Abstract
Accurately recognizing apples in complex environments is essential for automating apple picking operations, particularly under challenging natural conditions such as cloudy, snowy, foggy, and rainy weather, as well as low-light situations. To overcome the challenges of reduced apple target detection accuracy due to branch occlusion, apple overlap, and variations between near and far field scales, we propose the Rep-ViG-Apple algorithm, an advanced version of the YOLO model. The Rep-ViG-Apple algorithm features a sophisticated architecture designed to enhance apple detection performance in difficult conditions. To improve feature extraction for occluded and overlapped apple targets, we developed the inverted residual multi-scale structural reparameterized feature extraction block (RepIRD Block) within the backbone network. We also integrated the sparse graph attention mechanism (SVGA) to capture global feature information, concentrate attention on apples, and reduce interference from complex environmental features. Moreover, we designed a feature extraction network with a CNN-GCN architecture, termed Rep-Vision-GCN. This network combines the local multi-scale feature extraction capabilities of a convolutional neural network (CNN) with the global modeling strengths of a graph convolutional network (GCN), enhancing the extraction of apple features. The RepConvsBlock module, embedded in the neck network, forms the Rep-FPN-PAN feature fusion network, which improves the recognition of apple targets across various scales, both near and far. Furthermore, we implemented a channel pruning algorithm based on LAMP scores to balance computational efficiency with model accuracy. Experimental results demonstrate that the Rep-ViG-Apple algorithm achieves precision, recall, and average accuracy of 92.5%, 85.0%, and 93.3%, respectively, marking improvements of 1.5%, 1.5%, and 2.0% over YOLOv8n. Additionally, the Rep-ViG-Apple model benefits from a 22% reduction in size, enhancing its efficiency and suitability for deployment in resource-constrained environments while maintaining high accuracy.
1. Introduction
As a significant component of the fruit industry, apples occupy extensive planting areas and have a high total production volume. The intelligent and automated development of the apple industry is of paramount importance for the advancement of agriculture and the economy [1]. Apple harvesting is a crucial stage in the apple production process. Given the complex environment of apple orchards, apple harvesting is predominantly performed manually during the harvest season, leading to high labor costs and low production efficiency. Therefore, replacing manual labor with mechanical automation in apple harvesting is an inevitable trend [2,3]. Accurate detection of apples in the complex environment of orchards is essential for mechanical automated harvesting. However, the natural complexity of orchard environments poses significant challenges for apple target detection in real-world scenarios, making it difficult to accurately identify apple targets. Consequently, developing a method capable of reliably detecting apples in complex environments is of great practical significance and holds extensive application prospects.
With the increasing application of deep learning in agriculture [4,5,6,7,8], significant progress was made by domestic and international scholars in apple detection within complex orchard environments. Long Yan et al. [9] introduced a window multi-head self-attention mechanism and SIoU bounding box loss function to the YOLOv7 framework, achieving an average detection precision of 95.2% for apples, although the model size is relatively large at 81 MB. Pengfei Hao et al. [10] proposed a YOLO-RD-Apple detection algorithm for natural environments by improving the YOLOv4 algorithm, with a detection precision of 93.1% and a computational load of 34.12 G. Jun Sun et al. [11] developed an improved RetinaNet-based apple detection algorithm for complex orchard environments, achieving a detection precision of 91.26%, but the model size is 128 MB. Bin Yan et al. [12] proposed an improved YOLOv5m apple recognition method, with an average detection precision of 80.7%, a recall rate of 85.9%, and a precision rate of 81.0%, with the model size being 37 MB. The aforementioned methodologies effectively enhanced the precision of apple detection in complex environments. However, they all face the issue of increased model size post-improvement. Balancing the computational load and detection precision remains a key focus in current apple detection algorithm research. Furthermore, current methods often struggle with occlusion and varying lighting conditions, leading to decreased accuracy, and there is a paucity of research exploring apple detection in complex weather environments, several challenges persist in apple detection under complex environments, such as weather conditions and low-light scenarios in real orchard settings. Simple data training often results in weak model generalization. Additionally, the similar colors of leaves and apples, occlusions from branches, overlapping apples, and varying apple sizes and shapes complicate effective feature extraction and fusion, leading to missed or incorrect detections.
The YOLOv8 model, developed by the Ultralytics team and its contributors, is the latest version in the YOLO series. YOLOv8 [13] is available in five variants based on the number of parameters and computational complexity: n, s, m, l, and x. Due to its high accuracy, YOLOv8 was widely applied in various object detection tasks. However, in the context of apple detection in orchards under complex environmental conditions, the smallest YOLOv8n model tends to suffer from false negatives and false positives, resulting in lower accuracy. Conversely, the larger YOLOv8m model achieves higher accuracy but comes with a substantial parameter and computational overhead, which leads to increased computational costs and makes it challenging to deploy in practical applications.
In response to the aforementioned challenges, this paper focuses on enhancing and optimizing the baseline YOLOv8n model through several key contributions:
- We developed a novel dataset specifically for Aksu apple detection in complex environments due to the absence of publicly available datasets. This dataset was constructed through manual image collection and further expanded using an offline data augmentation algorithm (weather_aug). This algorithm simulates various real-world weather conditions—such as rainy, foggy, and cloudy days—as well as low-light environments, thereby improving the model’s generalization ability in diverse orchard conditions.
- We proposed the RepIRD Block module and introduced the sparse vision graph attention (SVGA) module to address issues related to insufficient apple feature information and environmental interference. Additionally, we developed a new CNN-GCN architecture for feature extraction, designated Rep-Vision-GCN. This architecture effectively captures both multi-scale local features and global contextual information, thereby enhancing apple detection performance under complex environmental conditions.
- We implemented the RepConvsBlock re-parameterization module and constructed the Rep-FPN-PAN feature fusion network to address the challenge of inadequate feature fusion. This network is designed to effectively manage significant size variations in apples due to different shooting distances, thereby improving feature integration and detection accuracy.
- We adopted a channel pruning algorithm based on LAMP scores to tackle the increased computational and parameter overhead in the enhanced Rep-ViG-Apple model. This algorithm prunes redundant feature maps to compress the model’s size while maintaining its accuracy.
2. Materials and Methods
2.1. Dataset Construction
The apple images in the dataset were collected from apple orchards around Aksu City, Xinjiang (longitude 80.30, latitude 41.14). The Aksu region has a temperate continental arid climate, with annual sunshine hours exceeding 2600 h and an annual average temperature of 7.9–11.29 °C. During the growing season (April to October), the average temperature is 16.7–19.89 °C, and there is an average of 210 days per year with temperatures above 5 °C, contributing to the high quality of Aksu apples. We conducted the data collection during the mid to early October period, when the apples were approaching maturity. To ensure the diversity of the data, we established two data sampling locations: the Ekantqi Town Apple Orchard and the Meilidiayemugu Orchard. The apple trees are planted with a spacing of 3–4 m, and the images were captured from distances ranging from 0.5 to 3 m. Apples were photographed at different scales, backgrounds, and lighting conditions, including various lighting environments (front light, backlight) and from different angles and distances, the visual representation of the apples is partially obscured by the foliage above, and the surface of the apples is shaded. The shooting time was from 10:00 to 16:00, The images were collected using a smartphone (iPhone 14 Pro, Apple Inc., Cupertino, CA, USA) at a resolution of 4032 × 3024. A total of 510 high-quality images were acquired. The data collection locations and environments are shown in Figure 1.

Figure 1.
Data collection locations and samples. (a) Meilidiayemugu fruit orchard. (b) Ekantqi Town apple plantation. (c) Backlight + long shot. (d) Front light + close-up. (e) Backlight + close-up. (f) Front light + long shot + complex background. (g) Obstruction + long shot (bag interference). (h) Few targets + simple background. (i) Multiple targets. (j) Severe obstruction + long shot.
Following the collection of apple images, a meticulous manual screening process was conducted to ensure that only clear and high-quality images were retained in the dataset. The curated dataset was then partitioned into training, testing, and validation sets following an 8:1:1 ratio.
To address the challenges of apple detection in complex environments, we use the imgaug library [14] to build a data enhancement method for complex orchard environments during the data construction phase. The imgaug library is primarily based on image processing methods that incorporate elements of the natural environment into the foreground of the image. The intensity range of the weather elements is set to simulate different degrees of real weather. Specifically, it randomly simulates several real-world weather conditions, such as snowy weather, sunny weather, cloudy weather, foggy weather and rainy weather, as well as low-light conditions. In addition to these weather simulations, the data augmentation algorithm incorporates contrast enhancement to improve the detail representation of apple targets. The image enhancement of the basic apple dataset constructed in this paper is performed using the weather_aug method, which simulates the perspective of the picking equipment in the complex weather environment in the orchard. The model is trained using the augmented data to improve the robustness of the model, thereby enhancing its ability to adapt to the detection of apples in the complex environment of the orchard. By enhancing the dataset with the augmentation algorithm, it more closely mirrors the complexities of real-world environments. This, in turn, significantly boosts the robustness of the apple detection model. The outcomes of the data augmentation algorithm are illustrated in Figure 2.

Figure 2.
Complex environment data augmentation. (a) Origin image. (b) Contrast enhance. (c) Low light. (d) Snowy weather. (e) Sunny weather. (f) Overcast weather. (g) Foggy weather. (h) Rainy weather.
The partitioned apple dataset was further augmented using the weather_aug image enhancement algorithm, resulting in a total of 4080 images. The enhanced apple dataset was manually annotated using the X-AnyLabeling 2.3.0 toolproducing annotations in the VOC format, with label files in the XML format. Subsequently, code was developed to convert these XML label files into the YOLO-compatible TXT format.
The distribution of the training, testing, and validation sets within the apple detection dataset, as well as the number of images corresponding to each type of augmentation, are detailed in Table 1.

Table 1.
Distribution of different types of data.
2.2. Rep-ViG-Apple Network Architecture
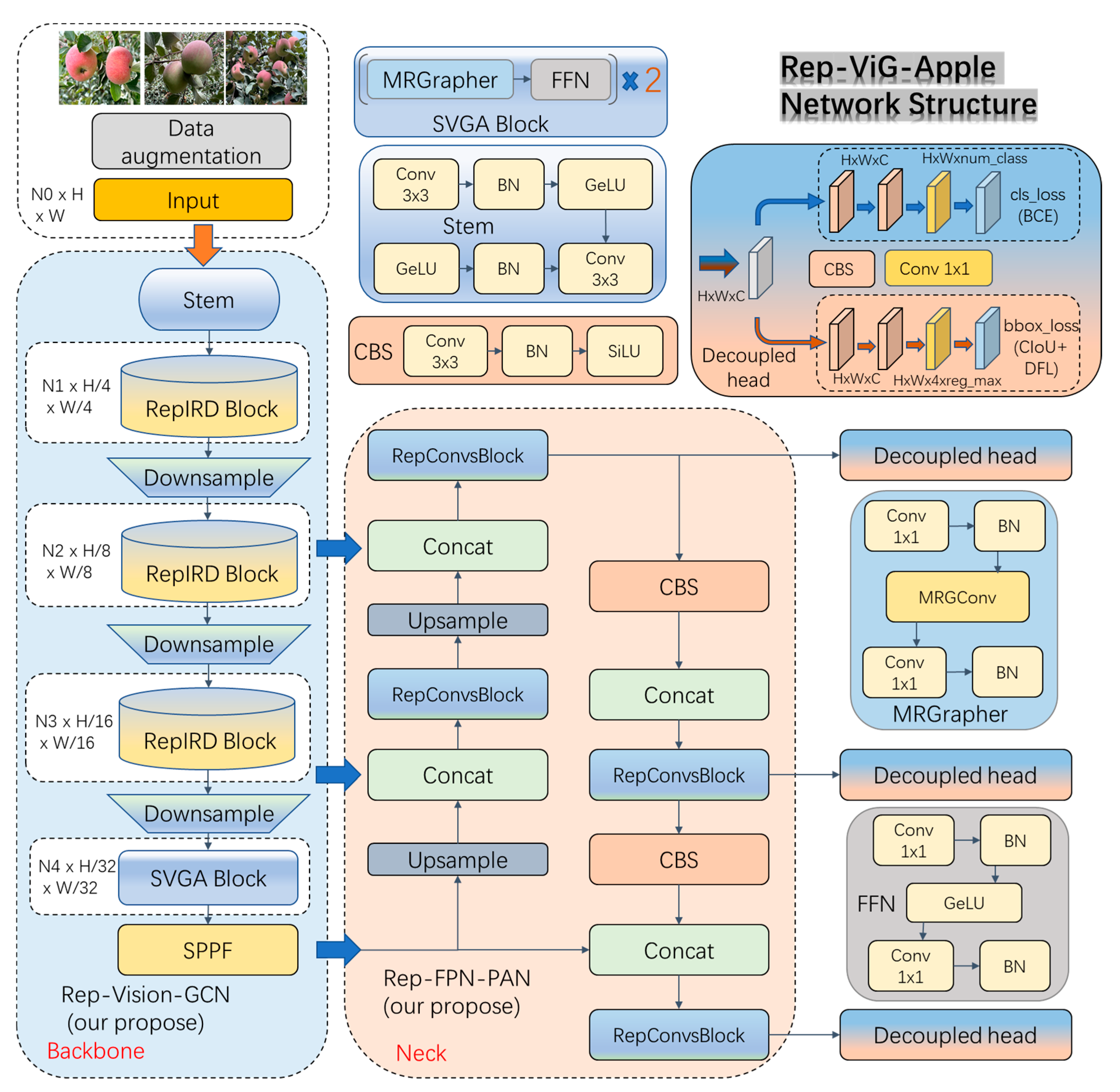
The Rep-ViG-Apple network architecture is illustrated in Figure 3. The feature extraction network is Rep-Vision-GCN (Backbone), and the feature fusion network is Rep-FPN-PAN (neck). The prediction head adopts the decoupled head concept from YOLOX [15], consisting of both a classification head and a regression head. The loss function for the regression head comprises two parts: CIoU and distribution focal loss (DFL). For sample matching, it uses the TaskAlignedAssigner [16] strategy for positive and negative sample assignment and the anchor-free [17] strategy. The classification head uses the binary cross-entropy (BCE) loss function.
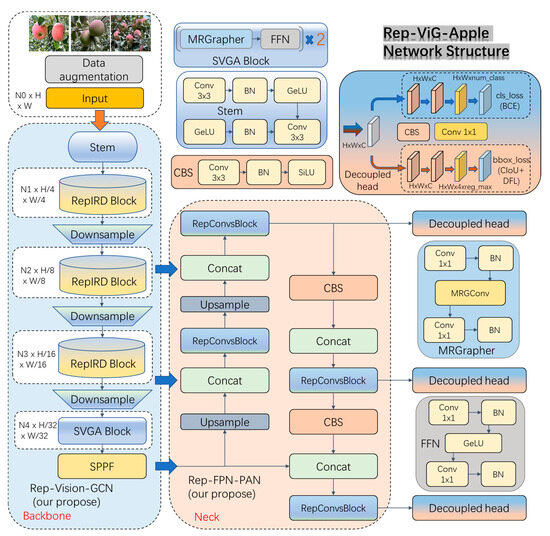
Figure 3.
Network structure of Rep-ViG-Apple.
2.2.1. Rep-Vision-GCN Feature Extraction Network
In the context of apple detection tasks within orchard environments, the complex weather conditions and distracting orchard backgrounds pose significant challenges. Issues such as occlusion by branches and leaves, as well as overlapping fruits, make it difficult to accurately identify apple targets. YOLOv8n, with its single-scale feature extraction, often fails to sufficiently capture feature information in these complex environments and multi-scale detection scenarios. To address these challenges, this paper proposes an inverted residual re-parameterized multi-scale feature extraction module (RepIRD Block), designed to enhance feature extraction capabilities for occluded and overlapping targets. Additionally, the YOLOv8n model employs the traditional convolutional neural network (CNN) architecture, which treats images as grid structures. Convolution operations in this architecture are performed within a fixed-size local receptive field, making it difficult to extract global, long-range feature information, and because it is difficult to suppress interference from complex environments, a sparse graph attention mechanism is employed to increase focus on apples and suppress interference from complex environmental features. Thus, a robust feature extraction network tailored for apple detection in complex environments is constructed.
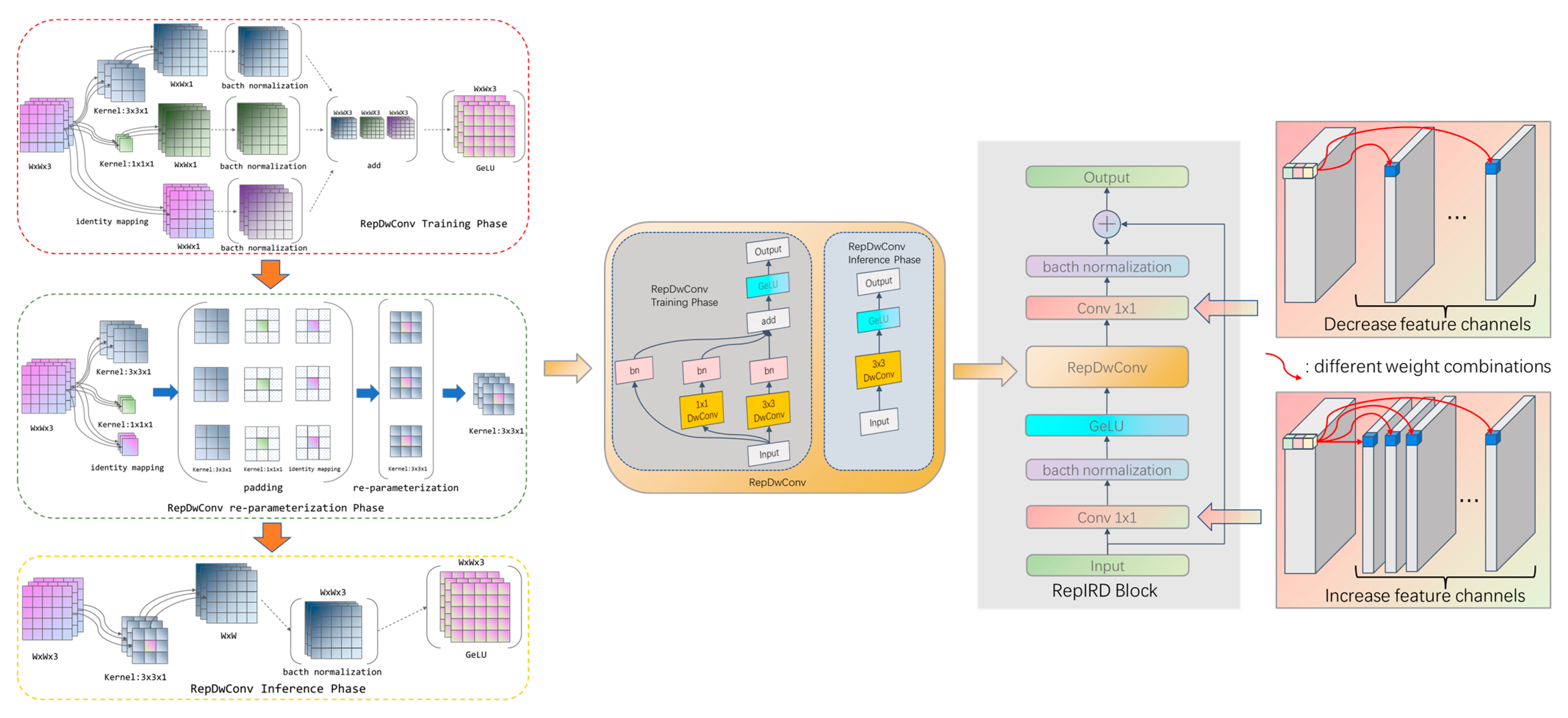
Our proposed inverted residual multi-scale re-parameterization feature extraction module (RepIRD Block) is a lightweight, multi-branch architecture that leverages depthwise convolutions to learn more expressive features across high-dimensional feature maps. The RepIRD Block achieves reduced computational complexity by decoupling the spatial and channel dimensions. Multi-scale feature information is extracted in the spatial dimension using RepDwConv, followed by feature extraction in the channel dimension using 1 × 1 standard convolutions. The features output by RepDwConv are then subjected to cross-channel information exchange to enhance the model’s non-linear representational capacity. Additionally, residual connections are incorporated to mitigate the risk of gradient vanishing. During the training phase, the RepIRD Block leverages the multi-branch structure of RepDwConv to capture rich apple feature information. In the inference phase, the RepDwConv is re-parameterized into a single-branch structure, thereby reducing the computational and parameter burden of the model. This approach ensures that computational efficiency is attained without sacrificing accuracy, resulting in a compressed model with no loss in precision for apple detection tasks. The structure of the RepIRD Block is illustrated in Figure 4.

Figure 4.
RepIRD Block.
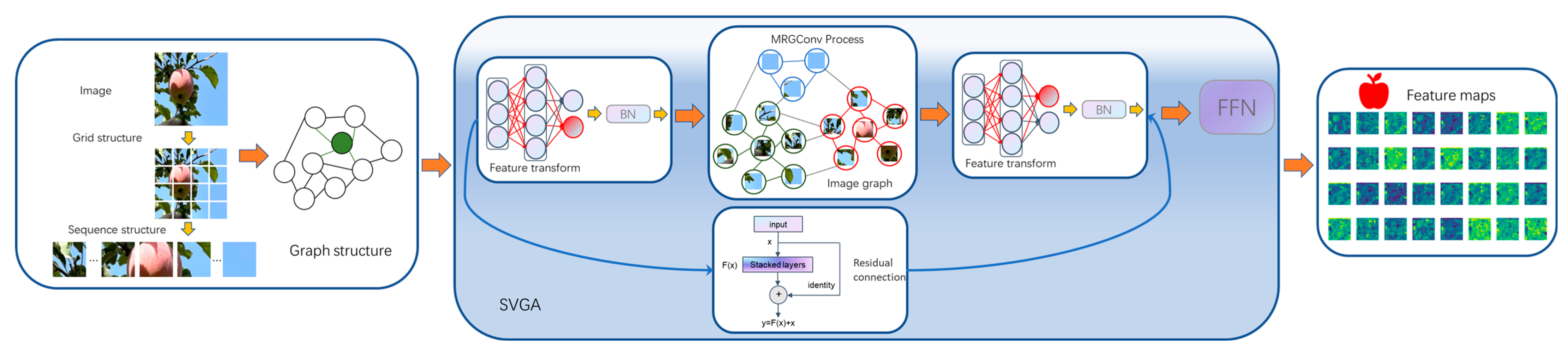
In 2016, Thomas Kpif et al. [18] first proposed graph convolutional neural networks, applying convolutional neural network methods to graph structures and showing excellent performance. Today, graph convolutional neural networks are applied to different fields, such as computer vision tasks [19,20] and natural language processing tasks [21,22,23]. The sparse vision graph attention [24] (SVGA) module in the graph convolutional network (GCN) architecture addresses this issue by constructing a sparse graph structure for feature extraction. The sparse graph attention mechanism captures global features, enhancing focus on apples and mitigating interference from complex environments. This method effectively improves the ability to recognize apple targets under challenging conditions, such as rainy, foggy, snowy weather, and low-light environments at night. SVGA is mainly divided into two processes: sparse graph construction and feature information aggregation update.
(1) Sparse Graph Construction Process in SVGA
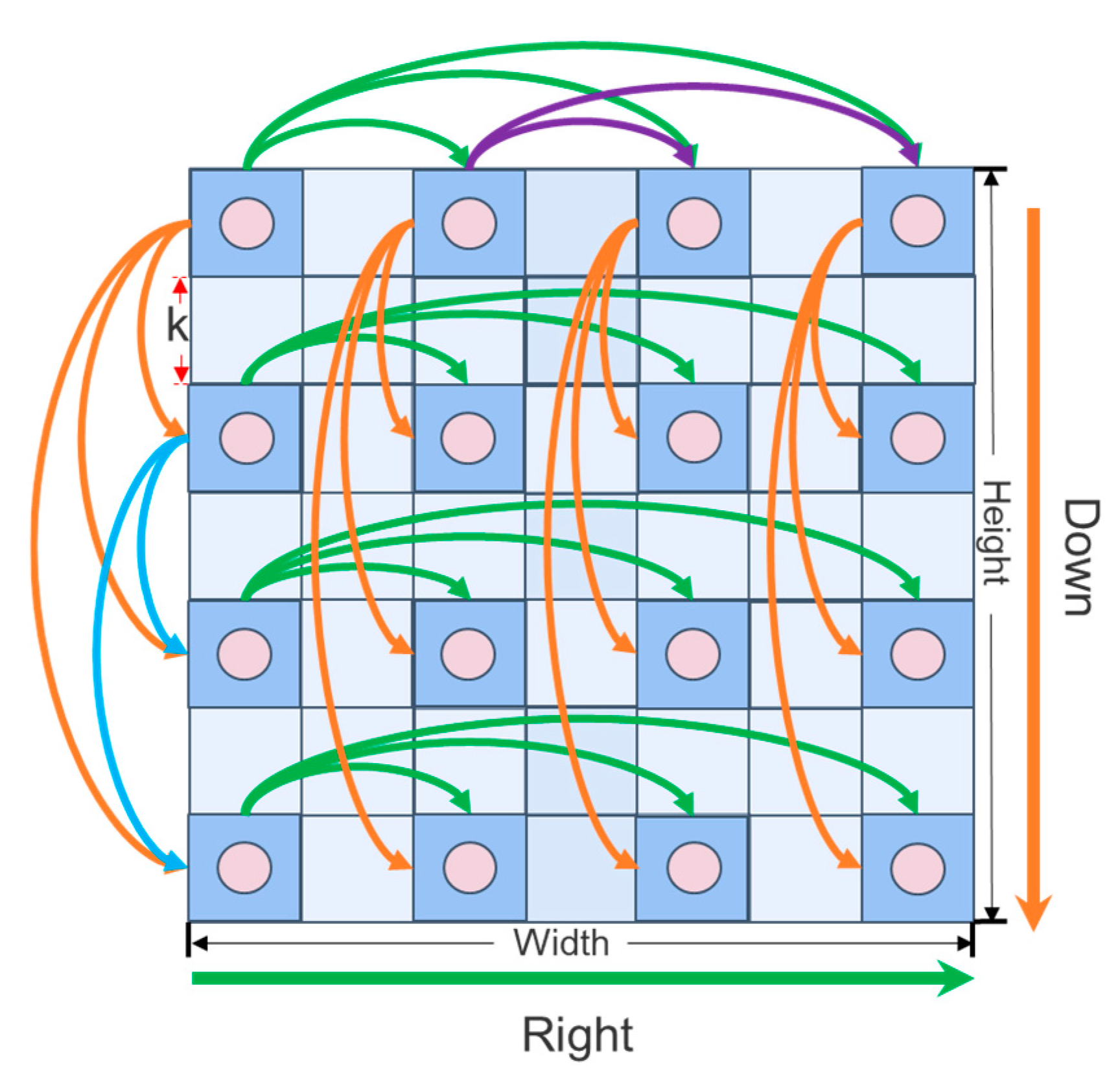
In constructing the sparse graph structure within the sparse vision graph attention (SVGA) module, the input feature map is segmented, with each image pixel considered as a vertex. Aggregation operations are performed in parallel along the width and height dimensions of the feature map. This process is illustrated in Figure 5.
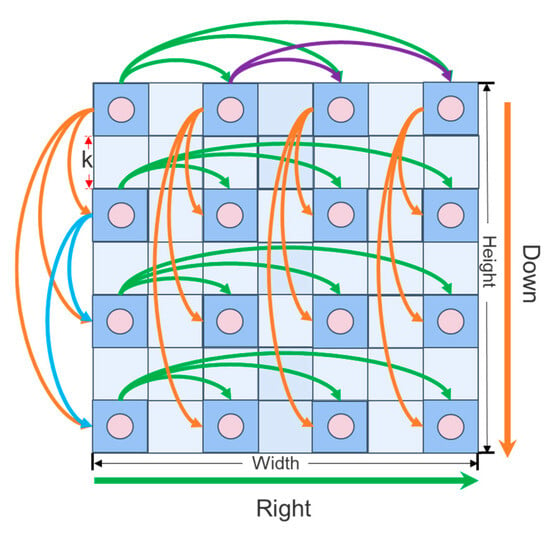
Figure 5.
SVGA sparse graph construction.
Where k denotes the moving step length of the aggregation operation (k = 2), Height represents the height of the feature map, Width indicates the width of the image, Down stands for the downward direction, and Right signifies the rightward direction.
(2) Process of Aggregating and Updating Feature Information in SVGA
The SVGA module employs max-neighbor graph convolution () for aggregation and update operations. The max aggregator consolidates feature information from the current vertex and its neighboring vertices. In the update operation, a fully connected layer is utilized to integrate the feature information from the current vertex and its neighbors. The specific methodology is illustrated by Equations (1)–(4):
In Equations (1)–(4), denotes a vertex and represents the vertex feature aggregation function. signifies the vertex feature update function, while indicates the feature information of vertex before aggregation and update. denotes the feature information of the sparse neighboring vertices of vertex , and represents the set of sparse neighboring vertices of vertex . refers to a sparse neighboring vertex of , and and stand for the weights of the aggregation and update functions. GeLU indicates the activation function, and mlp represents the multi-layer perceptron operation.
Finally, by integrating the module, the SVGA effectively mitigates the over-smoothing phenomenon caused by multiple serialization in deep network layers of graph convolution models, while also enhancing the model’s non-linear expressive capability. The specific procedures of the SVGA module are formalized in Equations (5) and (6):
where denotes the input feature map information. The refers to the multi-layer perceptron operations, which are combined with the residual connection to prevent network performance degradation in deeper layers. The act represents the GeLU activation function. The SVGA module is illustrated in Figure 6.
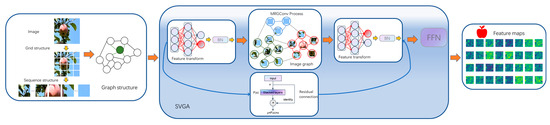
Figure 6.
SVGA module.
Combining the strengths of CNN in local multi-scale feature extraction with the advantages of GCN for global modeling, we designed a CNN-GCN architecture feature extraction network (Rep-Vision-GCN) using the RepIRD Block module and the SVGA block module. The combination of CNN and GCN allows for the effective capture of both local and global image information, thereby enhancing the model’s feature extraction ability and improving its overall performance and effectiveness.
The Rep-Vision-GCN network is composed of 9 layers, utilizing the RepIRD Block module to progressively extract multi-scale visual feature information of apples in complex environments from shallow to deep layers. In the deeper layers, semantic information is extracted using the SVGA block and the SPPF module. The SVGA block consists of two SVGA modules connected in series.
The Rep-Vision-GCN network uses the feature maps output from the 4th layer with a size of (84, 80, 80), from the 6th layer with a size of (168, 40, 40), and from the 9th layer with a size of (256, 20, 20) as inputs of three different scales for the feature fusion network. Detailed information on the Rep-Vision-GCN apple feature extraction network is provided in Table 2.
Table 2.
Detailed structural information of Rep-Vision-GCN network.
2.2.2. Rep-FPN-PAN Feature Fusion Network
In the task of apple detection within complex backgrounds, the varying sizes of apples in the same scene due to differences in distance pose a challenge for recognizing small distant objects. The feature fusion module (C2f) in the YOLOv8n model has a single scale, with a high complexity split operation. To enhance the multi-scale representational ability of the feature fusion module, a RepConvsBlock multi-scale feature fusion module is proposed. Additionally, a Rep-FPN-PAN multi-scale apple feature fusion network is designed to effectively address the issue of difficult recognition caused by varying apple sizes in near and far views. During training, the multi-branch structure is used to fuse features, which is then consolidated into a single-branch structure during inference. This approach reduces the model’s parameter count and computational load, thereby improving inference speed and preventing wastage of computational resources.
The activation function in the re-parameterization module of the RepConv [25] structure may lead to the vanishing gradient problem during training. The activation function, however, is smooth, continuous, and differentiable at zero, thereby mitigating the issue of local gradient vanishing. The computation of the activation function is illustrated in Equation (7):
The computation method for the ReLU activation function is illustrated in Equation (8):
The construction of the RepConvs module involves replacing the activation function with the activation function for output processing. The RepConvsBlock module and the RepConvsBlockPlus module are composed of serially connected RepConvs modules. Specifically, the RepConvsBlock module consists of two serially connected RepConvs, while the RepConvsBlockPlus module consists of three serially connected RepConvs.
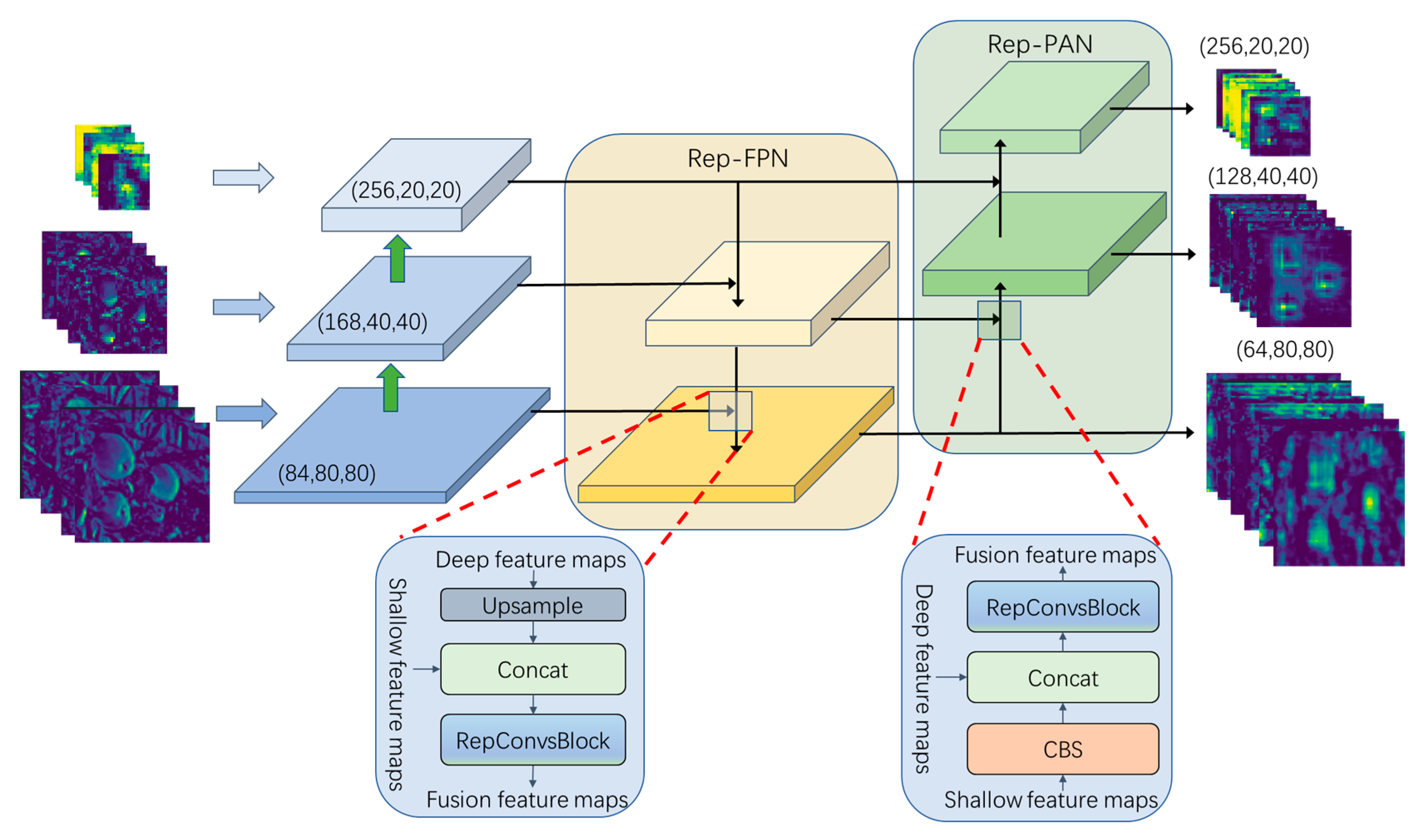
The Rep-FPN-PAN feature fusion network consists of Rep-FPN (rep feature pyramid networks) and the Rep-PAN (rep path aggregation network), as illustrated in Figure 7. The Rep-FPN is a top-down network that fuses deep multi-scale semantic information with shallow multi-scale visual information. Conversely, the Rep-PAN is a bottom-up network that further integrates the feature information outputted by the Rep-FPN with the deep semantic feature information.
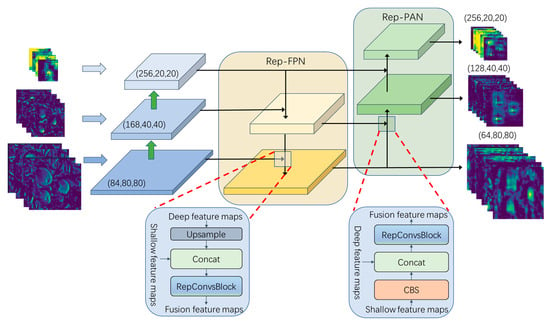
Figure 7.
Rep-FPN-PAN feature fusion network.
2.2.3. Model Pruning
The apple detection algorithm in complex backgrounds is a deep convolutional neural network model, which requires substantial computational power and memory for the inference process. By applying neural network pruning algorithms to eliminate channels that carry less feature information, the model’s parameter count and computational load can be effectively reduced. Layer-adaptive magnitude-based pruning [26] (LAMP) is an adaptive sparse pruning method for fine-grained unstructured pruning of model weights. However, the weight matrix after pruning is in sparse format with indexes, which is not conducive to parallel operations. Channel pruning is a sparse pruning method for the channel level, and the original convolutional structure of the pruned model is still preserved. We employ channel pruning based on LAMP scores for Rep-ViG-Apple model compression. The trained Rep-VG-Apple model is first pruned, and subsequently, a lower learning rate is employed for retraining and fine-tuning to recover any performance losses incurred due to pruning.
The channel pruning method based on LAMP scores involves computing the sum of squares of the weights for each input channel, followed by sorting these weights. Subsequently, an index mapping is established according to the order of the weights. That is, for indices and , if index is less than index , then the sum of squares of the channel weights corresponding to index is less than or equal to that of the channel weights corresponding to index . Cut off the channels with smaller weight squares to compress the model. The definition of the LAMP score is given by Equation (9):
Here represents the sum of squares of the weights of the target channel, and represents the sum of squares of the weights of all remaining channels that were not pruned and have indices greater than the target channel index. indirectly reflects the relative importance of the target channel compared to the unpruned channels; specifically, the larger the sum of squares of the channel’s weights, the more important the channel is. This is detailed in Equation (10):
Channel pruning based on can be classified into two categories: global pruning and local pruning. Global pruning assigns adaptive sparsity to different layers in the model based on the of the global channels of the model. However, this approach may result in the over-pruning of a specific layer, which can lead to a more pronounced degradation in the model’s accuracy after pruning. In contrast, local pruning involves the pruning of channels by calculating the of the local channels of each layer. This method ensures that the same pruning ratio of channels is applied to each layer, maintaining the number of channels in the model.
3. Experiments and Results
3.1. Experimental Environment and Parameter Settings
The experiment was conducted on a system running CentOS 7.9.2009, equipped with a 12 vCPU Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz, and an NVIDIA GeForce RTX 3090 GPU with 24 GB of memory. The development environment was set up using Anaconda 3, and the model was implemented using the PyTorch 1.11.0 and MMDetection deep learning frameworks. CUDA version 11.3 was utilized to accelerate the training process. The images were resized to a resolution of 640 × 640. The optimizer used was SGD with an initial learning rate of 1 × 10−2. A batch size of 64 was used for training. Both the baseline model and the improved model were trained for 200 epochs under these parameters, with mosaic data augmentation disabled during the last 10 epochs.
3.2. Evaluation Metrics
The performance of the apple detection model under complex backgrounds was assessed using commonly employed evaluation metrics. These metrics include mean average precision (), average precision (), recall (), precision (), the computational complexity of the model (GFLOPS), and the number of parameters in the model (params). The specific calculation formulas are shown in Equations (11)–(14):
3.3. Comparative Experiments of SVGA and Different Attention Mechanisms
To demonstrate the superiority of the sparse graph attention mechanism (SVGA), we conducted comparative experiments with SVGA, MLCA [27], CA, and EMA [28]. The specific experimental results are shown in Table 3. It can be observed that the SVGA attention mechanism achieves mAP@0.5 and mAP@0.5:0.95 performance metrics of 91.9% and 78.1%, which are higher than those of other attention mechanisms.
Table 3.
Comparative experiments with different attention mechanisms.
Simultaneously, heatmaps were utilized for visualization to compare the detection intensity of apple targets under different attention mechanisms. The specific visualization results are presented in Figure 8. As can be seen from the figure, the SVGA attention mechanism demonstrates the best performance, with the highest attention focused on the apple targets.

Figure 8.
Heatmaps for different attention mechanisms. (a) Input image. (b) MLCA mechanism. (c) CA mechanism. (d) EMA mechanism. (e) SVGA mechanism.
3.4. Comparative Experiments of Rep-Vision-GCN and Different Types of Feature Extraction Networks
To demonstrate the effectiveness of the proposed Rep-Vision-GCN feature extraction network, comparative experiments were conducted with various types of CNN architectures, including residual connections, depthwise separable convolutions, multi-scale feature extraction, large convolution kernels, and partial convolutions. The compared CNN architectures primarily include ResNet18, GhostNet, MobileNetv3, ResNeXt [29], ResNeSt [30], LcNet [31], LSKNet [32], and FasterNet [33], as well as the transformer-based feature extraction network EfficientViT [34]. The feature fusion network and prediction head in the experiments were kept consistent with those in YOLOv8n. The specific comparative experimental results of different feature extraction networks are presented in Table 4.
Table 4.
Comparison test of different feature extraction networks.
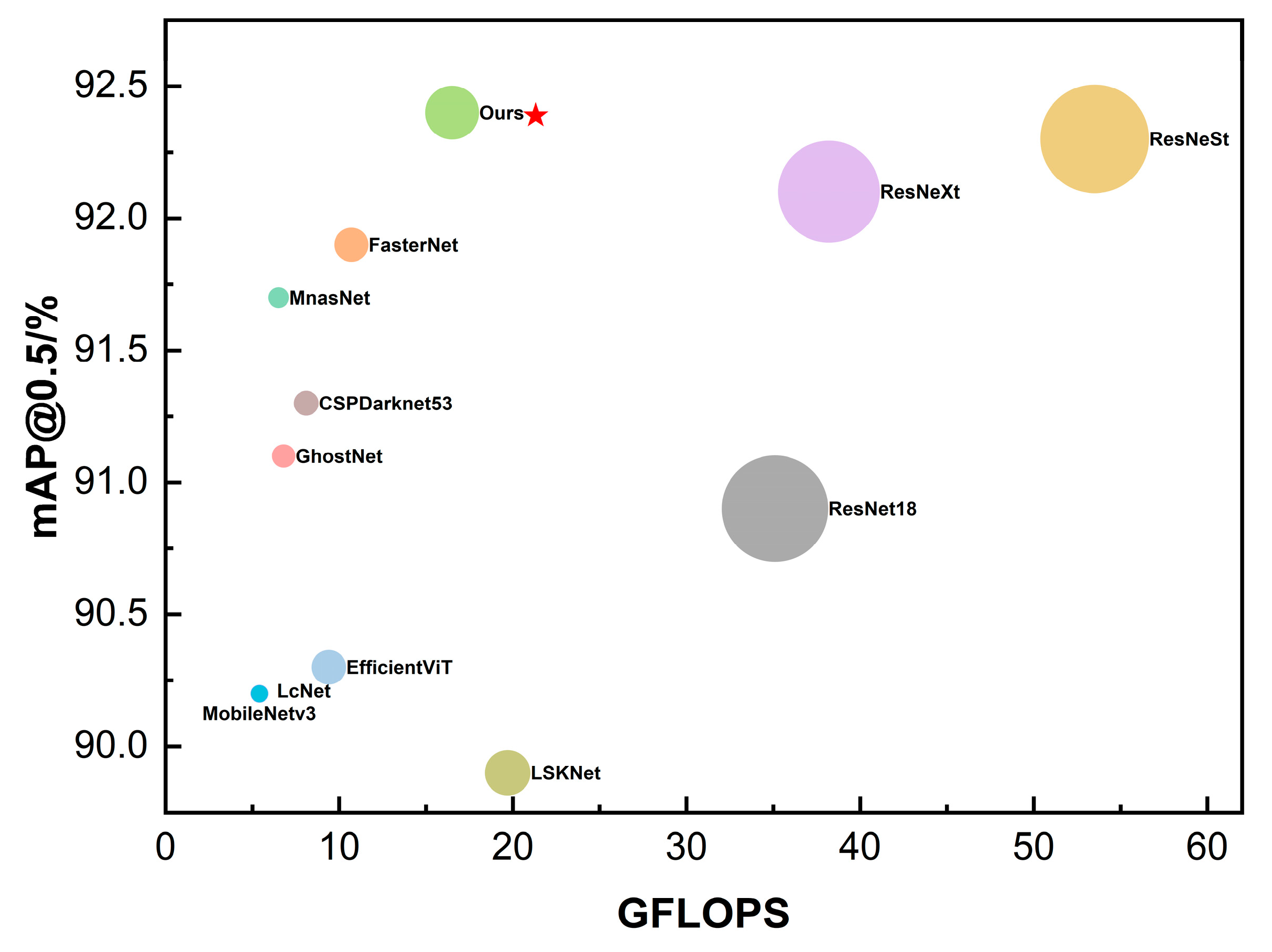
According to the experimental results presented in Table 4, for apple detection tasks in complex environments, the proposed Rep-Vision-GCN feature extraction network consistently outperforms other types of feature extraction networks. Although networks such as GhostNet, MobileNetv3, LcNet, YOLOv8n-Backbone, and LSKNet have lower computational complexity (GFLOPS) and smaller model sizes compared to the Rep-Vision-GCN network, their accuracies are significantly lower. On the other hand, models with accuracies comparable to the Rep-Vision-GCN network have substantially higher GFLOPS and sizes. Notably, the ResNet18 feature extraction network exhibits inferior performance across accuracy, GFLOPS, and size metrics compared to the Rep-Vision-GCN network. Using the Rep-Vision-GCN network as the feature extraction network for the YOLOv8n model results in a 1.1% improvement in mAP@0.5 accuracy and a 0.8% improvement in mAP@0.5:0.95 accuracy, compared to the original YOLOv8n Backbone feature extraction network.
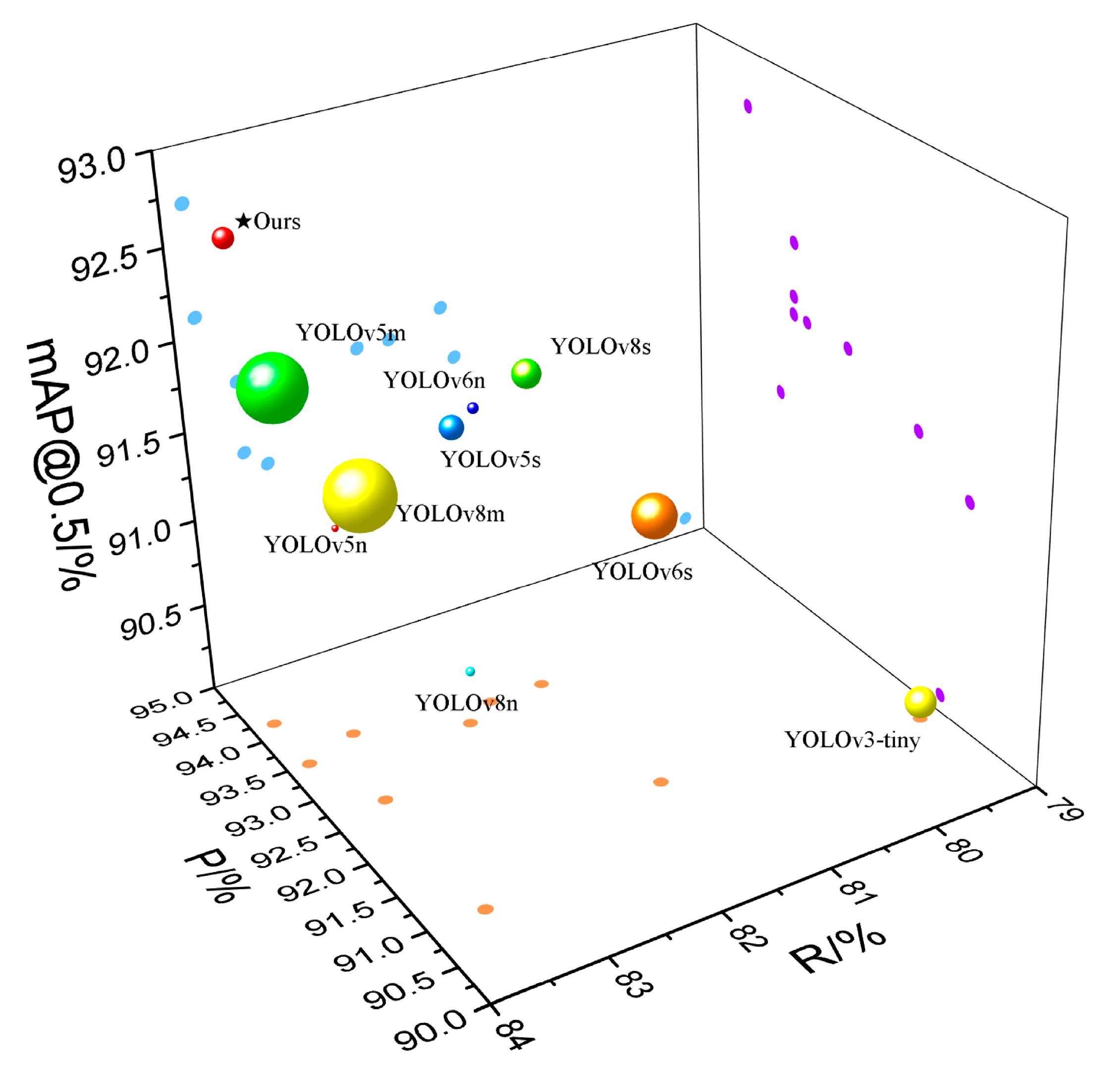
To more intuitively demonstrate the superiority of the proposed Rep-Vision-GCN feature extraction network, the comparative experimental results of different feature extraction networks were visualized, as shown in Figure 9. In this figure, the size of the circles represents the model size. Both the experimental results in Table 4 and the visualization in Figure 9 illustrate that the Rep-Vision-GCN feature extraction network, constructed using multi-scale structure re-parameterization techniques and sparse graph attention mechanisms, achieves superior performance. It offers high accuracy with relatively lower computational complexity and smaller model size, proving its efficacy in extracting feature information of apples in complex environments.
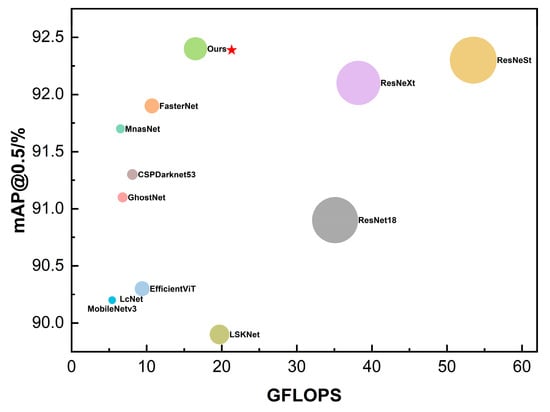
Figure 9.
Comparison of different feature extraction networks.
3.5. Ablation Study of the Improvement Process
To verify the effectiveness of the proposed improvement strategies for apple detection tasks in complex environments, different ablation experiments were designed using YOLOv8n as the baseline model. The experiments involved using the Rep-Vision-GCN feature extraction network, two types of feature fusion networks constructed based on the RepConvsBlock and RepConvsBlockPlus modules, and various combinations thereof to improve the baseline model. The specific ablation experimental results for different improvement strategies are presented in Table 5.
Table 5.
Ablation experiments for improved processes.
Based on the experimental results presented in Table 5, it can be observed that implementing the three different singular improvement strategies—Rep-Vision-GCN, Rep-FPN-PAN, and Rep-FPN-PAN-Plus—results in varying degrees of enhancement in the mAP@0.5 and mAP@0.5:0.95 performance metrics compared to the baseline model. Notably, when Rep-Vision-GCN is used as the feature extraction network, the model’s performance improves significantly, achieving an mAP@0.5 of 92.4%, which is a 1.1% improvement over the baseline model. This demonstrates that the integration of multi-scale re-parameterization structures and sparse graph attention mechanisms significantly enhances the extraction of apple features in complex environments. Moreover, different combinations of Rep-Vision-GCN with RepConvsBlock and RepConvsBlockPlus were employed in ablation experiments. The network combining Rep-Vision-GCN as the feature extraction network and the Rep-FPN-PAN feature fusion network constructed with RepConvsBlock (referred to as Rep-ViG-Apple) showed the best results. When the feature extraction network was constructed using RepConvsBlockPlus, the mAP@0.5 and precision (P) values were lower than those constructed with RepConvsBlock. This underperformance of the RepConvsBlockPlus module can be attributed to its deeper layers, which may result in less effective feature fusion. Compared to individual improvement strategies, the Rep-ViG-Apple network demonstrated significant improvements in both mAP@0.5 and mAP@0.5:0.95 metrics. On the complex environment apple dataset, the proposed Rep-ViG-Apple outperformed the baseline model YOLOv8n, with the mAP@0.5 and mAP@0.5:0.95 metrics showing improvements of 1.4% and 1.4%, and the precision (P) and recall (R) metrics increasing by 3.2% and 0.3%.
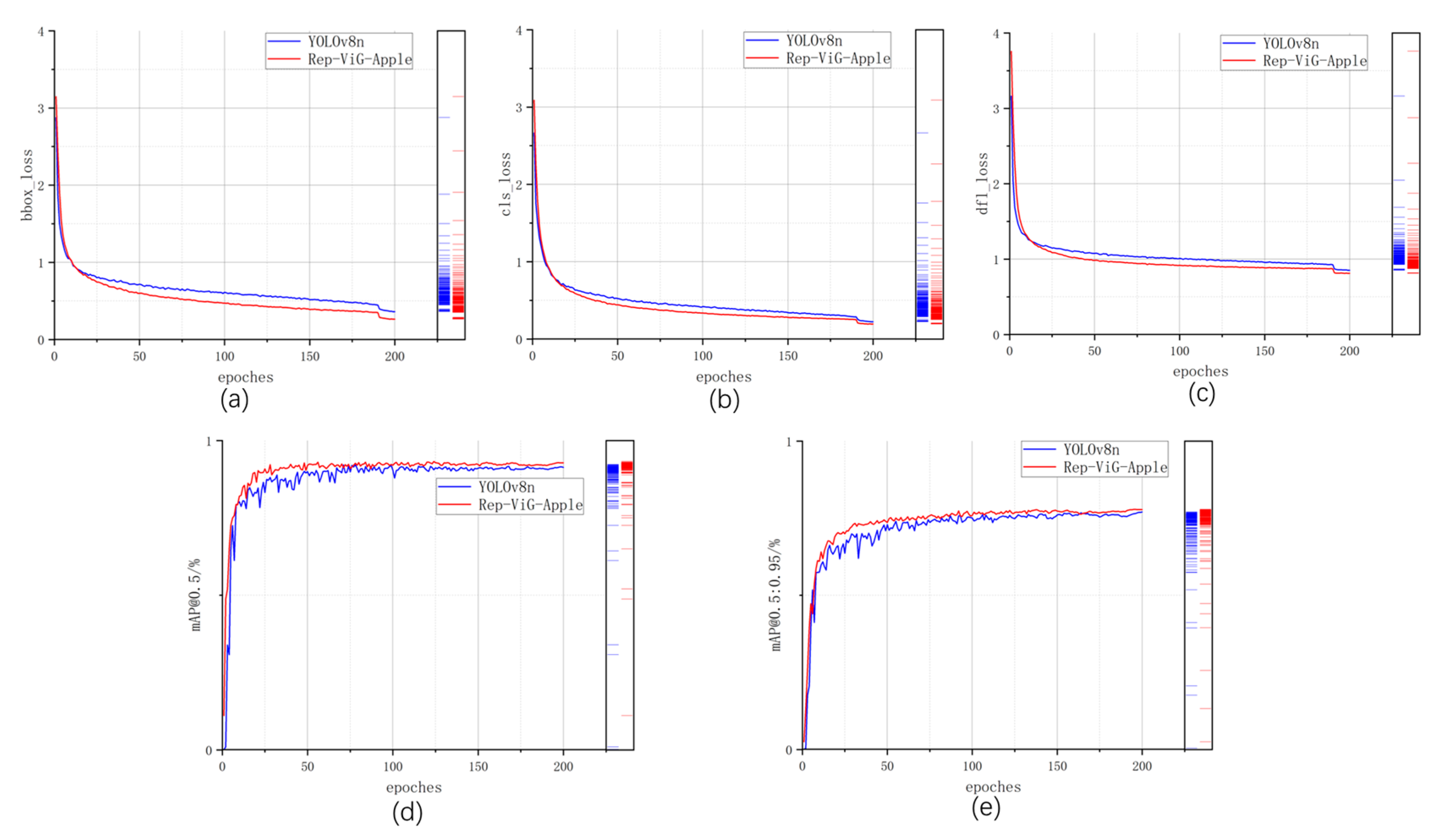
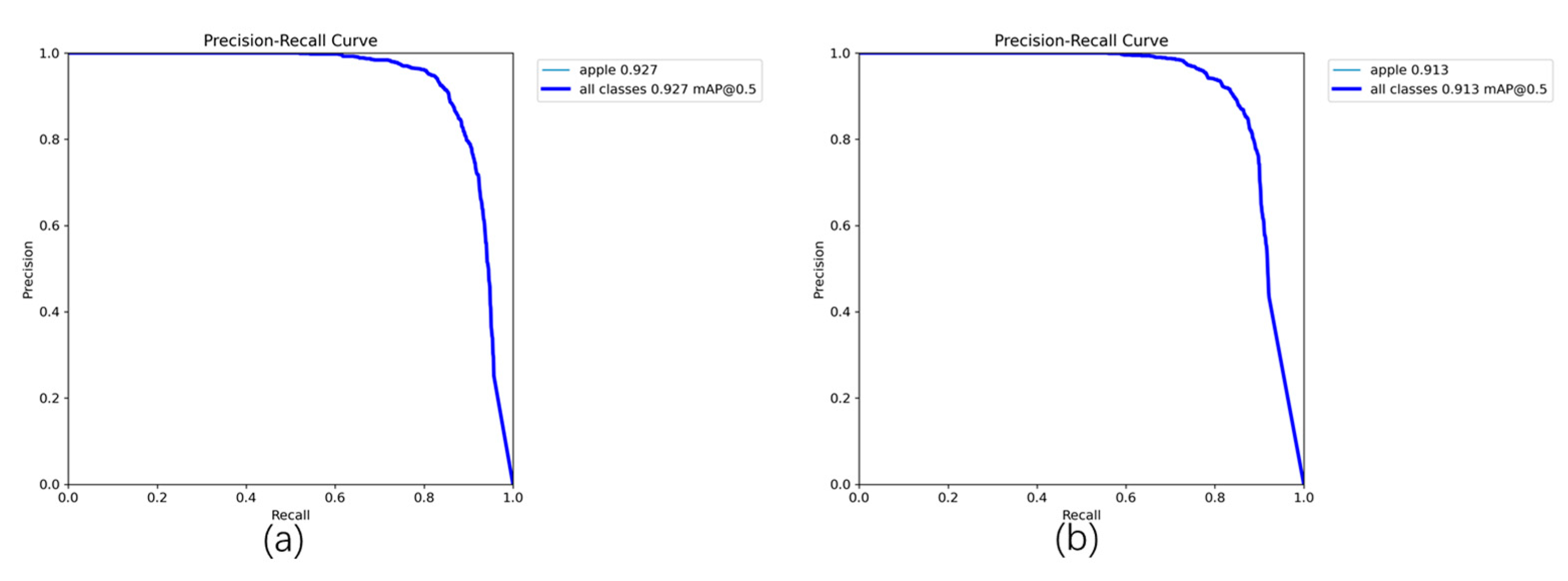
To more intuitively demonstrate the superior performance of the proposed Rep-ViG-Apple compared to the baseline model YOLOv8n, a comparison of the training process for cls_loss, bbox_loss, dfl_loss, mAP@0.5, and mAP@0.5:0.95 is conducted and visualized in Figure 10. As illustrated in the figure, the three types of losses during the training process for Rep-ViG-Apple all exhibit better performance than those for YOLOv8n, indicating superior convergence effects. Additionally, both mAP@0.5 and mAP@0.5:0.95 for Rep-ViG-Apple are higher than those for YOLOv8n, signifying higher accuracy. Furthermore, the mAP@0.5 values for Rep-ViG-Apple and YOLOv8n on the validation set are visualized, as shown in Figure 11.
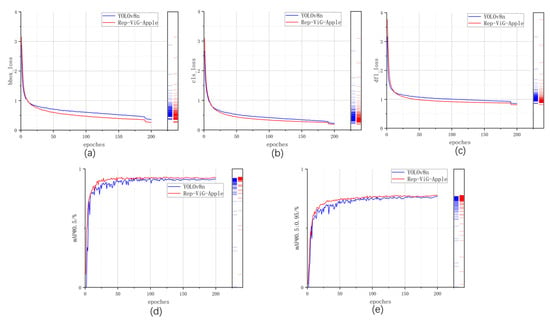
Figure 10.
Comparison of Performance Metrics Between Rep-ViG-Apple and YOLOv8n. (a) bbox_loss. (b) cls_loss. (c) dfl_loss. (d) mAP@0.5. (e) mAP@0.5:0.95.
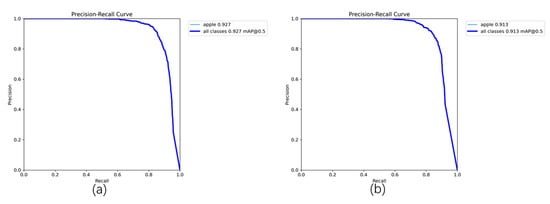
Figure 11.
Comparison of PR Curves Between Rep-ViG-Apple and YOLOv8n. (a) Rep-ViG-Apple. (b) YOLOv8n.
3.6. Comparison Experiments of Different Detection Models
In the structural re-parameterization experiments, comparisons were made between the Rep-Vision-GCN feature extraction network, the Rep-FPN-PAN feature fusion network, and the Rep-ViG-Apple model with respect to the number of parameters and computational cost during both the training and inference stages. The detailed results are presented in Table 6.
Table 6.
Comparison Experiments on Structural Re-parameterization.
From Table 6, it can be observed that in the inference stage, the parameter count and computational cost for Rep-Vision-GCN, Rep-FPN-PAN, and Rep-ViG-Apple are reduced to varying extents compared to the training stage. Importantly, there is no decline in the average precision of the models.
3.7. Comparison Experiments of Different Detection Models
To validate the superiority of the proposed Rep-ViG-Apple model in the apple detection task within complex environments, a comparison was made with current mainstream single-stage and two-stage object detection algorithms. The single-stage detection algorithms were further categorized into the YOLO series and non-YOLO series. The YOLO series included YOLOv8(n, s, m) [35], YOLOv6(n, s) [36], YOLOv5(n, s, m) [37], and YOLOv3(tiny) [38], where n, s, m, and tiny represent different model sizes, as well as YOLOX [39] and YOLOF [40] models. The non-YOLO series primarily comprised SSD [41], RetinaNet [42], and FCOS [43]. The two-stage algorithms mainly included Faster R-CNN [44] and Cascade R-CNN [45]. A comparative analysis was conducted based on the performance metrics of the different detection models, with the specific results of the comparison experiments presented in Table 7.
Table 7.
Comparison experiments of different detection models.
From the quantitative analysis results in Table 7, Rep-ViG-Apple achieves the highest values in both Precision (P) and mAP@0.5, at 94.2% and 92.7%, while when maintaining low levels of GFLOPS and size, the lower GFLOPS and size metrics indicate that the model is less computationally intensive and has lower resource requirements for the device. Conversely, the higher the other metrics indicate that the model’s detection performance is superior. Single-stage detection algorithms overall demonstrate superior performance compared to two-stage object detection algorithms. Among the single-stage YOLO series algorithms, YOLOv8, YOLOv6, and YOLOv5 exhibit increasing mAP@0.5:0.95 values as the model size increases. Although the s and m sizes in these series show higher mAP@0.5:0.95 values than Rep-ViG-Apple, demonstrating good detection performance, they come with larger GFLOPS and size, requiring higher equipment resources. While the n series models are smaller than Rep-ViG-Apple, they fall short in terms of accuracy. YOLOv3-Tiny, YOLOX, YOLOF, as well as the non-YOLO series and two-stage object detection algorithms perform poorly on the complex apple dataset used in this study, with YOLOF, the non-YOLO series, and the two-stage object detection algorithms having much larger model sizes than the proposed Rep-ViG-Apple. To offer a more intuitive analysis of the comparison between Rep-ViG-Apple and other detection methods, three evaluation metrics—P, mAP@0.5, R, and size—were visualized, and as shown in Figure 12, the size is represented by the size of the sphere. Different shapes were used to represent different types of detection algorithms. Based on Table 7 and Figure 12, it is evident that the proposed Rep-ViG-Apple model achieves a balance between model size and accuracy, maintaining high precision while ensuring low size. The Rep-ViG-Apple model is benchmarked against numerous existing models. The proposed model demonstrates state-of-the-art performance across a range of metrics, while maintaining the highest accuracy with lower computation. This outcome is attributed to the innovative combination of a multi-scale reparameterized structure and a sparse graph attention mechanism. This approach effectively integrates the strengths of local feature extraction and global feature perception, offering a competitive edge in complex environments. The proposed model is designed to address the challenges posed by the complex environment of apple feature extraction, demonstrating a notable enhancement in performance. In contrast, the other models employ a single-scale local feature extraction approach, which is unable to effectively capture the global feature information. While increasing the scale of the network can enhance the feature capability, this strategy often entails a substantial rise in the computational complexity and the number of parameters within the model.
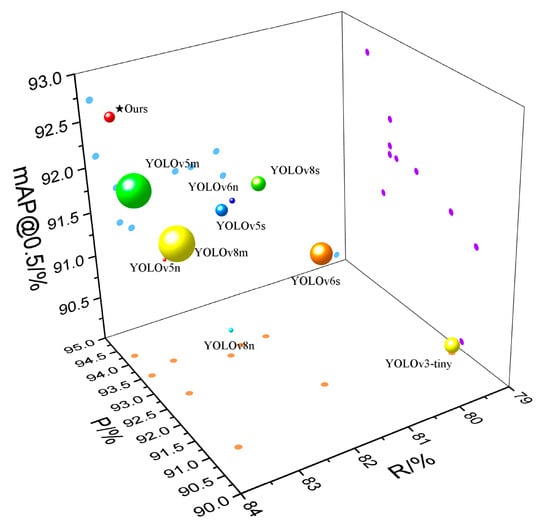
Figure 12.
Comparison of different detection models.
3.8. Pruning Comparison Experiments for the Rep-ViG-Apple Model
Due to the relatively larger size of the Rep-ViG-Apple model compared to the n-sized models in the YOLO series, a channel pruning method based on LAMP scores was employed to compress the model by removing redundant feature maps. The pruning experiments included both global pruning and non-global pruning approaches. Additionally, the performance of different pruning strategies at various compression rates was compared. The comparison results are detailed in Table 8.
Table 8.
Comparison experiments of model pruning with different speed up.
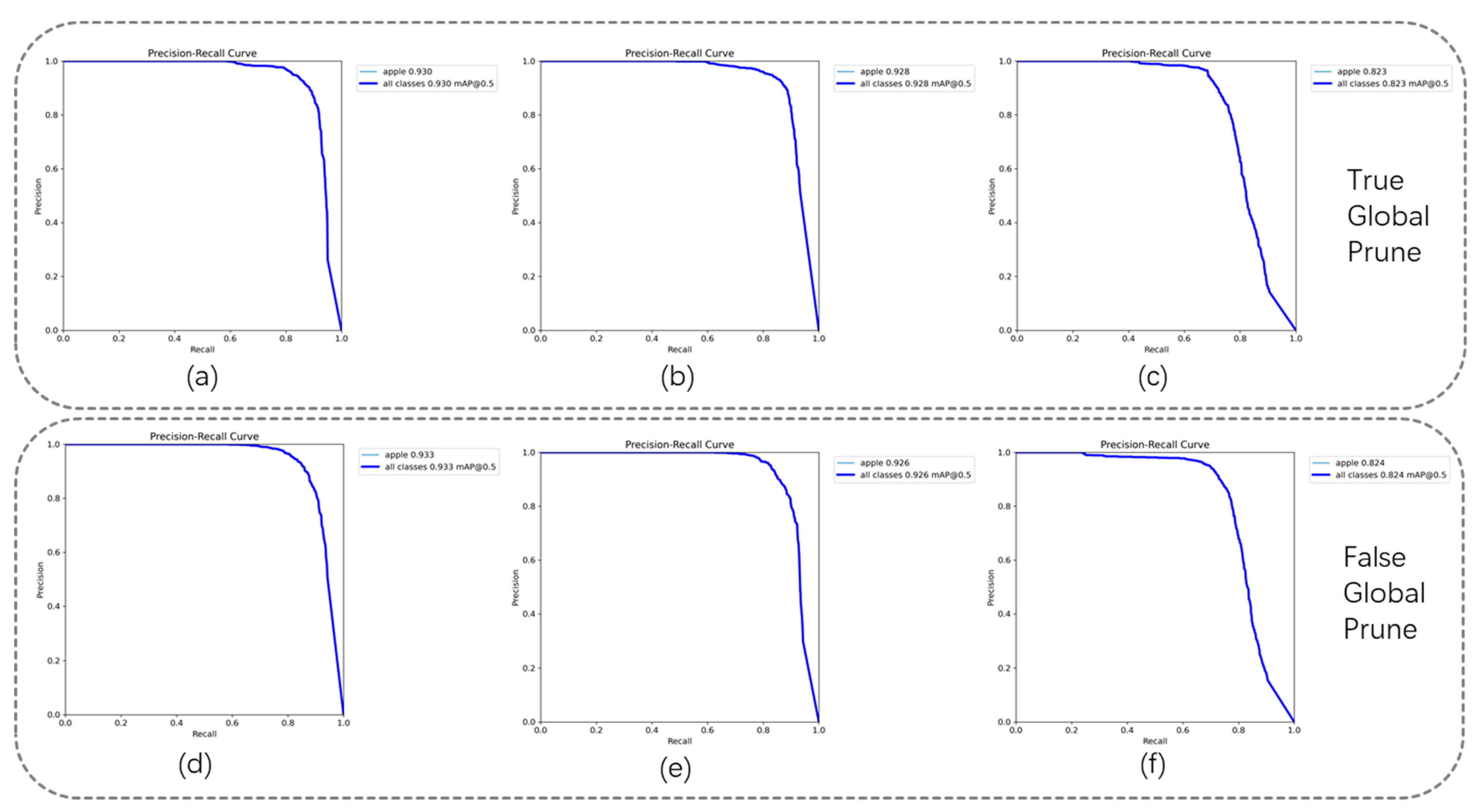
From Table 8, it can be observed that when the speed up is set to 1.8, there is a significant reduction in the model’s GFLOPS and size; however, this also results in a considerable decline in accuracy. On the other hand, when the compression rates are set to 1.3 and 1.5, the pruning process successfully removes redundant feature maps, leading to further improvement in the model’s accuracy. Specifically, at a compression rate of 1.3 with non-global pruning, the pruning effect is optimal, achieving a mAP@0.5 of 93.3% and a mAP@0.5:0.95 of 79.7%. This performance is comparable to that of the s-sized models in the YOLO series, but with a significantly smaller GFLOPS and size post-compression for Rep-ViG-Apple. The PR curves for different compression rates are illustrated in Figure 13.
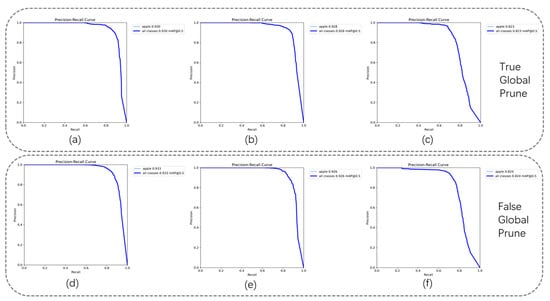
Figure 13.
Comparison of PR curves for different compression rates. (a) True global prune; speed up = 1.3. (b) True global prune; speed up = 1.5. (c) True global prune; speed up = 1.8. (d) False global prune; speed up = 1.3. (e) False global prune; speed up = 1.5. (f) False global prune; speed up = 1.8.
3.9. Comparative Experimental Results of Different Detection Models
To demonstrate the effectiveness of the proposed Rep-ViG-Apple in apple target detection under natural conditions, we selected various complex environments. These environments include several representative orchard conditions such as overcast sky, low light, rainy sky, and foggy sky. For comparison, we chose models from YOLO series detection algorithms. Specifically, the YOLO series include models of comparable size to Rep-ViG-Apple, such as YOLOv8n, YOLOv6n, YOLOv5n, and YOLOv3-tiny.
Figure 14 presents a comparative analysis of detection performance across various algorithms under different weather conditions and shading environments. The proposed Rep-ViG-Apple algorithm achieves the best detection performance for apples, demonstrating that the multi-scale structural re-parameterization approach enhances feature extraction and fusion, thereby improving the network’s ability to perceive occluded apples, and the sparse graph attention mechanism enhances the feature extraction network’s focus on apple-related information. Other detection models exhibit varying degrees of missed and false detections.

Figure 14.
Comparison of apple detection results in complex orchard environments. (a) YOLOv8n. (b) YOLOv6n. (c) YOLOv5n. (d) YOLOv3-tiny. (e) Rep-ViG-Apple.
4. Discussion
The available public apple appearance inspection datasets differ from the Akesu apple datasets in terms of both region and variety and does not include complex real weather conditions. This study addresses the characteristics of apple detection tasks in complex environments by capturing Akesu apple datasets under different conditions. For the first time, simulated weather data augmentation strategies, such as simulating rainy and foggy conditions, are applied to the apple detection task. Compared to existing apple datasets, the dataset constructed in this study is more diverse, enhancing the robustness of the model.
Research on apple detection algorithms primarily focuses on improving detection accuracy. However, these models often have many parameters and significant computational requirements, leading to high hardware deployment costs. Lightweighting the models generally results in reduced accuracy. Achieving an effective balance between accuracy and size is an unresolved issue. This paper proposes a lightweight apple detection method for complex environments, termed Rep-ViG-Apple. For apple detection tasks in complex environments, this study proposes two improvement strategies at the computational level.
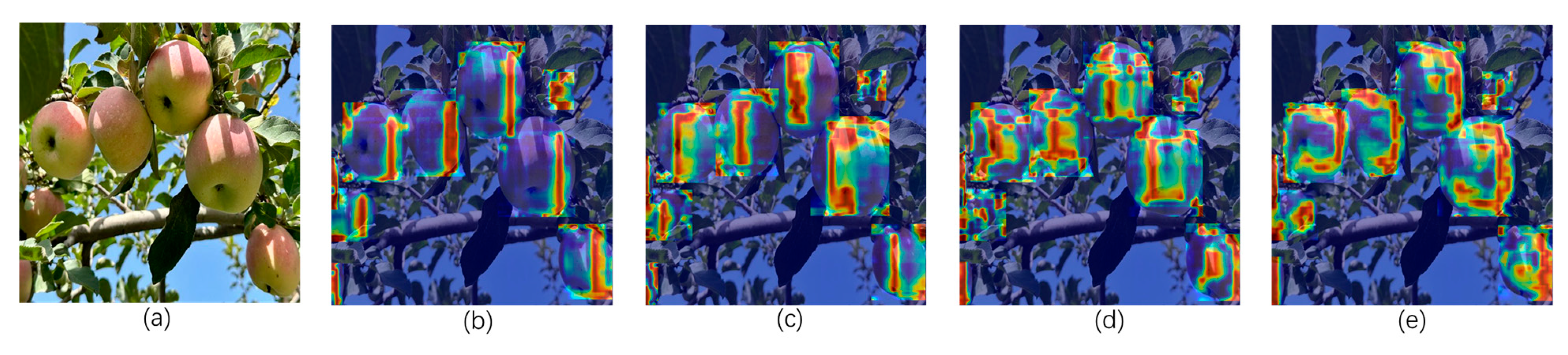
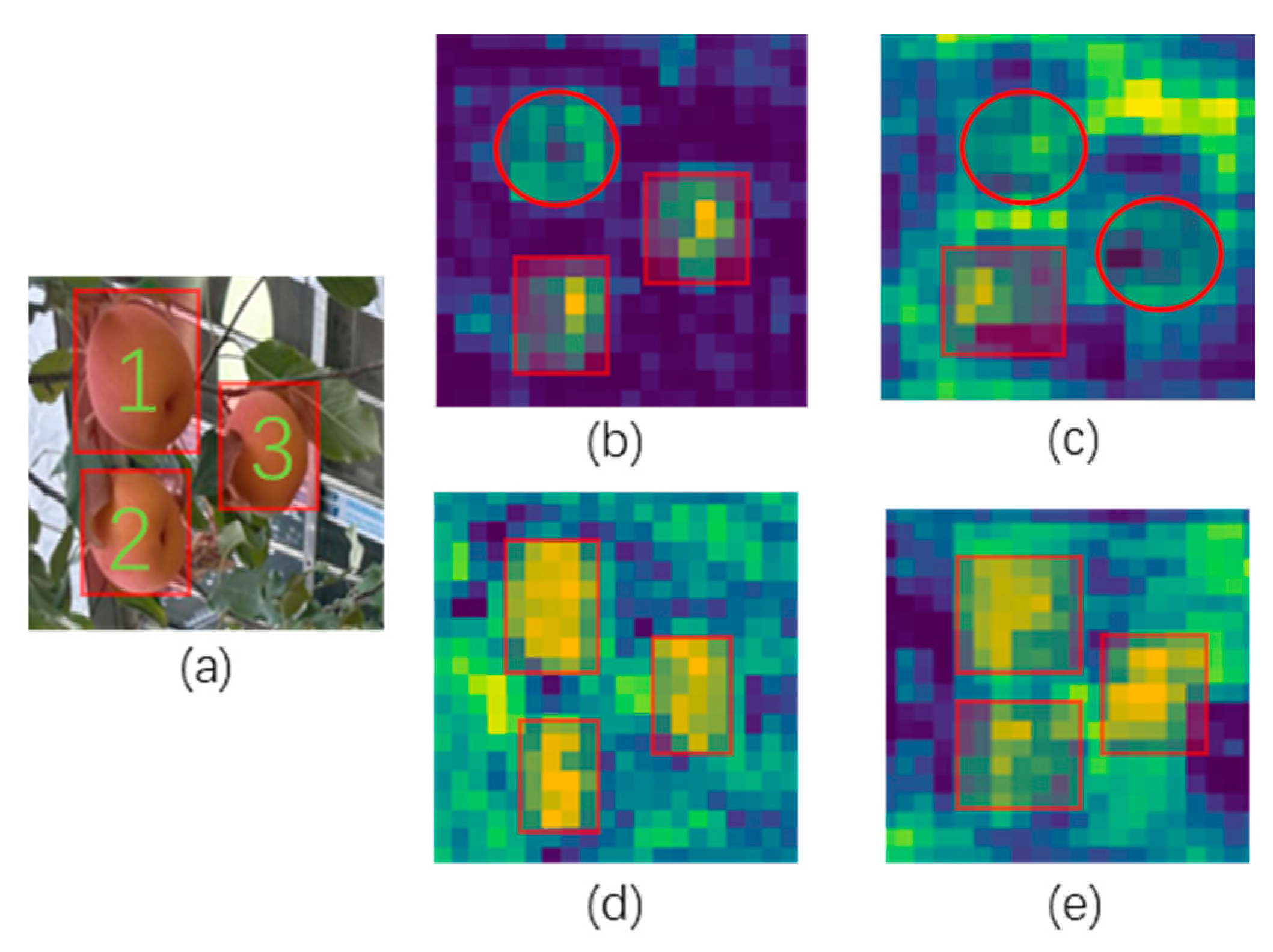
First, a lightweight Rep-Vision-GCN network is designed to enhance the model’s ability to extract apple features. To demonstrate the effectiveness of the Rep-Vision-GCN apple feature extraction network, we conducted a visual comparison of the deep semantic feature maps obtained from the Rep-Vision-GCN network and the feature extraction network of YOLOv8n. Specifically, we focused on the SPPF modules and the preceding SVGA and C2f modules of Rep-Vision-GCN and YOLOv8n. The comparative analysis is illustrated in Figure 15. The SVGA module (d) of Rep-Vision-GCN outperforms the C2f module (b) of YOLOv8n. In the feature maps extracted by the SVGA module, the regions of the three apples are more prominent, whereas the C2f module fails to effectively capture the feature information of the first apple. By utilizing the SVGA module, long-range global feature information can be better extracted. In contrast, the C2f module, constrained by the limited receptive field of convolution operations, performs relatively poorly. Furthermore, when comparing the outputs of the SPPF modules, YOLOv8n shows inferior performance in extracting semantic feature information (c) compared to Rep-Vision-GCN, which demonstrates more distinct semantic features (e) with a stronger focus on the apples.
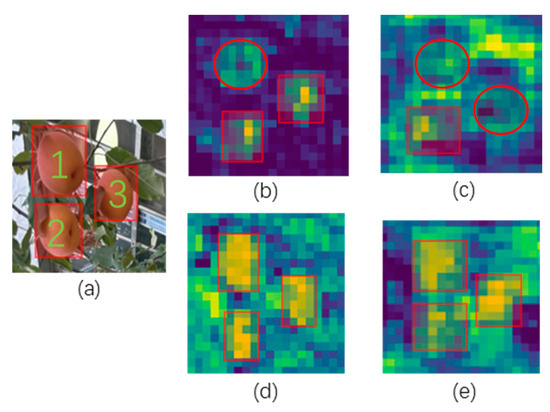
Figure 15.
Comparison of output feature maps of different feature extraction modules. (a) Input image. (b) Output feature map of C2f (YOLOv8). (c) Output feature map of SPPF (YOLOv8). (d) Output feature map of SVGA (Rep-Vision-GCN). (e) Output feature map of SPPF (Rep-Vision-GCN).
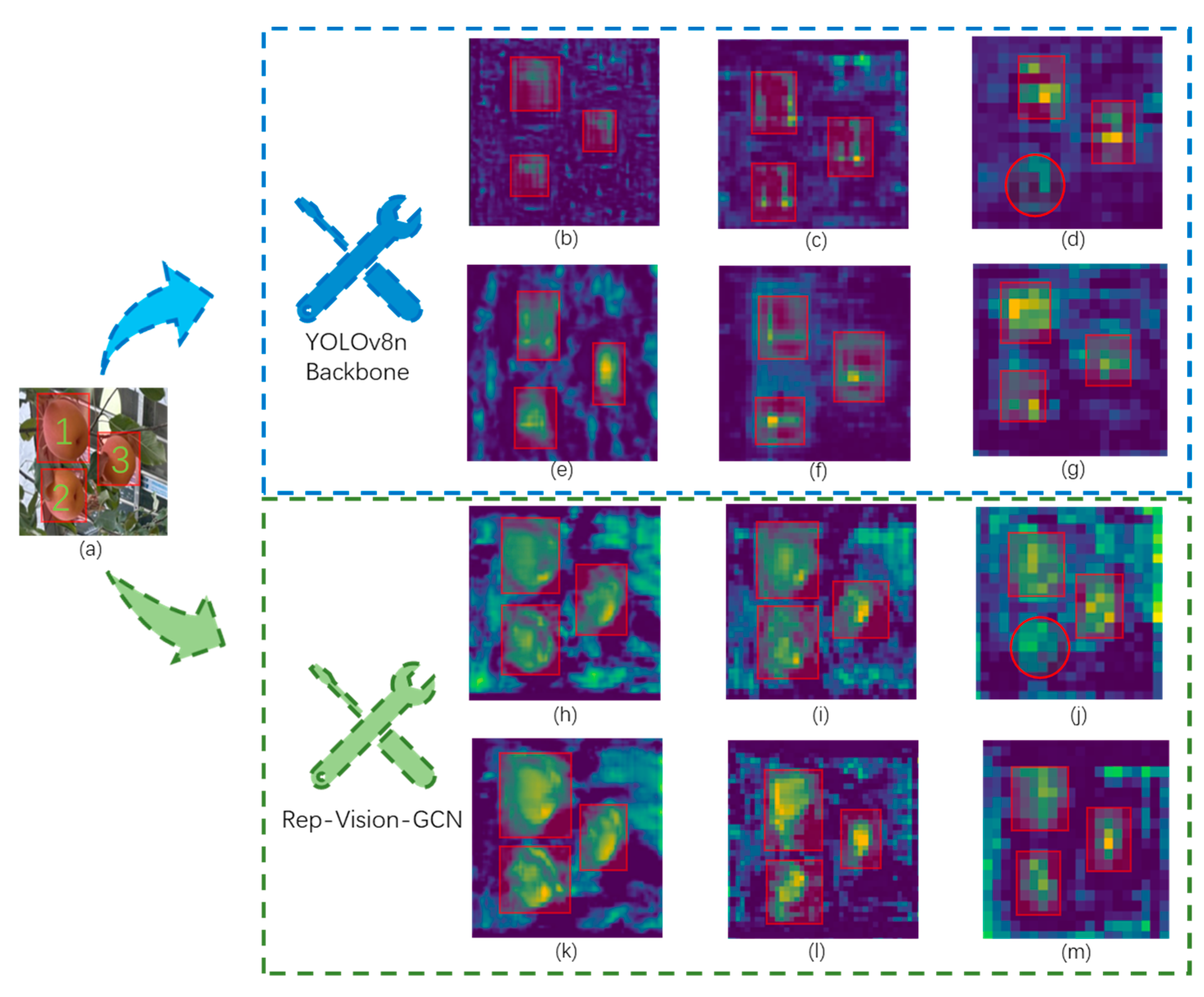
Second, the Rep-FPN-PAN feature fusion network is designed to improve the model’s feature fusion capability. Compared with existing methods, the Rep-ViG-Apple-based apple detection method demonstrates higher accuracy with similar parameter and computational complexity, meeting the needs of detection tasks. For methods with comparable accuracy, the Rep-ViG-Apple detection model is smaller and more easily deployable on resource-constrained devices. To demonstrate the superiority of the Rep-FPN-PAN feature fusion network proposed in this paper, the YOLOv8n-Backbone and Rep-Vision-GCN were used as feature extraction networks. The RepConvsBlock feature fusion module in the improved Rep-FPN-PAN network was compared with the C2f feature fusion module in the FPN-PAN network of YOLOv8n. The feature maps of the three output layers of the feature fusion networks were visualized, with the specific visual results shown in Figure 16. When using the backbone network (Backbone) of YOLOv8n as the feature extraction network, (b), (c), and (d) are the feature maps of the three output layers of the FPN-PAN network, while (e), (f), and (g) are the feature maps of the three output layers of the Rep-FPN-PAN network. A comparative analysis reveals that the RepConvsBlock module, which integrates multi-scale features, generally performs better than the single-scale C2f module. The RepConvsBlock module can better integrate apple feature information. When using Rep-Vision-GCN as the feature extraction network, the RepConvsBlock and RepConvsBlock Plus were separately employed to construct the Rep-FPN-PAN network. (k), (l), and (m) are the feature maps of the three output layers after feature fusion using the RepConvsBlock module, while (h), (i), and (j) are the feature maps of the three output layers after feature fusion using the RepConvsBlockPlus module. It is evident that due to its higher complexity and deeper layers, the RepConvsBlockPlus module resulted in poorer feature fusion performance.
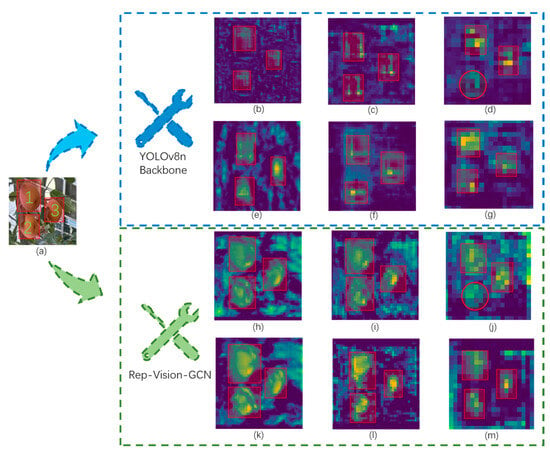
Figure 16.
Comparison of output feature maps of different feature fusion modules. (a) Input image. (b) Output feature map of C2f_1 (YOLOv8 Backbone). (c) Output feature map of C2f_2 (YOLOv8 Backbone). (d) Output feature map of C2f_3 (YOLOv8 Backbone). (e) Output feature map of RepConsBlock_1 (YOLOv8 Backbone). (f) Output feature map of RepConsBlock_2 (YOLOv8 Backbone). (g) Output feature map of RepConsBlock_3 (YOLOv8 Backbone). (h) Output feature map of RepConsBlockPlus_1 (Rep-Vision-GCN). (i) Output feature map of RepConsBlockPlus_2 (Rep-Vision-GCN). (j) Output feature map of RepConsBlockPlus_3 (Rep-Vision-GCN). (k) Output feature map of RepConsBlock_1 (Rep-Vision-GCN). (l) Output feature map of RepConsBlock_2 (Rep-Vision-GCN). (m) Output feature map of RepConsBlock_3 (Rep-Vision-GCN).
Despite the Rep-ViG-Apple model’s notable success in apple detection tasks within complex orchard settings, there remain areas for enhancement and optimization. Firstly, the performance of the model is contingent upon the scale and quality of the dataset. Despite the introduction of a data enhancement method, designated as weather_aug, which facilitates the model’s capacity to detect apples in diverse weather conditions, the actual weather circumstances within an orchard are likely to be more complex. Consequently, there is a continued necessity to optimize the construction of the dataset. Secondly, there are still challenges in deploying the model on apple picking robots and applying it to large-scale picking tasks.
The Rep-ViG-Apple model will be further investigated in the future, with the aim of applying it to other fruit detection tasks in diverse orchard settings. We will consider building a larger dataset in a real environment and introducing more image enhancement techniques and data preprocessing methods. Data will be gathered under a variety of real-world weather conditions. Given the considerable similarity between the augmented weather environment (weather_aug) and the real environment, a migration learning strategy will be employed to transfer the knowledge acquired by the model in the simulated weather environment to the real weather environment. This strategy enables the model to identify shared features between the source and target domains, thereby enhancing its performance and improving its robustness. Additionally, the efficient deployment of the model in practical applications will be a key focus of our research, an intelligent picking robot will be designed to enhance the model and facilitate its deployment on a picking robot for fruit harvesting.
5. Conclusions
In order to address the issue of low apple detection accuracy in complex orchard environments, this paper proposes the Rep-ViG-Apple apple detection algorithm. We propose the novel Rep-ViG-GCN feature extraction network, a CNN-GCN architecture-based feature extraction network, and Rep-FPN-PAN feature fusion network, which effectively address the challenges posed by complex background interference and small-size targets in orchards. The Rep-ViG-Apple model was shown to be an advanced apple detection model through a series of experiments. The Rep IRB module within Rep-Vision-GCN was demonstrated to possess the capacity for multi-scale feature extraction, thereby enhancing the expression of apple features. Furthermore, the SVGA module was demonstrated to effectively suppress the interference of complex environments, thereby enhancing the model’s ability to resist interference in real orchard environments. The FPN-PAN network enhances the capacity to detect small targets. Moreover, a data expansion strategy was developed for the model to accommodate weather variations, and a LAMP-based model compression method was employed. The experimental results demonstrate that the enhanced Rep-ViG-Apple model exhibits superior precision, recall, and average accuracy, reaching 92.5%, 85.0%, and 93.3%, respectively. This represents a 1.5%, 1.5%, and 2.0% improvement over that of YOLOv8n. Furthermore, the model size of Rep-ViG-Apple was reduced by 22%.
The Rep-ViG-Apple model not only exhibits superior accuracy and efficiency, but also provides a cutting-edge detection technique for apple picking tasks in challenging orchard environments. The Rep-ViG-Apple model represents a cutting-edge approach to apple harvesting technology, with the potential to enhance the efficiency of apple production and increase the profitability of the apple industry. Future work will entail further augmenting of the size and quality of the dataset, designing innovative methods, and proposing more competitive apple detection models.
Author Contributions
B.H.: Data collection, algorithm design, experiments, and writing; J.Z.: Supervision and writing review; R.A.: writing review; Z.L. and Z.W.: data collection and data organization; W.S. and L.D.: investigation and validation. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Natural Science Foundation of Xinjiang Uygur Autonomous Region [2022D01A202]; Autonomous Region Postgraduate Research Innovation Project [XJ2024G124]; Science and Technology Innovation 2030—“New Generation Artificial Intelligence” Major Project [2022ZD0115805]; Xinjiang Uygur Autonomous Region Major Science and Technology Project “Research on Key Technologies for Farm Digitalization and Intelligentization” [2022A02011].
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors are very grateful to the editor and reviewers for their valuable comments and suggestions to improve the paper.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Wang, X.; Zhao, Z.; Wang, J. Measurement of Concentration of Apple Production in China’s Main Production Areas and Analysis of Their Competitiveness. J. Hebei Agric. Sci. 2023, 27, 83–86. [Google Scholar]
- Chen, Q.; Yin, C.; Guo, Z.; Wang, J.; Zhou, H.; Jiang, X. Current status and future development of the key technologies for apple picking robots. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2023, 39, 1–15. [Google Scholar]
- Chang, Q.; Li, J. Development trend of apple industry in China since 2000. North. Hortic. 2021, 3, 155–160. [Google Scholar]
- Sun, M.; Zhao, R.; Yin, X.; Xu, L.; Ruan, C.; Jia, W. FBoT-Net: Focal bottleneck transformer network for small green apple detection. Comput. Electron. Agric. 2023, 205, 107609. [Google Scholar] [CrossRef]
- Yao, Q.; Zheng, X.; Zhou, G.; Zhang, J. SGR-YOLO: A method for detecting seed germination rate in wild rice. Front. Plant Sci. 2024, 14, 1305081. [Google Scholar] [CrossRef] [PubMed]
- Sekharamantry, P.K.; Melgani, F.; Malacarne, J. Deep Learning-Based Apple Detection with Attention Module and Improved Loss Function in YOLO. Remote Sens. 2023, 15, 1516. [Google Scholar] [CrossRef]
- Villacrés, J.; Viscaino, M.; Delpiano, J.; Vougioukas, S.; Cheein, F.A. Apple orchard production estimation using deep learning strategies: A comparison of tracking-by-detection algorithms. Comput. Electron. Agric. 2023, 204, 107513. [Google Scholar] [CrossRef]
- Shang, Y.; Xu, X.; Jiao, Y.; Wang, Z.; Hua, Z.; Song, H. Using lightweight deep learning algorithm for real-time detection of apple flowers in natural environments. Comput. Electron. Agric. 2023, 207, 107765. [Google Scholar] [CrossRef]
- Long, Y.; Yang, Z.; He, M. Recognizing apple targets before thinning using improved YOLOv7. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2023, 39, 191–199. [Google Scholar]
- HAO, P.; LIU, L.; GU, R. YOLO-RD-Apple orchard heterogenous image obscured fruit detection model. J. Graph. 2023, 44, 456–464. [Google Scholar]
- Sun, J.; Qian, L.; Zhu, W.; Zhou, X.; Dai, C.; Wu, X. Apple detection in complex orchard environment based on improved RetinaNet. Trans. Chin. Soc. Agric. Eng. (Trans. CSAE) 2022, 38, 314–322. [Google Scholar]
- Yan, B.; Fan, P.; Wang, M.; Shi, S.; Lei, X.; Yang, F. Real-time Apple Picking Pattern Recognition for Picking Robot Based on Improved YOLOv5m. Trans. Chin. Soc. Agric. Mach. 2022, 53, 28–38. [Google Scholar]
- Liu, R.-M.; Su, W.-H. APHS-YOLO: A Lightweight Model for Real-Time Detection and Classification of Stropharia Rugoso-Annulata. Foods 2024, 13, 1710. [Google Scholar] [CrossRef] [PubMed]
- Jung, A.; Wada, K.; Crall, J. Imgaug. 2020. Available online: https://github.com/aleju/imgaug (accessed on 1 February 2020).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:abs/2107.08430. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE Computer Society: Washington, DC, USA, 2021; pp. 3490–3499. [Google Scholar]
- Cheng, G.; Wang, J.; Li, K.; Xie, X.; Lang, C.; Yao, Y.; Han, J. Anchor-Free Oriented Proposal Generator for Object Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–11. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yang, A.; Li, M.; Ding, Y.; Hong, D.; Lv, Y.; He, Y. GTFN: GCN and transformer fusion with spatial-spectral features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3314616. [Google Scholar] [CrossRef]
- Wang, L.; Song, Z.; Zhang, X.; Wang, C.; Zhang, G.; Zhu, L.; Li, J.; Liu, H. SAT-GCN: Self-attention graph convolutional network-based 3D object detection for autonomous driving. Knowl. -Based Syst. 2023, 259, 110080. [Google Scholar] [CrossRef]
- Huang, B.; Zhang, J.; Ju, J.; Guo, R.; Fujita, H.; Liu, J. CRF-GCN: An effective syntactic dependency model for aspect-level sentiment analysis. Knowl.-Based Syst. 2023, 260, 110125. [Google Scholar] [CrossRef]
- Bao, Y.; Liu, J.; Shen, Q.; Cao, Y.; Ding, W.; Shi, Q. PKET-GCN: Prior knowledge enhanced time-varying graph convolution network for traffic flow prediction. Inf. Sci. 2023, 634, 359–381. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Yin, X.; Li, K.; Wang, L.; Wang, R.; Song, R. Distributed LSTM-GCN based spatial-temporal indoor temperature prediction in multi-zone buildings. IEEE Trans. Ind. Inform. 2023, 20, 482–491. [Google Scholar] [CrossRef]
- Liu, X.; Liu, J.; Cheng, X.; Li, J.; Wan, W.; Sun, J. VT-Grapher: Video Tube Graph Network with Self-Distillation for Human Action Recognition. IEEE Sens. J. 2024, 24, 14855–14868. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16091–16101. [Google Scholar]
- Wang, H.; Guo, P.; Zhou, P.; Xie, L. MLCA-AVSR: Multi-Layer Cross Attention Fusion based Audio-Visual Speech Recognition. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing, Seoul, Republic of Korea, 14–19 April 2024. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: New York, NY, USA, 2023; pp. 1–5. [Google Scholar]
- Li, L.; Zhu, Y.; Zhu, Z. Automatic modulation classification using resnext-gru with deep feature fusion. IEEE Trans. Instrum. Meas. 2023, 72, 1–10. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2736–2746. [Google Scholar]
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; et al. PP-LCNet: A lightweight CPU convolutional neural network. arXiv 2021, arXiv:2109.15099. [Google Scholar]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 16794–16805. [Google Scholar]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Han, B.; Lu, Z.; Dong, L.; Zhang, J. Lightweight Non-Destructive Detection of Diseased Apples Based on Structural Re-Parameterization Technique. Appl. Sci. 2024, 14, 1907. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Fu, X.; Zhao, S.; Wang, C.; Tang, X.; Tao, D.; Li, G.; Jiao, L.; Dong, D. Green Fruit Detection with a Small Dataset under a Similar Color Background Based on the Improved YOLOv5-AT. Foods 2024, 13, 1060. [Google Scholar] [CrossRef]
- Fu, L.; Feng, Y.; Wu, J.; Liu, Z.; Gao, F.; Majeed, Y.; Al-Mallahi, A.; Zhang, Q.; Li, R.; Cui, Y. Fast and accurate detection of kiwifruit in orchard using improved YOLOv3-tiny model. Precis. Agric. 2021, 22, 754–776. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Liu, G.H.; Chu, M.X.; Gong, R.F.; Zheng, Z.H. DLF-YOLOF: An improved YOLOF-based surface defect detection for steel plate. J. Iron Steel Res. Int. 2024, 31, 442–451. [Google Scholar] [CrossRef]
- Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-attention combined feature fusion-based SSD for small object detection in remote sensing. Remote Sens. 2023, 15, 3027. [Google Scholar] [CrossRef]
- Zhang, Y.; Cai, Z. CE-RetinaNet: A channel enhancement method for infrared wildlife detection in UAV images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Ren, H.; Cai, S.; Zhang, X. An improved faster R-CNN algorithm for assisted detection of lung nodules. Comput. Biol. Med. 2023, 153, 106470. [Google Scholar] [CrossRef]
- Cao, R.; Mo, W.; Zhang, W. MFMDet: Multi-scale face mask detection using improved Cascade rcnn. J. Supercomput. 2024, 80, 4914–4942. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).