Abstract
Estimating the accurate evaluation of product lifetime performance has always been a hot topic in manufacturing industry. This paper, based on the lifetime performance index, focuses on its evaluation when a lower specification limit is given. The progressive first-failure-censored data we discuss have a common log-logistic distribution. Both Bayesian and non-Bayesian method are studied. Bayes estimator of the parameters of the log-logistic distribution and the lifetime performance index are obtained using both the Lindley approximation and Monte Carlo Markov Chain methods under symmetric and asymmetric loss functions. As for interval estimation, we apply the maximum likelihood estimator to construct the asymptotic confidence intervals and the Metropolis–Hastings algorithm to establish the highest posterior density credible intervals. Moreover, we analyze a real data set for demonstrative purposes. In addition, different criteria for deciding the optimal censoring scheme have been studied.
1. Introduction
With the advancement of technology and the improvement of living standards, requirements for daily necessities have also increased. Product lifetime (PL), mentioned in Reference [1,2], is defined here as the functional life of a product. PL is related not only to the rights and interests of consumers but also to the survival and development of enterprises. The Process capability index (PCI), a parameter index used to appraise the performance of processes in the manufacturing and service industries, is used to test whether the manufactured products meet the minimum requirements. Generally, it is a default rule that the life span of a product can reflect its quality. In Reference [3], the lifetime performance index is proposed to measure such qualitative characteristics, and L represents an artificially set lower specification limit. Many scholars have considered the statistical inference for the lifetime performance index with various well-informed distributions from different censored samples; see References [4,5,6,7,8].
Generally, censoring is used in lifetime experiments owing to the restriction on time and funds in real life. Certain types of classic censoring schemes, of which type-I and type-II are the most common analyzed schemes, have been studied in survival analysis. In the former, it tests N units within a predetermined period of time t. On the contrary, the test will not terminate until units failed in the latter scheme. The sharing shortcoming of type-I and type-II censoring lies in the limitation that no test unit can be removed until the termination of the test. Later, a whole new censoring which allows removal of units at various stages during the lifetime test: progressive censoring is proposed in Reference [9].
Compared with the traditional censoring schemes mentioned above in reliability theory, progressive censoring greatly improves the efficiency of reasoning method. The two can also be used in combination; see Reference [10]. In the monograph [11], a more detailed statement on progressive censoring schemes is given. In order to shun the problem that the long life of the product in most cases leads to a long time for review experiments, statisticians introduce new censoring schemes. The first-failure examination scheme is defined in Reference [12]. Randomly group the total units to n batches, and each batch we get contains k identical units. All of the units are tested simultaneously. When the first failure of a unit contained in a batch is observed, the whole batch will be removed from the life test. Applying this model, a mass of time and economic costs can be saved.
Combining the advantage of progressive censoring and first-failure censoring mentioned in the previous paragraph, the progressive first-failure censoring is proposed in Reference [13]. We study this censoring, and the following is a brief introduction. Likewise, N samples are randomly assigned to n independent batches with k identical units (satisfy the equation ) during the initial life test. On observing the failure of the mth unit, the experiment is terminated. The batch containing the ith observed failure unit along with randomly selected batches are removed jointly, where . When the mth unit fails, the delete operation is performed to remove all surviving batches in life test. It is worthwhile to emphasize that m, k, and are predetermined constants. The progressive first-failure censoring has the advantages of reducing trial time, saving trial resources, and removing a significant number of risky units from the trial at various stages of the life test. It has been widely used in reliability studies and several researchers; refer to References [14,15,16,17,18,19,20].
Note the following:
- When k = 1, , we acquire the complete sample.
- When equations k = 1, , and are satisfied, we get type-II censoring.
- When , the progressive first-failure censoring reduces to the first-failure censoring.
- When k is equal to 1, we get a simplified form: the more familiar progressive type-II censoring.
The lifetime data we use is from log-logistic distribution. It is a kind of classical life distribution in reliability studies and is discussed by many scholars; refer to Reference [21,22,23]. When we have , the cumulative distribution function (cdf) and the probability density function (pdf) of the log-logistic distribution are
Note that is the shape parameter; is the scale parameter and the median of the log-logistic distribution.
Moreover, the hazard rate function of log-logistic distribution is
We assume for calculating the variance of the log-logistic distribution. As we can see from Figure 1, log-logistic distributions have a non-monotonic hazard function. It will decrease monotonically if and will become a unimodal function if . Therefore, the hazard function we will study is unimodal.
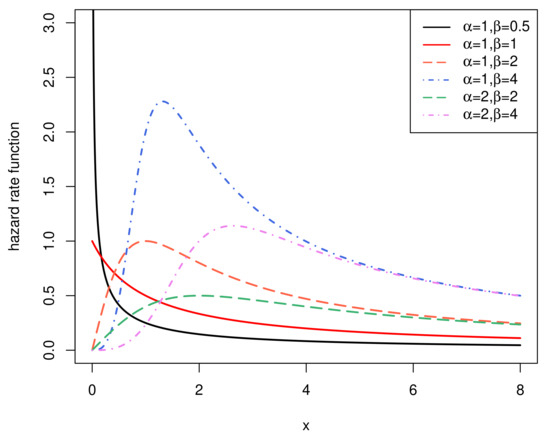
Figure 1.
The hazard rate function.
In Section 2, we will discuss some basic characters of as well as the relationship between the product qualification ratio and the lifetime performance index. In Section 3, attention will be paid to the Maximum Likelihood Estimation (MLE) of using Fisher information matrix. In Section 4, we study normal approximation of the MLE and the log-transformed MLE. Then, Section 5 will use the Bayesian method to estimate with the help of Lindley approximation and Monte Carlo Markov Chain method. Section 6 and Section 7 contain simulation studies and an illustrative example. Optimal censoring plan will be discussed in Section 8. In Section 9, some conclusions will be summarized.
2. The Lifetime Performance Index
Let X represent the lifetime of the products. The (the specific value of when using the random variable X) is defined in Reference [3] as follows:
where is the mean of X and is the standard deviation of X. , the lower specification limit predetermined according to the market demands, specifies the minimum acceptable life of the product. Note that random variable X follows a log-logistic distribution throughout the whole paper. Since the pdf and the cdf of log-logistic distribution are presented earlier as in Equations (1) and (2), we can easily calculate that and , where , and . Then, from Equation (4), the lifetime performance index is
Here, we have . It is evident that while . According to Equations (3) and (5), we can conservatively draw the conclusion that it is rational for to represent the lifetime performance of products since the hazard rate function and have the opposite performance when increases.
In this paper, a product is assumed to be qualified (subquality) when . We define the product qualification rate , which is also named as the conforming rate, as follows:
Visibly, a strictly monotonic increasing relationship exits between and for given .
All in all, has great practical relevance because it can represent the lifetime performance of products and can calculate the theoretical value of conforming rate .
3. Maximum Likelihood Estimation for
Based on progressive first-failure-censored samples, the maximum likelihood estimation (MLE) for , , and with log-logistic distribution are analysed in this section. Firstly, let be the sample generated from the log-logistic distribution following censoring schemes . Then, under this progressive first-failure-censored sample, the joint pdf based on the abovementioned censoring scheme is
where is a normal constant and is obligatory.
Both and are assumed to be unknown for further discussion. Take the logarithm of Equation (8) and the log-likelihood function becomes the following:
differentiates and respectively, and we can get the following:
Set the above two Equations (9) and (10) to zero, and the MLEs of and can be obtained through calculation. From Equation (9), we can observe the following:
where .
Choosing a suitable iterative procedure, the solution to Equation (12) can be evaluated numerically when values of are given. Let the MLE of be , and the MLE of b can be obtained as . Then, it is available to get , the MLE of , by substituting into Equation (11). Due to the invariance property, the MLE of is obtained as follows:
4. Confidence Intervals
4.1. Asymptotic Confidence Intervals for MLE
Let , and the Fisher information matrix of is as follows:
The specific expressions of sencond derivatives of l are presented in Appendix A.
It is infeasible to derive the expectation of above expressions; henceforward, the observed Fisher information matrix is utilized for calculation. Set to be the MLE of . When , the inverse of Equation (14) is the observed variance–covariance matrix of MLEs:
With mean as and covariance matrix as , the asymptotic distribution of MLEs is approximately bivariately normal; two-tailed asymptotic confidence intervals of and are respectively the following:
The percentile of the standard normal distribution is . Then, applying Monte Carlo simulation, the coverage probabilities (CPs) of and are respectively
.
In addition, we assume that and we have the following:
where
Then, we define the asymptotic estimator of as follows:
Using the delta method, we know that
Thus, the asymptotic confidence interval of can be derived as
4.2. Asymptotic Confidence Intervals for the Log-Transformed MLE
According to References [8,24], the asymptotic confidence intervals has better CP using log-transformed MLE. The asymptotic confidence intervals of and for the log-transformed MLE are
The approximate confidence intervals of and for log-transformed MLE are
Similarly, the normal approximation confidence interval of is
5. Bayesian Estimation
5.1. Prior Distribution and Posterior Analysis
A more precise and efficient method is considered to obtain approximate estimators of and here. First of all, prior distributions used in calculation are Gamma distributions:
The joint prior distribution is
The joint posterior distribution is
where
5.2. Asymmetric and Symmetric Loss Functions
In the Bayesian estimation, the loss function is of great importance. The Bayesian estimation for parameters and and lifetime performance index from a log-logistic distribution under both asymmetric as well as symmetric loss functions are carried out. The loss functions we chose are widely studied: the squared error loss function (SELF), the linex loss function (LF), the general entropy loss function (GELF). Their definitions are as follows:
Note that represents an estimate of , , and . In LF and GELF, the positive and negative natures of and show the direction of the asymmetry and the value size shows the degree of asymmetry.
The Bayesian estimation of under SELF, LF, and GELF are respectively as follows:
The Bayesian estimation under SELF, LF, and GELF of any given function of and , let us say , are
where .
Clearly, it is infeasible to get the accurate closed form of the Bayesian estimation. Hence, Lindley method is used in the next section to derive the Bayes estimator.
5.3. Lindley Approximation Method
Lindley approximation method is introduced by Reference [25] to approximate two integral ratios. According to this method, the Bayes estimate of any function of , , is
where
The specific expressions of (also known as third derivatives of l) are presented in Appendix B. represents the th element from the observed variance–covariance matrix in Equation (15) calculated in Section 4.1. We calculate for the estimation of (, ) = (, ).
5.3.1. The Squared Error Loss Function (SELF)
Taking , and , first of all, the Bayes estimator of and under SELF can be obtained respectively as
Similarly, we take , and the Bayes estimator of can be obtained as follows:
The specific expressions of and under SELF are presented in Appendix C.1.
5.3.2. The Linex Loss Function (LF)
For , taking , we obtain that
Similarly, taking , we can obtain that
The Bayes estimator of according to Equation (22) under LF is
Then, we compute the Bayesian estimation of under LF when is
The specific expressions of and under LF are presented in Appendix C.2.
5.3.3. The General Entropy Loss Function (GELF)
Taking = , we calculate that
Then, we can get the Bayesian estimation of under GELF as
Taking , we have
Then, we can get the Bayesian estimation of under GELF as
Similarly, taking , the Bayes estimate of under GELF is
The specific expressions of and under GELF are presented in Appendix C.3.
The Bayes estimator of parameters and and the lifetime performance index can be obtained using the Lindley method. Unfortunately, the Higher Posterior Density (HPD) credible intervals could not be studied since the Lindley approximation method only makes the point estimation. That is what we are going to focus on in the next section.
5.4. Monte Carlo Markov Chain Method
When estimating intricate Bayesian models, Monte Carlo Markov Chain (MCMC) is an effective method and have been used for research by many scholars; see Reference [16,26]. Metropolis–Hastings algorithm is the most commonly used Monte Carlo Markov Chain method in statistics, digital communication, signal processing, and other fields. In this paper, a mixed strategy combining the Metropolis–Hastings algorithm within the type of random walk chain is utilized for generating progressive first-failure-censored samples from each posterior distribution arising from log-logistic distribution. We apply the R function rwmetrop in the LearnBayes package. Reference [27] gave a detailed description.
From Equation (21), we acquire the joint posterior distributions of and :
Here, we have
Since is a standard gamma density function, samples of can be easily generated. Unfortunately, cannot be simplified to the widely studied distributions. Consequently, the required random samples are generated from the conditional posterior density by applying the Metropolis–Hastings method and the process is as follows:
- Step 1:
- Initialize the values of .
- Step 2:
- Set the initial value of t to 1.
- Step 3:
- Generate from .
- Step 4:
- Generate from , using the following algorithm:
- Step 4-1:
- Generate from .
- Step 4-2:
- Generate from .
- Step 4-3:
- Set and .
- Step 5:
- t = .
- Step 6:
- Repeat steps 3–5 for M times.
Under SELF, the approximate Bayes estimator of parameters and , and the lifetime performance index can be obtained as
HPD credible intervals of parameters and and the lifetime performance index can be obtained applying MCMC techniques as follows:
(1) Arrange and as and .
(2) The symmetric credible intervals of and are and , respectively.
(3) Similarly, the symmetric credible interval of is .
6. Simulation Results
The Monte Carlo simulation study is used for analyzing and comparing the performance of various estimators proposed in the preceding sections. Values of various scale parameters and and different sample sizes n, group sizes k, effective sample sizes m, and censored schemes from log-logistic distribution are used in simulation study. Reference [28] proposed referential algorithm for generating the progressive first-failure-censored samples. Briefly summarized, generating the progressive first-failure censored sample with cdf can be regarded as generating the progressive type-II censored sample with cdf on calculating. Furthermore, different censoring schemes presented in the Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8 are abbreviations. For example, (0*3) denotes (0,0,0) and ((0,1)*2) denotes (0,1,0,1). Note that we use R for simulation study.

Table 1.
Maximum Likelihood Estimations (MLEs) of , , and when , , , , and .
Table 2.
Bayes estimates of , , and using the Lindley approximation method under squared error loss function (SELF) when , , , , , a1 = 5, b1 = 4, a2 = 1.1, and b2 = 1.
Table 3.
Bayes estimates of , , and using the Lindley approximation method under linex loss function (LF) when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and = .
Table 4.
Bayes estimates of , , and using the Lindley approximation method under LF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and = 1.
Table 5.
Bayes estimates of , , and using the Lindley approximation method under general entropy loss function (GELF) when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and =.
Table 6.
Bayes estimates of , , and using the Lindley approximation method under GELF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and =.
Table 7.
Bayes estimates of , , and using the Metropolis–Hastings method when , , , , , a1 = 5, b1 = 4, a2 = 1.1, and b2 = 1.
Table 8.
Average length (AL) and coverage probability (CP) of 95% asymptotic confidence/Higher Posterior Density (HPD) credible intervals for the lifetime performance index when , , and M = 1000.
In simulation study, we generate the progressive first-failure-censored data from log-logistic distribution (, ). We suppose that , and according to Equation (5), the corresponding is 0.4761017. The command in the R software is utilized to acquire the approximate MLEs of , , and . Under symmetric loss function, the Lindley method and the Monte Carlo Markov Chain method are used to perform the Bayesian estimation precisely as well as under asymmetric loss functions. In Bayesian estimation, set the value of the hyperparameters equal to the true values and . We assume that and under LF and that and under GELF. Set in the Metropolis–Hastings algorithm, and the whole process is simulated for times; 95% asymptotic confidence intervals of the lifetime performance index are obtained using both the MLEs and the log-transformed MLEs. Using the Metropolis–Hastings algorithm, we obtain 95% symmetric credible intervals of . Under the abovementioned estimators, the calculation results of the expected values (EV) and the corresponding mean square error (MSE) are shown in Table 1, Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7. Table 8 presents the interval estimation of .
Due to limited space, we only list the results of group sizes and three cases in Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8. Table 1 and Table 2 are fully listed as representatives to show the affect of k on simulation results of MLE and Bayesian estimation, respectively. The complete results of group sizes are listed in Appendix D. From Table 1, Table 2, Table 3, Table 4, Table 5, Table 6, Table 7 and Table 8, we can draw the following conclusions:
- (1)
- From Table 1, we conclude that, in MLE, the MSEs of increase as k increases when n and m are invariant and decrease as n or m increases when k is invariant. The MSEs of and decrease when we assume that only one of the three parameters (k, m, and n) increases and that the other two are invariant. Figure 2 is drawn to better illustrate the relationship. In all cases, the MSEs of the parameters and the lifetime performance index perform well since the values of MSEs are close to 0.
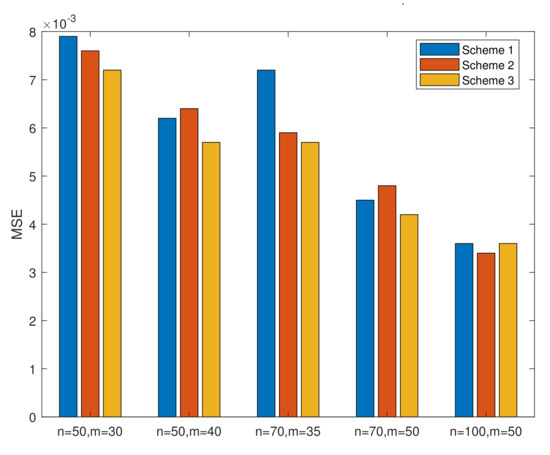 Figure 2. MSEs of in Table 1 when k = 2.
Figure 2. MSEs of in Table 1 when k = 2. - (2)
- From Table 2, we conclude that, in Bayesian estimation, the MSEs of , , and decrease when we assume that m or n increases and that the k is invariant. When m and n are invariant, the MSEs of increase while the MSEs of and decrease as k increases. From Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7, the Bayesian estimation results based on the Lindley method perform better than the Bayesian estimation based on Metropolis–Hastings method in respect of MSEs. From Table 3 and Table 4, the result of Lindley approximation under LF when performs better than when . From Table 5 and Table 6, the result of Lindley approximation under GELF when performs better than when . It is also concluded from Table 1, Table 2, Table 3, Table 4, Table 5, Table 6 and Table 7 that the point estimation performs better as the failure proportion increases when k is invariant.
- (3)
- In Table 8, when we set that only one of the three parameters (k, m, and n) increases and the other two are invariant, the average length (AL) of 95% asymptotic confidence/HPD credible intervals narrow down. In almost all cases, the CP of reaches their prescribed confidence intervals. To conclude, it is better to apply the log-transformed MLEs than MLEs when considering the asymptotic confidence intervals.
Broadly speaking, the Bayesian estimation of parameters and the lifetime performance index is recommended in this situation.
7. Real Data Analysis
To illustrate the reliability of the simulation results using the methods discussed above, a set of real data is used here. We consider a lifetime data of 100 observations of tensile strength of carbon fibers. Reference [29] originally reported this data set which was later discussed by Reference [30]. The dataset is presented in Table 9.
Table 9.
Real data set of breaking stress of carbon fibers (GPa).
In the first step, the complete data set is used for the log-logistic distribution fitting and the fitting results are compared to that of some well-informed distributions, for instance, Rayleigh distribution, inverse Weibull distribution, and generalized inverted exponential distribution (GIED). The probability density functions are , , and , respectively.
Based on the MLE method, various methods can be applied to test the fitting performance of the abovementioned distributions. We consider various indicators, , , , and Kolmogorov–Smirnov K-S statistics with p-value. is estimated to be a negative log-likelihood function. is the Akaike information criterion. is Bayesian information criterion, where p is the parameter value of distribution, n is sample size, and L is the maximum of . If log-logistic distribution fits the data well, it will have the lowest statistic values of , , , and K-S and the highest statistic value of p-value. A graphical method in R is used to show the goodness of fitness of different distributions mentioned above. Quantile-quantile plots (Q-Q) are drawn and are showed in Figure 3. In Table 10, the values of MLEs of parameters, , , , and K-S statistics with p-value of different distributions are shown, and it is obvious that the log-logistic distribution best fits the lifetime data. Simultaneously, the above conclusions are clearly shown in Figure 3.
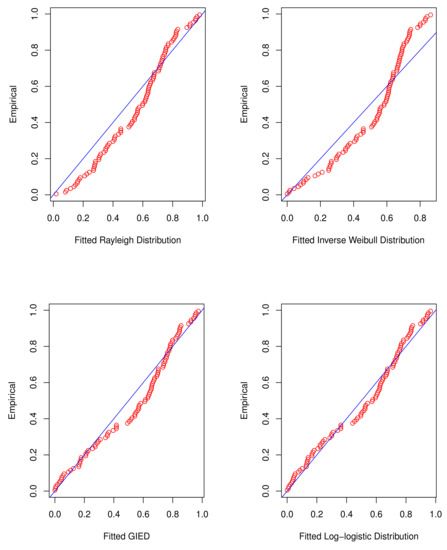
Figure 3.
Q-Q plots.
Table 10.
Fitting result.
Next, randomly grouping the given data into groups with items in each, we obtain the progressive first-failure-censored sample in Table 11.
Table 11.
Progressive first-failure-censored data of breaking stress of carbon fibers (GPa).
Then, for the abovementioned progressive first-failure censored data, three different censoring schemes when set at is applied to obtain three different censored samples. The first column in each row of Table 12 is a censored scheme, and the second column is the corresponding censored sample. We calculate the MLE and Bayes estimates of , , and for three censoring schemes. For the Metropolis–Hastings procedure, we take . We also obtain 95% asymptotic confidence and HPD credible intervals for and . The results are listed in Table 13.
Table 12.
The MLEs and Bayes estimates of , , and of a real data set.
Table 13.
Different progressive first-failure censored samples of various censored scheme when and .
8. Optimal Censoring Plan
The point and interval estimation of unknown quantities and and the lifetime performance index of log-logistic distribution is analysed with progressive first-failure censored data. In simulation and real data analysis, different censoring schemes have been considered. It raises the problem about how to decide the optimal censoring schemes. Many scholars and researchers—see [7,31]—have studied the criteria of comparing and analyzing different progressive and hybrid censored schemes. It is desirable in life-testing experiments to select the optimal censoring schemes from a set of censoring schemes as well as in reliability theory. Here are some evaluation criteria that we consider:
- Criterion 1:
- . Under this criterion, the optimal censoring scheme for the experiment is supposed to have the minimum value of the determinant of of MLEs.
- Criterion 2:
- . The optimal censoring scheme is considered to have the minimum value of the trace of of MLEs under this criterion. Without scale-invariant characteristic, criteria 1 and 2 are efficacious when lifetime distributions have one parameter.
- Criterion 3:
- . Under this criterion, the optimal censoring scheme has the minimum value of and the pth quantile of the MLE logarithmic variance of log-logistic distribution can also be written as . We can get the approximation value of as , where . The results of criterion 3 hinges on the selection of p.
- Criterion 4:
- . is defined in criterion 3. is nonnegative and satisfies . We take when .
: Based on the real data set analyzed in Section 7, we elaborate on how the above criteria are utilized in actual tests. p = 0.05 and p = 0.95 are two different values computed under criterion 3. The values that we calculated are shown in Table 14. Conclusions are that is the optimal scheme under criteria 3 and 4, and is optimal for criteria 1 and 2.
Table 14.
Comparison of censoring schemes when and .
9. Conclusions
Our main consideration is the lifetime performance index , an indicator employed to evaluate the performance of a progress. In this article, different methods of estimating with progressive first-failure-censored data with the log-logistic distribution is discussed carefully. Both the MLE and the Bayesian estimation of and and the lifetime performance index are investigated. The main difference between MLE and the Bayes estimate is the consideration of prior distributions. The parameters are regarded as unknown variables in MLE while they are random variables following known prior distributions in Bayesian estimation. For Bayesian estimation, Lindley method and the Monte Carlo Markov Chain method are applyed to approximate the Bayes estimator under asymmetric and symmetric loss functions. Asymptotic confidence intervals are constructed based on MLEs and log-transformed MLEs applying the observed Fisher information matrix. The HPD confidence intervals are studied applying the Metropolis–Hastings algorithm with the type of random walk chain. The performances of estimations have been compared and discussed. Also, four criteria of selecting optimal censoring plan in a real life test have been considered since it is significant for a researcher to determine under certain circumstances which censoring scheme will best fit the life-testing experiment.
It is worth noting that, here, we focus on the functional time of a product, which is strongly related to manufacturers and designers and can be enhanced on aspects of innovation, technology, design improvement, and systems approaches. Refurbishment, remanufacturing, and various business models can extend product life cycles since products can have one or more use. In this way, materials can be recycled into other products so that we can better defend the environment. For more detailed information, see References [32,33].
Author Contributions
Investigation, Y.X.; Supervision, W.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by Project 201910004093 which was supported by National Training Program of Innovation and Entrepreneurship for Undergraduates.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Second Derivatives of l
Appendix B. Third Derivatives of l (lij)
Appendix C. ϕi and ϕij
Appendix C.1. The Squared Error Loss Function
Appendix C.2. The Linex Loss Function
Appendix C.3. The General Entropy Loss Function
Appendix D. Complete Tables
Table A1.
Bayes estimates of , , and using the Lindley approximation method under LF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and =.
Table A1.
Bayes estimates of , , and using the Lindley approximation method under LF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and =.
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 50 | 30 | (10,0*28,10) | 1.2698 | 0.0095 | 3.6439 | 0.3285 | 0.4650 | 0.0072 | |
| (1*20,0*10) | 1.2674 | 0.0104 | 3.6252 | 0.2708 | 0.4635 | 0.0072 | |||
| (1*10,0*10,1*10) | 1.2638 | 0.0099 | 3.6553 | 0.3277 | 0.4602 | 0.0073 | |||
| 40 | (10,0*39) | 1.2626 | 0.0070 | 3.6085 | 0.2183 | 0.4725 | 0.0058 | ||
| (1*10,0*30) | 1.2605 | 0.0075 | 3.6145 | 0.2165 | 0.4709 | 0.0061 | |||
| (0*39,10) | 1.2655 | 0.0075 | 3.6111 | 0.2527 | 0.4702 | 0.0058 | |||
| 70 | 35 | (35,0*34) | 1.2637 | 0.0074 | 3.6280 | 0.2480 | 0.4740 | 0.0067 | |
| 2 | (1*35) | 1.2607 | 0.0082 | 3.6466 | 0.2640 | 0.4621 | 0.0055 | ||
| (0*34,35) | 1.2661 | 0.0097 | 3.6838 | 0.3380 | 0.4576 | 0.0055 | |||
| 50 | ((0,1)*20,1*10) | 1.2572 | 0.0056 | 3.5581 | 0.1704 | 0.4651 | 0.0039 | ||
| (1*20,0*30) | 1.2629 | 0.0064 | 3.5498 | 0.1446 | 0.4701 | 0.0041 | |||
| (0*30,1*20) | 1.2632 | 0.0055 | 3.5833 | 0.1900 | 0.4717 | 0.0042 | |||
| 100 | 50 | (25,0*48,25) | 1.2623 | 0.0053 | 3.5918 | 0.1952 | 0.4706 | 0.0039 | |
| (1*50) | 1.2659 | 0.0063 | 3.5857 | 0.1817 | 0.4720 | 0.0033 | |||
| (0*49,50) | 1.2640 | 0.0063 | 3.6134 | 0.2293 | 0.4659 | 0.0031 | |||
| 50 | 30 | (10,0*28,10) | 1.2719 | 0.0104 | 3.6619 | 0.3446 | 0.4599 | 0.0059 | |
| (1*20,0*10) | 1.2733 | 0.0113 | 3.6188 | 0.2704 | 0.4624 | 0.0056 | |||
| (1*10,0*10,1*10) | 1.2672 | 0.0106 | 3.6655 | 0.3519 | 0.4566 | 0.0059 | |||
| 40 | (10,0*39) | 1.2583 | 0.0072 | 3.6025 | 0.2321 | 0.4622 | 0.0050 | ||
| (1*10,0*30) | 1.2623 | 0.0075 | 3.6073 | 0.2108 | 0.4683 | 0.0051 | |||
| (0*39,10) | 1.2681 | 0.0072 | 3.6138 | 0.2479 | 0.4676 | 0.0044 | |||
| 70 | 35 | (35,0*34) | 1.2598 | 0.0078 | 3.6254 | 0.2461 | 0.4652 | 0.0062 | |
| 3 | (1*35) | 1.2716 | 0.0102 | 3.6170 | 0.2487 | 0.4612 | 0.0052 | ||
| (0*34,35) | 1.2849 | 0.01359 | 3.6439 | 0.3340 | 0.4577 | 0.0049 | |||
| 50 | ((0,1)*20,1*10) | 1.2622 | 0.0065 | 3.5916 | 0.1788 | 0.4699 | 0.0037 | ||
| (1*20,0*30) | 1.2621 | 0.0058 | 3.5629 | 0.1571 | 0.4698 | 0.0036 | |||
| (0*30,1*20) | 1.2654 | 0.0065 | 3.5757 | 0.1893 | 0.4667 | 0.0033 | |||
| 100 | 50 | (25,0*48,25) | 1.2661 | 0.00702 | 3.5754 | 0.1912 | 0.4644 | 0.0032 | |
| (1*50) | 1.2615 | 0.0065 | 3.5773 | 0.1625 | 0.4642 | 0.0032 | |||
| (0*49,50) | 1.2732 | 0.0099 | 3.5850 | 0.2182 | 0.4597 | 0.0034 | |||
Table A2.
Bayes estimates of , , and using the Lindley approximation method under LF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and = 1.
Table A2.
Bayes estimates of , , and using the Lindley approximation method under LF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and = 1.
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 50 | 30 | (10,0*28,10) | 1.2610 | 0.0081 | 3.3762 | 0.2431 | 0.4563 | 0.0067 | |
| (1*20,0*10) | 1.2555 | 0.0085 | 3.4266 | 0.1880 | 0.4595 | 0.0063 | |||
| (1*10,0*10,1*10) | 1.2526 | 0.0083 | 3.4054 | 0.2255 | 0.4523 | 0.0066 | |||
| 40 | (10,0*39) | 1.2539 | 0.0070 | 3.3997 | 0.1626 | 0.4640 | 0.0064 | ||
| (1*10,0*30) | 1.2586 | 0.0072 | 3.4048 | 0.1738 | 0.4656 | 0.0057 | |||
| (0*39,10) | 1.2548 | 0.0062 | 3.4168 | 0.1960 | 0.4625 | 0.0053 | |||
| 70 | 35 | (35,0*34) | 1.2545 | 0.0078 | 3.4026 | 0.1740 | 0.4628 | 0.0070 | |
| 2 | (1*35) | 1.2581 | 0.0081 | 3.4122 | 0.1888 | 0.4563 | 0.0051 | ||
| (0*34,35) | 1.2572 | 0.0084 | 3.4070 | 0.2300 | 0.4465 | 0.0064 | |||
| 50 | ((0,1)*20,1*10) | 1.2527 | 0.0055 | 3.4133 | 0.1301 | 0.4629 | 0.0042 | ||
| (1*20,0*30) | 1.2588 | 0.0054 | 3.4235 | 0.1313 | 0.4702 | 0.0040 | |||
| (0*30,1*20) | 1.2536 | 0.0056 | 3.4317 | 0.1467 | 0.4638 | 0.0039 | |||
| 100 | 50 | (25,0*48,25) | 1.2575 | 0.0051 | 3.4157 | 0.1479 | 0.4645 | 0.0033 | |
| (1*50) | 1.2575 | 0.0056 | 3.4257 | 0.1315 | 0.4642 | 0.0032 | |||
| (0*49,50) | 1.2557 | 0.0056 | 3.4371 | 0.1546 | 0.4593 | 0.0032 | |||
| 50 | 30 | (10,0*28,10) | 1.2608 | 0.0094 | 3.4006 | 0.2377 | 0.4496 | 0.0061 | |
| (1*20,0*10) | 1.2621 | 0.0094 | 3.4085 | 0.2194 | 0.4539 | 0.0056 | |||
| (1*10,0*10,1*10) | 1.2624 | 0.0094 | 3.3970 | 0.2268 | 0.4508 | 0.0058 | |||
| 40 | (10,0*39) | 1.2518 | 0.0072 | 3.4408 | 0.1851 | 0.4599 | 0.0055 | ||
| (1*10,0*30) | 1.2648 | 0.0068 | 3.3997 | 0.1563 | 0.4670 | 0.0046 | |||
| (0*39,10) | 1.2592 | 0.0067 | 3.4169 | 0.2072 | 0.4579 | 0.0038 | |||
| 70 | 35 | (35,0*34) | 1.2556 | 0.0072 | 3.4091 | 0.1545 | 0.4606 | 0.0053 | |
| 3 | (1*35) | 1.2636 | 0.0094 | 3.3899 | 0.1784 | 0.4517 | 0.0050 | ||
| (0*34,35) | 1.2701 | 0.0117 | 3.3897 | 0.2274 | 0.4458 | 0.0052 | |||
| 50 | ((0,1)*20,1*10) | 1.2612 | 0.0059 | 3.4059 | 0.1287 | 0.4647 | 0.0035 | ||
| (1*20,0*30) | 1.2568 | 0.0055 | 3.4389 | 0.1172 | 0.4673 | 0.0035 | |||
| (0*30,1*20) | 1.2579 | 0.0058 | 3.3978 | 0.1594 | 0.4572 | 0.0033 | |||
| 100 | 50 | (25,0*48,25) | 1.2573 | 0.0061 | 3.4185 | 0.1616 | 0.4566 | 0.0031 | |
| (1*50) | 1.2597 | 0.0066 | 3.426 | 0.1431 | 0.4599 | 0.0032 | |||
| (0*49,50) | 1.2620 | 0.0080 | 3.416 | 0.1604 | 0.4534 | 0.0033 | |||
Table A3.
Bayes estimates of , , and using the Lindley approximation method under GELF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and =.
Table A3.
Bayes estimates of , , and using the Lindley approximation method under GELF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and =.
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 50 | 30 | (10,0*28,10) | 1.2650 | 0.0086 | 3.5013 | 0.2675 | 0.4542 | 0.0073 | |
| (1*20,0*10) | 1.2619 | 0.0096 | 3.5038 | 0.2230 | 0.4521 | 0.0075 | |||
| (1*10,0*10,1*10) | 1.2644 | 0.0085 | 3.5304 | 0.2473 | 0.4572 | 0.0065 | |||
| 40 | (10,0*39) | 1.2553 | 0.0068 | 3.5103 | 0.1761 | 0.4632 | 0.0065 | ||
| (1*10,0*30) | 1.2574 | 0.0077 | 3.4775 | 0.1740 | 0.4587 | 0.0067 | |||
| (0*39,10) | 1.2618 | 0.0064 | 3.5001 | 0.2153 | 0.4630 | 0.0058 | |||
| 70 | 35 | (35,0*34) | 1.2593 | 0.0082 | 3.5016 | 0.1950 | 0.4598 | 0.0070 | |
| 2 | (1*35) | 1.2602 | 0.0081 | 3.5187 | 0.2008 | 0.4540 | 0.0052 | ||
| (0*34,35) | 1.2739 | 0.0095 | 3.5054 | 0.2496 | 0.4534 | 0.0054 | |||
| 50 | ((0,1)*20,1*10) | 1.2596 | 0.0055 | 3.4922 | 0.1518 | 0.4649 | 0.0039 | ||
| (1*20,0*30) | 1.2574 | 0.0059 | 3.4804 | 0.1226 | 0.4636 | 0.0043 | |||
| (0*30,1*20) | 1.2587 | 0.0055 | 3.4952 | 0.1588 | 0.4639 | 0.0041 | |||
| 100 | 50 | (25,0*48,25) | 1.2539 | 0.0049 | 3.5156 | 0.1729 | 0.4601 | 0.0039 | |
| (1*50) | 1.2610 | 0.0057 | 3.4682 | 0.1379 | 0.4603 | 0.0037 | |||
| (0*49,50) | 1.2616 | 0.0071 | 3.5032 | 0.1918 | 0.4546 | 0.0038 | |||
| 50 | 30 | (10,0*28,10) | 1.2654 | 0.0102 | 3.5405 | 0.2759 | 0.4491 | 0.0067 | |
| (1*20,0*10) | 1.2690 | 0.0104 | 3.5134 | 0.2123 | 0.4538 | 0.0064 | |||
| (1*10,0*10,1*10) | 1.2642 | 0.0104 | 3.5086 | 0.2310 | 0.4459 | 0.0066 | |||
| 40 | (10,0*39) | 1.2551 | 0.0068 | 3.5144 | 0.1702 | 0.4587 | 0.0050 | ||
| (1*10,0*30) | 1.2569 | 0.0066 | 3.5013 | 0.1836 | 0.4572 | 0.0051 | |||
| (0*39,10) | 1.2620 | 0.0068 | 3.4972 | 0.2024 | 0.4558 | 0.0045 | |||
| 70 | 35 | (35,0*34) | 1.2624 | 0.0081 | 3.4915 | 0.1846 | 0.4583 | 0.0057 | |
| 3 | (1*35) | 1.2673 | 0.0104 | 3.5076 | 0.2120 | 0.4494 | 0.0052 | ||
| (0*34,35) | 1.2774 | 0.0123 | 3.5015 | 0.2466 | 0.4428 | 0.0055 | |||
| 50 | ((0,1)*20,1*10) | 1.2582 | 0.0059 | 3.4849 | 0.1467 | 0.4586 | 0.0036 | ||
| (1*20,0*30) | 1.2585 | 0.0055 | 3.5161 | 0.1315 | 0.4664 | 0.0036 | |||
| (0*30,1*20) | 1.2600 | 0.0067 | 3.5050 | 0.1851 | 0.4570 | 0.0036 | |||
| 100 | 50 | (25,0*48,25) | 1.2644 | 0.0068 | 3.4909 | 0.1482 | 0.4591 | 0.0033 | |
| (1*50) | 1.2623 | 0.0070 | 3.5024 | 0.1658 | 0.4575 | 0.0034 | |||
| (0*49,50) | 1.2663 | 0.0082 | 3.5159 | 0.1780 | 0.4534 | 0.0036 | |||
Table A4.
Bayes estimates of , , and using the Lindley approximation method under GELF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and = .
Table A4.
Bayes estimates of , , and using the Lindley approximation method under GELF when , , , , , a1 = 5, b1 = 4, a2 = 1.1, b2 = 1, and = .
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 50 | 30 | (10,0*28,10) | 1.2097 | 0.0065 | 2.6748 | 0.6893 | 0.5273 | 0.0083 | |
| (1*20,0*10) | 1.2086 | 0.0071 | 2.7004 | 0.6471 | 0.5291 | 0.0091 | |||
| (1*10,0*10,1*10) | 1.2098 | 0.0069 | 2.6863 | 0.6661 | 0.5281 | 0.0089 | |||
| 40 | (10,0*39) | 1.2006 | 0.0060 | 2.6951 | 0.6388 | 0.5351 | 0.0086 | ||
| (1*10,0*30) | 1.2024 | 0.0062 | 2.7056 | 0.6257 | 0.5370 | 0.0088 | |||
| (0*39,10) | 1.2061 | 0.0054 | 2.6908 | 0.6571 | 0.5376 | 0.0085 | |||
| 70 | 35 | (35,0*34) | 1.2041 | 0.0065 | 2.6854 | 0.6556 | 0.5324 | 0.0087 | |
| 2 | (1*35) | 1.2097 | 0.0062 | 2.6992 | 0.6482 | 0.5310 | 0.0076 | ||
| (0*34,35) | 1.2138 | 0.0064 | 2.6912 | 0.6637 | 0.5257 | 0.0073 | |||
| 50 | ((0,1)*20,1*10) | 1.2049 | 0.0052 | 2.6973 | 0.6228 | 0.5410 | 0.0076 | ||
| (1*20,0*30) | 1.2023 | 0.0056 | 2.6907 | 0.6329 | 0.5370 | 0.0073 | |||
| (0*30,1*20) | 1.2015 | 0.0054 | 2.7052 | 0.6213 | 0.5374 | 0.0073 | |||
| 100 | 50 | (25,0*48,25) | 1.2044 | 0.0050 | 2.6879 | 0.6447 | 0.5358 | 0.0067 | |
| (1*50) | 1.2028 | 0.0055 | 2.7009 | 0.6240 | 0.5342 | 0.0063 | |||
| (0*49,50) | 1.2042 | 0.0059 | 2.7025 | 0.6282 | 0.5295 | 0.0060 | |||
| 50 | 30 | (10,0*28,10) | 1.2179 | 0.0064 | 2.6892 | 0.6642 | 0.5294 | 0.0077 | |
| (1*20,0*10) | 1.2083 | 0.0075 | 2.7018 | 0.6383 | 0.5231 | 0.0077 | |||
| (1*10,0*10,1*10) | 1.2143 | 0.0074 | 2.6812 | 0.6776 | 0.5210 | 0.0069 | |||
| 40 | (10,0*39) | 1.2034 | 0.0062 | 2.6922 | 0.6479 | 0.5310 | 0.0073 | ||
| (1*10,0*30) | 1.2086 | 0.0057 | 2.6930 | 0.6412 | 0.5356 | 0.0074 | |||
| (0*39,10) | 1.2073 | 0.0063 | 2.6806 | 0.6728 | 0.5261 | 0.0061 | |||
| 70 | 35 | (35,0*34) | 1.2030 | 0.0063 | 2.6958 | 0.6396 | 0.5289 | 0.0074 | |
| 3 | (1*35) | 1.2120 | 0.0071 | 2.6965 | 0.6438 | 0.5243 | 0.0062 | ||
| (0*34,35) | 1.2194 | 0.0075 | 2.6895 | 0.6633 | 0.5171 | 0.0062 | |||
| 50 | ((0,1)*20,1*10) | 1.2046 | 0.0053 | 2.7011 | 0.6161 | 0.5374 | 0.0066 | ||
| (1*20,0*30) | 1.2042 | 0.0054 | 2.6985 | 0.6184 | 0.5376 | 0.0066 | |||
| (0*30,1*20) | 1.2077 | 0.0051 | 2.6920 | 0.6361 | 0.5351 | 0.0061 | |||
| 100 | 50 | (25,0*48,25) | 1.2055 | 0.0055 | 2.7053 | 0.6235 | 0.5320 | 0.0059 | |
| (1*50) | 1.2098 | 0.0053 | 2.6885 | 0.6387 | 0.5342 | 0.0060 | |||
| (0*49,50) | 1.2139 | 0.0061 | 2.6811 | 0.6628 | 0.5247 | 0.0052 | |||
Table A5.
Bayes estimates of ,, and using the Metropolis–Hastings method when , , , , , a1 = 5, b1 = 4, a2 = 1.1, and b2 = 1.
Table A5.
Bayes estimates of ,, and using the Metropolis–Hastings method when , , , , , a1 = 5, b1 = 4, a2 = 1.1, and b2 = 1.
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| EV | MSE | EV | MSE | EV | MSE | ||||
| 50 | 30 | (10,0*28,10) | 1.2654 | 0.0113 | 3.5899 | 0.3877 | 0.4715 | 0.0089 | |
| (1*20,0*10) | 1.2717 | 0.0123 | 3.5746 | 0.2959 | 0.4750 | 0.0083 | |||
| (1*10,0*10,1*10) | 1.2596 | 0.0133 | 3.6023 | 0.3287 | 0.4668 | 0.0101 | |||
| 40 | (10,0*39) | 1.2666 | 0.0114 | 3.5591 | 0.2993 | 0.4761 | 0.0091 | ||
| (1*10,0*30) | 1.2523 | 0.0093 | 3.6125 | 0.3101 | 0.4714 | 0.0079 | |||
| (0*39,10) | 1.2668 | 0.0100 | 3.5813 | 0.2786 | 0.4783 | 0.0063 | |||
| 70 | 35 | (35,0*34) | 1.2578 | 0.0123 | 3.5666 | 0.2794 | 0.4681 | 0.0102 | |
| 2 | (1*35) | 1.2606 | 0.0103 | 3.5886 | 0.3060 | 0.4669 | 0.0062 | ||
| (0*34,35) | 1.2772 | 0.0136 | 3.5638 | 0.3636 | 0.4672 | 0.0063 | |||
| 50 | ((0,1)*20,1*10) | 1.2545 | 0.0081 | 3.5743 | 0.2166 | 0.4730 | 0.0062 | ||
| (1*20,0*30) | 1.2616 | 0.0075 | 3.5689 | 0.2004 | 0.4793 | 0.0057 | |||
| (0*30,1*20) | 1.2569 | 0.0075 | 3.5707 | 0.2447 | 0.4733 | 0.0056 | |||
| 100 | 50 | (25,0*48,25) | 1.2688 | 0.0084 | 3.5109 | 0.2082 | 0.4742 | 0.0054 | |
| (1*50) | 1.2584 | 0.0077 | 3.5934 | 0.2405 | 0.4734 | 0.0044 | |||
| (0*49,50) | 1.2674 | 0.0090 | 3.5566 | 0.2305 | 0.4723 | 0.0039 | |||
| 50 | 30 | (10,0*28,10) | 1.2788 | 0.0139 | 3.5777 | 0.3462 | 0.4731 | 0.0066 | |
| (1*20,0*10) | 1.2747 | 0.0150 | 3.5818 | 0.2870 | 0.4725 | 0.0072 | |||
| (1*10,0*10,1*10) | 1.2737 | 0.0146 | 3.5694 | 0.3354 | 0.4651 | 0.0069 | |||
| 40 | (10,0*39) | 1.2636 | 0.0104 | 3.5797 | 0.2753 | 0.4725 | 0.0064 | ||
| (1*10,0*30) | 1.2581 | 0.0095 | 3.6285 | 0.3061 | 0.4742 | 0.0072 | |||
| (0*39,10) | 1.2705 | 0.0112 | 3.5569 | 0.2895 | 0.4715 | 0.0060 | |||
| 70 | 35 | (35,0*34) | 1.2684 | 0.0104 | 3.5995 | 0.2798 | 0.4807 | 0.0073 | |
| 3 | (1*35) | 1.2739 | 0.0147 | 3.5713 | 0.2652 | 0.4678 | 0.0060 | ||
| (0*34,35) | 1.2999 | 0.0206 | 3.5305 | 0.3439 | 0.4690 | 0.0057 | |||
| 50 | ((0,1)*20,1*10) | 1.2575 | 0.0083 | 3.5933 | 0.2302 | 0.4723 | 0.0046 | ||
| (1*20,0*30) | 1.2551 | 0.0085 | 3.6030 | 0.2046 | 0.4731 | 0.0052 | |||
| (0*30,1*20) | 1.2690 | 0.0097 | 3.5733 | 0.2535 | 0.4754 | 0.0039 | |||
| 100 | 50 | (25,0*48,25) | 1.2729 | 0.0104 | 3.5749 | 0.2337 | 0.4773 | 0.0037 | |
| (1*50) | 1.2627 | 0.0090 | 3.6119 | 0.2165 | 0.4771 | 0.0044 | |||
| (0*49,50) | 1.2723 | 0.0125 | 3.6293 | 0.2923 | 0.4733 | 0.0038 | |||
Table A6.
AL and CP of 95% asymptotic confidence/HPD credible intervals for the lifetime performance index when , , and M = 1000.
Table A6.
AL and CP of 95% asymptotic confidence/HPD credible intervals for the lifetime performance index when , , and M = 1000.
| k | n | m | Censoring Scheme | ||||||
|---|---|---|---|---|---|---|---|---|---|
| AL | CP | AL | CP | AL | CP | ||||
| 50 | 30 | (10,0*28,10) | 0.3259 | 0.950 | 0.3422 | 0.966 | 0.3346 | 0.950 | |
| (1*20,0*10) | 0.3271 | 0.956 | 0.3364 | 0.962 | 0.3337 | 0.950 | |||
| (1*10,0*10,1*10) | 0.3210 | 0.980 | 0.3303 | 0.978 | 0.3253 | 0.974 | |||
| 40 | (10,0*39) | 0.3108 | 0.942 | 0.3171 | 0.966 | 0.3138 | 0.940 | ||
| (1*10,0*30) | 0.3037 | 0.946 | 0.3097 | 0.950 | 0.3053 | 0.924 | |||
| (0*39,10) | 0.2859 | 0.960 | 0.2908 | 0.970 | 0.2920 | 0.960 | |||
| 70 | 35 | (35,0*34) | 0.3282 | 0.960 | 0.3359 | 0.968 | 0.3318 | 0.944 | |
| 2 | (1*35) | 0.2852 | 0.976 | 0.2911 | 0.978 | 0.2897 | 0.960 | ||
| (0*34,35) | 0.2832 | 0.972 | 0.2924 | 0.988 | 0.2909 | 0.934 | |||
| 50 | ((0,1)*20,1*10) | 0.2505 | 0.952 | 0.2537 | 0.964 | 0.2532 | 0.936 | ||
| (1*20,0*30) | 0.2588 | 0.962 | 0.2624 | 0.964 | 0.2619 | 0.960 | |||
| (0*30,1*20) | 0.2426 | 0.964 | 0.2456 | 0.976 | 0.2465 | 0.950 | |||
| 100 | 50 | (25,0*48,25) | 0.2339 | 0.954 | 0.2366 | 0.974 | 0.2375 | 0.944 | |
| (1*50) | 0.2291 | 0.968 | 0.2321 | 0.984 | 0.2329 | 0.950 | |||
| (0*49,50) | 0.2266 | 0.958 | 0.2299 | 0.964 | 0.2339 | 0.946 | |||
| 50 | 30 | (10,0*28,10) | 0.2750 | 0.972 | 0.2796 | 0.980 | 0.2790 | 0.952 | |
| (1*20,0*10) | 0.2713 | 0.948 | 0.2780 | 0.950 | 0.2754 | 0.934 | |||
| (1*10,0*10,1*10) | 0.2559 | 0.954 | 0.2601 | 0.964 | 0.2648 | 0.940 | |||
| 40 | (10,0*39) | 0.2739 | 0.960 | 0.2785 | 0.970 | 0.2777 | 0.950 | ||
| (1*10,0*30) | 0.2708 | 0.952 | 0.2757 | 0.970 | 0.2743 | 0.934 | |||
| (0*39,10) | 0.2616 | 0.940 | 0.2666 | 0.964 | 0.2676 | 0.928 | |||
| 70 | 35 | (35,0*34) | 0.2921 | 0.956 | 0.2982 | 0.960 | 0.2967 | 0.932 | |
| 3 | (1*35) | 0.2779 | 0.970 | 0.2857 | 0.974 | 0.2816 | 0.942 | ||
| (0*34,35) | 0.2942 | 0.992 | 0.3098 | 0.990 | 0.3004 | 0.948 | |||
| 50 | ((0,1)*20,1*10) | 0.2315 | 0.958 | 0.2345 | 0.976 | 0.2330 | 0.948 | ||
| (1*20,0*30) | 0.2350 | 0.962 | 0.2379 | 0.964 | 0.2359 | 0.950 | |||
| (0*30,1*20) | 0.2259 | 0.960 | 0.2290 | 0.984 | 0.2293 | 0.948 | |||
| 100 | 50 | (25,0*48,25) | 0.2233 | 0.982 | 0.2262 | 0.980 | 0.2274 | 0.962 | |
| (1*50) | 0.2250 | 0.962 | 0.2301 | 0.988 | 0.2259 | 0.946 | |||
| (0*49,50) | 0.2364 | 0.968 | 0.2481 | 0.982 | 0.2365 | 0.938 |
References
- Cooper, T. Longer Lasting Products: Alternatives to the Throwaway Society; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Ertz, M.; Leblanc-Proulx, S.; Sarigllü, E.; Morin, V. Advancing quantitative rigor in the circular economy literature: New methodology for product lifetime extension business models. Resour. Conserv. Recycl. 2019, 150, 1–12. [Google Scholar] [CrossRef]
- Montgomery, D.C. Introduction to Statistical Quality Control; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Wu, J.W.; Lee, H.M.; Lei, C.L. Computational testing algorithmic procedure of assessment for lifetime performance index of products with two-parameter exponential distribution. Appl. Math. Comput. 2007, 190, 116–125. [Google Scholar] [CrossRef]
- Lee, W.C.; Wu, J.W.; Hong, C.W. Assessing the Lifetime Performance Index of Products with the Exponential Distribution under Progressively Type II Right Censored Samples; Elsevier Science: Amsterdam, The Netherlands, 2009. [Google Scholar]
- Lee, H.M.; Wu, J.W.; Lei, C.L.; Hung, W.L. Implementing lifetime performance index of products with two-parameter exponential distribution. Int. J. Syst. Sci. 2011, 42, 1305–1321. [Google Scholar] [CrossRef]
- Sultan, K.; Alsadat, N.; Kundu, D. Bayesian and maximum likelihood estimations of the inverse Weibull parameters under progressive type-II censoring. J. Stat. Comput. Simul. 2014, 84, 2248–2265. [Google Scholar] [CrossRef]
- Lee, K.; Cho, Y. Bayesian and maximum likelihood estimations of the inverted exponentiated half logistic distribution under progressive Type II censoring. J. Appl. Stat. 2016, 44, 811–832. [Google Scholar] [CrossRef]
- Cohen, A.C. Progressively Censored Samples in Life Testing. Technometrics 1963, 5, 327–339. [Google Scholar] [CrossRef]
- Mohammed, H.S. Statistical inferences based on an adaptive progressive type-II censoring from exponentiated exponential distribution. J. Egypt. Math. Soc. 2017, 25, 393–399. [Google Scholar]
- Balakrishnan, N.; Aggarwala, R. Progressive Censoring: Theory, Methods, and Applications; Birkhäuser: Boston, MA, USA, 2000. [Google Scholar]
- Johnson, L.G. Theory And Technique Of Variation Research; Elsevier Pub. Co.: Amsterdam, The Netherlands, 1964. [Google Scholar]
- Wu, S.J.; Kuş, C. On estimation based on progressive first-failure-censored sampling. Comput. Stat. Data Anal. 2009, 53, 3659–3670. [Google Scholar] [CrossRef]
- Ahmed, E.A. Estimation and prediction for the generalized inverted exponential distribution based on progressively first-failure-censored data with application. J. Appl. Stat. 2017, 44, 1576–1608. [Google Scholar] [CrossRef]
- Madhulika, D.; Renu, G.; Hare, K. On progressively first failure censored Lindley distribution. Comput. Stat. 2016, 31, 139–163. [Google Scholar]
- Soliman, A.A.; Abd-Ellah, A.H.; Abou-Elheggag, N.A.; Abd-Elmougod, G.A. Estimation of the parameters of life for Gompertz distribution using progressive first-failure censored data. Comput. Stat. Data Anal. 2012, 56, 2471–2485. [Google Scholar] [CrossRef]
- Ahmadi, M.V.; Doostparast, M.; Ahmadi, J. Estimating the lifetime performance index with Weibull distribution based on progressive first-failure censoring scheme. J. Comput. Appl. Math. 2013, 239, 93–102. [Google Scholar] [CrossRef]
- Madhulika, D.; Hare, K.; Renu, G. Generalized inverted exponential distribution under progressive first-failure censoring. J. Stat. Comput. Simul. 2016, 86, 1095–1114. [Google Scholar]
- Ahmed, A.; Soliman, M.M.A.S. Bayesian MCMC inference for the Gompertz distribution based on progressive first-failure censoring data. AIP Conf. Proc. 2015, 1643, 125–134. [Google Scholar]
- Ahmadi, M.V.; Doostparast, M. Pareto analysis for the lifetime performance index of products on the basis of progressively first-failure-censored batches under balanced symmetric and asymmetric loss functions. J. Appl. Stat. 2019, 46, 1196–1227. [Google Scholar] [CrossRef]
- Akhtar, M.T.; Khan, A.A.; Akhtar, M.T.; Khan, A.A. Log-logistic Distribution as a Reliability Model: A Bayesian Analysis. Am. J. Math. Stat. 2014, 4, 162–170. [Google Scholar]
- Al-Shomrani, A.A.; Shawky, A.I.; Arif, O.H.; Aslam, M. Log-logistic distribution for survival data analysis using MCMC. Springerplus 2016, 5, 1774. [Google Scholar] [CrossRef]
- Lesitha, G.P.Y.T. Estimation of the scale parameter of a log-logistic distribution. Metrika 2013, 76, 427–448. [Google Scholar] [CrossRef]
- William, Q.; Meeker; Luis, A. Escobar Statistical Methods for Reliability Data. Technometrics 1998, 40, 254–256. [Google Scholar]
- Lindley, D.V. Approximate Bayesian methods. Trab. Estad. Y Investig. Oper. 1980, 31, 223–245. [Google Scholar] [CrossRef]
- Nassar, M.; Abo-Kasem, O.; Zhang, C.; Dey, S. Analysis of Weibull Distribution Under Adaptive Type-II Progressive Hybrid Censoring Scheme. J. Ind. Soc. Probab. Stat. 2018, 19, 25–65. [Google Scholar] [CrossRef]
- Albert, J.; Chopin, N. Bayesian computation with R. Stat. Comput. 2009, 19, 111–112. [Google Scholar]
- Balakrishnan, N.; Sandhu, R.A. A Simple Simulational Algorithm for Generating Progressive Type-II Censored Samples. Am. Stat. 1995, 49, 229–230. [Google Scholar]
- Nichols, M.D.; Padgett, W.J. A Bootstrap Control Chart for Weibull Percentiles. Qual. Reliab. Eng. 2006, 22, 141–151. [Google Scholar] [CrossRef]
- Mohammed, H.S.; Ateya, S.F.; AL-Hussaini, E.K. Estimation based on progressive first-failure censoring from exponentiated exponential distribution. J. Appl. Stat. 2017, 44, 1479–1494. [Google Scholar] [CrossRef]
- Pradhan, B.; Kundu, D. On progressively censored generalized exponential distribution. Test 2009, 18, 497–515. [Google Scholar] [CrossRef]
- Den Hollander, M.C.; Bakker, C.A.; Hultink, E.J. Product Design in a Circular Economy: Development of a Typology of Key Concepts and Terms. J. Ind. Ecol. 2017, 21, 517–525. [Google Scholar] [CrossRef]
- Ertz, M.; Leblanc-Proulx, S.; Sarigollu, E.; Morin, V. Made to break? A taxonomy of business models on product lifetime extension. J. Clean. Prod. 2019, 234, 867–880. [Google Scholar] [CrossRef]



© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).