



Remote Sensing Images Secure Distribution Scheme Based on Deep Information Hiding


Abstract
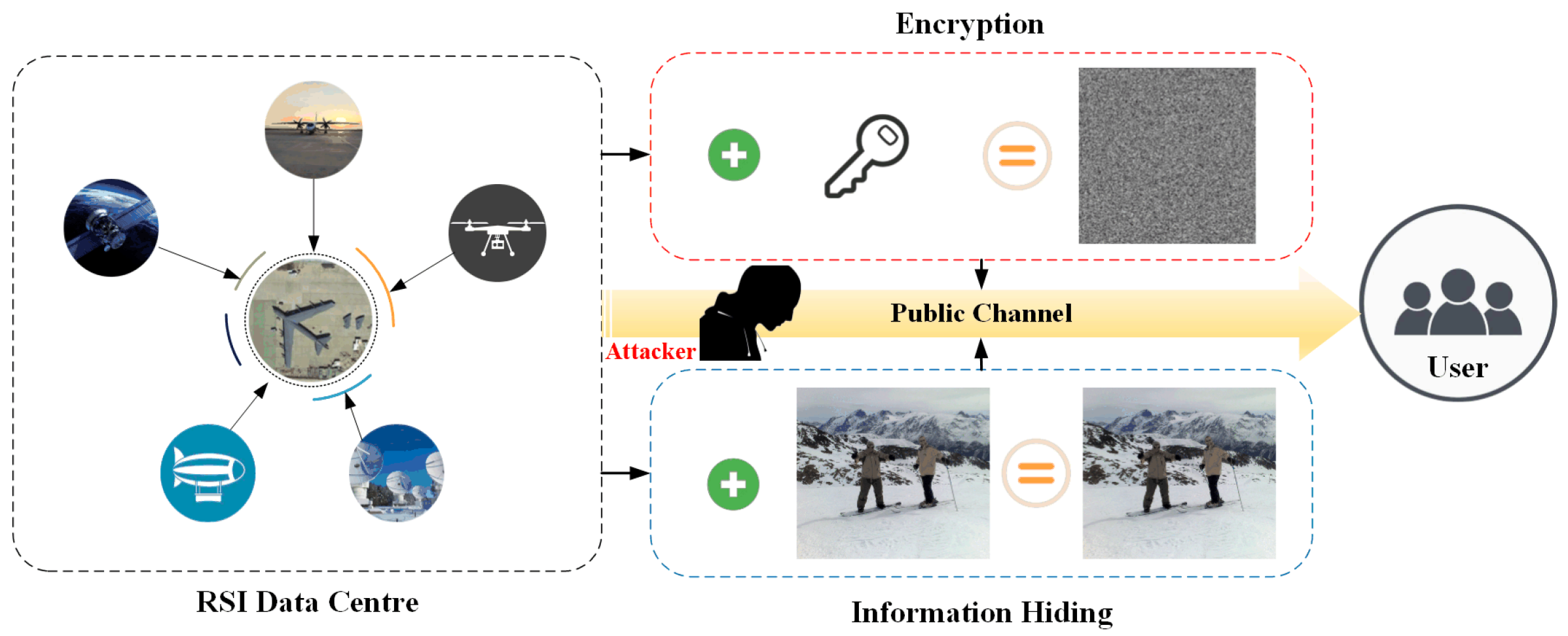
:1. Introduction
- To our knowledge, DIH4RSID is the first to explicitly propose using deep information-hiding technology to ensure the secure distribution of RSIs. Therefore, our method opens a new way of thinking about RSI security distribution and expands the application fields of information-hiding technology.
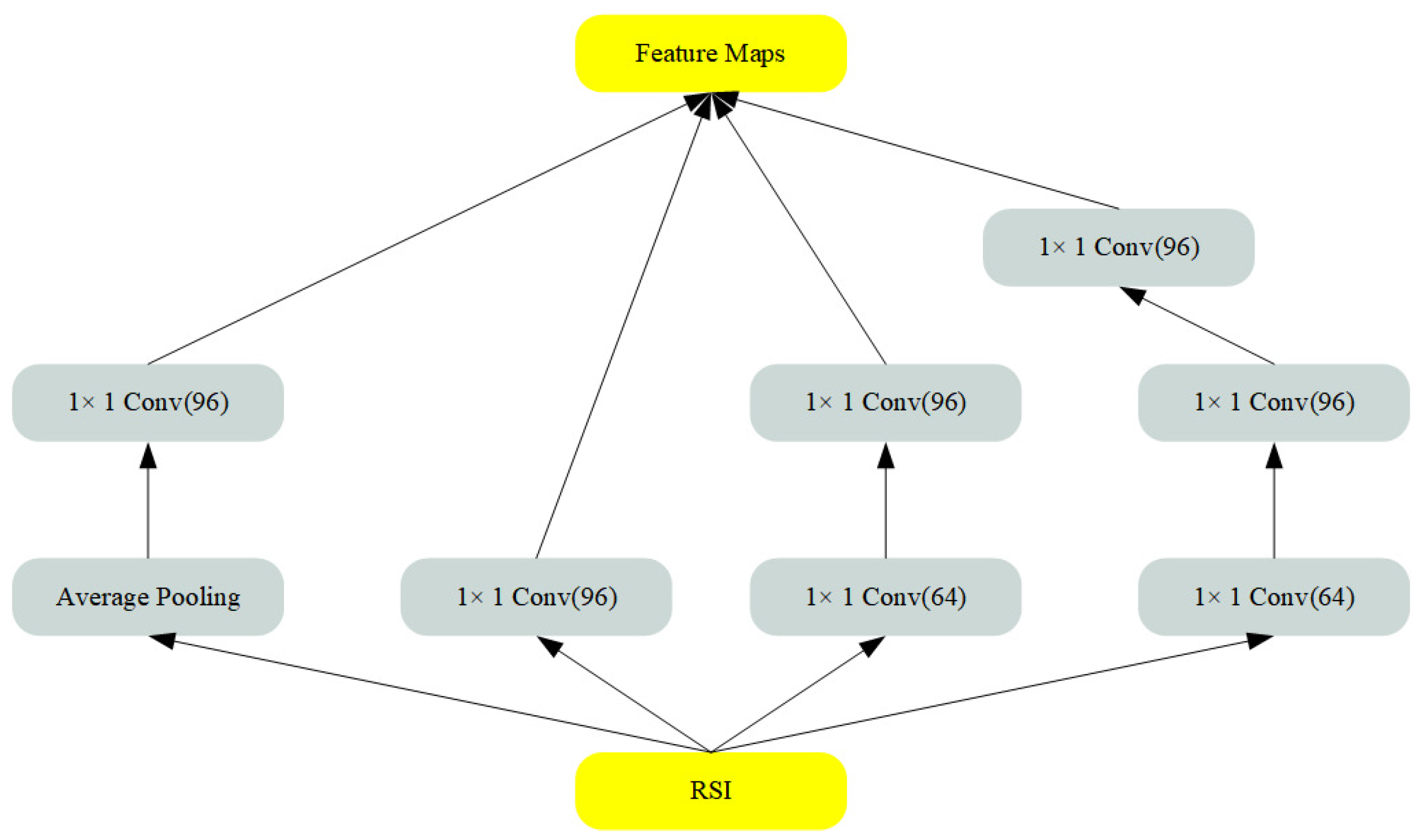
- Unlike the existing HIWI (Hiding images within images) framework, our study proposes a novel preprocessing network architecture, which is designed based on Inception networks and crafted to conform to the unique properties of remote sensing images, which can capture detailed information of objects at different scales.
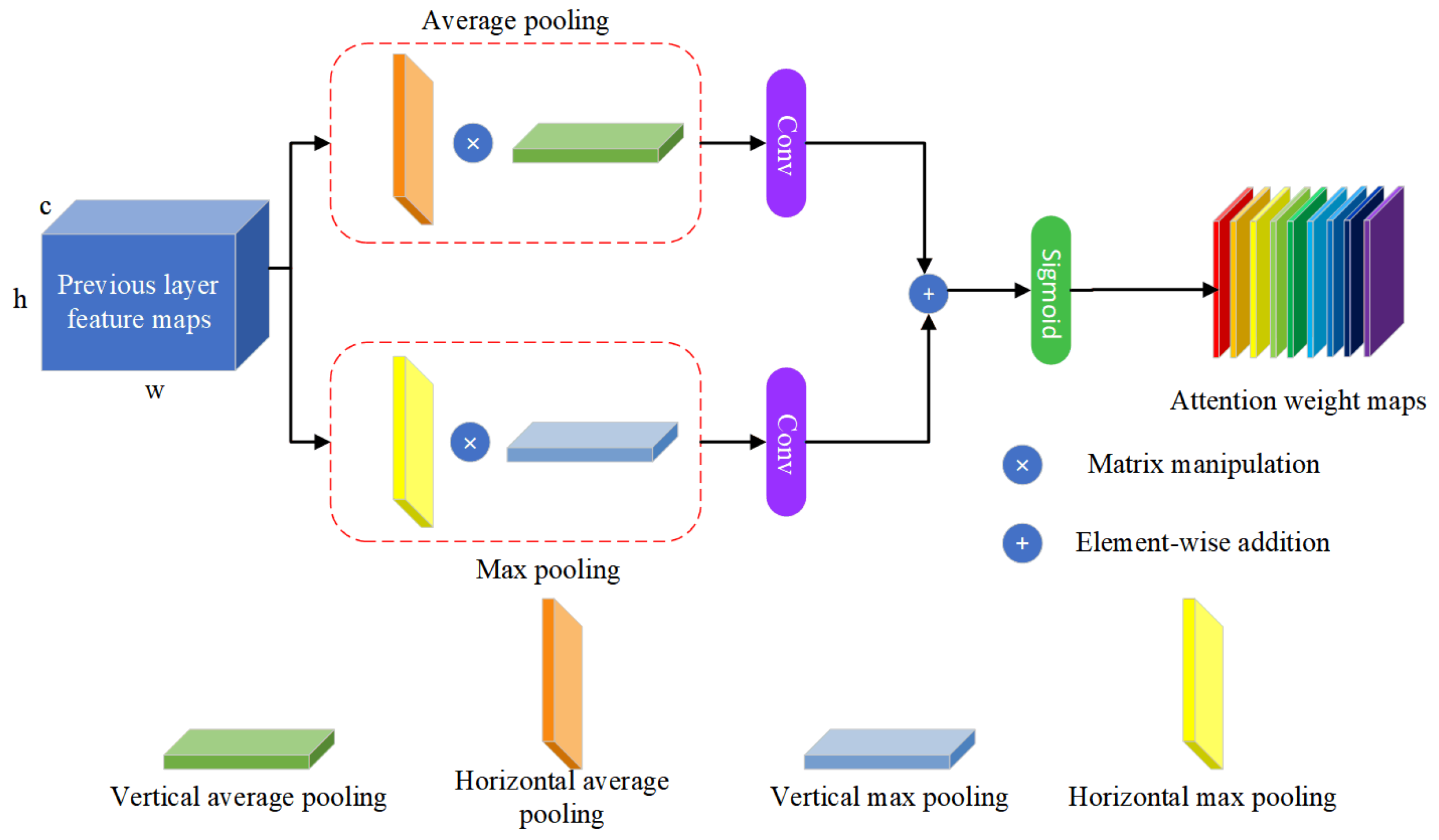
- According to the characteristics of our tasks and RSIs, a new attention mechanism, PAM, is designed in this paper, which carries out two kinds of pooling from two dimensions, respectively. Convolution operations can then capture cross-channel relationships and spatial remote dependencies.
- A discriminator is added to the scheme, and iterative training is carried out by WGAN-GP (Wasserstein Generative Adversarial Network with Gradient Penalty), which improves the model’s stability and correct convergence speed.
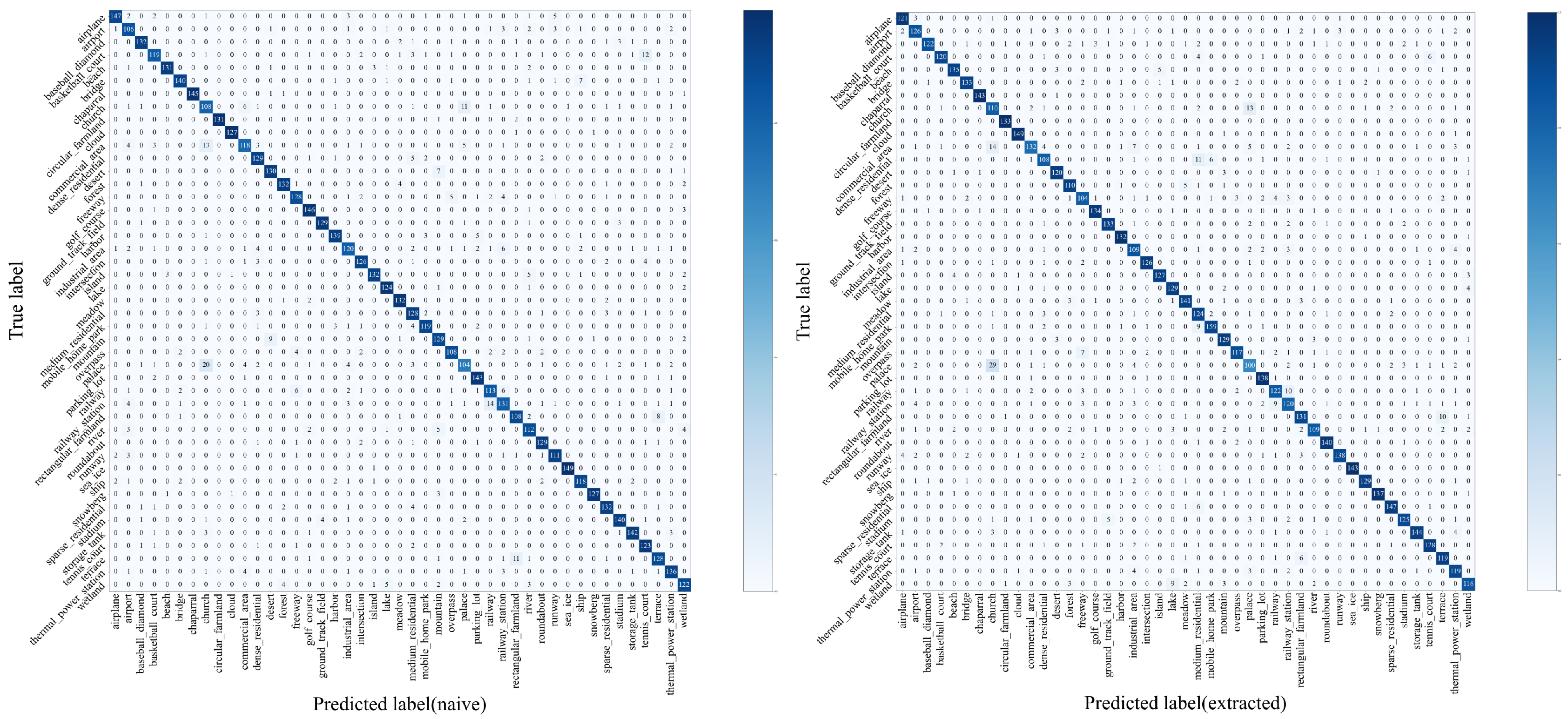
- In this study, a functional integrity retention test was performed on the extracted RSI, specifically an accuracy test of scene classification for the RSI after extraction. This offers a new perspective for assessing the performance of high-capacity information-hiding technologies.
2. Related Work
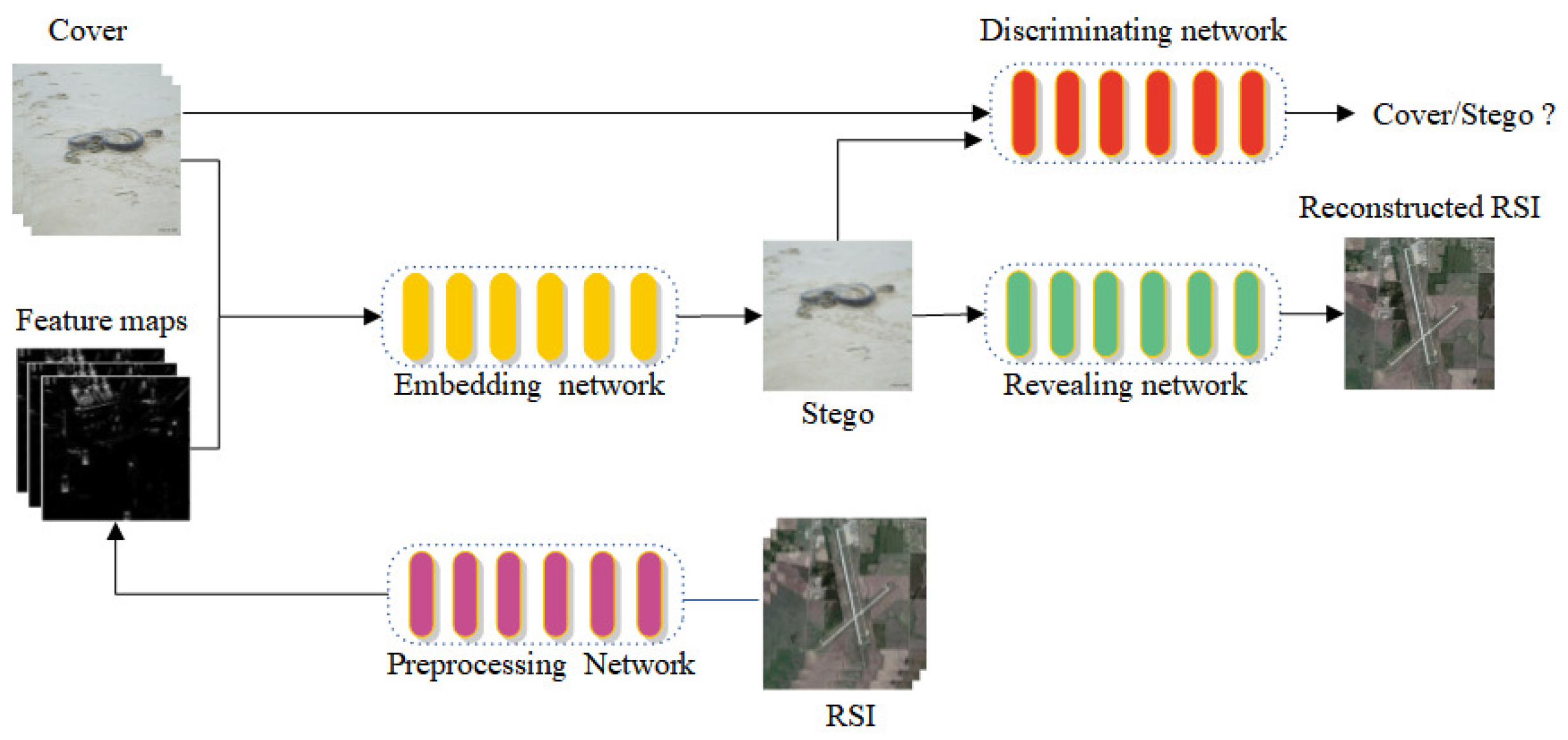
3. Proposed Scheme
3.1. Overview
3.2. Preprocessing Network
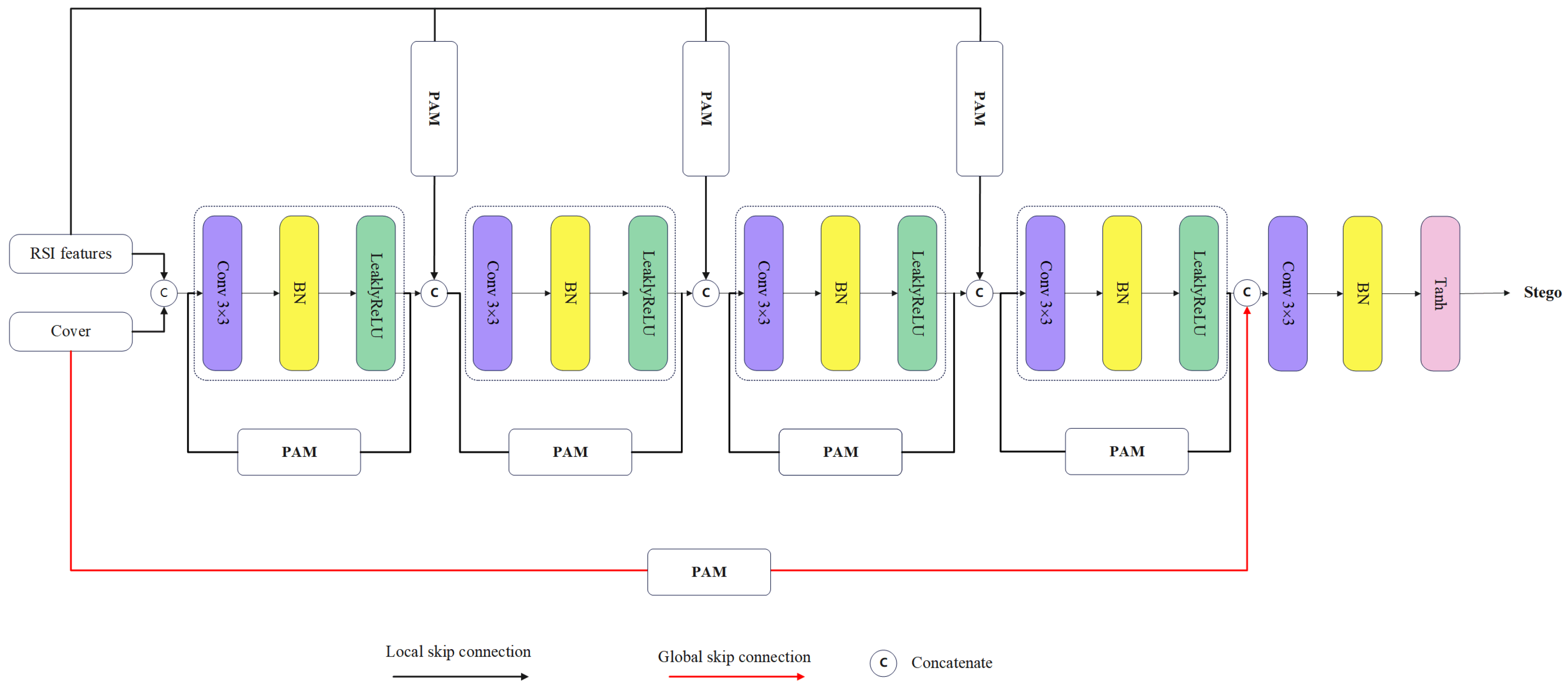
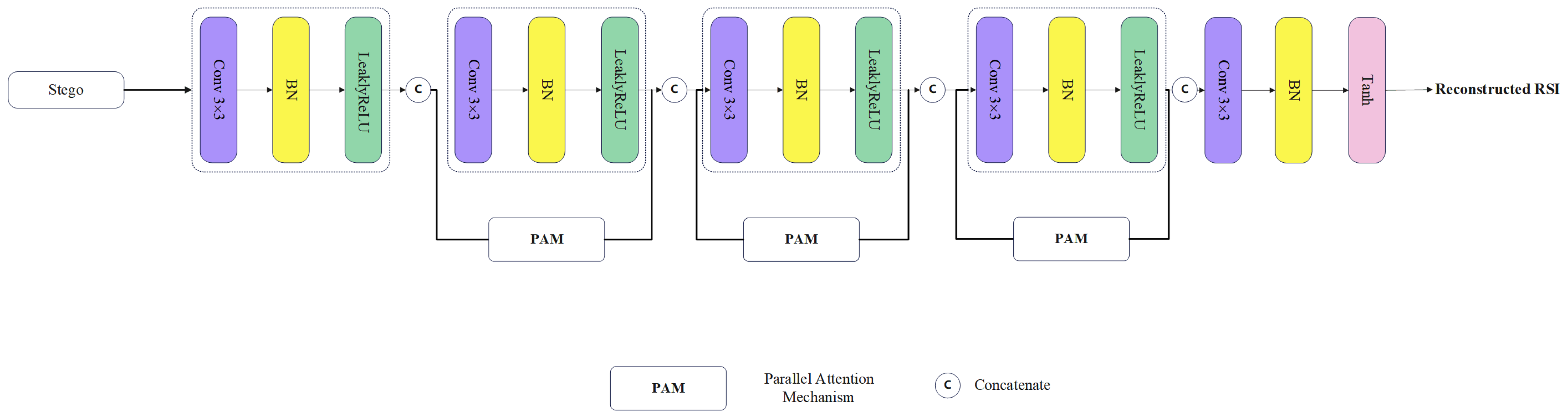
3.3. Parallel Attention Mechanism
3.4. Embedding Network
3.5. Revealing Network
3.6. Discriminating Network
| Algorithm 1: Training DIH4RSID. We use default values of , , , , |
 |
3.7. Loss Function Design
3.8. Training Process
4. Experimental Results and Analysis
4.1. Experimental Environment
4.2. Visual Quality Test and Analysis
4.3. Semantic Retention Capability Test
4.4. Security Test and Analysis
4.5. Comparison
4.6. Ablation Experiments
5. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.; Ren, L.; Shafiq, M.; Gu, Z. A Lightweight Privacy-Preserving System for the Security of Remote Sensing Images on IoT. Remote Sens. 2022, 14, 6371. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, G.; Huang, X.; Poslad, S. Granular Content Distribution for IoT Remote Sensing Data Supporting Privacy Preservation. Remote Sens. 2022, 14, 5574. [Google Scholar] [CrossRef]
- Alsubaei, F.S.; Alneil, A.A.; Mohamed, A.; Mustafa Hilal, A. Block-Scrambling-Based Encryption with Deep-Learning-Driven Remote Sensing Image Classification. Remote Sens. 2023, 15, 1022. [Google Scholar] [CrossRef]
- Naman, S.; Bhattacharyya, S.; Saha, T. Remote sensing and advanced encryption standard using 256-Bit key. In Emerging Technology in Modelling and Graphics: Proceedings of IEM Graph 2018; Springer: Berlin/Heidelberg, Germany, 2020; pp. 181–190. [Google Scholar]
- He, R.; Sun, Q.; Thangasamy, P.; Chen, X.; Zhang, Y.; Wang, H.; Luo, H.; Zhou, X.D.; Zhou, M. Accelerate oxygen evolution reaction by adding chemical mediator and utilizing solar energy. Int. J. Hydrogen Energy 2023, 48, 8898–8908. [Google Scholar] [CrossRef]
- Akhaee, M.A.; Marvasti, F. A Survey on Digital Data Hiding Schemes: Principals, Algorithms, and Applications. ISeCure 2013, 5, 5. [Google Scholar]
- Singh, A.K. Data hiding: Current trends, innovation and potential challenges. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–16. [Google Scholar] [CrossRef]
- Rehman, A.; Rahim, R.; Nadeem, M.; Hussain, S. End-to-end trained CNN encode-decoder networks for image steganography. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 723–729. [Google Scholar]
- Zhang, K.A.; Cuesta-Infante, A.; Xu, L.; Veeramachaneni, K. SteganoGAN: High Capacity Image Steganography with GANs. arXiv 2019, arXiv:1901.03892. [Google Scholar]
- Yu, C. Attention Based Data Hiding with Generative Adversarial Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 1120–1128. [Google Scholar]
- Chen, F.; Xing, Q.; Liu, F. Technology of hiding and protecting the secret image based on two-channel deep hiding network. IEEE Access 2020, 8, 21966–21979. [Google Scholar] [CrossRef]
- Chen, F.; Xing, Q.; Fan, C. Multilevel Strong Auxiliary Network for Enhancing Feature Representation to Protect Secret Images. IEEE Trans. Ind. Inform. 2022, 18, 4577–4586. [Google Scholar] [CrossRef]
- Shi, J.; Liu, W.; Shan, H.; Li, E.; Li, X.; Zhang, L. Remote Sensing Scene Classification Based on Multibranch Fusion Attention Network. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Mielikainen, J. LSB matching revisited. IEEE Signal Process. Lett. 2006, 13, 285–287. [Google Scholar] [CrossRef]
- Filler, T.; Judas, J.; Fridrich, J. Minimizing Additive Distortion in Steganography Using Syndrome-Trellis Codes. IEEE Trans. Inf. Forensics Secur. 2011, 6, 920–935. [Google Scholar] [CrossRef]
- Pevnỳ, T.; Filler, T.; Bas, P. Using high-dimensional image models to perform highly undetectable steganography. In Proceedings of the Information Hiding: 12th International Conference, IH 2010, Calgary, AB, Canada, 28–30 June 2010; Revised Selected Papers 12. Springer: Berlin/Heidelberg, Germany, 2010; pp. 161–177. [Google Scholar]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security (WIFS), Tenerife, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Digital image steganography using universal distortion. In Proceedings of the first ACM Workshop on Information Hiding and Multimedia Security, Montpellier, France, 17–19 June 2013; ACM: New York, NY, USA, 2013; pp. 59–68. [Google Scholar]
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 4206–4210. [Google Scholar]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. Hidden: Hiding data with deep networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 657–672. [Google Scholar]
- Baluja, S. Hiding Images within Images. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1685–1697. [Google Scholar] [CrossRef]
- Duan, X.; Jia, K.; Li, B.; Guo, D.; Zhang, E.; Qin, C. Reversible image steganography scheme based on a U-Net structure. IEEE Access 2019, 7, 9314–9323. [Google Scholar] [CrossRef]
- Huang, J.; Luo, T.; Li, L.; Yang, G.; Xu, H.; Chang, C.C. ARWGAN: Attention-guided Robust Image Watermarking Model Based on GAN. IEEE Trans. Instrum. Meas. 2023, 72, 5018417. [Google Scholar] [CrossRef]
- Tan, J.; Liao, X.; Liu, J.; Cao, Y.; Jiang, H. Channel attention image steganography with generative adversarial networks. IEEE Trans. Netw. Sci. Eng. 2021, 9, 888–903. [Google Scholar] [CrossRef]
- Chen, F.; Xing, Q.; Sun, B.; Yan, X.; Cheng, J. An Enhanced Steganography Network for Concealing and Protecting Secret Image Data. Entropy 2022, 24, 1203. [Google Scholar] [CrossRef]
- Xu, G.; Wu, H.Z.; Shi, Y.Q. Structural Design of Convolutional Neural Networks for Steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR.org, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. 2017. Available online: https://proceedings.neurips.cc/paper_files/paper/2017/hash/892c3b1c6dccd52936e27cbd0ff683d6-Abstract.html (accessed on 5 November 2023).
- Almohammad, A.; Ghinea, G. Stego image quality and the reliability of PSNR. In Proceedings of the International Conference on Image Processing, Hong Kong, China, 26–29 September 2010. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Boehm, B. Stegexpose-A tool for detecting LSB steganography. arXiv 2014, arXiv:1410.6656. [Google Scholar]
- Yedroudj, M.; Comby, F.; Chaumont, M. Yedroudj-net: An efficient CNN for spatial steganalysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2092–2096. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inputs | Modules | Kernel | Outputs |
|---|---|---|---|
| Stego () | HPF | Out1 () | |
| Input1 | Conv-ABS-BN-Tanh—Average | Out2 () | |
| Input2 | Conv-BN-Tanh—Average | Out3 () | |
| Input3 | Conv-BN-Tanh—Average | Out4 () | |
| Input4 | Conv-BN-Tanh—Average | Out5 () | |
| Input5 | Conv-BN-Tanh—Average | Out5 () | |
| Input6 | ASPP | Out5 () | |
| Input7 | Fully Connected | - | Out5 () |
| Input8 | SoftMax | - | Probabilities of classes () |
| The Test Pairs | Cover and Stego | RSI and Extracted RSI |
|---|---|---|
| PSNR/SSIM * | PSNR/SSIM * | |
| Row#1 | 46.8 db/0.97 | 38.7 db/0.86 |
| Row#2 | 47.1 db/0.98 | 39.3 db/0.84 |
| Row#3 | 46.9 db/0.96 | 39.2 db/0.86 |
| Row#4 | 46.8 db/0.97 | 38.6 db/0.88 |
| Row#5 | 47.2 db/0.98 | 38.8 db/0.86 |
| Row#6 | 46.9 db/0.96 | 39.1 db/0.85 |
| Method Based on CNN | 70% Training Ratio | 80% Training Ratio |
|---|---|---|
| Native/Extracted | Native/Extracted | |
| AlexNet | 91.5 ± 0.18/91.3 ± 0.17 | 92.7 ± 0.12/92.6 ± 0.11 |
| VGGNet16 | 90.5 ± 0.19/90.6 ± 0.15 | 92.6 ± 0.20/92.6 ± 0.19 |
| GoolgeLeNet | 91.8 ± 0.13/92.1 ± 0.12 | 92.3 ± 0.13/92.2 ± 0.15 |
| Fine-tuned AlexNet | 97.5 ± 0.18/97.2 ± 0.16 | 98.7 ± 0.10/98.5 ± 0.11 |
| Fine-tuned VGGNet16 | 97.6 ± 0.18/96.9 ± 0.19 | 98.9 ± 0.09/98.3 ± 0.08 |
| Fine-tuned GoolgeLeNet | 97.3 ± 0.18/97.5 ± 0.17 | 98.7 ± 0.12/98.4 ± 0.13 |
| Schemes | Cover and Stego | RSI and Extracted RSI | Acurracy of Detection | ACA |
|---|---|---|---|---|
| PSNR/SSIM * | PSNR/SSIM * | Stegexpose/YeNet | ||
| Literature [8] | 34.78 db/0.92 | 31.5 db/0.90 | 0.55/0.99 | 0.92 |
| Literature [24] | 34.6 db/0.96 | 36.1 db/0.94 | 0.53/0.98 | 0.91 |
| Literature [11] | 44.1 db/0.97 | 39.8 db/0.98 | 0.58/0.98 | 0.93 |
| Literature [23] | 41.3 db/0.95 | 33.1 db/0.97 | 0.52/0.98 | 0.91 |
| Literature [27] | 44.6 db/0.97 | 38.6 db/0.97 | 0.53/0.98 | 0.93 |
| Literature [12] | 42.3 db/0.99 | 38.8 db/0.96 | 0.52/0.96 | 0.94 |
| The proposed method | 47.1 db/0.99 | 38.9 db/0.99 | 0.51/0.90 | 0.98 |
| Variants | Cover and Stego | RSI and Extracted RSI | AD * | ACA |
|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | Stegexpose/YeNet | ||
| DIH4RSID-PAM-PN | 36.8 db/0.80 | 29.6 db/0.80 | 0.53/0.96 | 0.89 |
| DIH4RSID-PAM | 40.9 db/0.83 | 30.1 db/0.82 | 0.55/0.92 | 0.94 |
| DIH4RSID-PN | 42.1 db/0.92 | 32.3 db/0.88 | 0.52/0.91 | 0.93 |
| DIH4RSID | 47.1 db/0.99 | 38.9 db/0.99 | 0.51/0.90 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, P.; Liu, J.; Xu, J.; Dang, Q.; Mu, D. Remote Sensing Images Secure Distribution Scheme Based on Deep Information Hiding. Remote Sens. 2024, 16, 1331. https://doi.org/10.3390/rs16081331
Luo P, Liu J, Xu J, Dang Q, Mu D. Remote Sensing Images Secure Distribution Scheme Based on Deep Information Hiding. Remote Sensing. 2024; 16(8):1331. https://doi.org/10.3390/rs16081331
Chicago/Turabian StyleLuo, Peng, Jia Liu, Jingting Xu, Qian Dang, and Dejun Mu. 2024. "Remote Sensing Images Secure Distribution Scheme Based on Deep Information Hiding" Remote Sensing 16, no. 8: 1331. https://doi.org/10.3390/rs16081331
APA StyleLuo, P., Liu, J., Xu, J., Dang, Q., & Mu, D. (2024). Remote Sensing Images Secure Distribution Scheme Based on Deep Information Hiding. Remote Sensing, 16(8), 1331. https://doi.org/10.3390/rs16081331