Figure 1.
Prototype acquisition system used to create the PC3D dataset in the city of Paris. Sensors: Velodyne HDL32 LiDAR, Ladybug5 360° camera, Photonfocus MV1 16-band VIR and 25-band NIR hyperspectral cameras (hyperspectral data are not available in this dataset; they cannot be used in mobile mapping due to the limited exposure time).
Figure 1.
Prototype acquisition system used to create the PC3D dataset in the city of Paris. Sensors: Velodyne HDL32 LiDAR, Ladybug5 360° camera, Photonfocus MV1 16-band VIR and 25-band NIR hyperspectral cameras (hyperspectral data are not available in this dataset; they cannot be used in mobile mapping due to the limited exposure time).
Figure 2.
Paris-CARLA-3D dataset: (left) Paris point clouds with color information on LiDAR points; (right) manual semantic annotation of the LiDAR points (using the same tags from the CARLA simulator). We can see the large number of details in the manual annotation.
Figure 2.
Paris-CARLA-3D dataset: (left) Paris point clouds with color information on LiDAR points; (right) manual semantic annotation of the LiDAR points (using the same tags from the CARLA simulator). We can see the large number of details in the manual annotation.
Figure 3.
Left, prediction in test set of Paris data using KPConv model. Right, ground truth.
Figure 3.
Left, prediction in test set of Paris data using KPConv model. Right, ground truth.
Figure 4.
Left, prediction in test set of Paris data using KPConv model. Right, ground truth.
Figure 4.
Left, prediction in test set of Paris data using KPConv model. Right, ground truth.
Figure 5.
Left, prediction in test set of CARLA data using KPConv model. Right, ground truth.
Figure 5.
Left, prediction in test set of CARLA data using KPConv model. Right, ground truth.
Figure 6.
Left, prediction in test set of CARLA data using KPConv model. Right, ground truth.
Figure 6.
Left, prediction in test set of CARLA data using KPConv model. Right, ground truth.
Figure 7.
Instances of vehicles in test set (Paris data).
Figure 7.
Instances of vehicles in test set (Paris data).
Figure 8.
Pedestrians in Paris data: we can see inside the red circle the difficulty of differentiating the instances of pedestrians.
Figure 8.
Pedestrians in Paris data: we can see inside the red circle the difficulty of differentiating the instances of pedestrians.
Figure 9.
Top, vehicle instances from our proposed baseline using BEV projections and geometrical features in Paris data. Bottom, ground truth.
Figure 9.
Top, vehicle instances from our proposed baseline using BEV projections and geometrical features in Paris data. Bottom, ground truth.
Figure 10.
Paris data after removal of vehicles and pedestrians. Zones in red circles show the interest in conducting scene completion for 3D mapping, in order to fill holes from removed pedestrians, parked cars, and from the occlusion of other objects, and also to improve the sampling of points in areas far from the LiDAR.
Figure 10.
Paris data after removal of vehicles and pedestrians. Zones in red circles show the interest in conducting scene completion for 3D mapping, in order to fill holes from removed pedestrians, parked cars, and from the occlusion of other objects, and also to improve the sampling of points in areas far from the LiDAR.
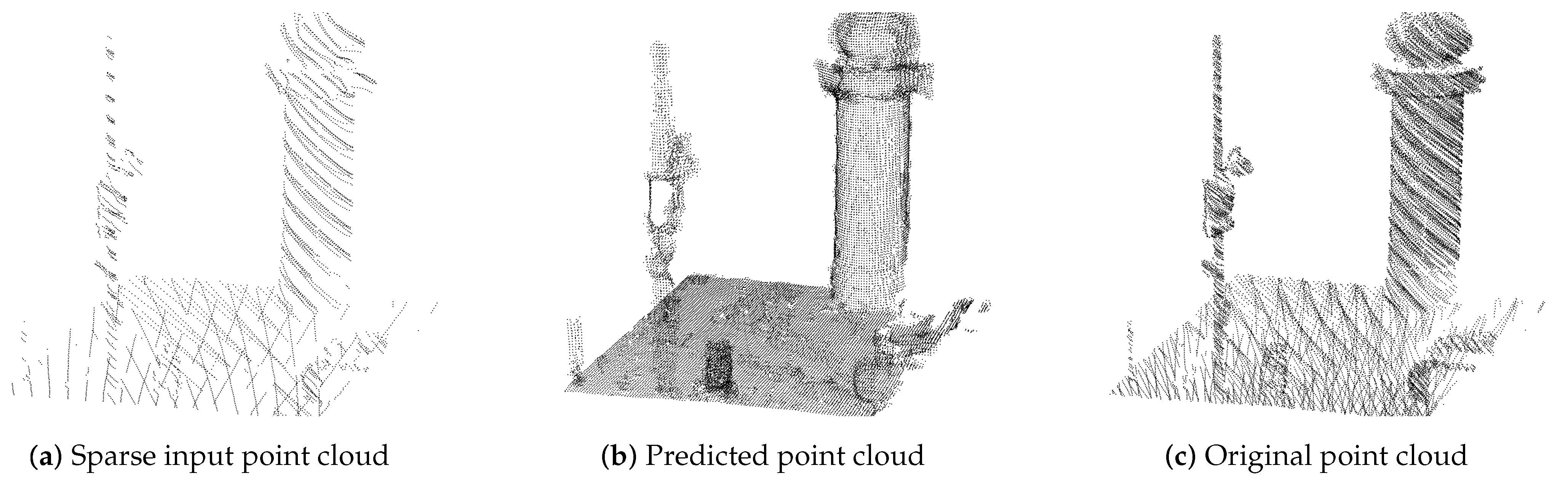
Figure 11.
Scene completion task for one chunk point cloud in Town1 () of CARLA test data (training on CARLA data).
Figure 11.
Scene completion task for one chunk point cloud in Town1 () of CARLA test data (training on CARLA data).
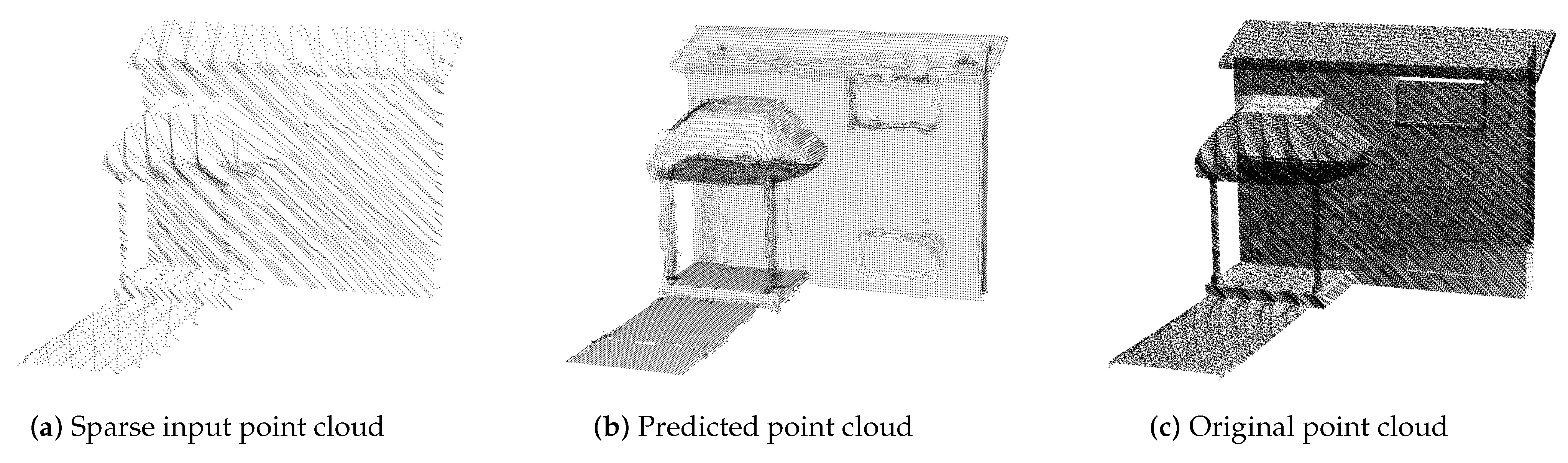
Figure 12.
Scene completion task for one chunk point cloud in Soufflot0 () of Paris test data (training on Paris data).
Figure 12.
Scene completion task for one chunk point cloud in Soufflot0 () of Paris test data (training on Paris data).
Table 1.
Point cloud datasets for semantic segmentation (SS), instance segmentation (IS), and scene completion (SC) tasks. RGB means color available on all points of the point clouds. In parentheses for SS, we show only the number of classes evaluated (the annotation can have more classes).
Table 1.
Point cloud datasets for semantic segmentation (SS), instance segmentation (IS), and scene completion (SC) tasks. RGB means color available on all points of the point clouds. In parentheses for SS, we show only the number of classes evaluated (the annotation can have more classes).
| Scene | Type | Dataset (Year) | World | # Points | RGB | Tasks |
|---|
| SS | IS | SC |
|---|
| Indoor | Mapping | SUN3D [8] (2013) | Real | 8 M | Yes | 🗸(11) | 🗸 | |
| SceneNet [9] (2015) | Synthetic | - | Yes | 🗸(11) | 🗸 | 🗸 |
| S3DIS [10] (2016) | Real | 696 M | Yes | 🗸(13) | 🗸 | 🗸 |
| ScanNet [11] (2017) | Real | 5581 M | Yes | 🗸(11) | 🗸 | 🗸 |
| Matterport3D [12] (2017) | Real | 24 M | Yes | 🗸(11) | 🗸 | 🗸 |
| Outdoor | Perception | PreSIL [13] (2019) | Synthetic | 3135 M | Yes | 🗸(12) | 🗸 | |
| SemanticKITTI [5] (2019) | Real | 4549 M | No | 🗸(25) | 🗸 | 🗸 |
| nuScenes-Lidarseg [14] (2019) | Real | 1400 M | Yes | 🗸(32) | 🗸 | |
| A2D2 [15] (2020) | Real | 1238 M | Yes | 🗸(38) | 🗸 | |
| SemanticPOSS [16] (2020) | Real | 216 M | No | 🗸(14) | 🗸 | |
| SynLiDAR [17] (2021) | Synthetic | 19,482 M | No | 🗸(32) | | |
| KITTI-CARLA [18] (2021) | Synthetic | 4500 M | Yes | 🗸(23) | 🗸 | |
| Mapping | Oakland [19] (2009) | Real | 2 M | No | 🗸(5) | | |
| Paris-rue-Madame [20] (2014) | Real | 20 M | No | 🗸(17) | 🗸 | |
| iQmulus [21] (2015) | Real | 12 M | No | 🗸(8) | 🗸 | 🗸 |
| Semantic3D [7] (2017) | Real | 4009 M | Yes | 🗸(8) | | |
| Paris-Lille-3D [22] (2018) | Real | 143 M | No | 🗸(9) | 🗸 | |
| SynthCity [23] (2019) | Synthetic | 368 M | Yes | 🗸(9) | | |
| Toronto-3D [6] (2020) | Real | 78 M | Yes | 🗸(8) | | |
| TUM-MLS-2016 [24] (2020) | Real | 41 M | No | 🗸(8) | | |
| Paris-CARLA-3D (2021) | Synthetic+Real | 700 + 60 M | Yes | 🗸(23) | 🗸 | 🗸 |
Table 2.
Results in semantic segmentation task using PointNet++ and KPConv architectures on our dataset, Paris-CARLA-3D. Results are mIoU in %. For and , training set is , . For and , training set is , , and . Overall mIoU is the mean IoU on the whole test sets (real and synthetic).
Table 2.
Results in semantic segmentation task using PointNet++ and KPConv architectures on our dataset, Paris-CARLA-3D. Results are mIoU in %. For and , training set is , . For and , training set is , , and . Overall mIoU is the mean IoU on the whole test sets (real and synthetic).
| Model | Paris | CARLA | Overall |
|---|
| | | | mIoU |
|---|
| PointNet++ [29] | 13.9 | 25.8 | 4.0 | 12.0 | 13.9 |
| KPConv [30] | 45.2 | 62.9 | 16.7 | 25.3 | 37.5 |
Table 3.
Results in semantic segmentation task using KPConv [
30] architecture on our PC3D dataset with and without RGB colors on LiDAR points. Results are mIoU in %. For
and
, training set is
,
. For
and
, training set is
,
,
and
. Overall mIoU is the mean IoU on the whole test sets (real and synthetic).
Table 3.
Results in semantic segmentation task using KPConv [
30] architecture on our PC3D dataset with and without RGB colors on LiDAR points. Results are mIoU in %. For
and
, training set is
,
. For
and
, training set is
,
,
and
. Overall mIoU is the mean IoU on the whole test sets (real and synthetic).
| Model | Paris | CARLA | Overall |
|---|
| | | | mIoU |
|---|
| KPConv w/o color | 39.4 | 41.5 | 35.3 | 17.0 | 33.3 |
| KPConv with color | 45.2 | 62.9 | 16.7 | 25.3 | 37.5 |
Table 4.
Results in transfer learning for the semantic segmentation task using KPConv architecture on our PC3D dataset. Results are mIoU in %. Pre-training was done using urban towns from CARLA (, , and ). No fine-tuning: the model was pre-trained on CARLA data without fine-tuning on Paris data. No frozen parameters: the model was pre-trained on CARLA without frozen parameters during fine-tuning on Paris data. No transfer: the model was trained only on the Paris training set.
Table 4.
Results in transfer learning for the semantic segmentation task using KPConv architecture on our PC3D dataset. Results are mIoU in %. Pre-training was done using urban towns from CARLA (, , and ). No fine-tuning: the model was pre-trained on CARLA data without fine-tuning on Paris data. No frozen parameters: the model was pre-trained on CARLA without frozen parameters during fine-tuning on Paris data. No transfer: the model was trained only on the Paris training set.
| Transfer Learning Scenarios | Paris | Overall |
|---|
| | mIoU |
|---|
| No fine-tuning | 20.6 | 17.7 | 19.2 |
| Freeze except last layer | 24.1 | 31.0 | 27.6 |
| Freeze feature extractor | 29.0 | 41.3 | 35.2 |
| No frozen parameters | 42.8 | 50.0 | 46.4 |
| No transfer | 45.2 | 62.9 | 51.7 |
Table 5.
Results on test sets of Paris-CARLA-3D for the instance segmentation task. SM: Segment Matching. PQ: Panoptic Quality. : mean IoU. All results are in %.
Table 5.
Results on test sets of Paris-CARLA-3D for the instance segmentation task. SM: Segment Matching. PQ: Panoptic Quality. : mean IoU. All results are in %.
| | # Instances | SM | PQ | mIoU |
|---|
| —Vehicles | 10 | 90.0 | 70.9 | 81.6 |
| —Vehicles | 86 | 32.6 | 40.5 | 28.0 |
| —Vehicles | 41 | 17.1 | 20.4 | 14.2 |
| —Vehicles | 27 | 74.1 | 72.6 | 61.2 |
| —Pedestrians | 49 | 18.4 | 17.0 | 13.9 |
| —Pedestrians | 3 | 100.0 | 9.0 | 66.0 |
| Mean | 216 | 55.3 | 38.4 | 44.2 |
Table 6.
Scene completion results on Paris-CARLA-3D. CD is the mean Chamfer Distance over 2000 chunks for the Paris test set ( and ) and 6000 chunks for the CARLA test set ( and ). is the mean distance between predicted and target TSDF measured in voxel units for 5 cm voxels and is the mean Intersection over Union of TSDF occupancy. Both metrics are computed on known voxel areas. means original point cloud, is input point cloud (10% of the original), is the predicted point cloud (computed from predicted TSDF).
Table 6.
Scene completion results on Paris-CARLA-3D. CD is the mean Chamfer Distance over 2000 chunks for the Paris test set ( and ) and 6000 chunks for the CARLA test set ( and ). is the mean distance between predicted and target TSDF measured in voxel units for 5 cm voxels and is the mean Intersection over Union of TSDF occupancy. Both metrics are computed on known voxel areas. means original point cloud, is input point cloud (10% of the original), is the predicted point cloud (computed from predicted TSDF).
| Test Set | | | | |
|---|
| and (Paris) | cm | cm | 0.40 | 85.3% |
| and (CARLA) | cm | cm | 0.49 | 80.3% |
Table 7.
Results of transfer learning for the scene completion task. CD is the mean Chamfer Distance between point clouds. is the mean distance between predicted and target TSDF measured in voxel units for 5 cm voxels and is the mean Intersection over Union of TSDF occupancy. The mean is over 2000 chunks for Paris data. means original point cloud, is input point cloud (10 % of the original), for CD is the predicted point cloud (computed from predicted TSDF), for IoU, is the predicted TSDF, and is the target TSDF.
Table 7.
Results of transfer learning for the scene completion task. CD is the mean Chamfer Distance between point clouds. is the mean distance between predicted and target TSDF measured in voxel units for 5 cm voxels and is the mean Intersection over Union of TSDF occupancy. The mean is over 2000 chunks for Paris data. means original point cloud, is input point cloud (10 % of the original), for CD is the predicted point cloud (computed from predicted TSDF), for IoU, is the predicted TSDF, and is the target TSDF.
| Test Set: and Paris data | | | | |
|---|
| Trained only on Paris | 16.6 cm | 10.7 cm | 0.40 | 85.3% |
| Trained only on CARLA | 16.6 cm | 8.0 cm | 0.48 | 84.0% |
| Pre-trained CARLA, fine-tuned on Paris | 16.6 cm | 7.5 cm | 0.35 | 88.7% |


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















