2. Materials and Methods
We started by selecting ZN-stained slides originating from positive and negative cases. (
Section 2.1). The ZN-stained slides were scanned and annotated, in the end more than 260,000 positive and more than 7,000,000 negative patches of 64 × 64 pixels were selected. (
Section 2.2). The dataset was further expanded by different augmentation techniques. (
Section 2.3). We identified and customized a deep learning architecture suitable for our task. (
Section 2.4). The model was validated on a validation dataset consisting of 286,000 patches (validation set) different from the dataset used for training. (
Section 2.5). The model configuration with the best results in validation was further tested in clinical trials. (
Section 2.6). In this phase, the scanned image of the ZN-stained slide was uploaded on a platform, divided in 64 × 64 pixels patches, and each patch was analyzed by the algorithm. The algorithm returned a score for each patch and the pathologist received a list of patches sorted in descending order by their corresponding score. The pathologist analyzed the patches, both separately and in context on the slide and decided if the patch was positive or not. Based on this evaluation, the pathologist decided if the slide was positive (one single positive patch is sufficient to diagnose the slide as positive) or not (AI-assisted diagnosis).
The pipeline’s performance was measured twice:
- -
First evaluation (“validation”) was performed using patches from pre-selected regions on the slides. On the one hand, the validation gave us the possibility to evaluate the performance of several architectures and allowed us to choose the best model for further use. On the other hand, the results obtained on other pre-selected patches (from slide areas used for active learning) were analyzed one by one by pathologists in order to establish errors (positive patches labeled as negative and vice versa; negative ones falsely labeled as positive). The mislabeled patches were correctly re-labeled and used for re-training and finetuning the model, thus improving its performance.
- -
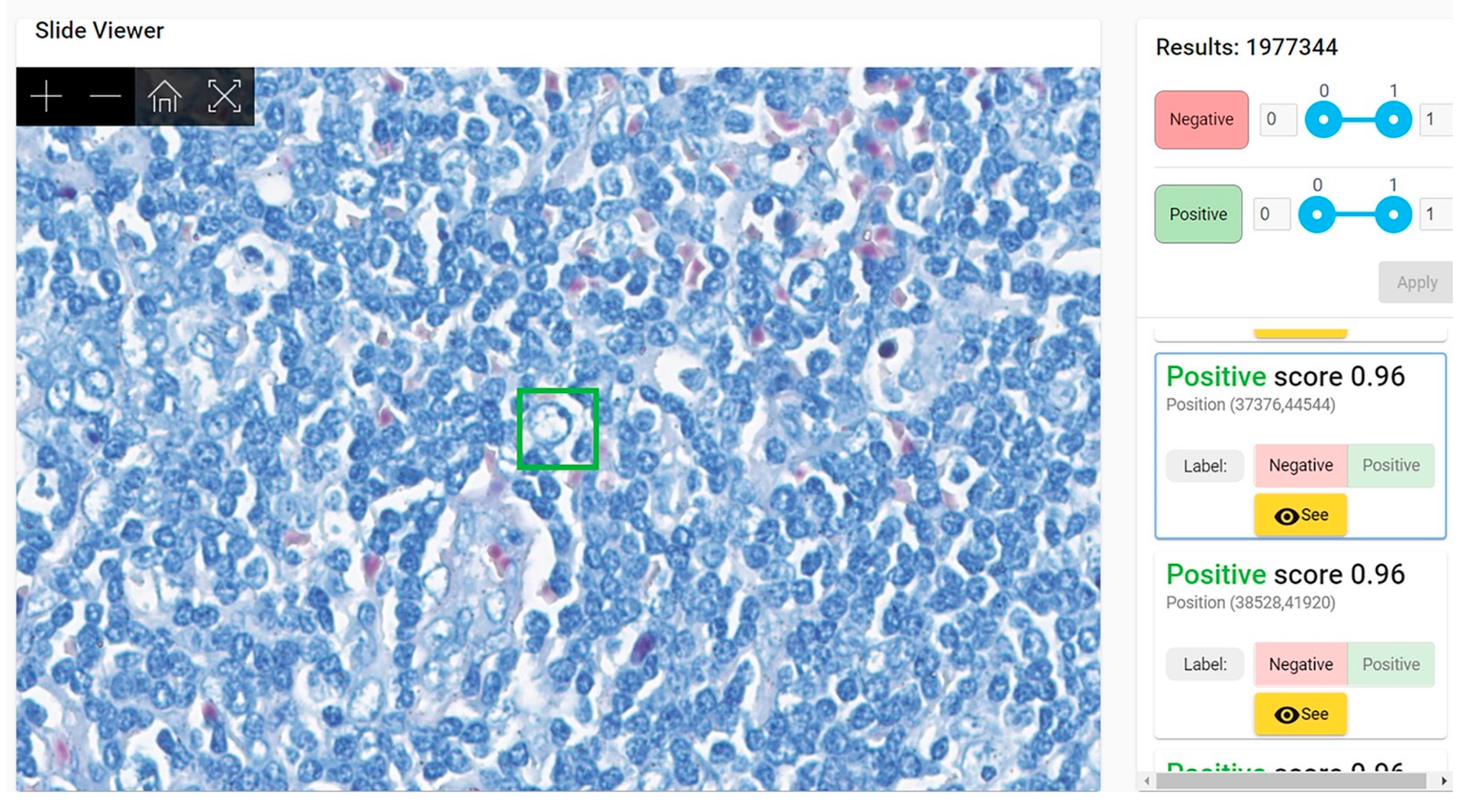
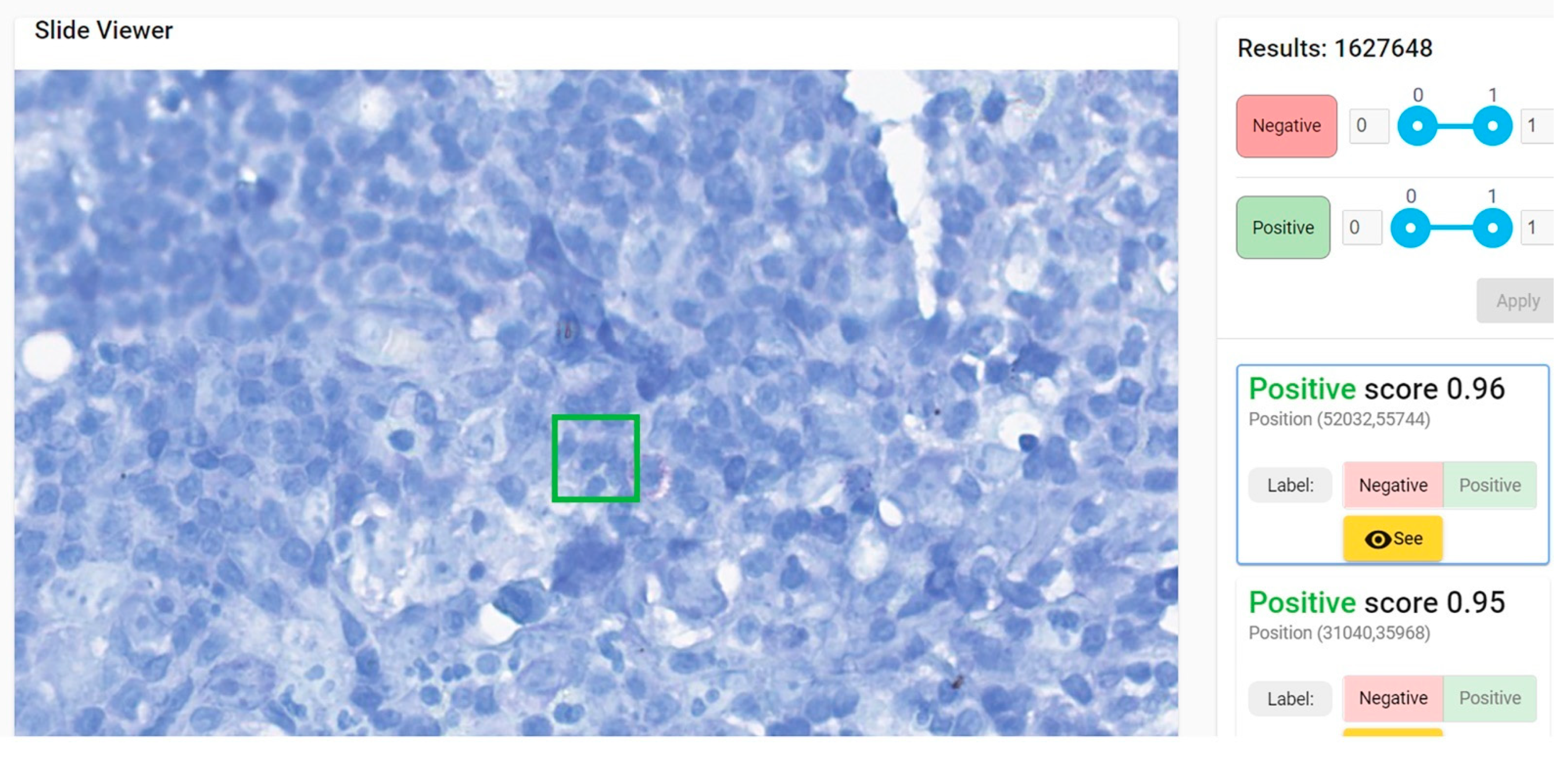
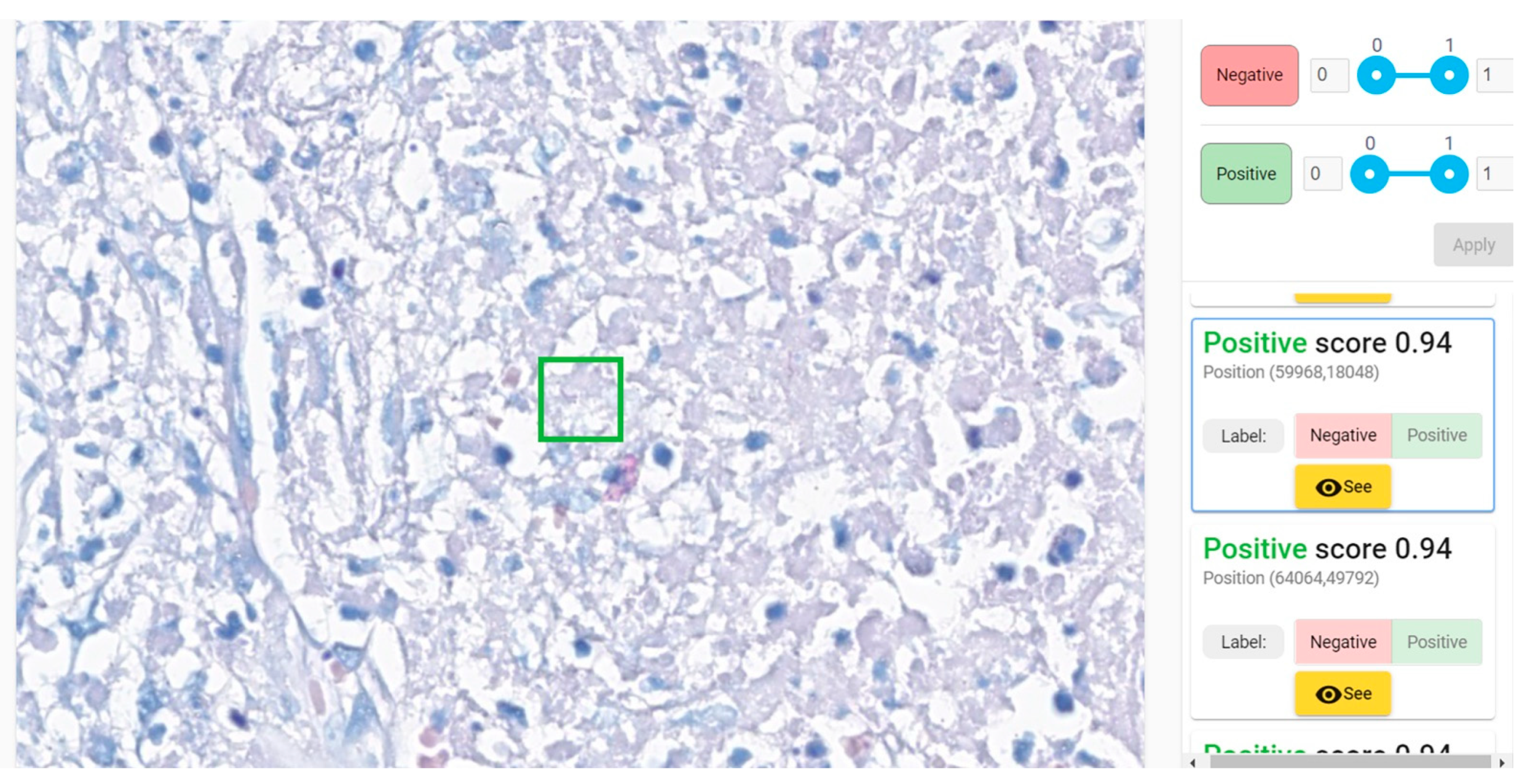
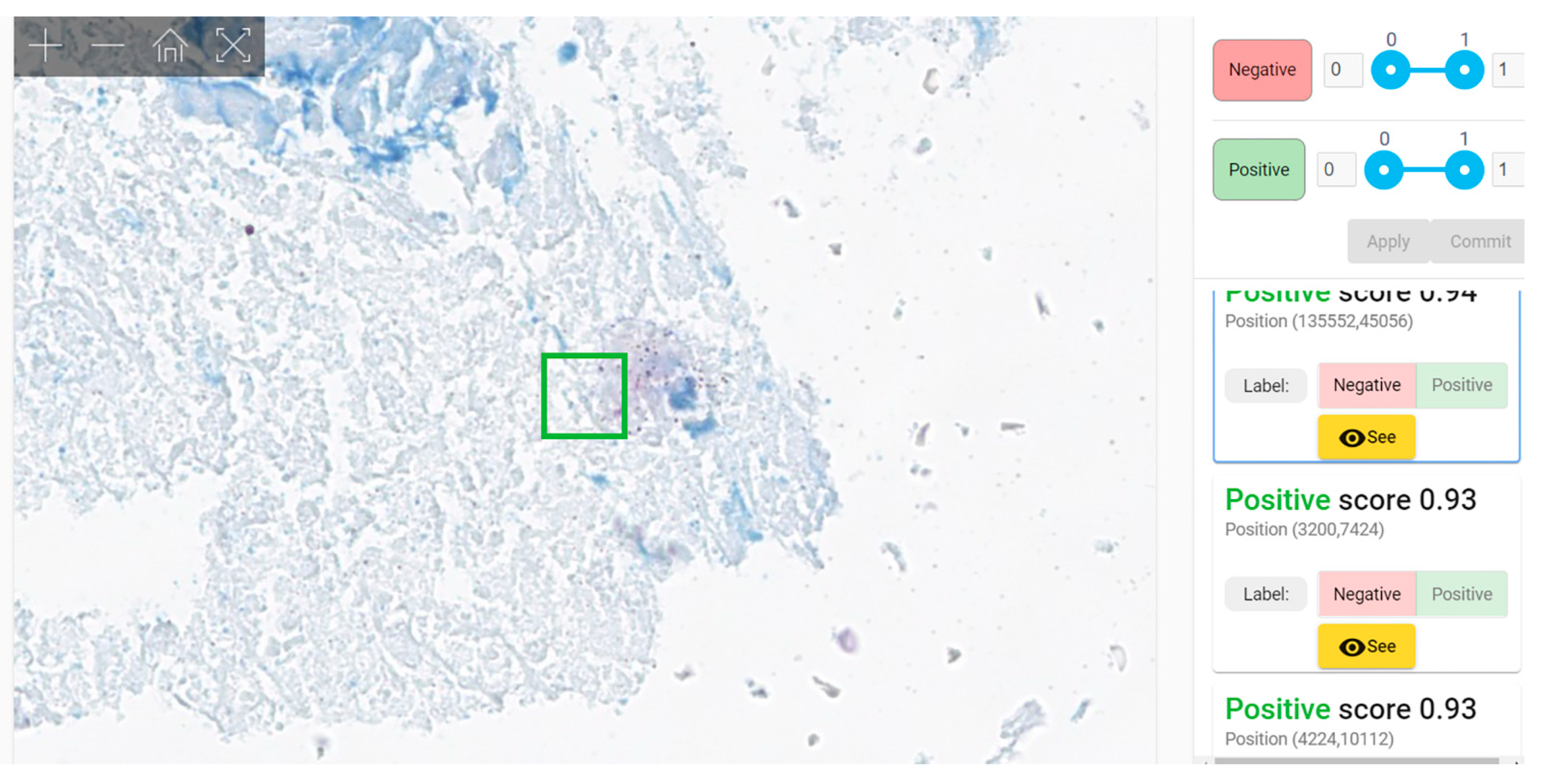
Second evaluation (“clinical testing”) was performed using WSIs. Each WSI was segmented in 64 × 64 pixels patches and all patches were fed to our model for analysis. The model examined each patch and gave a score of probability (0 to 1)—the probability of the patch to belong to the positive group of patches used for training = to present mycobacteria. The results were displayed as a column of patches with their class score, arranged in descending order of the score (i.e., the patch with the maximum score was listed first). A threshold must be established for a patch to be considered positive; the obvious choice should be 0.5. However, in our testing data we noticed that almost all patches with scores between 0.5 and 0.7 were negative. Our model was not classifying the WSI as positive or negative, instead it revealed to the pathologist the patches that are more probable to harbor bacilli, leaving the final decision of the diagnosis of WSI to the human examiner. (This is considered AI-assisted diagnosis).
2.1. Case Selection
We analyzed the archives of the Department of Pathology of Colentina University Hospital from 2010 to 2022. We selected 2187 cases with ZN stains mentioned in the histopathology report. Consultation cases were excluded.
All the cases were re-evaluated both on H&E and ZN stains available in the archive by SZ (a senior pathologist with 23 years of expertise). Cases with discordances between the initial histopathological report and SZ’s re-evaluation were excluded.
- -
Positive cases group: cases reported as diagnosed with TB with ZN-stain slides positive and reconfirmed as such by microscopic reevaluation.
- -
Negative cases group: cases without AFB bacilli in ZN stain (both primary—at the moment of diagnosis) and confirmed diagnosis of other illnesses than tuberculosis. Cases with histopathologic appearance highly suggestive of tuberculosis (epithelioid granulomatous inflammatory infiltrate with multinucleated giant cells and coagulative necrosis conserving reticulin network in Gömöri stain—specific morphological aspect of caseating necrosis) and negative ZN stain were NOT included.
All the cases were tissue fragments (either biopsies or surgical specimens) received by our department as fresh or formalin-fixed tissue. After the macroscopic examination (grossing), the fragments were immersed in 10% buffered formalin until the next day (18–24 h), routinely processed to paraffin (automatic tissue processors Leica ASP 200S (see
Table S1 Supplementary Material) and Leica Peloris 3 (see
Table S2 Supplementary Material) were used), embedded in paraffin blocks (embedding stations ThermoFisher Microm EC 1150 H, Leica EG 1150H, Sakura Tissue Tek and Leica Arcadia), sectioned at 3 microns thick (semi-automated Rotary Microtome Leica RM2255 and RM2265) and stained with ZN staining kit (Ziehl–Neelsen for mycobacteria—microbiology, BioOptica Italy) (see
Table S3 Supplementary Material).
H&E slides were used only for analyzing the morphologic lesions, to confirm the diagnosis in positive cases, and to exclude from the negative group the cases with high-morphology suggestive of TB but without AFB in the ZN stain. For our study we use only the ZN-stained slides classified as positive and negative as previously described.
ZN-stained slides were scanned using both manual and automatic scanners, each slide being entirely scanned as whole slide image (WSI) in “.svs” format. The manual scanner was provided by Microvisioneer, Esslingen am Neckar, Germany, and consisted of a Camera Basler Ace 3.2 MP (acA2040-55uc) with Sony IMX265 Sensor and Microvisioneer manual WSI Software Professional Edition. The automatic scanner was a Leica Aperio GT450.
Finally, we obtained 570 WSIs: 133 positive and 437 negative; 510 WSIs—group A (110 positive WSIs and 400 negative WSIs)—were used for training purposes while the remaining 60 WSIs—group B (23 positive WSIs and 37 negative WSIs)—were used for testing (
Table 2).
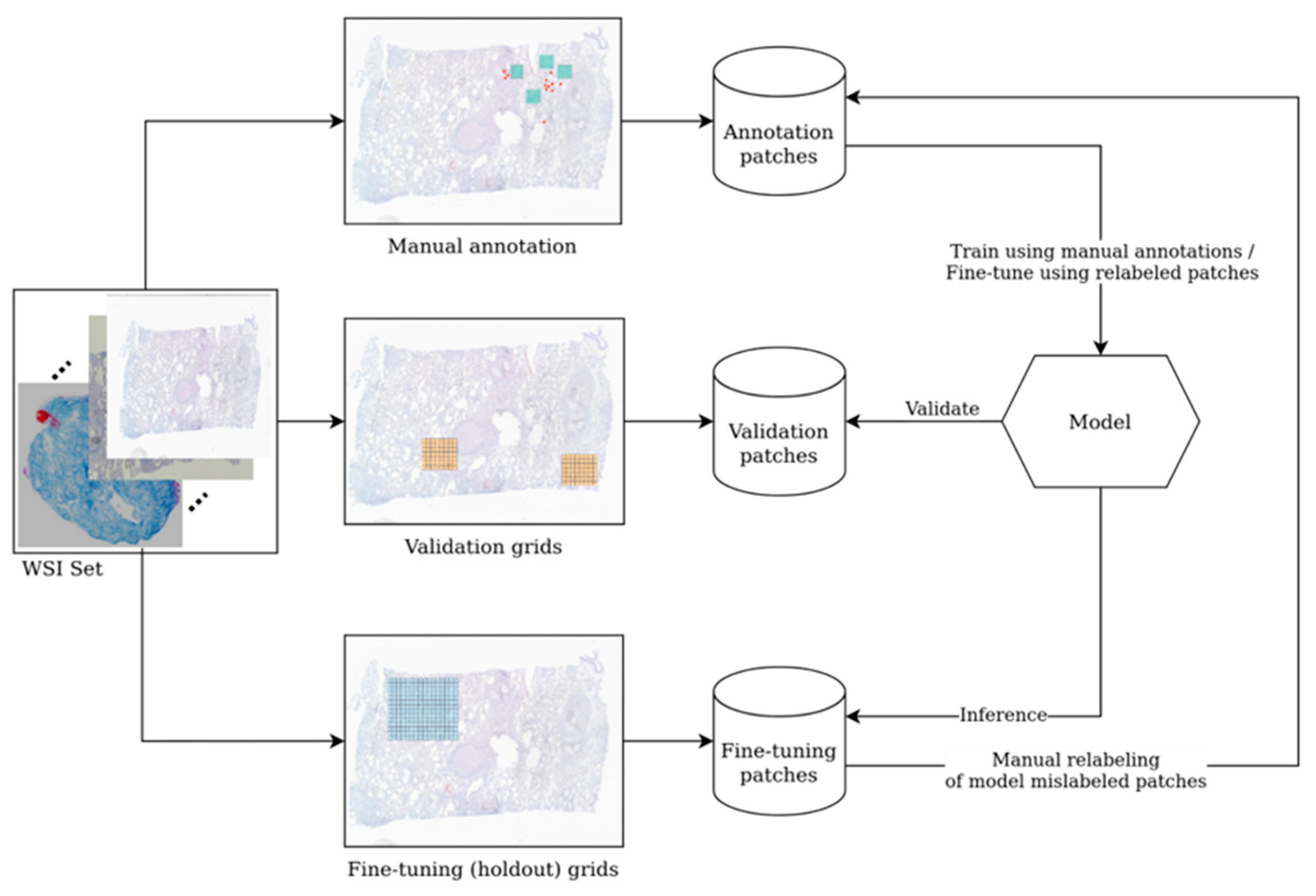
2.2. Annotation Process
The WSIs from group A were annotated by 7 pathologists with various experience (
Table S4 Supplementary Material) using an in-house platform for annotation and Cytomine application (Cytomine Corporation SA, Liège). Positive areas were identified either as patches (less than 64 × 64 px) in our in-house annotation platform or point-like annotations of the bacillus in Cytomine platform. Negative samples were drawn either from WSIs labeled as negative or from manually annotated negative areas inside WSIs labeled as positive. Patches selection from negative WSIs was performed in two steps: firstly, the WSI area was filtered to contain a sufficient amount of tissue (versus background); secondly, a 64 × 64 patch was sampled via a uniform distribution from this area. In the end, we obtained a pool of negative samples containing more than 700 million patches before applying any augmentations. Examples of positive and negative areas are depicted in
Figures S1–S6 (Supplementary Material).
2.3. Image Augmentation Techniques
Even though the dataset obtained via the annotation process contains more than 260,000 positive examples, there is a large diversity that the staining process induces to the color space of both positive and negative WSIs. In order to mitigate this, we have employed extensive augmentation techniques to cover a wider variety in WSIs. The augmentation transformations were applied to all training patches. These included random rotations in the range of 0 to 90 degrees (clockwise and counterclockwise); random shifts; random crops; and random brightness, contrast and saturation changes. In addition to these specific transformations, we also extracted positive patches around the annotated AFBs by shifting a maximum of 24 pixels in any of the two axes. Since all transformations were applied in a chain, specific to sample interpolation techniques, we considered that training examples have diversified by at least one order of magnitude.
2.4. Deep Learning Model Development and Training
Our patch-based classifier for AFB detection is based on RegNetX4 architecture. This deep convolutional neural network manages to yield state-of-the-art performance while preserving simplicity and speed. It has the advantage of requiring less hyperparameter tuning, which is an important consideration when dealing with the large amount of data and data manipulation techniques used in our setting. In order to better fit the task at hand, we have adapted the architecture through various custom modifications:
We reduced the kernel size in the stem layer (plausible morphology of bacillus can be constrained in a 3 × 3 convolution filter or 5 × 5 convolution filter);
We reduced the number of strided convolutions, as an overall larger receptive field in the final stages is not necessarily helpful due to the low spatial size of the target class;
We employed parallel dilated convolutions (i.e., selective kernel convolutions [
22], atrous convolutions [
23]) in order to accommodate morphologies that are not necessarily captured in a 3 × 3 filter while still keeping a reasonable amount of trainable parameters;
We opted for reflection padding instead of zero padding in all padded convolution layers to reduce locality bias learned by the network in order to be more robust to bacillus positioning inside boxes served at inference or testing time.
The network variant we used contains less than 160 million learnable parameters, allowing for adequate inference speed even when not using high-end hardware, without any degradation of the performance metrics.
We trained our model in a distributed fashion using parameter replicas for each Graphics Processing Unit (GPU) and gradient averaging before broadcasting parameter updates. We used a batch size of about 2048 per GPU with positive and negative examples roughly evenly split in order to mitigate the severe class imbalance. We experimented with various proportions (positive vs. negative) starting from 25–75% up to 75–25% using 5% increments. We limited our learning procedure to a maximum of 100 million samples seen (including augmented patches). The optimizer used was AdaBound where the step size α is provided by a linear warm-up cosine scheduler with periodic restarts [
24]. Inference is performed only on the parts of the WSI containing a relevant amount of tissue. Filtering the WSI was performed using the same method as for filtering the training areas used for extracting patches. Depending on the WSI size and CPU threads used for WSI patch area extraction our baseline processing pipeline (i.e., 1 CPU thread) manages to process a WSI in 5 to 15 min.
2.5. Model Validation
We constructed a set of validation patches by annotating several areas collected from 37 WSIs; obviously, none of the areas selected for validation were previously used for training. The areas thus collected have been divided in non-overlapping patches of 64 × 64 pixels, which were subsequently annotated by the team of pathologists as either positive or negative. We have obtained 286,000 validation patches of which 15,000 are positive and 271,000 negatives. The class imbalance is intentional, as it is much more likely for the model to generate false positives than false negatives and this data distribution is much closer to real conditions than a balanced one.
2.6. Testing Process
For the testing process four teams of two pathologists each were involved; each team included pathologists of similar experience (
Table S5 Supplementary Material). We compared three types of results: B1—results obtained by examining slides with a bright-field light microscope; B2—results obtained by examining the WSIs scanned with a Leica Aperio GT450 automated scanner; and B3—results obtained by algorithm-aided WSIs evaluation. A wash-out period of 2 weeks between each type of evaluation was respected. For each case, in each scenario (B1, B2, and B3), the pathologist registered the status (positive or negative) and the time required to reach the diagnosis. No time limit was established for examination of either slides or WSIs. All the results were compared with the “gold standard”—the original histopathological report reconfirmed by H&E and ZN stains reexamination (see
Section 2.1).
2.7. Statistical Analysis
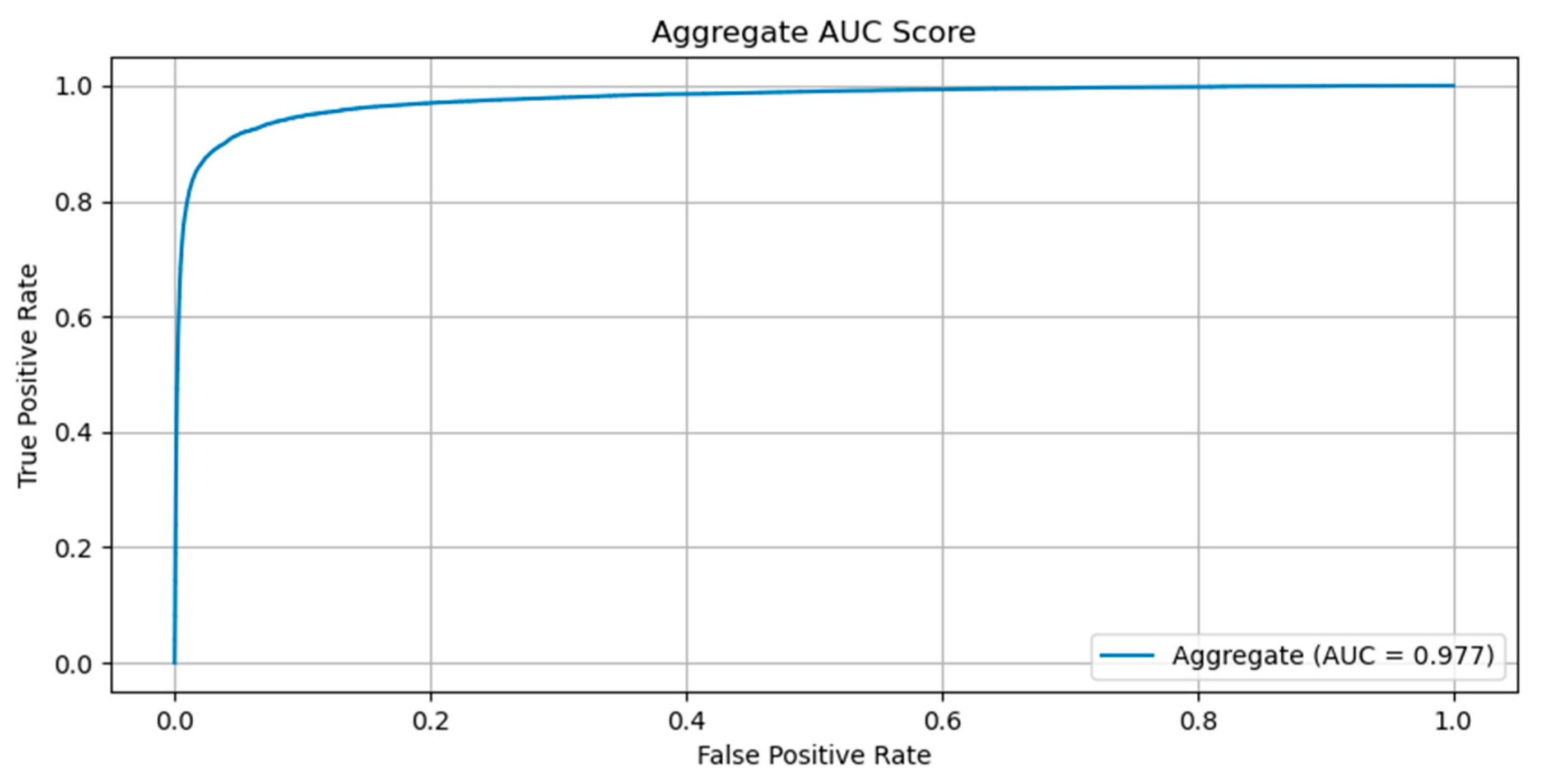
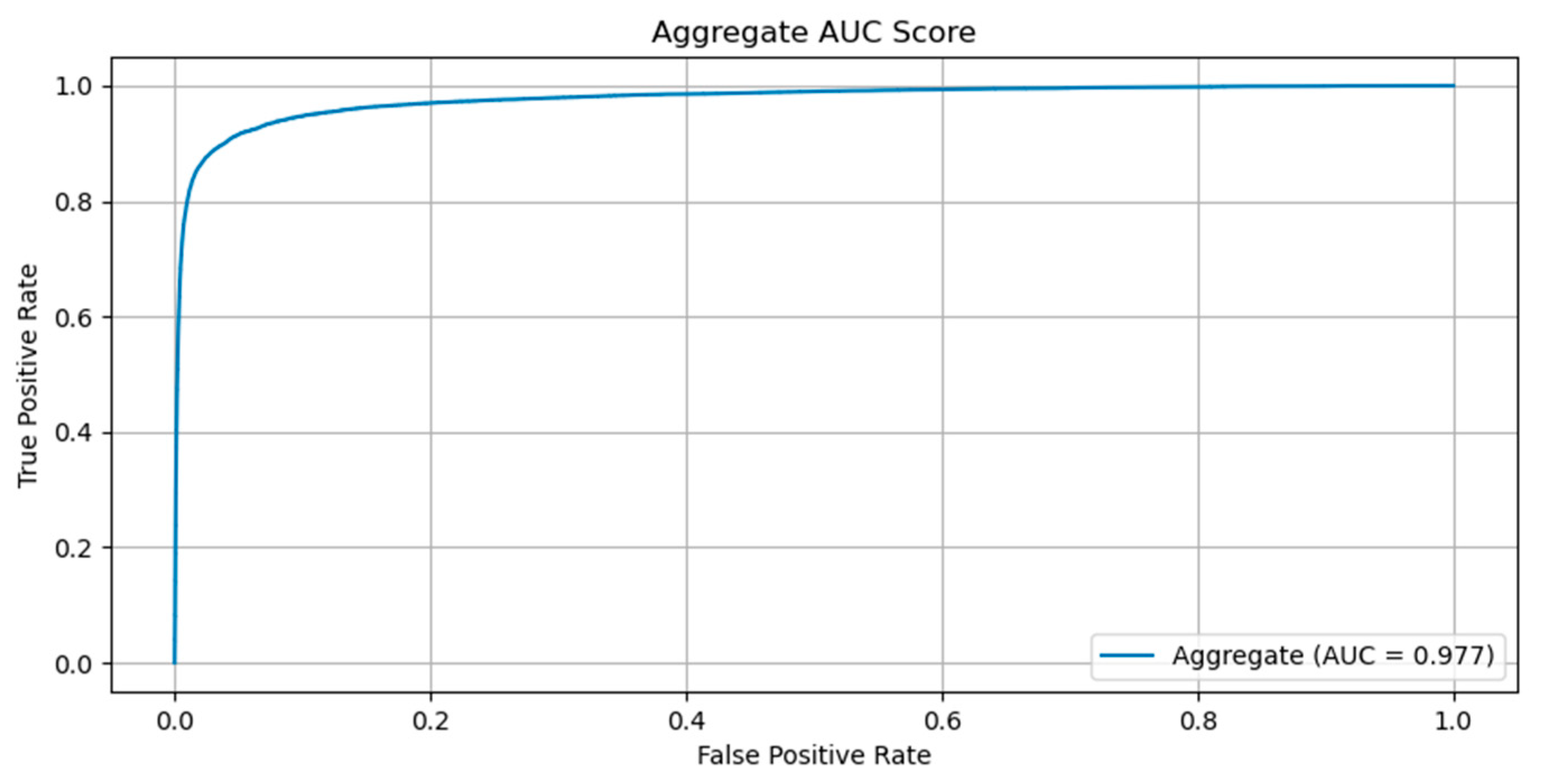
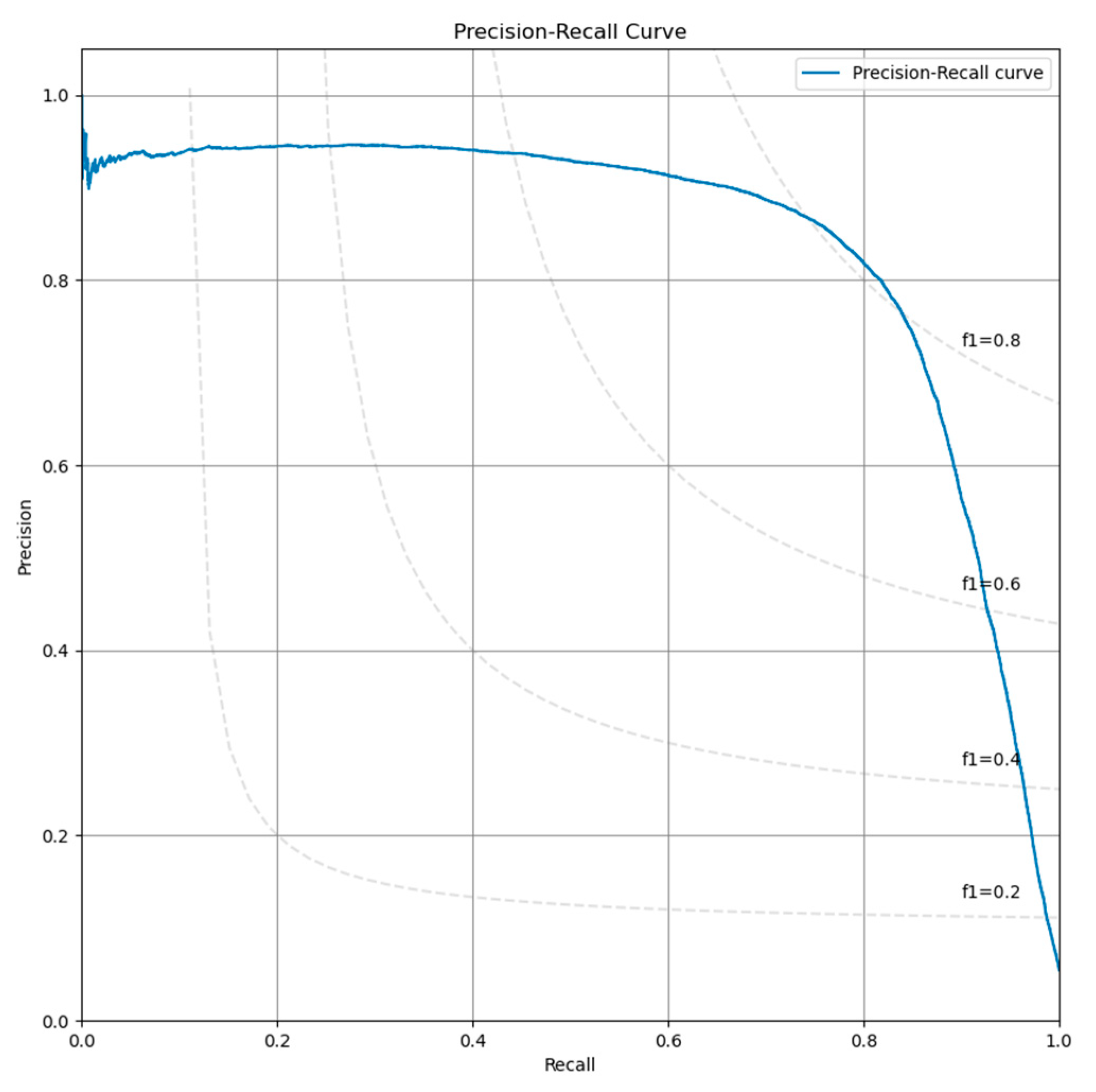
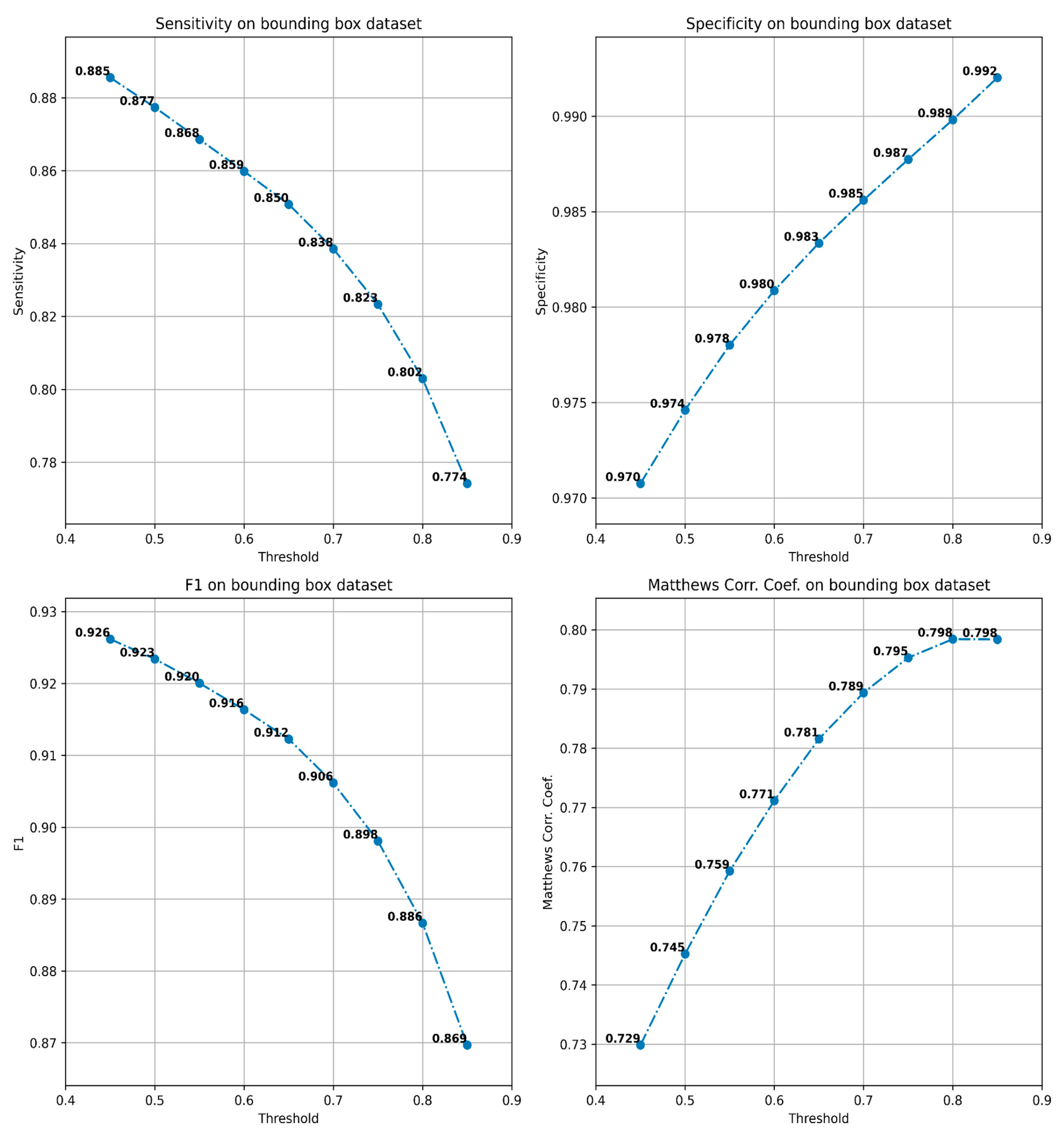
Model validation was performed using the validation set that the team of pathologists had produced. A receiver operating characteristic (ROC) curve was plotted to describe the diagnostic ability of the model to classify patches as containing AFB or not. The imbalance we have imposed between the number of positive and negative patches in the validation dataset has led us to select the Precision–Recall curve as a useful measure to compute the area under the receiver operating characteristic curve (AUC) for (AUPR). Due to the same reason, we also computed the F1 score and Matthew’s correlation coefficient (MCC). All metrics were computed using Python libraries scikit-learn and matplotlib.
Statistical significance of the difference between two groups was analyzed using the χ2 test, where applicable. Statistical significance was defined as p < 0.05, and all statistical analyses were performed using the EXCEL program.
4. Discussion
Diagnosis of TB can be difficult. A complex interpretation of clinical and radiological images supported by immunological, bacteriological, histopathological, and molecular tests is needed. Paucibacillary lesions are particularly difficult to diagnose. Sputum and/or tissue examination often fail to identify AFB. Bacteriological tests are more successful in identifying mycobacteria than pathology (up to 50–80% more sensitivity for bacteriology compared with histopathology) [
28] but the main drawback of the method is the time required by cultures—average of 14–21 days but it is not unusual to take up to 6–8 weeks [
29]. PCR and bacteriological tests may also offer divergent results [
30]. Immunohistochemistry for mycobacteria is expensive and due to the small dimensions of the bacillus, can be difficult to interpret in paucibacillary lesions.
Histopathologically identification of AFB in the appropriate morphological milieu represents the most precise diagnosis of TB possible because it corroborates the presence of specific lesions with the presence of the bacteria. TB is a form of “specific chronic inflammation”, i.e., inflammation with microscopic lesions so characteristic that, by their presence alone, one can affirm with certitude that the culprit provoking the morphologic alterations is a species of Mycobacterium. The lesions consists of confluent epithelioid granulomas with centrally located Langhans multinucleated giant cells and caseating necrosis. In these cases, the diagnosis requires only a routine H&E stain. However, in different circumstances (early lesions, associated illnesses such as cancers, immunosuppression or (auto)immune diseases, simultaneous infection with other microorganisms, etc.), this typical morphological picture is altered and several special stains are needed for diagnosis: Gömöri staining for reticulin and van Gieson Weighert for elastic fibers (to prove the preservation of reticulin and elastic fibers in necrotic area); ZN or auramine (to identify AFBs); some other special stains (Giemsa, Gram, Grochott, Warthin Starry, etc.) to exclude the presence of other microorganisms; in some cases immunohistochemical tests for mycobacteria; and/or polymerase chain reaction (PCR) for Mycobacterium tuberculosis are performed. Moreover, clinical, blood tests (QuantiFERON-TB), and imaging data are corroborated in order to establish a diagnosis of TB [
31,
32].
Understanding the details of the histopathologic diagnosis of TB is mandatory in order to explain the strict inclusion and exclusion criteria one has to use for constructing the dataset. A paucibacillary lesion may include very few bacilli easy to miss even by an experienced pathologist. This is why we excluded from the negative cases group the slides with morphological appearance highly suggestive of tuberculosis even if the ZN-stained slides did not reveal any bacilli no matter how thoroughly was the examination both at the moment of diagnosis and at reexamination. Additionally, in the B group, in the negative set of cases used for testing, cases with morphology similar to TB but with a clear diagnosis of diseases other than TB were included. This was conducted in order to avoid an involuntary bias created when the pathologist examines a ZN-stained slide that he/she is convinced that the diagnosis is not TB and obviously no bacilli may be present: “it does not look as TB, for sure no AFB are present; no careful scrutiny is needed”; “it looks as TB, maybe there are AFP present; and let’s look for them carefully”.
Xiong et al., describe reevaluation of the cases during the process of developing the algorithm. They reclassified seven cases initially labeled as negative [
15].
Zaizen et al., have an interesting approach when constructing the testing group: the positive cases were those with proven mycobacteriosis either when the biopsy was performed or during follow-up; based on this perspective, AI-supported pathological diagnosis identified 11 positive cases versus 2 positive cases in classical pathological diagnosis, without AI support [
19]. It is unusual for a pathologist to miss 9 cases from a total of 42 (12.5% sensitivity). The algorithm was able to identify 11 positive cases (2 cases identified as positive by human examiner and 9 more cases) and “missed” 5 cases. Due to the design of the testing process, these “missed” cases could be real negative ones at the moment of examination (if a patient is developing an illness in the future he or she is not mandatory presenting the microorganism months in advance) or, due to the scarcity and the not uniform distribution of the mycobacteria within the tissue it is possible that the tissue examined by algorithm did not contain bacilli in the moment of investigation.
Another important advantage of our dataset is represented by the number of the cases selected for annotation and the number of positive patches. We annotated 110 positive WSIs obtaining 263,000 positive patches. As it is shown in
Table 8, this is the biggest and most diverse AI training dataset for mycobacteria to date. The number of negative cases is also important; at first glance, few negative WSIs are necessary for obtaining a large number of negative patches (one slide with 1 cm
2 of tissue can be cut in more than 800,000 patches of 64 × 64 pixels). It is important, however, to have different types of tissue with different types of lesions to ensure a sufficient variability of the patches in both structure and color. The absolute number of negative WSIs of our training group is also the biggest, comparable with Pantanowitz et al., dataset but with several orders of magnitude higher than the others. The high number of ZN-stained slides is important due to the fact that it offers a higher diversity of images. ZN stain is a manual stain with high variability from lab to lab, being almost impossible to standardize. A “good” ZN stain is one that reveals mycobacteria from light pink to deep red or even purple rods on a light blue to dark blue background. In fact, its variability is so high that one technician cannot obtain two identical ZN stains on the same tissue block. This can be “a blessing in disguise” since the algorithm trained on a sufficiently large dataset (originating from a sufficiently numerous different WSIs), supplementary extended by augmentation techniques altering color, contrast, brightness, saturation, etc. will be able to properly recognize ZN-stained WSIs provided by labs worldwide.
In the five methods of automatic identification of mycobacteria in ZN-stained slides described in the literature, one study (Lo et al. [
17]) does not evaluate WSI. Its validation is solely made on patches. Xiong et al. [
15] present a completely automated method of diagnosis while Yang et al. [
16], Pantanowitz et al. [
18], and Zaizen et al. [
19] developed AI-assisted diagnostic methods as a tool in the hands (and eyes) of pathologists. In Yang et al.’s method, the pathologist evaluates a score heatmap superposed on the WSI. In Pantanowitz et al.’s method, the pathologists evaluated a gallery of patches displayed in reverse order of the probability score in relation with WSI. Both methods allow for the pathologist to evaluate the suspicious areas in the context of the specific histopathological lesion. Zaizen et al., do not describe precisely how the pathologist uses the platform for diagnosis. Instead, they specify that each probably positive patch was examined by six pathologists.
Our method is an AI-assisted diagnostic method with a similar approach to Pantanowitz’s et al.’s design of the platform (analyzing a list of patches displayed in reverse order of the probability score). However, our solution employs a much larger dataset (about two orders of magnitude larger) and an active learning approach that further increases the performance metrics, especially for difficult cases (i.e., artifacts) or WSIs with peculiar staining.
Our algorithm obtained very good results compared with previous studies. Our testing method compared the AI-assisted diagnosis with the pathologist’s diagnosis either on slides (by microscopic examination) or WSIs. Our test set included 60 cases based on general recommendation for the minimal size required for digital pathology validation [
33]. As expected, there is a definite improvement of AFB identification by pathologists when examining slides other than WSIs. It is known that pathologists are not very keen to change from conventional microscopy to remote WSI examination as a routine. The diagnostic concordance between WSI and slide examination varies from 63% to 100% in different studies [
34].
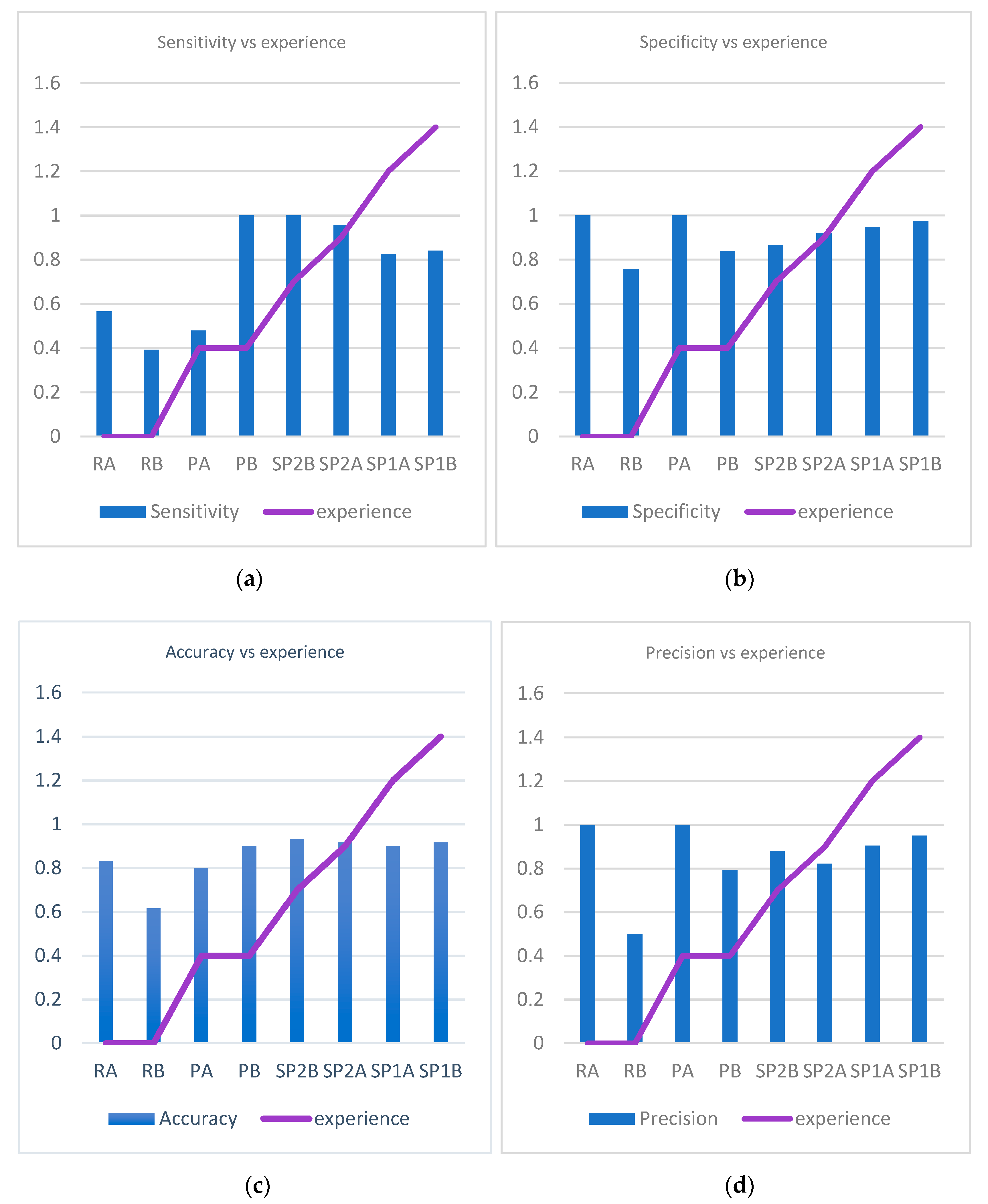
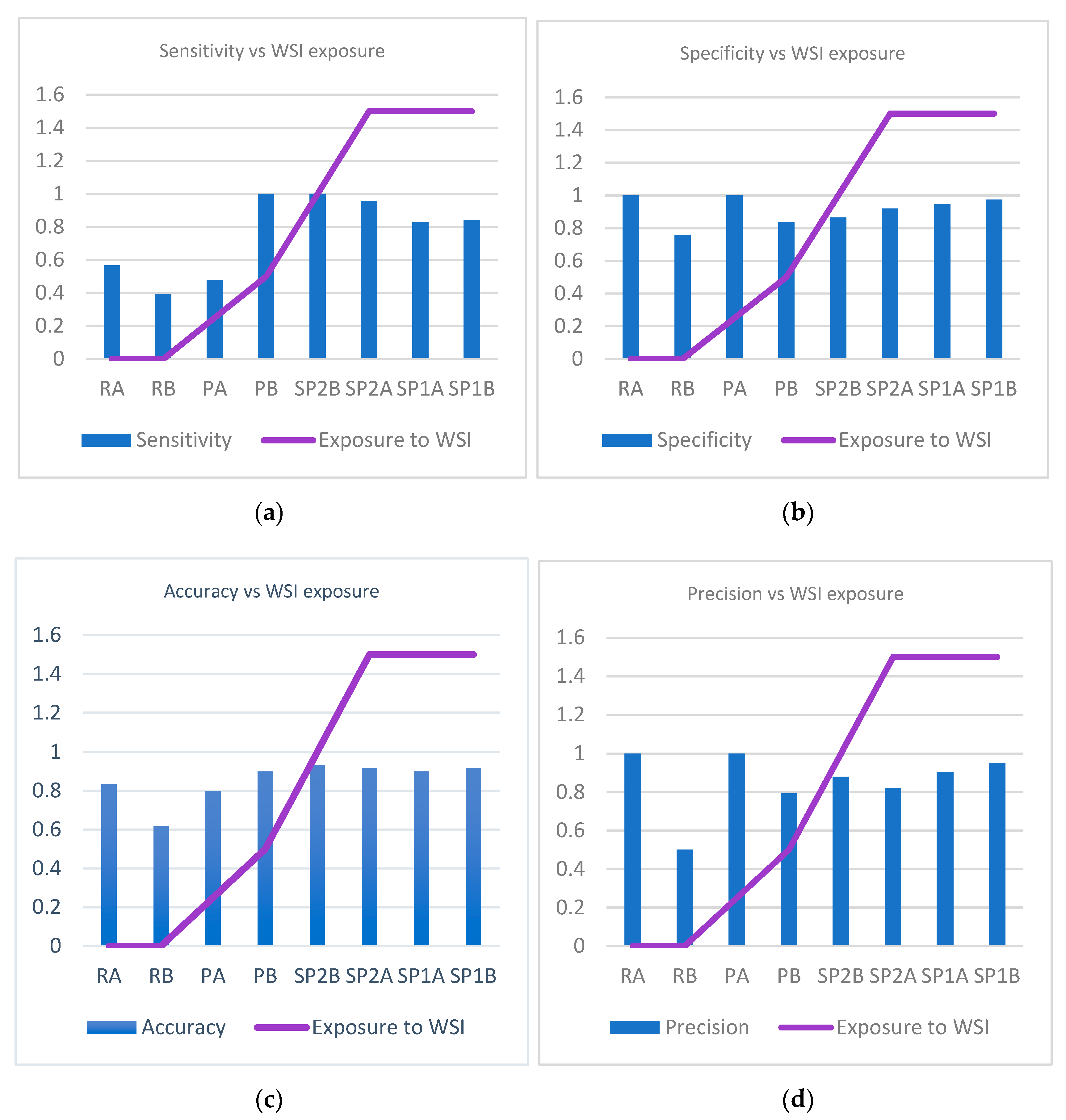
Moreover, pathologist’s experience in examining WSIs affected the accuracy of finding AFB—the longer the period of exposure to WSIs, the better the pathologist’s results. The accuracy of the diagnosis when our algorithm was used was higher than the accuracy of every pathologist, even when slides were examined. The algorithm was able to pick more bacilli than the human examiner alone, thus almost eliminating the false negatives. When examining slides, pathologists missed a total of 47 cases of TB (false negatives), in average almost 6 cases per person. Our algorithm helped pathologists improve Mycobacterium identification on WSIs, but the results were also better with AI-assisted evaluation than those where pathologists examined slides by microscope. In real life, a pathologist examining a slide may identify lesions suspicious of TB—epithelioid granulomas with giant cells and/or coagulative necrosis with reticuline preservation (caseum). When one suspect TB, he/she will ask for a ZN special stain in order to identify bacilli. AFB presence confirms the diagnosis of TB without biunivocal relation (i.e., AFB absence does not exclude TB diagnosis). In other words, when a pathologist fails to identify AFB, he/she will not necessarily miss TB but the positive diagnosis that will finally be obtained in most of the cases will be obtained with supplementary efforts (several costly techniques) and with some delays in significant cases. Altogether, both the patients and the medical system will benefit from implementation of such an algorithm in routine pathology.
Another issue for discussion is the debate about what metric should be preferred: specificity or sensitivity? A diagnostic method is preferable to be specific while a screening test is better to be more sensitive. We decided to use a higher specificity (fewer false positive cases) with the risk of missing some positive cases (false negative). The algorithm selects patches that are more probable to contain AFB and shows them to the pathologist. If the algorithm is picks up too many structures, the pathologist will be forced to look to a myriad of artifacts and he/she will lose a lot of time sorting through them.; In the end, it is more profitable to examine the slide without AI support.
Last but not least, when discussing our algorithm capabilities in comparison with human results, we should not forget that our team of pathologists are familiar with ZN stains and AFB identification on slides; we expect that a pathologist not used to examining ZN-stained slides would have poorer results with more numerous false negatives, especially in paucibacillary lesions.
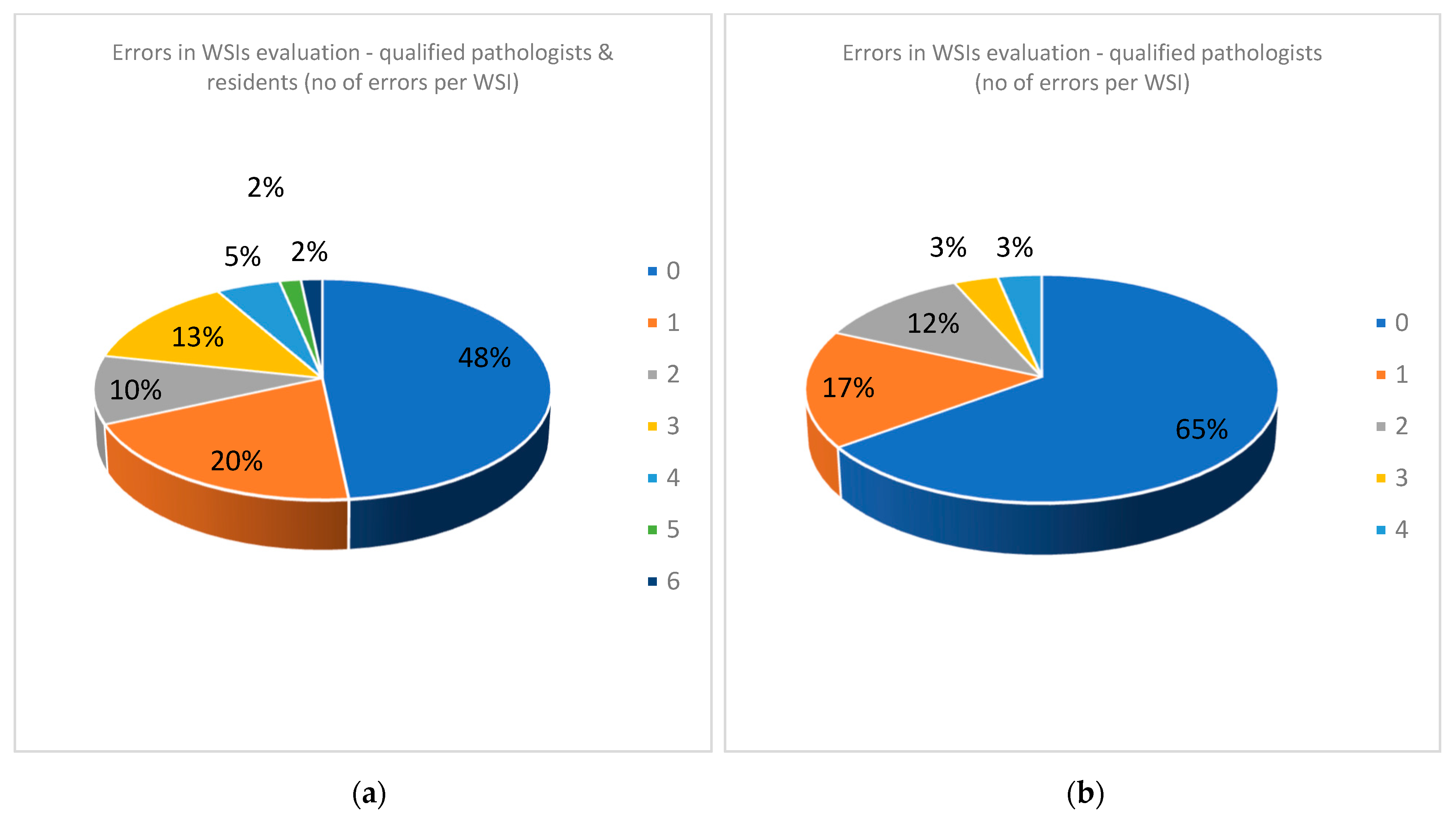
When looking at the errors in analyzing both WSIs and slides, there are huge differences between qualified pathologists and residents. The residents were in their final year of residency and are very good and hard-working people. However, we showed that no exposure to WSIs prior to this test poorly influenced the outcome.
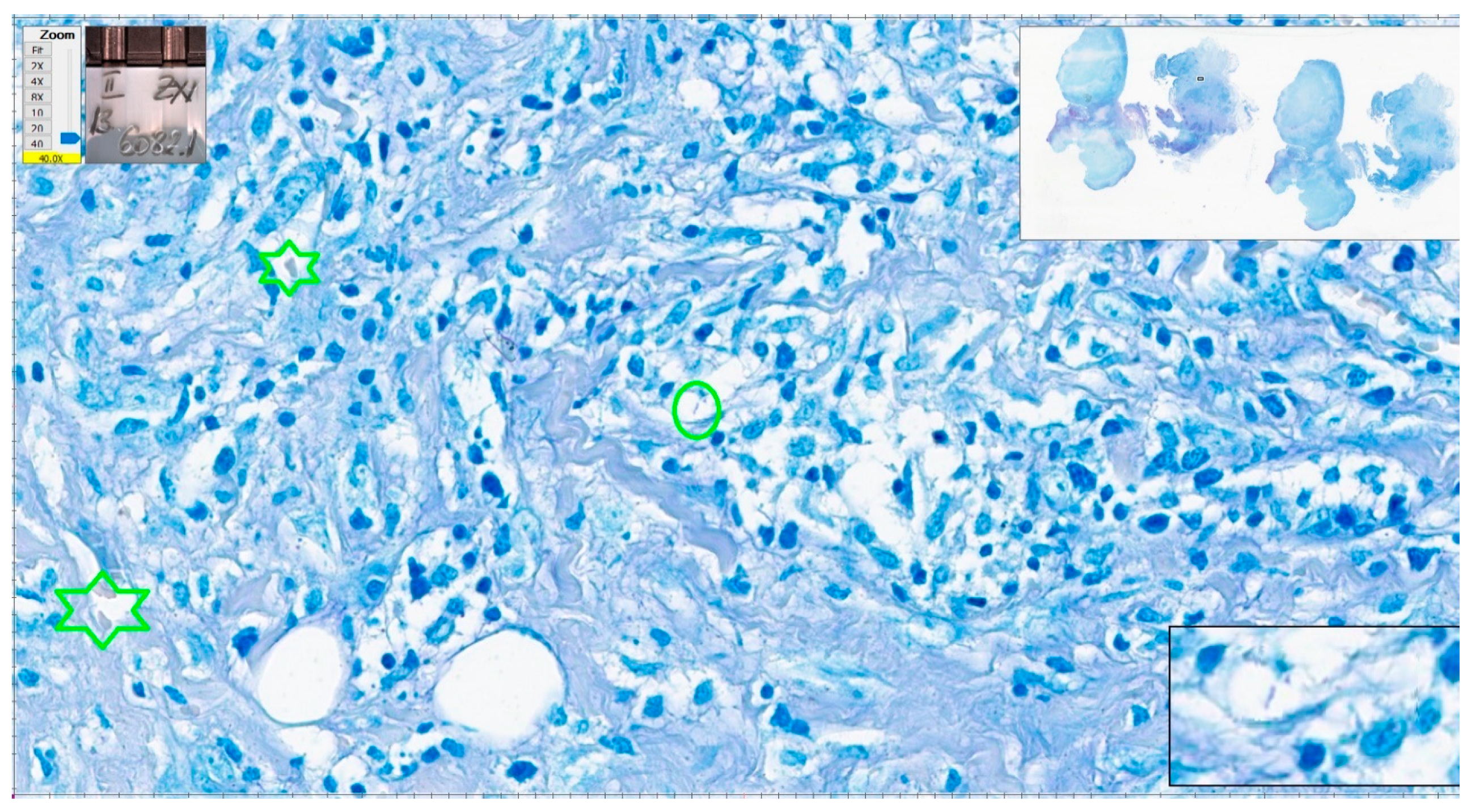
We have a closer look at the cases with the most numerous errors in interpretation. One negative case had five errors with eight examiners and four errors from six qualified pathologists (cat scratch disease—suppurative necrotizing granulomatous lymphadenitis). Some structures looked like AFB, but the overall quality of the stain was poor (slightly pink–pale red blood cells). In some areas, structures could be mistaken as AFB but the suspicious structures were not clear-cut bacillar structures (
Figure 13 and
Figure 14).
A case of tuberculosis in striated muscle had four errors from eight examiners. There were many fragments of tissue and almost 5 cm
2 of tissue with very few bacilli, which were easily missed by examiners (
Figure 15).
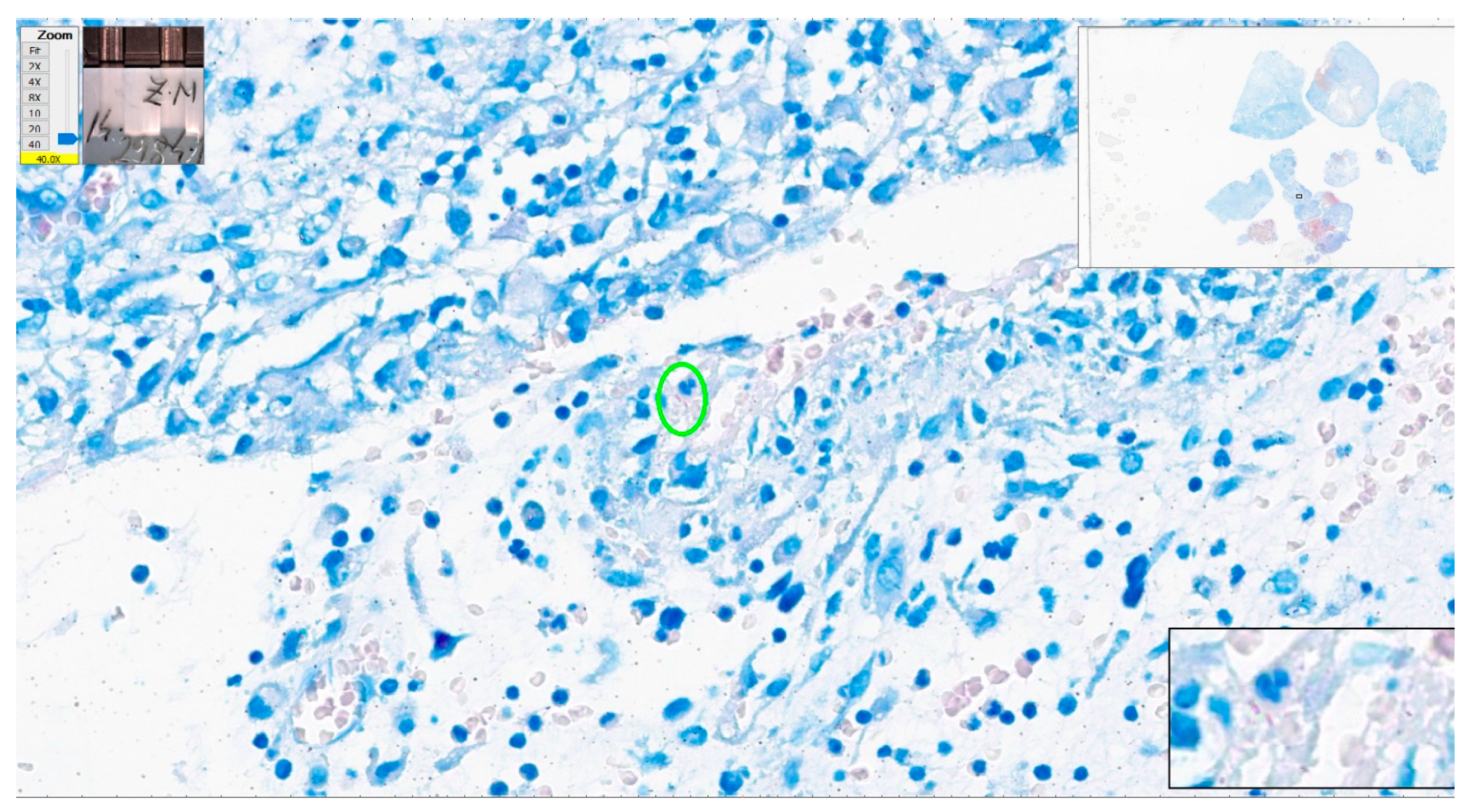
The case with most errors in interpretation was a tuberculous epithelioid granulomatous lymphadenitis with extensive caseation with very few bacilli present in ZN stain—one to four AFB present in each section. Due to the minute dimensions of Mycobacterium tuberculosis (one micron thick), a bacillus will be completely enclosed in one section of tissue and serial sections reveal different bacilli. The slide examined in this test included two sections of tissue with very few bacilli, one in one section (
Figure 16) and two on the other section. Considering the paucity of the bacilli, it is no wonder that the examiners missed them on WSIs. Interestingly, this was the case the algorithm was not able to identify bacilli. For this case, the algorithm identified 3 patches with positive scores over 0.7 and 145 patches with positive scores between 0.5 and 0.69. None of them presented convincing AFBs.
In fact, in order to avoid the examiner being biased by the overall picture of the lesion, the testing set was designed to include lesions with similar appearance to tuberculosis such as granulomatous inflammation, most of them with necrosis. The cases with reactive lymphadenitis, unspecific inflammation, or malignancies were not erroneously evaluated by any examiner.
The most impressive benefit of using the AI-assisted algorithm for AFB identification is saving time. AI-assisted evaluation was 2.84 times faster than human evaluation. We have to be aware that the pathologists involved in our clinical test had impressive experience in diagnosing tuberculosis and analyzing ZN stains. Our department has expertise in infectious diseases diagnosis. ZN stain is routine for lymph nodes and bronchial biopsies and, moreover, the pathologists were recently exposed to numerous positive and negative ZN-stained WSIs during the annotation period. A “regular” pathologist likely does not have the same level of exposure, so the time required for a thorough examination of a ZN-stained slide is usually much longer. We can estimate that our algorithm saves at least one-third of the pathologist’s time that can be spent on other more complex tasks.
Moreover, considering the inherent bias induced by the level of expertise of our team of pathologists, the results of our model argue in favor of an overall increase in the quality of AI-assisted diagnosis. In other words, if the model was able to reach the best performance of one of our most experienced pathologists (identifying convincing positive patches in all but one cases), for a less experienced pathologist the algorithm will certainly improve their performance. It is true that the final labeling of the status of the patch (positive versus negative) is established by the pathologist. The fact that the model is identifying highly suggestive areas helps the human examiner to make a final decision.
Situations when AI algorithms performed better than pathologists were reported during clinical testing for automatic identification of prostate cancer. One case previously missed by pathologists was suggested as malignant by the algorithm and confirmed as such by experts [
35]. Additionally, algorithms for Mycobacterium tuberculosis detection identified positive cases with subsequent expert’s confirmation [
15,
19].
Our algorithm is able to identify bacilli even in cases with a very low density of AFB and in cases that were missed by pathologists, even when considering experienced pathologists (AI-assisted diagnosis based on our method has a specificity 100% and sensibility 95.65%). The impact of this achievement is significant. Our automatic method being used to assist pathologists in identifying AFB is saving time and money that is otherwise required by other investigations. Therefore, it shortens the interval between the biopsy and the start of the treatment with major benefits, both for the patient (better results and faster improvement of health) and for society (faster decrease in the patient’s infectiousness, diminishing the medical costs for expensive investigations or, longer treatments required for old lesions, diminishing the social security costs by fewer days of medical leave, etc.).
There are many limitations for our technique. The main important limitations concern the dimensions and diversity of the dataset and our method of clinical testing.
Our dataset is the largest and most diverse of the datasets for mycobacteria presented in the literature. It is also the most “correct” one, due to our method selecting cases. Unfortunately, it is not a “perfect” dataset; to reach this goal, the dataset should include all the positive slides from all over the world. This is virtually impossible. We applied several techniques of augmentation to minimize this drawback, but we are aware of this impossible to overcome drawback.
Our method of clinical testing is also flawed because of the simple fact that the team of researchers who developed the algorithm also validated it. This forced manner of designing the test of the algorithm thus biases the validation of all AI-models developed in medicine. We tried to diminish this risk by separating the people who designed and selected the test group of cases from the people who actually performed the test. Our most experienced pathologist tried to further minimize the risk by including in the test group positive paucibacillary cases and negative cases with similar microscopic appearance to TB (see the discussions above). We are aware that the bias is not completely overcome due to the simple fact that the pathologists belong to the same school of pathology with similar methods of evaluation and routines. The only answer for this limitation is for independent validation to be performed by pathologists from completely different institutions and from as many countries as possible, ideally on international cohorts of patients. Overcoming this problem represents the key towards clinical implementation of the algorithm [
36].


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}