
An Index Used to Evaluate the Applicability of Mid-to-Long-Term Runoff Prediction in a Basin Based on Mutual Information


 and
and
Abstract
1. Introduction
2. Materials and Methods
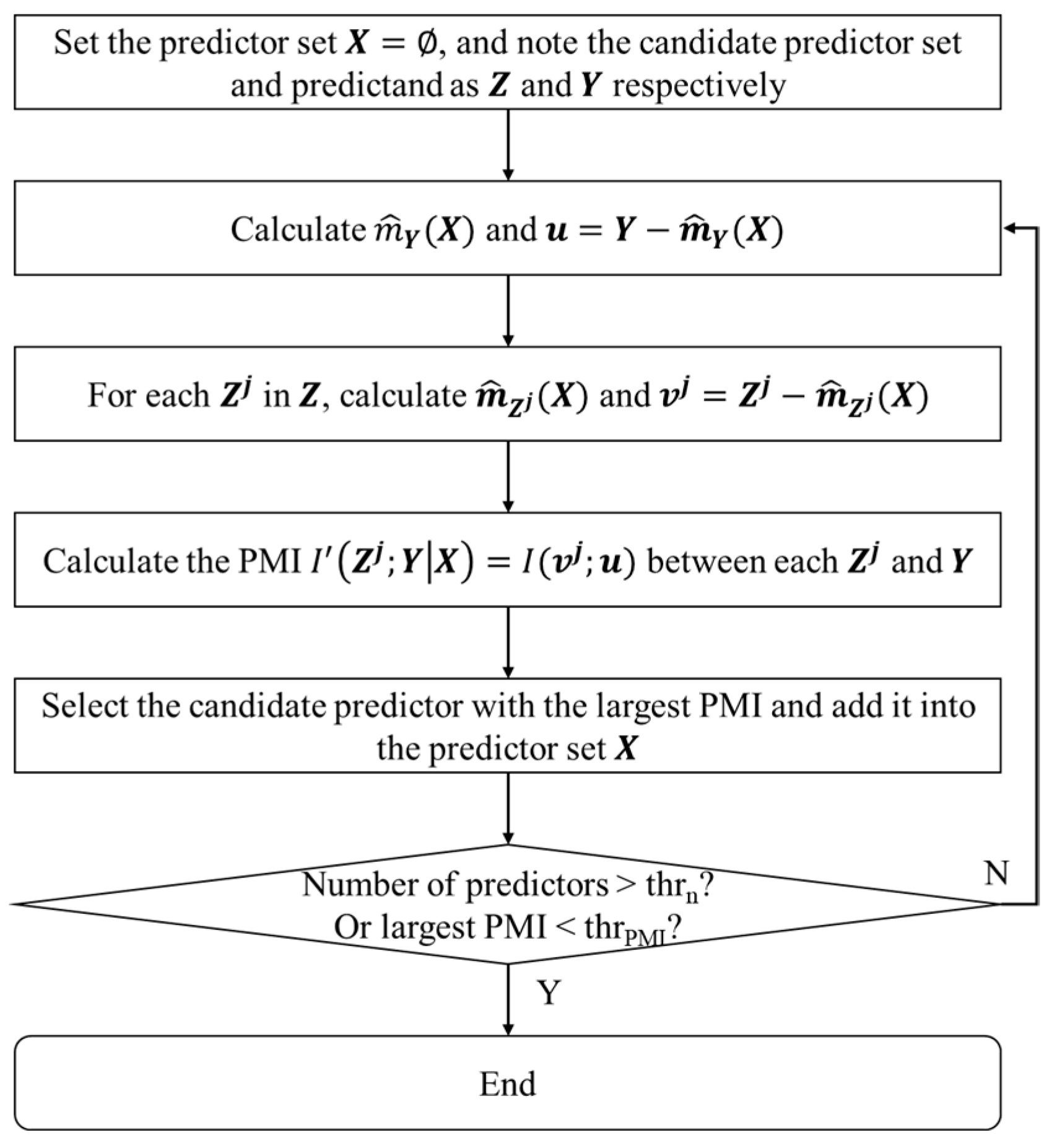
2.1. Predictor Selection and Total Mutual Information
2.1.1. The Predictor Selection Method
2.1.2. Total Mutual Information
2.2. Case Study and Data Preparing
2.3. Forecasting Models and Model Development Process
2.3.1. Forecasting Models
2.3.2. Model Development Process
2.4. Experiment Setup
3. Results
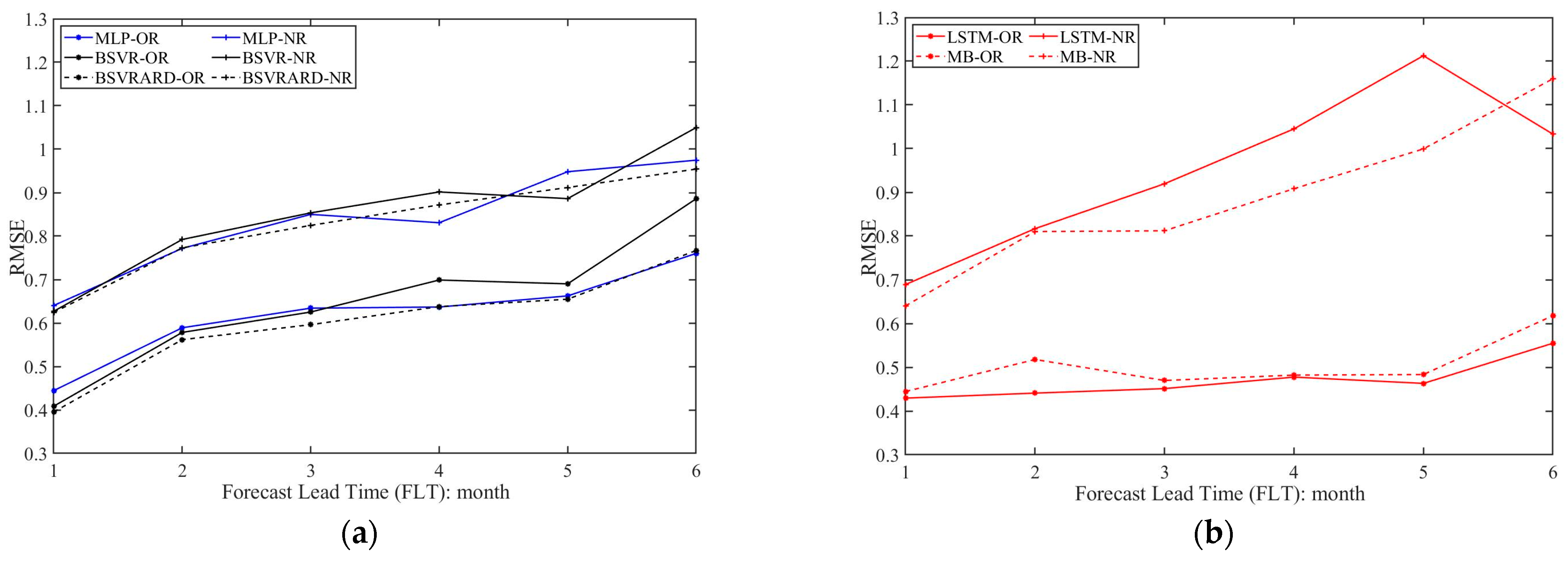
3.1. The Predictive Performance of Five Models without Rainfall in Predictors
3.2. The Predictive Performance of Five Models with Rainfall as Predictor
4. Discussion
4.1. The Comparison of Different Models
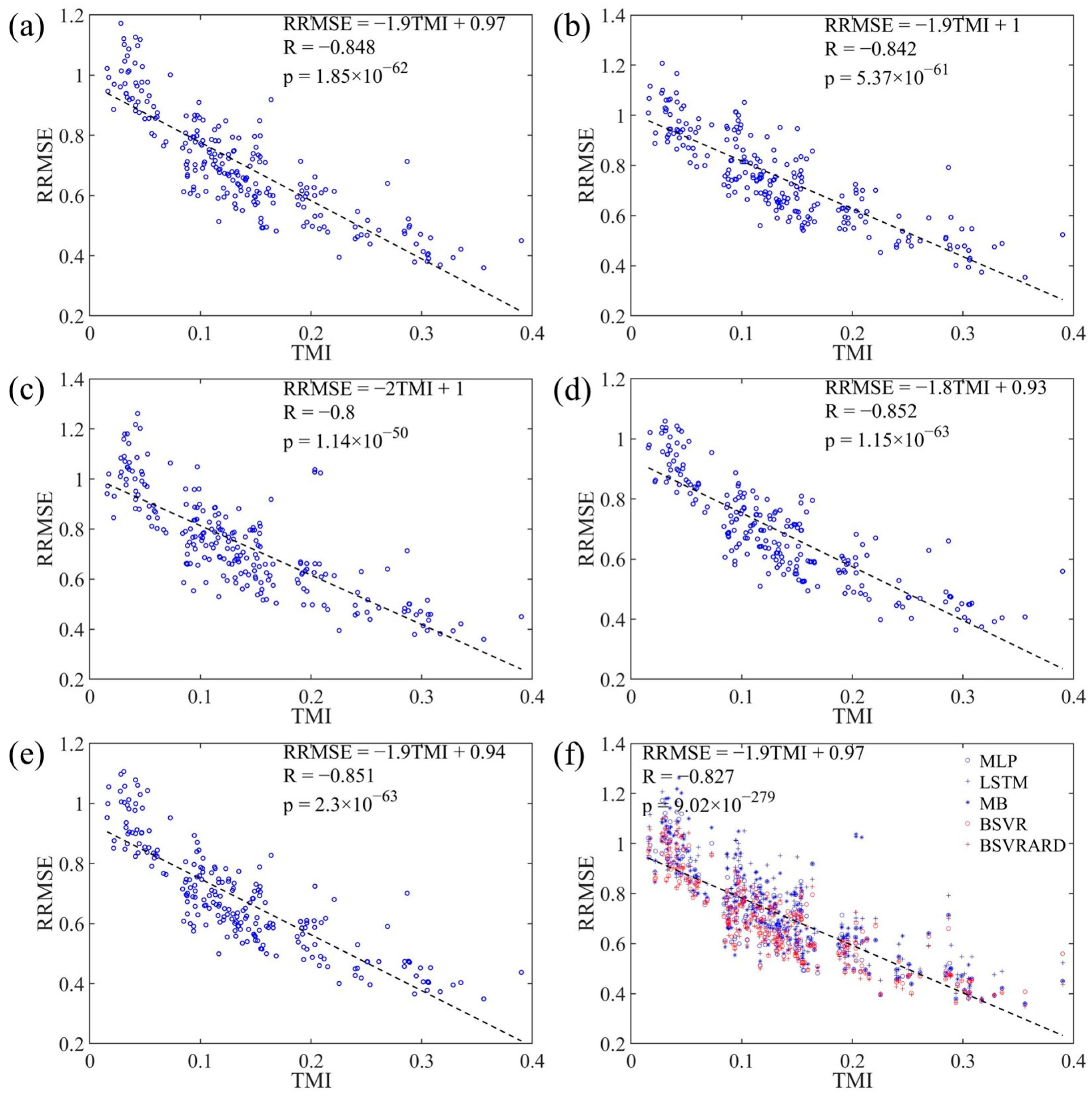
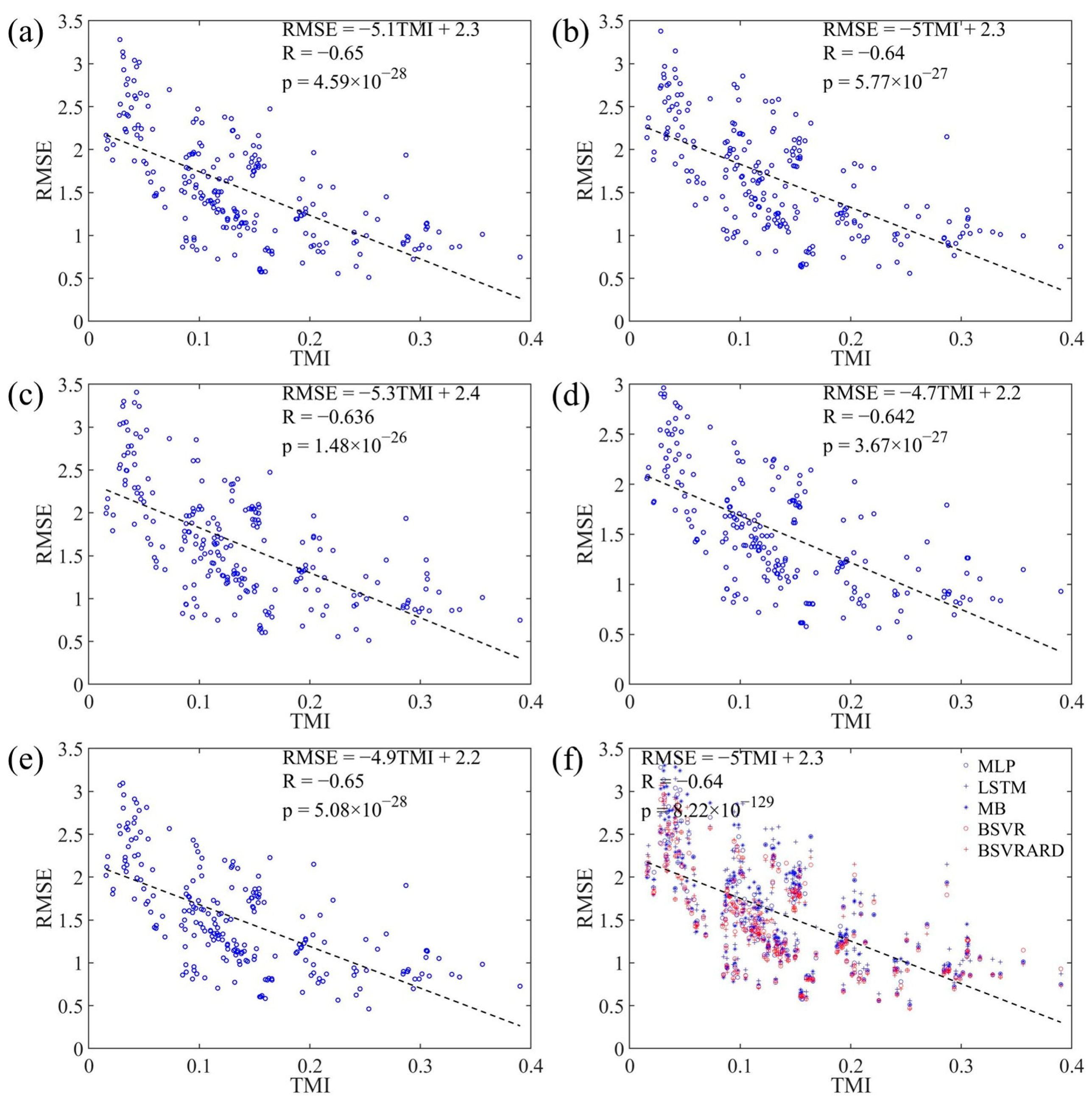
4.2. The Relationship between Predictive Performance and TMI, MI
4.2.1. RRMSE and MI in E1
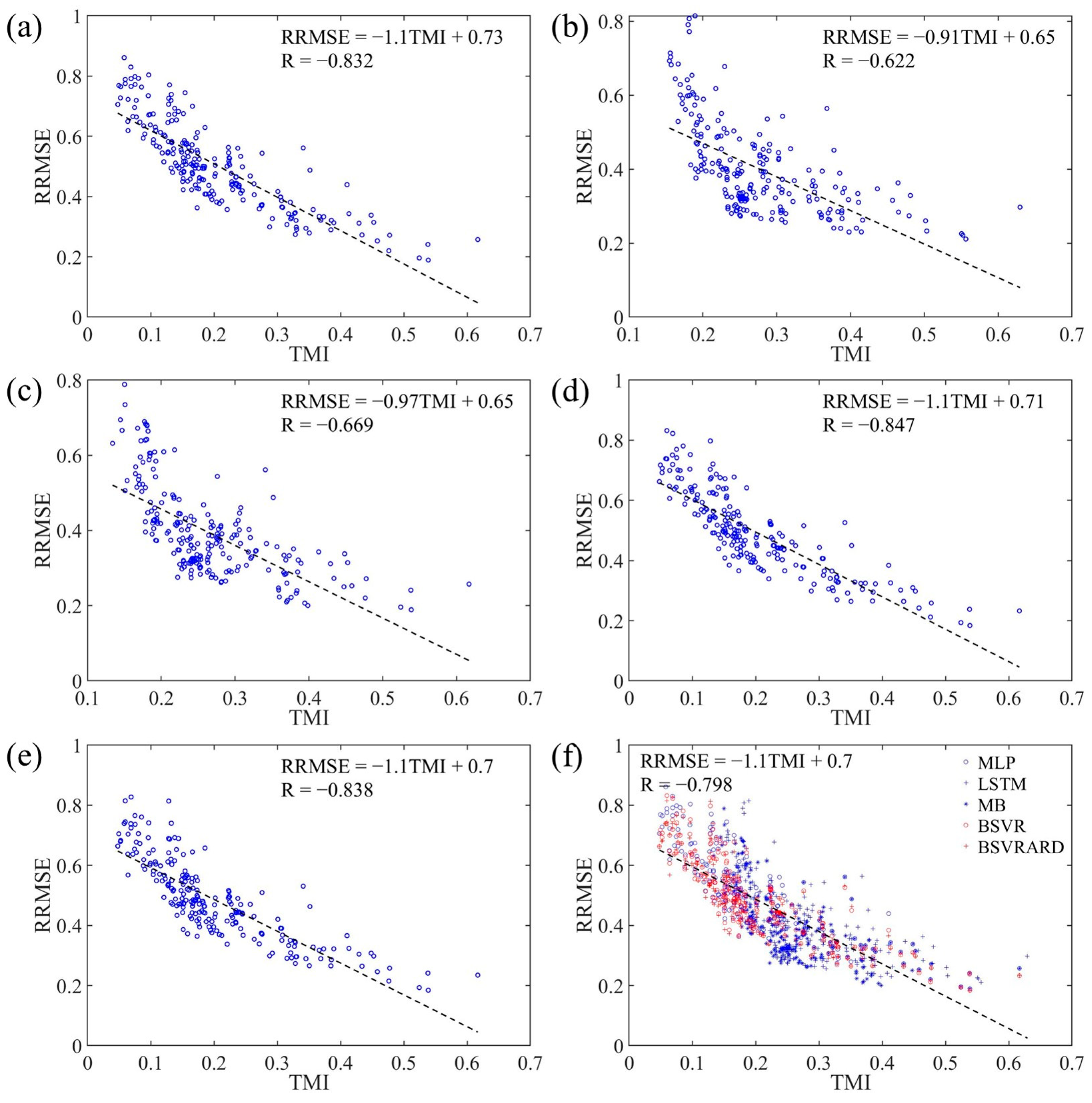
4.2.2. RMSE, RRMSE and TMI
4.2.3. The Linear Regression Equations between RRMSE and MI and TMI
4.3. The Influence of Rainfall on the Predictive Performance and TMI
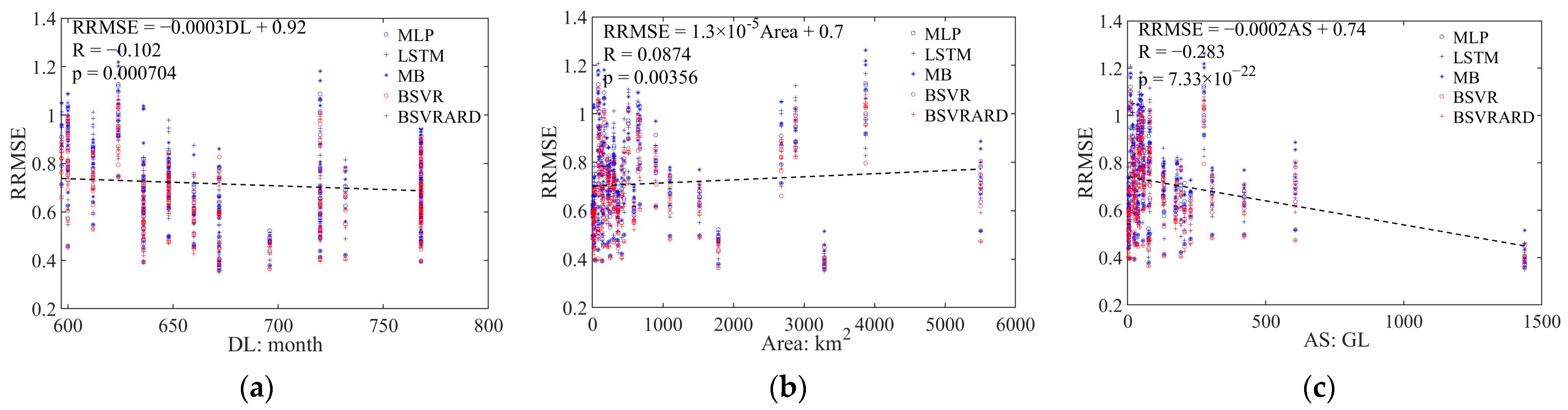
4.4. The Impact Factors of Predictive Performance
5. Conclusions
- (1)
- The developed TMI index can represent the available information in the predictors better than the MI index, and has a significant negative correlation with the RRMSE. The correlation coefficients are between −0.8 and −0.85 when the rainfall is not included as a predictor. And when the rainfall is included as a predictor, the coefficients are between −0.62 and −0.85.
- (2)
- The developed TMI index can be used to evaluate the applicability of MLTRP. Along with the increase in TMI, the available information increases and the model’s predictive performance becomes better. When the TMI is more than 0.1, the available information of the predictors can support the construction of MLTRP models, and the model can generate valuable predictions. When the TMI is less than 0.1 and near 0, the MLTRP may be not suitable in the forecasting scenarios.
- (3)
- The five AI models have significantly different performances in different scenarios. When the rainfall is not included as a predictor, the complex LSTM and MB models using time series as inputs perform worse than the MLP, BSVR, and BSVRARD models. After the incorporation of rainfall as a predictor, the TMI increases significantly, and the complex LSTM and MB models, which can better utilize the contained information in the predictors, perform better than the other three models.
- (4)
- The differences in the five models can be partly explained by the developed TMI index. The slopes of the linear regression equation between the RRMSE of the LSTM and MB models and the TMI are less than those for the BSVR and BSVRARD models. This means the LSTM and MB models are more sensitive to the available information of the predictors (i.e., TMI), and therefore, the changes in the predictive performance for the LSTM and MB models are more significant than that of the BSVR and BSVRARD models after the incorporation of rainfall as a predictor.
- (5)
- The developed TMI index is just a statistical indicator reflecting the available information in the predictor set, which affects the predictive performance of data-driven models, but the root cause for the difference in predictive performance is the characteristics of the basin.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID in This Study | ID in BOM | Basin | Station Name | Upstream Area: km2 | Data Length | Annual Streamflow: GL |
|---|---|---|---|---|---|---|
| 1 | 112002A | Johnstone River | Fisher Creek at Nerada | 16.2 | 768 | 37.3 |
| 2 | 116010A | Herbert River | Blencoe Creek at Blencoe Falls | 223.7 | 648 | 128.6 |
| 3 | 116011A | Herbert River | Millstream River at Ravenshoe | 90.1 | 648 | 59.4 |
| 4 | 116013A | Herbert River | Millstream river at Archer Creek | 309.3 | 636 | 178.4 |
| 5 | 116014A | Herbert River | Wild River at Silver Valley | 587.6 | 636 | 173.6 |
| 6 | 136202D | Burnett River | Barambah Creek at Litzows | 646.6 | 600 | 51.1 |
| 7 | 143009A | Brisbane River | Brisbane River at Gregors Creek | 3875.5 | 624 | 276.0 |
| 8 | 145101D | Logan-Albert Rivers | Albert River at Lumeah Number 2 | 165.9 | 720 | 47.7 |
| 9 | 146010A | South Coast | Coomera River at Army Camp | 96.6 | 624 | 37.1 |
| 10 | 223202 | Mitchell-Thomson Rivers | Tambo River at Swifts Creek | 899.3 | 768 | 76.6 |
| 11 | 224206 | Mitchell-Thomson Rivers | Wonnangatta River at Crooked River | 1099.5 | 648 | 305.7 |
| 12 | 231213 | Werribee River | Lerderderg River at Sardine Creek O’brien Crossing | 152.1 | 660 | 25.5 |
| 13 | 235205 | Otway Coast | Arkins Creek West Branch at Wyelangta | 4.5 | 672 | 4.1 |
| 14 | 238208 | Glenelg River | Jimmy Creek at Jimmy Creek | 23.3 | 768 | 3.3 |
| 15 | 401203 | Upper Murray | Mitta Mitta River at Hinnomunjie | 1518.8 | 720 | 422.1 |
| 16 | 401210 | Upper Murray | Snowy Creek at Below Granite Flat | 415.7 | 732 | 192.6 |
| 17 | 401212 | Upper Murray | Nariel Creek at Upper Nariel | 251.6 | 720 | 131.8 |
| 18 | 401216 | Upper Murray | Big River at Jokers Creek | 356.8 | 768 | 227.8 |
| 19 | 403209A | Ovens River | Reedy Creek at Wangaratta North | 5505.8 | 768 | 607.5 |
| 20 | 403213A | Ovens River | Fifteen Mile Creek at Greta South | 230.9 | 672 | 55.6 |
| 21 | 403214 | Ovens River | Happy Valley Creek at Rosewhite | 138 | 636 | 24.1 |
| 22 | 403221 | Ovens River | Reedy Creek at Woolshed | 205.5 | 600 | 33.8 |
| 23 | 404207 | Broken River | Holland Creek at Kelfeera | 448 | 648 | 80.4 |
| 24 | 405218 | Goulburn | Jamieson River at Gerrang Bridge | 364.2 | 660 | 205.9 |
| 25 | 406208 | Campaspe River | Campaspe River at Ashborne | 37.6 | 768 | 7.1 |
| 26 | 407214 | Loddon River | Creswick Creek at Clunes | 299.9 | 768 | 23.7 |
| 27 | 408200 | Avoca River | Avoca River at Coonooer | 2677.3 | 597 | 19.2 |
| 28 | 410705 | Murrumbidgee River | Molonglo River at Burbong | 508.6 | 768 | 42.7 |
| 29 | 410730 | Murrumbidgee River | Cotter River at Gingera | 130 | 612 | 42.5 |
| 30 | 410731 | Murrumbidgee River | Gudgenby River at Tennent | 671.6 | 600 | 57.0 |
| 31 | 415207 | Wimmera | Wimmera River at Eversley | 304.5 | 612 | 17.0 |
| 32 | 422202B | Barwon-Condamine-Culgoa | Dogwood Creek at Gilweir | 2881.5 | 768 | 79.9 |
| 33 | 422306A | Barwon-Condamine-Culgoa | Swan Creek at Swanfels | 82.6 | 768 | 10.4 |
| 34 | 604053 | Kent River | Kent River at Styx Junction | 1786 | 696 | 75.8 |
| 35 | 613146 | Murray River (WA) | Clarke Brook at Hillview Farm | 18.7 | 636 | 4.4 |
| 36 | 614044 | Murray River (WA) | Yarragil Brook at Yarragil Formation | 80 | 720 | 2.9 |
| 37 | 925001A | Wenlock River | Wenlock river at Moreton | 3290.3 | 672 | 1437.5 |
References
- Nguyen, Q.H.; Tran, V.N. Temporal Changes in Water and Sediment Discharges: Impacts of Climate Change and Human Activities in the Red River Basin (1958–2021) with Projections up to 2100. Water 2024, 16, 1155. [Google Scholar] [CrossRef]
- Jia, L.; Niu, Z.; Zhang, R.; Ma, Y. Sensitivity of Runoff to Climatic Factors and the Attribution of Runoff Variation in the Upper Shule River, North-West China. Water 2024, 16, 1272. [Google Scholar] [CrossRef]
- Xu, H.; Liu, L.; Wang, Y.; Wang, S.; Hao, Y.; Ma, J.; Jiang, T. Assessment of climate change impact and difference on the river runoff in four basins in China under 1.5 and 2.0 °C global warming. Hydrol. Earth Syst. Sci. 2019, 23, 4219–4231. [Google Scholar] [CrossRef]
- Zou, L.; Zhou, T. Near future (2016–40) summer precipitation changes over China as projected by a regional climate model (RCM) under the RCP8.5 emissions scenario: Comparison between RCM downscaling and the driving GCM. Adv. Atmos. Sci. 2013, 30, 806–818. [Google Scholar] [CrossRef]
- Piao, S.L.; Ciais, P.; Huang, Y.; Shen, Z.H.; Peng, S.S.; Li, J.S.; Zhou, L.P.; Liu, H.Y.; Ma, Y.C.; Ding, Y.H.; et al. The impacts of climate change on water resources and agriculture in China. Nature 2010, 467, 43–51. [Google Scholar] [CrossRef] [PubMed]
- Larraz, B.; García-Rubio, N.; Gámez, M.; Sauvage, S.; Cakir, R.; Raimonet, M.; Pérez, J.M.S. Socio-Economic Indicators for Water Management in the South-West Europe Territory: Sectorial Water Productivity and Intensity in Employment. Water 2024, 16, 959. [Google Scholar] [CrossRef]
- Haj-Amor, Z.; Acharjee, T.K.; Dhaouadi, L.; Bouri, S. Impacts of climate change on irrigation water requirement of date palms under future salinity trend in coastal aquifer of Tunisian oasis. Agric. Water Manag. 2020, 228, 105843. [Google Scholar] [CrossRef]
- Shukla, P.R.; Skeg, J.; Buendia, E.C.; Masson-Delmotte, V.; Pörtner, H.O.; Roberts, D.C.; Zhai, P.; Slade, R.; Connors, S.; Van Diemen, S.; et al. Climate Change and Land: An IPCC Special Report on Climate Change, Desertification, Land Degradation, Sustainable Land Management, Food Security, and Greenhouse Gas Fluxes in Terrestrial Ecosystems; IPCC: Geneva, Switzerland, 2019. [Google Scholar]
- Bărbulescu, A.; Zhen, L. Forecasting the River Water Discharge by Artificial Intelligence Methods. Water 2024, 16, 1248. [Google Scholar] [CrossRef]
- Chu, H.; Wei, J.; Wu, W. Streamflow prediction using LASSO-FCM-DBN approach based on hydro-meteorological condition classification. J. Hydrol. 2020, 580, 124253. [Google Scholar] [CrossRef]
- Xie, S.; Huang, Y.F.; Li, T.J.; Liu, C.Y.; Wang, J.H. Mid-long term runoff prediction based on a Lasso and SVR hybrid method. J. Basic Sci. Eng. 2018, 26, 709–722. [Google Scholar]
- Feng, Z.-K.; Niu, W.-J.; Tang, Z.-Y.; Jiang, Z.-Q.; Xu, Y.; Liu, Y.; Zhang, H.-R. Monthly runoff time series prediction by variational mode decomposition and support vector machine based on quantum-behaved particle swarm optimization. J. Hydrol. 2020, 583, 124627. [Google Scholar] [CrossRef]
- Sunday, R.; Masih, I.; Werner, M.; van der Zaag, P. Streamflow forecasting for operational water management in the Incomati River Basin, Southern Africa. Phys. Chem. Earth Parts A/B/C 2014, 72, 1–12. [Google Scholar] [CrossRef]
- Shamir, E. The value and skill of seasonal forecasts for water resources management in the Upper Santa Cruz River basin, southern Arizona. J. Arid. Environ. 2017, 137, 35–45. [Google Scholar] [CrossRef]
- Zhao, H.; Li, H.; Xuan, Y.; Bao, S.; Cidan, Y.; Liu, Y.; Li, C.; Yao, M. Investigating the critical influencing factors of snowmelt runoff and development of a mid-long term snowmelt runoff forecasting. J. Geogr. Sci. 2023, 33, 1313–1333. [Google Scholar] [CrossRef]
- Liang, Z.; Li, Y.; Hu, Y.; Li, B.; Wang, J. A data-driven SVR model for long-term runoff prediction and uncertainty analysis based on the Bayesian framework. Theor. Appl. Clim. 2018, 133, 137–149. [Google Scholar] [CrossRef]
- He, C.; Chen, F.; Long, A.; Qian, Y.; Tang, H. Improving the precision of monthly runoff prediction using the combined non-stationary methods in an oasis irrigation area. Agric. Water Manag. 2023, 279, 108161. [Google Scholar] [CrossRef]
- Samsudin, R.; Saad, P.; Shabri, A. River flow time series using least squares support vector machines. Hydrol. Earth Syst. Sci. 2011, 15, 1835–1852. [Google Scholar] [CrossRef]
- Bennett, J.C.; Wang, Q.J.; Li, M.; Robertson, D.E.; Schepen, A. Reliable long-range ensemble streamflow forecasts: Combining calibrated climate forecasts with a conceptual runoff model and a staged error model. Water Resour. Res. 2016, 52, 8238–8259. [Google Scholar] [CrossRef]
- Crochemore, L.; Ramos, M.-H.; Pappenberger, F. Bias correcting precipitation forecasts to improve the skill of seasonal streamflow forecasts. Hydrol. Earth Syst. Sci. 2016, 20, 3601–3618. [Google Scholar] [CrossRef]
- Jain, A.; Kumar, A.M. Hybrid neural network models for hydrologic time series forecasting. Appl. Soft Comput. 2007, 7, 585–592. [Google Scholar] [CrossRef]
- Firat, M.; Turan, M.E. Monthly river flow forecasting by an adaptive neuro-fuzzy inference system. Water Environ. J. 2010, 24, 116–125. [Google Scholar] [CrossRef]
- Le, X.H.; Ho, H.V.; Lee, G.; Jung, S. Application of long short-term memory (LSTM) neural network for flood forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef]
- Choi, J.; Won, J.; Jang, S.; Kim, S. Learning Enhancement Method of Long Short-Term Memory Network and Its Applicability in Hydrological Time Series Prediction. Water 2022, 14, 2910. [Google Scholar] [CrossRef]
- Mount, N.; Maier, H.; Toth, E.; Elshorbagy, A.; Solomatine, D.; Chang, F.-J.; Abrahart, R. Data-driven modelling approaches for socio-hydrology: Opportunities and challenges within the Panta Rhei Science Plan. Hydrol. Sci. J. 2016, 61, 1192–1208. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat, F. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Xie, S.; Huang, Y.; Li, T.; Chen, B. Performance Comparison of Autoregressive Runoff Prediction Methods for Different River Basins. J. Basic Sci. Eng. 2018, 26, 723–736. [Google Scholar]
- Jónsdóttir, J.F.; Uvo, C.B. Long-term variability in precipitation and streamflow in Iceland and relations to atmospheric circulation. Int. J. Clim. 2010, 29, 1369–1380. [Google Scholar] [CrossRef]
- Omondi, P.; Ogallo, L.A.; Anyah, R.; Muthama, J.M.; Ininda, J. Linkages between global sea surface temperatures and decadal rainfall variability over Eastern Africa region. Int. J. Clim. 2013, 33, 2082–2104. [Google Scholar] [CrossRef]
- Carlson, R.F.; MacCormick, A.J.A.; Watts, D.G. Application of Linear Random Models to Four Annual Streamflow Series. Water Resour. Res. 1970, 6, 1070–1078. [Google Scholar] [CrossRef]
- Valipour, M. Long-term runoff study using SARIMA and ARIMA models in the United States. Meteorol. Appl. 2015, 22, 592–598. [Google Scholar] [CrossRef]
- Valipour, M. Number of Required Observation Data for Rainfall Forecasting According to the Climate Conditions. Am. J. Sci. Res. 2012, 74, 79–86. [Google Scholar]
- Valipour, M.; Banihabib, M.E.; Behbahani, S.M.R. Comparison of the ARMA, ARIMA, and the autoregressive artificial neural network models in forecasting the monthly inflow of Dez dam reservoir. J. Hydrol. 2013, 476, 433–441. [Google Scholar] [CrossRef]
- Tesfaye, Y.G.; Meerschaert, M.M.; Anderson, P.L. Identification of periodic autoregressive moving average models and their application to the modeling of river flows. Water Resour. Res. 2006, 42, 87–94. [Google Scholar] [CrossRef]
- Wang, W.-C.; Chau, K.-W.; Cheng, C.-T.; Qiu, L. A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; El-Shafie, A.; Jaafar, O.; Afan, H.A.; Sayl, K.N. Artificial intelligence based models for stream-flow forecasting: 2000–2015. J. Hydrol. 2015, 530, 829–844. [Google Scholar] [CrossRef]
- Yang, T.; Asanjan, A.A.; Welles, E.; Gao, X.; Sorooshian, S.; Liu, X. Developing reservoir monthly inflow forecasts using artificial intelligence and climate phenomenon information. Water Resour. Res. 2017, 53, 2786–2812. [Google Scholar] [CrossRef]
- Zhang, W.; Hu, J.; Wang, Y.; Wang, L.; Li, L.; Cao, S. Mid-long term runoff forecasting model based on RS-RVM. MATEC Web Conf. 2018, 246, 02039. [Google Scholar] [CrossRef]
- Erdal, H.I.; Karakurt, O. Advancing monthly streamflow prediction accuracy of CART models using ensemble learning paradigms. J. Hydrol. 2013, 477, 119–128. [Google Scholar] [CrossRef]
- Kashid, S.; Ghosh, S.; Maity, R. Streamflow prediction using multi-site rainfall obtained from hydroclimatic teleconnection. J. Hydrol. 2010, 395, 23–38. [Google Scholar] [CrossRef]
- Wang, W.-C.; Wang, B.; Chau, K.-W.; Zhao, Y.-W.; Zang, H.-F.; Xu, D.-M. Monthly runoff prediction using gated recurrent unit neural network based on variational modal decomposition and optimized by whale optimization algorithm. Environ. Earth Sci. 2024, 83, 83. [Google Scholar] [CrossRef]
- Zhang, D.; Lin, J.; Peng, Q.; Wang, D.; Yang, T.; Sorooshian, S.; Liu, X.; Zhuang, J. Modeling and simulating of reservoir operation using the artificial neural network, support vector regression, deep learning algorithm. J. Hydrol. 2018, 565, 720–736. [Google Scholar] [CrossRef]
- Xu, D.-M.; Wang, X.; Wang, W.-C.; Chau, K.-W.; Zang, H.-F. Improved monthly runoff time series prediction using the SOA-SVM model based on ICEEMDAN-WD decomposition. J. Hydroinformatics 2023, 25, 943–970. [Google Scholar] [CrossRef]
- Kelly, R.A.; Jakeman, A.J.; Barreteau, O.; Borsuk, M.E.; ElSawah, S.; Hamilton, S.H.; Henriksen, H.J.; Kuikka, S.; Maier, H.R.; Rizzoli, A.E.; et al. Selecting among five common modelling approaches for integrated environmental assessment and management. Environ. Model. Softw. 2013, 47, 159–181. [Google Scholar] [CrossRef]
- Azmi, M.; Araghinejad, S.; Kholghi, M. Multi model data fusion for hydrological forecasting using k-nearest neighbour method. Iran. J. Sci. Technol. 2010, 34, 81. [Google Scholar]
- See, L.; Abrahart, R.J. Multi-model data fusion for hydrological forecasting. Comput. Geosci. 2001, 27, 987–994. [Google Scholar] [CrossRef]
- Liu, Y.; Yin, Z.; Zhang, Y.; Wang, Q. Mid and long-term hydrological classification forecasting model based on KDE-BDA and its application research. IOP Conf. Ser. Earth Environ. Sci. 2019, 330, 032010. [Google Scholar] [CrossRef]
- Wang, Q.J.; Robertson, D.E.; Chiew, F.H.S. A Bayesian joint probability modeling approach for seasonal forecasting of streamflows at multiple sites. Water Resour. Res. 2009, 45, 641–648. [Google Scholar] [CrossRef]
- Maity, R.; Bhagwat, P.P.; Bhatnagar, A. Potential of support vector regression for prediction of monthly streamflow using endogenous property. Hydrol. Process. 2010, 24, 917–923. [Google Scholar] [CrossRef]
- Zhang, G.; Hu, M.Y. Neural network forecasting of the British Pound/US Dollar exchange rate. Omega 1998, 26, 495–506. [Google Scholar] [CrossRef]
- Coulibaly, P.; Bobée, B.; Anctil, F. Improving extreme hydrologic events forecasting using a new criterion for artificial neural network selection. Hydrol. Process. 2010, 15, 1533–1536. [Google Scholar] [CrossRef]
- Nilsson, P.; Uvo, C.B.; Berndtsson, R. Monthly runoff simulation: Comparing and combining conceptual and neural network models. J. Hydrol. 2006, 321, 344–363. [Google Scholar] [CrossRef]
- Kirono, D.G.C.; Chiew, F.H.S.; Kent, D.M. Identification of best predictors for forecasting seasonal rainfall and runoff in Australia. Hydrol. Process. 2010, 24, 1237–1247. [Google Scholar] [CrossRef]
- Li, H.; Xie, M.; Jiang, S. Recognition method for mid- to long-term runoff forecasting factors based on global sensitivity analysis in the Nenjiang River Basin. Hydrol. Process. 2012, 26, 2827–2837. [Google Scholar] [CrossRef]
- May, R.; Dandy, G.; Maier, H. Review of input variable selection methods for artificial neural networks. Artif. Neural Netw.-Methodol. Adv. Biomed. Appl. 2011, 10, 16004. [Google Scholar]
- Xie, S.; Wu, W.; Mooser, S.; Wang, Q.; Nathan, R.; Huang, Y. Artificial neural network based hybrid modeling approach for flood inundation modeling. J. Hydrol. 2021, 592, 125605. [Google Scholar] [CrossRef]
- Wu, W.; Dandy, G.C.; Maier, H.R. Protocol for developing ANN models and its application to the assessment of the quality of the ANN model development process in drinking water quality modelling. Environ. Model. Softw. 2014, 54, 108–127. [Google Scholar] [CrossRef]
- Zhao, T.; Schepen, A.; Wang, Q. Ensemble forecasting of sub-seasonal to seasonal streamflow by a Bayesian joint probability modelling approach. J. Hydrol. 2016, 541, 839–849. [Google Scholar] [CrossRef]
- Hejazi, M.I.; Cai, X. Input variable selection for water resources systems using a modified minimum redundancy maximum relevance (mMRMR) algorithm. Adv. Water Resour. 2009, 32, 582–593. [Google Scholar] [CrossRef]
- May, R.J.; Dandy, G.C.; Maier, H.R.; Nixon, J.B. Application of partial mutual information variable selection to ANN forecasting of water quality in water distribution systems. Environ. Model. Softw. 2008, 23, 1289–1299. [Google Scholar] [CrossRef]
- May, R.J.; Maier, H.R.; Dandy, G.C.; Fernando, T.G. Non-linear variable selection for artificial neural networks using partial mutual information. Environ. Model. Softw. 2008, 23, 1312–1326. [Google Scholar] [CrossRef]
- Wang, Q.J.; Shrestha, D.L.; Robertson, D.E.; Pokhrel, P. A log-sinh transformation for data normalization and variance stabilization. Water Resour. Res. 2012, 48, W05514. [Google Scholar] [CrossRef]
- Wang, Q.J.; Zhao, T.; Yang, Q.; Robertson, D. A Seasonally Coherent Calibration (SCC) Model for Postprocessing Numerical Weather Predictions. Mon. Weather. Rev. 2019, 147, 3633–3647. [Google Scholar] [CrossRef]
- Van Gestel, T.; Suykens, J.; De Moor, B.; Vandewalle, J. Automatic relevance determination for least squares support vector machine regression. IJCNN’01 Int. Jt. Conf. Neural Networks. Proc. 2001, 4, 2416–2421. [Google Scholar]
- Van Gestel, T.; Suykens, J.; Baestaens, D.-E.; Lambrechts, A.; Lanckriet, G.; Vandaele, B.; De Moor, B.; Vandewalle, J. Financial time series prediction using least squares support vector machines within the evidence framework. IEEE Trans. Neural Netw. 2001, 12, 809–821. [Google Scholar] [CrossRef]
- Van Gestel, T.; Suykens, J.A.K.; Lanckriet, G.; Lambrechts, A.; De Moor, B.; Vandewalle, J. Bayesian framework for least-squares support vector machine classifiers, Gaussian processes, and kernel Fisher discriminant analysis. Neural Comput. 2002, 14, 1115–1147. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall-runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Lin, J.-Y.; Cheng, C.-T.; Chau, K.-W. Using support vector machines for long-term discharge prediction. Hydrol. Sci. J. 2006, 51, 599–612. [Google Scholar] [CrossRef]
- Tramblay, Y.; Amoussou, E.; Dorigo, W.; Mahé, G. Flood risk under future climate in data sparse regions: Linking extreme value models and flood generating processes. J. Hydrol. 2014, 519, 549–558. [Google Scholar] [CrossRef]
- Tramblay, Y.; Villarini, G.; Saidi, M.E.; Massari, C.; Stein, L. Classification of flood-generating processes in Africa. Sci. Rep. 2022, 12, 18920. [Google Scholar] [CrossRef] [PubMed]






| Model | Introduction |
|---|---|
| MLP | Commonly used three-layer neural network. |
| MB | Based on the MLP, a block data structure is used to incorporate the time series information. The details of this method can be found in [56]. |
| BSVR | A model in which the Bayesian inference framework is used to optimize the parameters of SVR. The details can be found in [64,65,66]. |
| BSVRARD | A model integrating the BSVR and ARD kernel. The details can be found in [64,65,66]. |
| LSTM | Commonly used deep learning neural network which is suitable for time series forecasting. The details of LSTM can be found in [67]. |
| Experiment | Candidate Predictors | Prediction | Validation Metrics | Evaluation Indices | Analysis |
|---|---|---|---|---|---|
| Experiment 1 (E1) | 130 climate factors and transformed runoff in the previous 12 months. | Runoff of the 37 stations in the future 1–6 months. In total 37 × 6 = 222 forecasting scenarios. | RMSE, RRMSE. | MI and TMI. | The relationships of RMSE-TMI, RRMSE-TMI, and RRMSE-MI. |
| Experiment 2 (E2) | The candidate predictors in E1 and rainfall in the previous 12 months and future FLT (forecast lead time) months. | Runoff of the 37 stations in the future 1–6 months. In total 37 × 6 = 222 forecasting scenarios. | RMSE, RRMSE. | MI and TMI. | The relationships of RMSE-TMI, RRMSE-TMI, and RRMSE-MI. |
| Independent Variable | Model | ||||||
|---|---|---|---|---|---|---|---|
| MLP | LSTM | MB | BSVR | BSVRARD | All | ||
| MI | Slope | −0.665 | −0.638 | −0.681 | −0.620 | −0.654 | −0.652 |
| Intercept | 1.192 | 1.215 | 1.240 | 1.142 | 1.159 | 1.190 | |
| TMI | Slope | −1.937 | −1.907 | −1.976 | −1.787 | −1.862 | −1.894 |
| Intercept | 0.970 | 1.008 | 1.011 | 0.932 | 0.935 | 0.972 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, S.; Xiang, Z.; Wang, Y.; Wu, B.; Shen, K.; Wang, J. An Index Used to Evaluate the Applicability of Mid-to-Long-Term Runoff Prediction in a Basin Based on Mutual Information. Water 2024, 16, 1619. https://doi.org/10.3390/w16111619
Xie S, Xiang Z, Wang Y, Wu B, Shen K, Wang J. An Index Used to Evaluate the Applicability of Mid-to-Long-Term Runoff Prediction in a Basin Based on Mutual Information. Water. 2024; 16(11):1619. https://doi.org/10.3390/w16111619
Chicago/Turabian StyleXie, Shuai, Zhilong Xiang, Yongqiang Wang, Biqiong Wu, Keyan Shen, and Jin Wang. 2024. "An Index Used to Evaluate the Applicability of Mid-to-Long-Term Runoff Prediction in a Basin Based on Mutual Information" Water 16, no. 11: 1619. https://doi.org/10.3390/w16111619
APA StyleXie, S., Xiang, Z., Wang, Y., Wu, B., Shen, K., & Wang, J. (2024). An Index Used to Evaluate the Applicability of Mid-to-Long-Term Runoff Prediction in a Basin Based on Mutual Information. Water, 16(11), 1619. https://doi.org/10.3390/w16111619