1. Introduction
A sub-health condition (SHC) or sub-optimal health status refers to a condition characterized by decreased vitality, physiological function, and capacity for adaptation. However, it is yet to be medically diagnosed as a disease or functional somatic syndrome [
1]. It is imperative to consider all SHC indicators to prevent chronic diseases and achieve better health outcomes. Metabolic syndrome (MetS) is a collection of indicators that define SHC risk and can assist in formulating strategies for preventing disease progression [
2,
3]. Metabolic factors, such as being overweight or obese and having hypertension, hyperlipidemia, and hyperglycemia, are critical metabolic changes that can increase the risk of chronic illness [
4]. MetS increases the risk of developing various chronic diseases, such as a 2.5-fold higher risk of chronic kidney disease (CKD) [
5], a 2.5-fold higher risk of myocardial infarction [
4], a 2–4-fold higher risk of cardiovascular stroke, and a 5-fold higher risk of type II diabetes mellitus [
6,
7].
CKD is characterized by abnormal kidney function and is stratified into stages 1, 2, 3a, 3b, 4, and 5 according to the Kidney Disease Improving Global Outcomes’ (KDIGO) guideline [
8]. Kidney diseases have become a major public health issue as they affect around 850 million individuals worldwide [
9,
10]. Patients with CKD often develop complications and MetS, accelerating their renal function deterioration, shortening the kidney lifespan, and ultimately increasing the incidence of CKD and intensifying its progression [
11,
12]. Both MetS and CKD are important risk factors for diverse complications [
13,
14]. Studies have demonstrated a positive correlation between MetS and CKD [
15,
16], and a MetS diagnosis effectively predicts CKD risk [
16,
17]. Among the existing studies, conventional statistical method usage is the approach that is commonly taken.
Machine learning (ML) approaches, being relatively unaffected by the limitations of conventional statistical methods that rely on predefined assumptions and hypotheses, have found widespread use in detecting and predicting diseases at various stages, demonstrating promising performance [
18,
19]. ML approaches can proficiently analyze latent and intricate relationships and information that underlie multiple predictor variables/risk factors and outcomes [
20]. Based on the feature selection results obtained from ML methods, the employment of the variable ensemble rule (VER) can aid in assessing the predictor variables of models to improve analytical outcomes. The VER consolidates the selection results of different variables using various approaches or principles to enhance the robustness of variable selection outcomes [
21].
Stage 3 CKD can be divided into Stages 3a and 3b, representing mild and moderate renal function impairment, respectively. Both substages are vital in assessing whether a patient should undergo kidney dialysis, and they are associated with different mortality risks and clinical features [
22,
23]. However, only a few studies have explored how metabolic syndrome (MetS) affects Stage 3a and 3b CKD in patients and their shared risk factors [
17]. While clinical health data, in general, can accumulate into a substantial amount of big data, in practice, whether addressing preventive healthcare for chronic diseases, including MetS, or assisting in the assessment of CKD at stages 3a-3b for high-risk diagnosis, establishing a risk prediction model for clinical use requires the incorporation of more appropriate or rational limited longitudinal healthcare data into research analysis. Collecting such data is essential for building predictive models and thereby identifying relevant risk factors more accurately, facilitating specialized physicians in clinical diagnosis, and aiding in medical decision making.
When dealing with limited medical datasets that are small or medium-sized, establishing conditional data under various variable ensemble rules can be beneficial in model building. ML algorithms, when applied with various variable ensemble rules, can compensate for the limitation of a small sample size, achieving a simultaneous improvement in predictive capabilities. Existing CKD analyses are primarily based on the findings of cross-sectional studies [
24,
25], which have mainly discussed CKD and evaluated its risk factors. The analysis of health examination data requires consideration of trends in the continuous change of data. That is, when conducting longitudinal data analysis, it is essential to give precedence to scrutinizing the trend and variability of the data, rather than exclusively depending on baseline data. Therefore, we generated four extended variables to gather trend and variability information from each of the predictor variables. These extended variables can provide a wide range of information and can be used as predictor variables for constructing the ML prediction model.
Given the significance of MetS as a risk factor for CKD and its pertinent role in CKD development mechanisms over times, evaluating the risk factors for CKD in patients with MetS using longitudinal data is a vital step in effectively managing and preventing CKD. This study aimed to use ML methods and VER schemes to identify the important risk factors for CKD in longitudinal data for patients with MetS diagnosed with stages 3a or 3b CKD. It assesses six effective ML methods—random forest (RF), multivariate adaptive regression splines (MARS), least absolute shrinkage and selection operator (Lasso), extreme gradient boosting (XGBoost), gradient boosting with categorical features support (CatBoost), and light gradient boosting machine (LightGBM)—as they are already being successfully utilized in various healthcare and medical applications [
26,
27,
28,
29], and five VERs in feature engineering—maximum aggregation (MA), arithmetic mean aggregation (AMA), geometric mean aggregation (GMA), Borda count aggregation (BCA), and ranking mean aggregation (RMA). Using these methods, we develop an ML- and VER-based hybrid multiphase CKD prediction scheme for evaluating and consolidating the key risk factors for patients with MetS and CKD.
The proposed scheme first aggregates the scoring generated from corresponding ML methods via the five VERs. Because each machine learning model can provide feature importance scores on both numerical and categorical scales, the corresponding Variable Explanation Ratio (VER) is chosen based on these scores, allowing for the consideration of a wider range of information. Then, a union operation is employed to create a final selection of the most important features. By implementing the proposed scheme, we can reduce the complexity associated with a large number of features, thereby providing clinicians with crucial information to support medical decision making. Furthermore, as the proposed scheme can select important features, model performance can be improved when using these selected features.
The accumulation of clinical health data often leads to big data challenges. However, creating effective risk prediction models for chronic diseases, such as MetS and high-risk CKD stages 3a-3b requires, focused longitudinal healthcare data analysis, which is often limited to small datasets. The limited longitudinal healthcare data make it challenging to build effective models in health promotion fields. This study innovates by proposing an effective scheme to enhance predictive accuracy with traditional machine learning algorithms, even with smaller datasets. The proposed scheme can effectively find features influencing CKD progression while improving the performance of the model in classifying CKD progression transitioning from stage 3a to 3b.
2. Materials and Methods
2.1. Data
This study used the regular health examination records of 71,108 patients in the Mei Jhao (MJ) Health Checkup-Based Population Database (MJPD), a Taiwanese long-term and continuous patient follow-up database, from 2005 to 2017. This timeframe was chosen to accumulate a sufficient number of consecutive samples. This decision was driven by the focus on a high-risk population with both CKD stages 3a to 3b and MetS. They included 201,807 health examination indicators and questionnaire records. We identified patients with MetS and stage 3a or 3b CKD using the MetS definition of the Health Promotion Administration (HPA) of the Ministry of Health and Welfare of Taiwan [
30] and the KDIGO guidelines and references. This study was approved by the Institutional Review Board of the Far Eastern Memorial Hospital (approval number: 110027-E; approval date: 3 March 2021) and the MJ Health Research Foundation (authorization code: MJHRF2023004A) and was registered at ClinicalTrials.gov ID:NCT05225454,
https://beta.clinicaltrials.gov/study/NCT05225454 (accessed on 27 February 2024).
2.2. Definitions of the Longitudinal Variables and Subjects
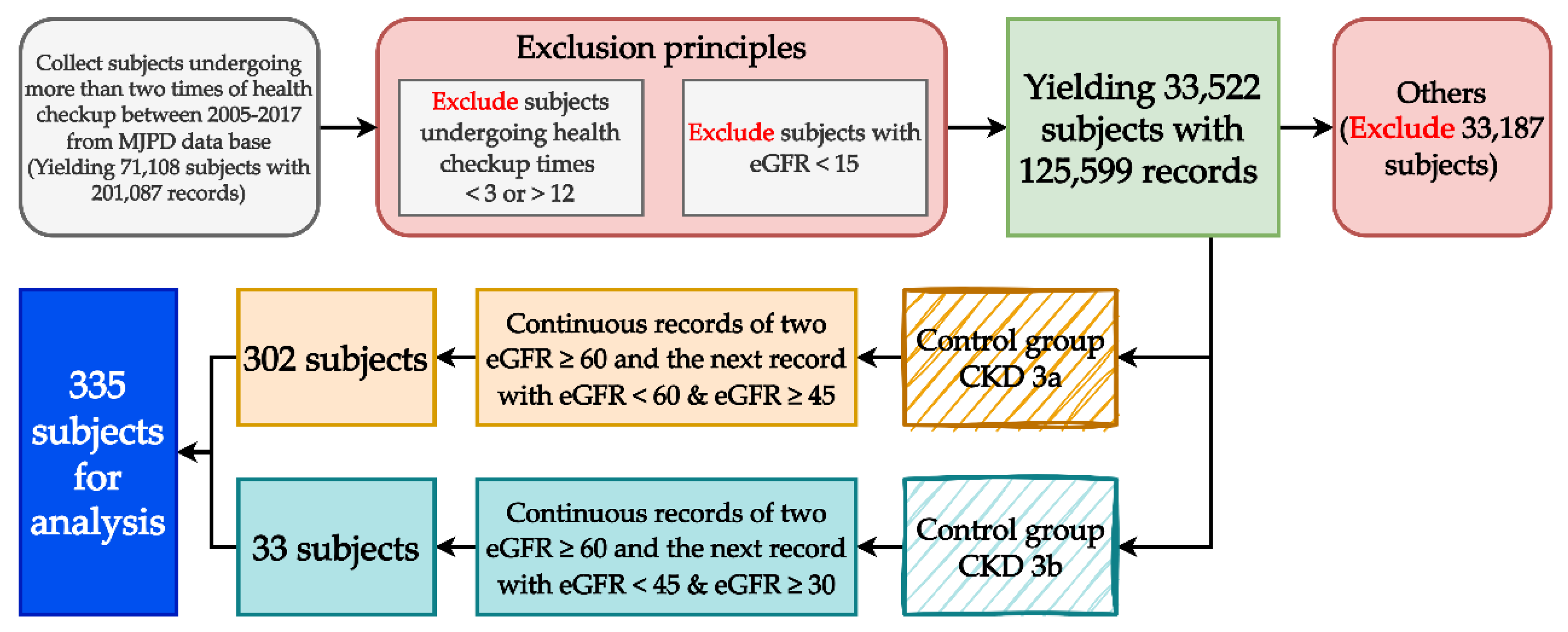
This study constructed the longitudinal variables and their data by using each subject’s first two examination results to predict their third CKD examination results. We collected subjects’ 12-year examination records (from 2005 to 2017). Consistent with the prediction goals and conversion principles of the longitudinal data (each subject completed one examination annually), we excluded subjects with less than 3 or more than 12 examination records, leaving 33,533 subjects (125,641 health examination records). The data may include patients on dialysis, and they were not within the scope of this study, so we excluded 11 subjects whose estimated glomerular filtration rate (eGFR) was below 15 (42 records in total), leaving 33,522 subjects (125,599 records). We grouped these subjects based on the definition and eGFR criterion of CKD into an experimental group, a control group, and an “others” group. The experimental group comprised subjects with two consecutive eGFR values ≥60 in their health examination records; in total, 33 subjects met the definition of stage 3a CKD as their eGFR was ≥30 and <45. The control group comprised 302 subjects who met the definition of stage 3b CKD. The remaining 33,187 subjects were placed in the others group as they did not meet the criteria for the experimental or control group. After a multiphase processing of all subjects’ data, there were 335 eligible subjects. The process of identifying the longitudinal subjects is shown in
Figure 1.
Among all 335 subjects, for each one, a total of three records were collected. As the aim of this study was to predict the relationship between each subject’s third CKD examination result and their risk factors, each subject’s previous two examination results were used as longitudinal predictor variables.
Table 1 provides detailed descriptions and definitions of the predictor and target variables in the longitudinal data. The predictor variable
represents the result of the
th variable at the
th examination (for example, the variable
is the BF value at the first examination), and the objective variable
represents the CKD result at the third examination. This study used 19 risk factors as predictor variables and can be further defined as Equation (1).
To generate extended variables, the four statistics involving the closest value, mean value, standard deviation (SD) value, and difference value of a predictor variable are considered. The closest value of a predictor variable uses the subjects’ latest examination results, which is the second examination in this study (). The predictor variable () generated based on the closest value is defined as Equation (2). For example, is the BF record () at the second examination, and it can be abbreviated as BF(C).The predictor variable () generated using the mean value of a predictor variable is the mean of the previous two examination results , and it can be defined as Equation (3). For example, is generated by obtaining the mean BF value of the last two examinations, and it can be abbreviated as BF(M). The predictor variable () is the SD of the last two examination results of a predictor variable, and it can be defined as Equation (4). For example, is generated by obtaining the SD of the BF result (at the first and second examinations. can be abbreviated as BF(S). A predictor variable () is the difference between the last two examination results of a predictor variable, and it can be defined as Equation (5). For example, is generated by subtracting the BF results of the first and second examinations. can be abbreviated as BF(D).
All four of the statistical approaches to generating extended variables are applied to all 19 predictor variables to generate the predictor variables for analysis. Therefore, a total of 76 predictor variables are considered, and they are also used to construct the ML prediction model. The demographics of the 19 variables from the subjects’ latest examination (
) are shown in
Table S1 in the Supplementary Materials.
2.3. Proposed Multiphase Hybrid Risk Factor Evaluation Scheme
In order to predict CKD outcomes and identify the key risk factors for CKD, this study proposes a multiphase hybrid CKD prediction scheme grounded in six ML algorithms (RF, MARS, Lasso, XGBoost, CatBoost, and LightGBM) that utilize the longitudinal variables generated in the previous section. RF is an ensemble learning method that consists of decision trees combined by bagging (bootstrap aggregation) [
31]. MARS is a multivariate, nonlinear, nonparametric regression method combining recursive partitioning and piecewise polynomial functions [
32]. Lasso shrinks predictor variables with weaker contributions to zero to control the trade-off between the bias and the variance in model fitting while reducing the likelihood of overfitting [
33].
XGBoost is an ensemble learning method based on gradient boosting [
34]. CatBoost is an improved decision tree algorithm that combines ordered boosting, gradient boosting, and classification features [
35]. LightGBM is a histogram-based distributed gradient boosting framework algorithm that restricts the maximum depth of the decision trees [
36]. These ML methods have been used successfully in various healthcare and medical applications [
26,
27,
28,
29], and all of them have the ability to select features while providing importance scoring to the input features. To evaluate the performance of the ML models, the balanced accuracy (BA), sensitivity (SEN), specificity (SPE), and area under the receiver operating characteristic (ROC) curve (AUC) are used. Furthermore, as it is widely utilized in many clinical-related studies, logistic regression (LGR) is also considered as the benchmark in this study to ensure all six of the ML models have reasonable performance.
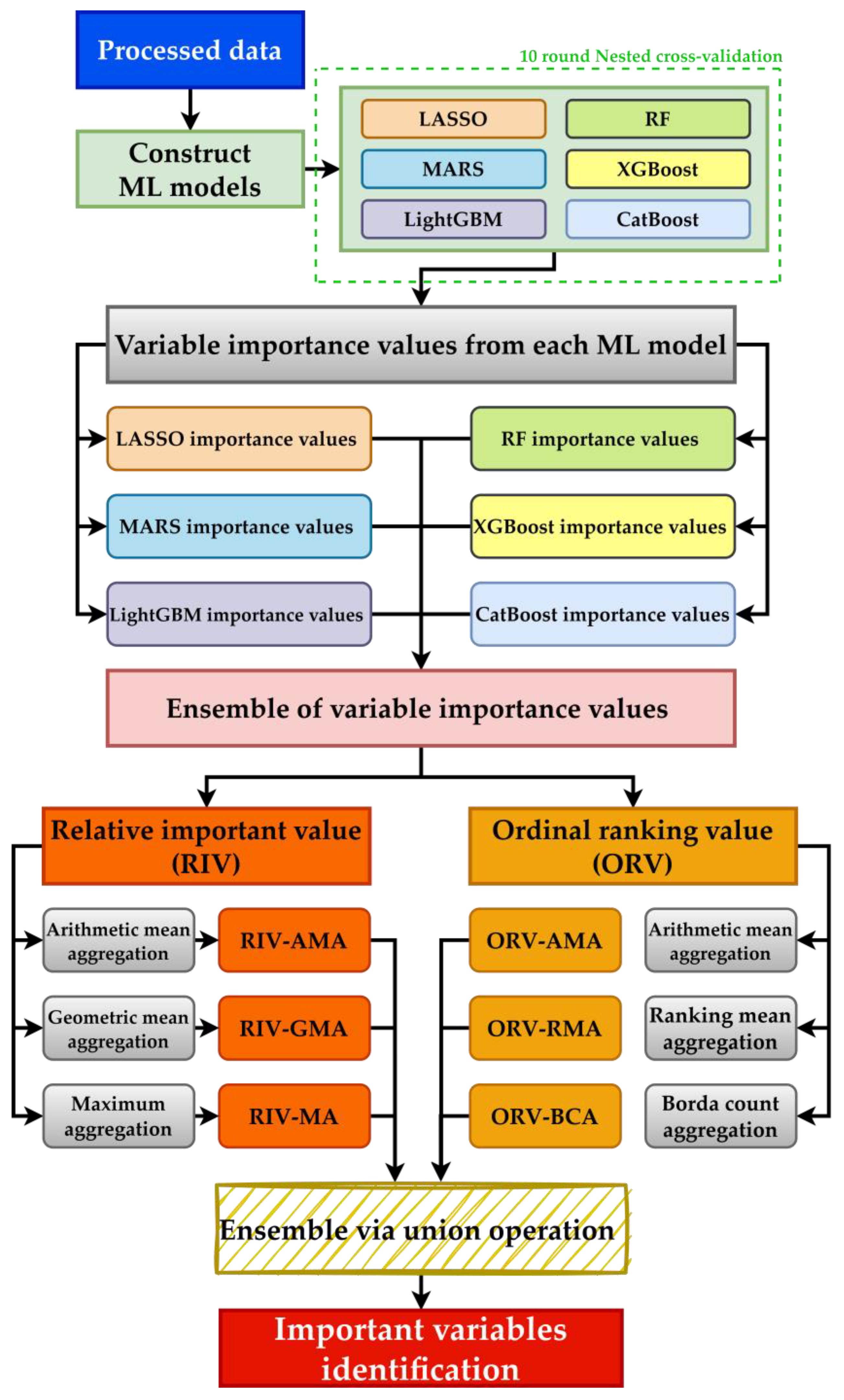
The procedure of the hybrid multiphase CKD prediction scheme is shown in
Figure 2. As shown in the figure, after obtaining the data with the generated longitudinal variables, ML models are constructed using the data. Additionally, an oversampling technique is utilized to address the class imbalance issue in the data. With the built ML models, the relevant importance value of each variable can be extracted from each ML model. Because each model has different hyper-parameters required to be tuned, 10-fold nested cross-validation (10f-NCV) is utilized for hyper-parameter tuning. Under the structure of 10f-NCV, in one iteration, the data are randomly split into 10 folds, where 1 fold is used for testing and the rest of the 9 folds are used for testing. During training, the 9 folds of the data will be further split into 8 folds for training and 1 fold for validation. Training ends when all of the 9 folds of data are used for validation once and the optimized hyper-parameter sets are found; then, the testing fold is used for evaluation. The entire 10f-NCV process is finished when all folds are used for testing once (a total of 10 iterations).
After constructing valid ML models, each can generate relevant information for each variable according to its model rules, thus generating two variable importance values: the ratio-scale-based relative importance value (RIV) and the ordinal-scale-based ordinal ranking value (ORV). In the RIV, the values of the most and least important variables are 100 and 0, respectively. The RIV is ordered from highest to lowest, and the given ranking value is the ORV. The most important variable, whose RIV is the highest or equal to 100, is placed at the top; the least important variable, whose RIV is the lowest or equal to 0, is placed at the bottom. Values can be repeated, which means that the variable importance of two or more variables may be similar. As each optimal ML method was repeated 10 times, there will be 10 corresponding variable importance values that are distinctive to each method. Each method’s mean importance was calculated to yield its single merged RIV and ORV.
Because a single selection variable algorithm has the propensity to choose a locally optimal solution, the ensemble variable has more opportunities to better approximate the optimal solution by averaging different assumptions [
37]. To derive more stable results, different VER approaches are considered. VER approaches can provide more robust variable selection results than a single variable selection method and reduce bias and variance. It has shown excellent results across various research domains [
38,
39]. Hence, MA, AMA, GMA, BCA, and RMA are used in this study as they are widely utilized in many studies [
37,
40]. Moreover, because different VER approaches are only applicable to a specific variable measurement scale, the RIV variable integration is based on MA, AMA, and GMA, whereas ORV is based on AMA, BCA, and RMA. The equations of each VER approach used are as follows:
where
is the RIV or ORV of the
th variable in the
th method. After aggregation via VER approaches, six sets of variable importance rankings are generated, namely RIV-AMA, RIV-GMA, RIV-MA, ORV-AMA, ORV-RMA, and ORV-BCA. Finally, union operation is used to integrate and compare the six importance ranking sets and to identify the most important risk factors for discussion.
This study used the R programming language (version 4.0.5;
http://www.R-project.org (accessed on 27 February 2024)) and RStudio software (version 1.1.453;
https://www.rstudio.com/products/rstudio/ (accessed on 27 February 2024)) to construct an effective ML model. All of the algorithm equations and estimated optimal hyperparameters of the models were built using R-related software packages. The package information is as following: The RF, LGR, MARS, Lasso, XGBoost, CatBoost, and LightGBM models were created using the randomForest (version 4.7-1.1) [
41], stats (version 4.0.5), earth (version 5.3.1) [
42], glmnet (version 4.1-7) [
43], xgboost (version 1.6.0.1) [
44], catboost (version 0.25.1) [
45], and lightgbm (version 3.3.2) [
46] packages, respectively. Lastly, the optimal hyperparameters were estimated for all models using the caret package (version 6.0-93) [
47].
3. Results
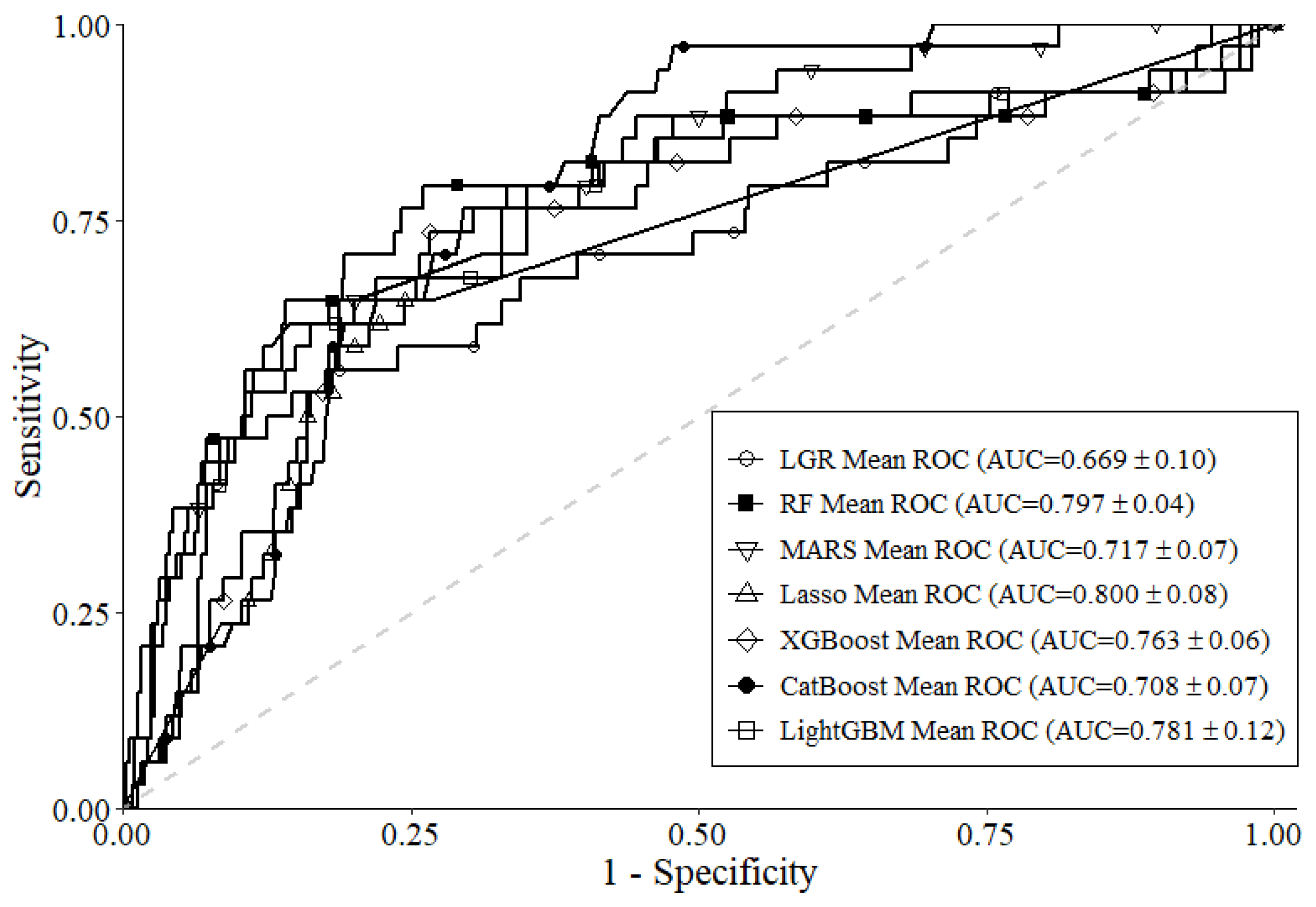
Table 2 shows the average performance of each ML model after 10f-NCV. As shown in the table, Lasso had the best BA of 0.813, LightGBM had the best SEN of 0.791, and RF had the best SPE of 0.898. Lasso had the best AUC of 0.800, and all six ML models had greater scores of AUC than the benchmark LGR model (AUC 0.669). This can also be found in the ROC curve presented in
Figure 3. Overall, according to the results in
Table 2 and
Figure 3, the usage of all six ML models for ensemble to identify important variables is reasonable.
The variable importance value of each variable generated from each ML model in terms of RIV (
Table 3) and ORV (
Table 4) can be found in the tables. In
Table 3, the first 12 variables are presented. As different ML models analyze the data with different approaches and mechanisms, it can be seen that each ML model yields a different RIV for each variable. For example, both Lasso and LightGBM yield the lowest RIV of zero to
, whereas the other four ML methods yield a relatively higher RIV. The same concept can be found in
Table 4. For example,
is ranked relatively lower by MARS (ORV 26) than the other five ML methods. Next, in order to derive more stable results and considerations when identifying important variables, the results of RIV and ORV are aggregated via the VER approaches, which are presented in
Table 5.
Table 5 presents the first 12 variables’ aggregation results from RIVs and ORVs via different VER approaches. As the characteristic of RIV, the aggregated importance values are generated from the six ML models with the corresponding VER equations. The aggregated importance value ranges between 0 and 100, and more important variables will have higher values. This concept suits all of the aggregated RIVs (RIV-AMA, RIV-GMA, and RIV-MA). Both the aggregations of ORV-AMA and ORV-RMA have similar concepts as RIVs, but with slight differences due to the characteristics of ORV. As the most important variable will be assigned the rank of one under the structure of ORV, the more important variable will have a value closer to one after aggregation. Under ORV-BCA, when two or more ML models are assigned the same ranking to a variable, that specific ranking will be the aggregated value of the variable. Taking ORVs of
in
Table 4 as an example, because both MARS and Lasso assigned the ranking of 70 to
, the aggregated value of
in ORV-BCA is 70, and this can also be seen in
Table 5. Furthermore, if all six ML models have assigned separate rankings to a variable, the worst-case scenario will be taken into consideration, in which the aggregated value will be the worst-ranking value. For example,
in
Table 4 can be found with separated rankings assigned from each ML model. Because the worst ranking of
is 26, the ORV-BCA of
is 26. Overall, as shown in
Table 5, with VER approaches, different information regarding the variables analyzed by each ML method can be brought into consideration. To better compare and interpret the rankings of each variable via VER approaches, the results in
Table 5 can be further organized into
Table 6.
Table 6 presents the top 12 ranking variables of RIV and ORV based on the corresponding VER approaches. As shown in the table, BUN(S) is the most important variable across all six aggregation results utilizing VER approaches; BUN(M) is the second most important variable, which only ranked the third in RIV-MA. Overall, the top three ranking important variables are similar and begin to vary in lower rankings.
To examine the association between important variables using different VER approaches, union operation is performed on
Table 6, and the results are organized into
Table 7. As presented in the table, important variables identified after union operation in different ranking combinations can be seen. Five conditions of the combination for union operation are used, which are within the first 4 rankings, within the first 6 rankings, within the first 8 rankings, within the first 10 rankings, and within the first 12 rankings. Taking the first condition (within the first four rankings) for the RIV rule as an example, the first four ranking variables from each aggregation rule in
Table 6 have to be identified first, then, with union operation, BUN(S), BUN(M), Hb(S), RBC(S), and r-GT(M) can be found, thus satisfying the condition in
Table 7. The same process is performed for all of the other conditions for both rules.
To evaluate the stability of the union operation results of the selected variable sets under the two proposed aggregation rules, Lasso is constructed based on variables selected in each variable combination condition of RIV and ORV from
Table 7, as the preliminary ML model performance results revealed that Lasso is the best one in this study. The performance of Lasso with different variable combination condition sets is shown in
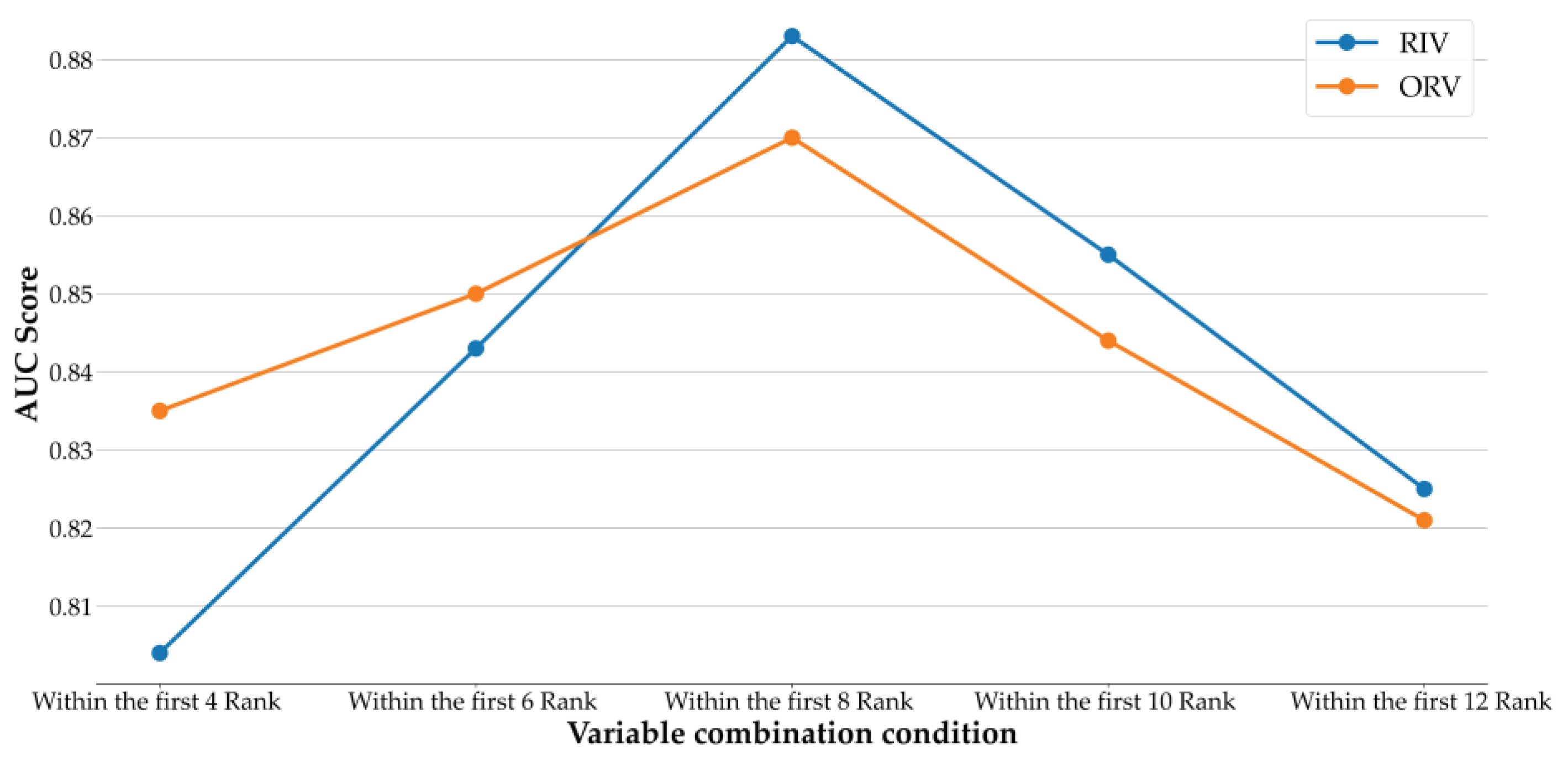
Table 8. According to the table, all AUCs of the union operations of the ranked variables under the two rules were greater than 0.804. Notably, variables within the first eight ranking conditions of RIV yield the best AUC of 0.883. Lasso uses 13 variables in total under the best variable combination condition; on the other hand, Lasso using all 76 variables has lower performance, with an AUC of 0.800. Therefore, the results are improved after variable selection, which greatly improves the overall prediction performance.
Figure 4 shows the AUC values of Lasso using different variable combination conditions with RIV and ORV. As shown in the figure, both RIV and ORV have increasing AUC values from the condition within the first four rankings to within the first eight rankings, and then both of their AUCs begin to decrease. ORV has better performance in AUC than RIV when the conditions are within the first four rankings and within the first six rankings; after that, RIV is superior to ORV in AUC when the amount of variables increases. In summary, the stability of the union operation is confirmed, and it indicates that the proposed risk factor evaluation scheme of this study can provide promising results.
4. Discussion
While clinical health data, in general, can accumulate into a substantial amount of big data, in practice, whether addressing preventive healthcare for chronic diseases, including metabolic syndrome (MetS), or assisting in the assessment of chronic kidney disease (CKD) at stages 3a-3b for high-risk diagnosis, the establishment of a risk prediction model for clinical use requires more appropriate or rational limited longitudinal healthcare data for research analysis. Collecting such data is essential to build predictive models, thereby identifying relevant risk factors more accurately, facilitating specialized physicians in clinical diagnosis, and aiding in medical decision making.
The analysis of clinical data often faces the challenge of dealing with limited sample sizes and complex variable interactions. Employing methods that consider multiple aspects can help compensate for these limitations. As the information can vary from different ML methods, consideration of VERs and union operation to aggregate them could enhance the overall predictive capability. Moreover, aggregated information, such as important features, can support healthcare or actual clinical scenarios. Furthermore, the analysis of health examination data requires consideration of the trends in the continuous change of data. Analyzing longitudinal data that meet the conditions is of greater research value and contributes to the subsequent predictive benefits of this study. Predicting CKD progression risk is a vital task in clinical management.
CKD is a progressive kidney disease characterized by deteriorating renal function. ML methods have been successfully used to predict CKD risk. This study used ML methods and feature engineering to construct a longitudinal variable set scheme to identify patients with MetS diagnosed with stages 3a or 3b CKD. Its results are highly significant for patients. For example, early CKD detection is conducive to providing effective interventions and measures to high-risk patients. Early treatment often leads to favorable treatment outcomes in the disease course. Next, in our longitudinal analysis, all six ML methods outperformed conventional LGR, and the Lasso model was the best, as reflected by its AUC of 0.800, which was 2.8% and 13.1% higher than that of conventional LGR. Our findings corroborate those of previous studies. Indeed, ML methods, especially Lasso [
48], can be used to resolve the classification bias in several categories while showing strong prediction performance with imbalanced data [
18].
In addition, this study used variable ensemble and union operation to integrate the ML-selected variable results and analyzed the Lasso-selected variables. Its experimental results demonstrated that the variable ensemble methods and union operation all effectively improved the Lasso model’s prediction performance. We offer reliable estimations of CKD risk factors based on different VERs. Specifically, we reduced the number of cross-sectional variables from 76 to 13 through variable selection, enhancing prediction performance. As reflected by the AUC, prediction performance increased from 5.6% to 8.3% after variable selection with Lasso. Like previous studies, the proposed hybrid scheme outperformed standalone schemes, as variable selection identified the important CKD variables and increased the model’s prediction performance [
49,
50,
51]. The results with the selected variables were similar to those of existing clinical studies. For example, Lasso identified BUN, Hb, RBC, r-GT, HDL, UA, SBP, and FPG as key risk factors for CKD based on the cross-sectional results. The associations between these risk factors and CKD are elaborated based on previous studies.
Past related publications have not emphasized the analysis of longitudinal data in small to medium-sized samples. For health or clinical data with two or more real instances, the consideration of statistics like closest (C), mean (M), standard deviation (S), and difference (D) among variables has been lacking. In this study, not only did we identify the significance of these variables (Hb, RBC, BUN, r-GT, HDL, UA, SBP, and FPG) again, but we also delved deeper to explore which statistical values among these continuous data variables hold more meaning. Hb or RBCs are important indicators of the blood’s oxygen-carrying capacity. An excessively low value can lead to anemia, a common complication of CKD and a recognized risk factor for CKD deterioration [
52,
53]. A survey found that 41% of 209,311 patients with CKD had anemia [
54]. Accordingly, study results found that in longitudinal data, the two variable statistical patterns, Hb(S), RBCs(M), and RBC(S), possess greater predictive capabilities.
BUN is an independent risk factor for CKD [
27]. Increasing studies have examined the relationship between CKD and BUN. For example, BUN and CKD are positively correlated. Moreover, Seki et al. (2019) also reported that BUN may predict kidney disease development [
55]. This study found that in longitudinal data, the important variable BUN may be more meaningfully assessed through the BUN(C), BUN(D), BUN(S), and BUN(M) values of each examination. Many studies have stressed the importance of UA in CKD. One of those studies identified the UA level as an important predictor of CKD [
56]. A recent study observed that higher UA levels correlated significantly with CKD in middle-aged men regardless of their BMI [
57]. Based on the findings of this study, it was discovered that in longitudinal data, the important variable UA may be more meaningfully assessed through the standard deviation “UA(S)” values of its multiple examinations.
r-GT is an enzyme found on the cell surface of all tissues. It is a typical indicator of alcohol consumption and hepatic impairment. Increasing studies have identified r-GT as an independent risk factor for CKD and ESRD [
58]. For example, two Japanese studies concurred that increased r-GT correlates positively with CKD [
59,
60]. A study on male South Korean workers found that r-GT and CKD correlated positively, and r-GT may predict early CKD [
61]. The research results indicate that exploring the mean value r-GT(M) of the variable r-GT(D) over longitudinal data may be more meaningful.
A recent 7472 person-years follow-up study in Korea showed that in patients with CKD, higher SBP and DBP levels were associated with a higher risk of a composite kidney outcome reflecting CKD progression. SBP had a greater association with adverse kidney outcomes than DBP [
62]. Blood pressure control is undoubtedly an important risk factor for CKD, but for the CKD high-risk group during 3a to 3b, the variability of systolic blood pressure DBP(S) may be cause for concern. There exists strong evidence that HDL is associated with patients with impairment of kidney function and/or progression of CKD. HDL-C concentrations, the composition of HDL particles, disturbances in functionality, and especially the reverse cholesterol transport, might be different between various stages of kidney impairment, especially between patients with and without nephrotic syndrome [
63]. Furthermore, a Mendelian randomization study showed HDL-C, LDL-C, and Triglycerides as CKD risk factors [
64]. Therefore, the variance of HDL(S) may cause concern for CKD during 3a to 3b.
To summarize, blood sugar management is conducive to preventing diabetes, nephropathy, and other diabetic microvascular complications. Research has identified FPG as an important risk factor for CKD [
52]. A retrospective study by Cao et al. (2022) [
65] identified age, sex, BMI, T2DM, FPG, stroke, and hypertension as risk factors for CKD. Regarding the FPG values, the results of this study indicate that investigating the difference in “FPG(D)” from the previous test as a research variable may have a higher predictive value for risk assessment.
6. Conclusions
The analysis of health screening data requires consideration of the trends in the continuous change of data. Analyzing longitudinal data that meet the conditions is of greater research value and contributes to the subsequent predictive benefits of this study. The hybrid multiphase scheme for predicting CKD in patients with MetS developed in this study through ML methods and feature engineering showed strong prediction performance. The limited longitudinal health screening data based on different feature ensembles demonstrated that the hybrid multiphase scheme effectively improved ML predictive performance. This study also examined common risk factors affecting CKD in patients with MetS using different models and ranked their importance for future reference. These rankings not only facilitate kidney condition assessment based on the risk factors but also the detection of other underlying diseases that patients with CKD might have. Moreover, our results are generalizable to a certain extent and may be used to enhance the understanding and treatment of other diseases by using the same ML methods and similar hybrid schemes. For healthcare professionals, information on how to incorporate the findings of this study into their clinical practice or decision-making processes would be beneficial. Based on the analysis results of this case study, for preventing CKD in the sub-healthy population with MetS, it is predictable that well-known factors like BUN, UA, and PFG play crucial roles. However, lesser-discussed factors, such as Hb, RBCs, or r-GT, should receive more attention in clinical practice or decision-making processes, which could be beneficial. Additionally, observing the mean, standard deviation, and difference of different variables across three consecutive data points carries distinct implications. The study’s findings may inform personalized medicine and targeted interventions for potential patients with high-risk CKD, thereby identifying clinical implications of risk factors and real-world healthcare applications. Validating the prediction model in a clinical setting and externally aligns with existing guidelines, potentially enhancing current CKD management practices.











{kind=link}
{kind=link}
{kind=link}
{kind=link}