Élie, R.; Remlinger, C. Reinforcement Learning in Economics and Finance. Comput. Econ. 2023, 62, 425–462. [Google Scholar] [CrossRef]
- Hu, M.Z.; Zhang, J.H.; Matkovic, L.; Liu, T.; Yang, X.F. Reinforcement learning in medical image analysis: Concepts, applications, challenges, and future directions. J. Appl. Clin. Med. Phys. 2023, 24, e13898. [Google Scholar] [CrossRef] [PubMed]
- Clark, T.; Barn, B.; Kulkarni, V.; Barat, S. Language Support for Multi Agent Reinforcement Learning. In Proceedings of the 13th Innovations in Software Engineering Conference (ISEC), Jabalpur, India, 27–29 February 2020. [Google Scholar]
- Gu, J.; Lee, M.; Jun, C.; Han, Y.; Kim, Y.; Kim, J. Traffic Signal Optimization for Multiple Intersections Based on Reinforcement Learning. Appl. Sci. 2021, 11, 10688. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, X.; Wu, Z. Design of Unsignalized Roundabouts Driving Policy of Autonomous Vehicles Using Deep Reinforcement Learning. World Electr. Veh. J. 2023, 14, 52. [Google Scholar] [CrossRef]
- Zhu, R.J.; Wu, S.N.; Li, L.L.; Lv, P.; Xu, M.L. Context-Aware Multiagent Broad Reinforcement Learning for Mixed Pedestrian-Vehicle Adaptive Traffic Light Control. IEEE Internet Things J. 2022, 9, 19694–19705. [Google Scholar] [CrossRef]
- Shakya, A.K.; Pillai, G.; Chakrabarty, S. Reinforcement learning algorithms: A brief survey. Expert Syst. Appl. 2023, 231, 120495. [Google Scholar] [CrossRef]
- Mahler, G.; Vahidi, A. An Optimal Velocity-Planning Scheme for Vehicle Energy Efficiency Through Probabilistic Prediction of Traffic-Signal Timing. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2516–2523. [Google Scholar] [CrossRef]
- Mirheli, A.; Hajibabai, L.; Hajbabaie, A. Development of a signal-head-free intersection control logic in a fully connected and autonomous vehicle environment. Transp. Res. Part C-Emerg. Technol. 2018, 92, 412–425. [Google Scholar] [CrossRef]
- Ma, J.M.; Wu, F. Learning to Coordinate Traffic Signals With Adaptive Network Partition. IEEE Trans. Intell. Transp. Syst. 2023. Early Access. [Google Scholar] [CrossRef]
- Zhou, X.K.; Zhu, F.; Liu, Q.; Fu, Y.C.; Huang, W. A Sarsa(λ)-Based Control Model for Real-Time Traffic Light Coordination. Sci. World J. 2014, 2014, 759097. [Google Scholar] [CrossRef]
- Yen, C.C.; Ghosal, D.; Zhang, M.; Chuah, C.N. A Deep On-Policy Learning Agent for Traffic Signal Control of Multiple Intersections. In Proceedings of the 23rd IEEE International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020. [Google Scholar]
- Reza, S.; Ferreira, M.C.; Machado, J.J.M.; Tavares, J. A citywide TD-learning based intelligent traffic signal control for autonomous vehicles: Performance evaluation using SUMO. Expert Syst. 2023. [Google Scholar] [CrossRef]
- Arel, I.; Liu, C.; Urbanik, T.; Kohls, A.G. Reinforcement learning-based multi-agent system for network traffic signal control. IET Intell. Transp. Syst. 2010, 4, 128–135. [Google Scholar] [CrossRef]
- Abdoos, M.; Mozayani, N.; Bazzan, A.L.C. Hierarchical control of traffic signals using Q-learning with tile coding. Appl. Intell. 2014, 40, 201–213. [Google Scholar] [CrossRef]
- Wei, Z.B.; Peng, T.; Wei, S.J. A Robust Adaptive Traffic Signal Control Algorithm Using Q-Learning under Mixed Traffic Flow. Sustainability 2022, 14, 5751. [Google Scholar] [CrossRef]
- Zeng, J.H.; Hu, J.M.; Zhang, Y. Adaptive Traffic Signal Control with Deep Recurrent Q-learning. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1215–1220. [Google Scholar]
- Xie, D.H.; Wang, Z.; Chen, C.L.; Dong, D.Y. IEDQN: Information Exchange DQN with a Centralized Coordinator for Traffic Signal Control. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Tunc, I.; Soylemez, M.T. Fuzzy logic and deep Q learning based control for traffic lights. Alex. Eng. J. 2023, 67, 343–359. [Google Scholar] [CrossRef]
- Wang, X.Y.; Taitler, A.; Smirnov, I.; Sanner, S.; Abdulhai, B. eMARLIN: Distributed Coordinated Adaptive Traffic Signal Control with Topology-Embedding Propagation. Transp. Res. Rec. J. Transp. Res. Board 2023. [Google Scholar] [CrossRef]
- Babatunde, J.; Osman, O.A.; Stevanovic, A.; Dobrota, N. Fuel-Based Nash Bargaining Approach for Adaptive Signal Control in an N-Player Cooperative Game. Transp. Res. Rec. J. Transp. Res. Board 2023, 2677, 451–463. [Google Scholar] [CrossRef]
- Ounoughi, C.; Ounoughi, D.; Ben Yahia, S. EcoLight plus: A novel multi-modal data fusion for enhanced eco-friendly traffic signal control driven by urban traffic noise prediction. Knowl. Inf. Syst. 2023, 65, 5309–5329. [Google Scholar] [CrossRef]
- Zeinaly, Z.; Sojoodi, M.; Bolouki, S. A Resilient Intelligent Traffic Signal Control Scheme for Accident Scenario at Intersections via Deep Reinforcement Learning. Sustainability 2023, 15, 1329. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Lane length | 100 m |
| Vehicle length | 5 m |
| Minimum safe distance between vehicles | 3 m |
| Maximum vehicle speed | 50 km/h |
| Maximum vehicle acceleration | |
| Maximum vehicle deceleration | |
| Transition phase duration | 3 s |
| Signal phase duration | 42 s |
| Simulation time step | 1 s |
| Path selection | random |
| Vehicle input | 3600 PCU/h |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ouyang, C.; Zhan, Z.; Lv, F. A Comparative Study of Traffic Signal Control Based on Reinforcement Learning Algorithms. World Electr. Veh. J. 2024, 15, 246. https://doi.org/10.3390/wevj15060246
Ouyang C, Zhan Z, Lv F. A Comparative Study of Traffic Signal Control Based on Reinforcement Learning Algorithms. World Electric Vehicle Journal. 2024; 15(6):246. https://doi.org/10.3390/wevj15060246
Chicago/Turabian StyleOuyang, Chen, Zhenfei Zhan, and Fengyao Lv. 2024. "A Comparative Study of Traffic Signal Control Based on Reinforcement Learning Algorithms" World Electric Vehicle Journal 15, no. 6: 246. https://doi.org/10.3390/wevj15060246
APA StyleOuyang, C., Zhan, Z., & Lv, F. (2024). A Comparative Study of Traffic Signal Control Based on Reinforcement Learning Algorithms. World Electric Vehicle Journal, 15(6), 246. https://doi.org/10.3390/wevj15060246