
Performance Assessment of ChatGPT versus Bard in Detecting Alzheimer’s Dementia

Abstract
1. Introduction
2. Methods
- Query 1 (Q1). “Could the following transcribed speech be from a Cognitive Normal or Alzheimer’s Dementia subject?”
- Query 2 (Q2). “Can you look at the syntax, vocabulary, structure, narration style, grammar, semantic discourse, stylistics, pragmatics and share your opinion in short concise points on what you think of the following paragraphs? These paragraphs are transcribed text from an interview with different subjects. Could they be narrated by a Cognitive Normal or an Alzheimer’s Dementia subject?”
3. Results
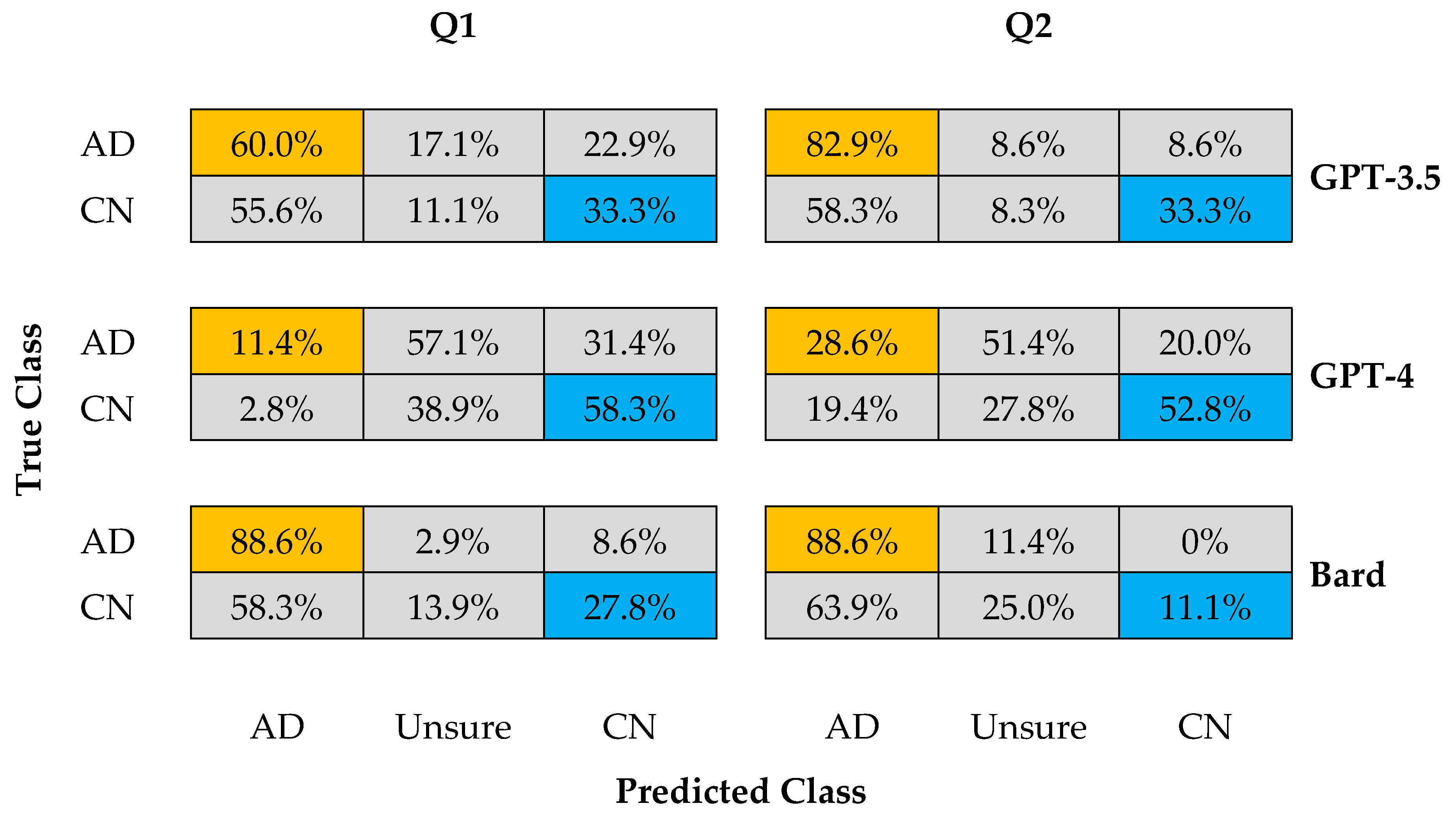
3.1. Performance and Outcomes from Prompts (Q1 and Q2)
3.2. Performance Metrics of Three LLM Chatbots for Q1 and Q2
3.3. Insights from Chain-of-Thought Prompting (Query 2)
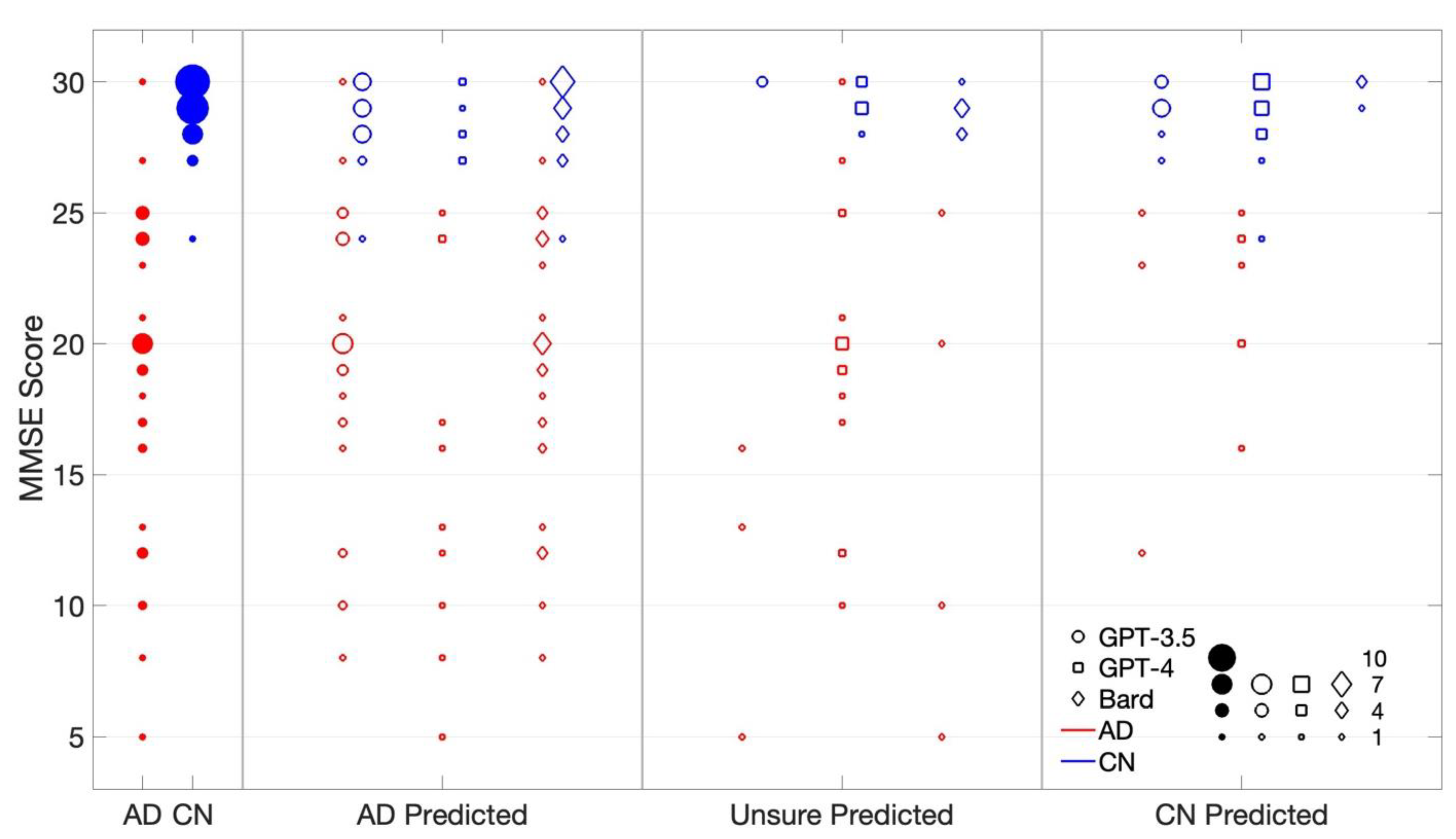
3.4. Insights from MMSE Score Comparison
4. Discussion
- Efficacy and Limitations of Prompts: Only two prompts (Q1 and Q2) were investigated here. It is worth considering whether more sophisticated prompting approaches would yield different outcomes. To necessitate the integration of such chatbots into healthcare practice further refinement through the formulation of more specific queries that can provide a deeper understanding of common language impairments is essential [47].
- “Snapshot” and Limited Probing: The potential variations of outcomes across different accounts, machines, and repetitions at different times were not explored—although, as we noted during preliminary explorations of repeated prompting, using the same text for a particular subject does elicit slight variations in textual response (the extent, consistency or variation of these differences was not studied nor quantified) but not enough to influence the overall prediction outcome.
- Non-repeatability and Dynamic Evolution of LLM chatbots: The efficacy and evolution of the LLM chatbots’ “personality” resulting from continuous querying and intervention (‘fine-tuning’) of service operators, including back-end updates to new versions, remain unknown and warrant further exploration. Performance differences between GPT-3.5 and GPT-4 is a stark example of this concern.
- Accuracy of Transcription (Source Text): An automated speech-to-text service was used to transcribe interview audio recordings, so it is expected that transcription errors and confusion will arise when the speaker’s voice is not clear (Signal-to-noise ratio concerns) or when the target speaker does not enunciate with clarity, or speaks with a non-standard accent. (Note: this difficulty is faced equally by all investigators using the same dataset).
- De-contextualized Speech: To ensure the query used only speech originating from the subject in question (and not the interviewer), audio segments corresponding to the interviewer were removed before speech-to-text transcription. Consequently, the semantic content of the transcriptions may appear fragmented or discontinuous due to the missing contextual information and may influence the LLM chatbots’ performance in predicting AD and CN.
- Due to the accessibility of the Dementia Bank repository, the possibility of the training data for the LLM chatbots containing instances from ADReSSo dataset cannot be entirely ruled out. This could limit the generalizability of the findings.
- Furthermore, it is important to delve into the longitudinal progression of speech samples, as this aspect holds potential in alerting healthcare professionals, to serve as an early indicator of cognitive decline. To facilitate this investigation, the acquisition of a language dataset comprising speech samples from individuals presenting with mild cognitive impairment (MCI) alongside knowledge of their outcomes after three years becomes essential; the timing is also important and could help in predicting progression of MCI to AD [48].
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brodaty, H.; Donkin, M. Family Caregivers of People with Dementia. Dialogues Clin. Neurosci. 2009, 11, 217–228. [Google Scholar] [CrossRef]
- Brookmeyer, R.; Johnson, E.; Ziegler-Graham, K.; Arrighi, H.M. Forecasting the Global Burden of Alzheimer’s Disease. Alzheimer’s Dement. 2007, 3, 186–191. [Google Scholar] [CrossRef] [PubMed]
- Nandi, A.; Counts, N.; Chen, S.; Seligman, B.; Tortorice, D.; Vigo, D.; Bloom, D.E. Global and Regional Projections of the Economic Burden of Alzheimer’s Disease and Related Dementias from 2019 to 2050: A Value of Statistical Life Approach. EClinicalMedicine 2022, 51, 101580. [Google Scholar] [CrossRef]
- Livingston, G.; Huntley, J.; Sommerlad, A.; Ames, D.; Ballard, C.; Banerjee, S.; Brayne, C.; Burns, A.; Cohen-Mansfield, J.; Cooper, C.; et al. Dementia Prevention, Intervention, and Care: 2020 Report of the Lancet Commission. Lancet 2020, 396, 413–446. [Google Scholar] [CrossRef] [PubMed]
- Banks, R.; Higgins, C.; Greene, B.R.; Jannati, A.; Gomes-Osman, J.; Tobyne, S.; Bates, D.; Pascual-Leone, A. Clinical Classification of Memory and Cognitive Impairment with Multimodal Digital Biomarkers. Alzheimer’s Dement. 2024, 16, e12557. [Google Scholar] [CrossRef]
- Mintun, M.A.; Lo, A.C.; Duggan Evans, C.; Wessels, A.M.; Ardayfio, P.A.; Andersen, S.W.; Shcherbinin, S.; Sparks, J.; Sims, J.R.; Brys, M.; et al. Donanemab in Early Alzheimer’s Disease. N. Engl. J. Med. 2021, 384, 1691–1704. [Google Scholar] [CrossRef]
- van Dyck, C.H.; Swanson, C.J.; Aisen, P.; Bateman, R.J.; Chen, C.; Gee, M.; Kanekiyo, M.; Li, D.; Reyderman, L.; Cohen, S.; et al. Lecanemab in Early Alzheimer’s Disease. N. Engl. J. Med. 2023, 388, 9–21. [Google Scholar] [CrossRef] [PubMed]
- Blair, M.; Marczinski, C.A.; Davis-Faroque, N.; Kertesz, A. A Longitudinal Study of Language Decline in Alzheimer’s Disease and Frontotemporal Dementia. J. Int. Neuropsychol. Soc. 2007, 13, 237–245. [Google Scholar] [CrossRef]
- Meilán, J.J.G.; Martínez-Sánchez, F.; Carro, J.; Sánchez, J.A.; Pérez, E. Acoustic Markers Associated with Impairment in Language Processing in Alzheimer’s Disease. Span. J. Psychol. 2012, 15, 487–494. [Google Scholar] [CrossRef]
- Priyadarshinee, P.; Clarke, C.J.; Melechovsky, J.; Lin, C.M.Y.; B.T, B.; Chen, J.-M. Alzheimer’s Dementia Speech (Audio vs. Text): Multi-Modal Machine Learning at High vs. Low Resolution. Appl. Sci. 2023, 13, 4244. [Google Scholar] [CrossRef]
- Rohanian, M.; Hough, J.; Purver, M. Alzheimer’s Dementia Recognition Using Acoustic, Lexical, Disfluency and Speech Pause Features Robust to Noisy Inputs. arXiv 2021, arXiv:2106.15684. [Google Scholar]
- Qiao, Y.; Yin, X.; Wiechmann, D.; Kerz, E. Alzheimer’s Disease Detection from Spontaneous Speech through Combining Linguistic Complexity and (Dis)Fluency Features with Pretrained Language Models. arXiv 2021, arXiv:2106.08689. [Google Scholar]
- Cintoli, S.; Favilli, L.; Morganti, R.; Siciliano, G.; Ceravolo, R.; Tognoni, G. Verbal Fluency Patterns Associated with the Amnestic Conversion from Mild Cognitive Impairment to Dementia. Sci. Rep. 2024, 14, 2029. [Google Scholar] [CrossRef] [PubMed]
- Themistocleous, C.; Eckerström, M.; Kokkinakis, D. Voice Quality and Speech Fluency Distinguish Individuals with Mild Cognitive Impairment from Healthy Controls. PLoS ONE 2020, 15, e0236009. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Li, X.; Ding, X.; Xu, F.; Ling, Z. Deep Learning-Based Speech Analysis for Alzheimer’s Disease Detection: A Literature Review. Alz. Res. Ther. 2022, 14, 186. [Google Scholar] [CrossRef] [PubMed]
- Pulido, M.L.B.; Hernández, J.B.A.; Ballester, M.Á.F.; González, C.M.T.; Mekyska, J.; Smékal, Z. Alzheimer’s Disease and Automatic Speech Analysis: A Review. Expert Syst. Appl. 2020, 150, 113213. [Google Scholar] [CrossRef]
- Petti, U.; Baker, S.; Korhonen, A. A Systematic Literature Review of Automatic Alzheimer’s Disease Detection from Speech and Language. J. Am. Med. Inform. Assoc. 2020, 27, 1784–1797. [Google Scholar] [CrossRef] [PubMed]
- Amini, S.; Hao, B.; Zhang, L.; Song, M.; Gupta, A.; Karjadi, C.; Kolachalama, V.B.; Au, R.; Paschalidis, I.C. Automated Detection of Mild Cognitive Impairment and Dementia from Voice Recordings: A Natural Language Processing Approach. Alzheimer’s Dement. 2022, 19, 946–955. [Google Scholar] [CrossRef]
- Searle, T.; Ibrahim, Z.; Dobson, R. Comparing Natural Language Processing Techniques for Alzheimer’s Dementia Prediction in Spontaneous Speech. arXiv 2020, arXiv:2006.07358. [Google Scholar]
- Syed, Z.S.; Syed, M.S.S.; Lech, M.; Pirogova, E. Automated Recognition of Alzheimer’s Dementia Using Bag-of-Deep-Features and Model Ensembling. IEEE Access 2021, 9, 88377–88390. [Google Scholar] [CrossRef]
- Meghanani, A.; Anoop, C.S.; Ramakrishnan, A.G. Recognition of Alzheimer’s Dementia from the Transcriptions of Spontaneous Speech Using fastText and CNN Models. Front. Comput. Sci. 2021, 3, 624558. [Google Scholar] [CrossRef]
- Yeung, A.; Iaboni, A.; Rochon, E.; Lavoie, M.; Santiago, C.; Yancheva, M.; Novikova, J.; Xu, M.; Robin, J.; Kaufman, L.D.; et al. Correlating Natural Language Processing and Automated Speech Analysis with Clinician Assessment to Quantify Speech-Language Changes in Mild Cognitive Impairment and Alzheimer’s Dementia. Alz. Res. Therapy 2021, 13, 109. [Google Scholar] [CrossRef]
- Shah, Z.; Sawalha, J.; Tasnim, M.; Qi, S.; Stroulia, E.; Greiner, R. Learning Language and Acoustic Models for Identifying Alzheimer’s Dementia from Speech. Front. Comput. Sci. 2021, 3, 624659. [Google Scholar] [CrossRef]
- Ying, Y.; Yang, T.; Zhou, H. Multimodal Fusion for Alzheimer’s Disease Recognition. Appl. Intell. 2023, 53, 16029–16040. [Google Scholar] [CrossRef]
- Biswas, S.S. Role of Chat GPT in Public Health. Ann. Biomed. Eng. 2023, 51, 868–869. [Google Scholar] [CrossRef]
- Lee, P.; Bubeck, S.; Petro, J. Benefits, Limits, and Risks of GPT-4 as an AI Chatbot for Medicine. N. Engl. J. Med. 2023, 388, 1233–1239. [Google Scholar] [CrossRef] [PubMed]
- Gellert, G.A.; Jaszczak, J. Cardiovascular Disease Prevention Recommendations from an Online Chat-Based AI Model. JAMA 2023, 330, 82. [Google Scholar] [CrossRef] [PubMed]
- Pappagari, R.; Cho, J.; Joshi, S.; Moro-Velázquez, L.; Żelasko, P.; Villalba, J.; Dehak, N. Automatic Detection and Assessment of Alzheimer Disease Using Speech and Language Technologies in Low-Resource Scenarios. In Proceedings of the Interspeech 2021 ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 3825–3829. [Google Scholar]
- Pan, Y.; Mirheidari, B.; Harris, J.M.; Thompson, J.C.; Jones, M.; Snowden, J.S.; Blackburn, D.; Christensen, H. Using the Outputs of Different Automatic Speech Recognition Paradigms for Acoustic- and BERT-Based Alzheimer’s Dementia Detection through Spontaneous Speech. In Proceedings of the Interspeech 2021 ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 3810–3814. [Google Scholar]
- Wang, W.; Zheng, V.W.; Yu, H.; Miao, C. A Survey of Zero-Shot Learning: Settings, Methods, and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–37. [Google Scholar] [CrossRef]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models Are Zero-Shot Reasoners. arXiv 2022, arXiv:2205.11916. [Google Scholar] [CrossRef]
- Wang, N.; Cao, Y.; Hao, S.; Shao, Z.; Subbalakshmi, K.P. Modular Multi-Modal Attention Network for Alzheimer’s Disease Detection Using Patient Audio and Language Data. In Proceedings of the Interspeech 2021 ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 3835–3839. [Google Scholar]
- Gauder, L.; Pepino, L.; Ferrer, L.; Riera, P. Alzheimer Disease Recognition Using Speech-Based Embeddings From Pre-Trained Models. In Proceedings of the Interspeech 2021 ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 3795–3799. [Google Scholar]
- Zhu, Y.; Obyat, A.; Liang, X.; Batsis, J.A.; Roth, R.M. WavBERT: Exploiting Semantic and Non-Semantic Speech Using Wav2vec and BERT for Dementia Detection. In Proceedings of the Interspeech 2021 ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 3790–3794. [Google Scholar]
- OpenAI. ChatGPT, Mar 14 Version. Large Language Model. Available online: https://chat.openai.com/chat (accessed on 16 March 2023).
- Google. Bard, May 10 Version. Large Language Model. Available online: https://bard.google.com/ (accessed on 14 May 2023).
- Sarawagi, S. Information Extraction. FNT Databases 2007, 1, 261–377. [Google Scholar] [CrossRef]
- Wei, X.; Cui, X.; Cheng, N.; Wang, X.; Zhang, X.; Huang, S.; Xie, P.; Xu, J.; Chen, Y.; Zhang, M.; et al. Zero-Shot Information Extraction via Chatting with ChatGPT. arXiv 2023, arXiv:2302.10205. [Google Scholar] [CrossRef]
- Luz, S.; Haider, F.; Fuente, S.D.L.; Fromm, D.; MacWhinney, B. Detecting Cognitive Decline Using Speech Only: The ADReSSo Challenge. In Proceedings of the Interspeech 2021 ISCA, Brno, Czechia, 30 August–3 September 2021; pp. 3780–3784. [Google Scholar]
- Goodglass, H.; Kaplan, E.; Sandra, W. BDAE: The Boston Diagnostic Aphasia Examination; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2001. [Google Scholar]
- Otter. AI. Available online: https://otter.ai/ (accessed on 21 April 2021).
- Temperature Check: A Guide to the Best ChatGPT Feature You’re (Probably) Not Using|LinkedIn. Available online: https://www.linkedin.com/pulse/temperature-check-guide-best-chatgpt-feature-youre-using-berkowitz/ (accessed on 17 January 2024).
- Klimova, B.; Maresova, P.; Valis, M.; Hort, J.; Kuca, K. Alzheimer’s Disease and Language Impairments: Social Intervention and Medical Treatment. Clin. Interv. Aging 2015, 10, 1401–1407. [Google Scholar] [CrossRef]
- Arevalo-Rodriguez, I.; Smailagic, N.; Roqué-Figuls, M.; Ciapponi, A.; Sanchez-Perez, E.; Giannakou, A.; Pedraza, O.L.; Bonfill Cosp, X.; Cullum, S. Mini-Mental State Examination (MMSE) for the Early Detection of Dementia in People with Mild Cognitive Impairment (MCI). Cochrane Database Syst. Rev. 2021, 7, CD010783. [Google Scholar] [CrossRef]
- Tombaugh, T.N.; McIntyre, N.J. The Mini-Mental State Examination: A Comprehensive Review. J. Am. Geriatr. Soc. 1992, 40, 922–935. [Google Scholar] [CrossRef]
- Crum, R.M. Population-Based Norms for the Mini-Mental State Examination by Age and Educational Level. JAMA 1993, 269, 2386. [Google Scholar] [CrossRef]
- Jin, Z.; Lu, W. Tab-CoT: Zero-Shot Tabular Chain of Thought. arXiv 2023, arXiv:2305.17812. [Google Scholar] [CrossRef]
- Moustafa, A.A.; Tindle, R.; Alashwal, H.; Diallo, T.M.O. A Longitudinal Study Using Latent Curve Models of Groups with Mild Cognitive Impairment and Alzheimer’s Disease. J. Neurosci. Methods 2021, 350, 109040. [Google Scholar] [CrossRef] [PubMed]
- Hoops, S.; Nazem, S.; Siderowf, A.D.; Duda, J.E.; Xie, S.X.; Stern, M.B.; Weintraub, D. Validity of the MoCA and MMSE in the Detection of MCI and Dementia in Parkinson Disease. Neurology 2009, 73, 1738–1745. [Google Scholar] [CrossRef] [PubMed]
- Nasreddine, Z.S.; Phillips, N.A.; Bédirian, V.; Charbonneau, S.; Whitehead, V.; Collin, I.; Cummings, J.L.; Chertkow, H. The Montreal Cognitive Assessment, MoCA: A Brief Screening Tool for Mild Cognitive Impairment. J. Am. Geriatr. Soc. 2005, 53, 695–699. [Google Scholar] [CrossRef]
- Borson, S.; Scanlan, J.M.; Chen, P.; Ganguli, M. The Mini-Cog as a Screen for Dementia: Validation in a Population-Based Sample. J. Am. Geriatr. Soc. 2003, 51, 1451–1454. [Google Scholar] [CrossRef]
- Ricci, M.; Graef, S.; Blundo, C.; Miller, L.A. Using the Rey Auditory Verbal Learning Test (RAVLT) to Differentiate Alzheimer’s Dementia and Behavioural Variant Fronto-Temporal Dementia. Clin. Neuropsychol. 2012, 26, 926–941. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AD Predicted | GPT-3.5 | GPT-4 | Bard | Metrics Averaged (across respective LLM chatbot) | |||
| Performance metrics | Query 1 | Query 2 | Query 1 | Query 2 | Query 1 | Query 2 | |
| Accuracy | 0.46 | 0.58 | 0.35 | 0.41 | 0.58 | 0.49 | (0.52 + 0.38 + 0.54)/3 = 0.48 |
| Sensitivity | 0.60 | 0.83 | 0.11 | 0.29 | 0.89 | 0.89 | (0.72 + 0.20 + 0.89)/3 = 0.60 |
| Specificity | 0.38 | 0.36 | 0.95 | 0.73 | 0.32 | 0.15 | (0.37 + 0.84 + 0.24)/3 = 0.48 |
| Precision | 0.51 | 0.58 | 0.80 | 0.59 | 0.60 | 0.57 | (0.55 + 0.70 + 0.59)/3 = 0.61 |
| F1 Score | 0.55 | 0.68 | 0.20 | 0.38 | 0.71 | 0.70 | (0.62 + 0.29 + 0.71)/3 = 0.54 |
| Overall Mean | 0.50 | 0.61 | 0.48 | 0.48 | 0.62 | 0.56 | (0.56 + 0.48 + 0.59)/3 = 0.54 |
| CN Predicted | GPT-3.5 | GPT-4 | Bard | Metrics Averaged (across respective LLM chatbot) | |||
| Performance metrics | Query 1 | Query 2 | Query 1 | Query 2 | Query 1 | Query 2 | |
| Accuracy | 0.46 | 0.58 | 0.35 | 0.41 | 0.58 | 0.49 | (0.52 + 0.38 + 0.54)/3 = 0.48 |
| Sensitivity | 0.33 | 0.33 | 0.58 | 0.53 | 0.28 | 0.11 | (0.33 + 0.56 + 0.20)/3 = 0.36 |
| Specificity | 0.72 | 0.91 | 0.27 | 0.59 | 0.91 | 1.00 | (0.82 + 0.43 + 0.96)/3 = 0.73 |
| Precision | 0.60 | 0.80 | 0.66 | 0.73 | 0.77 | 1.00 | (0.70 + 0.70 + 0.89)/3 = 0.76 |
| F1 Score | 0.43 | 0.47 | 0.62 | 0.61 | 0.41 | 0.20 | (0.45 + 0.62 + 0.31)/3 = 0.46 |
| Overall Mean | 0.51 | 0.62 | 0.50 | 0.57 | 0.59 | 0.56 | (0.57 + 0.54 + 0.58)/3 = 0.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
B.T, B.; Chen, J.-M. Performance Assessment of ChatGPT versus Bard in Detecting Alzheimer’s Dementia. Diagnostics 2024, 14, 817. https://doi.org/10.3390/diagnostics14080817
B.T B, Chen J-M. Performance Assessment of ChatGPT versus Bard in Detecting Alzheimer’s Dementia. Diagnostics. 2024; 14(8):817. https://doi.org/10.3390/diagnostics14080817
Chicago/Turabian StyleB.T, Balamurali, and Jer-Ming Chen. 2024. "Performance Assessment of ChatGPT versus Bard in Detecting Alzheimer’s Dementia" Diagnostics 14, no. 8: 817. https://doi.org/10.3390/diagnostics14080817
APA StyleB.T, B., & Chen, J.-M. (2024). Performance Assessment of ChatGPT versus Bard in Detecting Alzheimer’s Dementia. Diagnostics, 14(8), 817. https://doi.org/10.3390/diagnostics14080817