1. Introduction
Li-ion batteries (LIBs) are widely used in different areas due to their high energy capacity, fast charging, and light weight. The performances of LIBs, which are considered the best energy storage systems for electric vehicles, are gradually decreasing due to their chemical and physical mechanisms [
1]. An efficient battery management system needs to be developed due to high costs and limited repair opportunities. Moreover, in order to effectively manage the performance of batteries, the health indicators of the battery must be accurately predicted. Therefore, it is very important to estimate the state of health (SoH) of batteries and monitor their life cycle for long-lasting and high-performance battery use.
In the quest for advancing battery technology, the incorporation of symmetry plays a crucial role in the analysis of Li-ion batteries. Symmetry, embodying balance and harmonious patterns, has been systematically explored to unveil inherent structural regularities within battery data. Investigating symmetrical properties provide a detailed comprehension of the fundamental mechanisms governing battery operation. This, in turn, contributes to refining existing models and fostering the development of more resilient battery management systems.
Data-driven methods are being developed to analyze the dynamic behavior of a system without investigating the electrochemical reactions that occur during the battery discharge time. The data of raw measurements obtained from actual battery usage experiments are utilized to analyze the dynamic behavior. Abundant data are needed for the training of the models developed for these methods. For testing operations, the unused data in training is provided as input to the model for the testing process, so this is performed in data-based methods and statistically based approaches. In different studies, a fuzzy logic theory has been used to predict the SoH of LIBs [
2]. Moreover, in [
3], a Genetic Programming (GP)-based approach was developed to extract the optimal formula for the SoH prediction of batteries. A hybrid model developed in [
4] combines a Support Vector Machine (SVM) with an Unscented Particle Filter (UPF) to improve the performance of the SoH and state of charge (SoC) predictions in LIBs. In [
5], an adaptive Wiener process model using the Brownian motion process for RUL (remaining useful life) estimation was proposed. Machine learning (ML) algorithms have received particular attention due to their outstanding performance and minimal prediction errors. Cai et al. proposed a prediction model using Support Vector Regression (SVR) for battery SoH prediction; a Genetic algorithm was employed to optimize SVR parameters and feature selection [
6]. Xue et al. proposed a hybrid approach, a combination of an Adaptive Unscented Kalman Filter (AUKF) and SVR, for the remaining useful life (RUL) prediction of LIBs. SVR parameters were optimized using a genetic algorithm [
7].
In general, data-driven methods achieve superior accuracy than model-based methods. Recently, research on improving the battery state estimation accuracy has shown significant success. Several studies have conducted comparative analyses between machine learning algorithms to predict the internal states of LIBs. For instance, a comparative study of different machine learning algorithms such as SVR, Convolutional Neural Networks (CNNs), and Long Short-Term Memory (LSTM) was conducted in [
8].
In recent years, hybrid methods have been introduced to leverage multiple algorithms to increase the precision of a prediction method. Further studies have suggested a combination of LSTM networks with other methods to improve the prediction accuracy and achieve the best results. Liu et al. combined LSTM with Bayesian Model Averaging (BMA) for RUL estimations [
9]. In a different study, the performance results of the proposed GPR and LSTM methods were compared separately with the performance of Gaussian Process Regression—Empirical Mode Decomposition (GPR-EMD) and an LSTM-EMD combination [
10]. Convolutional neural networks play a crucial role in feature mapping. Combining CNN and LSTM networks increases the adequacy of diagnosis and prognosis methods. Several studies have proposed a combined CNN-LSTM to improve the prediction accuracy and overcome the performance degradation of batteries. Ren et al. applied a hybrid CNN-LSTM model for battery RUL prediction [
11]. The method performed well using a limited amount of data in the learning phase, and the prediction errors were satisfactorily small [
12]. In addition to all these methods, our research team discussed enhancements to the LSTM (long short-term memory) and Bi-LSTM (Bidirectional Long Short-Term Memory) methods. Evaluation metrics such as the Mean Squared Error (MSE), Mean Absolute Error (MAE), Root Mean Square Error (RMSE), and R-squared were applied in our previous publication [
13].
Recent studies on data-driven methodologies underscore a pivotal shift toward leveraging comprehensive raw measurement datasets from actual battery usage to analyze dynamic system behaviors, bypassing the need to investigate the intricacies of electrochemical reactions during discharge. These methodologies necessitate substantial data volumes for model training, ensuring that the predictive models are robust and generalizable. In the literature, the adoption of machine learning algorithms, particularly when optimized with genetic algorithms, has been shown to significantly reduce prediction errors. Comparative analyses have elucidated the superior efficacy of these data-driven approaches over traditional model-based methods, particularly highlighting the effectiveness of hybrid models that combine CNN and LSTM networks to enhance feature extraction and sequential data analysis. Such synergistic models are shown to be crucial in improving the predictive accuracy and reliability of battery status estimations.
This study focused on analyzing the change in the discharge capacity of LIBs over time and developing predictive models to anticipate capacity decline. In addition to analyzing the change in the discharge capacity of LIBs over time, it aimed to develop predictive models that predict the capacity decrease by taking into account the concept of symmetry. For this goal, LIBs were charged/discharged, and discharge capacity values were obtained by adhering to different temperature and charge/discharge procedures. Afterward, various modeling approaches were explored, ranging from classical machine learning algorithms to complex and hybrid deep learning models. The performances of algorithms such as Random Forests (RFs) [
14] and eXtreme Gradient Boosting (XGBoost) [
15] were evaluated alongside regression models like Elastic Net [
16] and artificial neural network models like Multilayer Perceptron (MLP) [
17].
Furthermore, efforts were made to improve success rates in time series data analysis by developing more sophisticated models. Complex architectures such as CNNs and Recurrent Neural Networks (RNNs) were developed and compared within hybrid frameworks like RNN-LSTM, CNN-LSTM, CNN-Gated Recurrent Unit (GRU), and RNN-GRU. This comprehensive approach aimed to enhance our understanding of battery behavior and facilitate the creation of more accurate prediction models for BMS applications for determining the critical indicators of its aging status, which can be identified through factors like increased internal resistance or diminished capacity. By effectively monitoring and assessing these parameters, the BMS contributes significantly to maximizing battery performance and longevity.
Unlike the hybrid methods mentioned in the literature, the methodology proposed in this study provides researchers with a comparative analysis by outlining the feature exploitation procedure for classical machine learning and two neural networks (CNN, RNN). Therefore, for future studies, it elucidates which method will obtain more accurate and faster results. Additionally, a comparison of the LSTM algorithm and GRU algorithms was conducted to demonstrate the superiority of the proposed method. A CNN was combined with an LSTM network for the SoH estimation and RUL assessment of LIBs. Improving the proficiency of machine learning algorithms has always been a subject of research. However, among these attempts, several studies have proposed more complex RNN combinations [
18]. Comparative results of an LSTM and GRU-based hybrid CNN and RNN methods are included in the study to demonstrate the superiority of the proposed methods. To compare observed and predicted discharge capacities, evaluation metrics such as the MSE, MAE, RMSE and R-Squared were applied to the proposed methods [
19].
The remainder of this paper is structured as follows; in the second section, the materials and methods used are provided. In the third section, the LIB data preparation is first discussed and then presented. The data were analyzed from different perspectives. In the fourth section, based on data analysis, various (RF, XGBoost, Elastic Net, MLP, CNN, RNN, CNN + LSTM, RNN + LSTM, CNN + GRU and RNN + GRU) models for LIB discharge performance were proposed with machine learning and deep learning techniques. In the following sections, the models are evaluated and compared in detail. Finally, the study concludes by providing results and recommendations. Additionally, the limitations and findings of the study are included. Thus, researchers are given predictions for future studies.
3. Experimental Studies
Within the scope of this study, various models were developed to estimate the discharge capacities of LIBs, each employing distinct computational strategies. The initial deployed model was based on the RF algorithm, a well-established machine learning technique. Subsequent models included those based on XGBoost, CNNs, RNNs, and integrated frameworks that combine CNN and RNN units with a GRU and LSTM to harness their respective strengths. The development of these models was meticulously structured, adhering to a prescribed sequence of steps. During the model development phase, the methodologies and procedural stages were rigorously followed as outlined in
Figure 7, ensuring systematic progression and integrity in the model development.
The process of developing a predictive model, as depicted in
Figure 7, commences with the gathering and pre-processing of historical data pertinent to the predictive task, such as discharge capacity data. This foundation is followed by feature selection, where key data attributes are identified to accurately predict the outcome variable. Afterward, the dataset is partitioned into distinct training and testing sets. The training set informs the model learning phase, which varies according to the algorithm employed—a subject extensively covered in the Materials and Methods section. The model performance is then assessed on the test set, employing metrics like the RMSE to ascertain the predictive accuracy. The finalized model, upon validation, becomes a tool for real-world application, capable of forecasting outcomes on novel data, thereby enabling empirical studies on actual data scenarios.
3.1. Data Collection and Pre-Processing
Table 1 presents the cycling test structure involving temperature, charge cut-off C-rate, and discharge C-rates; three stress factors that resulted in 24 testing conditions. Each condition was subjected to testing using eight cells. All cycling data were logged by the battery test system and were pre-processed for machine learning and deep learning purposes.
Pre-processing was applied to the obtained data, and missing values were checked. Scaler transformation was applied to the data for artificial intelligence algorithms. Features at different scales may cause the algorithm to over- or under-react to certain features, so an attempt was made to normalize values that may become more dominant in model training. Additionally, in deep learning models, the normalization of features helps train the model faster and more effectively. Normalization enables optimization algorithms such as gradient descent to converge faster and more effectively.
In working with deep learning models used in structures such as time series, image processing, or sequential data, the need to transform the data into a three-dimensional tensor is necessary to make the data suitable for the input format expected by the model so that the model can process the data correctly and learn effectively. Within the scope of the study, firstly, ‘X’ and ‘y’ variables were determined as the feature matrix and target vector. Here ‘X’ is an attribute matrix consisting of columns ‘Cycle_Index’, ‘Temperature’, ‘Voltage(V)’, and ‘Current(A)’. ‘y’ is the target vector defined by the ‘Discharge_Capacity(Ah)’ column. With the expression ‘X.values.reshape(−1, 4, 1)’, the ‘X’ matrix was subjected to appropriate resizing. With this process, each sample is transformed into a three-dimensional tensor in which it has four features, and these features are arranged in a single column. Thus, the dataset was made suitable to use in time series analysis or deep learning models.
3.2. Data Partition
The process of dividing the data prepared for the estimation of discharge capacity should be different according to the classification type of data because time-dependent data on discharge capacity have a sequential structure, and this structure must be preserved during the training and testing processes of the model. The problem addressed in this study was to predict future data based on past data. Therefore, if data division is not taken into consideration, it may create a model that tries to predict the past based on future information, which will create an undesirable situation in real problems. The data obtained within the scope of this study was divided on a time-based basis. With this partitioning process, a part of the dataset (75%) (usually old data) is reserved for training the model, and the remaining part (new data) is reserved for testing the model.
Given the limited size of the dataset in this study, a direct validation set was not allocated for rapid prototyping purposes. Instead, the test set, separated from the training set, served a secondary function as the validation set. Utilizing the test set in lieu of directly allocating a validation set presents a pragmatic solution by enlarging the dataset size, thereby ensuring that the model has sufficient data for training while also somewhat testing the model’s generalization capability [
21]. In this scenario, the ‘train_test_split’ function allocated 25% of the dataset as the test set, with the remaining 75% used as the training set. During model training, this test set was employed as the validation set, thus providing real-time feedback on the model’s performance throughout the training process.
3.3. Model Development
During the model development phase, the RF, XGBoost, Elastic Net, CNN, RNN, and hybrid structures of these models with a GRU and LSTM were developed. Different model development parameters were used for each model. RF is a very effective model as an ensemble learning algorithm. However, to make an RF model better and increase its performance, regular training data and feature selection need to be conducted well. Limiting the cycle to 300 and the clean training data we used enabled us to increase the success of RF. Additionally, the ‘n_estimators’ value was set to 100. Thus, the Random Forest model was prepared to include 100 decision trees. In this study, we set the ‘n_estimators’ parameter to 100 to provide a balance between model complexity and the ability to generalize beyond the training data. A lower value of this parameter tends toward a more simplistic model that is less likely to overfit, while a higher value contributes to an increase in the model’s complexity.
The second model developed within the scope of this study is XGBoost. XGBoost is a powerful implementation of gradient boosting algorithms and delivers high-performance models when used successfully. XGBoost has many hyperparameters: number of trees, learning rate, depth, number of sub-features, etc. Carefully tuning the hyperparameters is important for optimizing our model. The hyperparameters of the XGBoost model that we used are listed in
Table 2.
The selection of hyperparameters for the XGBoost model as presented in
Table 2 reflects a balanced approach aiming to ensure a robust model performance without overfitting. Among the parameters presented in
Table 2, ‘n_estimators’ indicates the number of trees. The number of trees is set similarly to that of the RF model. Moreover, learning_rate is used with and often interacts with other hyperparameters. Therefore, a higher learning_rate requires a larger number of trees (n_estimators). On the other hand, a larger max_depth value should be balanced with a lower learning_rate. The random_state parameter is a hyperparameter used for XGBoost and many other machine learning algorithms. A max_depth of three helps in preventing the model from becoming overly complex and capturing noise, thereby fostering a model that generalizes well to unseen data. Lastly, a random_state of 42 ensures the reproducibility of results, facilitating consistent model evaluations and comparisons.
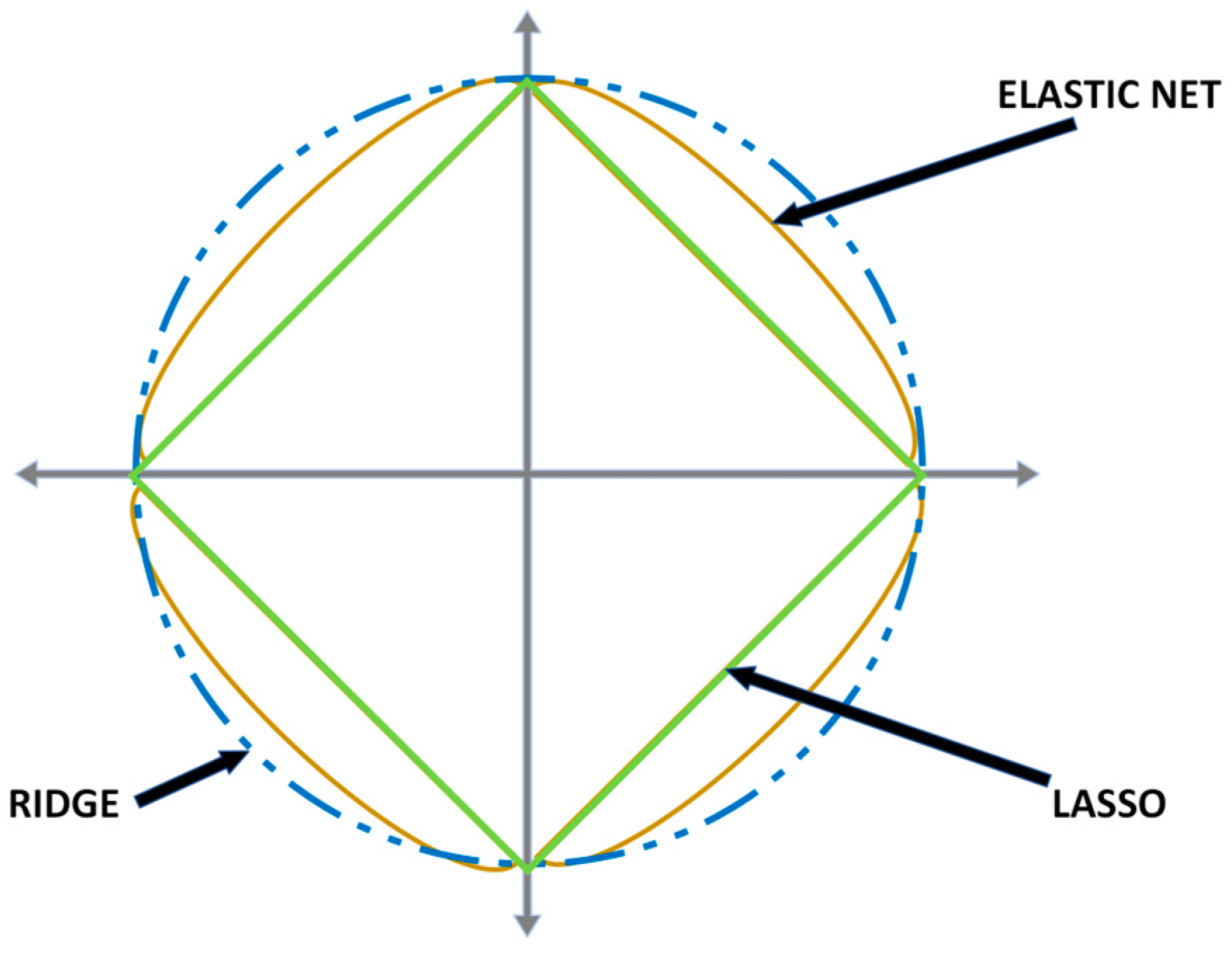
Another model developed within the scope of this study was Elastic Net. It is a regression method that can be used to estimate the discharge capacity of LIBs. Elastic Net combines L1 (Lasso) and L2 (Ridge) regularization terms and, thus, can both perform variable selection and control overfitting. Within the scope of this study, “alpha = 1” was chosen. In this case, Elastic Net uses only L1 regularization. This situation is equivalent to Lasso regression. Additionally, ‘l1_ratio = 1’ was set, and only L1 regularization (Lasso regression) was set to be effective. ‘random_state’ was set to 42, similar to XGBoost.
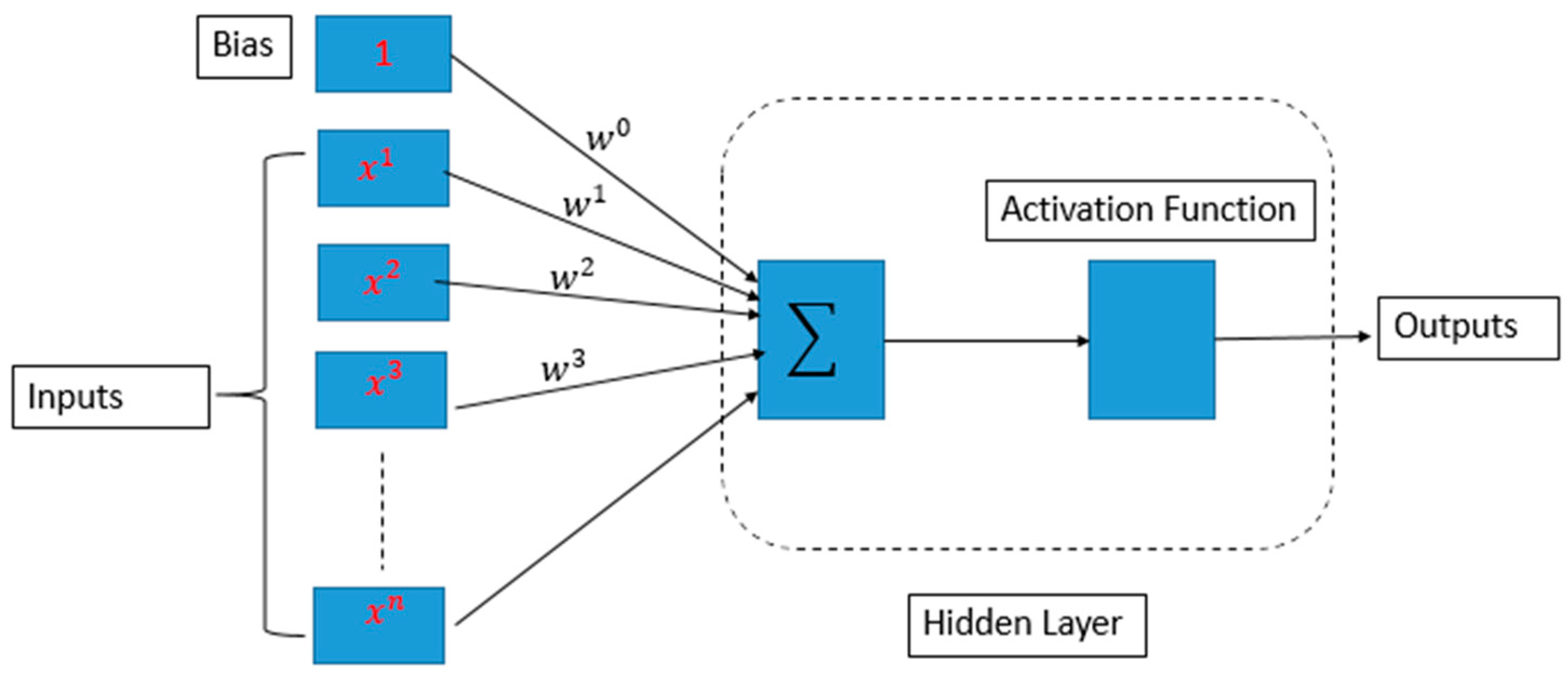
Another model developed within the scope of this study was an MLP, which is a type of deep learning and artificial neural network model. There may be complex and non-linear relationships between factors affecting the LIB capacity. An MLP has the capacity to capture such non-linear relationships and can model complexities.
Table 3 shows the hyperparameters used when developing the MLP model.
As stated in
Table 3, the first hidden layer had 100 neurons. This layer is used to process input data. The second hidden layer has 50 neurons. This layer receives and processes the outputs from the first hidden layer. The output of the second layer is often used to produce the outputs of the last layer. This means that an MLP has a structure with one or two hidden layers, and these hidden layers contain 100 and 50 neurons, respectively. Additionally, Relu, which is more computationally efficient than some other activation functions, was used. Relu has a non-zero derivative value on positive inputs. This reduces the problem of gradients disappearing during training. The MLP structure’s final layer would typically have a single neuron for regression tasks, outputting the continuous value prediction. The Relu activation function mentioned applies only to hidden layers; often, the output layer in a regression setup would have no activation function (i.e., it is a linear neuron).
In examining the developed models, it can be considered that the MLP is a subset of deep learning models in the process experienced from an RF to an MLP. An MLP is known as a neural network consisting of an input layer, one or more hidden layers, and output layers. Deep learning models, on the other hand, refer to neural networks containing more layers. These models can consist of much deeper networks (tens or hundreds of layers). MLPs are simpler models that handle smaller datasets and require less computing power. However, deep learning models are more complex and larger models that require larger datasets and higher computing power. Therefore, their success is higher. The first deep learning model developed within the scope of this study is CNN-based. The hyperparameters used in the developed CNN model are presented in
Table 4.
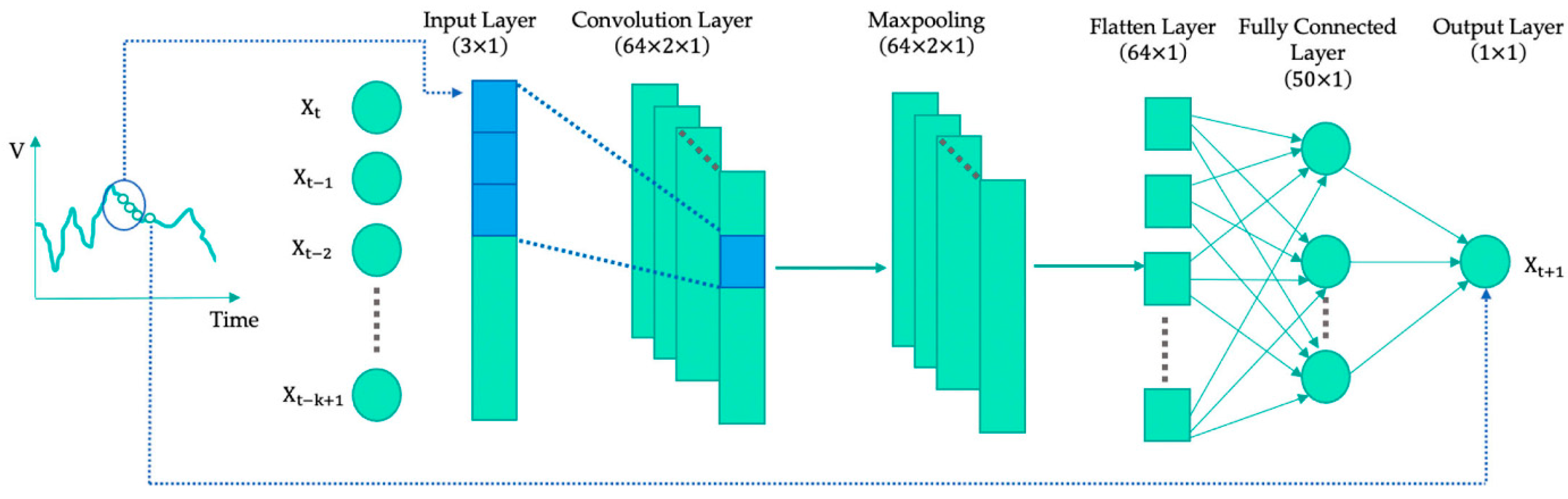
The convolution layer filters parameter determines the depth of the amount of information that the model can learn. Generally, a larger value of the state size allows more complex features to be learned. However, it also increases the risk of overfitting. Therefore, it must be determined according to the amount of data. The hyperparameters specified for the CNN model in
Table 4 were judiciously chosen to strike a balance between model complexity and computational efficiency while ensuring effective learning. Utilizing 64 filters in the convolution layer with a kernel size of three and ‘same’ padding enables the extraction of meaningful features without losing spatial dimensions. In order to increase the calculation efficiency and generalization ability of the model, the batch size value was determined to be 16. ‘Relu’ was used as the activation function in the model. The MSE was chosen as the loss function of the model. The MSE is a metric commonly used in regression tasks that takes the average square of the difference between predicted values and actual values. After the parameters were determined, the model was trained for 100 epochs. In this way, it was aimed for the model to achieve sufficient learning from the training dataset and at the same time avoid the risk of overfitting. Each of these parameters was carefully selected to optimize both the performance and generalization of the model. After the completion of the CNN training, a different deep learning model, the RNN model, was developed within the scope of this study. Similar hyperparameters to those listed in
Table 3 were used in the development of the RNN, which was designed to process sequential data and temporal dependencies. Thus, preparations were made for comparing experimental results and interpreting them on similar infrastructures.
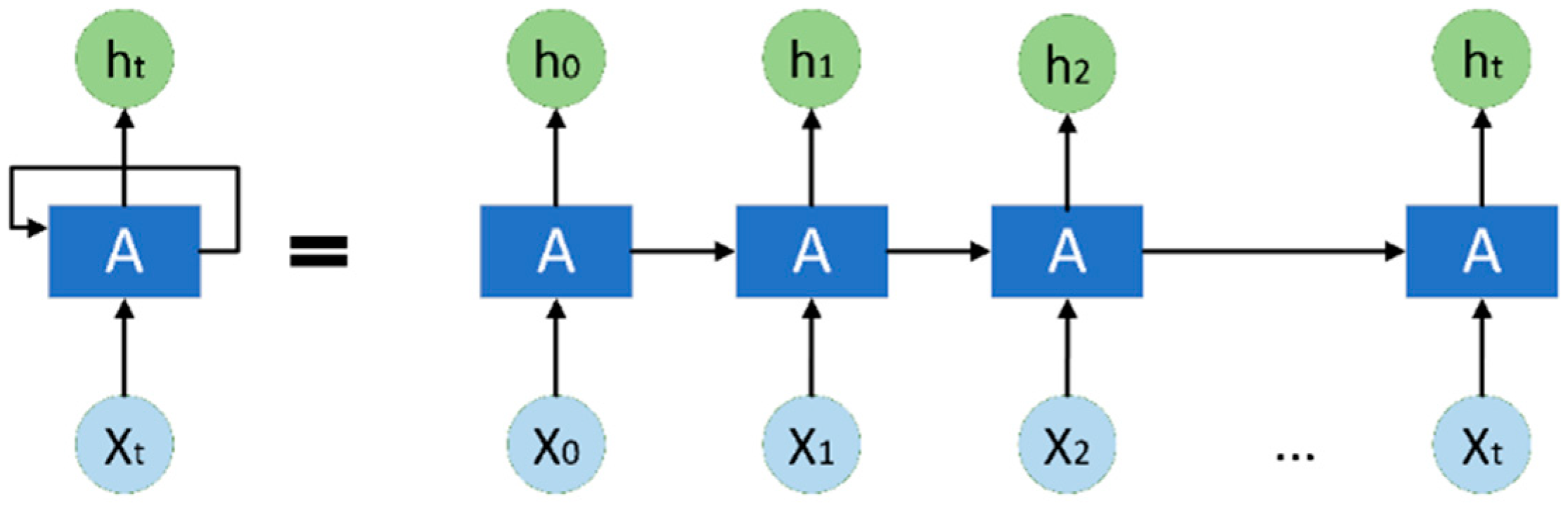
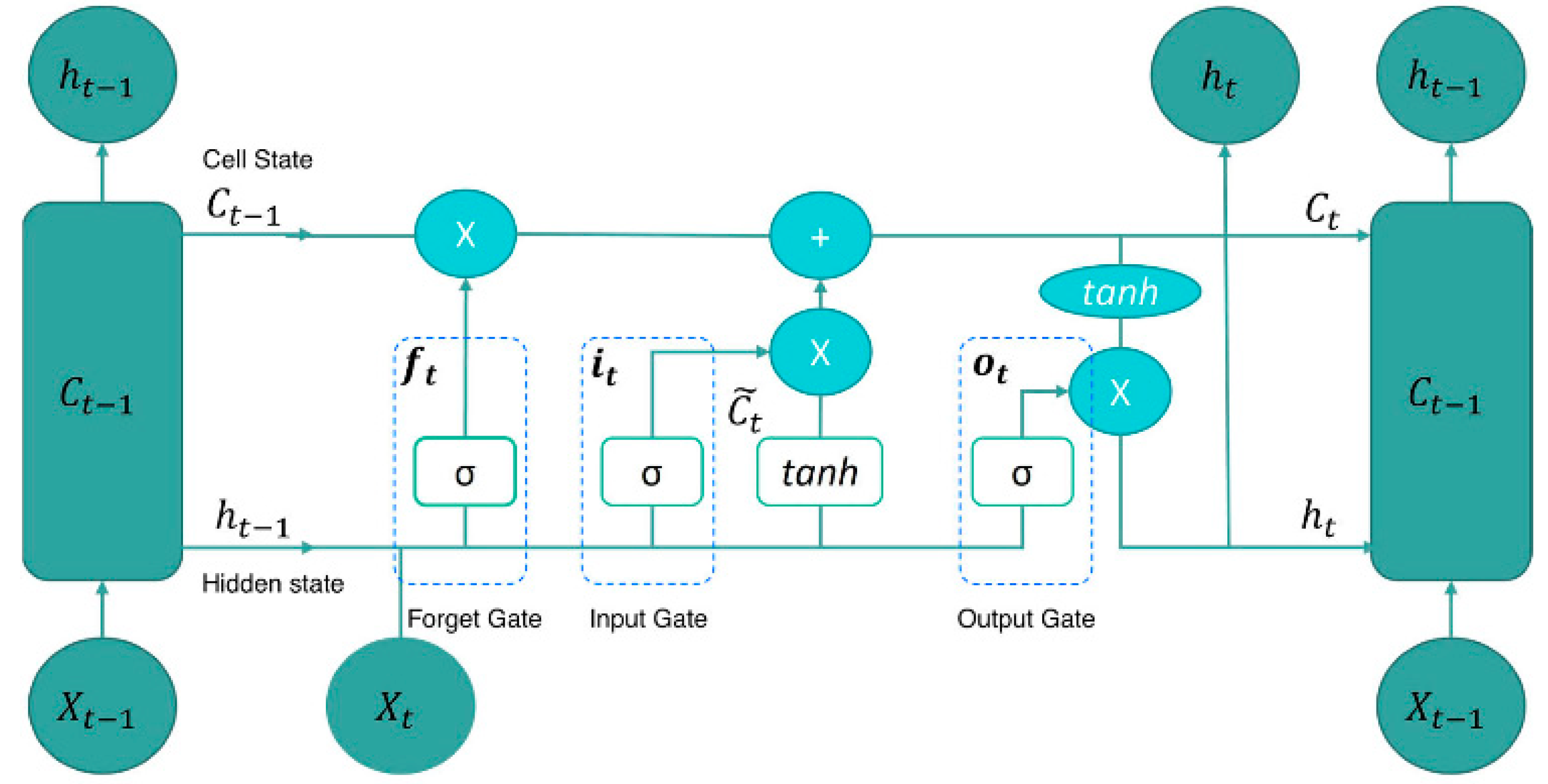
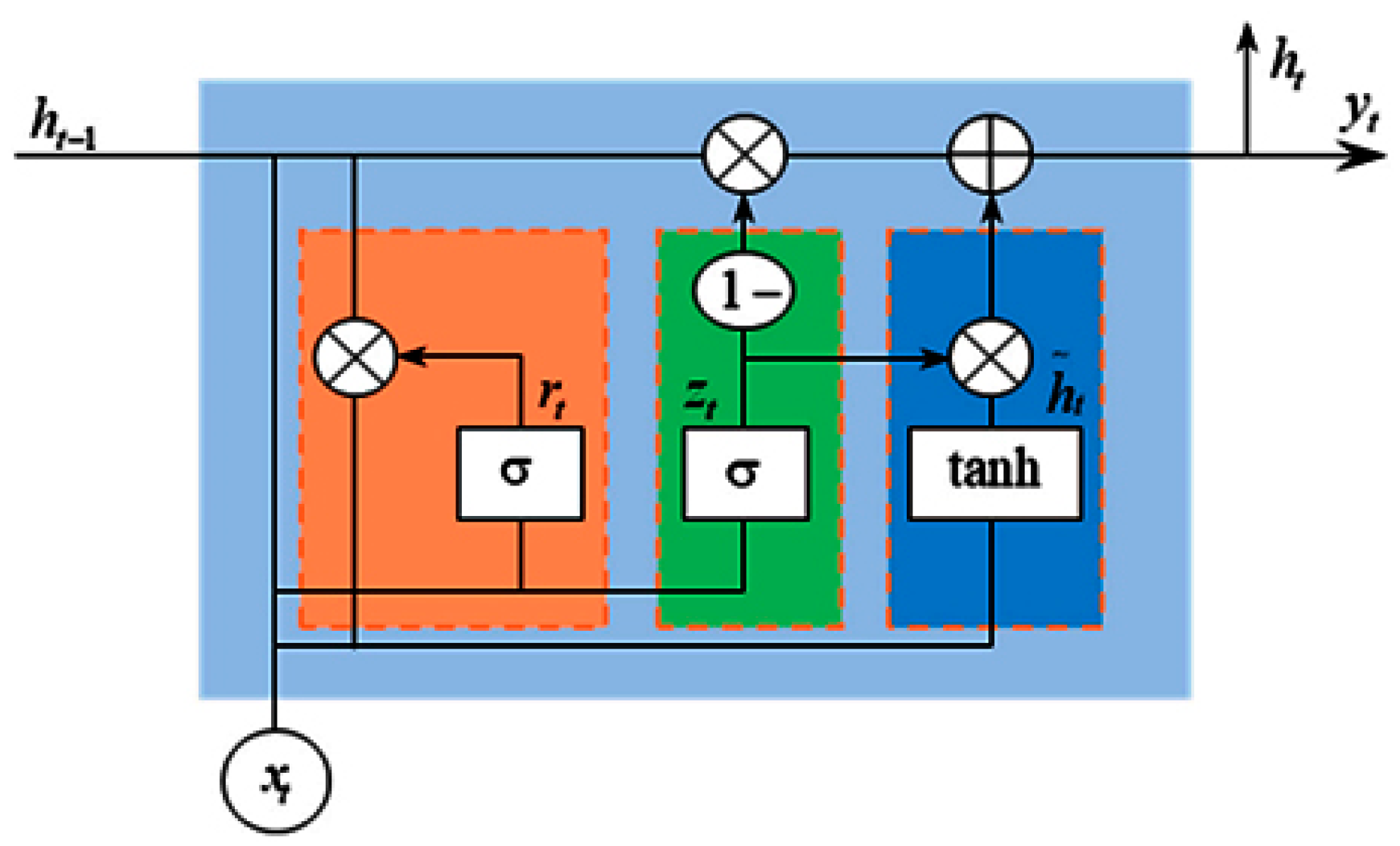
The time dependencies for the RNN developed in this study are related to its ability to process sequential data and temporal dependencies. Unlike feed-forward neural networks, RNNs have a memory that captures information about what has been calculated so far, integrating past information to the current task. This memory is crucial for tasks involving sequences, where the context and the order of elements are important for understanding or prediction. In the context of estimating the discharge capacity of LIBs, the RNN model would leverage its capacity to process sequential data to model how the battery’s discharge capacity changes over time. This involves analyzing time series data of battery usage, including charge/discharge cycles at various C-rates and temperatures, to predict the future capacity or identify patterns indicating battery health.
5. Discussion
In this study, we examined the challenges that predictive models, which play a critical role in monitoring the discharge capacity of LIBs, face as they grapple with the evolving technology landscape and increasing complexity. To address the symmetry in battery degradation and charging patterns, we also explored the advantages that deep learning-based models can offer in overcoming these challenges, particularly focusing on how these models can exploit symmetry to enhance predictive accuracy. We also explored the advantages that deep learning-based models can offer in overcoming these challenges and highlighted the importance of these benefits. The advantages of the technology, which emerge through the use of advanced prediction models, make LIBs more efficient and adaptable in terms of battery management and scalability.
Unlike traditional machine learning methods, tree-based and deep learning-based, complex and comprehensive models offer more dynamic structures that can increase the operational efficiency. However, the integration of deep learning-based Li-ion discharge capacity prediction models with contemporary technologies such as decision support systems and big data analytics will increase efficiency and manageability, especially by incorporating symmetry considerations to better mirror the inherent characteristics of battery behavior.
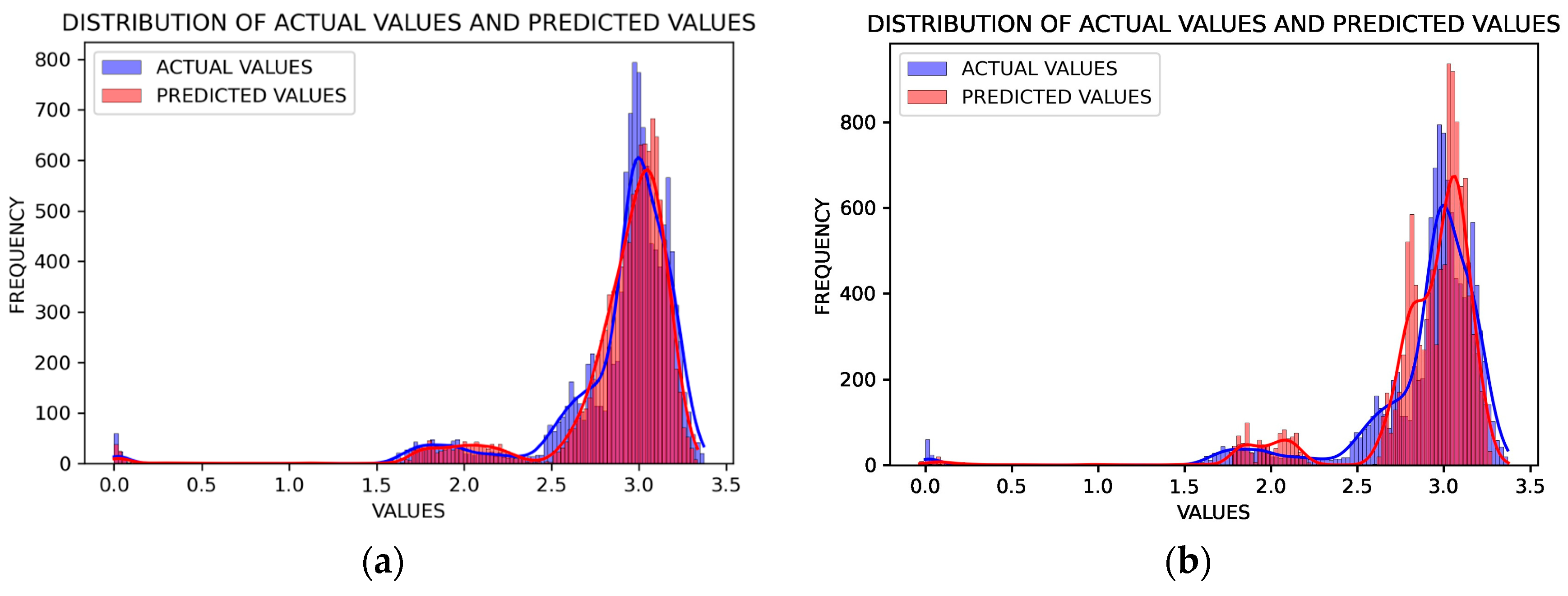
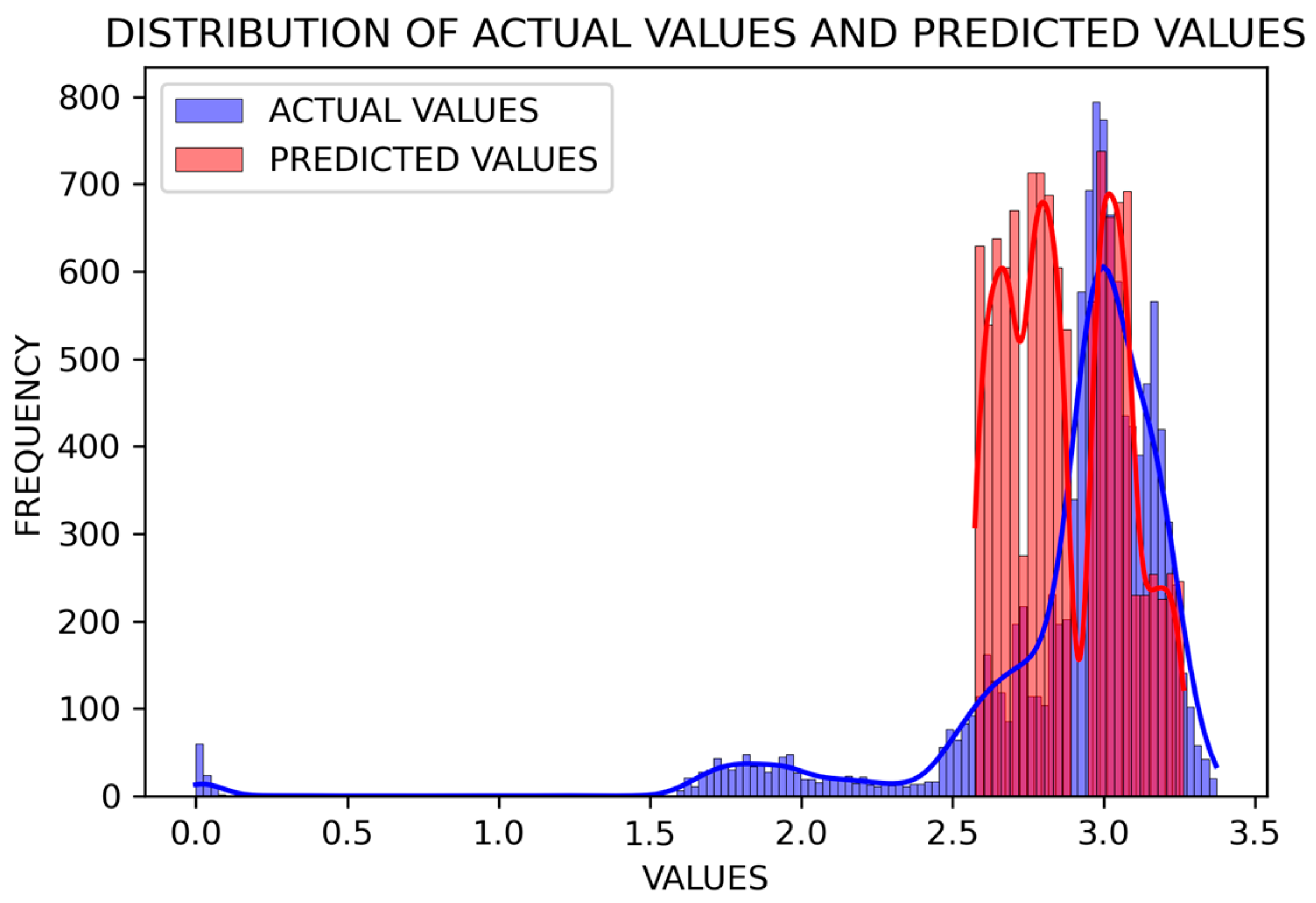
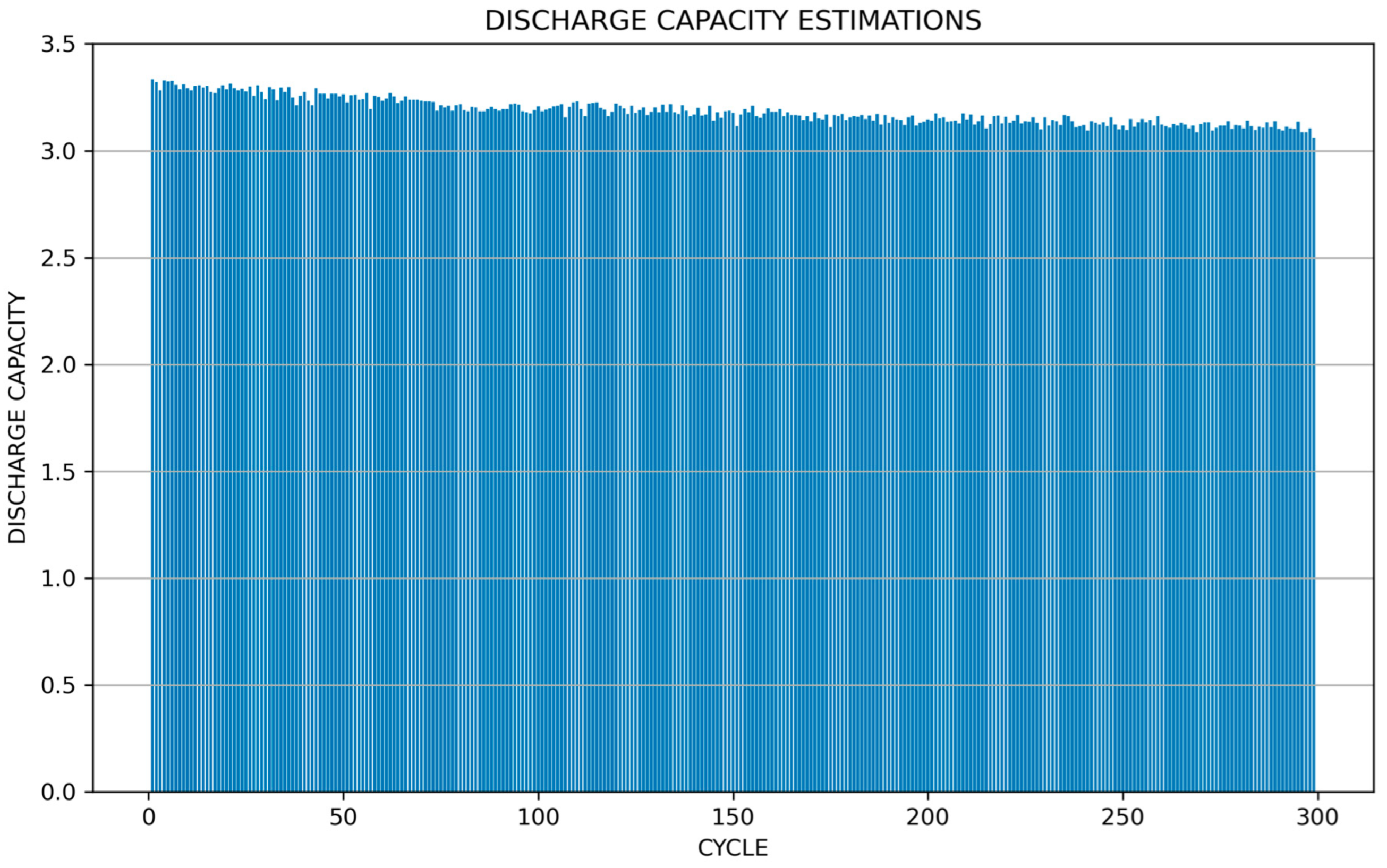
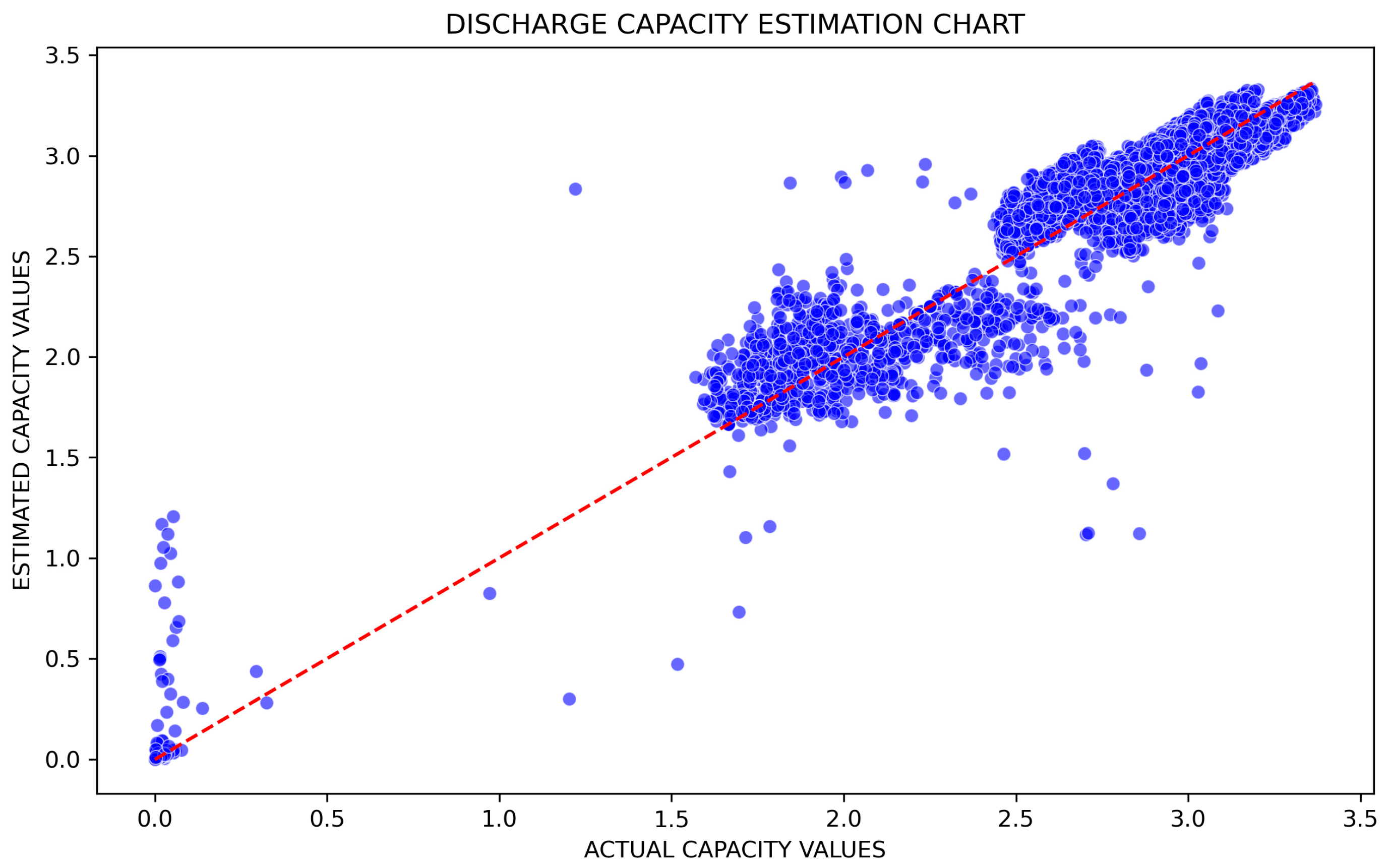
The most important disadvantage of machine learning models is that there is no standard way to determine model parameters. Model parameters were chosen based on default values that are widely accepted. These parameters may vary depending on the dataset and problem used, and similar parameters used as much as possible in order to better evaluate the common results of different models. When the results were examined, it could be seen that RF is the most successful method among the different models created for estimating the discharge capacity of batteries. The fact that the RMSE and MAE values were close to zero and the R-Squared value was close to 1 showed that our proposed model is more successful. In addition, when the POCID and other evaluation criteria were examined, it was seen that the RF model was more successful than other machine learning models and minimized the prediction error. Based on the experiments conducted with the RF machine learning model, an estimation graph is shown in
Figure 10, and a discharge capacity estimation graph is shown in
Figure 11.
In examining
Figure 10, it is seen that the SoH estimation decreases regularly in line with the cycle increase.
Figure 11 is presented to better visualize this situation. If the results are considered as part of a regression problem, it can be said that the results obtained provide important information about discharge capacities. The experiments carried out in this study were compared with complex processes from many studies. So, in order to demonstrate understandability within the scope of this study, the experiments were carried out on many models, from basic machine learning approaches to hybrid deep learning approaches. The strategic use of various evaluation metrics notably improved the explainability of our findings, making the sophisticated processes more accessible and comprehensible. This comprehensive evaluation approach ensures that complex modeling processes are broken down into more understandable parts, facilitating clearer insights into how the model performs under different conditions.
We proposed a decision support system designed for the prediction of discharge capacities through the application of an RF-based model approach. This approach achieved the best results on the dataset used in this study. The integration of factors such as feature selection, the development of different models, and hyperparameter settings contributed to improving the efficiency of LIBs. The findings of this study will make a valuable contribution to the development of efficient and high-performance battery technologies in the energy sector by further advancing the integration of LIB technology into future decision support systems and electronic devices that use batteries. There are many articles published in the literature on solving the problem of estimating discharge capacities. In these studies, test data containing different temperatures and charge and discharge currents are generally used to estimate the discharge capacities of LIBs from traditional machine learning and hybrid models. Considering these data, machine learning-based prediction methods such as SVM, KNN, RF, and MLP are frequently used for prediction algorithms and models.
Table 9 shows a comparison of the proposed model with those of previous studies. However, the data, methods, and success rates obtained vary from study to study.
The comparative performance analyses as shown in
Table 7,
Table 8 and
Table 9 show that the MLP, RNN, and CNN models have different degrees of effectiveness in comparison to the benchmark literature values as measured using the R-squared, RMSE and MAE metrics. In particular, the hybrid deep learning models RNN + LSTM, RNN + GRU, CNN + LSTM, and CNN + GRU outperform their counterparts and the cited literature models. The improved performances of these hybrid models are attributed to their superior handling of the complexities inherent in the dataset used in this study, showcasing their robustness in modeling and prediction tasks.
6. Conclusions and Future Trends
This study presented an end-to-end model research on predicting the discharge capacity of LIBs and achieved significant results. Our research started with collecting original data and applying data pre-processing steps, followed by conducting a series of experiments to evaluate the performances of various machine learning algorithms and deep learning models.
The results obtained show that this study, when using original data, could develop powerful models that can successfully predict the discharge capacity of LIBs. Traditional machine learning algorithms such as RF, XGBoost, and MLP yielded valuable results in terms of prediction performance. In addition, hybrid models developed with deep learning-based CNN and RNN architectures demonstrated high performances on time series data, and their performance effects became more explainable when analyzed within the scope of the concept of symmetry. Hybrid models developed with deep learning-based CNN and RNN architectures demonstrated high performance on time series data. The performances of hybrid models such as CNN-LSTM, CNN-GRU, RNN-LSTM, and RNN-GRU highlighted the power of deep learning approaches in time series forecasting. On the other hand, the first values obtained showed that RF-based models achieved more successful results.
This study offers important insights for guiding future researchers in estimating the discharge capacity of LIBs, which are an important component of energy storage technologies. This study shows that deep learning models have great potential in LIB capacity prediction. Future works might focus on further improving and extending deep learning methods. LIBs are used under many different models and operating conditions. Future research might contribute to better establishing generalizations by considering different battery models and environmental conditions, with a particular focus on symmetrical behaviors. Collecting more data and improving data pre-processing methods can improve model performances. Future works might also focus more on choosing optimal models and algorithms for specific applications. Techniques such as automatic model selection and hyperparameter tuning may help researchers.
This research laid the foundation for future innovations and developments in the field of LIBs and energy storage systems and contributes to researchers making further progress in this field. Future studies may build on this foundation to achieve further achievements and contributions in this field.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}