

CDEST: Class Distinguishability-Enhanced Self-Training Method for Adopting Pre-Trained Models to Downstream Remote Sensing Image Semantic Segmentation

 ,
, 

Abstract
1. Introduction
- (1)
- We propose a novel fine-tuning method to provide effective support for the most recent global-to-local transfer learning paradigm. By leveraging both labeled and unlabeled data to enhance the class distinguishability of features, our method can efficiently maintain useful features in self-supervised pre-trained models while adapting them to downstream semantic segmentation tasks.
- (2)
- We combine self-training and contrastive learning mechanisms and design three modules to mine effective supervisory information from both labeled and unlabeled data, to guide model fine-tuning to overcome overfitting and catastrophic forgetting issues.
- (3)
- We evaluate our proposed method on two public datasets and two realistic datasets. The experimental results show that our method outperforms both traditional supervised fine-tuning and several representative semi-supervised fine-tuning methods.
2. Methodology
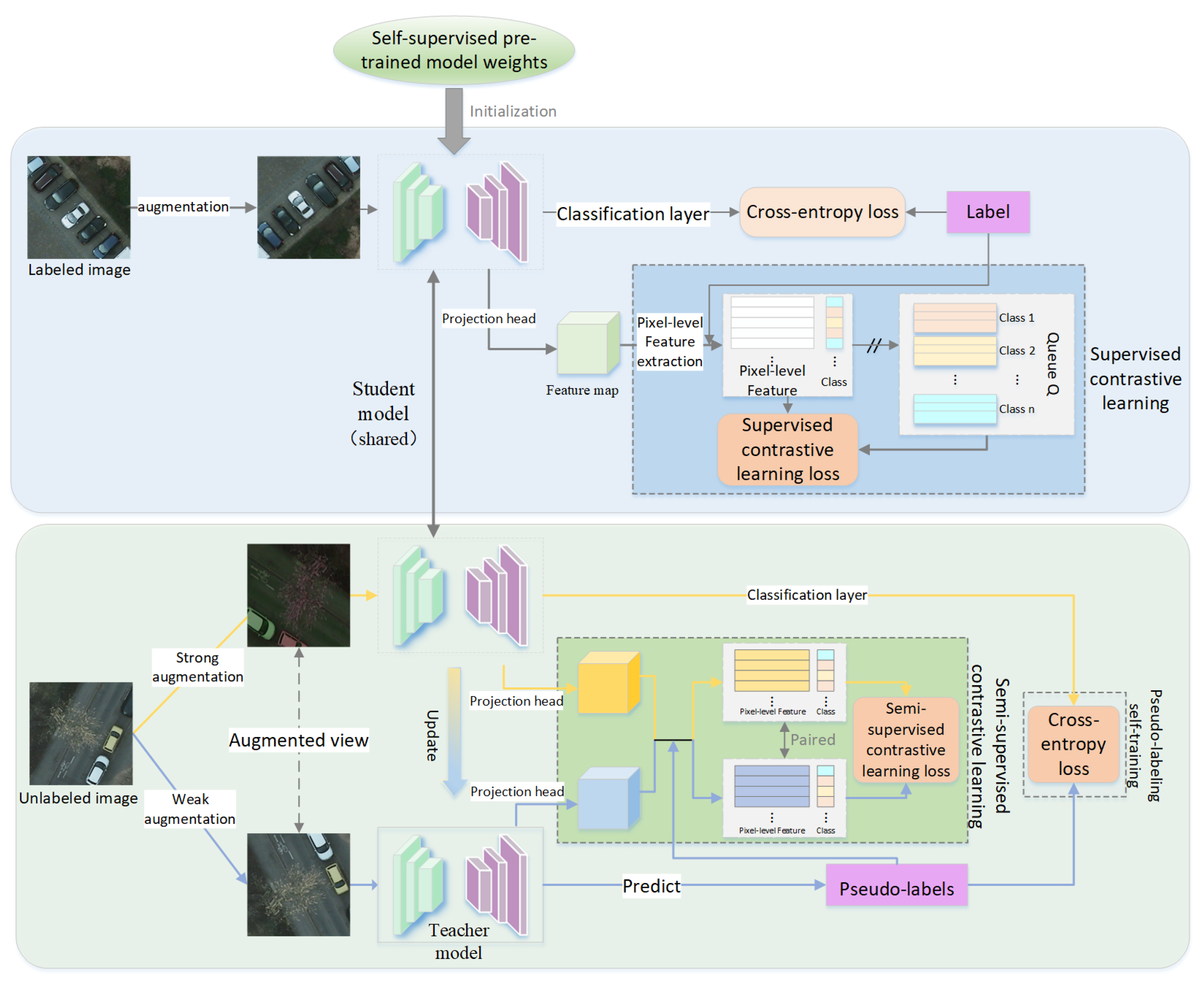
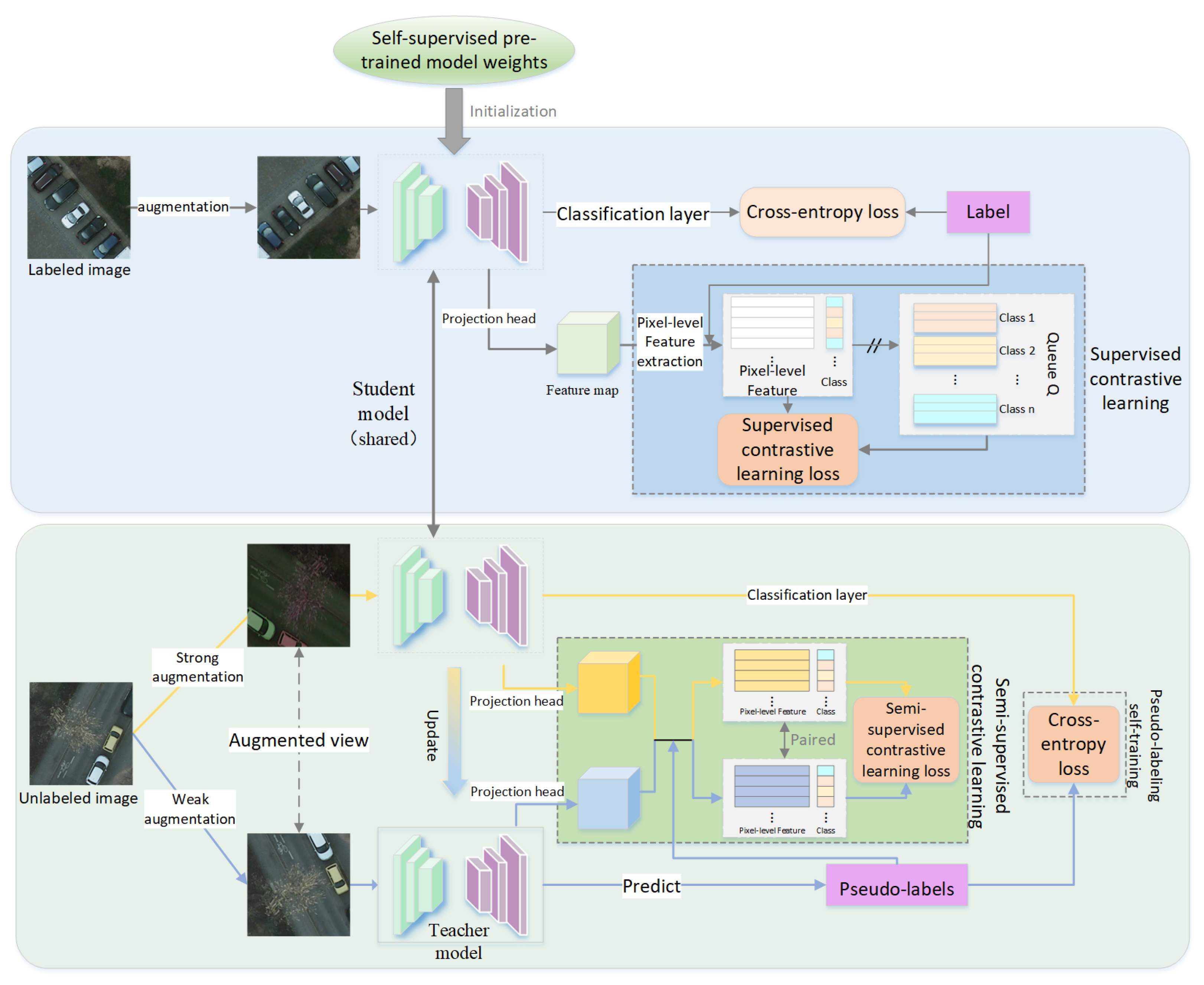
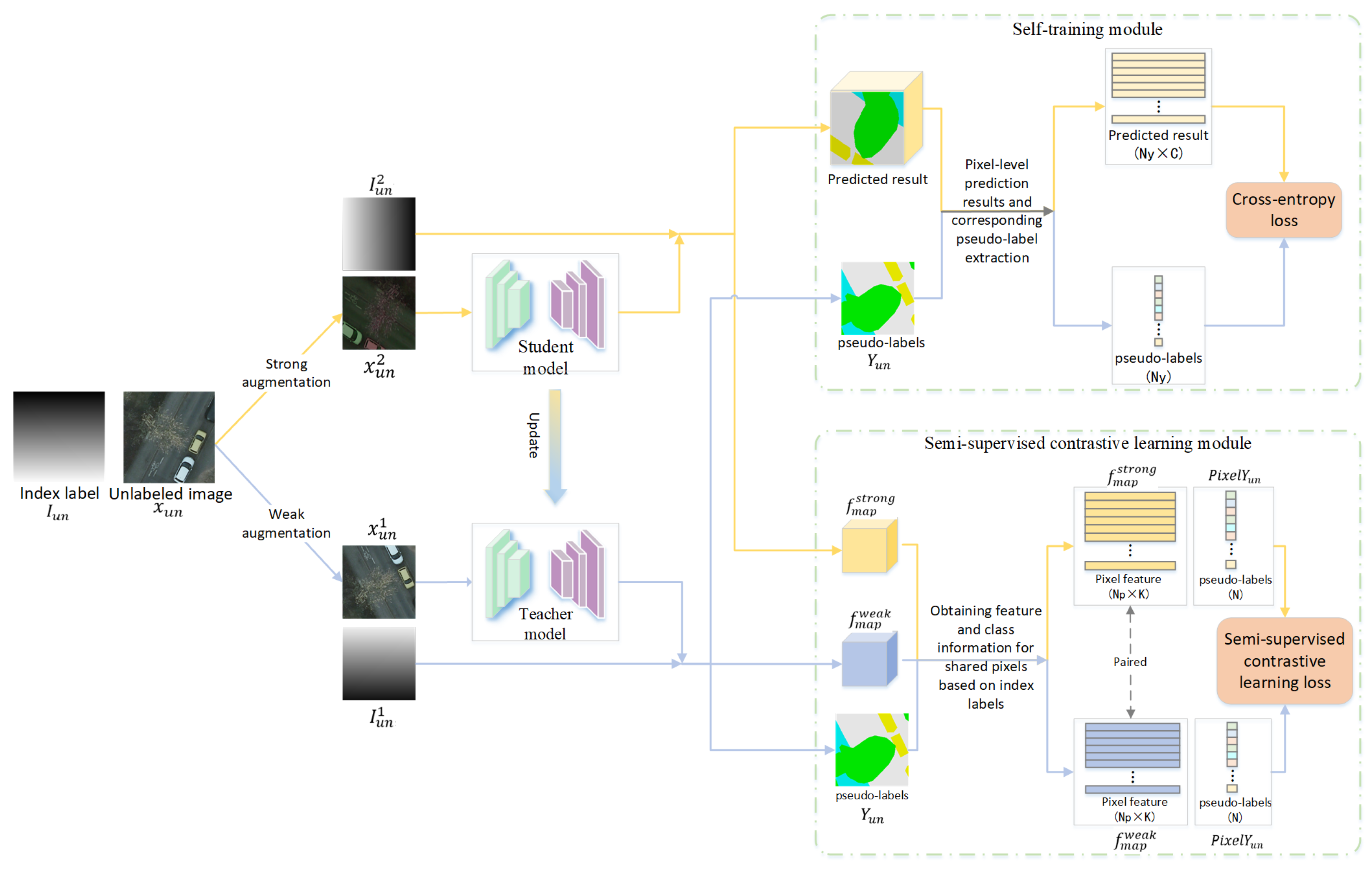
2.1. The Overall Framework of CDEST
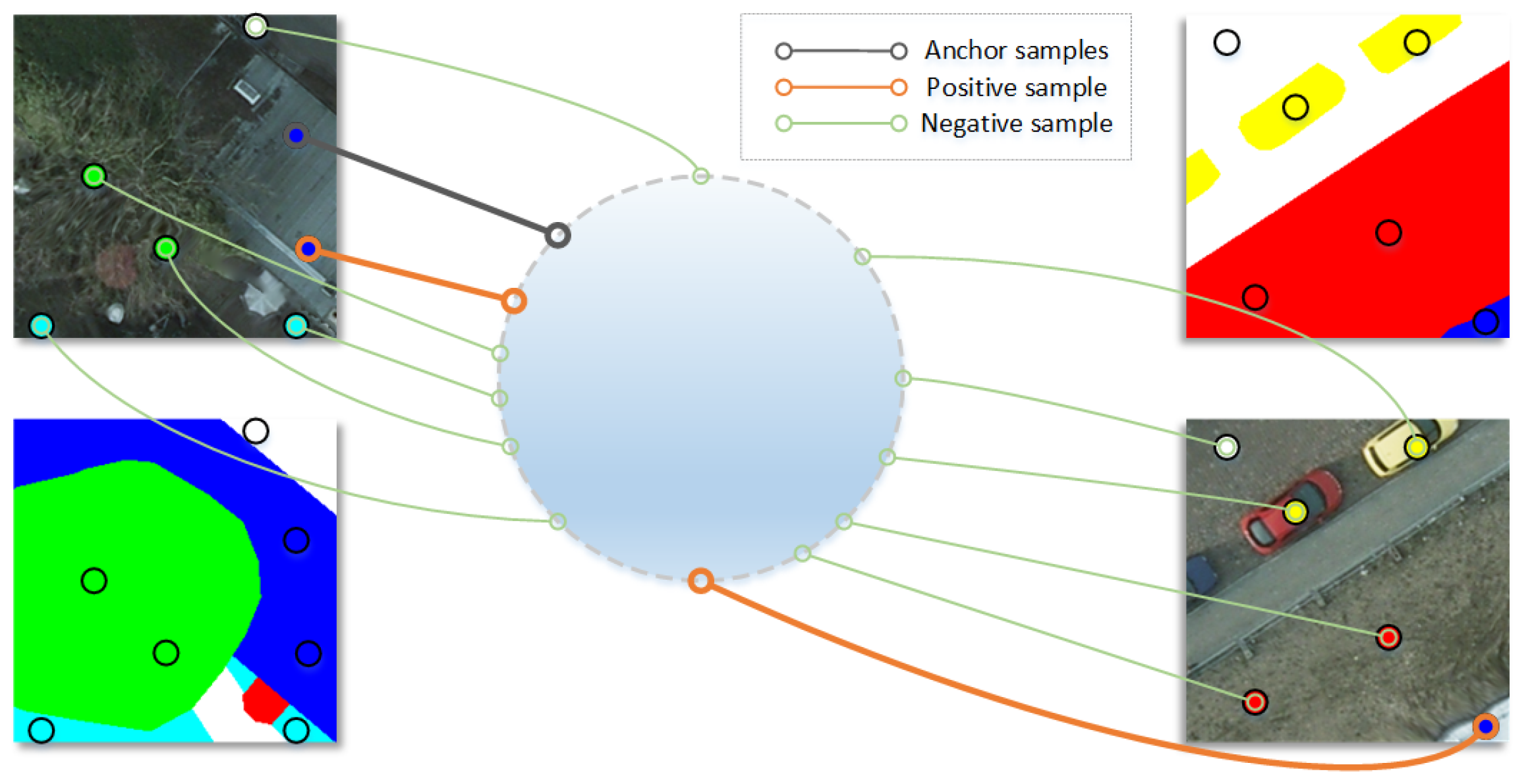
2.2. Supervised Contrastive Learning Module with Labeled Data
- (1)
- Image encoding to generate feature maps
- (2)
- Sample queue construction and update
- (3)
- Constructing positive and negative samples
- (4)
- Supervised contrastive loss
2.3. Self-Training Module with Unlabeled Data
2.4. Semi-Supervised Contrastive Learning Module with Unlabeled Data
- (1)
- Generate index labels: Given an unlabeled image , we generate the corresponding index label to facilitate the subsequent determination of pixel correspondences from different augmentation results. The specific details of the index label are consistent with those described in the ST module above.
- (2)
- Data augmentation: Before feeding the data into the student and teacher models, we preprocess each pair of data (, ) with weak and strong types of augmentation to generate (, ) and (, ). The design of the two types of data enhancements here is consistent with that in the ST module.
- (3)
- Feature map extraction: To obtain the pixel features for contrastive learning, we feed into the teacher network to generate feature maps and . At the same time, we feed into the student model to generate K-dimensional . The specific generation process of and is consistent with that described by Equation (1).
- (4)
- Acquisition of pairwise pixel features and their class information: Based on the index labels and , we can determine the correspondence between the pixels on the feature maps , , and to obtain all the paired pixels and their labels. Then, to reduce the redundancy, all paired pixel features are randomly filtered and only pixel features are finally retained.
- (5)
- Loss function for semi-supervised contrastive learning: For each anchor sample , the positive sample is the pixel feature paired with it, and its negative samples are all the pixel features in the current training batch data that are not in the same class as . The class information of these samples is obtained from the pseudo-label . The final semi-supervised contrastive learning loss is defined as follows:where denotes the total number of paired pixel features selected in the whole batch, denotes the pixel features of other categories among the pixel features whose pseudo-labeling categories do not belong to the same sample class as , and is a temperature hyperparameter.
2.5. The Complete Loss Function of the CDEST Method
3. Experiments
3.1. Data Description
- (1)
- ISPRS Potsdam Dataset: The Potsdam dataset [64] includes 38 high-resolution (HR) aerial images with a size of 6000 × 6000 pixels. Each image features a spatial resolution of 0.05 m, encompassing four spectral bands: red, blue, green, and near-infrared reflectance (NIR). The dataset is annotated with six categories: low vegetation, trees, buildings, impervious surfaces, cars, and others. For training purposes, 24 images are cropped into 13,824 patches as samples, each 256 × 256 pixels in size, with 1% labeled. For testing, 1500 labeled patches of 256 × 256 size were randomly selected from the cropped results of the remaining 14 images.
- (2)
- DGLCC Dataset: The DGLCC [65] dataset consists of HR satellite images, each 2448 × 2448 pixels in size. The dataset is annotated with seven categories: urban, agriculture, rangeland, forest, water, barren, and unknown. For training, we randomly selected 730 images and cropped them into patches of 512 × 512 pixels, with 1% labeled. The remaining 73 images were cropped into patches of pixels and used as testing samples.
- (3)
- Hubei Dataset: The Hubei dataset consists of images acquired from the Gaofen-2 satellite, covering the province of Hubei, China. These RGB images measure 13,889 × 9259 pixels and have a spatial resolution of 2 m. The dataset includes annotations in ten categories: background, farmland, urban, rural areas, water, woodland, grassland, other artificial facilities, roads, and others. We processed 34 images for training and 5 for testing, cropping them into 256 × 256-pixel patches to obtain the final samples. The number of samples is detailed in Table 1.
- (4)
- Xiangtan Dataset: The Xiangtan dataset consists of images also sourced from the Gaofen-2 satellite, covering the city of Xiangtan, China. This dataset is annotated with nine categories: background, farmland, urban, rural areas, water, woodland, grassland, road, and others. We processed 85 images for training and 21 for testing, cropping them into 256 × 256-pixel patches to generate the final samples. The number of samples is detailed in Table 1.
3.2. Comparison Experiments and Baseline
- (1)
- Supervised fine-tuning: Fine-tuning the model to downstream semantic segmentation tasks using only labeled data.
- (2)
- CCT: A semi-supervised fine-tuning method based on the consistency assumption that the model should be able to obtain stable and consistent predictions based on inputs containing small perturbations. Specifically, the CCT consists of an encoder, a main decoder, and several auxiliary decoders. The labeled data are used directly to train the encoder and the main decoder. For the features extracted by the encoder from the unlabeled data, their original versions are used as inputs to the main decoder, while the versions with added perturbations (e.g., added noise, dropped features, random rotations, etc.) are used as inputs to the auxiliary decoders. Then, by requiring the predictions of the primary and secondary decoders to be identical, the use of unlabeled data is achieved to enhance the robustness of the model itself and its adaptability to downstream tasks.
- (3)
- FixMatch: A semi-supervised fine-tuning method that incorporates the consistency constraint assumption and the idea of pseudo-label training. For annotated data, FixMatch performs normal supervised semantic segmentation training; for unlabeled data, FixMatch generates pseudo-labels for unlabeled images that are weakly augmented (e.g., random flip and shift) and discards those that are not predicted with high confidence. It then trains the model to complete semantic segmentation tasks by predicting the same pseudo-labels for the strongly augmented (e.g., Cutout [66] and AutoAugment [67]) versions of the same images.
- (4)
- NoisyStudent: A self-training semi-supervised method based on distillation learning, which leverages massive unlabeled data to improve the accuracy and robustness of the task model, NoisyStudent consists of the following steps: (I) It initializes the encoder part of the semantic segmentation model with a self-supervised pre-trained model and trains the teacher model on the annotated data. (II) It generates pseudo-labels by using the teacher model to predict the unlabeled data. (III) It selects the high-confidence predictions from the unlabeled data and trains the student model with the annotated data and the selected predictions. It also adds noise to the student model during training, such as random noise, color distortion, and data augmentation via RandAugment [68]. These noisy operations are more intense and diverse than the ones used in the normal semantic segmentation training, to make the student model more robust to noise. (IV) It makes the student model the new teacher model to predict the unlabeled data. (V) It repeats (III) and (IV) until convergence.
3.3. Implementation Details
3.4. Experimental Results
4. Discussions
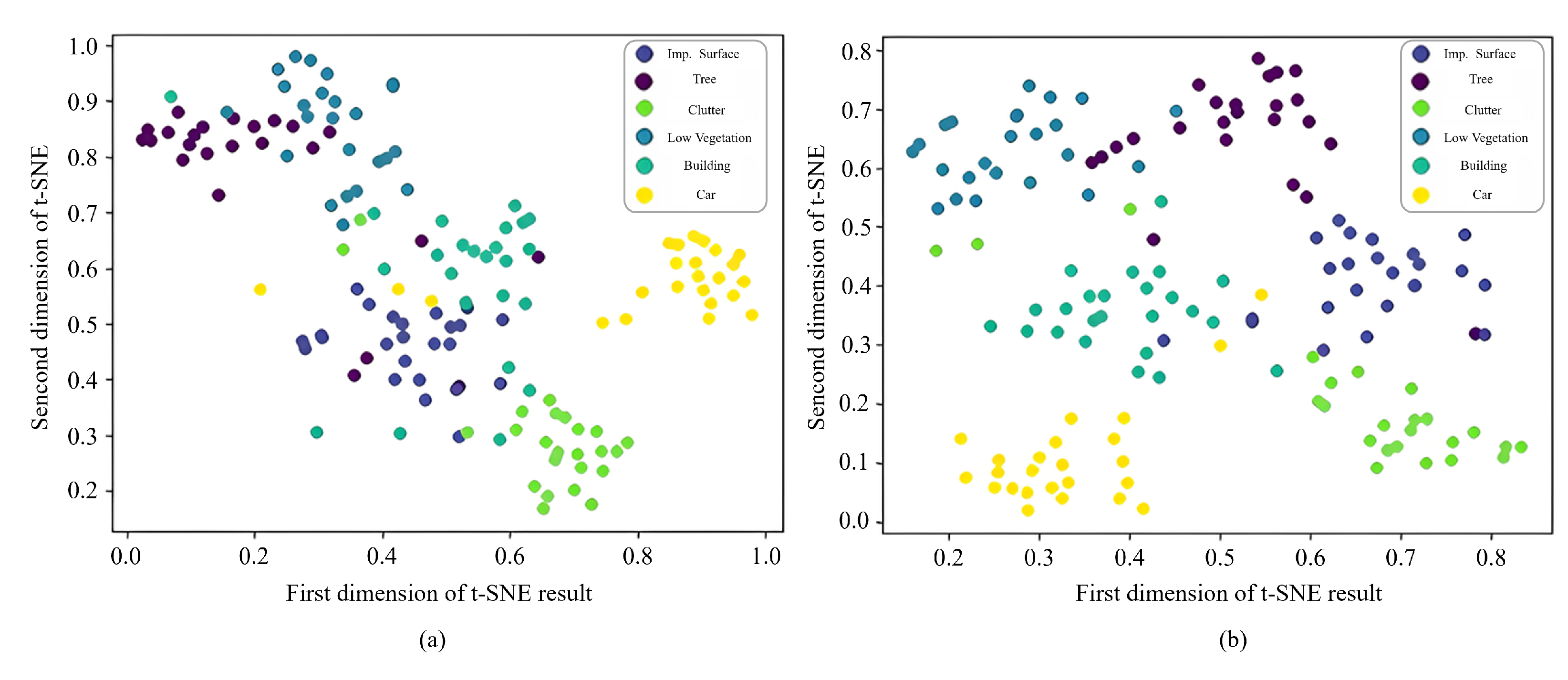
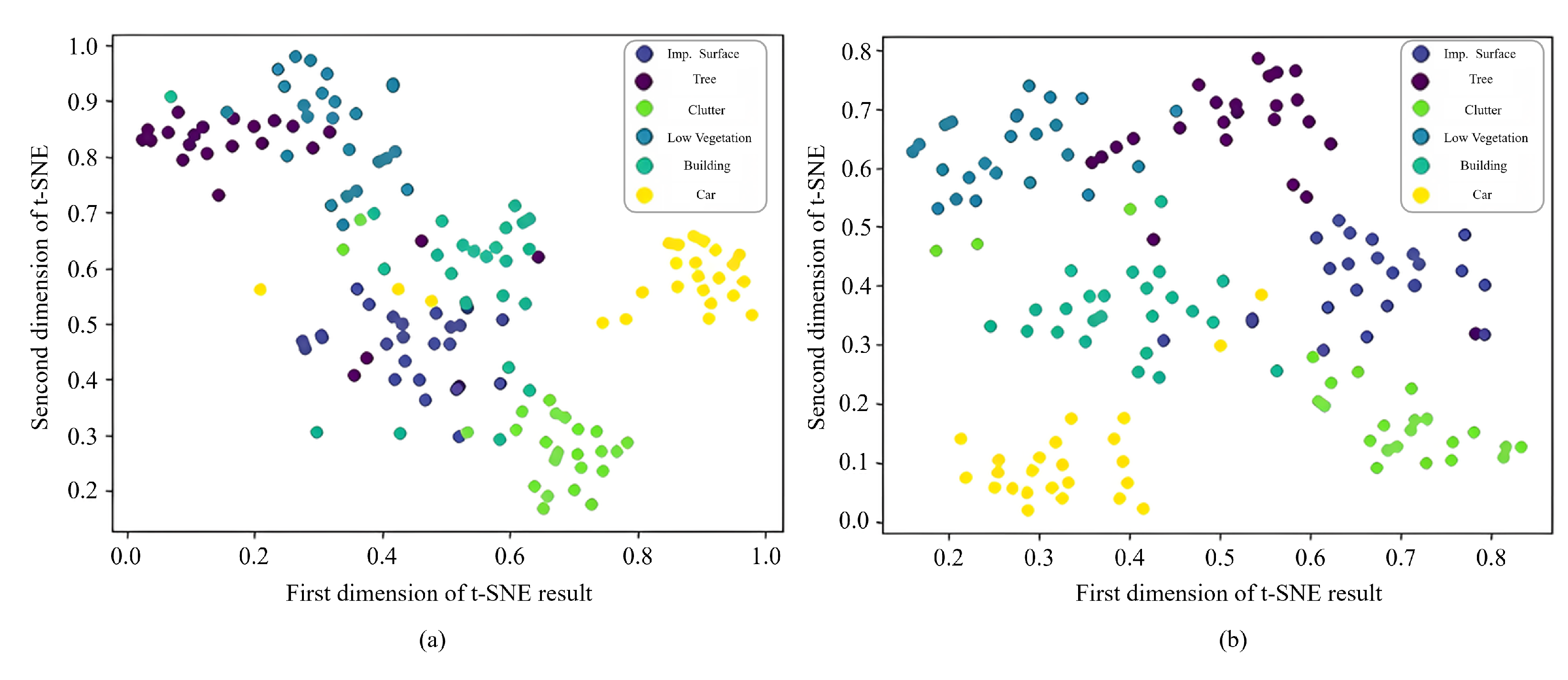
4.1. Ablation Study
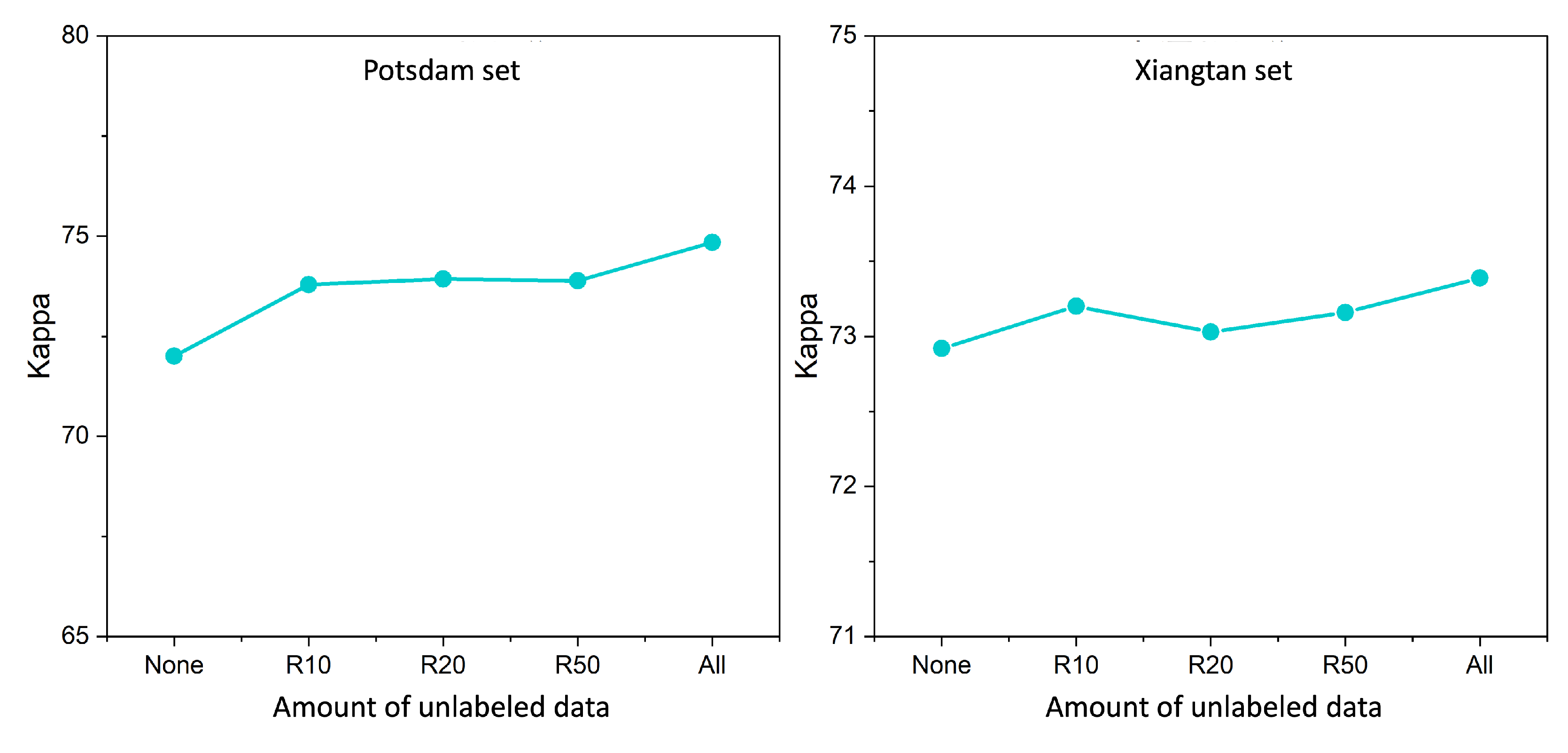
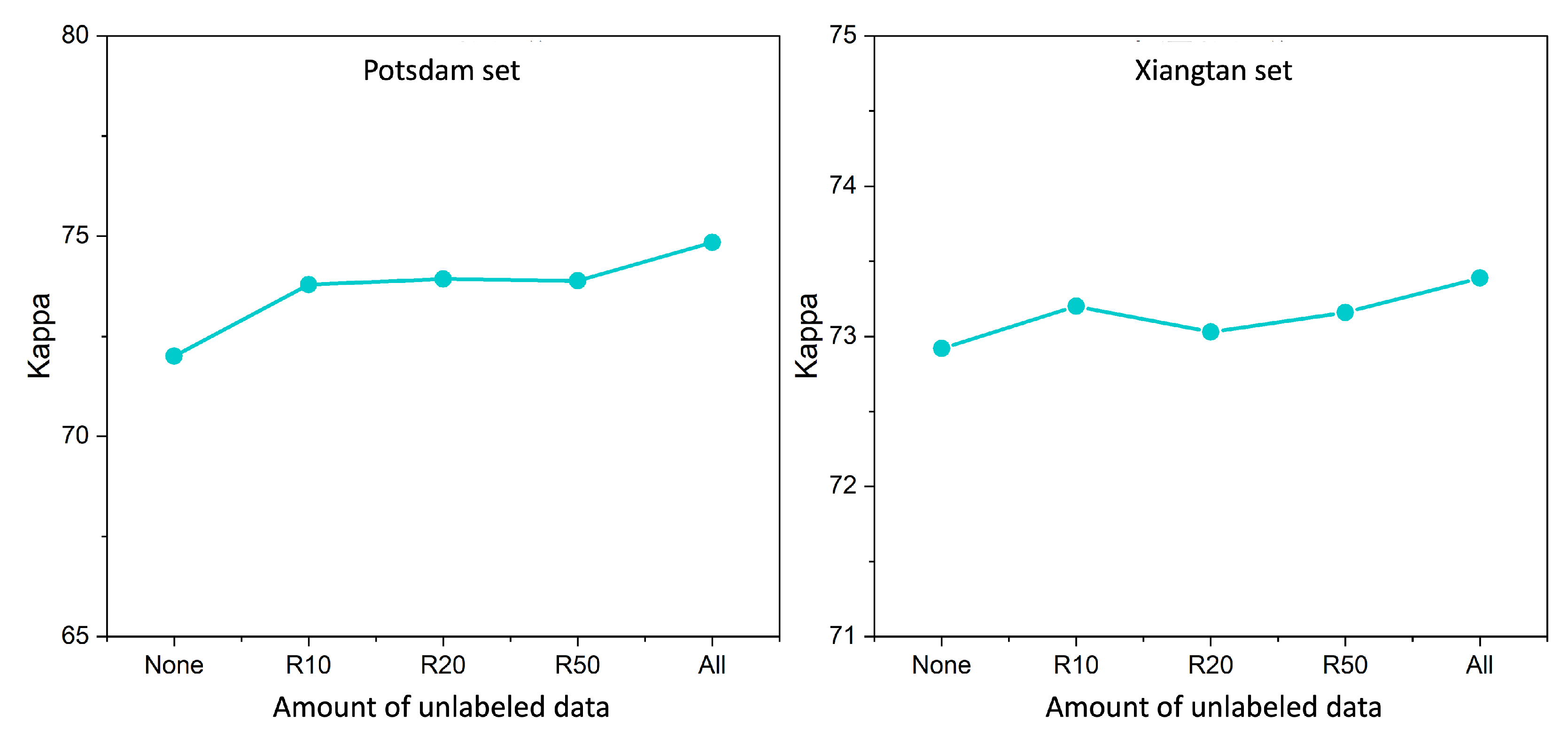
4.2. Study of the Quantity of Unlabeled Data
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Zang, N.; Cao, Y.; Wang, Y.; Huang, B.; Zhang, L.; Mathiopoulos, P.T. Land-Use Mapping for High-Spatial Resolution Remote Sensing Image Via Deep Learning: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5372–5391. [Google Scholar] [CrossRef]
- Schumann, G.J.; Brakenridge, G.R.; Kettner, A.J.; Kashif, R.; Niebuhr, E. Assisting flood disaster response with earth observation data and products: A critical assessment. Remote Sens. 2018, 10, 1230. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D. Dense Semantic Labeling of Subdecimeter Resolution Images with Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 881–893. [Google Scholar] [CrossRef]
- Tuia, D.; Persello, C.; Bruzzone, L. Recent advances in domain adaptation for the classification of remote sensing data. arXiv 2021, arXiv:2104.07778. [Google Scholar] [CrossRef]
- Li, Y.; Shi, T.; Zhang, Y.; Chen, W.; Wang, Z.; Li, H. Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation. ISPRS J. Photogramm. Remote Sens. 2021, 175, 20–33. [Google Scholar] [CrossRef]
- Cui, H.; Zhang, G.; Wang, T.; Li, X.; Qi, J. Combined Model Color-Correction Method Utilizing External Low-Frequency Reference Signals for Large-Scale Optical Satellite Image Mosaics. IEEE Trans. Geosci. Remote Sens. 2021, 59, 4993–5007. [Google Scholar] [CrossRef]
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A remote sensing land-cover dataset for domain adaptive semantic segmentation. arXiv 2021, arXiv:2110.08733. [Google Scholar]
- Wang, H.; Tao, C.; Qi, J.; Xiao, R.; Li, H. Avoiding negative transfer for semantic segmentation of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Ma, Y.; Chen, S.; Ermon, S.; Lobell, D.B. Transfer learning in environmental remote sensing. Remote Sens. Environ. 2024, 301, 113924. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Shen, J.; Cao, X.; Li, Y.; Xu, D. Feature adaptation and augmentation for cross-scene hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2018, 15, 622–626. [Google Scholar] [CrossRef]
- Li, S.; Song, S.; Huang, G.; Ding, Z.; Wu, C. Domain invariant and class discriminative feature learning for visual domain adaptation. IEEE Trans. Image Process. 2018, 27, 4260–4273. [Google Scholar] [CrossRef] [PubMed]
- Song, S.; Yu, H.; Miao, Z.; Zhang, Q.; Lin, Y.; Wang, S. Domain adaptation for convolutional neural networks-based remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1324–1328. [Google Scholar] [CrossRef]
- Aksoy, S.; Haralick, R.M. Feature normalization and likelihood-based similarity measures for image retrieval. Pattern Recognit. Lett. 2001, 22, 563–582. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Zhu, L.; Liu, Y. Centroid and covariance alignment-based domain adaptation for unsupervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2305–2323. [Google Scholar] [CrossRef]
- Tasar, O.; Giros, A.; Tarabalka, Y.; Alliez, P.; Clerc, S. DAugNet: Unsupervised, multisource, multitarget, and life-long domain adaptation for semantic segmentation of satellite images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1067–1081. [Google Scholar] [CrossRef]
- Cui, H.; Zhang, G.; Qi, J.; Li, H.; Tao, C.; Li, X.; Hou, S.; Li, D. MDANet: Unsupervised, Mixed-Domain Adaptation for Semantic Segmentation of Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Guo, M.; Zhu, Q.; Li, H. Self-supervised remote sensing feature learning: Learning paradigms, challenges, and future works. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–26. [Google Scholar] [CrossRef]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-supervised learning in remote sensing: A review. arXiv 2022, arXiv:2206.13188. [Google Scholar] [CrossRef]
- Li, H.; Cao, J.; Zhu, J.; Luo, Q.; He, S.; Wang, X. Augmentation-Free Graph Contrastive Learning of Invariant-Discriminative Representations. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Lu, W.; Wang, H.; Li, H. Remote sensing image scene classification with self-supervised paradigm under limited labeled samples. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Yang, X.; He, X.; Liang, Y.; Yang, Y.; Zhang, S.; Xie, P. Transfer learning or self-supervised learning? A tale of two pretraining paradigms. arXiv 2020, arXiv:2007.04234. [Google Scholar]
- Tao, C.; Qi, J.; Zhang, G.; Zhu, Q.; Lu, W.; Li, H. TOV: The Original Vision Model for Optical Remote Sensing Image Understanding via Self-Supervised Learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4916–4930. [Google Scholar] [CrossRef]
- Ericsson, L.; Gouk, H.; Loy, C.C.; Hospedales, T.M. Self-supervised representation learning: Introduction, advances, and challenges. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Saha, S.; Shahzad, M.; Mou, L.; Song, Q.; Zhu, X.X. Unsupervised Single-Scene Semantic Segmentation for Earth Observation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Muhtar, D.; Zhang, X.; Xiao, P. Index your position: A novel self-supervised learning method for remote sensing images semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, X.; Mei, X.; Tao, C.; Li, H. FALSE: False negative samples aware contrastive learning for semantic segmentation of high-resolution remote sensing image. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, Z.; Ren, Z.; Tao, C.; Zhang, Y.; Peng, C.; Li, H. GraSS: Contrastive Learning with Gradient-Guided Sampling Strategy for Remote Sensing Image Semantic Segmentation. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, R.; Shen, C.; Kong, T.; Li, L. Dense contrastive learning for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 3024–3033. [Google Scholar]
- Berg, P.; Pham, M.T.; Courty, N. Self-Supervised Learning for Scene Classification in Remote Sensing: Current State of the Art and Perspectives. Remote Sens. 2022, 14, 3995. [Google Scholar] [CrossRef]
- Marsocci, V.; Scardapane, S. Continual barlow twins: Continual self-supervised learning for remote sensing semantic segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 5049–5060. [Google Scholar] [CrossRef]
- Li, H.; Jing, W.; Wei, G.; Wu, K.; Su, M.; Liu, L.; Wu, H.; Li, P.; Qi, J. RiSSNet: Contrastive Learning Network with a Relaxed Identity Sampling Strategy for Remote Sensing Image Semantic Segmentation. Remote Sens. 2023, 15, 3427. [Google Scholar] [CrossRef]
- Wang, Y.; Braham, N.A.A.; Xiong, Z.; Liu, C.; Albrecht, C.M.; Zhu, X.X. SSL4EO-S12: A large-scale multimodal, multitemporal dataset for self-supervised learning in Earth observation [Software and Data Sets]. IEEE Geosci. Remote Sens. Mag. 2023, 11, 98–106. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Swersky, K.; Norouzi, M.; Hinton, G.E. Big self-supervised models are strong semi-supervised learners. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Virtual, 6–12 December 2020; Volume 33, pp. 22243–22255. [Google Scholar]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Ouali, Y.; Hudelot, C.; Tami, M. Semi-Supervised Semantic Segmentation with Cross-Consistency Training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12671–12681. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised Data Augmentation for Consistency Training. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Virtual, 6–12 December 2020; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 6256–6268. [Google Scholar]
- Yang, X.; Song, Z.; King, I.; Xu, Z. A Survey on Deep Semi-Supervised Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 8934–8954. [Google Scholar] [CrossRef]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-Training with Noisy Student Improves ImageNet Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10684–10695. [Google Scholar]
- Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of the Eleventh Annual Conference on Computational Learning Theory, Madison WI, USA, 24–26 July 1998; ACM: New York, NY, USA, 1998; pp. 92–100. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Virtual, 6–12 December 2020; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 596–608. [Google Scholar]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv 2013, arXiv:1312.6211. [Google Scholar]
- Peng, J.; Ye, D.; Tang, B.; Lei, Y.; Liu, Y.; Li, H. Lifelong Learning with Cycle Memory Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Luo, Q.; He, S.; Han, X.; Wang, Y.; Li, H. LSTTN: A Long-Short Term Transformer-based spatiotemporal neural network for traffic flow forecasting. Knowl.-Based Syst. 2024, 293, 111637. [Google Scholar] [CrossRef]
- Jean, N.; Wang, S.; Samar, A.; Azzari, G.; Lobell, D.; Ermon, S. Tile2vec: Unsupervised representation learning for spatially distributed data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3967–3974. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Yang, M.; Li, Y.; Huang, Z.; Liu, Z.; Hu, P.; Peng, X. Partially view-aligned representation learning with noise-robust contrastive loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1134–1143. [Google Scholar]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, J.; Li, Y.; Zhang, H. Semantic segmentation with attention mechanism for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Cui, H.; Zhang, G.; Chen, Y.; Li, X.; Hou, S.; Li, H.; Ma, X.; Guan, N.; Tang, X. Knowledge evolution learning: A cost-free weakly supervised semantic segmentation framework for high-resolution land cover classification. ISPRS J. Photogramm. Remote Sens. 2024, 207, 74–91. [Google Scholar] [CrossRef]
- Khosla, P.; Teterwak, P.; Wang, C.; Sarna, A.; Tian, Y.; Isola, P.; Maschinot, A.; Liu, C.; Krishnan, D. Supervised contrastive learning. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Virtual, 6–12 December 2020; Volume 33, pp. 18661–18673. [Google Scholar]
- Jun, C.; Ban, Y.; Li, S. Open access to Earth land-cover map. Nature 2014, 514, 434. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Raina, R.; Battle, A.; Lee, H.; Packer, B.; Ng, A.Y. Self-taught learning: Transfer learning from unlabeled data. In Proceedings of the International Conference on Machine Learning (ICML), Corvallis, OR, USA, 20 June 2007; pp. 759–766. [Google Scholar]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 293–298. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
- Devries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Policies from Data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar]
- Arpit, D.; Jastrzębski, S.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.; Bengio, Y.; et al. A closer look at memorization in deep networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 233–242. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the Advances in neural information processing systems (NIPS), Montréal, QC, Canada, 3–8 December 2018; Volume 31, pp. 8792–8802. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Potsdam | DGLCC | Hubei | Xiangtan |
|---|---|---|---|---|
| Number of categories | 6 | 7 | 10 | 9 |
| Sample size (pixels) | 256 × 256 | 512 × 512 | 256 × 256 | 256 × 256 |
| Spatial resolution (m) | 0.05 | 0.5 | 2 | 2 |
| Number of labeled training samples | 138 | 182 | 664 | 160 |
| Number of unlabeled training samples | 13,686 | 18,066 | 65,807 | 15,891 |
| Number of testing samples | 1500 | 1825 | 9211 | 3815 |
| Methods | Potsdam | DGLCC | Hubei | Xiangtan | ||||
|---|---|---|---|---|---|---|---|---|
| Kappa | OA | Kappa | OA | Kappa | OA | Kappa | OA | |
| Supervised fine-tuning | 72.01 | 78.21 | 68.03 | 80.42 | 53.10 | 63.04 | 72.92 | 82.81 |
| CCT | 70.50 | 76.91 | 66.68 | 79.59 | 53.07 | 62.92 | 71.78 | 82.26 |
| FixMatch | 73.15 | 78.95 | 67.26 | 80.22 | 52.25 | 62.55 | 73.20 | 83.04 |
| CDEST | 74.85 | 80.37 | 68.47 | 81.14 | 55.04 | 64.67 | 73.39 | 83.26 |
| NoisyStudent * | 75.46 | 80.86 | 70.34 | 81.92 | 54.41 | 63.71 | 73.18 | 82.97 |
| CDEST * | 75.65 | 80.98 | 71.74 | 82.45 | 54.91 | 64.54 | 73.23 | 83.02 |
| Kappa/OA | ||||
|---|---|---|---|---|
| ✔ | 72.16/78.22 | |||
| ✔ | ✔ | 72.80/78.79 | ||
| ✔ | ✔ | 74.10/79.81 | ||
| ✔ | ✔ | 72.22/78.27 | ||
| ✔ | ✔ | ✔ | 74.86/80.33 | |
| ✔ | ✔ | ✔ | 73.39/79.20 | |
| ✔ | ✔ | ✔ | 74.47/80.11 | |
| ✔ | ✔ | ✔ | ✔ | 74.85/80.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Gu, X.; Qi, J.; Zhang, Z.; Yang, H.; Xu, J.; Peng, C.; Li, H. CDEST: Class Distinguishability-Enhanced Self-Training Method for Adopting Pre-Trained Models to Downstream Remote Sensing Image Semantic Segmentation. Remote Sens. 2024, 16, 1293. https://doi.org/10.3390/rs16071293
Zhang M, Gu X, Qi J, Zhang Z, Yang H, Xu J, Peng C, Li H. CDEST: Class Distinguishability-Enhanced Self-Training Method for Adopting Pre-Trained Models to Downstream Remote Sensing Image Semantic Segmentation. Remote Sensing. 2024; 16(7):1293. https://doi.org/10.3390/rs16071293
Chicago/Turabian StyleZhang, Ming, Xin Gu, Ji Qi, Zhenshi Zhang, Hemeng Yang, Jun Xu, Chengli Peng, and Haifeng Li. 2024. "CDEST: Class Distinguishability-Enhanced Self-Training Method for Adopting Pre-Trained Models to Downstream Remote Sensing Image Semantic Segmentation" Remote Sensing 16, no. 7: 1293. https://doi.org/10.3390/rs16071293
APA StyleZhang, M., Gu, X., Qi, J., Zhang, Z., Yang, H., Xu, J., Peng, C., & Li, H. (2024). CDEST: Class Distinguishability-Enhanced Self-Training Method for Adopting Pre-Trained Models to Downstream Remote Sensing Image Semantic Segmentation. Remote Sensing, 16(7), 1293. https://doi.org/10.3390/rs16071293