1. Introduction
Cells are the building blocks of human tissues, and tissues eventually form organs. Every cell has some functions to perform; once their work is done, they die. However, sometimes, cells do not die after their performance due to internal and external issues, and new tissues are formed without need. This abnormal division of cells or production of extra cells causes tumors. Different factors such as alcohol consumption, obesity, birth control pills or injections, estrogen, progesterone, diethylstilbestrol during pregnancy, radiation treatment, and inheritance mutations can cause breast cancer. In the same manner, some factors can reduce the chances of breast cancer, such as breastfeeding, early age pregnancy, and hormonal balance [
1]. The uncontrolled division of cells can occur in any body part, but here, we discuss the cells in the glands that produce milk (called lobules). Their abnormal growth causes breast cancer [
2]. New research shows that breast cancer is about 23% in females out of all cancer types, which is much more rational than in males. Every eighth or ninth female is exposed to breast cancer at any stage of their life in Europe [
3]. According to the World Health Organization (WHO), early cancer detection considerably increases the probability of making suitable decisions for a successful treatment plan [
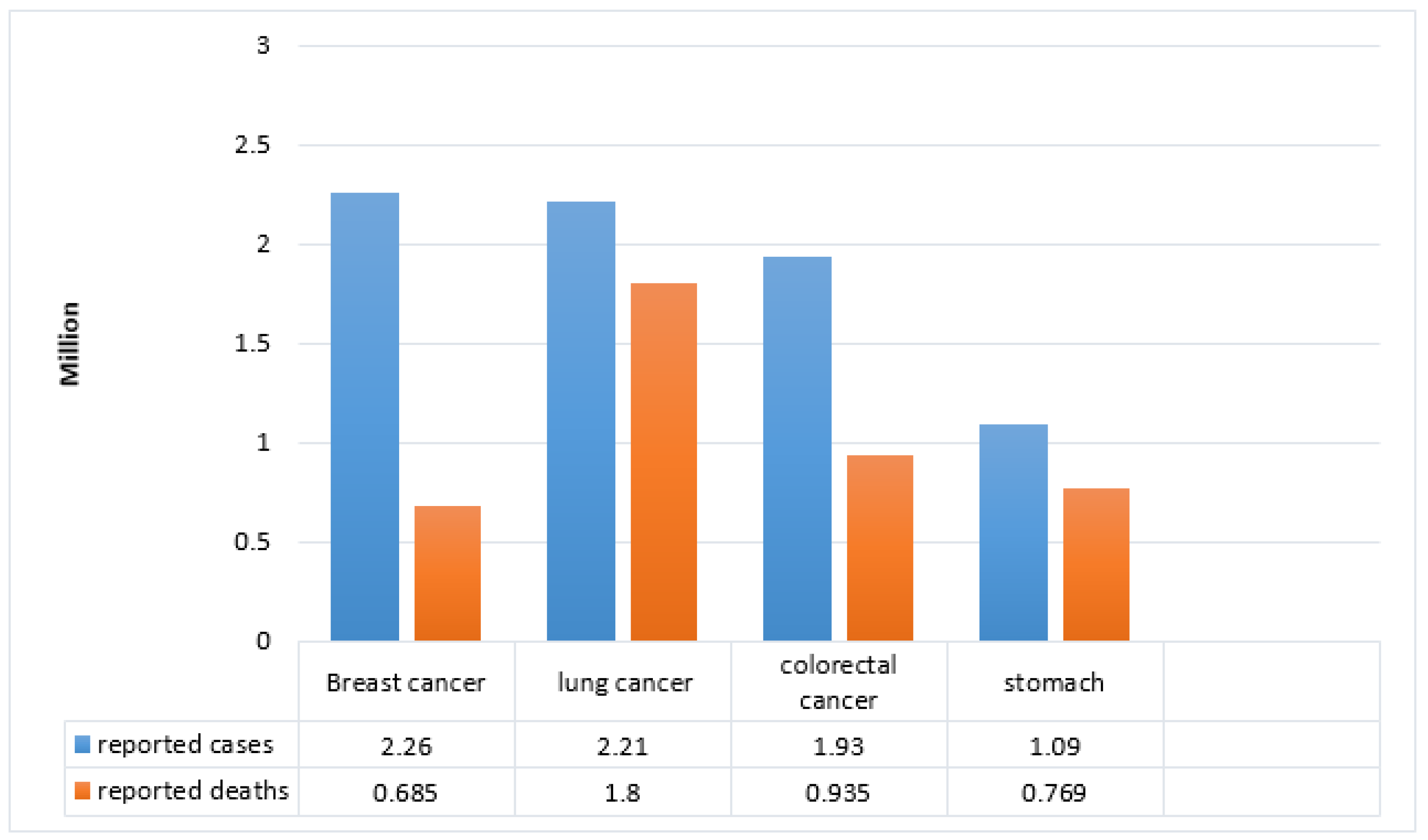
4]. There are different types of cancers worldwide causing a considerable rate of annual deaths as illustrated [
5] in
Figure 1.
Breast cancer has a high mortality rate; early detection is required to avoid this. Early diagnosis of breast mass can improve the survival rate in women [
6]. Therefore, automatic systems to improve breast cancer masses detectors are becoming better day by day to help radiologists [
7]. Our research aims to facilitate physicians to diagnose breast cancer at its early stages. In the past, many AI techniques have been applied to classify tumors. Our contribution improves the detection accuracy rate using the SVM, which helps the healthcare system detect tumors in the initial stages to avoid further complications [
8]. Below are the key contributions of this research.
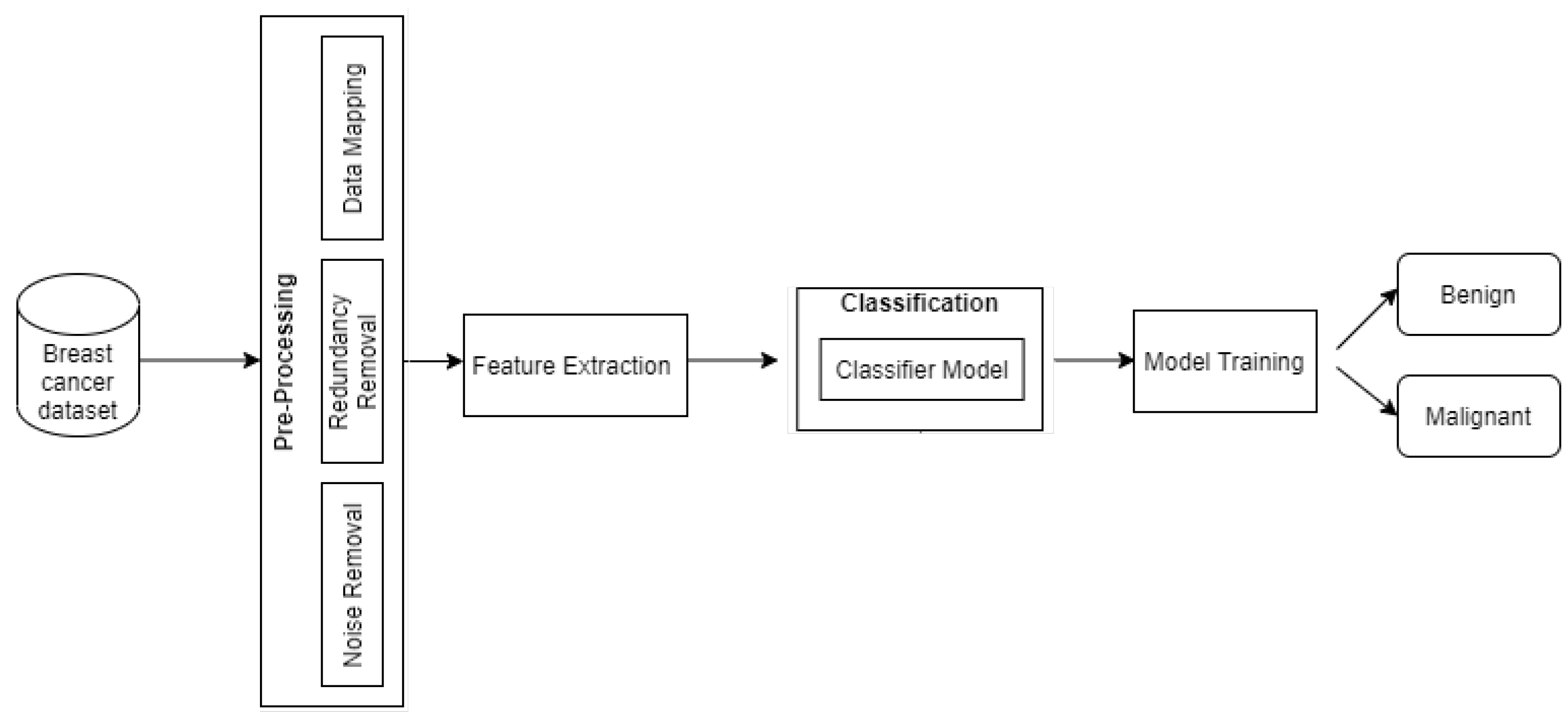
We apply preprocessing techniques and segmentation to patient data collected from the mammograms’ Breast Cancer Wisconsin Diagnostic Dataset (BCWD).
We bring forth the classification of patient’s data (cancerous or non-cancerous) by using the SVM classifier.
We contribute to precisely detecting the Breast Cancer stage (Benign or Malignant) by using SVM, KNN, and LR.
We reduce the false-negative rate (FNR) and false-positive rate (FPR) without reducing the degree of precision and accuracy.
We compare our proposed results with state-of-the-art models to assess performance.
We practically implement the simulations for data classification through SVM, KNN, and LR, furthermore helping to increase the accuracy rate by approximately 97.7 % with an error rate of 2.3%.
The rest of the paper is organized as follows.
Section 3 presents related work that is done in this field by researchers.
Section 4 explains the whole proposed methodology,
Section 5 explains SVM, KNN, and LR in detail with simulation results and discussion. Finally, the paper is concluded in
Section 6.
3. Related Works
Breast cancer is a deadly disease in the present era. Different researchers are working hard to help diagnose it at the initial stage to avoid an acute phase. In this classification field, CNN and SVM are essential to help the researchers to classify patients’ data. Here, we overview different machine learning and deep learning techniques on different bio-images. However, our primary focus is on mammographic images.
The authors in [
34] have proposed a cloud and decision-based fusion AI system using a hierarchical DL (CF-BCP) model to predict breast cancer. This simulation uses MATLAB (2019a) and deep learning techniques, i.e., CNN and DELM on 7909 and 569 fused samples. Their model attains 97.975% accuracy in the detection of breast cancer. The research in [
35] analyzed SVM, KNN, LR, random forest, naïve Bayes, and decision tree techniques on a dataset from Dr. William H. Walberg of Wisconsin Hospital breast cancer in the early stages. The LR model gave the best result with 98.1% accuracy. The study in [
36] compares different classification methods such as KNN, decision tree, SVM, Bayesian network, and naïve Bayes under the WEKA environment to check the best accuracy. The overall experiment shows that Bayesian network gave the highest accuracy with fewer features. Still, the highest accuracy for the more featured dataset was given by SVM. The study in [
37] reviews several segmentation techniques on ultrasound and mammographic images. For this, preprocessing is necessary to remove the redundant data. High-quality data will help achieve the best possible accuracy in classifying whether the cancer is benign or malignant.
The authors in [
38] proposed a model based on the local pixel information and neural network for segmentation and extraction of the region of interest (ROI) on a dataset having 250 ultrasound images using machine learning ANN and BPNN to differentiate benign and malignant tumors. They have done breast cancer classification on two datasets, the first having 380 and the second having 163 ultrasound images from University Hospital, Amman, Jordan. They used CNN and SVM classifiers for the feature extraction and classification of breast cancer. They successfully achieved the performance of 94.2% [
39]. The proposed work in [
40] classifies breast cancer that is benign or malignant. The authors used 151 images, out of which 79 images are benign tumors (BIRADS 2–3) and 72 are malignant tumors (BIRADS 4–5) for the experiment. They used CAD systems, specifically random forest (RF), SVM, CNN, and conducted Segmentation, Feature Extraction, and Classification, attaining the accuracy of 80.00%, 77.78%, and 85.42%, respectively. Ultrasound-based existing research is mentioned in
Table 1.
The authors in [
41] proposed a parallel model including CNN and RNN to classify hematoxylin–eosin-stained breast biopsy images. They experiment on three datasets: BACH2018 has 400 images. Bio-imaging2015 has 249 histology images, and Extended Bioimaging2015 includes 1319 images to classify normal tissues, benign lesions, carcinomas, and invasive carcinomas. The authors in [
42] have proposed a new hybrid convolutional and recurrent deep neural network for the classification of breast cancer. They used recurrent neural network (RNN), CNN, SVM, and NVIDIA GPUs on an Image Net dataset, ICIAR, ISBI, ICPR, and MICCAI, having 3771 images, 249 images from Bioimaging2015, and 400 histopathological images in 2019. The highest accuracy achieved was 91.3%. The authors in [
43] have introduced a novel transfer learning-based approach to automate normal tissues, benign lesions, and malignant lesions. They applied the deep neural network ResNet-18 and enhanced its adoption by using global contrast normalization (GCN) on data augmentation. They used DNN and softmax classifier on 7909 histopathological images from Anatomy and Cytopathology (P&D) Lab, Brazil, and conducted binary classification. The authors in [
44] used Breast Cancer Computer-Aided Diagnosis (BC-CAD) and deep neural network (DNN) and RNN binary classification techniques on 92 histopathological images from Wisconsin UCI to differentiate normal and tumor cells. The proposed methodology in [
45] focused on CNN, ML, DL, IHC-Net, a combination of naïve Bayes, SVM, and RFD as segmentation, feature extraction, and classification techniques. They used a dataset of 400 histopathological images and finally obtained the best accuracy (98.24%). The classifier with hand-engineered features gave more performance with a 98.41% F-score and 97.66%. Histopathological image dataset-based research and its results are given in
Table 2.
SVM is used to obtain better results in classification in [
46]. CAD systems follow two segmentation methods. First, one region of interest (ROI) is detected, and second, they use a threshold. The author used a DCNN architecture named AlexNet to classify two classes. They used y(DDSM) and DDSM (CBIS-DDSM) datasets. AUC obtained an accuracy of about 88% using the (CBIS-DDSM) dataset, the accuracy of DCNN also improved to 73.6% and overall AUC with the involvement of SVM obtained an accuracy of 94%. The work in [
47] applied the CNN technique to train two datasets: the Full-Field Digital Mammography Dataset (FFDM) and the Digital Dataset of Screening Mammography (DDSM), the latter having 14,860 Mammographic images. CNN, AlexNet, and ImageNet are used to classify benign and malignant.
The authors in [
48] worked on the segmentation and classification of breast cancer using DL, SVM Soft-Max function, and Sigmoid function on a dataset of 400 mammographic images. They found that SVM showed better results than DL techniques. The authors in [
49] proposed different segmentation techniques such as HDF K-means clustering, OKFCA, OKFC algorithm, fuzzy and region growing technique, and AOKFCA algorithm on a dataset of 322 mammographic images from the Society (MIAS) database. The whole experiment shows that MFKFCS produces the highest accuracy of 80.42%. Mammographic dataset-based research and its results are given in
Table 3.
Thermograms are also used in breast cancer classification. The authors have used a public dataset containing 146 breast thermograms (117 benign and 29 malignant) and achieved a sensitivity of around (79.86%) [
51]. The authors in [
50] proposed a method to detect breast cancer using mammograms. This study employs preprocessing, segmentation, feature extraction, and classification. Breast cancer is classified using LR, AdaBoost, decision tree, KNN, and random forest classifiers. The obtained accuracy was 90%, 85%, 57%, 54%, 76%, and 61% for SVM, LR, AdaBoost, decision tree, KNN, and random forest classifiers, respectively. Overall, SVM achieved the highest accuracy among others.
From the above literature review, mammographic bio-imaging shows low response accuracy compared to histopathological bio-imaging. We propose a model by applying machine learning techniques such as SVM, KNN, and LR on mammographic bio-imaging to enhance the accuracy of breast cancer detection. This research will help the radiologists and physicians diagnose this disease, and accordingly, they will prescribe precautions and medication to the patients.
5. Evaluation and Results
According to the literature review of existing work, the overall histopathological bio-images show better accuracy results than others, as mentioned in
Table 4. We use accuracy as an evaluation measure. “Accuracy is derived by dividing the number of correct predicted classes by the total number of samples evaluated, as shown in Equation (
15)”.
Sensitivity or recall is used to calculate the fraction of positive patterns that are correctly classified, as shown in Equation (
16). The accuracy is directly related to the true-negative and false-positive classes. Here, true positive (
TP) indicates that cancer exists and is predicted positive. True negative (
TN) indicates that cancer exists but is predicted negative. False positive (
FP) indicates that cancer does not exist but is predicted to be positive. False negative (
FN) indicates that cancer does not exist and is predicted negatively.
Precision is used to compute the percentage of “positive patterns correctly predicted by all predicted patterns in a positive class”, as shown in Equation (
17).
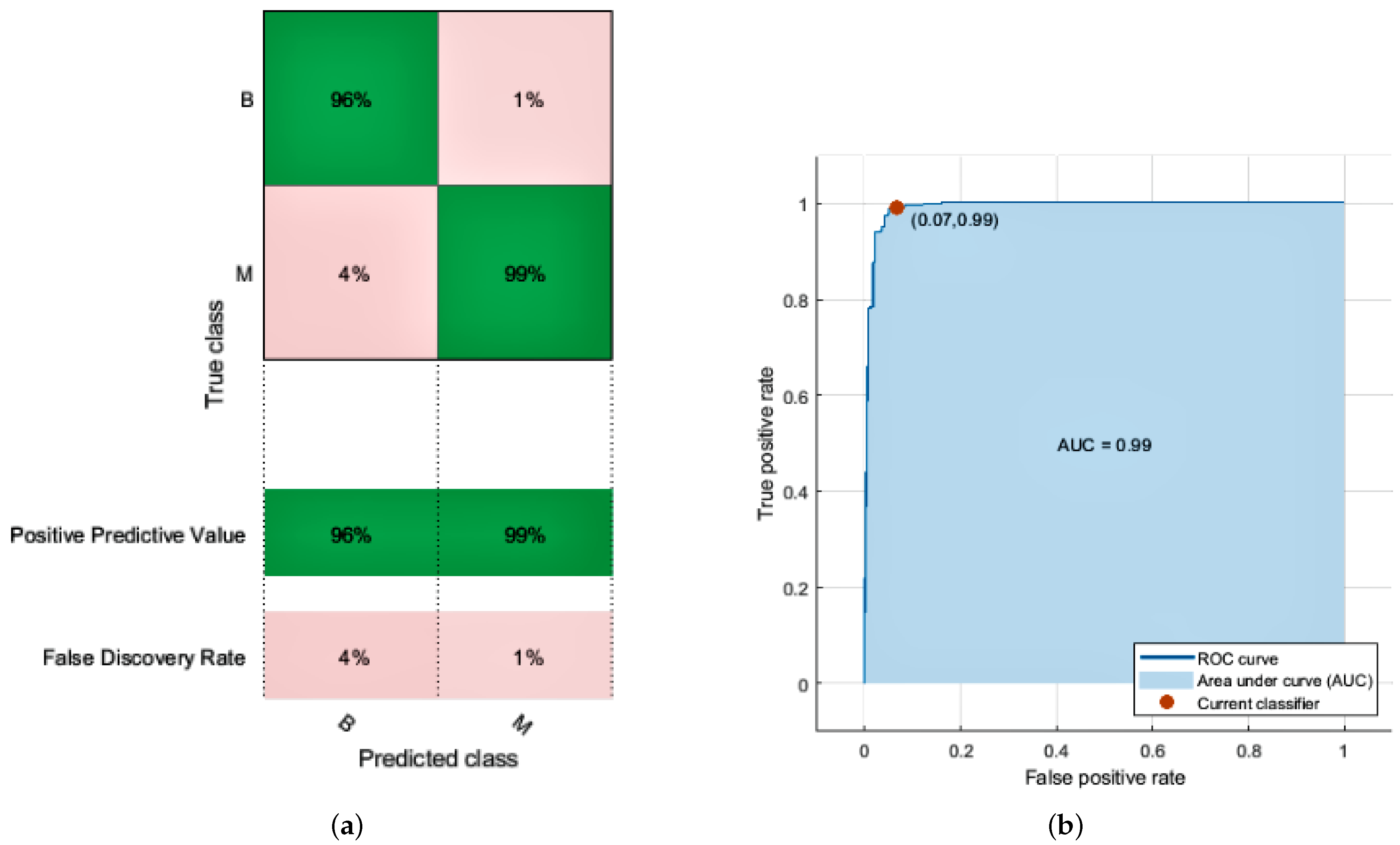
KNN relies on distances between neighbors measured by Euclidean, and data normalization helps to enhance classification accuracy. In the KNN model, a k-value is required to predict the unknown points to differentiate the classes eventually. A k-value decides the number of nearest neighbors to obtain the value for unlabeled data. The k-value is always a positive integer. We used an odd number of neighbors (3,5,7) and k at the value of 7 to give the best result in the simulation.The KNN employed in the proposed approach achieves the highest accuracy of 100% in the training dataset and 97.0% in the test with the weighted model. This model has a prediction speed of 2500 observations per second and a training time of 6.1157 s. The fine model achieved 94% accuracy with a prediction speed of 2500 observations per second and a training time of 2.9811 s. The medium model of KNN achieved 96% accuracy with a prediction speed of 1500 observations per second and a training time of 3.9217 s. Coarse gave us the least accuracy out of all the KNN models. When no other classifier is available, the results achieved by employing KNN are satisfactory; nevertheless, because the value of the k is chosen at random, its performance is less than the SVM classifier. The receiver operating characteristic (ROC) curve plot graph defines the diagnostic capability of a binary classifier. The ROC graph contains FPR on the
x-axis and TRP on the
y-axis. The limit for the
x and
y-axis lies between 0 and 1 to plot a graph of all possible threshold values of the classifier. So, the ROC curve gave us a tradeoff between cost and benefit. As we obtained more values close to 1, our model attains high accuracy. The confusion matrix and ROC curve of the KNN classifier is given in
Figure 3a,b. We achieve the following accuracy from KNN models as given in
Table 5.
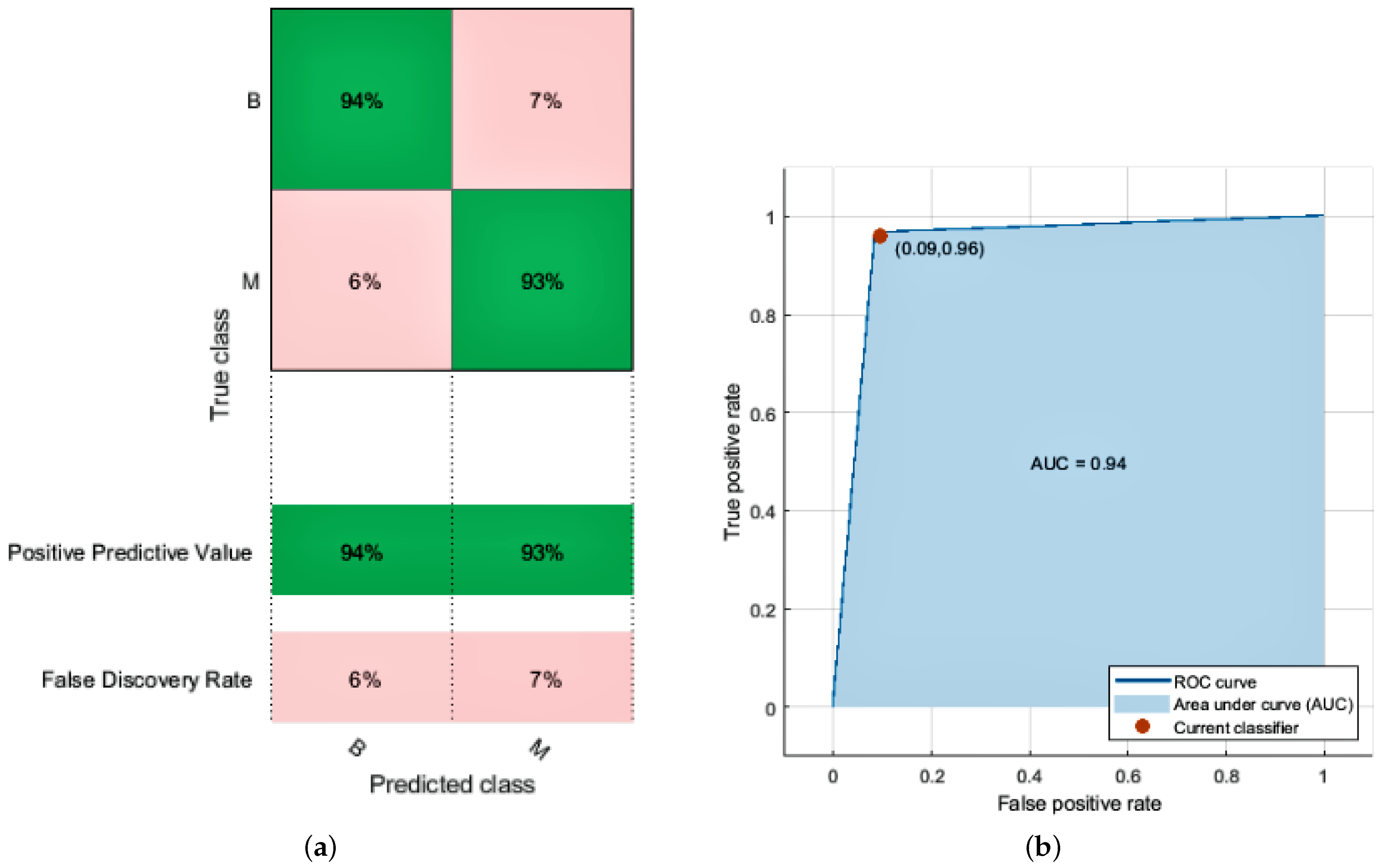
The logistic regression model’s perimeters are estimated using LR classification. The LR classifier achieves 94.0% accuracy with a prediction speed of 2400 observations per second and a training time of 52.778 s. The confusion matrix and ROC curve of the LR classifier are given in
Figure 4a,b. We achieve the following accuracy by using this model given in
Table 6.
We simply tuned our model using parameters in SVM. We have two classes, malignant and benign, graded by colors: blue color for malignant and red for benign. Tuning the area-mean and concave points-mean proves efficient classifiers. Our data lie in different magnitudes. We use unity-based normalization and tuned all data records to a 0–1 range. SVM creates a hyper plane that divides the two classes into malignant and benign. To avoid under fitting and over fitting problems, we optimized the parameters by applying C parameter and Gamma techniques. SVM achieves the highest accuracy of 97.7% with quadratic and cubic models. The quadratic model takes 2.4081 s to train with a prediction speed of 3700 observations per second, while the cubic model takes 4.7405 s to train with a prediction speed of 2300 observations per second. Quadratic is the best fit model regarding prediction speed and training time. With a prediction speed of 2000 observations per second, the linear model achieved 97.5% accuracy in 3.509 s. With fine Gaussian, SVM achieved the lowest accuracy. Overall, the number of positive identifiers in both classes is much more than the incorrect ones. These findings show that SVM can forecast breast cancer and distinguish between benign and malignant tumors.
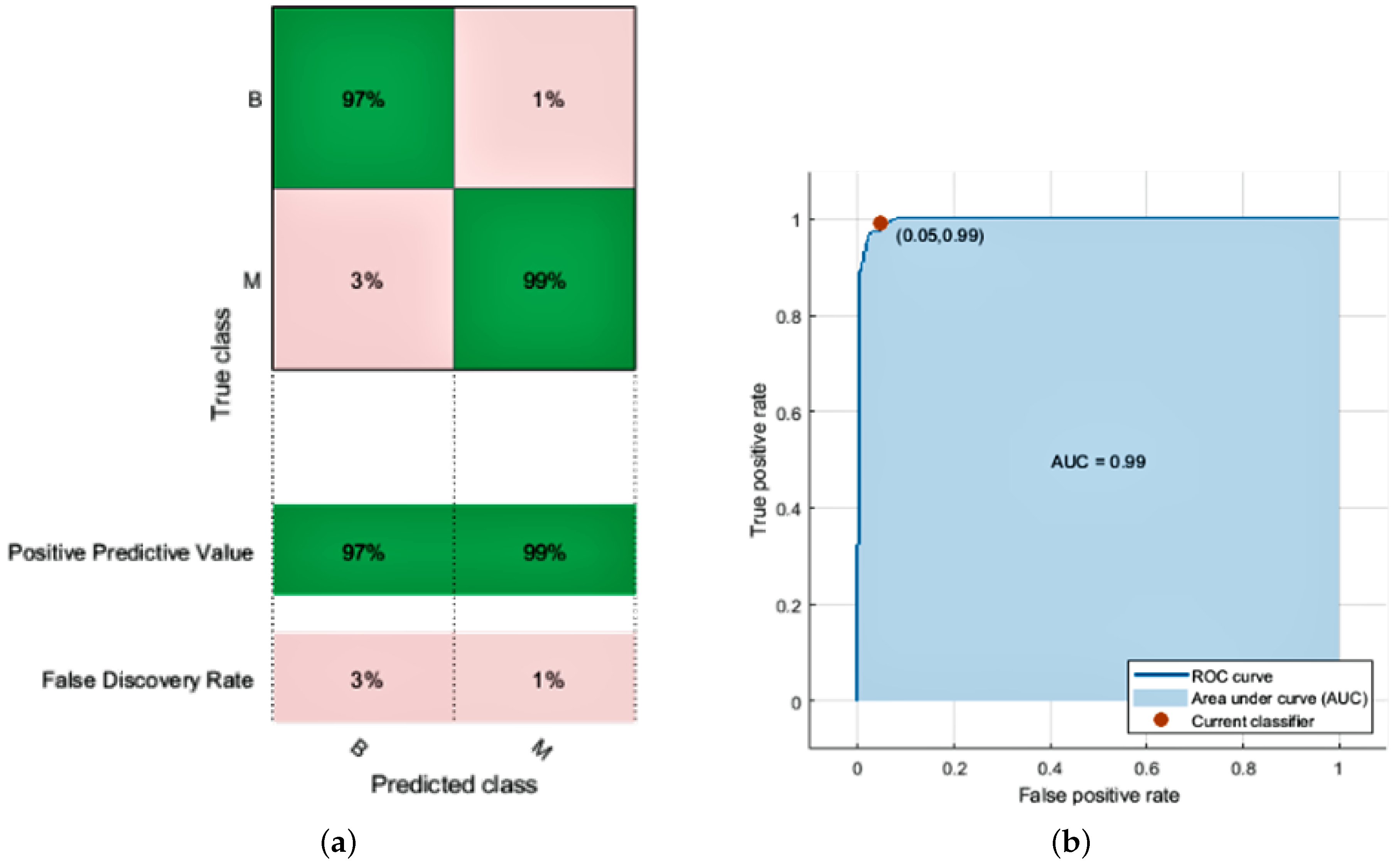
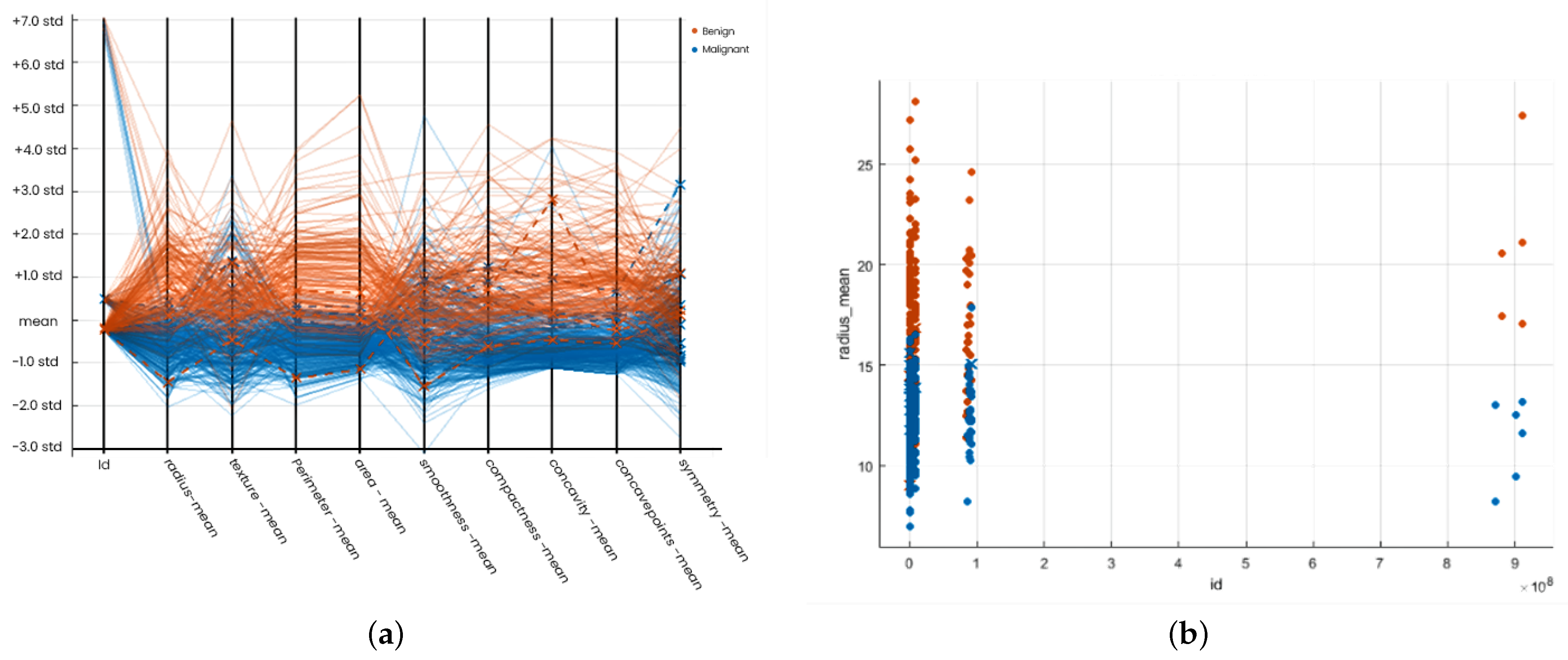
After overall simulation, we obtain a confusion matrix; the receiver operating characteristic (ROC), parallel coordination, and scattered plot of SVM models are given in
Figure 5a,b and
Figure 6a,b, respectively. Finally, we obtain the following accuracy percentage of different SVM models given in
Table 7.



 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}