Abstract
We compute the exact root-mean-square end-to-end distance of the interacting self-avoiding walk (ISAW) up to 27 steps on the simple cubic lattice. These data are used to construct a fixed point equation to estimate the theta temperature of the collapse transition of the ISAW. With the Bulirsch–Stoer extrapolation method, we obtain accurate results that can be compared with large-scale long-chain simulations. The free parameter in extrapolation is precisely determined using a parity property of the ISAW. The systematic improvement of this approach is feasible by adopting the combination of exact enumeration and multicanonical simulations.
1. Introduction
With the rapid development of computer hardware and software, computational approaches [1,2,3] are increasingly important in polymer science. Among various computational methods, exact enumeration is a very primitive technique. Almost four decades passed since W.J.C. Orr [4] studied the equilibrium properties of a single polymer chain at dilute solution by exact enumeration. In this paper, we show that exact enumeration can already produce quantitative results as accurate as those of large-scale simulations. We focus on the interacting self-avoiding walk (ISAW) on the simple cubic lattice [5,6,7,8,9,10]. The ISAW model is a very basic polymer model that serves as the framework of most lattice protein models [11,12].
An ISAW is a self-avoiding walk with attraction between monomers. The energy of an ISAW chain is defined as m(-), where m is the number of nonconsecutive nearest-neighbor contacts, and - is the attractive contact energy between two monomers. The canonical partition function of a N-step ISAW is
where , is the number of ISAW configurations with m contacts, and M is the maximal number of contacts. Here, and can be set to 1 by adjusting the units. Another important function related to the square of the end-to-end distance is defined as follows:
where is the square end-to-end distance, is the number of ISAW configurations with m contacts and square end-to-end distance , and satisfies . Both and are polynomials of x with positive integer coefficients. The root-mean-square end-to-end distance at a certain temperature can be expressed as follows:
Two examples of the normalized end-to-end function are shown in Figure 1. Both of them are increasing functions, and the slope of the function with larger N is also larger around the intersection point.
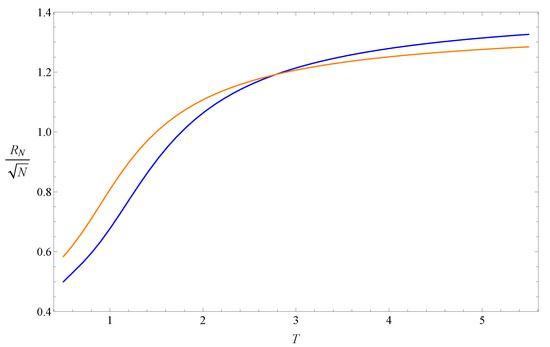
Figure 1.
Curves of defined in Equation (3) and normalized by with (blue) and (orange).
A polymer chain with attraction between monomers undergoes a collapse transition at theta temperature . has different scaling behaviors at different temperature regions [13]:
In three dimensions, and can be determined by the mean-field theory to both be . can be determined with great accuracy by simulation to be 0.587597(7) [14].
The precise estimation of the theta temperature of the ISAW on the simple cubic lattice came from large-scale simulations [15,16,17,18,19,20]. P. Grassberger [17] proposed the well-known pruned-enriched Rosenbluth method (PERM) on the basis of the Rosenbluth–Rosenbluth method and the idea of enrichment. For free chains with N = 10,000, the best estimate of the theta temperature was 3.717(3). The recursive sampling algorithm used by P. Grassberger and R. Hegger [15] was a previous version, and the estimated theta temperature was 3.721(6) with N = 5000. H. Frauenkron and P. Grassberger [18] used the PERM to simulate polymer solutions with N = 2048 and obtained an estimated theta temperature of 3.717(2). T. Vogel et al. [20] used the new PERM with simple sampling up to N = 32,000 and performed a scaling analysis to obtain an estimate of 3.72(1). The above are all chain-growth methods. Tesi et al. [16] used two Markov chain-sampling methods, the multiple Markov chain method and umbrella sampling, to obtain an estimated theta temperature of 3.62(8) with N = 1600. Yan et al. [19] used the expanded grand-canonical ensemble simulation for polymer solutions with N = 16,000 and obtained an estimate of 3.71(1). In general, Monte Carlo methods must be able to generate unbiased samples and overcome the trapping problems. Exact enumeration, in contrast, is much clearer and simpler. The only challenge with exact enumeration is how to count the total number of larger systems. This is more of a computational problem than a theoretical problem. The solution to this problem benefits directly from the rapid development of computer hardware and software.
2. Method
The computational methods used in this paper are the exact enumeration algorithm to count the total number of ISAW configurations, and the Bulirsch–Stoer algorithm to extrapolate the finite-size data.
2.1. Exact Enumeration
To determine and in Equations (1) and (2), we used a direct counting algorithm that we developed [10] to exhaustively enumerate all configurations of an ISAW chain on the simple cubic lattice. The original goal of this algorithm was to generate enough typical sequences for the 27-mers [21] to study the relationship between protein sequences and structures. Using this algorithm to count all configurations (not just the ground states) of a protein sequence with 27 monomers on the simple cubic lattice now only takes the order of days. The algorithm includes not only direct counting but also reduction in the degrees of freedom in the beginning and final stages. These procedures lead to a significant reduction in computation time.
In the following, we explain some details of the counting process. Figure 2 shows all 22 representative configurations of a four-step ISAW on the simple cubic lattice. The convention is the first monomer being placed at the origin and the second monomer at (1, 0, 0), which fixes the first direction (the darker bond in every configuration). The third monomer has four or five possible directions to choose from, and so on. The three numbers above each configuration in Figure 2 are the number of contacts m, the square end-to-end distance , and degeneracy coming from the symmetry of the next direction taken. If the numbers are 0, 10, and 4, variable would be incremented by 4 in the program.
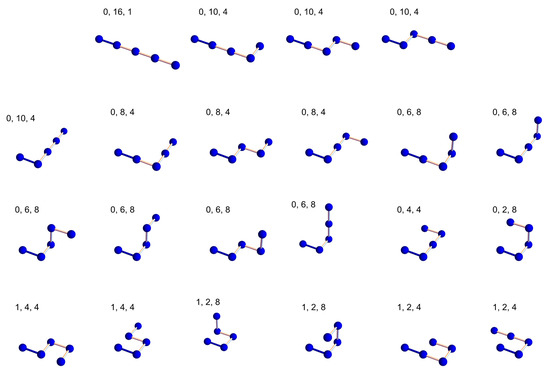
Figure 2.
All configurations of a 4-step ISAW on the simple cubic lattice.
Let us consider the six configurations in the last row of Figure 2 as an example. They are configurations with one contact, and they contribute to the coefficients of the linear terms in and . . . . The coefficient . The final results are and . The root-mean-square end-to-end distance is thus
The direct counting algorithm has the advantage of easily integrating different ideas and techniques. One straightforward parallel implementation for this direct counting algorithm runs 22 jobs with 22 initial configurations shown in Figure 2. The number of jobs can be flexibly adjusted by choosing a different number of initial configurations depending on how many computer cores are available. Lastly, all results are collected and summed up to be the exact coefficients of and . All counting jobs can be completed within a few weeks using a small PC cluster.
2.2. Bulirsch–Stoer Extrapolation
The Bulirsch–Stoer algorithm [22,23,24,25] may be the most powerful extrapolation method in existence. Its idea was borrowed from recursive algorithms such as the Richardson and Neville algorithms, but the result is much more general. In this subsection, we briefly introduce the Bulirsch–Stoer algorithm and explain how to use its main formula. The detailed derivation and proof can be found in [25].
In this paper, the data of the finite-size theta temperature of the ISAW needs to be extrapolated. Suppose its finite-size scaling behavior can be described by power-law functions:
where N is the number of steps of the ISAW chain, is the leading exponent, , and is the finite-size scaling function. We may first consider the approximation that , , , …. Define , then becomes a polynomial function, to which the Neville algorithm can be applied. Below, we use five data points, , as an example to illustrate explicitly the basic procedures of the Neville and Bulirsch–Stoer algorithms, while general formulas are also provided. First, a triangular matrix is prepared, and its first column is filled with :
This matrix can also be expressed as a lower triangular matrix. In this case, the indices in the formulas need a little adjustment. The elements of the second column are then defined as the first-degree Lagrangian polynomials for the data in the first column. For example,
obviously passes through and . Neville noticed that the formula of the same form can be used in the third column. For example,
can be shown by straightforward algebra to be the second-degree Lagrangian polynomial passing through , , and . The same is true for all following columns. Thus, the general formula is:
Equation (9) is the main formula of the Neville algorithm. The final output for this five-point example is , the fourth-degree Lagrange polynomial passing through all five data points. It is an extrapolation function that can be used to approximate the finite-size scaling function . Neville showed that the Lagrangian polynomials can be generated in such an iterated way. The Neville algorithm is very efficient in evaluating function values for interpolation or extrapolation.
Bulirsch and Stoer inserted an additional term: , in the denominator in Equation (9):
The appearance of requires to be defined first. They can be set to zero in the beginning. The effect of the additional term is that now becomes a rational function , where both and are polynomials. This rational function also passes through all the data points and is another extrapolation function that can be used to approximate the finite-size scaling function . Since is actually not a polynomial, it is expected that the more general rational functions are more suitable to model than polynomials. Our extrapolation results also show that the Bulirsch–Stoer algorithm is always more accurate than the Neville algorithm. More details on the properties of such rational functions appearing in Bulirsch–Stoer extrapolation can be found in [25].
Equation (11) is the main formula used in this paper to extrapolate the finite-size theta temperatures. Now is the extrapolation estimation of the theta temperature with five data points. and are also the estimations of the theta temperature but with only four data points used. They are less accurate than , while their difference can serve as an estimate of the error of . A simple argument is as follows. Suppose , , and , where , , and are the statistical errors of , , and . can be expressed as . Its range is larger than , since both and are larger than . Thus, can roughly play the role of . Although there are actually no statistics for , this error estimation is appropriate for most testing examples where the answers are known. The premise is that , , and should be close to each other to indicate that the extrapolation values have entered a stable region. In this paper, we adopt the following definition of the error of :
In Equation (11), is a free parameter. does not need to be equal to , but it won’t be very different either. Each is associated with an extrapolation function that passes through all the data points. A different results in a different extrapolation value. It is, thus, very important to choose carefully. A reasonable choice of is the one that minimizes the error defined in Equation (12). In this paper, we use the parity property of the ISAW on the simple cubic lattice to more precisely determine .
3. Result
On the basis of Equation (4), the solution of the following equation is an estimation of theta temperature :
The choice of N and should be both odd or both even. The random walks on the square or simple cubic lattice are naturally divided into two groups, namely, random walks with the even number of steps and the odd number of steps. On the simple cubic lattice, even-step walks only stop at the point with even , and odd-step walks only stop at the point with odd . For this reason, random walks with the same parity are more similar to each other. When N and are closer, the two walks would also be more similar, and Equation (13) would give more accurate estimations. Our numerical results confirmed this expectation. Therefore, we only discuss the case of in this paper. Equation (13) becomes
We generated square end-to-end functions for (listed in Appendix A), and used them and Equation (14) to calculate . The results were divided into two groups according to parity and are listed in Table 1. Figure 3 also shows that the data points were clearly divided into two groups. The two lines passing through the data points are seventh-degree Lagrangian polynomials. They will merge as . The estimation of the theta temperature could be reasonably set as ≡ (. Its error is defined as , where and are errors of and (Equation (12)) in the Bulirsch–Stoer extrapolation method. Two extrapolations need to be performed here, and the chosen needs to make both and smaller. Since there are two constraints, the extrapolation value would be less biased.

Table 1.
Estimation of the theta temperature determined by Equation (14).
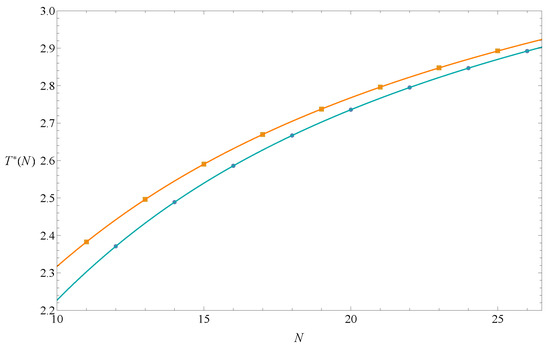
Figure 3.
determined by Equation (14) for odd and even N. The two lines that pass through eight odd data points and eight even data points are seventh-degree Lagrangian polynomial graphs.
To determine an optimal , a wide range of is scanned first to find the region with small errors. The adjacent area is then zoomed in until the results do not change. Table 2 lists the estimations and errors of the theta temperature in the range of . The error is minimal as , so the best estimation was . This result is consistent with the long-chain results of large-scale simulations [15,16,17,18,19,20]. We also used the Neville algorithm (Equation (9)) instead of the Bulirsch–Stoer algorithm to extrapolate the same data. The best estimation was with . For all data that we examined, the results of the Bulirsch-Stoer algorithm were always better than the results of the Neville algorithm. Extrapolation with rational functions is expected to be better than extrapolation with polynomials unless the finite-size scaling function is inherently a polynomial.
Table 2.
Extrapolation with different for the data listed in Table 1, where , and error .
We also considered a correction term predicted by the field-theoretic renormalization group calculation [26]:
This correction term is small and may not agree with the simulations [15,17]. We followed the same procedure as above to calculate with Equation (15), and list the results in Table 3 for comparison.
Table 3.
The estimation of theta temperature determined by Equation (15).
The best estimation from the data in Table 3 was with . Since listed in Table 3 was closer to the value of the “real” than those in Table 1, the extrapolation result seemed to be also improved.
We may use the same procedure to calculate other quantities. For example, we can verify the value of the crossing exponent in Equation (4) in the following way.
Equation (17) is a ratio method. We took 3.713 as the value of . The results are listed in Table 4. The best estimation of was with , while the exact value is . This result is not as accurate as that of theta temperature estimation. The correction term seems to be important when computing critical exponents. We have tried to include a correction term and obtained much more accurate results. However, since this paper mainly regards the efficiency of direct computation, we do not discuss the effect of correction further.
Table 4.
The estimation of crossing exponent determined by Equation (17).
4. Discussion
The longest ISAW chain used in the calculation of this paper is the 27-step walk. The total number of its configurations is huge: 431,645,810,810,533,429 . From such a large number and others, we obtained an accurate estimate of the theta temperature of ISAW on the simple cubic lattice. Nevertheless, a 27-step ISAW is very short in three dimensions. The finite-size effect should be obvious. There are two reasons why short chains can still give accurate results. The first reason is the careful determination of the free parameter in the Bulirsch–Stoer algorithm. For ISAWs on the simple cubic lattice, we could just take advantage of their natural division into odd and even groups. There are two constraints on the choice of , resulting in more stable and accurate extrapolation results. This experience may be extended to other problems where data points are not smooth. The way of classifying the data points and combining the extrapolation results could work. If only one series of data is extrapolated, unless the data points are very smooth, the corresponding to the minimal error does not necessarily produce extrapolation values very close to the true answer.
Another reason is that Equation (13) may be regarded as a fixed-point equation of the real-space renormalization group transformation for the coarse-graining process, where each N-step segment of the ISAW is replaced by a -step segment (). In this view, N and are the block sizes of the transformation and not the length of the whole ISAW chain. The finite-size effect could, therefore, be less obvious. Equation (13) can be rewritten as the equation to transform T to : , which will drive the temperature away from the intersectional temperature . Figure 1 shows this feature: if , is larger than T, and , is smaller than T. A simple explanation is that, if , , so needs to be larger to balance the transformation equation. A similar logic could be used for the case of . Only in the critical region around , , and the normalized end-to-end distances of the two ISAW segments with length N and are approximately the same. The larger and closer N and are, the more similar these two segments are, and the transformation equation is more accurate, so that is closer to . Traditional real-space renormalization approaches for polymer models usually focus on the variable fugacity, e.g., [27]. The above scenario of the real-space renormalization along the ISAW chain is only for the variable temperature and can be developed in more detail. It is also similar to phenomenological renormalization, e.g., [28], in which the correlation length plays the same role as and can be calculated by the transfer matrix method.
The number of configurations of an N-step ISAW grows exponentially with N, e.g., with for the simple cubic lattice. From 27 to 30 steps, the number of configurations is increased by about 100 times. To go further, the degree of freedom of the problem must be reduced in some way. The transfer matrix technique is efficient for the counting problem of the two-dimensional ISAW [29,30], but difficult to extend to the three-dimensional case. Matrix methods have been used in polymer science for many years, e.g., [31,32], and deserve further development. The length-doubling method [33,34] reduces the degree of freedom by counting and saving the information of two short walks and then joining them to form a longer walk. It is very feasible for us to use this approach because we had developed a counting algorithm with a similar idea [35]. We counted the number of graphs in the percolation and Potts models by dividing the graphs into two parts (or several layers) and then combining the two parts of the data to obtain the complete result. This algorithm was used to study the partition function zeros of the Potts model on the self-dual lattices [36].
We can push to the limit the size of the system that can be exactly enumerated to obtain more accurate results. However, this direction may become very technical. A more practical approach is to perform the multicanonical simulation [37,38] to count the configurations of longer chains. The multicanonical simulation accumulates the density of states during Monte Carlo sampling and is very different from the Metropolis algorithm, in which sampling is just for averaging. This approach can be called Monte Carlo counting, corresponding to exact counting. Among multicanonical methods, the Wang–Landau algorithm [39] is commonly used because of its concise steps and high efficiency. It has been applied to polymer simulations of various systems, including the ISAW [40]. We have tried to combine the data of medium-length chains by Wang–Landau sampling with the data of short chains by exact enumeration. Although the numbers of configurations from the Wang–Landau method are approximate, they carry information about the longer chains and would stabilize the extrapolation curve around the medium-length region. Therefore, the data from the Wang–Landau method would certainly improve the accuracy of exact enumeration. If there is no need to reach the limit, the total computation time spent on exact enumeration and Wang–Landau sampling together could still be less than that of large-scale simulations. This approach of combining exact counting and Monte Carlo counting might become a practical and general technique in computational science.
In summary, we used exact enumeration and Bulirsch–Stoer extrapolation to obtain an accurate estimate of the theta temperature of the ISAW on the simple cubic lattice. The systematic improvement of this approach by increasing the chain length is achievable. Research in this direction is in progress.
Author Contributions
Three authors designed the project. Y.-H.H. and C.-N.C. generated the exact data of end-to-end distances, which were analyzed by S.-S.H. and C.-N.C. C.-N.C. wrote the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported by the National Science and Technology Council of ROC in Taiwan (grant number: 109-2112-M-259-004).
Acknowledgments
We would like to thank Chin-Kun Hu.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Square end-to-end distance function was used in the calculation of this paper. can be found in [8,9,10] and references therein. The convention adopted in these references was , where n is the number of monomers, i.e., .
References
- Binder, K. (Ed.) Monte Carlo and Molecular Dynamics Simulations in Polymer Science; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Binder, K.; Heermann, D.W. Monte Carlo Simulation in Statistical Physics: An Introduction, 6th ed.; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Zierenberg, J.; Marenz, M.; Janke, W. Dilute semiflexible polymers with attraction Collapse, folding and aggregation. Polymers 2016, 8, 333. [Google Scholar] [CrossRef] [PubMed]
- Orr, W.J.C. Statistical treatment of polymer solutions at infinite dilution. Trans. Faraday Soc. 1947, 43, 12–27. [Google Scholar] [CrossRef]
- Rapaport, D.C. On the polymer phase transition. Phys. Lett. A 1947, 48, 339–340. [Google Scholar] [CrossRef]
- Finsy, R. Internal transition in an infinitely long polymer chain. J. Phys. A Math. Gen. 1975, 8, L106–L109. [Google Scholar] [CrossRef]
- Schiemann, R.; Bachmann, M.; Janke, W. Exact enumeration of three-dimensional lattice proteins. Comput. Phys. Commun. 2005, 166, 8–16. [Google Scholar] [CrossRef]
- Lee, J.H.; Kim, S.Y.; Lee, J. Exact partition function zeros of a polymer on a simple cubic lattice. Phys. Rev. E 2012, 86, 011802. [Google Scholar] [CrossRef]
- Chen, C.N.; Hsieh, Y.H.; Hu, C.K. Heat capacity decomposition by partition function zeros for interacting self-avoiding walks. EPL 2013, 104, 20005. [Google Scholar] [CrossRef]
- Hsieh, Y.H.; Chen, C.N.; Hu, C.K. Efficient algorithm for computing exact partition functions of lattice polymer models. Comput. Phys. Commun. 2016, 209, 27–33. [Google Scholar] [CrossRef]
- Dill, K.A.; Bromberg, S.; Yue, K.; Fiebig, K.M.; Yee, D.P.; Thomas, P.D.; Chan, H.S. Principles of protein folding—A perspective from simple exact models. Protein Sci. 1995, 4, 561–602. [Google Scholar] [CrossRef]
- Thirumalai, D.; Samanta, H.S.; Maity, H.; Reddy, G. Universal nature of collapsibility in the context of protein folding and evolution. Trends Biochem. Sci. 2019, 44, 675–687. [Google Scholar] [CrossRef]
- de Gennes, P.G. Scaling Concepts in Polymer Physics; Cornell University Press: Ithaca, NY, USA, 1979. [Google Scholar]
- Clisby, N. Accurate Estimate of the critical exponent ν for self-avoiding walks via a fast implementation of the pivot algorithm. Phys. Rev. Lett. 2010, 104, 055702. [Google Scholar] [CrossRef] [PubMed]
- Grassberger, P.; Hegger, R. Simulations of three-dimensional θ polymers. J. Chem. Phys. 1995, 102, 6881–6899. [Google Scholar] [CrossRef]
- Tesi, M.C.; van Rensburg, E.J.J.; Orlandini, E.; Whittington, S.G. Interacting self-avoiding walks and polygons in three dimensions. J. Phys. A Math. Gen. 1996, 29, 2451–2463. [Google Scholar] [CrossRef]
- Grassberger, P. Pruned-enriched Rosenbluth method Simulations of theta polymers of chain length up to 1000000. Phys. Rev. E 1997, 56, 3682–3693. [Google Scholar] [CrossRef]
- Frauenkron, H.; Grassberger, P. Critical unmixing of polymer solutions. J. Chem. Phys. 1997, 107, 9599–9608. [Google Scholar] [CrossRef]
- Yan, Q.; de Pablo, J.J. Critical behavior of lattice polymers studied by Monte Carlo simulations. J. Chem. Phys. 2000, 113, 5954–5957. [Google Scholar] [CrossRef]
- Vogel, T.; Bachmann, M.; Janke, W. Freezing and collapse of flexible polymers on regular lattices in three dimensions. Phys. Rev. E 2007, 76, 061803. [Google Scholar] [CrossRef]
- Shakhnovich, E.; Farztdinov, G.; Gutin, A.M.; Karplus, M. Protein folding bottlenecks: A lattice Monte Carlo simulation. Phys. Rev. Lett. 1991, 67, 1665–1668. [Google Scholar] [CrossRef]
- Bulirsch, R.; Stoer, J. Fehlerabschätzungen und Extrapolation mit rationalen Funktionen bei Verfahren vom Richardson-Typus. Numer. Math. 1964, 6, 413–427. [Google Scholar] [CrossRef]
- Henkel, M.; Schütz, G. Finite-lattice extrapolation algorithms. J. Phys. A. 1988, 21, 2617–2633. [Google Scholar] [CrossRef]
- Monroe, J.L. Extrapolation and the Bulirsch-Stoer algorithm. Phys. Rev. E 2002, 21, 066116. [Google Scholar] [CrossRef] [PubMed]
- Stoer, J.; Bulirsch, R. Introduction to Numerical Analysis, 3rd ed.; Springer: New York, NY, USA, 2002; Chapter 2. [Google Scholar]
- Duplantier, B. Geometry of polymer chains near the theta-point and dimensional regularization. J. Chem. Phys. 1987, 86, 4233–4244. [Google Scholar] [CrossRef]
- Maritan, A.; Seno, F.; Stella, A.L. Real space renormalization group approach to the theta point of a linear polymer in 2 and 3 dimensions. Physica A 1989, 156, 679–688. [Google Scholar] [CrossRef]
- Derrida, B.; De Seze, L. Application of the phenomenological renormalization to percolation and lattice animals in dimension 2. J. Phys. 1982, 43, 475–483. [Google Scholar] [CrossRef]
- Beaton, N.R.; Guttmann, A.J.; Jensen, I. Two-dimensional interacting self-avoiding walks new estimates for critical temperatures and exponents. J. Phys. A Math. Theor. 2020, 53, 165002. [Google Scholar] [CrossRef]
- Lee, J. Transfer matrix algorithm for computing the exact partition function of a square lattice polymer. Comput. Phys. Commun. 2018, 228, 11–21. [Google Scholar] [CrossRef]
- Flory, P.J.; Jernigan, R.L. Second and Fourth Moments of Chain Molecules. J. Chem. Phys. 1965, 42, 3509–3519. [Google Scholar] [CrossRef]
- Blanco, P.M.; Madurga, S.; Mas, F.; Garcés, J.L. Coupling of Charge Regulation and Conformational Equilibria in Linear Weak Polyelectrolytes Treatment of Long-Range Interactions via Effective Short-Ranged and pH-Dependent Interaction Parameters. Polymers 2018, 10, 811. [Google Scholar] [CrossRef]
- Schram, R.D.; Barkema, G.T.; Bisseling, R.H. Exact enumeration of self-avoiding walks. J. Stat. Phys. 2011, 6, P06019. [Google Scholar] [CrossRef]
- Schram, R.D.; Barkema, G.T.; Bisseling, R.H. SAWdoubler: A program for counting self-avoiding walks. Comput. Phys. Commun. 2013, 184, 891–898. [Google Scholar] [CrossRef]
- Chen, C.N.; Hu, C.K. Fast algorithm to calculate exact geometrical factors for the q-state Potts model. Phys. Rev. B 1991, 13, 11519–11522. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.N.; Hu, C.K.; Wu, F.Y. Partition function zeros of the square lattice Potts model. Phys. Rev. Lett. 1996, 76, 169–172. [Google Scholar] [CrossRef] [PubMed]
- Berg, B.A.; Neuhau, T. Multicanonical algorithms for first order phase transitions. Phys. Lett. B 1991, 267, 249–253. [Google Scholar] [CrossRef]
- Berg, B.A.; Neuhau, T. Multicanonical ensemble: A new approach to simulate first-order phase transitions. Phys. Rev. Lett. 1992, 68, 9–12. [Google Scholar] [CrossRef]
- Wang, F.; Landau, D.P. Efficient, multiple-range random walk algorithm to calculate the density of states. Phys. Rev. Lett. 2001, 86, 2050–2053. [Google Scholar] [CrossRef]
- Wüst, T.; Landau, D.P. Versatile approach to access the low temperature thermodynamics of lattice polymers and proteins. Phys. Rev. Lett. 2009, 102, 178101. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).