The Consistency of Estimators in a Heteroscedastic Partially Linear Model with ρ−-Mixing Errors


Abstract
1. Introduction
2. Estimation and Conditions
- (i) ;(ii) ;(iii) and are continuous functions on compact set .
- (i) ;(ii) for some .
- (i) ;(ii) for any .
- .
3. Main Results
4. Some Lemmas
5. Proofs of the Main Results
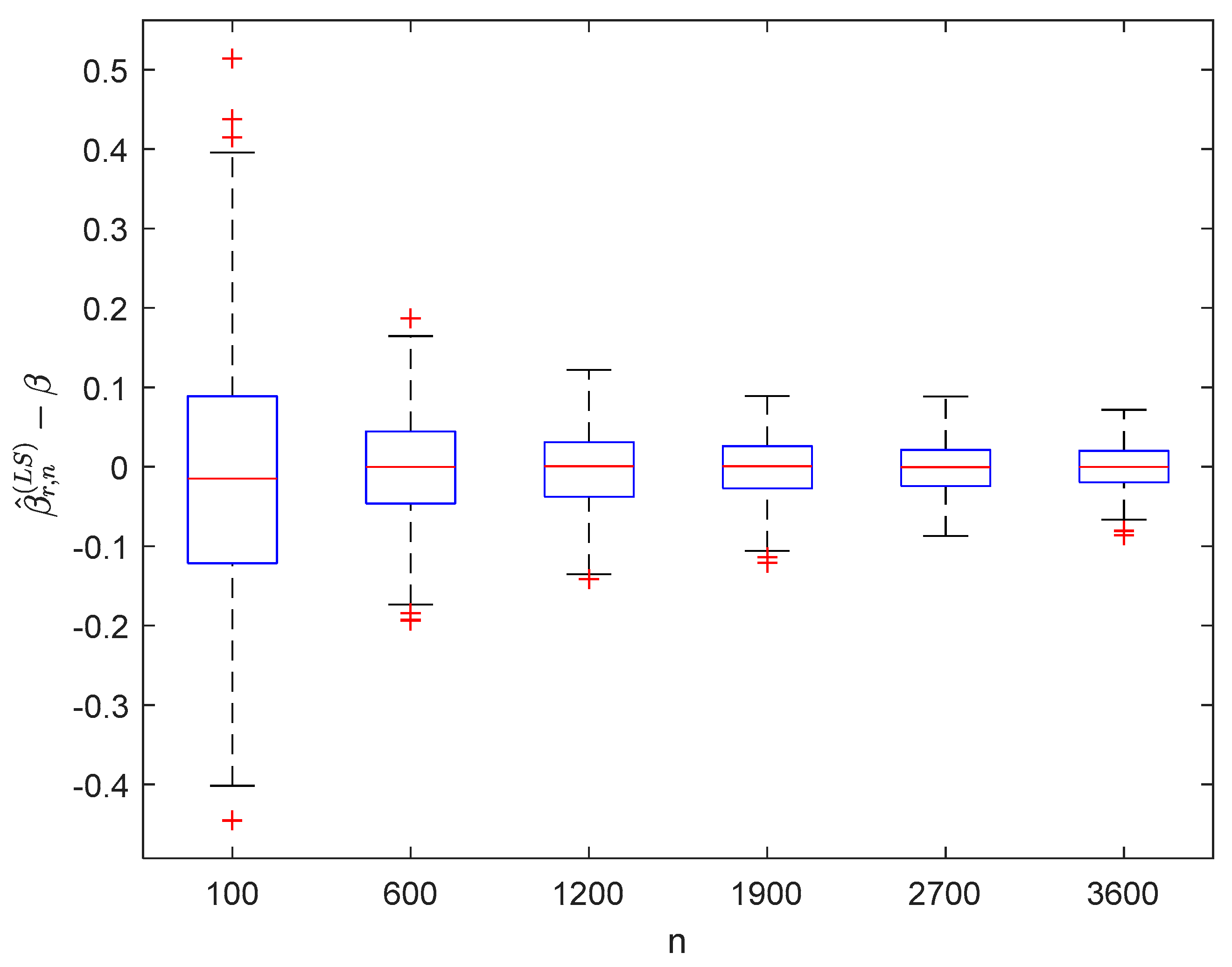
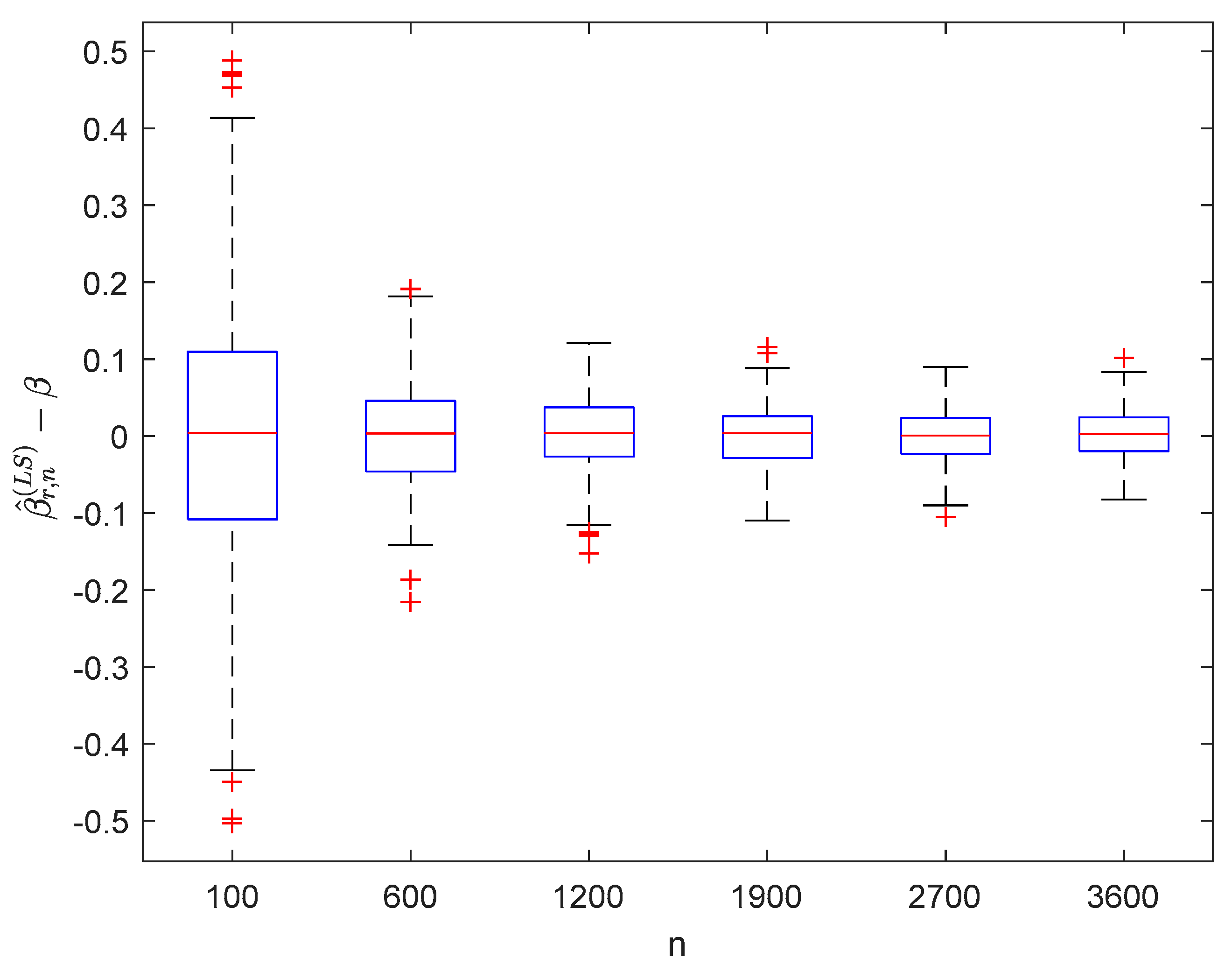
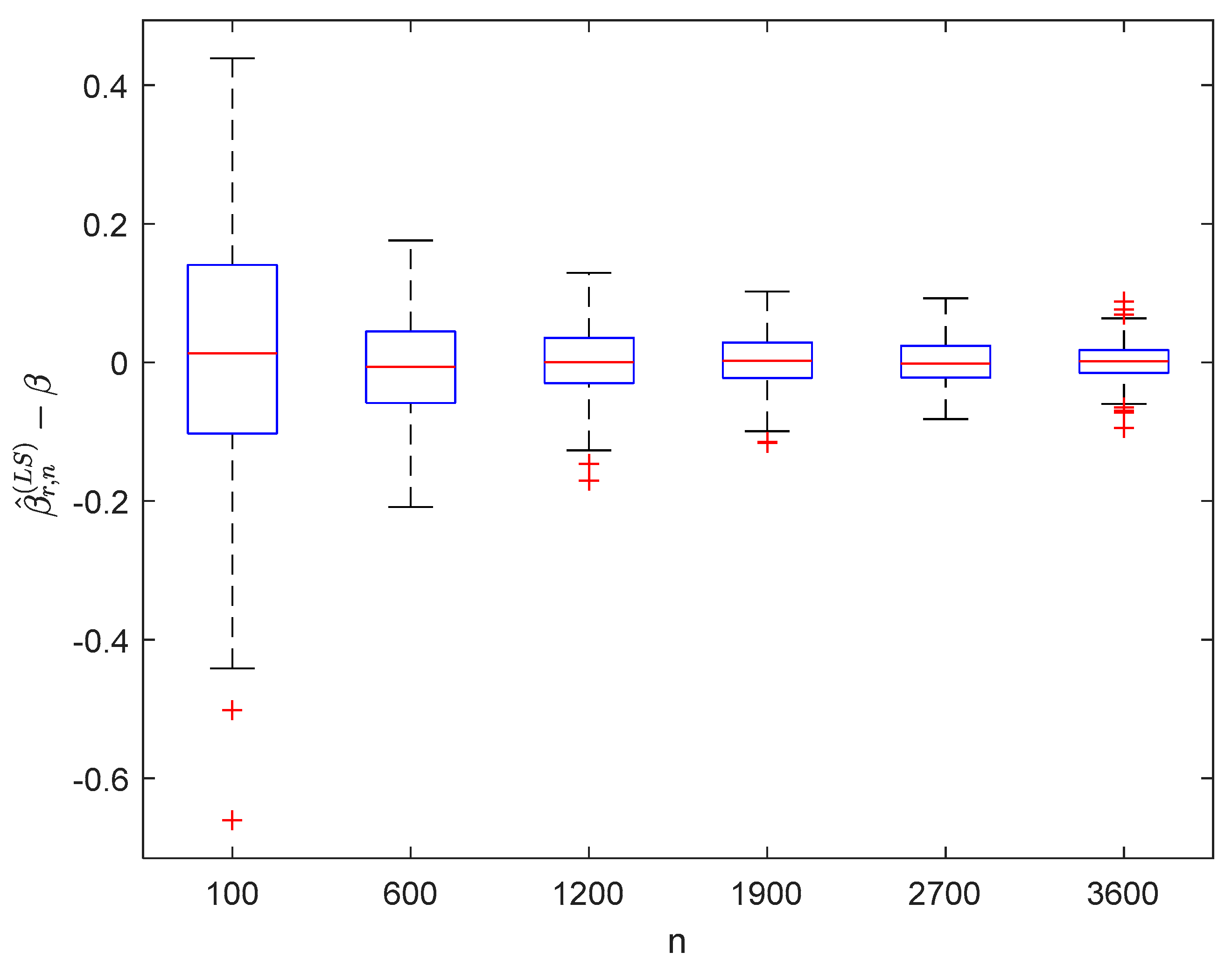
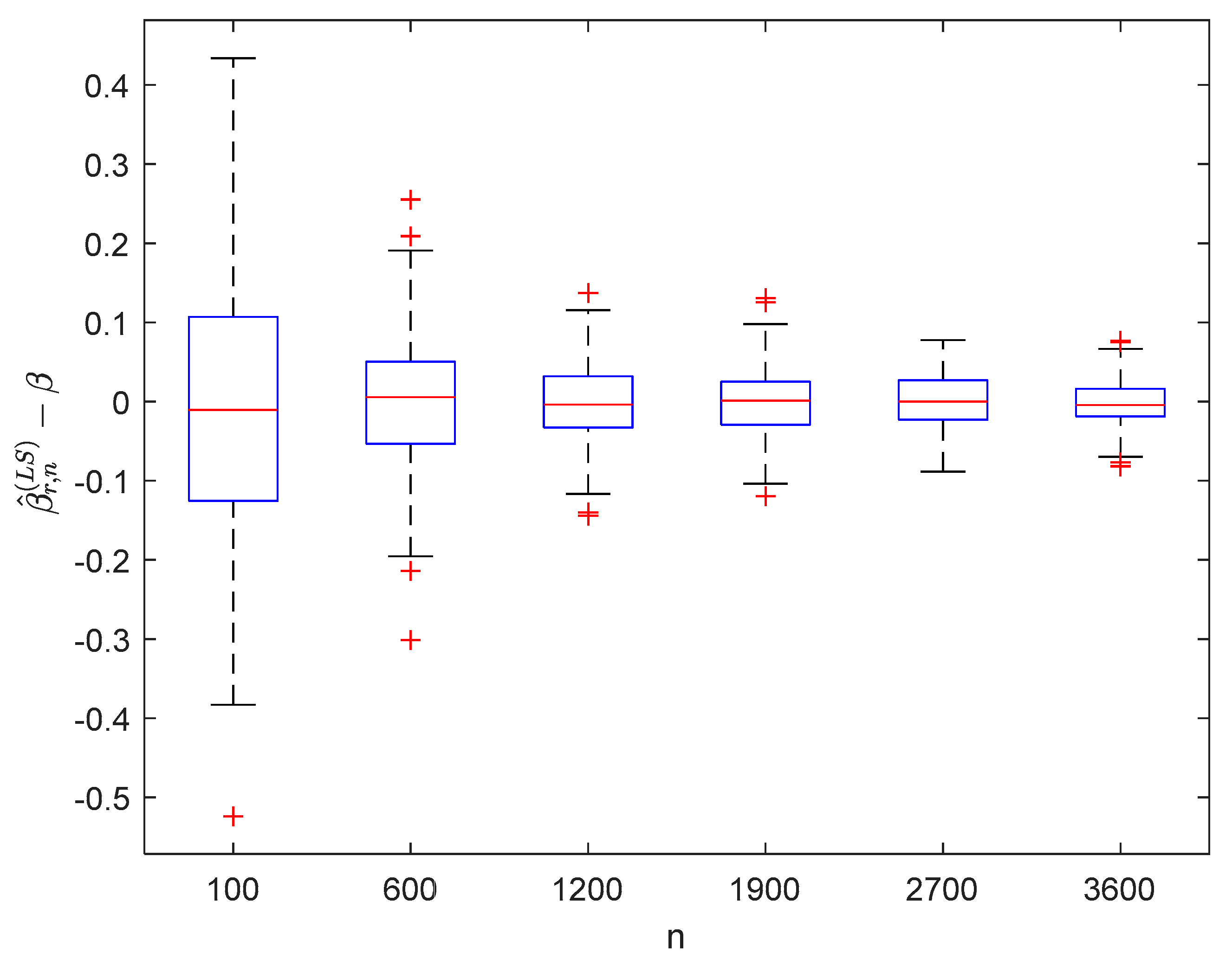
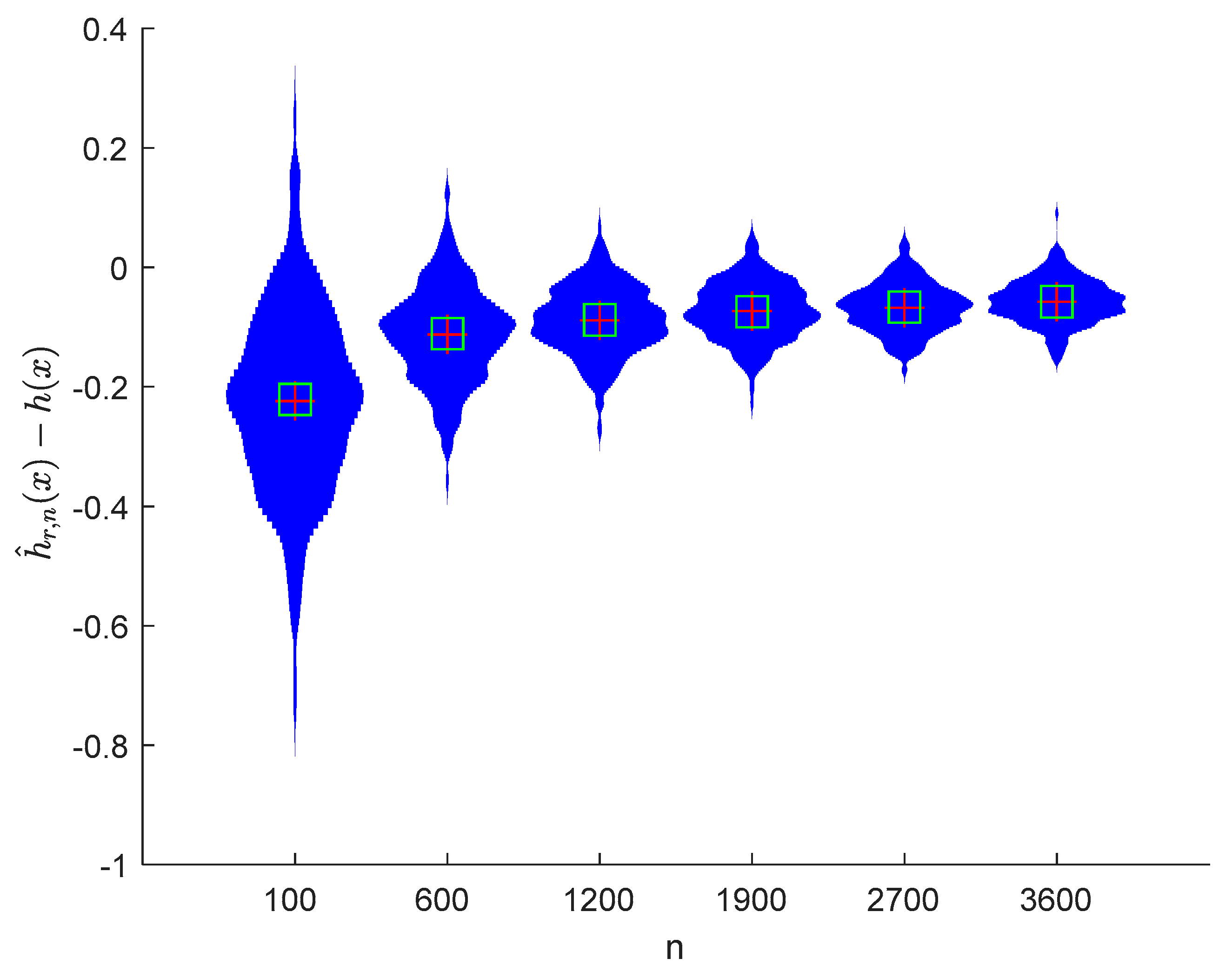
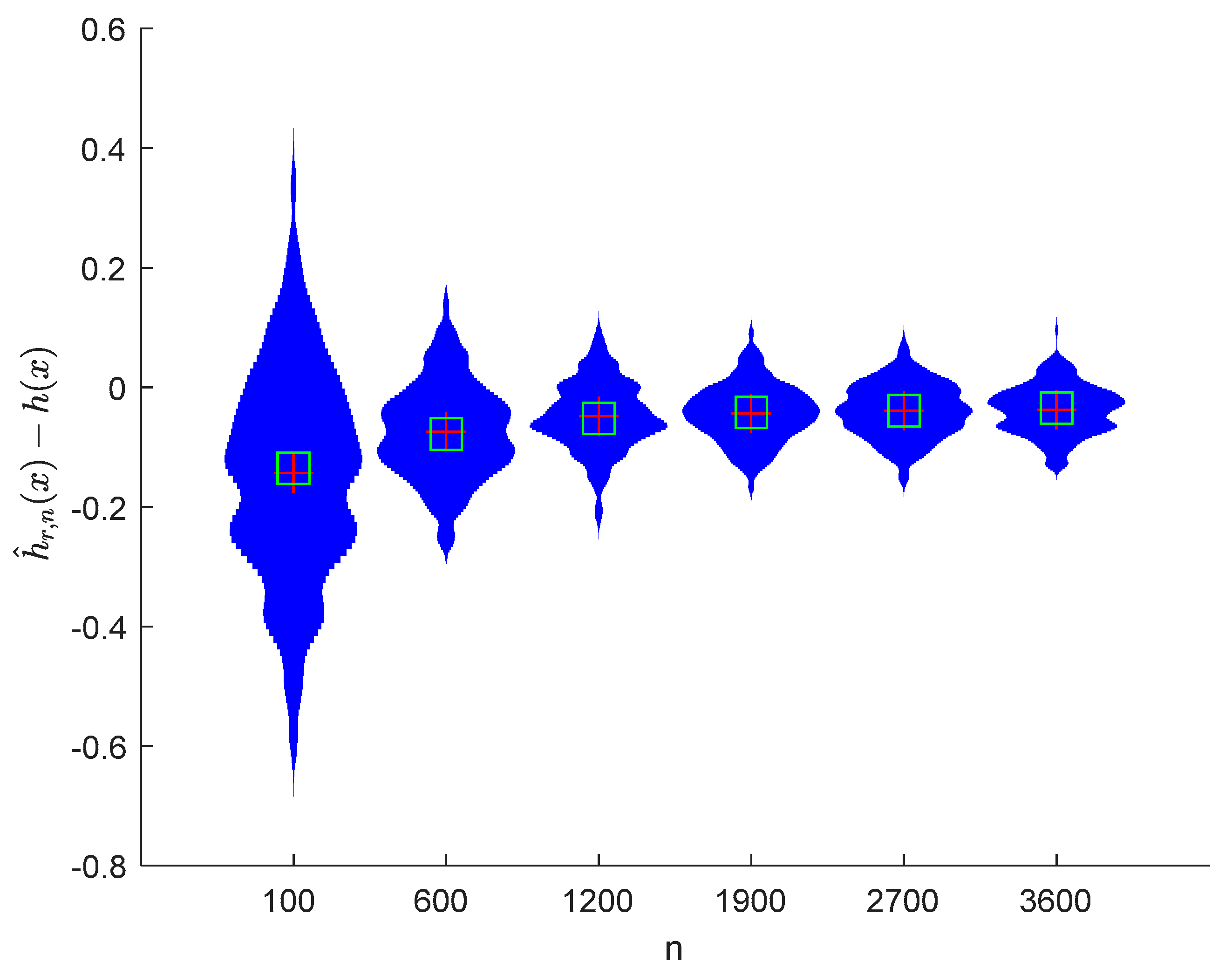
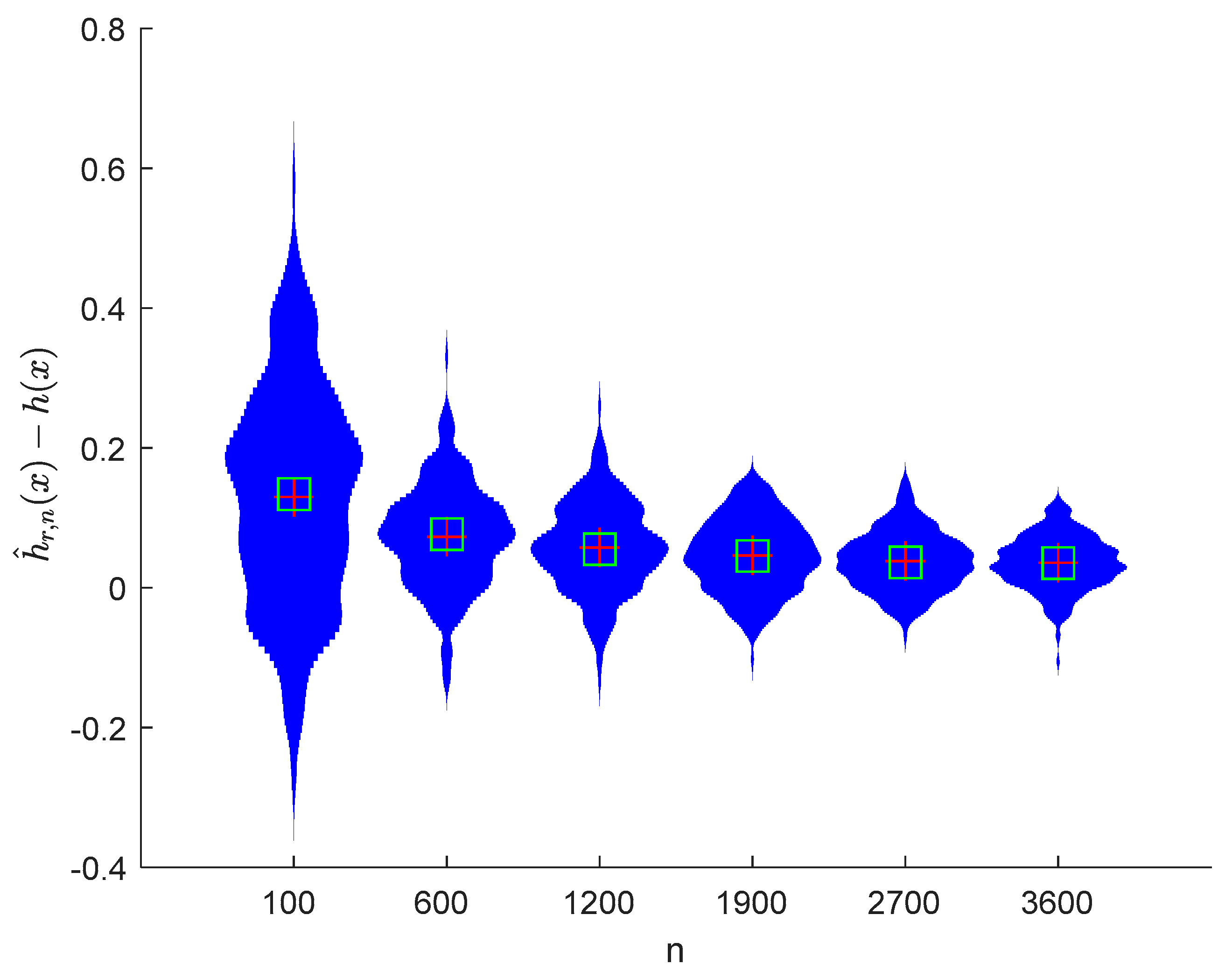
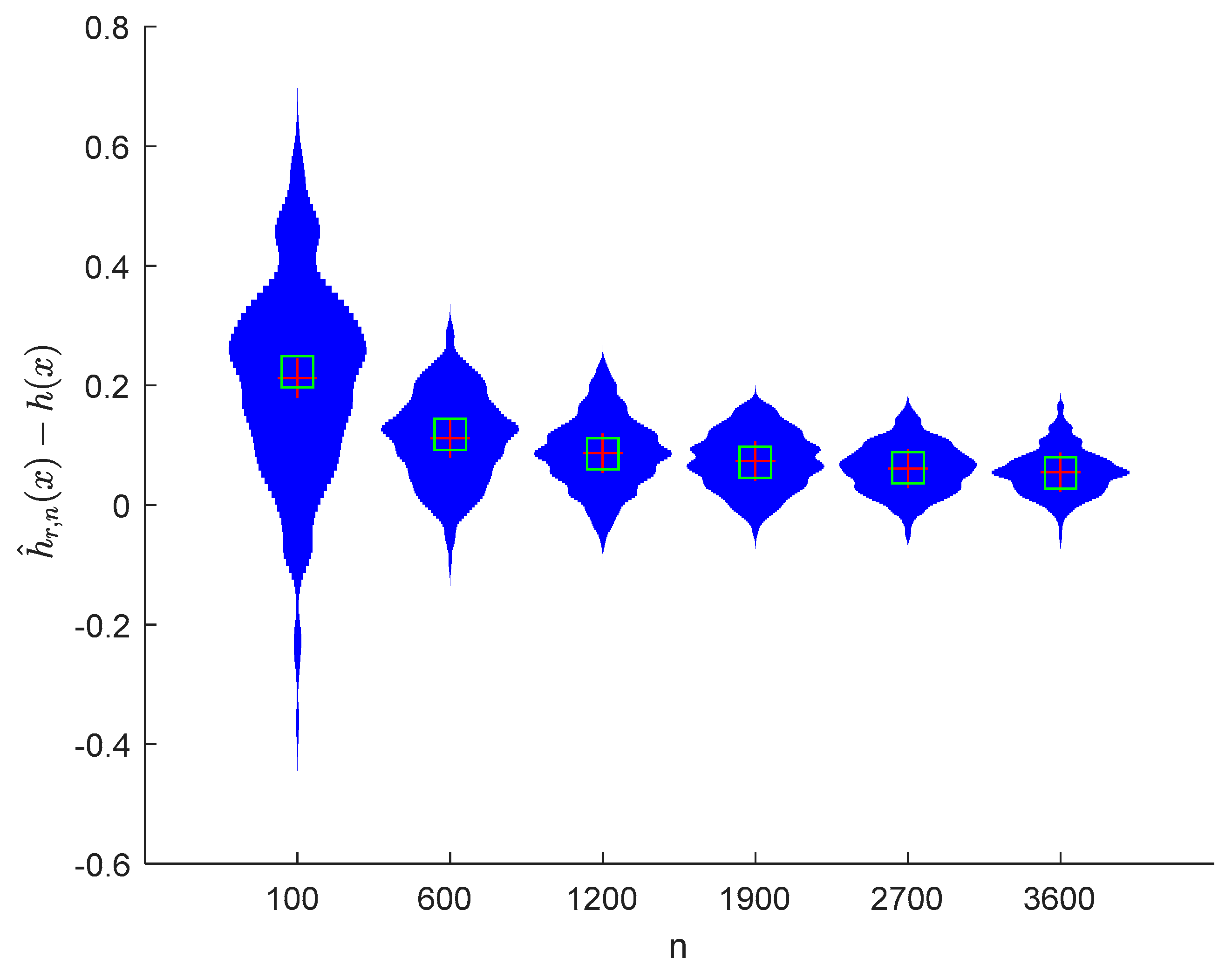
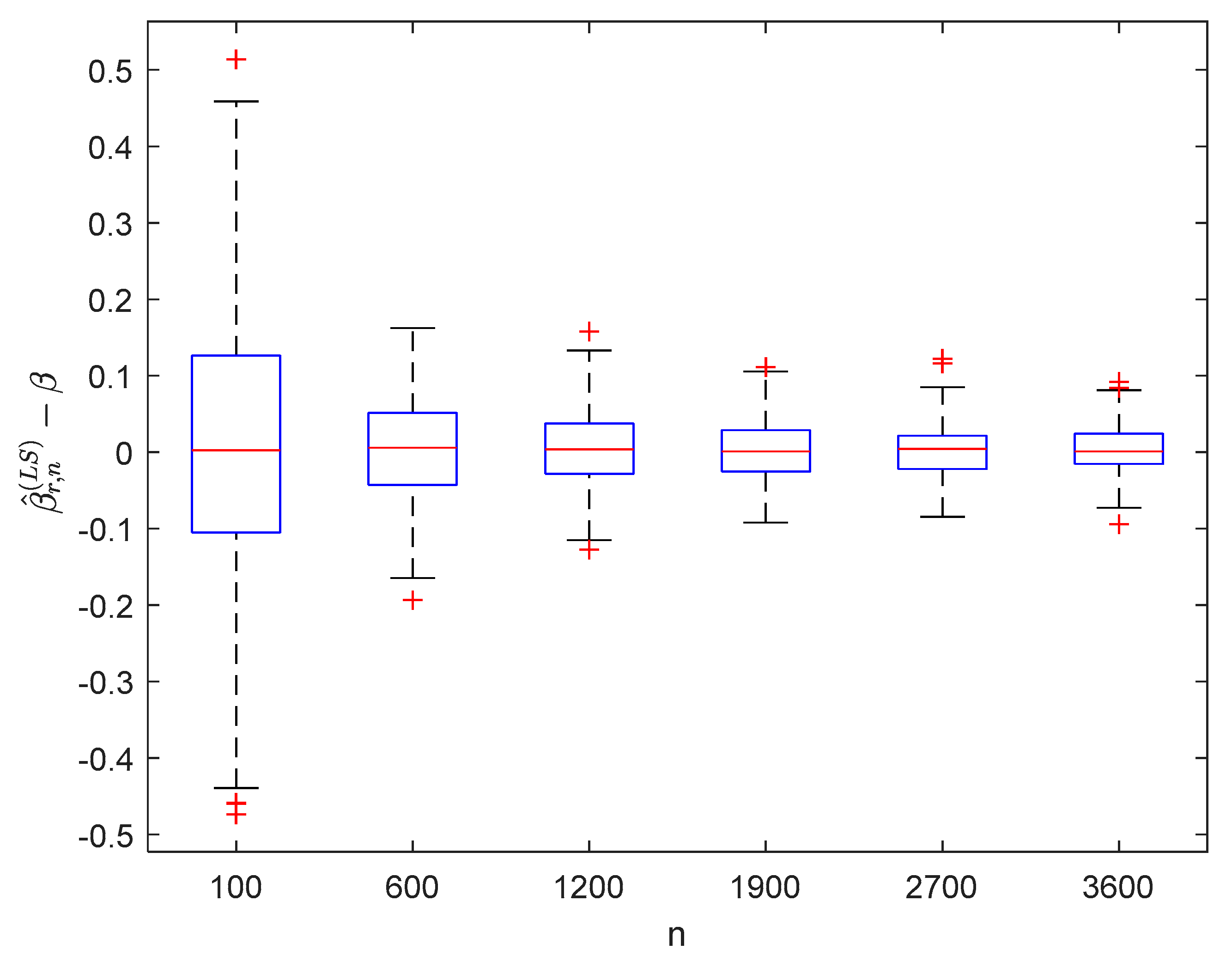
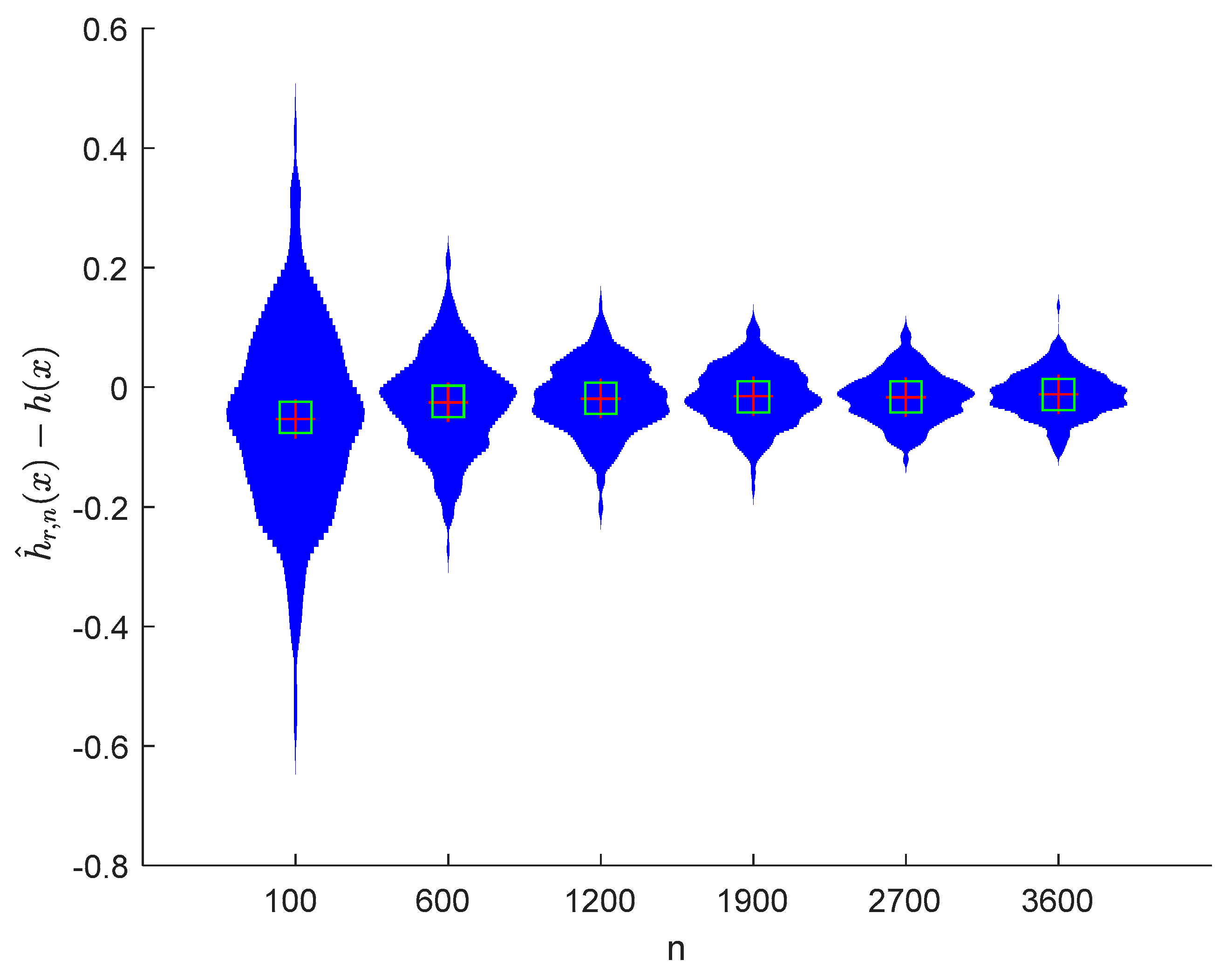
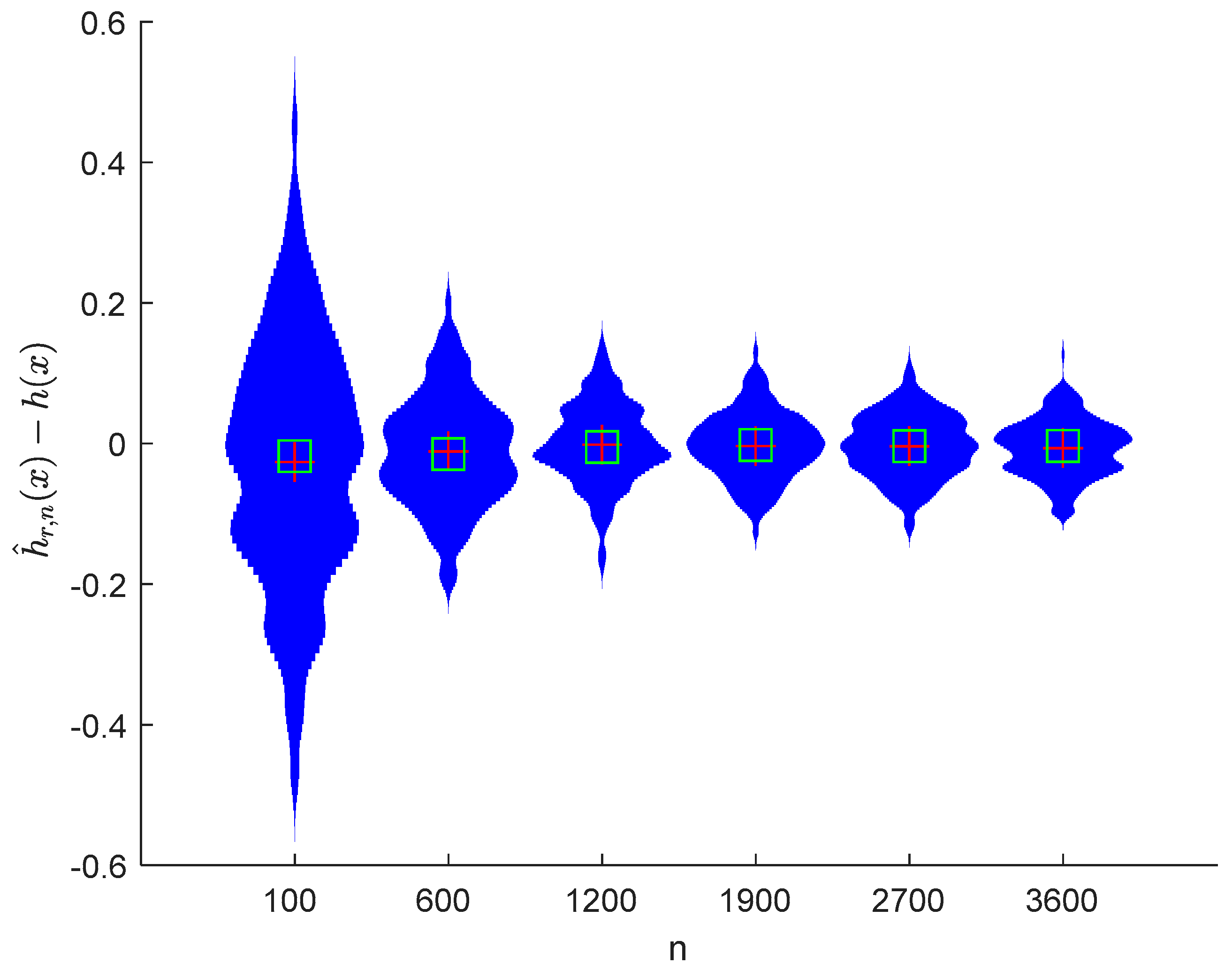
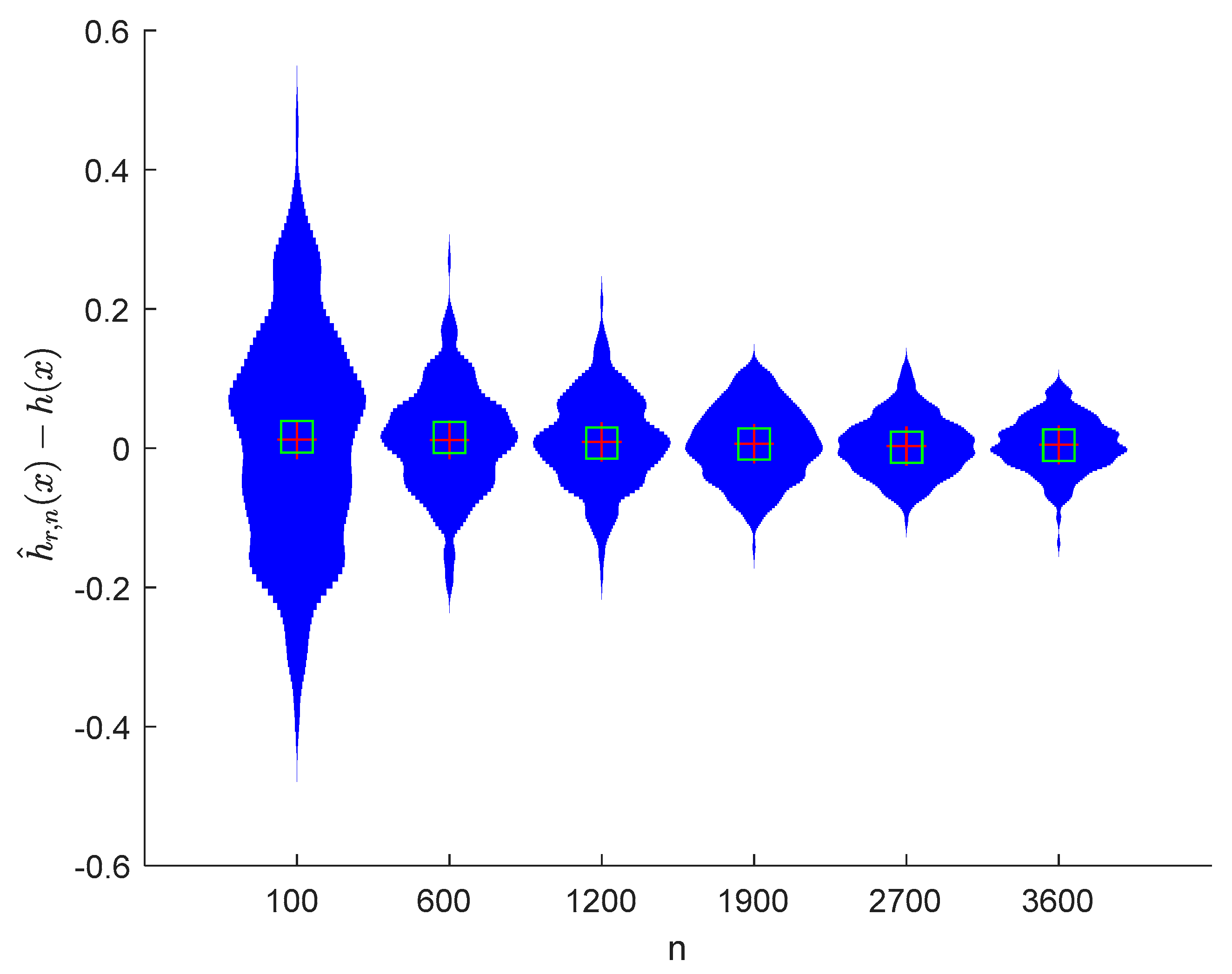
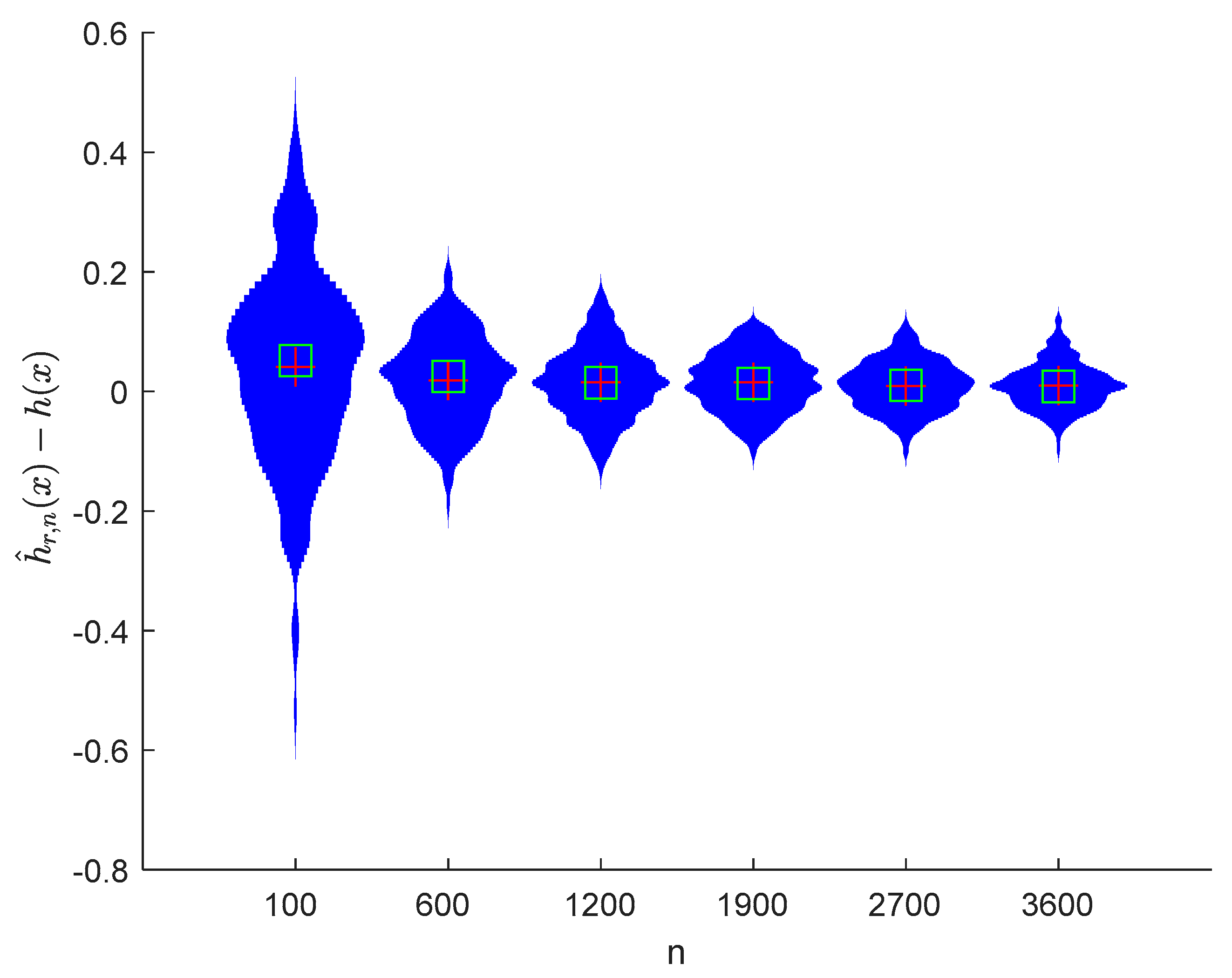
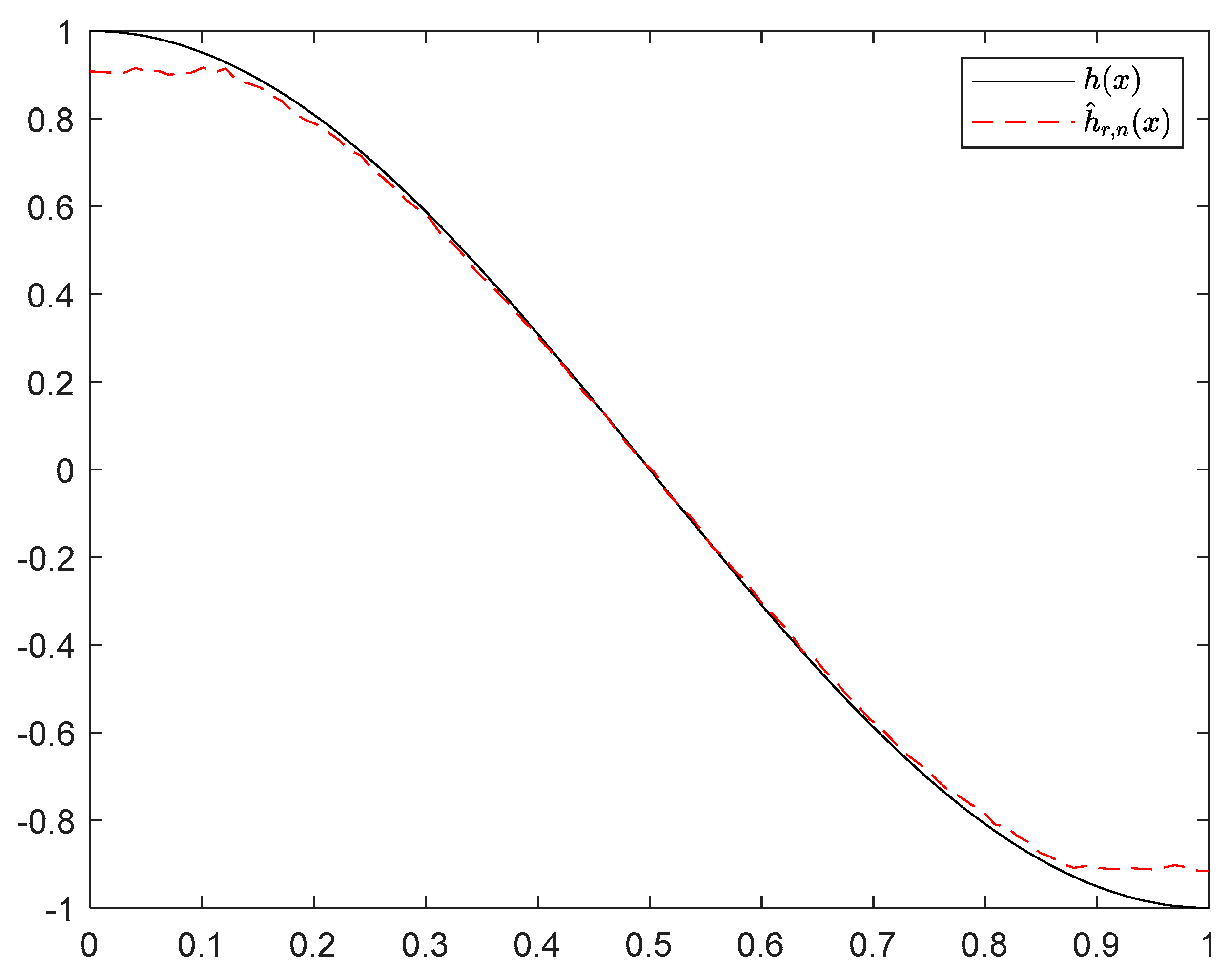
6. Numerical Simulations
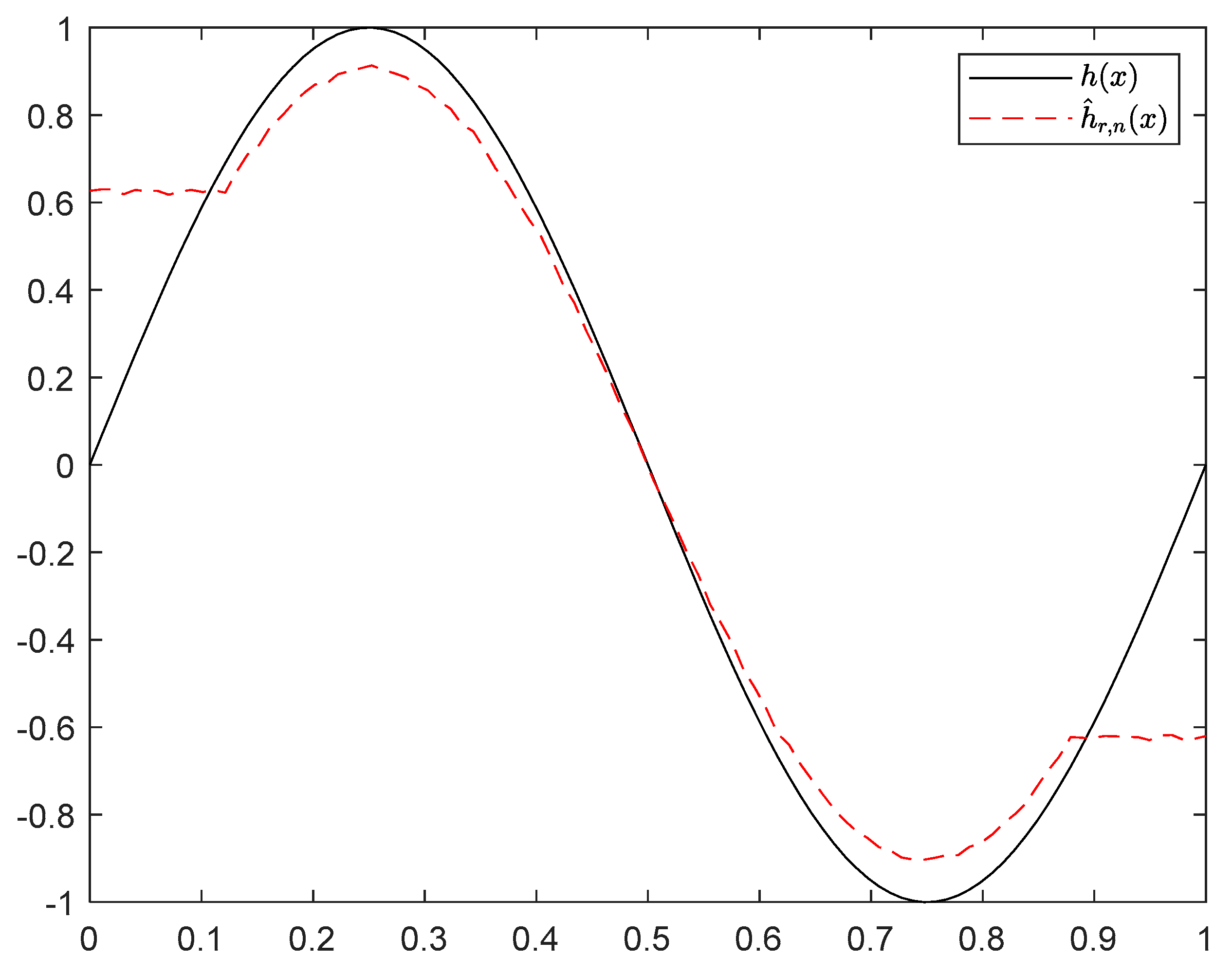
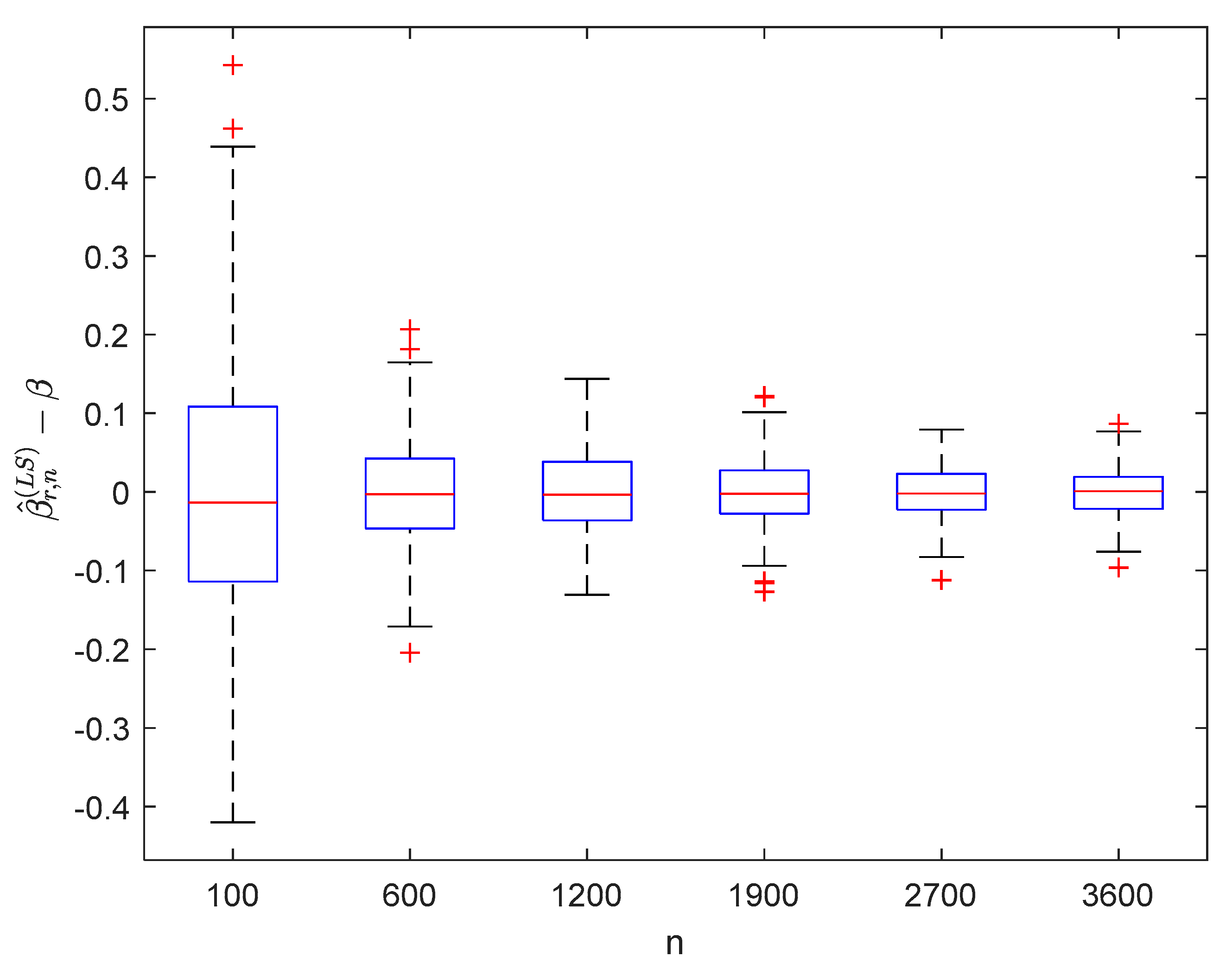
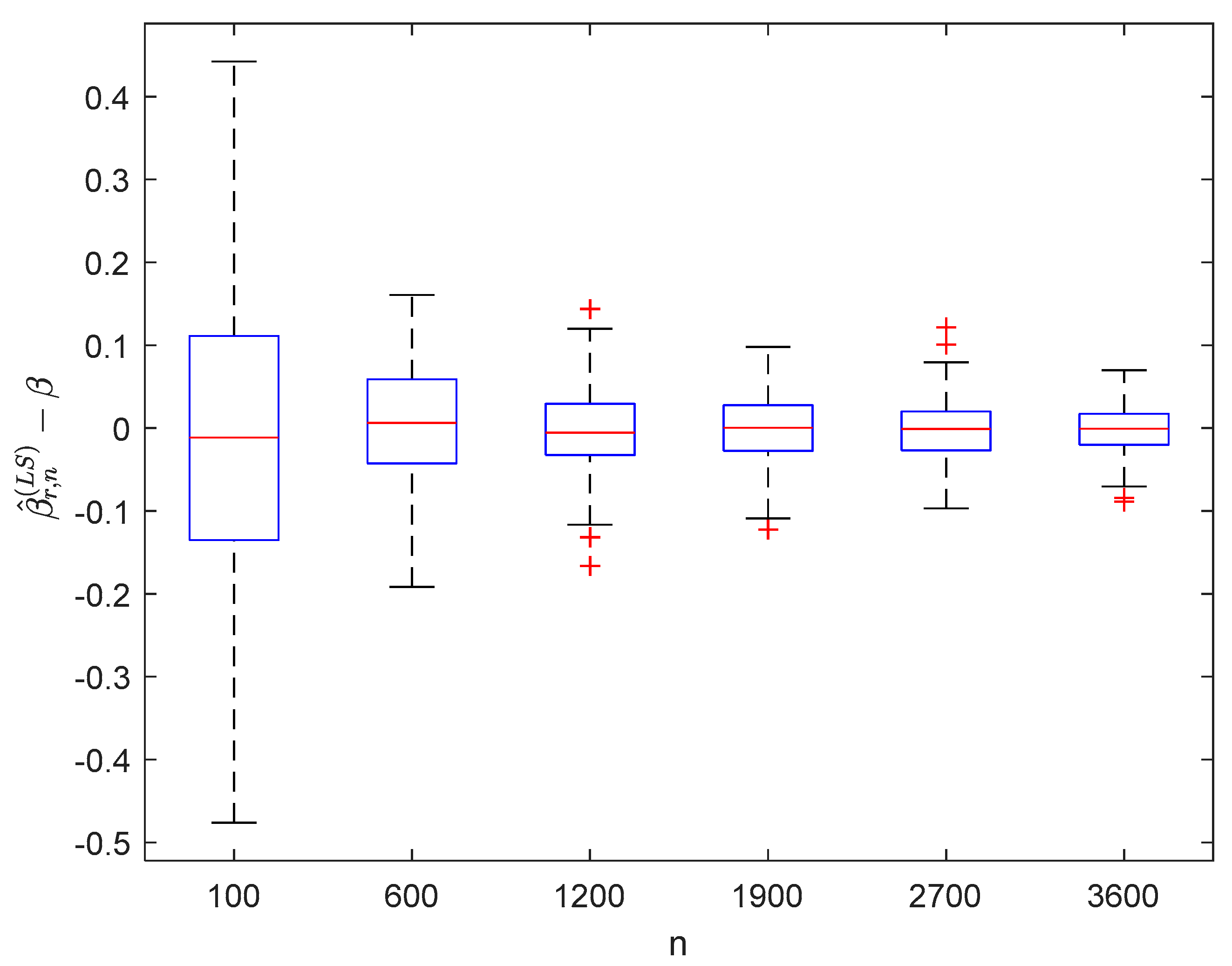
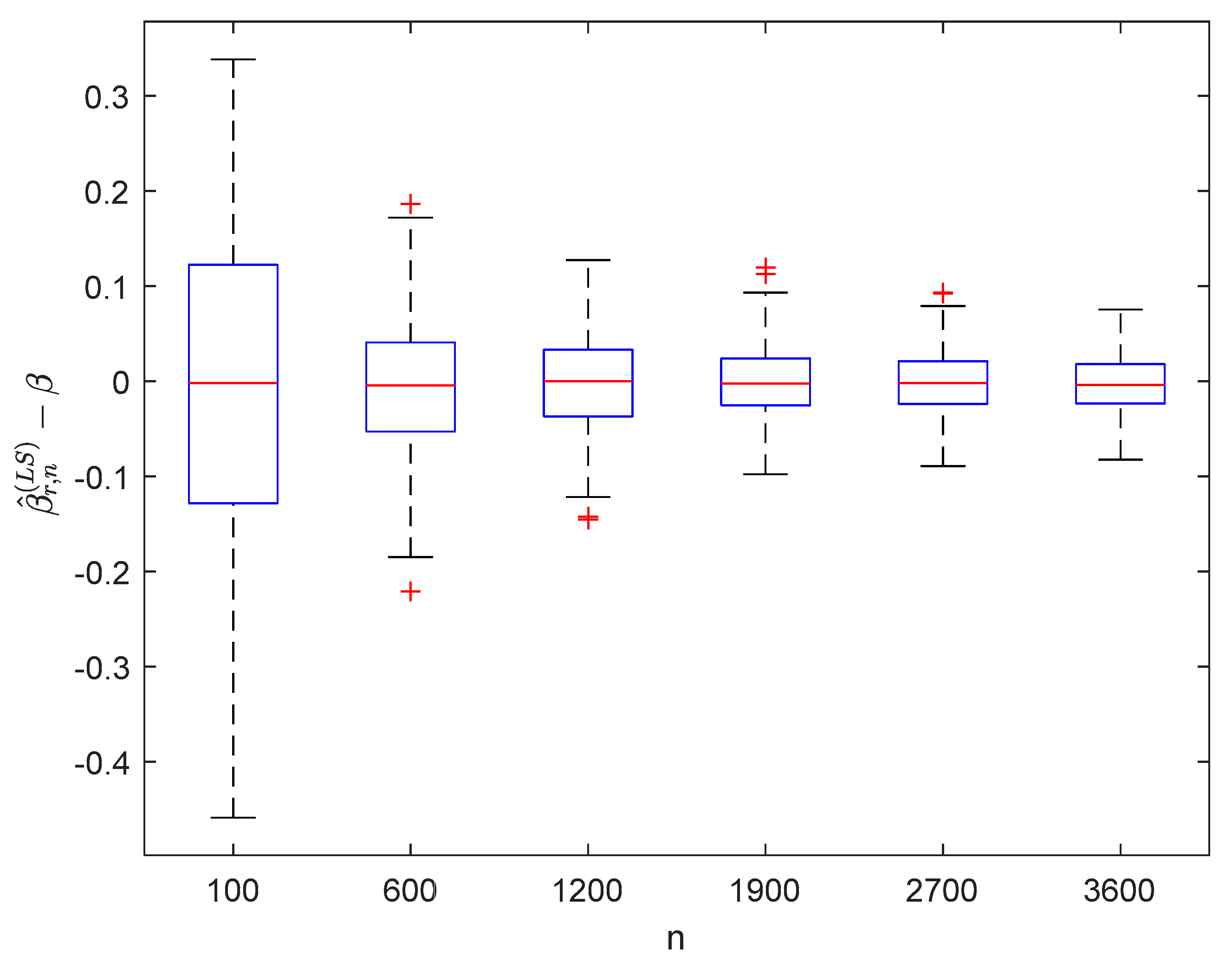
6.1. Simulation 1
6.2. Simulation 2
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Engle, R.; Granger, C.; Rice, J.; Weiss, A. Nonparametric estimates of the relation between weather and electricity sales. J. Am. Stat. Assoc. 1986, 81, 310–320. [Google Scholar] [CrossRef]
- Heckman, N. Spline smoothing in partly linear models. J. R. Stat. Soc. Ser. B 1986, 48, 244–248. [Google Scholar] [CrossRef]
- Speckman, P. Kernel smoothing in partial linear models. J. R. Stat. Soc. Ser. B 1988, 50, 413–436. [Google Scholar] [CrossRef]
- Gao, J.T. Consistency of estimation in a semiparametric regression model (I). J. Syst. Sci. Math. Sci. 1992, 12, 269–272. [Google Scholar]
- Härdle, W.; Liang, H.; Gao, J.T. Partially Linear Models; Physica-Verlag: Heidelberg, Germany, 2000. [Google Scholar]
- Hu, H.C.; Zhang, Y.; Pan, X. Asymptotic normality of DHD estimators in a partially linear model. Stat. Papers 2016, 57, 567–587. [Google Scholar] [CrossRef]
- Zeng, Z.; Liu, X.D. Asymptotic normality of difference-based estimator in partially linear model with dependent errors. J. Inequal. Appl. 2018, 2018, 267. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.T.; Chen, X.R.; Zhao, L.C. Asymptotic normality of a class of estimators in partial linear models. Acta Math. Sin. 1994, 37, 256–268. [Google Scholar]
- Baek, J.; Liang, H.Y. Asymptotic of estimators in semi-parametric model under NA samples. J. Stat. Plan. Inference 2006, 136, 3362–3382. [Google Scholar] [CrossRef]
- Zhou, X.C.; Hu, S.H. Moment consistency of estimators in semiparametric regression model under NA samples. Pure Appl. Math. 2010, 6, 262–269. [Google Scholar]
- Hu, S.H. Consistency estimate for a new semiparametric regression model. Acta Math. Sci. 1997, 40, 527–536. [Google Scholar]
- Li, J.; Yang, S.C. Moment consistency of estimators for semiparametric regression. Acta Math. Appl. Sin. 2004, 17, 257–262. [Google Scholar]
- Li, J.; Yang, S.C. Strong consistency of estimators for semiparametric regression. J. Math. Study 2004, 37, 431–437. [Google Scholar]
- Wang, X.J.; Deng, X.; Xia, F.X.; Hu, S.H. The consistency for the estimators of semiparametric regression model based on weakly dependent errors. Stat. Papers 2017, 58, 303–318. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, X.J. A note on the consistency for the estimators of semiparametric regression model. Stat. Papers 2018, 59, 1117–1130. [Google Scholar] [CrossRef]
- Zhou, X.C.; Liu, X.S.; Hu, S.H. Moment consistency of estimators in partially linear models under NA samples. Metrika 2010, 72, 415–432. [Google Scholar] [CrossRef]
- Joag, D.K.; Proschan, F. Negative association of random variables with applications. Ann. Stat. 1983, 11, 286–295. [Google Scholar] [CrossRef]
- Bradley, R.C. On the spectral density and asymptotic normality of weakly dependent random fields. J. Theor. Probab. 1992, 5, 355–373. [Google Scholar] [CrossRef]
- Zhang, L.X.; Wang, X.Y. Convergence rates in the strong laws of asymptotically negatively associated random fields. Appl. Math. J. Chin. Univ. 1999, 14, 406–416. [Google Scholar]
- Zhang, L.X. A functional central limit theorem for asymptotically negatively dependent random fields. Acta Math. Hung. 2000, 86, 237–259. [Google Scholar] [CrossRef]
- Liang, H.Y. Complete convergence for weighted sums of negatively associated random variables. Stat. Probab. Lett. 2000, 48, 317–325. [Google Scholar] [CrossRef]
- Wu, Q.Y. Strong consistency of M Estimator in linear model for negatively associated samples. J. Syst. Complex. 2006, 19, 592–600. [Google Scholar] [CrossRef]
- Thanh, L.V.; Yin, G.G.; Wang, L.Y. State observers with random sampling times and convergence analysis of double-indexed and randomly weighted sums of mixing processes. SIAM J. Control. Optim. 2011, 49, 106–124. [Google Scholar] [CrossRef]
- Tang, X.F.; Xi, M.M.; Wu, Y.; Wang, X.J. Asymptotic normality of a wavelet estimator for asymptotically negatively associated errors. Stat. Probab. Lett. 2018, 140, 191–201. [Google Scholar] [CrossRef]
- Wang, J.F.; Lu, F.B. Inequalities of maximum partial sums and weak convergence for a class of weak dependent random variables. Acta Math. Sin. 2006, 22, 693–700. [Google Scholar] [CrossRef]
- Yuan, D.M.; Wu, X.S. Limiting behavior of the maximum of the partial sum for asymptotically negatively associated random variables under residual Cesaro alpha-integrability assumption. J. Stat. Plan. Inference 2010, 140, 2395–2402. [Google Scholar] [CrossRef]
- Zhang, L.X. Central limit theorems for asymptotically negatively associated random fields. Acta Math. Sin. 2000, 16, 691–710. [Google Scholar] [CrossRef]
- Chen, Z.; Lu, C.; Shen, Y.; Wang, R.; Wang, X.J. On complete and complete moment convergence for weighted sums of ANA random variables and applications. J. Stat. Comput. Simul. 2009, 89, 2871–2898. [Google Scholar] [CrossRef]
- Zhang, Y. Complete moment convergence for moving average process generated by -mixing random variables. J. Inequal. Appl. 2015, 2015, 245. [Google Scholar] [CrossRef]
- Wu, Q.Y.; Jiang, Y.Y. Some Limiting behavior for asymptotically negative associated random variables. Probab. Eng. Inf. Sci. 2018, 32, 58–66. [Google Scholar] [CrossRef]
- Xu, F.; Wu, Q.Y. Almost sure central limit theorem for self-normalized partial -mixing sequences. Stat. Probab. Lett. 2017, 129, 17–27. [Google Scholar] [CrossRef]
- Shen, A.T.; Zhang, Y.; Volodin, A. Applications of the Rosenthal-Type inequality for negatively superadditive dependent random variables. Metrika 2015, 78, 295–311. [Google Scholar] [CrossRef]
- Chen, M.H.; Ren, Z.; Hu, S.H. Strong consistency of a class of estimators in partial linear model. Acta Math. Sin. 1998, 41, 429–439. [Google Scholar]
- Zhou, X.C.; Hu, S.H. Strong consistency of estimators in partially linear models under NA samples. J. Syc. Sci. Math. Sci. 2010, 30, 60–71. [Google Scholar]
- Hu, S.H. Fixed-Design semiparametric regression for linear time series. Acta Math. Sci. 2006, 26, 74–82. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.2 | 0.029564 | 0.0040429 | 0.0027393 | 0.0017879 | 0.0011778 | 0.00096205 |
| 0.4 | 0.027563 | 0.0048107 | 0.002557 | 0.0013618 | 0.0012225 | 0.00083697 |
| 0.6 | 0.032418 | 0.0045437 | 0.0030247 | 0.0017816 | 0.001016 | 0.0007695 |
| 0.8 | 0.026715 | 0.0049648 | 0.0026033 | 0.0014911 | 0.00099622 | 0.00083525 |
| 0.2 | 0.072899 | 0.0132846 | 0.0064122 | 0.00450755 | 0.00408198 | 0.00309342 |
| 0.4 | 0.064407 | 0.012605 | 0.0061076 | 0.0040173 | 0.0037297 | 0.0027017 |
| 0.6 | 0.0651945 | 0.01143844 | 0.0061647 | 0.0048246 | 0.0031893 | 0.002914 |
| 0.8 | 0.067254 | 0.0134688 | 0.0701644 | 0.00515616 | 0.00397691 | 0.0030646 |
| 0.2 | 0.028735 | 0.0046935 | 0.002547 | 0.0017209 | 0.0010944 | 0.00085433 |
| 0.4 | 0.032703 | 0.0053621 | 0.0022595 | 0.0015934 | 0.001206 | 0.0008074 |
| 0.6 | 0.027853 | 0.0048229 | 0.0025756 | 0.0014096 | 0.0011848 | 0.00084765 |
| 0.8 | 0.03042 | 0.004848 | 0.002352 | 0.0014649 | 0.0011824 | 0.00084588 |
| 0.2 | 0.025536 | 0.0068733 | 0.0035259 | 0.0025282 | 0.0019082 | 0.0015027 |
| 0.4 | 0.029859 | 0.0061945 | 0.0032347 | 0.0022321 | 0.002002 | 0.0016778 |
| 0.6 | 0.02415 | 0.005475 | 0.0040859 | 0.0026873 | 0.0017436 | 0.0014589 |
| 0.8 | 0.027164 | 0.0055904 | 0.0036775 | 0.0024326 | 0.0017396 | 0.0014935 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Liu, X. The Consistency of Estimators in a Heteroscedastic Partially Linear Model with ρ−-Mixing Errors. Symmetry 2020, 12, 1188. https://doi.org/10.3390/sym12071188
Zhang Y, Liu X. The Consistency of Estimators in a Heteroscedastic Partially Linear Model with ρ−-Mixing Errors. Symmetry. 2020; 12(7):1188. https://doi.org/10.3390/sym12071188
Chicago/Turabian StyleZhang, Yu, and Xinsheng Liu. 2020. "The Consistency of Estimators in a Heteroscedastic Partially Linear Model with ρ−-Mixing Errors" Symmetry 12, no. 7: 1188. https://doi.org/10.3390/sym12071188
APA StyleZhang, Y., & Liu, X. (2020). The Consistency of Estimators in a Heteroscedastic Partially Linear Model with ρ−-Mixing Errors. Symmetry, 12(7), 1188. https://doi.org/10.3390/sym12071188