1. Introduction
With the increasing use of Computer Tomography (CT) in medicine [
1], pericardial effusions (PEFs) are often first diagnosed on CT [
2]. A PEF is most commonly defined as a volume larger than 50 mL [
2,
3,
4]. However, PEF diagnosis is often missed on CT as shown by Verdini et al. with a sensitivity of only 59.0% for pericardial disease [
5]. Whilst volumetry is the most accurate method to diagnose PEF, taking into account the complex three-dimensional geometrical structure of the pericardial sac [
4,
6,
7], counting voxels is time consuming and impractical in clinical practice [
8]. Therefore, an automatically generated segmentation and volumetry tool would substantially improve the quality of CT-based PEF diagnosis.
Whilst echocardiography is the primary tool for PEF diagnosis [
6], CT plays an ever-increasing role. This is because CT is a “catch all” investigation for patients presenting
in extremis, which requires prompt, thorough and rapid diagnostic workup to identify life threatening pathologies and guide management. Evidently, missing a PEF diagnosis in this context must be avoided. Additionally, the echocardiographic diagnostic accuracy of PEFs is affected by the presence of clots, complex loculations, posterior PEFs and post-surgical changes, making CT the primary and most straightforward tool for the investigation of these complications [
9,
10].
The effectiveness of deep convolutional neural networks for the automated analysis of chest CTs has been proven [
11,
12,
13,
14]. However, to date, only two studies are available utilizing Artificial Intelligence to automatically identify or quantify PEF on CT [
15,
16]. Currently, the most commonly implemented deep learning architecture in medical imaging is the U-Net [
17], which was adapted by Isensee et al. producing a robust tool called nnU-Net. nnU-Nets can automatically configure themselves, including preprocessing, network architecture, training and post-processing for any new task [
18]. Its advantages have been demonstrated by winning multiple Medical Image Computing and Computer Assisted Interventions challenges.
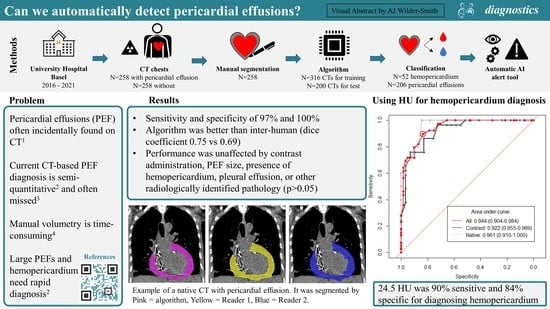
Our model presents the first openly available dataset and tool to automatically segment, quantify and classify PEFs on CT. It fulfills the clinical need for a more reliable, more accurate, and faster diagnosis of PEF and hemopericardium, which performs reliably even in the presence of additional chest pathology. The incorporation of this tool into clinical practice may help reduce or even avoid missed diagnoses completely, as well as improve the time-to-diagnosis, ultimately improving patient outcomes.
2. Materials and Methods
The local ethics committee approved this retrospective study (Project ID: 2021-00946). For the external dataset consisting of anonymized post-mortem CT data, an ethical waiver was issued by the Ethical Committee of the Canton of Zurich (Project ID: 2022-00173). We structured our manuscript according to SPIRIT-AI and CLAIM [
19,
20].
2.1. Study Population
Two study cohorts were defined as follows. The positive cohort, consisting of simple PEF and hemopericardium cases, was identified through the search of structured radiology reports using the search terms “pericardial effusion” and “hemopericardium” from January 2016 to January 2021. No patient was present in both groups. The corresponding CTs including chest imaging were identified using the Radiology Information System/Picture Archiving and Communication system in a tertiary hospital. The search and the exclusion of patients without consent, duplicates and follow-up studies were carried out by Reader 2 (postgraduate year (PGY) 4). Additionally, a negative cohort was identified on a local database of CT studies without significant radiological findings by Reader 1 (PGY 2).
All CTs identified above were quality controlled by Reader 1 under the supervision of Reader 3 (Board certified, 15 years of cardiothoracic imaging experience). All hemopericardium cases were reviewed by Readers 1 and 2 to ensure an accurate diagnosis. Most cases had a concomitant aortic dissection, recent cardiac intervention, or chest trauma (
n = 51/53, 96.23%). Studies with strong artifacts affecting the delineation of the heart, insufficient image quality, and extreme difficulty in delineating between PEF and pleural effusion were excluded with the recommendation from Reader 3. Studies in the PEF/hemopericardium and negative cohort were manually reviewed to ensure a PEF thickness of >4 mm and <4 mm, respectively [
2], whilst blinded to the radiology report. In areas of diagnostic uncertainty, the consensus was achieved through discussion with Readers 2 and 3. A detailed overview of the patient selection is graphically presented in
Figure 1. All data were anonymized.
2.2. Image Acquisition Parameters
CT scans were performed using four different models manufactured by Siemens Healthineers, Germany: Definition AS+ (n = 220), Definition Flash (n = 158), Definition Edge (n = 118), and Somatom Force (n = 20). Acquisition parameters were as follows: mean peak tube voltage 102.82 kVp (SD: 12.18), mean tube current time product 113.03 mAs (SD: 41.47), mean computed tomography dose index (CTDI) 4.07 mGy (SD: 3.62) and mean dose length product (DLP) 152.60 mGy*cm (SD: 162.07). A soft tissue kernel reconstruction (30f) of 1.0 mm served as the only input for the model.
Iopromide (Ultravist 370, Bayer Pharmaceuticals) was administered in 274 cases (arterial phase = 143, biphasic = 25, venous = 7, pulmonary arterial phase = 99).
2.3. Segmentation
All images with PEF were manually segmented by two readers Reader 1 (n = 187) and Reader 2 (n = 71) under supervision of Reader 3. Segmentation was standardized by using the same software and windowing. The three-dimensional segmented masks were used as a reference for training and testing.
To measure inter-rater variability, 40 studies initially segmented by Reader 2 were randomly selected and segmented by Reader 1; 20 with and 20 without contrast.
2.4. Model Training, Validation, and Testing
The model architecture is presented in
Table 1. Hemopericardium studies were often not chest only CTs (
n = 26). Therefore, pre-processing was carried out to crop the CT to the chest region, which is predicted by Hofmanninger et al.’s lung segmentation model [
21].
The positive and negative cohorts (
n = 516) were divided randomly into a training/validation (
n = 316) and a test cohort (
n = 200) whilst preserving the distribution of cases with and without contrast administration. Hemopericardium cases were divided with increased weighting towards the test cohort in order to ensure good statistical power of the accuracy of hemopericardium segmentation and classification. Therefore, hemopericardium compromised only 10% of the positive cohort within the training cohort (
n = 14), matching our local hemopericardium prevalence amongst PEFs. The remaining were used in the test cohort (
n = 38). A deep convolutional neural network using nnU-Net [
18] was trained and validated with a 5-fold cross validation. Each fold took 1.5 days.
2.5. Hardware and Software
The images were organized, viewed, labeled, predicted, pre- and post-processed on the web-based image platform NORA [
https://www.nora-imaging.com/ (accessed on 15 February 2022)] which is installed on an inhouse server with GPU Tesla T4. The training was performed on an Ubuntu workstation with 12 Cores CPU, 64 GB RAM and two Nvidia RTX 2080Ti.
2.6. Classification of Hemopericardium
The model’s prediction mask was used to extract a Hounsfield unit (HU) for each voxel segmented. All values outside the range of 0 to 80 HU were removed as these are outside the HU range for fluid and blood. The remaining values were used to compute a median HU per case, as demonstrated in
Figure 2. A total of 38 hemopericardium cases from the hemopericardium sub-cohort together with one incidentally identified hemopericardium case in our positive cohort were compared to the remaining 61 simple PEF cases (without hemopericardium).
2.7. The Model’s Output
The resulting output from the segmentation prediction will be: the presence of PEF > 50 mL, volume in mL, large PEF (>100 mL) and the HU. The presence of hemopericardium and a PEF volume > 100 mL could set off an alert for the emergency physicians and radiologists.
2.8. External Data Set
Our model was tested on an external dataset consisting of 22 post-mortem CTs (PMCTs) with autopsy-confirmed hemopericardium, performed on a Siemens Definition Flash CT scanner. The image acquisition parameters are based on the chest and abdomen scanning protocol described by Flach et al. [
22]. Patient selection criteria are described by Ebert et al. [
23]. The CTs were cropped using the aforementioned technique at our institution. Our model’s performance was compared to the external institution’s post-mortem volume measurements and manual segmentation masks, the methodology of which is described by Ebert et al. [
15].
2.9. Statistical Analyses
To evaluate PEF detection and segmentation performance, we used sensitivity, specificity, and Dice coefficient. Volumetry was compared using Bland–Altman analysis and by plotting the reference volumes against the predicted volumes and calculating Pearson’s correlation coefficient (r
2). To compare model performance within the sub-groups and to the inter-rater agreement, we used the Dice coefficient,
t-test, Mann–Whitney U test, and intraclass correlation coefficient (ICC). The receiver operating characteristic (ROC) curve was used to identify a HU threshold for the diagnosis of hemopericardium. Dice coefficient was computed on local software. The remaining statistical tests were computed using the packages “pROC” and “irr” using RStudio (Rstudio, PBC, Boston, MA, USA) [
24,
25], and visualized graphically using “ggplot2” and “tidyverse” [
26,
27].
2.10. Publicly Available Data
To encourage the use of this model and ensure the validity of our results, the CT datasets, reference segmentations and model code are openly available online [
28].
4. Discussion
We developed and comprehensively tested a tool for the automatic detection, volumetry and classification of PEFs using a complex set of clinical cases, containing cases of simple PEF, hemopericardium and a negative control without PEF. A highly accurate detection (97% sensitivity and 100% specificity) and good segmentation accuracy (Dice 0.75) were achieved. Of note, the volume difference and Dice coefficient between the reference and model were better than those of the inter-reader. The model’s performance was not significantly affected by acquisition parameters, such as contrast administration nor by clinical pathologies, such as PEF volume, hemopericardium, pleural effusions, and other radiologically identified pathology. A robust method using HUs for the classification of hemopericardium was developed, which had a sensitivity and specificity of 89.7% and 83.6%, which was unaffected by contrast administration. HUs are highly effective for the classification of PEFs [
29]. Using the median HU of an entire PEF segmentation is a simple and reproducible method, superior to the current approach of viewing HU values in randomly selected areas of the PEF (with corresponding inter and intra observer variability). To our knowledge, this is the only study to date where this methodology is carried out. However, a few false positive cases were found, in particular, two CTs with a contrast of patients with pericarditis, resulting in pericardial enhancement affecting the HU values. We encourage that HU should not be used in isolation, but in addition to radiological and clinical findings.
Similar to other recent state-of-the-art Convoluted Neural Network (CNN) models, we show great utility and performance despite a highly complex dataset [
30,
31,
32]. In fact, the high diagnostic accuracy in this study is comparable to Ay and Kahraman’s study comparing the manual diagnostic accuracy of CT and echocardiography in PEF detection after open heart surgery [
33]. CT had a much lower false negative risk compared to echocardiography (8% vs. 61%) in a complex patient database that may be comparable to ours. Liu et al. [
16] and Ebert et al. [
15] investigated the feasibility of CT-based PEF segmentation on limited case numbers (
n = 25 and
n = 28, respectively). They both used two-step approaches and did not publish their model publicly. Both studies trained their models slice by slice, in comparison to more appropriate three-dimensional training in our study. Additionally, neither of the studies offers a PEF classification tool. Liu et al. analyzed the segmentation performance of two different neural network architectures. The best performing model was U-Net, which forms the basis of the nnU-Net architecture utilized in our study. Their model’s performance was similar to ours (Dice 0.77) but may not be comparable as no negative control cohort was included in the training or testing cohort. Ebert et al. studied whether automatic segmentation of hemopericardium on PMCTs was feasible and had 25 negative control cases. Direct analysis of their model is not possible because a commercial software was used. Ebert et al.’s dataset was used to perform an external validation. Here, we found a good segmentation quality (Dice 0.65) but a large difference in volume segmentation. This is explained by the difference between PMCTs and CTs of living patients. First, the images are higher resolution and without contrast. Second, radiological findings are starkly different, for example, the heart chambers collapse, occasionally contain air and hematomas, and therefore, the hemopericardium is denser and more inhomogeneous. This and the fact that PMCTs were not part of the training dataset might explain the lower quality of the segmentation.
Clinical Implications
This automatic identification, volumetry and classification tool can facilitate and improve radiology triage and workflows as well as report quality. A well embedded tool could directly alert emergency physicians to the presence of hemopericardium and/or large PEF, with its association with cardiac tamponade [
4]. Early CT has previously been shown to facilitate rapid patient management in the emergency department [
34], and our tool may further enhance it. Additionally, this tool can make PEF volume and HU measurements objective, replacing current semi-quantitative classifications plagued by variable cut-off thresholds and inter and intra-reader variability [
10,
35]. As long as input parameters are standardized, this automatic tool can standardize these measurements, and therefore, be used to identify a less arbitrary cutoff for distinguishing between PEF and physiological pericardial fluid, taking into account age, sex, height, and concomitant disease. This will allow more accurate detection of PEF and hemopericardium which may reduce unnecessary echocardiograms or identify patients where an echocardiogram is urgent. It may also allow better prognostication. The incorporation of this tool into clinical practice requires seamless communication between the Radiology Information System/Picture Archiving and Communication System and the model. In addition to this infrastructure, a simple output is required which should be easy and intuitive for the radiologist or clinician to access.
There are several limitations to our study. First, the model was trained on the latest generation CTs from a single scanner manufacturer at a single institution. While the use of older CT scanners could theoretically reduce the diagnostic accuracy, we at least showed a good performance on CTs from a different institution on a completely different patient group: post-mortem hemopericardium cases. This suggests that the model’s performance is highly robust in different protocols, institutions and patient groups. Second, the ground truth was identified using the radiology report, which was mitigated by the use of structured reports in our institution. The two-dimensional CT diagnosis of PEF was used in our inclusion criteria, which resulted in a total of 29/258 (11.24%) PEF cases >4 mm which turned out to be physiological pericardial fluid volumes (<50 mL). No alternative mechanism exists to circumvent this drawback whilst maintaining a large case number. Third, inter-reader variability was worse compared to reference-prediction variability. This may be because segmentation style and errors have a proportionately large effect on outcome in complex, narrow and often small structures, such as PEFs.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





