Abstract
This study addresses the challenges of high-dimensional data, such as the curse of dimensionality and feature redundancy, which can be viewed as an inherent asymmetry in the data space. To restore a balanced symmetry and build a more complete feature representation, we propose an enhanced feature engineering model (EFEM) that employs a novel dual-strategy approach. First, we present a symmetrical feature selection algorithm that combines an improved Dolphin Swarm Algorithm (DSA) with the Maximum Relevance–Minimum Redundancy (mRMR) criterion. This method not only selects an optimal, high-relevance feature subset, but also identifies the remaining features as a complementary, redundant subset. Second, an ensemble learning-based feature reconstruction algorithm is introduced to mine potential information from these redundant features. This process transforms fragmented, redundant information into a new, synthetic feature, thereby establishing a form of information symmetry with the selected optimal subset. Finally, the EFEM constructs a high-performance feature space by symmetrically integrating the optimal feature subset with the synthetic feature. The model’s superior performance is extensively validated on nine standard UCI regression datasets, with comparative analysis showing that it significantly outperforms similar algorithms and achieves an average goodness-of-fit of 0.9263. The statistical significance of this improvement is confirmed by the Wilcoxon signed-rank test. Comprehensive analyses of parameter sensitivity, robustness, convergence, and runtime, as well as ablation experiments, further validate the efficiency and stability of the proposed algorithm. The successful application of the EFEM in a real-world product demand forecasting task fully demonstrates its practical value in complex scenarios.
1. Introduction
1.1. Research Background and Challenges
Feature engineering is the process of transforming raw data into features that better represent the underlying problem. As an essential component of the data mining process, it bridges data cleaning and modeling, and is closely related to the performance of model algorithms. High-quality feature engineering can effectively improve data quality and reveal features that benefit algorithm models.
It is a key technology for improving the performance of machine learning models and has demonstrated enormous application value in fields such as healthcare, fintech, industrial IoT, intelligent recommendation, and autonomous driving. In the medical field, An et al. [] reduced misdiagnosis rates by the automated extraction of critical interaction features to improve the diagnostic accuracy of acute appendicitis. Zhao et al. [] proposed a model to simultaneously capture spatial and temporal features to improve portfolio management and trading decision-making performance. In industrial scenarios, Siemens [] utilized vibration characteristics to achieve a 95% accuracy rate for fault warning. Research has shown that excellent feature engineering can improve model performance by 3–5 times compared to algorithm improvement, while reducing computational costs by 70% [,]. Behind these practical achievements, it is inseparable from the continuous breakthroughs and innovations in feature engineering methodology.
In recent years, feature engineering has made significant progress in many areas. In automated feature engineering, Abhyankar et al. [] proposed a new automatic feature engineering framework that combines large language models with evolutionary search. Wang et al. [] proposed an automatic feature engineering architecture based on reinforcement learning. In interpretability research, Verdonck et al. [] emphasized the importance of feature engineering in improving the performance of machine learning models, and believed that carefully designed features can still greatly improve the performance of such models, while Duan et al. [] used a graph structure and causal inference modules to automatically identify key causal nodes from transaction history, significantly reducing false positives. In cross-modality, progress includes Radford et al.’s [] contrastive learning model, which outperformed the combination of a deep residual network and bidirectional Transformer encoder by 17% in cross-modal retrieval. Yu et al. [] employed a time series autoencoder to significantly enhance industrial fault detection performance, achieving high F1-scores. Studies such as Da et al. [] and Rieke et al. [] demonstrated that federated learning frameworks can achieve feature processing and model performance (up to 98% of centralized training) with close approximation and stability. OpenAI [] demonstrated GPT-4′s ability to generate business-usable features (with an adoption rate of 73%). This also extends to cutting-edge fields like federated learning, digital twins, and distributed systems, which are crucial for industrial IoT and smart grid applications [,,,,].
Beyond automated and interpretable feature engineering, intelligent bio-inspired algorithms have emerged as a powerful tool to further enhance feature selection and optimization. Intelligent bionic algorithms also have many applications in feature engineering. Gulati et al. [] developed a hierarchical feature engineering method combining nonlinear transformations and genetic algorithms with bootstrapped selection, boosting interpretable model performance while reducing dimensionality. Song et al. [] proposed a surrogate sample-assisted particle swarm optimization hybrid feature selection algorithm, which effectively addressed high-dimensional feature selection problems while reducing computational costs through a collaborative sample partitioning and feature clustering mechanism. Ma et al. [] proposed a two-stage hybrid ant colony optimization algorithm for high-dimensional feature selection, significantly improving search efficiency and feature selection performance on high-dimensional data. Saheed et al. [] proposed a binary firefly algorithm-based feature selection method that achieved a 99.72% detection accuracy on high-dimensional datasets through a three-stage processing framework. Pethe et al. [] proposed a bat optimization algorithm-based feature selection method that achieved a peak accuracy of 98.92% while effectively reducing feature dimensionality.
With the assistance of intelligent bionic algorithms, the quality of feature engineering is improved, and high-quality feature engineering is crucial to the success of regression analysis. Arroba et al. [] constructed a highly information-based feature expression, reducing prediction error to an average of 3.98%. Research on regression analysis methods has demonstrated diversified development trends. Regarding traditional method optimization, Prokhorenkova et al. [] developed the CatBoost-R algorithm, which substantially reduced overfitting risk in time series regression tasks through ordered target encoding. In ensemble learning, Lim et al. [] designed the Temporal Fusion Transformer, which reduced MAE by 23% in multivariate time series regression problems.
Beyond traditional industrial applications, recent advancements in structural health monitoring (SHM) and vibration-based damage detection have also demonstrated that data-driven and optimization-based approaches play a crucial role in identifying hidden structural defects and predicting failures. In particular, machine learning and bio-inspired algorithms have been widely applied in tasks such as beam crack detection, joint-induced vibration analysis, and defect prediction, showing strong potential for enhancing reliability in mechanical and civil engineering systems [,,,,,]. These studies highlight the broader applicability of advanced feature selection and optimization techniques beyond traditional industrial fault detection. Inspired by this line of research, the proposed semi-supervised feature selection framework in this study may also provide valuable insights for vibration-based SHM applications, further underscoring the generality and adaptability of the method.
The above research status indicates that feature engineering has become a core driving force for improving the performance of machine learning models, especially in regression analysis and prediction tasks, where it demonstrates significant value. These advances provide important insights for this study. First, there is an urgent need to develop a hybrid feature selection framework that integrates swarm intelligence and statistical criteria to balance automation efficiency and business interpretability. Second, feature optimization for regression tasks needs to consider both global correlation and local redundancy simultaneously. Finally, algorithm design should focus on reducing computational complexity to adapt to industrial-level application scenarios.
1.2. Gaps in Existing Research
Although feature engineering technology has made significant progress, there are still many problems and challenges in feature engineering, as follows:
- (1)
- Insufficient robustness of feature selection algorithms
Existing feature selection methods, such as those based on statistics, information theory, or embedded algorithms, are sensitive to data noise. When the data distribution changes or there are outliers, the stability of the selected feature subset is poor. Most studies only focus on the accuracy of feature selection and neglect the stability evaluation of algorithms in noisy environments [,,,].
- (2)
- Insufficient utilization of redundant features
Traditional feature selection methods, such as filters, wrappers, and embedded methods, typically reduce data dimensionality and improve model efficiency by eliminating redundant or low-information features based on their correlation or importance to the target variable. However, these methods have a key limitation: features marked as “redundant” are not completely useless, but may contain supplementary information or potential patterns indirectly related to the target variable. Directly discarding these features may lead to information loss, especially in high-dimensional or complex scenarios, where the synergistic effect of features may significantly affect model performance [,,].
1.3. Motivation and Contributions
To address these issues, this study proposes a new feature construction paradigm that synthesizes low-dimensional but informative features by integrating valuable information from redundant features. This method not only reduces the number of features and alleviates the curse of dimensionality, but also avoids the inherent information waste in traditional feature selection, thereby improving model efficiency while fully utilizing the potential of data. This method has significant prospects in handling high-dimensional data, resource-constrained scenarios, and tasks that require strong interpretability.
The main contributions of this study are as follows: A dolphin swarm feature selection algorithm based on the theory of maximum correlation and minimum redundancy is proposed, specifically designed for regression datasets. Through this algorithm, important feature subsets and potential redundant feature subsets are identified. Considering that redundant feature subsets may contain key information, ensemble learning methods are adopted, where multiple machine learning models process these redundant features and generate new feature subsets. Subsequently, the model with the best performance is selected for secondary training to construct a new composite feature that fully preserves all the basic information in the redundant features. By combining the features selected by the Dolphin Swarm Algorithm with the newly constructed features, the final feature subset is formed to complete the entire feature engineering process. The proposed method is ultimately validated through regression algorithms, and comparative experiments and statistical analysis demonstrate its superior performance compared to other similar methods.
1.4. Structure and Organization
The content of this study is organized as follows: Section 2 explains the basic theory of feature engineering and predictive regression; Section 3 proposes an improved Dolphin Swarm Algorithm and constructs the overall framework of feature engineering; and Section 4 comprehensively validates the effectiveness of the proposed EFEM algorithm. We conduct comparative evaluations against various advanced feature selection algorithms on nine UCI regression datasets. Through ablation studies, statistical tests, and convergence analysis, we quantify the contributions of each algorithm component and verify the reliability of its conclusions. We also conduct parameter sensitivity analysis and noise robustness tests. Finally, we apply the algorithm to a real-world product demand forecasting task. Section 5 summarizes the research results, explains the innovations, and looks forward to future research directions. The organizational structure of the full paper is shown in Figure 1.
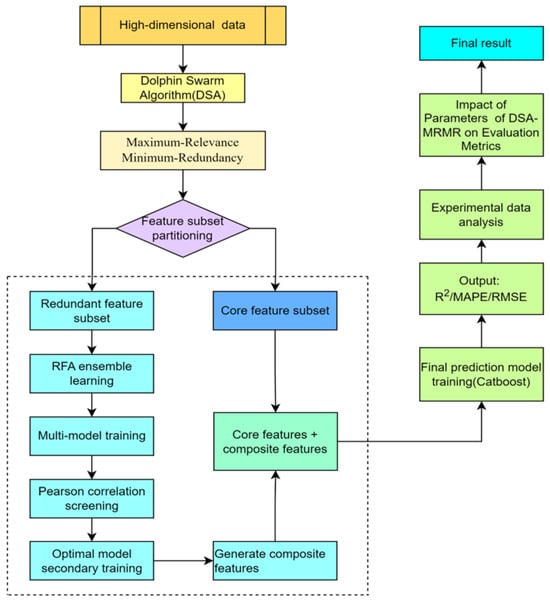
Figure 1.
Research framework diagram.
2. Background
2.1. Feature Engineering
Feature engineering is the core process of machine learning, which improves model prediction performance, reduces computational complexity, alleviates dimensional disaster, enhances generalization ability, prevents overfitting, and improves interpretability by optimizing feature expression, reducing noise and redundant features, and screening key features, thereby comprehensively improving model performance and efficiency [].
Feature engineering includes feature selection and feature construction, which are indispensable and important parts of the feature engineering process. Feature selection refers to the process of selecting the most relevant and valuable subset of features from an original feature set. Its core goal is to reduce data dimensionality, decrease computational overhead, improve model performance, and enhance the interpretability of results. By removing redundant and irrelevant features, feature selection can help machine learning models learn key patterns in data more efficiently and improve generalization ability.
Feature construction refers to the process of creating new, more predictive features by transforming, combining, or decomposing original features. Its core goal is to enhance the representation ability of features, mine hidden relationships in data, and improve the expression ability of models. Unlike feature selection, feature construction does not simply select existing features, but creates new features through mathematical transformations or domain knowledge, making it easier for machine learning algorithms to discover potential patterns in data. Feature construction can be either explicit (based on domain knowledge) or implicit (generated through algorithms) [].
2.2. Regression and Predictive
Regression is an important branch of supervised learning, whose core feature is that the target variable is a continuous numerical value rather than a discrete class label. This requires different methods to be used for modeling and optimizing regression problems []. Traditionally, regression analysis is based on statistical methods such as linear regression, which assumes a linear relationship between input features and output variables and fits the model by minimizing prediction error. When there is a nonlinear relationship in the data, polynomial regression or machine learning methods can be used to enhance the expressive power. In addition, regression problems often face challenges such as overfitting, noisy data, and feature collinearity, so regularization techniques such as ridge regression and Lasso regression are widely used to improve model robustness. The evaluation of regression models typically uses metrics such as mean squared error (), mean absolute error (), and the coefficient of determination () to measure prediction accuracy.
The core purpose of regression problems is to predict continuous numerical values, thereby providing a quantitative basis for decision making. In practical applications, regression models are widely used in scenarios such as housing price prediction, temperature trend analysis, stock price trends, and sales forecasting.
Modern machine learning provides various modeling tools for regression problems. Traditional methods include linear regression, polynomial regression, and regularized regression (such as ridge regression and Lasso regression), which are suitable for linear or mildly nonlinear data. For more complex nonlinear relationships, support vector regression (SVR) maps data to high-dimensional space through kernel functions, while ensemble methods such as decision trees and random forests can automatically capture interactions between features [].
3. Research Methodology
Given the gap in feature engineering research mentioned in Section 1.3, this study proposes our solutions to address these issues.
3.1. Principle of Standard Dolphin Swarm Algorithm
The Dolphin Swarm Algorithm (DSA) simulates the cooperative hunting behavior of dolphin groups, leveraging acoustic communication and dynamic capture mechanisms, demonstrating unique advantages in optimization problems. Its swarm intelligence collaboration can efficiently share information and avoid premature convergence, dynamically adjusting strategies to balance exploration and development capabilities, making it suitable for handling high-dimensional and nonlinear problems. Compared to particle swarm optimization and genetic algorithms, it is more adaptable between global search and local refinement, making it especially suitable for complex scenarios such as path planning and parameter optimization. However, the computational cost may increase with an increase in population size. We need to use its advantage for feature selection.
In this article, is defined as the set of all samples and is defined as the set of all features, with being a subset of (i.e., ). The target variable is denoted by , The number of samples is represented by and the number of features is represented by . The basic principles of the Dolphin Swarm Algorithm are shown in Algorithm 1.
| Algorithm 1. Original Dolphin Swarm Algorithm |
| Input: Regression Dataset, Parameters, Population size, Maximum iterations, Objective function. Output: Optimal Feature Subset: Step 1: Each dolphin in the population is represented by a binary vector , where is the total number of features. indicates that the -th feature is selected, and indicates it is not selected. Step 2: Randomly generate initial individuals in the population. Step 3: Use the binary vector to extract the selected features subsets from . Step 4: Train a regression model (e.g., linear regression, random forest) using the selected features subsets and the target . Step 5: Use the objective function compute the fitness value. Step 6: Randomly update individuals based on a global best solution. Step 7: Simulate local search behavior by refining individual solutions, such as flipping specific feature selection states. Step 8: Update the global best features subsets based on fitness values. Step 9: Record the best feature subset found so far. Step 10: Terminate the algorithm when the maximum number of iterations is reached or when the fitness value stabilizes. |
Step 6 represents the weight for approaching the optimal solution, the weight for random perturbation, and the random perturbation term, which uses either Gaussian noise or uniform noise.
3.2. Maximum Relevance and Minimal Redundancy (mRMR) for Regression
Then, we introduce the maximum correlation and minimum redundancy. The Maximum Relevance–Minimum Redundancy (mRMR) model maximizes the correlation between features and the target variable while minimizing the redundancy between features, which can more effectively filter out feature subsets with strong discriminability. Therefore, this study proposes integrating the optimization criteria of mRMR into the Dolphin Swarm Algorithm, enhancing the global search capability using the biomimetic optimization mechanism of the DSA, and combining the information theory evaluation criteria of mRMR to enable the algorithm to maintain efficient search while accurately balancing the correlation and redundancy of features, thereby improving the robustness and interpretability of feature selection.
The Maximum Relevance–Minimum Redundancy (mRMR) framework is a feature selection methodology that balances the following two competing objectives: (1) Maximum Relevance, which prioritizes features with the strongest statistical association with the target variable, and (2) Minimum Redundancy, which minimizes information overlap among selected features to avoid redundancy. While mRMR is widely adopted in classification tasks using mutual information, its direct application to regression problems—where the target h is continuous—requires critical adaptations. This study addresses this gap by redesigning mRMR’s relevance metric for regression while retaining its core redundancy control mechanism.
In classification, mutual information measures nonlinear dependencies between discrete features and targets. However, regression tasks often involve linear relationships between continuous variables. To bridge this gap, we propose the following two key modifications:
- (1)
- Relevance Metric: Replace mutual information with the F-statistic, which quantifies the linear dependence between a feature and the continuous target .
- (2)
- Redundancy Metric: Retain Pearson correlation to evaluate pairwise feature redundancy [], ensuring computational efficiency and interpretability.
To operationalize the aforementioned adaptations for regression tasks, we formalize the mRMR framework through rigorously defined mathematical metrics. Specifically, the replacement of mutual information with the F-statistic and the retention of Pearson correlation are concretized as follows (the parameter descriptions in the formula are shown in Table 1):

Table 1.
Symbol definition.
- (1)
- Feature Relevance via F-Statistic:
The F-statistic, chosen for its sensitivity to linear dependencies in continuous variables, quantifies the ratio of between-group variance to within-group variance. For a feature and target , it is defined as follows:
Since the target variable in the research datasets is continuous, it requires discretization through binning for actual computation.
- (2)
- Feature Redundancy via Pearson Correlation:
Redundancy between features and is measured as follows:
The covariance captures the co-variation trend between two features, while the standard deviations and perform normalization to eliminate scale effects. The absolute value ensures non-negative results. An R-value below 0.3 indicates low redundancy between features, while values above 0.7 suggest high redundancy requiring special attention.
- (3)
- mRMR Optimization Criterion:
The optimal feature subset maximizes relevance while minimizing redundancy, as follows:
: Balances the trade-off between relevance and redundancy (default = 1).
Traditional mRMR frameworks for classification fail to handle continuous targets due to their reliance on mutual information []. By integrating the F-statistic, our adaptation extends applicability to regression problems by replacing mutual information with the F-statistic for relevance assessment, enhances robustness through statistical significance testing, automatically filtering non-predictive features, maintains efficiency by leveraging ANOVA-based approximations for high-dimensional data, and preserves interpretability by keeping the redundancy term based on Pearson correlation.
3.3. Fitness Function
As can be seen from the previous section, the key to the Dolphin Swarm Algorithm is to define the fitness function. To this end, we define a new fitness function by combining the mRMR formula with reduction rate.
In Formula (4), parameter is used to balance the trade-off between the maximum relevance and minimum redundancy of the feature subset, while parameter controls the computational efficiency of feature selection.
: Average relevance of selected features to the target .
: Average redundancy among selected features.
: Weight balancing relevance and redundancy.
: Ratio of selected features () to total original features ().
: Weight controlling the penalty for high dimensionality.
3.4. DSA–mRMR Algorithm for Feature Selection
In the previous chapters, the standard Dolphin Swarm Algorithm (DSA) achieved global search by simulating dolphin swarm intelligence. Based on the Maximum Relevance–Minimum Redundancy (mRMR) criterion, this section proposes a DSA–mRMR hybrid algorithm, which integrates the DSA’s search capability with mRMR’s feature evaluation criterion. The fitness function (Formula (4)) dynamically balances the correlation and redundancy of feature subsets.
Next, we propose a new mRMR-based Dolphin Swarm Algorithm for feature selection. The algorithm is shown in Algorithm 2.
| Algorithm 2. A novel feature selection algorithm (DSA–mRMR) |
| Input: An information system, initial values of various parameters. Output: A feature subset S 1. Initialize a population of dolphins , where each dolphin represents a binary vector , = 1 if the feature is selected else 0. 2. Compute Fitness for each dolphin using the Formula (4). 3. Calculate Adaptive Mutation Probability for the current iteration: |
| 4. Individual Exploration(Mutation): For each dolphin, mutate each bit in its vector with the current adaptive probability : |
| 5. Move toward the current best solution: For each dolphin and for each bit , update as: |
|
6. Update best solution: 7. Stop if maximum iterations reached or fitness improvement < ( = 10−5) and output the best subsets. |
The initial mutation rate () is set high to encourage extensive exploration in the early search phase, allowing dolphins to radically alter their feature subsets.
The minimum rate () is set low to ensure that the algorithm stabilizes and finely exploits the most promising regions of the search space in later iterations.
The decay rate ( = 5) is chosen to create a smooth, exponential decay curve that effectively transitions the search focus from exploration to exploitation. The values are empirically tuned on a validation set to achieve a balance between rapid initial progress and precise final convergence.
The computational complexity of the algorithm is primarily determined by the following three components: the initial population size, fitness discriminant function, and number of iterations.
Step 1 involves generating the initial dolphin population. The time complexity is .
Step 2 involves evaluating the fitness of each dolphin using Formula 4. If linear regression is used for evaluation, the time complexity is approximately .
Step 3 involves calculating the adaptive mutation probability for the current iteration, with a time complexity of .
In Step 4, the mutation probability is dynamic and controlled by the equation in Step 3, replacing the fixed. The time complexity of .
In Step 5, the individual with the highest fitness is selected, and the time complexity is .
Since the first step operates outside the loop, the algorithm iterates from Step 2 to the final step T times. Thus, the total time complexity is .
In this total time complexity, since is a constant, it can be ignored. The space complexity of the entire algorithm is .
3.5. Ensemble Learning for Redundant Features
After feature selection using the Dolphin Swarm Algorithm, the system retains certain redundant features with potential informational value. To fully exploit their latent information, we design a feature-fusion-based algorithm to reconstruct selected redundant features into synthetic features. This approach maintains effective features while significantly improving feature space utilization. The algorithm is shown in Algorithm 3.
| Algorithm 3. Redundant feature aggregation (RFA) |
| Input: A redundant feature subset . Output: A composite feature constructed from , or if no valid feature is generated. 1. Select n machine learning models (e.g., Liner Regression, Random Forest) suitable for regression tasks to perform modeling and training. 2. Input sub information systems based on redundant features from DSA–mRMR. For each redundant feature subset , train the n models independently to generate n reconstructed features subsets . 3. Calculate Pearson’s correlation coefficient between each and the target variable . If < threshold, return , Exit the loop. Else, proceed to Step 4. 4. Select the model with the highest (or lowest RMSE) as the optimal model M*. 5. Retrain on the entire to produce the final composite feature . 6. Return if valid, otherwise . |
The overall time complexity of the algorithm is principally determined by the computational complexity of the constituent machine learning algorithms, with the remaining steps contributing negligibly to the total complexity.
Figure 2 illustrates the workflow of Algorithm 3, which primarily focuses on leveraging redundant features for model construction.
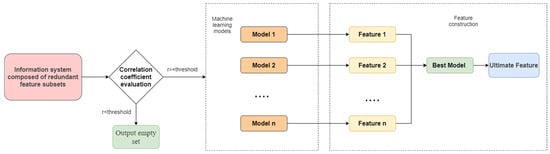
Figure 2.
Feature construction flowchart.
In this study, model performance is assessed by employing goodness of fit () along with error metrics such as root mean square error () and mean absolute percent error (). These metrics evaluate both the model’s ability to fit the observed data and its predictive accuracy. The goodness of fit () is calculated as follows:
is often used to evaluate the degree of fit of sample data in the model.
Root mean square error reflects the deviation between predicted values and true values. It strengthens the influence of large errors in the indicator, thereby making the sensitivity of the indicator higher. The formula is as follows:
The mean absolute percent error () is a commonly used metric in forecasting and prediction analysis. The is calculated using the following formula:
3.6. The Overall Algorithm of Feature Engineering
Then, we integrate the first two algorithms to design a new feature engineering algorithm. The algorithm is shown in Algorithm 4.
| Algorithm 4. Enhanced feature engineering model (EFEM) |
| Input: An information system Output: , and 1. Using the DSA–mRMR algorithm, the feature subset and its redundant feature subset are obtained. 2. Evaluate whether the correlation coefficient of the redundant feature subset is greater than the threshold. If the correlation coefficient , proceed next step; otherwise, jump to step 5. 3. Input the redundant feature subset as an information system to algorithm RFA, generating a new feature . 4. Merge the feature subset selected by the DSA–mRMR with the feature constructed in Step 3 to form a new feature subset . 5. Select the best machine learning model from algorithm RFA to train the extracted feature subset . 6. Output the results of evaluation indicators, including , RMSE and MAPE. |
The enhanced feature engineering model (EFEM) is a machine learning pipeline that combines feature selection and feature construction to improve predictive model performance. The algorithm first employs the DSA–mRMR method to filter out a highly relevant, low-redundancy feature subset and a redundant subset . It then checks the correlation coefficient of the redundant features—if it exceeds a threshold, the RFA algorithm constructs new features from the redundant subset and merges them with the originally selected features. Finally, the optimal machine learning model is selected for training, and evaluation metrics () are output. The EFEM’s uniqueness lies in dynamically leveraging redundant information to generate new features, reducing dimensionality while enhancing model expressiveness, making it suitable for high-dimensional regression tasks.
The EFEM model employs a symmetrical dual strategy. A symmetrical decomposition of the feature space is first performed. The DSA–mRMR method is used to precisely select an optimal, highly relevant feature subset, while the remaining features are concurrently identified as a redundant subset. Instead of simply discarding this redundant information, a second symmetrical process is employed: a new synthetic feature is created by the RFA algorithm, which aggregates the seemingly useless features. This new feature serves as a symmetrical complement to the initially selected optimal subset.
The computational complexity of the EFEM is determined by the integration of its feature selection, redundancy handling, and model training phases. Therefore, the overall complexity is dominated by the DSA–mRMR and RFA steps.
4. Experimental Analysis
This section systematically evaluates the regression performance of the enhanced feature engineering model (EFEM) on nine standard UCI datasets [] to comprehensively validate the model’s effectiveness. In the RFA algorithm, the correlation threshold is set to 0.7. The algorithm employs the following four base models: Bayesian linear regression, random forest regression, CatBoost, and support vector machine. To avoid information leakage, the RFA composite features are constructed within each cross-validation fold using only the training subset. The validation/test folds are strictly excluded from this process, ensuring that the performance estimates remain unbiased. Through comparative analysis, CatBoost is identified as the top-performing algorithm and is consequently selected as the final training model in the framework. The selected features are retrained using CatBoost, with its performance evaluated through 10-fold cross-validation. This process ultimately identifies the optimal feature set for model construction. These parameters undergo extensive validation and tuning to ensure model interpretability while maintaining a stable performance across diverse datasets.
Through multidimensional metrics, the study compares and analyzes the EFEM’s prediction accuracy and feature selection capabilities, and the evaluation metrics include the root mean square error (), mean absolute percentage error (), and goodness-of-fit ().
All experiments in this study were conducted on a high-performance computing cluster equipped with an Intel Xeon (R) Platinum 8352 V 32-core processor and 60 GB of RAM. The implementation utilized Python 3.8 within the Anaconda 2021.05 distribution environment, with core dependencies on machine learning libraries, including scikit-learn 1.0.2 and CatBoost 1.0.6, for algorithm development. To ensure reproducibility, results were aggregated over 10 independent trials, with final metrics derived from the arithmetic mean.
4.1. Algorithm Comparison
In order to better evaluate the effectiveness of the EFEM, five similar feature engineering algorithms are selected for comparison. These five algorithms are as follows:
Guo et al. (2020) proposed an Improved Whale Optimization Algorithm for Feature Selection (IWOA-FS) that enhances feature selection performance through dynamic-inertia weights and elite opposition-based learning strategies [].
Ren et al. (2023) developed a Hybrid High-Dimensional Multi-Target Sparrow Search Algorithm (HDMT-SSA) framework that integrates tent chaotic mapping and Lévy flight strategies to optimize feature selection in high-dimensional data [].
Aghelpour et al. (2021) integrated the Hybrid Dragonfly Algorithm (HDA-ADP) into an artificial neural network (ANN) framework, developing a novel hybrid model for agricultural drought forecasting [].
Rostami et al. (2020) proposed a Multi-Objective Particle Swarm Optimization algorithm with Node Centrality (MOPSO-NC) to select biologically significant genetic features using node centrality analysis [].
Wang et al. (2022) developed the SWDE-FS algorithm, a self-adaptive weighted differential evolution approach that reduces computational complexity to for large-scale feature selection through an efficient grouped mutation strategy [].
Next, we further examine the experimental parameters. First, to discretize the target variable, we employ K-means clustering for binning, converting continuous targets into categorical bins, which enables effective F-statistic calculation.
This study employs the DSA–mRMR for feature selection, with the following parameter settings: dolphin population size , mutation probability , maximum iterations , and convergence threshold . The fitness function evaluates feature subsets using the performance metric of a random forest model via 10-fold cross-validation. The critical parameters and are configured depending on the dataset, with detailed procedures provided in Section 4.5.
As shown in Table 2, the experiments use multiple datasets from the UCI Machine Learning Repository. These datasets vary significantly in size (1059–53,500 samples) and complexity (28–529 features), providing a comprehensive test bench for evaluating the scalability and robustness of the EFEM.
Table 2.
Detailed description of the datasets.
The bold values in Table 3 indicate the minimum number of feature selections for each set of experiments. The results show that, except for HDA-ADP, which is superior on the PDJI and DFT datasets, the EFEM selects the least features in all other cases, and has a significant advantage in the average number of feature selections, while HDMT-SSA performs relatively weakest.
Table 3.
Number of selected features.
In Table 4, we define the feature reduction rate, and the reduction rate is calculated as follows:
Table 4.
Comparison of feature reduction rates.
The bold data in Table 4 indicates the row with the best reduction rate. Comparative analysis shows that the EFEM algorithm exhibits the best reduction performance in most cases. Specifically, with the exception of the HDA-ADP algorithm, which performs slightly better on the PDJI and DFT datasets, the EFEM algorithm achieves the best reduction results in all other comparison experiments. Statistical results show that the EFEM algorithm achieves an average reduction rate of 76.89%, significantly outperforming the other compared algorithms. A comprehensive evaluation shows that the EFEM algorithm achieves the best overall performance, while the HDFT-SSA performs relatively poorly.
As shown in Table 5, the numbers in brackets represent the ranking of the goodness of fit () of each algorithm. The analysis results show that the EFEM algorithm ranks first on six of the nine datasets and ranks third on the remaining three datasets, with an average ranking of 1.67, which is significantly better than other comparison algorithms. In addition, the average goodness of fit of the EFEM algorithm reaches 0.9263, further verifying its excellent performance in model fitting. In contrast, the SWDE-FS algorithm performs poorly.
Table 5.
Algorithm goodness-of-fit () comparison and ranking.
As shown in Table 6, the numbers in parentheses indicate the root mean square error () ranking of each algorithm. The experimental results show that the EFEM algorithm performs exceptionally well on the nine datasets, ranking first on five, second on two, third on one, and fourth on one. Its overall ranking significantly outperforms the other compared algorithms. In contrast, the SWDE-FS algorithm performs poorly overall.
Table 6.
Algorithm root mean square error () comparison and ranking.
As shown in Table 7, the numbers in brackets represent the ranking of the mean absolute percentage error () of each algorithm. The analysis results show that the EFEM algorithm once again performs best, with an average of 1.2023. The on the SLD dataset is only 0.0209, which is 77.5% lower than the 0.093 of SWDE-FS, and it is 5.5687 on the SD dataset, which is 36.5% lower than the 8.7652 of SWDE-FS, demonstrating its excellent reliability in controlling relative prediction errors. In contrast, the MOPSO-NC algorithm performs poorly.
Table 7.
Algorithm mean absolute percentage error (MAPE) comparison and ranking.
4.2. Statistical Analysis
To rigorously compare algorithm performance, we conducted Wilcoxon signed-rank tests under a paired experimental design to assess statistical significance. The results of the Wilcoxon signed-rank tests between the EFEM algorithm and other comparative algorithms are presented in Table 8. With a significance level of , indicates statistically significant differences between the algorithms.
Table 8.
Wilcoxon paired test results for algorithms’ comparison.
Table 8 displays the model test results (median, p-value, degrees of freedom, significance value, and effect size), with an analysis of the statistical significance of p-values for each paired sample group. If it is significant (), the null hypothesis is rejected, indicating that there are differences between each group of paired samples. Otherwise, it means that there is no significant difference between each group of paired samples. Cohen’s d value represents the difference effect size. A value less than 0.2 indicates that the difference is very small; a value within [0.2, 0.5) indicates that the difference is small; a value within [0.5, 0.8) indicates that the difference is medium; and a value greater than 0.8 indicates that the difference is very large.
Table 8 presents the results of paired comparisons involving the variable EFEM across five pairings, analyzed using non-parametric tests (indicated by Z-scores). All pairings exhibited statistically significant differences, with p-values ranging from 0.01172 to 0.04995. The EFEM pairing with SWDE-FS exhibited the largest effect size (Cohen’s d = 0.681), along with the highest median difference (0.054 ± 0.069) among all pairings.
In contrast, the EFEM pairing with HDA-ADP showed the smallest median difference (0.004 ± 0.047) and effect size (d = 0.317), though they were still statistically significant.
The overall performance of the EFEM algorithm is robust, it can consistently detect statistically significant differences, and it shows a strong discrimination ability in some pairings. Therefore, the performance of the EFEM algorithm is good and worthy of further promotion.
4.3. Algorithm Convergence and Runtime
To comprehensively evaluate the convergence, efficiency, and robustness of the proposed DSA–mRMR algorithm, convergence experiments were conducted on four different datasets. Figure 3 shows the relationship between the number of algorithm iterations and the number of selected features for these datasets. As shown, the number of selected features decreases steadily with increasing iterations and eventually stabilizes. This demonstrates that the DSA–mRMR algorithm, through its iterative optimization mechanism, gradually eliminates redundant and irrelevant features, thereby effectively compressing the feature dimension.
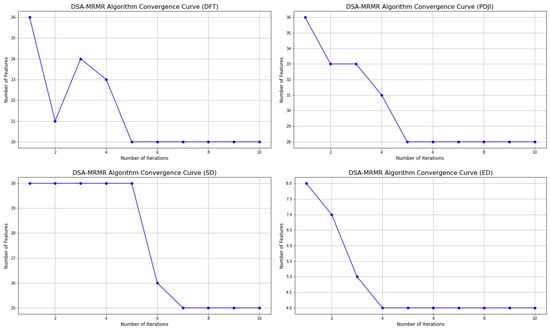
Figure 3.
DSA–mRMR algorithm convergence curve.
The plateau of the curve indicates successful convergence of the algorithm. This not only demonstrates that the DSA–mRMR algorithm can find an optimal or suboptimal feature subset, but also demonstrates the effectiveness and reliability of its optimization process. The number of features stabilizes after a relatively small number of iterations, indicating that the algorithm can efficiently complete the feature selection task, avoiding unnecessary redundant computations and significantly improving overall efficiency. The stable convergence curve indicates that after reaching the optimal solution, the algorithm’s search process does not experience drastic fluctuations or performance degradation, demonstrating its high robustness in complex data environments.
The computational efficiency of the EFEM algorithm was compared with other algorithms on four datasets. The results showed that EFEM’s runtime exhibited dataset-dependent characteristics. Table 9 shows that on the VD and CVPUD datasets, the algorithm achieved the shortest runtime, demonstrating a clear advantage in computational efficiency. However, on the DFT and PDJI datasets, its runtime ranked relatively low, second and fourth, respectively.
Table 9.
Comparison and ranking of algorithm running time (unit: seconds).
Overall, although the EFEM ranked fourth in average runtime, it generally ranked high in predictive performance (as shown in Table 5, Table 6 and Table 7). This demonstrates that the EFEM strikes a balance between computational efficiency and model performance, providing a reliable solution for applications requiring a high accuracy.
4.4. Ablation Study
A series of ablation experiments were conducted to evaluate the effectiveness of the EFEM model and the contributions of its key components. The experimental results are shown in Table 10. The goodness of fit of the following four different model configurations was evaluated: the EFEM model (the full model), the RFA model (using only redundant feature aggregation, without DSA–mRMR, and using all dataset features), the DSA–mRMR model (using only DSA–mRMR feature selection, without redundant feature aggregation), and the DSA model (the baseline model, without DSA–mRMR and redundant feature aggregation). The experimental results showed that on most datasets, the model goodness of fit exhibited a consistent ranking: DSA < DSA–mRMR < RFA < EFEM. This result strongly demonstrates the effectiveness of the DSA–mRMR feature selection and the redundant feature aggregation (RFA) module. The DSA–mRMR module significantly improved model performance by selecting the most representative features. The redundant feature aggregation (RFA) module further enhanced the model’s fit by effectively utilizing redundant information.
Table 10.
Results of ablation study on the different algorithm ().
A comparison of the EFEM algorithm with two independent deep learning-based feature extraction methods and self-supervised learning feature extraction was also performed to verify the effectiveness of our hybrid strategy. As shown in Table 10, they achieved an average ranking of third and second, respectively, demonstrating the powerful capabilities of deep learning for feature extraction, especially when working with complex datasets.
As a complete model integrating all optimized components, the EFEM exhibited the best goodness of fit among all configurations, validating the superiority of its design.
4.5. Parameter Sensitivity Analysis
To determine the optimal number of clusters (K) for discretizing the target variable, the elbow method was employed. As shown in Figure 4, our analysis of the PDJI, CVPUD, DFT, and VD datasets reveals that the elbow of the curves consistently appeared at K = 2. This indicates that discretizing the target variables of these datasets into two categories is the most effective choice for reducing intra-cluster error and provides a solid theoretical foundation for our algorithm.
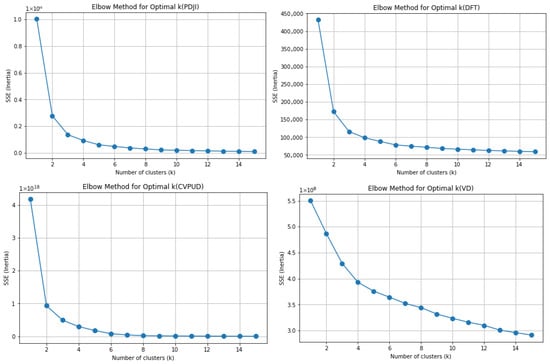
Figure 4.
Elbow method for optimal k.
While the elbow rule provides a theoretical basis for choosing K = 2, sensitivity analysis was further conducted on the choice of K to verify the robustness of our algorithm. This analysis was performed on four datasets. As shown in Figure 5, while changes in K slightly affect model performance, the curves for metrics such as , , and all fluctuate within a narrow range, indicating that model performance remains stable and high. This strongly demonstrates that our algorithm can reliably identify core feature subsets under different discretization methods, ultimately achieving a robust predictive performance.
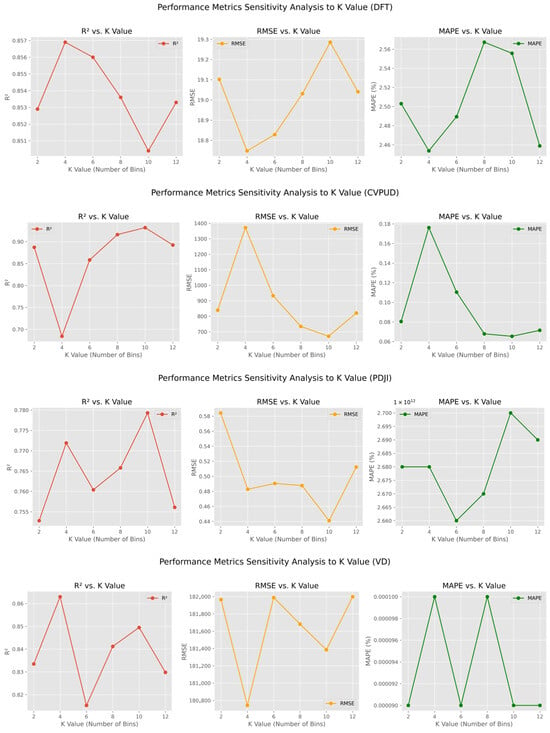
Figure 5.
Performance metrics sensitivity analysis to K value.
Analysis on the DFT dataset, as a representative subplot in Figure 5, visually confirms this robustness. The curves for , , and show that while performance varies slightly as K increases, the overall trend remains strong. Specifically, the value remains consistently high, while the and values stay low across different K values. This further validates that the algorithm’s performance is not overly sensitive to the choice of K and can maintain stability in a variety of scenarios.
To evaluate the impact of parameters (controlling the trade-off between feature relevance and redundancy) and (adjusting the penalty term for dimensionality reduction) on model performance, this study conducted a grid search to test values under different parameter combinations, visualized through 3D surface plots (as shown in Figure 6). The analysis revealed that the model achieved an optimal performance ( > 0.92) when ranged between 0.4 and 0.6 and ≤ 0.3.
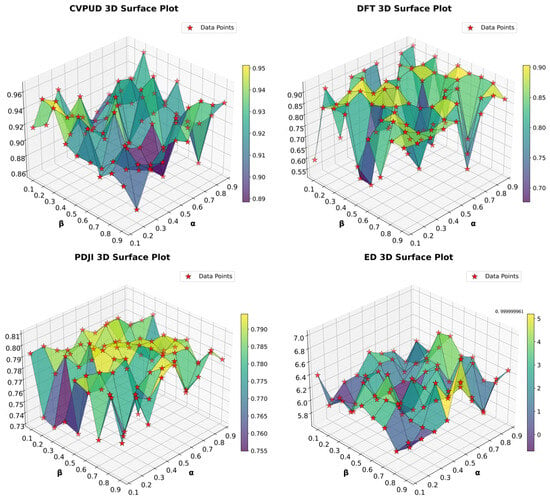
Figure 6.
Three-dimensional surface plots.
The 3D surface plot shown in subfigure (PDJI 3D Surface Plot) clearly illustrates the results of a parameter sensitivity analysis of the EFEM on the PDJI dataset. The horizontal axis () represents the balance coefficient between feature relevance and redundancy, the vertical axis () represents the regularization strength during dimensionality reduction, and this axis quantifies the model performance index (ranging from 0.1 to 0.81). The results indicate that surface fluctuations are primarily due to the following mechanisms: nonlinear coupling between parameters, with the model achieving an optimal performance when and , and performance degradation caused by suboptimal parameter combinations (minimum 0.7).
Under these conditions, the feature subset effectively retains highly informative features while suppressing redundancy. The surface plot exhibits a distinct peak at = 0.5 and = 0.2, demonstrating the synergistic effect of the mRMR criterion and the dimensionality reduction penalty. Conversely, when > 0.7 or > 0.5, sharply declines, indicating that overemphasizing relevance or dimensionality reduction leads to information loss. These results confirm the sensitivity of parameter selection and provide quantitative guidance for parameter tuning in practical applications.
A sensitivity analysis was also conducted on the correlation threshold , a key parameter of the RFA algorithm. Although the thresholds and model selections might appear empirical, their robustness was examined through sensitivity analyses. Specifically, correlation thresholds of 0.6, 0.7, and 0.8 were compared, and the BLR and RF models were used for evaluating the performance. As shown in Table 11, the results showed that 0.7 provided a good balance between redundancy reduction and information retention, and CatBoost consistently outperformed other models in terms of accuracy and stability. These findings confirm that our design choices are both theoretically sound and empirically justified.
Table 11.
Comparison of RFA thresholds under different models.
4.6. Robustness Analysis
To comprehensively evaluate the robustness of an algorithm, the following steps are typically required: normal condition testing, noise testing, abnormal condition testing, and stress testing. Among these experiments, noise testing focuses on examining the algorithm’s robustness to noise. Specifically, noise is introduced into the dataset and the algorithm is run multiple times on it to assess its noise resistance. Four datasets were selected from Table 2 for this experiment, with 25% of the real-valued data randomly selected from each dataset for noise injection testing.
In the experiments conducted on the four original datasets, the EFEM significantly outperformed the other algorithms. On the noisy datasets, it was readily apparent that these values degraded to varying degrees compared to the data in Table 5, Table 6 and Table 7. A comparative analysis of the six algorithms was conducted, with detailed experimental results listed in Table 12, Table 13 and Table 14. However, the EFEM’s overall performance remained superior. The noise experiments further demonstrate the EFEM’s superior performance.
Table 12.
Algorithm goodness-of-fit () comparison and ranking on noisy datasets.
Table 13.
Algorithm root mean square error () comparison and ranking on noisy datasets.
Table 14.
Algorithm mean absolute percentage error () comparison and ranking on noisy data.
4.7. Application on Order Demand Prediction
To further evaluate the applicability of the EFEM model in real-world, high-dimensional forecasting scenarios, the algorithm was applied to product demand forecasting. The algorithm used historical data [] (2015–2018) from a Chinese manufacturing company to forecast product demand, focusing on the first quarter of 2019. The experimental dataset contained 597,694 samples. The original dataset contained 8 features, which were expanded to 18 features after feature reconstruction, reflecting product pricing and demand in different sales regions.
Four machine learning algorithms, namely random forest (RF), Bayesian linear regression (BLR), Support Vector Regression (SVR), and CatBoost, were selected to constitute the foundational base models for the EFEM ensemble framework. Optimized feature selection was performed by the EFEM, ultimately identifying a refined subset of the following five significant features: season, holiday type, holiday, promotion type, and promotion activity. As shown in Table 15, Table 16 and Table 17, the individual methods were significantly outperformed by the EFEM. In a comparison of the experimental EFEMs, the CatBoost-based ensemble model achieved the highest accuracy ().
Table 15.
Model prediction results.
Table 16.
Comparison of RMSE.
Table 17.
Comparison of MAPE.
Long Short-Term Memory (LSTM) networks are an improvement upon Recurrent Neural Networks (RNNs). LSTM demonstrates a good performance in long-term memory tasks, and as a result, it is widely applied in nonlinear time series prediction. In this section, products are classified based on regions, and products within the same region are extracted and demand is aggregated on a monthly basis. Data is organized with products as rows and time as columns. Finally, LSTM is employed for single-step forecasting.
After adjusting the learning rate and iterations, the final forecast results indicate a significant presence of negative values, which are treated as zeros. Due to these zero values, is not suitable as a model evaluation metric. Therefore, only and are computed to gauge the predictive accuracy of the model. The predicted results are shown in Table 18. The results of the aforementioned forecast highlight significant errors, with both and RMSE indicating a poor predictive performance of the model.
Table 18.
LSTM prediction results.
We ultimately concluded that the EFEM provides the most effective and accurate forecasts for enterprise production planning.
5. Conclusions
This study proposes an enhanced feature engineering model (EFEM) that effectively addresses the key challenges in high-dimensional regression tasks, including local optimal convergence and inefficient redundant feature processing. The model achieves this by integrating the Dolphin Swarm Algorithm (DSA) with the Maximum Relevance–Minimum Redundancy (mRMR) method. EFEM contains the following two major innovations: (1) the DSA–mRMR algorithm, which uses a dynamic fitness function to optimize feature selection and balance feature relevance and redundancy, and (2) a developed feature construction algorithm that employs an ensemble learning strategy to fuse redundant features and generate more discriminative synthetic features. Finally, the model combines the optimal feature subset with the synthetic features to further improve prediction performance.
Experiments conducted on nine UCI regression datasets showed that the EFEM significantly outperformed baseline methods in both prediction accuracy and computational efficiency, achieving average performance metrics of = 0.9263, = 22,022.81, and = 1.2023. The statistical significance of this performance improvement was confirmed by a Wilcoxon signed-rank test. Furthermore, the model selected an average of only 47.89 features (achieving a dimensionality reduction rate of 76.89%), which substantially improved computational efficiency while maintaining accuracy. A comprehensive analysis of parameter sensitivity, robustness, convergence, and ablation experiments demonstrated the EFEM’s exceptional stability and reliability in complex data environments. The model’s successful application in a real-world product demand forecasting task further validated its practical value in industrial scenarios.
Future research will concentrate on two main directions. On one hand, we will focus on optimizing the algorithm’s architecture by integrating adaptive learning with new intelligent algorithms to further improve model efficiency. On the other hand, we will expand its industrial application scenarios, verify its real-time performance in fields such as intelligent manufacturing and financial forecasting, and develop incremental learning functions to promote technological implementation. These works will provide more powerful and practical solutions for high-dimensional data processing.
Author Contributions
Conceptualization, methodology, software, validation, formal analysis, investigation, data curation, writing—original draft preparation, visualization: F.G.; writing—review and editing, supervision, project administration: M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- An, J.; Kim, I.S.; Kim, K.-J.; Park, J.H.; Kang, H.; Kim, H.J.; Kim, Y.S.; Ahn, J.H. Efficacy of automated machine learning models and feature engineering for diagnosis of equivocal appendicitis using clinical and computed tomography findings. Sci. Rep. 2024, 14, 22658. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Zhang, W.; Yang, T.; Jiang, Y.; Huang, F.; Lim, W.Y.B. STORM: A Spatio-Temporal Factor Model Based on Dual Vector Quantized Variational Autoencoders for Financial Trading. arXiv 2024, arXiv:2412.09468. [Google Scholar] [CrossRef]
- Siemens Senseye. The Transformative Role of Generative AI in Predictive Maintenance [White Paper]; Siemens Digital Industries: Plano, TX, USA, 2024. [Google Scholar]
- Kraev, E.; Koseoglu, B.; Traverso, L.; Topiwalla, M. Shap-Select: Lightweight feature selection using SHAP values and regression. arXiv 2024, arXiv:2410.06815. [Google Scholar] [CrossRef]
- Benítez-Peña, S.; Blanquero, R.; Carrizosa, E.; Ramírez-Cobo, P. Cost-sensitive feature selection for support vector machines. arXiv 2024, arXiv:2401.07627. [Google Scholar] [CrossRef]
- Abhyankar, N.; Shojaee, P.; Reddy, C.K. LLM-FE: Automated feature engineering for tabular data with LLMs as evolutionary optimizers. arXiv 2025, arXiv:2503.14434. [Google Scholar] [CrossRef]
- Wang, K.; Wang, P.; Xu, C. Toward efficient automated feature engineering. arXiv 2022, arXiv:2212.13152. [Google Scholar] [CrossRef]
- Verdonck, T.; Baesens, B.; Oskarsdottir, M.; van den Broucke, S. Special Issue on Advances in Feature Engineering. Mach. Learn. 2021, 113, 3917–3928. [Google Scholar] [CrossRef]
- Duan, Y.; Zhang, G.; Wang, S.; Peng, X.; Ziqi, W.; Mao, J.; Wu, H.; Jiang, X.; Wang, K. CaT-GNN: Enhancing credit card fraud detection via causal temporal graph neural networks. arXiv 2024, arXiv:2402.14708. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Yu, W.; Liu, Y.; Dillon, T.; Rahayu, W. Edge computing-assisted IIoT framework with an autoencoder for fault detection in manufacturing predictive maintenance. IEEE Trans. Ind. Inform. 2022, 19, 5701–5710. [Google Scholar] [CrossRef]
- da Silva, F.R.; Camacho, R.; Tavares, J.M.R. Federated learning in medical image analysis: A systematic survey. Electronics 2023, 13, 47. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletarì, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. GPT-4 technical report. arXiv 2023, arXiv:2303.08774v6. [Google Scholar] [CrossRef]
- Yang, H.; Yuan, J.; Li, C.; Zhao, G.; Sun, Z.; Yao, Q.; Bao, B.; Vasilakos, A.V.; Zhang, J. BrainIoT: Brain-like productive services provisioning with federated learning in industrial IoT. IEEE Internet Things J. 2021, 9, 2014–2024. [Google Scholar] [CrossRef]
- Yang, H.; Yu, T.; Liu, W.; Yao, Q.; Meng, D.; Vasilakos, A.V.; Cheriet, M. PAINet: An integrated passive and active intent network for digital twins in automatic driving. IEEE Commun. Mag. 2024, 63, 32–38. [Google Scholar] [CrossRef]
- Yang, H.; Zhao, X.; Yao, Q.; Yu, A.; Zhang, J.; Ji, Y. Accurate fault location using deep neural evolution network in cloud data center interconnection. IEEE Trans. Cloud Comput. 2020, 10, 1402–1412. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, H.; Zhang, C.; Zhang, J.; Yao, Q.; Wang, Z.; Vasilakos, A.V. Federated cross-chain trust training for distributed smart grid in Web 3.0. Appl. Soft Comput. 2025, 180, 113313. [Google Scholar] [CrossRef]
- Yao, Q.; Yang, H.; Li, C.; Bao, B.; Zhang, J.; Cheriet, M. Federated transfer learning framework for heterogeneous edge IoT networks. China Commun. 2023. [Google Scholar] [CrossRef]
- Gulati, A.; Felahatpisheh, A.; Valderrama, C.E. Feature engineering through two-level genetic algorithm. Mach. Learn. Appl. 2025, 21, 100696. [Google Scholar] [CrossRef]
- Song, X.; Zhang, Y.; Gong, D.; Liu, H.; Zhang, W. Surrogate sample-assisted particle swarm optimization for feature selection on high-dimensional data. IEEE Trans. Evol. Comput. 2022, 27, 595–609. [Google Scholar] [CrossRef]
- Ma, W.; Zhou, X.; Zhu, H.; Li, L.; Jiao, L. A two-stage hybrid ant colony optimization for high-dimensional feature selection. Pattern Recognit. 2021, 116, 107933. [Google Scholar] [CrossRef]
- Saheed, Y.K. A binary firefly algorithm based feature selection method on high dimensional intrusion detection data. In Illumination of Artificial Intelligence in Cybersecurity and Forensics; Springer International Publishing: Cham, Switzerland, 2022; pp. 273–288. [Google Scholar]
- Pethe, Y.S.; Gourisaria, M.K.; Singh, P.K.; Das, H. FSBOA: Feature selection using bat optimization algorithm for software fault detection. Discov. Internet Things 2024, 4, 6. [Google Scholar] [CrossRef]
- Arroba, P.; Risco-Martín, J.L.; Zapater, M.; Moya, J.M.; Ayala, J.L. Enhancing regression models for complex systems using evolutionary techniques for feature engineering. arXiv 2024, arXiv:2407.00001. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Adv. Neural Inf. Process. Syst. 2018, 31, 6639–6649. [Google Scholar]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal fusion transformers for interpretable multi-horizon forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Khatir, A.; Capozucca, R.; Khatir, S.; Magagnini, E.; Le Thanh, C.; Riahi, M.K. Advancements and emerging trends in integrating machine learning and deep learning for SHM in mechanical and civil engineering: A comprehensive review. J. Braz. Soc. Mech. Sci. Eng. 2025, 47, 419. [Google Scholar] [CrossRef]
- Mansouri, A.; Tiachacht, S.; Ait-Aider, H.; Khatir, S.; Khatir, A.; Cuong-Le, T. A novel Optimization-Based Damage Detection in Beam Systems Using Advanced Algorithms for Joint-Induced Structural Vibrations. J. Vib. Eng. Technol. 2025, 13, 486. [Google Scholar] [CrossRef]
- Khatir, A.; Capozucca, R.; Khatir, S.; Magagnini, E.; Cuong-Le, T. Enhancing damage detection using reptile search algorithm-optimized neural network and frequency response function. J. Vib. Eng. Technol. 2025, 13, 88. [Google Scholar] [CrossRef]
- Khatir, A.; Capozucca, R.; Khatir, S.; Magagnini, E.; Benaissa, B.; Le Thanh, C.; Wahab, M.A. A new hybrid PSO-YUKI for double cracks identification in CFRP cantilever beam. Compos. Struct. 2023, 311, 116803. [Google Scholar] [CrossRef]
- Khatir, A.; Capozucca, R.; Khatir, S.; Magagnini, E. Vibration-based crack prediction on a beam model using hybrid butterfly optimization algorithm with artificial neural network. Front. Struct. Civ. Eng. 2022, 16, 976–989. [Google Scholar] [CrossRef]
- Khatir, A.; Brahim, A.O.; Magagnini, E. An efficient computational system for defect prediction through neural network and bio-inspired algorithms. HCMCOU J. Sci. Adv. Comput. Struct. 2024, 14, 66–80. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Zhang, Y. A survey on automated feature engineering for machine learning. Comput. Appl. Softw. 2025, 42, 1–10,40. [Google Scholar]
- Tu, T.; Su, Y.; Tang, Y.; Tan, W.; Ren, S. A more flexible and robust feature selection algorithm. IEEE Access 2023, 11, 141512–141522. [Google Scholar] [CrossRef]
- Pau, S.; Perniciano, A.; Pes, B.; Rubattu, D. An evaluation of feature selection robustness on class noisy data. Information 2023, 14, 438. [Google Scholar] [CrossRef]
- Yi, S.; Liang, Y.; Lu, J.; Liu, W.; Hu, T.; Zhenyu, H.E. Robust feature selection method via joint low-rank reconstruction and projection reconstruction. Tongxin Xuebao 2023, 44, 209–219. [Google Scholar]
- Theng, D.; Bhoyar, K.K. Feature selection techniques for machine learning: A survey of more than two decades of research. Knowl. Inf. Syst. 2024, 66, 1575–1637. [Google Scholar] [CrossRef]
- Patankar, A.; Patil, P.; Brahmane, M. Feature Forgetting: A Novel Approach to Redundant Feature Pruning in Automated Feature Engineering. 2025. Available online: https://www.researchsquare.com/article/rs-7130210/v1 (accessed on 26 July 2025).
- Li, J.; Wen, Y.; He, L. Scconv: Spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6153–6162. [Google Scholar]
- Kuhn, M.; Johnson, K. Feature Engineering and Selection: A Practical Approach for Predictive Models; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Batista, J.E. Embedding domain-specific knowledge from LLMs into the feature engineering pipeline. arXiv 2025, arXiv:2503.21155. [Google Scholar] [CrossRef]
- Stewart, L.; Bach, F.; Berthet, Q. Building Bridges between Regression, Clustering, and Classification. arXiv 2025, arXiv:2502.02996. [Google Scholar] [CrossRef]
- Avelino, J.G.; Cavalcanti, G.D.C.; Cruz, R.M.O. Resampling strategies for imbalanced regression: A survey and empirical analysis. Artif. Intell. Rev. 2024, 57, 82. [Google Scholar] [CrossRef]
- Bennasar, M.; Sayadi, M.K.; Caiado, J.; Figueira, R.; Oliveira, E.; Suárez, J. Feature selection using joint mutual information maximization and correlation-based redundancy control. Expert Syst. Appl. 2021, 183, 115408. [Google Scholar] [CrossRef]
- Faletto, G.; Bien, J. Cluster Stability Selection for Feature Selection. arXiv 2022, arXiv:2201.00494. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/datasets (accessed on 26 April 2025).
- Guo, W.; Liu, T.; Dai, F.; Xu, P. An Improved Whale Optimization Algorithm for Feature Selection. Comput. Mater. Contin. 2020, 62, 337–354. [Google Scholar] [CrossRef]
- Ren, L.; Zhang, W.; Ye, Y.; Li, X. Hybrid Strategy to Improve the High-Dimensional Multi-Target Sparrow Search Algorithm and Its Application. Appl. Sci. 2023, 13, 3589. [Google Scholar] [CrossRef]
- Aghelpour, P.; Mohammadi, B.; Mehdizadeh, S.; Bahrami-Pichaghchi, H.; Duan, Z. A novel hybrid dragonfly optimization algorithm for agricultural drought prediction. Stoch. Environ. Res. Risk Assess. 2021, 35, 2459–2477. [Google Scholar] [CrossRef]
- Rostami, M.; Forouzandeh, S.; Berahmand, K.; Soltani, M. Integration of multi-objective PSO based feature selection and node centrality for medical datasets. Genomics 2020, 112, 4370–4384. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Wong, K.-C.; Li, X. A self-adaptive weighted differential evolution approach for large-scale feature selection. Knowl. Based Syst. 2022, 235, 107633. [Google Scholar] [CrossRef]
- Gao, F. Data for Enhanced Feature Engineering Symmetry Model base on a Novel Dolphin Swarm Algorithm [Order Dataset]. Baidu Netdisk. Note: This Is an Informal Resource Hosted on Baidu Netdisk 2025, a Personal Cloud Storage Service. Available online: https://pan.baidu.com/s/1vm6bv8sw0kyX0ATRsDTgkw?pwd=575z (accessed on 26 August 2025).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).