
SFDA-CD: A Source-Free Unsupervised Domain Adaptation for VHR Image Change Detection

Abstract
:1. Introduction
- We propose a domain generation-based SFDA framework for change detection. This framework can adapt from the source domain to the target domain without any source data and target data annotation, which is essential yet rare in real-world tasks;
- We utilise domain generation methods to synthesise fake samples, addressing the lack of source data. We employ a dual-attention mechanism to ensure the framework captures valuable changed semantic information during training. Meanwhile, we adopt an intra-domain adaptation self-supervised module to obtain more accurate detection maps for self-supervision;
- We demonstrate the efficiency of this framework in cross-regional and cross-scenario change detection tasks. It achieves accuracy comparable to current state-of-the-art source-driven UDA methods, in cross-regional tasks our method has 0.6% cIoU and 1.5% F1 score up, and in cross-scenario tasks has 1.4% cIoU and 1.9% F1 score up. Both qualitative results have shown that our methods can effectively avoid inner hole and detect edge precisely.
2. Related Works
2.1. Fully Convolutional Networks-Based VHR Image Change Detection Frameworks
2.2. Unsupervised Domain Adaptation for VHR Image Change Detection
2.3. Source-Free Unsupervised Domain Adaptation Based on Domain Generation
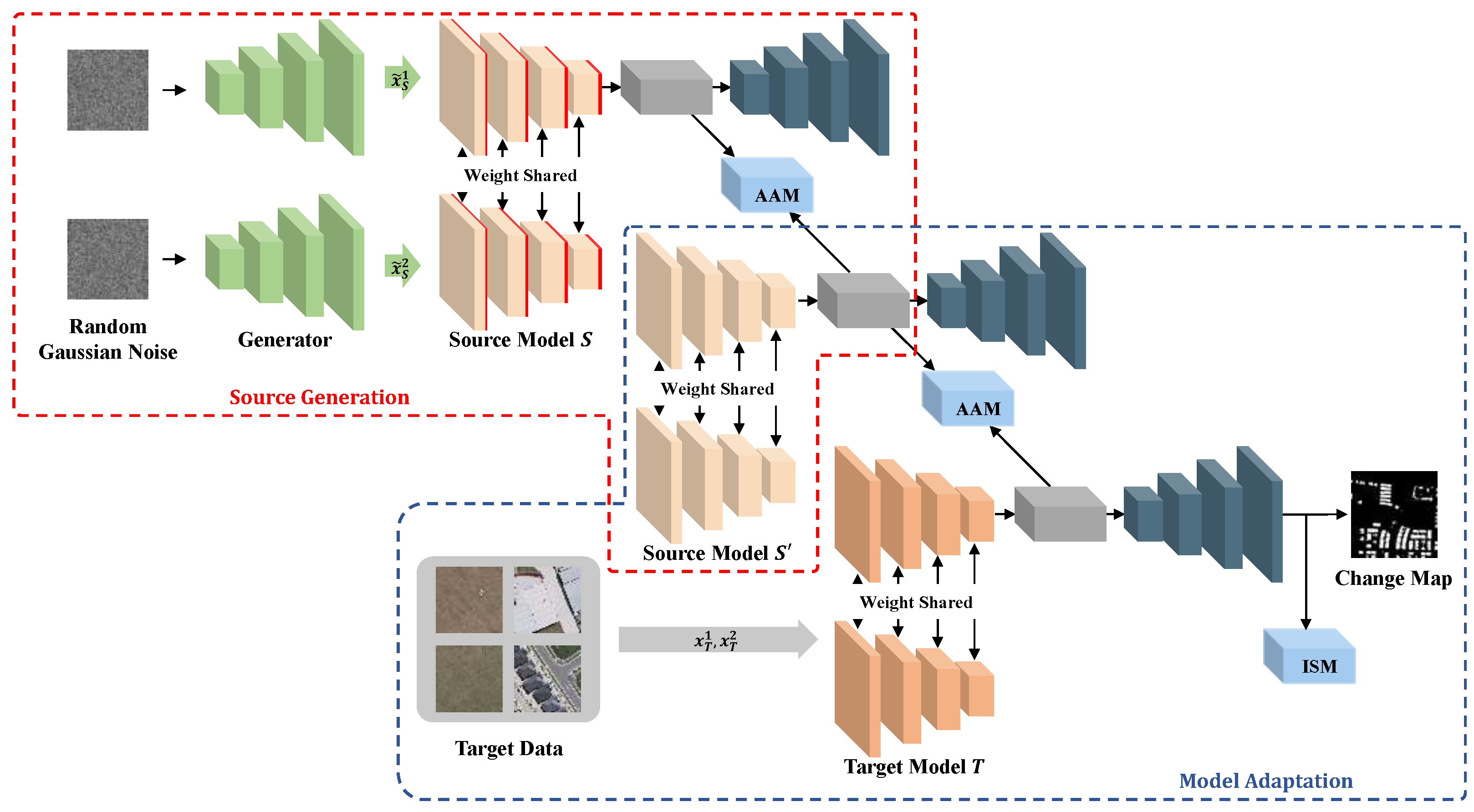
3. Methodology
| Algorithm 1 SFDA-CD |
| Input: Random gaussian noise , , bi-temporal VHR image pairs 1: Initialization: Generators , target model , hyper-parameters: epoch , , ; 2: Freeze: Source model (except BN layers), source model ; 3: for epoch to Max Epoch: N do 4: Forward 5: Source Generation: ; 6: 7: Backward 8: Update parameters in ; 9: until 10: end for 11: Update parameters in ; Output: Change map |
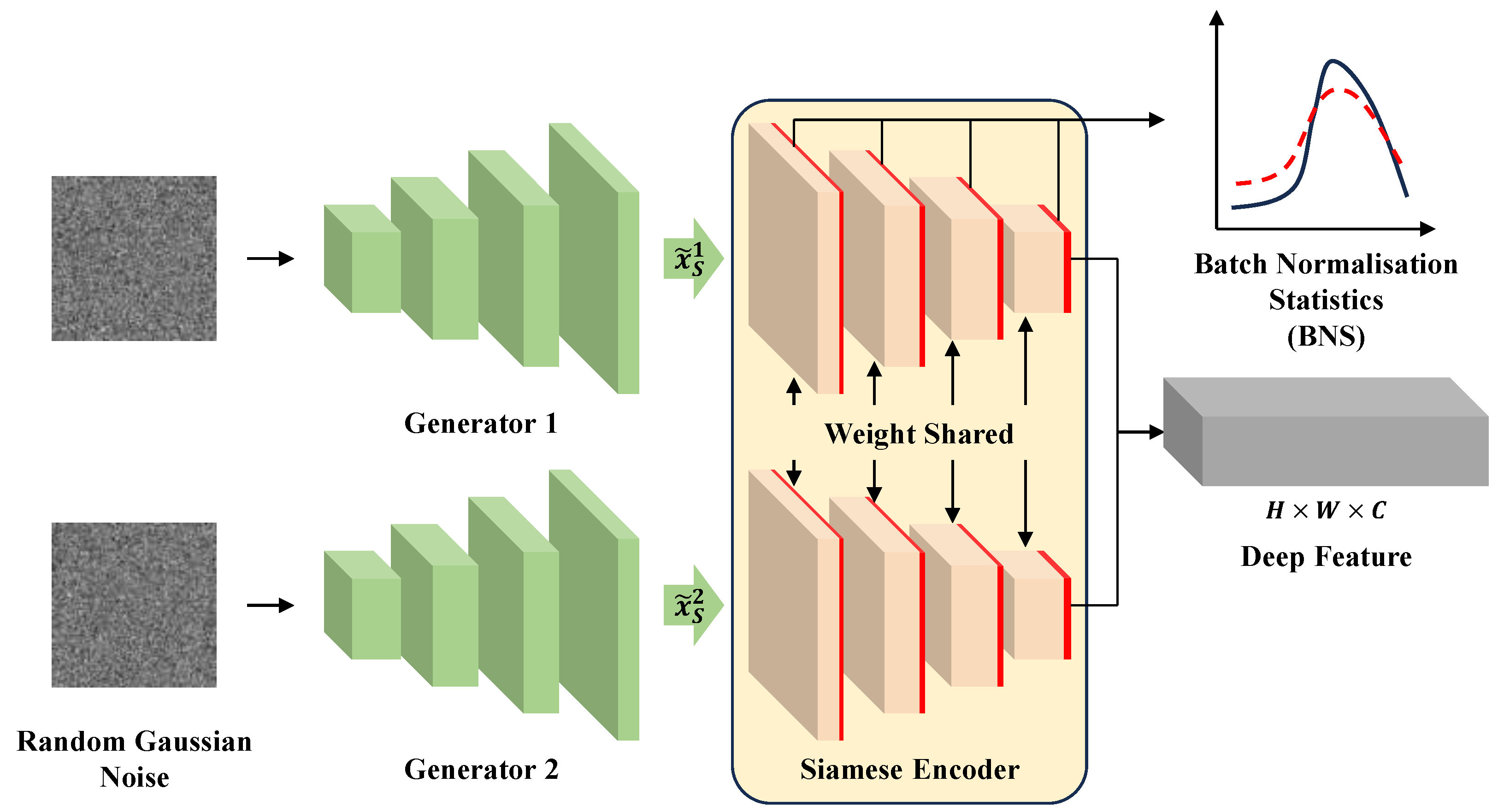
3.1. Source Generation
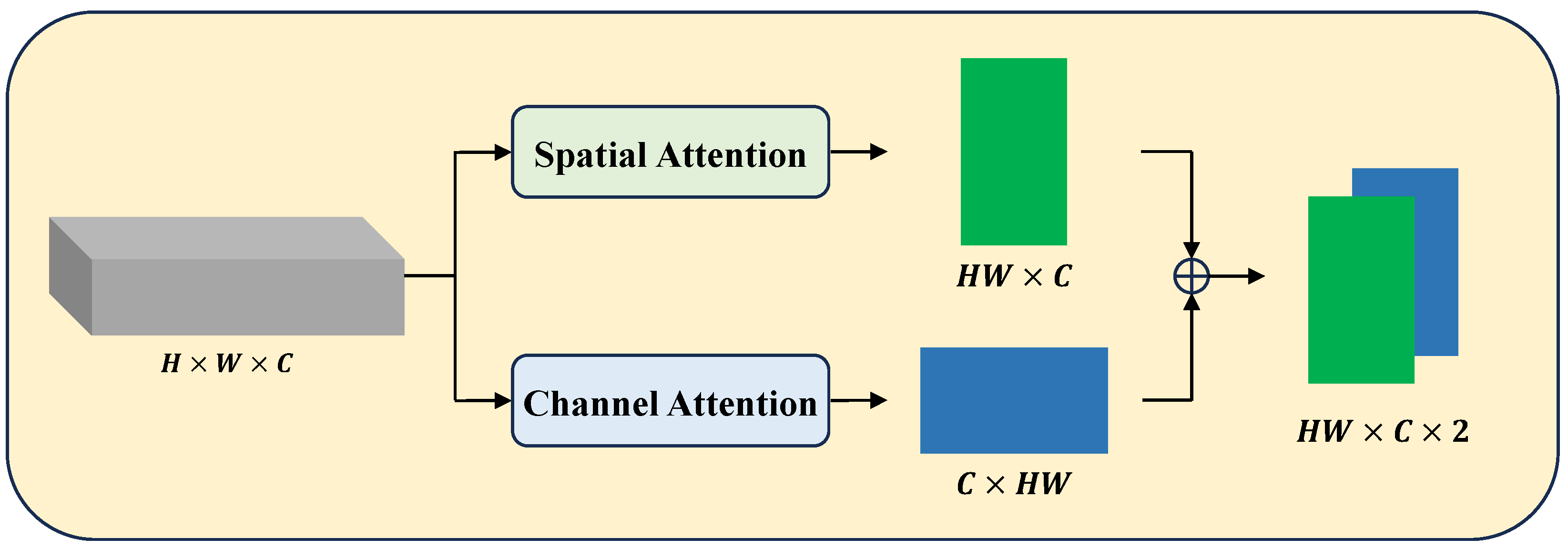
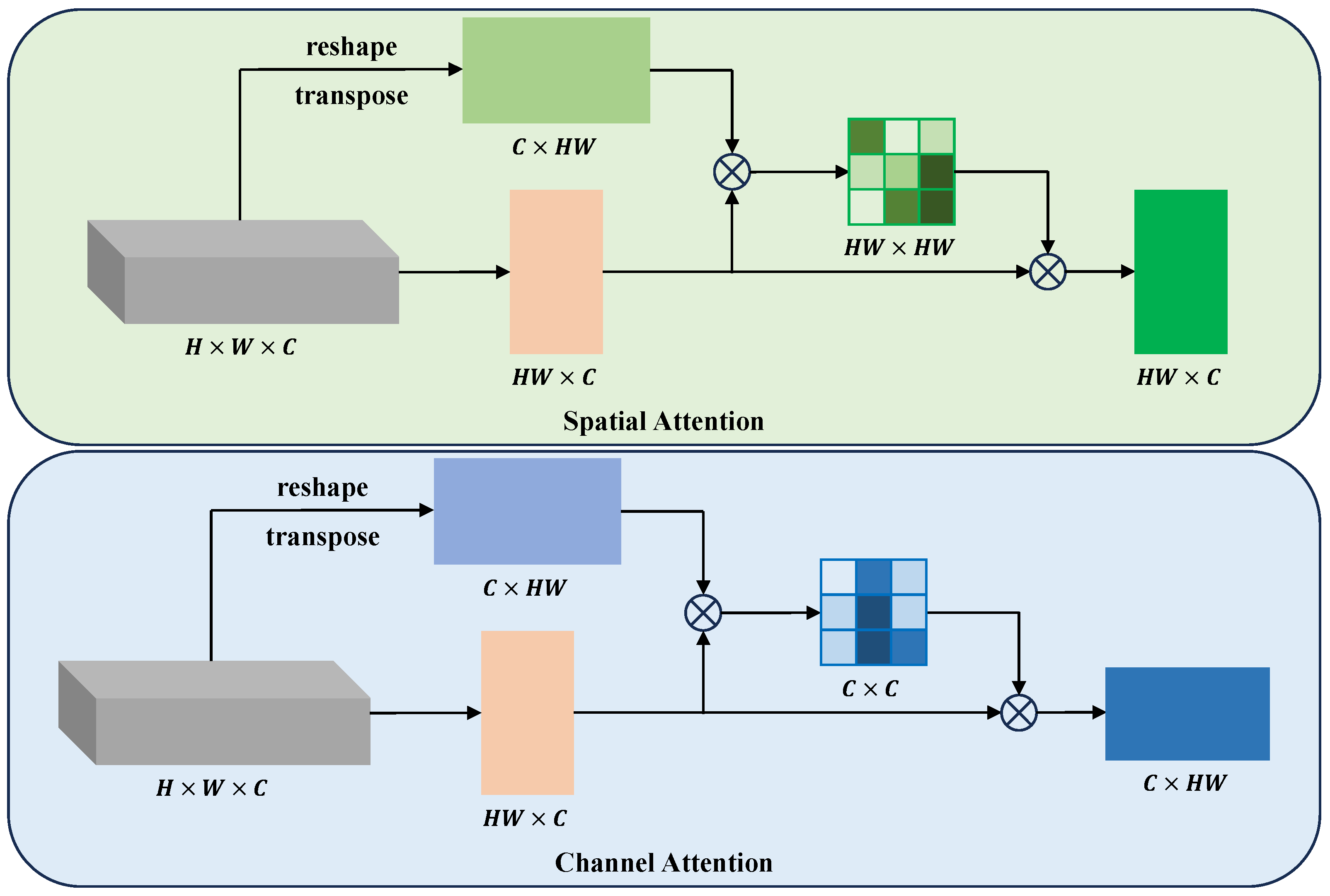
3.2. Attention Adaptation Module
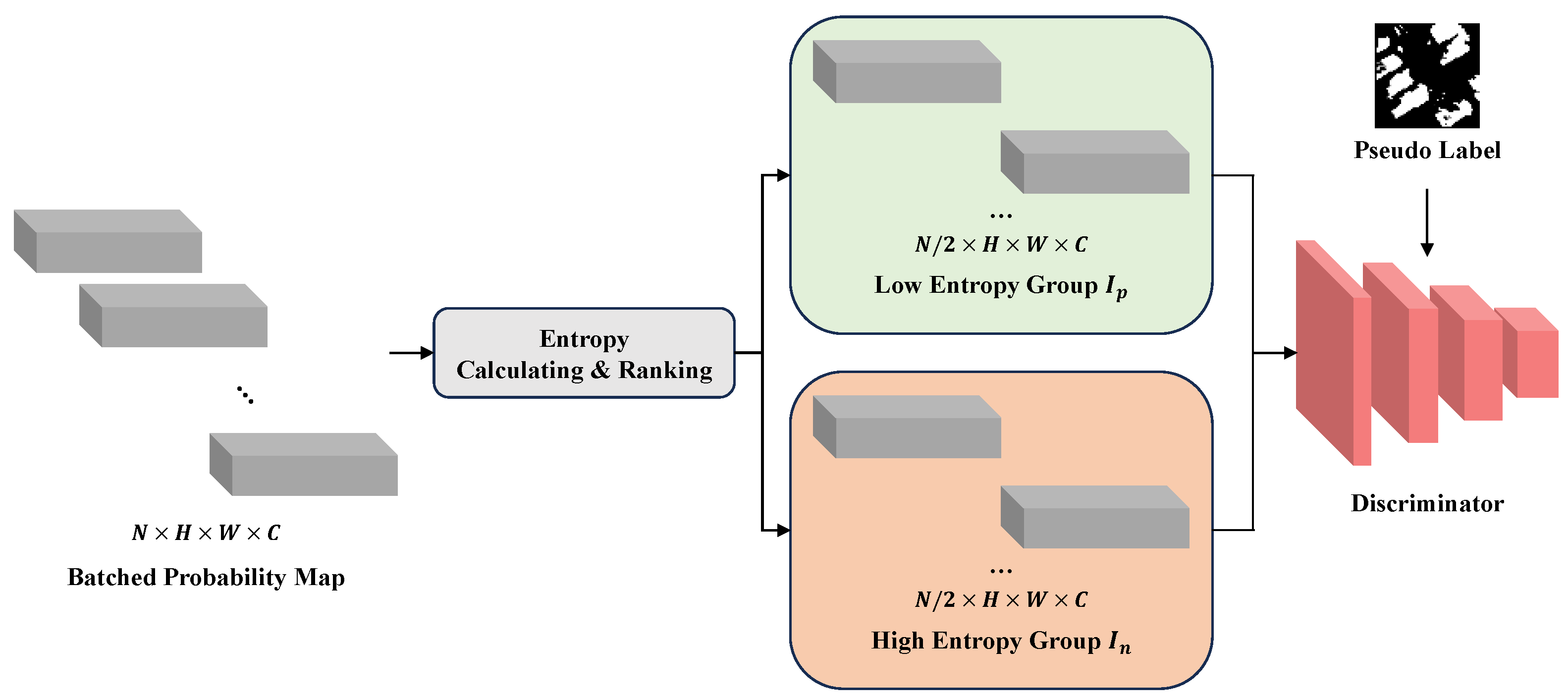
3.3. Intra-Domain Self-Supervision Module
3.4. Loss Function
4. Experiment
4.1. Experiment Settings
4.1.1. Datasets
4.1.2. Experiment Setup
4.1.3. Evaluation Metrics
4.2. Experiment Results
5. Discussion
5.1. Comparison
5.1.1. Cross-Regional Adaptation
5.1.2. Cross-Scenario Adaptation
5.2. Ablation
5.2.1. Effects of AAM
5.2.2. Effects of ISM
5.2.3. Effects of Loss Functions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Avola, D.; Foresti, G.L.; Martinel, N.; Micheloni, C.; Pannone, D.; Piciarelli, C. Aerial video surveillance system for small-scale UAV environment monitoring. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- De Bem, P.P.; de Carvalho Junior, O.A.; Fontes Guimarães, R.; Trancoso Gomes, R.A. Change detection of deforestation in the Brazilian Amazon using landsat data and convolutional neural networks. Remote Sens. 2020, 12, 901. [Google Scholar] [CrossRef]
- Mukupa, W.; Roberts, G.W.; Hancock, C.M.; Al-Manasir, K. A review of the use of terrestrial laser scanning application for change detection and deformation monitoring of structures. Surv. Rev. 2017, 49, 99–116. [Google Scholar] [CrossRef]
- Ayele, G.; Hayicho, H.; Alemu, M. Land use land cover change detection and deforestation modeling: In Delomena District of Bale Zone, Ethiopia. J. Environ. Prot. 2019, 10, 532–561. [Google Scholar] [CrossRef]
- Lunetta, R.S.; Knight, J.F.; Ediriwickrema, J.; Lyon, J.G.; Worthy, L.D. Land-cover change detection using multi-temporal MODIS NDVI data. In Geospatial Information Handbook for Water Resources and Watershed Management, Volume II; CRC Press: New York, NY, USA, 2022; pp. 65–88. [Google Scholar]
- Willis, K.S. Remote sensing change detection for ecological monitoring in United States protected areas. Biol. Conserv. 2015, 182, 233–242. [Google Scholar] [CrossRef]
- Bai, T.; Wang, L.; Yin, D.; Sun, K.; Chen, Y.; Li, W.; Li, D. Deep learning for change detection in remote sensing: A review. Geo-Spat. Inf. Sci. 2022, 26, 262–288. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Chen, H.; Wu, C.; Du, B.; Zhang, L. DSDANet: Deep Siamese domain adaptation convolutional neural network for cross-domain change detection. arXiv 2020, arXiv:2006.09225. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the Computer Vision–ECCV 2016 Workshops: Amsterdam, The Netherlands, 8–10 and 15–16 October 2016, Proceedings, Part III 14; Springer: Berlin, Germany, 2016; pp. 443–450. [Google Scholar]
- Li, R.; Jiao, Q.; Cao, W.; Wong, H.S.; Wu, S. Model adaptation: Unsupervised domain adaptation without source data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9641–9650. [Google Scholar]
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1180–1189. [Google Scholar]
- Chi, M.; Plaza, A.; Benediktsson, J.A.; Sun, Z.; Shen, J.; Zhu, Y. Big data for remote sensing: Challenges and opportunities. Proc. IEEE 2016, 104, 2207–2219. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L. Artificial intelligence for remote sensing data analysis: A review of challenges and opportunities. IEEE Geosci. Remote. Sens. Mag. 2022, 10, 270–294. [Google Scholar] [CrossRef]
- Liang, J.; Hu, D.; Feng, J. Do we really need to access the source data? source hypothesis transfer for unsupervised domain adaptation. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 6028–6039. [Google Scholar]
- Fang, Y.; Yap, P.T.; Lin, W.; Zhu, H.; Liu, M. Source-free unsupervised domain adaptation: A survey. arXiv 2022, arXiv:2301.00265. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- Daudt, R.C.; Le Saux, B.; Boulch, A. Fully convolutional siamese networks for change detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Varghese, A.; Gubbi, J.; Ramaswamy, A.; Balamuralidhar, P. ChangeNet: A deep learning architecture for visual change detection. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sefrin, O.; Riese, F.M.; Keller, S. Deep learning for land cover change detection. Remote Sens. 2020, 13, 78. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018, Proceedings 4; Springer: Berlin, Germany, 2018; pp. 3–11. [Google Scholar]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A densely connected Siamese network for change detection of VHR images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Peng, X.; Zhong, R.; Li, Z.; Li, Q. Optical remote sensing image change detection based on attention mechanism and image difference. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7296–7307. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A spatial-temporal attention-based method and a new dataset for remote sensing image change detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Rizzolatti, G.; Craighero, L. Spatial attention: Mechanisms and theories. Adv. Psychol. Sci. 1998, 2, 171–198. [Google Scholar]
- Huang, G.; Zhu, J.; Li, J.; Wang, Z.; Cheng, L.; Liu, L.; Li, H.; Zhou, J. Channel-attention U-Net: Channel attention mechanism for semantic segmentation of esophagus and esophageal cancer. IEEE Access 2020, 8, 122798–122810. [Google Scholar] [CrossRef]
- Li, W.; Xue, L.; Wang, X.; Li, G. ConvTransNet: A CNN–Transformer Network for Change Detection With Multiscale Global–Local Representations. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Li, Z.; Cao, S.; Deng, J.; Wu, F.; Wang, R.; Luo, J.; Peng, Z. STADE-CDNet: Spatial–Temporal Attention with Difference Enhancement-Based Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–17. [Google Scholar] [CrossRef]
- Toldo, M.; Maracani, A.; Michieli, U.; Zanuttigh, P. Unsupervised domain adaptation in semantic segmentation: A review. Technologies 2020, 8, 35. [Google Scholar] [CrossRef]
- Kang, G.; Jiang, L.; Yang, Y.; Hauptmann, A.G. Contrastive adaptation network for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4893–4902. [Google Scholar]
- Tasar, O.; Happy, S.; Tarabalka, Y.; Alliez, P. ColorMapGAN: Unsupervised domain adaptation for semantic segmentation using color mapping generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7178–7193. [Google Scholar] [CrossRef]
- Vega, P.J.S.; da Costa, G.A.O.P.; Feitosa, R.Q.; Adarme, M.X.O.; de Almeida, C.A.; Heipke, C.; Rottensteiner, F. An unsupervised domain adaptation approach for change detection and its application to deforestation mapping in tropical biomes. ISPRS J. Photogramm. Remote Sens. 2021, 181, 113–128. [Google Scholar] [CrossRef]
- Biasetton, M.; Michieli, U.; Agresti, G.; Zanuttigh, P. Unsupervised domain adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Benjdira, B.; Bazi, Y.; Koubaa, A.; Ouni, K. Unsupervised domain adaptation using generative adversarial networks for semantic segmentation of aerial images. Remote Sens. 2019, 11, 1369. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, X.; Wu, W.; Li, G. Continuous Change Detection of Flood Extents with Multisource Heterogeneous Satellite Image Time Series. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–18. [Google Scholar] [CrossRef]
- Roy, S.; Trapp, M.; Pilzer, A.; Kannala, J.; Sebe, N.; Ricci, E.; Solin, A. Uncertainty-guided source-free domain adaptation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin, Germany, 2022; pp. 537–555. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Source-free domain adaptation for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1215–1224. [Google Scholar]
- Xia, H.; Zhao, H.; Ding, Z. Adaptive adversarial network for source-free domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9010–9019. [Google Scholar]
- Yang, S.; Wang, Y.; Van De Weijer, J.; Herranz, L.; Jui, S. Generalized source-free domain adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8978–8987. [Google Scholar]
- Ding, N.; Xu, Y.; Tang, Y.; Xu, C.; Wang, Y.; Tao, D. Source-free domain adaptation via distribution estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7212–7222. [Google Scholar]
- Vu, T.H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar]
- Chen, M.; Xue, H.; Cai, D. Domain adaptation for semantic segmentation with maximum squares loss. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Replic of Korea, 27 October–2 November 2019; pp. 2090–2099. [Google Scholar]
- Singh, S.; Shrivastava, A. Evalnorm: Estimating batch normalization statistics for evaluation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Replic of Korea, 27 October–2 November 2019; pp. 3633–3641. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arxiv 2016, arXiv:1511.06434. [Google Scholar]
- Pan, F.; Shin, I.; Rameau, F.; Lee, S.; Kweon, I.S. Unsupervised intra-domain adaptation for semantic segmentation through self-supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3764–3773. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.A.; Rubis, A.Y. Change detection in remote sensing images using conditional adversarial networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traditional Domain Adaptation | Unsupervised Domain Adaptation | Source-Free Unsupervised Domain Adaptation | |
|---|---|---|---|
| Source Model | ✓ | ✓ | ✓ |
| Source Data | ✓ | ✓ | ✗ |
| Target Data | Part-labelled | No label | No label |
| Method | Source Free | WHU-CD → LEVIR-CD | LEVIR-CD → WHU-CD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| cIoU | F1 | Precision | Recall | cIoU | F1 | Precision | Recall | ||
| Source model-only | ✗ | 24.82% | 30.18% | 56.47% | 20.59% | 26.61% | 31.22% | 58.54% | 21.29% |
| ColourMapGAN | ✗ | 54.97% | 68.38% | 78.78% | 60.41% | 52.51% | 63.37% | 72.32% | 56.39% |
| CGDA-CD | ✗ | 54.38% | 68.75% | 68.42% | 69.09% | 52.33% | 62.83% | 71.19% | 56.22% |
| SGDA | ✗ | 55.52% | 69.49% | 78.00% | 62.65% | 53.01% | 63.30% | 73.39% | 55.65% |
| Ours(Siam-ResUnet) | ✓ | 55.96% | 70.83% | 77.57% | 65.17% | 53.18% | 63.79% | 74.41% | 55.82% |
| Ours(SNUnet) | ✓ | 56.01% | 71.14% | 76.25% | 66.68% | 53.77% | 63.76% | 73.72% | 56.17% |
| Method | Source Free | CDD (Season-Varying) → LEVIR-CD | CDD (Season-Varying) → WHU-CD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| cIoU | F1 | Precision | Recall | cIoU | F1 | Precision | Recall | ||
| Source-only | ✗ | 20.02% | 27.34% | 55.51% | 18.14% | 14.31% | 22.53% | 49.50% | 14.58% |
| ColourMapGAN | ✗ | 50.17% | 59.77% | 73.33% | 50.44% | 46.89% | 52.91% | 59.11% | 47.88% |
| CGDA-CD | ✗ | 51.68% | 63.30% | 62.17% | 64.47% | 32.14% | 40.40% | 53.17% | 32.58% |
| SGDA | ✗ | 51.48% | 62.52% | 64.48% | 60.68% | 49.85% | 57.17% | 66.47% | 50.15% |
| Ours(Siam-ResUnet) | ✓ | 52.16% | 63.67% | 73.84% | 55.97% | 51.54% | 59.52% | 68.41% | 52.67% |
| Ours(SNUnet) | ✓ | 52.88% | 64.37% | 72.78% | 57.71% | 52.01% | 60.93% | 72.77% | 52.41% |
| Method | CDD (Season-Varying) → LEVIR-CD | CDD (Season-Varying) → WHU-CD | ||||||
|---|---|---|---|---|---|---|---|---|
| cIoU | F1 | Precision | Recall | cIoU | F1 | Precision | Recall | |
| Ours(w/o AAM & ISM) | 28.21% | 31.66% | 54.71% | 22.28% | 26.92% | 29.48% | 48.15% | 21.24% |
| Ours(w/o ISM) | 40.16% | 46.78% | 52.54% | 42.16% | 45.57% | 50.51% | 61.68% | 42.77% |
| Ours(w/o AAM) | 49.85% | 61.96% | 66.19% | 58.24% | 49.10% | 59.66% | 75.56% | 49.29% |
| Ours | 56.01% | 71.14% | 76.25% | 66.68% | 53.77% | 63.76% | 73.72% | 56.17% |
| Method | CDD (Season-Varying) → LEVIR-CD | CDD (Season-Varying) → WHU-CD | ||||||
|---|---|---|---|---|---|---|---|---|
| cIoU | F1 | Precision | Recall | cIoU | F1 | Precision | Recall | |
| Ours(w/o AAM & ISM) | 28.74% | 32.08% | 42.07% | 25.93% | 29.17% | 35.14% | 45.18% | 28.75% |
| Ours(w/o ISM) | 39.69% | 42.00% | 51.24% | 35.58% | 36.28% | 38.61% | 48.45% | 32.09% |
| Ours(w/o AAM) | 45.15% | 49.38% | 59.67% | 42.12% | 42.34% | 46.63% | 57.41% | 39.26% |
| Ours | 52.88% | 64.37% | 72.78% | 57.71% | 52.01% | 60.93% | 72.77% | 52.41% |
| Loss Function | Cross-Region | Cross-Scenario | |||||
|---|---|---|---|---|---|---|---|
| WHU-CD → LEVIR-CD | LEVIR-CD → WHU-CD | CDD → LEVIR-CD | CDD → WHU-CD | ||||
| ✓ | ✗ | ✗ | ✗ | 20.47% | 21.44% | 20.28% | 15.32% |
| ✓ | ✓ | ✗ | ✗ | 28.21% | 26.92% | 28.74% | 29.17% |
| ✓ | ✓ | ✓ | ✗ | 40.16% | 45.57% | 39.69% | 36.28% |
| ✓ | ✓ | ✓ | ✓ | 56.01% | 53.77% | 52.88% | 52.01% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wu, C. SFDA-CD: A Source-Free Unsupervised Domain Adaptation for VHR Image Change Detection. Remote Sens. 2024, 16, 1274. https://doi.org/10.3390/rs16071274
Wang J, Wu C. SFDA-CD: A Source-Free Unsupervised Domain Adaptation for VHR Image Change Detection. Remote Sensing. 2024; 16(7):1274. https://doi.org/10.3390/rs16071274
Chicago/Turabian StyleWang, Jingxuan, and Chen Wu. 2024. "SFDA-CD: A Source-Free Unsupervised Domain Adaptation for VHR Image Change Detection" Remote Sensing 16, no. 7: 1274. https://doi.org/10.3390/rs16071274