


CVTNet: A Fusion of Convolutional Neural Networks and Vision Transformer for Wetland Mapping Using Sentinel-1 and Sentinel-2 Satellite Data


Abstract

1. Introduction
2. Materials and Methods
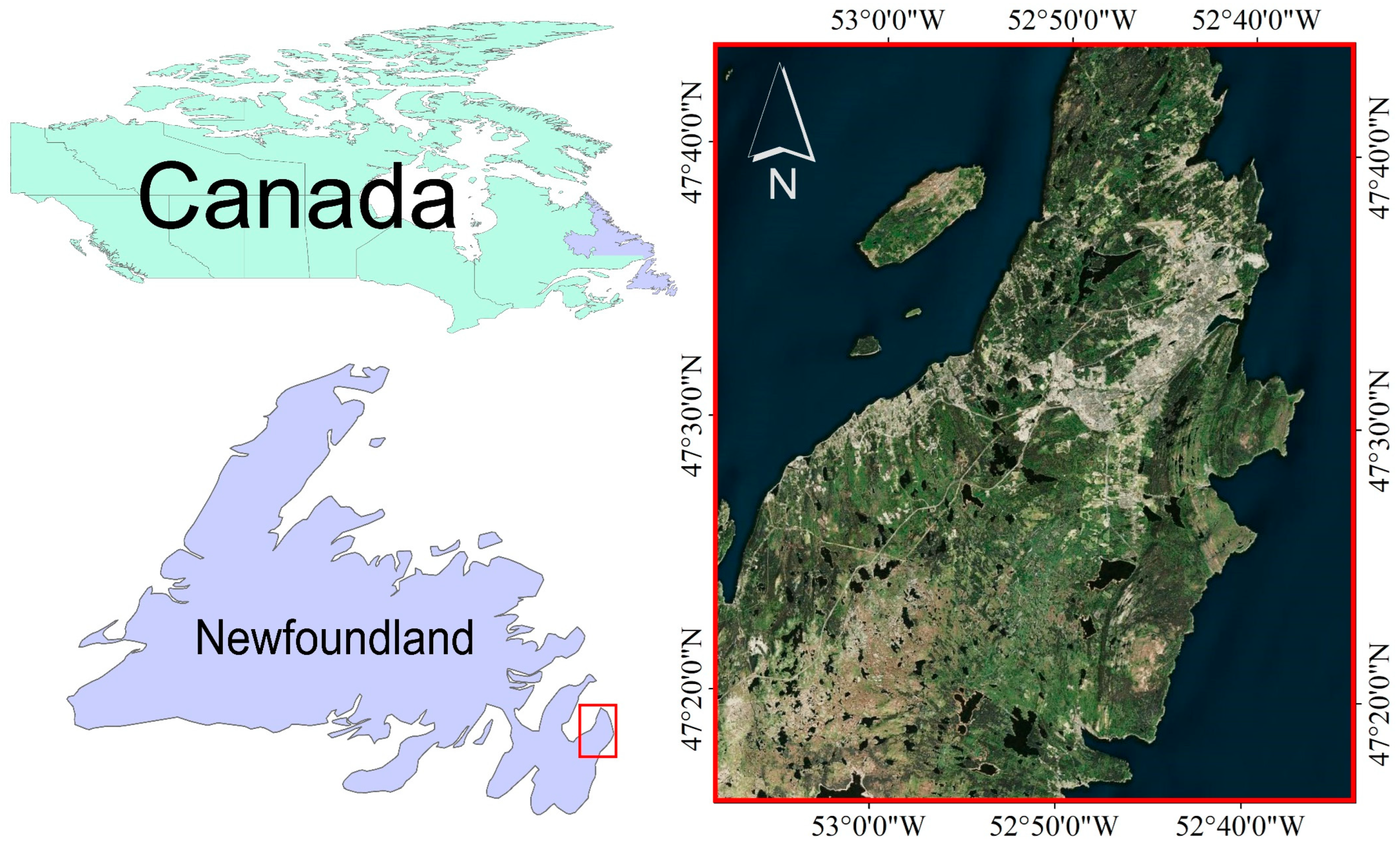
2.1. Study Area
2.2. Data
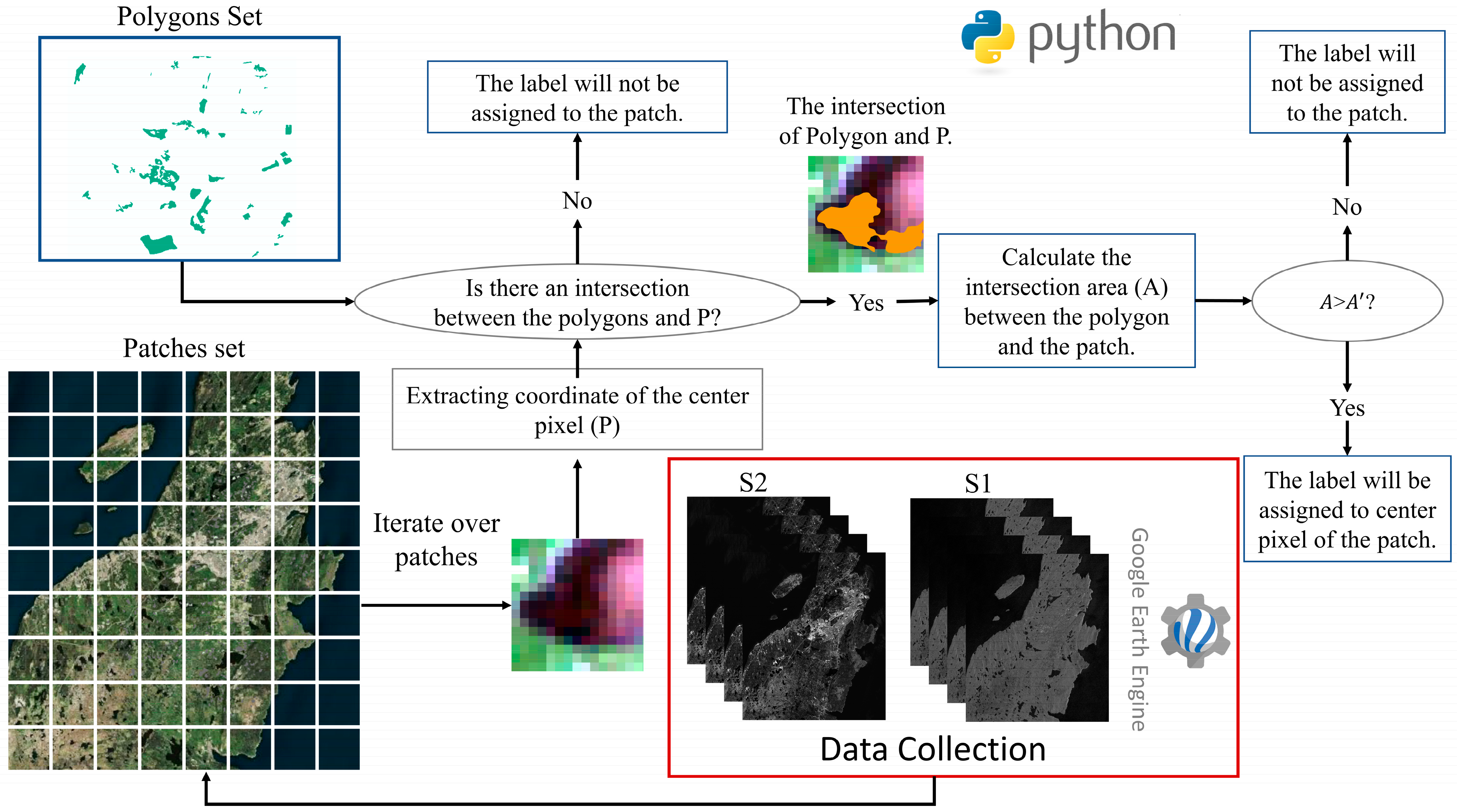
2.3. Data Preparation and Label Assigning
2.4. Convolutional Neural Network (CNN)
2.4.1. Dilated CNN (DCNN)
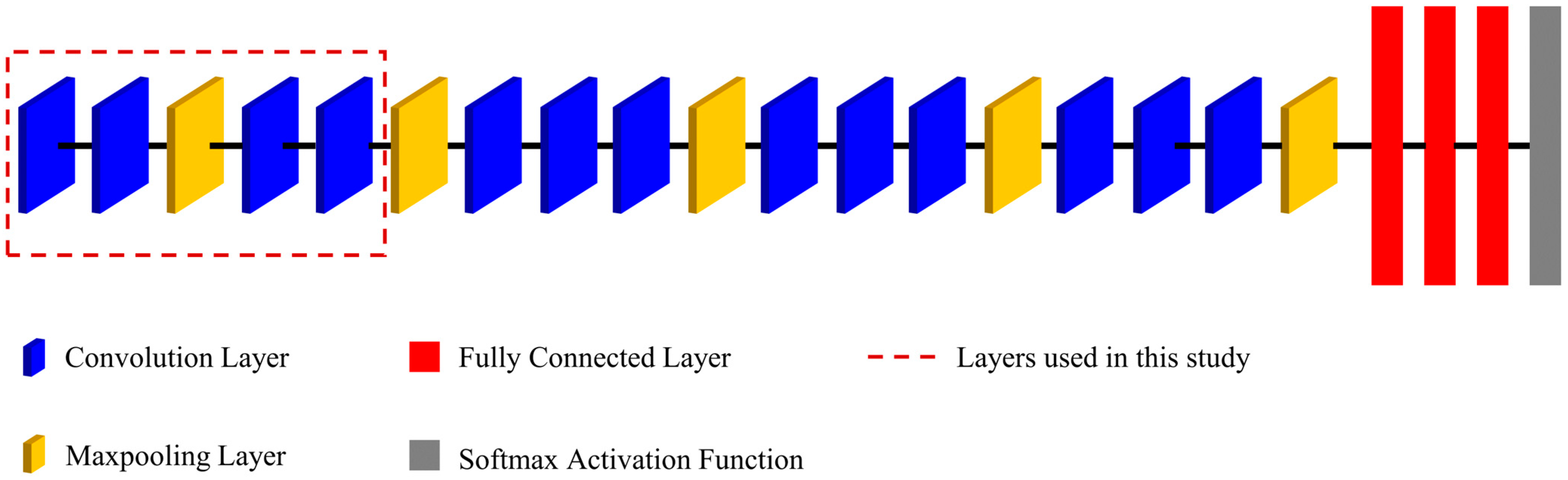
2.4.2. VGG16
2.5. Attention Mechanism (AM)
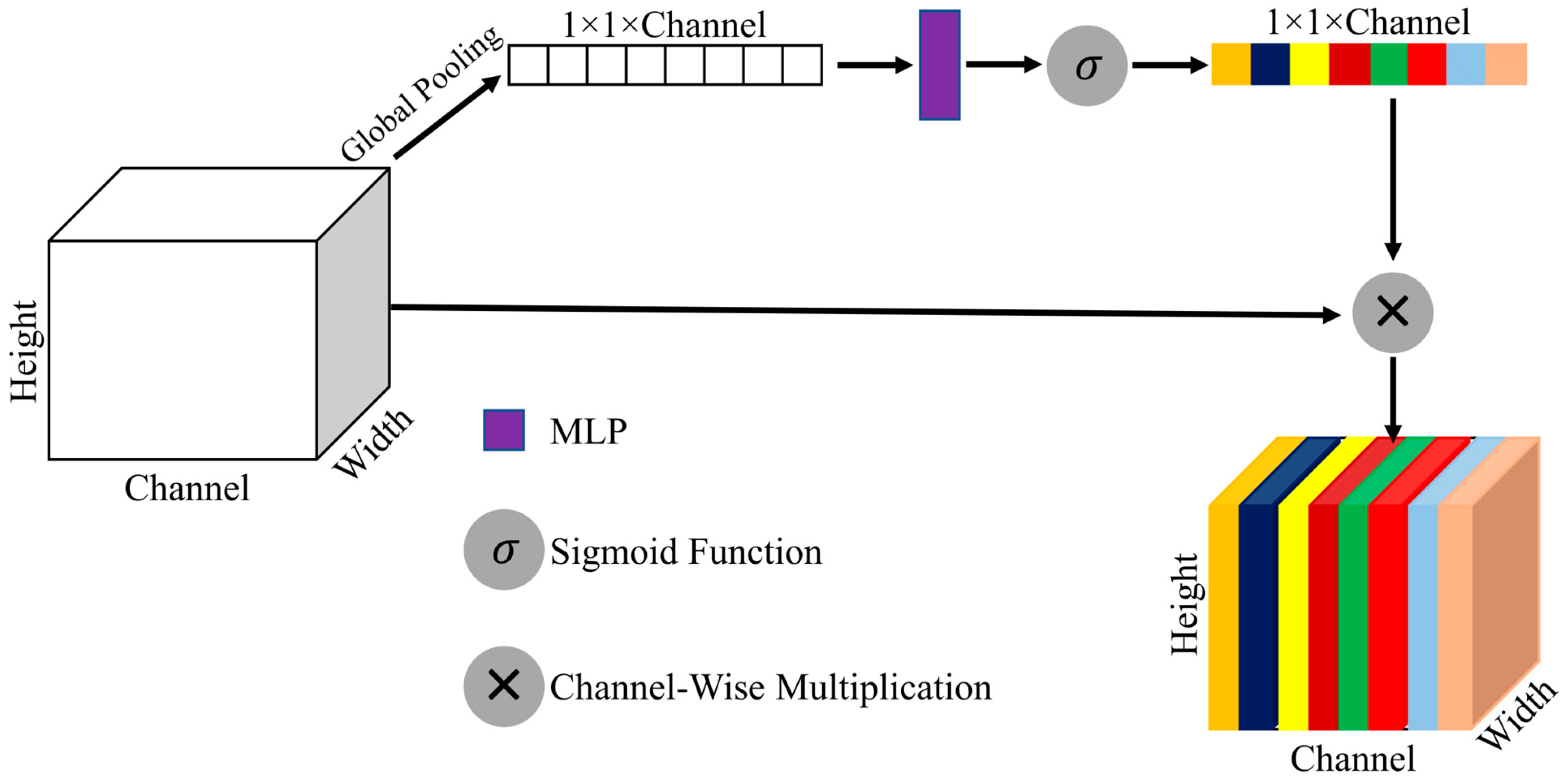
2.5.1. Channel Attention (CA)
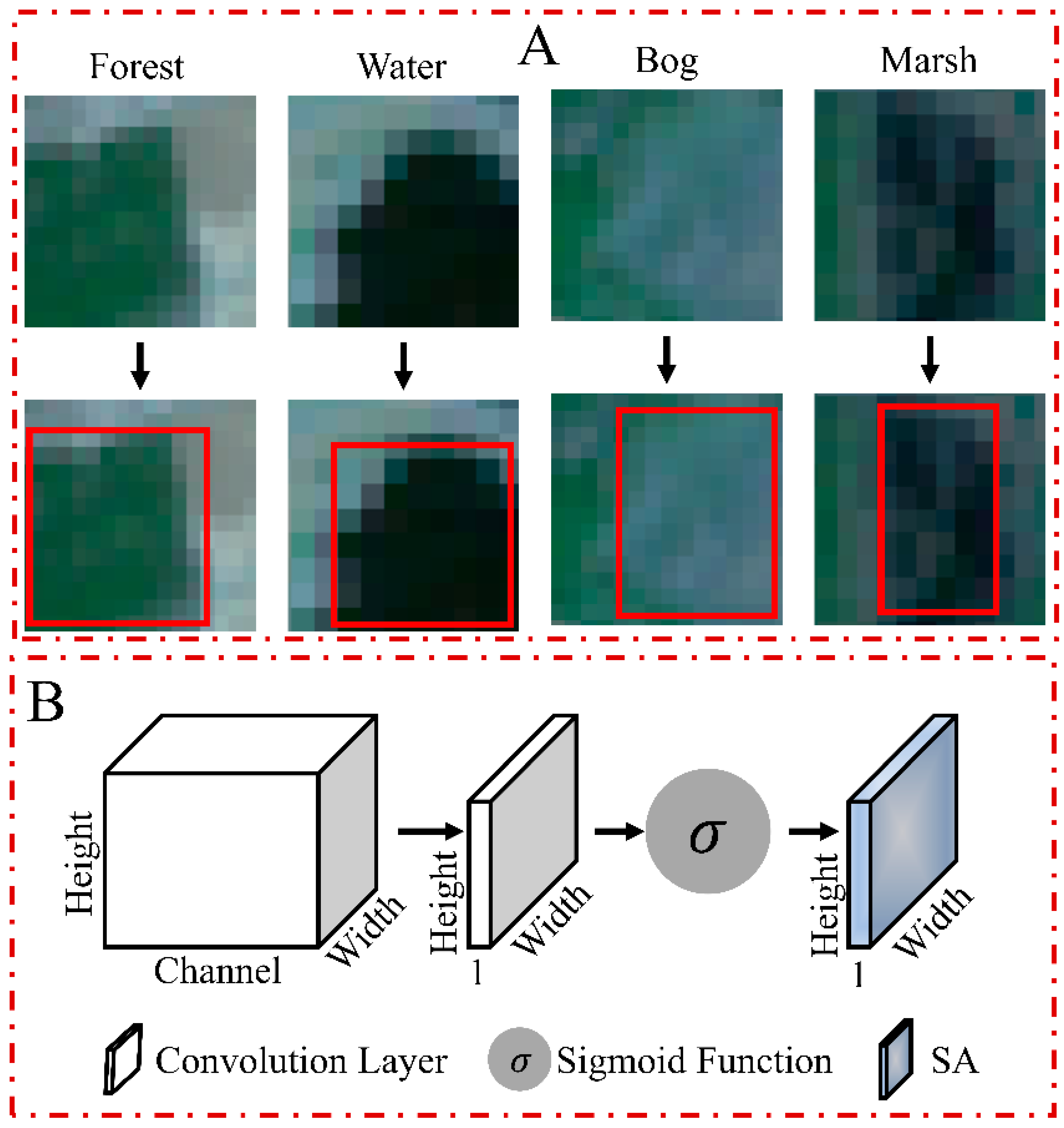
2.5.2. Spatial Attention (SA)
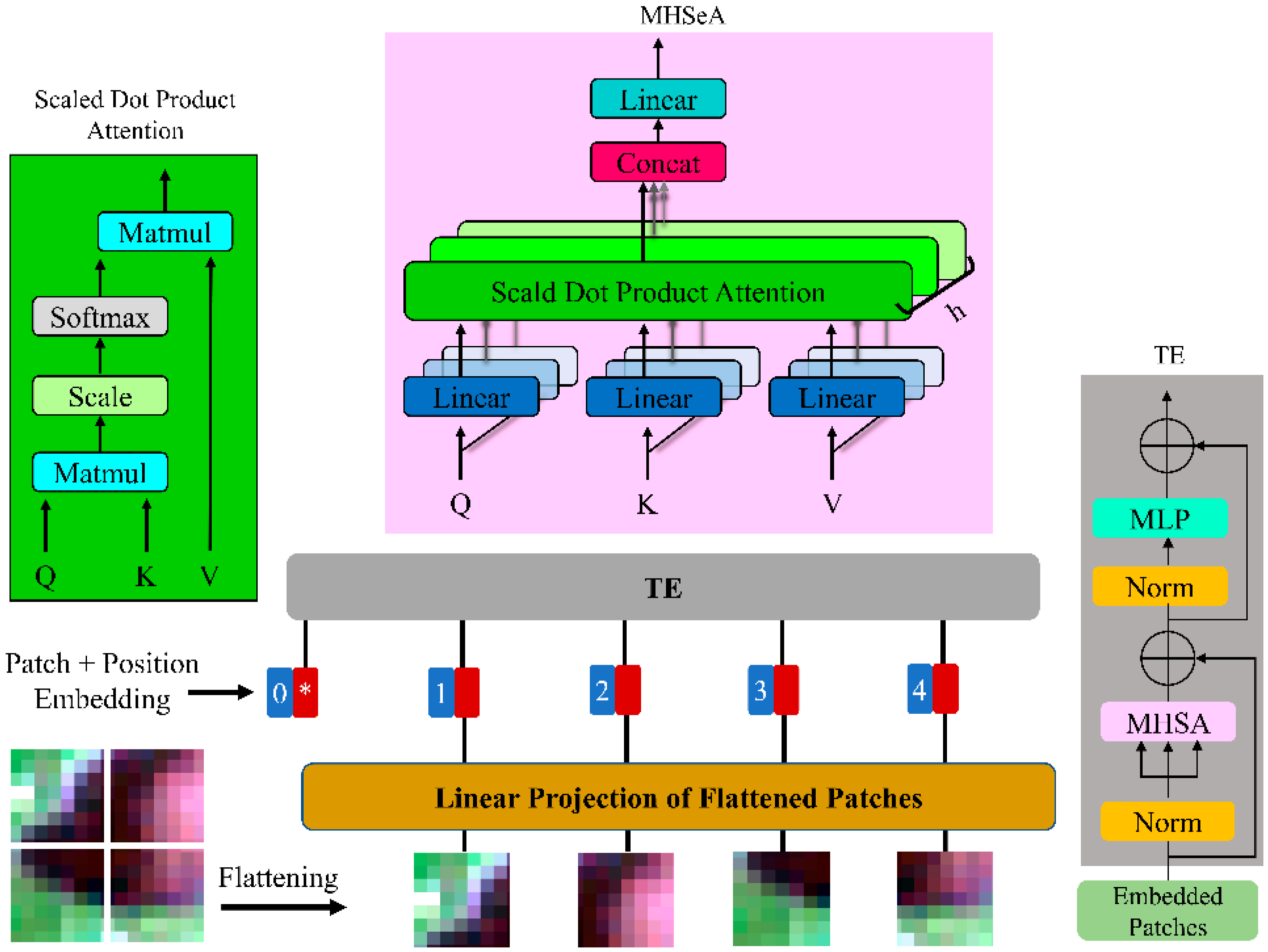
2.5.3. Self-Attention (SeA)
2.5.4. Multi-Head Self-Attention (MHSeA)
2.5.5. Vision Transformer (ViT)
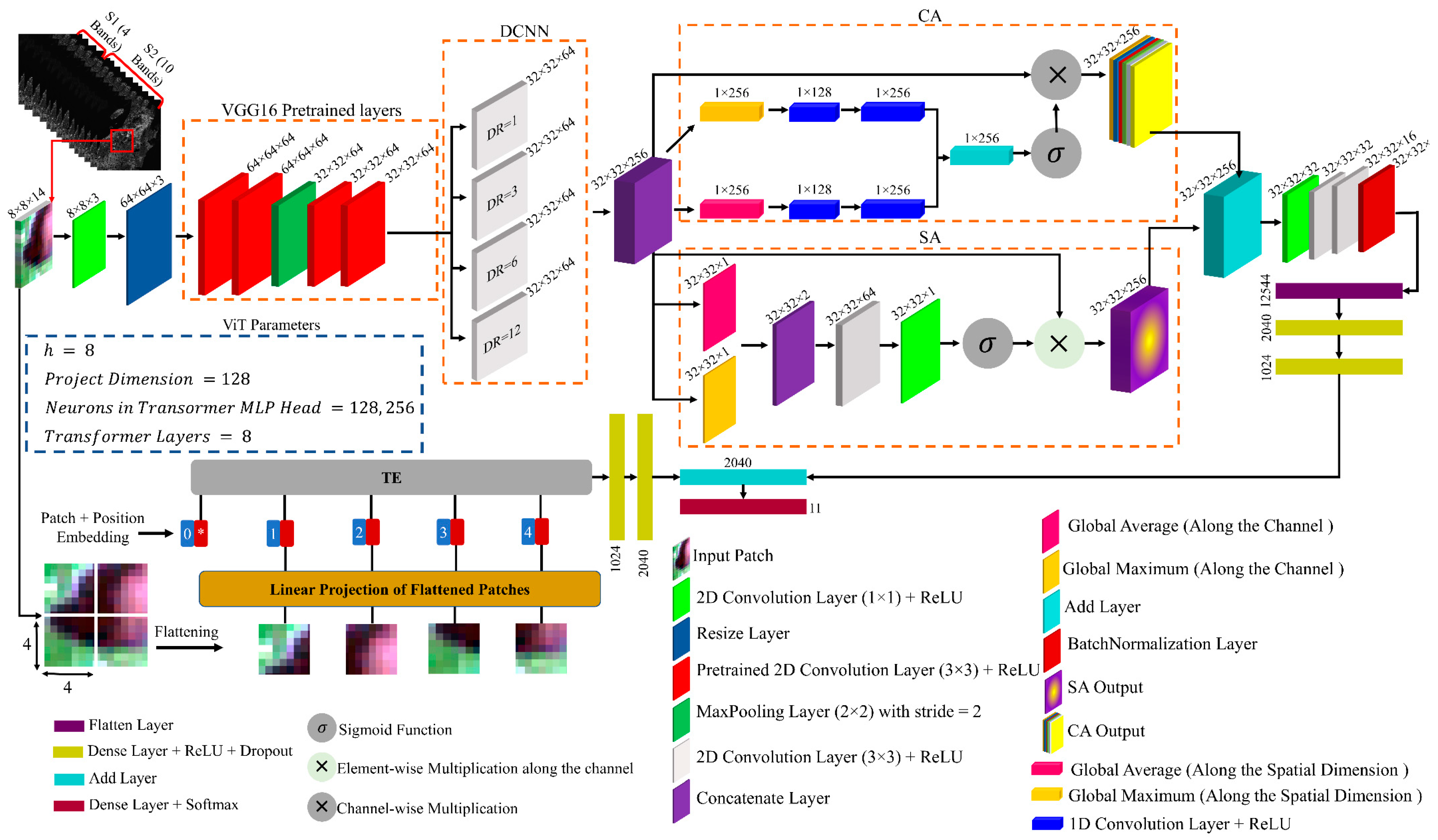
2.6. The Proposed Model (CVTNet)
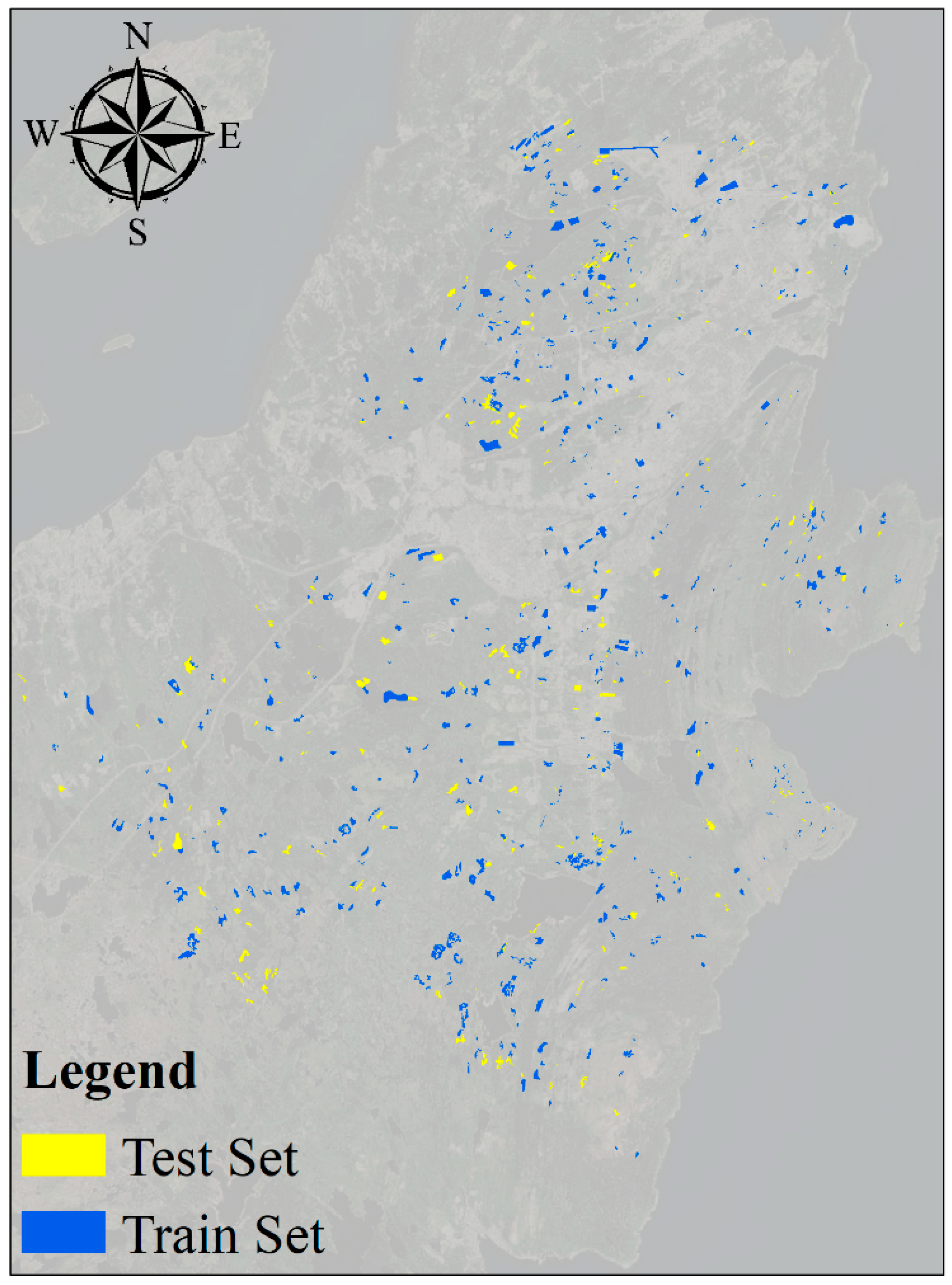
2.7. Validation Process
2.8. Occlusion Sensitivity
2.9. Experimental Settings
3. Results
3.1. Quantitative Results
3.2. Models Results Comparison
4. Discussion
4.1. Attention Mechanism Effects and Sensitivity Analysis
4.2. Investigating the Model’s Performance at the Class Boundaries
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jamali, A.; Mahdianpari, M.; Brisco, B.; Mao, D.; Salehi, B.; Mohammadimanesh, F. 3DUNetGSFormer: A deep learning pipeline for complex wetland mapping using generative adversarial networks and Swin transformer. Ecol. Inform. 2022, 72, 101904. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M.; Mohammadimanesh, F.; Brisco, B.; Salehi, B. 3-D hybrid CNN combined with 3-D generative adversarial network for wetland classification with limited training data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 8095–8108. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M. Swin transformer and deep convolutional neural networks for coastal wetland classification using sentinel-1, sentinel-2, and LiDAR data. Remote Sens. 2022, 14, 359. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep convolutional neural network for complex wetland classification using optical remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Lang, M.W.; Bourgeau-Chavez, L.L.; Tiner, R.W.; Klemas, V.V. 5 Advances in Remotely. In Remote Sensing of Wetlands: Applications and Advances; CRC Press: Boca Raton, FL, USA, 2015; p. 79. [Google Scholar]
- Mahdianpari, M.; Salehi, B.; Mohammadimanesh, F.; Motagh, M. Random forest wetland classification using ALOS-2 L-band, RADARSAT-2 C-band, and TerraSAR-X imagery. ISPRS J. Photogramm. Remote Sens. 2017, 130, 13–31. [Google Scholar] [CrossRef]
- Torres, R.; Snoeij, P.; Geudtner, D.; Bibby, D.; Davidson, M.; Attema, E.; Potin, P.; Rommen, B.; Floury, N.; Brown, M.; et al. GMES Sentinel-1 mission. Remote Sens. Environ. 2012, 120, 9–24. [Google Scholar] [CrossRef]
- Henderson, F.M.; Lewis, A.J. Radar detection of wetland ecosystems: A review. Int. J. Remote Sens. 2008, 29, 5809–5835. [Google Scholar] [CrossRef]
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s optical high-resolution mission for GMES operational services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Slagter, B.; Tsendbazar, N.-E.; Vollrath, A.; Reiche, J. Mapping wetland characteristics using temporally dense Sentinel-1 and Sentinel-2 data: A case study in the St. Lucia wetlands, South Africa. Int. J. Appl. Earth Obs. Geoinf. 2020, 86, 102009. [Google Scholar] [CrossRef]
- DeLancey, E.R.; Simms, J.F.; Mahdianpari, M.; Brisco, B.; Mahoney, C.; Kariyeva, J. Comparing deep learning and shallow learning for large-scale wetland classification in Alberta, Canada. Remote Sens. 2019, 12, 2. [Google Scholar] [CrossRef]
- Igwe, V.; Salehi, B.; Mahdianpari, M. Rapid Large-Scale Wetland Inventory Update Using Multi-Source Remote Sensing. Remote Sens. 2023, 15, 4960. [Google Scholar] [CrossRef]
- Jafarzadeh, H.; Mahdianpari, M.; Gill, E.W. Wet-GC: A Novel Multimodel Graph Convolutional Approach for Wetland Classification Using Sentinel-1 and 2 Imagery with Limited Training Samples. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5303–5316. [Google Scholar] [CrossRef]
- Hosseiny, B.; Mahdianpari, M.; Brisco, B.; Mohammadimanesh, F.; Salehi, B. WetNet: A spatial–temporal ensemble deep learning model for wetland classification using Sentinel-1 and Sentinel-2. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M.; Brisco, B.; Granger, J.; Mohammadimanesh, F.; Salehi, B. Deep Forest classifier for wetland mapping using the combination of Sentinel-1 and Sentinel-2 data. GIScience Remote Sens. 2021, 58, 1072–1089. [Google Scholar] [CrossRef]
- Hemati, M.A.; Hasanlou, M.; Mahdianpari, M.; Mohammadimanesh, F. Wetland mapping of northern provinces of Iran using Sentinel-1 and Sentinel-2 in Google Earth Engine. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 96–99. [Google Scholar]
- Jamali, A.; Mahdianpari, M.; Brisco, B.; Granger, J.; Mohammadimanesh, F.; Salehi, B. Wetland mapping using multi-spectral satellite imagery and deep convolutional neural networks: A case study in Newfoundland and Labrador, Canada. Can. J. Remote Sens. 2021, 47, 243–260. [Google Scholar] [CrossRef]
- Marjani, M.; Mahdianpari, M.; Mohammadimanesh, F. CNN-BiLSTM: A Novel Deep Learning Model for Near-Real-Time Daily Wildfire Spread Prediction. Remote Sens. 2024, 16, 1467. [Google Scholar] [CrossRef]
- Merchant, M.; Bourgeau-Chavez, L.; Mahdianpari, M.; Brisco, B.; Obadia, M.; DeVries, B.; Berg, A. Arctic ice-wedge landscape mapping by CNN using a fusion of Radarsat constellation Mission and ArcticDEM. Remote Sens. Environ. 2024, 304, 114052. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Mahdianpari, M.; Mohammadimanesh, F.; Behrens, T.; Toomanian, N.; Scholten, T.; Schmidt, K. Multi-task convolutional neural networks outperformed random forest for mapping soil particle size fractions in central Iran. Geoderma 2020, 376, 114552. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Brisco, B.; Granger, J.; Mohammadimanesh, F.; Salehi, B.; Homayouni, S.; Bourgeau-Chavez, L. The third generation of pan-Canadian wetland map at 10 m resolution using multisource earth observation data on cloud computing platform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8789–8803. [Google Scholar] [CrossRef]
- Mohammadimanesh, F.; Salehi, B.; Mahdianpari, M.; Gill, E.; Molinier, M. A new fully convolutional neural network for semantic segmentation of polarimetric SAR imagery in complex land cover ecosystem. ISPRS J. Photogramm. Remote Sens. 2019, 151, 223–236. [Google Scholar] [CrossRef]
- Alhichri, H.; Alswayed, A.S.; Bazi, Y.; Ammour, N.; Alajlan, N.A. Classification of remote sensing images using EfficientNet-B3 CNN model with attention. IEEE Access 2021, 9, 14078–14094. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Khan, M.A.; Akram, T.; Zhang, Y.-D.; Sharif, M. Attributes based skin lesion detection and recognition: A mask RCNN and transfer learning-based deep learning framework. Pattern Recognit. Lett. 2021, 143, 58–66. [Google Scholar] [CrossRef]
- Cao, J.; Cui, H.; Zhang, Q.; Zhang, Z. Ancient mural classification method based on improved AlexNet network. Stud. Conserv. 2020, 65, 411–423. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 2440–2448. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral image classification using the bidirectional encoder representation from transformers. IEEE Trans. Geosci. Remote Sens. 2019, 58, 165–178. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Wu, F.; Fan, A.; Baevski, A.; Dauphin, Y.N.; Auli, M. Pay less attention with lightweight and dynamic convolutions. arXiv 2019, arXiv:1901.10430. [Google Scholar]
- Wu, Z.; Liu, Z.; Lin, J.; Lin, Y.; Han, S. Lite transformer with long-short range attention. arXiv 2020, arXiv:2004.11886. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Marjani, M.; Ahmadi, S.A.; Mahdianpari, M. FirePred: A hybrid multi-temporal convolutional neural network model for wildfire spread prediction. Ecol. Inform. 2023, 78, 102282. [Google Scholar] [CrossRef]
- Marjani, M.; Mesgari, M.S. The large-scale wildfire spread prediction using a multi-kernel convolutional neural network. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, X-4/W1-2022, 483–488. [Google Scholar] [CrossRef]
- Radman, A.; Mahdianpari, M.; Varon, D.J.; Mohammadimanesh, F. S2MetNet: A novel dataset and deep learning benchmark for methane point source quantification using Sentinel-2 satellite imagery. Remote Sens. Environ. 2023, 295, 113708. [Google Scholar] [CrossRef]
- Liu, R.; Tao, F.; Liu, X.; Na, J.; Leng, H.; Wu, J.; Zhou, T. RAANet: A Residual ASPP with Attention Framework for Semantic Segmentation of High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 3109. [Google Scholar] [CrossRef]
- Paymode, A.S.; Malode, V.B. Transfer learning for multi-crop leaf disease image classification using convolutional neural networks VGG. Artif. Intell. Agric. 2022, 6, 23–33. [Google Scholar] [CrossRef]
- Ba, J.; Mnih, V.; Kavukcuoglu, K. Multiple Object Recognition with Visual Attention. arXiv 2014, arXiv:1412.7755. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. CvT: Introducing Convolutions to Vision Transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Sharma, S.; Kiros, R.; Salakhutdinov, R. Action Recognition using Visual Attention. arXiv 2015, arXiv:1511.04119. [Google Scholar]
- Du, W.; Wang, Y.; Qiao, Y. Recurrent Spatial-Temporal Attention Network for Action Recognition in Videos. IEEE Trans. Image Process. 2018, 27, 1347–1360. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2021, 8, 331–368. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Marjani, M.; Mahdianpari, M.; Ahmadi, S.A.; Hemmati, E.; Mohammadimanesh, F.; Mesgari, M.S. Application of Explainable Artificial Intelligence in Predicting Wildfire Spread: An ASPP-Enabled CNN Approach. IEEE Geosci. Remote Sens. Lett. 2024. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.-S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. ACM Comput. Surv. 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bolmer, E.; Abulaitijiang, A.; Kusche, J.; Roscher, R. Occlusion Sensitivity Analysis of Neural Network Architectures for Eddy Detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 623–626. [Google Scholar]
- Géron, A. Hands-On Machine Learning with Scikit-Learn and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Manaswi, N. Understanding and Working with Keras. In Deep Learning with Applications Using Python; Apress: Berkeley, CA, USA, 2018. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mahsereci, M.; Balles, L.; Lassner, C.; Hennig, P. Early Stopping without a Validation Set. arXiv 2017, arXiv:1703.09580. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An all-MLP Architecture for Vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2016, 128, 336–359. [Google Scholar] [CrossRef]
- Jamali, A.; Mahdianpari, M.; Mohammadimanesh, F.; Homayouni, S. A deep learning framework based on generative adversarial networks and vision transformer for complex wetland classification using limited training samples. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103095. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Rezaee, M.; Zhang, Y.; Salehi, B. Wetland classification using deep convolutional neural network. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; IEEE: Piscataway, NJ, USA; pp. 9249–9252. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Spectral Band/Backscattering Coefficients | Date Range | Spatial Resolution |
|---|---|---|---|
| S2 | B2, B3, B4, B5, B6, B7, B8, B8A, B11, B12 | 15 May to 27 May 2022 | 10 m |
| S1 | , , , |
| Class | Number of Polygon | Area (km2) | ||
|---|---|---|---|---|
| Training | Validation | Training | Validation | |
| Bog | 72 | 26 | 1.79 | 0.55 |
| Fen | 80 | 33 | 1.11 | 0.51 |
| Exposed | 20 | 4 | 0.05 | 0.02 |
| Forest | 72 | 31 | 1.41 | 0.59 |
| Grassland | 87 | 39 | 0.55 | 0.34 |
| Marsh | 29 | 20 | 0.12 | 0.04 |
| Pasture | 30 | 17 | 0.85 | 0.29 |
| Shrub | 21 | 16 | 0.18 | 0.13 |
| Swamp | 83 | 33 | 0.52 | 0.2 |
| Urban | 35 | 13 | 1.24 | 0.29 |
| Water | 52 | 17 | 1.14 | 0.36 |
| Class | Number of Patches | |
|---|---|---|
| Training | Validation | |
| Bog | 1101 | 349 |
| Fen | 679 | 325 |
| Exposed | 36 | 12 |
| Forest | 890 | 365 |
| Grassland | 346 | 216 |
| Marsh | 67 | 24 |
| Pasture | 537 | 183 |
| Shrubland | 116 | 93 |
| Swamp | 313 | 128 |
| Urban | 750 | 189 |
| Water | 708 | 234 |
| Dataset | Metric | ||||
|---|---|---|---|---|---|
| OA | KC | F1 | Recall | Precision | |
| Validation | 0.925 | 0.899 | 0.911 | 0.923 | 0.898 |
| Training | 0.961 | 0.936 | 0.942 | 0.961 | 0.924 |
| Class | Training | Validation | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1 | Recall | Precision | F1 | |
| Bog | 0.97 | 0.95 | 0.96 | 0.96 | 0.94 | 0.95 |
| Exposed | 0.87 | 0.83 | 0.85 | 0.78 | 0.78 | 0.78 |
| Fen | 0.99 | 0.95 | 0.97 | 0.93 | 0.93 | 0.93 |
| Forest | 0.94 | 0.98 | 0.96 | 0.94 | 0.94 | 0.94 |
| Grassland | 0.95 | 0.83 | 0.89 | 0.81 | 0.91 | 0.86 |
| Marsh | 0.92 | 0.94 | 0.93 | 0.89 | 0.89 | 0.89 |
| Pasture | 1 | 0.96 | 0.98 | 1 | 0.88 | 0.94 |
| Shrubland | 1 | 0.94 | 0.97 | 1 | 0.94 | 0.97 |
| Swamp | 0.95 | 0.97 | 0.96 | 0.91 | 0.97 | 0.94 |
| Urban | 1 | 1 | 1 | 0.98 | 1 | 0.99 |
| Water | 1 | 1 | 1 | 1 | 0.94 | 0.97 |
| Model | Metric | ||||
|---|---|---|---|---|---|
| OA | KC | F1 | Recall | Precision | |
| RF | 0.815 | 0.751 | 0.779 | 0.743 | 0.819 |
| ViT | 0.862 | 0.839 | 0.847 | 0.857 | 0.838 |
| MLP-mixer | 0.884 | 0.856 | 0.872 | 0.882 | 0.864 |
| HybridSN | 0.762 | 0.725 | 0.749 | 0.761 | 0.739 |
| CVTNet | 0.921 | 0.899 | 0.911 | 0.923 | 0.898 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marjani, M.; Mahdianpari, M.; Mohammadimanesh, F.; Gill, E.W. CVTNet: A Fusion of Convolutional Neural Networks and Vision Transformer for Wetland Mapping Using Sentinel-1 and Sentinel-2 Satellite Data. Remote Sens. 2024, 16, 2427. https://doi.org/10.3390/rs16132427
Marjani M, Mahdianpari M, Mohammadimanesh F, Gill EW. CVTNet: A Fusion of Convolutional Neural Networks and Vision Transformer for Wetland Mapping Using Sentinel-1 and Sentinel-2 Satellite Data. Remote Sensing. 2024; 16(13):2427. https://doi.org/10.3390/rs16132427
Chicago/Turabian StyleMarjani, Mohammad, Masoud Mahdianpari, Fariba Mohammadimanesh, and Eric W. Gill. 2024. "CVTNet: A Fusion of Convolutional Neural Networks and Vision Transformer for Wetland Mapping Using Sentinel-1 and Sentinel-2 Satellite Data" Remote Sensing 16, no. 13: 2427. https://doi.org/10.3390/rs16132427
APA StyleMarjani, M., Mahdianpari, M., Mohammadimanesh, F., & Gill, E. W. (2024). CVTNet: A Fusion of Convolutional Neural Networks and Vision Transformer for Wetland Mapping Using Sentinel-1 and Sentinel-2 Satellite Data. Remote Sensing, 16(13), 2427. https://doi.org/10.3390/rs16132427